
🗒 Регулярные выражения для задач NLP в Python. Часть1
Рассморим основные функции Python-модуля re.
Регулярные выражения - это набор символов, который определяет паттерн для поиска в тексте. Например, в задачах NLP можно использовать Python-библиотеку Yargy для поиска именованных сущностей. Но использование выражений может вызвать неоднозначность, так как выражения, содержащие искомый паттерн, также будут найдены.
В Python модуль re используется для работы с регулярными выражениями и содержит 4 основные функции: search, match, findall, finditer и sub.
Первые четыре функции имеют одинаковую сигнатуру и принимают на вход шаблон и выражение, а функция sub дополнительно требует строку замены.
re.search() – находит первое вхождение фрагмента в любом месте и возвращает объект match. Если в строке есть другие фрагменты, соответствующие запросу, re.search их проигнорирует.
Обратите внимание, что функция search находит только первый попавшийся шаблон, дальше она уже не смотрит:
Нельзя забывать, что шаблон представляет собой последовательность символов, а не сами слова.
Например, как можно найти последовательность "love" в составном слове в Python, показано ниже.
Как найти все вхождения при помощи findall и finditer.
В отличие от функции search, две другие функции findall и finditer найдут все вхождения. Разница между findall и finditer заключается в том, что первый возвращает список (list), а второй возвращает итератор (iterator), который мы обсудили ранее.
Возвращаясь к предыдущему примеру, регулярное выражение для обнаружения всех вхождений в Python будет иметь следующий вид:
Проверяем начало строки с помощью функции match.
Функция match проверяет начало строки на соответствие шаблону.
Пример выше не начинается с "love", поэтому эта функция вернет значение None. С другой стороны, если выражение начинается с шаблона, функция match вернет объект Match. Рассмотрите следующие регулярные выражения в Python:
Исключаем шаблон из строки с sub
Ещё одной полезной функцией Python-модуля re является sub. Она необходима, когда один шаблон нужно заменить на другой и пригодится для подготовки текстов перед применением NLP-методов в Python, например, для избавления от всех цифр, знаков препинания и символов. К сигнатуре этой функции добавляется аргумент repl — на какую строку заменяем. Ниже регулярные выражения в Python это демонстрируют. Обратите внимание, что sub возвращает строку, поэтому их стоит переприсвоить.
Также отметим, что функция заменяет все вхождения. Если требуется ограничить это число, то оно указывается в аргументе count.
▪шпаргалка по регулярным выражениям
@data_analysis_ml
Рассморим основные функции Python-модуля re.
Регулярные выражения - это набор символов, который определяет паттерн для поиска в тексте. Например, в задачах NLP можно использовать Python-библиотеку Yargy для поиска именованных сущностей. Но использование выражений может вызвать неоднозначность, так как выражения, содержащие искомый паттерн, также будут найдены.
В Python модуль re используется для работы с регулярными выражениями и содержит 4 основные функции: search, match, findall, finditer и sub.
Первые четыре функции имеют одинаковую сигнатуру и принимают на вход шаблон и выражение, а функция sub дополнительно требует строку замены.
re.search() – находит первое вхождение фрагмента в любом месте и возвращает объект match. Если в строке есть другие фрагменты, соответствующие запросу, re.search их проигнорирует.
import re
expr = 'i love Data Science'
pattern = 'love'
print(re.search(pattern, expr))
<re.Match object; span=(2, 6), match='love'>Обратите внимание, что функция search находит только первый попавшийся шаблон, дальше она уже не смотрит:
expr = 'I love data science, i love @data_analysis_ml' print( re.search(pattern, expr))<re.Match object; span=(2, 6), match='love'>Нельзя забывать, что шаблон представляет собой последовательность символов, а не сами слова.
Например, как можно найти последовательность "love" в составном слове в Python, показано ниже.
expr = 'So many lovers
re.search('love', expr)Как найти все вхождения при помощи findall и finditer.
В отличие от функции search, две другие функции findall и finditer найдут все вхождения. Разница между findall и finditer заключается в том, что первый возвращает список (list), а второй возвращает итератор (iterator), который мы обсудили ранее.
Возвращаясь к предыдущему примеру, регулярное выражение для обнаружения всех вхождений в Python будет иметь следующий вид:
expr = 'I love data science, I love @data_analysis_ml'
re.findall('love', expr)
['love', 'love']re.finditer('love', expr)<callable_iterator object at 0x7efd1caf6b60>Проверяем начало строки с помощью функции match.
Функция match проверяет начало строки на соответствие шаблону.
Пример выше не начинается с "love", поэтому эта функция вернет значение None. С другой стороны, если выражение начинается с шаблона, функция match вернет объект Match. Рассмотрите следующие регулярные выражения в Python:
expr = 'i love Data Science'
re.match('Data', expr)
None
re.match('love', expr) is None
TrueИсключаем шаблон из строки с sub
Ещё одной полезной функцией Python-модуля re является sub. Она необходима, когда один шаблон нужно заменить на другой и пригодится для подготовки текстов перед применением NLP-методов в Python, например, для избавления от всех цифр, знаков препинания и символов. К сигнатуре этой функции добавляется аргумент repl — на какую строку заменяем. Ниже регулярные выражения в Python это демонстрируют. Обратите внимание, что sub возвращает строку, поэтому их стоит переприсвоить.
expr = 'i love Data Science'
pattern = 'love'
repl = 'hate'
re.sub(pattern, repl, expr)
'i hate Data Science'
Также отметим, что функция заменяет все вхождения. Если требуется ограничить это число, то оно указывается в аргументе count.
re.sub(pattern, repl, expr, count=1)▪шпаргалка по регулярным выражениям
@data_analysis_ml
👍13🔥4❤2
🤖12 сервисов искусственного интеллекта, для написания кода.
Mutable AI
Альтернатива Copilot, которая предлагает бесплатную версию со сокращенным функционалом, а стоимость ее платной подписки варьируется от $10 до $25 в месяц. Эта альтернатива также предлагает следующие возможности: автодополнение кода, управление с помощью промптов, рефакторинг кода и автоматическую документацию.
SpellBox
Это AI-помощник для программистов, который можно установить как настольное приложение (для Windows и macOS), так и как плагин для VS Code. Он способен генерировать код в ответ на запросы, объяснять принципы работы программы и сохранять фрагменты кода в закладках.
StarCoder
Это AI-ассистент, который может создавать код на 80 языках, обученный на данных из GitHub. Эта модель похожа на GitHub Copilot, но с открытым исходным кодом и, по мнению разработчиков, она лучше других моделей.
Blackbox AI
BlackboxAI поддерживает более 20 языков программирования, включая Python, Java, C, C++, C#, JavaScript, SQL, PHP, Go, TypeScript, Kotlin, MATLAB, R, Swift, Rust, Ruby, Dart и Scala.
Ghostwriter Chat
Разработчики Replit создали не имеющую себе равных онлайн-IDE, которая основана на искусственном интеллекте. Эта инновационная система способна написать код в соответствии с контекстом проекта и не только дополняет код, написанный программистом, но и помогает отслеживать ошибки.
CodeSquire.ai
Это ИИ-ассистент, который помогает дата-сайентистам, инженерам и аналитикам. Он способен генерировать код в ответ на вопросы, создавать функции различной сложности, преобразовывать вводимые команды в SQL-запросы и детально объяснять, как работает каждый блок кода.
Toolbuilder
Toolbuilder позволяет быстро создавать ИИ-приложения и чат-боты, которые хранятся и запускаются на сайте. Вы можете поделиться ссылками на приложения с друзьями, а для выбора подходящего инструмента есть каталог готовых приложений, например, инструменты для поиска персонализированных подарков, анализа SEO показателей, рекомендации коктейлей и описания товаров. Еще один популярный инструмент - генератор постов для блога. Также вы можете использовать Toolbuilder для описания сюжета фильма с помощью эмодзи и иконок.
Safurai
Это бесплатный инструмент на основе искусственного интеллекта, который можно использовать как плагин для VS Code. Для того чтобы воспользоваться ее возможностями, достаточно выделить фрагмент кода: Safurai объяснит, как он работает, предложит советы по оптимизации и рефакторингу, напишет необходимые тесты и документацию. Будучи обучаемым на коде проекта, он запомнит все заданные вопросы.
Text2SQL
Text2SQL - данный искусственный интеллект создает запросы SQL, регулярные выражения, дизайны баз данных и формулы для Excel и Google Sheets. Присутствует бесплатный тариф, в то время как цены платной подписки варьируются от $2.49 до $4.99 в месяц.
Code Snippets AI
Приложение, использующее технологию GPT-4 для генерации кода. По вопросу о необходимости данного инструмента, разработчики отвечают, что это более экономичный вариант по сравнению с оригинальным ChatGPT Plus, подписка на который стоит $24 в месяц, в то время как подписка на Code Snippets AI обойдется в $10 в месяц.
CodiumAI
CodiumAI - программа для тестирования, использующая TestGPT-1 и GPT-3.5 & 4 для интеллектуального создания тестов и обработки кода, выявления ошибок и багов. В настоящее время этот инструмент работает с кодом Python, JavaScript и TypeScript. Благодаря подключению к VS Code и другим IDE от JetBrains, использование CodiumAI бесплатно.
Metabob
Metabob исправляет ошибки и выявляет уязвимости в коде, а также интегрируется с такими платформами, как VS Code, GitHub, BitBucket и GitLab. Эта программа берет под контроль все самые популярные языки программирования, включая Python, Javascript, Typescript, C++, С и Java, и предоставляет своевременные рекомендации по улучшению кода. B процессе работы Metabob автоматически производит рефакторинг кода разработчиков и искусственный разум.
@data_analysis_ml
Mutable AI
Альтернатива Copilot, которая предлагает бесплатную версию со сокращенным функционалом, а стоимость ее платной подписки варьируется от $10 до $25 в месяц. Эта альтернатива также предлагает следующие возможности: автодополнение кода, управление с помощью промптов, рефакторинг кода и автоматическую документацию.
SpellBox
Это AI-помощник для программистов, который можно установить как настольное приложение (для Windows и macOS), так и как плагин для VS Code. Он способен генерировать код в ответ на запросы, объяснять принципы работы программы и сохранять фрагменты кода в закладках.
StarCoder
Это AI-ассистент, который может создавать код на 80 языках, обученный на данных из GitHub. Эта модель похожа на GitHub Copilot, но с открытым исходным кодом и, по мнению разработчиков, она лучше других моделей.
Blackbox AI
BlackboxAI поддерживает более 20 языков программирования, включая Python, Java, C, C++, C#, JavaScript, SQL, PHP, Go, TypeScript, Kotlin, MATLAB, R, Swift, Rust, Ruby, Dart и Scala.
Ghostwriter Chat
Разработчики Replit создали не имеющую себе равных онлайн-IDE, которая основана на искусственном интеллекте. Эта инновационная система способна написать код в соответствии с контекстом проекта и не только дополняет код, написанный программистом, но и помогает отслеживать ошибки.
CodeSquire.ai
Это ИИ-ассистент, который помогает дата-сайентистам, инженерам и аналитикам. Он способен генерировать код в ответ на вопросы, создавать функции различной сложности, преобразовывать вводимые команды в SQL-запросы и детально объяснять, как работает каждый блок кода.
Toolbuilder
Toolbuilder позволяет быстро создавать ИИ-приложения и чат-боты, которые хранятся и запускаются на сайте. Вы можете поделиться ссылками на приложения с друзьями, а для выбора подходящего инструмента есть каталог готовых приложений, например, инструменты для поиска персонализированных подарков, анализа SEO показателей, рекомендации коктейлей и описания товаров. Еще один популярный инструмент - генератор постов для блога. Также вы можете использовать Toolbuilder для описания сюжета фильма с помощью эмодзи и иконок.
Safurai
Это бесплатный инструмент на основе искусственного интеллекта, который можно использовать как плагин для VS Code. Для того чтобы воспользоваться ее возможностями, достаточно выделить фрагмент кода: Safurai объяснит, как он работает, предложит советы по оптимизации и рефакторингу, напишет необходимые тесты и документацию. Будучи обучаемым на коде проекта, он запомнит все заданные вопросы.
Text2SQL
Text2SQL - данный искусственный интеллект создает запросы SQL, регулярные выражения, дизайны баз данных и формулы для Excel и Google Sheets. Присутствует бесплатный тариф, в то время как цены платной подписки варьируются от $2.49 до $4.99 в месяц.
Code Snippets AI
Приложение, использующее технологию GPT-4 для генерации кода. По вопросу о необходимости данного инструмента, разработчики отвечают, что это более экономичный вариант по сравнению с оригинальным ChatGPT Plus, подписка на который стоит $24 в месяц, в то время как подписка на Code Snippets AI обойдется в $10 в месяц.
CodiumAI
CodiumAI - программа для тестирования, использующая TestGPT-1 и GPT-3.5 & 4 для интеллектуального создания тестов и обработки кода, выявления ошибок и багов. В настоящее время этот инструмент работает с кодом Python, JavaScript и TypeScript. Благодаря подключению к VS Code и другим IDE от JetBrains, использование CodiumAI бесплатно.
Metabob
Metabob исправляет ошибки и выявляет уязвимости в коде, а также интегрируется с такими платформами, как VS Code, GitHub, BitBucket и GitLab. Эта программа берет под контроль все самые популярные языки программирования, включая Python, Javascript, Typescript, C++, С и Java, и предоставляет своевременные рекомендации по улучшению кода. B процессе работы Metabob автоматически производит рефакторинг кода разработчиков и искусственный разум.
@data_analysis_ml
👍14❤4🔥4
⚡Python со скоростью света
Задача: заполнить список из n целых чисел.
Запуск функции с size = 10 000 000 занял в среднем 765 мс на моей машине.
Ускорим этот процесс!
▪Numpy
Запуск функции с тем же количеством элементов занял 964 мс.
▪Numba
Как мы видим, функция почти такая же. Просто добавил декоратор и prange (функция диапазона в numba, которая работает параллельно). На этот раз время вычислений составило всего 16 мс! Почти в 50 раз быстрее, чем на голом Python. Это впечатляющий результат.
▪Julia
Julia – еще один язык, который набирает обороты. Его цель – предложить почти такую же гибкость и понятный синтаксис, как у Python, но с высокой скоростью компиляции кода.
В Julia нет проблем с GIL, поэтому потоки могут работать параллельно. Это заняло всего 12 мс.
▪Mojo
Mojo – это новый язык, находящийся в стадии активной разработки.
Приведенная выше функция отработала всего за 7 мс, в 110 раз быстрее, чем Python, и намного быстрее, чем Julia. Это Python со скоростью света!
📌 Почитать про Mojo
@data_analysis_ml
Задача: заполнить список из n целых чисел.
def populate_python(size:int)->list:
b = []
for i in range(size):
b.append(i)
return bЗапуск функции с size = 10 000 000 занял в среднем 765 мс на моей машине.
Ускорим этот процесс!
▪Numpy
import numpy as np
def populate_numpy(size:int)->np.ndarray:
b = np.empty((size),dtype=np.int64)
for i in range(size):
b[i] = i
return bЗапуск функции с тем же количеством элементов занял 964 мс.
▪Numba
from numba import njit, prange
@njit
def populate_numba(size:int)->np.ndarray:
b = np.empty((size),dtype=np.int64)
for i in prange(size):
b[i] = i
return bКак мы видим, функция почти такая же. Просто добавил декоратор и prange (функция диапазона в numba, которая работает параллельно). На этот раз время вычислений составило всего 16 мс! Почти в 50 раз быстрее, чем на голом Python. Это впечатляющий результат.
▪Julia
Julia – еще один язык, который набирает обороты. Его цель – предложить почти такую же гибкость и понятный синтаксис, как у Python, но с высокой скоростью компиляции кода.
function populate_array(size::Int)::AbstractVector{Int64}
b = Vector{Int64}(undef,size)
Threads.@threads for i=1:size
b[i] = i
end
return b
endВ Julia нет проблем с GIL, поэтому потоки могут работать параллельно. Это заняло всего 12 мс.
▪Mojo
Mojo – это новый язык, находящийся в стадии активной разработки.
from Pointer import DTypePointer
from Random import rand, random_ui64
from DType import DType
from Range import range
from Functional import parallelize
import SIMD
struct Vect:
var data: DTypePointer[DType.uint64]
var rows: Int
fn __init__(inout self, rows: Int):
self.data = DTypePointer[DType.uint64].alloc(rows)
self.rows = rows
fn __del__(owned self):
self.data.free()
@always_inline
fn len(self)->UInt64:
return self.rows
fn zero(inout self):
memset_zero(self.data, self.rows)
@always_inline
fn __getitem__(self, x: Int) -> UInt64:
return self.data.load(x)
@always_inline
fn __setitem__(self, x: Int, val: UInt64):
return self.data.store( x, val)
fn populate_mojo(b:Vect):
@parameter
fn process_row(i:Int):
b[i] = i
parallelize[process_row](b.rows)Приведенная выше функция отработала всего за 7 мс, в 110 раз быстрее, чем Python, и намного быстрее, чем Julia. Это Python со скоростью света!
📌 Почитать про Mojo
@data_analysis_ml
👍14🔥5❤4👎2
В мире, где с 1974 года доминирует SQL, в 2008 году появился Pandas, предлагающий привлекательные функции, такие как встроенная визуализация и гибкая обработка данных. Он быстро стал популярным инструментом для исследования данных, затмив собой SQL.
Но не обманывайте себя, SQL по-прежнему держит свои позиции. Это второй по востребованности и третий по скорости роста язык для Data science (см. здесь ). Таким образом, в то время как Pandas привлекает всеобщее внимание, SQL остаётся жизненно важным навыком для любого специалиста по данным.
Давайте узнаем, как легко выучить SQL, если вы уже знаете Pandas.
▪ Читать
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
👍9🔥2❤1🤣1
🖋 Нечеткое сравнение строк с помощью rapidfuzz
Недавно у меня возникла Недавно у меня возникла задача, в процессе которой потребовалось нечеткое сравнение строк. Ниже кратко опишу суть.
Проблема: на входе большое количество сканов документов в pdf формате, которые с помощью Adobe FineReader переведены в текстовые документы формата docx и мне необходимо произвести некоторую классификацию. К счастью тренировать NLP модель для этого не потребуется, т.к. документы легко классифицируются по содержанию в них конкретной фразы и мне остается лишь определить есть ли эта фраза в документе. С другой стороны, я еще далек от идеального будущего, в котором computer vision правильно распознает даже скан плохого качества, и поэтому текст в формат docx трансформировался с ошибками. Например, фраза «объект залога» может превратиться в «обb ект %алога».
Задача: написать функцию, которая определяет есть ли в документе определенная формулировка, с учетом неправильного преобразования текста., в процессе которой потребовалось нечеткое сравнение строк. Ниже кратко опишу суть.
Проблема: на входе большое количество сканов документов в pdf формате, которые с помощью Adobe FineReader переведены в текстовые документы формата docx и мне необходимо произвести некоторую классификацию. К счастью тренировать NLP модель для этого не потребуется, т.к. документы легко классифицируются по содержанию в них конкретной фразы и мне остается лишь определить есть ли эта фраза в документе. С другой стороны, я еще далек от идеального будущего, в котором computer vision правильно распознает даже скан плохого качества, и поэтому текст в формат docx трансформировался с ошибками. Например, фраза «объект залога» может превратиться в «обb ект %алога».
Задача: написать функцию, которая определяет есть ли в документе определенная формулировка, с учетом неправильного преобразования текста.
С чего начнем?
Прежде чем бежать писать функцию, надо определиться каким методом производить нечеткое сопоставление строк. Выбор тут не самый широкий, было решено протестировать три варианта: сравнение по косинусному сходству; сравнение по сходству Левенштейна; сравнение по сходству Джаро-Винклера. Критерии, по которым предстоит выбрать лучший вариант: скорость выполнения (документов довольно много, нужно находить подстроку за разумное время); правильность сравнения (нечеткое сравнение на то и нечеткое, потому что требуется некая экспертная оценка того, как отрабатывает критерий сравнения), простота реализации.
▪Читать дальше
▪RapidFuzz
@data_analysis_ml
Недавно у меня возникла Недавно у меня возникла задача, в процессе которой потребовалось нечеткое сравнение строк. Ниже кратко опишу суть.
Проблема: на входе большое количество сканов документов в pdf формате, которые с помощью Adobe FineReader переведены в текстовые документы формата docx и мне необходимо произвести некоторую классификацию. К счастью тренировать NLP модель для этого не потребуется, т.к. документы легко классифицируются по содержанию в них конкретной фразы и мне остается лишь определить есть ли эта фраза в документе. С другой стороны, я еще далек от идеального будущего, в котором computer vision правильно распознает даже скан плохого качества, и поэтому текст в формат docx трансформировался с ошибками. Например, фраза «объект залога» может превратиться в «обb ект %алога».
Задача: написать функцию, которая определяет есть ли в документе определенная формулировка, с учетом неправильного преобразования текста., в процессе которой потребовалось нечеткое сравнение строк. Ниже кратко опишу суть.
Проблема: на входе большое количество сканов документов в pdf формате, которые с помощью Adobe FineReader переведены в текстовые документы формата docx и мне необходимо произвести некоторую классификацию. К счастью тренировать NLP модель для этого не потребуется, т.к. документы легко классифицируются по содержанию в них конкретной фразы и мне остается лишь определить есть ли эта фраза в документе. С другой стороны, я еще далек от идеального будущего, в котором computer vision правильно распознает даже скан плохого качества, и поэтому текст в формат docx трансформировался с ошибками. Например, фраза «объект залога» может превратиться в «обb ект %алога».
Задача: написать функцию, которая определяет есть ли в документе определенная формулировка, с учетом неправильного преобразования текста.
С чего начнем?
Прежде чем бежать писать функцию, надо определиться каким методом производить нечеткое сопоставление строк. Выбор тут не самый широкий, было решено протестировать три варианта: сравнение по косинусному сходству; сравнение по сходству Левенштейна; сравнение по сходству Джаро-Винклера. Критерии, по которым предстоит выбрать лучший вариант: скорость выполнения (документов довольно много, нужно находить подстроку за разумное время); правильность сравнения (нечеткое сравнение на то и нечеткое, потому что требуется некая экспертная оценка того, как отрабатывает критерий сравнения), простота реализации.
▪Читать дальше
▪RapidFuzz
@data_analysis_ml
{kind=link}
👍11❤5🔥5👎1
🔥 Подборка каналов для Дата сайентиста
🖥 Machine learning
ai_ml – машинное обучение, ии, нейросети!
@bigdatai - Big Data
@machinelearning_ru – гайды по машинному обучению
@machinelearning_interview – подготовка к собеседованию мл.
@datascienceiot – бесплатные книги ds
@ArtificialIntelligencedl – ИИ
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - вакансии ds, ml
@Machinelearning_Jobs - чат с вакансиями
#️⃣ c# c++
C# - погружение в C#
@csharp_cplus чат
С++ - обучающий канал по C++.
@csharp_1001_notes - инструменты C#
🖥 SQL базы данных
@sqlhub - Повышение эффективности кода с грамотным использованием бд.
@chat_sql - чат изучения бд.
👣 Golang
@Golang_google - восхитительный язык от Google, мощный и перспективный.
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@golangtests - интересные тесты и задачи GO
@golangl - чат изучающих Go
@GolangJobsit - отборные вакансии и работа GO
@golang_jobsgo - чат для ищущих работу.
@golang_books - полезные книги Golang
@golang_speak - обсуждение языка Go
@golangnewss - новости go
🖥 Linux
linux - kali linux ос для хакинга
linux chat - чат linux для обучения и помощи.
@linux_read - бесплатные книги linux
🖥 Python
@pythonl - главный канал самого популярного языка программирования.
@pro_python_code – учим python с ментором.
@python_job_interview – подготовка к Python собеседованию.
@python_testit - проверочные тесты на python
@pythonlbooks - современные книги Python
@python_djangojobs - работа для Python программистов
@python_django_work - чат обсуждения вакансий
🖥 Javascript / front
@react_tg - - 40,14% разработчиков сайтов использовали React в 2022 году - это самая популярная библиотека для создания сайтов.
@javascript -канал для JS и FrontEnd разработчиков. Лучшие практики и примеры кода. Туториалы и фишки JS
@Js Tests - каверзные тесты JS
@hashdev - погружение в web разработку.
@javascriptjobjs - отборные вакансии и работа FrontEnd.
@jsspeak - чат поиска FrontEnd работы.
🖥 Java
@javatg - выучить Java с senior разработчиком на практике
@javachats - чат для ответов на вопросы по Java
@java_library - библиотека книг Java
@android_its - Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
👷♂️ IT работа
https://t.iss.one/addlist/_zyy_jQ_QUsyM2Vi -ит каналы по яп с вакансиями
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - Rust избавлен от болевых точек, которые есть во многих современных яп
@rust_chats - чат rust
📓 Книги
https://t.iss.one/addlist/HwywK4fErd8wYzQy - актуальные книги по всем яп
⭐️ Нейронные сети
@vistehno - chatgpt ведет блог, решает любые задачи и отвечает на любые ваши вопросы.
@aigen - сети для генерации картинок. видео, музыки и многого другого.
@neural – погружение в нейросети.
📢 English for coders
@english_forprogrammers - Английский для программистов
🖥 Devops
Devops - канал для DevOps специалистов.
ai_ml – машинное обучение, ии, нейросети!
@bigdatai - Big Data
@machinelearning_ru – гайды по машинному обучению
@machinelearning_interview – подготовка к собеседованию мл.
@datascienceiot – бесплатные книги ds
@ArtificialIntelligencedl – ИИ
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - вакансии ds, ml
@Machinelearning_Jobs - чат с вакансиями
#️⃣ c# c++
C# - погружение в C#
@csharp_cplus чат
С++ - обучающий канал по C++.
@csharp_1001_notes - инструменты C#
@sqlhub - Повышение эффективности кода с грамотным использованием бд.
@chat_sql - чат изучения бд.
@Golang_google - восхитительный язык от Google, мощный и перспективный.
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@golangtests - интересные тесты и задачи GO
@golangl - чат изучающих Go
@GolangJobsit - отборные вакансии и работа GO
@golang_jobsgo - чат для ищущих работу.
@golang_books - полезные книги Golang
@golang_speak - обсуждение языка Go
@golangnewss - новости go
linux - kali linux ос для хакинга
linux chat - чат linux для обучения и помощи.
@linux_read - бесплатные книги linux
@pythonl - главный канал самого популярного языка программирования.
@pro_python_code – учим python с ментором.
@python_job_interview – подготовка к Python собеседованию.
@python_testit - проверочные тесты на python
@pythonlbooks - современные книги Python
@python_djangojobs - работа для Python программистов
@python_django_work - чат обсуждения вакансий
@react_tg - - 40,14% разработчиков сайтов использовали React в 2022 году - это самая популярная библиотека для создания сайтов.
@javascript -канал для JS и FrontEnd разработчиков. Лучшие практики и примеры кода. Туториалы и фишки JS
@Js Tests - каверзные тесты JS
@hashdev - погружение в web разработку.
@javascriptjobjs - отборные вакансии и работа FrontEnd.
@jsspeak - чат поиска FrontEnd работы.
@javatg - выучить Java с senior разработчиком на практике
@javachats - чат для ответов на вопросы по Java
@java_library - библиотека книг Java
@android_its - Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
👷♂️ IT работа
https://t.iss.one/addlist/_zyy_jQ_QUsyM2Vi -ит каналы по яп с вакансиями
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - Rust избавлен от болевых точек, которые есть во многих современных яп
@rust_chats - чат rust
📓 Книги
https://t.iss.one/addlist/HwywK4fErd8wYzQy - актуальные книги по всем яп
@vistehno - chatgpt ведет блог, решает любые задачи и отвечает на любые ваши вопросы.
@aigen - сети для генерации картинок. видео, музыки и многого другого.
@neural – погружение в нейросети.
@english_forprogrammers - Английский для программистов
Devops - канал для DevOps специалистов.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5🔥3👍2😁2🥰1
Продвинутый NumPy: оттачивайте навыки с помощью 25 иллюстрированных упражнений
В этой статье мы рассмотрим 25 различных упражнений, используя библиотеку NumPy (и сравним с тем, как мы бы реализовали их без неё).
Рекомендуется, чтобы читатель имел средний уровень знаний Python, NumPy, numpy.dtype, numpy.ndarray.strides и numpy.ndarray.itemsize.
▪Читать
@data_analysis_ml
В этой статье мы рассмотрим 25 различных упражнений, используя библиотеку NumPy (и сравним с тем, как мы бы реализовали их без неё).
Рекомендуется, чтобы читатель имел средний уровень знаний Python, NumPy, numpy.dtype, numpy.ndarray.strides и numpy.ndarray.itemsize.
▪Читать
@data_analysis_ml
👍7🔥3❤2
Набор инструментов Data Scientist: гайд по использованию основных функций sklearn с примерами кода.
Python имеет множество библиотек, которые делают его одним из наиболее часто используемых языков программирования. Большинство из них имеют схожие функции и могут использоваться друг с другом и достигать одинаковых результатов. Но когда дело доходит до машинного обучения, единственная библиотека, о которой мы можем говорить, это sklearn.
Итак, в этой статье я расскажу про пять самых важных особенностей sklearn.
Читать
@data_analysis_ml
Python имеет множество библиотек, которые делают его одним из наиболее часто используемых языков программирования. Большинство из них имеют схожие функции и могут использоваться друг с другом и достигать одинаковых результатов. Но когда дело доходит до машинного обучения, единственная библиотека, о которой мы можем говорить, это sklearn.
Итак, в этой статье я расскажу про пять самых важных особенностей sklearn.
Читать
@data_analysis_ml
❤10👍4🔥1
Датасет использовали для обучения функции оценки релевантности изображения введенному запросу.
Сравнение PickScore с FID, устоявшейся метрикой для оценки генеративных моделей, показало, что даже при оценке по подписям MS-COCO, PickScore демонстрирует сильную корреляцию с предпочтениями пользователей (0,917), в то время как ранжирование с помощью FID дает отрицательную корреляцию (-0,900). PickScore коррелирует с ранжированием «экспертов» гораздо сильнее, что делает PickScore наиболее надежной метрикой скоринга по сравнению с существующими.
▪Github
▪Статья
▪Модель
▪Датасет
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
👍9❤2🔥1
Когда вы отправляете свой код машинного обучения команде инженеров, могут возникнуть проблемы совместимости с различными операционными системами и версиями библиотек. Эти проблемы могут вызвать сбои в выполнении кода и затруднить совместную работу. Однако есть мощный инструмент, способный облегчить эти проблемы — Docker .
В этом подробном руководстве мы не только познакомим вас с основными понятиями Docker, но и проведем вас через процесс установки. Затем мы продемонстрируем его практическое использование на реальных примерах, что позволит вам воочию убедиться в его эффективности. Кроме того, мы углубимся в лучшие отраслевые практики, предоставив ценные идеи и стратегии для оптимизации рабочего процесса машинного обучения с помощью Docker.
▪ Читать
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
👍9❤3🔥2
HInt: Ускорение регулярных выржаений в 127 раз в 2 строках кода
Скомпилируйте ваш шаблоны Regex с помощью re.compile(<pattern>).
Функция предварительно скомпилирует регулярные выражения в байткод.
Далее мы будем используйте кэш LRU. Кэш хранит результат вызова функции, возвращая ранее вычисленный результат при последующих вызовах для тех же входных параметров. Таким образом, медленный Regex будет выполняться только один раз для каждой уникальной строки (~1 мкс), а последующие вызовы происходят за время O(1) (~20 нс).
@data_analysis_ml
Скомпилируйте ваш шаблоны Regex с помощью re.compile(<pattern>).
Функция предварительно скомпилирует регулярные выражения в байткод.
Далее мы будем используйте кэш LRU. Кэш хранит результат вызова функции, возвращая ранее вычисленный результат при последующих вызовах для тех же входных параметров. Таким образом, медленный Regex будет выполняться только один раз для каждой уникальной строки (~1 мкс), а последующие вызовы происходят за время O(1) (~20 нс).
import re
from functools import lru_cache
text = '''Lorem ipsum dolor sit amet...'''
compiled = re.compile(r'i')
@lru_cache
def cache(text):
return compiled.findall(text) # Протестировано на: Apple M2 Pro, 32 ГБ оперативной памяти, Python 3.11.3 %%timeit
re.findall(r'i', text)
%%timeit
re.compile(r'i')
%%timeit
cache(text)
# Naive: 3.13 µs ± 24.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
# Compiled: 2.96 µs ± 43.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
# Cached: 24.8 ns ± 0.325 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)@data_analysis_ml
🔥8👍7❤4👎1👏1
У меня возникла необходимость автоматизированного анализа текста постов на habr.com. Рассмотрю задачу, которая позволяет находить в заданном тексте ответы на вопросы (Context Question Answering, далее CQA).
В процессе работы над решением задачи оказался полезным сервис HuggingFace, предлагающий множество мультиязычных передобученных NLP моделей. Однако, при обработке текста на русском языке предпочтение было отдано российскому инструменту DeepPavlov, специализирующемуся на задачах NLP. Тем более, что DeepPavlov позволяет работать с NLP-моделями, представленными на HuggingFace «из коробки».
Разобью задачу на три этапа:
Загрузить текст поста с habr.com.
Подготовить набор вопросов из ответов.
Настроить deepPavlov для решения задачи CQA.
Для получения текста постов с habr.com воспользуюсь библиотеками urllib для загрузки html-документа с сайта и bs4 для доступа к элементам. Библиотека urllib входит в состав предустановленных библиотек языка Python, а библиотеку bs4 можно установить с помощью команды:
pip install beautifulsoup4Код для получения текста по заданному url представлю в виде функций
getHtmlDocument и getTextFromHtml:from urllib import request
def getHtmlDocument(url):
""" Получаем html-документ с сайта по url. """
fp = request.urlopen(url)
mybytes = fp.read()
fp.close()
return mybytes.decode('utf8')
from bs4 import BeautifulSoup
def getTextFromHtml(HtmlDocument):
""" Получаем текст из html-документа. """
soup = BeautifulSoup(HtmlDocument,
features='html.parser')
content = soup.find('div', {'id': 'post-content-body'})
return content.textНабор вопросов из ответов выглядит следующим образом:
questions = (
'О чём пост?',
'Какая цель поста?',
'Какая задача решалась?',
'Что использовалось в работе?',
'Какие выводы?',
'Что использовалось?',
'Какие алгоритмы использовались?',
'Какой язык программирования использовали?',
'В чём отличия?',
'Что особенного проявилось?',
'Какова область применения?',
'Что получено?',
'Каков результат?',
'Что получено в заключении?',
)Далее перейду к настройке deepPavlov для решения задачи СQA. Установлю библиотеку deeppavlov в соответствии с официальным сайтом проекта:
pip install deeppavlov, transformersИмпортирую объекты configs и build_model с помощью команд:
from deeppavlov import configs, build_modelДалее инициализирую загрузку модели
squad_ru_bert командой:model = build_model('squad_ru_bert', download=True)
Модель squad_ru_bert — это модель глубокого обучения на основе архитектуры BERT, обученная на наборе данных SQuAD-Ru, который содержит пары вопрос-ответ на русском языке.Выберу посты с habr.com:
paper_urls = (
'https://habr.com/ru/articles/339914/',
'https://habr.com/ru/articles/339915/',
'https://habr.com/ru/articles/339916/',
)
for url in paper_urls:
content = getTextFromHtml(getHtmlDocument(url))
for q in questions:
answer = model([content], [q])
if abs(answer[2] – 1) > 1e-6:
print(q, ' ', answer[0])Результатом работы модели является:
— фрагмент текста, который является ответом на заданный вопрос на основании текста,
— позиция этого ответа в тексте и качество полученного результата. Примеры «удачных» ответов, по моему мнению, на вопросы отмечены зелёным цветом на рисунках 1-3.
▪ Статья
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
👍13❤4🔥2🎉1
✔ Плохие модели машинного обучения? Но их можно откалибровать
Модели машинного обучения часто оцениваются по их производительности, близости какого-либо показателя к нулю или единице, но это не единственный фактор, которым определяется их полезность. В некоторых случаях модель, в целом не очень точную, можно откалибровать и найти ей применение. В чем же разница между хорошими калибровкой и производительностью, и когда одна предпочтительнее другой?
Калибровка вероятности
Калибровка вероятности — это степень, с которой прогнозируемые в модели классификации вероятности соответствуют истинной частотности целевых классов в наборе данных. Прогнозы откалиброванной модели в совокупности тесно соотносятся с фактическими результатами.
На практике это означает, что если из множества прогнозов идеально откалиброванной модели двоичной классификации учесть только те, для которых моделью предсказана 70%-ная вероятность положительного класса, то модель должна быть корректной в 70% случаев. Аналогично, если учесть только примеры, для которых моделью прогнозируется 10%-ная вероятность положительного класса, эталонные данные окажутся положительными в 1 из 10 случаев.
▪ Читать
@data_analysis_ml
Модели машинного обучения часто оцениваются по их производительности, близости какого-либо показателя к нулю или единице, но это не единственный фактор, которым определяется их полезность. В некоторых случаях модель, в целом не очень точную, можно откалибровать и найти ей применение. В чем же разница между хорошими калибровкой и производительностью, и когда одна предпочтительнее другой?
Калибровка вероятности
Калибровка вероятности — это степень, с которой прогнозируемые в модели классификации вероятности соответствуют истинной частотности целевых классов в наборе данных. Прогнозы откалиброванной модели в совокупности тесно соотносятся с фактическими результатами.
На практике это означает, что если из множества прогнозов идеально откалиброванной модели двоичной классификации учесть только те, для которых моделью предсказана 70%-ная вероятность положительного класса, то модель должна быть корректной в 70% случаев. Аналогично, если учесть только примеры, для которых моделью прогнозируется 10%-ная вероятность положительного класса, эталонные данные окажутся положительными в 1 из 10 случаев.
▪ Читать
@data_analysis_ml
❤6👍3🔥1👌1
27 июня X5 Tech проведёт Customer Analytics Meetup
Спикеры компании поделятся, как удалось найти замену Vendor-Lock и оперативно внедрить альтернативное решение для предоставления клиентской аналитики в режиме реального времени на базе open-source технологий Clickhouse и Redis.
В спикерах - менеджер направления клиентской аналитики в цифровых каналах, архитектор данных и старший разработчик.
Регистрация обязательна.
Больше информации здесь
Спикеры компании поделятся, как удалось найти замену Vendor-Lock и оперативно внедрить альтернативное решение для предоставления клиентской аналитики в режиме реального времени на базе open-source технологий Clickhouse и Redis.
В спикерах - менеджер направления клиентской аналитики в цифровых каналах, архитектор данных и старший разработчик.
Регистрация обязательна.
Больше информации здесь
👍8
Это пошаговое руководство, представляет собой введение в Prompt Engineering для
Python программистов и датасаентистов.
Цель руководства, состоит в том, чтобы помочь вам понять, как эффективно управлять GPT-4 для достижения оптимальных результатов в процессе разработки на Python.
▪Читать
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6👍1👎1🔥1
1. Introduction to Generative AI - введение в генеративный ИИ Этот курс погрузит вас в основаы генеративного ИИ,
2. Introduction to Large Language Models - в курсе вы узнаете о больших языковых моделях (LLM), которые представляют собой разновидность искусственного интеллекта, способного генерировать текст, переводить языки, писать различные виды креативного контента и информативно отвечать на ваши вопросы.
3. Introduction to Responsible AI - этот курс расскажет вам об этичном и ответственном использовании искусственного интеллекта. Вы узнаете о различных этических проблемах ИИ, таких как предвзятость, конфиденциальность и безопасность. Вы также узнаете о некоторых лучших практиках разработки ИИ.
4. Introduction to Image Generation - этот курс расскажет вам о генерации изображений, разновидности искусственного интеллекта, способного создавать изображения на основе текстовых описаний. Вы узнаете о различных типах алгоритмов генерации изображений, о том, как они работают, и о некоторых из их наиболее распространенных применений.
5. Encoder-Decoder Architecture -
этот курс расскажет вам об архитектуре модели кодера-декодера, которые представляют собой тип архитектуры нейронной сети, широко используемой для задач обработки естественного языка, таких как машинный перевод и резюмирование текста. Вы узнаете о различных компонентах архитектур энкодер-декодер, о том, как они работают, и о некоторых наиболее распространенных областях их применения.
6. Attention Mechanism - В этом курсе вы узнаете о механизме attention - технике, которая используется для повышения производительности нейронных сетей в задачах обработки естественного языка.
7. Transformer Models and BERT Model - В этом курсе вы изучите архитектуру трансформеров, которые представляют собой тип архитектуры нейронной сети, показавшей свою эффективность при решении задач обработки естественного языка.
8. Create Image Captioning Models - Этот курс научит вас создавать модели автоматического описания изображений, которые представляют собой разновидность искусственного интеллекта, способного генерировать подписи к изображениям.
@data_analysis_ml
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
👍12❤4🔥1
Forwarded from YTsaurus Community Chat (RU)
🦖 Вебинар YTsaurus. DWH Яндекс Go: как мы готовим наши петабайты
Новый вебинар YTsaurus — об использовании платформы в реальных сервисах. В гостях — Яндекс Go, суперапп с разными сервисами внутри, который основан на data driven подходе. Владимир Верстов и Николай Гребенщиков из команды разработки Data Management Platform Яндекс Go расскажут, какие требования команда предъявляет к системам хранения и расскажет, как с этими требованиями справляется YTsaurus.
Ждём 28 июня в 18:30 Мск. Участие бесплатное, зарегистрироваться можно по ссылке.
Также запись вебинара будет доступна на YouTube.
Новый вебинар YTsaurus — об использовании платформы в реальных сервисах. В гостях — Яндекс Go, суперапп с разными сервисами внутри, который основан на data driven подходе. Владимир Верстов и Николай Гребенщиков из команды разработки Data Management Platform Яндекс Go расскажут, какие требования команда предъявляет к системам хранения и расскажет, как с этими требованиями справляется YTsaurus.
Ждём 28 июня в 18:30 Мск. Участие бесплатное, зарегистрироваться можно по ссылке.
Также запись вебинара будет доступна на YouTube.
❤5👍3🔥2👎1
🤖 Заставляем трансформеров отвечать на вопросы
Интеллектуальные системы призваны облегчать жизнь человека, выполняя за него рутинные задачи. Одной из таких задач является поиск информации в большом количестве текста. Возможно ли и эту задачу перенести на плечи интеллектуальных систем? Этим вопросом я решил задаться.
▪ Читать
@data_analysis_ml
Интеллектуальные системы призваны облегчать жизнь человека, выполняя за него рутинные задачи. Одной из таких задач является поиск информации в большом количестве текста. Возможно ли и эту задачу перенести на плечи интеллектуальных систем? Этим вопросом я решил задаться.
▪ Читать
@data_analysis_ml
👍10❤1🔥1
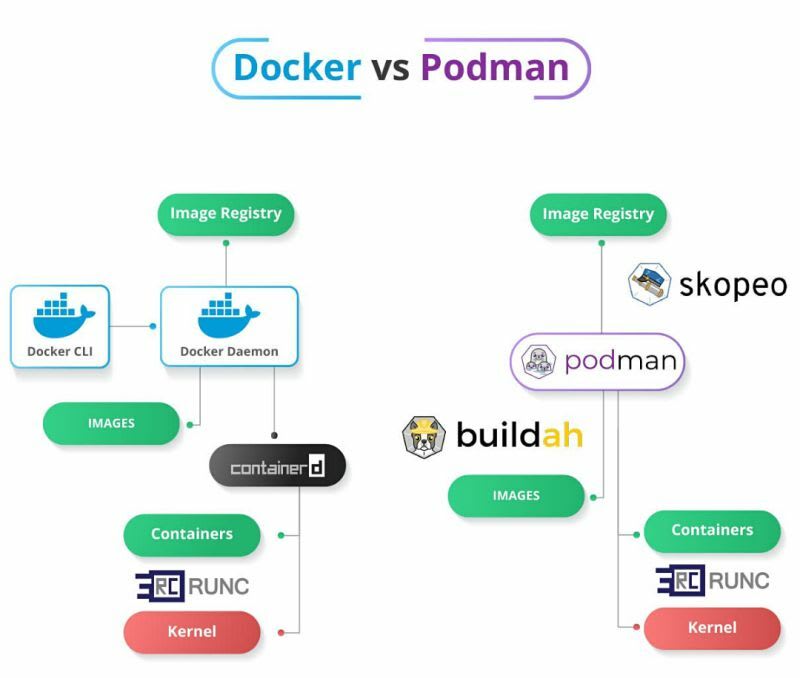
🔍 Podman: Альтернатива Docker без deamon
Хотя Docker, безусловно, перевернул наше представление о разработке, развертывании и запуске приложений, стоит изучить, чем отличается Podman (Pod Manager) и почему вам может быть интересно начать использовать его вместо Docker.
Podman — это менеджер контейнеров и падов с открытым исходным кодом.
Аналогично Docker, он позволяет создавать, запускать, останавливать и удалять контейнеры OCI, а также управлять образами контейнеров.
Он также поддерживает пады в рамках своего функционала, а значит, вы можете создавать и управлять падами так же, как с Kubernetes.
Что такое OCI-контейнеры
OCI (Open Container Initiative) — это организация отраслевого стандарта, которая стремится создать набор правил (спецификаций и стандартов), обеспечивающих согласованную работу контейнеров на разных платформах.
Это означает, что образы/контейнеры Podman полностью совместимы с Docker или любой другой технологией контейнеризации, которая использует совместимый с OCI исполнитель контейнеров.
Большинство пользователей Docker могут просто сделать псевдоним Docker для Podman (
Это означает, что все команды Docker остаются такими же, за исключением команды
Архитектура Podman
Архитектура Podman не подразумевает использование демонов (deamons).
Демоны — это процессы, которые выполняются в фоновом режиме системы, они обычно работают непрерывно на заднем плане, ожидая определенных событий или запросов.
Возвращаясь к контейнерам, представьте себе демона Docker в качестве посредника, общающегося между пользователем и самим контейнером.
Использование демона для управления контейнерами приводит к нескольким проблемам:
Одна точка отказа.
Когда демон падает, падают все контейнеры.
Требуются привилегии root
Поэтому демоны в Docker — это идеальная цель для хакеров, которые хотят получить контроль над вашими контейнерами и проникнуть в хост-систему.
Podman решает упомянутые проблемы, напрямую взаимодействуя с реестрами контейнеров, контейнерами и хранилищем образов без необходимости в демоне.
Переходя в режим без прав root, пользователи могут создавать, запускать и управлять контейнерами, что снижает риски безопасности.
Утилита buildah заменяет команду docker build как инструмент для создания контейнерного образа.
Аналогично, skopeo заменяет команду docker push и позволяет перемещать контейнерные образы между реестрами.
Эти инструменты обеспечивают эффективное и прямое взаимодействие с необходимыми компонентами, исключая необходимость в отдельном демоне в процессе.
Нужно ли переписывать каждый Dockerfile и docker-compose файл, чтобы использовать Podman с существующими проектами
Абсолютно нет. Podman предлагает совместимость с синтаксисом Docker для файлов контейнеров (containerfile).
Также Podman предлагает инструмент под названием pod compose в качестве альтернативы docker compose.
Pod compose использует тот же синтаксис, позволяя вам определять и управлять многоконтейнерными приложениями с использованием того же подхода или даже с использованием существующих файлов "docker-compose.yml".
Podman также поставляется с Podman Desktop, предлагая расширенные функции, которые делают его мощнее и проще. Он совместим с Docker и Kubernetes, расширяя их возможности и обеспечивая простую работу.
Руководство по установке и документацию по Podman можно найти на их официальном веб-сайте podman.io.
@data_analysis_ml
Хотя Docker, безусловно, перевернул наше представление о разработке, развертывании и запуске приложений, стоит изучить, чем отличается Podman (Pod Manager) и почему вам может быть интересно начать использовать его вместо Docker.
Podman — это менеджер контейнеров и падов с открытым исходным кодом.
Аналогично Docker, он позволяет создавать, запускать, останавливать и удалять контейнеры OCI, а также управлять образами контейнеров.
Он также поддерживает пады в рамках своего функционала, а значит, вы можете создавать и управлять падами так же, как с Kubernetes.
Что такое OCI-контейнеры
OCI (Open Container Initiative) — это организация отраслевого стандарта, которая стремится создать набор правил (спецификаций и стандартов), обеспечивающих согласованную работу контейнеров на разных платформах.
Это означает, что образы/контейнеры Podman полностью совместимы с Docker или любой другой технологией контейнеризации, которая использует совместимый с OCI исполнитель контейнеров.
Большинство пользователей Docker могут просто сделать псевдоним Docker для Podman (
alias docker=podman) без каких-либо проблем.Это означает, что все команды Docker остаются такими же, за исключением команды
docker swarm.
Архитектура Podman
Архитектура Podman не подразумевает использование демонов (deamons).
Демоны — это процессы, которые выполняются в фоновом режиме системы, они обычно работают непрерывно на заднем плане, ожидая определенных событий или запросов.
Возвращаясь к контейнерам, представьте себе демона Docker в качестве посредника, общающегося между пользователем и самим контейнером.
Использование демона для управления контейнерами приводит к нескольким проблемам:
Одна точка отказа.
Когда демон падает, падают все контейнеры.
Требуются привилегии root
Поэтому демоны в Docker — это идеальная цель для хакеров, которые хотят получить контроль над вашими контейнерами и проникнуть в хост-систему.
Podman решает упомянутые проблемы, напрямую взаимодействуя с реестрами контейнеров, контейнерами и хранилищем образов без необходимости в демоне.
Переходя в режим без прав root, пользователи могут создавать, запускать и управлять контейнерами, что снижает риски безопасности.
Утилита buildah заменяет команду docker build как инструмент для создания контейнерного образа.
Аналогично, skopeo заменяет команду docker push и позволяет перемещать контейнерные образы между реестрами.
Эти инструменты обеспечивают эффективное и прямое взаимодействие с необходимыми компонентами, исключая необходимость в отдельном демоне в процессе.
Нужно ли переписывать каждый Dockerfile и docker-compose файл, чтобы использовать Podman с существующими проектами
Абсолютно нет. Podman предлагает совместимость с синтаксисом Docker для файлов контейнеров (containerfile).
Также Podman предлагает инструмент под названием pod compose в качестве альтернативы docker compose.
Pod compose использует тот же синтаксис, позволяя вам определять и управлять многоконтейнерными приложениями с использованием того же подхода или даже с использованием существующих файлов "docker-compose.yml".
Podman также поставляется с Podman Desktop, предлагая расширенные функции, которые делают его мощнее и проще. Он совместим с Docker и Kubernetes, расширяя их возможности и обеспечивая простую работу.
Руководство по установке и документацию по Podman можно найти на их официальном веб-сайте podman.io.
@data_analysis_ml
{kind=link}
👍16🔥4❤3