
эйай ньюз
⚡️Яндекс подарил миру самую большую на текущий момент публичную языковую модель: YALM 100B. - 65 дней тренировки на 800 A100 - 1.7 TB текста на русском и английском - требует 200GB VRAM для инференса https://github.com/yandex/YaLM-100B @ai_newz
В соседнем телеграм канале подняли YaLM-100B и во всю ее тестируют.
Модель в пассивно-агрессивной манере говорит, что она разумна 🌚.
Модель в пассивно-агрессивной манере говорит, что она разумна 🌚.
👍55😁28👎8❤4
This media is not supported in your browser
VIEW IN TELEGRAM
Привет, друзья! Воскресенье - хороший день, чтобы изучить что-то новое.
Для социальной коммуникации человек использует свое тело, лицо, глаза и руки. Как научить машину понимать все это в трехмерном пространстве?
А вот как! Посмотрите лекцию о параметрической модели человека SMPL (A Skinned Multi-Person Linear Model) от ее создателя Майкла Блэка.
Из лекции вы узнаете, как по картинке или видео восстанавливается 3Д поза и форма человека, и много подробностей об устройстве модели SMPL.
Несколько ключевых тем из лекции:
- История методов для моделирования человека.
- Что за данные нужны для обучения
- Как устроена модель SMPL, и как из нее получается полигональная 3Д сетка человека
- Что такое Linear Blend Skinning, и какие проблемы скиннинга решает SMPL
- Модели SMPL-X и FLAME и др.
▶️ SMPL made Simple -- Introduction (1ч 20мин)
📝 SMPL сайт проекта
@ai_newz
Для социальной коммуникации человек использует свое тело, лицо, глаза и руки. Как научить машину понимать все это в трехмерном пространстве?
А вот как! Посмотрите лекцию о параметрической модели человека SMPL (A Skinned Multi-Person Linear Model) от ее создателя Майкла Блэка.
Из лекции вы узнаете, как по картинке или видео восстанавливается 3Д поза и форма человека, и много подробностей об устройстве модели SMPL.
Несколько ключевых тем из лекции:
- История методов для моделирования человека.
- Что за данные нужны для обучения
- Как устроена модель SMPL, и как из нее получается полигональная 3Д сетка человека
- Что такое Linear Blend Skinning, и какие проблемы скиннинга решает SMPL
- Модели SMPL-X и FLAME и др.
▶️ SMPL made Simple -- Introduction (1ч 20мин)
📝 SMPL сайт проекта
@ai_newz
👍32❤14🔥7
Я и сам часто замечал, что фичи выдранные сетками, которые не до конца сошлись лучше подходят для всяких downstream задач, вроде поиска и ранжирования. А теперь пацаны из Гугла и Баиду официально оформили (и эмпирически доказали) эту гипотезу в статьях*.
Поразительно, но ResNet-6 затыкает за пояс двухсотслойный ResNet на бенчмарке по perceptual similarity после 6 эпох обучения на ImageNet. Главное не передержать.
Но (из статьи Баиду): если хотите дальше файнтюнить сеть на другом датасете, то все же лучше сначала дообучить ее до сходимости на первом датасете. Тогда точность будет выше.
❱❱ On the surprising tradeoff between ImageNet accuracy and perceptual similarity [Google]
❱❱ Inadequately Pre-trained Models are Better Feature Extractors [Baidu]
@ai_newz
Поразительно, но ResNet-6 затыкает за пояс двухсотслойный ResNet на бенчмарке по perceptual similarity после 6 эпох обучения на ImageNet. Главное не передержать.
Но (из статьи Баиду): если хотите дальше файнтюнить сеть на другом датасете, то все же лучше сначала дообучить ее до сходимости на первом датасете. Тогда точность будет выше.
❱❱ On the surprising tradeoff between ImageNet accuracy and perceptual similarity [Google]
❱❱ Inadequately Pre-trained Models are Better Feature Extractors [Baidu]
@ai_newz
Telegram
AbstractDL
Недообученные нейросети — лучшие feature экстракторы
К удивительному выводу пришли две независимые группы исследователей из Google и Baidu — чем дольше учить нейронную сеть, тем хуже выразительная способность её фичей. То есть, не смотря на рост top-1 accuracy…
К удивительному выводу пришли две независимые группы исследователей из Google и Baidu — чем дольше учить нейронную сеть, тем хуже выразительная способность её фичей. То есть, не смотря на рост top-1 accuracy…
🔥31👍8❤5🤯3🤔1🤩1
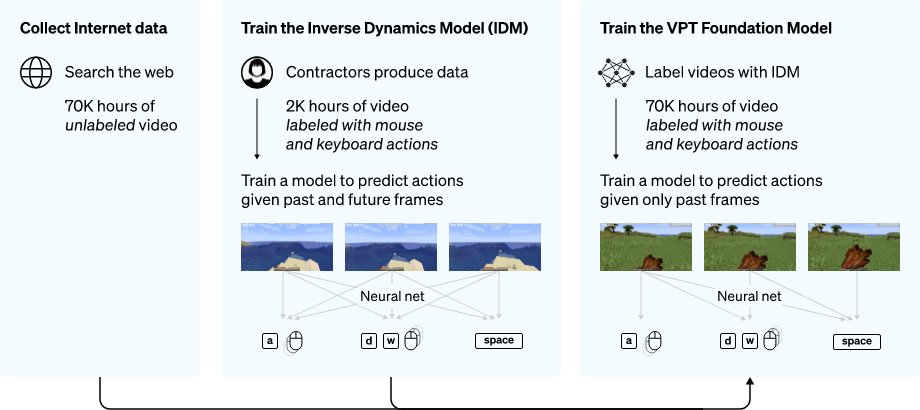
Теперь не только ты, но и боты будут фармить голду в Minecraft
OpenAI обучили нейронку играть в Minecraft с помощью тренировки на огромном неразмеченном наборе стримов. В итоге RL модель оказалась (не удивлен) эффективнее человека. Она научилась изготавливать алмазную кирку за 5 минут (4.8к действий), что обычно занимает более 20 минут (24к действий) у опытных игроков.
Как?
Чтобы хорошо инициализировать модель, ей мало смотреть реплеи игр людей, нужно знать какие действия были совершены в каждый момент времени (клавиатура + мышь). Поэтому, ученые собрали небольшой набор данных от подрядчиков, где они записывали не только видео процесса игры, но и действия (нажатия клавиш и движения мыши). С помощью этих данных они обучили модель обратной динамики (IDM), которая предсказывает действия, предпринимаемые на каждом кадре видео.
Ну а теперь, в модель можно запихнуть терабайты видео с реплеями игр с ютуба и твича, заранее предсказав действия игроков с помощью IDM. А затем сетку немного зафайнтюнили с помощью Reinforcement Learning, с целью научиться быстро добывать алмазную кирку.
В итоге, агент создает алмазную кирку за 5 минут. И это всё благодаря претрейну на неразмеченных видео. Ведь, если обучать модель с нуля с помошью RL, то агент вообще не способен случайно выучить как создавать сложные объекты.
На видео в посте ниже - процесс создания ботом каменной кирки.
@ai_newz
OpenAI обучили нейронку играть в Minecraft с помощью тренировки на огромном неразмеченном наборе стримов. В итоге RL модель оказалась (не удивлен) эффективнее человека. Она научилась изготавливать алмазную кирку за 5 минут (4.8к действий), что обычно занимает более 20 минут (24к действий) у опытных игроков.
Как?
Чтобы хорошо инициализировать модель, ей мало смотреть реплеи игр людей, нужно знать какие действия были совершены в каждый момент времени (клавиатура + мышь). Поэтому, ученые собрали небольшой набор данных от подрядчиков, где они записывали не только видео процесса игры, но и действия (нажатия клавиш и движения мыши). С помощью этих данных они обучили модель обратной динамики (IDM), которая предсказывает действия, предпринимаемые на каждом кадре видео.
Ну а теперь, в модель можно запихнуть терабайты видео с реплеями игр с ютуба и твича, заранее предсказав действия игроков с помощью IDM. А затем сетку немного зафайнтюнили с помощью Reinforcement Learning, с целью научиться быстро добывать алмазную кирку.
В итоге, агент создает алмазную кирку за 5 минут. И это всё благодаря претрейну на неразмеченных видео. Ведь, если обучать модель с нуля с помошью RL, то агент вообще не способен случайно выучить как создавать сложные объекты.
На видео в посте ниже - процесс создания ботом каменной кирки.
@ai_newz
{kind=link}
👍32🤯17🔥12😁4
Свежее интервью с Яном Лекуном (20 мин) с парижской конфы Viva Trchnology.
В нем он коротко прошелся по своему вижену AGI и немного унизил DALL-E, GPT-3 и прочие хайповые сетки, сказав что в них нет нужного ингредиента, чтобы стать реально умными. Масштабировать размер моделей и закидывать их ресурсами – это неверный путь.
Посмотрите, интервью короткое и не напряжное.
@ai_newz
В нем он коротко прошелся по своему вижену AGI и немного унизил DALL-E, GPT-3 и прочие хайповые сетки, сказав что в них нет нужного ингредиента, чтобы стать реально умными. Масштабировать размер моделей и закидывать их ресурсами – это неверный путь.
Посмотрите, интервью короткое и не напряжное.
@ai_newz
🔥44👍15🤔2
Привет, друзья!
Собрал для вас список лекций и туториалов про 3D Human Understanding от топовых ученых из этой сферы.
Рекомендасион для всех, кто хочет основательно погрузиться в тему.
1. Andreas Geiger. Diverse Topics in Computer Vision: Human Body Models [video]
2. Michael Black. SMPL made Simple -- Introduction [video]
3. Dimitris Tzionas. SMPL from Images via Optimization [video]
4. Michael Black. SMPL: Frequently Asked Questions [video]
2. Angjoo Kanazawa. Perceiving Humans in the 3D World [video]
3. Iasonas Kokkinos. Humans, hands, and horses [video]
4. Michael Black. Meta-commerce in the Age of Avatars [video]
5. Ahmed Osman. Problems with SMPL and fixing them with STAR [video]
6. Gerard Pons-Moll. Clothing SMPL [video]
7. Siyu Tang. Putting SMPL into Scenes [video]
8. Joachim Tesch. SMPL-X Application Integrations. Using SMPL-X in Blender, Unity and Unreal [video]
9. Datasets of and for SMPL and related models [video]
10. SMPLpix: Combining SMPL and Neural Rendering [video]
@Artem
#ликбез
Собрал для вас список лекций и туториалов про 3D Human Understanding от топовых ученых из этой сферы.
Рекомендасион для всех, кто хочет основательно погрузиться в тему.
1. Andreas Geiger. Diverse Topics in Computer Vision: Human Body Models [video]
2. Michael Black. SMPL made Simple -- Introduction [video]
3. Dimitris Tzionas. SMPL from Images via Optimization [video]
4. Michael Black. SMPL: Frequently Asked Questions [video]
2. Angjoo Kanazawa. Perceiving Humans in the 3D World [video]
3. Iasonas Kokkinos. Humans, hands, and horses [video]
4. Michael Black. Meta-commerce in the Age of Avatars [video]
5. Ahmed Osman. Problems with SMPL and fixing them with STAR [video]
6. Gerard Pons-Moll. Clothing SMPL [video]
7. Siyu Tang. Putting SMPL into Scenes [video]
8. Joachim Tesch. SMPL-X Application Integrations. Using SMPL-X in Blender, Unity and Unreal [video]
9. Datasets of and for SMPL and related models [video]
10. SMPLpix: Combining SMPL and Neural Rendering [video]
@Artem
#ликбез
👍45🔥25❤4
эйай ньюз
Привет, друзья! Собрал для вас список лекций и туториалов про 3D Human Understanding от топовых ученых из этой сферы. Рекомендасион для всех, кто хочет основательно погрузиться в тему. 1. Andreas Geiger. Diverse Topics in Computer Vision: Human Body Models…
Посмотрев все эти лекции, и закодив все описываемые методы, сразу смело пишите Майклу Блэку по поводу вакансии в его лабе 😏.
Telegram
эйай ньюз
ICCV в 1990 году - как оно было?
Michael J. Black (MJB) - известный профессор по CV, который занимается оценкой геометрии и поз людей в 3D. Мне посчастливилось быть с ним лично знакомым (однажды я делал доклад в его лабе). Человек он очень незаурядного…
Michael J. Black (MJB) - известный профессор по CV, который занимается оценкой геометрии и поз людей в 3D. Мне посчастливилось быть с ним лично знакомым (однажды я делал доклад в его лабе). Человек он очень незаурядного…
😁18🌭4❤3👍1
Media is too big
VIEW IN TELEGRAM
Бесконечная красота с DALLE-2
Я обалдел от того, какие офигенные штуки можно сделать с Dalle-2. Можно бесконечно долго уменьшать кадр, и подавать его после преобразования на вход сети опять. Получаются такие сочные красивые анимации, как на видео (автор @too_motion).
@ai_newz
Я обалдел от того, какие офигенные штуки можно сделать с Dalle-2. Можно бесконечно долго уменьшать кадр, и подавать его после преобразования на вход сети опять. Получаются такие сочные красивые анимации, как на видео (автор @too_motion).
@ai_newz
❤106🔥36👍7👎2
This media is not supported in your browser
VIEW IN TELEGRAM
6DRepNet: 6D Rotation representation for unconstrained head pose estimation
Статейка о распознавании 3Д позы головы в дикой природе. Основной трюк метода в "удобном для нейросети" 6D представлении матрицы поворота.
Есть репозиторий с кодом, весами и демкой для веб -камеры.
@ai_newz
Статейка о распознавании 3Д позы головы в дикой природе. Основной трюк метода в "удобном для нейросети" 6D представлении матрицы поворота.
Есть репозиторий с кодом, весами и демкой для веб -камеры.
@ai_newz
👍59🔥8😁2
This media is not supported in your browser
VIEW IN TELEGRAM
Охренеть просто! Тут State-of-The-Art модель для Pose Estimation подвезли.
Обратите внимание на когерентность во времени!
Код и веса моделей скоро обещают выложить.
@ai_newz
Обратите внимание на когерентность во времени!
Код и веса моделей скоро обещают выложить.
@ai_newz
🤣289🔥32😁13🌚8🤔4💯3👍2🤬2👏1
⚡️Эксклюзив. Избранные доклады по NLP с ODS DataFest 2022
Недавно тихо и без лишнего шума прошел 3.5-недельный датафест от open data science.
Подписчик (@seeyouall) собрал список интересных докладов по NLP. Многие видео еще не опубликованы и доступны только по ссылке, так что это эксклюзив, если хотите.
🔺 Корпус RuCoLA: бенчмарк и способ сравнить языковые модели по-новому (link)
🔺 A small BERT towards Large Medical Models (link)
🔺 Современные техники обучения retrieval based моделей для поддержания диалога виртуальных ассистентов (link)
🔺 mGPT: мультиязычная генеративная модель для 61 языков и ее применения (link)
🔺 Делаем суммаризацию текстов на русском языке (link)
🔺 Трансформеры для обобщения поведения пользователей Яндекс Такси (link)
🔺 Трансформеры для персонализации в Яндексе (link)
🔺 Nearest Neighbors Language Models (part1 + part2)
На фесте были доклады не только по NLP, всю программу можно посмотреть на сайте дата-феста (нужна регистрация).
@ai_newz
Недавно тихо и без лишнего шума прошел 3.5-недельный датафест от open data science.
Подписчик (@seeyouall) собрал список интересных докладов по NLP. Многие видео еще не опубликованы и доступны только по ссылке, так что это эксклюзив, если хотите.
🔺 Корпус RuCoLA: бенчмарк и способ сравнить языковые модели по-новому (link)
🔺 A small BERT towards Large Medical Models (link)
🔺 Современные техники обучения retrieval based моделей для поддержания диалога виртуальных ассистентов (link)
🔺 mGPT: мультиязычная генеративная модель для 61 языков и ее применения (link)
🔺 Делаем суммаризацию текстов на русском языке (link)
🔺 Трансформеры для обобщения поведения пользователей Яндекс Такси (link)
🔺 Трансформеры для персонализации в Яндексе (link)
🔺 Nearest Neighbors Language Models (part1 + part2)
На фесте были доклады не только по NLP, всю программу можно посмотреть на сайте дата-феста (нужна регистрация).
@ai_newz
👍38🔥7🤯1
Media is too big
VIEW IN TELEGRAM
3D трекинг игроков и автоматическая детекция офсайдов в FIFA
На видео показывают как в FIFA теперь трекаюткожаных мешков игроков на поле. Да не просто трекают, а восстанавливают реальные 3D координаты скелета каждого игрока на поле и автоматически засекают, если был офсайд.
По технологиям, там 2D pose detection + триангуляция за счет того, что игроки видны сразу с нескольких камер. Вот и получается точная 3D позиция даже левого мизинца. Блин, они даже встроили датчик внутрь мяча!
@ai_newz
На видео показывают как в FIFA теперь трекают
По технологиям, там 2D pose detection + триангуляция за счет того, что игроки видны сразу с нескольких камер. Вот и получается точная 3D позиция даже левого мизинца. Блин, они даже встроили датчик внутрь мяча!
@ai_newz
🔥44👍4
Скоро выходит новая улучшалка изображений от Neural Love на базе диффузионной модели
На сайте проекта есть и другие модели для улучшения аудио и фото, которые можно попробовать бесплатно.
@ai_newz
На сайте проекта есть и другие модели для улучшения аудио и фото, которые можно попробовать бесплатно.
@ai_newz
Telegram
Denis Sexy IT 🤖
Готовим к релизу на neural.love новую модельку для AI апскейла, только посмотрите какая магия.
Плохой нейминг – наша фишка, поэтому модель назвали Enhance 9000 🌚
В примере 256 px -> 1024 px
Плохой нейминг – наша фишка, поэтому модель назвали Enhance 9000 🌚
В примере 256 px -> 1024 px
🔥46👍13👎7❤4
BSTRO: Body-Scene contact TRansfOrmer
Для понимания поведения человека, нужно уметь понимать его взаимодействие со сценой и различными предметами. И в новой статье от MJB представлен подход, который предсказывает 3Д контакт человека со сценой по фото. Осторожно! В модели используются трансформеры.
Для тренировки сети собрали датасет:
- Отсканировали cцены c помощью лазерного сканера Leica RTC360
- Сняли синхронные видео людей взаимодействующих со сценами с нескольких камер
- Зафитили параметрические модели SMPL-X, использую отснятые multi-view видео (про то, как фитили, напишу позже)
- Автоматически разметили контакт 3D модели человека со сценой, находя пересечения между поверхностями
Затем обучили трансформер предсказывать вероятность того, что вершина меши человека взаимодействует со сценой. На вход подаются CNN фичи входного фото и шаблонная мешь человека SMPL.
В общем, интересная работа, где для сбора датасета использовались SOTA методы для реконструкции позы и формы человека. Интересно читать.
❱❱ Код для трейна не выложили, жуки. Но можно запустить инференс на предобученных весах.
❱❱ Сайт проекта
❱❱ Мой пост с основами 3D Human Understanding: тык.
@ai_newz
Для понимания поведения человека, нужно уметь понимать его взаимодействие со сценой и различными предметами. И в новой статье от MJB представлен подход, который предсказывает 3Д контакт человека со сценой по фото. Осторожно! В модели используются трансформеры.
Для тренировки сети собрали датасет:
- Отсканировали cцены c помощью лазерного сканера Leica RTC360
- Сняли синхронные видео людей взаимодействующих со сценами с нескольких камер
- Зафитили параметрические модели SMPL-X, использую отснятые multi-view видео (про то, как фитили, напишу позже)
- Автоматически разметили контакт 3D модели человека со сценой, находя пересечения между поверхностями
Затем обучили трансформер предсказывать вероятность того, что вершина меши человека взаимодействует со сценой. На вход подаются CNN фичи входного фото и шаблонная мешь человека SMPL.
В общем, интересная работа, где для сбора датасета использовались SOTA методы для реконструкции позы и формы человека. Интересно читать.
❱❱ Код для трейна не выложили, жуки. Но можно запустить инференс на предобученных весах.
❱❱ Сайт проекта
❱❱ Мой пост с основами 3D Human Understanding: тык.
@ai_newz
🔥15👍6
Почему дипфейки все ещё выглядят фейково, или как королева Англии говорит по-арабски.
Такие приколы – это смешно, да и липсинк уже довольно стабильно работает. Единственное, чего часто не хватает в дипфейках и видосах с переозвучкой голов – так это когерентности между текстом, стилем его произношения, выражением лица и движениями головы. Невербальная составляющая (которую смоделировать сложнее) усиливает сигнал и придает реализма. Я ожидаю следующий виток развития дипфейков в этом направлении.
@ai_newz
Такие приколы – это смешно, да и липсинк уже довольно стабильно работает. Единственное, чего часто не хватает в дипфейках и видосах с переозвучкой голов – так это когерентности между текстом, стилем его произношения, выражением лица и движениями головы. Невербальная составляющая (которую смоделировать сложнее) усиливает сигнал и придает реализма. Я ожидаю следующий виток развития дипфейков в этом направлении.
@ai_newz
YouTube
Queen of England Speaks Arabic مهرجان اخواتي - ابطال الجمهورية
#deepfake #vfx #AI #egypt
Queen of England Speak Arabic مهرجان اخواتي - ابطال الجمهورية
DeepWesh VFX: https://www.facebook.com/DeepWeshVFX
Deepfaker: Hassan Ibrahim https://www.facebook.com/HassanIbrahimML
Queen of England Speak Arabic مهرجان اخواتي - ابطال الجمهورية
DeepWesh VFX: https://www.facebook.com/DeepWeshVFX
Deepfaker: Hassan Ibrahim https://www.facebook.com/HassanIbrahimML
❤19👍11😁7
Image Inpainting: Partial Convolution vs Gated convolution
Продолжая рубрику #fundamentals,
поговорим о конволюциях, используемых в нейронных сетях для инпейнтинга. В модели для инпейнтинга изображений на вход обычно подается поврежденное изображение (с некоторыми замаскированными частями). Однако, мы не хотим, чтобы свёртки полагались на пустые области при вычислении фичей. У этой проблемы есть простое решение (Partial convolution) и более элегантное (Gated convolution).
🔻Partial Convolutions делают свертки зависимыми только от валидных пикселей. Они похожи на обычные свертки, где к каждой выходной feature-map применяется умножение на жесткую маску. Первая маска вычисляется непосредственно из покоцанного изображения или предоставляется пользователем в качестве входных данных. Маски для каждой следующей частичной свертки вычисляются путем нахождения ненулевых элементов в промежуточных feature-мапах.
- Для частичной свертки недопустимые пиксели будут постепенно исчезать в глубоких слоях, постепенно преобразовывая все значения маски в единицы.
- частичная свертка несовместима с дополнительным вводом пользователя. Однако мы хотели бы иметь возможность использовать дополнительные пользовательские инпуты для условной генерации (например, скетч внутри маски).
- Все каналы в каждом слое используют одну и ту же маску, что ограничивает гибкость. По сути, частичную свертку можно рассматривать как необучаемое одноканальное зануление фичей по маске.
🔻Gated convolutions. Вместо жесткой маски, обновляемой с помощью жестких правил, закрытые свертки автоматически учат soft маску из данных. Дополнительная конволюция берет входную feature-map и предсказывает соответствующую soft маску, которая применяется к выходу оригинальной свертки.
- Gated convolution может принимать любой дополнительный инпут пользователя (например, маску, эскиз) в качестве входных данных. Все они могут быть склеены с поврежденным изображением и скормлены в сеть.
- Gated convolution динамически учит механизм выбора признаков для каждого канала и каждого пространственного расположения.
- Интересно, что визуализация промежуточных значений предсказанных масок показывает, что gated convolution учится выбирать фичи не только по фону, маске, эскизу, но и с учетом семантической сегментации в некоторых каналах.
- Даже в глубоких слоях gated convolution учится выделять именно маскированные области и информацию о входном скетче в отдельных каналах, что позволяет более качественно генерировать восстановленную картинку.
@ai_newz
Продолжая рубрику #fundamentals,
поговорим о конволюциях, используемых в нейронных сетях для инпейнтинга. В модели для инпейнтинга изображений на вход обычно подается поврежденное изображение (с некоторыми замаскированными частями). Однако, мы не хотим, чтобы свёртки полагались на пустые области при вычислении фичей. У этой проблемы есть простое решение (Partial convolution) и более элегантное (Gated convolution).
🔻Partial Convolutions делают свертки зависимыми только от валидных пикселей. Они похожи на обычные свертки, где к каждой выходной feature-map применяется умножение на жесткую маску. Первая маска вычисляется непосредственно из покоцанного изображения или предоставляется пользователем в качестве входных данных. Маски для каждой следующей частичной свертки вычисляются путем нахождения ненулевых элементов в промежуточных feature-мапах.
- Для частичной свертки недопустимые пиксели будут постепенно исчезать в глубоких слоях, постепенно преобразовывая все значения маски в единицы.
- частичная свертка несовместима с дополнительным вводом пользователя. Однако мы хотели бы иметь возможность использовать дополнительные пользовательские инпуты для условной генерации (например, скетч внутри маски).
- Все каналы в каждом слое используют одну и ту же маску, что ограничивает гибкость. По сути, частичную свертку можно рассматривать как необучаемое одноканальное зануление фичей по маске.
🔻Gated convolutions. Вместо жесткой маски, обновляемой с помощью жестких правил, закрытые свертки автоматически учат soft маску из данных. Дополнительная конволюция берет входную feature-map и предсказывает соответствующую soft маску, которая применяется к выходу оригинальной свертки.
- Gated convolution может принимать любой дополнительный инпут пользователя (например, маску, эскиз) в качестве входных данных. Все они могут быть склеены с поврежденным изображением и скормлены в сеть.
- Gated convolution динамически учит механизм выбора признаков для каждого канала и каждого пространственного расположения.
- Интересно, что визуализация промежуточных значений предсказанных масок показывает, что gated convolution учится выбирать фичи не только по фону, маске, эскизу, но и с учетом семантической сегментации в некоторых каналах.
- Даже в глубоких слоях gated convolution учится выделять именно маскированные области и информацию о входном скетче в отдельных каналах, что позволяет более качественно генерировать восстановленную картинку.
@ai_newz
{kind=link}
❤22👍18🐳3🔥1