
Что такое ошибка отбора (в отношении данных), и почему она важна? Как предварительная обработка данных может ухудшить ситуацию?
Ответ
Ошибка отбора – это выбор для анализа людей, групп или данных методом, не обеспечивающим должную рандомизацию, в результате чего выборка не является репрезентативной.
Существуют следующие виды ошибок отбора:
ошибка выборки: выборка, полученная не в результате случайного отбора.
интервал времени: выбор особого интервала времени, поддерживающего желаемый вывод – например, исследование продаж перед Рождеством.
воздействие: включает клиническую уязвимость, протопатическую ошибку и ошибку показателей (подробнее см. здесь).
ошибка данных: выборочное представление фактов, избирательный подход, выборочное цитирование.
ошибка истощения: включает «ошибку выжившего», когда в анализ включаются только те, кто «пережил» длительный процесс и «ошибку неудачников», когда в анализ включаются только те, кто потерпел неудачу.
Обработка пропущенных данных может усилить влияние ошибок отбора. Например, если вы заменяете значения null на средние значения, вы добавляете в данные ошибку, поскольку считаете, что данные не имеют такого разброса, который они могут иметь на самом деле.
@machinelearning_interview
Ответ
Ошибка отбора – это выбор для анализа людей, групп или данных методом, не обеспечивающим должную рандомизацию, в результате чего выборка не является репрезентативной.
Существуют следующие виды ошибок отбора:
ошибка выборки: выборка, полученная не в результате случайного отбора.
интервал времени: выбор особого интервала времени, поддерживающего желаемый вывод – например, исследование продаж перед Рождеством.
воздействие: включает клиническую уязвимость, протопатическую ошибку и ошибку показателей (подробнее см. здесь).
ошибка данных: выборочное представление фактов, избирательный подход, выборочное цитирование.
ошибка истощения: включает «ошибку выжившего», когда в анализ включаются только те, кто «пережил» длительный процесс и «ошибку неудачников», когда в анализ включаются только те, кто потерпел неудачу.
Обработка пропущенных данных может усилить влияние ошибок отбора. Например, если вы заменяете значения null на средние значения, вы добавляете в данные ошибку, поскольку считаете, что данные не имеют такого разброса, который они могут иметь на самом деле.
@machinelearning_interview
👍6🔥3
Data Study - канал с полезными и практическими материалами про аналитику данных, бизнес-анализ и развитие soft-навыков от ведущего BI аналитика.
На канале Даниил также организовывает бесплатные вокршопы по обсуждению аналитических тем.
Воркшоп по теме создания data-продуктов в компания
Статья на habr про оконные функции простым языком
Шаблон оформления документации про профайлинге нового data-источника
Материалы канала помогут улучшить профессиональные навыки в аналитике.
🎁 Большой бонус: бесплатный гайд по профессии аналитика данных, чтобы еще лучше погрузиться в специализацию аналитика
Подписаться 👨💻
На канале Даниил также организовывает бесплатные вокршопы по обсуждению аналитических тем.
Воркшоп по теме создания data-продуктов в компания
Статья на habr про оконные функции простым языком
Шаблон оформления документации про профайлинге нового data-источника
Материалы канала помогут улучшить профессиональные навыки в аналитике.
🎁 Большой бонус: бесплатный гайд по профессии аналитика данных, чтобы еще лучше погрузиться в специализацию аналитика
Подписаться 👨💻
🔥10
Что такое выброс и внутренняя ошибка? Объясните, как их обнаружить, и что бы вы делали, если нашли их в наборе данных?
Ответ
Выброс (англ. outlier) – это значение в данных, существенно отличающееся от прочих наблюдений.
В зависимости от причины выбросов, они могут быть плохими с точки зрения машинного обучения, поскольку ухудшают точность модели. Если выброс вызван ошибкой измерения, важно удалить его из набора данных. Есть пара способов обнаружения выбросов.
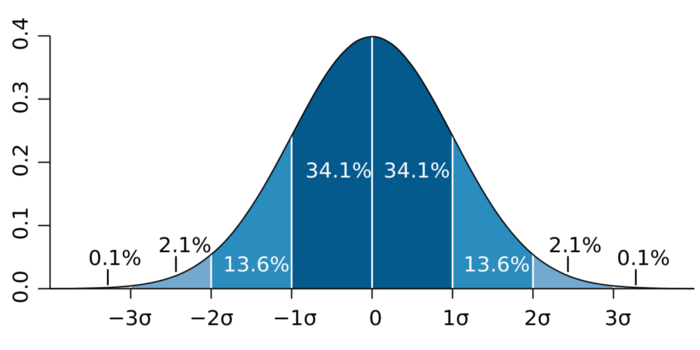
1) Z-оценка/стандартные отклонения: если мы знаем, что 99.7% данных в наборе лежат в пределах тройного стандартного отклонения, мы можем найти элементы данных, выходящие за эти пределы. Точно так же, мы можем рассчитать z-оценку каждого элемента, и если она равна +/- 3, это выброс.
Внимание
При использовании указанного метода надо принимать во внимание обстоятельства: данные должны быть нормально распределены, метод неприменим для малых наборов данных, а слишком большое количество выбросов может исказить z-оценку.
2) Межквартильное расстояние (Inter-Quartile Range, IQR) – концепция, положенная в основу ящиков с усами (box plots), которую также можно использовать для нахождения выбросов. МКР – это расстояние между 3-м и 1-м квартилями. После его расчета можно считать значение выбросом, если оно меньше Q1-1.5*IQR или больше Q3+1.5*IQR. Это составляет примерно 2.7 стандартных отклонений.
Другие методы включают кластеризацию DBScan, Лес Изоляции и устойчивый случайно-обрубленный лес.
Внутренняя ошибка (inlier) – это наблюдение, лежащее в пределах общего набора данных, но необычное либо ошибочное. Поскольку оно находится там же, где остальные данные, его труднее идентифицировать, чем выброс. Внутренние ошибки обычно можно просто удалить из набора данных.
@machinelearning_interview
Ответ
Выброс (англ. outlier) – это значение в данных, существенно отличающееся от прочих наблюдений.
В зависимости от причины выбросов, они могут быть плохими с точки зрения машинного обучения, поскольку ухудшают точность модели. Если выброс вызван ошибкой измерения, важно удалить его из набора данных. Есть пара способов обнаружения выбросов.
1) Z-оценка/стандартные отклонения: если мы знаем, что 99.7% данных в наборе лежат в пределах тройного стандартного отклонения, мы можем найти элементы данных, выходящие за эти пределы. Точно так же, мы можем рассчитать z-оценку каждого элемента, и если она равна +/- 3, это выброс.
Внимание
При использовании указанного метода надо принимать во внимание обстоятельства: данные должны быть нормально распределены, метод неприменим для малых наборов данных, а слишком большое количество выбросов может исказить z-оценку.
2) Межквартильное расстояние (Inter-Quartile Range, IQR) – концепция, положенная в основу ящиков с усами (box plots), которую также можно использовать для нахождения выбросов. МКР – это расстояние между 3-м и 1-м квартилями. После его расчета можно считать значение выбросом, если оно меньше Q1-1.5*IQR или больше Q3+1.5*IQR. Это составляет примерно 2.7 стандартных отклонений.
Другие методы включают кластеризацию DBScan, Лес Изоляции и устойчивый случайно-обрубленный лес.
Внутренняя ошибка (inlier) – это наблюдение, лежащее в пределах общего набора данных, но необычное либо ошибочное. Поскольку оно находится там же, где остальные данные, его труднее идентифицировать, чем выброс. Внутренние ошибки обычно можно просто удалить из набора данных.
@machinelearning_interview
{kind=link}
👍19🔥1
Что Лучше – Хорошие Данные Или Хорошие Модели?
Это можно назвать одним из самых популярных вопросов по Big data, несмотря на то, что он также подпадает под категорию вопросов по Data science.
Ответ на этот вопрос на самом деле субъективен и зависит от ситуации. Крупные компании могут предпочесть хорошие данные, так как они являются основой для любого успешного бизнеса. С другой стороны, хорошие модели не могут быть созданы без хороших данных.
Вы должны ответить на этот вопрос в соответствии с вашими предпочтениями – здесь нет неправильного или правильного ответа (если конечно компания сама не пытается его найти).
@machinelearning_interview
Это можно назвать одним из самых популярных вопросов по Big data, несмотря на то, что он также подпадает под категорию вопросов по Data science.
Ответ на этот вопрос на самом деле субъективен и зависит от ситуации. Крупные компании могут предпочесть хорошие данные, так как они являются основой для любого успешного бизнеса. С другой стороны, хорошие модели не могут быть созданы без хороших данных.
Вы должны ответить на этот вопрос в соответствии с вашими предпочтениями – здесь нет неправильного или правильного ответа (если конечно компания сама не пытается его найти).
@machinelearning_interview
👍10🔥1
Что Такое Кластерная Выборка?
Кластерная выборка относится к типу метода выборки. С кластерной выборкой, исследователь делит популяцию на несколько отдельных групп под названием кластеры. Затем, из популяции выбирается простой случайный образец кластеров. Исследователь проводит свой анализ данных на основе выбранных кластеров.
@machinelearning_interview
Кластерная выборка относится к типу метода выборки. С кластерной выборкой, исследователь делит популяцию на несколько отдельных групп под названием кластеры. Затем, из популяции выбирается простой случайный образец кластеров. Исследователь проводит свой анализ данных на основе выбранных кластеров.
@machinelearning_interview
🔥8
Как Много Стандартных Форматов Ввода Hadoop Существует? Какие Они?
Один из вопросов для аналитика данных, который также может быть задан. Он довольно сложный, так как вам не только нужно знать число, но и сам формат.
Всего существует три распространённых формата ввода Hadoop. Это: формат key-value, sequence file и text.
@machinelearning_interview
Один из вопросов для аналитика данных, который также может быть задан. Он довольно сложный, так как вам не только нужно знать число, но и сам формат.
Всего существует три распространённых формата ввода Hadoop. Это: формат key-value, sequence file и text.
@machinelearning_interview
👍10🔥1
В Чём Различие Между Двумерным, Многомерным и Одномерным Анализом?
Двумерный (bivariate) анализ касается двух переменных одновременно, тогда как многомерный (multivariate) анализ имеет дело с несколькими переменными. Одномерный (univariate) анализ является самой простой формой анализа данных. “Uni” означает “один“, другими словами, ваши данные имеют только одну переменную. Он не имеет отношения к причинам или отношениям (в отличие от регрессии), и его главная цель – описать; он берёт данные, суммирует эти данные и находит шаблоны в данных.
@machinelearning_interview
Двумерный (bivariate) анализ касается двух переменных одновременно, тогда как многомерный (multivariate) анализ имеет дело с несколькими переменными. Одномерный (univariate) анализ является самой простой формой анализа данных. “Uni” означает “один“, другими словами, ваши данные имеют только одну переменную. Он не имеет отношения к причинам или отношениям (в отличие от регрессии), и его главная цель – описать; он берёт данные, суммирует эти данные и находит шаблоны в данных.
@machinelearning_interview
🔥11👍1
Что Такое fsck?
Дата сайентист должен знать, что fsck является аббревиатурой для “File System Check” или “Проверки Файловой Системы”. Это тип команды, который ищет возможные ошибки внутри файла и при их нахождении сообщает об этом в распределённую файловую систему Hadoop.
@machinelearning_interview
Дата сайентист должен знать, что fsck является аббревиатурой для “File System Check” или “Проверки Файловой Системы”. Это тип команды, который ищет возможные ошибки внутри файла и при их нахождении сообщает об этом в распределённую файловую систему Hadoop.
@machinelearning_interview
🔥8👎5👍1
Приведите три примера распределений с длинным хвостом. Почему они важны в задачах классификации и регрессии?
Три практических примера: степенной закон, закон Парето и продажи продуктов (например, продукты-бестселлеры против обычных).
При решении задач классификации и регрессии важно не забывать о распределении с длинным хвостом, поскольку редко встречающиеся значения составляют существенную часть выборки. Это влияет на выбор метода обработки выбросов. Кроме того, некоторые методики машинного обучения предполагают, что данные распределены нормально.
@machinelearning_interview
Три практических примера: степенной закон, закон Парето и продажи продуктов (например, продукты-бестселлеры против обычных).
При решении задач классификации и регрессии важно не забывать о распределении с длинным хвостом, поскольку редко встречающиеся значения составляют существенную часть выборки. Это влияет на выбор метода обработки выбросов. Кроме того, некоторые методики машинного обучения предполагают, что данные распределены нормально.
@machinelearning_interview
👍14🔥1
Дайте Определение Коллаборативной Фильтрации.
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
👎11🔥7👍2🤯2
Делимся с вами подкастом Рандомные Дрова, который делает команда @ozon_tech. Они рассказывают о разном из мира DS и DA, в частности, про собесы, кейсы, обучение, тех.интервью.
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Google
🎧Vk
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Vk
👍13🔥2
Вы летите в Казань, и хотите решить, стоит ли брать зонт. Вы звоните трем случайным казанцам и спрашиваете, идет ли дождь. Каждый из них говорит правду с вероятностью 2/3, а с вероятностью 1/3 обманывает вас. Все трое говорят, что дождь идет. Какова вероятность, что он идет на самом деле?
Поскольку последнее предложение фактически спрашивает: «какова вероятность A при условии, что верно B?», можно сразу сказать, что здесь нужна теорема Байеса. Нам потребуется информация о вероятности дождя в Казани в произвольный день, не связанный с полетом Допустим, она равна 25%.
P(A) = вероятность дождя = 25%
P(B) = вероятность, что все три казанца говорят, что идет дождь.
P(A|B) = вероятность дождя, при условии, что все трое говорят, что он идет.
P(B|A) = вероятность, что все трое говорят, что идет дождь, при условии, что он действительно идет = (2/3)3=8/27.
Шаг 1. Находим P(B)
Формулу Байеса P(A|B) = P(B|A) * P(A) / P(B) можно переписать в виде
P(B) = P(B|A) * P(A) + P(B| не А) * P(не A)
P(B) = (2/3)3*0.25 + (1/3)3*0.75 = 0.25*8/27 + 0.75*1/27.
Шаг 2. Находим P(A|B)
P(A|B) = 0.25*(8/27) / (0.25*8/27 + 0.75*1/27) = 8 / (8+3) = 8/11.
Таким образом, если все три казанца говорят, что идет дождь, то он действительно идет с вероятностью 8/11.
@machinelearning_interview
Поскольку последнее предложение фактически спрашивает: «какова вероятность A при условии, что верно B?», можно сразу сказать, что здесь нужна теорема Байеса. Нам потребуется информация о вероятности дождя в Казани в произвольный день, не связанный с полетом Допустим, она равна 25%.
P(A) = вероятность дождя = 25%
P(B) = вероятность, что все три казанца говорят, что идет дождь.
P(A|B) = вероятность дождя, при условии, что все трое говорят, что он идет.
P(B|A) = вероятность, что все трое говорят, что идет дождь, при условии, что он действительно идет = (2/3)3=8/27.
Шаг 1. Находим P(B)
Формулу Байеса P(A|B) = P(B|A) * P(A) / P(B) можно переписать в виде
P(B) = P(B|A) * P(A) + P(B| не А) * P(не A)
P(B) = (2/3)3*0.25 + (1/3)3*0.75 = 0.25*8/27 + 0.75*1/27.
Шаг 2. Находим P(A|B)
P(A|B) = 0.25*(8/27) / (0.25*8/27 + 0.75*1/27) = 8 / (8+3) = 8/11.
Таким образом, если все три казанца говорят, что идет дождь, то он действительно идет с вероятностью 8/11.
@machinelearning_interview
👍19🤯5🔥2
Как уменьшить количество ошибок выборки?
Ответ
Два простых метода – это рандомизация, при которой наблюдения выбираются случайным образом, и случайная выборка, при которой каждое наблюдение имеет равный шанс попасть в выборку.
Подробнее
@machinelearning_interview
Ответ
Два простых метода – это рандомизация, при которой наблюдения выбираются случайным образом, и случайная выборка, при которой каждое наблюдение имеет равный шанс попасть в выборку.
Подробнее
@machinelearning_interview
👍10🔥1
Выборка 9 человек из интересующей нас популяции выявила средний объем мозга = 1100 куб.см. со стандартным отклоненим 30 куб.см. Каким будет 95% Т-доверительный интервал Стьюдента для среднего объема мозга в этой популяции?
Ответ
Используем формулу доверительного интервала для выборки (картинка)
Учитывая уровень доверительности 95% и количество степеней свободы, равное 8, t-оценка = 2.306.
Доверительный интервал = 1100 +/- 2.306*(30/3) = [1076.94, 1123.06].
38. Девять испытуемых получали диетические пилюли на протяжении 6 недель. Средняя потеря веса составила -2 кг. Каким должно быть стандартное отклонение потери веса, чтобы верхняя граница 95% Т-доверительного интервала была равна 0?
Верхняя граница = среднее + t-оценка * (стандартное отклонение / квадратный корень из размера выборки).
0 = -2 + 2.306*(s/3)
2 = 2.306 * s / 3
s = 2.601903
Таким образом, стандартное отклонение должно быть примерно 2.60, чтобы Т-доверительный интервал заканчивался в нуле.
@machinelearning_interview
Ответ
Используем формулу доверительного интервала для выборки (картинка)
Учитывая уровень доверительности 95% и количество степеней свободы, равное 8, t-оценка = 2.306.
Доверительный интервал = 1100 +/- 2.306*(30/3) = [1076.94, 1123.06].
38. Девять испытуемых получали диетические пилюли на протяжении 6 недель. Средняя потеря веса составила -2 кг. Каким должно быть стандартное отклонение потери веса, чтобы верхняя граница 95% Т-доверительного интервала была равна 0?
Верхняя граница = среднее + t-оценка * (стандартное отклонение / квадратный корень из размера выборки).
0 = -2 + 2.306*(s/3)
2 = 2.306 * s / 3
s = 2.601903
Таким образом, стандартное отклонение должно быть примерно 2.60, чтобы Т-доверительный интервал заканчивался в нуле.
@machinelearning_interview
👍18🔥1
Количество убийств в Шотландии упало со 115 до 99. Является ли это изменение значимым?
Ответ
Эта задача аналогична предыдущей – зесь тоже используется распределение Пуассона. Доверительный интервал равен 115 +/- 21.45 = [93.55, 136.45]. Поскольку 99 находится в этом доверительном интервале, мы можем сделать вывод, что это изменение не является значимым.
@machinelearning_interview
Ответ
Эта задача аналогична предыдущей – зесь тоже используется распределение Пуассона. Доверительный интервал равен 115 +/- 21.45 = [93.55, 136.45]. Поскольку 99 находится в этом доверительном интервале, мы можем сделать вывод, что это изменение не является значимым.
@machinelearning_interview
🔥13🤔3👍2
КОГДА ЛУЧШЕ ИСПОЛЬЗОВАТЬ TENSORFLOW [ИЛИ ДРУГУЮ БИБЛИОТЕКУ, ТЕХНОЛОГИЮ ИЛИ ПОДХОД]?
Когда дело доходит до машинного обучения (или даже собеседований по науке о данных для тех, кто хочет получить работу в C-Suite), ожидайте вопросов, которые проверят, насколько вы в курсе текущих технологий и тенденций. Сюда входят вопросы, связанные с библиотеками Python, такими как TensorFlow. Бабич, которому однажды пришлось нанять семь кандидатов наук в области науки о данных для трехмесячного проекта (то есть он провел более 100 собеседований), любит разбрасывать подобные вопросы между более математическими. «Мне очень нравятся вопросы о современных технологиях и подходах».
Итог: не бойтесь высказывать свое мнение, если вы можете его обосновать.
Краткое описание популярных мл библиотек
@machinelearning_interview
Когда дело доходит до машинного обучения (или даже собеседований по науке о данных для тех, кто хочет получить работу в C-Suite), ожидайте вопросов, которые проверят, насколько вы в курсе текущих технологий и тенденций. Сюда входят вопросы, связанные с библиотеками Python, такими как TensorFlow. Бабич, которому однажды пришлось нанять семь кандидатов наук в области науки о данных для трехмесячного проекта (то есть он провел более 100 собеседований), любит разбрасывать подобные вопросы между более математическими. «Мне очень нравятся вопросы о современных технологиях и подходах».
Итог: не бойтесь высказывать свое мнение, если вы можете его обосновать.
Краткое описание популярных мл библиотек
@machinelearning_interview
👍10
Рассмотрим эпидемию инфлюэнцы для гетеросексуальных семей с двумя родителями. Предположим, что вероятность заражения хотя бы одного родителя 17%. Вероятность заражения отца 12%, а заражения обоих родителей – 6%. Какова вероятность заражения матери?
Ответ
Используем общее правило сложения вероятностей:
P(мать или отец) = P(мать) + P(отец) – P(мать и отец)
P(мать) = P(мать или отец) + P(мать и отец) – P(отец) = 0.17 + 0.06 – 0.12 = 0.11
Правила сложения вероятностей
@machinelearning_interview
Ответ
Используем общее правило сложения вероятностей:
P(мать или отец) = P(мать) + P(отец) – P(мать и отец)
P(мать) = P(мать или отец) + P(мать и отец) – P(отец) = 0.17 + 0.06 – 0.12 = 0.11
Правила сложения вероятностей
@machinelearning_interview
👍22🔥6🤔3👎1
Случайная величина X распределена нормально со средним значением 1020 и стандартным отклонением 50. Вычислите P(X>1200).
Ответ
Используем Excel: p = 1-norm.dist(1200, 1020, 50, true). Получаем p=0.000159.
@machinelearning_interview
Ответ
Используем Excel: p = 1-norm.dist(1200, 1020, 50, true). Получаем p=0.000159.
@machinelearning_interview
👍19🔥3
Назовите жизненные этапы разработки модели в проекте машинного обучения.
Ответ
Разработка модели машинного обучения проходит в следующие этапы:
1 Определить бизнес-задачу: понять бизнес-цели и преобразовать задачу ИТ-аналитики
Конструирование данных: определение необходимых источников данных, извлечение и агрегирование данных на необходимом уровне.
2 Исследовательский анализ: понимание данных, проверка переменных на наличие ошибок, выбросов и пропущенных значений. Определите взаимосвязь между различными типами переменных. Проверьте предположения.
3 Подготовка данных: исключения, преобразование типов, обработка выбросов, обработка пропущенных значений. Создайте новые гипотетически релевантные переменные, например max, min, sum, change, ratio. Группирование переменных, создание фиктивных переменных и т. Д.
4 Разработка функций: Избегайте мультиколлинеарности и оптимизируйте сложность модели за счет сокращения количества входных переменных – кластера переменных, корреляции, факторного анализа, RFE и т. Д.
5 Разделение данных: разделите данные на обучающую и тестовую выборки.
6 Построение модели: подгонка, проверка точности, перекрестная проверка и настройка модели с помощью параметров и гиперпараметров.
7 Тестирование модели: проверьте модель на тестовом образце, запустите диагностику и при необходимости повторите модель.
8 Реализация модели: Подготовьте окончательные результаты модели – представьте модель. Определите ограничения модели. Реализуйте модель (преобразование решения машинного обучения в рабочую среду).
9 Отслеживание производительности: периодически отслеживайте производительность модели и обновляйте ее по мере необходимости. В условиях развивающейся бизнес-среды производительность любой модели машинного обучения может со временем ухудшиться.
@machinelearning_interview
Ответ
Разработка модели машинного обучения проходит в следующие этапы:
1 Определить бизнес-задачу: понять бизнес-цели и преобразовать задачу ИТ-аналитики
Конструирование данных: определение необходимых источников данных, извлечение и агрегирование данных на необходимом уровне.
2 Исследовательский анализ: понимание данных, проверка переменных на наличие ошибок, выбросов и пропущенных значений. Определите взаимосвязь между различными типами переменных. Проверьте предположения.
3 Подготовка данных: исключения, преобразование типов, обработка выбросов, обработка пропущенных значений. Создайте новые гипотетически релевантные переменные, например max, min, sum, change, ratio. Группирование переменных, создание фиктивных переменных и т. Д.
4 Разработка функций: Избегайте мультиколлинеарности и оптимизируйте сложность модели за счет сокращения количества входных переменных – кластера переменных, корреляции, факторного анализа, RFE и т. Д.
5 Разделение данных: разделите данные на обучающую и тестовую выборки.
6 Построение модели: подгонка, проверка точности, перекрестная проверка и настройка модели с помощью параметров и гиперпараметров.
7 Тестирование модели: проверьте модель на тестовом образце, запустите диагностику и при необходимости повторите модель.
8 Реализация модели: Подготовьте окончательные результаты модели – представьте модель. Определите ограничения модели. Реализуйте модель (преобразование решения машинного обучения в рабочую среду).
9 Отслеживание производительности: периодически отслеживайте производительность модели и обновляйте ее по мере необходимости. В условиях развивающейся бизнес-среды производительность любой модели машинного обучения может со временем ухудшиться.
@machinelearning_interview
👍24🔥6❤1👏1
Когда нам следует использовать SVM?
SVM означает машины опорных векторов; это контролируемый алгоритм машинного обучения, который может использоваться для решения проблем, связанных с классификацией и регрессией. В классификации он используется для различения нескольких групп или классов, а в регрессии он используется для получения математической модели, которая могла бы предсказывать вещи. Одним из очень больших преимуществ использования SVM является то, что его можно использовать как в линейных, так и в нелинейных задачах.
➡️ SVM. Подробный разбор метода опорных векторов
@machinelearning_interview
SVM означает машины опорных векторов; это контролируемый алгоритм машинного обучения, который может использоваться для решения проблем, связанных с классификацией и регрессией. В классификации он используется для различения нескольких групп или классов, а в регрессии он используется для получения математической модели, которая могла бы предсказывать вещи. Одним из очень больших преимуществ использования SVM является то, что его можно использовать как в линейных, так и в нелинейных задачах.
➡️ SVM. Подробный разбор метода опорных векторов
@machinelearning_interview
🔥12👍4👎4❤1
👨💻 Перечислите основнные методы уменьшения размерностей.
- Многомерное шкалирование (MDS)
- Метод главных компонент (PCA)
- Визуализация многомерных пространств
- Применение Автоэнкодеров
- Isomap
- CA, MCA
- LDA (Linear Discriminant Analysis), DCA (Discriminant - Correspondence Analysis)
- tSNE (t-Distributed Stochastic Neighbor Embedding)
и другие
➡️ Читать подробнее
@machinelearning_interview
- Многомерное шкалирование (MDS)
- Метод главных компонент (PCA)
- Визуализация многомерных пространств
- Применение Автоэнкодеров
- Isomap
- CA, MCA
- LDA (Linear Discriminant Analysis), DCA (Discriminant - Correspondence Analysis)
- tSNE (t-Distributed Stochastic Neighbor Embedding)
и другие
➡️ Читать подробнее
@machinelearning_interview
👍14🔥2