
✅ Введение в параллельные вычисления для дата-инженеров.
Обычно дата-инженерам приходится получать данные из нескольких источников, а затем очищать их и агрегировать. Часто эти процессы необходимо применять на больших объемах данных.
Сегодня мы рассмотрим одно из самых фундаментальных понятий в области вычислительных технологий и в частности дата-инженерии — параллельные вычисления. С их помощью современные приложения могут обрабатывать огромные объемы данных за относительно небольшие промежутки времени.
Обсудим преимущества параллельных вычислений в целом, а также их недостатки. Изучим несколько программных пакетов и фреймворков, использующих возможности современных многоядерных систем и кластеров компьютеров для распределения и параллелизации рабочих нагрузок.
Читать
@data_analysis_ml
Обычно дата-инженерам приходится получать данные из нескольких источников, а затем очищать их и агрегировать. Часто эти процессы необходимо применять на больших объемах данных.
Сегодня мы рассмотрим одно из самых фундаментальных понятий в области вычислительных технологий и в частности дата-инженерии — параллельные вычисления. С их помощью современные приложения могут обрабатывать огромные объемы данных за относительно небольшие промежутки времени.
Обсудим преимущества параллельных вычислений в целом, а также их недостатки. Изучим несколько программных пакетов и фреймворков, использующих возможности современных многоядерных систем и кластеров компьютеров для распределения и параллелизации рабочих нагрузок.
Читать
@data_analysis_ml
{kind=link}
👍14🤔5
🖼 Обзор архитектур image-to-image translation
В этой статье я расскажу про основные архитектуры генеративных сетей для задачи перевода изображения из одного домена в другой (image-to-image translation). В конце расскажу, для чего именно мы применяем синтетические данные и приведу примеры изображений, которых нам удалось достичь. Но перед погружением в данную тему рекомендую ознакомиться с тем, что такое свёрточная сеть, U-Net и генеративная сеть. Если же Вы готовы, поехали.
Читать дальше
@data_analysis_ml
В этой статье я расскажу про основные архитектуры генеративных сетей для задачи перевода изображения из одного домена в другой (image-to-image translation). В конце расскажу, для чего именно мы применяем синтетические данные и приведу примеры изображений, которых нам удалось достичь. Но перед погружением в данную тему рекомендую ознакомиться с тем, что такое свёрточная сеть, U-Net и генеративная сеть. Если же Вы готовы, поехали.
Читать дальше
@data_analysis_ml
Telegraph
Обзор архитектур image-to-image translation
Я работаю инженером компьютерного зрения в направлении искусственного интеллекта. Мы разрабатываем и внедряем модели с применением машинного обучения на наши производственные площадки. В скоуп наших проектов попадают как системы, управляющие (или частично…
👍13👎4
This media is not supported in your browser
VIEW IN TELEGRAM
🎇 Продвинутый уровень визуализации данных для Data Science на Python
Как сделать крутые, полностью интерактивные графики с помощью одной строки Python.
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
Читать дальше
@data_analysis_ml
Как сделать крутые, полностью интерактивные графики с помощью одной строки Python.
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
Читать дальше
@data_analysis_ml
🔥27👍5
🗣️ Решаем задачу перевода русской речи в текст с помощью Python и библиотеки Vosk
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
🤮9👍7👎1
1️⃣9️⃣ скрытых фич Sklearn для аналитика данных, о которых вам следует знать
Изучив справочник API Sklearn, я понял, что наиболее часто используемые модели и функции — это лишь малая часть того, что может делать библиотека. Конечно, встречаются чрезвычайно узконаправленные функции, которые используются в редких случаях. Но все же мне удалось обнаружить множество оценщиков, преобразователей и полезных фич, которые являются более элегантными эквивалентами обычных операций, выполняемых человеком вручную.
Поэтому я решил составить список самых важных из них и кратко рассказать об их особенностях, чтобы вы смогли значительно расширить свой набор инструментов Sklearn. Поехали!
Читать
@data_analysis_ml
Изучив справочник API Sklearn, я понял, что наиболее часто используемые модели и функции — это лишь малая часть того, что может делать библиотека. Конечно, встречаются чрезвычайно узконаправленные функции, которые используются в редких случаях. Но все же мне удалось обнаружить множество оценщиков, преобразователей и полезных фич, которые являются более элегантными эквивалентами обычных операций, выполняемых человеком вручную.
Поэтому я решил составить список самых важных из них и кратко рассказать об их особенностях, чтобы вы смогли значительно расширить свой набор инструментов Sklearn. Поехали!
Читать
@data_analysis_ml
🔥17👍10❤1🥰1🤔1
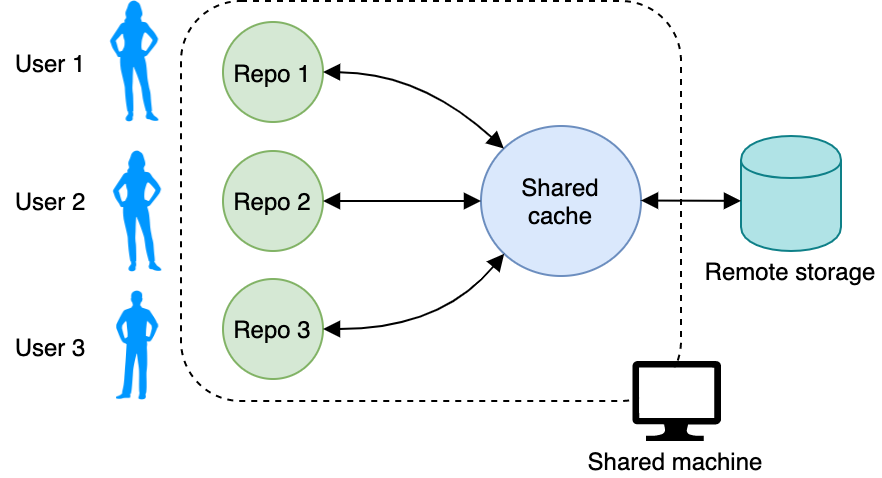
⚡️ Git для Аналитика данных: контроль версий моделей и датасетов с помощью DVC
Подробный туториал о том, как с помощью DVC и Git эффективно хранить датасеты и модели машинного обучения, чтобы перемещаться между разными их версиями посредством пары команд.
читать дальше
@data_analysis_ml
Подробный туториал о том, как с помощью DVC и Git эффективно хранить датасеты и модели машинного обучения, чтобы перемещаться между разными их версиями посредством пары команд.
читать дальше
@data_analysis_ml
{kind=link}
🔥9👍8
This media is not supported in your browser
VIEW IN TELEGRAM
10 лучших примеров визуализации данных из прошлого и по настоящее время
Визуализация данных, хотя часто и наводит на мысли о бизнес-информации и традиционном анализе, обычно гораздо более живописна и изобретательна, чем можно себе представить. Разброс тем для визуализации очень широк: от показателей предприятия до состояния здоровья населения и деления поп-культуры на тренды. Для создания действительно запоминающейся и яркой инфографики нужны знания графического дизайна, умение рассказать интересную историю и сильные аналитические способности.
В этой статье мы рассмотрим некоторые наиболее заметные, интересные и показательные примеры инфографики. Сначала взглянем на несколько примечательных исторических работ, а затем перейдем к более современным визуализациям. Советуем также обратить внимание на подробное руководство к визуализации данных и посмотреть некоторые из наших любимых примеров.
Читать
@data_analysis_ml
Визуализация данных, хотя часто и наводит на мысли о бизнес-информации и традиционном анализе, обычно гораздо более живописна и изобретательна, чем можно себе представить. Разброс тем для визуализации очень широк: от показателей предприятия до состояния здоровья населения и деления поп-культуры на тренды. Для создания действительно запоминающейся и яркой инфографики нужны знания графического дизайна, умение рассказать интересную историю и сильные аналитические способности.
В этой статье мы рассмотрим некоторые наиболее заметные, интересные и показательные примеры инфографики. Сначала взглянем на несколько примечательных исторических работ, а затем перейдем к более современным визуализациям. Советуем также обратить внимание на подробное руководство к визуализации данных и посмотреть некоторые из наших любимых примеров.
Читать
@data_analysis_ml
👍11🔥4👎1🥰1
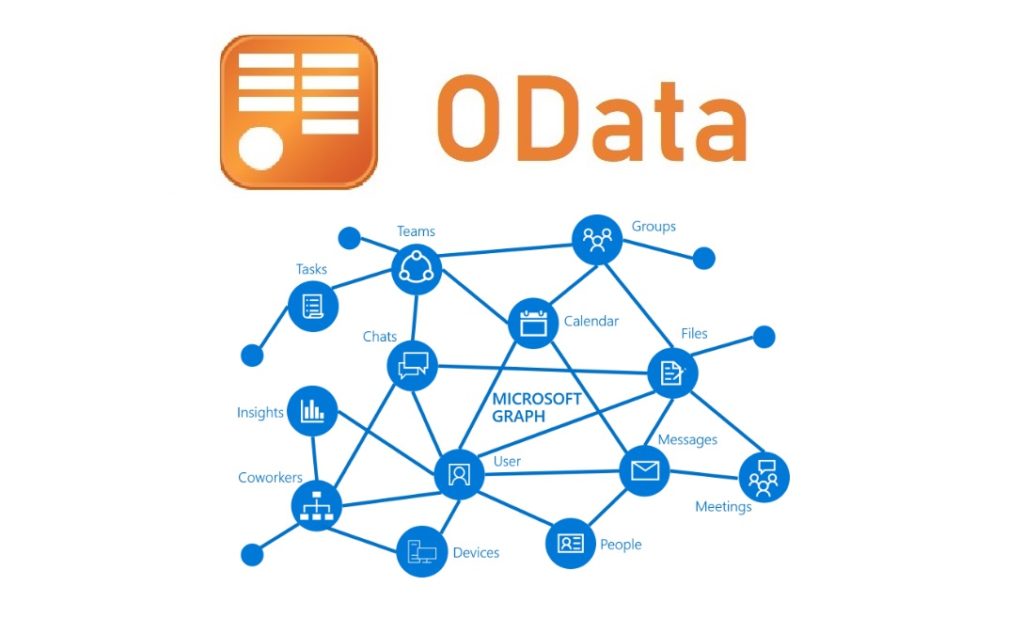
💼 Кратко об OData
Недавно, пришлось работать на проекте с внешним API. Работал, я, к слову, всегда либо с простым REST, либо с GET/POST only запросами, но в этом нужно было работать с API Timetta. Он использует OData и что же это такое?
REST vs OData
В то время как REST - набор архитектурных правил создания хорошего API, OData - это уже веб-протокол, собравший в себя "лучшие архитектурные практики": defines a set of best practices for building and consuming RESTful APIs (как написано на официальном сайте). Сам протокол очень большой, поэтому я затрону наиболее практически-значимые аспекты.
Схема
Каждая система использующая OData должна описать свою схему данных. По ней можно понять все: какие сущности есть в системе, какие операции над ними можно производить. Схема может описывается в формате XML или JSON. Для получения схемы нужно сделать запрос по адресу:
<root>/$metadata
Где <root> - корень сервиса OData. Примеры дальше будут предполагать, что мы делаем запросы из этого <root>. Для Timetta этот адрес такой:
https://api.timetta.com/odata/$metadata
Примеры дальше будут с использованием XML схем.
Читать
@data_analysis_ml
Недавно, пришлось работать на проекте с внешним API. Работал, я, к слову, всегда либо с простым REST, либо с GET/POST only запросами, но в этом нужно было работать с API Timetta. Он использует OData и что же это такое?
REST vs OData
В то время как REST - набор архитектурных правил создания хорошего API, OData - это уже веб-протокол, собравший в себя "лучшие архитектурные практики": defines a set of best practices for building and consuming RESTful APIs (как написано на официальном сайте). Сам протокол очень большой, поэтому я затрону наиболее практически-значимые аспекты.
Схема
Каждая система использующая OData должна описать свою схему данных. По ней можно понять все: какие сущности есть в системе, какие операции над ними можно производить. Схема может описывается в формате XML или JSON. Для получения схемы нужно сделать запрос по адресу:
<root>/$metadata
Где <root> - корень сервиса OData. Примеры дальше будут предполагать, что мы делаем запросы из этого <root>. Для Timetta этот адрес такой:
https://api.timetta.com/odata/$metadata
Примеры дальше будут с использованием XML схем.
Читать
@data_analysis_ml
{kind=link}
👍7❤4
🏎 Библиотека pypolars, превосходит Pandas по производительности для анализа данных.
Выпуск pandas датируется 2008 годом, и написана она была на Python, Cython и Си. Выясним, насколько высокопроизводительна написанная на Rust pypolars. Сравним её с pandas на алгоритме сортировке и при конкатенации данных с 25 миллионами записей, а также объединении двух CSV-файлов.
Читать дальше
Github
@data_analysis_ml
Выпуск pandas датируется 2008 годом, и написана она была на Python, Cython и Си. Выясним, насколько высокопроизводительна написанная на Rust pypolars. Сравним её с pandas на алгоритме сортировке и при конкатенации данных с 25 миллионами записей, а также объединении двух CSV-файлов.
Читать дальше
Github
@data_analysis_ml
👍22🔥6
📊 20 идей эффективной визуализации данных
Приложения, которые мы создаем, с каждым годом содержат все больше информации.
Потребность в качественной визуализации данных высока как никогда. Мы повсюду встречаем графические материалы, которые сбивают нас с толку и вводят в заблуждение, но можем изменить это, следуя простым правилам.
Читать
@data_analysis_ml
Приложения, которые мы создаем, с каждым годом содержат все больше информации.
Потребность в качественной визуализации данных высока как никогда. Мы повсюду встречаем графические материалы, которые сбивают нас с толку и вводят в заблуждение, но можем изменить это, следуя простым правилам.
Читать
@data_analysis_ml
{kind=link}
👍27🔥4❤1🥰1
This media is not supported in your browser
VIEW IN TELEGRAM
🔝 Лучшие практики Python для специалистов по обработке данных
Если вы когда-либо «гуглили» одни и теже вопросы, термины или синтаксис снова и снова, знайте — вы не одиноки.
Я делаю это постоянно! Это нормально, если вы постоянно заглядываете на StackOverflow или на другие ресурсы в поисках ответов на ваши вопросы. Однако это замедляет ваш рабочий процесс и ставит знак вопроса относительно вашего полного понимания языка. Сегодня, у нас есть бесконечное множество свободных и доступных источников информации, найти которые мы можем по одному запросу в поисковике — в любое удобное для нас время. Однако данное явление может стать как благословением, так и проклятием. Иногда мы просто не в состоянии эффективно обрабатывать большие объемы информации. Кроме того, ежеминутно обращаясь к различным информационным ресурсам, мы начинаем зависеть от них — что в долгосрочной перспективе может стать очень плохой привычкой.
Читать
@data_analysis_ml
Если вы когда-либо «гуглили» одни и теже вопросы, термины или синтаксис снова и снова, знайте — вы не одиноки.
Я делаю это постоянно! Это нормально, если вы постоянно заглядываете на StackOverflow или на другие ресурсы в поисках ответов на ваши вопросы. Однако это замедляет ваш рабочий процесс и ставит знак вопроса относительно вашего полного понимания языка. Сегодня, у нас есть бесконечное множество свободных и доступных источников информации, найти которые мы можем по одному запросу в поисковике — в любое удобное для нас время. Однако данное явление может стать как благословением, так и проклятием. Иногда мы просто не в состоянии эффективно обрабатывать большие объемы информации. Кроме того, ежеминутно обращаясь к различным информационным ресурсам, мы начинаем зависеть от них — что в долгосрочной перспективе может стать очень плохой привычкой.
Читать
@data_analysis_ml
👍19🔥8
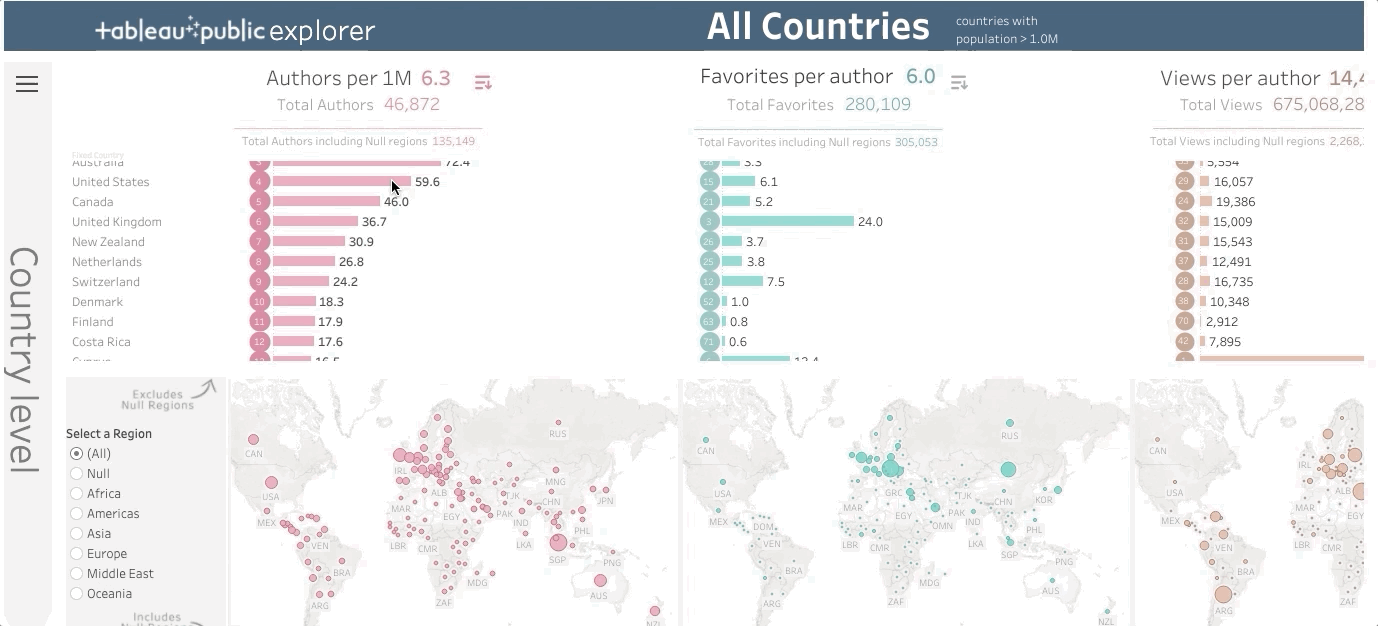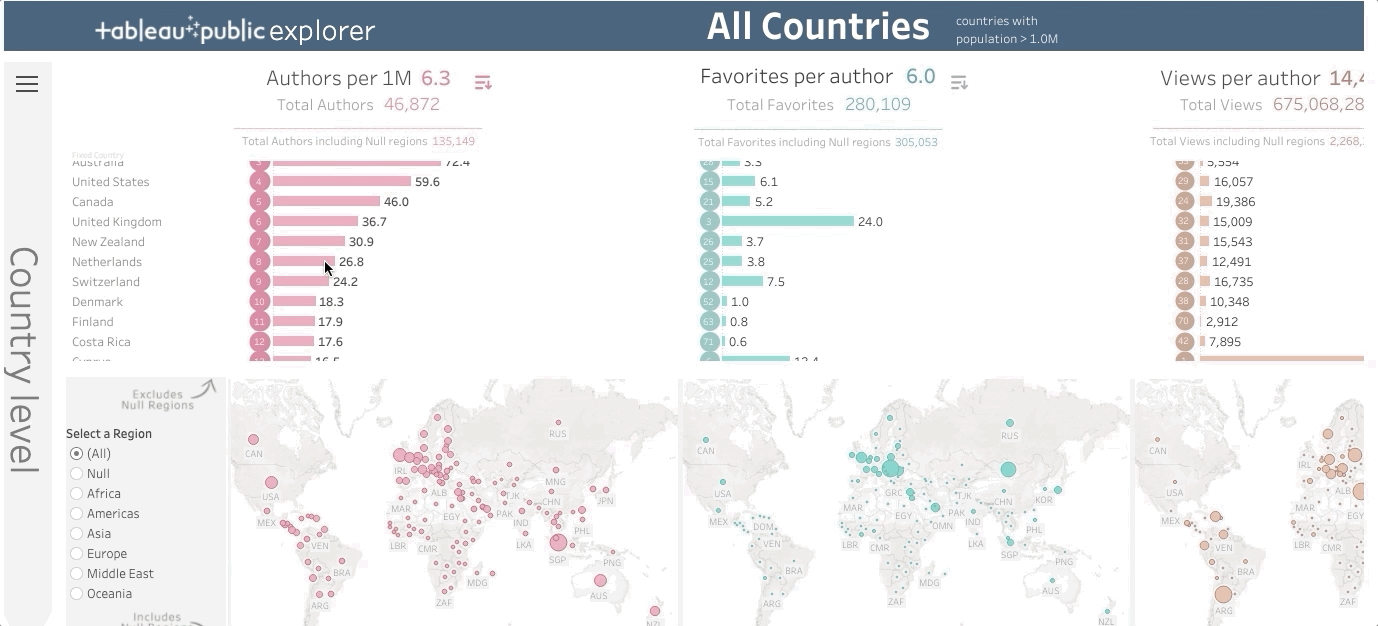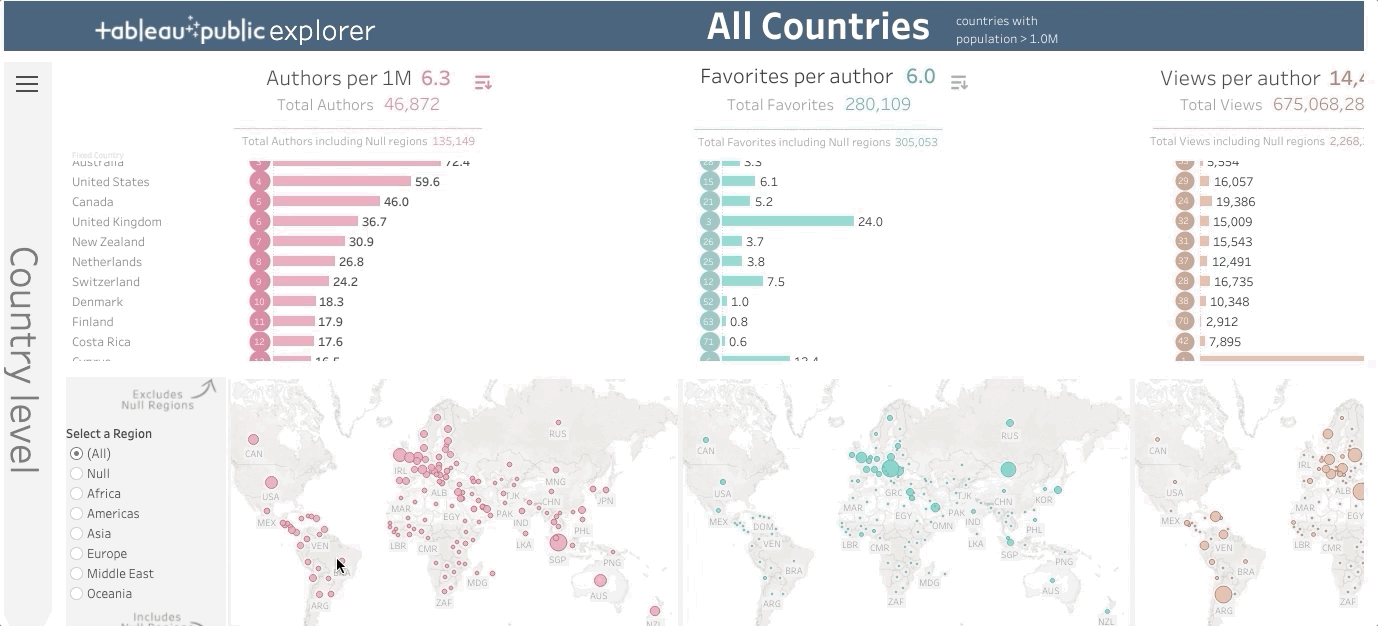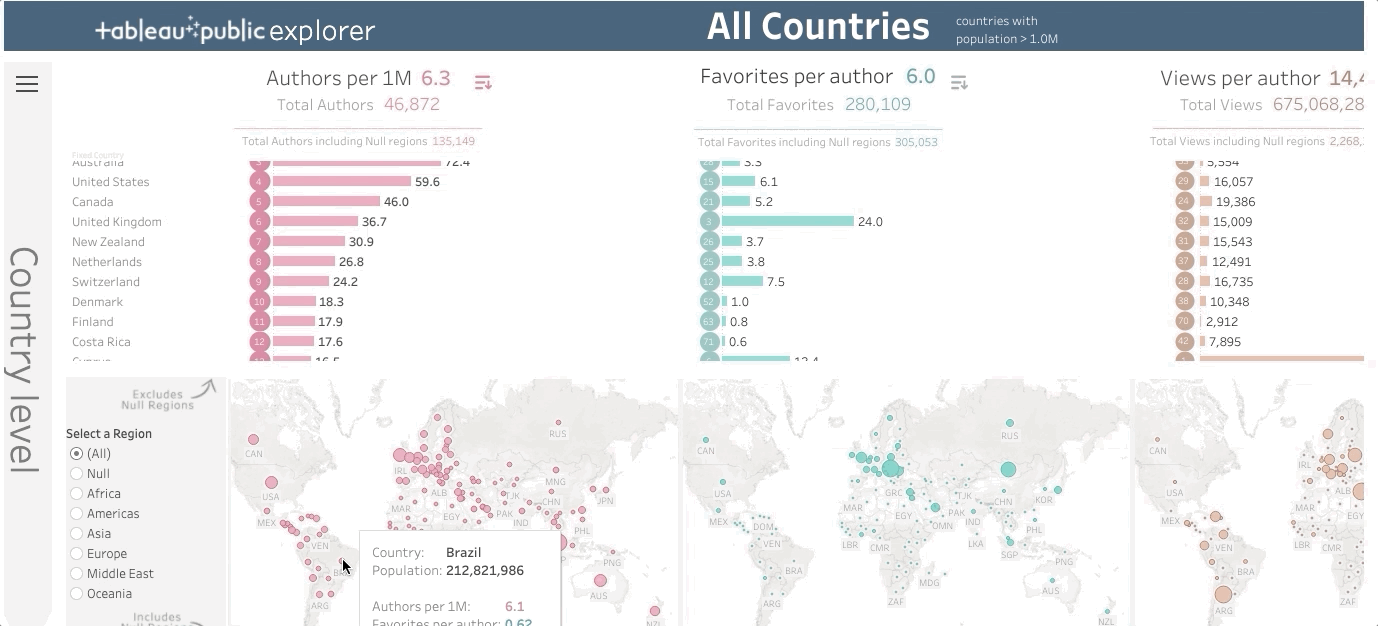
8️⃣ бесплатных инструментов для создания интерактивных визуализаций данных без необходимости написания кода
Когда тот, кто работает в сфере Data Science, собирается показать результаты своей деятельности другим людям, оказывается, что таблиц и отчётов, полных текстов, недостаточно для того чтобы представить всё наглядно и понятно. Именно в таких ситуациях возникает нужда в визуализации данных, в такой их обработке, которая позволит всем желающим в них разобраться и ухватить суть тех сложных процессов, которые они описывают.
В этом материале я расскажу о лучших бесплатных инструментах, позволяющих без особых сложностей создавать впечатляющие визуальные представления данных. При этом тут я не буду говорить о сложных системах вроде Power BI и Google Studio. Я выбрал те 8 инструментов, о которых пойдёт речь, из-за того, что ими легко пользоваться, из-за их приятного внешнего вида, из-за того, что работать с ними можно, не написав ни единой строчки программного кода и из-за того, что они бесплатны. Кроме того, они позволяют создавать интерактивные визуализации. А это значит, что графики, представляющие некие данные, могут содержать в себе больше сведений об этих данных, чем обычные изображения. Да и работать с такими графиками интереснее.
Читать
@data_analysis_ml
Когда тот, кто работает в сфере Data Science, собирается показать результаты своей деятельности другим людям, оказывается, что таблиц и отчётов, полных текстов, недостаточно для того чтобы представить всё наглядно и понятно. Именно в таких ситуациях возникает нужда в визуализации данных, в такой их обработке, которая позволит всем желающим в них разобраться и ухватить суть тех сложных процессов, которые они описывают.
В этом материале я расскажу о лучших бесплатных инструментах, позволяющих без особых сложностей создавать впечатляющие визуальные представления данных. При этом тут я не буду говорить о сложных системах вроде Power BI и Google Studio. Я выбрал те 8 инструментов, о которых пойдёт речь, из-за того, что ими легко пользоваться, из-за их приятного внешнего вида, из-за того, что работать с ними можно, не написав ни единой строчки программного кода и из-за того, что они бесплатны. Кроме того, они позволяют создавать интерактивные визуализации. А это значит, что графики, представляющие некие данные, могут содержать в себе больше сведений об этих данных, чем обычные изображения. Да и работать с такими графиками интереснее.
Читать
@data_analysis_ml
{kind=link}
👍19🔥3
9️⃣ отвлекающих моментов в визуализации данных
Xaquín González Veira, визуальный редактор The Guardian, на днях опубликовал свою версию мема distracted boyfriend. 3,5 тыс. лайков навели его на мысль, что пора уже исчерпать этот мем. Он собрал вместе девять отвлекающих моментов при работе с визуализацией данных и проиллюстрировал их.
Читать дальше
@data_analysis_ml
Xaquín González Veira, визуальный редактор The Guardian, на днях опубликовал свою версию мема distracted boyfriend. 3,5 тыс. лайков навели его на мысль, что пора уже исчерпать этот мем. Он собрал вместе девять отвлекающих моментов при работе с визуализацией данных и проиллюстрировал их.
Читать дальше
@data_analysis_ml
👍12😁5🤮1
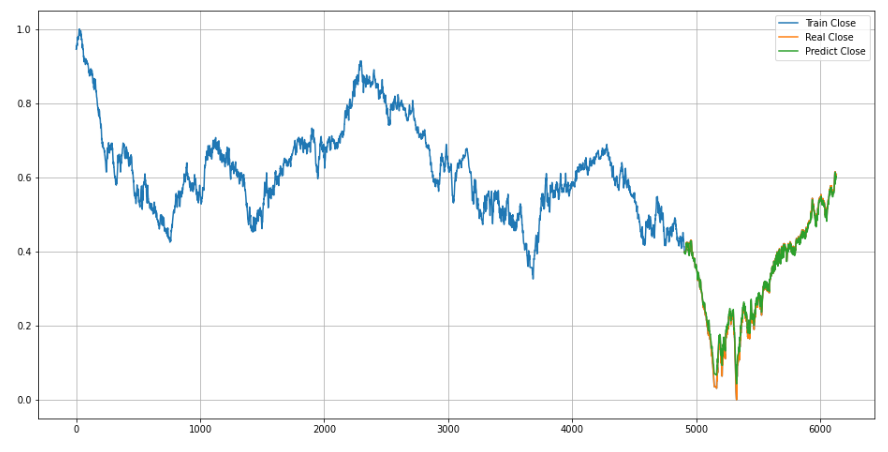
Предсказание временных рядов с помощью Keras
Машинное обучение имеет множество применений, одним из которых является прогнозирование временных рядов.
Состояние сферы искусственного интеллекта сегодня включает в себя множество разных методов, которые позволяют расширить спектр возможностей компьютера. Например, машинное обучение, big data, нейронные сети, когнитивные вычисления и другие.
Машинное обучение – один из передовых методов, который может быть использован для идентификации, интерпретации и анализа чрезвычайно сложных структур и шаблонов данных. Это позволяет проводить последовательное обучение и улучшать прогнозы моделей с помощью систематического ввода более свежих данных.
В данной статье цель состоит в том, чтобы построить современную модель для прогнозирования временного ряда, которая фокусируется на краткосрочном прогнозировании.
Задачи
Поиск источников данных, содержащих информацию о курсе валюты.
Получение, обработка и преобразование данных к необходимому виду, интеллектуальный анализ данных.
Обозначение критериев оценивания для исследования, поиск и выбор наиболее подходящих моделей машинного обучения, разработка программных средств.
Решение задач на основе выбранных моделей машинного обучения, выполнение эмпирического исследования, сбор материала, анализ полученных данных, сравнение результатов.
Читать дальше
@data_analysis_ml
Машинное обучение имеет множество применений, одним из которых является прогнозирование временных рядов.
Состояние сферы искусственного интеллекта сегодня включает в себя множество разных методов, которые позволяют расширить спектр возможностей компьютера. Например, машинное обучение, big data, нейронные сети, когнитивные вычисления и другие.
Машинное обучение – один из передовых методов, который может быть использован для идентификации, интерпретации и анализа чрезвычайно сложных структур и шаблонов данных. Это позволяет проводить последовательное обучение и улучшать прогнозы моделей с помощью систематического ввода более свежих данных.
В данной статье цель состоит в том, чтобы построить современную модель для прогнозирования временного ряда, которая фокусируется на краткосрочном прогнозировании.
Задачи
Поиск источников данных, содержащих информацию о курсе валюты.
Получение, обработка и преобразование данных к необходимому виду, интеллектуальный анализ данных.
Обозначение критериев оценивания для исследования, поиск и выбор наиболее подходящих моделей машинного обучения, разработка программных средств.
Решение задач на основе выбранных моделей машинного обучения, выполнение эмпирического исследования, сбор материала, анализ полученных данных, сравнение результатов.
Читать дальше
@data_analysis_ml
{kind=link}
👍12🔥2👎1
Топ-5 браузерных расширений для специалистов по анализу данных
Сейчас исследователи данных в основном работают в браузере с помощью Jupyter Notebook или другого подобного браузерного блокнота. Некоторые задачи можно выполнять вне браузера, но затем дата-сайентист опять возвращается в браузерный блокнот.
Учитывая такую специфику работы специалистов по данным, эти 5 браузерных расширений точно пригодятся любому дата-сайентисту.
Читать дальше
@data_analysis_ml
Сейчас исследователи данных в основном работают в браузере с помощью Jupyter Notebook или другого подобного браузерного блокнота. Некоторые задачи можно выполнять вне браузера, но затем дата-сайентист опять возвращается в браузерный блокнот.
Учитывая такую специфику работы специалистов по данным, эти 5 браузерных расширений точно пригодятся любому дата-сайентисту.
Читать дальше
@data_analysis_ml
🔥22👍4👎2
Как собрать платформу обработки данных «своими руками»?
Один заказчик, который заинтересовался нашими компетенциям в построении инфраструктур, предложил крупный интеграционный проект. Архитекторы клиента придумали сложную и большую платформу, которая включала в себя машинное обучение, обработку данных и управлялась с помощью Kubernetes. Нам поставили задачу реализовать проект платформы, настроить связность элементов, построить и запустить инфраструктуру в эксплуатацию.
В итоге всё прошло хорошо и заказчик доволен. А у нас возникла идея скомпоновать свою платформу — такую, чтобы она была доступной не только большому бизнесу, но и компаниям среднего и малого масштаба. То есть сделать так, чтобы можно было получать большие возможности и не платить при этом огромные деньги.
Читать дальше
@data_analysis_ml
Один заказчик, который заинтересовался нашими компетенциям в построении инфраструктур, предложил крупный интеграционный проект. Архитекторы клиента придумали сложную и большую платформу, которая включала в себя машинное обучение, обработку данных и управлялась с помощью Kubernetes. Нам поставили задачу реализовать проект платформы, настроить связность элементов, построить и запустить инфраструктуру в эксплуатацию.
В итоге всё прошло хорошо и заказчик доволен. А у нас возникла идея скомпоновать свою платформу — такую, чтобы она была доступной не только большому бизнесу, но и компаниям среднего и малого масштаба. То есть сделать так, чтобы можно было получать большие возможности и не платить при этом огромные деньги.
Читать дальше
@data_analysis_ml
👍12🔥4
#01TheNotSoToughML | Что означает “подогнать линию”
Что такое подгонка линии?
Когда мы начинаем изучать любой курс по МО, первое, с чем мы сталкиваемся, — это проведение линии вблизи точек. В связи с этим вы часто можете встретить термин “линейная регрессия”.
Примечание. Хотя в этой статье пойдет речь в основном об интуитивных решениях, лежащих в основе линейной регрессии, мы также будем использовать уравнения.
Кстати, мы будем создавать эти уравнения самостоятельно!
Читать дальше
@data_analysis_ml
Что такое подгонка линии?
Когда мы начинаем изучать любой курс по МО, первое, с чем мы сталкиваемся, — это проведение линии вблизи точек. В связи с этим вы часто можете встретить термин “линейная регрессия”.
Примечание. Хотя в этой статье пойдет речь в основном об интуитивных решениях, лежащих в основе линейной регрессии, мы также будем использовать уравнения.
Кстати, мы будем создавать эти уравнения самостоятельно!
Читать дальше
@data_analysis_ml
👍13🔥2
🎯 Снижаем размерность. Факторный анализ и метод главных компонент
Задача была такая: набор признаков должен обеспечить максимальную информативность. Это значит, что отбираются признаки, способные объяснить наибольшую долю дисперсии исходного набора.
Факторный анализ – многомерный метод, который применяется для изучения связей между переменными, когда существует предположение об избыточности исходных данных. Вращение Varimax в ходе факторного анализа способствует нахождению наилучшего подпространства признаков.
Метод главных компонент – метод статистического анализа, позволяющих снизить размерность пространства признаков и потерять при этом минимальное количество информации. Достигается это за счёт построения подпространства признаков меньшей размерности таким образом, чтобы дисперсия, распределённая по получаемым осям, была максимальна.
Первым этапом будет генерация исходных данных: DataFrame, большее количество столбцов которого будут заполнены случайными числами с заданной амплитудой, и лишь некоторые признаки (назову их существенными), которые будут выступать переменными, используемыми в модели. Я рассмотрю представленные выше методы на примере снижения размерности полученного набора данных.
Читать дальше
@data_analysis_ml
Задача была такая: набор признаков должен обеспечить максимальную информативность. Это значит, что отбираются признаки, способные объяснить наибольшую долю дисперсии исходного набора.
Факторный анализ – многомерный метод, который применяется для изучения связей между переменными, когда существует предположение об избыточности исходных данных. Вращение Varimax в ходе факторного анализа способствует нахождению наилучшего подпространства признаков.
Метод главных компонент – метод статистического анализа, позволяющих снизить размерность пространства признаков и потерять при этом минимальное количество информации. Достигается это за счёт построения подпространства признаков меньшей размерности таким образом, чтобы дисперсия, распределённая по получаемым осям, была максимальна.
Первым этапом будет генерация исходных данных: DataFrame, большее количество столбцов которого будут заполнены случайными числами с заданной амплитудой, и лишь некоторые признаки (назову их существенными), которые будут выступать переменными, используемыми в модели. Я рассмотрю представленные выше методы на примере снижения размерности полученного набора данных.
Читать дальше
@data_analysis_ml
{kind=link}
🔥11👍8
🚀 @machinelearning_interview - в Канале собраны все возможные вопросы и ответы с собеседований по Аналитике данных и Машинному обучению. Для всех уровней разработчиков от авторов популярного канала Machine learning.
Материалы канала реально помогут подготовиться к data science собеседованию.
👉Перейти
Материалы канала реально помогут подготовиться к data science собеседованию.
👉Перейти
👍8❤1