This media is not supported in your browser
VIEW IN TELEGRAM
Llama 3.1 405B, квантизированная до 4 бит, запущенная на двух макбуках (128 гиг оперативки у каждого). Возможно это с помощью exo - тулы, позволяющей запускать модельку распределённо на нескольких девайсов. Поддерживаются практически любые GPU, телефоны, планшеты, макбуки и почти всё о чём можно подумать.
Запустить ламу на домашнем кластере
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Запустить ламу на домашнем кластере
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
This media is not supported in your browser
VIEW IN TELEGRAM
Генерация видео от Black Forest Labs
Они релизнули FLUX.1 всего неделю назад, а уже тизерят SOTA видеогенерацию. Видео искажено эффектом телевизора, но выглядит очень впечатляюще.
Ребята наглядно показывают насколько в Stability был фиговый менеджмент. Если за полгода с нуля те же самые люди, которые сделали SD3 забахали такое, то в Stability всё очень запущено, некому пилить ресерчи, а новый менеджмент может и не спасти.
Как думаете, будет опенсорс?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Они релизнули FLUX.1 всего неделю назад, а уже тизерят SOTA видеогенерацию. Видео искажено эффектом телевизора, но выглядит очень впечатляюще.
Ребята наглядно показывают насколько в Stability был фиговый менеджмент. Если за полгода с нуля те же самые люди, которые сделали SD3 забахали такое, то в Stability всё очень запущено, некому пилить ресерчи, а новый менеджмент может и не спасти.
Как думаете, будет опенсорс?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
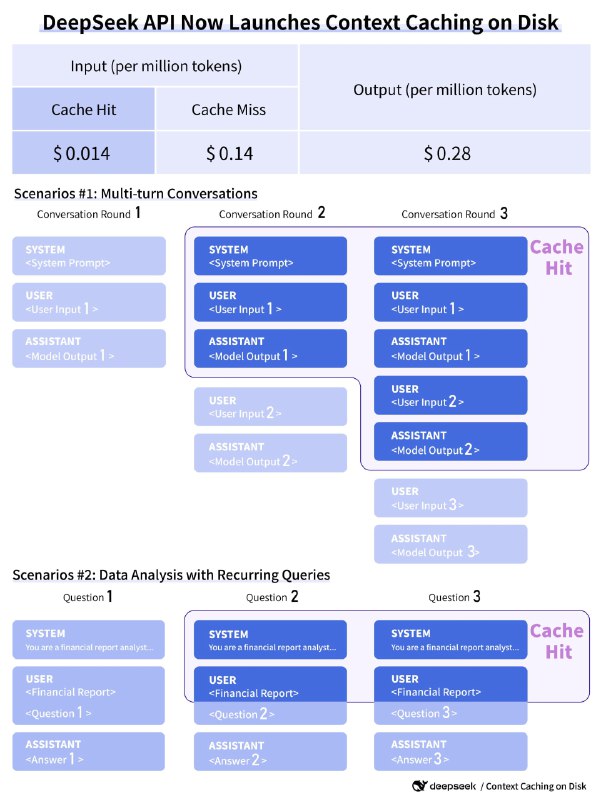
Дешёвые, как грязь, LLM
API-провайдеры невероятно быстро снижают стоимость использования своих LLM. При отсутствии ярко выраженного лидера по качеству моделей, главным аргументом становится цена.
➖ Google с 12 августа дропает цены на Gemini Flash на 80%. Вот и реакция на GPT-4o mini, спустя две недели после релиза. Вот бы то же самое сделали с Pro 1.5.
➖ Новая версия GPT-4o упала в цене до $2.5 input/$10 output за миллион токенов, прошлые версии стоили $5 input/$15 output за миллион токенов. Последний месяц Claude 3.5 Sonnet и Llama 3.1 405B сильно поджимали OpenAI по цене, пришлось отвечать.
➖Deepseek релизит обещанный месяц назад Context Caching. Цены поражают: стоимость токенов при попадании в кэш падает не в 2x, как у гугла, а в 10x, при этом с бесплатным хранением. DeepSeek V2 и так произвёл эффект разорвавшейся бомбы на китайском рынке три месяца назад: модель была в разы дешевле конкурентов, при лучшем качестве. А сейчас нанесли добивающий удар.
С такими темпами цена за миллион токенов станет меньше цента менее чем через год. И будем мы мерять цены в долларах за миллиард токенов.
А помните, цены на GPT-4 доходили до $60 input/$120 output?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
API-провайдеры невероятно быстро снижают стоимость использования своих LLM. При отсутствии ярко выраженного лидера по качеству моделей, главным аргументом становится цена.
➖ Google с 12 августа дропает цены на Gemini Flash на 80%. Вот и реакция на GPT-4o mini, спустя две недели после релиза. Вот бы то же самое сделали с Pro 1.5.
➖ Новая версия GPT-4o упала в цене до $2.5 input/$10 output за миллион токенов, прошлые версии стоили $5 input/$15 output за миллион токенов. Последний месяц Claude 3.5 Sonnet и Llama 3.1 405B сильно поджимали OpenAI по цене, пришлось отвечать.
➖Deepseek релизит обещанный месяц назад Context Caching. Цены поражают: стоимость токенов при попадании в кэш падает не в 2x, как у гугла, а в 10x, при этом с бесплатным хранением. DeepSeek V2 и так произвёл эффект разорвавшейся бомбы на китайском рынке три месяца назад: модель была в разы дешевле конкурентов, при лучшем качестве. А сейчас нанесли добивающий удар.
С такими темпами цена за миллион токенов станет меньше цента менее чем через год. И будем мы мерять цены в долларах за миллиард токенов.
А помните, цены на GPT-4 доходили до $60 input/$120 output?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Сверхзвуковые LLM https://t.iss.one/ai_newz/3169
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости побили в более чем два раза для 8B. В будущем обещают добавить больше моделей, начиная с Llama 3.1 405B
Сделал это стартап Cerebras. Он производит железо для нейронок, известен самым большим чипом в мире (в 57 раз больше по размеру H100!). Предыдущий рекорд по скорости поставил тоже стартап со своим железом - Groq.
Хороший пример того что специализированные только под нейронки чипы вроде могут в разы превосходить видеокарты по скорости инференса, а ведь скоро ещё будут чипы которые заточены под конкретные модели, например Sohu. Кстати, давно хотел разобрать разные стартапы по производству железа и разницу их подходов. Интересно?
Попробовать можно тут.
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости побили в более чем два раза для 8B. В будущем обещают добавить больше моделей, начиная с Llama 3.1 405B
Сделал это стартап Cerebras. Он производит железо для нейронок, известен самым большим чипом в мире (в 57 раз больше по размеру H100!). Предыдущий рекорд по скорости поставил тоже стартап со своим железом - Groq.
Хороший пример того что специализированные только под нейронки чипы вроде могут в разы превосходить видеокарты по скорости инференса, а ведь скоро ещё будут чипы которые заточены под конкретные модели, например Sohu. Кстати, давно хотел разобрать разные стартапы по производству железа и разницу их подходов. Интересно?
Попробовать можно тут.
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Telegram
эйай ньюз
Сверхзвуковые LLM
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости…
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости…
Как LLM хранят факты?
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в LLM. Это третье и последний эпизод в серии о работе LLM. D первых двух объяснялось как работают эмбеддинги и как работает механизм внимания. Эта серия - лучшее объяснение для непрограммистов о том, как работают LLM, с кучей хороших визуализаций.
www.youtube.com
Смотрим здесь.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в LLM. Это третье и последний эпизод в серии о работе LLM. D первых двух объяснялось как работают эмбеддинги и как работает механизм внимания. Эта серия - лучшее объяснение для непрограммистов о том, как работают LLM, с кучей хороших визуализаций.
www.youtube.com
Смотрим здесь.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Telegram
эйай ньюз
Как LLM хранят факты?
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в…
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в…
Reflection 70B - дообученная Llama 3.1, обгоняющая все GPT-4o
Модель была дообучена на синтетических данных (созданных другой нейросетью) и по бенчмаркам обходит GPT-4o, а в скором времени обещают выпуск модели на 405B параметров.
Особенность модели - она проверяет сама себя и исправляет, перед тем как дать финальный ответ. Из-за этого время генерации ответа увеличивается, но и улучшается качество ответа.
Модель доступна в для загрузки, но даже квантованная до 4-bit GGUF версия требует 42.5 Гигабайта видео или оперативной памяти, а версия квантованная до 2-bit - 29.4 Gb.
Тем не менее, протестировать ее можно тут: Reflection 70B Playground, но из-за большой нагрузки сайт периодически ложится
#llm #ai #chatgpt
_______
Источник | #neurogen_news
@F_S_C_P
-------
Секретики!
-------
Модель была дообучена на синтетических данных (созданных другой нейросетью) и по бенчмаркам обходит GPT-4o, а в скором времени обещают выпуск модели на 405B параметров.
Особенность модели - она проверяет сама себя и исправляет, перед тем как дать финальный ответ. Из-за этого время генерации ответа увеличивается, но и улучшается качество ответа.
Модель доступна в для загрузки, но даже квантованная до 4-bit GGUF версия требует 42.5 Гигабайта видео или оперативной памяти, а версия квантованная до 2-bit - 29.4 Gb.
Тем не менее, протестировать ее можно тут: Reflection 70B Playground, но из-за большой нагрузки сайт периодически ложится
#llm #ai #chatgpt
_______
Источник | #neurogen_news
@F_S_C_P
-------
Секретики!
-------
Media is too big
VIEW IN TELEGRAM
Если вам когда-либо было интересно, как получить мегакластер GPU, то вот вам подробный гайд от Ларри Эллисона, фаундера того самого Оракла. Челу 80, кстати, похоже, он всё-таки нашёл эликсир вечной молодости.
Ну так вот, записываем:
1) Приходим на ужин к Дженсену Хуангу.
2) Вместе с Маском умоляем Кожанку взять ваши миллиарды.
3) Поздравляю, если вам повезёт, то партию свеженьких GPU не задержат.
Теперь повторяем😂
Кроме шуток, Oracle – одна из немногих компаний, которая смогла заполучить контракт на более чем 100.000 видеокарт NVIDIA Blackwell (это GB200, например). Они уже строят огромный кластер, который заработает в первой половине 2025. А сбоку еще планируют пристроить 3 маленьких атомных реактора на ~1000 MW, чтобы все это дело запитывать электроэнергией.
Короче, если GPU - это новая нефть, то AI – это новый автомобиль.
_______
Источник | #ai_newz
@F_S_C_P
-------
Секретики!
-------
Ну так вот, записываем:
1) Приходим на ужин к Дженсену Хуангу.
2) Вместе с Маском умоляем Кожанку взять ваши миллиарды.
3) Поздравляю, если вам повезёт, то партию свеженьких GPU не задержат.
Теперь повторяем😂
Кроме шуток, Oracle – одна из немногих компаний, которая смогла заполучить контракт на более чем 100.000 видеокарт NVIDIA Blackwell (это GB200, например). Они уже строят огромный кластер, который заработает в первой половине 2025. А сбоку еще планируют пристроить 3 маленьких атомных реактора на ~1000 MW, чтобы все это дело запитывать электроэнергией.
Короче, если GPU - это новая нефть, то AI – это новый автомобиль.
_______
Источник | #ai_newz
@F_S_C_P
-------
Секретики!
-------
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
А вот ещё примеры генерации нашей модели вам на обозрение.
Те примеры, где показано маленькое фото в правом верхнем углу – это результат персонализированной генерации с заданным лицом (Personalized Movie Gen).
Переходим на качественно новый уровень!
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!
Те примеры, где показано маленькое фото в правом верхнем углу – это результат персонализированной генерации с заданным лицом (Personalized Movie Gen).
Переходим на качественно новый уровень!
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!
О компенсации в FAANG+ (часть 1)
В MAANG и прочих Биг-Техах существует четкая иерархия инженерных уровней, которая определяет ваш карьерный рост и компенсацию. Подробнее о левелах от L3 до L8 и различиях между ними я писал в . Сейчас же поговорим про компенсацию (зп в простонародии) и из чего она обычно состоит.
Зп как правило зависит от грейда, но грейды в FAANG не 1 к 1 совпадают между компаниями, ну и компенсация тоже может варьироваться. Как вы видите на картинке с levels.fyi, есть различия между фирмами, например Senior - это L5 в Мете, L6 в Амазоне и L4 в Эппл. Поэтому в этом посте мы рассмотрим линейку грейдов Гугла/Меты как хрестоматийную, от нее и будем отталкиваться.
Total comp (полная компенсация) в FAANG обычно состоит из базовой компенсации (кеш), equity (стоков) и бонусов.
- Base (кеш) - это то, что вы получаете на свою банковский счет ежемесячно. Кешевые вилки обычно строго определены для каждого уровня. Эти деньги вы получаете всегда, независимо от вашего перформанса. Обычно указывется как Gross (до налогов) в год.
- Еquity - это как правило частичка компании в виде акций (stocks) или опционов, которые вам выдают как часть компенсации. Обычно пакет акций выделяется на 4 года, и они попадают вам в руки (vesting) раз в квартал – вы получаете в полное владение 1/16 от общего числа акций и можете с ними делать, что хотите. Это делается для того, чтобы замотивировать сотрудника (а) остаться подольше (б) хорошо работать, чтобы компания росла в цене.
- Refreshers - это дополнительные небольшие пакеты акций, которые вы получаете раз в год по итогам вашего перформанса. Они тоже вестятся в течение 4-х лет. Таким образом за несколько лет работы в одной компании у вас накапливается несколько пакетов акций, из каждого из которых раз в квартал вы получаете 1/16. Кумулятивный эффект может быть весьма заметным, значительно увеличивая ваш total comp.
- Бонусы - это % от Base, который вам дается по итогам перформанса за год. Размер бонуса (в % ) зависит от вашей синьорности и коэффициентов, которые высчитываются из вашего перформанса и успехов компании за год. Для L3 это обычно 10%, для L4 и L5 - 15%, для L6 - 20%.
- Sign-on bonus - разовая бонусная выплата в начале работы на новой месте. Часто используется чтобы компенсировать упущенную выгоду при смене работы кандидатом либо для покрытия расходов на переезд. Обычно от $10,000 до $100,000. У меня некоторые знакомые, с помощью таких сайн-онов закрывали долги за обучение и спокойно уезжали работать.
Размер Equity, Refreshers и бонусов сильно зависит от вашего уровня и того, насколько вы востребованный специалист. Например, Base компенсация у SWE и AI Researcher-ов не отличается, а вот размер пакета акций и сайн-он бонуса может быть совсем разным для рядового SWE и для AI Research Scientist / AI Engineer, который прям очень нужен компании.
Медианная total comp у SWE (Software Engineer) в США по статистике с Glassdoor на сентябрь 2024 - $181,000/год. Но это число может быть слегка завышено.
В FAANG+ же зарплаты стартуют от $150к для джунов и до $550к для синьоров. А грейды Staff+ могут зарабатывать от $600к до нескольких миллионов.
В Европе везде в среднем платят значительно ниже чем в США, кроме Швейцарии (там заработок +- как в США), и Англии (там выше чем в остальной Европе, но ниже чем в Швейцарии). Но все равно FAANG+ далеко в лидерах по total comp, а довольно высокий уровень жизни в Европе будет обходиться сильно дешевле чем в США или Швейцарии.
Если вы сейчас планируете сделать рывок в своей Total comp, то я как раз скоро буду в первый раз проводить интенсив по подготовке к собесам на AI/ML роли в FAANG+. Будут фишки и best practices как готовиться и чего ожидать. По {...продолжить в источнике}
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!
В MAANG и прочих Биг-Техах существует четкая иерархия инженерных уровней, которая определяет ваш карьерный рост и компенсацию. Подробнее о левелах от L3 до L8 и различиях между ними я писал в . Сейчас же поговорим про компенсацию (зп в простонародии) и из чего она обычно состоит.
Зп как правило зависит от грейда, но грейды в FAANG не 1 к 1 совпадают между компаниями, ну и компенсация тоже может варьироваться. Как вы видите на картинке с levels.fyi, есть различия между фирмами, например Senior - это L5 в Мете, L6 в Амазоне и L4 в Эппл. Поэтому в этом посте мы рассмотрим линейку грейдов Гугла/Меты как хрестоматийную, от нее и будем отталкиваться.
Total comp (полная компенсация) в FAANG обычно состоит из базовой компенсации (кеш), equity (стоков) и бонусов.
- Base (кеш) - это то, что вы получаете на свою банковский счет ежемесячно. Кешевые вилки обычно строго определены для каждого уровня. Эти деньги вы получаете всегда, независимо от вашего перформанса. Обычно указывется как Gross (до налогов) в год.
- Еquity - это как правило частичка компании в виде акций (stocks) или опционов, которые вам выдают как часть компенсации. Обычно пакет акций выделяется на 4 года, и они попадают вам в руки (vesting) раз в квартал – вы получаете в полное владение 1/16 от общего числа акций и можете с ними делать, что хотите. Это делается для того, чтобы замотивировать сотрудника (а) остаться подольше (б) хорошо работать, чтобы компания росла в цене.
- Refreshers - это дополнительные небольшие пакеты акций, которые вы получаете раз в год по итогам вашего перформанса. Они тоже вестятся в течение 4-х лет. Таким образом за несколько лет работы в одной компании у вас накапливается несколько пакетов акций, из каждого из которых раз в квартал вы получаете 1/16. Кумулятивный эффект может быть весьма заметным, значительно увеличивая ваш total comp.
- Бонусы - это % от Base, который вам дается по итогам перформанса за год. Размер бонуса (в % ) зависит от вашей синьорности и коэффициентов, которые высчитываются из вашего перформанса и успехов компании за год. Для L3 это обычно 10%, для L4 и L5 - 15%, для L6 - 20%.
- Sign-on bonus - разовая бонусная выплата в начале работы на новой месте. Часто используется чтобы компенсировать упущенную выгоду при смене работы кандидатом либо для покрытия расходов на переезд. Обычно от $10,000 до $100,000. У меня некоторые знакомые, с помощью таких сайн-онов закрывали долги за обучение и спокойно уезжали работать.
Размер Equity, Refreshers и бонусов сильно зависит от вашего уровня и того, насколько вы востребованный специалист. Например, Base компенсация у SWE и AI Researcher-ов не отличается, а вот размер пакета акций и сайн-он бонуса может быть совсем разным для рядового SWE и для AI Research Scientist / AI Engineer, который прям очень нужен компании.
Медианная total comp у SWE (Software Engineer) в США по статистике с Glassdoor на сентябрь 2024 - $181,000/год. Но это число может быть слегка завышено.
В FAANG+ же зарплаты стартуют от $150к для джунов и до $550к для синьоров. А грейды Staff+ могут зарабатывать от $600к до нескольких миллионов.
В Европе везде в среднем платят значительно ниже чем в США, кроме Швейцарии (там заработок +- как в США), и Англии (там выше чем в остальной Европе, но ниже чем в Швейцарии). Но все равно FAANG+ далеко в лидерах по total comp, а довольно высокий уровень жизни в Европе будет обходиться сильно дешевле чем в США или Швейцарии.
Если вы сейчас планируете сделать рывок в своей Total comp, то я как раз скоро буду в первый раз проводить интенсив по подготовке к собесам на AI/ML роли в FAANG+. Будут фишки и best practices как готовиться и чего ожидать. По {...продолжить в источнике}
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!
{kind=link}
Треним Лоры для Flux 1.0 [dev] бесплатно
Люблю опенсорс. А ещё больше нонпрофит проекты, основанные на опенсорсе (да, OpenAI?).
Ежедневно выходит куча проектов с исходным кодом, о которых я даже не успеваю писать, но ведь, кроме обзора статей, хочется ещё и потыкаться самостоятельно. А установка у таких проектов обычно муторная — кто-то всё ещё с сетапом Comfy мучается.
Так вот, Tost.AI — сайт, на котором можно потыкать новые модельки и пайплайны по типу Live Portrait, до которого у меня так и не дошли руки.
Там же можно натренировать свою LoRa и делать всякие ништяки. Кстати, LoRa на Flux выходят бомбические. По набору из 6 фотографий можно консистентно генерить один и тот же объект. Детали реального объекта передаются настолько точно, что сохраняется даже текст (салют креативным фотографам).
Можно, например, по фотографиям из white бокса сделать фото продукта с моделью (или на модели), или красивую картинку где-то в необычной локации и пр.
Тут стоит отметить, что, хоть веса под non-profit лицензией, вы полностью владеете картинками, которые генерит Flux:
d. Outputs. We claim no ownership rights in and to the Outputs. You are solely responsible for the Outputs you generate and their subsequent uses in accordance with this License. You may use Output for any purpose (including for commercial purposes), except as expressly prohibited herein. You may not use the Output to train, fine-tune or distill a model that is competitive with the FLUX.1 [dev] Model.
Делаем так (см. видос):
1. Заходим, регистрируемся на tost.ai
2. В первой плашке выбираем Train Lora
3. Придумываем триггер-ворд
4. Подгружаем файлы через кнопку Add
5. Жмём Enter и ждём минут 30
6. Качаем файл safetensor
LoRa готова, теперь можно генерить!
Для этого:
1. В первой плашке идём в Text to Image, во второй — Flux 1 Dev. Custom Lora
2. Загружаем файл LoRa, ждём, пока обновится ссылка
3. Далее всё как обычно, главное не забыть триггер-ворд
Жду ваши тесты в комментариях!
UPD: Добавили Flux.1 Dev - ControlNet inpating
Tost.ai
Лицензия FLUX.1 [Dev]
#tutorial
@ai_newz
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Люблю опенсорс. А ещё больше нонпрофит проекты, основанные на опенсорсе (да, OpenAI?).
Ежедневно выходит куча проектов с исходным кодом, о которых я даже не успеваю писать, но ведь, кроме обзора статей, хочется ещё и потыкаться самостоятельно. А установка у таких проектов обычно муторная — кто-то всё ещё с сетапом Comfy мучается.
Так вот, Tost.AI — сайт, на котором можно потыкать новые модельки и пайплайны по типу Live Portrait, до которого у меня так и не дошли руки.
Там же можно натренировать свою LoRa и делать всякие ништяки. Кстати, LoRa на Flux выходят бомбические. По набору из 6 фотографий можно консистентно генерить один и тот же объект. Детали реального объекта передаются настолько точно, что сохраняется даже текст (салют креативным фотографам).
Можно, например, по фотографиям из white бокса сделать фото продукта с моделью (или на модели), или красивую картинку где-то в необычной локации и пр.
Тут стоит отметить, что, хоть веса под non-profit лицензией, вы полностью владеете картинками, которые генерит Flux:
d. Outputs. We claim no ownership rights in and to the Outputs. You are solely responsible for the Outputs you generate and their subsequent uses in accordance with this License. You may use Output for any purpose (including for commercial purposes), except as expressly prohibited herein. You may not use the Output to train, fine-tune or distill a model that is competitive with the FLUX.1 [dev] Model.
Делаем так (см. видос):
1. Заходим, регистрируемся на tost.ai
2. В первой плашке выбираем Train Lora
3. Придумываем триггер-ворд
4. Подгружаем файлы через кнопку Add
5. Жмём Enter и ждём минут 30
6. Качаем файл safetensor
LoRa готова, теперь можно генерить!
Для этого:
1. В первой плашке идём в Text to Image, во второй — Flux 1 Dev. Custom Lora
2. Загружаем файл LoRa, ждём, пока обновится ссылка
3. Далее всё как обычно, главное не забыть триггер-ворд
Жду ваши тесты в комментариях!
UPD: Добавили Flux.1 Dev - ControlNet inpating
Tost.ai
Лицензия FLUX.1 [Dev]
#tutorial
@ai_newz
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Telegram
эйай ньюз
Треним Лоры для Flux 1.0 [dev] бесплатно
Люблю опенсорс. А ещё больше нонпрофит проекты, основанные на опенсорсе (да, OpenAI?).
Ежедневно выходит куча проектов с исходным кодом, о которых я даже не успеваю писать, но ведь, кроме обзора статей, хочется ещё…
Люблю опенсорс. А ещё больше нонпрофит проекты, основанные на опенсорсе (да, OpenAI?).
Ежедневно выходит куча проектов с исходным кодом, о которых я даже не успеваю писать, но ведь, кроме обзора статей, хочется ещё…
This media is not supported in your browser
VIEW IN TELEGRAM
Авторы Chatbot Arena выпустили расширение для VS Code для оценки моделей для кодинга. По сути, это бесплатный копайлот, где предлагают выбирать из нескольких вариантов, сгенеренных разными моделями. Это должно позитивно повлиять на оценку моделей для кода, ведь именно автодополнение никто больше не бенчит. Отдельная арена тут может помочь до какой-то степени, пока разработчики на неё не оверфитнулись. А дальше придётся придумывать новые бенчи.
Если хотите попользоваться, учтите, что ваш код будут отправлять хостерам моделек на арене, что допустимо для опенсорс разработок и каких-то личных проектов. А вот для коммерческой разработки, конечно же, такое использовать не стоит.
Скачать
@ai_newz
_______
Источник | #ai_newz
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney
Если хотите попользоваться, учтите, что ваш код будут отправлять хостерам моделек на арене, что допустимо для опенсорс разработок и каких-то личных проектов. А вот для коммерческой разработки, конечно же, такое использовать не стоит.
Скачать
@ai_newz
_______
Источник | #ai_newz
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney
Запускаем Voice Mode ChatGPT если вы не из США 😆
и устанавливаем официальную апку на андройд.
Недавно интернет заполонили тесты новой фичи OpenAI, которую (наконец-то!) раскатили для всех платных подписчиков аккурат перед презентацией Meta, ведь там показали тоже показали голосовой режим.
Но потестить новый функционал в OpenAI удалось далеко не всем, потому что большинство русскоговорящих пользователей используют чат в браузере, где Voice Mode не работает, а приложения в плейсторе нет.
#гайд ChatGPT из Play Market и как пользоваться им без VPN.
Шаг 1. Самый муторный.
Меняем страну аккаунта Google на США.
(Можно попытаться пропустить этот шаг и скачать apk с какого-нибудь зеркала, но, скорее всего, это не сработает)
1.1 Открываем payments.google.com > Настройки.
1.2 Создаём новый платёжный профиль в США. Жмём на карандаш рядом с пунктом «Страна», см. скрин.
1.3 Переходим на сайт bestrandoms.com и генерируем американский адрес.
(Желательно в Аляске — если вдруг что-то будете оплачивать с карты US, не будет налога. Аналогично можно сгенерировать адрес для других стран и карт)
1.4 Для надёжности можно удалить старый non-US профиль.
1.5 Заходим в Google Play (Play Market) > Настройки > Общие > Настройки аккаунта и устройства. В разделе «Страна и профили» меняем страну на США.
Плеймаркет обновится не сразу, так что если не получилось с первого раза, подождите ещё суток, и приложение появится. (По крайней мере вышло именно, так когда мы тестировали)
Шаг 2. Кайфовый.
Включаем Private DNS.
2.1 Открываем настройки устройства, вводим в поиске «Private DNS» и вписываем туда адрес сервиса DoT от Comss (подробнее здесь).
2.2 Идём в Настройки > Подключение и общий доступ > Частный DNS сервер и вставляем туда адрес: comss.dns.controld.com.
2.3 Всё! Теперь ChatGPT (а также Bing, Bard и Claude) будет работать без VPN. К тому же, это избавит от большей части рекламы на сайтах и в приложениях, ещё и повысит безопасность сети.
Шаг 3. Финальный.
Устанавливаем приложение ChatGPT из Google Play.
3.1 Установили.
3.2 Вошли.
Готово! Если у вас есть подписка, то Voice Mode уже должен быть доступен. Делитесь своими экспериментами в комментах.
Источник 4PDA
_______
Источник | #ai_newz
#полезности
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney
и устанавливаем официальную апку на андройд.
Недавно интернет заполонили тесты новой фичи OpenAI, которую (наконец-то!) раскатили для всех платных подписчиков аккурат перед презентацией Meta, ведь там показали тоже показали голосовой режим.
Но потестить новый функционал в OpenAI удалось далеко не всем, потому что большинство русскоговорящих пользователей используют чат в браузере, где Voice Mode не работает, а приложения в плейсторе нет.
#гайд ChatGPT из Play Market и как пользоваться им без VPN.
Шаг 1. Самый муторный.
Меняем страну аккаунта Google на США.
(Можно попытаться пропустить этот шаг и скачать apk с какого-нибудь зеркала, но, скорее всего, это не сработает)
1.1 Открываем payments.google.com > Настройки.
1.2 Создаём новый платёжный профиль в США. Жмём на карандаш рядом с пунктом «Страна», см. скрин.
1.3 Переходим на сайт bestrandoms.com и генерируем американский адрес.
(Желательно в Аляске — если вдруг что-то будете оплачивать с карты US, не будет налога. Аналогично можно сгенерировать адрес для других стран и карт)
1.4 Для надёжности можно удалить старый non-US профиль.
1.5 Заходим в Google Play (Play Market) > Настройки > Общие > Настройки аккаунта и устройства. В разделе «Страна и профили» меняем страну на США.
Плеймаркет обновится не сразу, так что если не получилось с первого раза, подождите ещё суток, и приложение появится. (По крайней мере вышло именно, так когда мы тестировали)
Шаг 2. Кайфовый.
Включаем Private DNS.
2.1 Открываем настройки устройства, вводим в поиске «Private DNS» и вписываем туда адрес сервиса DoT от Comss (подробнее здесь).
2.2 Идём в Настройки > Подключение и общий доступ > Частный DNS сервер и вставляем туда адрес: comss.dns.controld.com.
2.3 Всё! Теперь ChatGPT (а также Bing, Bard и Claude) будет работать без VPN. К тому же, это избавит от большей части рекламы на сайтах и в приложениях, ещё и повысит безопасность сети.
Шаг 3. Финальный.
Устанавливаем приложение ChatGPT из Google Play.
3.1 Установили.
3.2 Вошли.
Готово! Если у вас есть подписка, то Voice Mode уже должен быть доступен. Делитесь своими экспериментами в комментах.
Источник 4PDA
_______
Источник | #ai_newz
#полезности
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney
Telegram
эйай ньюз
Показали голосовой режим для Meta AI!
Первый прямой конкурент Advanced Voice Mode. Будет доступен уже сегодня - бесплатно!
Будет доступно куча голосов знаменитостей - John Cena, Awkwafina, etc.
Раньше OpenAI релизили перед анонсами гугла, теперь перед…
Первый прямой конкурент Advanced Voice Mode. Будет доступен уже сегодня - бесплатно!
Будет доступно куча голосов знаменитостей - John Cena, Awkwafina, etc.
Раньше OpenAI релизили перед анонсами гугла, теперь перед…
Новый Sonnet и Haiku от Anthropic!
www.anthropic.com
Claude 3.5 Sonnet сильно прокачали по всем фронтам, особенно в кодинге (где дальше o1 обошли). А маленький Claude 3.5 Haiku теперь на уровне прошлой большой модели, в том числе в кодинге и размышлениях, при этом стоит копейки.
Плюс сделали фичу Computer Use - www.anthropic.com
Теперь можно попросить модель "использовать компьютер за вас": двигать мышкой, кликать, вводить. Пока только для разработчиков и работает нестабильно, но выглядит круто. RPA-провайдеры нервно закурили
Смотрите крутой видос - youtu.be
_______
Источник | #ai_product
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney
www.anthropic.com
Claude 3.5 Sonnet сильно прокачали по всем фронтам, особенно в кодинге (где дальше o1 обошли). А маленький Claude 3.5 Haiku теперь на уровне прошлой большой модели, в том числе в кодинге и размышлениях, при этом стоит копейки.
Плюс сделали фичу Computer Use - www.anthropic.com
Теперь можно попросить модель "использовать компьютер за вас": двигать мышкой, кликать, вводить. Пока только для разработчиков и работает нестабильно, но выглядит круто. RPA-провайдеры нервно закурили
Смотрите крутой видос - youtu.be
_______
Источник | #ai_product
@F_S_C_P
▪️Генерируй картинки в боте:
Flux + MidJourney