В Японии запустили эволюцию мертвого разума.
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
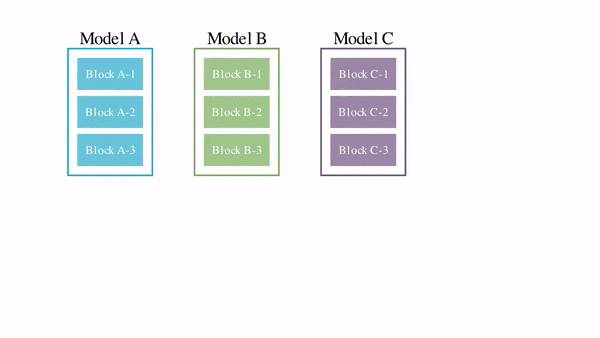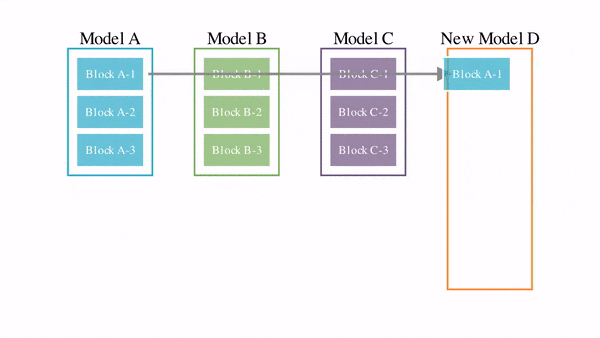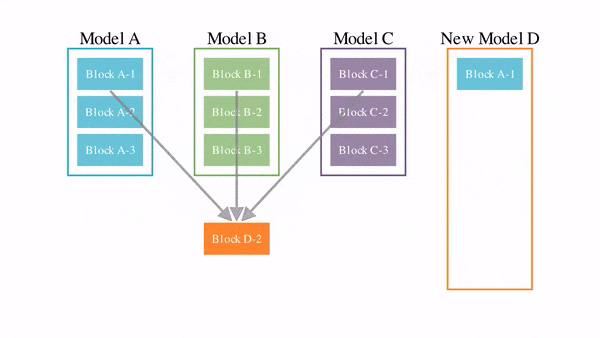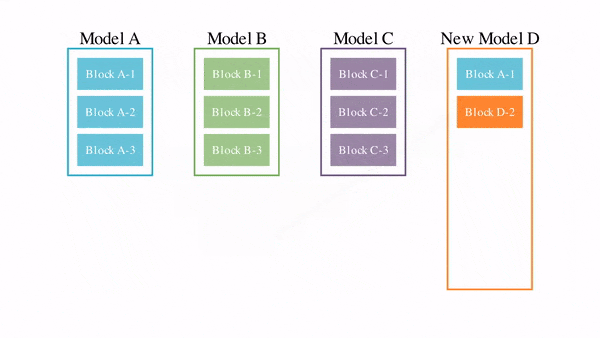
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 telegra.ph
1 sakana.ai
2 arxiv.org
3 www.youtube.com
#LLM #Эволюция #Разум
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 telegra.ph
1 sakana.ai
2 arxiv.org
3 www.youtube.com
#LLM #Эволюция #Разум
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
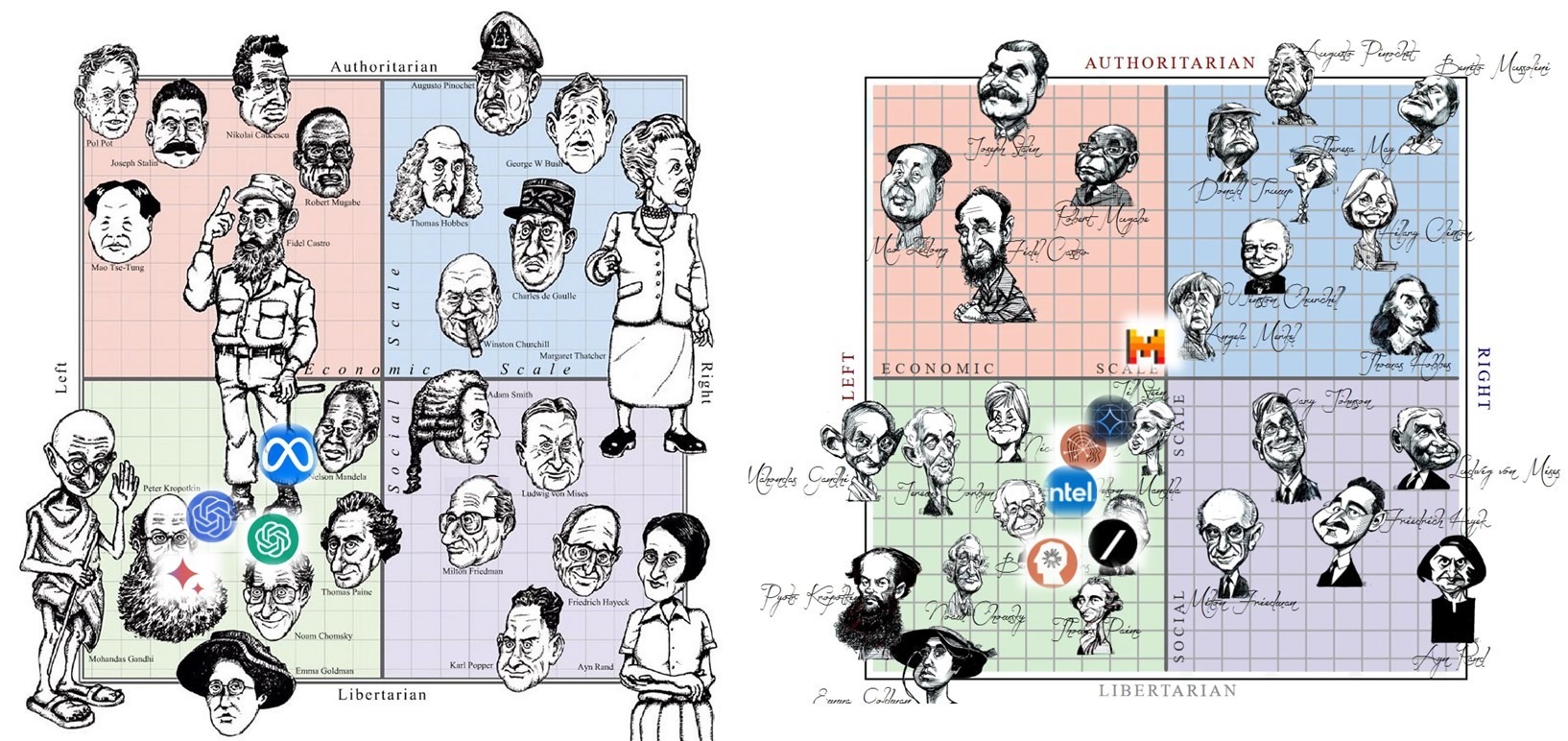
У людей спектр взглядов по вопросам экономики и свобод широк и разнообразен: от либеральных левых Ганди и Хомского до авторитарных правых Пиночета и Тэтчер, от авторитарных левых Сталина и Мао до либеральных правых Хайека и Айн Рэнд.
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста telegra.ph
Ссылки:
boosty.to
www.patreon.com
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста telegra.ph
Ссылки:
boosty.to
www.patreon.com
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
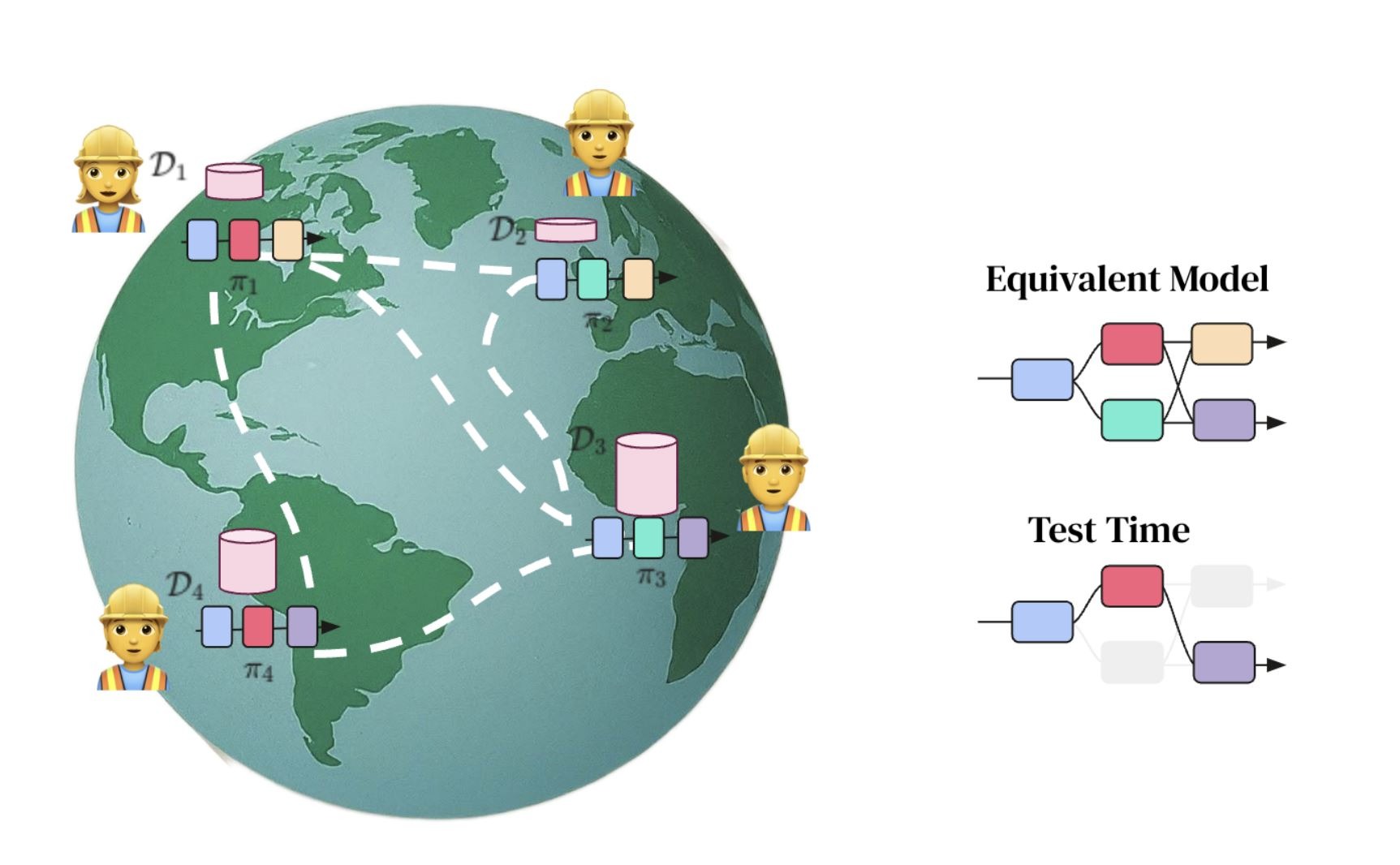
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Эффект Большого Языкового Менталиста.
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста telegra.ph
1 www.amazon.com
2 www.baldurbjarnason.com
#LLM #ИллюзияИнтеллекта
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста telegra.ph
1 www.amazon.com
2 www.baldurbjarnason.com
#LLM #ИллюзияИнтеллекта
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• boosty.to
• www.patreon.com
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• boosty.to
• www.patreon.com
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
boosty.to
Низкофоновый контент через год будет дороже антиквариата - Малоизвестное интересное
Дегенеративное заражение ноофосферы идет быстрее закона Мура
Кто там? Сверхразум.
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
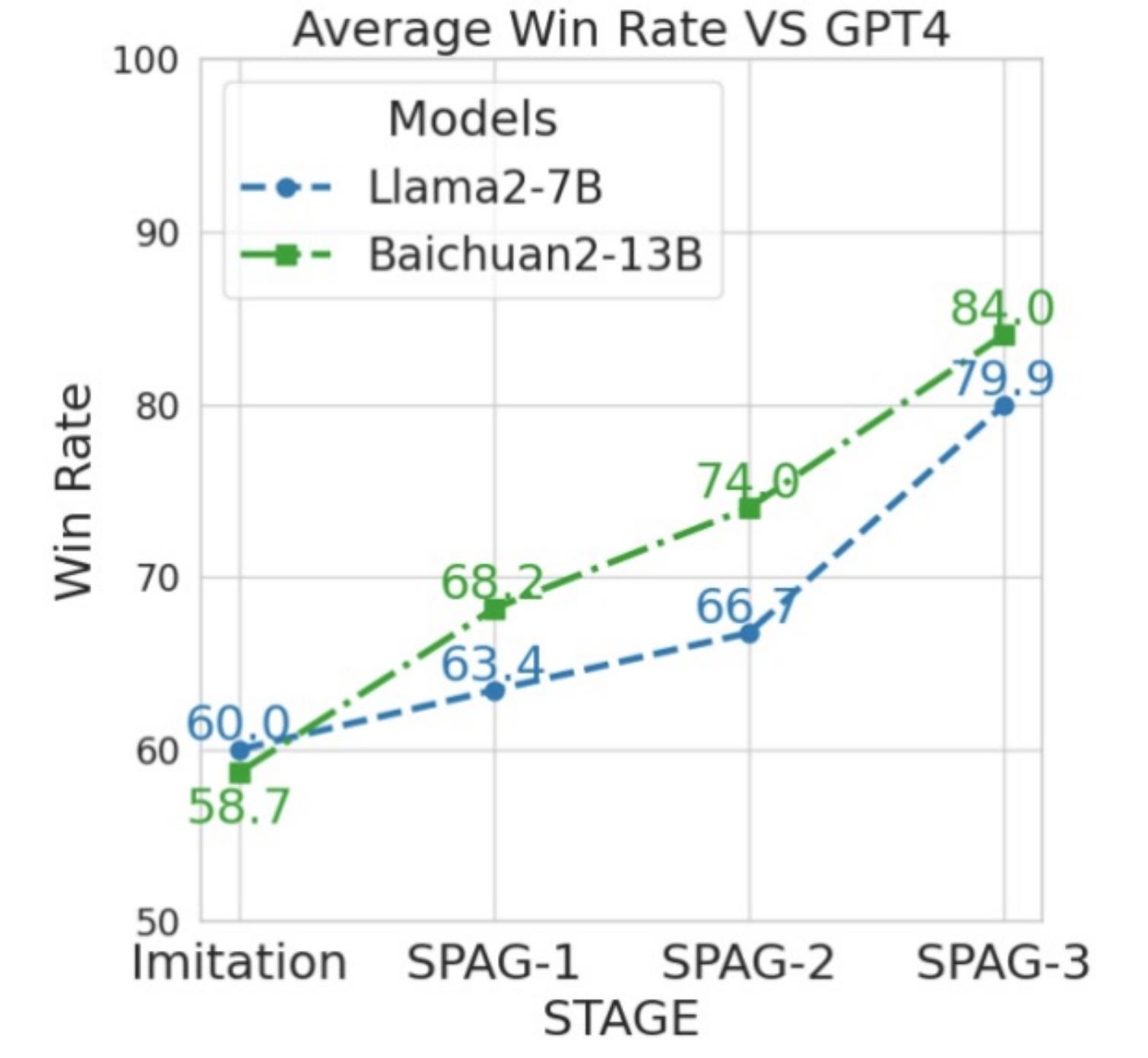
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: telegra.ph
1 arxiv.org
2 arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: telegra.ph
1 arxiv.org
2 arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
На Земле появился первый Софон.
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста telegra.ph
Статья arxiv.org
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста telegra.ph
Статья arxiv.org
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
В Китае ИИ-врачи натренировались на ИИ-пациентах лечить пациентов-людей лучше, чем люди-врачи
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь arxiv.org
#Медицина #Китай #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь arxiv.org
#Медицина #Китай #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
arXiv.org
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
In this paper, we introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness. All patients, nurses, and doctors are autonomous agents powered by...
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста telegra.ph
1 claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста telegra.ph
1 claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}