
👍6
🗾 Посмотрим, как ИИ учится классифицировать изображения
Загляним под капот алгоритмов машинного обучения, пока они работают.
Cуществует множество руководств и статей, которые хорошо показывают, как алгоритмы машинного обучения могут обучаться на изображениях и выполнять различные удивительные задачи. Итак, эта статья не о том, что они могут сделать,а о том что происходит, пока машины учатся.
Я надеюсь, что анимации в этой статье смогут ннаглядно показать, как современные алгоритмы машинного обучения работают с различными данными и очень быстро учатся тому, как извлекать значимые признаки из данных для эффективного решения поставленной задачи. Итак, давайте сразу приступим!
Статья
Код
Набор данных
@data_analysis_ml
Загляним под капот алгоритмов машинного обучения, пока они работают.
Cуществует множество руководств и статей, которые хорошо показывают, как алгоритмы машинного обучения могут обучаться на изображениях и выполнять различные удивительные задачи. Итак, эта статья не о том, что они могут сделать,а о том что происходит, пока машины учатся.
Я надеюсь, что анимации в этой статье смогут ннаглядно показать, как современные алгоритмы машинного обучения работают с различными данными и очень быстро учатся тому, как извлекать значимые признаки из данных для эффективного решения поставленной задачи. Итак, давайте сразу приступим!
Статья
Код
Набор данных
@data_analysis_ml
{kind=link}
👍11🔥3❤1
🗣️ Решаем задачу перевода русской речи в текст с помощью Python и библиотеки Vosk
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
👍4
14 проектов по науке о данных
Возможно, самые короткие по срокам проекты визуализации данных! Ниже приведены интересные наборы данных, с помощью которых вы сможете пополнить свои портфолио, проведя анализ данных и создав несколько интересных визуализаций .
Читать дальше
@data_analysis_ml
Возможно, самые короткие по срокам проекты визуализации данных! Ниже приведены интересные наборы данных, с помощью которых вы сможете пополнить свои портфолио, проведя анализ данных и создав несколько интересных визуализаций .
Читать дальше
@data_analysis_ml
👍26
✅ Лассо- и ридж-регрессии: интуитивное сравнение
Знакомство с машинным обучением часто начинается с линейной регрессии — одного из самых простых алгоритмов.
Однако эта модель быстро раскрывает свои недостатки, особенно при работе с наборами данных, которые требуют перестройки моделей. Основные решения этой проблемы — ридж- и лассо-регрессии.
Читать дальше
@data_analysis_ml
Знакомство с машинным обучением часто начинается с линейной регрессии — одного из самых простых алгоритмов.
Однако эта модель быстро раскрывает свои недостатки, особенно при работе с наборами данных, которые требуют перестройки моделей. Основные решения этой проблемы — ридж- и лассо-регрессии.
Читать дальше
@data_analysis_ml
👍25
🤖 Подборка полезных ресурсов по машинному обучению и аннализу данных
@ai_machinelearning_big_data - продвинутый ML
@datascienceiot - книги по аннализу данных
@machinelearning_ru - машиннное обучение с нуля до профи
@ArtificialIntelligencedl - искусственный интеллект
@Machinelearningtest - тесты по мл
@machinee_learning - чат дата саентистов
@programming_books_it - книги по прогрраммированию
@pro_python_code - глубокий python
@Golang_google -golang
@itchannels_telegram - полный список полезных ресурсов
@ai_machinelearning_big_data - продвинутый ML
@datascienceiot - книги по аннализу данных
@machinelearning_ru - машиннное обучение с нуля до профи
@ArtificialIntelligencedl - искусственный интеллект
@Machinelearningtest - тесты по мл
@machinee_learning - чат дата саентистов
@programming_books_it - книги по прогрраммированию
@pro_python_code - глубокий python
@Golang_google -golang
@itchannels_telegram - полный список полезных ресурсов
👍19
🛠 Главные ошибки при анализе данных
Аналитик данных — лучший в статистике среди программистов и лучший программист среди статистиков. В этом топе обсудим, как программисту стать лучше в статистике.
Примеры, код и детальный вывод доступны на github и в Jupyter Notebook. В коде библиотека d6tflowуправляет рабочим процессом, а d6tpipe обеспечивает публичное хранение данных.
Статья
Код
@data_analysis_ml
Аналитик данных — лучший в статистике среди программистов и лучший программист среди статистиков. В этом топе обсудим, как программисту стать лучше в статистике.
Примеры, код и детальный вывод доступны на github и в Jupyter Notebook. В коде библиотека d6tflowуправляет рабочим процессом, а d6tpipe обеспечивает публичное хранение данных.
Статья
Код
@data_analysis_ml
{kind=link}
👍24🔥2👏1
Immudb – самая быстрая в мире неизменная база данных, построенная на модели нулевого доверия
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@data_analysis_ml
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@data_analysis_ml
👍19
5️⃣ преимуществ low-code подхода к аналитике данных.
Возможность мало кодировать, а больше использовать готовые компоненты и визуальное проектирование позволяет решать задачи анализа с меньшими затратами сил разработчиков. В статье расскажем об основных преимуществах подобного подхода.
Потребность в инструментах, минимизирующих программирование, существовала давно. Цель любой организации — быстро и с минимальными затратами решить задачу, при этом учесть особенности бизнеса компании. Проблема в том, что сложно удовлетворить этим критериям одновременно. Можно либо воспользоваться готовыми решениями, позволяющими получить результат быстро, но без учета нюансов бизнеса и с потерей гибкости. Либо разработать уникальное решение под себя, что требует много времени и дорогостоящих специалистов.
Low-code — это метод разработки, позволяющий проектировать логику быстро, с небольшими затратами на внедрение и поддержку. Low-code сводит к минимуму использование программного кода, заменяя его визуальными средствами конструирования.
Мы выделили 5 основных преимуществ low-code подхода при работе над аналитическими проектами.
Читать дальше
@data_analysis_ml
Возможность мало кодировать, а больше использовать готовые компоненты и визуальное проектирование позволяет решать задачи анализа с меньшими затратами сил разработчиков. В статье расскажем об основных преимуществах подобного подхода.
Потребность в инструментах, минимизирующих программирование, существовала давно. Цель любой организации — быстро и с минимальными затратами решить задачу, при этом учесть особенности бизнеса компании. Проблема в том, что сложно удовлетворить этим критериям одновременно. Можно либо воспользоваться готовыми решениями, позволяющими получить результат быстро, но без учета нюансов бизнеса и с потерей гибкости. Либо разработать уникальное решение под себя, что требует много времени и дорогостоящих специалистов.
Low-code — это метод разработки, позволяющий проектировать логику быстро, с небольшими затратами на внедрение и поддержку. Low-code сводит к минимуму использование программного кода, заменяя его визуальными средствами конструирования.
Мы выделили 5 основных преимуществ low-code подхода при работе над аналитическими проектами.
Читать дальше
@data_analysis_ml
{kind=link}
👍13
This media is not supported in your browser
VIEW IN TELEGRAM
Pulse – инструмент, который превращает пиксилезированные фотографии лица в картинки с высоким качеством
Получив входное изображение с низким разрешением, PULSE ищет в выходных данных генеративной модели (StyleGAN) изображения с высоким разрешением, которые перцептивно схожи с входной картинкой | #Python #AI #Interesting
@data_analysis_ml
Получив входное изображение с низким разрешением, PULSE ищет в выходных данных генеративной модели (StyleGAN) изображения с высоким разрешением, которые перцептивно схожи с входной картинкой | #Python #AI #Interesting
@data_analysis_ml
👍15😁6
💡10 фич для ускорения анализа данных в Python
Советы и рекомендации, особенно в программировании, могут быть очень полезны. Маленький шоткат, аддон или хак может сэкономить кучу времени и серьёзно увеличить производительность. Я собрала свои самые любимые и сделала из них эту статью. Какие-то из советов ниже уже известны многим, а какие-то появились совсем недавно. Так или иначе, я уверена, они точно не будут лишними, когда вы в очередной раз приступите к проекту по анализу данных.
Читать дальше
@data_analysis_ml
Советы и рекомендации, особенно в программировании, могут быть очень полезны. Маленький шоткат, аддон или хак может сэкономить кучу времени и серьёзно увеличить производительность. Я собрала свои самые любимые и сделала из них эту статью. Какие-то из советов ниже уже известны многим, а какие-то появились совсем недавно. Так или иначе, я уверена, они точно не будут лишними, когда вы в очередной раз приступите к проекту по анализу данных.
Читать дальше
@data_analysis_ml
👍49🔥5
➕ SQL-запросы, о которых должен знать каждый дата-инженер. Гайд по по работе с SQL в Data Science.
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
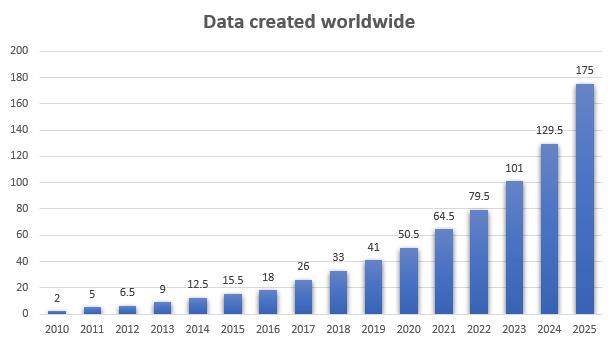
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
{kind=link}
👍28😢1
Python FastAPI: OpenAPI, CRUD, PostgreSQL в Docker и внедрение зависимостей
https://nuancesprog.ru/p/14818/
https://nuancesprog.ru/p/14818/
👍9👎1
📲 Собеседование на позицию Data Scientist: 46 типичных вопросов.
Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. Вопросы будут смешаны по темам, но все они относятся к машинному обучению и Data Science. Попробуйте сначала ответить на каждый вопрос самостоятельно!
Часть 1
Часть 2
@data_analysis_ml
Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. Вопросы будут смешаны по темам, но все они относятся к машинному обучению и Data Science. Попробуйте сначала ответить на каждый вопрос самостоятельно!
Часть 1
Часть 2
@data_analysis_ml
👍39
🎓 Опенсорсные массивы данных для Computer Vision
Computer Vision (CV) — одна из самых увлекательных тем в сфере искусственного интеллекта (Artificial Intelligence, AI) и машинного обучения (Machine Learning, ML). Это важная часть многих современных конвейеров AI/ML, преобразующая практически все отрасли и позволяющая компаниям осуществлять революцию в работе машин и бизнес-систем.
В науке CV многие десятилетия была уважаемой областью computer science, и за многие годы в этой сфере было проведено множество исследований по её совершенствованию. Однако революцию в ней совершило недавно начавшееся применение глубоких нейросетей, ставшее стимулом ускорения её развития.
Читать дальше
@data_analysis_ml
Computer Vision (CV) — одна из самых увлекательных тем в сфере искусственного интеллекта (Artificial Intelligence, AI) и машинного обучения (Machine Learning, ML). Это важная часть многих современных конвейеров AI/ML, преобразующая практически все отрасли и позволяющая компаниям осуществлять революцию в работе машин и бизнес-систем.
В науке CV многие десятилетия была уважаемой областью computer science, и за многие годы в этой сфере было проведено множество исследований по её совершенствованию. Однако революцию в ней совершило недавно начавшееся применение глубоких нейросетей, ставшее стимулом ускорения её развития.
Читать дальше
@data_analysis_ml
👍7
♻️ Мета выпустила переводчик на 200 языков.
В открытом доступе теперь лежит модель No language left behind (Ни один язык не останется за бортом), которая переводит с 200+ различных языков.
Модель уже применняется для улучшения переводов на Facebook, Instagram и Wikipedia.
Код
Статья
Demo
Blog
#AI #ML #NLP
@data_analysis_ml
В открытом доступе теперь лежит модель No language left behind (Ни один язык не останется за бортом), которая переводит с 200+ различных языков.
Модель уже применняется для улучшения переводов на Facebook, Instagram и Wikipedia.
Код
Статья
Demo
Blog
#AI #ML #NLP
@data_analysis_ml
👍15🔥7
🔍 Как обнаружить выбросы в проекте по исследованию данных
Выброс — это данные, которые имеют слишком высокое или слишком низкое значение по отношению к другим исследуемым данным. Конечно, в наборе данных может быть несколько выбросов, поэтому приходится неоднократно исключать их из набора данных. В противном случае выбросы способны вызывать статистические проблемы в анализе данных.
Но каковы критерии исключения выбросов? Чтобы ответить на этот вопрос, рассмотрим три метода обнаружения выбросов.
Читать дальше
@data_analysis_ml
Выброс — это данные, которые имеют слишком высокое или слишком низкое значение по отношению к другим исследуемым данным. Конечно, в наборе данных может быть несколько выбросов, поэтому приходится неоднократно исключать их из набора данных. В противном случае выбросы способны вызывать статистические проблемы в анализе данных.
Но каковы критерии исключения выбросов? Чтобы ответить на этот вопрос, рассмотрим три метода обнаружения выбросов.
Читать дальше
@data_analysis_ml
{kind=link}
❤16👍10🔥1
Копируем голос за 5 секунд, для генерации речи в реальном времени
⚙️ GitHub/Инструкция
📹 Видео
@data_analysis_ml
⚙️ GitHub/Инструкция
📹 Видео
@data_analysis_ml
👍8
📎 Крутые наборы данных для машинного обучения
Более 50 открытых наборов для ваших исследований
Хорошее исследование в машинном обучении начинается с подходящего набора данных. Нет необходимости тратить целый вечер на создание собственного набора в MySQL или, что еще хуже, в Excel. В принципе, все что угодно — от статистики COVID-19 до заклинаний Гарри Поттера — можно найти в виде базы данных.
Читать дальше
@data_analysis_ml
Более 50 открытых наборов для ваших исследований
Хорошее исследование в машинном обучении начинается с подходящего набора данных. Нет необходимости тратить целый вечер на создание собственного набора в MySQL или, что еще хуже, в Excel. В принципе, все что угодно — от статистики COVID-19 до заклинаний Гарри Поттера — можно найти в виде базы данных.
Читать дальше
@data_analysis_ml
👍20🔥10🥰1🤔1