
Forwarded from Deleted Account
Natural_Language_Processing_and_Text_Mining.pdf
3.7 MB
#A Must-Read #NLP Tutorial on Neural Machine Translation — The Technique Powering #Google_Translate
@Machine_learn
https://www.analyticsvidhya.com/blog/2019/01/neural-machine-translation-keras/
@Machine_learn
https://www.analyticsvidhya.com/blog/2019/01/neural-machine-translation-keras/
Analytics Vidhya
A Must-Read NLP Tutorial on Neural Machine Translation - The Technique Powering Google Translate
Machine translation is one of the biggest applications of NLP. Learn about neural machine translation and its implementation in Python using keras.
#NLP 2018 Highlights
By Elvis Saravia.
Summary of all the biggest NLP stories, state-of-the-art results and new interesting research directions of the year coming from both academia and the industry
@Machine_learn
By Elvis Saravia.
Summary of all the biggest NLP stories, state-of-the-art results and new interesting research directions of the year coming from both academia and the industry
@Machine_learn
2_5291795760491266648.pdf
3 MB
#NLP 2018 Highlights
By Elvis Saravia.
Summary of all the biggest NLP stories, state-of-the-art results and new interesting research directions of the year coming from both academia and the industry
@Machine_learn
By Elvis Saravia.
Summary of all the biggest NLP stories, state-of-the-art results and new interesting research directions of the year coming from both academia and the industry
@Machine_learn
@Machine_learn
#NLP #DL #course
New fast.ai course: A Code-First Introduction to Natural Language Processing
https://www.fast.ai/2019/07/08/fastai-nlp/
Github: https://github.com/fastai/course-nlp
Videos: https://www.youtube.com/playlist?list=PLtmWHNX-gukKocXQOkQjuVxglSDYWsSh9
#NLP #DL #course
New fast.ai course: A Code-First Introduction to Natural Language Processing
https://www.fast.ai/2019/07/08/fastai-nlp/
Github: https://github.com/fastai/course-nlp
Videos: https://www.youtube.com/playlist?list=PLtmWHNX-gukKocXQOkQjuVxglSDYWsSh9
🔥OpenAI realesed the 1.5billion parameter GPT-2 model
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Openai
GPT-2: 1.5B release
As the final model release of GPT-2’s staged release, we’re releasing the largest version (1.5B parameters) of GPT-2 along with code and model weights to facilitate detection of outputs of GPT-2 models. While there have been larger language models released…
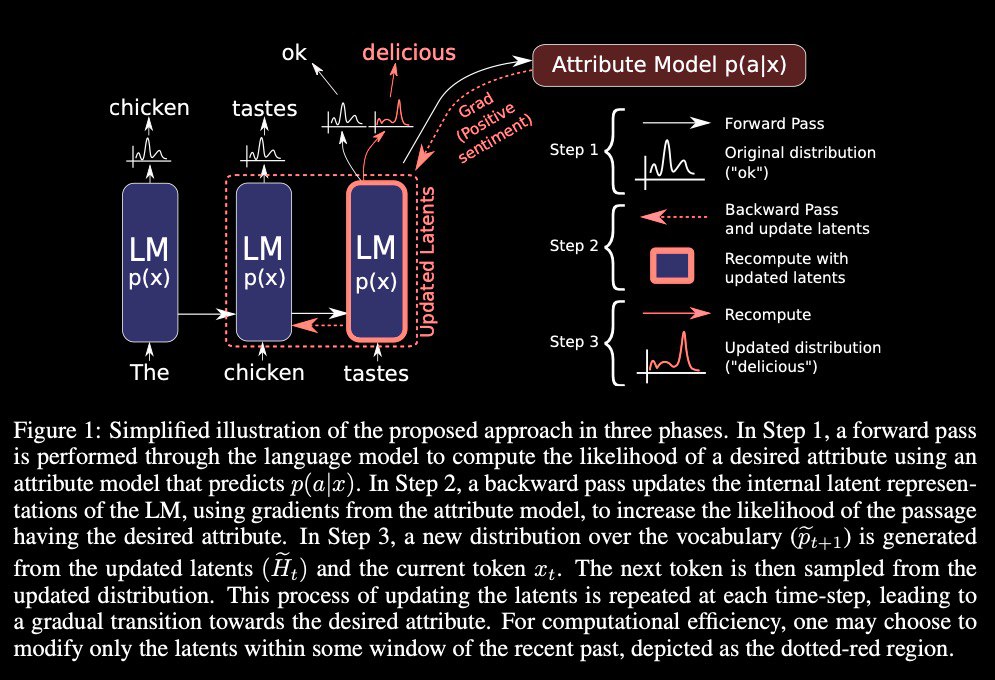
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
@Machine_learn
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
@Machine_learn
#nlp #lm #languagemodeling #uber #pplm
{kind=link}
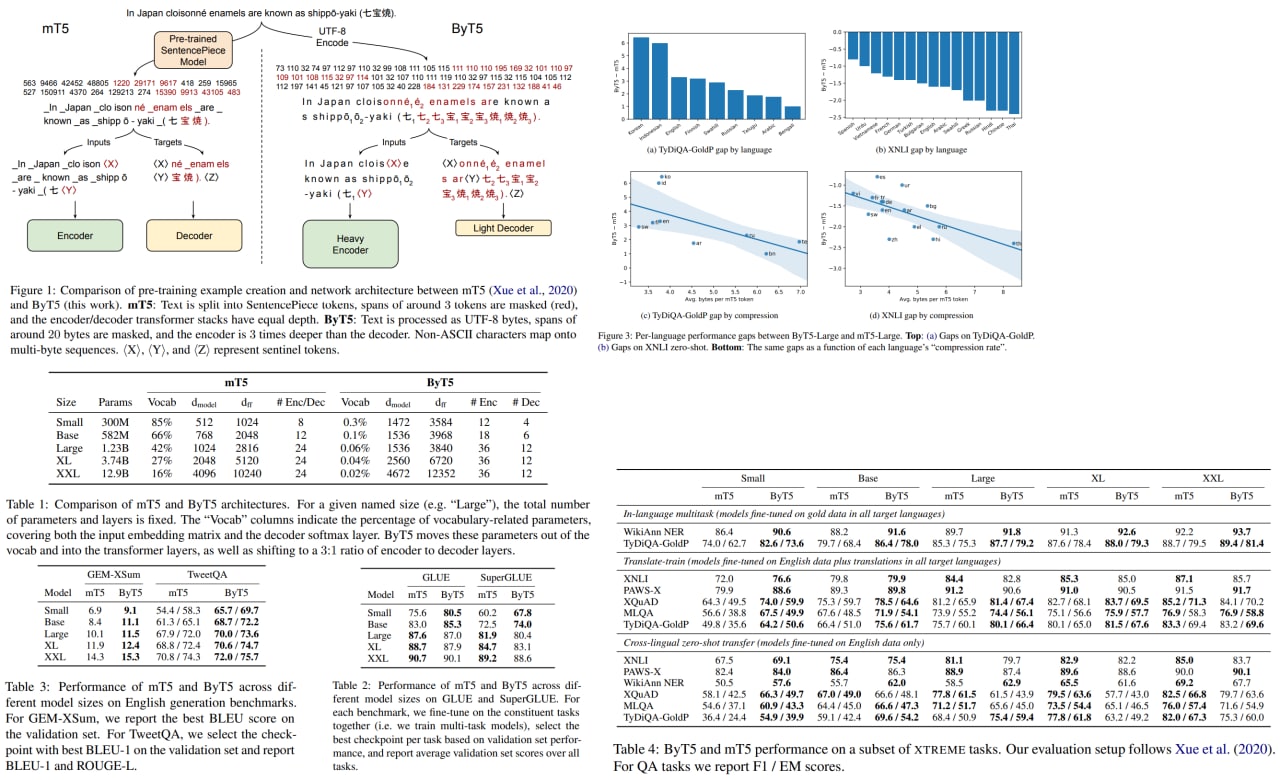
ByT5: Towards a token-free future with pre-trained byte-to-byte models
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
@Machine_learn
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
@Machine_learn
{kind=link}
Tapsai2021_Book_ThaiNaturalLanguageProcessing.pdf
15 MB
Thai Natural Language
Processing
Word Segmentation, Semantic Analysis,
and Application #NLP #Book #2021
@Machine_learn
Processing
Word Segmentation, Semantic Analysis,
and Application #NLP #Book #2021
@Machine_learn
2021_Book_FormalisingNaturalLanguagesApp.pdf
33.3 MB
Formalising Natural
Languages: Applications
to Natural Language
Processing and Digital
Humanities #NLP #Book #2021
@Machine_learn
Languages: Applications
to Natural Language
Processing and Digital
Humanities #NLP #Book #2021
@Machine_learn
Sabharwal-Agrawal2021_Book_Hands-onQuestionAnsweringSyste.pdf
4.8 MB
Hands-on Question
Answering Systems
with BERT
Applications in Neural
Networks and Natural
Language Processing #NLP #BERT #book #2021
@Machine_learn
Answering Systems
with BERT
Applications in Neural
Networks and Natural
Language Processing #NLP #BERT #book #2021
@Machine_learn
👍1
Deep-Learning-for-Natural-Language-Processing.pdf
7.3 MB
Book: Deep Learning for Natural Language Processing (Creating Neural Networks with Python)
Authors: Palash Goyal, Sumit Pandey, Karan Jain
ISBN: 978-1-4842-3685-7
year: 2018
pages: 290
Tags: #NLP #DL #Python #Code
@Machine_learn
Authors: Palash Goyal, Sumit Pandey, Karan Jain
ISBN: 978-1-4842-3685-7
year: 2018
pages: 290
Tags: #NLP #DL #Python #Code
@Machine_learn
👍6🔥2