
✒️ Обучение алгоритма генерации текста на основе высказываний философов и писателей
Наверняка вы мечтали поговорить с великим философом: задать ему вопрос о своей жизни, узнать его мнение или просто поболтать. В наше время это возможно за счет чат-ботов, которые поддерживают диалог, имитируя манеру общения живого человека. Подобные чат-боты создаются благодаря технологиям обработки естественного языка и генерации текста. Уже сейчас существуют обученные модели, которые неплохо справляются с данной задачей.
В этой статье я расскажу о своем опыте обучения алгоритма генерации текста, основанного на высказываниях великих личностей. В датасете для обучения модели используются цитаты десяти известных философов, писателей и ученых.
Конечный текст будет генерироваться на основе высказываний всех десяти мыслителей.Но если вы захотите “пообщаться” с кем-то конкретным, например, с Сократом или Ницше, то Google Colab, в котором велась работа, прилагается в конце статьи. С его помощью можно будет поэкспериментировать только с генерацией выбранного вами философа.
Читать дальше
@data_analysis_ml
Наверняка вы мечтали поговорить с великим философом: задать ему вопрос о своей жизни, узнать его мнение или просто поболтать. В наше время это возможно за счет чат-ботов, которые поддерживают диалог, имитируя манеру общения живого человека. Подобные чат-боты создаются благодаря технологиям обработки естественного языка и генерации текста. Уже сейчас существуют обученные модели, которые неплохо справляются с данной задачей.
В этой статье я расскажу о своем опыте обучения алгоритма генерации текста, основанного на высказываниях великих личностей. В датасете для обучения модели используются цитаты десяти известных философов, писателей и ученых.
Конечный текст будет генерироваться на основе высказываний всех десяти мыслителей.Но если вы захотите “пообщаться” с кем-то конкретным, например, с Сократом или Ницше, то Google Colab, в котором велась работа, прилагается в конце статьи. С его помощью можно будет поэкспериментировать только с генерацией выбранного вами философа.
Читать дальше
@data_analysis_ml
{kind=link}
👍9❤1🔥1
📊 Улучшение визуализации данных с помощью диаграмм с двумя осями в Python
Визуализация данных облегчает понимание тенденций и позволяет принимать обоснованные решения. Для оптимального представления данных важно правильно выбрать вид диаграммы. Более того, некоторые диаграммы, такие как столбиковые и многолинейные, можно дополнительно настроить для лучшего разъяснения данных.
Помимо косметических преобразований графических изображений (с помощью цвета и шрифта), можно воспользоваться дополнительными функциями, такими как общее направление линий, прогнозы и двухосевая реализация. В этой статье мы расскажем, как использовать двухосевую линейную диаграмму, чтобы более наглядно продемонстрировать аудитории корреляции и тенденции между точками данных. Мы также кратко рассмотрим, как может выглядеть обычная диаграмма без двойной оси, чтобы вы могли решить, какое из двух графических представлений максимально соответствует вашим потребностям в визуализации.
Читать дальше
@data_analysis_ml
Визуализация данных облегчает понимание тенденций и позволяет принимать обоснованные решения. Для оптимального представления данных важно правильно выбрать вид диаграммы. Более того, некоторые диаграммы, такие как столбиковые и многолинейные, можно дополнительно настроить для лучшего разъяснения данных.
Помимо косметических преобразований графических изображений (с помощью цвета и шрифта), можно воспользоваться дополнительными функциями, такими как общее направление линий, прогнозы и двухосевая реализация. В этой статье мы расскажем, как использовать двухосевую линейную диаграмму, чтобы более наглядно продемонстрировать аудитории корреляции и тенденции между точками данных. Мы также кратко рассмотрим, как может выглядеть обычная диаграмма без двойной оси, чтобы вы могли решить, какое из двух графических представлений максимально соответствует вашим потребностям в визуализации.
Читать дальше
@data_analysis_ml
👍17
This media is not supported in your browser
VIEW IN TELEGRAM
Используем библиотеку matplotlib для создания интересной анимации данных.
Изображение имитации дождя выполнено с помощью библиотеки Matplotlib, известной как прародитель пакетов для визуализации данных на python. Matplotlib имитирует капли дождя на поверхности путем анимирования масштаба и непрозрачности 50 точек графика разброса. В этой статье мы рассмотрим анимации в Matplotlib и несколько способов их создания.
Читать дальше
@data_analysis_ml
Изображение имитации дождя выполнено с помощью библиотеки Matplotlib, известной как прародитель пакетов для визуализации данных на python. Matplotlib имитирует капли дождя на поверхности путем анимирования масштаба и непрозрачности 50 точек графика разброса. В этой статье мы рассмотрим анимации в Matplotlib и несколько способов их создания.
Читать дальше
@data_analysis_ml
👍20🔥3👎1
5️⃣ грязных трюков в соревновательном Data Science, о которых тебе не расскажут в приличном обществе. 🔥
Привет, чемпион! Возможно, ты сейчас участвуешь в соревновании по анализу данных или просто решил погрузиться в мира Data Science. Тогда эта статья будет тебе очень полезна!
Сражу скажу, что трюки, о которых мы сегодня поговорим, я не просто так назвал "грязными". Речь пойдет о вещах, которые в каком-то смысле нечестные или просто вводят в заблуждение других участников соревнований. Долго думал, стоит ли про эти техники вообще рассказывать, ведь в борьбе за призовые всегда велик соблазн начать хитрить. Решил, что все-таки расскажу про некоторые приемы, дабы вооружить честных людей, которые играют по правилам.
Будем разбирать приемы по ходу увеличения уровня их "грязи" - поехали!
Читать дальше
@data_analysis_ml
Привет, чемпион! Возможно, ты сейчас участвуешь в соревновании по анализу данных или просто решил погрузиться в мира Data Science. Тогда эта статья будет тебе очень полезна!
Сражу скажу, что трюки, о которых мы сегодня поговорим, я не просто так назвал "грязными". Речь пойдет о вещах, которые в каком-то смысле нечестные или просто вводят в заблуждение других участников соревнований. Долго думал, стоит ли про эти техники вообще рассказывать, ведь в борьбе за призовые всегда велик соблазн начать хитрить. Решил, что все-таки расскажу про некоторые приемы, дабы вооружить честных людей, которые играют по правилам.
Будем разбирать приемы по ходу увеличения уровня их "грязи" - поехали!
Читать дальше
@data_analysis_ml
{kind=link}
👍21❤3👎3
📊 Путеводитель по Big Data для начинающих: методы и техники анализа больших данных
Методы и техники анализа Big Data: Machine Learning, Data mining, краудсорсинг, нейросети, предиктивный и статистический анализ, визуализация, смешение и интеграция данных, имитационные модели. Как разобраться во множестве названий и аббревиатур? Читайте наш путеводитель.
читать дальше
@data_analysis_ml
Методы и техники анализа Big Data: Machine Learning, Data mining, краудсорсинг, нейросети, предиктивный и статистический анализ, визуализация, смешение и интеграция данных, имитационные модели. Как разобраться во множестве названий и аббревиатур? Читайте наш путеводитель.
читать дальше
@data_analysis_ml
👍7👎2
3️⃣6️⃣ лучших инструментов для визуализации данных ↩️
Если вы ищете способ просто и понятно рассказать о сложных данных, географии, объяснить неочевидные взаимосвязи, сложные или простые идеи, то вам нужна визуализация. Она хороша тем, что сразу привлекает внимание к ключевому посланию, демонстрирует закономерности, которые трудно уловить в тексте или в таблице с цифрами.
Существует много специальных инструментов для визуализации: некоторые из них совсем простые: нужно только загрузить данные и выбрать, как они будут отображаться. Другие программы более сложные и комплексные — требуют настройки и, например, знаний JavaScript.
Мы подобрали самые разные варианты: и для тех, кому нужен быстрый понятный результат, и для продвинутых пользователей. Есть из чего выбрать.
Читать дальше
@data_analysis_ml
Если вы ищете способ просто и понятно рассказать о сложных данных, географии, объяснить неочевидные взаимосвязи, сложные или простые идеи, то вам нужна визуализация. Она хороша тем, что сразу привлекает внимание к ключевому посланию, демонстрирует закономерности, которые трудно уловить в тексте или в таблице с цифрами.
Существует много специальных инструментов для визуализации: некоторые из них совсем простые: нужно только загрузить данные и выбрать, как они будут отображаться. Другие программы более сложные и комплексные — требуют настройки и, например, знаний JavaScript.
Мы подобрали самые разные варианты: и для тех, кому нужен быстрый понятный результат, и для продвинутых пользователей. Есть из чего выбрать.
Читать дальше
@data_analysis_ml
👍19👎3
Основная математика для науки о данных
https://www.kdnuggets.com/2022/06/essential-math-data-science-eigenvectors-application-pca.html
@data_analysis_ml
https://www.kdnuggets.com/2022/06/essential-math-data-science-eigenvectors-application-pca.html
@data_analysis_ml
KDnuggets
Essential Math for Data Science: Eigenvectors and Application to PCA - KDnuggets
In this article, you’ll learn about the eigendecomposition of a matrix.
👍13👎2
🎯 Обогащение данных — что это и почему без него никак
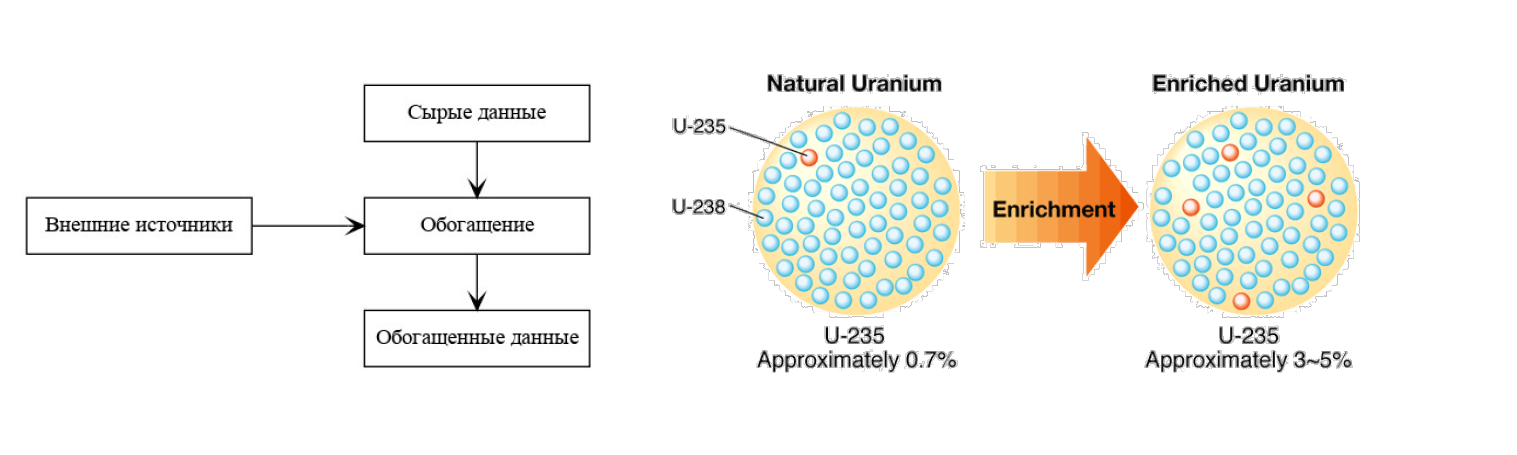
Задача обогащения данных напрямую связана с темой их обработки и анализа. Обогащение нужно для того, чтобы конечные потребители данных получали качественную и полную информацию.
Сам термин "обогащение данных" — это перевод англоязычного Data enrichment, который проводит аналогию между данными и... ураном. Точно так же, как промышленники насыщают урановую руду, увеличивая долю изотопа 235U, чтобы её можно было использовать (хочется надеяться, в мирных целях), в процессе обогащения данных мы насыщаем их информацией.
Читать дальше
@data_analysis_ml
Задача обогащения данных напрямую связана с темой их обработки и анализа. Обогащение нужно для того, чтобы конечные потребители данных получали качественную и полную информацию.
Сам термин "обогащение данных" — это перевод англоязычного Data enrichment, который проводит аналогию между данными и... ураном. Точно так же, как промышленники насыщают урановую руду, увеличивая долю изотопа 235U, чтобы её можно было использовать (хочется надеяться, в мирных целях), в процессе обогащения данных мы насыщаем их информацией.
Читать дальше
@data_analysis_ml
{kind=link}
👍14
3️⃣ распространенные ошибки при поиске работы в области науки о данных в 2022 году
Читать
@data_analysis_ml
Читать
@data_analysis_ml
Telegraph
3 распространенные ошибки при поиске работы в области науки о данных в 2022 году
Ищете работу в области науки о данных и замечаете, что ваши усилия не приносят результатов? Не исключено, что вы практически все делаете правильно, но допускаете одну оплошность, которая не оставляет ни единого шанса на получение работы. Какие распространенные…
👍14🤔1
✅ Введение в параллельные вычисления для дата-инженеров.
Обычно дата-инженерам приходится получать данные из нескольких источников, а затем очищать их и агрегировать. Часто эти процессы необходимо применять на больших объемах данных.
Сегодня мы рассмотрим одно из самых фундаментальных понятий в области вычислительных технологий и в частности дата-инженерии — параллельные вычисления. С их помощью современные приложения могут обрабатывать огромные объемы данных за относительно небольшие промежутки времени.
Обсудим преимущества параллельных вычислений в целом, а также их недостатки. Изучим несколько программных пакетов и фреймворков, использующих возможности современных многоядерных систем и кластеров компьютеров для распределения и параллелизации рабочих нагрузок.
Читать
@data_analysis_ml
Обычно дата-инженерам приходится получать данные из нескольких источников, а затем очищать их и агрегировать. Часто эти процессы необходимо применять на больших объемах данных.
Сегодня мы рассмотрим одно из самых фундаментальных понятий в области вычислительных технологий и в частности дата-инженерии — параллельные вычисления. С их помощью современные приложения могут обрабатывать огромные объемы данных за относительно небольшие промежутки времени.
Обсудим преимущества параллельных вычислений в целом, а также их недостатки. Изучим несколько программных пакетов и фреймворков, использующих возможности современных многоядерных систем и кластеров компьютеров для распределения и параллелизации рабочих нагрузок.
Читать
@data_analysis_ml
{kind=link}
👍14🤔5
🖼 Обзор архитектур image-to-image translation
В этой статье я расскажу про основные архитектуры генеративных сетей для задачи перевода изображения из одного домена в другой (image-to-image translation). В конце расскажу, для чего именно мы применяем синтетические данные и приведу примеры изображений, которых нам удалось достичь. Но перед погружением в данную тему рекомендую ознакомиться с тем, что такое свёрточная сеть, U-Net и генеративная сеть. Если же Вы готовы, поехали.
Читать дальше
@data_analysis_ml
В этой статье я расскажу про основные архитектуры генеративных сетей для задачи перевода изображения из одного домена в другой (image-to-image translation). В конце расскажу, для чего именно мы применяем синтетические данные и приведу примеры изображений, которых нам удалось достичь. Но перед погружением в данную тему рекомендую ознакомиться с тем, что такое свёрточная сеть, U-Net и генеративная сеть. Если же Вы готовы, поехали.
Читать дальше
@data_analysis_ml
Telegraph
Обзор архитектур image-to-image translation
Я работаю инженером компьютерного зрения в направлении искусственного интеллекта. Мы разрабатываем и внедряем модели с применением машинного обучения на наши производственные площадки. В скоуп наших проектов попадают как системы, управляющие (или частично…
👍13👎4
This media is not supported in your browser
VIEW IN TELEGRAM
🎇 Продвинутый уровень визуализации данных для Data Science на Python
Как сделать крутые, полностью интерактивные графики с помощью одной строки Python.
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
Читать дальше
@data_analysis_ml
Как сделать крутые, полностью интерактивные графики с помощью одной строки Python.
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
Читать дальше
@data_analysis_ml
🔥27👍5
🗣️ Решаем задачу перевода русской речи в текст с помощью Python и библиотеки Vosk
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
https://proglib.io/p/reshaem-zadachu-perevoda-russkoy-rechi-v-tekst-s-pomoshchyu-python-i-biblioteki-vosk-2022-06-30
@data_analysis_ml
🤮9👍7👎1
1️⃣9️⃣ скрытых фич Sklearn для аналитика данных, о которых вам следует знать
Изучив справочник API Sklearn, я понял, что наиболее часто используемые модели и функции — это лишь малая часть того, что может делать библиотека. Конечно, встречаются чрезвычайно узконаправленные функции, которые используются в редких случаях. Но все же мне удалось обнаружить множество оценщиков, преобразователей и полезных фич, которые являются более элегантными эквивалентами обычных операций, выполняемых человеком вручную.
Поэтому я решил составить список самых важных из них и кратко рассказать об их особенностях, чтобы вы смогли значительно расширить свой набор инструментов Sklearn. Поехали!
Читать
@data_analysis_ml
Изучив справочник API Sklearn, я понял, что наиболее часто используемые модели и функции — это лишь малая часть того, что может делать библиотека. Конечно, встречаются чрезвычайно узконаправленные функции, которые используются в редких случаях. Но все же мне удалось обнаружить множество оценщиков, преобразователей и полезных фич, которые являются более элегантными эквивалентами обычных операций, выполняемых человеком вручную.
Поэтому я решил составить список самых важных из них и кратко рассказать об их особенностях, чтобы вы смогли значительно расширить свой набор инструментов Sklearn. Поехали!
Читать
@data_analysis_ml
🔥17👍10❤1🥰1🤔1
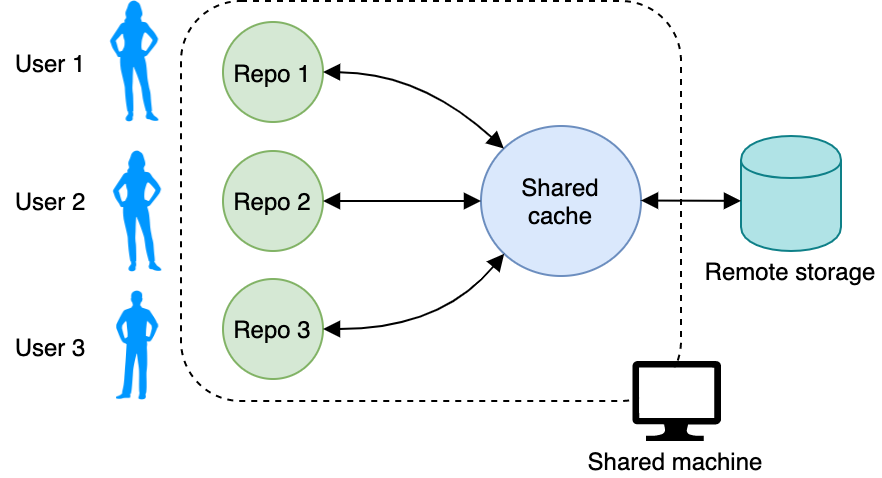
⚡️ Git для Аналитика данных: контроль версий моделей и датасетов с помощью DVC
Подробный туториал о том, как с помощью DVC и Git эффективно хранить датасеты и модели машинного обучения, чтобы перемещаться между разными их версиями посредством пары команд.
читать дальше
@data_analysis_ml
Подробный туториал о том, как с помощью DVC и Git эффективно хранить датасеты и модели машинного обучения, чтобы перемещаться между разными их версиями посредством пары команд.
читать дальше
@data_analysis_ml
{kind=link}
🔥9👍8
This media is not supported in your browser
VIEW IN TELEGRAM
10 лучших примеров визуализации данных из прошлого и по настоящее время
Визуализация данных, хотя часто и наводит на мысли о бизнес-информации и традиционном анализе, обычно гораздо более живописна и изобретательна, чем можно себе представить. Разброс тем для визуализации очень широк: от показателей предприятия до состояния здоровья населения и деления поп-культуры на тренды. Для создания действительно запоминающейся и яркой инфографики нужны знания графического дизайна, умение рассказать интересную историю и сильные аналитические способности.
В этой статье мы рассмотрим некоторые наиболее заметные, интересные и показательные примеры инфографики. Сначала взглянем на несколько примечательных исторических работ, а затем перейдем к более современным визуализациям. Советуем также обратить внимание на подробное руководство к визуализации данных и посмотреть некоторые из наших любимых примеров.
Читать
@data_analysis_ml
Визуализация данных, хотя часто и наводит на мысли о бизнес-информации и традиционном анализе, обычно гораздо более живописна и изобретательна, чем можно себе представить. Разброс тем для визуализации очень широк: от показателей предприятия до состояния здоровья населения и деления поп-культуры на тренды. Для создания действительно запоминающейся и яркой инфографики нужны знания графического дизайна, умение рассказать интересную историю и сильные аналитические способности.
В этой статье мы рассмотрим некоторые наиболее заметные, интересные и показательные примеры инфографики. Сначала взглянем на несколько примечательных исторических работ, а затем перейдем к более современным визуализациям. Советуем также обратить внимание на подробное руководство к визуализации данных и посмотреть некоторые из наших любимых примеров.
Читать
@data_analysis_ml
👍11🔥4👎1🥰1
💼 Кратко об OData
Недавно, пришлось работать на проекте с внешним API. Работал, я, к слову, всегда либо с простым REST, либо с GET/POST only запросами, но в этом нужно было работать с API Timetta. Он использует OData и что же это такое?
REST vs OData
В то время как REST - набор архитектурных правил создания хорошего API, OData - это уже веб-протокол, собравший в себя "лучшие архитектурные практики": defines a set of best practices for building and consuming RESTful APIs (как написано на официальном сайте). Сам протокол очень большой, поэтому я затрону наиболее практически-значимые аспекты.
Схема
Каждая система использующая OData должна описать свою схему данных. По ней можно понять все: какие сущности есть в системе, какие операции над ними можно производить. Схема может описывается в формате XML или JSON. Для получения схемы нужно сделать запрос по адресу:
<root>/$metadata
Где <root> - корень сервиса OData. Примеры дальше будут предполагать, что мы делаем запросы из этого <root>. Для Timetta этот адрес такой:
https://api.timetta.com/odata/$metadata
Примеры дальше будут с использованием XML схем.
Читать
@data_analysis_ml
Недавно, пришлось работать на проекте с внешним API. Работал, я, к слову, всегда либо с простым REST, либо с GET/POST only запросами, но в этом нужно было работать с API Timetta. Он использует OData и что же это такое?
REST vs OData
В то время как REST - набор архитектурных правил создания хорошего API, OData - это уже веб-протокол, собравший в себя "лучшие архитектурные практики": defines a set of best practices for building and consuming RESTful APIs (как написано на официальном сайте). Сам протокол очень большой, поэтому я затрону наиболее практически-значимые аспекты.
Схема
Каждая система использующая OData должна описать свою схему данных. По ней можно понять все: какие сущности есть в системе, какие операции над ними можно производить. Схема может описывается в формате XML или JSON. Для получения схемы нужно сделать запрос по адресу:
<root>/$metadata
Где <root> - корень сервиса OData. Примеры дальше будут предполагать, что мы делаем запросы из этого <root>. Для Timetta этот адрес такой:
https://api.timetta.com/odata/$metadata
Примеры дальше будут с использованием XML схем.
Читать
@data_analysis_ml
{kind=link}
👍7❤4
🏎 Библиотека pypolars, превосходит Pandas по производительности для анализа данных.
Выпуск pandas датируется 2008 годом, и написана она была на Python, Cython и Си. Выясним, насколько высокопроизводительна написанная на Rust pypolars. Сравним её с pandas на алгоритме сортировке и при конкатенации данных с 25 миллионами записей, а также объединении двух CSV-файлов.
Читать дальше
Github
@data_analysis_ml
Выпуск pandas датируется 2008 годом, и написана она была на Python, Cython и Си. Выясним, насколько высокопроизводительна написанная на Rust pypolars. Сравним её с pandas на алгоритме сортировке и при конкатенации данных с 25 миллионами записей, а также объединении двух CSV-файлов.
Читать дальше
Github
@data_analysis_ml
👍22🔥6
📊 20 идей эффективной визуализации данных
Приложения, которые мы создаем, с каждым годом содержат все больше информации.
Потребность в качественной визуализации данных высока как никогда. Мы повсюду встречаем графические материалы, которые сбивают нас с толку и вводят в заблуждение, но можем изменить это, следуя простым правилам.
Читать
@data_analysis_ml
Приложения, которые мы создаем, с каждым годом содержат все больше информации.
Потребность в качественной визуализации данных высока как никогда. Мы повсюду встречаем графические материалы, которые сбивают нас с толку и вводят в заблуждение, но можем изменить это, следуя простым правилам.
Читать
@data_analysis_ml
{kind=link}
👍27🔥4❤1🥰1