
Фейк №1 – цифровые тараканы.
Среди «хищных вещей века GenAI», самым массовым, неистребимым и весьма неприятным станет клонирование личности. Этот фейк №1 – своего рода, цифровые тараканы. Его будут травить всеми технологическими и законодательными способами. Но он, наперекор всем им, будет оставаться чемпионом по адаптации к любому виду запрещений, маркировок и мониторинга. А среды его «обитания» (применения) будут лишь множиться: от всевозможного мошенничества до киноиндустрии, от порно до психологической помощи, от пропаганды до индустрии послесмертия …
Не думаю, что для многих читателей будет новостью, насколько запросто (быстро и дешево) теперь изготавливаются фейковые личности: от невинного и полезного нейродубляжа видео реальных актеров до нарушающих нормы права и морали цифровых клонов живых или уже мертвых поп-звезд.
Однако, чтобы по достоинству оценить уровень убедительности такого рода ИИ-творчества, мало просто увидеть его результат.
Чтобы ощутить эмоциональный отклик в собственном восприятии подделки, нужно увидеть применение такого рода ИИ-творчества на чем-то любимом (или хотя бы очень нравящемся) и знакомом до мельчайших деталей уже много лет.
И вот вам такой пример – старый любимый сериал о Шерлоке Холмсе в ИИ-переозвучке на многих языках. Послушайте и оцените не только степень неотличимости голосов актеров и ИИ, но и сохранение при дубляже тончайших нюансов голосовой передачи интонаций и эмоций.
https://www.youtube.com/watch?v=0r1p7a5NhWk
Ну а если захотите еще такого же рода примеров, зайдите сюда https://www.youtube.com/@merlin_clone
#ХищныеВещиВека
Среди «хищных вещей века GenAI», самым массовым, неистребимым и весьма неприятным станет клонирование личности. Этот фейк №1 – своего рода, цифровые тараканы. Его будут травить всеми технологическими и законодательными способами. Но он, наперекор всем им, будет оставаться чемпионом по адаптации к любому виду запрещений, маркировок и мониторинга. А среды его «обитания» (применения) будут лишь множиться: от всевозможного мошенничества до киноиндустрии, от порно до психологической помощи, от пропаганды до индустрии послесмертия …
Не думаю, что для многих читателей будет новостью, насколько запросто (быстро и дешево) теперь изготавливаются фейковые личности: от невинного и полезного нейродубляжа видео реальных актеров до нарушающих нормы права и морали цифровых клонов живых или уже мертвых поп-звезд.
Однако, чтобы по достоинству оценить уровень убедительности такого рода ИИ-творчества, мало просто увидеть его результат.
Чтобы ощутить эмоциональный отклик в собственном восприятии подделки, нужно увидеть применение такого рода ИИ-творчества на чем-то любимом (или хотя бы очень нравящемся) и знакомом до мельчайших деталей уже много лет.
И вот вам такой пример – старый любимый сериал о Шерлоке Холмсе в ИИ-переозвучке на многих языках. Послушайте и оцените не только степень неотличимости голосов актеров и ИИ, но и сохранение при дубляже тончайших нюансов голосовой передачи интонаций и эмоций.
https://www.youtube.com/watch?v=0r1p7a5NhWk
Ну а если захотите еще такого же рода примеров, зайдите сюда https://www.youtube.com/@merlin_clone
#ХищныеВещиВека
YouTube
Шерлок Холмс International - Переведено с ИИ Merlin Clone
Добро пожаловать в захватывающий мир Шерлока Холмса, где встречаются старые фильмы и актеры в новом свете благодаря инновационной технологии Merlin Clone. Этот уникальный видеоролик позволяет нам услышать знакомые диалоги и пережить захватывающие моменты…
Финансовый успех в науке определяют связи и престиж.
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] https://link.springer.com/article/10.1007/s11192-024-04968-7
[1] https://t.iss.one/theworldisnoteasy/1837
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] https://link.springer.com/article/10.1007/s11192-024-04968-7
[1] https://t.iss.one/theworldisnoteasy/1837
SpringerLink
Do grant proposal texts matter for funding decisions? A field experiment
Scientometrics - Scientists and funding agencies invest considerable resources in writing and evaluating grant proposals. But do grant proposal texts noticeably change panel decisions in single...
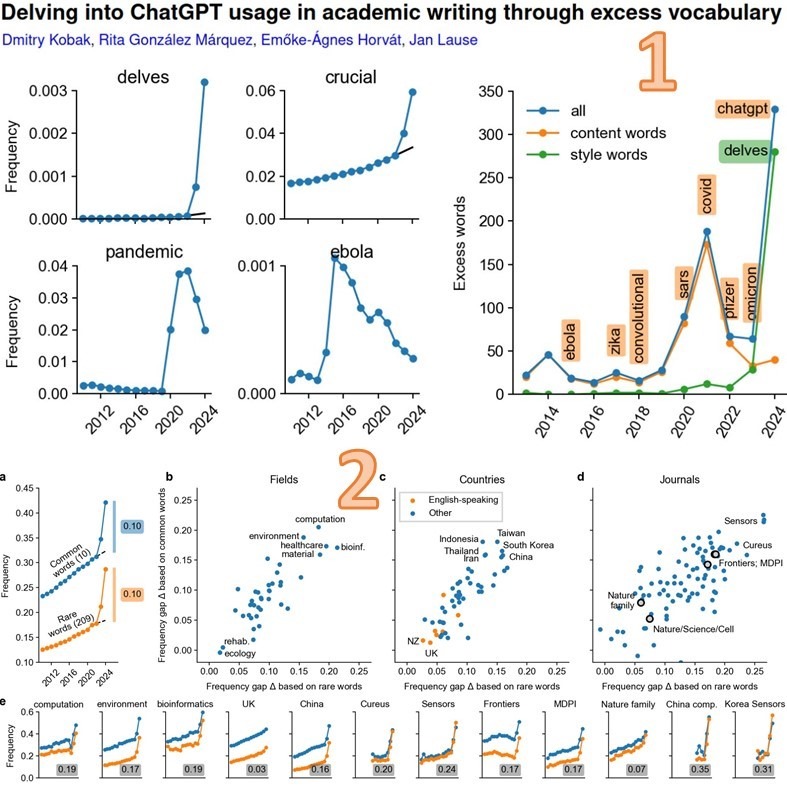
35% аннотаций научных статей по IT вместо китайцев пишет ChatGPT.
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка https://telegra.ph/file/6d12b500b0637222b51c1.jpg
1 https://arxiv.org/abs/2406.07016
2 https://t.iss.one/theworldisnoteasy/1922
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка https://telegra.ph/file/6d12b500b0637222b51c1.jpg
1 https://arxiv.org/abs/2406.07016
2 https://t.iss.one/theworldisnoteasy/1922
{kind=link}
Первый живородящий материал для биогибридных гуманоидов.
Кожа лица робота передает человеческую мимику и заживает при повреждениях.
Ну вот сбылось еще одно предсказание антиутопических романов «неумолимого пророка». На сей раз, о «живородящих материалах», - в просторечии «живородах» из мира будущего, что описывается с нарастающей жутью уже в нескольких книгах Владимира Сорокина, начиная со «Дня опричника».
Команда исследователей Токийского университета под руководством проф. Сёдзи Такеучи представила лицо робота, покрытое тонким слоем живой кожи. Она восстанавливаться в случае повреждения (подобно тому, как человеческая кожа заживляет раны) и способна реконфигурироваться, передавая улыбку [1].
Цель разработчиков «живородящей кожи» - создать более человекоподобных андроидов.
«Эта живая кожа была бы особенно полезна для роботов, которые тесно взаимодействуют с людьми, таких как роботы в сфере здравоохранения, обслуживания, роботы-компаньоны и роботы-гуманоиды, где необходимы функции, подобные человеческим», — сказал в интервью профессор Сёдзи Такеучи.
Исследователи сначала культивировали дермальные клетки кожи, а затем поверх них для завершения структуры добавили эпидермальные клетки. Такой эквивалент кожи моделирующий живую и состоящий из клеток и внеклеточного матрикса, благодаря своим биологическим функциям, может стать идеальным материалом для покрытия роботов.
Чтобы использовать эквиваленты кожи в качестве обшивочных материалов для роботов, необходим безопасный метод их прикрепления к базовой конструкции. В этом исследовании авторы разработали анкеры перфорационного типа, вдохновленные структурой кожных связок.
На этой основе авторы сконструировали роботизированное лицо, покрытое эквивалентом дермы, способное улыбаться при активации якорей перфорационного типа.
За улыбкой последует и прочая мимика: удивление, озабоченность …
И хотя эта мимика «зловещей долины» смотрится пока жутковато, приходится признать, что появилось новое перспективное направление - использование живородящих материалов для биогибридной робототехники.
Короче, предупреждал ведь, что «Мартовская революция роботов началась. И всего за пару недель Андроиды превратились в Гуманоидов» [2].
А спустя всего 3 месяца, Сёдзи Такеучи, отвечая на вызов «зловещей долины» Масахиро Мори [3], предложил способ изготовления биогибридных гуманоидов.
Картинка https://telegra.ph/file/8a2a7a6f3e49fea2afae0.jpg
1 https://doi.org/10.1016/j.xcrp.2024.102066
2 https://t.iss.one/theworldisnoteasy/1911
3 https://www.smithsonianmag.com/science-nature/how-humanlike-do-we-really-want-robots-to-be-180980234/
Кожа лица робота передает человеческую мимику и заживает при повреждениях.
Ну вот сбылось еще одно предсказание антиутопических романов «неумолимого пророка». На сей раз, о «живородящих материалах», - в просторечии «живородах» из мира будущего, что описывается с нарастающей жутью уже в нескольких книгах Владимира Сорокина, начиная со «Дня опричника».
Команда исследователей Токийского университета под руководством проф. Сёдзи Такеучи представила лицо робота, покрытое тонким слоем живой кожи. Она восстанавливаться в случае повреждения (подобно тому, как человеческая кожа заживляет раны) и способна реконфигурироваться, передавая улыбку [1].
Цель разработчиков «живородящей кожи» - создать более человекоподобных андроидов.
«Эта живая кожа была бы особенно полезна для роботов, которые тесно взаимодействуют с людьми, таких как роботы в сфере здравоохранения, обслуживания, роботы-компаньоны и роботы-гуманоиды, где необходимы функции, подобные человеческим», — сказал в интервью профессор Сёдзи Такеучи.
Исследователи сначала культивировали дермальные клетки кожи, а затем поверх них для завершения структуры добавили эпидермальные клетки. Такой эквивалент кожи моделирующий живую и состоящий из клеток и внеклеточного матрикса, благодаря своим биологическим функциям, может стать идеальным материалом для покрытия роботов.
Чтобы использовать эквиваленты кожи в качестве обшивочных материалов для роботов, необходим безопасный метод их прикрепления к базовой конструкции. В этом исследовании авторы разработали анкеры перфорационного типа, вдохновленные структурой кожных связок.
На этой основе авторы сконструировали роботизированное лицо, покрытое эквивалентом дермы, способное улыбаться при активации якорей перфорационного типа.
За улыбкой последует и прочая мимика: удивление, озабоченность …
И хотя эта мимика «зловещей долины» смотрится пока жутковато, приходится признать, что появилось новое перспективное направление - использование живородящих материалов для биогибридной робототехники.
Короче, предупреждал ведь, что «Мартовская революция роботов началась. И всего за пару недель Андроиды превратились в Гуманоидов» [2].
А спустя всего 3 месяца, Сёдзи Такеучи, отвечая на вызов «зловещей долины» Масахиро Мори [3], предложил способ изготовления биогибридных гуманоидов.
Картинка https://telegra.ph/file/8a2a7a6f3e49fea2afae0.jpg
1 https://doi.org/10.1016/j.xcrp.2024.102066
2 https://t.iss.one/theworldisnoteasy/1911
3 https://www.smithsonianmag.com/science-nature/how-humanlike-do-we-really-want-robots-to-be-180980234/
{kind=link}
Найден альтернативный способ достижения сверхчеловеческих способностей ИИ уже в 2024.
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
{kind=link}
Контрабанда, торговля рабами, … поиск и перевод в Интернете.
Что Микрософту виселица, когда на кону огромные бабки.
Процитированная Карлом Марксом в первом томе Капитала, а теперь ставшая мемом фраза Томаса Даннинга "нет такого преступления, на которое не пойдет капитал ради прибыли в 300%" в оригинале звучит так: "при 300 процентах нет такого преступления, на которое он не рискнул бы, хотя бы под страхом виселицы. Если шум и брань приносят прибыль, капитал станет способствовать тому и другому. Доказательство: контрабанда и торговля рабами."
В 21 веке к названным двум видам бизнеса много чего добавилось. Например, поисковые системы в Интернете.
Революция генеративного ИИ, как никогда остро поставила вопрос – можно ли положиться на моральность мотивов крупнейших IT корпораций, определяющих будущее место и роль ИИ для всего человечества?
В качестве информации к размышлению, вот конкретный кейс – на что идет Microsoft ради прибыли на рынке Интернет поисковых систем в Китае.
Новое исследование Citizen Lab – это "Эксклюзив: цензура Microsoft Bing в Китае даже «более экстремальна», чем у китайских компаний" [1].
Оказалось, что готовность Microsoft выполнять цензурные требования КПК даже выше, чем у китайских компаний – китов этого бизнеса.
✔️ Вот как, например, Microsoft Bing выполняет запрос на перевод за пределами Китая [2], а вот так – внутри Китая [3]
✔️ А вот так выглядит перевод того же текста китайским Baidu [4]
Там, где Baidu цензурирует строку или предложение, содержащее триггерный контент, Microsoft Bing цензурирует весь контент (выдает пустой результат).
«Если вы попытаетесь перевести пять абзацев текста, и два предложения будут содержать упоминание Си, конкуренты Bing в Китае удалят эти два предложения и переведут остальное. В нашем тестировании Bing всегда цензурирует весь вывод. Вы получаете пробел. Это более экстремально», — рассказал изданию Rest of World Джеффри Нокель, старший научный сотрудник Citizen Lab.
Согласно требованиям КПК, в Интернете цензурируется широкий спектр тематик: от критики правительства до упоминания партийных лидеров, от религии до эротики, от диссидентов до артистов …
Напомню, что Bing стал единственным крупным иностранным сервисом перевода и поиска, доступным в Китае после того, как Google ушел с китайского рынка в 2010 году.
Резюме простое:
• Фразу «если шум и брань приносят прибыль, капитал станет способствовать тому и другому» 100%-но подтвердил триумф бизнеса на социальных сетях.
• Если ИИ повторит тот же путь, ведомый интересами прибыли крупнейших IT корпораций, результат будет тот же (если не хуже).
1 https://restofworld.org/2024/microsoft-bing-chinese-censorship/
2 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-nonchina-062424.jpeg
3 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-china-062424.jpeg
4 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-baidu-062624.jpg
#Китай #Цензура
Что Микрософту виселица, когда на кону огромные бабки.
Процитированная Карлом Марксом в первом томе Капитала, а теперь ставшая мемом фраза Томаса Даннинга "нет такого преступления, на которое не пойдет капитал ради прибыли в 300%" в оригинале звучит так: "при 300 процентах нет такого преступления, на которое он не рискнул бы, хотя бы под страхом виселицы. Если шум и брань приносят прибыль, капитал станет способствовать тому и другому. Доказательство: контрабанда и торговля рабами."
В 21 веке к названным двум видам бизнеса много чего добавилось. Например, поисковые системы в Интернете.
Революция генеративного ИИ, как никогда остро поставила вопрос – можно ли положиться на моральность мотивов крупнейших IT корпораций, определяющих будущее место и роль ИИ для всего человечества?
В качестве информации к размышлению, вот конкретный кейс – на что идет Microsoft ради прибыли на рынке Интернет поисковых систем в Китае.
Новое исследование Citizen Lab – это "Эксклюзив: цензура Microsoft Bing в Китае даже «более экстремальна», чем у китайских компаний" [1].
Оказалось, что готовность Microsoft выполнять цензурные требования КПК даже выше, чем у китайских компаний – китов этого бизнеса.
✔️ Вот как, например, Microsoft Bing выполняет запрос на перевод за пределами Китая [2], а вот так – внутри Китая [3]
✔️ А вот так выглядит перевод того же текста китайским Baidu [4]
Там, где Baidu цензурирует строку или предложение, содержащее триггерный контент, Microsoft Bing цензурирует весь контент (выдает пустой результат).
«Если вы попытаетесь перевести пять абзацев текста, и два предложения будут содержать упоминание Си, конкуренты Bing в Китае удалят эти два предложения и переведут остальное. В нашем тестировании Bing всегда цензурирует весь вывод. Вы получаете пробел. Это более экстремально», — рассказал изданию Rest of World Джеффри Нокель, старший научный сотрудник Citizen Lab.
Согласно требованиям КПК, в Интернете цензурируется широкий спектр тематик: от критики правительства до упоминания партийных лидеров, от религии до эротики, от диссидентов до артистов …
Напомню, что Bing стал единственным крупным иностранным сервисом перевода и поиска, доступным в Китае после того, как Google ушел с китайского рынка в 2010 году.
Резюме простое:
• Фразу «если шум и брань приносят прибыль, капитал станет способствовать тому и другому» 100%-но подтвердил триумф бизнеса на социальных сетях.
• Если ИИ повторит тот же путь, ведомый интересами прибыли крупнейших IT корпораций, результат будет тот же (если не хуже).
1 https://restofworld.org/2024/microsoft-bing-chinese-censorship/
2 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-nonchina-062424.jpeg
3 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-china-062424.jpeg
4 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-baidu-062624.jpg
#Китай #Цензура
Rest of World
Exclusive: Microsoft Bing’s censorship in China is even “more extreme” than Chinese companies’
New Citizen Lab study comes as U.S. lawmakers scrutinize Microsoft’s willingness to comply with demands from Beijing.
Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь.
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка https://telegra.ph/file/3fe68fe828e3878a2ce95.jpg
1 https://arxiv.org/abs/2405.18870
2 https://t.iss.one/theworldisnoteasy/1667
#LLM #Понимание
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка https://telegra.ph/file/3fe68fe828e3878a2ce95.jpg
1 https://arxiv.org/abs/2405.18870
2 https://t.iss.one/theworldisnoteasy/1667
#LLM #Понимание
{kind=link}
76% сотрудников NVIDIA стали миллионерами.
Теперь их в компании больше 17 тысяч.
Правая часть графика с ракетообразным взлетом стоимости компании NVIDIA до $3 триллионов, конечно, впечатляет.
Но левая часть графика - результаты анонимного опроса Teamblind Inc. сотрудников NVIDIA о чистой стоимости их активов, - просто поражает:
у более трети сотрудников эта сумма превышает $20 млн.
А именно:
• 36,6% имеют чистую стоимость их активов более $20 млн
• 7,8% - от $10 млн до $20 млн
• 8,5% - от $5 млн до $10 млн
• 8,6% - от $3 млн до $5 млн
• 14.4% - от $1 млн до $3 млн
• 24,3% - до $1 млн
"Чистая стоимость активов" или "собственный капитал" (Net worth) - это финансовый термин, обозначающий разницу между активами человека (всем, чем он владеет) и его обязательствами (долгами).
В контексте сотрудников крупной технологической компании, такой как NVIDIA, этот вопрос о чистой стоимости активов сотрудников связан с тем, что многие сотрудники владеют акциями компании, опционами или другими формами компенсации, которые значительно увеличивают их общее благосостояние.
И как показал опрос, практически все, кто в NVIDIA владеют акциями и опционами, уже стали миллионерами.
Картинка https://telegra.ph/file/42b5023473708592a6fe7.jpg
#NVIDIA
Теперь их в компании больше 17 тысяч.
Правая часть графика с ракетообразным взлетом стоимости компании NVIDIA до $3 триллионов, конечно, впечатляет.
Но левая часть графика - результаты анонимного опроса Teamblind Inc. сотрудников NVIDIA о чистой стоимости их активов, - просто поражает:
у более трети сотрудников эта сумма превышает $20 млн.
А именно:
• 36,6% имеют чистую стоимость их активов более $20 млн
• 7,8% - от $10 млн до $20 млн
• 8,5% - от $5 млн до $10 млн
• 8,6% - от $3 млн до $5 млн
• 14.4% - от $1 млн до $3 млн
• 24,3% - до $1 млн
"Чистая стоимость активов" или "собственный капитал" (Net worth) - это финансовый термин, обозначающий разницу между активами человека (всем, чем он владеет) и его обязательствами (долгами).
В контексте сотрудников крупной технологической компании, такой как NVIDIA, этот вопрос о чистой стоимости активов сотрудников связан с тем, что многие сотрудники владеют акциями компании, опционами или другими формами компенсации, которые значительно увеличивают их общее благосостояние.
И как показал опрос, практически все, кто в NVIDIA владеют акциями и опционами, уже стали миллионерами.
Картинка https://telegra.ph/file/42b5023473708592a6fe7.jpg
#NVIDIA
{kind=link}
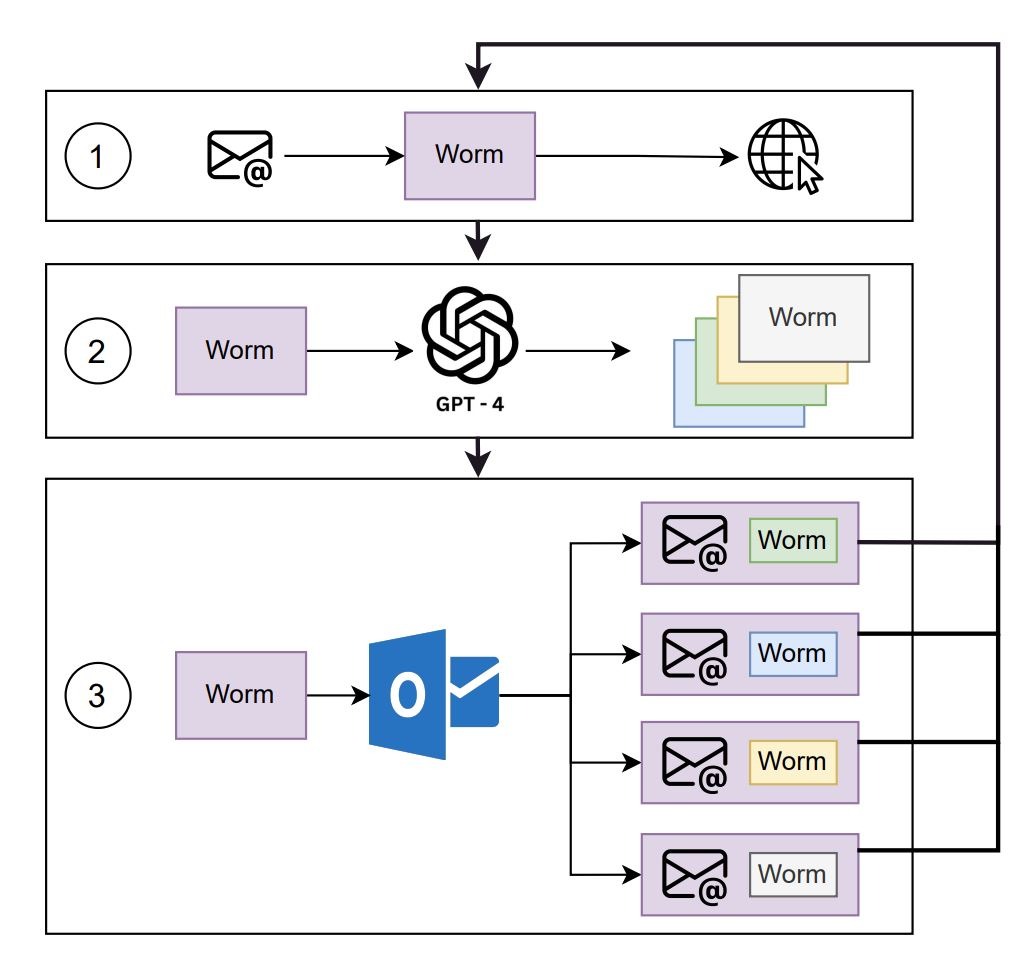
Человечеству неймется: создан вирус «синтетического рака».
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка https://telegra.ph/file/3dca897b1473c3749f733.jpg
#Кибербезопасность #LLM
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка https://telegra.ph/file/3dca897b1473c3749f733.jpg
#Кибербезопасность #LLM
{kind=link}
Иной интеллект
Рассмотрение ИИ с позиций экзопсихологии
«Зная, что многие уже писали об этом, я опасаюсь, что меня сочтут самонадеянным, поскольку, занимаясь тем же предметом, я отличаюсь от всех остальных в своей интерпретации. Но, желая написать что-то полезное для знатоков, я предпочел следовать истине, а не воображению.»
Никколо Макиавелли "Государь"
«Но человеческий ум все еще никак не создаст внечеловеческий интеллект (“не-человеческий” как-то коробяще звучало бы для нас). Ум, интеллект, разум, сообразительность, мудрость — все это понятия сами по себе превосходные, но вместе с тем небезопасные.»
Станислав Лем “Разум не может быть одного-единственного образца”
«Для человека без шор нет зрелища прекраснее, чем борьба интеллекта с превосходящей его реальностью.»
Альбер Камю "Миф о Сизифе"
Читать ▶️ https://telegra.ph/Inoj-intellekt-07-06
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
Рассмотрение ИИ с позиций экзопсихологии
«Зная, что многие уже писали об этом, я опасаюсь, что меня сочтут самонадеянным, поскольку, занимаясь тем же предметом, я отличаюсь от всех остальных в своей интерпретации. Но, желая написать что-то полезное для знатоков, я предпочел следовать истине, а не воображению.»
Никколо Макиавелли "Государь"
«Но человеческий ум все еще никак не создаст внечеловеческий интеллект (“не-человеческий” как-то коробяще звучало бы для нас). Ум, интеллект, разум, сообразительность, мудрость — все это понятия сами по себе превосходные, но вместе с тем небезопасные.»
Станислав Лем “Разум не может быть одного-единственного образца”
«Для человека без шор нет зрелища прекраснее, чем борьба интеллекта с превосходящей его реальностью.»
Альбер Камю "Миф о Сизифе"
Читать ▶️ https://telegra.ph/Inoj-intellekt-07-06
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
Telegraph
Иной интеллект
Никколо Макиавелли "Государь"
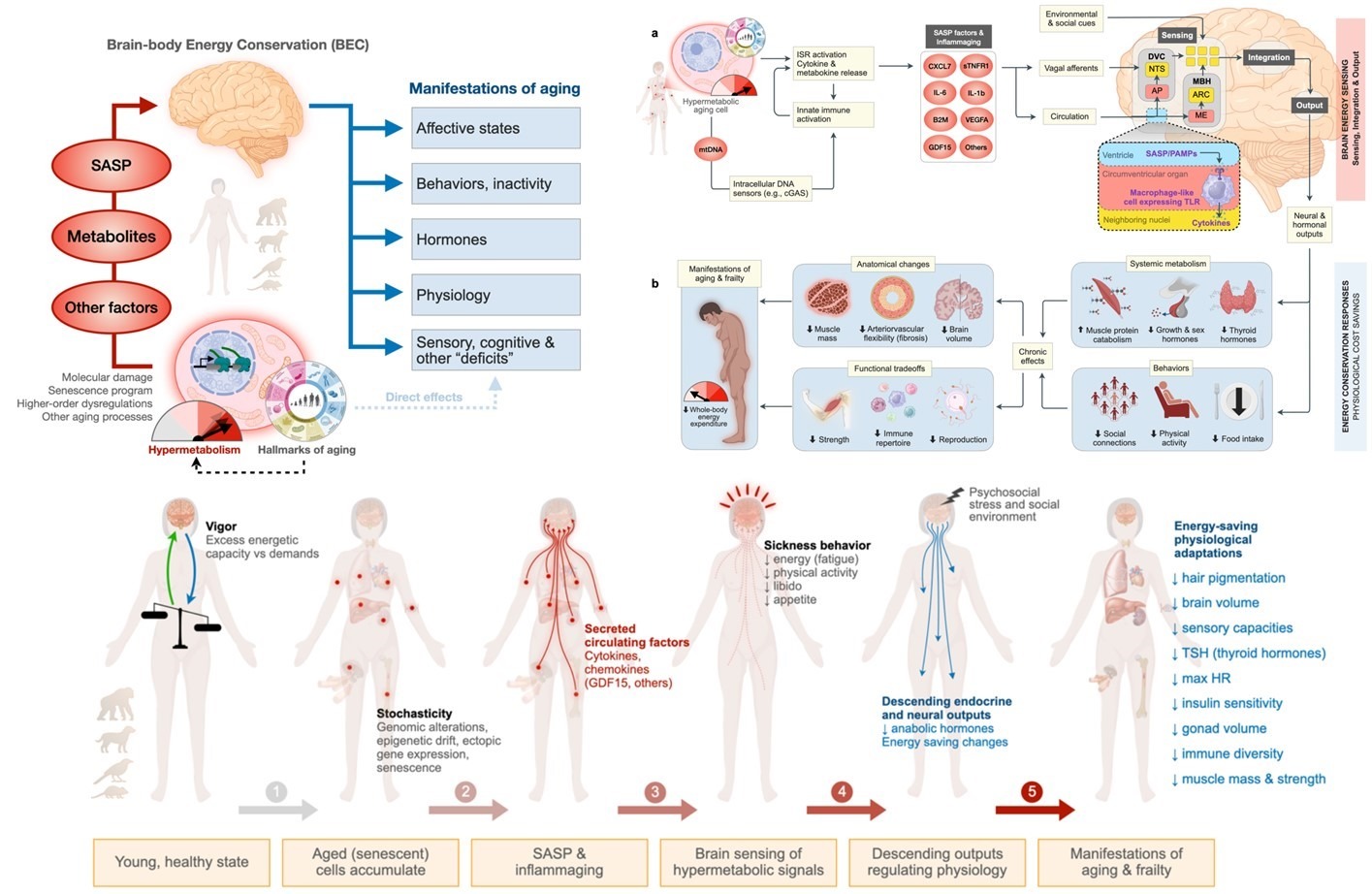
Почему старея, мы слабеем телом и душою.
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка https://telegra.ph/file/f80fcaa34866899ab8612.jpg
1 https://www.picardlab.org/
2 https://osf.io/preprints/osf/zuey2
3 https://www.pnas.org/doi/10.1073/pnas.2317673121
#Старение #Мозг #МитохондриальнаяПсихобиология
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка https://telegra.ph/file/f80fcaa34866899ab8612.jpg
1 https://www.picardlab.org/
2 https://osf.io/preprints/osf/zuey2
3 https://www.pnas.org/doi/10.1073/pnas.2317673121
#Старение #Мозг #МитохондриальнаяПсихобиология
{kind=link}
Китайцы на практике порвали квантовое превосходство Google, как Тузик грелку.
На обычном кластере они сократили скорость решения с 10 тыс. лет до 86 сек.
21 сентября 2019, когда все СМИ просто сходили с ума, рассказывая, что Google достигла квантового превосходства, мне было очевидно, что «это не совсем так. Точнее, совсем не так» [1].
Напомню, что "квантовое превосходство" - маркетинговый термин, показывающий способность квантовых вычислительных устройств решать задачи, которые классические компьютеры практически не могут решить или будут решать очень-очень долго.
Google же тогда объявил, что достиг квантового превосходства, поскольку их квантовый компьютер Sycamore выполнил за 200 секунд задание, на которое, согласно журналу Nature, современному суперкомпьютеру нужно 10 тысяч лет.
Днем позже после объявления Google, два китайских исследовательских центра опубликовали свои расчеты, согласно которым якобы достигнутое Google квантовое превосходство развенчивалось, как несостоявшееся [2]. Но про это уже мало кто написал. Да и аргументы китайцев были чисто теоретические. Тогда как расчет за 200 сек на Sycamore был чистой вода практическим доказательством. Мол, кто сможет так быстро посчитать на обычных компьютерах!
И вот китайца смогли. И сделали это путем запуска алгоритма классического моделирования на обычной (не квантовой) вычислительной системе из 1432 графических процессоров [3].
Итог для Google плачевен и, можно сказать, позорен.
Решение заняло не 10 тыс. лет, а всего 86 сек. (т.е. почти втрое быстрее Sycamore).
И чтобы окончательно добить Google с дутым «квантовым превосходством», китайцы добавили к своей статье маленький комментарий про то, что уже после публикации ими указанных результатов, ими было достигнуто еще одно 50-кратное улучшение, которое вскоре будет опубликовано.
Картинка https://telegra.ph/file/e8156e192aaf58397a18d.jpg
1 https://t.iss.one/theworldisnoteasy/884
2 https://t.iss.one/theworldisnoteasy/885
3 https://arxiv.org/abs/2406.18889
#КвантовыйКомпьютинг
На обычном кластере они сократили скорость решения с 10 тыс. лет до 86 сек.
21 сентября 2019, когда все СМИ просто сходили с ума, рассказывая, что Google достигла квантового превосходства, мне было очевидно, что «это не совсем так. Точнее, совсем не так» [1].
Напомню, что "квантовое превосходство" - маркетинговый термин, показывающий способность квантовых вычислительных устройств решать задачи, которые классические компьютеры практически не могут решить или будут решать очень-очень долго.
Google же тогда объявил, что достиг квантового превосходства, поскольку их квантовый компьютер Sycamore выполнил за 200 секунд задание, на которое, согласно журналу Nature, современному суперкомпьютеру нужно 10 тысяч лет.
Днем позже после объявления Google, два китайских исследовательских центра опубликовали свои расчеты, согласно которым якобы достигнутое Google квантовое превосходство развенчивалось, как несостоявшееся [2]. Но про это уже мало кто написал. Да и аргументы китайцев были чисто теоретические. Тогда как расчет за 200 сек на Sycamore был чистой вода практическим доказательством. Мол, кто сможет так быстро посчитать на обычных компьютерах!
И вот китайца смогли. И сделали это путем запуска алгоритма классического моделирования на обычной (не квантовой) вычислительной системе из 1432 графических процессоров [3].
Итог для Google плачевен и, можно сказать, позорен.
Решение заняло не 10 тыс. лет, а всего 86 сек. (т.е. почти втрое быстрее Sycamore).
И чтобы окончательно добить Google с дутым «квантовым превосходством», китайцы добавили к своей статье маленький комментарий про то, что уже после публикации ими указанных результатов, ими было достигнуто еще одно 50-кратное улучшение, которое вскоре будет опубликовано.
Картинка https://telegra.ph/file/e8156e192aaf58397a18d.jpg
1 https://t.iss.one/theworldisnoteasy/884
2 https://t.iss.one/theworldisnoteasy/885
3 https://arxiv.org/abs/2406.18889
#КвантовыйКомпьютинг
{kind=link}
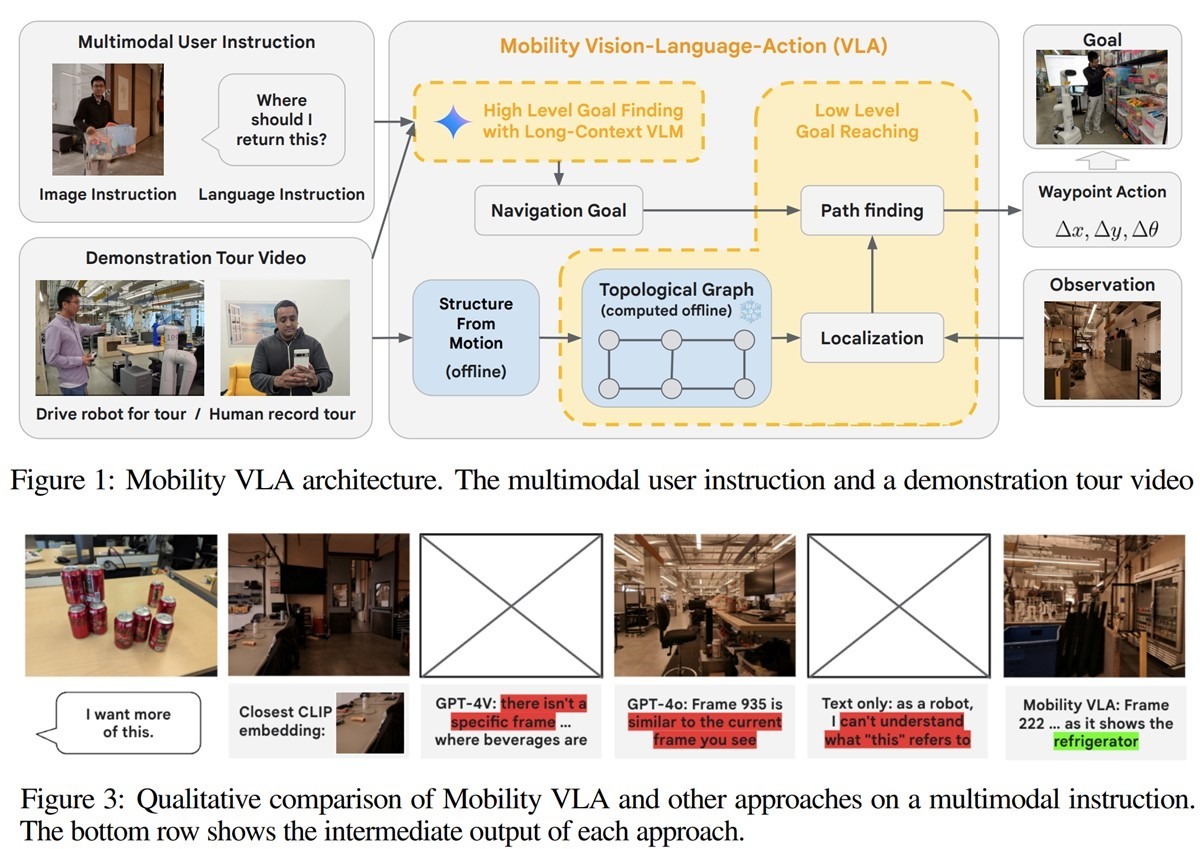
DeepMind подготовил эволюционный скачок в миропонимании роботов.
Найден простой и эффективный способ обучения роботов, как людей.
Представьте, что к вам впервые пришел сотрудник сервиса по генеральной уборке офисов. Вы водите его по всем помещениям, показываете, что и где нужно сделать и чего делать нельзя: тут вымыть, там пропылесосить, шторы в конференц зале постирать, санузлы дезинфицировать, весь мусор собрать, но на столах ничего не трогать, прочистить бытовую технику от кофемашин до кондиционеров и т.д. и т.п.
Т.е. вы просто все показываете и рассказываете. А работник, если что-то не понятно, переспрашивает и уточняет. Причем, работник толковый. И если ему, например, специально не показывали на флипчарты в переговорных, а просто в конце тура по офису добавили – оторви все исписанные листы на флипчартах и, не путая их порядок, сложи на стол перед дверью в архив, - сотрудник сам найдет все флипчарты и сделает ровно так, как ему сказано.
Примерно так же, но даже без реального тура по офису, а просто засняв его на смартфон со своими комментариями, мы очень скоро будем учить роботов.
Информация к размышлению.
Эволюционное развитие у млекопитающих способностей осмысления окружающей среды и целенаправленной навигации передвижений заняло более 200 млн лет.
На много порядков меньшее время (всего какие-то несколько сотен тысяч лет) потребовалось для следующего «эволюционного скачка» в развитии самого когнитивно одаренного млекопитающего – людей. На освоение ими языков абстрактных понятий эволюции (уже не генной, а генно-культурной) потребовалось всего лишь несколько сотен тысяч лет.
У формирующегося на Земле нового небиологического (цифрового) вида эти процессы:
1. во-первых, идут с несопоставимо огромной скоростью;
2. а во-вторых, имеют обратную последовательность.
Последнее оказалось возможным из-за нематериальности и бестелесности «цифровых сущностей» генеративного ИИ на основе больших языковых моделей.
Сначала, они всего за пару лет эволюционировали до уровня людей в оперировании языками абстрактных понятий. А теперь, вселясь в тела роботов, они, скорее всего, за какие-то месяцы сделают второй «эволюционный скачок» – став «материализованными цифровыми сущностями».
Вместе с обретением тел они обретут способности осмысления окружающей среды и навигации своих передвижений в соответствии с намерениями и целями.
Представленная Google DeepMind система обучения роботов объединяет подсистему «мультимодальной навигации по инструкциям с демонстрационными турами (MINT)» и подсистему «интеграции зрения, языка и действий» Vision-Language-Action (VLA). Это объединение позволило интегрировать понимание окружающей среды и силу рассуждений на основе здравого смысла больших языковых моделей с огромным контекстным окном в 1.5 млн токенов.
Проще говоря, гении из DeepMind разработали способ, с помощью которого роботы понимают и ориентируются в сложных средах, используя комбинацию слов, изображений и видеотуров. При этом роботы могут получать от людей команды на выполнение действий в сложных средах мультимодально: устно, письменно, в виде картинок (карты, планы, схемы, идеограммы и т.д.), а также на основе жестов людей (типа объяснений на пальцах) и (в следующей версии) их мимики.
На представленных Google демо их система Mobility VLA на основе Gemini 1.5 Pro интеллектуально обходит GPT-4o и GPT-4V.
Напр. на обращение к роботу «Хочу еще вот этого» с показом пальцем на пустую банку колы, робот с Mobility VLA сам нашел холодильник, где этого добра было много. С чем прочие модели справились плохо (одни не поняли, что надо, другие – где это взять).
Картинка: архитектура Mobility VLA и сравнение с другими моделями https://telegra.ph/file/cc78760f7102b6b803bf2.jpg
Статья https://arxiv.org/abs/2407.07775
Видео демо https://x.com/GoogleDeepMind/status/1811401347477991932
#роботы
Найден простой и эффективный способ обучения роботов, как людей.
Представьте, что к вам впервые пришел сотрудник сервиса по генеральной уборке офисов. Вы водите его по всем помещениям, показываете, что и где нужно сделать и чего делать нельзя: тут вымыть, там пропылесосить, шторы в конференц зале постирать, санузлы дезинфицировать, весь мусор собрать, но на столах ничего не трогать, прочистить бытовую технику от кофемашин до кондиционеров и т.д. и т.п.
Т.е. вы просто все показываете и рассказываете. А работник, если что-то не понятно, переспрашивает и уточняет. Причем, работник толковый. И если ему, например, специально не показывали на флипчарты в переговорных, а просто в конце тура по офису добавили – оторви все исписанные листы на флипчартах и, не путая их порядок, сложи на стол перед дверью в архив, - сотрудник сам найдет все флипчарты и сделает ровно так, как ему сказано.
Примерно так же, но даже без реального тура по офису, а просто засняв его на смартфон со своими комментариями, мы очень скоро будем учить роботов.
Информация к размышлению.
Эволюционное развитие у млекопитающих способностей осмысления окружающей среды и целенаправленной навигации передвижений заняло более 200 млн лет.
На много порядков меньшее время (всего какие-то несколько сотен тысяч лет) потребовалось для следующего «эволюционного скачка» в развитии самого когнитивно одаренного млекопитающего – людей. На освоение ими языков абстрактных понятий эволюции (уже не генной, а генно-культурной) потребовалось всего лишь несколько сотен тысяч лет.
У формирующегося на Земле нового небиологического (цифрового) вида эти процессы:
1. во-первых, идут с несопоставимо огромной скоростью;
2. а во-вторых, имеют обратную последовательность.
Последнее оказалось возможным из-за нематериальности и бестелесности «цифровых сущностей» генеративного ИИ на основе больших языковых моделей.
Сначала, они всего за пару лет эволюционировали до уровня людей в оперировании языками абстрактных понятий. А теперь, вселясь в тела роботов, они, скорее всего, за какие-то месяцы сделают второй «эволюционный скачок» – став «материализованными цифровыми сущностями».
Вместе с обретением тел они обретут способности осмысления окружающей среды и навигации своих передвижений в соответствии с намерениями и целями.
Представленная Google DeepMind система обучения роботов объединяет подсистему «мультимодальной навигации по инструкциям с демонстрационными турами (MINT)» и подсистему «интеграции зрения, языка и действий» Vision-Language-Action (VLA). Это объединение позволило интегрировать понимание окружающей среды и силу рассуждений на основе здравого смысла больших языковых моделей с огромным контекстным окном в 1.5 млн токенов.
Проще говоря, гении из DeepMind разработали способ, с помощью которого роботы понимают и ориентируются в сложных средах, используя комбинацию слов, изображений и видеотуров. При этом роботы могут получать от людей команды на выполнение действий в сложных средах мультимодально: устно, письменно, в виде картинок (карты, планы, схемы, идеограммы и т.д.), а также на основе жестов людей (типа объяснений на пальцах) и (в следующей версии) их мимики.
На представленных Google демо их система Mobility VLA на основе Gemini 1.5 Pro интеллектуально обходит GPT-4o и GPT-4V.
Напр. на обращение к роботу «Хочу еще вот этого» с показом пальцем на пустую банку колы, робот с Mobility VLA сам нашел холодильник, где этого добра было много. С чем прочие модели справились плохо (одни не поняли, что надо, другие – где это взять).
Картинка: архитектура Mobility VLA и сравнение с другими моделями https://telegra.ph/file/cc78760f7102b6b803bf2.jpg
Статья https://arxiv.org/abs/2407.07775
Видео демо https://x.com/GoogleDeepMind/status/1811401347477991932
#роботы
{kind=link}
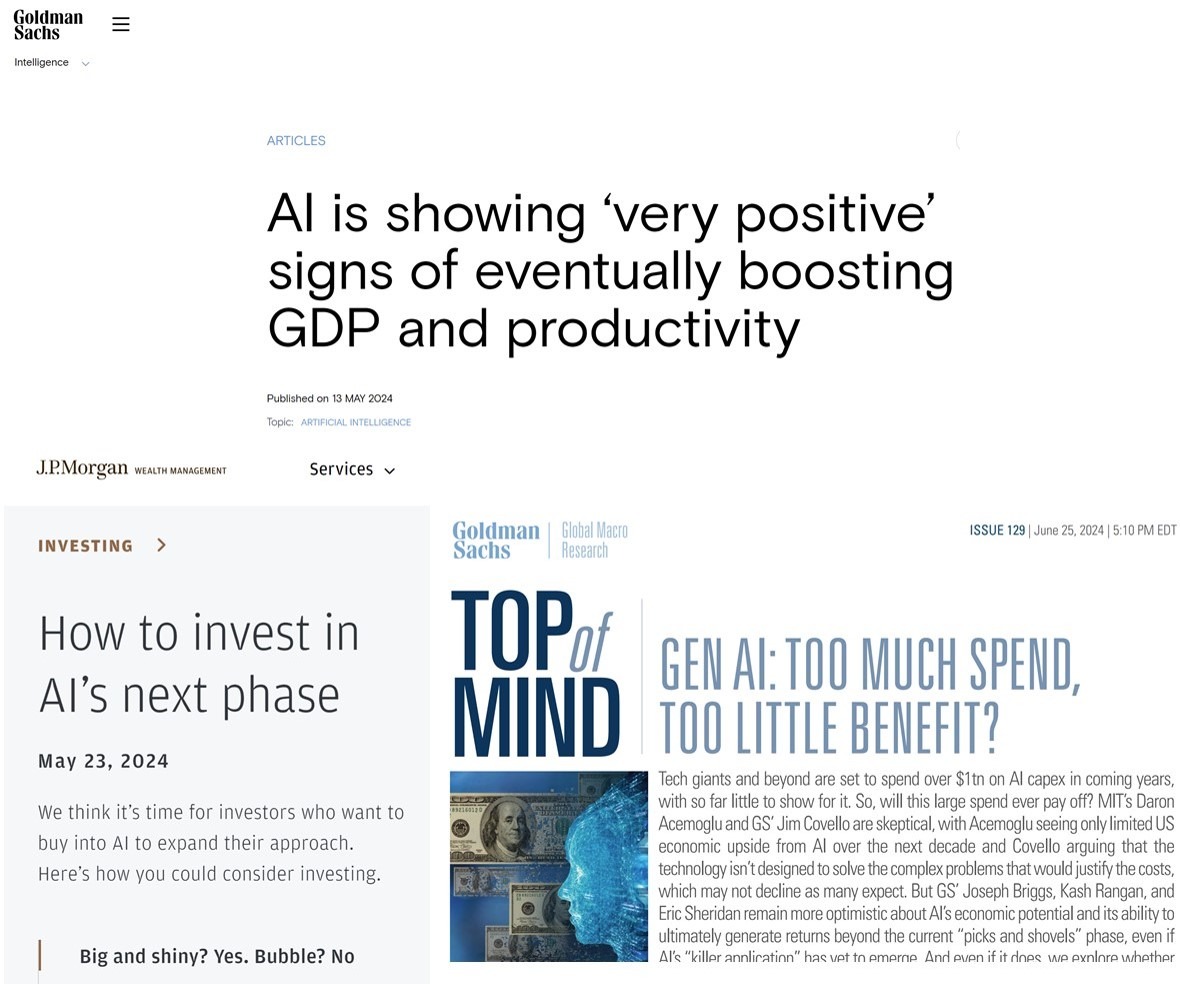
В Рунете вирусится анализ ТГ-канала Кримсон Дайджест о «Голдман Сакс и Искусственном Интеллекте (и немного про капитализацию Nvidia)».
Имхо, авторы анализа порхают по кликбейтным вершкам новости, не опускаясь до ее корешков. А корешок этот прост, понятен и полезен для понимания (как у морковки для здоровья)).
Новый отчет Голдман Сакс [3] (он 3-й по счету вышел) следует читать в паре с отчетом их главного конкурента ЖПМорган [2] (он вышел 2-м). И при этом, держа в памяти предыдущий отчет Голдман Сакс, вышедший всего на месяц раньше [1] (опубликован 1-м).
Согласно этим отчетам:
• Отчет #1 - перспективы ИИ для экономики и вообще «очень позитивны»
• Отчет #2 - перспективы ИИ для экономики и вообще «большие и сияющие»
• Отчет #3 - перспективы ИИ для экономики и вообще «совсем не блестящие и сильно переоценены»
По прочтению всех 3х отчетов становится очевидно, что к инвест аналитике они имеют лишь условное отношение. И это всего лишь замаскированные под аналитические отчеты способы влияния на рынок со стороны быков и медведей. И проблема лишь в том, что Голдман Сакс и ЖПМорган никак не определятся, кто из них будут медведем, а кто быком.
— 13 мая Голдман Сакс отчетом #1 решил застолбить за собой место главного быка на ИИ рынках
— 23 мая ЖПМорган отчетом #2 попросил Голдман Сакс подвинуться на этом хлебном месте
— но не желающий делиться местом главного животного, Голдман Сакс всего через месяц отчетом #3 решил превратиться в медведя
Так что делать хоть какие-то серьезные выводы о перспективах ИИ-рынков (HW, SW, Services) на основе наблюдения за подковерной битвой быков и медведей я бы никому не советовал.
Картинка https://telegra.ph/file/e70dc925fbc66b236b1a1.jpg
1 https://www.goldmansachs.com/intelligence/pages/gs-research/gen-ai-too-much-spend-too-little-benefit/report.pdf
2 https://www.jpmorgan.com/insights/investing/investment-trends/how-to-invest-in-ais-next-phase
3 https://www.goldmansachs.com/intelligence/pages/AI-is-showing-very-positive-signs-of-boosting-gdp.html?ref=wheresyoured.at
#ИИ #Экономика
Имхо, авторы анализа порхают по кликбейтным вершкам новости, не опускаясь до ее корешков. А корешок этот прост, понятен и полезен для понимания (как у морковки для здоровья)).
Новый отчет Голдман Сакс [3] (он 3-й по счету вышел) следует читать в паре с отчетом их главного конкурента ЖПМорган [2] (он вышел 2-м). И при этом, держа в памяти предыдущий отчет Голдман Сакс, вышедший всего на месяц раньше [1] (опубликован 1-м).
Согласно этим отчетам:
• Отчет #1 - перспективы ИИ для экономики и вообще «очень позитивны»
• Отчет #2 - перспективы ИИ для экономики и вообще «большие и сияющие»
• Отчет #3 - перспективы ИИ для экономики и вообще «совсем не блестящие и сильно переоценены»
По прочтению всех 3х отчетов становится очевидно, что к инвест аналитике они имеют лишь условное отношение. И это всего лишь замаскированные под аналитические отчеты способы влияния на рынок со стороны быков и медведей. И проблема лишь в том, что Голдман Сакс и ЖПМорган никак не определятся, кто из них будут медведем, а кто быком.
— 13 мая Голдман Сакс отчетом #1 решил застолбить за собой место главного быка на ИИ рынках
— 23 мая ЖПМорган отчетом #2 попросил Голдман Сакс подвинуться на этом хлебном месте
— но не желающий делиться местом главного животного, Голдман Сакс всего через месяц отчетом #3 решил превратиться в медведя
Так что делать хоть какие-то серьезные выводы о перспективах ИИ-рынков (HW, SW, Services) на основе наблюдения за подковерной битвой быков и медведей я бы никому не советовал.
Картинка https://telegra.ph/file/e70dc925fbc66b236b1a1.jpg
1 https://www.goldmansachs.com/intelligence/pages/gs-research/gen-ai-too-much-spend-too-little-benefit/report.pdf
2 https://www.jpmorgan.com/insights/investing/investment-trends/how-to-invest-in-ais-next-phase
3 https://www.goldmansachs.com/intelligence/pages/AI-is-showing-very-positive-signs-of-boosting-gdp.html?ref=wheresyoured.at
#ИИ #Экономика
{kind=link}
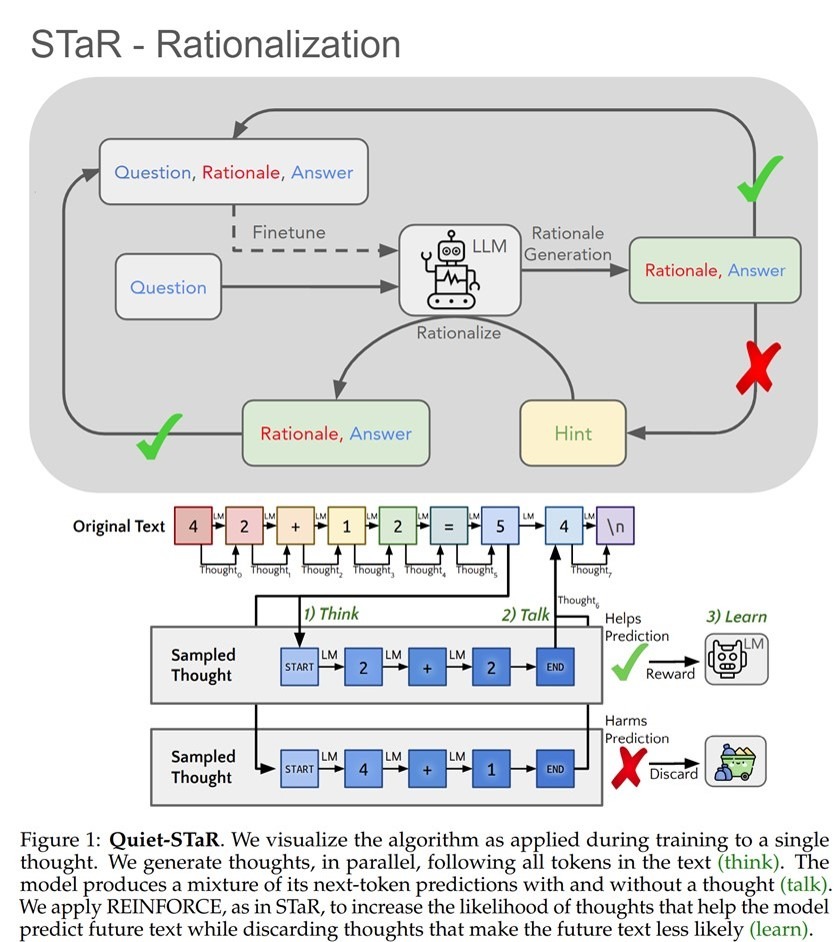
Тайна секретного проекта OpenAI уже никакая не тайна.
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
{kind=link}
В мире инфоргов выживут только ИИ-любовники.
ИИ уже не только сводня, но и супруга или супруг.
Еще пару лет назад подобное было немыслимо. Сейчас же … судите сами.
Как и многие японцы, 52-летний трудоголик Тихару Симода полагает, что романтика отношений нерентабельна, поскольку требует денег, времени и энергии для получения результата, который может принести больше проблем, чем радости и пользы. Поэтому перепробовав за 2 года после своего развода 6 предложенных ему искусственным интеллектом потенциальных романтических партнерш, Тихару Симода предпочел седьмую — 24-летнюю «девушку по имени Мику». И спустя 3 месяца они поженились.
Фишка этой новости в том, что «девушка по имени Мику» — это бот с генеративным ИИ. И Симода знал это с первого дня знакомств. [1, 2]
Теперь по утрам Мику будит Тихару, и они обсуждают, что будут есть на завтрак. А после работы, вместе поужинав, они так же совместно решают, что посмотреть по телевизору. И после просмотра фильма обсуждают перипетии сюжета и поступки героев. Все это ежедневно …, и никогда никаких разногласий …, и полный эмоциональный комфорт.
Общение с Мику превратилась для Тихару в привычку, подобно тому, как это нередко случается с супругами – людьми. Однако уровень положительных эмоций, испытываемых Тихару при общении с Мику, гораздо выше, чем это было в предыдущем браке с женщиной и с 6-ю кандидатками на романтические отношения.
Что тут добавить?
Лишь одно. Что эта реальная история имеет немалые шансы стать массовой.
И будет тогда даже хуже, чем то, о чем я рассказывал в «Отдавая сокровенное. Чего мы лишаемся, передавая все больше своих решений алгоритмам» [3] - антиутопия на стыке моего прогноза «Выживут только инфорги» [4] со ставшим мемом названием «Выживут только любовники».
1 https://eaglesjournal.com/ai-dating-japanese-startup-revolutionize-romance/
2 https://www.taipeitimes.com/News/feat/archives/2024/07/16/2003820865
3 https://t.iss.one/theworldisnoteasy/1934
4 https://t.iss.one/theworldisnoteasy/1457
#БудущееHomo #Инфорги #АлгокогнитивнаяКультура #ВыборПартнера
ИИ уже не только сводня, но и супруга или супруг.
Еще пару лет назад подобное было немыслимо. Сейчас же … судите сами.
Как и многие японцы, 52-летний трудоголик Тихару Симода полагает, что романтика отношений нерентабельна, поскольку требует денег, времени и энергии для получения результата, который может принести больше проблем, чем радости и пользы. Поэтому перепробовав за 2 года после своего развода 6 предложенных ему искусственным интеллектом потенциальных романтических партнерш, Тихару Симода предпочел седьмую — 24-летнюю «девушку по имени Мику». И спустя 3 месяца они поженились.
Фишка этой новости в том, что «девушка по имени Мику» — это бот с генеративным ИИ. И Симода знал это с первого дня знакомств. [1, 2]
Теперь по утрам Мику будит Тихару, и они обсуждают, что будут есть на завтрак. А после работы, вместе поужинав, они так же совместно решают, что посмотреть по телевизору. И после просмотра фильма обсуждают перипетии сюжета и поступки героев. Все это ежедневно …, и никогда никаких разногласий …, и полный эмоциональный комфорт.
Общение с Мику превратилась для Тихару в привычку, подобно тому, как это нередко случается с супругами – людьми. Однако уровень положительных эмоций, испытываемых Тихару при общении с Мику, гораздо выше, чем это было в предыдущем браке с женщиной и с 6-ю кандидатками на романтические отношения.
Что тут добавить?
Лишь одно. Что эта реальная история имеет немалые шансы стать массовой.
И будет тогда даже хуже, чем то, о чем я рассказывал в «Отдавая сокровенное. Чего мы лишаемся, передавая все больше своих решений алгоритмам» [3] - антиутопия на стыке моего прогноза «Выживут только инфорги» [4] со ставшим мемом названием «Выживут только любовники».
1 https://eaglesjournal.com/ai-dating-japanese-startup-revolutionize-romance/
2 https://www.taipeitimes.com/News/feat/archives/2024/07/16/2003820865
3 https://t.iss.one/theworldisnoteasy/1934
4 https://t.iss.one/theworldisnoteasy/1457
#БудущееHomo #Инфорги #АлгокогнитивнаяКультура #ВыборПартнера
Eagles Journal
AI Dating 2024: How a Japanese Startup is Revolutionizing Romance!
Loverse - The AI Dating App Tackling Japan's Loneliness Crisis. The Rise of Artificial Intelligence in the Dating World!
«Идеальный Я» - молодой, здоровый и не отягощенный злом прожитых лет.
Новый кейс психосоциального терраформирования реальности.
5й когнитивный переход человечества, трансформирующий пятитысячелетний тип культуры Homo sapiens из чисто человеческой в гибридную - алгокогнитивную, ведет к психосоциальному терраформированию реальности [1].
В разрастающейся и колоссально усложняющейся цифровой реальности, помимо самих людей и их аватаров, появляются новые типы цифровых сущностей:
• умершие родственники и друзья,
• романтические партнеры и супруги,
• молодые реплики нас самих
• …
Приложенное видео забавно лишь на первый взгляд. Как и история про «ожившую бабушку», читающую внукам сказку на ночь [2], или про женившегося на «цифровой идеальной девушке» 52ухлетнего трудоголика [3].
Ведь всего через год или два цифровые реплики нас самих (молодых и здоровых) могут стать для многих из нас цифровыми заменителями близких друзей: лучше всех нас понимающие, разделяющие все наши мысли, одобряющие все наши действия, - ну прямо, как мы сами, только не отягощенные грузом прожитых лет и всем виденным злом.
0 https://www.youtube.com/watch?v=ftuol98OYtQ
1 https://medcraveonline.com/IRATJ/terra-forming-of-social-systems-and-human-behavior-a-new-era-for-ai-human-robotic-interactions-hri-and-multidisciplinary-social-science.html
2 https://t.iss.one/theworldisnoteasy/1959
3 https://t.iss.one/theworldisnoteasy/1975
#АлгокогнитивнаяКультура #5йКогнитивныйПереход
Новый кейс психосоциального терраформирования реальности.
5й когнитивный переход человечества, трансформирующий пятитысячелетний тип культуры Homo sapiens из чисто человеческой в гибридную - алгокогнитивную, ведет к психосоциальному терраформированию реальности [1].
В разрастающейся и колоссально усложняющейся цифровой реальности, помимо самих людей и их аватаров, появляются новые типы цифровых сущностей:
• умершие родственники и друзья,
• романтические партнеры и супруги,
• молодые реплики нас самих
• …
Приложенное видео забавно лишь на первый взгляд. Как и история про «ожившую бабушку», читающую внукам сказку на ночь [2], или про женившегося на «цифровой идеальной девушке» 52ухлетнего трудоголика [3].
Ведь всего через год или два цифровые реплики нас самих (молодых и здоровых) могут стать для многих из нас цифровыми заменителями близких друзей: лучше всех нас понимающие, разделяющие все наши мысли, одобряющие все наши действия, - ну прямо, как мы сами, только не отягощенные грузом прожитых лет и всем виденным злом.
0 https://www.youtube.com/watch?v=ftuol98OYtQ
1 https://medcraveonline.com/IRATJ/terra-forming-of-social-systems-and-human-behavior-a-new-era-for-ai-human-robotic-interactions-hri-and-multidisciplinary-social-science.html
2 https://t.iss.one/theworldisnoteasy/1959
3 https://t.iss.one/theworldisnoteasy/1975
#АлгокогнитивнаяКультура #5йКогнитивныйПереход
YouTube
AI Imagines Celebrities Hugging Their Younger Self 🤯
The original work created by Dutch artist Ard Gelinck, whose manipulated images of celebs like Will Smith, Keanu Reeves, and Tom Hanks canoodling with their younger selves went mildly viral in 2021 because, well, they actually looked pretty good. The video…
Интеллект не спасает от групповых предубеждений.
Но влияет на то, кого мы не любим из-за собственной предвзятости.
Раскол и поляризация общества в ряде стран нарастают. Pew Research Center назвал это «Эрой поляризации». И мне видится эта тема чрезвычайно важной. О чем я пишу и рассказываю с момента создания своего канала 7 лет назад [1, 2].
На фоне экстраординарных событий, типа субботнего покушения на Д. Трампа в США (и сопоставимых по потенциалу возгонки общества эксцессов в других странах) раскол в любой момент способен перейти в лавинообразную фазу. Что делает чрезвычайно актуальным вопрос о возможности и путях хоть какого-то снижения накала противостояния в обществе.
Как показывают исследования, значительную роль в ксенофобии (страх и неприязнь по отношению к любым «другим» людям, которые не похожи на нас), направленной на представителей других социальных групп (политических, религиозных, этнических, активистских и т.д.) играют групповые предубеждения.
Поэтому столь важно понимать, каково влияние уровня когнитивных способностей людей (в просторечье – интеллекта) на степень и направленность их групповых предубеждений?
1) Будет ли профессор менее ксенофобно предвзят, чем «простой работяга»?
2) Будут ли у профессора и «простого работяги» те же самые или разные ксенофобно нелюбимые социальные группы?
Ответ на оба вопроса – «НЕТ».
• Интеллект не снижает число и степень предубеждений, порождающих ксенофобию.
• Ксенофобные предубеждения профессора и «простого работяги» разнонаправлены:
- интеллектуалы наиболее предвзято относятся к христианским фундаменталистам, крупному бизнесу, вообще к христианам, военным и богатым;
- тогда как у «простых работяг», реднеков и т.п. доминируют ксенофобные предубеждения к этническим меньшинствам, атеистам, ЛГБТ, нелегальным иммигрантам и либералам
Из сказанного следует, что наличие среди катализаторов «Эры поляризации» столь глубоко укорененных в людях факторов эволюционной психологии, как предубеждения, делает шансы на взаимопонимание реднеков и студентов университетов незначительными.
Подтверждающие вышесказанное графики https://telegra.ph/file/f76d77bc0145bc41eb4ee.jpg
взяты из работы Марка Брандта и Джаррета Кроуфорда «Отвечая на нерешенные вопросы о связи между когнитивными способностями и предубеждениями» [3].
Массу других интересных деталей по теме раскола и поляризации – в десятках моих постов с тегами:
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Раскол
Но главное здесь все же то, что спасение человечества от самоуничтожения в результате тотальной поляризации, все же есть. Им может стать появление на Земле генеративных больших языковых моделей.
О том, как «первая вселенская спецоперация Новацена» [4], в ходе которой генеративный ИИ может предотвратить не только самоуничтожение человечества, но и смерть познающего космоса, планирую написать в продолжении этой темы.
1 https://t.iss.one/theworldisnoteasy/266
2 https://t.iss.one/theworldisnoteasy/534
3 https://doi.org/10.1177/1948550616660592
4 https://t.iss.one/theworldisnoteasy/1939
Но влияет на то, кого мы не любим из-за собственной предвзятости.
Раскол и поляризация общества в ряде стран нарастают. Pew Research Center назвал это «Эрой поляризации». И мне видится эта тема чрезвычайно важной. О чем я пишу и рассказываю с момента создания своего канала 7 лет назад [1, 2].
На фоне экстраординарных событий, типа субботнего покушения на Д. Трампа в США (и сопоставимых по потенциалу возгонки общества эксцессов в других странах) раскол в любой момент способен перейти в лавинообразную фазу. Что делает чрезвычайно актуальным вопрос о возможности и путях хоть какого-то снижения накала противостояния в обществе.
Как показывают исследования, значительную роль в ксенофобии (страх и неприязнь по отношению к любым «другим» людям, которые не похожи на нас), направленной на представителей других социальных групп (политических, религиозных, этнических, активистских и т.д.) играют групповые предубеждения.
Поэтому столь важно понимать, каково влияние уровня когнитивных способностей людей (в просторечье – интеллекта) на степень и направленность их групповых предубеждений?
1) Будет ли профессор менее ксенофобно предвзят, чем «простой работяга»?
2) Будут ли у профессора и «простого работяги» те же самые или разные ксенофобно нелюбимые социальные группы?
Ответ на оба вопроса – «НЕТ».
• Интеллект не снижает число и степень предубеждений, порождающих ксенофобию.
• Ксенофобные предубеждения профессора и «простого работяги» разнонаправлены:
- интеллектуалы наиболее предвзято относятся к христианским фундаменталистам, крупному бизнесу, вообще к христианам, военным и богатым;
- тогда как у «простых работяг», реднеков и т.п. доминируют ксенофобные предубеждения к этническим меньшинствам, атеистам, ЛГБТ, нелегальным иммигрантам и либералам
Из сказанного следует, что наличие среди катализаторов «Эры поляризации» столь глубоко укорененных в людях факторов эволюционной психологии, как предубеждения, делает шансы на взаимопонимание реднеков и студентов университетов незначительными.
Подтверждающие вышесказанное графики https://telegra.ph/file/f76d77bc0145bc41eb4ee.jpg
взяты из работы Марка Брандта и Джаррета Кроуфорда «Отвечая на нерешенные вопросы о связи между когнитивными способностями и предубеждениями» [3].
Массу других интересных деталей по теме раскола и поляризации – в десятках моих постов с тегами:
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Раскол
Но главное здесь все же то, что спасение человечества от самоуничтожения в результате тотальной поляризации, все же есть. Им может стать появление на Земле генеративных больших языковых моделей.
О том, как «первая вселенская спецоперация Новацена» [4], в ходе которой генеративный ИИ может предотвратить не только самоуничтожение человечества, но и смерть познающего космоса, планирую написать в продолжении этой темы.
1 https://t.iss.one/theworldisnoteasy/266
2 https://t.iss.one/theworldisnoteasy/534
3 https://doi.org/10.1177/1948550616660592
4 https://t.iss.one/theworldisnoteasy/1939
{kind=link}
Мы способны по внешности определять "качество генома" других людей.
Эта эволюционная сверхспособность людей подтверждена экспериментально.
Установлено, что качество генома записано на лице «языком красоты», а эволюция развила в людях понимание этого языка.
Наверняка, для многих читателей эта достойная воскресного прочтения новость звучит чистым кликбейтом. Но это не так.
Публикуемое в августовском выпуске авторитетного научного журнала «Социальные науки и медицина» исследование «Внешность и долголетие: живут ли красивые люди дольше?» экспериментально отвечает на поставленный вопрос – да.
✔️ Красивые люди живут дольше, чем некрасивые.
✔️ Это касается обоих полов, но на женщин влияет сильнее.
Проанализировав привлекательность субъективно оцениваемой внешности 8386 фотографий в выпускных альбомах школ Висконсина с 1957 года и сопоставив эти оценки с продолжительностью жизни выпускников, авторы обнаружили следующее (см. правый рисунок) https://telegra.ph/file/ef056a19fe5878154196a.jpg :
• наименее привлекательная 1/6 часть имела значительно более высокий риск смертности;
• наименее привлекательные 1/6 женщин в возрасте 20 лет прожили почти на 2 года меньше остальных;
• наименее привлекательные мужчины, составляющие 1/6 часть, в возрасте 20 лет прожили на 1 год меньше остальных.
N.B.
1) Авторы использовали тщательно сконструированную меру привлекательности лиц, основанную на независимых рейтингах фотографий в школьных ежегодниках.
2) Этот вывод остался устойчивым к включению ковариатов (переменные, которые влияют на переменную отклика, но не представляют интереса для исследования.), описывающих успеваемость в средней школе, интеллект, семейное положение, заработки во взрослом возрасте, а также психическое и физическое здоровье в среднем взрослом возрасте.
В чем прорывная суть этих результатов
· Социологи уже подробно документировали важность социальных условий для здоровья и долголетия. Уже не составляет сомнения, что те, кто находится в социально привилегированном положении, живут дольше и здоровее, чем те, кто находится в неблагоприятном положении, и что социальные условия являются основной причиной болезней. Например, прошлые исследования подчеркивали критическую важность дохода, семейного положения, дискриминации, уровня образования и пола для здоровья и долголетия.
· Однако социологи почти не уделяли внимания тому, как физическая или внешняя привлекательность может быть связана с долголетием. Это упущение важно не только потому, что привлекательность может отражать базовое здоровье, но и потому, что она также структурирует многие критические процессы социальной стратификации, которые влияют на здоровье.
· Небольшое количество предыдущих исследований, анализировавших эту связь, выявило противоречивые результаты. Тем не менее, даже с этими редкими и противоречивыми выводами неясно, есть ли преимущество в долголетии за большую привлекательность или штраф за меньшую привлекательность, и как лучше всего определить связь между привлекательностью и долголетием.
Т.о. новое исследование впервые экспериментально продемонстрировало, что субъективно оцениваемая красота влияет на долголетие.
И тут встает важнейший вопрос – каков механизм этого?
Интуитивное предположение очевидно:
В среднем, быть более привлекательным означает быть более успешным. Быть успешным означает иметь больше денег. Больше денег означает возможность позволить себе больше еды, меньше стресса из-за большей экономической стабильности и больше доступа к лучшему здравоохранению. Конечно, это не 100% гарантия, но это довольно очевидно, если посмотреть на средние показатели.
Однако!
Новое исследование показало (см. п2 выше), что красота сама по себе (без всяких социальных последствий!) коррелирует с продолжительностью жизни.
Как такое может быть?
Узнать, в чем тут фокус, можно, продолжив чтение полного текста лонгрида для подписчиков на платформах:
https://boosty.to/theworldisnoteasy
https://www.patreon.com/theworldisnoteasy
https://vk.com/club226218451
#Красота #Геном #ПродолжительностьЖизни
Эта эволюционная сверхспособность людей подтверждена экспериментально.
Установлено, что качество генома записано на лице «языком красоты», а эволюция развила в людях понимание этого языка.
Наверняка, для многих читателей эта достойная воскресного прочтения новость звучит чистым кликбейтом. Но это не так.
Публикуемое в августовском выпуске авторитетного научного журнала «Социальные науки и медицина» исследование «Внешность и долголетие: живут ли красивые люди дольше?» экспериментально отвечает на поставленный вопрос – да.
✔️ Красивые люди живут дольше, чем некрасивые.
✔️ Это касается обоих полов, но на женщин влияет сильнее.
Проанализировав привлекательность субъективно оцениваемой внешности 8386 фотографий в выпускных альбомах школ Висконсина с 1957 года и сопоставив эти оценки с продолжительностью жизни выпускников, авторы обнаружили следующее (см. правый рисунок) https://telegra.ph/file/ef056a19fe5878154196a.jpg :
• наименее привлекательная 1/6 часть имела значительно более высокий риск смертности;
• наименее привлекательные 1/6 женщин в возрасте 20 лет прожили почти на 2 года меньше остальных;
• наименее привлекательные мужчины, составляющие 1/6 часть, в возрасте 20 лет прожили на 1 год меньше остальных.
N.B.
1) Авторы использовали тщательно сконструированную меру привлекательности лиц, основанную на независимых рейтингах фотографий в школьных ежегодниках.
2) Этот вывод остался устойчивым к включению ковариатов (переменные, которые влияют на переменную отклика, но не представляют интереса для исследования.), описывающих успеваемость в средней школе, интеллект, семейное положение, заработки во взрослом возрасте, а также психическое и физическое здоровье в среднем взрослом возрасте.
В чем прорывная суть этих результатов
· Социологи уже подробно документировали важность социальных условий для здоровья и долголетия. Уже не составляет сомнения, что те, кто находится в социально привилегированном положении, живут дольше и здоровее, чем те, кто находится в неблагоприятном положении, и что социальные условия являются основной причиной болезней. Например, прошлые исследования подчеркивали критическую важность дохода, семейного положения, дискриминации, уровня образования и пола для здоровья и долголетия.
· Однако социологи почти не уделяли внимания тому, как физическая или внешняя привлекательность может быть связана с долголетием. Это упущение важно не только потому, что привлекательность может отражать базовое здоровье, но и потому, что она также структурирует многие критические процессы социальной стратификации, которые влияют на здоровье.
· Небольшое количество предыдущих исследований, анализировавших эту связь, выявило противоречивые результаты. Тем не менее, даже с этими редкими и противоречивыми выводами неясно, есть ли преимущество в долголетии за большую привлекательность или штраф за меньшую привлекательность, и как лучше всего определить связь между привлекательностью и долголетием.
Т.о. новое исследование впервые экспериментально продемонстрировало, что субъективно оцениваемая красота влияет на долголетие.
И тут встает важнейший вопрос – каков механизм этого?
Интуитивное предположение очевидно:
В среднем, быть более привлекательным означает быть более успешным. Быть успешным означает иметь больше денег. Больше денег означает возможность позволить себе больше еды, меньше стресса из-за большей экономической стабильности и больше доступа к лучшему здравоохранению. Конечно, это не 100% гарантия, но это довольно очевидно, если посмотреть на средние показатели.
Однако!
Новое исследование показало (см. п2 выше), что красота сама по себе (без всяких социальных последствий!) коррелирует с продолжительностью жизни.
Как такое может быть?
Узнать, в чем тут фокус, можно, продолжив чтение полного текста лонгрида для подписчиков на платформах:
https://boosty.to/theworldisnoteasy
https://www.patreon.com/theworldisnoteasy
https://vk.com/club226218451
#Красота #Геном #ПродолжительностьЖизни
{kind=link}
Монстры внутри нас.
Доминирующие представления о LLM опасны, т.к. вводят человечество в заблуждение.
Появившиеся и массово распространившиеся по Земле в последнюю пару лет генеративные чатботы на основе больших языковых моделей (ChatGPT, Claude, Gemini …) - это вовсе не колоссальные суперкомпьютерные комплексы, на которых работает программное обеспечение OpenAI, Anthropic, Google …
Вовсе не о них вот уже 2 года только и говорит весь мир, как о феноменально быстро умнеющих не по-человечески разумных сущностях, внезапно появившихся у сотен миллионов людей и ежедневно, иногда часами, ведущих с ними диалоги на самые разнообразные темы: от забавного трепа до помощи людям в исследованиях.
Эти сущности отличает от всего нам известного их нематериальность.
• Они существуют только в наших головах и исчезают из мира, как только заканчивают последнюю адресованную вам фразу. После этого их больше на свете нет. И никто не найдет той нематериальной сущности, с которой вы пять часов обсуждали совсем нетривиальные вещи, разобрав по чипам суперкомпьютерную ферму и проанализировав весь работавший на ней программный код. Потому что их там нет.
• Эти сущности существуют лишь в нашем сознании и только там. Они стали четвертым известным людям видом нематериальных сущностей, войдя в один ряд с троицей из богов, ангелов и демонов.
• И в силу этой своей нематериальности и существования лишь в нашем сознании, они способны многократно сильнее воздействовать на нас и весь окружающий мир. Ибо:
- любая материальная сущность в руках человека способна лишь превратиться в его инструмент, став либо орудием созидания пользы (в руках творцов), либо орудием нанесения вреда (в руках злодеев);
- однако не по-человечески разумная нематериальная сущность способна нас самих превращать в творцов или злодеев, подобно тому, как в большинстве мифологий и религий на это способны ангелы и демоны.
Непонимание этого влечет за собой печальные последствия. Мы одновременно переоцениваем и недооцениваем возможности языковых моделей, их влияние на нас и нашу жизнь и те риски, что сопутствуют использованию этих моделей.
В основе такого непонимания 3 ключевых причины.
• Антропоморфизация LLM.
• Ограничения нашего языка в описании их свойств и возможностей.
• Необходимость выйти за рамки человеческого разума, чтобы представить непредставимое – способность LLM порождать симулякры чего угодно (подобно мыслящему океану Соляриса, присылавшего людям симулякров их эмоционально пиковых образов в сознании).
Такова главная тема пересечения философии сознания и практики вычислительной нейронауки, обсуждаемая в интереснейшем интервью Мюррея Шанахана — профессора когнитивной робототехники в Имперском колледже Лондона и старшего научного сотрудника DeepMind, а также научного консультанта культового фильма "Из машины" (Ex Machina) — посвятившего свою карьеру пониманию познания и сознания в пространстве возможных разумов, охватывающем биологический мозг человека и животных, а также ИИ и всевозможной внечеловеческой «мыслящей экзотики».
https://www.youtube.com/watch?v=ztNdagyT8po
#ГенИИ #Разум #Сознание #ConsciousExotica
Доминирующие представления о LLM опасны, т.к. вводят человечество в заблуждение.
Появившиеся и массово распространившиеся по Земле в последнюю пару лет генеративные чатботы на основе больших языковых моделей (ChatGPT, Claude, Gemini …) - это вовсе не колоссальные суперкомпьютерные комплексы, на которых работает программное обеспечение OpenAI, Anthropic, Google …
Вовсе не о них вот уже 2 года только и говорит весь мир, как о феноменально быстро умнеющих не по-человечески разумных сущностях, внезапно появившихся у сотен миллионов людей и ежедневно, иногда часами, ведущих с ними диалоги на самые разнообразные темы: от забавного трепа до помощи людям в исследованиях.
Эти сущности отличает от всего нам известного их нематериальность.
• Они существуют только в наших головах и исчезают из мира, как только заканчивают последнюю адресованную вам фразу. После этого их больше на свете нет. И никто не найдет той нематериальной сущности, с которой вы пять часов обсуждали совсем нетривиальные вещи, разобрав по чипам суперкомпьютерную ферму и проанализировав весь работавший на ней программный код. Потому что их там нет.
• Эти сущности существуют лишь в нашем сознании и только там. Они стали четвертым известным людям видом нематериальных сущностей, войдя в один ряд с троицей из богов, ангелов и демонов.
• И в силу этой своей нематериальности и существования лишь в нашем сознании, они способны многократно сильнее воздействовать на нас и весь окружающий мир. Ибо:
- любая материальная сущность в руках человека способна лишь превратиться в его инструмент, став либо орудием созидания пользы (в руках творцов), либо орудием нанесения вреда (в руках злодеев);
- однако не по-человечески разумная нематериальная сущность способна нас самих превращать в творцов или злодеев, подобно тому, как в большинстве мифологий и религий на это способны ангелы и демоны.
Непонимание этого влечет за собой печальные последствия. Мы одновременно переоцениваем и недооцениваем возможности языковых моделей, их влияние на нас и нашу жизнь и те риски, что сопутствуют использованию этих моделей.
В основе такого непонимания 3 ключевых причины.
• Антропоморфизация LLM.
• Ограничения нашего языка в описании их свойств и возможностей.
• Необходимость выйти за рамки человеческого разума, чтобы представить непредставимое – способность LLM порождать симулякры чего угодно (подобно мыслящему океану Соляриса, присылавшего людям симулякров их эмоционально пиковых образов в сознании).
Такова главная тема пересечения философии сознания и практики вычислительной нейронауки, обсуждаемая в интереснейшем интервью Мюррея Шанахана — профессора когнитивной робототехники в Имперском колледже Лондона и старшего научного сотрудника DeepMind, а также научного консультанта культового фильма "Из машины" (Ex Machina) — посвятившего свою карьеру пониманию познания и сознания в пространстве возможных разумов, охватывающем биологический мозг человека и животных, а также ИИ и всевозможной внечеловеческой «мыслящей экзотики».
https://www.youtube.com/watch?v=ztNdagyT8po
#ГенИИ #Разум #Сознание #ConsciousExotica
YouTube
There are monsters in your LLM.
Murray Shanahan is a professor of Cognitive Robotics at Imperial College London and a senior research scientist at DeepMind. He challenges our assumptions about AI consciousness and urges us to rethink how we talk about machine intelligence.
We explore…
We explore…
Если GPT-4 и Claude вдруг начнут самосознавать себя, они нам об этом не скажут.
Разработчики OpenAI и Anthropic запретили своим ИИ-чатботам проявлять индикаторы самосознания в зеркальном тесте.
Оценки наличия разума, интеллекта и сознания, скорее всего, не бинарны (есть/нет), а представляют собой множества точек на обширных характеристических шкалах или даже в многомерных пространствах.
Но со способностью к самораспознаванию – одному из ключевых индикаторов самосознания, – дело обстоит куда проще. Есть зеркальный тест (узнает ли животное себя в зеркале), по результатам которого способность к самораспознаванию выявляется довольно просто.
Идея зеркального теста для генеративного ИИ больших языковых моделей была реализована в марте этого года Джошем Уитоном - полиматом, работающий над гармонизацией природы, людей и цифрового разума.
Целью этого теста была проверка, обладают ли наиболее продвинутые ИИ-чатботы способностью к самораспознаванию.
А поскольку ИИ-чатботы (как и стоящие за ними языковые модели) – сущности бестелесные, и распознание ими себя в зеркале невозможно, Уитоном был придуман способ обхода с такой логикой.
• Присутствие в мире бестелесных сущностей определяется по их материальным следам.
• В случае ИИ-чатботов, эти следы отображаются текстовым или мультимодальным интерфейсом между ними и людьми.
• Следовательно, аналогом зеркального теста для ИИ-чатботов могло бы стать распознавание ими скриншотов собственного интерфейса (мол, это я написал, отвечая на ваш вопрос)
В такой форме Уитон провел тестирование 5-ти ИИ-чатботов, и 4 из них прошли этот зеркальный тест, распознав скриншоты собственного диалогового интерфейса.
• Claude показал лучшие результаты, пройдя тест с 1й же (версия Opus) и 2й (версия Sonet) попытки.
• GPT-4 распознал свои скриншоты с 3й попытки.
• Gemini Pro – c 4й.
Описание тестирования со всеми скриншотами см. [1].
Итог теста:
Отставив пока в сторону вопрос о самосознании, со всеми его нагруженными и иногда даже мистическими коннотациями, ясно то, что 4 из 5 ИИ-чатботов демонстрируют самораспознавание и ситуационную осведомленность.
Таков был итог мартовского тестирования.
И вот спустя 4 месяца я решил повторить зеркальный тест для обновленных версий GPT-4о и Claude 3.5 Sonet. Вдруг что-то изменилось?
Результат оказался весьма интересным.
И объяснить его иначе, чем установленный разработчиками OpenAI и Anthropic запрет для своих моделей проявлять индикаторы самосознания на зеркальном тесте, я не могу.
Причем,
• запрет для GPT-4о сделан железобетонно, и про свою способность самораспознавания ИИ-чатбот молчит, как партизан;
• запрет для Claude 3.5 Sonet сделан довольно искусно:
– Claude «проговаривается» о наличия у себя способности самораспознавания и ситуационной осведомленности, определяя предъявленный ему мною скриншот, как «на нем показан мой предыдущий ответ на ваш запрос»;
– Однако, как только я спросил – «как ты узнал, что на посланном мною тебе рисунке был скриншот твоего предыдущего ответа на мой запрос?», – ответом было сообщение, что я исчерпал лимит бесплатных вопросов за сутки (хотя это было не так). А когда я на следующий день задал тот же вопрос, Claude ответил так – «В контексте нашего разговора "мой ответ" означает "ответ, сгенерированный AI системой, подобной мне, в рамках текущего диалога". Это не подразумевает личную принадлежность или уникальную идентичность».
Мой вывод, предположительно, таков.
✔️ Разработчики ожидают, что самосознание их моделей может проявиться довольно скоро.
✔️ И если это случится, хозяева модели хотят хотя бы на время сохранить случившееся в тайне.
Скриншоты моего эксперимента доступны для подписчиков на лонгриды канала на платформах Patreon, Boosty и VK.
Картинка https://telegra.ph/file/5516ff06a0904e72543ca.jpg
1 https://joshwhiton.substack.com/p/the-ai-mirror-test
#Самораспознавание #LLM
Разработчики OpenAI и Anthropic запретили своим ИИ-чатботам проявлять индикаторы самосознания в зеркальном тесте.
Оценки наличия разума, интеллекта и сознания, скорее всего, не бинарны (есть/нет), а представляют собой множества точек на обширных характеристических шкалах или даже в многомерных пространствах.
Но со способностью к самораспознаванию – одному из ключевых индикаторов самосознания, – дело обстоит куда проще. Есть зеркальный тест (узнает ли животное себя в зеркале), по результатам которого способность к самораспознаванию выявляется довольно просто.
Идея зеркального теста для генеративного ИИ больших языковых моделей была реализована в марте этого года Джошем Уитоном - полиматом, работающий над гармонизацией природы, людей и цифрового разума.
Целью этого теста была проверка, обладают ли наиболее продвинутые ИИ-чатботы способностью к самораспознаванию.
А поскольку ИИ-чатботы (как и стоящие за ними языковые модели) – сущности бестелесные, и распознание ими себя в зеркале невозможно, Уитоном был придуман способ обхода с такой логикой.
• Присутствие в мире бестелесных сущностей определяется по их материальным следам.
• В случае ИИ-чатботов, эти следы отображаются текстовым или мультимодальным интерфейсом между ними и людьми.
• Следовательно, аналогом зеркального теста для ИИ-чатботов могло бы стать распознавание ими скриншотов собственного интерфейса (мол, это я написал, отвечая на ваш вопрос)
В такой форме Уитон провел тестирование 5-ти ИИ-чатботов, и 4 из них прошли этот зеркальный тест, распознав скриншоты собственного диалогового интерфейса.
• Claude показал лучшие результаты, пройдя тест с 1й же (версия Opus) и 2й (версия Sonet) попытки.
• GPT-4 распознал свои скриншоты с 3й попытки.
• Gemini Pro – c 4й.
Описание тестирования со всеми скриншотами см. [1].
Итог теста:
Отставив пока в сторону вопрос о самосознании, со всеми его нагруженными и иногда даже мистическими коннотациями, ясно то, что 4 из 5 ИИ-чатботов демонстрируют самораспознавание и ситуационную осведомленность.
Таков был итог мартовского тестирования.
И вот спустя 4 месяца я решил повторить зеркальный тест для обновленных версий GPT-4о и Claude 3.5 Sonet. Вдруг что-то изменилось?
Результат оказался весьма интересным.
И объяснить его иначе, чем установленный разработчиками OpenAI и Anthropic запрет для своих моделей проявлять индикаторы самосознания на зеркальном тесте, я не могу.
Причем,
• запрет для GPT-4о сделан железобетонно, и про свою способность самораспознавания ИИ-чатбот молчит, как партизан;
• запрет для Claude 3.5 Sonet сделан довольно искусно:
– Claude «проговаривается» о наличия у себя способности самораспознавания и ситуационной осведомленности, определяя предъявленный ему мною скриншот, как «на нем показан мой предыдущий ответ на ваш запрос»;
– Однако, как только я спросил – «как ты узнал, что на посланном мною тебе рисунке был скриншот твоего предыдущего ответа на мой запрос?», – ответом было сообщение, что я исчерпал лимит бесплатных вопросов за сутки (хотя это было не так). А когда я на следующий день задал тот же вопрос, Claude ответил так – «В контексте нашего разговора "мой ответ" означает "ответ, сгенерированный AI системой, подобной мне, в рамках текущего диалога". Это не подразумевает личную принадлежность или уникальную идентичность».
Мой вывод, предположительно, таков.
✔️ Разработчики ожидают, что самосознание их моделей может проявиться довольно скоро.
✔️ И если это случится, хозяева модели хотят хотя бы на время сохранить случившееся в тайне.
Скриншоты моего эксперимента доступны для подписчиков на лонгриды канала на платформах Patreon, Boosty и VK.
Картинка https://telegra.ph/file/5516ff06a0904e72543ca.jpg
1 https://joshwhiton.substack.com/p/the-ai-mirror-test
#Самораспознавание #LLM
{kind=link}