
How to Configure XGBoost for Imbalanced Classification
https://machinelearningmastery.com/xgboost-for-imbalanced-classification/
https://machinelearningmastery.com/xgboost-for-imbalanced-classification/
Torch-Struct: Deep Structured Prediction Library
Code: https://github.com/harvardnlp/pytorch-struct
Paper: https://arxiv.org/abs/2002.00876v1
Fast, general, and tested differentiable structured prediction in PyTorch: https://nlp.seas.harvard.edu/pytorch-struct/
Code: https://github.com/harvardnlp/pytorch-struct
Paper: https://arxiv.org/abs/2002.00876v1
Fast, general, and tested differentiable structured prediction in PyTorch: https://nlp.seas.harvard.edu/pytorch-struct/
GitHub
GitHub - harvardnlp/pytorch-struct: Fast, general, and tested differentiable structured prediction in PyTorch
Fast, general, and tested differentiable structured prediction in PyTorch - harvardnlp/pytorch-struct
Using ‘radioactive data’ to detect if a data set was used for training
https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
Paper: https://arxiv.org/abs/2002.00937
https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
Paper: https://arxiv.org/abs/2002.00937
Facebook
Using ‘radioactive data’ to detect if a dataset was used for training
Facebook AI has developed a new technique to mark the images in a dataset, so that researchers can then determine if a particular machine learning model has been trained using those images.
Forwarded from Data Science
Agile Machine Learning.pdf
4.1 MB
Agile Machine Learning: Effective Machine Learning Inspired by the Agile Manifesto (2019)
@datascienceiot
@datascienceiot
🔥Multi-Channel Attention Selection GANs for Guided Image-to-Image Translation
SelectionGAN for guided image-to-image translation, where we translate an input image into another while respecting an external semantic guidance
Code: : https://github.com/Ha0Tang/SelectionGAN
Paper: https://arxiv.org/abs/2002.01048v1
@ai_machinelearning_big_data
SelectionGAN for guided image-to-image translation, where we translate an input image into another while respecting an external semantic guidance
Code: : https://github.com/Ha0Tang/SelectionGAN
Paper: https://arxiv.org/abs/2002.01048v1
@ai_machinelearning_big_data
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
CCMatrix: A billion-scale bitext data set for training translation models
CCMatrix is the largest data set of high-quality, web-based bitexts for training translation models
https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
Paper: https://arxiv.org/abs/1911.04944
Github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
@ai_machinelearning_big_data
CCMatrix is the largest data set of high-quality, web-based bitexts for training translation models
https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
Paper: https://arxiv.org/abs/1911.04944
Github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
@ai_machinelearning_big_data
This media is not supported in your browser
VIEW IN TELEGRAM
Mutual Information-based State-Control for Intrinsically Motivated Reinforcement Learning
Agent Learning Framework: https://github.com/HorizonRobotics/alf
Github: https://github.com/ruizhaogit/misc
Paper: https://arxiv.org/abs/2002.01963v1
Agent Learning Framework: https://github.com/HorizonRobotics/alf
Github: https://github.com/ruizhaogit/misc
Paper: https://arxiv.org/abs/2002.01963v1
The Annotated Transformer
The Transformer – a model that uses attention to boost the speed with which these models can be trained.
https://nlp.seas.harvard.edu/2018/04/03/attention.html
The Illustrated Transformer: https://jalammar.github.io/illustrated-transformer/
Habr: https://habr.com/ru/post/486358/
The Transformer – a model that uses attention to boost the speed with which these models can be trained.
https://nlp.seas.harvard.edu/2018/04/03/attention.html
The Illustrated Transformer: https://jalammar.github.io/illustrated-transformer/
Habr: https://habr.com/ru/post/486358/
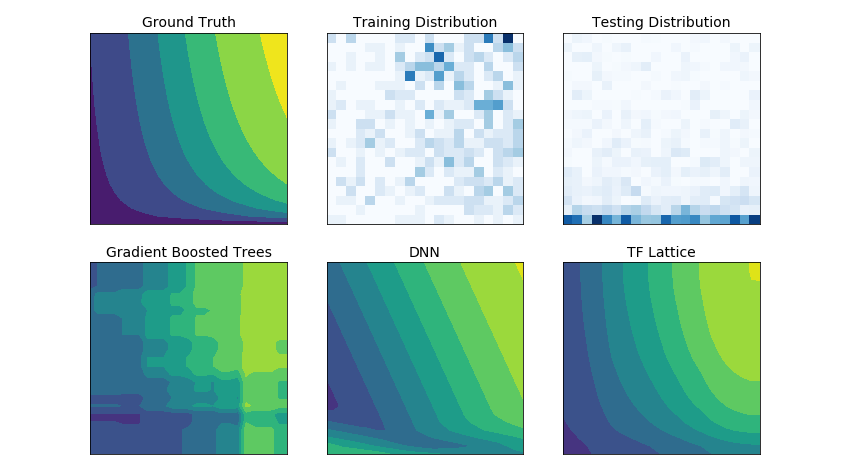
TensorFlow Lattice: Flexible, controlled and interpretable ML
The library enables you to inject domain knowledge into the learning process through common-sense or policy-driven shape constraints.
https://blog.tensorflow.org/2020/02/tensorflow-lattice-flexible-controlled-and-interpretable-ML.html
Video: https://www.youtube.com/watch?v=ABBnNjbjv2Q&feature=emb_logo
Github: https://github.com/tensorflow/lattice
The library enables you to inject domain knowledge into the learning process through common-sense or policy-driven shape constraints.
https://blog.tensorflow.org/2020/02/tensorflow-lattice-flexible-controlled-and-interpretable-ML.html
Video: https://www.youtube.com/watch?v=ABBnNjbjv2Q&feature=emb_logo
Github: https://github.com/tensorflow/lattice
{kind=link}
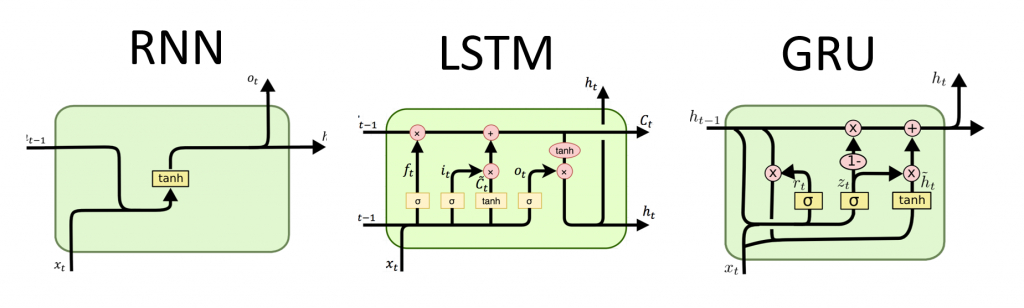
Recurrent Neural Networks (RNN) with Keras
Recurrent neural networks (RNN) are a class of neural networks that is powerful for modeling sequence data such as time series or natural language.
https://www.tensorflow.org/guide/keras/rnn
Source code: https://github.com/tensorflow/docs/blob/master/site/en/guide/keras/rnn.ipynb
Habr : https://habr.com/ru/post/487808/
Recurrent neural networks (RNN) are a class of neural networks that is powerful for modeling sequence data such as time series or natural language.
https://www.tensorflow.org/guide/keras/rnn
Source code: https://github.com/tensorflow/docs/blob/master/site/en/guide/keras/rnn.ipynb
Habr : https://habr.com/ru/post/487808/
{kind=link}
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Official PyTorch implementation of pre-print Unsupervised Discovery of Interpretable Directions in the GAN Latent
Code: https://github.com/anvoynov/GANLatentDiscovery
Paper: https://arxiv.org/abs/2002.03754
Official PyTorch implementation of pre-print Unsupervised Discovery of Interpretable Directions in the GAN Latent
Code: https://github.com/anvoynov/GANLatentDiscovery
Paper: https://arxiv.org/abs/2002.03754
{kind=link}
The popularity of machine learning is so great that people try to use it wherever they can. Some attempts to replace classical approaches with neural networks turn up unsuccessful. This time we'll consider machine learning in terms of creating effective static code analyzers for finding bugs and potential vulnerabilities.
The PVS-Studio team believes that with machine learning, there are many pitfalls lurking in code analysis tasks.
https://bit.ly/2vqmeV7
The PVS-Studio team believes that with machine learning, there are many pitfalls lurking in code analysis tasks.
https://bit.ly/2vqmeV7
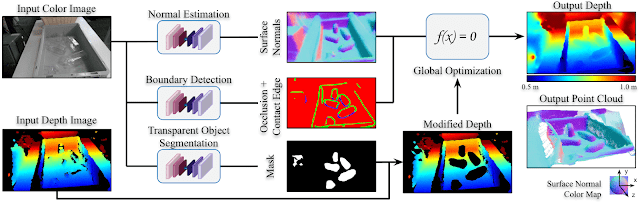
Learning to See Transparent Objects
ClearGrasp uses 3 neural networks: a network to estimate surface normals, one for occlusion boundaries (depth discontinuities), and one that masks transparent objects
Google research: https://ai.googleblog.com/2020/02/learning-to-see-transparent-objects.html
Code: https://github.com/Shreeyak/cleargrasp
Dataset: https://sites.google.com/view/transparent-objects
3D Shape Estimation of Transparent Objects for Manipulation: https://sites.google.com/view/cleargrasp
ClearGrasp uses 3 neural networks: a network to estimate surface normals, one for occlusion boundaries (depth discontinuities), and one that masks transparent objects
Google research: https://ai.googleblog.com/2020/02/learning-to-see-transparent-objects.html
Code: https://github.com/Shreeyak/cleargrasp
Dataset: https://sites.google.com/view/transparent-objects
3D Shape Estimation of Transparent Objects for Manipulation: https://sites.google.com/view/cleargrasp
{kind=link}
fastai—A Layered API for Deep Learning
https://www.fast.ai//2020/02/13/fastai-A-Layered-API-for-Deep-Learning/
Complete documentation and tutorials:
https://docs.fast.ai/
https://www.fast.ai//2020/02/13/fastai-A-Layered-API-for-Deep-Learning/
Complete documentation and tutorials:
https://docs.fast.ai/
Capsules with Inverted Dot-Product Attention Routing
New routing algorithm for capsule networks, in which a child capsule is routed to a parent based only on agreement between the parent’s state and the child’s vote.
Code: https://github.com/apple/ml-capsules-inverted-attention-routing
Paper: https://openreview.net/pdf?id=HJe6uANtwH
New routing algorithm for capsule networks, in which a child capsule is routed to a parent based only on agreement between the parent’s state and the child’s vote.
Code: https://github.com/apple/ml-capsules-inverted-attention-routing
Paper: https://openreview.net/pdf?id=HJe6uANtwH
GitHub
GitHub - apple/ml-capsules-inverted-attention-routing
Contribute to apple/ml-capsules-inverted-attention-routing development by creating an account on GitHub.
Matrix Compression Operator
https://blog.tensorflow.org/2020/02/matrix-compression-operator-tensorflow.html
Experimental API that facilitates matrix compression of a neural network's weight tensors: https://github.com/google-research/google-research/tree/master/graph_compression
Full documentation: https://drive.google.com/file/d/1843aNpKx_rznpuh9AmEshgAKmISVdpJY/view
https://blog.tensorflow.org/2020/02/matrix-compression-operator-tensorflow.html
Experimental API that facilitates matrix compression of a neural network's weight tensors: https://github.com/google-research/google-research/tree/master/graph_compression
Full documentation: https://drive.google.com/file/d/1843aNpKx_rznpuh9AmEshgAKmISVdpJY/view
GANILLA: Generative Adversarial Networks for Image to Illustration Translation.
Github: https://github.com/giddyyupp/ganilla
Dataset: https://github.com/giddyyupp/ganilla/blob/master/docs/datasets.md
Paper: https://arxiv.org/abs/2002.05638v1
Github: https://github.com/giddyyupp/ganilla
Dataset: https://github.com/giddyyupp/ganilla/blob/master/docs/datasets.md
Paper: https://arxiv.org/abs/2002.05638v1
{kind=link}
Learning to Rank with XGBoost and GPU | NVIDIA Developer Blog
https://devblogs.nvidia.com/learning-to-rank-with-xgboost-and-gpu/
https://devblogs.nvidia.com/learning-to-rank-with-xgboost-and-gpu/
NVIDIA Technical Blog
Learning to Rank with XGBoost and GPU
XGBoost is a widely used machine learning library, which uses gradient boosting techniques to incrementally build a better model during the training phase by combining multiple weak models.
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
https://jalammar.github.io/illustrated-bert/
Habr ru: https://habr.com/ru/post/487358/
BERT FineTuning with Cloud TPUs notebook: https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb
https://jalammar.github.io/illustrated-bert/
Habr ru: https://habr.com/ru/post/487358/
BERT FineTuning with Cloud TPUs notebook: https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb
{kind=link}