
Data Leakage: как незаметно сломать модель
Самая коварная ошибка в ML — это не плохая модель.
Это data leakage.
Потому что:
👉 модель показывает идеальные метрики
👉 ты радуешься
👉 выкатываешь в прод
👉 всё разваливается
Что такое Data Leakage
Data leakage — это ситуация, когда модель
получает доступ к информации из будущего или из target’а,
которой не будет в реальном использовании.
Почему это так опасно
Потому что leakage:
👉 не очевиден
👉 не даёт ошибок
👉 сильно улучшает метрики
Классические примеры leakage
1. Нормализация до split
Сделали scaling на всём датасете,
а потом разбили на train/test.
2. Target encoding на всех данных
Посчитали средний target по категории
используя весь датасет.
3. Фичи из будущего
Пример:
👉 предсказываем отток
👉 используем действия после момента предсказания
4. Дубликаты
Один и тот же объект:
👉 в train
👉 и в test
5. Неправильный split
Временные ряды:
👉 случайный split
Как понять, что у тебя leakage
Сигналы:
👉 слишком высокий score
👉 огромный разрыв между offline и продом
👉 модель «слишком уверена»
👉 странно важные фичи
Как защититься
1. Делай split до любых преобразований
Сначала:
👉 train / test
Потом:
👉 scaling
👉 encoding
👉 feature engineering
2. Следи за временем
👉 train = прошлое
👉 test = будущее
3. Используй pipeline
Все трансформации:
👉 обучаются только на train
👉 применяются к test
4. Проверяй фичи
Задай вопрос:
Если нет — удаляй.
5. Делай sanity check
👉 обучись на случайных данных
👉 убери подозрительные фичи
Главный инсайт
В одном предложении
Самая коварная ошибка в ML — это не плохая модель.
Это data leakage.
Потому что:
👉 модель показывает идеальные метрики
👉 ты радуешься
👉 выкатываешь в прод
👉 всё разваливается
И ты не понимаешь почему.
Что такое Data Leakage
Data leakage — это ситуация, когда модель
получает доступ к информации из будущего или из target’а,
которой не будет в реальном использовании.
Модель читерит, а не учится.
Почему это так опасно
Потому что leakage:
👉 не очевиден
👉 не даёт ошибок
👉 сильно улучшает метрики
Чем лучше скор — тем подозрительнее.
Классические примеры leakage
1. Нормализация до split
Сделали scaling на всём датасете,
а потом разбили на train/test.
Модель уже «видела» test.
2. Target encoding на всех данных
Посчитали средний target по категории
используя весь датасет.
В train попала информация из test.
3. Фичи из будущего
Пример:
👉 предсказываем отток
👉 используем действия после момента предсказания
Модель знает будущее.
4. Дубликаты
Один и тот же объект:
👉 в train
👉 и в test
Модель просто запоминает.
5. Неправильный split
Временные ряды:
👉 случайный split
Модель обучается на будущем.
Как понять, что у тебя leakage
Сигналы:
👉 слишком высокий score
👉 огромный разрыв между offline и продом
👉 модель «слишком уверена»
👉 странно важные фичи
Если выглядит слишком хорошо — скорее всего, так и есть.
Как защититься
1. Делай split до любых преобразований
Сначала:
👉 train / test
Потом:
👉 scaling
👉 encoding
👉 feature engineering
2. Следи за временем
👉 train = прошлое
👉 test = будущее
3. Используй pipeline
Все трансформации:
👉 обучаются только на train
👉 применяются к test
4. Проверяй фичи
Задай вопрос:
Эта информация доступна в момент предсказания?
Если нет — удаляй.
5. Делай sanity check
👉 обучись на случайных данных
👉 убери подозрительные фичи
Если качество не падает — что-то не так.
Главный инсайт
Data leakage — это не баг.
Это иллюзия качества.
В одном предложении
Если модель слишком хороша —
сначала проверь leakage, а потом радуйся.
{kind=link}
❤4🔥2
Роскошный максимум: получить приглашение в команду SberAds за один день! 😉
Сделать это можно на One Day Offer* для Data Analyst**, который пройдёт уже 25 апреля. Сбер ждёт специалистов, которые готовы:
✔️ создавать и улучшать модели для real-time аукционов
✔️ трансформировать SberAds — вывести на пик эффективности, качества и релевантности рекламы
✔️ стать частью команды из 8000+ коллег (это вау! 🤩)
Занимай место в проекте мечты!
* One Day Offer — предложение о работе за один день.
** Data Analyst — аналитик данных.
Сделать это можно на One Day Offer* для Data Analyst**, который пройдёт уже 25 апреля. Сбер ждёт специалистов, которые готовы:
✔️ создавать и улучшать модели для real-time аукционов
✔️ трансформировать SberAds — вывести на пик эффективности, качества и релевантности рекламы
✔️ стать частью команды из 8000+ коллег (это вау! 🤩)
Занимай место в проекте мечты!
* One Day Offer — предложение о работе за один день.
** Data Analyst — аналитик данных.
Forwarded from xCode Journal
На GitHub появился прокси, который подменяет API и гоняет запросы через бесплатные или локальные модели. Запросы перенаправляются к NVIDIA NIM (~40 запросов в минуту бесплатно), OpenRouter, где более 100 моделей, а также через LM Studio или llama.cpp.
Весь остальной функционал на месте — агентский режим, работа с файлами и другие фичи будут доступны.
Please open Telegram to view this post
VIEW IN TELEGRAM
👍5👎3🔥2
Большие данные требуют порядка, а платформа — инструментов, которые этот порядок поддерживают. Такой вывод можно сделать после митапа YTsaurus, посвященного трехлетию выхода платформы в опенсорс.
Максим Бабенко — руководитель команды, преподаватель ШАДа и ВШЭ, кандидат физико-математических наук — рассказал о развитии платформы и её возможностях для ML. В Яндексе YTsaurus активно используется как основная инфраструктура для запуска GPU-вычислений. Все обучение моделей и batch-инференс делается при помощи YTsaurus.
Команда активно развивает платформу, появились разные вспомогательные инструменты и микросервисы, за последний год вышло много обновлений.
Максим Бабенко — руководитель команды, преподаватель ШАДа и ВШЭ, кандидат физико-математических наук — рассказал о развитии платформы и её возможностях для ML. В Яндексе YTsaurus активно используется как основная инфраструктура для запуска GPU-вычислений. Все обучение моделей и batch-инференс делается при помощи YTsaurus.
Команда активно развивает платформу, появились разные вспомогательные инструменты и микросервисы, за последний год вышло много обновлений.
ytsaurus.tech
YTsaurus Блог
YTsaurus — платформа с открытым исходным кодом, способная хранить и обрабатывать большие данные для десятков тысяч пользователей одновременно. Выполняйте задачи по Batch-обработке, Ad hoc аналитике, OLTP, машинному обучению, построению хранилищ данных и ETL!
❤2👍2👎2🔥1
Forwarded from xCode Journal
This media is not supported in your browser
VIEW IN TELEGRAM
Этот сервис на Go даёт OpenAI-совместимый API поверх всего зоопарка: от OpenAI и Claude до Groq и Ollama. По сути это уже API-шлюз для LLM, как nginx когда-то для веба.
Главный кайф — двухслойный кэш
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4❤1👎1
Random Forest vs Gradient Boosting — реальное сравнение
Самый частый вопрос в табличных данных:
что выбрать — Random Forest или Gradient Boosting?
Но давай разберёмся по-честному, без мифов.
Что такое Random Forest
Это ансамбль деревьев, где:
👉 каждое дерево обучается независимо
👉 используются случайные подвыборки данных и фич
Что такое Gradient Boosting
Это ансамбль деревьев, где:
👉 каждое следующее дерево исправляет ошибки предыдущего
👉 обучение идёт последовательно
Главное отличие
👉 Random Forest → деревья независимы
👉 Gradient Boosting → деревья зависят друг от друга
👉 RF = параллель
👉 GB = последовательность
Качество модели
В большинстве задач:
👉 Gradient Boosting выигрывает
Почему:
👉 лучше улавливает сложные зависимости
👉 оптимизирует ошибку напрямую
Поэтому:
👉 XGBoost
👉 LightGBM
👉 CatBoost
Переобучение
Random Forest:
👉 устойчив к переобучению
👉 работает «из коробки»
Gradient Boosting:
👉 легко переобучается
👉 требует настройки
Скорость
Обучение:
👉 RF → быстрее и параллелится
👉 GB → медленнее (последовательность)
Инференс:
👉 часто сопоставим
Чувствительность к данным
Random Forest:
👉 менее чувствителен к шуму
👉 проще в использовании
Gradient Boosting:
👉 чувствителен к:
👉 шуму
👉 выбросам
👉 плохим фичам
Когда выбирать Random Forest
👉 нужен быстрый baseline
👉 мало времени на тюнинг
👉 данные шумные
👉 нужна стабильность
Когда выбирать Gradient Boosting
👉 нужна максимальная точность
👉 есть время на тюнинг
👉 данные относительно чистые
👉 важен результат
Главный инсайт
В одном предложении
Самый частый вопрос в табличных данных:
что выбрать — Random Forest или Gradient Boosting?
Ответ, который никто не любит:
зависит от задачи.
Но давай разберёмся по-честному, без мифов.
Что такое Random Forest
Это ансамбль деревьев, где:
👉 каждое дерево обучается независимо
👉 используются случайные подвыборки данных и фич
Идея: уменьшить variance за счёт усреднения.
Что такое Gradient Boosting
Это ансамбль деревьев, где:
👉 каждое следующее дерево исправляет ошибки предыдущего
👉 обучение идёт последовательно
Идея: минимизировать ошибку шаг за шагом.
Главное отличие
👉 Random Forest → деревья независимы
👉 Gradient Boosting → деревья зависят друг от друга
👉 RF = параллель
👉 GB = последовательность
Качество модели
В большинстве задач:
👉 Gradient Boosting выигрывает
Почему:
👉 лучше улавливает сложные зависимости
👉 оптимизирует ошибку напрямую
Поэтому:
👉 XGBoost
👉 LightGBM
👉 CatBoost
Стали стандартом индустрии.
Переобучение
Random Forest:
👉 устойчив к переобучению
👉 работает «из коробки»
Gradient Boosting:
👉 легко переобучается
👉 требует настройки
GB мощнее, но опаснее.
Скорость
Обучение:
👉 RF → быстрее и параллелится
👉 GB → медленнее (последовательность)
Инференс:
👉 часто сопоставим
Чувствительность к данным
Random Forest:
👉 менее чувствителен к шуму
👉 проще в использовании
Gradient Boosting:
👉 чувствителен к:
👉 шуму
👉 выбросам
👉 плохим фичам
Зато раскрывает хороший feature engineering.
Когда выбирать Random Forest
👉 нужен быстрый baseline
👉 мало времени на тюнинг
👉 данные шумные
👉 нужна стабильность
«Запустил и работает».
Когда выбирать Gradient Boosting
👉 нужна максимальная точность
👉 есть время на тюнинг
👉 данные относительно чистые
👉 важен результат
«Выжать максимум».
Главный инсайт
Random Forest — надёжный середняк.
Gradient Boosting — инструмент для победы.
В одном предложении
Хочешь быстро и стабильно → Random Forest.
Хочешь максимум качества → Gradient Boosting.
{kind=link}
❤11👍1
Forwarded from xCode Journal
Разработчик Митчелл Хашимото, создатель популярного эмулятора терминала Ghostty, переносит проект из-за проблем со стабильностью платформы.
«Я пользователь GitHub под номером 1299, присоединился в феврале 2008 года. Я заходил на GitHub почти каждый день в течение более 18 лет. Для меня никогда не было вопроса, куда размещать свои проекты: всегда GitHub. Мне очень грустно это говорить, но пришло время уходить», — пишет он.
Please open Telegram to view this post
VIEW IN TELEGRAM
👀8❤3
Forwarded from xCode Journal
Так говорит айтишник Disney. Дело в том, что компания Disney сделала для своих программистов «панель мониторинга внедрения ИИ» с лидербордом. Чем больше дней подряд ты используешь Cursor или Claude, тем больше у тебя ачивок.
Некоторые сотрудники говорят, что чувствуют давление «максимально использовать токены».
Please open Telegram to view this post
VIEW IN TELEGRAM
😁11❤2
This media is not supported in your browser
VIEW IN TELEGRAM
🤔Что происходит, когда AI выходит за пределы прототипа?
20 мая в 15:00 приглашаем на Inside AI Meetup от Wildberries & Russ.
Там обсудят реальные кейсы: от высоконагруженной модерации с векторным поиском и AIOps-подходов к управлению ML-сервисами до практики построения RAG-систем, тонкостей реранкинга и реальных этапов запуска LLM-продуктов.
Среди спикеров эксперты Wildberries & Russ, MWS, Avito, Сбера, Альфа-Банка, red_mad_robot. Принять участие советуем senior ML/AI инженерам, MLE, DS, инженерам платформ и всем, кто строит или масштабирует AI-системы в продакшене.
Митап пройдет в Москве + будет трансляция. Подробности и регистрация — на сайте.
20 мая в 15:00 приглашаем на Inside AI Meetup от Wildberries & Russ.
Там обсудят реальные кейсы: от высоконагруженной модерации с векторным поиском и AIOps-подходов к управлению ML-сервисами до практики построения RAG-систем, тонкостей реранкинга и реальных этапов запуска LLM-продуктов.
Среди спикеров эксперты Wildberries & Russ, MWS, Avito, Сбера, Альфа-Банка, red_mad_robot. Принять участие советуем senior ML/AI инженерам, MLE, DS, инженерам платформ и всем, кто строит или масштабирует AI-системы в продакшене.
Митап пройдет в Москве + будет трансляция. Подробности и регистрация — на сайте.
❤4👀3🔥2👎1
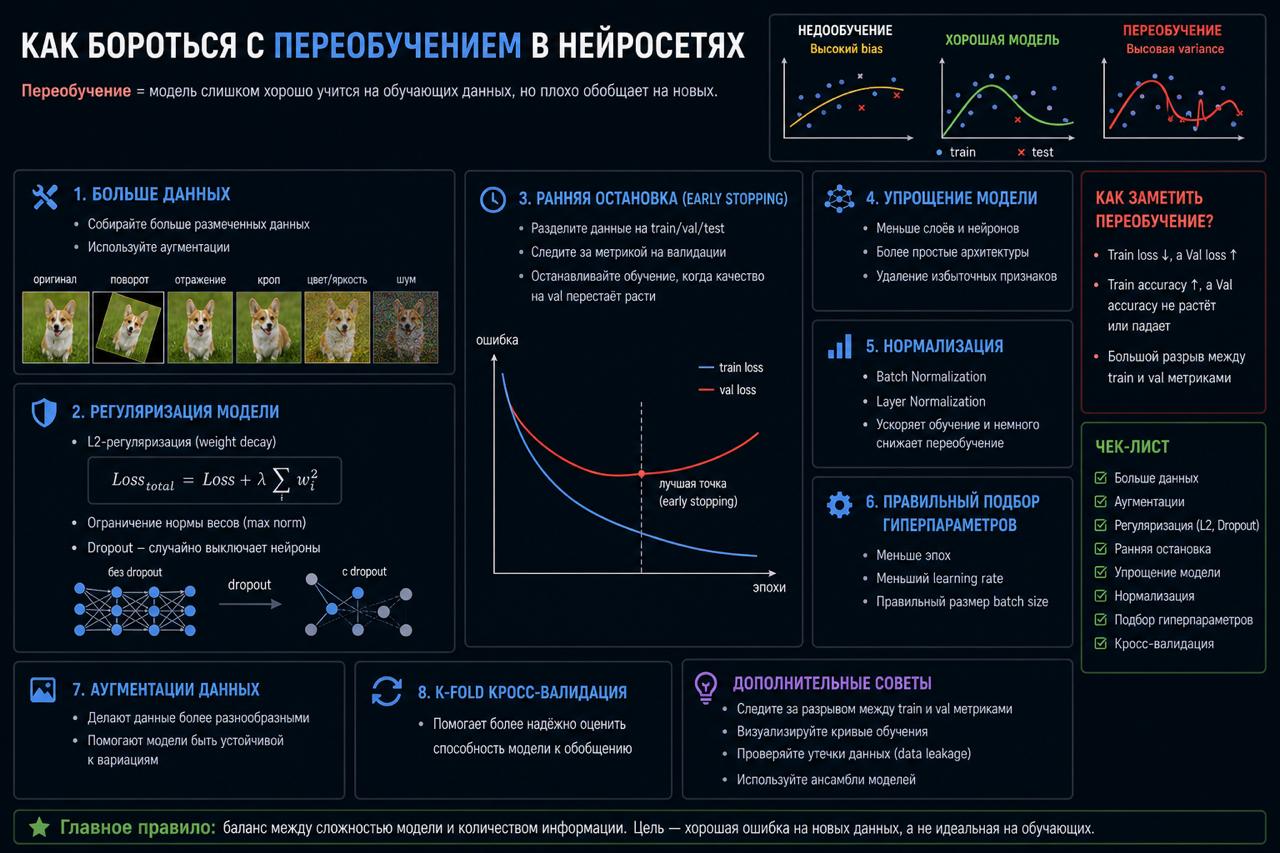
Как бороться с переобучением в нейросетях
Переобучение — это момент, когда модель:
👉 идеально знает train
👉 и плохо работает на новых данных
Разберём, как с этим бороться на практике.
1. Больше данных
Самый надёжный способ.
Если данных мало:
👉 собирай новые
👉 делай data augmentation
👉 используй синтетические данные
2. Regularization
Добавляем штраф за сложность модели.
Основные варианты:
👉 L2 (weight decay)
👉 L1
3. Dropout
Во время обучения случайные нейроны «выключаются».
Что происходит:
👉 модель не может полагаться на конкретные связи
👉 учится быть более устойчивой
Обычно используют:
👉 0.2 – 0.5
4. Early Stopping
Следим за валидацией:
👉 train loss падает
👉 val loss сначала падает, потом растёт
Это один из самых эффективных методов.
5. Упростить модель
Иногда решение очевидное:
👉 меньше слоёв
👉 меньше параметров
👉 проще архитектура
6. Data Augmentation
Особенно важно для:
CV:
👉 повороты
👉 шум
👉 кропы
NLP:
👉 перефразирование
👉 замены
7. Batch Normalization
Помогает:
👉 стабилизировать обучение
👉 немного снижает переобучение
8. Правильная валидация
Если плохой split — ты не заметишь проблему.
Используй:
👉 train / val / test
👉 k-fold при малых данных
Главный инсайт
Переобучение — это сигнал:
👉 либо мало данных
👉 либо модель слишком сложная
👉 либо обучение настроено неправильно
В одном предложении
Переобучение — это момент, когда модель:
👉 идеально знает train
👉 и плохо работает на новых данных
Она запоминает, а не обобщает.
Разберём, как с этим бороться на практике.
1. Больше данных
Самый надёжный способ.
Если данных мало:
👉 собирай новые
👉 делай data augmentation
👉 используй синтетические данные
Больше разнообразия = меньше шансов запомнить шум.
2. Regularization
Добавляем штраф за сложность модели.
Основные варианты:
👉 L2 (weight decay)
👉 L1
Меньше веса → проще модель → меньше overfitting.
3. Dropout
Во время обучения случайные нейроны «выключаются».
Что происходит:
👉 модель не может полагаться на конкретные связи
👉 учится быть более устойчивой
Обычно используют:
👉 0.2 – 0.5
4. Early Stopping
Следим за валидацией:
👉 train loss падает
👉 val loss сначала падает, потом растёт
Останавливаем обучение в момент роста val loss.
Это один из самых эффективных методов.
5. Упростить модель
Иногда решение очевидное:
👉 меньше слоёв
👉 меньше параметров
👉 проще архитектура
Большая модель легче переобучается.
6. Data Augmentation
Особенно важно для:
CV:
👉 повороты
👉 шум
👉 кропы
NLP:
👉 перефразирование
👉 замены
Модель видит больше вариантов одного и того же.
7. Batch Normalization
Помогает:
👉 стабилизировать обучение
👉 немного снижает переобучение
Не основное решение, но усиливает остальные.
8. Правильная валидация
Если плохой split — ты не заметишь проблему.
Используй:
👉 train / val / test
👉 k-fold при малых данных
Иначе будешь оптимизировать иллюзию.
Главный инсайт
Переобучение — это сигнал:
👉 либо мало данных
👉 либо модель слишком сложная
👉 либо обучение настроено неправильно
В одном предложении
Чтобы уменьшить переобучение —
добавь данных или убери сложность модели.
{kind=link}
❤5👍1👀1
Forwarded from xCode Journal
Запускаешь
npx autoskills, и он сканирует репозиторий: читает package.json и конфиги, определяет технологический стек и ставит нужные скиллы из проверенного списка. Короче, сильно экономит время на ручной настройке и поиске.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4
Меня недавно позвали в папку IT On и я согласился почти не раздумывая, потому что давно искал что-то похожее.
Там собраны люди, которые реально шарят в своей теме: разработчики, продакты, основатели стартапов, эксперты по карьере в tech. Каждый пишет про своё и в сумме получается полная картина индустрии.
Читаешь и чувствуешь что находишься внутри IT, а не наблюдаешь снаружи. Разница есть, проверено на себе.
Добавляй папку себе, советую!
Там собраны люди, которые реально шарят в своей теме: разработчики, продакты, основатели стартапов, эксперты по карьере в tech. Каждый пишет про своё и в сумме получается полная картина индустрии.
Читаешь и чувствуешь что находишься внутри IT, а не наблюдаешь снаружи. Разница есть, проверено на себе.
Добавляй папку себе, советую!
Когда логистическая регрессия лучше XGBoost
В мире ML есть странный культ сложных моделей.
Если задача табличная —
многие сразу запускают:
👉 XGBoost
👉 LightGBM
👉 CatBoost
А потом удивляются,
что простая логистическая регрессия работает не хуже.
Почему все недооценивают Logistic Regression
Потому что она:
👉 старая
👉 простая
👉 «не хайповая»
Но у неё есть огромный плюс:
Когда Logistic Regression выигрывает
1. Мало данных
Если у тебя:
👉 маленький датасет
👉 мало наблюдений
👉 мало signal
Логистическая регрессия:
👉 проще
👉 стабильнее
👉 менее чувствительна к шуму
2. Линейная зависимость
Если данные разделяются почти линейно:
XGBoost будет:
👉 строить сложные деревья
👉 искать несуществующие паттерны
3. Высокая размерность
Особенно:
👉 NLP
👉 sparse features
👉 TF-IDF
Почему:
👉 хорошо работает с разреженными данными
👉 быстро обучается
👉 эффективно регуляризуется
4. Нужна интерпретируемость
Логистическая регрессия:
👉 прозрачна
👉 объяснима
👉 понятна бизнесу
Можно сказать:
👉 какой признак влияет
👉 насколько влияет
👉 в какую сторону влияет
5. Ограничения по скорости
Logistic Regression:
👉 быстро обучается
👉 быстро работает
👉 мало потребляет памяти
Где XGBoost всё-таки сильнее
Когда:
👉 сложные нелинейные зависимости
👉 interaction effects
👉 много данных
👉 хороший feature engineering
Самая частая ошибка
Люди сравнивают:
👉 плохо настроенную Logistic Regression
👉 и хорошо настроенный XGBoost
А потом говорят:
Нет.
Часто baseline даже не пытались нормально сделать.
Главный инсайт
Сложная модель не делает тебя хорошим ML-инженером.
В одном предложении
В мире ML есть странный культ сложных моделей.
Если задача табличная —
многие сразу запускают:
👉 XGBoost
👉 LightGBM
👉 CatBoost
А потом удивляются,
что простая логистическая регрессия работает не хуже.
Иногда — даже лучше.
Почему все недооценивают Logistic Regression
Потому что она:
👉 старая
👉 простая
👉 «не хайповая»
Но у неё есть огромный плюс:
Она очень хорошо обобщает.
Когда Logistic Regression выигрывает
1. Мало данных
Если у тебя:
👉 маленький датасет
👉 мало наблюдений
👉 мало signal
Бустинг легко переобучается.
Логистическая регрессия:
👉 проще
👉 стабильнее
👉 менее чувствительна к шуму
2. Линейная зависимость
Если данные разделяются почти линейно:
Сложная модель просто не нужна.
XGBoost будет:
👉 строить сложные деревья
👉 искать несуществующие паттерны
3. Высокая размерность
Особенно:
👉 NLP
👉 sparse features
👉 TF-IDF
Logistic Regression здесь очень сильна.
Почему:
👉 хорошо работает с разреженными данными
👉 быстро обучается
👉 эффективно регуляризуется
4. Нужна интерпретируемость
Логистическая регрессия:
👉 прозрачна
👉 объяснима
👉 понятна бизнесу
Можно сказать:
👉 какой признак влияет
👉 насколько влияет
👉 в какую сторону влияет
Для финтеха, медицины и скоринга это критично.
5. Ограничения по скорости
Logistic Regression:
👉 быстро обучается
👉 быстро работает
👉 мало потребляет памяти
Иногда latency важнее +2% качества.
Где XGBoost всё-таки сильнее
Когда:
👉 сложные нелинейные зависимости
👉 interaction effects
👉 много данных
👉 хороший feature engineering
Тогда бустинг почти всегда победит.
Самая частая ошибка
Люди сравнивают:
👉 плохо настроенную Logistic Regression
👉 и хорошо настроенный XGBoost
А потом говорят:
«Линейные модели умерли».
Нет.
Часто baseline даже не пытались нормально сделать.
Главный инсайт
Сложная модель не делает тебя хорошим ML-инженером.
Умение понять, когда хватит простой модели — делает.
В одном предложении
Если задача простая, данных мало или нужна интерпретируемость —
Logistic Regression может быть лучше XGBoost.
{kind=link}
❤10👍5
Forwarded from xCode Journal
Она показывает, почему сайт не открывается — из-за проблем сети или из-за блокировок.
«Инструмент определяет, находится ли ваше соединение в зоне блокировки RKN/TSPU — и, что более полезно, какой именно тип блокировки (отравление DNS, сброс TCP, TLS DPI на SNI или страница‑заглушка от провайдера).»
Please open Telegram to view this post
VIEW IN TELEGRAM
❤11🔥5👍3😁1
ИИ-агенты уже внедряют в поддержку, продажи, аналитику и внутренние процессы. Но у многих всё упирается в сложную инфраструктуру и непонимание, с чего начать.
📆 20 мая в 18:00 МСК приглашаем на открытый урок курса «Разработка ИИ агентов».
На занятии вы пошагово соберёте мини-агента: он примет сообщение из Telegram, передаст его в большую языковую модель, примет решение по сценарию и выполнит цепочку действий. Разберём, чем агент отличается от обычного чат-бота, как устроена минимальная архитектура и как получить рабочий результат без тяжёлой серверной части.
🧑💻 Также вы сможете познакомиться с преподавателем курса, увидеть формат обучения и задать вопросы.
Зарегистрируйтесь, чтобы не пропустить: https://vk.cc/cXLnrA
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru, erid: 2VtzqwCoN6j
📆 20 мая в 18:00 МСК приглашаем на открытый урок курса «Разработка ИИ агентов».
На занятии вы пошагово соберёте мини-агента: он примет сообщение из Telegram, передаст его в большую языковую модель, примет решение по сценарию и выполнит цепочку действий. Разберём, чем агент отличается от обычного чат-бота, как устроена минимальная архитектура и как получить рабочий результат без тяжёлой серверной части.
🧑💻 Также вы сможете познакомиться с преподавателем курса, увидеть формат обучения и задать вопросы.
Зарегистрируйтесь, чтобы не пропустить: https://vk.cc/cXLnrA
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru, erid: 2VtzqwCoN6j
👎1😁1
Почему знание математики не гарантирует работу
Неприятная правда для начинающих в Data Science:
Можно понимать:
👉 линейную алгебру
👉 статистику
👉 градиентный спуск
👉 вероятности
И всё равно провалиться на практике.
Почему так происходит
Потому что работа Data Scientist — это не только формулы.
Это ещё:
👉 грязные данные
👉 непонятные требования
👉 слабые baseline’ы
👉 странные бизнес-ограничения
👉 коммуникация с людьми
Математика помогает, но не заменяет практику
Математика даёт понимание:
👉 почему модель работает
👉 где она может сломаться
👉 как читать метрики
👉 как не верить магии
Но она не научит:
👉 чистить данные
👉 строить pipeline
👉 писать production-код
👉 делать нормальный train/test split
👉 объяснять результат бизнесу
Главная ошибка новичков
Они думают:
Проблема в том,
что «вся математика» не заканчивается никогда.
Что реально смотрят на собеседованиях
Обычно хотят понять:
👉 можешь ли ты работать с данными
👉 понимаешь ли метрики
👉 умеешь ли делать baseline
👉 видишь ли leakage
👉 можешь ли объяснить решение
👉 есть ли у тебя проекты
Что делать вместо бесконечной теории
Лучший путь:
👉 учить математику по мере необходимости
👉 параллельно делать проекты
👉 разбирать ошибки моделей
👉 писать код руками
👉 учиться объяснять выводы простыми словами
Главный инсайт
В одном предложении
Неприятная правда для начинающих в Data Science:
Хорошая математика ≠ готовность к реальной работе.
Можно понимать:
👉 линейную алгебру
👉 статистику
👉 градиентный спуск
👉 вероятности
И всё равно провалиться на практике.
Почему так происходит
Потому что работа Data Scientist — это не только формулы.
Это ещё:
👉 грязные данные
👉 непонятные требования
👉 слабые baseline’ы
👉 странные бизнес-ограничения
👉 коммуникация с людьми
В реальности задача редко выглядит как в учебнике.
Математика помогает, но не заменяет практику
Математика даёт понимание:
👉 почему модель работает
👉 где она может сломаться
👉 как читать метрики
👉 как не верить магии
Но она не научит:
👉 чистить данные
👉 строить pipeline
👉 писать production-код
👉 делать нормальный train/test split
👉 объяснять результат бизнесу
Главная ошибка новичков
Они думают:
«Сначала выучу всю математику, потом начну проекты».
Проблема в том,
что «вся математика» не заканчивается никогда.
Работу дают не за знание формул,
а за способность решать задачи.
Что реально смотрят на собеседованиях
Обычно хотят понять:
👉 можешь ли ты работать с данными
👉 понимаешь ли метрики
👉 умеешь ли делать baseline
👉 видишь ли leakage
👉 можешь ли объяснить решение
👉 есть ли у тебя проекты
Математика важна.
Но сама по себе она не продаёт тебя как специалиста.
Что делать вместо бесконечной теории
Лучший путь:
👉 учить математику по мере необходимости
👉 параллельно делать проекты
👉 разбирать ошибки моделей
👉 писать код руками
👉 учиться объяснять выводы простыми словами
Теория должна усиливать практику,
а не заменять её.
Главный инсайт
Математика — это фундамент.
Но дом строится не фундаментом одним.
В одном предложении
Чтобы получить работу в DS/ML, мало знать формулы —
нужно уметь превращать данные в работающие решения.
{kind=link}
🔥6❤5😁1