
#Вакансия: Data Engineer (Middle)
📍 В классном офисе в Москве/гибрид;
📍200-350К руб., белая ЗП или ИП;
📍Большой датасет, интересные задачи, возможность влиять на продукт.
✅ОБЯЗАННОСТИ
✅ТРЕБОВАНИЯ
✅БУДЕТ ПЛЮСОМ:
Понравилась вакансия? Присылай CV @naikava
📍 В классном офисе в Москве/гибрид;
📍200-350К руб., белая ЗП или ИП;
📍Большой датасет, интересные задачи, возможность влиять на продукт.
✅ОБЯЗАННОСТИ
• Проектировать, разрабатывать и поддерживать пайплайны для сбора и обработки данных; • Обеспечивать SLA и качество данных; • Готовить данные для моделей машинного обучения и участвовать в их продукционализации совместно с data science командой.✅ТРЕБОВАНИЯ
• Хорошее знание технологий из стека: Python, SQL, Spark, Airflow; • Опыт работы на проектах с большими данными, понимание принципов распределенной обработки данных; • Опыт продуктовой разработки в технологических компаниях.✅БУДЕТ ПЛЮСОМ:
• Опыт работы с облаками, особенно, с Яндекс.Облаком; • Опыт разработки высоконагруженных бэкенд сервисов на Java, Scala или Python; • Опыт работы с моделями машинного обучения в продакшене; • Опыт работы с базами данных для аналитики, особенно, с ClickHouse.Понравилась вакансия? Присылай CV @naikava
👍7
This media is not supported in your browser
VIEW IN TELEGRAM
Добро пожаловать в мир главного ит тренда - машинного обучения: @machinelearning_ru
В канале вы найдет :
📃Статьи ,
📚Книги
👨💻 Код
🔗Ссылки
и много другой полезной информации
#ArtificialIntelligence #DeepLearning
#MachineLearning #DataScience
#Python
1 канал вместо тысячи учебников и курсов 👇👇👇
🤖 @machinelearning_ru
В канале вы найдет :
📃Статьи ,
📚Книги
👨💻 Код
🔗Ссылки
и много другой полезной информации
#ArtificialIntelligence #DeepLearning
#MachineLearning #DataScience
#Python
1 канал вместо тысячи учебников и курсов 👇👇👇
🤖 @machinelearning_ru
👍8🔥1
Продолжим разбираться в сортах разных аналитиков, а именно: Бизнес-аналитик, Системный аналитик, продуктовый аналитик, аналитик данных и web-аналитик
Само понятие «профессия аналитик» очень широкое. У аналитиков, как и у других профессий, например врачей или инженеров, есть деление на узконаправленные специализации, ведь один человек не может хорошо разбираться во всех вопросах сразу. К таким специализациям можно отнести: бизнес-аналитика, системного аналитика, продуктового аналитика, аналитика данных, web-аналитика и тд.
Во многих компаниях данные специализации могут пересекаться и выполняться один и тем же специалистом, все зависит от сферы деятельности компании и от ее требований, от самого специалиста. Например может быть роль Бизнес/Системный аналитик.
Также вы легко сможете перейти из одной в другую специализацию на своём карьерном пути, но есть и более узконаправленные, выделяющиеся из общего потока.
Для детального погружения, предлагаю прочесть пару статей:
✅Я в аналитики пойду, пусть меня научат: советы по входу в профессию для начинающих - Статья поможет нам разобраться с ответом на один из самых частых вопросов: как стать аналитиком? Еще раз проведя грань между системным и бизнес-аналитиком, а также продуктовым аналитиком, аналитиком данных и веб-аналитиком.
✅Зачем вам столько аналитиков: чем бизнес-аналитик отличается от системного и Data Analyst’а - в данной статье пойдет речь в чем сходства и отличия 3-х разных профессий: бизнес-аналитика, системного аналитика и Data Analyst’а (аналитика данных)
@data_analysis_ml
Само понятие «профессия аналитик» очень широкое. У аналитиков, как и у других профессий, например врачей или инженеров, есть деление на узконаправленные специализации, ведь один человек не может хорошо разбираться во всех вопросах сразу. К таким специализациям можно отнести: бизнес-аналитика, системного аналитика, продуктового аналитика, аналитика данных, web-аналитика и тд.
Во многих компаниях данные специализации могут пересекаться и выполняться один и тем же специалистом, все зависит от сферы деятельности компании и от ее требований, от самого специалиста. Например может быть роль Бизнес/Системный аналитик.
Также вы легко сможете перейти из одной в другую специализацию на своём карьерном пути, но есть и более узконаправленные, выделяющиеся из общего потока.
Для детального погружения, предлагаю прочесть пару статей:
✅Я в аналитики пойду, пусть меня научат: советы по входу в профессию для начинающих - Статья поможет нам разобраться с ответом на один из самых частых вопросов: как стать аналитиком? Еще раз проведя грань между системным и бизнес-аналитиком, а также продуктовым аналитиком, аналитиком данных и веб-аналитиком.
✅Зачем вам столько аналитиков: чем бизнес-аналитик отличается от системного и Data Analyst’а - в данной статье пойдет речь в чем сходства и отличия 3-х разных профессий: бизнес-аналитика, системного аналитика и Data Analyst’а (аналитика данных)
@data_analysis_ml
👍8
Автоматическое масштабирование БД в Kubernetes для MongoDB, MySQL и PostgreSQL
Читать
@data_analysis_ml
Читать
@data_analysis_ml
Telegraph
Автоматическое масштабирование БД в Kubernetes для MongoDB, MySQL и PostgreSQL
Автор оригинала: Dmitriy Kostiuk и Mykola Marzhan Стремясь к повышению производительности базы данных, вы можете столкнуться с ситуацией, когда оптимизации и настройки уже недостаточно. Если вы не можете заменить движок БД, а для настройки параметры рабочей…
👍4
Данные часто могут сделать решения хуже, а не лучше. Этот пост в блоге дает пример одной из таких ситуаций.
https://saturncloud.io/blog/relying-too-much/
@data_analysis_ml
https://saturncloud.io/blog/relying-too-much/
@data_analysis_ml
saturncloud.io
You're Relying on Data Too Much | Saturn Cloud Blog
Data can often make decisions worse, not better. This blog post gives an example of one such situation as a metaphor.
👍8👎1
😱Запросы в гугле и твиты помогут предсказать следующий всплеск заболеваемости
Так, отзывы на ароматические свечи Yankee Candles в интернет магазинах были дополнительным индикатором распространения нового штамма. В конце 2021 года как раз посыпались жалобы от покупателей на отсутствие аромата и неприятный запах у свечей. Исследователи построили график роста отрицательных отзывов, и он очень смахивал на всплеск заболеваемости омикроном (на картинке как раз он).
Несчастным свечкам досталось еще и в начале пандемии: оценка ранее любимых покупателями свечей за год потеряла целую звезду. Помимо отзывов на свечи, ученые заметили связь с ростом поиска доставок сиропов от кашля и куриного супа с лапшой
Исследователи предлагают ориентироваться не только на число подтвержденных случаев, а еще и на такие специфические цифровые следы: авторы их назвают «хлебными крошками». Ученые считают, что эти маркеры помогут предсказать следующие волны заболеваемости, и тогда мы сможем как следует к ним подготовиться🌊
Так, отзывы на ароматические свечи Yankee Candles в интернет магазинах были дополнительным индикатором распространения нового штамма. В конце 2021 года как раз посыпались жалобы от покупателей на отсутствие аромата и неприятный запах у свечей. Исследователи построили график роста отрицательных отзывов, и он очень смахивал на всплеск заболеваемости омикроном (на картинке как раз он).
Несчастным свечкам досталось еще и в начале пандемии: оценка ранее любимых покупателями свечей за год потеряла целую звезду. Помимо отзывов на свечи, ученые заметили связь с ростом поиска доставок сиропов от кашля и куриного супа с лапшой
Исследователи предлагают ориентироваться не только на число подтвержденных случаев, а еще и на такие специфические цифровые следы: авторы их назвают «хлебными крошками». Ученые считают, что эти маркеры помогут предсказать следующие волны заболеваемости, и тогда мы сможем как следует к ним подготовиться🌊
👍17
5 полезных запросов для MS SQL
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
https://tproger.ru/articles/5-poleznyh-zaprosov-dlja-ms-sql/
@data_analysis_ml
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
https://tproger.ru/articles/5-poleznyh-zaprosov-dlja-ms-sql/
@data_analysis_ml
Tproger
5 полезных запросов MS SQL на каждый день
За 2 года работы с MS SQL у меня накопился перечень из 5 запросов: для поиска, отладки, агрегации и обработки множеств и таблиц.
👍5❤1
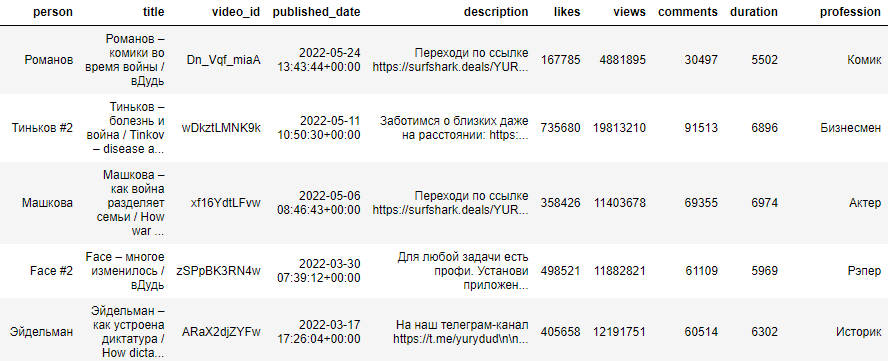
🔎 Анализируем речь с помощью Python: Сколько раз в минуту матерятся на интервью YouTube-канала «вДудь»?
Дисклеймер номер один: 18+. В этой статье присутствует ненормативная лексика, так как некоторые гости Юрия не стесняются в выражениях. Мы не хотим никого задеть или оскорбить чьи-то чувства, присутствие мата объясняется лишь объектом нашего исследования.
Выход практически каждого ролика на канале «вДудь» считается событием, а некоторые из этих релизов даже сопровождаются скандалами из-за неосторожных высказываний его гостей.
Сегодня при помощи статистических подходов и алгоритмов ML мы будем анализировать прямую речь. В качестве данных используем интервью, которые журналист Юрий Дудь (признан иностранным агентом на территории РФ) берет для своего YouTube-канала. Посмотрим с помощью Python, о чем таком интересном говорили в интервью на канале «вДудь».
Читать дальше
@data_analysis_ml
Дисклеймер номер один: 18+. В этой статье присутствует ненормативная лексика, так как некоторые гости Юрия не стесняются в выражениях. Мы не хотим никого задеть или оскорбить чьи-то чувства, присутствие мата объясняется лишь объектом нашего исследования.
Выход практически каждого ролика на канале «вДудь» считается событием, а некоторые из этих релизов даже сопровождаются скандалами из-за неосторожных высказываний его гостей.
Сегодня при помощи статистических подходов и алгоритмов ML мы будем анализировать прямую речь. В качестве данных используем интервью, которые журналист Юрий Дудь (признан иностранным агентом на территории РФ) берет для своего YouTube-канала. Посмотрим с помощью Python, о чем таком интересном говорили в интервью на канале «вДудь».
Читать дальше
@data_analysis_ml
{kind=link}
👍9🥰3
Как повысить эффективность логистики с помощью неклассических тестов?
Ответ можно найти в последней статье Delivery Club на Хабре. В ней команда операционных аналитиков поделилась тонкостями эксперимента по внедрению switchback A/B-тестов. Вы узнаете об особенностях таких тестов, сути сетевого эффекта, об этапах запуска switchback A/B-эксперимента в логистике и его итогах.
Подробнее по ссылке.
Ответ можно найти в последней статье Delivery Club на Хабре. В ней команда операционных аналитиков поделилась тонкостями эксперимента по внедрению switchback A/B-тестов. Вы узнаете об особенностях таких тестов, сути сетевого эффекта, об этапах запуска switchback A/B-эксперимента в логистике и его итогах.
Подробнее по ссылке.
👍8
📊 Фреймворк для Анализа Временных Рядов на Python
Простой в использовании и универсальный фреймворк для анализа временных рядов
Статья: https://denshub.com/ru/kats-for-time-series-analysis/
Официальная страница: https://facebookresearch.github.io/Kats/
Kats Python package: https://pypi.org/project/kats/0.1.0/
Репозиторий исходной кода: https://github.com/facebookresearch/kats
@data_analysis_ml
Простой в использовании и универсальный фреймворк для анализа временных рядов
Статья: https://denshub.com/ru/kats-for-time-series-analysis/
Официальная страница: https://facebookresearch.github.io/Kats/
Kats Python package: https://pypi.org/project/kats/0.1.0/
Репозиторий исходной кода: https://github.com/facebookresearch/kats
@data_analysis_ml
👍9🔥3
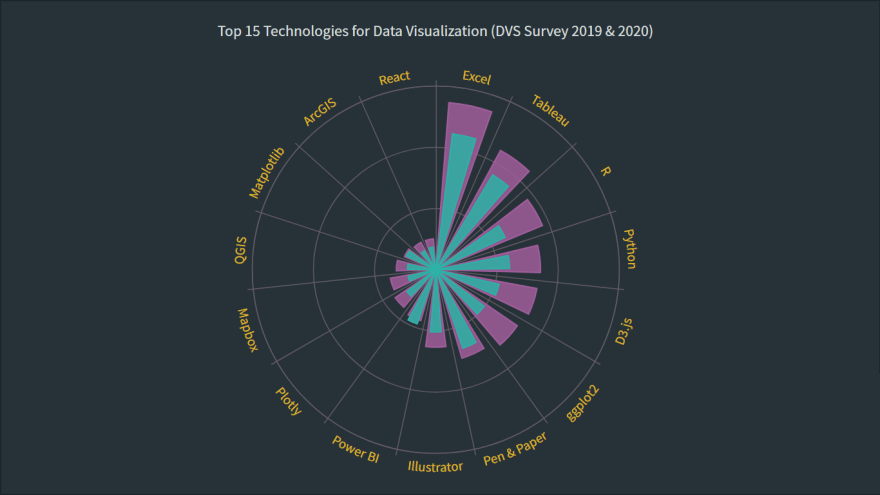
🟢 Создание полярной диаграммы JS за 4 шага
Полярные диаграммы часто выглядят впечатляюще, что заставляет некоторых людей думать, что их создание - сложный процесс, требующий большого количества навыков и опыта. Что ж, я собираюсь развенчать этот миф прямо сейчас! Позвольте мне показать вам, как легко визуализировать данные в красивой интерактивной полярной диаграмме JavaScript.
По сути, полярная диаграмма - это разновидность кругового графика, нарисованного с полярными координатами. Она также может хорошо работать для визуализации некоторых видов категориальных данных для сравнений, и это именно тот случай, который я хочу сейчас продемонстрировать. В этом уроке я построю столбчатую полярную диаграмму с полосами, растущими из центра диаграммы, чтобы представить значения с их длиной.
Общество визуализации данных (DVS) проводит ежегодный опрос специалистов по обработке данных о состоянии отрасли, и я подумал, что это может стать отличной возможностью поиграть с некоторыми из его последних данных. В частности, я хотел посмотреть на наиболее популярные технологии, используемые для визуализации данных на основе ответов. Итак, здесь я создам полярную диаграмму JS, на которой будут показаны 15 лучших из них, составив классный иллюстративный пример из реального мира.
Читать дальше
@data_analysis_ml
Полярные диаграммы часто выглядят впечатляюще, что заставляет некоторых людей думать, что их создание - сложный процесс, требующий большого количества навыков и опыта. Что ж, я собираюсь развенчать этот миф прямо сейчас! Позвольте мне показать вам, как легко визуализировать данные в красивой интерактивной полярной диаграмме JavaScript.
По сути, полярная диаграмма - это разновидность кругового графика, нарисованного с полярными координатами. Она также может хорошо работать для визуализации некоторых видов категориальных данных для сравнений, и это именно тот случай, который я хочу сейчас продемонстрировать. В этом уроке я построю столбчатую полярную диаграмму с полосами, растущими из центра диаграммы, чтобы представить значения с их длиной.
Общество визуализации данных (DVS) проводит ежегодный опрос специалистов по обработке данных о состоянии отрасли, и я подумал, что это может стать отличной возможностью поиграть с некоторыми из его последних данных. В частности, я хотел посмотреть на наиболее популярные технологии, используемые для визуализации данных на основе ответов. Итак, здесь я создам полярную диаграмму JS, на которой будут показаны 15 лучших из них, составив классный иллюстративный пример из реального мира.
Читать дальше
@data_analysis_ml
{kind=link}
👍9
📊 Коллекция продвинутой визуализации в Matplotlib и Seaborn с примерами
В этой статье не будет базовых приемов визуализации – все примеры, приведенные в этой статье, будут продвинутыми. Если вам нужно освежить базовые приемы, пожалуйста, обратитесь к статье «Ваша повседневная шпаргалка по Matplotlib».
Напоминаю: если вы используете эту статью для обучения, загрузите набор данных и выполняйте все примеры вслед за мной. Это единственный способ чему-нибудь научиться. Также найдите какой-нибудь другой набор данных и попробуйте применить аналогичные методы визуализации на нем.
Вот ссылка на набор данных, который я буду использовать в этой статье. Мы начнем с немного проблематичных диаграмм для нескольких переменных и будем двигаться к более ясным, но и более сложным решениям.
Читать дальше
@data_analysis_ml
В этой статье не будет базовых приемов визуализации – все примеры, приведенные в этой статье, будут продвинутыми. Если вам нужно освежить базовые приемы, пожалуйста, обратитесь к статье «Ваша повседневная шпаргалка по Matplotlib».
Напоминаю: если вы используете эту статью для обучения, загрузите набор данных и выполняйте все примеры вслед за мной. Это единственный способ чему-нибудь научиться. Также найдите какой-нибудь другой набор данных и попробуйте применить аналогичные методы визуализации на нем.
Вот ссылка на набор данных, который я буду использовать в этой статье. Мы начнем с немного проблематичных диаграмм для нескольких переменных и будем двигаться к более ясным, но и более сложным решениям.
Читать дальше
@data_analysis_ml
👍17🥰2
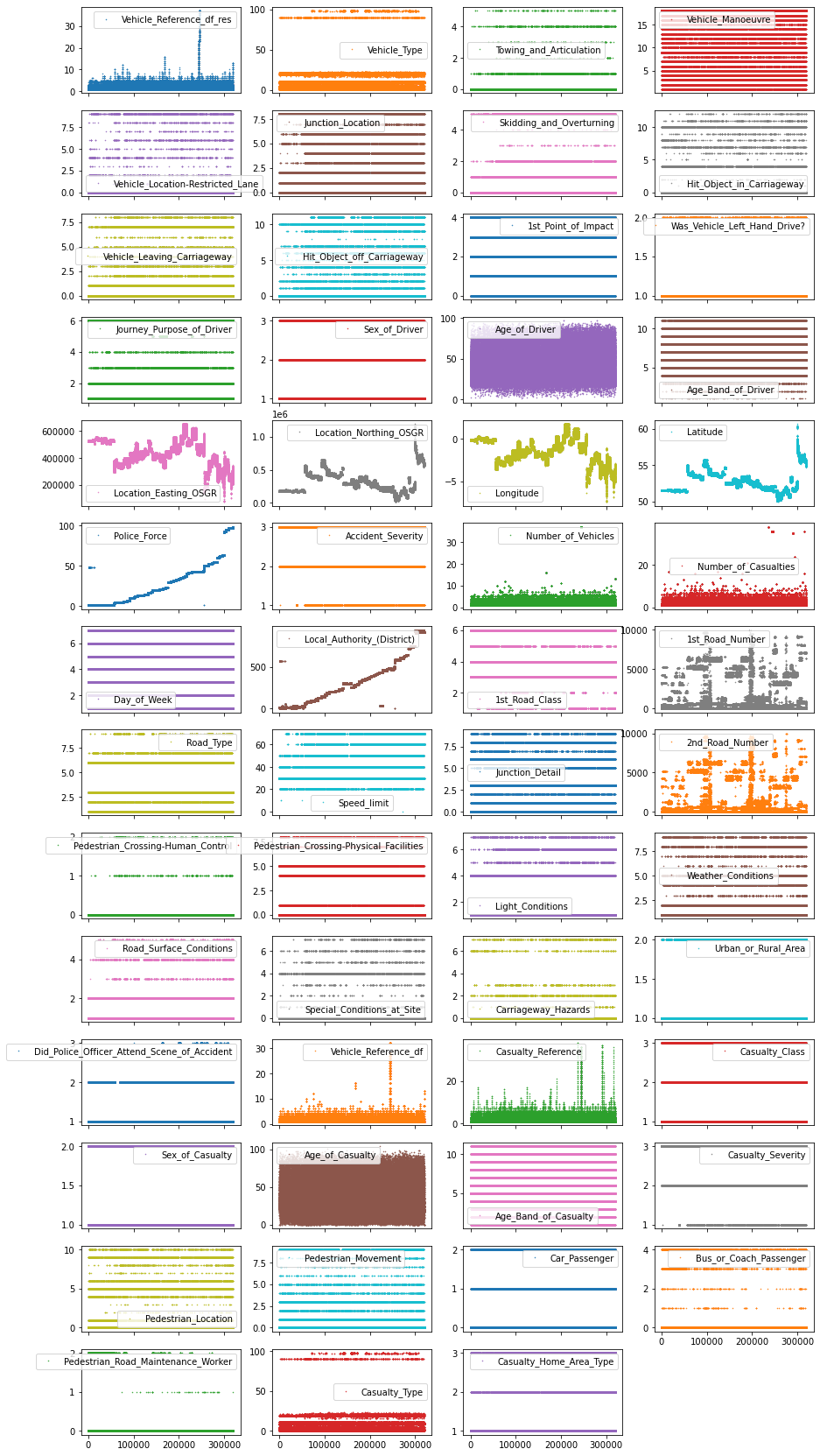
🔎 Разведочный анализ данных на Python
Получение хорошего представления о новом наборе данных не всегда бывает легким и зачастую требует времени. Тем не менее, хороший и широкий исследовательский анализ данных (EDA) может очень помочь понять ваш набор данных, понять, как данные взаимосвязаны и что необходимо сделать для правильной обработки вашего датасета.
В этой статье мы коснемся нескольких полезных алгоритмов EDA. На самом деле, часто необходимо потратить достаточно времени на правильный EDA, чтобы полностью понять ваш набор данных и это является ключевой частью любого хорошего проекта по науке о данных. Как правило, вы, вероятно, потратите 80% своего времени на подготовку и исследование данных и только 20% на реальное моделирование машинного обучения.
А тепеь давайте погрузимся прямо в анализ данных!
Статья
Git
@data_analysis_ml
Получение хорошего представления о новом наборе данных не всегда бывает легким и зачастую требует времени. Тем не менее, хороший и широкий исследовательский анализ данных (EDA) может очень помочь понять ваш набор данных, понять, как данные взаимосвязаны и что необходимо сделать для правильной обработки вашего датасета.
В этой статье мы коснемся нескольких полезных алгоритмов EDA. На самом деле, часто необходимо потратить достаточно времени на правильный EDA, чтобы полностью понять ваш набор данных и это является ключевой частью любого хорошего проекта по науке о данных. Как правило, вы, вероятно, потратите 80% своего времени на подготовку и исследование данных и только 20% на реальное моделирование машинного обучения.
А тепеь давайте погрузимся прямо в анализ данных!
Статья
Git
@data_analysis_ml
{kind=link}
👍20
Двухэтапный кластерный анализ
Процедура Двухэтапный кластерный анализ представляет собой средство разведочного анализа для выявления естественного разбиения набора данных на группы (или кластеры), которое без ее применения трудно обнаружить. Алгоритм, используемый этой процедурой, имеет несколько привлекательных особенностей, которые отличают его от традиционных методов кластерного анализа:
Работа с категориальными и непрерывными переменными. Предполагая независимость переменных, можно считать, что категориальные и непрерывные переменные имеют совместное полиномиально-нормальное распределение.
Автоматический выбор числа кластеров. Сравнивая значения критерия отбора модели для различных кластерных решений, процедура может автоматически определить оптимальное число кластеров.
Масштабируемость. Формируя дерево свойств кластеров (СК), которое является компактным представлением информации о наблюдениях, двухэтапный алгоритм позволяет анализировать большие файлы данных.
Пример. Компании производства потребительских товаров и розничной торговли регулярно применяют методы кластерного анализа к данным, описывающим покупательские привычки их клиентов, а также их пол, возраст, уровень доходов и т.д. Эти компании настраивают стратегии маркетинга и развития производства на каждую из групп потребителей, чтобы увеличить продажи и повысить приверженность потребителей маркам товаров.
Двухэтапный кластерный анализ
Параметры процедуры Двухэтапный кластерный анализ
Вывод процедуры Двухэтапный кластерный анализ
Средство просмотра кластеров
10 алгоритмов кластеризации на Python
@data_analysis_ml
Процедура Двухэтапный кластерный анализ представляет собой средство разведочного анализа для выявления естественного разбиения набора данных на группы (или кластеры), которое без ее применения трудно обнаружить. Алгоритм, используемый этой процедурой, имеет несколько привлекательных особенностей, которые отличают его от традиционных методов кластерного анализа:
Работа с категориальными и непрерывными переменными. Предполагая независимость переменных, можно считать, что категориальные и непрерывные переменные имеют совместное полиномиально-нормальное распределение.
Автоматический выбор числа кластеров. Сравнивая значения критерия отбора модели для различных кластерных решений, процедура может автоматически определить оптимальное число кластеров.
Масштабируемость. Формируя дерево свойств кластеров (СК), которое является компактным представлением информации о наблюдениях, двухэтапный алгоритм позволяет анализировать большие файлы данных.
Пример. Компании производства потребительских товаров и розничной торговли регулярно применяют методы кластерного анализа к данным, описывающим покупательские привычки их клиентов, а также их пол, возраст, уровень доходов и т.д. Эти компании настраивают стратегии маркетинга и развития производства на каждую из групп потребителей, чтобы увеличить продажи и повысить приверженность потребителей маркам товаров.
Двухэтапный кластерный анализ
Параметры процедуры Двухэтапный кластерный анализ
Вывод процедуры Двухэтапный кластерный анализ
Средство просмотра кластеров
10 алгоритмов кластеризации на Python
@data_analysis_ml
{kind=link}
👍12🔥3
This media is not supported in your browser
VIEW IN TELEGRAM
Plotly — потрясающая интерактивная библиотека визуализации, но она может работать довольно медленно, когда визуализируется множество точек данных (более 100 000 точек). Библиотека Plotly Resampler решает эту проблему, уменьшая (агрегируя) данные, а затем отображает агрегированные точки. Библиотека, позволяюяет динамически перерисовывать графики в колабах.
Github: https://github.com/predict-idlab/plotly-resampler
Демо: https://github.com/predict-idlab/plotly-resampler/blob/main/examples/basic_example.ipynb
@data_analysis_ml
Github: https://github.com/predict-idlab/plotly-resampler
Демо: https://github.com/predict-idlab/plotly-resampler/blob/main/examples/basic_example.ipynb
@data_analysis_ml
👍20👏4
🐍📈 Как «оживлять» графики и впечатлять всех красивыми анимациями с помощью Python
Показываем на примерах, как создавать красивые анимации с помощью Python, чтобы удивлять даже самых искушенных зрителей.
https://proglib.io/p/kak-ozhivlyat-grafiki-i-vpechatlyat-vseh-krasivymi-animaciyami-s-pomoshchyu-python-2022-03-29
@data_analysis_ml
Показываем на примерах, как создавать красивые анимации с помощью Python, чтобы удивлять даже самых искушенных зрителей.
https://proglib.io/p/kak-ozhivlyat-grafiki-i-vpechatlyat-vseh-krasivymi-animaciyami-s-pomoshchyu-python-2022-03-29
@data_analysis_ml
👍7
🔊 Анализ аудиоданных с помощью глубокого обучения и Python
Аудиоанализ — область, включающая автоматическое распознавание речи (ASR), цифровую обработку сигналов, а также классификацию, тегирование и генерацию музыки — представляет собой развивающийся поддомен приложений глубокого обучения. Некоторые из самых популярных и распространенных систем машинного обучения, такие как виртуальные помощники Alexa, Siri и Google Home, — это продукты, созданные на основе моделей, извлекающих информацию из аудиосигналов.
Читать дальше
25 наборов аудиоданных для исследований
Статья Анализ аудио. Идентификация голоса
@data_analysis_ml
Аудиоанализ — область, включающая автоматическое распознавание речи (ASR), цифровую обработку сигналов, а также классификацию, тегирование и генерацию музыки — представляет собой развивающийся поддомен приложений глубокого обучения. Некоторые из самых популярных и распространенных систем машинного обучения, такие как виртуальные помощники Alexa, Siri и Google Home, — это продукты, созданные на основе моделей, извлекающих информацию из аудиосигналов.
Читать дальше
25 наборов аудиоданных для исследований
Статья Анализ аудио. Идентификация голоса
@data_analysis_ml
{kind=link}
👍9🔥2
Eportal – Симулятор эволюции с капелькой ИИ
Когда начинается эволюция, вместе с ней начинаются великие битвы; объекты делают все возможное, чтобы заполнить как можно больше места для победы своего «вида»; некоторые из них становятся пассивными, едят растения и размножаются, некоторые из них становятся агрессивными, пытаясь атаковать объекты других видов
В общем и целом, довольно интересный проект с которым можно поиграться, посмотреть исходный код
#Python #AI #simulation
@data_analysis_ml
Когда начинается эволюция, вместе с ней начинаются великие битвы; объекты делают все возможное, чтобы заполнить как можно больше места для победы своего «вида»; некоторые из них становятся пассивными, едят растения и размножаются, некоторые из них становятся агрессивными, пытаясь атаковать объекты других видов
В общем и целом, довольно интересный проект с которым можно поиграться, посмотреть исходный код
#Python #AI #simulation
@data_analysis_ml
👍14💩1
💬 Yandex: An Open-source Yet another Language Model 100B
Яндекс выложил модель YaLM 100B, сейчас это крупнейшая GPT-подобная нейросеть в свободном доступе, обученная на 2 терабайтах текста: датасетах и сайтах, включающих Wikipedia, новостные статьи и книги, Github и arxiv.org. Яндекс использует генеративные нейронные сети YaLM в недавнем обновлении поиска Y1. Сейчас модель уже помогает давать ответы в Яндекс поиске и Алисе.
Github: https://github.com/yandex/YaLM-100B
Статья: https://habr.com/ru/company/yandex/blog/672396/
@data_analysis_ml
Яндекс выложил модель YaLM 100B, сейчас это крупнейшая GPT-подобная нейросеть в свободном доступе, обученная на 2 терабайтах текста: датасетах и сайтах, включающих Wikipedia, новостные статьи и книги, Github и arxiv.org. Яндекс использует генеративные нейронные сети YaLM в недавнем обновлении поиска Y1. Сейчас модель уже помогает давать ответы в Яндекс поиске и Алисе.
Github: https://github.com/yandex/YaLM-100B
Статья: https://habr.com/ru/company/yandex/blog/672396/
@data_analysis_ml
👍25