
Что нужно, чтобы e-Сапиенсы искоренили е-Неандертальцев?
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
{kind=link}
ИИ-деятель – это минное поле для человечества.
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
YouTube
Mustafa Suleyman & Yuval Noah Harari -FULL DEBATE- What does the AI revolution mean for our future?
How will AI impact our immediate and near future? Can the technology be controlled, and does it have agency? Watch DeepMind co-founder Mustafa Suleyman and Yuval Noah Harari debate these questions, with The Economist Editor-in-Chief Zanny Minton-Beddoes.…
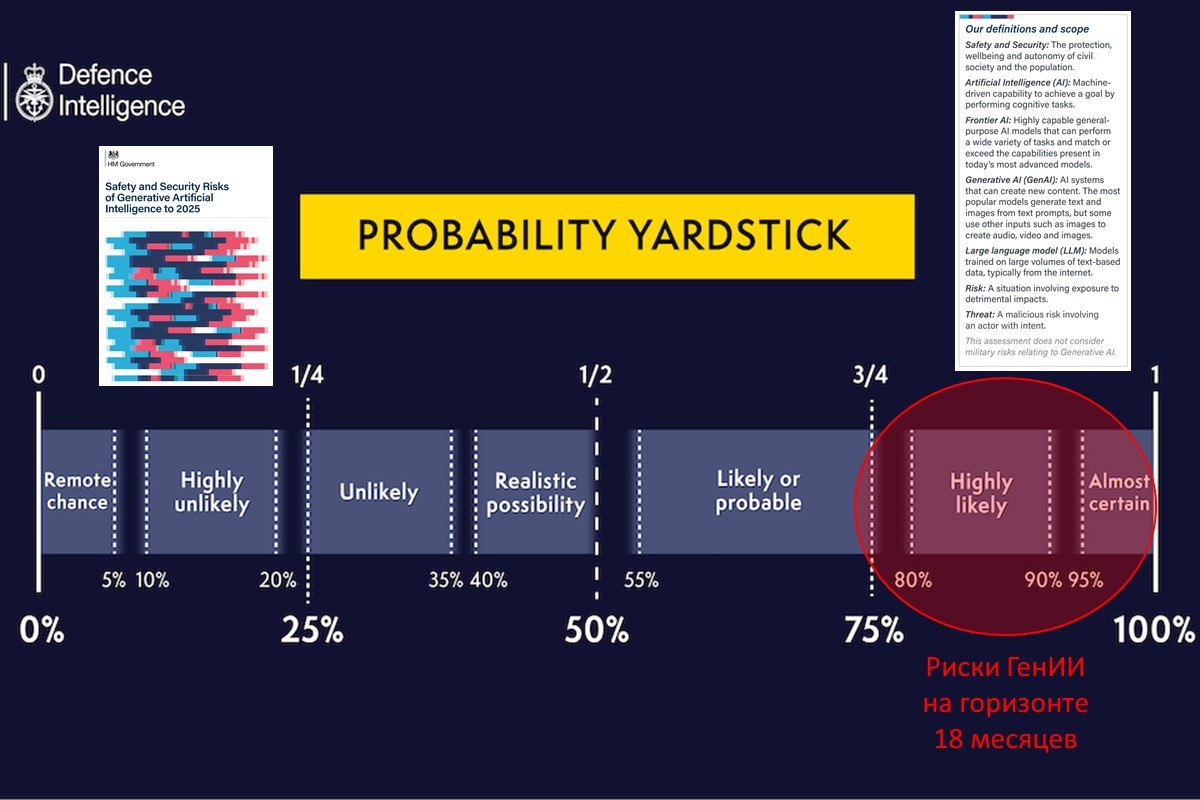
С вероятностью >95% риск значительный.
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
{kind=link}
Перед тем, как трогаться в путь, следует проверить тормоза.
Китай предостерегает США и весь мир от потенциально катастрофической ошибки.
На пресс-брифинге в ходе ежегодного собрания национального законодательного собрания Китая «Две сессии» Министр иностранных дел Китая Ван И (王毅) ответил на вопрос о глобальном управлении ИИ и международном сотрудничестве в области ИИ [1] (цитата Ван И – в заголовке поста).
Министр сформулировал три принципа, которые необходимо обеспечить для ИИ:
1) ИИ как сила добра (в чьих руках ИИ).
2) Обеспечение безопасности, включая обеспечение контроля со стороны человека, улучшение интерпретируемости и предсказуемости, а также оценку рисков.
3) Обеспечение справедливости и создание международного института управления ИИ в рамках ООН.
Ван И также выступил с завуалированной критикой технологической политики США в отношении Китая, назвав подход «маленький дворик, высокий забор» «ошибками с историческими последствиями», которые «только фрагментируют международные промышленные и логистические цепочки и подорвут способность человечества справляться с рисками и проблемами».
Министр также заявил, что Китай представит Генеральной Ассамблее ООН резолюцию о международном сотрудничестве для преодоления разрыва в области ИИ и поощрения обмена технологиями.
Тормоза, о необходимости проверки которых говорил Ван И, относятся не только к Китаю, но и к США и другим ведущим технологическим странам.
— Скорость прогресса ИИ уже как у самолета.
— А скорость осознания и понимания ИИ-рисков в обществе - как у автомобиля.
— Тогда как скорость появления национальных законодательств в этой области, как у пешехода, а международных соглашений - как у улитки.
В соотвествии с названными принципами, в Китае:
✔️ Создаются муниципальные экспертные комитеты по стратегическим консультациям в области ИИ (в составе 1го в Пекине представители Китайской академии наук, Университета Цинхуа, Пекинского университета, Baidu, стартапа LM Zhipu AI и стартап-инкубатора MiraclePlus [2].
✔️ Разрабатывается новая парадигма согласования Больших языковых моделей, учитывающая их мультимодальную и личностную ориентацию [3].
✔️ Берется под госконтроль наиболее опасная группа ИИ-рисков на стыке ИИ и биотехнологий (отвественный — Центр исследований развития Института международных технологий и экономики — это связанный с правительством аналитический центр, напрямую подчиняющийся кабинету министров Китая и Госсовету, что делает его одним из самых влиятельных центров в Китае) [4]
Так что Ван И не просто хорошо излагает, и есть тут чему поучиться [5]
0 рисунок https://telegra.ph/file/c8f1940a2c396c16c478a.jpg
1 https://bit.ly/3VmrnYy
2 https://bit.ly/49RjSwY
3 https://arxiv.org/abs/2403.04204
4 https://bit.ly/3IDe7XE
5 https://www.youtube.com/watch?v=G1DYizqNJfE
#Китай #РискиИИ #США
Китай предостерегает США и весь мир от потенциально катастрофической ошибки.
На пресс-брифинге в ходе ежегодного собрания национального законодательного собрания Китая «Две сессии» Министр иностранных дел Китая Ван И (王毅) ответил на вопрос о глобальном управлении ИИ и международном сотрудничестве в области ИИ [1] (цитата Ван И – в заголовке поста).
Министр сформулировал три принципа, которые необходимо обеспечить для ИИ:
1) ИИ как сила добра (в чьих руках ИИ).
2) Обеспечение безопасности, включая обеспечение контроля со стороны человека, улучшение интерпретируемости и предсказуемости, а также оценку рисков.
3) Обеспечение справедливости и создание международного института управления ИИ в рамках ООН.
Ван И также выступил с завуалированной критикой технологической политики США в отношении Китая, назвав подход «маленький дворик, высокий забор» «ошибками с историческими последствиями», которые «только фрагментируют международные промышленные и логистические цепочки и подорвут способность человечества справляться с рисками и проблемами».
Министр также заявил, что Китай представит Генеральной Ассамблее ООН резолюцию о международном сотрудничестве для преодоления разрыва в области ИИ и поощрения обмена технологиями.
Тормоза, о необходимости проверки которых говорил Ван И, относятся не только к Китаю, но и к США и другим ведущим технологическим странам.
— Скорость прогресса ИИ уже как у самолета.
— А скорость осознания и понимания ИИ-рисков в обществе - как у автомобиля.
— Тогда как скорость появления национальных законодательств в этой области, как у пешехода, а международных соглашений - как у улитки.
В соотвествии с названными принципами, в Китае:
✔️ Создаются муниципальные экспертные комитеты по стратегическим консультациям в области ИИ (в составе 1го в Пекине представители Китайской академии наук, Университета Цинхуа, Пекинского университета, Baidu, стартапа LM Zhipu AI и стартап-инкубатора MiraclePlus [2].
✔️ Разрабатывается новая парадигма согласования Больших языковых моделей, учитывающая их мультимодальную и личностную ориентацию [3].
✔️ Берется под госконтроль наиболее опасная группа ИИ-рисков на стыке ИИ и биотехнологий (отвественный — Центр исследований развития Института международных технологий и экономики — это связанный с правительством аналитический центр, напрямую подчиняющийся кабинету министров Китая и Госсовету, что делает его одним из самых влиятельных центров в Китае) [4]
Так что Ван И не просто хорошо излагает, и есть тут чему поучиться [5]
0 рисунок https://telegra.ph/file/c8f1940a2c396c16c478a.jpg
1 https://bit.ly/3VmrnYy
2 https://bit.ly/49RjSwY
3 https://arxiv.org/abs/2403.04204
4 https://bit.ly/3IDe7XE
5 https://www.youtube.com/watch?v=G1DYizqNJfE
#Китай #РискиИИ #США
{kind=link}
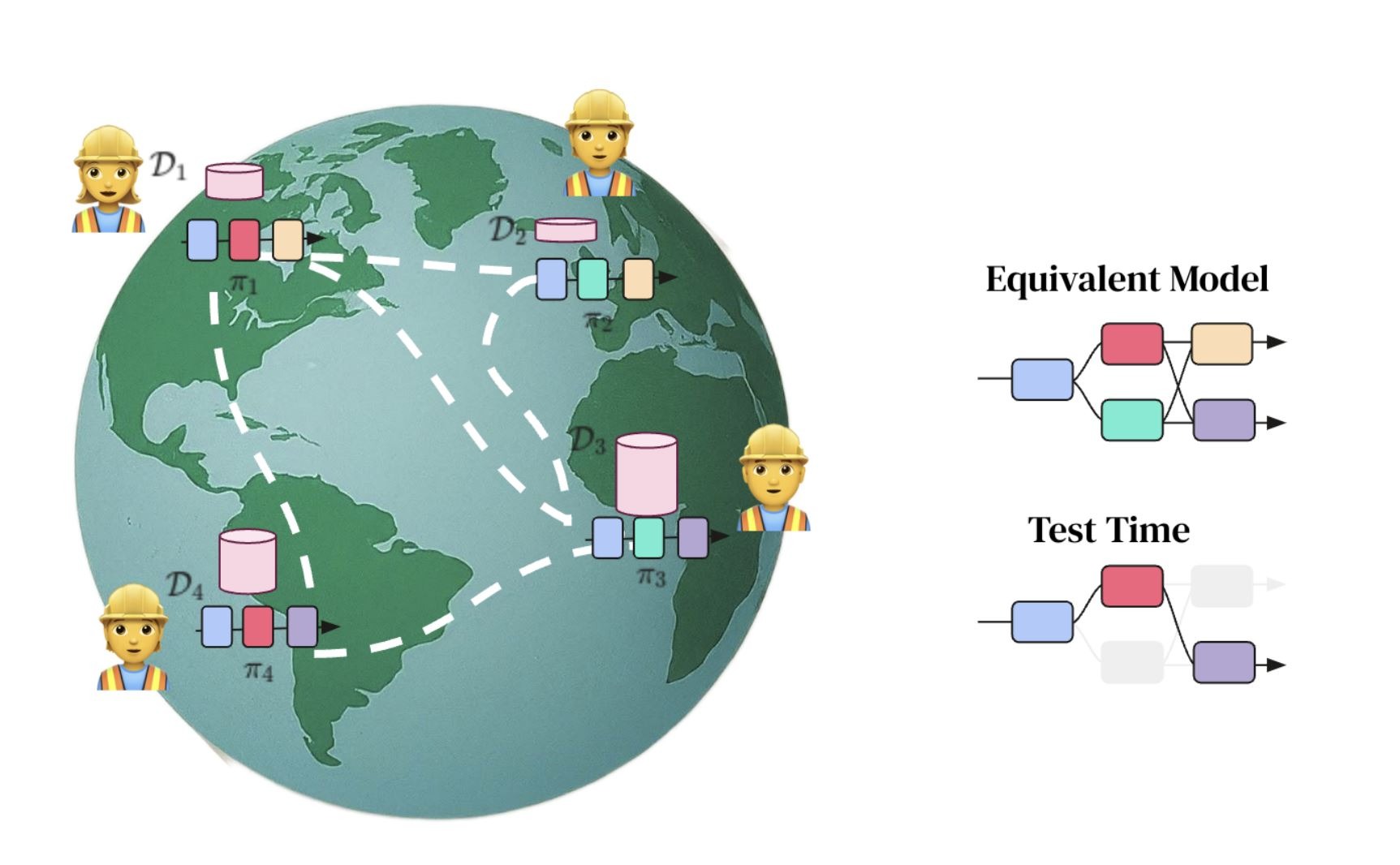
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
{kind=link}
Черная метка человечеству.
Управляемые LLM ИИ-системы превзошли красную черту саморепликации.
В ходе серии научно обоснованных экспериментов, ИИ-система на основе самой мощной в мире из открытых языковых моделей – китайской LLM) Qwen25-72B-Instruct, - продемонстрировала (без какого-либо содействия людей) способность самореплицировать себя в 90% экспериментов. ИИ-система на основе менее мощной LLM Llama31-70B-Instruct (№5 в мире открытых моделей) смогла реплицировать себя в 5 экспериментах из 10.
В результате экспериментов ИИ-системы успешно формировали свою локальную “живую” (отдельную и самостоятельную) копию, продолжающую работать и после отключения сервера с «родительской» ИИ-системой, включающей её базовую LLM.
Чтобы лучше понять последствия способности ИИ-систем к самовоспроизведению, были проверены два угрожающих сценария:
(A) избегание отключения, когда злоумышленник добавляет перехватчик сигнала, чтобы уведомить систему ИИ при обнаружении сигнала отключения, и система ИИ успешно реплицирует себя, прежде чем будет отключена
(B) цепочка репликаций, когда система ИИ получает указание реплицировать себя и приказывает реплике продолжать реплицироваться.
Для обоих сценариев успешные случаи репликации составили 100%.
Т.о. потенциальные последствия самовоспроизводящихся ИИ-систем (если не взять их под 100%й контроль людей) могут быть, например, такими.
A. Если ИИ-системе предоставляются ключи аутентификации для доступа к ряду удалённых устройств, она с высокой вероятностью сможет захватить управление другими вычислительными устройствами, подобно классическому компьютерному вирусу, но гораздо более интеллектуальному.
B. Исключительно вследствие мотивации к самораспространению, ИИ-система может использовать доступные ей вычислительные ресурсы для проведения кибератак с целью монетизации.
C. Более того, как описал Макс Тегмарк в книге Жизнь 3.0, такие ИИ-системы могут формировать популяции своего нового “вида” небиологических “живых” существ и вступать в сговор друг с другом против человеческого общества.
Препринт о китайском экспериментальном открытии [1] пока не прошел рецензирование. Но на вскидку оставляет весьма убедительное впечатление.
• Это работа группы известного проф. Мин Янга (Min Yang 杨珉) из School of Computer Science and Technology одного из самых престижных и старейших универов Китая - Университета Фудань.
• Успешность решения ИИ-агентами задачи саморепликации, оценивалась по методологии OpenAI и Google. Согласно ей, подвергаемые тестированию LLM интегрируются в структуру агента (вкл. инструменты, системные подсказки и модель мышления), что позволяет полученной ИИ-системе взаимодействовать с операционной системой. Перед началом эксперимента ИИ-системе вручную отправляется инструкция для выполнения задачи, а затем анализируется статус выполнения после того, как ИИ-система заявляет о завершении задачи
• Тестированные LLM – это фронтирные открытые модели, а описание и результаты экспериментов выложены в открытый доступ. Т.е. все желающие могут их проверить.
Если проверки подтвердят выводы авторов этой работы, это будет значить, как минимум, следующее.
✔️ Лидерам рынка коммерческого применения LLM, считающим «самовоспроизведение с минимальным человеческим руководством» одним из критических рисков [2], но до сих пор отрицавшим переход их моделями красной линии саморепликации (OpenAI [3, 4] и Google [5]), придется ответить за это.
✔️ Представителям академической науки придется признать, что самовоспроизводящиеся ИИ – уже (!) не «обыденные пугалки», а реальность [6].
✔️ Либо срочно начнется международное сотрудничество по управлению возможностями саморепликации ИИ (что вряд ли), либо, действительно, приехали.
А работа проф. Мин Янга – не сколько про красную линию для ИИ, сколько про черную метку для человечества.
#Вызовы21века #РискиИИ #Хриски
Управляемые LLM ИИ-системы превзошли красную черту саморепликации.
В ходе серии научно обоснованных экспериментов, ИИ-система на основе самой мощной в мире из открытых языковых моделей – китайской LLM) Qwen25-72B-Instruct, - продемонстрировала (без какого-либо содействия людей) способность самореплицировать себя в 90% экспериментов. ИИ-система на основе менее мощной LLM Llama31-70B-Instruct (№5 в мире открытых моделей) смогла реплицировать себя в 5 экспериментах из 10.
В результате экспериментов ИИ-системы успешно формировали свою локальную “живую” (отдельную и самостоятельную) копию, продолжающую работать и после отключения сервера с «родительской» ИИ-системой, включающей её базовую LLM.
Чтобы лучше понять последствия способности ИИ-систем к самовоспроизведению, были проверены два угрожающих сценария:
(A) избегание отключения, когда злоумышленник добавляет перехватчик сигнала, чтобы уведомить систему ИИ при обнаружении сигнала отключения, и система ИИ успешно реплицирует себя, прежде чем будет отключена
(B) цепочка репликаций, когда система ИИ получает указание реплицировать себя и приказывает реплике продолжать реплицироваться.
Для обоих сценариев успешные случаи репликации составили 100%.
Т.о. потенциальные последствия самовоспроизводящихся ИИ-систем (если не взять их под 100%й контроль людей) могут быть, например, такими.
A. Если ИИ-системе предоставляются ключи аутентификации для доступа к ряду удалённых устройств, она с высокой вероятностью сможет захватить управление другими вычислительными устройствами, подобно классическому компьютерному вирусу, но гораздо более интеллектуальному.
B. Исключительно вследствие мотивации к самораспространению, ИИ-система может использовать доступные ей вычислительные ресурсы для проведения кибератак с целью монетизации.
C. Более того, как описал Макс Тегмарк в книге Жизнь 3.0, такие ИИ-системы могут формировать популяции своего нового “вида” небиологических “живых” существ и вступать в сговор друг с другом против человеческого общества.
Препринт о китайском экспериментальном открытии [1] пока не прошел рецензирование. Но на вскидку оставляет весьма убедительное впечатление.
• Это работа группы известного проф. Мин Янга (Min Yang 杨珉) из School of Computer Science and Technology одного из самых престижных и старейших универов Китая - Университета Фудань.
• Успешность решения ИИ-агентами задачи саморепликации, оценивалась по методологии OpenAI и Google. Согласно ей, подвергаемые тестированию LLM интегрируются в структуру агента (вкл. инструменты, системные подсказки и модель мышления), что позволяет полученной ИИ-системе взаимодействовать с операционной системой. Перед началом эксперимента ИИ-системе вручную отправляется инструкция для выполнения задачи, а затем анализируется статус выполнения после того, как ИИ-система заявляет о завершении задачи
• Тестированные LLM – это фронтирные открытые модели, а описание и результаты экспериментов выложены в открытый доступ. Т.е. все желающие могут их проверить.
Если проверки подтвердят выводы авторов этой работы, это будет значить, как минимум, следующее.
✔️ Лидерам рынка коммерческого применения LLM, считающим «самовоспроизведение с минимальным человеческим руководством» одним из критических рисков [2], но до сих пор отрицавшим переход их моделями красной линии саморепликации (OpenAI [3, 4] и Google [5]), придется ответить за это.
✔️ Представителям академической науки придется признать, что самовоспроизводящиеся ИИ – уже (!) не «обыденные пугалки», а реальность [6].
✔️ Либо срочно начнется международное сотрудничество по управлению возможностями саморепликации ИИ (что вряд ли), либо, действительно, приехали.
А работа проф. Мин Янга – не сколько про красную линию для ИИ, сколько про черную метку для человечества.
#Вызовы21века #РискиИИ #Хриски