Реактивность
Этот пост я бы хотел посвятить понятию реактивности в программировании. Как и многие другие понятия, оно основано на устоявшихся процессах в природе и других областях человеческой жизни, например, в медицине.
«Реактивность – (от латинского reactia – противодействие) – свойство организма реагировать изменениями жизнедеятельности на воздействие различных факторов окружающей среды» - учебно-методическое пособие по медицине.
Реактивное программирование - парадигма, ориентированная на потоки данных и автоматическое распространение изменений от нижестоящих моделей к вышестоящим.
Рассмотрим пример:
1.
2.
3.
4.
В императивном программировании ожидается, что
В реактивном программировании ожидается, что значения выражений будут равны:
Лучше понять этот пример можно, если представить что в качестве значения каждой переменной используются не просто числа, а лямбда-функции: https://compiler-explorer.com/z/Ge589afdW
Давайте подумаем, какие преимущества дает данное свойство реактивности:
1. Удобное распространение изменений
Разработчику не нужно проверять изменения каждой переменной, т.к. в механизм изменений заложено предсказуемое поведение.
2. Высокая отзывчивость
Изменения распространяются сразу, как только было сделано изменение, а результат вычислений будет вычислен тогда, когда он понадобится (в отличие от каких-то механизмов пересчета изменений).
3. Масштабируемость
Достаточно изменить лишь какую-то часть алгоритма, чтобы добавить новую функциональность.
4. Удобное создание сложных алгоритмов обработки
Алгоритм обработки не требует полного пересоздания с нуля, а может усложняться там, где это удобнее всего сделать.
Конечно, использование функций, это не самый эффективный способ, но он наглядно демонстрирует идею реактивности. Это понимание мне понадобится, чтобы обосновать некоторые другие идеи, о которых я хочу рассказать в следующих постах.
#howitworks #fun
Этот пост я бы хотел посвятить понятию реактивности в программировании. Как и многие другие понятия, оно основано на устоявшихся процессах в природе и других областях человеческой жизни, например, в медицине.
«Реактивность – (от латинского reactia – противодействие) – свойство организма реагировать изменениями жизнедеятельности на воздействие различных факторов окружающей среды» - учебно-методическое пособие по медицине.
Реактивное программирование - парадигма, ориентированная на потоки данных и автоматическое распространение изменений от нижестоящих моделей к вышестоящим.
Рассмотрим пример:
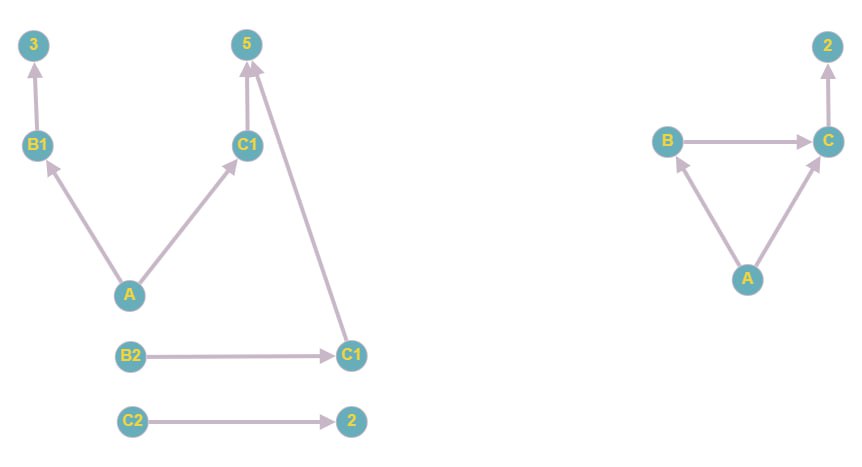
1.
b = 3; c = 5;2.
a = b + c;3.
b = c;4.
c = 2;В императивном программировании ожидается, что
a = 8; b = 5; c = 2;, т.к. при вычислении результата каждой операции используется значение переменной на текущий момент исполнения.В реактивном программировании ожидается, что значения выражений будут равны:
a = 4; b = 2; c = 2;, т.е. изменения, примененные к нижестоящим моделям (в данном контексте, переменные b и c), автоматически распространят свои изменения на вышестоящие модели (переменные a и b). Получаются такие цепочки зависимостей c -> a и c -> b -> a. Лучше понять этот пример можно, если представить что в качестве значения каждой переменной используются не просто числа, а лямбда-функции: https://compiler-explorer.com/z/Ge589afdW
Давайте подумаем, какие преимущества дает данное свойство реактивности:
1. Удобное распространение изменений
Разработчику не нужно проверять изменения каждой переменной, т.к. в механизм изменений заложено предсказуемое поведение.
2. Высокая отзывчивость
Изменения распространяются сразу, как только было сделано изменение, а результат вычислений будет вычислен тогда, когда он понадобится (в отличие от каких-то механизмов пересчета изменений).
3. Масштабируемость
Достаточно изменить лишь какую-то часть алгоритма, чтобы добавить новую функциональность.
4. Удобное создание сложных алгоритмов обработки
Алгоритм обработки не требует полного пересоздания с нуля, а может усложняться там, где это удобнее всего сделать.
Конечно, использование функций, это не самый эффективный способ, но он наглядно демонстрирует идею реактивности. Это понимание мне понадобится, чтобы обосновать некоторые другие идеи, о которых я хочу рассказать в следующих постах.
#howitworks #fun
{kind=link}
🤔10❤5😨2
std::transform
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
{kind=link}
❤11🥰2👍1
Как узнать размер блока, выделенного malloc?
Маллок в современном С++ не играет такую важную роль в разработке, как это есть и было в разработке на чистом С. Однако мы до сих пор встречаемся с легаси кодом(и вряд ли когда-нибудь перестанем это делать) и поэтому нам нужно знать некоторые тонкости и особенности языка С.
Маллок и еще несколько функций всегда используются в паре с free() как комбинация выделения и освобождения памяти. Но задумывались ли вы, почему в маллок мы передаем размер массива, а во free - нет? Что делать, если я забыл, сколько я памяти выделил и мне нужно это узнать?
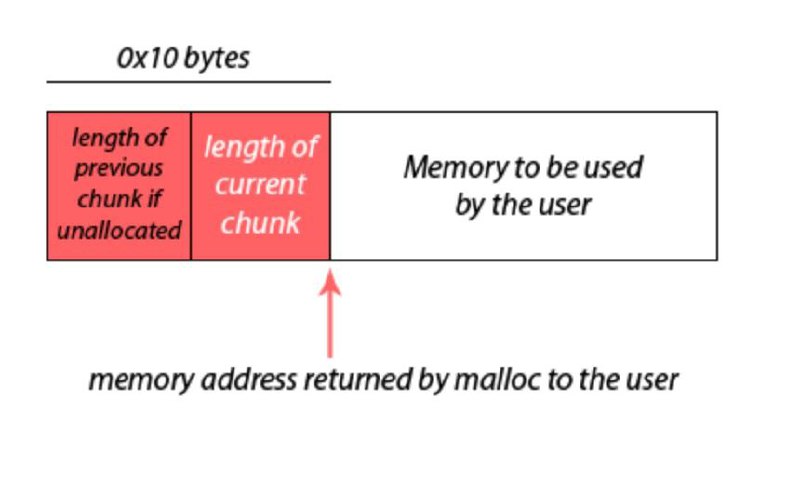
Дело в том, что это знание естественно хранится, просто ответственность за хранение не перекладывается на пользователя. Стандартный аллокатор выделяет на самом деле немного больше памяти, чем просите вы. Дополнительная память выделятся под внутренние структуры аллокатора и, ожидаемо, размер выделенной памяти. Напоминаю, что это все очень сильно привязано к реальной реализации стандартной библиотеки С, поэтому сказать нечто большее без привязки к реальной системе и коду нельзя.
Поэтому, зная указатель на выделенный блок, аллокатор сам знает, как ему найти реальное начало выделенного блока и реальное количество выделенных байт. Значит для освобождения памяти пользователю не нужно знать размер блока.
Что насчет того, может ли пользователь узнать размер выделенной памяти. И да, и нет. Скорее нет, чем да. Библиотека Linux систем предоставляет такую функцию, как malloc_usable_size, которая возвращает длину реально выделенного блока памяти. Это значит, что вы не получите то количество байт, которое вы запросили. Вам вернется несколько большее число. И это число определяется только имплементацией. Никто заранее в точности вам не скажет верное число.
Вряд ли вы когда-нибудь забывали размер выделенного блока, поэтому тоже вряд ли, что в продакшен коде вы будете это использовать(учитывая, что решение неточное и непереносимое). Но, надеюсь, вы немного больше узнали о стандартном аллокаторе.
Stay aware. Stay cool.
#cppcore #memory #howitworks #hardcore
Маллок в современном С++ не играет такую важную роль в разработке, как это есть и было в разработке на чистом С. Однако мы до сих пор встречаемся с легаси кодом(и вряд ли когда-нибудь перестанем это делать) и поэтому нам нужно знать некоторые тонкости и особенности языка С.
Маллок и еще несколько функций всегда используются в паре с free() как комбинация выделения и освобождения памяти. Но задумывались ли вы, почему в маллок мы передаем размер массива, а во free - нет? Что делать, если я забыл, сколько я памяти выделил и мне нужно это узнать?
Дело в том, что это знание естественно хранится, просто ответственность за хранение не перекладывается на пользователя. Стандартный аллокатор выделяет на самом деле немного больше памяти, чем просите вы. Дополнительная память выделятся под внутренние структуры аллокатора и, ожидаемо, размер выделенной памяти. Напоминаю, что это все очень сильно привязано к реальной реализации стандартной библиотеки С, поэтому сказать нечто большее без привязки к реальной системе и коду нельзя.
Поэтому, зная указатель на выделенный блок, аллокатор сам знает, как ему найти реальное начало выделенного блока и реальное количество выделенных байт. Значит для освобождения памяти пользователю не нужно знать размер блока.
Что насчет того, может ли пользователь узнать размер выделенной памяти. И да, и нет. Скорее нет, чем да. Библиотека Linux систем предоставляет такую функцию, как malloc_usable_size, которая возвращает длину реально выделенного блока памяти. Это значит, что вы не получите то количество байт, которое вы запросили. Вам вернется несколько большее число. И это число определяется только имплементацией. Никто заранее в точности вам не скажет верное число.
Вряд ли вы когда-нибудь забывали размер выделенного блока, поэтому тоже вряд ли, что в продакшен коде вы будете это использовать(учитывая, что решение неточное и непереносимое). Но, надеюсь, вы немного больше узнали о стандартном аллокаторе.
Stay aware. Stay cool.
#cppcore #memory #howitworks #hardcore
{kind=link}
❤14🔥2❤🔥1
Дублирование - зло. Ч1
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
{kind=link}
❤11🔥3❤🔥1👍1
CREATE TABLE IF NOT EXIST Ч2
В прошлом посте я рассказал о возможном race condition'е при использовании условного создания таблицы.
Что же можно сделать, чтобы предотвратить гонки?
Ну для начала не использовать условный запрос. Это исправит ситуацию с гонкой, но не решит проблему из-за которой условный запрос в принципе использовался. Следующие несколько советов помогут ее решить:
1️⃣ Используйте транзакции базы данных. Инкапсулируя запрос в транзакцию, вы обеспечиваете атомарное выполнение, предотвращая создание одной и той же таблицы несколькими параллельными транзакциями.
2️⃣ Механизмы блокировки. Используйте механизм блокировки вашей базы данных для сериализации доступа к запросу на создание таблицы, гарантируя, что только одна транзакция выполняет его одновременно.
3️⃣ Синхронизация. В многопоточных средах реализуйте методы синхронизации для поочередного доступа к подобным запросам.
4️⃣ Предварительная подготовка таблицы. Создавать таблицы стоит во время инициализации приложения. Так как обычно это происходит в одном потоке, то попасть в гонку будет невозможно.
Эти простые рекомендации помогут избежать race condition'а при таком запросе и в принципе обезопасит работу с базами данных в вашем приложении.
Не позволяйте гонкам нарушить ваш покой. Stay cool.
#database #miltitasking
В прошлом посте я рассказал о возможном race condition'е при использовании условного создания таблицы.
Что же можно сделать, чтобы предотвратить гонки?
Ну для начала не использовать условный запрос. Это исправит ситуацию с гонкой, но не решит проблему из-за которой условный запрос в принципе использовался. Следующие несколько советов помогут ее решить:
1️⃣ Используйте транзакции базы данных. Инкапсулируя запрос в транзакцию, вы обеспечиваете атомарное выполнение, предотвращая создание одной и той же таблицы несколькими параллельными транзакциями.
2️⃣ Механизмы блокировки. Используйте механизм блокировки вашей базы данных для сериализации доступа к запросу на создание таблицы, гарантируя, что только одна транзакция выполняет его одновременно.
3️⃣ Синхронизация. В многопоточных средах реализуйте методы синхронизации для поочередного доступа к подобным запросам.
4️⃣ Предварительная подготовка таблицы. Создавать таблицы стоит во время инициализации приложения. Так как обычно это происходит в одном потоке, то попасть в гонку будет невозможно.
Эти простые рекомендации помогут избежать race condition'а при таком запросе и в принципе обезопасит работу с базами данных в вашем приложении.
Не позволяйте гонкам нарушить ваш покой. Stay cool.
#database #miltitasking
{kind=link}
❤10👍5❤🔥1
Копаемся в маллоке
Короче. Попробуем новый формат на канале - статьи. Вот пожалуйста ссылочка https://telegra.ph/Nahodim-razmer-bloka-malloc-11-30. Это продолжение песни, начатой здесь. Инфы там многовато, поэтому пришлось в немного более длинном формате ее упаковать.
Было прикольно немного поисследовать вопрос, лично я кайфанул во время писания статьи.
Пишите свои мысли по поводу вопроса. Буду рад пообсуждать в комментах.
You are the best.
#fun #howitworks #memory #goodoldc #hardcore
Короче. Попробуем новый формат на канале - статьи. Вот пожалуйста ссылочка https://telegra.ph/Nahodim-razmer-bloka-malloc-11-30. Это продолжение песни, начатой здесь. Инфы там многовато, поэтому пришлось в немного более длинном формате ее упаковать.
Было прикольно немного поисследовать вопрос, лично я кайфанул во время писания статьи.
Пишите свои мысли по поводу вопроса. Буду рад пообсуждать в комментах.
You are the best.
#fun #howitworks #memory #goodoldc #hardcore
Telegraph
Находим размер блока malloc
Недавно рассказывал в общих чертах про то, как malloc на самом деле аллоцирует память. Попробуем теперь самостоятельно найти нужную циферку. Почти очевидно, что размер должен храниться с отрицательным смещением от указателя на начало блока. Размер ведь динамический…
❤11👍5🔥3
Nodiscard
Вдогонку к варнингам. Самый простой и strait-forward способ узнать, где ты накосячил в программе - это варнинги компилятора. Да, мы их все не любим. Пишешь ты вот такую небольшую программку на с++ просто, чтобы затестить что-нибудь. Или там задачку решить. А гцц тебе такой - преобразование сужения из sizet в инт. Или, переменная happylifeaftermarrige не используется. «Бабку, переходящую через дорогу, предупреждай, чтобы смотрела по сторонам. Опасность - мое второе имя». И игнорируем их все.
В реальных проектах, конечно, такое не прокатывает. Там, даже если ты Лев Толстой, а не член общества невежд, все равно варнинги нужно исправлять. Потому что не только ты один ответственен за код, а вся команда.
А вообще, при дизайне класса/интерфейса/метода/функции нужно заботиться о том, чтобы вашу сущность не могли использовать неправильно. Например, зачем проектировать многопоточный стек с методом empty()? Это чистейший дата рэйс, даже если код написан со всеми правилами защиты. Проблема интерфейсная: между вызовом empty() и pop() может вклиниться ещё один pop(), который достанет последний элемент из стека и второй pop() завершится с ошибкой, даже если стек при изначальной проверке не был пустым.
С 17-х плюсах появился ещё один способ сделать функции более безопасными - атрибут [[nodiscard]]. Этим атрибутом помечается возвращаемое значение функции и это сигнализирует компилятору о том, что возвращаемое значение функции обязательно надо использовать.
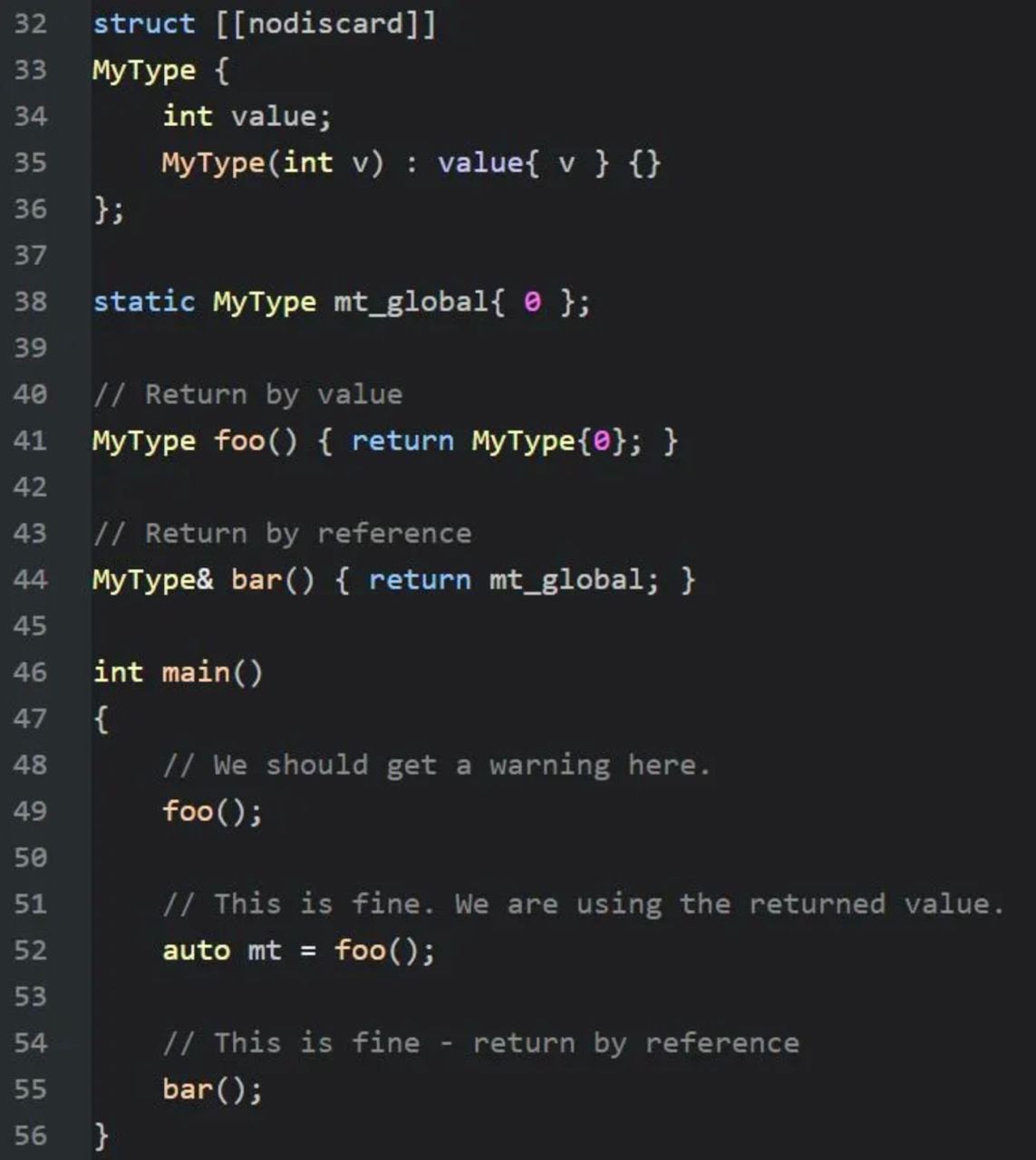
Объявив функцию так:
[[nodiscard]] int Compute();
И использовав ее так:
void Foo() {
Compute();
}
Вы получите примерно такое предупреждение:
warning: ignoring return value of 'int Compute()',
declared with attribute nodiscard
Вы можете пойти ещё дальше и пометить этим атрибутом весь класс:
[[nodiscard]] struct MoreImportantThatAdamKadirovRewardingType {};
Тогда любой вызов функции, которая возвращает этот тип, без использования возвращаемого значения будет бросать этот варнинг.
На самом деле, это очень полезный инструмент, ведь пропуск возвращаемого значения часто может приводить к серьёзным ошибкам.
Поэтому stay alerted. Stay cool.
#cpp17 #compiler
Вдогонку к варнингам. Самый простой и strait-forward способ узнать, где ты накосячил в программе - это варнинги компилятора. Да, мы их все не любим. Пишешь ты вот такую небольшую программку на с++ просто, чтобы затестить что-нибудь. Или там задачку решить. А гцц тебе такой - преобразование сужения из sizet в инт. Или, переменная happylifeaftermarrige не используется. «Бабку, переходящую через дорогу, предупреждай, чтобы смотрела по сторонам. Опасность - мое второе имя». И игнорируем их все.
В реальных проектах, конечно, такое не прокатывает. Там, даже если ты Лев Толстой, а не член общества невежд, все равно варнинги нужно исправлять. Потому что не только ты один ответственен за код, а вся команда.
А вообще, при дизайне класса/интерфейса/метода/функции нужно заботиться о том, чтобы вашу сущность не могли использовать неправильно. Например, зачем проектировать многопоточный стек с методом empty()? Это чистейший дата рэйс, даже если код написан со всеми правилами защиты. Проблема интерфейсная: между вызовом empty() и pop() может вклиниться ещё один pop(), который достанет последний элемент из стека и второй pop() завершится с ошибкой, даже если стек при изначальной проверке не был пустым.
С 17-х плюсах появился ещё один способ сделать функции более безопасными - атрибут [[nodiscard]]. Этим атрибутом помечается возвращаемое значение функции и это сигнализирует компилятору о том, что возвращаемое значение функции обязательно надо использовать.
Объявив функцию так:
[[nodiscard]] int Compute();
И использовав ее так:
void Foo() {
Compute();
}
Вы получите примерно такое предупреждение:
warning: ignoring return value of 'int Compute()',
declared with attribute nodiscard
Вы можете пойти ещё дальше и пометить этим атрибутом весь класс:
[[nodiscard]] struct MoreImportantThatAdamKadirovRewardingType {};
Тогда любой вызов функции, которая возвращает этот тип, без использования возвращаемого значения будет бросать этот варнинг.
На самом деле, это очень полезный инструмент, ведь пропуск возвращаемого значения часто может приводить к серьёзным ошибкам.
Поэтому stay alerted. Stay cool.
#cpp17 #compiler
{kind=link}
👍21❤3🏆2
Как обмануть nodiscard?
В комментах к предыдущему посту Евгений правильно заметил, что аттрибут nodiscard можно заигнорировать. Правда непонятны кейсы, в которых это нужно делать и которые еще не притянутые были бы за уши. Думаю, что при корректном использовании атрибута, такой надобности не возникнет. Ну да ладно. Об этом мы поговорим попозже. Сейчас я перечислю некоторые способы обхода nodiscard, чисто из научного интереса. Предупреждаю сразу. Уберите маленьких детей от экрана и ни в коем случае не повторять дома. За последствия не отвечаю.
std::ignore. На этот вариант и ссылался Евгений. Суть в том, что этому безтиповому можно присвоить любое значение и не использовать его. Тогда и возвращаемое значение типа было использовано для преобразования в ignore, и мы потом этот ignore можем игнорировать. Подробнее тут. А для любителей покопаться в костях динозавров есть функция boost::ignore_unused.
Скастовать возвращаемое значение в void. Типа вот так: (void)someFunction(). Или более по-плюсовому co static_cast.
Присвоить возращаемое значение какому-то объекту. Но не использовать его.
Тогда появится варнинг, что переменная, которой мы присвоили возвращаемое значение, не используется нигде. А вот чтобы это обойти, нужно пометить эту переменную другим атрибутом [[maybe_unused]]. Например так: [[maybe_unused]] int i = foo ();
Сделать красивую шаблонную обертку над предыдущим пунктом, с variadic-templates и прочими радостями. И назвать ее discard.
Отличные новости для пользователей clang! Можно обернуть вызов функции в
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Weverything"
#endif
func_with_result();
#pragma clang diagnostic pop
#endif
Тогда и никаких варнингов генерироваться не будет. Для gcc есть что-то подобное, но там нельзя вроде все сразу отключить.
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wunused-result"
func_with_result();
#pragma GCC diagnostic pop
На этом моя фантазия кончилась. Но получилось все равно солидно)
Повторю, что в большинстве случаев вы этим будете стрелять себе в лицо, и это скорее всего признак того, что вы что-то делаете не так или система спроектирована плохо.
Возможно вы знаете какие-нибудь еще способы? Обязательно делитесь ими в комментариях)
Stay dangerous. Stay cool.
#fun #cpp17 #compiler
В комментах к предыдущему посту Евгений правильно заметил, что аттрибут nodiscard можно заигнорировать. Правда непонятны кейсы, в которых это нужно делать и которые еще не притянутые были бы за уши. Думаю, что при корректном использовании атрибута, такой надобности не возникнет. Ну да ладно. Об этом мы поговорим попозже. Сейчас я перечислю некоторые способы обхода nodiscard, чисто из научного интереса. Предупреждаю сразу. Уберите маленьких детей от экрана и ни в коем случае не повторять дома. За последствия не отвечаю.
std::ignore. На этот вариант и ссылался Евгений. Суть в том, что этому безтиповому можно присвоить любое значение и не использовать его. Тогда и возвращаемое значение типа было использовано для преобразования в ignore, и мы потом этот ignore можем игнорировать. Подробнее тут. А для любителей покопаться в костях динозавров есть функция boost::ignore_unused.
Скастовать возвращаемое значение в void. Типа вот так: (void)someFunction(). Или более по-плюсовому co static_cast.
Присвоить возращаемое значение какому-то объекту. Но не использовать его.
Тогда появится варнинг, что переменная, которой мы присвоили возвращаемое значение, не используется нигде. А вот чтобы это обойти, нужно пометить эту переменную другим атрибутом [[maybe_unused]]. Например так: [[maybe_unused]] int i = foo ();
Сделать красивую шаблонную обертку над предыдущим пунктом, с variadic-templates и прочими радостями. И назвать ее discard.
Отличные новости для пользователей clang! Можно обернуть вызов функции в
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Weverything"
#endif
func_with_result();
#pragma clang diagnostic pop
#endif
Тогда и никаких варнингов генерироваться не будет. Для gcc есть что-то подобное, но там нельзя вроде все сразу отключить.
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wunused-result"
func_with_result();
#pragma GCC diagnostic pop
На этом моя фантазия кончилась. Но получилось все равно солидно)
Повторю, что в большинстве случаев вы этим будете стрелять себе в лицо, и это скорее всего признак того, что вы что-то делаете не так или система спроектирована плохо.
Возможно вы знаете какие-нибудь еще способы? Обязательно делитесь ими в комментариях)
Stay dangerous. Stay cool.
#fun #cpp17 #compiler
{kind=link}
🆒11👍7❤1🔥1
Variable length array
У большинства разработчиков есть стереотип, что С++ - это надмножество Си. Плюсовики же знают, что это не так, но зачастую на вопрос о различиях ничего ответить не могут. Так и что же есть такого в Си, чего нет в С++? Сделаю оговорку, что сейчас речь пойдет только о стандартах языков. Так как любой кастомный крестовый компилятор может поддерживать те или иные фичи языка Си. Это называется расширения компилятора. Мы всё-таки говорим о стандарте.
Сегодня мы рассмотрим только один из примеров. Механизм называется VLA или Variable Length Array. Или массивы переменной длины. В сущности он позволяет создавать массивы, размер которых не известен на момент компиляции, а память под них выделяется в автоматической области, то есть на стеке. Синтаксис ничем не отличается от статических массивов.
int n = 10;
int array[n];
Во всех учебниках по С++ написано, что создание динамических массивов на стеке запрещено и код выше запрещен стандартом (у значение переменной n нет квалификатора const). Однако в Си это часть стандарта, начиная с С99.
Фича довольно полезная в контексте простоты написания кода, не нужно городить дополнительных конструкций с выделением динамической памяти. Да и само выделение на стеке быстрее и операции с его памятью тоже происходят ощутимо быстрее. Однако всегда есть опасность выделить слишком много памяти и словить переполнение. Из-за этого о фиче мнение неоднозначно. В самом сишном стандарте то ограничивают ее, то вновь вводят поддержку в С23. А в один момент времени она даже была в драфте плюсового стандарта 14 года. Но на момент релиза ее убрали оттуда. Из-за этого кстати в некоторых компиляторах, например гцц, есть поддержка VLA. И код выше там скомпиляруется. Как-то я и сам неосознанно ею пользовался для написания небольшой библиотечки. А потом мне на ревью сказали, что вместо динамических массивов на стеке в плюсах принято пользоваться вектором. Так бы и не узнал, что использую запрещенку.
Но то, что в gcc есть поддержка vla, не значит, что она реализована так, как это предполагается по сишному стандарту. vla - лишь одна из граней variable length types. И в контексте этого понятия поведение кода, написанном на чистом С и на плюсах под гцц, будет разным. Не будем углубляться в детали. Просто надо понимать, что в данном случае лучше не использовать это расширение gcc, да и в принципе стараться придерживаться стандарта.
Stay cool.
#goodoldc
У большинства разработчиков есть стереотип, что С++ - это надмножество Си. Плюсовики же знают, что это не так, но зачастую на вопрос о различиях ничего ответить не могут. Так и что же есть такого в Си, чего нет в С++? Сделаю оговорку, что сейчас речь пойдет только о стандартах языков. Так как любой кастомный крестовый компилятор может поддерживать те или иные фичи языка Си. Это называется расширения компилятора. Мы всё-таки говорим о стандарте.
Сегодня мы рассмотрим только один из примеров. Механизм называется VLA или Variable Length Array. Или массивы переменной длины. В сущности он позволяет создавать массивы, размер которых не известен на момент компиляции, а память под них выделяется в автоматической области, то есть на стеке. Синтаксис ничем не отличается от статических массивов.
int n = 10;
int array[n];
Во всех учебниках по С++ написано, что создание динамических массивов на стеке запрещено и код выше запрещен стандартом (у значение переменной n нет квалификатора const). Однако в Си это часть стандарта, начиная с С99.
Фича довольно полезная в контексте простоты написания кода, не нужно городить дополнительных конструкций с выделением динамической памяти. Да и само выделение на стеке быстрее и операции с его памятью тоже происходят ощутимо быстрее. Однако всегда есть опасность выделить слишком много памяти и словить переполнение. Из-за этого о фиче мнение неоднозначно. В самом сишном стандарте то ограничивают ее, то вновь вводят поддержку в С23. А в один момент времени она даже была в драфте плюсового стандарта 14 года. Но на момент релиза ее убрали оттуда. Из-за этого кстати в некоторых компиляторах, например гцц, есть поддержка VLA. И код выше там скомпиляруется. Как-то я и сам неосознанно ею пользовался для написания небольшой библиотечки. А потом мне на ревью сказали, что вместо динамических массивов на стеке в плюсах принято пользоваться вектором. Так бы и не узнал, что использую запрещенку.
Но то, что в gcc есть поддержка vla, не значит, что она реализована так, как это предполагается по сишному стандарту. vla - лишь одна из граней variable length types. И в контексте этого понятия поведение кода, написанном на чистом С и на плюсах под гцц, будет разным. Не будем углубляться в детали. Просто надо понимать, что в данном случае лучше не использовать это расширение gcc, да и в принципе стараться придерживаться стандарта.
Stay cool.
#goodoldc
{kind=link}
👍15🏆2❤🔥1
Дублирование - зло. Ч2
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
{kind=link}
👍10⚡2🔥1
Экспресс совет
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
👍11❤3🔥1🫡1
Терминал
Вот иногда живешь-живешь, учишь иностранный язык или в какую-то другую сферу погружаешься, и в какой-то момент тебе приходит озарение по поводу ориджина простых вещей, которые мы все принимаем как данность. Например, слово банкнота. Для нас это одна единица бумажных денег. И мы не задумываемся, почему это слово обозначает одну деньгу. А все просто. Записка из банка. Bank note. Взорвало мозг? Если нет, то вы либо очень умный, либо потеряли энтузиазм к жизни.
Хочу поделиться с вами похожим приколом только из мира computer science. Думаю, что все мы хоть раз в жизни открывали графический терминал на своих Unix системах(реальных или виртуальных), ну или хотя бы подключались удалённо к ним. Все-таки, знание команд для unix - это маст хэв и де факто стандарт для сферы разработки. Если вы хоть раз разрабатывали не локально, то с 99% вероятности вы подключались к Линукс системе и ей надо бы уметь управлять.
Ну дак вот. Помните, какие раньше были компьютеры? Я вот тоже не помню, потому застал время уже полностью персональных компьютеров, где все было соединено вместе. А лет 50 назад нормальной практикой в компании было иметь один здоровый ЭВМ, размером с самомнение веганов, и много-много отдельных «терминалов», через которые сотрудники могли общаться с эвм. Они имели клавиатуру, дисплей, печатающее устройство, динамик и ещё пару простых прибамбасов. Пользователь вводит команду, команда по проводам попадает в эвм, обрабатывается и передаётся в виде текстовой или графической информации на терминал.
Мы сейчас делаем тоже самое, только виртуально. Открываем окошко, через которое управляем системой. Правда все мы воспринимаем это как данность и как обыкновенный, так и задуманный способ взаимодействия с компьютером. Терминал - это симулякр в чистом виде.
Надеюсь, что вас удивило мое недавнее открытие и это сделало ваш день немного приятнее.
Stay surprised. Stay cool.
#fun #tools #OS
Вот иногда живешь-живешь, учишь иностранный язык или в какую-то другую сферу погружаешься, и в какой-то момент тебе приходит озарение по поводу ориджина простых вещей, которые мы все принимаем как данность. Например, слово банкнота. Для нас это одна единица бумажных денег. И мы не задумываемся, почему это слово обозначает одну деньгу. А все просто. Записка из банка. Bank note. Взорвало мозг? Если нет, то вы либо очень умный, либо потеряли энтузиазм к жизни.
Хочу поделиться с вами похожим приколом только из мира computer science. Думаю, что все мы хоть раз в жизни открывали графический терминал на своих Unix системах(реальных или виртуальных), ну или хотя бы подключались удалённо к ним. Все-таки, знание команд для unix - это маст хэв и де факто стандарт для сферы разработки. Если вы хоть раз разрабатывали не локально, то с 99% вероятности вы подключались к Линукс системе и ей надо бы уметь управлять.
Ну дак вот. Помните, какие раньше были компьютеры? Я вот тоже не помню, потому застал время уже полностью персональных компьютеров, где все было соединено вместе. А лет 50 назад нормальной практикой в компании было иметь один здоровый ЭВМ, размером с самомнение веганов, и много-много отдельных «терминалов», через которые сотрудники могли общаться с эвм. Они имели клавиатуру, дисплей, печатающее устройство, динамик и ещё пару простых прибамбасов. Пользователь вводит команду, команда по проводам попадает в эвм, обрабатывается и передаётся в виде текстовой или графической информации на терминал.
Мы сейчас делаем тоже самое, только виртуально. Открываем окошко, через которое управляем системой. Правда все мы воспринимаем это как данность и как обыкновенный, так и задуманный способ взаимодействия с компьютером. Терминал - это симулякр в чистом виде.
Надеюсь, что вас удивило мое недавнее открытие и это сделало ваш день немного приятнее.
Stay surprised. Stay cool.
#fun #tools #OS
{kind=link}
👍6🤔3❤2🔥2
Полезные __builtin функции
Иногда требуется выполнить какую-то неочевидную битовую операцию, например, проверить число на степень двойки. Кстати, на leadcode / codeforces часто попадаются такие задачки, которые надо решить еще и эффективно. На помощь приходят __builtin функции 😉
__builtin_popcount / __builtin_popcountll:
подсчитывает количество установленных битов в целом числе (32 bit / 64 bit).
__builtin_parity / __builtin_parityll:
проверяет четность числа (32 bit / 64 bit).
__builtin_clz / __builtin_clzll:
подсчитывает количество нулей "слева" у целого числа (little endian, 32 bit / 64 bit).
__builtin_ctz / __builtin_ctzll:
подсчитывает количество нулей "справа" у целого числа (little endian, 32 bit / 64 bit).
__builtin_ffs / __builtin_ffsll:
возвращает индекс + 1 младшего 1-го бита x, или, если x равен нулю, возвращает ноль (32 bit / 64 bit).
__builtin_offsetof:
считает отступ полей от начала в POD (С подобных) структурах.
Живой пример: https://compiler-explorer.com/z/6s5nEE8sb
Конечно, есть еще и другие! Пишите в комментариях👇, какие еще вам пригодились на практике?
#compiler #NONSTANDARD
Иногда требуется выполнить какую-то неочевидную битовую операцию, например, проверить число на степень двойки. Кстати, на leadcode / codeforces часто попадаются такие задачки, которые надо решить еще и эффективно. На помощь приходят __builtin функции 😉
__builtin_popcount / __builtin_popcountll:
подсчитывает количество установленных битов в целом числе (32 bit / 64 bit).
__builtin_parity / __builtin_parityll:
проверяет четность числа (32 bit / 64 bit).
__builtin_clz / __builtin_clzll:
подсчитывает количество нулей "слева" у целого числа (little endian, 32 bit / 64 bit).
__builtin_ctz / __builtin_ctzll:
подсчитывает количество нулей "справа" у целого числа (little endian, 32 bit / 64 bit).
__builtin_ffs / __builtin_ffsll:
возвращает индекс + 1 младшего 1-го бита x, или, если x равен нулю, возвращает ноль (32 bit / 64 bit).
__builtin_offsetof:
считает отступ полей от начала в POD (С подобных) структурах.
Живой пример: https://compiler-explorer.com/z/6s5nEE8sb
Конечно, есть еще и другие! Пишите в комментариях👇, какие еще вам пригодились на практике?
#compiler #NONSTANDARD
{kind=link}
👍9🔥4❤2🆒1
Понимание режима ядра Linux
Режим ядра Linux — это сердце операционной системы. Это один из двух режимов работы программных средств и он работает с наивысшими привилегиями и отвечает за управление оборудованием, драйверами устройств, памятью, файловыми системами и планированием процессов. Вот некоторые ключевые функции режима ядра Linux:
1️⃣ Абстракция оборудования. Ядро управляет взаимодействием с аппаратными устройствами такими, как дисководы, сетевые интерфейсы и контроллеры ввода/вывода. Оно обеспечивает унифицированный интерфейс, который позволяет избежать аппаратных сложностей.
2️⃣ Управление процессами. Кернел отвечает за распределение времени ЦП между выполняющимися задачами. Оно создает такие сущности как потоки и процессы, которые являются единицами исполнения кода и его окружением, а также диспетчер, который и реализует алгоритмы распределения времени.
3️⃣ Управление памятью. Ядро распределяет пространство ОЗУ между процессами с помощью механизма страничного отображения - выделяет и освобождает процессам страничные кадры физической памяти и отображает на страницы их адресного пространства. Это адресное пространство реализуется с помощью абстракции виртуальной памяти, где каждому процессу принадлежит весь спектр виртуальных адресов, которые мэтчатся с адресами реальной памяти.
4️⃣ Управление файловой системой. Она предоставляет процессам унифицированный интерфейс файлового доступа к ПЗУ. Она также организует взаимодействие с другими системами. Например, доступ с CD/DVD-накопителю через файл /dev/sr0, к мыши - через /dev/input/mouse0, доступ процессов к страницам памяти друг друга - через файлы /proc/PID/mem, и тд.
5️⃣ Управление устройствами ввода-вывода. Эта подсистема распределяет доступ к устройствам ввода-вывода между процессами и предоставляет унифицированный интерфейс для чтения/записи. Для устройств ВЗУ она организует кэширование с помощью подсистемы управления памятью.
Это лишь несколько самых основных функций ядра линукса. Еще всякие штуки, типа межпроцессного взаимодействия и тд. Но они уже как будто бы комбинация определенного набора основных функций.
Ваша программа не может быть выполнена в режиме ядра(если вы не кодите само ядро конечно), потому что с наивысшими привилегиями идет большая ответственность в виде практически полного отсутствия защиты памяти. А никто вам такую ответственность не доверит. Но пользователь и программист очевидно могут использовать ядро линукса для своих нужд. Оно как бы для этого и предназначено. Но об этом в другой раз.
Stay based. Stay cool.
#OS
Режим ядра Linux — это сердце операционной системы. Это один из двух режимов работы программных средств и он работает с наивысшими привилегиями и отвечает за управление оборудованием, драйверами устройств, памятью, файловыми системами и планированием процессов. Вот некоторые ключевые функции режима ядра Linux:
1️⃣ Абстракция оборудования. Ядро управляет взаимодействием с аппаратными устройствами такими, как дисководы, сетевые интерфейсы и контроллеры ввода/вывода. Оно обеспечивает унифицированный интерфейс, который позволяет избежать аппаратных сложностей.
2️⃣ Управление процессами. Кернел отвечает за распределение времени ЦП между выполняющимися задачами. Оно создает такие сущности как потоки и процессы, которые являются единицами исполнения кода и его окружением, а также диспетчер, который и реализует алгоритмы распределения времени.
3️⃣ Управление памятью. Ядро распределяет пространство ОЗУ между процессами с помощью механизма страничного отображения - выделяет и освобождает процессам страничные кадры физической памяти и отображает на страницы их адресного пространства. Это адресное пространство реализуется с помощью абстракции виртуальной памяти, где каждому процессу принадлежит весь спектр виртуальных адресов, которые мэтчатся с адресами реальной памяти.
4️⃣ Управление файловой системой. Она предоставляет процессам унифицированный интерфейс файлового доступа к ПЗУ. Она также организует взаимодействие с другими системами. Например, доступ с CD/DVD-накопителю через файл /dev/sr0, к мыши - через /dev/input/mouse0, доступ процессов к страницам памяти друг друга - через файлы /proc/PID/mem, и тд.
5️⃣ Управление устройствами ввода-вывода. Эта подсистема распределяет доступ к устройствам ввода-вывода между процессами и предоставляет унифицированный интерфейс для чтения/записи. Для устройств ВЗУ она организует кэширование с помощью подсистемы управления памятью.
Это лишь несколько самых основных функций ядра линукса. Еще всякие штуки, типа межпроцессного взаимодействия и тд. Но они уже как будто бы комбинация определенного набора основных функций.
Ваша программа не может быть выполнена в режиме ядра(если вы не кодите само ядро конечно), потому что с наивысшими привилегиями идет большая ответственность в виде практически полного отсутствия защиты памяти. А никто вам такую ответственность не доверит. Но пользователь и программист очевидно могут использовать ядро линукса для своих нужд. Оно как бы для этого и предназначено. Но об этом в другой раз.
Stay based. Stay cool.
#OS
{kind=link}
❤11🔥2👍1
Почему не нужно указывать размер освобождаемого блока для free()
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Telegraph
Почему не нужно указывать размер освобождаемого блока для free()
Мы уже знаем, почему стандартный сишный аллокатор при удалении не просит указывать количество освобождаемых байт. Это более подробно раскрывается тут и тут. Вопрос скорее в другом. Почему вообще malloc+free было создано таким образом. Поскольку C - это язык…
🔥11👍2🆒2❤1
__builtin Ч2
Предыдущий пост получил неожиданное продолжение благодаря нашим подписчикам - Сергею Нефедову и @Roman657. Взаимопомощь и отзывчивость всегда помогает добиваться бо́льшего 😃
Как было подмечено, строго говоря, использование __builtin функции сопряжено с потенциальными рисками. Например, список аргументов поменяется в будущих версиях компилятора или код нельзя будет скомпилировать на другой платформе...
На практике нам неизвестны такие печальные истории, но если вы сомневаетесь — для вас есть другое решение 😉
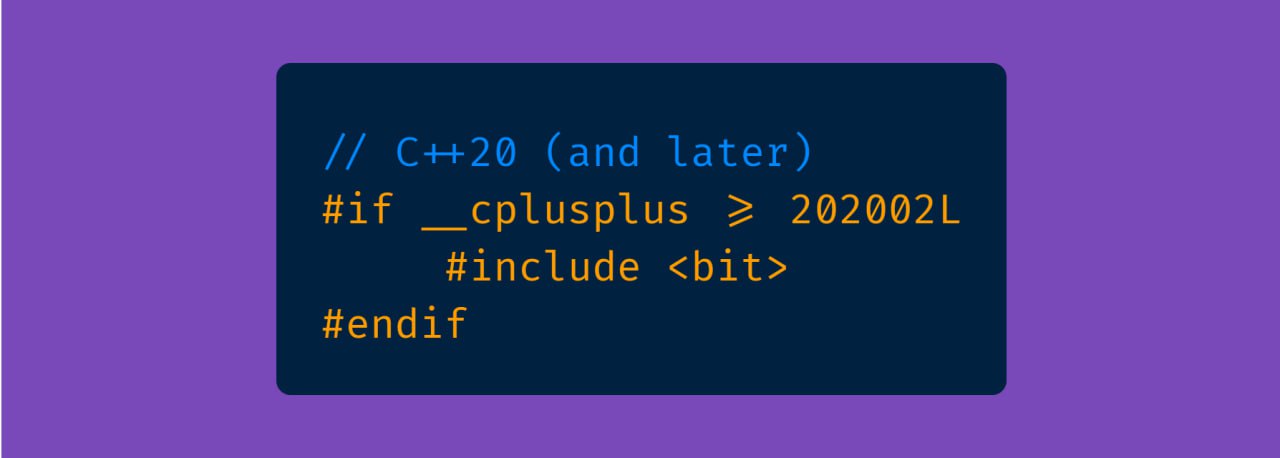
Начиная с C++20 появляется стандартизированная поддержка некоторых нетривиальных битовых операций. Библиотека bit предоставляет набор реализаций. Рассмотрим некоторые из них:
std::has_single_bit - проверяет целое число на степень двойки.
std::popcount - подсчитывает количество установленных битов в целом числе.
std::countl_zero - подсчитывает количество нулей "слева" у целого числа.
std::countr_zero - подсчитывает количество нулей "справа" у целого числа.
std::rotr - выполняет циклический сдвиг битов вправо для целого числа.
std::rotl - выполняет циклический сдвиг битов влево для целого числа.
Живой пример: ссылка.
Могу еще отметить, что это еще и шаблонные
#cpp20 #STL
Предыдущий пост получил неожиданное продолжение благодаря нашим подписчикам - Сергею Нефедову и @Roman657. Взаимопомощь и отзывчивость всегда помогает добиваться бо́льшего 😃
Как было подмечено, строго говоря, использование __builtin функции сопряжено с потенциальными рисками. Например, список аргументов поменяется в будущих версиях компилятора или код нельзя будет скомпилировать на другой платформе...
На практике нам неизвестны такие печальные истории, но если вы сомневаетесь — для вас есть другое решение 😉
Начиная с C++20 появляется стандартизированная поддержка некоторых нетривиальных битовых операций. Библиотека bit предоставляет набор реализаций. Рассмотрим некоторые из них:
std::has_single_bit - проверяет целое число на степень двойки.
std::popcount - подсчитывает количество установленных битов в целом числе.
std::countl_zero - подсчитывает количество нулей "слева" у целого числа.
std::countr_zero - подсчитывает количество нулей "справа" у целого числа.
std::rotr - выполняет циклический сдвиг битов вправо для целого числа.
std::rotl - выполняет циклический сдвиг битов влево для целого числа.
Живой пример: ссылка.
Могу еще отметить, что это еще и шаблонные
constexpr функции 😋#cpp20 #STL
{kind=link}
👍8🔥3❤2😍2🥰1
Когда использовать Nodiscard?
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
{kind=link}
👍4🆒4❤2❤🔥1
Универсальная инициализация и непростые пути инициализации векторов
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
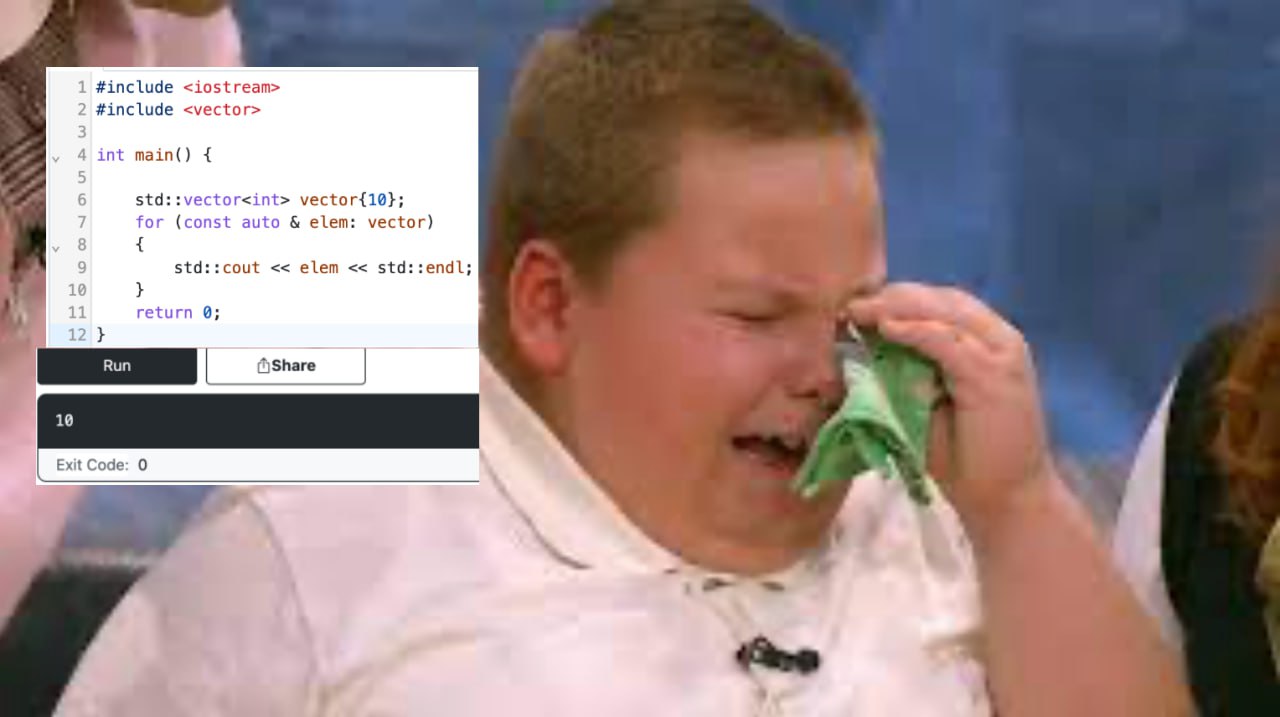
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
{kind=link}
👍9❤3❤🔥1
Вызываем метод класса через указатель
Настоящего плюсовика не должны пугать указатели на функции. И хоть в С++ есть нормальная обертка над всеми сущностями, которые можно исполнить - std::function - она довольно тяжеловесная и медленная. Да и с сишным апи с ней не поработаешь. К чему это я. Да. Указатели на функции. С ними, в целом, все просто.
int func() {
return 1;
}
using func_ptr = int (*) ();
func_ptr ptr = func;
std::cout << ptr();
Этот код со всеми обертками должен написать единичку на экран. С более сложными функциями сделать что-то похожее не составит труда. Но вот как насчет методов класса? Можно ли вызвать метод класса через указатель на него, а не через объект?
Ответ - можно. Но прежде чем посмотреть на рабочий код, попробуйте сами это сделать. Уверяю, что это не так тривиально)
Если читаете с телефона или нет времени, лучше вернитесь к этому посту после того, как попробуете сами. Эмоции будут совершенно другие)
Ну а для тех, кто уже попробовал или для ленивых дяденек, продолжаю.
Первое, что приходит на ум - такой же подход, как и с функциями.
auto ptr = RandomType::MemberFunction;
И тут же гцц плюнет вам в лицо с фразой error: invalid use of non-static member function ‘void RandomType::MemberFunction()’
auto ptr = RandomType::MemberFunction;
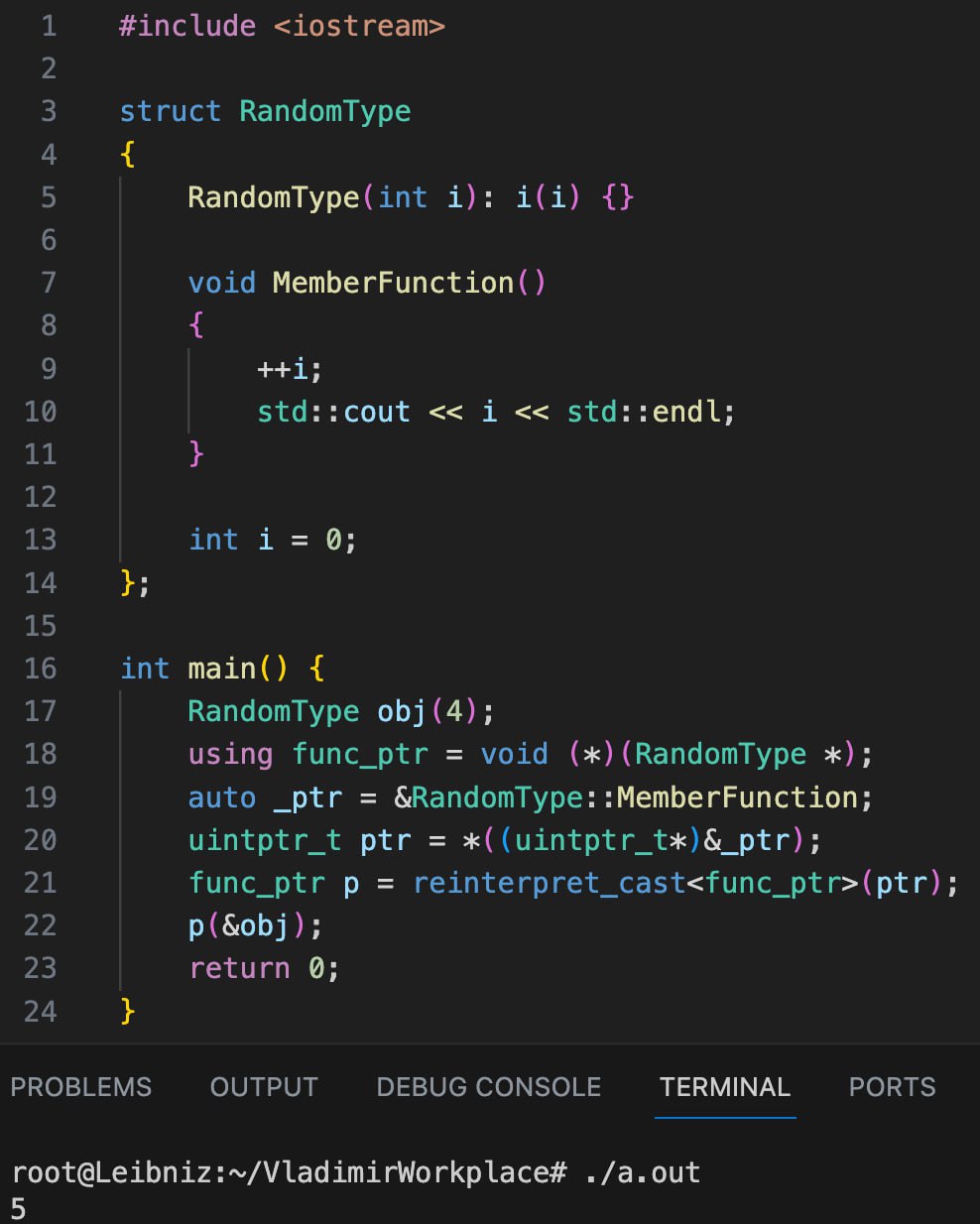
На этом я и закончил пробовать и пошел ресерчить. А снизу код, который у меня получился по итогам моих поисков. Все в духе С, ничего не понятно, одни указатели. Выглядит как фокус и по факту им и является. В следующий раз объясню, почему все так.
Stay hardcore. Stay cool.
#fun #hardcore #memory #cppcore
Настоящего плюсовика не должны пугать указатели на функции. И хоть в С++ есть нормальная обертка над всеми сущностями, которые можно исполнить - std::function - она довольно тяжеловесная и медленная. Да и с сишным апи с ней не поработаешь. К чему это я. Да. Указатели на функции. С ними, в целом, все просто.
int func() {
return 1;
}
using func_ptr = int (*) ();
func_ptr ptr = func;
std::cout << ptr();
Этот код со всеми обертками должен написать единичку на экран. С более сложными функциями сделать что-то похожее не составит труда. Но вот как насчет методов класса? Можно ли вызвать метод класса через указатель на него, а не через объект?
Ответ - можно. Но прежде чем посмотреть на рабочий код, попробуйте сами это сделать. Уверяю, что это не так тривиально)
Если читаете с телефона или нет времени, лучше вернитесь к этому посту после того, как попробуете сами. Эмоции будут совершенно другие)
Ну а для тех, кто уже попробовал или для ленивых дяденек, продолжаю.
Первое, что приходит на ум - такой же подход, как и с функциями.
auto ptr = RandomType::MemberFunction;
И тут же гцц плюнет вам в лицо с фразой error: invalid use of non-static member function ‘void RandomType::MemberFunction()’
auto ptr = RandomType::MemberFunction;
На этом я и закончил пробовать и пошел ресерчить. А снизу код, который у меня получился по итогам моих поисков. Все в духе С, ничего не понятно, одни указатели. Выглядит как фокус и по факту им и является. В следующий раз объясню, почему все так.
Stay hardcore. Stay cool.
#fun #hardcore #memory #cppcore
{kind=link}
🤯9❤3👍2🎄1