
ИИ научится думать быстрее: что такое DeepConf
Meta* AI и исследователи из Университета Калифорнии показали технологию DeepConf (Deep Think with Confidence) — новый метод, который помогает языковым моделям решать сложные задачи логики и математики быстрее и точнее.
Почему это важно? С ростом числа больших моделей нагрузка на инфраструктуру становится критичной. DeepConf показывает, что можно не просто обучать ИИ на всё больших объёмах данных, а учить его мыслить рациональнее, сокращая лишние шаги и снижая цену вычислений🍑
*Meta признана экстремистской организацией и запрещена на территории РФ
Data Science
Meta* AI и исследователи из Университета Калифорнии показали технологию DeepConf (Deep Think with Confidence) — новый метод, который помогает языковым моделям решать сложные задачи логики и математики быстрее и точнее.
Как работает DeepConf? Вместо того чтобы одинаково рассматривать все возможные варианты решения (включая ошибочные), DeepConf анализирует уровень «уверенности» самой модели. Если вероятность правильного ответа падает ниже порога — такой путь просто отсекается. В итоге остаются только сильные кандидаты, среди которых проходит «взвешенное голосование».
Экономия ресурсов и рост точности. DeepConf умеет работать в двух режимах: offline (после генерации) и online (на лету). Второй вариант особенно полезен — слабые цепочки обрубаются ещё до конца рассуждений. Это не только ускоряет процесс, но и экономит вычислительные мощности. В тестах метод показал впечатляющий результат: 99,9% точности на AIME 2025 при сокращении числа токенов почти на 85%.
Почему это важно? С ростом числа больших моделей нагрузка на инфраструктуру становится критичной. DeepConf показывает, что можно не просто обучать ИИ на всё больших объёмах данных, а учить его мыслить рациональнее, сокращая лишние шаги и снижая цену вычислений
*Meta признана экстремистской организацией и запрещена на территории РФ
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5❤1
ИИ против 15-летнего цикла: новые лекарства быстрее и дешевле
Reuters опубликовал статью о том, что комбинация искусственного интеллекта и новых методов оценки безопасности (NAM) способна сократить сроки и стоимость разработки лекарств более чем вдвое уже в ближайшие 3–5 лет. Сейчас путь от идеи до таблетки занимает до 15 лет и обходится фарме примерно в $2 млрд.
А вы как думаете?
👍 — ИИ реально ускорит появление новых лекарств
👎 — В итоге всё упрётся в бюрократию и испытания
Data Science
Reuters опубликовал статью о том, что комбинация искусственного интеллекта и новых методов оценки безопасности (NAM) способна сократить сроки и стоимость разработки лекарств более чем вдвое уже в ближайшие 3–5 лет. Сейчас путь от идеи до таблетки занимает до 15 лет и обходится фарме примерно в $2 млрд.
Как это работает? ИИ быстро перебирает миллионы молекул, отбраковывает заведомо слабые варианты и подсказывает, какие стоит тестировать дальше. В ход идут базы знаний, данные экспериментов и измерений. Параллельно NAM заменяют часть классических испытаний: «органы-на-чипе», культуры клеток, цифровые модели. Результаты ближе к реальности, а количество опытов на животных уменьшается.
Пример: компания Recursion вывела молекулу REC-1245 на клинические испытания всего за 18 месяцев вместо привычных 42. Предполагается, что препарат будет тормозить рост некоторых раковых опухолей.
Что это значит? ИИ не отменяет долгих клинических фаз — пока на рынке нет ни одного реально одобренного «ИИ-препарата». Но сам процесс становится быстрее, прозрачнее и дешевле. Если прогнозы сбудутся, фармацевтика в ближайшие годы войдёт в новую эпоху.
А вы как думаете?
👍 — ИИ реально ускорит появление новых лекарств
👎 — В итоге всё упрётся в бюрократию и испытания
Data Science
👍17🔥5👎3🐳2
Как собрать резюме-матчер за вечер на TypeScript и tRPC
На Хабре вышла статья о том, как можно быстро собрать MVP-сервис для сравнения резюме и вакансий. Автор решил задачу на стыке NLP и ИИ: из PDF резюме и описания вакансии извлекаются ключевые навыки, а затем модель Gemini от Vertex AI выдаёт оценку совпадения.
В итоге получился рабочий инструмент, который не претендует на замену LinkedIn, но отлично показывает, как современные фреймворки и ИИ можно объединять в боевую связку🍆
Data Science
На Хабре вышла статья о том, как можно быстро собрать MVP-сервис для сравнения резюме и вакансий. Автор решил задачу на стыке NLP и ИИ: из PDF резюме и описания вакансии извлекаются ключевые навыки, а затем модель Gemini от Vertex AI выдаёт оценку совпадения.
— Почему tRPC: вместо REST или GraphQL используется TypeScript-first RPC-фреймворк. Он позволяет описывать API без схем, прямо функциями, а типы автоматически «протягиваются» на фронтенд. Итог — меньше бойлерплейта и меньше багов на ранних этапах.
— Как работает пайплайн: резюме и вакансия загружаются в сервис, оттуда извлекается текст, ключевые слова выделяются с помощью простых NLP-приёмов (токенизация, поиск существительных и заглавных слов), а дальше результат прогоняется через Gemini, который возвращает JSON с оценкой совпадения, сильными сторонами и рекомендациями.
Идея проста: зачем писать свой алгоритм сопоставления навыков, если можно отдать работу модели? Такой подход ускоряет прототипирование и отлично подходит для внутренних инструментов или быстрых демо.
В итоге получился рабочий инструмент, который не претендует на замену LinkedIn, но отлично показывает, как современные фреймворки и ИИ можно объединять в боевую связку
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4👎4
ИИ против лишних зависимостей
Раньше у разработчиков был один рефлекс: нужна функция — ищем библиотеку. Хоть простую валидацию, хоть мини-парсер. Вместе с решением приходили десятки транзитивных зависимостей, багфиксы и неожиданные апдейты.
ИИ не «убивает» open source, а просто сдвигает баланс. Узкие задачи проще генерировать под себя, а всё сложное и критичное — оставлять за проверенными библиотеками. Чем меньше зависимостей — тем ниже риски и проще поддержка🍑
Сейчас все уже массово доверяют свой код ии. Норма или ещё рано?
Data Science
Раньше у разработчиков был один рефлекс: нужна функция — ищем библиотеку. Хоть простую валидацию, хоть мини-парсер. Вместе с решением приходили десятки транзитивных зависимостей, багфиксы и неожиданные апдейты.
Теперь с появлением рабочих моделей кода всё проще. Мы описываем задачу на человеческом языке, добавляем тесты — и получаем небольшой модуль без лишнего «жира». Такой кусочек кода легко читать, менять и проверять.
Где ИИ уже заменяет OSS
— Индикаторы и статистика: EMA, RSI, Z-score, корреляции окон — Узкие клиенты для работы с API биржи — Скелеты бэктестов или пайплайнов — Адаптеры и конвертеры форматов
Где границы? ИИ отлично справляется с утилитарными задачами. Но криптография, протоколы с жёсткими SLA, движки БД и численные солверы остаются в зоне зрелого OSS — там нужна предсказуемость и годами проверенные решения.
ИИ не «убивает» open source, а просто сдвигает баланс. Узкие задачи проще генерировать под себя, а всё сложное и критичное — оставлять за проверенными библиотеками. Чем меньше зависимостей — тем ниже риски и проще поддержка
Сейчас все уже массово доверяют свой код ии. Норма или ещё рано?
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥3❤2
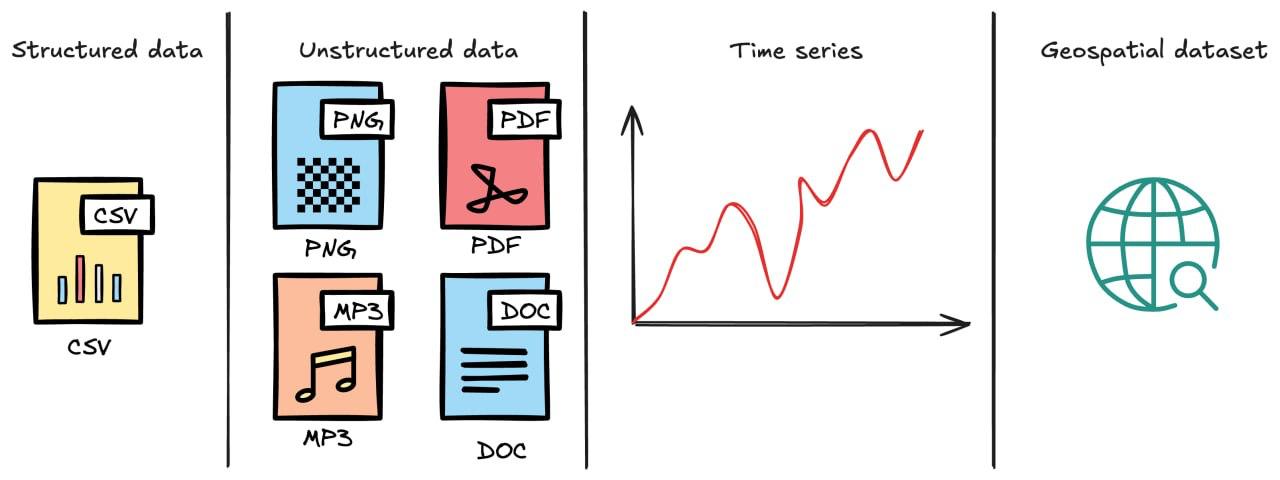
В статье собраны недавние релизы крупных ML-датасетов разных типов: структурированные таблицы, временные ряды, аудио и геоданные. Среди них Yambda-5B от Яндекса, крупнейший музыкальный рекомендательный датасет с 4,79 млрд взаимодействий (прослушивания, лайки, дизлайки). В мировом ML-сообществе уже отметили его пользу для науки и индустрии. Эксперты считают, что такие датасеты значительно ускорят развитие рекомендательных систем.
Читать…
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
❤3🔥3🐳1
Статья от инженера Google «Agentic Design Patterns»
В статье одна из самых амбициозных работ в области проектирования интеллектуальных систем. Эта книга предоставляет исчерпывающее руководство по разработке систем, которые могут мыслить, принимать решения и взаимодействовать с внешней средой, основываясь на уникальных «агентных» паттернах😐
Что вы думаете о применении таких систем в реальных проектах?
👍 — Могут изменить подход к разработке
👎 — Технология ещё не готова
Data Science
В статье одна из самых амбициозных работ в области проектирования интеллектуальных систем. Эта книга предоставляет исчерпывающее руководство по разработке систем, которые могут мыслить, принимать решения и взаимодействовать с внешней средой, основываясь на уникальных «агентных» паттернах
В первой части книги внимание уделяется ключевым аспектам работы с агентами, таким как цепочка команд, маршрутизация и параллелизация — все это с реальными примерами кода. Важно подчеркнуть, что каждый из разделов направлен на то, чтобы разработчики могли не только понять теорию, но и интегрировать эти методы в свои проекты.
Вторая часть книги посвящена памяти и адаптивности, а также ключевым протоколам взаимодействия между агентами. В процессе изучения материалов разработчики смогут научиться строить модели, которые способны не только решать поставленные задачи, но и улучшать свою работу на основе предыдущего опыта.
Также стоит отметить, что книга включает в себя полезные приложения: от углубленных техник подсказок до подробного описания внутреннего устройства агентов, что позволит читателям получить полное представление о создании эффективных и безопасных интеллектуальных систем.
Что вы думаете о применении таких систем в реальных проектах?
👍 — Могут изменить подход к разработке
👎 — Технология ещё не готова
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5👍4⚡1❤1👎1😁1
OpenAI ускоряет «сжигание» денег: прогноз расходов вырос до $115 млрд
Reuters сообщает, что OpenAI пересмотрела свои финансовые ожидания. До конца 2029 года компания потратит около $115 млрд — это на $80 млрд больше, чем прогнозировалось всего полгода назад.
Чем больше OpenAI тратит, тем выше поднимает планку выручки. Но первые реальные прибыли компания ожидает только ближе к 2029–2030 годам💻
Data Science
Reuters сообщает, что OpenAI пересмотрела свои финансовые ожидания. До конца 2029 года компания потратит около $115 млрд — это на $80 млрд больше, чем прогнозировалось всего полгода назад.
Где горят деньги? По новым расчетам, в 2025 году расходы превысят $8 млрд, а уже к 2028-му достигнут $45 млрд. Для сравнения: в старом прогнозе на этот год фигурировала сумма всего $11 млрд. Львиная доля пойдет на обучение моделей ($9 млрд в 2025-м и $19 млрд в 2026-м), а также на компенсации сотрудникам акциями — их объем в прогнозе вырос на $20 млрд.
А как с доходами? Только ChatGPT в 2025-м должен принести почти $10 млрд — на $2 млрд выше прежних ожиданий. К 2030-му выручка чатбота оценивается уже в $90 млрд. Общая выручка компании к концу десятилетия должна достичь $200 млрд. Главная ставка — монетизация бесплатной аудитории через подписки и рекламу: ожидается около $110 млрд допдохода за 2026–2030 годы. При этом OpenAI планирует увеличить средний доход на пользователя с $2 до $15 и довести число еженедельных активных пользователей до 2 млрд.
Чем больше OpenAI тратит, тем выше поднимает планку выручки. Но первые реальные прибыли компания ожидает только ближе к 2029–2030 годам
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥6🐳3😁2
This media is not supported in your browser
VIEW IN TELEGRAM
big tech night — это «ночь музеев» в мире IT, где Яндекс, Сбер, X5, Т-Банк и Lamoda впервые приглашают за кулисы.
Формат, придуманный в Яндексе, для тех, кто уже в IT или только стремится туда попасть. Здесь можно увидеть, как создаются технологии, меняющие окружающую среду, познакомиться с коллегами, обменяться опытом, задать неудобные вопросы и почувствовать себя частью комьюнити.
Вас ждут доклады, иммерсивные экскурсии и атмосфера IT-андеграунда. А если вы не в Москве, подключайтесь к онлайн-студии с двумя потоками — от серьезных дискуссий для гиков до лампового ночного шоу с историями из жизни.
Когда: 12 сентября.
Где: Москва или онлайн.
Регистрация - здесь.
Формат, придуманный в Яндексе, для тех, кто уже в IT или только стремится туда попасть. Здесь можно увидеть, как создаются технологии, меняющие окружающую среду, познакомиться с коллегами, обменяться опытом, задать неудобные вопросы и почувствовать себя частью комьюнити.
Вас ждут доклады, иммерсивные экскурсии и атмосфера IT-андеграунда. А если вы не в Москве, подключайтесь к онлайн-студии с двумя потоками — от серьезных дискуссий для гиков до лампового ночного шоу с историями из жизни.
Когда: 12 сентября.
Где: Москва или онлайн.
Регистрация - здесь.
❤4👎1🔥1🐳1
Будущее джунов в эпоху ИИ: угроза или шанс?
В мире технологий часто возникает вопрос: могут ли ИИ и автоматизация полностью заменить начинающих разработчиков? В статье утверждают, что это невозможно и даже опасно. Именно джуны — будущие тимлиды и лидеры команд, и их роль в индустрии по-прежнему крайне важна. Однако чтобы оставаться востребованными, начинающим разработчикам предстоит освоить «новую версию» своей профессии и научиться эффективно работать с ИИ😂
В будущем роль джуна не исчезнет, но изменится. Те, кто не боится принятия новых технологий и адаптации, смогут пройти этот путь и стать лидерами, которые не просто пишут код, но и ведут команды, разрабатывают стратегии и принимают важные решения.
Что думаете?
🔥— Нет, это лишь инструмент
👎— Да, ИИ возьмёт на себя всё
Data Science
В мире технологий часто возникает вопрос: могут ли ИИ и автоматизация полностью заменить начинающих разработчиков? В статье утверждают, что это невозможно и даже опасно. Именно джуны — будущие тимлиды и лидеры команд, и их роль в индустрии по-прежнему крайне важна. Однако чтобы оставаться востребованными, начинающим разработчикам предстоит освоить «новую версию» своей профессии и научиться эффективно работать с ИИ
Сегодня мы видим, как сокращаются команды, увольняют сотрудников, и компании активно утверждают, что ИИ повысит продуктивность. Но кто будет управлять командами разработки в будущем, если исключить джунов из процесса обучения? Джуны играют ключевую роль в подготовке нового поколения инженеров, и без их участия в обучении мы рискуем потерять тех, кто впоследствии станет лидерами.
Да, ИИ изменяет правила игры, но он не может заменить начальные позиции в команде, которые дают шанс развиваться и расти. Современные джуны должны научиться работать с ИИ, адаптируя его возможности под реальные задачи, а не полагаться на него как на замену человеческого труда.
Для этого джунам стоит не только овладеть новыми техническими навыками, но и развивать коммуникацию и способность работать с различными стейкхолдерами. Самый важный навык на пути к успеху — это способность к обучению и адаптации в условиях изменений, а ИИ может стать отличным помощником на этом пути, если научиться правильно его использовать.
Инструменты ИИ, такие как агентные IDE и автодополнение, помогают ускорить рутинные задачи, но ключевым остаётся умение понимать, где ИИ работает лучше, а где нужен человеческий подход. Джунам нужно освоить этот баланс, чтобы не только эффективно работать с ИИ, но и стать полноценными участниками команды, готовыми к лидерству в будущем.
В будущем роль джуна не исчезнет, но изменится. Те, кто не боится принятия новых технологий и адаптации, смогут пройти этот путь и стать лидерами, которые не просто пишут код, но и ведут команды, разрабатывают стратегии и принимают важные решения.
Что думаете?
🔥— Нет, это лишь инструмент
👎— Да, ИИ возьмёт на себя всё
Data Science
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥18👎8🐳1
Forwarded from xCode Journal
Media is too big
VIEW IN TELEGRAM
Можно не просто почитать про слои моделей, а буквально пощупать их, покрутить со всех сторон, посмотреть как работают веса и матричные операции.
На выбор есть внутрянка GPT-2, nanoGPT, GPT-2 XL и GPT-3.
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥7👍4❤1⚡1