
Как создать хранилище данных за 5 шагов
Будучи участником многочисленных проектов по преобразованию сложных типов данных, могу подтвердить статистику, согласно которой 85% проектов по обработке данных терпят неудачу.
Вот основные причины этих неудач.
Трансформирование стеков данных.
Недостаточная подготовленность данных.
Некомпетентность команды.
Нетерпеливость заинтересованных сторон.
Чрезмерное усердие руководства.
Отсутствие инвестиций, необходимых для изменения организационной культуры.
➡️ Читать дальше
@data_analysis_ml
Будучи участником многочисленных проектов по преобразованию сложных типов данных, могу подтвердить статистику, согласно которой 85% проектов по обработке данных терпят неудачу.
Вот основные причины этих неудач.
Трансформирование стеков данных.
Недостаточная подготовленность данных.
Некомпетентность команды.
Нетерпеливость заинтересованных сторон.
Чрезмерное усердие руководства.
Отсутствие инвестиций, необходимых для изменения организационной культуры.
➡️ Читать дальше
@data_analysis_ml
👍10🔥1
8 показателей эффективности классификации
Классификация — это тип контролируемой задачи машинного обучения. Цель классификации — предсказание признаков одного или нескольких наблюдаемых объектов или класса, к которому они принадлежат.
Важным элементом любого рабочего процесса машинного обучения является оценка эффективности модели. Это процесс, при котором обученную модель используют для прогнозирования на материале ранее не отображенных, помеченных данных. При классификации оценивают количество правильных прогнозов, сделанных моделью.
В реальных задачах классификации обычно невозможно достичь 100% верных прогнозов, поэтому при оценке модели полезно знать не только то, насколько она была неверна, но в чем.
➡️ Читать дальше
@data_analysis_ml
Классификация — это тип контролируемой задачи машинного обучения. Цель классификации — предсказание признаков одного или нескольких наблюдаемых объектов или класса, к которому они принадлежат.
Важным элементом любого рабочего процесса машинного обучения является оценка эффективности модели. Это процесс, при котором обученную модель используют для прогнозирования на материале ранее не отображенных, помеченных данных. При классификации оценивают количество правильных прогнозов, сделанных моделью.
В реальных задачах классификации обычно невозможно достичь 100% верных прогнозов, поэтому при оценке модели полезно знать не только то, насколько она была неверна, но в чем.
➡️ Читать дальше
@data_analysis_ml
🔥8👍4
💫 4 пакета Python для причинно-следственного анализа данных
Причинно-следственный анализ — это область экспериментальной статистики, направленная на установление и обоснование причинно-следственных связей. Использование статистических алгоритмов для доказательства причинно-следственных связей в наборе данных при строгом допущении называется эксплораторным причинно-следственным анализом (ЭПСА).
ЭПСА — это способ доказать причинно-следственные связи с помощью более контролируемых экспериментов, а не только на основе корреляции. Часто требуется испытать контрфактическое состояние — иное состояние при других обстоятельствах. Проблема в том, что корреляционный анализ позволяет приблизительно установить только причинно-следственные связи, но не контрфактические.
Анализ причинно-следственных связей — это совершенно другая область исследований в науке о данных, поскольку он отличается от предсказаний, полученных в результате моделирования с помощью машинного обучения. Можно всегда предсказать результат МО на основе имеющихся данных, но не то, что выходит за рамки этих данных.
Чтобы узнать больше о причинно-следственном анализе, познакомимся с 4 пакетами Python, которые можно использовать для исследования данных.
➡️ Читать дальше
@data_analysis_ml
Причинно-следственный анализ — это область экспериментальной статистики, направленная на установление и обоснование причинно-следственных связей. Использование статистических алгоритмов для доказательства причинно-следственных связей в наборе данных при строгом допущении называется эксплораторным причинно-следственным анализом (ЭПСА).
ЭПСА — это способ доказать причинно-следственные связи с помощью более контролируемых экспериментов, а не только на основе корреляции. Часто требуется испытать контрфактическое состояние — иное состояние при других обстоятельствах. Проблема в том, что корреляционный анализ позволяет приблизительно установить только причинно-следственные связи, но не контрфактические.
Анализ причинно-следственных связей — это совершенно другая область исследований в науке о данных, поскольку он отличается от предсказаний, полученных в результате моделирования с помощью машинного обучения. Можно всегда предсказать результат МО на основе имеющихся данных, но не то, что выходит за рамки этих данных.
Чтобы узнать больше о причинно-следственном анализе, познакомимся с 4 пакетами Python, которые можно использовать для исследования данных.
➡️ Читать дальше
@data_analysis_ml
🔥18👍6❤2
✒️ Распознавание чисел в прописном виде.
Суть задачи
Есть большой объём данных отсканированных через Adobe File reader документов в виде txt файлов, разного формата. Нам нужно распарсить эти документы по некоторым параметрам и достать из них число, записанное прописью. Для того чтобы вытаскивать параметры мы используем Natasha, но из-за «мусорных» данных, вызванных либо качеством сканов, либо не идеальности самого сканера, она не всегда справляется со своей задачей. Тут нам и приходит на помощь алгоритм, о котором далее пойдёт речь.
➡️ Читать дальше
⚙️ Код на Python
@data_analysis_ml
Суть задачи
Есть большой объём данных отсканированных через Adobe File reader документов в виде txt файлов, разного формата. Нам нужно распарсить эти документы по некоторым параметрам и достать из них число, записанное прописью. Для того чтобы вытаскивать параметры мы используем Natasha, но из-за «мусорных» данных, вызванных либо качеством сканов, либо не идеальности самого сканера, она не всегда справляется со своей задачей. Тут нам и приходит на помощь алгоритм, о котором далее пойдёт речь.
➡️ Читать дальше
⚙️ Код на Python
@data_analysis_ml
👍8
📁 Автоматизированная загрузка массива CSV в БД
Потребность в подобной разработке возникла в связи с необходимостью перемещения больших объемов данных из одной системы управления базами данных в другую. Из-за большого размера выгрузки её пришлось разбивать на множество мелких CSV. Загрузка каждого файла вручную заняла бы много времени. Это и стало причиной создания программы, о которой пойдет речь. Разработанный ноутбук Python будет сам определять типы данных внутри CSV и автоматически загружать их в таблицу БД. В каталоге с ноутбуком должны быть созданы две папки: in (куда нужно сложить загружаемые CSV) и out (куда будут перемещены уже загруженные файлы). После создания папок можно приступить к написанию кода.
➡️ Читать дальше
⚙️ Код
@data_analysis_ml
Потребность в подобной разработке возникла в связи с необходимостью перемещения больших объемов данных из одной системы управления базами данных в другую. Из-за большого размера выгрузки её пришлось разбивать на множество мелких CSV. Загрузка каждого файла вручную заняла бы много времени. Это и стало причиной создания программы, о которой пойдет речь. Разработанный ноутбук Python будет сам определять типы данных внутри CSV и автоматически загружать их в таблицу БД. В каталоге с ноутбуком должны быть созданы две папки: in (куда нужно сложить загружаемые CSV) и out (куда будут перемещены уже загруженные файлы). После создания папок можно приступить к написанию кода.
➡️ Читать дальше
⚙️ Код
@data_analysis_ml
👍12🔥2
This media is not supported in your browser
VIEW IN TELEGRAM
⚡️ 10 простых хаков, которые ускорят анализ данных Python
Сделать анализ данных Python быстрее и лучше – мечта каждого разработчика. Вот наглядные примеры: узнайте, как добавить чуточку магии в код.
В этой статье собраны лучшие советы и приёмы. Некоторые из них распространённые, а некоторые новые, но обязательно пригодятся в будущем.
➡️ Читать дальше
@data_analysis_ml
Сделать анализ данных Python быстрее и лучше – мечта каждого разработчика. Вот наглядные примеры: узнайте, как добавить чуточку магии в код.
В этой статье собраны лучшие советы и приёмы. Некоторые из них распространённые, а некоторые новые, но обязательно пригодятся в будущем.
➡️ Читать дальше
@data_analysis_ml
👍33🔥5❤3
📊 ТОП-10 инструментов для Data Science
Хотите сделать свою работу в области науки о данных продуктивнее? Подбирайте удобные и эффективные инструменты. Рассмотрим десять лучших, получивших наибольшее распространение среди специалистов по Data Science во всем мире.
➡️ Часть 1
➡️ Часть 2
@data_analysis_ml
Хотите сделать свою работу в области науки о данных продуктивнее? Подбирайте удобные и эффективные инструменты. Рассмотрим десять лучших, получивших наибольшее распространение среди специалистов по Data Science во всем мире.
➡️ Часть 1
➡️ Часть 2
@data_analysis_ml
👍13🔥4
🪐 Визуализация архитектуры и отдельных блоков нейросети с помощью Netron
Netron поддерживает как наиболее популярные фреймворки глубокого обучения – Keras и PyTorch – так и менее известные, и даже scikit-learn.
Установка в виде сервера для python производится стандартным образом через pip. Также можно установить netron в виде отдельной программы командой.
winget install -s winget netron
(для Windows) или
snap install netron
(для Linux).
➡️ Читать дальше
⚙️ Github
@data_analysis_ml
Netron поддерживает как наиболее популярные фреймворки глубокого обучения – Keras и PyTorch – так и менее известные, и даже scikit-learn.
Установка в виде сервера для python производится стандартным образом через pip. Также можно установить netron в виде отдельной программы командой.
winget install -s winget netron
(для Windows) или
snap install netron
(для Linux).
➡️ Читать дальше
⚙️ Github
@data_analysis_ml
👍7🔥2
🌍 Kepler.gl — инструмент для визуализации геоданных.
Если вы когда-либо работали с геоданными, то знаете, насколько нецелесообразно просматривать их в формате CSV, таблицы или JSON. Геоданные необходимо нанести на карту для последующего изучения и выявления закономерностей. Процесс сбора информации не ограничивается только этими действиями и обязательно требует выполнения качественного анализа или/и запуска моделей МО.
➡️ Читать дальше
⚙️ Github
@data_analysis_ml
Если вы когда-либо работали с геоданными, то знаете, насколько нецелесообразно просматривать их в формате CSV, таблицы или JSON. Геоданные необходимо нанести на карту для последующего изучения и выявления закономерностей. Процесс сбора информации не ограничивается только этими действиями и обязательно требует выполнения качественного анализа или/и запуска моделей МО.
➡️ Читать дальше
⚙️ Github
@data_analysis_ml
👍12🔥4👎1
machinelearning_interview - канал подготовит к собеседованию по машинному обучению, статисике ,алгоритмам и науке о данных.
golang_interview - Вопросы с настоящих Golang собеседований, помогут Вам получить успешно пройти интервью.
python_job_interview - здесь собраны все возможные вопросы и ответы с собеседований по Python.
ai_machinelearning_big_data - Мл, Наука о данных.
golang_interview - Вопросы с настоящих Golang собеседований, помогут Вам получить успешно пройти интервью.
python_job_interview - здесь собраны все возможные вопросы и ответы с собеседований по Python.
ai_machinelearning_big_data - Мл, Наука о данных.
🔥7👍1
🤖🎨 ИИ для рисования: раскрываем секреты нейронного переноса стиля
Раскладываем по полочками, как «думает» нейронная сеть VGG-19, когда ей прилетает задача скопировать стиль художника из вида Homo sapiens.
➡️ Читать дальше
⚙️ Ноутбук на Kaggle
⚙️ Код
🧠 Нейронный алгоритм переноса стиля
@data_analysis_ml
Раскладываем по полочками, как «думает» нейронная сеть VGG-19, когда ей прилетает задача скопировать стиль художника из вида Homo sapiens.
➡️ Читать дальше
⚙️ Ноутбук на Kaggle
⚙️ Код
🧠 Нейронный алгоритм переноса стиля
@data_analysis_ml
👍10🔥2🤩1
📖 От 0 до 300 SQL-запросов в месяц: практические советы для аналитика данных.
До текущей работы бизнес-аналитиком, на которую я устроилась в августе 2021 года, я написала всего несколько SQL-запросов. Меня наняли не из-за знания SQL (Structured Query Language, язык структурированных запросов). Однако в ноябре в нашей компании внедрялась новая база данных. Я, как единственный человек в команде, который когда-либо писал на языке программирования, стала самым подходящим кандидатом в специалисты по извлечению данных из новой БД.
Сегодня я делаю запросы к базе данных по 7-10 раз в день. В следующем месяце получу доступ ко второй БД, а позже еще к нескольким за счет привлечения в компанию других бизнес-направлений.
Помимо базовых правил использования операторов, я полагаюсь на несколько лайфхаков, помогающих упростить запросы и загрузить данные в дашборд более эффективно.
➡️ Читать дальше
@data_analysis_ml
До текущей работы бизнес-аналитиком, на которую я устроилась в августе 2021 года, я написала всего несколько SQL-запросов. Меня наняли не из-за знания SQL (Structured Query Language, язык структурированных запросов). Однако в ноябре в нашей компании внедрялась новая база данных. Я, как единственный человек в команде, который когда-либо писал на языке программирования, стала самым подходящим кандидатом в специалисты по извлечению данных из новой БД.
Сегодня я делаю запросы к базе данных по 7-10 раз в день. В следующем месяце получу доступ ко второй БД, а позже еще к нескольким за счет привлечения в компанию других бизнес-направлений.
Помимо базовых правил использования операторов, я полагаюсь на несколько лайфхаков, помогающих упростить запросы и загрузить данные в дашборд более эффективно.
➡️ Читать дальше
@data_analysis_ml
👍17🔥5
🎲 Байесовская статистика для специалистов по данным c примерами на Python.
Возможно, вы помните теорему Байеса как громоздкое уравнение из курса статистики, которое вам нужно было заучить. Но за ним кроется нечто большее. Эта теорема лежит в основе альтернативного взгляда на статистику и вероятность, противостоящего мнению сторонников частотного подхода (или фреквентистов), и доброй половины величайших (или нуднейших) священных войн в академической среде.
➡️ Читать дальше
@data_analysis_ml
Возможно, вы помните теорему Байеса как громоздкое уравнение из курса статистики, которое вам нужно было заучить. Но за ним кроется нечто большее. Эта теорема лежит в основе альтернативного взгляда на статистику и вероятность, противостоящего мнению сторонников частотного подхода (или фреквентистов), и доброй половины величайших (или нуднейших) священных войн в академической среде.
➡️ Читать дальше
@data_analysis_ml
👍12❤1🔥1
🌅 GAN-модели для генерации набора данных из изображений
Для работы с данными в специфических областях очень остро стоит проблема нехватки данных для обучения. Давайте рассмотрим один из способов генерировать изображения.
➡️ Читать дальше
⚙️ Полный код
@data_analysis_ml
Для работы с данными в специфических областях очень остро стоит проблема нехватки данных для обучения. Давайте рассмотрим один из способов генерировать изображения.
➡️ Читать дальше
⚙️ Полный код
@data_analysis_ml
👍12🔥2
💻 Как быстро и легко создавать прототипы датасайенс-проектов
Проект в области науки о данных можно успешно реализовать при наличии минимального стека технологий. Более того, чем меньше стек, тем лучше проект!
Jupyter Notebook — неотъемлемая часть повседневной работы специалистов по данным. Большинство проектов в этой области также нуждаются в интерактивном дашборде.
А что если превратить ноутбуки в многофункциональные дашборды? Это возможно!
Как правило, для разработки дашборда требуются знания HTML, JavaScript и CSS. Такие инструменты, как Streamlit и Dash, позволяют обойтись без этих знаний.
Тем не менее преобразовывать ноутбуки в функциональные приложения все равно нужно вручную, для чего потребуется копировать множество фрагментов.
Однако с помощью Mercury можно мгновенно превратить Jupyter Notebook в интерактивный дашборд, онлайн-слайд-шоу или веб-сервис.
➡️ Читать дальше
@data_analysis_ml
Проект в области науки о данных можно успешно реализовать при наличии минимального стека технологий. Более того, чем меньше стек, тем лучше проект!
Jupyter Notebook — неотъемлемая часть повседневной работы специалистов по данным. Большинство проектов в этой области также нуждаются в интерактивном дашборде.
А что если превратить ноутбуки в многофункциональные дашборды? Это возможно!
Как правило, для разработки дашборда требуются знания HTML, JavaScript и CSS. Такие инструменты, как Streamlit и Dash, позволяют обойтись без этих знаний.
Тем не менее преобразовывать ноутбуки в функциональные приложения все равно нужно вручную, для чего потребуется копировать множество фрагментов.
Однако с помощью Mercury можно мгновенно превратить Jupyter Notebook в интерактивный дашборд, онлайн-слайд-шоу или веб-сервис.
➡️ Читать дальше
@data_analysis_ml
👍15❤1🔥1😁1
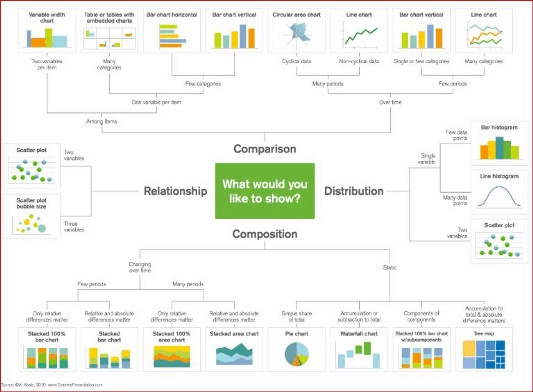
📈 Различные варианты визуализации данных с примерами кода.
Визуализация данных — это большая часть работы специалистов в области data science. На ранних стадиях развития проекта часто необходимо выполнять разведочный анализ данных (РАД, Exploratory data analysis (EDA)), чтобы выявить закономерности, которые обнаруживают данные. Визуализация данных помогает представить большие и сложные наборы данных в простом и наглядном виде. На этапе окончания проекта важно суметь отчитаться о его результатах так, чтобы даже непрофессионалам, не обладающим техническими знаниями, всё стало ясно и понятно.
Matplotlib — это популярная библиотека для визуализации данных, написанная на языке Python. Хоть пользоваться ей очень просто, настройка данных, параметров, графиков и отрисовки для каждого нового проекта — занятие нудное и утомительное. В этом посте мы разберем 6 способов визуализации данных и напишем быстрые и простые функции для их реализации с помощью питоновской библиотеки Matplotlib. А пока взгляните на прекрасный график, который поможет вам выбрать правильный тип визуализации данных!
Алгоритм выбора техники визуализации в зависимости от задачи
➡️ Читать дальше
@data_analysis_ml
Визуализация данных — это большая часть работы специалистов в области data science. На ранних стадиях развития проекта часто необходимо выполнять разведочный анализ данных (РАД, Exploratory data analysis (EDA)), чтобы выявить закономерности, которые обнаруживают данные. Визуализация данных помогает представить большие и сложные наборы данных в простом и наглядном виде. На этапе окончания проекта важно суметь отчитаться о его результатах так, чтобы даже непрофессионалам, не обладающим техническими знаниями, всё стало ясно и понятно.
Matplotlib — это популярная библиотека для визуализации данных, написанная на языке Python. Хоть пользоваться ей очень просто, настройка данных, параметров, графиков и отрисовки для каждого нового проекта — занятие нудное и утомительное. В этом посте мы разберем 6 способов визуализации данных и напишем быстрые и простые функции для их реализации с помощью питоновской библиотеки Matplotlib. А пока взгляните на прекрасный график, который поможет вам выбрать правильный тип визуализации данных!
Алгоритм выбора техники визуализации в зависимости от задачи
➡️ Читать дальше
@data_analysis_ml
{kind=link}
👍16❤5🔥1
Какие учебники по математическому анализу, линейной алгебре и теории вероятностей лучше подходят для изучения анализа данных?
К сожалению, анализ данных не устроен как стройная теория - это лоскутное одеяло методов, которые опираются на определенные идеи, беря, иногда, для решения одной задачи, половину курса теории оптимизации.
Более того, существует некоторое количество абсолютно необходимых практических навыков для работы в этой области, которые не будут подвязаны к существующим учебникам, поэтому существенную часть, вероятно, придется изучать по документации пакетов.
Для старта:
1 Начните изучение с практических навыков описательной статистики (может взять учебник с названием "статистика" (не математическая статистика), взять датасет на kaggle и начать баловаться с pandas. Это даст вам существенное понимание про элементарную предобработку.
2 Возьмите книжку по практике математической статистики Гмурмана и попытайтесь средствами того же pandas по-постраивать доверительные интервалы, да по-проверять гипотезы.
3 После освоения pandas - вам стоит перейти к библиотеке scikit-learn, почитать ее документацию, поупражняться на конкретных датасетах с кластеризациями, предобработкой, тренировкой моделей и визуализацией. Для визуализации следует ознакомиться с matplotlib и bokeh.
4 Дальше желательно изучить SQL. На фоне владения pandas он окажется простым
5 Потом, почти наверняка наступит период овладения torch и keras.
Вот дальше можно пойти в разные стороны:
• копать в сторону теории без библиотек (типа HMM) и в совершенстве овладеть numpy и stats;
• копать в сторону больших данных и изучать Hadoop и Spark;
• копать в сторону компьютерного зрения и изучать opencv;
• узучать биоинформатику и изучать взаимодействия с GenBank и другими биоинформатическими сервисами
• уйти в изучение по информационному поиску, изучать какой-нибудь EllasticSearch, NLTK, pymorphy, request и регулярные выражения.
Ну и там на самом деле это просто верхушка айсберга.
Поймите тут такую вещь, что понимание - это круто, конечно, но есть отдельно огромная работа уже просто освоить готовые технологии.
Если Вы параллельно сможете еще и теорию осваивать на тему, то советую
1 по анализу трехтомник У. Рудина,
2 по линейной алгебре "Задачи и теоремы линейной алгебры" Прасолова,
3 а по теории вероятностей начать с "Гмурмана" чисто с практических соображений,
4 потом перейти на "Боровкова".
5 Есть еще хорошая книга "Коралов-Синай", но у нее безумно маленький тираж на русском языке.
Еще, разумеется, вам абсолютно необходимо будет знать что-то про конечномерную оптимизацию - это вообще лучше всего по методичкам на сайтах различных вузов посмотреть.
@data_analysis_ml
К сожалению, анализ данных не устроен как стройная теория - это лоскутное одеяло методов, которые опираются на определенные идеи, беря, иногда, для решения одной задачи, половину курса теории оптимизации.
Более того, существует некоторое количество абсолютно необходимых практических навыков для работы в этой области, которые не будут подвязаны к существующим учебникам, поэтому существенную часть, вероятно, придется изучать по документации пакетов.
Для старта:
1 Начните изучение с практических навыков описательной статистики (может взять учебник с названием "статистика" (не математическая статистика), взять датасет на kaggle и начать баловаться с pandas. Это даст вам существенное понимание про элементарную предобработку.
2 Возьмите книжку по практике математической статистики Гмурмана и попытайтесь средствами того же pandas по-постраивать доверительные интервалы, да по-проверять гипотезы.
3 После освоения pandas - вам стоит перейти к библиотеке scikit-learn, почитать ее документацию, поупражняться на конкретных датасетах с кластеризациями, предобработкой, тренировкой моделей и визуализацией. Для визуализации следует ознакомиться с matplotlib и bokeh.
4 Дальше желательно изучить SQL. На фоне владения pandas он окажется простым
5 Потом, почти наверняка наступит период овладения torch и keras.
Вот дальше можно пойти в разные стороны:
• копать в сторону теории без библиотек (типа HMM) и в совершенстве овладеть numpy и stats;
• копать в сторону больших данных и изучать Hadoop и Spark;
• копать в сторону компьютерного зрения и изучать opencv;
• узучать биоинформатику и изучать взаимодействия с GenBank и другими биоинформатическими сервисами
• уйти в изучение по информационному поиску, изучать какой-нибудь EllasticSearch, NLTK, pymorphy, request и регулярные выражения.
Ну и там на самом деле это просто верхушка айсберга.
Поймите тут такую вещь, что понимание - это круто, конечно, но есть отдельно огромная работа уже просто освоить готовые технологии.
Если Вы параллельно сможете еще и теорию осваивать на тему, то советую
1 по анализу трехтомник У. Рудина,
2 по линейной алгебре "Задачи и теоремы линейной алгебры" Прасолова,
3 а по теории вероятностей начать с "Гмурмана" чисто с практических соображений,
4 потом перейти на "Боровкова".
5 Есть еще хорошая книга "Коралов-Синай", но у нее безумно маленький тираж на русском языке.
Еще, разумеется, вам абсолютно необходимо будет знать что-то про конечномерную оптимизацию - это вообще лучше всего по методичкам на сайтах различных вузов посмотреть.
@data_analysis_ml
👍49🔥11
⭐️ Как работает коллаборативная фильтрация?
Коллаборативная фильтрация – метод, используемый в рекомендательных системах, для прогнозирования неизвестных предпочтений одного пользователя по известным предпочтениям других пользователей. Наиболее часто применяется для повышения продаж, конверсии, эффективности публикации информационных материалов и других метрик в электронной коммерции.
Метод основан на предположении о том, что пользователи, которые одинаково оценивали какие-либо товары (услуги) в прошлом, склонны давать похожие оценки другим товарам в будущем. Исходя из этого допущения, рекомендательная система будет предлагать те товары, которыми интересовалась аудитория, а конкретный пользователь еще нет. В этом и будет проявляться коллаборация – прогнозы составляются индивидуально для каждого, хотя используемая для них информация собрана от многих участников.
На задачу рекомендательной системы можно смотреть как на заполнение пропусков в матрице оценок товаров пользователями. Для этого применяют два основных подхода, основанные на сходстве пользователей (user-based collaborative filtering) и похожести предлагаемых продуктов (item-based collaborative filtering).
В общем виде алгоритм состоит из следующих шагов:
Найти, насколько другие пользователи (продукты) похожи на пользователя (продукт), для которого необходимо выдать рекомендацию.
По оценкам других пользователей (продуктов) предсказать, какую оценку даст исследуемый пользователь определенному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
В качестве меры похожести часто используют косинусную меру, коэффициент корреляции Пирсона, евклидово расстояние, коэффициент Танимото и манхэттенское расстояние.
Разработчики коллаборативной фильтрации применяют различные решения для учета явности и неявности оценок и предпочтений пользователей. Примером явной оценки является количество звезд, поставленных зрителем после просмотра фильма в онлайн-кинотеатре Okko, или нажатие кнопки “дизлайк” у статьи Яндекс Дзен. В наше динамичное время, как правило, объем неявных оценок превышает явную обратную связь, поэтому высокий потенциал для повышения качества рекомендаций несет именно неявный рейтинг, когда есть все основания полагать, что пользователь воспользовался услугой, но не захотел сообщить своё мнение о ней. В этом случае рекомендательная система может попытаться спрогнозировать оценку по другим метрикам, например времени чтения статьи или просмотра видео. Недосмотренный фильм, как и статья, которая удержала на себе внимание не больше 5 секунд, скорее всего не смогли понравиться.
Важно понимать, что результативность коллаборативной фильтрации может быть низкой, когда рекомендательная система еще не накопила достаточного набора данных о новом пользователе или товаре. Эта ситуация называется проблемой холодного старта. Она может проявляться так же для непопулярных товаров и неактивных пользователей.
➡️ Коллаборативная фильтрация и ее реализация
@data_analysis_ml
Коллаборативная фильтрация – метод, используемый в рекомендательных системах, для прогнозирования неизвестных предпочтений одного пользователя по известным предпочтениям других пользователей. Наиболее часто применяется для повышения продаж, конверсии, эффективности публикации информационных материалов и других метрик в электронной коммерции.
Метод основан на предположении о том, что пользователи, которые одинаково оценивали какие-либо товары (услуги) в прошлом, склонны давать похожие оценки другим товарам в будущем. Исходя из этого допущения, рекомендательная система будет предлагать те товары, которыми интересовалась аудитория, а конкретный пользователь еще нет. В этом и будет проявляться коллаборация – прогнозы составляются индивидуально для каждого, хотя используемая для них информация собрана от многих участников.
На задачу рекомендательной системы можно смотреть как на заполнение пропусков в матрице оценок товаров пользователями. Для этого применяют два основных подхода, основанные на сходстве пользователей (user-based collaborative filtering) и похожести предлагаемых продуктов (item-based collaborative filtering).
В общем виде алгоритм состоит из следующих шагов:
Найти, насколько другие пользователи (продукты) похожи на пользователя (продукт), для которого необходимо выдать рекомендацию.
По оценкам других пользователей (продуктов) предсказать, какую оценку даст исследуемый пользователь определенному продукту, учитывая с большим весом тех пользователей (продукты), которые больше похожи на данный.
В качестве меры похожести часто используют косинусную меру, коэффициент корреляции Пирсона, евклидово расстояние, коэффициент Танимото и манхэттенское расстояние.
Разработчики коллаборативной фильтрации применяют различные решения для учета явности и неявности оценок и предпочтений пользователей. Примером явной оценки является количество звезд, поставленных зрителем после просмотра фильма в онлайн-кинотеатре Okko, или нажатие кнопки “дизлайк” у статьи Яндекс Дзен. В наше динамичное время, как правило, объем неявных оценок превышает явную обратную связь, поэтому высокий потенциал для повышения качества рекомендаций несет именно неявный рейтинг, когда есть все основания полагать, что пользователь воспользовался услугой, но не захотел сообщить своё мнение о ней. В этом случае рекомендательная система может попытаться спрогнозировать оценку по другим метрикам, например времени чтения статьи или просмотра видео. Недосмотренный фильм, как и статья, которая удержала на себе внимание не больше 5 секунд, скорее всего не смогли понравиться.
Важно понимать, что результативность коллаборативной фильтрации может быть низкой, когда рекомендательная система еще не накопила достаточного набора данных о новом пользователе или товаре. Эта ситуация называется проблемой холодного старта. Она может проявляться так же для непопулярных товаров и неактивных пользователей.
➡️ Коллаборативная фильтрация и ее реализация
@data_analysis_ml
{kind=link}
👍14🔥3
✒️ Валидация моделей машинного обучения и анализа данных.
Cегодня мы разберем валидацию моделей.
Иногда термин «валидация» ассоциируется с вычислением одной точечной статистической метрики (например, ROC AUC) на отложенной выборке данных. Однако такой подход может привести к ряду ошибок.
В статье разберем, о каких ошибках идет речь, подробнее рассмотрим процесс валидации и дадим ответы на вопросы:
- на каком этапе жизненного цикла модели проводится валидация? Спойлер: это происходит больше одного раза;
- какие метрики обычно применяются при валидации и с какой целью?
- почему важно использовать не только количественные, но и качественные метрики?
Примеры в статье будут из финансового сектора. Финансовый сектор отличается от других областей (больше предписаний со стороны регулятора — Центрального банка), но в то же время в секторе большой опыт применения моделирования для решения бизнес-задач и есть широкий спектр опробованных на практике тестов по валидации моделей. Поэтому статья будет интересна как тем, кто работает в ритейле, телекоме, промышленности, так и специалистам любой другой сферы, где применяются модели машинного обучения.
➡️ Читать дальше
@data_analysis_ml
Cегодня мы разберем валидацию моделей.
Иногда термин «валидация» ассоциируется с вычислением одной точечной статистической метрики (например, ROC AUC) на отложенной выборке данных. Однако такой подход может привести к ряду ошибок.
В статье разберем, о каких ошибках идет речь, подробнее рассмотрим процесс валидации и дадим ответы на вопросы:
- на каком этапе жизненного цикла модели проводится валидация? Спойлер: это происходит больше одного раза;
- какие метрики обычно применяются при валидации и с какой целью?
- почему важно использовать не только количественные, но и качественные метрики?
Примеры в статье будут из финансового сектора. Финансовый сектор отличается от других областей (больше предписаний со стороны регулятора — Центрального банка), но в то же время в секторе большой опыт применения моделирования для решения бизнес-задач и есть широкий спектр опробованных на практике тестов по валидации моделей. Поэтому статья будет интересна как тем, кто работает в ритейле, телекоме, промышленности, так и специалистам любой другой сферы, где применяются модели машинного обучения.
➡️ Читать дальше
@data_analysis_ml
👍11
Карл Андерсон / Аналитическая культура
Это практическое пошаговое руководство по внедрению в вашей организации управления на основе данных. Карл Андерсон, директор по аналитике в компании Warby Parker, провел интервью с ведущими аналитиками и учеными и собрал кейсы, которые и легли в основу данной книги. Вы узнаете, какие процессы следует ввести на всех уровнях и как именно это сделать, с какими трудностями можно столкнуться на этом пути и как их преодолеть. Автор рассказывает об аналитической цепочке ценностей, которая поможет принимать правильные решения и достигать лучших бизнес-результатов.
Книга будет интересна CEO и владельцам бизнеса, менеджерам, аналитикам.
📖 Книга
@data_analysis_ml
Это практическое пошаговое руководство по внедрению в вашей организации управления на основе данных. Карл Андерсон, директор по аналитике в компании Warby Parker, провел интервью с ведущими аналитиками и учеными и собрал кейсы, которые и легли в основу данной книги. Вы узнаете, какие процессы следует ввести на всех уровнях и как именно это сделать, с какими трудностями можно столкнуться на этом пути и как их преодолеть. Автор рассказывает об аналитической цепочке ценностей, которая поможет принимать правильные решения и достигать лучших бизнес-результатов.
Книга будет интересна CEO и владельцам бизнеса, менеджерам, аналитикам.
📖 Книга
@data_analysis_ml
👍21🔥5