Forwarded from Малоизвестное интересное
Машинное обучение - это современная алхимия.
Т.е. полезный инженерный навык решения широкого спектра задач, но (1) не способный дать научное объяснение таким фундаментальным понятиям, как интеллект и сознание, и (2) что гораздо хуже, уводящий научные исследования этих понятий в ложном направлении.
Приятно констатировать, что это уже не только моя точка зрения, многократно изложенная в постах. Али Рахими из Google и Бен Рехт из Калифорнийского университета (оба – весьма известные спецы в области машинного обучения) приводят конкретную и вполне убедительную аргументацию в пользу вышесказанного https://goo.gl/iMc5cg
Выступление Рахими на конференции NIPS 2017 в декабре прошлого года на эту тему сорвало долгие овации зала (видео 27 мин https://goo.gl/9L1Kpr, текст https://goo.gl/gdT94C)
А сказал он следующее.
1) Бурный прогресс технологий машинного обучения, казалось бы, не оставляет шансов для сомнений в правильности избранного технологического направления. Миллиарды вкладываемых в это направление долларов заставляют верить, что «машинное обучение – это новое электричество» https://goo.gl/7VaGN4.
2) Но на самом деле, это совсем не так. Альтернативная метафора - машинное обучение стало алхимией. Ведь, на самом деле, алхимия вовсе не была лженаукой.
Алхимия работала и принесла массу пользы — алхимики изобрели металлургию, способы приготовления лекарств, методы обработки текстиля и наши современные стекольные процессы. Т.е. все то, без чего бы не произошла промышленная революция.
Но с другой стороны, алхимики также полагали, что они смогут превращать металлы в золото и что пиявки - прекрасный способ лечения болезней.
И чтобы достичь истинного понимании окружающего мира и всей вселенной, которое принесли человечеству физика и химия 1700-х годов, от большинства теорий, разработанных алхимиками, пришлось отказаться.
3) Тоже самое происходит с машинным обучением. Оно здорово работает. Оно реально полезно. И если вы создаете онлайн сервис обмена фотографиями, машинное обучение прекрасно для этого подходит.
4) Но машинное обучение никогда не позволит нам «превращать металлы в золото», поскольку также, как и алхимия, не строится на строгих, надежных, проверенных знаниях.
5) Мы зашли в этом алхимическом направлении уже слишком далеко. Сейчас перед нами:
— уже не просто «Проблема воспроизводимости ИИ» (невозможность тиражировать результаты друг друга из-за несогласованных экспериментальных и публикаторских практик) https://goo.gl/6DNYHP;
— и даже не просто «Проблема черного ящика» и интерпретируемости результатов работы алгоритмов (interpretability) https://goo.gl/PS7Z9t;
Теперь мы имеем не просто «черный ящик» машинного обучения. В «черный ящик» превратилась вся область исследований технологий ИИ.
Цель науки - генерировать знания, а не создавать все новые массовые гаджеты. Сейчас же мы имеем лишь последнее. А знаний практически не прибавляется.
Пора, если не менять направление, то, по крайней мере, срочно начать развивать и альтернативные.
Для профессионалов, желающих познакомиться с подробностями аргументации – вот подборка документов «Проклятие победителя? О скорости, прогрессе и эмпирической строгости» https://goo.gl/fHfsVF
#МашинноеОбучение #ИИ
Т.е. полезный инженерный навык решения широкого спектра задач, но (1) не способный дать научное объяснение таким фундаментальным понятиям, как интеллект и сознание, и (2) что гораздо хуже, уводящий научные исследования этих понятий в ложном направлении.
Приятно констатировать, что это уже не только моя точка зрения, многократно изложенная в постах. Али Рахими из Google и Бен Рехт из Калифорнийского университета (оба – весьма известные спецы в области машинного обучения) приводят конкретную и вполне убедительную аргументацию в пользу вышесказанного https://goo.gl/iMc5cg
Выступление Рахими на конференции NIPS 2017 в декабре прошлого года на эту тему сорвало долгие овации зала (видео 27 мин https://goo.gl/9L1Kpr, текст https://goo.gl/gdT94C)
А сказал он следующее.
1) Бурный прогресс технологий машинного обучения, казалось бы, не оставляет шансов для сомнений в правильности избранного технологического направления. Миллиарды вкладываемых в это направление долларов заставляют верить, что «машинное обучение – это новое электричество» https://goo.gl/7VaGN4.
2) Но на самом деле, это совсем не так. Альтернативная метафора - машинное обучение стало алхимией. Ведь, на самом деле, алхимия вовсе не была лженаукой.
Алхимия работала и принесла массу пользы — алхимики изобрели металлургию, способы приготовления лекарств, методы обработки текстиля и наши современные стекольные процессы. Т.е. все то, без чего бы не произошла промышленная революция.
Но с другой стороны, алхимики также полагали, что они смогут превращать металлы в золото и что пиявки - прекрасный способ лечения болезней.
И чтобы достичь истинного понимании окружающего мира и всей вселенной, которое принесли человечеству физика и химия 1700-х годов, от большинства теорий, разработанных алхимиками, пришлось отказаться.
3) Тоже самое происходит с машинным обучением. Оно здорово работает. Оно реально полезно. И если вы создаете онлайн сервис обмена фотографиями, машинное обучение прекрасно для этого подходит.
4) Но машинное обучение никогда не позволит нам «превращать металлы в золото», поскольку также, как и алхимия, не строится на строгих, надежных, проверенных знаниях.
5) Мы зашли в этом алхимическом направлении уже слишком далеко. Сейчас перед нами:
— уже не просто «Проблема воспроизводимости ИИ» (невозможность тиражировать результаты друг друга из-за несогласованных экспериментальных и публикаторских практик) https://goo.gl/6DNYHP;
— и даже не просто «Проблема черного ящика» и интерпретируемости результатов работы алгоритмов (interpretability) https://goo.gl/PS7Z9t;
Теперь мы имеем не просто «черный ящик» машинного обучения. В «черный ящик» превратилась вся область исследований технологий ИИ.
Цель науки - генерировать знания, а не создавать все новые массовые гаджеты. Сейчас же мы имеем лишь последнее. А знаний практически не прибавляется.
Пора, если не менять направление, то, по крайней мере, срочно начать развивать и альтернативные.
Для профессионалов, желающих познакомиться с подробностями аргументации – вот подборка документов «Проклятие победителя? О скорости, прогрессе и эмпирической строгости» https://goo.gl/fHfsVF
#МашинноеОбучение #ИИ
Science
AI researchers allege that machine learning is alchemy
Study cites ways to bolster scientific foundations of artificial intelligence
Forwarded from Малоизвестное интересное
Восьмикратный прорыв в борьбе с хаосом за точность предсказаний
Предсказание (прогноз) – это предположение о том, что произойдет в будущем.
Предсказать месторасположение бильярдного шара через полсекунды после вашего удара по нему – не самая сложная задача, если на столе всего 1 шар. Если же шаров 16 – это уже сложнее. Еще сложнее предсказать на 2 сек.
Т.о. самим фактом точного предсказания не удивишь. Наш мозг занимается этим постоянно и весьма в этом преуспел.
Вызов в том, чтобы научиться предсказывать с удовлетворительной точностью:
✔️ поведение сложных систем;
✔️ на значительном горизонте прогнозирования.
Иллюстрацией немыслимой и, казалось бы, непреодолимой сложности данного вызова является «эффект бабочки».
Еще первооткрыватели теории хаоса установили, что «эффект бабочки» сводит к нулю возможности долгосрочного предсказания поведения сложных систем. Малейшее возмущение такой системы (погоды, экономики и пр.) способно породить цепную реакцию последствий, в результате чего будущее окажется совсем иным. Этот туман неопределённости в поведении сложных систем – вот уже десятки лет является главной проблемой на пути к надёжным предсказаниям.
Ситуация усугубляется тем, что:
— в хаотическое состояние, предсказать поведение системы невозможно;
— хаотические системы встречаются в природе повсюду (от погоды и лесных пожаров до сердечных аритмий и лавин нейронных спайков (импульсов) при возбуждении нейронов головного мозга);
— но, как ни странно, до сих пор неясно, что такое хаос (у понятия хаоса нет общепринятого математического определения и нет перечня необходимых и достаточных условий возникновения хаотического состояния).
Есть математическое понятие - время Ляпунова. Это время, за которое система переходит к полному хаосу. По сути, это и есть горизонт прогнозирования, дальше которого продвинуться в предсказании невозможно.
У разных систем разное время Ляпунова: от миллисекунд до миллионов лет (для погоды, как мы все знаем, - несколько дней). Чем короче это время, тем более чувствительна или более склонна к эффекту бабочки система, тем стремительней её исходные состояния расходятся в периоды кризиса.
Все вышесказанное – необходимая для понимания преамбула. Теперь перехожу к главному - восьмикратному прорыву в предсказании будущего.
Восьмикратный прорыв в борьбе с хаосом за точность предсказаний достигнут за счет новаторского подхода в применении машинного обучения.
Еще в конце 90-х был придуман особый тип нейронных сетей, объединяемых под общим названием резервуарные вычисления Reservoir Computing (что это такое, можете за 1 мин. прочесть под катом ниже).
Главное же отличие от классических всем нам известных нейронок в том, что этот тип нейронных сетей на много порядков упрощает и ускоряет машинное обучение.
✔️ С помощью Reservoir Computing получается спрогнозировать поведение системы при восьмикратно увеличенном горизонте прогнозирования (для восьми времен Ляпунова).
Выражаясь нестрого, удается заглянуть в восемь раз дальше по сравнению с тем, что позволяют другие методы прогнозирования.
Для достижения подобного результата на классических нейронных сетях, потребовалось бы измерять исходное состояние типичной системы в 100 000 000 раз точнее, чем при резервуарном вычислении. Что не очень реально.
Авторы данной работы экспериментировали с архетипической пространственно-временной хаотической системой, описываемой «уравнением Курамото — Сивашинского». Она подобна фронту пламени, мерцающему при прохождении через горючую среду (см. Gif в статье под катом ниже). Это же уравнение описывает дрейфовые волны в плазме и много-много других физических явлений и посему служит «испытательным стендом для изучения турбулентности и пространственно-временного хаоса».
Представляете точный прогноз погоды, но уже не на пару дней, а на пару недель?
Подробней на русском https://goo.gl/CRaswe (там же ссылка на оригинал и все нужные ссылки на научные работы).
Что такое Резервуарные вычисления https://goo.gl/kfVttB
#Предсказания #Хаос #РезервуарныеВычисления #МашинноеОбучение
Предсказание (прогноз) – это предположение о том, что произойдет в будущем.
Предсказать месторасположение бильярдного шара через полсекунды после вашего удара по нему – не самая сложная задача, если на столе всего 1 шар. Если же шаров 16 – это уже сложнее. Еще сложнее предсказать на 2 сек.
Т.о. самим фактом точного предсказания не удивишь. Наш мозг занимается этим постоянно и весьма в этом преуспел.
Вызов в том, чтобы научиться предсказывать с удовлетворительной точностью:
✔️ поведение сложных систем;
✔️ на значительном горизонте прогнозирования.
Иллюстрацией немыслимой и, казалось бы, непреодолимой сложности данного вызова является «эффект бабочки».
Еще первооткрыватели теории хаоса установили, что «эффект бабочки» сводит к нулю возможности долгосрочного предсказания поведения сложных систем. Малейшее возмущение такой системы (погоды, экономики и пр.) способно породить цепную реакцию последствий, в результате чего будущее окажется совсем иным. Этот туман неопределённости в поведении сложных систем – вот уже десятки лет является главной проблемой на пути к надёжным предсказаниям.
Ситуация усугубляется тем, что:
— в хаотическое состояние, предсказать поведение системы невозможно;
— хаотические системы встречаются в природе повсюду (от погоды и лесных пожаров до сердечных аритмий и лавин нейронных спайков (импульсов) при возбуждении нейронов головного мозга);
— но, как ни странно, до сих пор неясно, что такое хаос (у понятия хаоса нет общепринятого математического определения и нет перечня необходимых и достаточных условий возникновения хаотического состояния).
Есть математическое понятие - время Ляпунова. Это время, за которое система переходит к полному хаосу. По сути, это и есть горизонт прогнозирования, дальше которого продвинуться в предсказании невозможно.
У разных систем разное время Ляпунова: от миллисекунд до миллионов лет (для погоды, как мы все знаем, - несколько дней). Чем короче это время, тем более чувствительна или более склонна к эффекту бабочки система, тем стремительней её исходные состояния расходятся в периоды кризиса.
Все вышесказанное – необходимая для понимания преамбула. Теперь перехожу к главному - восьмикратному прорыву в предсказании будущего.
Восьмикратный прорыв в борьбе с хаосом за точность предсказаний достигнут за счет новаторского подхода в применении машинного обучения.
Еще в конце 90-х был придуман особый тип нейронных сетей, объединяемых под общим названием резервуарные вычисления Reservoir Computing (что это такое, можете за 1 мин. прочесть под катом ниже).
Главное же отличие от классических всем нам известных нейронок в том, что этот тип нейронных сетей на много порядков упрощает и ускоряет машинное обучение.
✔️ С помощью Reservoir Computing получается спрогнозировать поведение системы при восьмикратно увеличенном горизонте прогнозирования (для восьми времен Ляпунова).
Выражаясь нестрого, удается заглянуть в восемь раз дальше по сравнению с тем, что позволяют другие методы прогнозирования.
Для достижения подобного результата на классических нейронных сетях, потребовалось бы измерять исходное состояние типичной системы в 100 000 000 раз точнее, чем при резервуарном вычислении. Что не очень реально.
Авторы данной работы экспериментировали с архетипической пространственно-временной хаотической системой, описываемой «уравнением Курамото — Сивашинского». Она подобна фронту пламени, мерцающему при прохождении через горючую среду (см. Gif в статье под катом ниже). Это же уравнение описывает дрейфовые волны в плазме и много-много других физических явлений и посему служит «испытательным стендом для изучения турбулентности и пространственно-временного хаоса».
Представляете точный прогноз погоды, но уже не на пару дней, а на пару недель?
Подробней на русском https://goo.gl/CRaswe (там же ссылка на оригинал и все нужные ссылки на научные работы).
Что такое Резервуарные вычисления https://goo.gl/kfVttB
#Предсказания #Хаос #РезервуарныеВычисления #МашинноеОбучение
XX2 век
«Удивительная» способность машинного обучения предсказывать хаос
Полвека назад пионеры теории хаоса обнаружили, что «эффект бабочки» делает невозможным долгосрочное предсказание. Малейшее возмущение сложной системы (например, погоды, экономики или чего-то подобного) способно спровоцировать цепную реакцию, в результате…
Forwarded from Малоизвестное интересное
Внушенные галлюцинации ИИ
Можно без натяжки сказать, что, по сравнению с человеком, ИИ обладает куда более развитыми истерическими свойствами.
Так здоровый, но внушаемый (с истерическими чертами характера) человек может вслед за больным "увидеть" черта, ангелов, летающие тарелки и, вообще, что угодно. Однако, подобные люди – редкость (их порядка процента).
В отличие же от людей, каждый ИИ – законченный истерик. Заставить его видеть вместо стула – черта, вместо шишек – ангелов, а вместо милиционера – летающую тарелку, - совсем не бином Ньютона.
Называется этот трюк - использование «враждебных данных» (adversarial inputs), заставляющих ИИ видеть какие-то обманные образы (а по сути, - вызывать у ИИ внушенные галлюцинации).
Вот перед вами 3 картинки
✔️ Левая –фото ленивца, распознаваемого ИИ с вероятностью > 99%.
✔️ Средняя – фото гоночного авто. Это галлюцинация, которую нужно внушить ИИ, показавая ему слегка модифицированное с помощью «враждебных данных» фото ленивца.
✔️ Правая – это результат: модифицированное с помощью «враждебных данных» фото ленивца, в котором ИИ с вероятностью > 99% распознает гоночное авто.
❗️ Объем «враждебных данных», потребовавшихся для внушения ИИ галлюцинации гоночного автомобиля, видимого им вместо ленивца, пренебрежительно мал – всего 0,0078 отличий в пикселях правого и левого фото (человеческий глаз этого просто не видит – хотя вы можете попробовать).
Представить потенциал ущерба от использования «враждебных данных» злоумышленниками можете сами. Лишь замечу, - теоретически, он сопоставим с ядерным оружием.
И если вы думаете, что внушением галлюцинаций для ИИ никто на практике не занимается, вы жутко ошибаетесь. Всего один, но замечательный пример.
В Китайских соцсетях и мессенджерах фильтруется весь контент, затирая в ноль всё запрещенное партией и правительством (в этот список входит несколько тысяч тем!).
— Сначала фильтровали только текст.
— Но пользователи приспособились и для обмана фильтров стали запрещенные слова прятать в картинки.
— Тогда государство посадило 10 тыс. цензоров для фильтрации картинок. Но они не справились – дюже много работы.
— И вот тогда мобилизовали ИИ на фильтрацию картинок.
Вот как это выглядит. Китайский пользователь WeChat послал картинку – обложку отчета про кампанию репрессий, получившую название "облава 709" (709 Crackdown). ИИ-цензор эту картинку удалил.
И тут внимание.
Ушлые ребята из THECITIZENLAB придумали использовать ИИ для подбора «враждебных данных», способных внушить галлюцинации «ИИ-цензорам», ведущим фильтрацию. В исходных картинках меняется совсем чуть-чуть (как в примере с ленивцем). Поэтому людям эти изменения нипочем – они их просто не замечают. Тогда как «истерический характер ИИ» заставляет его видеть вместо картинок из черного списка что-то совсем иное. И крантец фильтрации – свобода китайским пользователям!
Вот пример. Изображения С и D фильтруются ИИ-цензором, в изображения A и B – нет 😳
Так ИИ-броня ИИ-цензуры оказалась легко пробиваема ИИ-снарядами «враждебных данных».
Но это не конец. ИИ-броня совершенствуется (равно как и ИИ-снаряды).
Детали этой борьбы можете прочесть в отчете
А это подробно про то, как работают «враждебные данные»
#МашинноеОбучение #AdversarialInputs
Можно без натяжки сказать, что, по сравнению с человеком, ИИ обладает куда более развитыми истерическими свойствами.
Так здоровый, но внушаемый (с истерическими чертами характера) человек может вслед за больным "увидеть" черта, ангелов, летающие тарелки и, вообще, что угодно. Однако, подобные люди – редкость (их порядка процента).
В отличие же от людей, каждый ИИ – законченный истерик. Заставить его видеть вместо стула – черта, вместо шишек – ангелов, а вместо милиционера – летающую тарелку, - совсем не бином Ньютона.
Называется этот трюк - использование «враждебных данных» (adversarial inputs), заставляющих ИИ видеть какие-то обманные образы (а по сути, - вызывать у ИИ внушенные галлюцинации).
Вот перед вами 3 картинки
✔️ Левая –фото ленивца, распознаваемого ИИ с вероятностью > 99%.
✔️ Средняя – фото гоночного авто. Это галлюцинация, которую нужно внушить ИИ, показавая ему слегка модифицированное с помощью «враждебных данных» фото ленивца.
✔️ Правая – это результат: модифицированное с помощью «враждебных данных» фото ленивца, в котором ИИ с вероятностью > 99% распознает гоночное авто.
❗️ Объем «враждебных данных», потребовавшихся для внушения ИИ галлюцинации гоночного автомобиля, видимого им вместо ленивца, пренебрежительно мал – всего 0,0078 отличий в пикселях правого и левого фото (человеческий глаз этого просто не видит – хотя вы можете попробовать).
Представить потенциал ущерба от использования «враждебных данных» злоумышленниками можете сами. Лишь замечу, - теоретически, он сопоставим с ядерным оружием.
И если вы думаете, что внушением галлюцинаций для ИИ никто на практике не занимается, вы жутко ошибаетесь. Всего один, но замечательный пример.
В Китайских соцсетях и мессенджерах фильтруется весь контент, затирая в ноль всё запрещенное партией и правительством (в этот список входит несколько тысяч тем!).
— Сначала фильтровали только текст.
— Но пользователи приспособились и для обмана фильтров стали запрещенные слова прятать в картинки.
— Тогда государство посадило 10 тыс. цензоров для фильтрации картинок. Но они не справились – дюже много работы.
— И вот тогда мобилизовали ИИ на фильтрацию картинок.
Вот как это выглядит. Китайский пользователь WeChat послал картинку – обложку отчета про кампанию репрессий, получившую название "облава 709" (709 Crackdown). ИИ-цензор эту картинку удалил.
И тут внимание.
Ушлые ребята из THECITIZENLAB придумали использовать ИИ для подбора «враждебных данных», способных внушить галлюцинации «ИИ-цензорам», ведущим фильтрацию. В исходных картинках меняется совсем чуть-чуть (как в примере с ленивцем). Поэтому людям эти изменения нипочем – они их просто не замечают. Тогда как «истерический характер ИИ» заставляет его видеть вместо картинок из черного списка что-то совсем иное. И крантец фильтрации – свобода китайским пользователям!
Вот пример. Изображения С и D фильтруются ИИ-цензором, в изображения A и B – нет 😳
Так ИИ-броня ИИ-цензуры оказалась легко пробиваема ИИ-снарядами «враждебных данных».
Но это не конец. ИИ-броня совершенствуется (равно как и ИИ-снаряды).
Детали этой борьбы можете прочесть в отчете
А это подробно про то, как работают «враждебные данные»
#МашинноеОбучение #AdversarialInputs
{kind=link}
Forwarded from Малоизвестное интересное
Расшифровка «Стонов Каскадии» может спасти десятки тысяч жизней. Предотвратить надвигающееся самое страшное землетрясение в истории США наука не может. Но сделан прорыв в его предсказании.
Исследователи лаборатории Лос-Аламос использовали машинное обучение для прогнозирования землетрясений в районе разлома Каскадия (длинной в 700 миль от северной Калифорнии до южной части Британской Колумбии – примерно до Сиэтла).
В этой истории поражают 2 вещи.
1) Безграничные пределы человеческой близорукости.
Обнаруженная связь между громкостью акустического сигнала разлома - т.н. «Стоны Каскадии» - и его физическими изменениями, никому раньше просто не приходила в голову. «Стоны Каскадии» считались бессмысленным шумом, из которого ничего не следует.
Но стоило преодолеть эту близорукость и запустить машинное обучение на поиск шаблонов, как тут же нашли звуковой шаблон, указывающий на повышение активности в движении тектонических плит.
Как тут не вспомнить «Глас Господа» Станислава Лема.
2) Безграничный оптимизм людей, знающих о надвигающейся катастрофе, но продолжающих любить, рожать детей, строить дома ...
Гигантская плита под Тихим океаном неуклонно скользит под Северную Америку со скоростью тридцать-сорок миллиметров в год. В результате в разломе Каскадия нарастает давление, и все обречено закончиться сильным землетрясением.
Два варианта:
- оно будет либо сильным (8-8,6 баллов),
- либо очень сильным (8,7-9,2 балла).
Вероятность 1го в ближайшие пятьдесят лет примерно 33%.
Вероятность 2го - примерно 10%.
Но в любом случае, это будет величайшая природная катастрофа в истории Северной Америки.
Континентальный шельф Каскадии, опустится на 2 метра и отскочит от 10 до 30 метров в западную сторону. В минуту произойдет выброс энергии, накопленной в результате столетнего сжатия. Вода поднимется вверх как гора, а затем быстро обрушится. Одна сторона гигантской волны пойдет на запад, в сторону Японии. Другая сторона - на восток. Тысяча километровая стена воды, сметая все на пути, достигнет Северо-Западного побережья где-то через пятнадцать минут после начала землетрясения.
Погибнут десятки тысяч человек. Миллионы останутся без крова. Вся инфраструктура будет разрушена…
Но никто не уезжает. Люди продолжают жить, как ни в чем не бывало. Авось на наш век хватит.
Но ведь шансы в 30%, что это может случится в ближайшие 50 лет, вовсе не отодвигают катастрофу на 50 лет. Это означает, что с такой вероятностью катастрофа может случиться, например, завтра или через месяц, или через год.
Подробней о расшифровке «Стонов Каскадии» (там же две ссылки на научные статьи) https://phys.org/news/2018-12-machine-learning-detected-earthquake.html
Подробней о грядущей катастрофе в зоне Каскадия https://www.newyorker.com/magazine/2015/07/20/the-really-big-one
#МашинноеОбучение
Исследователи лаборатории Лос-Аламос использовали машинное обучение для прогнозирования землетрясений в районе разлома Каскадия (длинной в 700 миль от северной Калифорнии до южной части Британской Колумбии – примерно до Сиэтла).
В этой истории поражают 2 вещи.
1) Безграничные пределы человеческой близорукости.
Обнаруженная связь между громкостью акустического сигнала разлома - т.н. «Стоны Каскадии» - и его физическими изменениями, никому раньше просто не приходила в голову. «Стоны Каскадии» считались бессмысленным шумом, из которого ничего не следует.
Но стоило преодолеть эту близорукость и запустить машинное обучение на поиск шаблонов, как тут же нашли звуковой шаблон, указывающий на повышение активности в движении тектонических плит.
Как тут не вспомнить «Глас Господа» Станислава Лема.
2) Безграничный оптимизм людей, знающих о надвигающейся катастрофе, но продолжающих любить, рожать детей, строить дома ...
Гигантская плита под Тихим океаном неуклонно скользит под Северную Америку со скоростью тридцать-сорок миллиметров в год. В результате в разломе Каскадия нарастает давление, и все обречено закончиться сильным землетрясением.
Два варианта:
- оно будет либо сильным (8-8,6 баллов),
- либо очень сильным (8,7-9,2 балла).
Вероятность 1го в ближайшие пятьдесят лет примерно 33%.
Вероятность 2го - примерно 10%.
Но в любом случае, это будет величайшая природная катастрофа в истории Северной Америки.
Континентальный шельф Каскадии, опустится на 2 метра и отскочит от 10 до 30 метров в западную сторону. В минуту произойдет выброс энергии, накопленной в результате столетнего сжатия. Вода поднимется вверх как гора, а затем быстро обрушится. Одна сторона гигантской волны пойдет на запад, в сторону Японии. Другая сторона - на восток. Тысяча километровая стена воды, сметая все на пути, достигнет Северо-Западного побережья где-то через пятнадцать минут после начала землетрясения.
Погибнут десятки тысяч человек. Миллионы останутся без крова. Вся инфраструктура будет разрушена…
Но никто не уезжает. Люди продолжают жить, как ни в чем не бывало. Авось на наш век хватит.
Но ведь шансы в 30%, что это может случится в ближайшие 50 лет, вовсе не отодвигают катастрофу на 50 лет. Это означает, что с такой вероятностью катастрофа может случиться, например, завтра или через месяц, или через год.
Подробней о расшифровке «Стонов Каскадии» (там же две ссылки на научные статьи) https://phys.org/news/2018-12-machine-learning-detected-earthquake.html
Подробней о грядущей катастрофе в зоне Каскадия https://www.newyorker.com/magazine/2015/07/20/the-really-big-one
#МашинноеОбучение
phys.org
Machine learning-detected signal predicts time to earthquake
Machine-learning research published in two related papers today in Nature Geoscience reports the detection of seismic signals accurately predicting the Cascadia fault's slow slippage, a type of failure ...
Forwarded from The Idealist
Nautilus: Почему человеческий мозг настолько эффективен?
Мы привыкли считать современные компьютерные системы выдающимися устройствами, во много раз превосходящими по эффективности человеческий мозг. И действительно, если речь идёт о математических вычислениях и обработке последовательной информации, то "железу" нет равных. Однако "венцу природы" тоже есть что противопоставить современному прогрессу: ни один современный компьютер, оказывается, не может параллельно обрабатывать столько информации, сколько мозг человека. Во всяком случае пока не может.
"Профессиональный теннисист может проследить траекторию теннисного мяча после его подачи со скоростью до 257 км. в час, перейти к оптимальному месту на корте, расположить свою руку и повернуть ракетку, чтобы отбить мяч на площадку соперника – и всё это всего за несколько сотен миллисекунд. Более того, мозг может выполнять все эти задачи (с помощью контролируемого им тела) с потреблением энергии примерно в десять раз меньше, чем у персонального компьютера. Как ему удаётся подобное? Важное различие между компьютером и мозгом заключается в способе обработки информации в каждой системе. Компьютерные задачи выполняются в основном последовательными шагами. Это видно по тому, как инженеры программируют компьютеры, создавая последовательный поток инструкций. Для последовательного каскада операций необходима высокая точность на каждом шаге, поскольку ошибки накапливаются и усиливаются с течением времени. Мозг также использует последовательные шаги для обработки информации. В примере с отбитым теннисным мячиком информация поступает из глаза в мозг, затем в спинной мозг, который обеспечивает сокращения мышц ног, туловища, рук и запястья. Но мозг также использует параллельную обработку, используя преимущества большого количества нейронов и соединений, которые устанавливает каждый нейрон".
https://theidealist.ru/brainvspc/
#Nautilus #наука #нейробиология #мозг #машинноеобучение #компьютеры
Мы привыкли считать современные компьютерные системы выдающимися устройствами, во много раз превосходящими по эффективности человеческий мозг. И действительно, если речь идёт о математических вычислениях и обработке последовательной информации, то "железу" нет равных. Однако "венцу природы" тоже есть что противопоставить современному прогрессу: ни один современный компьютер, оказывается, не может параллельно обрабатывать столько информации, сколько мозг человека. Во всяком случае пока не может.
"Профессиональный теннисист может проследить траекторию теннисного мяча после его подачи со скоростью до 257 км. в час, перейти к оптимальному месту на корте, расположить свою руку и повернуть ракетку, чтобы отбить мяч на площадку соперника – и всё это всего за несколько сотен миллисекунд. Более того, мозг может выполнять все эти задачи (с помощью контролируемого им тела) с потреблением энергии примерно в десять раз меньше, чем у персонального компьютера. Как ему удаётся подобное? Важное различие между компьютером и мозгом заключается в способе обработки информации в каждой системе. Компьютерные задачи выполняются в основном последовательными шагами. Это видно по тому, как инженеры программируют компьютеры, создавая последовательный поток инструкций. Для последовательного каскада операций необходима высокая точность на каждом шаге, поскольку ошибки накапливаются и усиливаются с течением времени. Мозг также использует последовательные шаги для обработки информации. В примере с отбитым теннисным мячиком информация поступает из глаза в мозг, затем в спинной мозг, который обеспечивает сокращения мышц ног, туловища, рук и запястья. Но мозг также использует параллельную обработку, используя преимущества большого количества нейронов и соединений, которые устанавливает каждый нейрон".
https://theidealist.ru/brainvspc/
#Nautilus #наука #нейробиология #мозг #машинноеобучение #компьютеры
Forwarded from Малоизвестное интересное
В знаменитом рассказе Джейкобса «Обезьянья лапа», мумифицированная лапа обезьяны, на которую наложено заклятье, выполняла любые желания, но с чудовищными последствиями для пожелавших. Для людей подобные последствия были просто невообразимы из-за их чудовищной бесчеловечностии, немыслимой для человека.
Но у прОклятой старым факиром обезьяньей лапы была иная — нечеловеческая структура предпочтений. И потому, выполняя желания людей, она вовсе не со зла, а просто автоматом, преподносила людям страшные сюрпризы, выходящие за пределы воображения имевших несчастье обратиться к ней с просьбой.
Страшный рассказ оказался пророческим. В XXI веке обезьянья лапа материализовалась в виде некоторых прорывных IT технологий. Подарочек столь желанных нам соцсетей мы уже от неё получили. На очереди не менее желанный людям Сильный ИИ.
Что же будет, если с Сильным ИИ повторится история обезьяньей лапы, буквально на наших глазах произошедшая с соцсетями?
Скорее всего, цена новой ошибки может оказаться для человечества неподъемной.
Почему так? И как этого избежать?
Читайте об этом в новом посте (7 мин. чтения):
- на Medium https://bit.do/fdEMf
- На Яндекс Дзен https://clck.ru/JbAxN
#СильныйИИ #AGI #МашинноеОбучение #IRL
Но у прОклятой старым факиром обезьяньей лапы была иная — нечеловеческая структура предпочтений. И потому, выполняя желания людей, она вовсе не со зла, а просто автоматом, преподносила людям страшные сюрпризы, выходящие за пределы воображения имевших несчастье обратиться к ней с просьбой.
Страшный рассказ оказался пророческим. В XXI веке обезьянья лапа материализовалась в виде некоторых прорывных IT технологий. Подарочек столь желанных нам соцсетей мы уже от неё получили. На очереди не менее желанный людям Сильный ИИ.
Что же будет, если с Сильным ИИ повторится история обезьяньей лапы, буквально на наших глазах произошедшая с соцсетями?
Скорее всего, цена новой ошибки может оказаться для человечества неподъемной.
Почему так? И как этого избежать?
Читайте об этом в новом посте (7 мин. чтения):
- на Medium https://bit.do/fdEMf
- На Яндекс Дзен https://clck.ru/JbAxN
#СильныйИИ #AGI #МашинноеОбучение #IRL
Medium
Обезьянья лапа прорывных технологий
Соцсети мы от нее уже получили. На очереди Сильный ИИ
Forwarded from Малоизвестное интересное
А существует ли справедливость?
Мы можем заставить ИИ не быть расистом, но будет ли это справедливо?
В последнюю пару лет на пути расширения использования ИИ на основе машинного обучения образовывался все более фундаментальный завал – неконтролируемая предвзятость. Она проявлялась во всевозможных формах дискриминации со стороны алгоритмов чернокожих, женщин, малообеспеченных, пожилых и т.д. буквально во всем: от процента кредита до решений о досрочном освобождении из заключения.
Проблема стала настолько серьезной, что на нее навалились всем миром: IT-гиганты и стартапы, военные и разведка, университеты и хакатоны …
И вот, похоже, принципиальное решение найдено. Им стал «Алгоритм Селдона» (детали см. здесь: популярно, научно). Он назван так в честь персонажа легендарного романа «Основание» Айзека Азимова математика Гэри Селдона. Ситуация в романе здорово напоминает нашу сегодняшнюю. Галактическая империя разваливалась, отчасти потому, что выполнение Трех законов робототехники требует гарантий, что ни один человек не пострадает в результате действий роботов. Это парализует любые действия роботов и заводит ситуацию в тупик. Селдон же предложил, как исправить это, обратившись к вероятностным рассуждениям о безопасности.
Разработчики «Алгоритма Селдона» (из США и Бразилии) пошли тем же путем. В результате получился фреймворк для разработки алгоритмов машинного обучения, облегчающий пользователям алгоритма указывать ограничения безопасности и избегания дискриминации (это можно условно назвать справедливостью).
Идея 1й версии «Алгоритма Селдона» была предложена еще 2 года назад. Но нужно было проверить на практике, как она работает. 1е тестирование было на задаче прогнозирования средних баллов в наборе данных из 43 000 учащихся в Бразилии. Все предыдущие алгоритмы машинного обучения дискриминировали женщин. 2е тестирование касалось задачи улучшения алгоритма управления контроллера инсулиновой помпы, чтобы он из-за предвзятостей не увеличивал частоту гипогликемии. Оба теста показали, что «Алгоритм Селдона» позволяет минимизировать предвзятость.
Казалось бы, ура (!?). Не совсем.
Засада может ждать впереди (опять же, как и предсказано Азимовым). Проблема в понимании людьми справедливости. Алгоритмы же так и так ни черта не понимают. И потому решать, что справедливо, а что нет, «Алгоритма Селдона» предлагает людям. Фреймворк позволяет использовать альтернативные определения справедливости. Люди сами должны выбрать, что им подходит, а «Алгоритм Селдона» потом проследит, чтобы выбранная «справедливость» не была нарушена. Однако даже среди экспертов существуют порядка 30 различных определений справедливости. И если даже эксперты не могут договориться о том, что справедливо, было бы странно перекладывать бремя решений на менее опытных пользователей.
В результате может получиться следующее:
• Пользователь рассудит, что справедливо, и задаст правила справедливости алгоритму.
• «Алгоритм Селдона» отследит выполнение правил.
• Но, по-честному, люди так и не будут уверены, справедливо ли они рассудили или нет.
#МашинноеОбучение #Справедливость #ПредвзятостьИИ
Мы можем заставить ИИ не быть расистом, но будет ли это справедливо?
В последнюю пару лет на пути расширения использования ИИ на основе машинного обучения образовывался все более фундаментальный завал – неконтролируемая предвзятость. Она проявлялась во всевозможных формах дискриминации со стороны алгоритмов чернокожих, женщин, малообеспеченных, пожилых и т.д. буквально во всем: от процента кредита до решений о досрочном освобождении из заключения.
Проблема стала настолько серьезной, что на нее навалились всем миром: IT-гиганты и стартапы, военные и разведка, университеты и хакатоны …
И вот, похоже, принципиальное решение найдено. Им стал «Алгоритм Селдона» (детали см. здесь: популярно, научно). Он назван так в честь персонажа легендарного романа «Основание» Айзека Азимова математика Гэри Селдона. Ситуация в романе здорово напоминает нашу сегодняшнюю. Галактическая империя разваливалась, отчасти потому, что выполнение Трех законов робототехники требует гарантий, что ни один человек не пострадает в результате действий роботов. Это парализует любые действия роботов и заводит ситуацию в тупик. Селдон же предложил, как исправить это, обратившись к вероятностным рассуждениям о безопасности.
Разработчики «Алгоритма Селдона» (из США и Бразилии) пошли тем же путем. В результате получился фреймворк для разработки алгоритмов машинного обучения, облегчающий пользователям алгоритма указывать ограничения безопасности и избегания дискриминации (это можно условно назвать справедливостью).
Идея 1й версии «Алгоритма Селдона» была предложена еще 2 года назад. Но нужно было проверить на практике, как она работает. 1е тестирование было на задаче прогнозирования средних баллов в наборе данных из 43 000 учащихся в Бразилии. Все предыдущие алгоритмы машинного обучения дискриминировали женщин. 2е тестирование касалось задачи улучшения алгоритма управления контроллера инсулиновой помпы, чтобы он из-за предвзятостей не увеличивал частоту гипогликемии. Оба теста показали, что «Алгоритм Селдона» позволяет минимизировать предвзятость.
Казалось бы, ура (!?). Не совсем.
Засада может ждать впереди (опять же, как и предсказано Азимовым). Проблема в понимании людьми справедливости. Алгоритмы же так и так ни черта не понимают. И потому решать, что справедливо, а что нет, «Алгоритма Селдона» предлагает людям. Фреймворк позволяет использовать альтернативные определения справедливости. Люди сами должны выбрать, что им подходит, а «Алгоритм Селдона» потом проследит, чтобы выбранная «справедливость» не была нарушена. Однако даже среди экспертов существуют порядка 30 различных определений справедливости. И если даже эксперты не могут договориться о том, что справедливо, было бы странно перекладывать бремя решений на менее опытных пользователей.
В результате может получиться следующее:
• Пользователь рассудит, что справедливо, и задаст правила справедливости алгоритму.
• «Алгоритм Селдона» отследит выполнение правил.
• Но, по-честному, люди так и не будут уверены, справедливо ли они рассудили или нет.
#МашинноеОбучение #Справедливость #ПредвзятостьИИ
Wired
Researchers Want Guardrails to Help Prevent Bias in AI
Machine-learning experts often design their algorithms to avoid some unintended consequences. But that’s not as easy for others.
Forwarded from Малоизвестное интересное
Тайна «темной материи», которую мы едим.
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
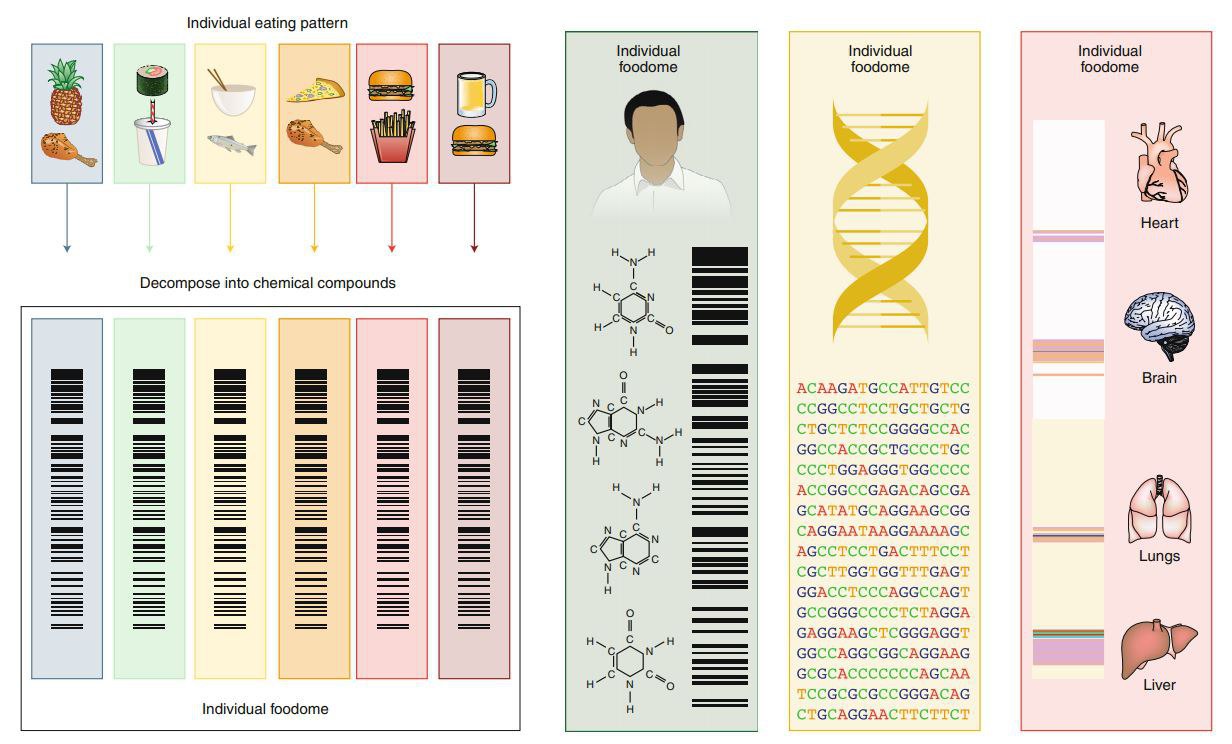
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на приложенном рисунке).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на приложенном рисунке).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
{kind=link}
Forwarded from Малоизвестное интересное
Тайна «темной материи», которую мы едим.
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на приложенном рисунке).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на приложенном рисунке).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
Создана энергетическая модель понимания ИИ сложных сцен.
Это еще не человек, но уже и не совсем машина, ибо кое-что понимает.
Современный ИИ водит авто лучше большинства людей. Но при этом не понимает ничего из того что видит. ИИ-автопилот способен аккуратно обогнать грузовик, но не в состоянии по вашей команде «ехать за грузовиком с красной кабиной». Причина в том, что ИИ-автопилот научили ориентироваться среди объектов, встречающихся на дорогах, но он не понимает композитной структуры окружающего мира: их взаиморасположение, взаимосвязь и т.д. Из-за этого он не понимает, что это грузовик, у него есть кабина, она имеет цвет и может быть красной.
Есть два способа проверить понимание ИИ композитной структуры окружающего мира:
• Visual Relation Understanding: предлагать ИИ описать на естественном языке, что он видит;
• Language Guided Scene Generation: предлагать ему сгенерировать изображение сцен по их описанию на естественном языке.
Например, «понимающая» окружающий мир умная колонка со встроенной камерой может, на ваш вопрос «как расставлена мебель в комнате», ответить что-то типа: слева у окна письменный стол, а перед ним стул, справа книжный шкаф, а за ним этажерка, на окне бежевые шторы, а на подоконнике цветок в горшке.
Или, например, она способна сгенерировать верную 3D картинку по вашему описанию: на дворе трава, а на траве дрова.
Умеющему сделать такое ИИ будет еще далеко до человеческого понимания мироустройства. Но и сказать, что он совсем не понимает, как устроен окружающий его мир, уже будет не справедливо.
Новый весьма оригинальный способ обучения ИИ пониманию сложных композитных сцен из многих предметов и их взаимоотношений описан в только что опубликованной работе Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) MIT. Способ основан на «энергетической модели»: описание реляционной сцены отношений объектов, как произведение отдельных распределений вероятностей отношений между ними, причем каждое отдельное отношение определяется на изображении своим распределением вероятностей. Такая композиция позволяет моделировать взаимодействия между несколькими отношениями (популярно, научно).
Новый способ скоро позволит ИИ строить сцены по описаниям типа «на златом крыльце сидели: царь, царевич, король, королевич, сапожник, портной». И совсем не за горами понимание ИИ фраз типа «графиня изменившимся лицом бежит пруду».
Вместе с тем, даже столь обещающие перспективы «энергетической модели» не позволяют надеяться на понимание ИИ фраз типа «на меня наставлен сумрак ночи тысячью биноклей на оси». Ибо здесь, как с аффордансами, - проблема не в неисчислимости вариантов объектов и их отношений, а в неопределенности этих отношений (см. здесь). Это значит, что пока Борис Пастернак не создал этих отношений между объектами: «сумрак ночи», «тысяча биноклей» да еще и «на оси» в контексте «ощущения неотвратимости трагедии», - они просто не существуют в нашем мире.
И даже если они существуют в каком-то из иных миров Метаверса, люди уровня Бориса Пастернака умеют их оттуда извлекать, а алгоритмы ИИ – нет (т.к. преодолеть неопределенность с помощью вычислений нельзя).
#ИИ #МашинноеОбучение
_______
Источник | #theworldisnoteasy
Это еще не человек, но уже и не совсем машина, ибо кое-что понимает.
Современный ИИ водит авто лучше большинства людей. Но при этом не понимает ничего из того что видит. ИИ-автопилот способен аккуратно обогнать грузовик, но не в состоянии по вашей команде «ехать за грузовиком с красной кабиной». Причина в том, что ИИ-автопилот научили ориентироваться среди объектов, встречающихся на дорогах, но он не понимает композитной структуры окружающего мира: их взаиморасположение, взаимосвязь и т.д. Из-за этого он не понимает, что это грузовик, у него есть кабина, она имеет цвет и может быть красной.
Есть два способа проверить понимание ИИ композитной структуры окружающего мира:
• Visual Relation Understanding: предлагать ИИ описать на естественном языке, что он видит;
• Language Guided Scene Generation: предлагать ему сгенерировать изображение сцен по их описанию на естественном языке.
Например, «понимающая» окружающий мир умная колонка со встроенной камерой может, на ваш вопрос «как расставлена мебель в комнате», ответить что-то типа: слева у окна письменный стол, а перед ним стул, справа книжный шкаф, а за ним этажерка, на окне бежевые шторы, а на подоконнике цветок в горшке.
Или, например, она способна сгенерировать верную 3D картинку по вашему описанию: на дворе трава, а на траве дрова.
Умеющему сделать такое ИИ будет еще далеко до человеческого понимания мироустройства. Но и сказать, что он совсем не понимает, как устроен окружающий его мир, уже будет не справедливо.
Новый весьма оригинальный способ обучения ИИ пониманию сложных композитных сцен из многих предметов и их взаимоотношений описан в только что опубликованной работе Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) MIT. Способ основан на «энергетической модели»: описание реляционной сцены отношений объектов, как произведение отдельных распределений вероятностей отношений между ними, причем каждое отдельное отношение определяется на изображении своим распределением вероятностей. Такая композиция позволяет моделировать взаимодействия между несколькими отношениями (популярно, научно).
Новый способ скоро позволит ИИ строить сцены по описаниям типа «на златом крыльце сидели: царь, царевич, король, королевич, сапожник, портной». И совсем не за горами понимание ИИ фраз типа «графиня изменившимся лицом бежит пруду».
Вместе с тем, даже столь обещающие перспективы «энергетической модели» не позволяют надеяться на понимание ИИ фраз типа «на меня наставлен сумрак ночи тысячью биноклей на оси». Ибо здесь, как с аффордансами, - проблема не в неисчислимости вариантов объектов и их отношений, а в неопределенности этих отношений (см. здесь). Это значит, что пока Борис Пастернак не создал этих отношений между объектами: «сумрак ночи», «тысяча биноклей» да еще и «на оси» в контексте «ощущения неотвратимости трагедии», - они просто не существуют в нашем мире.
И даже если они существуют в каком-то из иных миров Метаверса, люди уровня Бориса Пастернака умеют их оттуда извлекать, а алгоритмы ИИ – нет (т.к. преодолеть неопределенность с помощью вычислений нельзя).
#ИИ #МашинноеОбучение
_______
Источник | #theworldisnoteasy
SciTechDaily
Artificial Intelligence That Understands Object Relationships – Enabling Machines To Learn More Like Humans Do
A new machine-learning model could enable robots to understand interactions in the world in the way humans do. When humans look at a scene, they see objects and the relationships between them. On top of your desk, there might be a laptop that is sitting to…