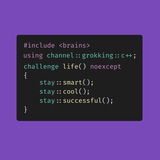
std::lock
#опытным
Сейчас уже более менее опытные разрабы знают про std::scoped_lock и как он решает проблему блокировки множества мьютексов. Однако и в более старом стандарте С++11 есть средство, позволяющее решать ту же самую проблему. Более того std::scoped_lock - это всего лишь более удобная обертка над этим средством. Итак, std::lock.
Эта функция блокирует 2 и больше объектов, чьи типы удовлетворяют требованию Locable. То есть для них определены методы lock(), try_lock() и unlock() с соответствующей семантикой.
Причем порядок, в котором блокируются объекты - не определен. В стандарте сказано, что объекты блокируются с помощью неопределенной серии вызовов методов lock(), try_lock и unlock(). Однако гарантируется, что эта серия вызовов не может привести к дедлоку. Собстна, для этого все и затевалось.
Штука эта полезная, но не очень удобная. Сами посудите. Эта функция просто блокирует объекты, но не отпускает их. И это в эпоху RAII. Ай-ай-ай.
Поэтому ее безопасное использование выглядит несколько вычурно:
Раз мы все-таки за безопасность и полезные практики, то нам приходится использовать std::unique_lock'и на мьютексах. Только нужно передать туда параметр std::defer_lock, который говорит, что не нужно локать замки при создании unique_lock'а, его залочит кто-то другой. Тем самым мы убиваем 2-х зайцев: и RAII используем для автоматического освобождения мьютексов, и перекладываем ответственность за блокировку замков на std::lock.
Можно использовать и более простую обертку, типа std::lock_guard:
Здесь мы тоже используем непопулярный конструктор std::lock_guard: передаем в него параметр std::adopt_lock, который говорит о том, что мьютекс уже захвачен и его не нужно локать в конструкторе lock_guard.
Можно и ручками вызвать .unlock() у каждого замка, но это не по-православному.
Использование unique_lock может быть оправдано соседством с условной переменной, но если вам доступен C++17, то естественно лучше использовать std::scoped_lock.
Use modern things. Stay cool.
#cpp11 #cpp17 #concurrency
#опытным
Сейчас уже более менее опытные разрабы знают про std::scoped_lock и как он решает проблему блокировки множества мьютексов. Однако и в более старом стандарте С++11 есть средство, позволяющее решать ту же самую проблему. Более того std::scoped_lock - это всего лишь более удобная обертка над этим средством. Итак, std::lock.
Эта функция блокирует 2 и больше объектов, чьи типы удовлетворяют требованию Locable. То есть для них определены методы lock(), try_lock() и unlock() с соответствующей семантикой.
Причем порядок, в котором блокируются объекты - не определен. В стандарте сказано, что объекты блокируются с помощью неопределенной серии вызовов методов lock(), try_lock и unlock(). Однако гарантируется, что эта серия вызовов не может привести к дедлоку. Собстна, для этого все и затевалось.
Штука эта полезная, но не очень удобная. Сами посудите. Эта функция просто блокирует объекты, но не отпускает их. И это в эпоху RAII. Ай-ай-ай.
Поэтому ее безопасное использование выглядит несколько вычурно:
struct SomeSharedResource {
void swap(SomeSharedResource& obj) {
{
// !!!
std::unique_lock<std::mutex> lk_c1(mtx, std::defer_lock);
std::unique_lock<std::mutex> lk_c2(obj.mtx, std::defer_lock);
std::lock(mtx, obj.mtx);
// handle swap
}
}
std::mutex mtx;
};
int main() {
SomeSharedResource resource1;
SomeSharedResource resource2;
std::mutex m2;
std::thread t1([&resource1, &resource2] {
resource1.swap(resource2);
std::cout << "1 Do some work" << std::endl;
});
std::thread t2([&resource1, &resource2] {
resource2.swap(resource1);
std::cout << "2 Do some work" << std::endl;
});
t1.join();
t2.join();
}Раз мы все-таки за безопасность и полезные практики, то нам приходится использовать std::unique_lock'и на мьютексах. Только нужно передать туда параметр std::defer_lock, который говорит, что не нужно локать замки при создании unique_lock'а, его залочит кто-то другой. Тем самым мы убиваем 2-х зайцев: и RAII используем для автоматического освобождения мьютексов, и перекладываем ответственность за блокировку замков на std::lock.
Можно использовать и более простую обертку, типа std::lock_guard:
struct SomeSharedResource {
void swap(SomeSharedResource& obj) {
{
// !!!
std::lock(mtx, obj.mtx);
std::lock_guard<std::mutex> lk_c1(mtx, std::adopt_lock);
std::lock_guard<std::mutex> lk_c2(obj.mtx, std::adopt_lock);
// handle swap
}
}
std::mutex mtx;
};Здесь мы тоже используем непопулярный конструктор std::lock_guard: передаем в него параметр std::adopt_lock, который говорит о том, что мьютекс уже захвачен и его не нужно локать в конструкторе lock_guard.
Можно и ручками вызвать .unlock() у каждого замка, но это не по-православному.
Использование unique_lock может быть оправдано соседством с условной переменной, но если вам доступен C++17, то естественно лучше использовать std::scoped_lock.
Use modern things. Stay cool.
#cpp11 #cpp17 #concurrency
{kind=link}
😁29🔥14👍7❤4
Порядок взятия замков. Ч1
#опытным
В этом посте я намеренно совершил одну ошибку, как байт на комменты и следующие посты. Но вы как-то пропустили ее, хотя и разбирали ту же самую тему в комментариях.
На самом деле залочивание мьютексов в одном и том же порядке - не общепринятая концепция решения проблемы блокировки множества замков. Это лишь одна из стратегий. И она не используется в стандартной библиотеке!
Когда-то у меня тоже была уверенность, что std::scoped_lock блочит мьютексы в порядоке их адресов. Условно, в начале лочим замок с меньшим адресом. Потом с большим и так далее.
Но как я и написал в середине того же поста, что std::scoped_lock вообще не гарантирует никакого порядка залочивания. Гарантируется только что такой порядок не может привести к дедлоку.
Давайте посмотрим на следующий пример:
Все довольно просто. Определяем класс-обертку вокруг std::mutex, который позволит нам логировать все операции с ним, указывая идентификатор потока. Определяем все методы, включая try_lock, чтобы MyLock можно было использовать с std::scoped_lock.
Также определяем 2 функции, которые будут запускаться в разных потоках и пытаться локнуть сразу 3 замка. И блокируют они их в разных порядках. Все это в циклах, чтобы какую-то статистику иметь. С потоками сложно детерминировано общаться.
Запускаем это дело и смотрим на вывод консоли. Там будет огромное полотно текста, но вы сможете заметить в нем "несостыковочку" с теорией про блокировку по адресам. Возможный кусочек вывода:
Тут наглядно показано, что мьютексы лочатся в противоположном порядке в разных потоках. И в коде мьютексы передаются в скоупд лок в противоположном порядке. А значит дело тут не в адресах, а в чем-то другом. О этом в следующий раз.
Don't get fooled. Stay cool.
#concurrency #cpp17
#опытным
В этом посте я намеренно совершил одну ошибку, как байт на комменты и следующие посты. Но вы как-то пропустили ее, хотя и разбирали ту же самую тему в комментариях.
Cтандартное решение этой проблемы дедлока из постов выше - лочить замки в одном и том же порядке во всех потоках.
На самом деле залочивание мьютексов в одном и том же порядке - не общепринятая концепция решения проблемы блокировки множества замков. Это лишь одна из стратегий. И она не используется в стандартной библиотеке!
Когда-то у меня тоже была уверенность, что std::scoped_lock блочит мьютексы в порядоке их адресов. Условно, в начале лочим замок с меньшим адресом. Потом с большим и так далее.
Но как я и написал в середине того же поста, что std::scoped_lock вообще не гарантирует никакого порядка залочивания. Гарантируется только что такой порядок не может привести к дедлоку.
Давайте посмотрим на следующий пример:
std::mutex log_mutex;
struct MyLock {
MyLock() = default;
void lock() {
mtx.lock();
std::lock_guard lg{log_mutex};
std::cout << "Lock at address " << &mtx << " is acquired." << std::endl;
}
bool try_lock() {
auto result = mtx.try_lock();
std::lock_guard lg{log_mutex};
std::cout << std::this_thread::get_id() << " Try lock at address " << &mtx << ". " << (result ? "Success" : "Failed") << std::endl;
return result;
}
void unlock() {
mtx.unlock();
std::lock_guard lg{log_mutex};
std::cout << "Lock at address " << &mtx << " is released." << std::endl;
}
private:
std::mutex mtx;
};
MyLock lock1;
MyLock lock2;
MyLock lock3;
constexpr size_t iteration_count = 100;
void func_thread1() {
size_t i = 0;
while(i++ < iteration_count) {
{
std::lock_guard lg{log_mutex};
std::cout << std::endl << std::this_thread::get_id() << " Start acquiring thread1" << std::endl << std::endl;
}
std::scoped_lock scl{lock1, lock2, lock3};
std::lock_guard lg{log_mutex};
std::cout << std::endl << std::this_thread::get_id() << " End acquiring thread1" << std::endl << std::endl;
}
}
void func_thread2() {
size_t i = 0;
while(i++ < iteration_count) {
{
std::lock_guard lg{log_mutex};
std::cout << std::endl << std::this_thread::get_id() << " Start acquiring thread2" << std::endl << std::endl;
}
std::scoped_lock scl{lock3, lock2, lock1};
std::lock_guard lg{log_mutex};
std::cout << std::endl << std::this_thread::get_id() << " End acquiring thread2" << std::endl << std::endl;
}
}
int main() {
std::jthread thr1{func_thread1};
std::jthread thr2{func_thread2};
}
Все довольно просто. Определяем класс-обертку вокруг std::mutex, который позволит нам логировать все операции с ним, указывая идентификатор потока. Определяем все методы, включая try_lock, чтобы MyLock можно было использовать с std::scoped_lock.
Также определяем 2 функции, которые будут запускаться в разных потоках и пытаться локнуть сразу 3 замка. И блокируют они их в разных порядках. Все это в циклах, чтобы какую-то статистику иметь. С потоками сложно детерминировано общаться.
Запускаем это дело и смотрим на вывод консоли. Там будет огромное полотно текста, но вы сможете заметить в нем "несостыковочку" с теорией про блокировку по адресам. Возможный кусочек вывода:
129777453237824 Start acquiring thread1
129777453237824 Lock at address 0x595886d571e0 is acquired.
129777453237824 Try lock at address 0x595886d57220
129777453237824 Try lock at address 0x595886d57260
...
129777442752064 Start acquiring thread2
129777442752064 Lock at address 0x595886d57260 is acquired.
129777442752064 Try lock at address 0x595886d57220
129777442752064 Try lock at address 0x595886d571e0
Тут наглядно показано, что мьютексы лочатся в противоположном порядке в разных потоках. И в коде мьютексы передаются в скоупд лок в противоположном порядке. А значит дело тут не в адресах, а в чем-то другом. О этом в следующий раз.
Don't get fooled. Stay cool.
#concurrency #cpp17
🔥11👍7❤5😱3
Порядок взятия замков. Ч2
#опытным
Так в каком же порядке блокируются мьютексы в std::scoped_lock? Как я уже и говорил - в неопределенном. Но и здесь можно немного раскрыть детали.
Mutex-like объекты блочатся недетерминированной серией вызовов методов lock(), unlock() и try_lock().
Алгоритм можно представить некой игрой в поддавки. Мы пытаемся поочереди захватить мьютексы. И если на каком-то из какой-то из них занят, то мы не ждем, пока он освободится. Мы освобождаем все свои мьютексы, давая возможность другим потокам их захватить, и после этого начинаем пытаться захватывать замки заново.
Зачем так сложно?
А просто физически не может произойти ситуации, когда два потока захватили по набору замков и ждут, пока другие освободятся(а это и есть дедлок). Один из потоков точно пожертвует захваченными ресурсами в пользу другого и исполнение продолжится.
При запуске кода из предыдущего поста вы можете увидеть вот такую картину(но не гарантирую):
Надо понимать, что это многопоточка и каких-то упорядоченных логов между потоками быть не может, поэтому надо немного напрячь извилины.
(0x56aef94a31e0 - первый мьютекс, 0x56aef94a3220 - второй, 0x56aef94a3260 - третий)
Смотрим. Поток 128616222426688 локает первый замок, пытается локнуть второй и делает это успешно, а вот третий не получается. Значит он освобождает свои два и пытается начать заново. Дальше видим такую же картину - на третьем мьютексе try_lock прошел неудачно -> освобождаем имеющиеся.
Тут просыпается второй поток 128616211940928. И пишет, что он сразу заполучил третий замок.
То есть поток 128616222426688 пожертвовал своими захваченными замками в пользу потока 128616211940928.
Вот так выглядит реализация функции std::lock(которая лежит под капотом std::scoped_lock) в gcc:
Кто сможет - разберется, но что тут происходит в сущности - я описал выше.
Give something up to get something else. Stay cool.
#concurrency #cpp17
#опытным
Так в каком же порядке блокируются мьютексы в std::scoped_lock? Как я уже и говорил - в неопределенном. Но и здесь можно немного раскрыть детали.
The objects are locked by an unspecified series of calls tolock,try_lock, andunlock.
Mutex-like объекты блочатся недетерминированной серией вызовов методов lock(), unlock() и try_lock().
Алгоритм можно представить некой игрой в поддавки. Мы пытаемся поочереди захватить мьютексы. И если на каком-то из какой-то из них занят, то мы не ждем, пока он освободится. Мы освобождаем все свои мьютексы, давая возможность другим потокам их захватить, и после этого начинаем пытаться захватывать замки заново.
Зачем так сложно?
А просто физически не может произойти ситуации, когда два потока захватили по набору замков и ждут, пока другие освободятся(а это и есть дедлок). Один из потоков точно пожертвует захваченными ресурсами в пользу другого и исполнение продолжится.
При запуске кода из предыдущего поста вы можете увидеть вот такую картину(но не гарантирую):
128616222426688 Lock at address 0x56aef94a31e0 is acquired.
128616222426688 Try lock at address 0x56aef94a3220. Success
128616222426688 Try lock at address 0x56aef94a3260. Failed
128616222426688 Lock at address 0x56aef94a3220 is released.
128616222426688 Lock at address 0x56aef94a31e0 is released.
128616222426688 Lock at address 0x56aef94a31e0 is acquired.
128616222426688 Try lock at address 0x56aef94a3220. Success
128616222426688 Try lock at address 0x56aef94a3260. Failed
128616222426688 Lock at address 0x56aef94a3220 is released.
128616211940928 Lock at address 0x56aef94a3260 is acquired.
128616211940928 Try lock at address 0x56aef94a3220. Success
128616211940928 Try lock at address 0x56aef94a31e0. Success
Надо понимать, что это многопоточка и каких-то упорядоченных логов между потоками быть не может, поэтому надо немного напрячь извилины.
(0x56aef94a31e0 - первый мьютекс, 0x56aef94a3220 - второй, 0x56aef94a3260 - третий)
Смотрим. Поток 128616222426688 локает первый замок, пытается локнуть второй и делает это успешно, а вот третий не получается. Значит он освобождает свои два и пытается начать заново. Дальше видим такую же картину - на третьем мьютексе try_lock прошел неудачно -> освобождаем имеющиеся.
Тут просыпается второй поток 128616211940928. И пишет, что он сразу заполучил третий замок.
На самом деле он заблочил его еще до начала этой ситуации, так как первый поток не мог залочить третий мьютекс. Просто поток 128616211940928 уснул между локом и выводом на консоль. И дальше пытается захватить второй и первый замки и у него это успешно получается.То есть поток 128616222426688 пожертвовал своими захваченными замками в пользу потока 128616211940928.
Вот так выглядит реализация функции std::lock(которая лежит под капотом std::scoped_lock) в gcc:
template<typename _L1, typename _L2, typename... _L3>
void lock(_L1& __l1, _L2& __l2, _L3&... __l3)
{
#if __cplusplus >= 201703L
if constexpr (is_same_v<_L1, _L2> && (is_same_v<_L1, _L3> && ...))
{
constexpr int _Np = 2 + sizeof...(_L3);
unique_lock<_L1> __locks[] = {
{__l1, defer_lock}, {__l2, defer_lock}, {__l3, defer_lock}...
};
int __first = 0;
do {
__locks[__first].lock();
for (int __j = 1; __j < _Np; ++__j)
{
const int __idx = (__first + __j) % _Np;
if (!__locks[__idx].try_lock())
{
for (int __k = __j; __k != 0; --__k)
__locks[(__first + __k - 1) % _Np].unlock();
__first = __idx;
break;
}
}
} while (!__locks[__first].owns_lock());
for (auto& __l : __locks)
__l.release();
}
else
#endif
{
int __i = 0;
__detail::__lock_impl(__i, 0, __l1, __l2, __l3...);
}
}
Кто сможет - разберется, но что тут происходит в сущности - я описал выше.
Give something up to get something else. Stay cool.
#concurrency #cpp17
{kind=link}
❤16👍11🔥8🤯6
Почему не используют стратегию блокировки по адресам?
#опытным
Точного ответа от разработчиков стандартной библиотеки мы не услышим, но я приведу некоторые рассуждения, которые могут натолкнуть на некоторые мысли.
Начнем с того, что локать один мьютекс - это норма. Все так делают, никто от этого не помер.
Проблемы и эти ваши дедлоки начинаются только тогда, когда поток по какой-то причине блокируется с уже захваченным локом.
А именно это и происходит при вызове метода lock(). Поток мытается захватить мьютекс и если не получается - блокируется до того момента, пока мьютекс не освободится.
Поэтому любая схема с последовательным вызовом методов lock() будет подвержена дедлокам.
А в схеме с упорядоченным по адресам блокировкой именно так и происходит.
Да, эта схема безопасна, если все мьютексы будут захватываться только так. Но в реальных системах все намного сложнее.
А что если в одном потоке замки будут лочиться через scoped_lock по адресной схеме, а в другом потоке - одиночно?
В этом случае настанет дедлок. Спасибо за пример Сергею Борисову.
Ну или другую ситуацию рассмотрим: есть 4 замка l1, l2, l3, l4. Поток захватил замок с самым большим адресом l4 и надолго(потенциально навсегда) заблокировался.
Но другие треды продолжают нормально работать. И они иногда захватывают пары мьютексов. Все продолжается нормально, пока один из потоков не пытается залочить l3 и l4. Из-за ордеринга захватится l3, а дальше поток будет ждать освобождения l4 aka заблокируется. Дальше другой поток будет пытаться захватить l2 и l3. Он захватит l2 и будет дожидаться l3.
Логику можно продолжать и дальше. Таким образом из-за одного мьютекса и немного поломанного потока может остановиться вся программа.
Примеры немного преувеличены, но тем не менее они говорят о том, что схема с адресами не совсем безопасна.
Так может тогда вообще не будем блокироваться при уже захваченном мьютексе? Именно это и делают в реализации стандартной библиотеки. Первый захват мьютекса происходит через обычный lock(), а остальные мьютексы пытаются заблокировать через try_lock. Можно сказать, что это lock-free взятие замка. Если мьютекс можно захватить - захватываем, если нет, то не блокируемся и дальше продолжаем исполнение. Так вот в случае, если хотя бы один try_lock для оставшихся замков вернул false, то реализация освобождает все захваченные замки и начинает попытку снова.
Такой алгоритм позволит избежать неприятных последствий обеих ситуаций, представленных выше.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
#concurrency
#опытным
Точного ответа от разработчиков стандартной библиотеки мы не услышим, но я приведу некоторые рассуждения, которые могут натолкнуть на некоторые мысли.
Начнем с того, что локать один мьютекс - это норма. Все так делают, никто от этого не помер.
Проблемы и эти ваши дедлоки начинаются только тогда, когда поток по какой-то причине блокируется с уже захваченным локом.
А именно это и происходит при вызове метода lock(). Поток мытается захватить мьютекс и если не получается - блокируется до того момента, пока мьютекс не освободится.
Поэтому любая схема с последовательным вызовом методов lock() будет подвержена дедлокам.
А в схеме с упорядоченным по адресам блокировкой именно так и происходит.
Да, эта схема безопасна, если все мьютексы будут захватываться только так. Но в реальных системах все намного сложнее.
А что если в одном потоке замки будут лочиться через scoped_lock по адресной схеме, а в другом потоке - одиночно?
1 поток | 2 поток |
-------------------------------|---------------------------------|
lock(mutex2) // УСПЕШНО | |
| scoped_lock() |
| lock(mutex1) // УСПЕШНО |
| lock(mutex2) // ОЖИДАНИЕ ... |
lock(mutex1) // ОЖИДАНИЕ... | |
В этом случае настанет дедлок. Спасибо за пример Сергею Борисову.
Ну или другую ситуацию рассмотрим: есть 4 замка l1, l2, l3, l4. Поток захватил замок с самым большим адресом l4 и надолго(потенциально навсегда) заблокировался.
Но другие треды продолжают нормально работать. И они иногда захватывают пары мьютексов. Все продолжается нормально, пока один из потоков не пытается залочить l3 и l4. Из-за ордеринга захватится l3, а дальше поток будет ждать освобождения l4 aka заблокируется. Дальше другой поток будет пытаться захватить l2 и l3. Он захватит l2 и будет дожидаться l3.
Логику можно продолжать и дальше. Таким образом из-за одного мьютекса и немного поломанного потока может остановиться вся программа.
std::mutex l1, l2, l3, l4;
// Пусть я как-то гарантирую, что они пронумерованы в порядке
возрастания адресов и std::scoped_lock(sc_lock для краткости)
работает с помощью сортировки по адресам
1 поток | 2 поток | 3 поток | 4 поток
-------------|----------------|----------------|----------------
l4.lock(); | | |
//blocks here| | |
|sc_lock(l3, l4);| |
| // lock l3 | |
| // blocks on l4| |
|sc_lock(l2, l3);|
| // lock l2 |
| // blocks on l3|
| | sc_lock(l1, l2);
| // lock l1
| // blocks on l2
Примеры немного преувеличены, но тем не менее они говорят о том, что схема с адресами не совсем безопасна.
Так может тогда вообще не будем блокироваться при уже захваченном мьютексе? Именно это и делают в реализации стандартной библиотеки. Первый захват мьютекса происходит через обычный lock(), а остальные мьютексы пытаются заблокировать через try_lock. Можно сказать, что это lock-free взятие замка. Если мьютекс можно захватить - захватываем, если нет, то не блокируемся и дальше продолжаем исполнение. Так вот в случае, если хотя бы один try_lock для оставшихся замков вернул false, то реализация освобождает все захваченные замки и начинает попытку снова.
Такой алгоритм позволит избежать неприятных последствий обеих ситуаций, представленных выше.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
#concurrency
❤15👍15🔥5😱2🫡1
Еще один способ залочить много мьютексов
Последний пост из серии.
Вот у мьютекса есть метод lock, который его захватывает. А разработчики stdlib взяли и сделали функцию std::lock, которая лочит сразу несколько замков.
Также у мьютекса есть метод try_lock, который пытается в неблокирующем режиме его захватить. "Авось да получится". И видимо по аналогии с lock в стандартной библиотеке существует свободная функция std::try_lock, которая пытается захватить несколько мьютексов так же в неблокирующем режиме.
То есть в этой функции банально в цикле на каждом из переданных аргументов вызывается try_lock и, если какой-то из вызовов завершился неудачно, то все занятые замки освобождаются и возвращается индекс мьютекса, на котором выполнение зафейлилось. Если все завершилось успешно aka все замки захвачены, возвращается -1.
Чтобы с помощью std::try_lock наверняка захватить все замки, нужно крутиться в горячем цикле и постоянно вызывать std::try_lock, пока она не вернет -1.
Непонятно, зачем эта функция нужна в прикладном программировании при наличии std::scoped_lock и std::lock, которые еще и удобно оборачивают все эти циклы, скрывая все эти кишки в деталях реализации.
Единственное, что пришло в голову - реализация своего scoped_lock'а с блэкджеком и другим алгоритмом предотвращения дедлока. Этот алгоритм должен быть чем-то похож на поддавки, но как-то изменен. У кого есть кейсы применения - отпишитесь в комменты.
В общем, на мой взгляд, это пример избыточного апи. Если человек сам что-то свое мудрит, то ему особо не сложно самому цикл написать. Однако обычные пользователи стандартных примитивов синхронизации возможно никогда в своей жизни этого не применят. Все-таки стандартная библиотека должна быть сборником решения актуальных проблем реальных, а не воображаемых,людей.
Stay useful. Stay cool.
#concurrency
Последний пост из серии.
Вот у мьютекса есть метод lock, который его захватывает. А разработчики stdlib взяли и сделали функцию std::lock, которая лочит сразу несколько замков.
Также у мьютекса есть метод try_lock, который пытается в неблокирующем режиме его захватить. "Авось да получится". И видимо по аналогии с lock в стандартной библиотеке существует свободная функция std::try_lock, которая пытается захватить несколько мьютексов так же в неблокирующем режиме.
template< class Lockable1, class Lockable2, class... LockableN >
int try_lock( Lockable1& lock1, Lockable2& lock2, LockableN&... lockn );
То есть в этой функции банально в цикле на каждом из переданных аргументов вызывается try_lock и, если какой-то из вызовов завершился неудачно, то все занятые замки освобождаются и возвращается индекс мьютекса, на котором выполнение зафейлилось. Если все завершилось успешно aka все замки захвачены, возвращается -1.
Чтобы с помощью std::try_lock наверняка захватить все замки, нужно крутиться в горячем цикле и постоянно вызывать std::try_lock, пока она не вернет -1.
Непонятно, зачем эта функция нужна в прикладном программировании при наличии std::scoped_lock и std::lock, которые еще и удобно оборачивают все эти циклы, скрывая все эти кишки в деталях реализации.
Единственное, что пришло в голову - реализация своего scoped_lock'а с блэкджеком и другим алгоритмом предотвращения дедлока. Этот алгоритм должен быть чем-то похож на поддавки, но как-то изменен. У кого есть кейсы применения - отпишитесь в комменты.
В общем, на мой взгляд, это пример избыточного апи. Если человек сам что-то свое мудрит, то ему особо не сложно самому цикл написать. Однако обычные пользователи стандартных примитивов синхронизации возможно никогда в своей жизни этого не применят. Все-таки стандартная библиотека должна быть сборником решения актуальных проблем реальных, а не воображаемых,людей.
Stay useful. Stay cool.
#concurrency
{kind=link}
❤17🔥9👍6❤🔥3😁1
std::jthread
С std::thread в С++ есть один интересный и возможно назойливый нюанс. Давайте посмотрим на код:
Простой Хелло Ворлд в другом потоке. Но при запуске программы она тут же завершится примерно с таким сообщением:
Эм. "Я же просто хотелбыть счастливым вывести в другом потоке сообщение. Неужели просто так не работает?"
В плюсах много чего просто так не работает)
А вот такая программа:
Все-таки напечатает Hello, World!, но потом все равно завершится с std::terminate.
Уже лучше, но осадочек остался. Ничего не понятно. Давайте разбираться.
С помощью слипа мы немного затормозили main тред и сообщение появилось. То есть мы оттянули выход из main и завершение программы и дали возможность подольше поработать новосозданному потоку. А что происходит при выходе из скоупа функции? Вызов деструкторов локальных объектов.
Так вот в деструкторе единственного локального объекта и проблема. Согласно документации, для каждого потока мы обязательно должны выбрать одну из 2-х стратегий поведения: отсоединить его от родительского потока или дождаться его завершения. Делается это методами detach и join соответственно.
И если мы не вызовем один из этих методов для объекта потока, то в своем деструкторе он вызовет std::terminate. То есть корректный код выглядит так:
Мы дожидаемся конца исполнения потока и только после этого завершаем программу. Теперь никаких терминаторов.
Но зачем эти формальности? Вообще говоря, часто мы хотим присоединить поток почти сразу перед вызовом его деструктора. А вот отсоединяем поток мы почти сразу после создания объекта. Мы же заранее знаем, хотим ли мы отпустить поток в свободное плавание или нет. И, учитывая эти факты, было бы приятно иметь возможность не вызывать join самостоятельно, а чтобы он за нас вызывался в деструкторе.
И С++20 приходит здесь нам на помощь с помощью std::jthread. Он делает ровно это. Если его не освободили и не присоединили мануально, то он присоединяется в деструкторе.
Поэтому такой код сделает то, что мы ожидаем:
jthread не только этим хорош. Его исполнение можно еще отменять/приостанавливать. Но об этом уже в другой раз.
Кстати. Вопрос на засыпку. Слышал, что там какие-то сложности у кланга с jthread были. Сейчас все нормально работает?
Make life easier. Stay cool.
#cpp20 #concurrency
С std::thread в С++ есть один интересный и возможно назойливый нюанс. Давайте посмотрим на код:
int main()
{
std::thread thr{[]{ std::cout << "Hello, World!" << std::endl;}};
}
Простой Хелло Ворлд в другом потоке. Но при запуске программы она тут же завершится примерно с таким сообщением:
terminate called without an active exception.Эм. "Я же просто хотел
В плюсах много чего просто так не работает)
А вот такая программа:
int main()
{
std::thread thr{[]{ std::cout << "Hello, World!" << std::endl;}};
std::this_thread::sleep_for(std::chrono::seconds(1));
}
Все-таки напечатает Hello, World!, но потом все равно завершится с std::terminate.
Уже лучше, но осадочек остался. Ничего не понятно. Давайте разбираться.
С помощью слипа мы немного затормозили main тред и сообщение появилось. То есть мы оттянули выход из main и завершение программы и дали возможность подольше поработать новосозданному потоку. А что происходит при выходе из скоупа функции? Вызов деструкторов локальных объектов.
Так вот в деструкторе единственного локального объекта и проблема. Согласно документации, для каждого потока мы обязательно должны выбрать одну из 2-х стратегий поведения: отсоединить его от родительского потока или дождаться его завершения. Делается это методами detach и join соответственно.
И если мы не вызовем один из этих методов для объекта потока, то в своем деструкторе он вызовет std::terminate. То есть корректный код выглядит так:
int main()
{
std::thread thr{[]{ std::cout << "Hello, World!" << std::endl;}};
thr.join();
}
Мы дожидаемся конца исполнения потока и только после этого завершаем программу. Теперь никаких терминаторов.
Но зачем эти формальности? Вообще говоря, часто мы хотим присоединить поток почти сразу перед вызовом его деструктора. А вот отсоединяем поток мы почти сразу после создания объекта. Мы же заранее знаем, хотим ли мы отпустить поток в свободное плавание или нет. И, учитывая эти факты, было бы приятно иметь возможность не вызывать join самостоятельно, а чтобы он за нас вызывался в деструкторе.
И С++20 приходит здесь нам на помощь с помощью std::jthread. Он делает ровно это. Если его не освободили и не присоединили мануально, то он присоединяется в деструкторе.
Поэтому такой код сделает то, что мы ожидаем:
int main()
{
std::jthread thr{[]{ std::cout << "Hello, World!" << std::endl;}};
}
jthread не только этим хорош. Его исполнение можно еще отменять/приостанавливать. Но об этом уже в другой раз.
Кстати. Вопрос на засыпку. Слышал, что там какие-то сложности у кланга с jthread были. Сейчас все нормально работает?
Make life easier. Stay cool.
#cpp20 #concurrency
{kind=link}
🔥30👍20❤🔥6❤4😁1
RAII обертки мьютекса
#новичкам
Иногда замечаю, что неопытные либо вообще не используют raii обертки над замками, либо используют их неправильно. Давайте сегодня разберемся с этим вопросом.
Для начала - для работы с мьютексами нужны обертки. Очень некрасиво в наше время использовать чистые вызовы lock и unlock. Это наплевательское отношение к современному и безопасному(посмеемся) С++.
Здесь прямая аналогия с выделением памяти. Для каждого new нужно вызывать соответствующий delete. Чтобы случайно не забыть этого сделать(а в большом объеме кода что-то забыть вообще не проблема), используют умные указатели. Это классы, используя концепцию Resource Acquisition Is Initialization, помогают нам автоматически освобождать ресурсы, когда они нам более не нужны.
Также для каждого lock нужно вызвать unlock. Так может по аналогии сделаем класс, который в конструкторе будет лочить мьютекс, а в деструкторе - разблокировать его?
Хорошая новость в том, что это уже сделали за нас. И таких классов даже несколько. Если не уходить в специфическую функциональность, то их всего 2. Это std::lock_guard и std::unique_lock.
lock_guard - базовая и самая простая обертка. В конструкторе лочим, в деструкторе разлачиваем. И все. Больше ничего мы с ним делать не можем. Мы можем только создать объект и удалить его. Даже получить доступ к самому мьютексу нельзя. Очень лаконичный и безопасный интерфейс. Но и юзкейсы его применения довольно ограничены. Нужна простая критическая секция. Обезопасил и идешь дальше.
unique_lock же больше походит на std::unique_ptr. Уже можно получить доступ в объекты, поменяться содержимым с другим объектом unique_lock, поменять нижележащий объект на другой. Ну и раз мы все равно даем возможность пользователю получить доступ к нижележащему объекту, то удобно вынести в публичный интерфейс unique_lock те же методы, которыми можно управлять самим мьютексом. То есть lock, unlock, try_lock и тд - это часть интерфейса std::unique_lock.
Уже понятно, что этот вид обертки нужно использовать в более сложных случаях, когда функциональности lock_guard не хватает.
А в основном не хватает возможности использовать методы lock и unlock. Например, при работе в кондварами std::unique_lock просто необходим. Читатель заходит в критическую секцию, локает замок и затем видит, что определенные условия еще не наступили. Допустим еще нет данных для чтения. В такой ситуации надо отпустить мьютекс и заснуть до лучших времен. А при пробуждении и наступлении подходящих условий, опять залочить замок и начать делать работу.
Кондвар в методе wait при ложном условии вызывает unlock у unique_lock. При пробуждении и правдивом условии вызывает lock и ждет освобождения мьютекса.
Юзкейсы можно обсуждать очень долго, но вывод один: всегда используйте обертки над мьютексами! Возможно, они спасут вашу жизнь.
А уж какую обертку использовать подскажет сама задача.
Stay safe. Stay cool.
#concurrency
#новичкам
Иногда замечаю, что неопытные либо вообще не используют raii обертки над замками, либо используют их неправильно. Давайте сегодня разберемся с этим вопросом.
Для начала - для работы с мьютексами нужны обертки. Очень некрасиво в наше время использовать чистые вызовы lock и unlock. Это наплевательское отношение к современному и безопасному(посмеемся) С++.
Здесь прямая аналогия с выделением памяти. Для каждого new нужно вызывать соответствующий delete. Чтобы случайно не забыть этого сделать(а в большом объеме кода что-то забыть вообще не проблема), используют умные указатели. Это классы, используя концепцию Resource Acquisition Is Initialization, помогают нам автоматически освобождать ресурсы, когда они нам более не нужны.
Также для каждого lock нужно вызвать unlock. Так может по аналогии сделаем класс, который в конструкторе будет лочить мьютекс, а в деструкторе - разблокировать его?
Хорошая новость в том, что это уже сделали за нас. И таких классов даже несколько. Если не уходить в специфическую функциональность, то их всего 2. Это std::lock_guard и std::unique_lock.
lock_guard - базовая и самая простая обертка. В конструкторе лочим, в деструкторе разлачиваем. И все. Больше ничего мы с ним делать не можем. Мы можем только создать объект и удалить его. Даже получить доступ к самому мьютексу нельзя. Очень лаконичный и безопасный интерфейс. Но и юзкейсы его применения довольно ограничены. Нужна простая критическая секция. Обезопасил и идешь дальше.
bool MapInsertSafe(std::unordered_map<Key, Value>& map, const Key& key, Value value) {
std::lock_guard lck(mtx);
if (auto it = map.find(key))
return false;
else {
it->second = std::move(value);
return true;
}
}
unique_lock же больше походит на std::unique_ptr. Уже можно получить доступ в объекты, поменяться содержимым с другим объектом unique_lock, поменять нижележащий объект на другой. Ну и раз мы все равно даем возможность пользователю получить доступ к нижележащему объекту, то удобно вынести в публичный интерфейс unique_lock те же методы, которыми можно управлять самим мьютексом. То есть lock, unlock, try_lock и тд - это часть интерфейса std::unique_lock.
Уже понятно, что этот вид обертки нужно использовать в более сложных случаях, когда функциональности lock_guard не хватает.
А в основном не хватает возможности использовать методы lock и unlock. Например, при работе в кондварами std::unique_lock просто необходим. Читатель заходит в критическую секцию, локает замок и затем видит, что определенные условия еще не наступили. Допустим еще нет данных для чтения. В такой ситуации надо отпустить мьютекс и заснуть до лучших времен. А при пробуждении и наступлении подходящих условий, опять залочить замок и начать делать работу.
void worker_thread()
{
std::unique_lock lk(m);
cv.wait(lk, []{ return ready; });
// process data
lk.unlock();
}
Кондвар в методе wait при ложном условии вызывает unlock у unique_lock. При пробуждении и правдивом условии вызывает lock и ждет освобождения мьютекса.
Юзкейсы можно обсуждать очень долго, но вывод один: всегда используйте обертки над мьютексами! Возможно, они спасут вашу жизнь.
А уж какую обертку использовать подскажет сама задача.
Stay safe. Stay cool.
#concurrency
{kind=link}
👍28🔥13❤6😁3
Еще один плюс RAII
#опытным
Основная мотивации использования raii - вам не нужно думать об освобождении ресурсов. Мол ручное управление ресурсами небезопасно, так как можно забыть освободить их и вообще не всегда понятно, когда это нужно делать.
Но не все всегда зависит от вашего понимания программы. Вы можете в правильных местах расставить все нужные освобождения, но код будет все равно небезопасен. В чем проблема? В исключениях.
Это такие противные малявки, которые прерывают нормальное выполнение программы в исключительных ситуациях. Так вот вы рассчитываете на "нормальное выполнение программы" и, исходя из этого, расставляете освобождения. А тут бац! И программа просто не доходит до нужной строчки.
Простой код запроса к базе с кэшом. Что будет в том случае, если метод Select бросит исключение? unlock никогда не вызовется и мьютекс коннектора к базе будет навсегда залочен! Это очень печально, потому что ни один поток больше не сможет получить доступ к критической секции. Даже может произойти deadlock текущего потока, если он еще раз попытается захватить этот мьютекс. А это очень вероятно, потому что на запросы к базе скорее всего есть ретраи.
Мы могли бы сделать обработку исключений и руками разлочить замок:
Однако самое обидное, что исключения, связанные с работой с базой, мы даже обработать не может внутри метода SelectWithCache. Это просто не его компетенция и код сверху некорректен с этой точки зрения.
А снаружи метода объекта мы уже не сможем разблокировать мьютекс при обработке исключения, потому что это приватное поле.
Выход один - использовать RAII.
При захвате исключения происходит раскрутка стека и вызов деструкторов локальных объектов. Это значит, что в любом случае вызовется деструктор lg и мьютекс освободится.
Спасибо Михаилу за идею)
Stay safe. Stay cool.
#cpp11 #concurrency #cppcore #goodpractice
#опытным
Основная мотивации использования raii - вам не нужно думать об освобождении ресурсов. Мол ручное управление ресурсами небезопасно, так как можно забыть освободить их и вообще не всегда понятно, когда это нужно делать.
Но не все всегда зависит от вашего понимания программы. Вы можете в правильных местах расставить все нужные освобождения, но код будет все равно небезопасен. В чем проблема? В исключениях.
Это такие противные малявки, которые прерывают нормальное выполнение программы в исключительных ситуациях. Так вот вы рассчитываете на "нормальное выполнение программы" и, исходя из этого, расставляете освобождения. А тут бац! И программа просто не доходит до нужной строчки.
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
mtx_.lock();
if (auto it = cache.find(key); it != cache_.end()) {
mtx_.unlock();
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
mtx_.unlock();
return result;
}
}Простой код запроса к базе с кэшом. Что будет в том случае, если метод Select бросит исключение? unlock никогда не вызовется и мьютекс коннектора к базе будет навсегда залочен! Это очень печально, потому что ни один поток больше не сможет получить доступ к критической секции. Даже может произойти deadlock текущего потока, если он еще раз попытается захватить этот мьютекс. А это очень вероятно, потому что на запросы к базе скорее всего есть ретраи.
Мы могли бы сделать обработку исключений и руками разлочить замок:
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
try {
mtx_.lock();
if (auto it = cache.find(key); it != cache_.end()) {
mtx_.unlock();
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
mtx_.unlock();
return result;
}
}
catch (...) {
Log("Caught an exception");
mtx_.unlock();
}
}Однако самое обидное, что исключения, связанные с работой с базой, мы даже обработать не может внутри метода SelectWithCache. Это просто не его компетенция и код сверху некорректен с этой точки зрения.
А снаружи метода объекта мы уже не сможем разблокировать мьютекс при обработке исключения, потому что это приватное поле.
Выход один - использовать RAII.
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
std::lock_guard lg{mtx_};
if (auto it = cache.find(key); it != cache_.end()) {
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
return result;
}
}При захвате исключения происходит раскрутка стека и вызов деструкторов локальных объектов. Это значит, что в любом случае вызовется деструктор lg и мьютекс освободится.
Спасибо Михаилу за идею)
Stay safe. Stay cool.
#cpp11 #concurrency #cppcore #goodpractice
{kind=link}
🔥33👍12❤6⚡2
Потокобезопасный интерфейс
#новичкам
Не для всех очевидная новость: не всегда можно превратить класс из небезопасного в потокобезопасный, просто по уши обложившись лок гардами. Да, вызов конкретного метода будет безопасен. Но это не значит, что классом безопасно пользоваться.
Возьмем максимально простую реализацию самой простой очереди:
Она конечно потокоНЕбезопасная. То есть ей можно адекватно пользоваться только в рамках одного потока.
Как может выглядеть код простого консьюмера этой очереди?
И вот мы захотели разделить обязанности производителя чисел и их потребителя между разными потокам. Значит, нам надо как-то защищать очередь от многопоточных неприятностей.
Бабахаем везде лок гард на один мьютекс и дело в шляпе!
Все доступы к очереди защищены. Но спасло ли реально это нас?
Вернемся к коду консюмера:
А вдруг у нас появится еще один консюмер? Тогда в первом из них мы можем войти условие, а в это время второй достанет последний элемент. Получается, что мы получим доступ к неинициализированной памяти в методе front.
То есть по факту в многопоточном приложении полученный стейт сущности сразу же утрачивает свою актуальность.
Что делать? Не только сами методы класса должны быть потокобезопасными. Но еще и комбинации использования этих методов тоже должны обладать таким свойством. И с данным интерфейсом это сделать просто невозможно.
Если стейт утрачивает актуальность, то мы вообще не должны давать возможность приложению получать стейт очереди. Нам нужны только команды управления. То есть push и pop.
Внутри метода
Теперь консюмер выглядит так:
Можно конечно было использовать кондвары и прочее. Но я хотел сфокусироваться именно на интерфейсе. Теперь реализация просто не позволяет получать пользователю потенциально неактульные данные.
Stay safe. Stay cool.
#concurrency #design #goodpractice
#новичкам
Не для всех очевидная новость: не всегда можно превратить класс из небезопасного в потокобезопасный, просто по уши обложившись лок гардами. Да, вызов конкретного метода будет безопасен. Но это не значит, что классом безопасно пользоваться.
Возьмем максимально простую реализацию самой простой очереди:
struct Queue {
void push(int value) {
storage.push_back(value);
}
void pop() {
storage.pop_front();
}
bool empty() {
return storage.empty();
}
int& front() {
return storage.front();
}
private:
std::deque<int> storage;
};Она конечно потокоНЕбезопасная. То есть ей можно адекватно пользоваться только в рамках одного потока.
Как может выглядеть код простого консьюмера этой очереди?
while(condition)
if (!queue.empty()) {
auto & elem = queue.front();
process_elem(elem);
queue.pop();
}
И вот мы захотели разделить обязанности производителя чисел и их потребителя между разными потокам. Значит, нам надо как-то защищать очередь от многопоточных неприятностей.
Бабахаем везде лок гард на один мьютекс и дело в шляпе!
struct Queue {
void push(int value) {
std::lock_guard lg{m};
storage.push_back(value);
}
void pop() {
std::lock_guard lg{m};
storage.pop_front();
}
bool empty() {
std::lock_guard lg{m};
return storage.empty();
}
int& front() {
std::lock_guard lg{m};
return storage.front();
}
private:
std::deque<int> storage;
std::mutex m;
};Все доступы к очереди защищены. Но спасло ли реально это нас?
Вернемся к коду консюмера:
while(true)
if (!queue.empty()) {
auto & elem = queue.front();
process_elem(elem);
queue.pop();
}
А вдруг у нас появится еще один консюмер? Тогда в первом из них мы можем войти условие, а в это время второй достанет последний элемент. Получается, что мы получим доступ к неинициализированной памяти в методе front.
То есть по факту в многопоточном приложении полученный стейт сущности сразу же утрачивает свою актуальность.
Что делать? Не только сами методы класса должны быть потокобезопасными. Но еще и комбинации использования этих методов тоже должны обладать таким свойством. И с данным интерфейсом это сделать просто невозможно.
Если стейт утрачивает актуальность, то мы вообще не должны давать возможность приложению получать стейт очереди. Нам нужны только команды управления. То есть push и pop.
struct ThreadSafeQueue {
void push(int value) {
std::lock_guard lg{m};
storage.push_back(value);
}
std::optional<int> pop() {
std::lock_guard lg{m};
if (!storage.empty()) {
int elem = storage.front();
storage.pop_front();
return elem;
}
return nullopt;
}
private:
std::deque<int> storage;
std::mutex m;
};Внутри метода
pop мы можем использовать проверять и получать стейт очереди, так как мы оградились локом. Возвращаем из него std::optional, который будет хранить фронтальный элемент, если очередь была непуста. В обратном случае он будет пуст.Теперь консюмер выглядит так:
while(true) {
auto elem = queue.pop();
if (elem)
process_elem(elem.value());
}Можно конечно было использовать кондвары и прочее. Но я хотел сфокусироваться именно на интерфейсе. Теперь реализация просто не позволяет получать пользователю потенциально неактульные данные.
Stay safe. Stay cool.
#concurrency #design #goodpractice
{kind=link}
10👍42🔥11❤7😁2🤔1
Ответ
#опытным
Правильный ответ на квиз из предыдущего поста- 0. Вообще ни одного мьютекса не нужно.
Много можно вариантов придумать. И даже в комментах написали несколько рабочих способов.
Вообще говоря, в определении дедлока не звучит слово "мьютекс". Потоки должны ждать освобождения ресурсов. А этими ресурсами может быть что угодно.
Для организации дедлока достаточно просто, чтобы 2 потока запустились в попытке присоединить друг друга. Естественно, что они будут бесконечно ждать окончания работы своего визави.
Однако не совсем очевидно, как это организовать. Вот мы определяем первый объект потока и его надо запустить с функцией, которая ждем еще не существующего потока.
Заметьте, что мы пытаемся сделать грязь. Так давайте же применим самые опасные вещи из плюсов и у нас все получится! Надо лишь добавить 50 грамм указателей и чайную ложку глобальных переменных. Получается вот такая каша:
Все просто. Вводим глобальный указатель на поток. В функции первого потока мы даем время инициализировать указатель и присоединяем поток по указателю. А тем временем в main создаем динамический объект потока и записываем его по указателю t_ptr. Таким образом первый поток получает доступ ко второму. В функцию второго потока передаем объект первого потока по ссылке и присоединяем его. Обе функции после инструкции join выводят на консоль запись.
Чтобы это все дело работало, нужно продлить существование основных потоков. В обратном случае, вызовутся деструкторы неприсоединенных потоков, а эта ситуация в свою очередь стриггерит вызов std::terminate. Поэтому делаем бесконечный цикл, чтобы иметь возможность посмотреть на этот самый дедлок.
И действительно. При запуске программы ничего не выводится. Более того, пока писался этот пост, программа работала и ничего так и не вывела. Учитывая, что потоки особо ничего не делают, то логично предположить, что ситуация и не поменяется.
Естественно, что потоков может быть больше и кольцо из ожидающих потоков может быть больше. Но это такой минимальный пример.
Если вы думаете, что это какая-то сова в вакууме, то подумайте еще раз. Владение потоками можно передавать в функции. Могут быть довольно сложные схемы организации взаимодействия потоков. И если вы присоединяете поток не в его родителе, то возникает благоприятные условия для возникновения такого безлокового дедлока.
Поэтому лучше избегать такого присоединения, или быть супервнимательным, если вы уж решились вступить на эту дорожку.
Stay surprised. Stay cool.
#concurrency #cppcore
#опытным
Правильный ответ на квиз из предыдущего поста- 0. Вообще ни одного мьютекса не нужно.
Много можно вариантов придумать. И даже в комментах написали несколько рабочих способов.
Вообще говоря, в определении дедлока не звучит слово "мьютекс". Потоки должны ждать освобождения ресурсов. А этими ресурсами может быть что угодно.
Для организации дедлока достаточно просто, чтобы 2 потока запустились в попытке присоединить друг друга. Естественно, что они будут бесконечно ждать окончания работы своего визави.
Однако не совсем очевидно, как это организовать. Вот мы определяем первый объект потока и его надо запустить с функцией, которая ждем еще не существующего потока.
Заметьте, что мы пытаемся сделать грязь. Так давайте же применим самые опасные вещи из плюсов и у нас все получится! Надо лишь добавить 50 грамм указателей и чайную ложку глобальных переменных. Получается вот такая каша:
std::thread * t_ptr = nullptr;
void func1() {
std::this_thread::sleep_for(std::chrono::seconds(1));
t_ptr->join();
std::cout << "Never reached this point1" << std::endl;
}
void func2(std::thread& t) {
t.join();
std::cout << "Never reached this point2" << std::endl;
}
int main() {
std::thread t1{func1};
t_ptr = new std::thread(func2, std::ref(t1));
while(true) {
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
Все просто. Вводим глобальный указатель на поток. В функции первого потока мы даем время инициализировать указатель и присоединяем поток по указателю. А тем временем в main создаем динамический объект потока и записываем его по указателю t_ptr. Таким образом первый поток получает доступ ко второму. В функцию второго потока передаем объект первого потока по ссылке и присоединяем его. Обе функции после инструкции join выводят на консоль запись.
Чтобы это все дело работало, нужно продлить существование основных потоков. В обратном случае, вызовутся деструкторы неприсоединенных потоков, а эта ситуация в свою очередь стриггерит вызов std::terminate. Поэтому делаем бесконечный цикл, чтобы иметь возможность посмотреть на этот самый дедлок.
И действительно. При запуске программы ничего не выводится. Более того, пока писался этот пост, программа работала и ничего так и не вывела. Учитывая, что потоки особо ничего не делают, то логично предположить, что ситуация и не поменяется.
Естественно, что потоков может быть больше и кольцо из ожидающих потоков может быть больше. Но это такой минимальный пример.
Если вы думаете, что это какая-то сова в вакууме, то подумайте еще раз. Владение потоками можно передавать в функции. Могут быть довольно сложные схемы организации взаимодействия потоков. И если вы присоединяете поток не в его родителе, то возникает благоприятные условия для возникновения такого безлокового дедлока.
Поэтому лучше избегать такого присоединения, или быть супервнимательным, если вы уж решились вступить на эту дорожку.
Stay surprised. Stay cool.
#concurrency #cppcore
👍28❤8🔥5🤯3😱3😁1