
Судить журнал по обложке: 65 лет советской фотографии
Журнал «Советское фото» издавался в Москве с 1926 по 1991 год. Это был единственный специализированный фотожурнал в Советском Союзе, рассчитанный на широкую аудиторию и профессиональных фотожурналистов, и фотографов-любителей.
«Советское фото» выходило ежемесячно за некоторыми исключениями. Например, издание журнала было приостановлено между 1942 и 1956 годами из-за Великой Отечественной войны и долгого послевоенного восстановления. Но, несмотря на это, жизнь «Советского фото» охватывает все основные этапы культурной и политической истории страны, а обложки журналов отражают историческую специфику каждого из этих моментов.
В 2017 году команда лаборатории культурной аналитики: директор лаборатории Лев Манович, Августин Индако (Agustín Indaco) и Элис Тифентале (Alise Tifentale) начали работу над анализом базы обложек «Советского фото».
Изначально был подготовлен корпус из 455 обложек журналов, однако из-за большого количества неточностей первичной оцифровки (дубликаты, половинчатые сканы) в корпус вошло всего 401 хорошее изображение.
Посмотрев на коллаж, мы видим, что с самого начала существования журнала на обложку всегда помещали «фото номера» и слова «Советское фото», а вот расположение названия и его шрифт проходит через несколько преобразований: от жирного дублирования названия на верхней и нижней части обложки в 1926 году до гораздо более изящного и мелкого шрифта для названия в верхней части обложки в 1991.
«Близкий взгляд» на отдельные обложки
Не каждая обложка представляет собой культурную и художественную ценность, но если внимательнее рассмотреть отдельные кадры, можно выявить глубокие различия и даже общие тенденции в дизайне и макете журнала. Например, в середине двадцатых годов в «Советском фото» вполне могли быть опубликованы фотографии Александра Родченко, а начиная с 1930-х, вместо творческих и экспериментальных фотографий на обложках все чаще появляются изображения Ленина и Сталина. Эпоха перестройки и духа гласности лучше всего воплощена на обложке августовского-сентябрьского номера за 1991 год, на которой изображена полуобнаженная модель среди книг, цветов и ярких этикеток (остродефицитного по тем временами лондонского сухого джина Gordon’s).
Таким образом, первый анализ учёных подтверждает, что оцифровка и оцифрованные номера журналов могут служить полезным инструментом для более детального исследования событий в советской фотографии и контекстуализации их как части новой, более глобальной истории фотографии.
Михаил Мингазов
Журнал «Советское фото» издавался в Москве с 1926 по 1991 год. Это был единственный специализированный фотожурнал в Советском Союзе, рассчитанный на широкую аудиторию и профессиональных фотожурналистов, и фотографов-любителей.
«Советское фото» выходило ежемесячно за некоторыми исключениями. Например, издание журнала было приостановлено между 1942 и 1956 годами из-за Великой Отечественной войны и долгого послевоенного восстановления. Но, несмотря на это, жизнь «Советского фото» охватывает все основные этапы культурной и политической истории страны, а обложки журналов отражают историческую специфику каждого из этих моментов.
В 2017 году команда лаборатории культурной аналитики: директор лаборатории Лев Манович, Августин Индако (Agustín Indaco) и Элис Тифентале (Alise Tifentale) начали работу над анализом базы обложек «Советского фото».
Изначально был подготовлен корпус из 455 обложек журналов, однако из-за большого количества неточностей первичной оцифровки (дубликаты, половинчатые сканы) в корпус вошло всего 401 хорошее изображение.
Посмотрев на коллаж, мы видим, что с самого начала существования журнала на обложку всегда помещали «фото номера» и слова «Советское фото», а вот расположение названия и его шрифт проходит через несколько преобразований: от жирного дублирования названия на верхней и нижней части обложки в 1926 году до гораздо более изящного и мелкого шрифта для названия в верхней части обложки в 1991.
«Близкий взгляд» на отдельные обложки
Не каждая обложка представляет собой культурную и художественную ценность, но если внимательнее рассмотреть отдельные кадры, можно выявить глубокие различия и даже общие тенденции в дизайне и макете журнала. Например, в середине двадцатых годов в «Советском фото» вполне могли быть опубликованы фотографии Александра Родченко, а начиная с 1930-х, вместо творческих и экспериментальных фотографий на обложках все чаще появляются изображения Ленина и Сталина. Эпоха перестройки и духа гласности лучше всего воплощена на обложке августовского-сентябрьского номера за 1991 год, на которой изображена полуобнаженная модель среди книг, цветов и ярких этикеток (остродефицитного по тем временами лондонского сухого джина Gordon’s).
Таким образом, первый анализ учёных подтверждает, что оцифровка и оцифрованные номера журналов могут служить полезным инструментом для более детального исследования событий в советской фотографии и контекстуализации их как части новой, более глобальной истории фотографии.
Михаил Мингазов
{kind=link}
👍1
Разбираем нейросети по частям: как работает градиентный спуск
Нейросети сейчас везде, и даже цифровому гуманитарию от них не скрыться. Word2vec при помощи нейросети кодирует смысл слов (вот тут мы объясняли, как), а новые модели ELMO и BERT даже научились учитывать, что слова появляются в разных контекстах и от этого из смысл тоже может меняться. Этот текст — про то, что значит «обучить» нейросеть и кто «подбирает веса» отдельных нейронов.
Градиентный спуск ищет ближайшую к случайно выбранной точке впадину на графике функции. А поскольку в нейросетях функции очень сложные и локальных впадин-минимумов на них много, такой подход должен быть неэффективен в вопросах обучения нейросети и всегда натыкаться на локальные минимумы.
Тем не менее градиентный спуск как метод обучения почему-то работает хорошо. В 2015 группа ученых из Курантовского института математических наук в Нью-Йорке нашла этому объяснение, показав, что большая часть локальных минимумов функций потерь, используемых в нейросетях, располагается близко к глобальному минимуму. Эта близость и позволяет натренированным при помощи градиентного спуска нейросетям справляться с задачами достаточно эффективно.
https://sysblok.ru/knowhow/razbiraem-nejroseti-po-chastjam-kak-rabotaet-gradientnyj-spusk/
Нейросети сейчас везде, и даже цифровому гуманитарию от них не скрыться. Word2vec при помощи нейросети кодирует смысл слов (вот тут мы объясняли, как), а новые модели ELMO и BERT даже научились учитывать, что слова появляются в разных контекстах и от этого из смысл тоже может меняться. Этот текст — про то, что значит «обучить» нейросеть и кто «подбирает веса» отдельных нейронов.
Градиентный спуск ищет ближайшую к случайно выбранной точке впадину на графике функции. А поскольку в нейросетях функции очень сложные и локальных впадин-минимумов на них много, такой подход должен быть неэффективен в вопросах обучения нейросети и всегда натыкаться на локальные минимумы.
Тем не менее градиентный спуск как метод обучения почему-то работает хорошо. В 2015 группа ученых из Курантовского института математических наук в Нью-Йорке нашла этому объяснение, показав, что большая часть локальных минимумов функций потерь, используемых в нейросетях, располагается близко к глобальному минимуму. Эта близость и позволяет натренированным при помощи градиентного спуска нейросетям справляться с задачами достаточно эффективно.
https://sysblok.ru/knowhow/razbiraem-nejroseti-po-chastjam-kak-rabotaet-gradientnyj-spusk/
Роботы вступают в гонку вооружений: военные применения ИИ
Искусственный интеллект (ИИ) в последние годы развивался очень быстро, что привело к его широкому спектру как гражданских, так и военных применений. Очевидно, что военным необходимо постоянно разрабатывать более совершенные технологии и оружие, и попытки применить ИИ становятся логичным шагом в гонке вооружений.
Диалог солдата и машины
Когда речь заходит о применении ИИ в военной сфере, человеко-машинные отношения становятся одной из основных обсуждаемых тем. В настоящее время можно говорить о трех типах отношений.
Первый, когда машина контролирует окружающую среду, но именно человек принимает окончательное решение — называется полуавтономной системой.
Контролируемая автономная система — второй тип, когда машина может действовать самостоятельно, но человек имеет возможность наблюдать за ее поведением и вмешиваться в случае необходимости.
Третий тип — полностью автономная система, человек не имеет никакого контроля над машиной. Пока в военной сфере используются только системы первого или второго типа отношений, т. е. дроны и высокоточные ракеты.
Другие способы использовать ИИ в военной сфере — анализ данных. Хороший пример — американский проект Maven, где машина обрабатывает и интерпретирует видео с беспилотников. С использованием ИИ беспилотникам, самолетам, кораблям, танкам и т. д. перестанет быть нужен человек. Так, почти полностью автономным является израильский беспилотник Harpy.
Война и политика
Однако ИИ не может оставаться в руках лишь нескольких государств, как, например, в случае с ядерным оружием. Достаточно скоро значительное число государств и даже негосударственных организаций смогут использовать со своей стороны военный потенциал ИИ. Уже на этом этапе качество используемых машин станет куда более важным.
ИИ поможет справиться с военными «большими данными» (Big Data). Обращение к данным позволит системам ИИ учитывать те факторы, о которых люди могут не думать, когда находятся в бою. Тогда это будет служить преимуществом над врагом.
Наконец, по мере того, как будет появляться все больше ПО для военного ИИ, неизбежны и новые споры об оптимальном соотношении количества и качества. Здесь возможно такое же разделение, как и в остальном оружейном рынке: простые, дешевые в изготовлении массовые устройства с одной стороны — и сверхдорогие разработки для элитных войск с другой.
Женя Заковоротная
Искусственный интеллект (ИИ) в последние годы развивался очень быстро, что привело к его широкому спектру как гражданских, так и военных применений. Очевидно, что военным необходимо постоянно разрабатывать более совершенные технологии и оружие, и попытки применить ИИ становятся логичным шагом в гонке вооружений.
Диалог солдата и машины
Когда речь заходит о применении ИИ в военной сфере, человеко-машинные отношения становятся одной из основных обсуждаемых тем. В настоящее время можно говорить о трех типах отношений.
Первый, когда машина контролирует окружающую среду, но именно человек принимает окончательное решение — называется полуавтономной системой.
Контролируемая автономная система — второй тип, когда машина может действовать самостоятельно, но человек имеет возможность наблюдать за ее поведением и вмешиваться в случае необходимости.
Третий тип — полностью автономная система, человек не имеет никакого контроля над машиной. Пока в военной сфере используются только системы первого или второго типа отношений, т. е. дроны и высокоточные ракеты.
Другие способы использовать ИИ в военной сфере — анализ данных. Хороший пример — американский проект Maven, где машина обрабатывает и интерпретирует видео с беспилотников. С использованием ИИ беспилотникам, самолетам, кораблям, танкам и т. д. перестанет быть нужен человек. Так, почти полностью автономным является израильский беспилотник Harpy.
Война и политика
Однако ИИ не может оставаться в руках лишь нескольких государств, как, например, в случае с ядерным оружием. Достаточно скоро значительное число государств и даже негосударственных организаций смогут использовать со своей стороны военный потенциал ИИ. Уже на этом этапе качество используемых машин станет куда более важным.
ИИ поможет справиться с военными «большими данными» (Big Data). Обращение к данным позволит системам ИИ учитывать те факторы, о которых люди могут не думать, когда находятся в бою. Тогда это будет служить преимуществом над врагом.
Наконец, по мере того, как будет появляться все больше ПО для военного ИИ, неизбежны и новые споры об оптимальном соотношении количества и качества. Здесь возможно такое же разделение, как и в остальном оружейном рынке: простые, дешевые в изготовлении массовые устройства с одной стороны — и сверхдорогие разработки для элитных войск с другой.
Женя Заковоротная
{kind=link}
Кто это сказал? Разбирается Google AI
В последние годы речевые и языковые технологии коренным образом меняют наше повседневное взаимодействие с девайсами: мы можем одним голосом включить любимую музыку на умных колонках, узнать погоду на завтра или просто поболтать с голосовым помощником, всегда готовым тебя выслушать. Но несмотря на заметный прогресс в этой сфере, компьютеры до сих пор плохо справляются с задачей понимания естественной речи в случаях разговоров нескольких человек: интервью, конференции, телефонные звонки или записи медицинского приёма пациентов. Для понимания естественной речи необходимо не только распознавать слова, но и определять говорящего их человека.
Недавняя разработка инженеров Google AI использует для решения этой проблемы рекуррентную нейронную сеть, что позволяет обойти ограничения традиционно используемой системы диаризации (Speech Diarization, SD).
Разрабтка Google AI состоит их трех сетей:
1) сеть транскрипции, которая устанавливает соответствие между последовательностями звуков и фонемами;
2) сеть прогнозирования, которая предсказывает следующий тег говорящего с учетом уже определенных ранее тегов;
3) объединенная сеть, которая соединяет выводы двух предыдущих сетей и задает распределение вероятностей в наборе тегов на каждом отрезке времени. Также в архитектуре модели предусмотрен цикл обратной связи, где слова, распознанные ранее, снова отправляются на ввод, что позволяет модели учитывать такие данные как, например, конец вопроса.
https://sysblok.ru/linguistics/kto-jeto-skazal-razbiraetsja-google-ai/
В последние годы речевые и языковые технологии коренным образом меняют наше повседневное взаимодействие с девайсами: мы можем одним голосом включить любимую музыку на умных колонках, узнать погоду на завтра или просто поболтать с голосовым помощником, всегда готовым тебя выслушать. Но несмотря на заметный прогресс в этой сфере, компьютеры до сих пор плохо справляются с задачей понимания естественной речи в случаях разговоров нескольких человек: интервью, конференции, телефонные звонки или записи медицинского приёма пациентов. Для понимания естественной речи необходимо не только распознавать слова, но и определять говорящего их человека.
Недавняя разработка инженеров Google AI использует для решения этой проблемы рекуррентную нейронную сеть, что позволяет обойти ограничения традиционно используемой системы диаризации (Speech Diarization, SD).
Разрабтка Google AI состоит их трех сетей:
1) сеть транскрипции, которая устанавливает соответствие между последовательностями звуков и фонемами;
2) сеть прогнозирования, которая предсказывает следующий тег говорящего с учетом уже определенных ранее тегов;
3) объединенная сеть, которая соединяет выводы двух предыдущих сетей и задает распределение вероятностей в наборе тегов на каждом отрезке времени. Также в архитектуре модели предусмотрен цикл обратной связи, где слова, распознанные ранее, снова отправляются на ввод, что позволяет модели учитывать такие данные как, например, конец вопроса.
https://sysblok.ru/linguistics/kto-jeto-skazal-razbiraetsja-google-ai/
{kind=link}
Черных — в тюрьму, женщин — в секретарши: этика в эпоху искусственного интеллекта
Любая технологическая «революция» входит в нашу жизнь незаметно. И то, что вчера казалось фантастикой о далёком будущем, сегодня стало тем, на что мы уже просто не обращаем внимания — бытом и повседневностью.
Ещё вчера бизнес с крайней осторожностью использовал ИИ только в системах поддержки принятия решений, предлагая человеку оценить предложенный системой вариант и всё-таки самому принять решение — ведь человек может объяснить почему, а ИИ — нет. Сегодня же крупные компании готовы, пусть пока и частично, доверить свой финансовый результат полностью автоматическим решениям — как, например, это уже делает Сбербанк, планируя перевести 100% решений о кредитах физическим лицам в зону ответственности ИИ уже до конца 2020 года
Люди не могут проанализировать весь свой опыт, полученный за длительный период времени, а машины делают это с лёгкостью. Люди исключают факторы, которые на их взгляд несущественны для решаемого вопроса, тогда так машины не отбросят ничего. Отсутствие избирательности предоставляет машинам возможность рассматривать факторы, которые человек посчитал бы неуместными для принятия решения.
ProPublica предоставила яркое свидетельство этого явления в 2016 году. В судах США использовалась компьютерная программа для выявления подсудимых, которые с большей вероятностью повторят преступление в будущем. Программа ошибочно отмечала чёрнокожих подсудимых, не совершавших рецидивных правонарушений в течение периода более двух лет, практически в два раза чаще по сравнению с белыми правонарушителями. Если бы то же самое сделал человек, его бы объявили расистом.
Действительно ли мы хотим передать процесс принятия решений машинам, обучающимся исключительно на прошлом и потому полностью зависящим от него, вместо того, чтобы самим формировать будущее?
В дивном новом мире сложные решения сводятся к повторяющимся выборам и ограничиваются обозримыми результатами. Сложность урезана до простоты, мораль сведена к выгоде. Сегодня этика обосновывает наши решения. Но не так много времени осталось до того момента, когда наши решения поставят под сомнение всю нашу мораль.
Александра Сахарова
Любая технологическая «революция» входит в нашу жизнь незаметно. И то, что вчера казалось фантастикой о далёком будущем, сегодня стало тем, на что мы уже просто не обращаем внимания — бытом и повседневностью.
Ещё вчера бизнес с крайней осторожностью использовал ИИ только в системах поддержки принятия решений, предлагая человеку оценить предложенный системой вариант и всё-таки самому принять решение — ведь человек может объяснить почему, а ИИ — нет. Сегодня же крупные компании готовы, пусть пока и частично, доверить свой финансовый результат полностью автоматическим решениям — как, например, это уже делает Сбербанк, планируя перевести 100% решений о кредитах физическим лицам в зону ответственности ИИ уже до конца 2020 года
Люди не могут проанализировать весь свой опыт, полученный за длительный период времени, а машины делают это с лёгкостью. Люди исключают факторы, которые на их взгляд несущественны для решаемого вопроса, тогда так машины не отбросят ничего. Отсутствие избирательности предоставляет машинам возможность рассматривать факторы, которые человек посчитал бы неуместными для принятия решения.
ProPublica предоставила яркое свидетельство этого явления в 2016 году. В судах США использовалась компьютерная программа для выявления подсудимых, которые с большей вероятностью повторят преступление в будущем. Программа ошибочно отмечала чёрнокожих подсудимых, не совершавших рецидивных правонарушений в течение периода более двух лет, практически в два раза чаще по сравнению с белыми правонарушителями. Если бы то же самое сделал человек, его бы объявили расистом.
Действительно ли мы хотим передать процесс принятия решений машинам, обучающимся исключительно на прошлом и потому полностью зависящим от него, вместо того, чтобы самим формировать будущее?
В дивном новом мире сложные решения сводятся к повторяющимся выборам и ограничиваются обозримыми результатами. Сложность урезана до простоты, мораль сведена к выгоде. Сегодня этика обосновывает наши решения. Но не так много времени осталось до того момента, когда наши решения поставят под сомнение всю нашу мораль.
Александра Сахарова
{kind=link}
Как начать свой путь в NLP (не путать с НЛП)
NLP расшифровывается как Natural Language Processing и представляет собой целое направление, связанное с обработкой и распознаванием языковых данных. На сегодняшний день в числе достижений NLP можно отметить машинный перевод, чат-боты, голосовых помощников, автоматических переводчиков и умную контекстную рекламу.
Где используется?
Во множестве приложений и инструментов, от роботов в колл-центрах, электронных консультантов на сайтах, таргетированной рекламы и Google Translate, до проверки грамматики в Microsoft Word и Grammarly. Не забудем о голосовых помощниках вроде Siri, Алисы и Алексы.
Как работает?
Основная задача и идея NLP (и NLU, Natural Language Understanding) — превратить неструктурированные (сырые) языковые данные в форму, понятную компьютеру.
В чем сложности?
Сама природа человеческого естественного языка делает некоторые задачи NLP непростыми: не все закономерности можно эффективно формализовать, некоторые феномены являются очень абстрактными (например, до сих пор эффективно не решена задача автоматического обнаружения сарказма, иронии и импликатур в текстах. Некоторые более простые — например, описать использование окончаний множественного числа в существительных.Но как разобраться во всем этом?
Шаг 1. Выяснить, что такое NLP — только что вами пройден.
Шаг 2. Познакомиться с арсеналом методов: лемматизацией, токенизацией и морфологическим разбором.
Шаг 3. Осознать поле типичных NLP-задач (от автоматического распознавания речи до создания языковых моделей и генерации текста)
Шаг 4. Найти полезные Ресурсы: классическая книга Дэна Журафски и Криса Мэннинга, датасеты, видео и курсы по обработке естественного языка на coursera.
https://sysblok.ru/nlp/kak-nachat-svoj-put-v-nlp-ne-putat-s-nlp/
NLP расшифровывается как Natural Language Processing и представляет собой целое направление, связанное с обработкой и распознаванием языковых данных. На сегодняшний день в числе достижений NLP можно отметить машинный перевод, чат-боты, голосовых помощников, автоматических переводчиков и умную контекстную рекламу.
Где используется?
Во множестве приложений и инструментов, от роботов в колл-центрах, электронных консультантов на сайтах, таргетированной рекламы и Google Translate, до проверки грамматики в Microsoft Word и Grammarly. Не забудем о голосовых помощниках вроде Siri, Алисы и Алексы.
Как работает?
Основная задача и идея NLP (и NLU, Natural Language Understanding) — превратить неструктурированные (сырые) языковые данные в форму, понятную компьютеру.
В чем сложности?
Сама природа человеческого естественного языка делает некоторые задачи NLP непростыми: не все закономерности можно эффективно формализовать, некоторые феномены являются очень абстрактными (например, до сих пор эффективно не решена задача автоматического обнаружения сарказма, иронии и импликатур в текстах. Некоторые более простые — например, описать использование окончаний множественного числа в существительных.Но как разобраться во всем этом?
Шаг 1. Выяснить, что такое NLP — только что вами пройден.
Шаг 2. Познакомиться с арсеналом методов: лемматизацией, токенизацией и морфологическим разбором.
Шаг 3. Осознать поле типичных NLP-задач (от автоматического распознавания речи до создания языковых моделей и генерации текста)
Шаг 4. Найти полезные Ресурсы: классическая книга Дэна Журафски и Криса Мэннинга, датасеты, видео и курсы по обработке естественного языка на coursera.
https://sysblok.ru/nlp/kak-nachat-svoj-put-v-nlp-ne-putat-s-nlp/
Системный Блокъ
Как начать свой путь в NLP (не путать с НЛП) - Системный Блокъ
Хотите разобраться в автоматической обработке языка и стать NLP-инженером? Вам сюда
Скажи мне, какой у тебя индекс Хирша, и я скажу, кто ты
Наукометрия — область науковедения, исследующая науку количественными методами. Наукометрические подходы используются для принятия решений о финансировании научных групп и отдельных исследователей, а также для оценки значимости учёных в их научной области. Основную часть таких подходов составляют библиометрические показатели — параметры, которые оценивают опубликованные результаты исследований.
Основными библиометрическими показателями в науке являются количество статей и их цитируемость (использование предложенных в статье идей другими учёными). Считается, что по количеству статей можно сделать вывод о том, насколько продуктивен учёный, а по количеству цитирований — насколько его работа значима в научном сообществе.
Индекс Хирша
В 2005 году физик Хорхе Хирш предложил использовать для расчета вклада учёного индекс, который учитывает и продуктивность исследователя, и значимость его работы. Этот индекс, получивший название «индекс Хирша» (h-index), рассчитывается так: индекс Хирша учёного равен h, если h из его N статей цитируются как минимум h раз каждая, а остальные (N-h) статей цитируются не более чем h раз каждая.
Что не так с индексом Хирша?
Индекс Хирша, безусловно, обладает достоинствами. Этих достоинств, впрочем, оказывается недостаточно для того, чтобы научное сообщество приняло h-index таким, какой он есть. И у учёных есть на то причины.
Во-первых, h-index непригоден для сравнения исследователей из разных научных областей. Количество публикаций и цитирований отличается в зависимости от количества исследователей в данной области, темы исследования, языка публикаций, возраста области науки и других параметров.
Во-вторых, h-index одного и того же учёного в разных базах данных будет разным. Индекс Хирша рассчитывается автоматически на основании информации, имеющейся в базе данных. Поэтому, чем больше там публикаций, тем более высоким будет индекс Хирша.
В-третьих, индекс Хирша не учитывает количество соавторов и индивидуальный вклад каждого из них.
«О, радость взаимного цитирования!»
Основные способы накрутки количества цитирований — самоцитирование и взаимное цитирование. Летом 2019 года был опубликован список 100 тыс. самых цитируемых исследователей, где нобелевские лауреаты и выдающиеся учёные стоят плечом к плечу с менее известными деятелями, такими как Сундарапандьян Вайдьянатан из Индии. 94% цитирований его работ — это ссылки из статей Сундарапандьяна и его соавторов. И этот случай не единичный. Как минимум у 250 исследователей из опубликованного списка процент самоцитирования и цитирования от соавторов превышает 50%.
Кардашьян от науки
Кроме библиометрических показателей есть показатели альтметрические. Это альтернативные метрики, которыми могут оцениваться публикации: количество просмотров, количество скачиваний, количество упоминаний и репостов публикации в социальных сетях, СМИ, блогах и т.д.
Есть и экстравагантные метрики — в 2014 был предложен индекс Кардашьян. (K-index) — это мера несоответствия профиля учёного в социальных медиа и его публикационной активности, основанная на сравнении количества цитирований его работ и количества подписчиков в Твиттере. Так, высокий K-index указывает на безосновательную популярность учёного, а низкий предполагает, что учёного недооценивают.
С другой стороны, участие в популяризации науки — это ли не вклад в неё?
Наукометрия — область науковедения, исследующая науку количественными методами. Наукометрические подходы используются для принятия решений о финансировании научных групп и отдельных исследователей, а также для оценки значимости учёных в их научной области. Основную часть таких подходов составляют библиометрические показатели — параметры, которые оценивают опубликованные результаты исследований.
Основными библиометрическими показателями в науке являются количество статей и их цитируемость (использование предложенных в статье идей другими учёными). Считается, что по количеству статей можно сделать вывод о том, насколько продуктивен учёный, а по количеству цитирований — насколько его работа значима в научном сообществе.
Индекс Хирша
В 2005 году физик Хорхе Хирш предложил использовать для расчета вклада учёного индекс, который учитывает и продуктивность исследователя, и значимость его работы. Этот индекс, получивший название «индекс Хирша» (h-index), рассчитывается так: индекс Хирша учёного равен h, если h из его N статей цитируются как минимум h раз каждая, а остальные (N-h) статей цитируются не более чем h раз каждая.
Что не так с индексом Хирша?
Индекс Хирша, безусловно, обладает достоинствами. Этих достоинств, впрочем, оказывается недостаточно для того, чтобы научное сообщество приняло h-index таким, какой он есть. И у учёных есть на то причины.
Во-первых, h-index непригоден для сравнения исследователей из разных научных областей. Количество публикаций и цитирований отличается в зависимости от количества исследователей в данной области, темы исследования, языка публикаций, возраста области науки и других параметров.
Во-вторых, h-index одного и того же учёного в разных базах данных будет разным. Индекс Хирша рассчитывается автоматически на основании информации, имеющейся в базе данных. Поэтому, чем больше там публикаций, тем более высоким будет индекс Хирша.
В-третьих, индекс Хирша не учитывает количество соавторов и индивидуальный вклад каждого из них.
«О, радость взаимного цитирования!»
Основные способы накрутки количества цитирований — самоцитирование и взаимное цитирование. Летом 2019 года был опубликован список 100 тыс. самых цитируемых исследователей, где нобелевские лауреаты и выдающиеся учёные стоят плечом к плечу с менее известными деятелями, такими как Сундарапандьян Вайдьянатан из Индии. 94% цитирований его работ — это ссылки из статей Сундарапандьяна и его соавторов. И этот случай не единичный. Как минимум у 250 исследователей из опубликованного списка процент самоцитирования и цитирования от соавторов превышает 50%.
Кардашьян от науки
Кроме библиометрических показателей есть показатели альтметрические. Это альтернативные метрики, которыми могут оцениваться публикации: количество просмотров, количество скачиваний, количество упоминаний и репостов публикации в социальных сетях, СМИ, блогах и т.д.
Есть и экстравагантные метрики — в 2014 был предложен индекс Кардашьян. (K-index) — это мера несоответствия профиля учёного в социальных медиа и его публикационной активности, основанная на сравнении количества цитирований его работ и количества подписчиков в Твиттере. Так, высокий K-index указывает на безосновательную популярность учёного, а низкий предполагает, что учёного недооценивают.
С другой стороны, участие в популяризации науки — это ли не вклад в неё?
VK Видео
Индекс Хирша и радость взаимного цитирования
О, радость! О, радость Взаимного цитирования!!!! Я пошёл писать статью ;-)
Помедленнее, я записываю!
Научить машину распознаванию речи можно либо с помощью сравнения с эталоном, либо методом контекстно-зависимой классификации («узнавания» отдельных мелких элементов, которые складываются в полноценные слова).
В первом случае в память устройства закладывается некоторый объем исходных примеров. Во втором на помощь приходят методы дискриминантного анализа и марковские модели (оба метода основаны на статистике), а также нейронные сети.
Вариант 1: действуем по шаблону
Вопрос системы: «На какой месяц вы планируете поездку?»
Ответ человека: «Август».
В этом случае анализируется ответ, соотносящийся с ключевым словом («месяц»). База соответствий этому слову включает двенадцать наименований; система ожидает, что человек выберет нужное и произнесет его в именительном падеже. Если вместо «Август» пользователь ответит «В августе», могут возникнуть затруднения.
Вопрос системы: «В какое время вы хотите записаться к терапевту?»
Ответ человека: «14:25».
В систему, работающую со встроенными грамматиками, уже заложено большинство необходимых значений, поэтому она работает с семантикой и темой ответа. Обратите внимание, что в этом примере пользователь не называет «ровное» время — и, следовательно, ожидает, что устройство не запишет его на два или половину третьего.
Вариант 2: ищем ключевые слова и взаимосвязи
Вопрос системы: «Что вас интересует?»
Ответ человека: «Как подать документы на химический факультет МГУ?»
В подобном запросе будут важны «как» (а не «когда»), «подать» (а не «забрать»), «химический» (а не «физический») и «МГУ» (а не «МГИМО»). Система должна будет оценить все слова запроса или команды и учесть их взаимосвязь.
Находка для шпиона
Для распознавания устной речи необязательно говорить что-то вслух: одна из новых разработок — интерфейсы безмолвного доступа (SSI, silent speech interfaces), системы, распознающие речевые сигналы на самой ранней стадии артикулирования. Движения лицевых мышц несут информацию о том, что именно мы произносим.
Весной 2018 года модель под названием AlterEgo представили в Массачусетском технологическом институте (MIT). В серии экспериментов с десятью добровольцами удалось добиться 92% распознаваемости. Ученые обещают, что скоро этот показатель вырастет еще на несколько пунктов.
Говорить о том, что машина сможет заменить человека в создании и понимании действительно сложных текстов, еще очень рано — но она уже совершенно точно готова выслушать тех, кто в этом нуждается.
Наталия Крякина
Научить машину распознаванию речи можно либо с помощью сравнения с эталоном, либо методом контекстно-зависимой классификации («узнавания» отдельных мелких элементов, которые складываются в полноценные слова).
В первом случае в память устройства закладывается некоторый объем исходных примеров. Во втором на помощь приходят методы дискриминантного анализа и марковские модели (оба метода основаны на статистике), а также нейронные сети.
Вариант 1: действуем по шаблону
Вопрос системы: «На какой месяц вы планируете поездку?»
Ответ человека: «Август».
В этом случае анализируется ответ, соотносящийся с ключевым словом («месяц»). База соответствий этому слову включает двенадцать наименований; система ожидает, что человек выберет нужное и произнесет его в именительном падеже. Если вместо «Август» пользователь ответит «В августе», могут возникнуть затруднения.
Вопрос системы: «В какое время вы хотите записаться к терапевту?»
Ответ человека: «14:25».
В систему, работающую со встроенными грамматиками, уже заложено большинство необходимых значений, поэтому она работает с семантикой и темой ответа. Обратите внимание, что в этом примере пользователь не называет «ровное» время — и, следовательно, ожидает, что устройство не запишет его на два или половину третьего.
Вариант 2: ищем ключевые слова и взаимосвязи
Вопрос системы: «Что вас интересует?»
Ответ человека: «Как подать документы на химический факультет МГУ?»
В подобном запросе будут важны «как» (а не «когда»), «подать» (а не «забрать»), «химический» (а не «физический») и «МГУ» (а не «МГИМО»). Система должна будет оценить все слова запроса или команды и учесть их взаимосвязь.
Находка для шпиона
Для распознавания устной речи необязательно говорить что-то вслух: одна из новых разработок — интерфейсы безмолвного доступа (SSI, silent speech interfaces), системы, распознающие речевые сигналы на самой ранней стадии артикулирования. Движения лицевых мышц несут информацию о том, что именно мы произносим.
Весной 2018 года модель под названием AlterEgo представили в Массачусетском технологическом институте (MIT). В серии экспериментов с десятью добровольцами удалось добиться 92% распознаваемости. Ученые обещают, что скоро этот показатель вырастет еще на несколько пунктов.
Говорить о том, что машина сможет заменить человека в создании и понимании действительно сложных текстов, еще очень рано — но она уже совершенно точно готова выслушать тех, кто в этом нуждается.
Наталия Крякина
{kind=link}
Нейросеть помогла ученым разгадать античные тексты
Исследователи Оксфордского университета и команда DeepMind создали программу «Пифия» (Pythia), которая способна вставить пропущенные слова или знаки в греческих записях с помощью нейронной сети. Эти надписи, созданные от 1,5 до 2,6 тысяч лет назад, высечены на камне, металле или керамике.
Немного статистики: Если эпиграфистам требуется 2 часа, чтобы расшифровать 50 текстов, то Пифия справляется со сплошным текстом за пару секунд. В среднем ученые совершают ошибки на 30% чаще. Пифия обучена узнавать отрывки среди 35000 найденных реликвий, а это более 3 миллионов слов. Программа находит отрывки, включенные в контекст, и делает выводы об истории слова, развитии грамматики и содержании текста.
Ученые предполагают, что Пифия будет и в дальнейшем помогать цифровой эпиграфике. Архитектура этой программы работает как на уровне отдельных символов, так и на уровне лексем, эффективно обрабатывая и объемный информационный контекст, и отдельные лакуны в древнем тексте. Это и делает её полезной для дисциплин, исследующих как древние (филология, папирология, кодикология), так и к современные тексты.
Ольга Чхотуа
Исследователи Оксфордского университета и команда DeepMind создали программу «Пифия» (Pythia), которая способна вставить пропущенные слова или знаки в греческих записях с помощью нейронной сети. Эти надписи, созданные от 1,5 до 2,6 тысяч лет назад, высечены на камне, металле или керамике.
Немного статистики: Если эпиграфистам требуется 2 часа, чтобы расшифровать 50 текстов, то Пифия справляется со сплошным текстом за пару секунд. В среднем ученые совершают ошибки на 30% чаще. Пифия обучена узнавать отрывки среди 35000 найденных реликвий, а это более 3 миллионов слов. Программа находит отрывки, включенные в контекст, и делает выводы об истории слова, развитии грамматики и содержании текста.
Ученые предполагают, что Пифия будет и в дальнейшем помогать цифровой эпиграфике. Архитектура этой программы работает как на уровне отдельных символов, так и на уровне лексем, эффективно обрабатывая и объемный информационный контекст, и отдельные лакуны в древнем тексте. Это и делает её полезной для дисциплин, исследующих как древние (филология, папирология, кодикология), так и к современные тексты.
Ольга Чхотуа
Tech Xplore
Deep learning enlightens scholars puzzling over ancient texts
Deep learning can help scholars restore ancient Greek texts. Specifically, researchers at University of Oxford (Thea Sommerschield and Professor Jonathan Prag) and DeepMind (Yannis Assael) built Pythia, ...
Где учить Python: обзор онлайн-курсов от «Системного Блока»
Научиться программировать мечтают многие, но как выбрать подходящий курс из сотен доступных вариантов? Мы сделали обзор курсов по Python, которые проходили сами
1. Python for everybody — курс для тех, кого в принципе всегда пугала идея программирования: здесь не будет математики и каких-либо сложных задач. Если вы — полный новичок, или уже в бессилии бросили несколько других курсов, которые с первых занятий погружали слушателей в линейную алгебру и статистику, то этот курс для вас.
2. Алгоритмы на Python 3. — этот курс подходит тем, кто интересовался программированием на школьном уровне, но за последнее время мог что-нибудь забыть. Лектор по большей части не учит синтаксису языка (хотя знакомит с некоторыми полезными приемами), концентрируется на принципиальном подходе, который решил бы текущую задачу.
3. Python tutor — этот курс идеально подходит для того, чтобы понять, что вообще такое программирование. Авторы курса начинают с самых азов — понятия переменных, ввода данных с клавиатуры. Дальше ученики начинают понемногу осваивать основные инструкции языка (циклы и условия), а также знакомятся с структурами данных.
4. Нетология. Python и математика для анализа данных (в составе курса Data Science) — это онлайн курс по основам языка Python с уклоном использования языка для анализа данных. Первая часть по основам Python, а вторая по линейной алгебре, математической оптимизации и статистике и их реализации в Python. Курс рассчитан на тех, кто хочет научится анализу данных с помощью Python.
5. Skillfactory — курс состоит из 16 модулей на разные темы: от основ синтаксиса до инструментов работы с данными. Самыми полезными оказались разделы по очистке и визуализации данных, работе с HTML и API. В целом кажется, что человеку, который придет учиться с нуля, курс сможет дать достаточно мощную базу, на которую потом легче «положить» все дополнительные умения.
Бонус: бесплатные мобильные приложения
Solo Learn Python — Приложение не сможет заменить полноценный курс, но будет полезно для закрепления навыков в игровой форме
Stepik — Системный Блокъ рекомендует эту платформу с курсами именно в виде мобильного приложения: видеолекции удобно сохранять в кэш и смотреть в дороге вместо видео с котиками
Python Рецепты — 250 примеров кода на Python для различных задач. StackOverflow
для ленивых
Решить «просто научиться программировать» и достигнуть этой цели очень сложно. Гораздо эффективнее придумать себе интересную задачу и посмотреть, какими инструментами Python вы можете ее решить и что для этого нужно уметь. Иногда это даже проще, чем кажется!
Научиться программировать мечтают многие, но как выбрать подходящий курс из сотен доступных вариантов? Мы сделали обзор курсов по Python, которые проходили сами
1. Python for everybody — курс для тех, кого в принципе всегда пугала идея программирования: здесь не будет математики и каких-либо сложных задач. Если вы — полный новичок, или уже в бессилии бросили несколько других курсов, которые с первых занятий погружали слушателей в линейную алгебру и статистику, то этот курс для вас.
2. Алгоритмы на Python 3. — этот курс подходит тем, кто интересовался программированием на школьном уровне, но за последнее время мог что-нибудь забыть. Лектор по большей части не учит синтаксису языка (хотя знакомит с некоторыми полезными приемами), концентрируется на принципиальном подходе, который решил бы текущую задачу.
3. Python tutor — этот курс идеально подходит для того, чтобы понять, что вообще такое программирование. Авторы курса начинают с самых азов — понятия переменных, ввода данных с клавиатуры. Дальше ученики начинают понемногу осваивать основные инструкции языка (циклы и условия), а также знакомятся с структурами данных.
4. Нетология. Python и математика для анализа данных (в составе курса Data Science) — это онлайн курс по основам языка Python с уклоном использования языка для анализа данных. Первая часть по основам Python, а вторая по линейной алгебре, математической оптимизации и статистике и их реализации в Python. Курс рассчитан на тех, кто хочет научится анализу данных с помощью Python.
5. Skillfactory — курс состоит из 16 модулей на разные темы: от основ синтаксиса до инструментов работы с данными. Самыми полезными оказались разделы по очистке и визуализации данных, работе с HTML и API. В целом кажется, что человеку, который придет учиться с нуля, курс сможет дать достаточно мощную базу, на которую потом легче «положить» все дополнительные умения.
Бонус: бесплатные мобильные приложения
Solo Learn Python — Приложение не сможет заменить полноценный курс, но будет полезно для закрепления навыков в игровой форме
Stepik — Системный Блокъ рекомендует эту платформу с курсами именно в виде мобильного приложения: видеолекции удобно сохранять в кэш и смотреть в дороге вместо видео с котиками
Python Рецепты — 250 примеров кода на Python для различных задач. StackOverflow
для ленивых
Решить «просто научиться программировать» и достигнуть этой цели очень сложно. Гораздо эффективнее придумать себе интересную задачу и посмотреть, какими инструментами Python вы можете ее решить и что для этого нужно уметь. Иногда это даже проще, чем кажется!
{kind=link}
Обзор просветительских проектов в сфере IT в 2019 году
На этой неделе завершился конкурс медийных IT-проектов, организованный Яндекс.Практикумом, ВКонтакте и Типичным программистом @tproger_official. Победители оказались очень разными: здесь и видеоуроки по программированию, и крафтовый блог о «выживании в мире технологий», и подкасты для фронтендеров, и наш «Системный Блокъ» с IT-тьюториалами для непрограммистов, компьютерной лингвистикой, наукометрией и EdTech’ом
Вдохновившись разнообразием айтишных медиа, мы решили сделать свою подборку по следам конкурса. В нее вошли все победители и один проект, не попавший в число призеров, но тоже симпатичный.
— @codeblog — это, в первую очередь, канал на YouTube, где можно методично погружаться в C# (автор канала — .NET разработчик с 8-летним стажем и стилем подачи материала «добродушный старший сержант»), а можно и позалипать на общеайтишные темы: релокация в другую страну, зарплаты, «войтивайти»... Еще у code blog есть паблик в вк и телеграм-канал. Тут кроме собственных роликов автора есть видеоподборки по другим языкам программирования (Python, Javascript, C++, Java...), PDF-ы с полезными книжками для обучения программированию и, конечно, обязательные мемы про джунов, тестирование на мастере и пятничный деплой. Да, с котиками.
— @vas3k_channel — канал того-самого-Вастрика. Даже если вы не знаете, кто такой Вастрик, вы наверняка встречали картинки из его лонгридов, которые ворует на презентации весь интернет. Для описания стиля, в котором пишет Вастрик, лучше всего подходит труднопереводимое английское выражение «cut the crap». О работе, технологиях, путешествиях и чём только не — без маркетинговой лапши из мотивационных книжек. Ну а лонгриды сделаны так, что по ним можно провести пару у очень неглупых студентов — и вам будут хлопать (да, мы проверяли; нам стыдно, но не очень).
— @frontendweekend — качественные интервью с известными людьми из мира frontend-разработки. Здесь разговаривают с теми, кто делает «морду» Яндекса и Мэйла, Booking и Avito, ЦИАНа и Тинькофф. В разное время в подкасте появлялись люди из Acronis, Voximplant, JetBrains, Uber, Deutsche Bank... В общем, действительно «человеческое лицо фронтенда». Но на фронтенде авторы не замыкаются: есть выпуски и про бэкенд, и про менеджмент IT-проектов, и про психологию в IT. Отдельный плюс — интервью с авторами других известных IT-подкастов: «Подлодки», Moscow Python Podcast-а, The Art Of Programming.
— @oleg_log — приют асоциальных программистов или канал разработчика Go о практиках разработки и soft skills при работе в команде. Здесь вы найдете обзоры opensource проектов, новости языка Go и современные подходы к ревью кода. Помимо основного проекта автор развивает youtube канал, подкаст и библиотеку материалов.
— @sysblok — образовательный и научно-популярный проект «Системный Блокъ» о проникновении IT в культуру и общество: машинный перевод египетских иероглифов, цифровые технологии для юристов, количественные исследования текстов Егора Летова и Ивана Голунова. Здесь вы найдете и обзор курсов по Питону для новичков, и тьюториалы по скачиванию твиттера или по вычислению расстояния Левенштейна. Хотите начать свой путь в технологии NLP (не путать с НЛП!) или следить за влиянием технологий на культуру — присоединяйтесь.
На этой неделе завершился конкурс медийных IT-проектов, организованный Яндекс.Практикумом, ВКонтакте и Типичным программистом @tproger_official. Победители оказались очень разными: здесь и видеоуроки по программированию, и крафтовый блог о «выживании в мире технологий», и подкасты для фронтендеров, и наш «Системный Блокъ» с IT-тьюториалами для непрограммистов, компьютерной лингвистикой, наукометрией и EdTech’ом
Вдохновившись разнообразием айтишных медиа, мы решили сделать свою подборку по следам конкурса. В нее вошли все победители и один проект, не попавший в число призеров, но тоже симпатичный.
— @codeblog — это, в первую очередь, канал на YouTube, где можно методично погружаться в C# (автор канала — .NET разработчик с 8-летним стажем и стилем подачи материала «добродушный старший сержант»), а можно и позалипать на общеайтишные темы: релокация в другую страну, зарплаты, «войтивайти»... Еще у code blog есть паблик в вк и телеграм-канал. Тут кроме собственных роликов автора есть видеоподборки по другим языкам программирования (Python, Javascript, C++, Java...), PDF-ы с полезными книжками для обучения программированию и, конечно, обязательные мемы про джунов, тестирование на мастере и пятничный деплой. Да, с котиками.
— @vas3k_channel — канал того-самого-Вастрика. Даже если вы не знаете, кто такой Вастрик, вы наверняка встречали картинки из его лонгридов, которые ворует на презентации весь интернет. Для описания стиля, в котором пишет Вастрик, лучше всего подходит труднопереводимое английское выражение «cut the crap». О работе, технологиях, путешествиях и чём только не — без маркетинговой лапши из мотивационных книжек. Ну а лонгриды сделаны так, что по ним можно провести пару у очень неглупых студентов — и вам будут хлопать (да, мы проверяли; нам стыдно, но не очень).
— @frontendweekend — качественные интервью с известными людьми из мира frontend-разработки. Здесь разговаривают с теми, кто делает «морду» Яндекса и Мэйла, Booking и Avito, ЦИАНа и Тинькофф. В разное время в подкасте появлялись люди из Acronis, Voximplant, JetBrains, Uber, Deutsche Bank... В общем, действительно «человеческое лицо фронтенда». Но на фронтенде авторы не замыкаются: есть выпуски и про бэкенд, и про менеджмент IT-проектов, и про психологию в IT. Отдельный плюс — интервью с авторами других известных IT-подкастов: «Подлодки», Moscow Python Podcast-а, The Art Of Programming.
— @oleg_log — приют асоциальных программистов или канал разработчика Go о практиках разработки и soft skills при работе в команде. Здесь вы найдете обзоры opensource проектов, новости языка Go и современные подходы к ревью кода. Помимо основного проекта автор развивает youtube канал, подкаст и библиотеку материалов.
— @sysblok — образовательный и научно-популярный проект «Системный Блокъ» о проникновении IT в культуру и общество: машинный перевод египетских иероглифов, цифровые технологии для юристов, количественные исследования текстов Егора Летова и Ивана Голунова. Здесь вы найдете и обзор курсов по Питону для новичков, и тьюториалы по скачиванию твиттера или по вычислению расстояния Левенштейна. Хотите начать свой путь в технологии NLP (не путать с НЛП!) или следить за влиянием технологий на культуру — присоединяйтесь.
Что не так с машинным переводом?
С наступлением эры нейросетей СМИ любят писать, что машинный перевод вот-вот сравнится по качеству с продуктом профессионального переводчика. «Искусственный интеллект в машинном переводе догоняет человека», уверяют заголовки уважаемых технологических медиа. Но так ли это?
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом.
Как работает машинный перевод и какие у него недостатки?
С начала 2000-х и до 2015-2016 гг. в переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based). Он рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. С приходом нейросетей машинные переводчики перешли на них. Нейросети не нужно заранее выделять в тексте фиксированные фразы: алгоритмы сами постепенно выучивают на больших объемах данных оптимальные решения. Благодаря этому качество работы машинных переводчиков так подскочило.
Однако действительно ли нейронный машинный перевод (НМП) приближается к человеческому? Ответ: нет! Пока что системы машинного перевода не сопоставимы с мозгом переводчика-человека. Они допускают ошибки, которых человек никогда бы не допустил — и которые свидетельствуют о том, что разговоры об «искусственном интеллекте» преждевременны.
Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
1. Достоверность
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода.
Например, важнейшую строчку в знаменитом стихотворении Пушкина Я вас любил: любовь ещё, быть может нейросеть смогла развернуть на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
Как дай вам бог любимой быть другим > How god forbid you be loved to be different
Используя данные реального мира, система НМТ вводит необоснованную информацию, и искажает не только данные, но и свои переводы. Так, переведенный с малайского текст, не содержащий никакой гендерной информации, в переводе на английский обозначает женскую и мужскую роль:
Dia bekerja sebagai jururawant > She works as a nurse
Dia bekerja sebagai pengaturcara > He works as a programmer
2. Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений.
Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят. Например, если бы в предыдущем примере система НМП имела доступ к другим предложениям этого текста, и в них упоминалось бы, что программист — женщина, система все равно не смогла бы использовать правильные местоимения.
3. Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Предположим, вы читаете статью о музыкальном концерте и отправляете французский перевод (выполненный системой НМП) своим франкоязычным друзьям. В английской версии в статье есть интервью различных концертмейстеров, в том числе одного молодого человека, который восклицает: «Я большой поклонник металла!»
Однако в переводе, это предложение становится таким:
«Je suis un énorme ventilateur en métal» («Я огромный вентилятор из металла»)
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных.
Мы работаем над этим… Как выглядит будущее?
Определение качества перевода — непростая задача. Сейчас наиболее распространенным способом является использование оценки BLEU, но она не может решить все озвученные проблемы. Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
Можно ожидать и ускорения распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — теперь другие легко могут брать за основу лучшие системы.
С наступлением эры нейросетей СМИ любят писать, что машинный перевод вот-вот сравнится по качеству с продуктом профессионального переводчика. «Искусственный интеллект в машинном переводе догоняет человека», уверяют заголовки уважаемых технологических медиа. Но так ли это?
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом.
Как работает машинный перевод и какие у него недостатки?
С начала 2000-х и до 2015-2016 гг. в переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based). Он рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. С приходом нейросетей машинные переводчики перешли на них. Нейросети не нужно заранее выделять в тексте фиксированные фразы: алгоритмы сами постепенно выучивают на больших объемах данных оптимальные решения. Благодаря этому качество работы машинных переводчиков так подскочило.
Однако действительно ли нейронный машинный перевод (НМП) приближается к человеческому? Ответ: нет! Пока что системы машинного перевода не сопоставимы с мозгом переводчика-человека. Они допускают ошибки, которых человек никогда бы не допустил — и которые свидетельствуют о том, что разговоры об «искусственном интеллекте» преждевременны.
Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
1. Достоверность
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода.
Например, важнейшую строчку в знаменитом стихотворении Пушкина Я вас любил: любовь ещё, быть может нейросеть смогла развернуть на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
Как дай вам бог любимой быть другим > How god forbid you be loved to be different
Используя данные реального мира, система НМТ вводит необоснованную информацию, и искажает не только данные, но и свои переводы. Так, переведенный с малайского текст, не содержащий никакой гендерной информации, в переводе на английский обозначает женскую и мужскую роль:
Dia bekerja sebagai jururawant > She works as a nurse
Dia bekerja sebagai pengaturcara > He works as a programmer
2. Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений.
Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят. Например, если бы в предыдущем примере система НМП имела доступ к другим предложениям этого текста, и в них упоминалось бы, что программист — женщина, система все равно не смогла бы использовать правильные местоимения.
3. Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Предположим, вы читаете статью о музыкальном концерте и отправляете французский перевод (выполненный системой НМП) своим франкоязычным друзьям. В английской версии в статье есть интервью различных концертмейстеров, в том числе одного молодого человека, который восклицает: «Я большой поклонник металла!»
Однако в переводе, это предложение становится таким:
«Je suis un énorme ventilateur en métal» («Я огромный вентилятор из металла»)
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных.
Мы работаем над этим… Как выглядит будущее?
Определение качества перевода — непростая задача. Сейчас наиболее распространенным способом является использование оценки BLEU, но она не может решить все озвученные проблемы. Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
Можно ожидать и ускорения распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — теперь другие легко могут брать за основу лучшие системы.
{kind=link}
Новый мобильный Google Translate
В прошлом году Google внес изменения в функцию камеры в своем мобильном приложении Translate. Новая версия приложения поддерживает 60 новых языков и лучше фиксирует переведенный текст на изображении; кроме того, компания обновила основные модели перевода, в некоторых случаях сократив частотность ошибок на 85 %.
Все это на радость постоянным пользователям приложения Google Translate, которым функция камеры нужна, чтобы переводить, например, меню или дорожные знаки. Ранее неоднократно звучали жалобы на некачественный перевод, нестабильную работу приложения и ограниченное число языков.Теперь поводов для недовольства должно стать меньше.
Как это работает?
Google наконец-то добавил в приложение свою систему нейронного машинного перевода (ранее она была доступна только в веб-версии Google Translate). Благодаря возможностям Google Lens приложение распознает текст и переводит его на целевой язык в режиме реального времени.
Сервис Google Lens был создан для мгновенного распознавания и обработки информации с изображений. Интеграция с ним позволяет Google Translate переводить как ранее сделанные фотографии, так и текст на незнакомом языке, который еще не сфотографирован, — достаточно просто навести на него камеру. Перевод можно прослушать, причем система маркером выделит для пользователя слово, которое читает прямо сейчас.
Куда теперь можно поехать, не зная языка?
Новая версия теперь поддерживает африкаанс, арабский, бенгальский, эстонский, греческий, хинди, игбо, яванский, курдский, латинский, латышский, малайский, монгольский, непальский, пушту, персидский, самоанский, сесото, словенский, суахили, тайский, вьетнамский, валлийский, коса, йоруба и зулу — всего поддерживаемых языков более 80. Google Translate также автоматически определит язык текста, что весьма полезно для путешествий в регионах, где распространено несколько языков. Путешествуем смело!
Источник: Google’s live camera translation is getting better AI and 60 new languages
В прошлом году Google внес изменения в функцию камеры в своем мобильном приложении Translate. Новая версия приложения поддерживает 60 новых языков и лучше фиксирует переведенный текст на изображении; кроме того, компания обновила основные модели перевода, в некоторых случаях сократив частотность ошибок на 85 %.
Все это на радость постоянным пользователям приложения Google Translate, которым функция камеры нужна, чтобы переводить, например, меню или дорожные знаки. Ранее неоднократно звучали жалобы на некачественный перевод, нестабильную работу приложения и ограниченное число языков.Теперь поводов для недовольства должно стать меньше.
Как это работает?
Google наконец-то добавил в приложение свою систему нейронного машинного перевода (ранее она была доступна только в веб-версии Google Translate). Благодаря возможностям Google Lens приложение распознает текст и переводит его на целевой язык в режиме реального времени.
Сервис Google Lens был создан для мгновенного распознавания и обработки информации с изображений. Интеграция с ним позволяет Google Translate переводить как ранее сделанные фотографии, так и текст на незнакомом языке, который еще не сфотографирован, — достаточно просто навести на него камеру. Перевод можно прослушать, причем система маркером выделит для пользователя слово, которое читает прямо сейчас.
Куда теперь можно поехать, не зная языка?
Новая версия теперь поддерживает африкаанс, арабский, бенгальский, эстонский, греческий, хинди, игбо, яванский, курдский, латинский, латышский, малайский, монгольский, непальский, пушту, персидский, самоанский, сесото, словенский, суахили, тайский, вьетнамский, валлийский, коса, йоруба и зулу — всего поддерживаемых языков более 80. Google Translate также автоматически определит язык текста, что весьма полезно для путешествий в регионах, где распространено несколько языков. Путешествуем смело!
Источник: Google’s live camera translation is getting better AI and 60 new languages
{kind=link}
«Best of Блокъ»: лучшие посты 2019 года
Весь 2019 год «Системный Блокъ» рассказывал, как высокие технологии становятся частью современной науки, культуры и повседневности, принося хорошее и плохое.
За год в «СБъ» вышло больше 220 материалов. Предлагаем вам подборку из 12 постов, которые стоит перечитать:
Новый, мертвый, хороший: визуализация текстов Гражданской Обороны
Пост-трибьют иконе русского панк-рока, написанный к 11-летию со дня смерти. Мы исследовали корпус текстов Летова цифровыми методами и визуализировали результаты.
Word2Vec: покажи мне свой контекст, и я скажу, кто ты
Рассказываем, как работает одна из самых актуальных технологий в основе современной компьютерной лингвистики и искусственного интеллекта — дистрибутивная семантика.
Зачем нужны гуманитарии в эпоху машинного обучения?
Наш перевод эссе Теда Андервуда о том, почему «непрактичные» и «невостребованные» навыки гуманитариев могут оказаться тем самым, что спасет всех нас в эпоху всепроникающих технологий и торжества ИИ.
Данные нас связали: где и как применяют статью 20.2 КоАП РФ
Изучаем статистику применения административной статьи 20.2 — той самой, которую в 2019 году массово использовали против задержанных на митингах и шествиях. Данные собрали и опубликовали «ОВД-Инфо», а мы исследовали их и нашли в два нестандартные случаи применения статьи 20.2.
Как работают фильтры в Инстаграме + Как посмотреть на мир глазами нейросетей
Технологический лонгрид в двух частях о том, как работает современное компьютерное зрение, что делает Instagram с вашими фотографиями и как нейросеть отличает дорогой дом на снимке — от дешевого.
Прокачиваем гуманитария до программиста: инструкция
Я — филолог (лингвист, историк, философ, культуролог, etc) и хочу заняться программированием. В чем мои сильные стороны? Что делать? Рассказывает гуманитарий, перековавшийся в программиста.
Пусти пожить болельщика: чемпионат в Москве и рынок Airbnb
Исследуем статистику Airbnb по Москве, чтобы понять, как Чемпионат мира по футболу 2018 года повлиял на рынок съемного жилья. Какие районы наводнили туристы, как они селились вокруг стадионов, а кто переоценил свою привлекательность для болельщиков?
Учат в школе… Чему?
Чему учат в современной началке? Мы проанализировали более 20 тыс. заданий в учебниках по русскому языку 1-4 классов и постарались разобраться, из чего они состоят — и чего требуют от школьника. Специальный пост к 1 сентября.
Что случилось с самыми унылыми стихотворениями XIX века
Элегия — ключевой поэтический жанр «золотого века» русской поэзии. Что можно узнать о нем, используя количественные методы: подсчет частотности слов, тематическое моделирование, статистику длины стихотворений?
Я/МЫ НКРЯ: что происходит с национальным корпусом
Этот текст стал частью борьбы за сохранение Национального корпуса русского языка, который переживал в 2019 году нелегкие времена. Осенью лингвисты обнаружили по знакомому адресу сильно урезанный и криво работающий корпус. Давно тлевшие слухи о полном отказе «Яндекса» от поддержки НКРЯ и его «закрытии» стали разлетаться по сети со скоростью фейсбучного репоста. Поисковику пришлось реагировать: старую версию НКРЯ вернули, а ученых заверили, что «Яндекс» корпус не бросит, т.к. его завещал беречь сам Илья Сегалович.
Жутко громко, запредельно тихо: звуки в романах
Цифровые методы анализируют голоса героев романа и их громкость. Одно исследование — в рамках отдельной книги («Идиот» Достоевского). Другое — на матреиале тысячи британских романов.
Зрение, мозг и нейросети
Если с помощью томографии зафиксировать активность мозга, когда человек смотрит на разные картинки, а потом скормить это вместе с картинками нейросети… она научится считывать то, что видит человек, прямо из мозга. Звучит как фантастика, но это уже здесь.
Весь 2019 год «Системный Блокъ» рассказывал, как высокие технологии становятся частью современной науки, культуры и повседневности, принося хорошее и плохое.
За год в «СБъ» вышло больше 220 материалов. Предлагаем вам подборку из 12 постов, которые стоит перечитать:
Новый, мертвый, хороший: визуализация текстов Гражданской Обороны
Пост-трибьют иконе русского панк-рока, написанный к 11-летию со дня смерти. Мы исследовали корпус текстов Летова цифровыми методами и визуализировали результаты.
Word2Vec: покажи мне свой контекст, и я скажу, кто ты
Рассказываем, как работает одна из самых актуальных технологий в основе современной компьютерной лингвистики и искусственного интеллекта — дистрибутивная семантика.
Зачем нужны гуманитарии в эпоху машинного обучения?
Наш перевод эссе Теда Андервуда о том, почему «непрактичные» и «невостребованные» навыки гуманитариев могут оказаться тем самым, что спасет всех нас в эпоху всепроникающих технологий и торжества ИИ.
Данные нас связали: где и как применяют статью 20.2 КоАП РФ
Изучаем статистику применения административной статьи 20.2 — той самой, которую в 2019 году массово использовали против задержанных на митингах и шествиях. Данные собрали и опубликовали «ОВД-Инфо», а мы исследовали их и нашли в два нестандартные случаи применения статьи 20.2.
Как работают фильтры в Инстаграме + Как посмотреть на мир глазами нейросетей
Технологический лонгрид в двух частях о том, как работает современное компьютерное зрение, что делает Instagram с вашими фотографиями и как нейросеть отличает дорогой дом на снимке — от дешевого.
Прокачиваем гуманитария до программиста: инструкция
Я — филолог (лингвист, историк, философ, культуролог, etc) и хочу заняться программированием. В чем мои сильные стороны? Что делать? Рассказывает гуманитарий, перековавшийся в программиста.
Пусти пожить болельщика: чемпионат в Москве и рынок Airbnb
Исследуем статистику Airbnb по Москве, чтобы понять, как Чемпионат мира по футболу 2018 года повлиял на рынок съемного жилья. Какие районы наводнили туристы, как они селились вокруг стадионов, а кто переоценил свою привлекательность для болельщиков?
Учат в школе… Чему?
Чему учат в современной началке? Мы проанализировали более 20 тыс. заданий в учебниках по русскому языку 1-4 классов и постарались разобраться, из чего они состоят — и чего требуют от школьника. Специальный пост к 1 сентября.
Что случилось с самыми унылыми стихотворениями XIX века
Элегия — ключевой поэтический жанр «золотого века» русской поэзии. Что можно узнать о нем, используя количественные методы: подсчет частотности слов, тематическое моделирование, статистику длины стихотворений?
Я/МЫ НКРЯ: что происходит с национальным корпусом
Этот текст стал частью борьбы за сохранение Национального корпуса русского языка, который переживал в 2019 году нелегкие времена. Осенью лингвисты обнаружили по знакомому адресу сильно урезанный и криво работающий корпус. Давно тлевшие слухи о полном отказе «Яндекса» от поддержки НКРЯ и его «закрытии» стали разлетаться по сети со скоростью фейсбучного репоста. Поисковику пришлось реагировать: старую версию НКРЯ вернули, а ученых заверили, что «Яндекс» корпус не бросит, т.к. его завещал беречь сам Илья Сегалович.
Жутко громко, запредельно тихо: звуки в романах
Цифровые методы анализируют голоса героев романа и их громкость. Одно исследование — в рамках отдельной книги («Идиот» Достоевского). Другое — на матреиале тысячи британских романов.
Зрение, мозг и нейросети
Если с помощью томографии зафиксировать активность мозга, когда человек смотрит на разные картинки, а потом скормить это вместе с картинками нейросети… она научится считывать то, что видит человек, прямо из мозга. Звучит как фантастика, но это уже здесь.
{kind=link}
👍1
Код «Мастера и Маргариты»
С помощью методов цифрового литературоведения можно увидеть скрытые закономерности в художественном произведении. Мы проанализировали роман М. А. Булгакова «Мастер и Маргарита», используя методы сетевого анализа и анализа тональности текста (сентимент-анализа).
Социальная сеть персонажей
При построении социальной сети персонажей видно, что все они распределены по сюжетным линиям романа. Выделяются три персонажа-посредника: Иешуа, Левий Матвей и Пилат, которые соединяют две сюжетные линии. Главный из этой тройки — Пилат. Именно он выступает одним из главных действующих лиц в Ершалаиме, и именно о нем говорят и главные герои во время событий в Москве. Без него система персонажей романа развалится на две обособленные и самодостаточные части.
Распределение персонажей в романе
Построим диаграмму рассеяния, своего рода «рентген» текста романа, на которой видно распределение персонажей по сюжету. Чтобы построить эту диаграмму, представим текст романа как список слов, идущих друг за другом в том же порядке, в каком их расположил автор. Далее представим текст романа как вектор, равный по длине числу слов в романе. Если в конкретном месте романа есть упоминание соответствующего персонажа, то там ставится значение 1, а если нет, то 0.
На диаграмме видно, как чередуются между собой основные сюжетные линии персонажей, как московские главы сменяются библейскими и наоборот. Заметно, как внимание автора перешло от линии Иван — Воланд к линии Воланд — Маргарита.
Анализ сюжета
Сюжет романа можно исследовать с помощью анализа тональности текста (сентимент-анализа). Этот метод поможет увидеть динамику сюжета и смену настроений. Сентимент-анализ опирается на выделение восьми «основных» эмоций человека — это гнев, ожидание, радость, принятие, страх, удивление, грусть и отвращение. Каждую из этих эмоций можно назвать разными словами, имеющими положительную или отрицательную окраску.
Таким образом, проанализировав, какие и как эмоционально окрашенные слова представлены в тексте, можно предположить эмоциональное состояние читателя этого текста.
В первой главе «Мастера и Маргариты» — умеренно положительный настрой. Затем автор рассказывает о допросе и пытках Иешуа, смерти Берлиоза и погоне Ивана за Воландом и его свитой, что приводит к резкому падению настроения. Небольшой просвет есть в момент, когда Иван приходит к Грибоедову, но затем снова начинает преобладать негатив вплоть до успокаивающего разговора с профессором.
Далее, в 10-й и 11-й главе, сюжет идет ровно, рассказывая о серии проделок нечистой силы в Москве, о расколе Ивана. Но потом, когда в 13-й главе романа появляется главный персонаж, Мастер, настроение снова идет вверх.
Хотя роман и имеет положительную динамику в конце, он все же не выбирается в плюс: слов с отрицательной эмоциональной окраской оказалось больше, и сцена с допросом в начале очень сильно влияет на всю тональность романа.
https://sysblok.ru/philology/kod-mastera-i-margarity/
С помощью методов цифрового литературоведения можно увидеть скрытые закономерности в художественном произведении. Мы проанализировали роман М. А. Булгакова «Мастер и Маргарита», используя методы сетевого анализа и анализа тональности текста (сентимент-анализа).
Социальная сеть персонажей
При построении социальной сети персонажей видно, что все они распределены по сюжетным линиям романа. Выделяются три персонажа-посредника: Иешуа, Левий Матвей и Пилат, которые соединяют две сюжетные линии. Главный из этой тройки — Пилат. Именно он выступает одним из главных действующих лиц в Ершалаиме, и именно о нем говорят и главные герои во время событий в Москве. Без него система персонажей романа развалится на две обособленные и самодостаточные части.
Распределение персонажей в романе
Построим диаграмму рассеяния, своего рода «рентген» текста романа, на которой видно распределение персонажей по сюжету. Чтобы построить эту диаграмму, представим текст романа как список слов, идущих друг за другом в том же порядке, в каком их расположил автор. Далее представим текст романа как вектор, равный по длине числу слов в романе. Если в конкретном месте романа есть упоминание соответствующего персонажа, то там ставится значение 1, а если нет, то 0.
На диаграмме видно, как чередуются между собой основные сюжетные линии персонажей, как московские главы сменяются библейскими и наоборот. Заметно, как внимание автора перешло от линии Иван — Воланд к линии Воланд — Маргарита.
Анализ сюжета
Сюжет романа можно исследовать с помощью анализа тональности текста (сентимент-анализа). Этот метод поможет увидеть динамику сюжета и смену настроений. Сентимент-анализ опирается на выделение восьми «основных» эмоций человека — это гнев, ожидание, радость, принятие, страх, удивление, грусть и отвращение. Каждую из этих эмоций можно назвать разными словами, имеющими положительную или отрицательную окраску.
Таким образом, проанализировав, какие и как эмоционально окрашенные слова представлены в тексте, можно предположить эмоциональное состояние читателя этого текста.
В первой главе «Мастера и Маргариты» — умеренно положительный настрой. Затем автор рассказывает о допросе и пытках Иешуа, смерти Берлиоза и погоне Ивана за Воландом и его свитой, что приводит к резкому падению настроения. Небольшой просвет есть в момент, когда Иван приходит к Грибоедову, но затем снова начинает преобладать негатив вплоть до успокаивающего разговора с профессором.
Далее, в 10-й и 11-й главе, сюжет идет ровно, рассказывая о серии проделок нечистой силы в Москве, о расколе Ивана. Но потом, когда в 13-й главе романа появляется главный персонаж, Мастер, настроение снова идет вверх.
Хотя роман и имеет положительную динамику в конце, он все же не выбирается в плюс: слов с отрицательной эмоциональной окраской оказалось больше, и сцена с допросом в начале очень сильно влияет на всю тональность романа.
https://sysblok.ru/philology/kod-mastera-i-margarity/
{kind=link}
GPS против автобусного хаоса: как студенты и волонтеры оцифровывали городские маршруты в Ливане
Жители большинства городов мира привыкли к тому, что общественный транспорт работает так: человек приходит на специально определенное место и садится на определенный вид транспорта. Транспорт доставляет его в другое определенное место, где поездку можно прекратить. Но это возможно только если создана система остановок и маршрутов, по которым этот транспорт ходит. Согласитесь, это применимо к любым видам, будь то самолеты (хотя не очень-то он и общественный), паромы или автобусы.
Автобусы и война
Но есть и особые случаи. Ливан — страна Ближнего Востока, расположенная на побережье Средиземного моря. С 1975 по 1990 годы, целых 15 лет, здесь бушевала гражданская война, которая оставила после себя полностью уничтоженную систему автобусного сообщения внутри страны и крупных городов. Прошло уже почти тридцать лет с момента установления мира, но в столице страны Бейруте вы не найдете ни одной автобусной остановки.
Связать водителя и пассажиров: YallaBus
Группа студентов из Американского университета Бейрута взялась исправить ситуацию с общественным транспортом в городе. Конечно, речь не идет о запуске собственных маршрутов — но о документировании уже существующих. Для этого использовались данные GPS и наблюдения волонтеров, и в результате команда, давшая своему продукту название YallaBus, получила примерную схему маршрутов городских автобусов Бейрута. Основываясь на ней, разработчики хотели «соединить» водителей автобусов и потенциальных пассажиров, показывая последним виртуальные места остановок, где проще всего поймать автобус, а первым — места сосредоточения пассажиров. К сожалению, сейчас проект выглядит замороженным, но хочется надеяться, что это временно.
Автобус с GPS
Похожий проект Bus Map Project был основан двумя ливанцами в 2016 году, и также собирает информацию о маршрутах автобусов, в основном самым простым способом — волонтеры проекта ездят на автобусах и записывают GPS-трек перемещения. В этом году участники проекта также сделали печатную карту маршрутов автобусов, которую старались распространять по мере возможности.
Частая проблема в попытке картографировать маршруты общественного транспорта (возможно, присущая странам Ближнего Востока) — место здесь не всегда имеет четкую привязку, вроде координат или номеров домов, а чаще описывается особенными деталями и признаками. Нет смысла искать дом по адресу, если ими все равно никто не пользуется, гораздо быстрее найти место по его описанию.
Из-за таких особенностей Bus Map Project часто подчеркивает, что все собранные ими данные не являются полными и полностью достоверными — всегда есть чем их улучшить, к чему они и приглашают всех заинтересовавшихся.
Нелли Бурцева
Жители большинства городов мира привыкли к тому, что общественный транспорт работает так: человек приходит на специально определенное место и садится на определенный вид транспорта. Транспорт доставляет его в другое определенное место, где поездку можно прекратить. Но это возможно только если создана система остановок и маршрутов, по которым этот транспорт ходит. Согласитесь, это применимо к любым видам, будь то самолеты (хотя не очень-то он и общественный), паромы или автобусы.
Автобусы и война
Но есть и особые случаи. Ливан — страна Ближнего Востока, расположенная на побережье Средиземного моря. С 1975 по 1990 годы, целых 15 лет, здесь бушевала гражданская война, которая оставила после себя полностью уничтоженную систему автобусного сообщения внутри страны и крупных городов. Прошло уже почти тридцать лет с момента установления мира, но в столице страны Бейруте вы не найдете ни одной автобусной остановки.
Связать водителя и пассажиров: YallaBus
Группа студентов из Американского университета Бейрута взялась исправить ситуацию с общественным транспортом в городе. Конечно, речь не идет о запуске собственных маршрутов — но о документировании уже существующих. Для этого использовались данные GPS и наблюдения волонтеров, и в результате команда, давшая своему продукту название YallaBus, получила примерную схему маршрутов городских автобусов Бейрута. Основываясь на ней, разработчики хотели «соединить» водителей автобусов и потенциальных пассажиров, показывая последним виртуальные места остановок, где проще всего поймать автобус, а первым — места сосредоточения пассажиров. К сожалению, сейчас проект выглядит замороженным, но хочется надеяться, что это временно.
Автобус с GPS
Похожий проект Bus Map Project был основан двумя ливанцами в 2016 году, и также собирает информацию о маршрутах автобусов, в основном самым простым способом — волонтеры проекта ездят на автобусах и записывают GPS-трек перемещения. В этом году участники проекта также сделали печатную карту маршрутов автобусов, которую старались распространять по мере возможности.
Частая проблема в попытке картографировать маршруты общественного транспорта (возможно, присущая странам Ближнего Востока) — место здесь не всегда имеет четкую привязку, вроде координат или номеров домов, а чаще описывается особенными деталями и признаками. Нет смысла искать дом по адресу, если ими все равно никто не пользуется, гораздо быстрее найти место по его описанию.
Из-за таких особенностей Bus Map Project часто подчеркивает, что все собранные ими данные не являются полными и полностью достоверными — всегда есть чем их улучшить, к чему они и приглашают всех заинтересовавшихся.
Нелли Бурцева
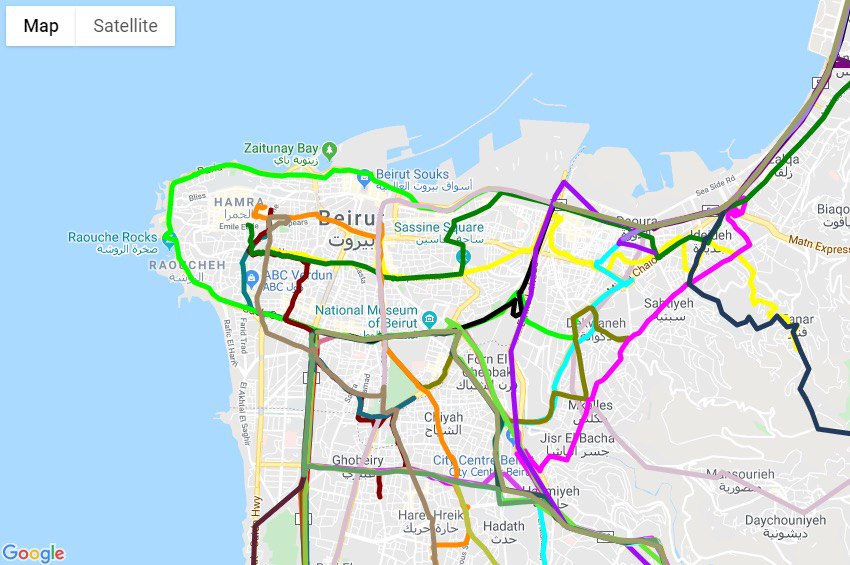{kind=link}
Лучшие посты "Системного Блока" о кино (к 100-летию Феллини)
Сегодня 100 лет со дня рождения Федерико Феллини. В этот исторический для мирового кинематографа день мы решили вспомнить лучшие посты «Системного Блока» о киноисследованиях.
1. Спецэффекты на минималках
Первый фильм со спецэффектом был снят уже в 1895 году — на киностудии Томаса Эдисона «обезглавили» Марию Шотландскую, заменив актрису на манекен. Остальным актерам пришлось в это время замереть. А как еще исхитрялись режиссеры в эпоху, когда не было компьютерной графики и 3D?
2. О чем говорят герои фильмов Уэса Андерсона?
Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Это своего рода «сказки для взрослых» с терапевтическим эффектом. К юбилею режиссера мы исследовали, что говорят его герои, собрав и проанализировав корпус субтитров. В посте описано, как можно повторить такое исследование.
3. Диалоги в голливудских фильмах: герои против героинь
Голливуд активно пытается справиться с проблемами неравенства на экране. Но пока белые мужчины получают больше всего экранного времени, а женщин перестают снимать, когда они стареют. Не верите? Смотрите статистику.
4. Технологии в кино: как работают спецэффекты
В материале «Спецэффекты на минималках» мы рассказывали о том, как режиссеры создавали космические миры и ужасных монстров с помощью картона, папье маше и умелого монтажа. Теперь пришло время компьютерных эффектов. Разбираемся, как делают кинотрюки в XXI веке и что пришлось делать Бенедикту Камбербэтчу, когда он играл в «Хоббите» дракона Смауга.
5. За гранью разумного: нейросеть придумала кино
Да-да, именно так. Автор сценария — рекуррентная нейросеть (LSTM) по имени Бенджамин. Фильм сняли — и он получился на удивление неплох. Посмотрите сами.
Сегодня 100 лет со дня рождения Федерико Феллини. В этот исторический для мирового кинематографа день мы решили вспомнить лучшие посты «Системного Блока» о киноисследованиях.
1. Спецэффекты на минималках
Первый фильм со спецэффектом был снят уже в 1895 году — на киностудии Томаса Эдисона «обезглавили» Марию Шотландскую, заменив актрису на манекен. Остальным актерам пришлось в это время замереть. А как еще исхитрялись режиссеры в эпоху, когда не было компьютерной графики и 3D?
2. О чем говорят герои фильмов Уэса Андерсона?
Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Это своего рода «сказки для взрослых» с терапевтическим эффектом. К юбилею режиссера мы исследовали, что говорят его герои, собрав и проанализировав корпус субтитров. В посте описано, как можно повторить такое исследование.
3. Диалоги в голливудских фильмах: герои против героинь
Голливуд активно пытается справиться с проблемами неравенства на экране. Но пока белые мужчины получают больше всего экранного времени, а женщин перестают снимать, когда они стареют. Не верите? Смотрите статистику.
4. Технологии в кино: как работают спецэффекты
В материале «Спецэффекты на минималках» мы рассказывали о том, как режиссеры создавали космические миры и ужасных монстров с помощью картона, папье маше и умелого монтажа. Теперь пришло время компьютерных эффектов. Разбираемся, как делают кинотрюки в XXI веке и что пришлось делать Бенедикту Камбербэтчу, когда он играл в «Хоббите» дракона Смауга.
5. За гранью разумного: нейросеть придумала кино
Да-да, именно так. Автор сценария — рекуррентная нейросеть (LSTM) по имени Бенджамин. Фильм сняли — и он получился на удивление неплох. Посмотрите сами.
{kind=link}
Невидимые кинозвезды: как Голливуд не замечает женщин-режиссеров
В 2010 году «Оскар» за лучшую режиссуру впервые получила женщина — Кэтрин Бигелоу с фильмом «Повелитель бури». Стали ли после этого режиссеры женского пола более заметными фигурами в киноиндустрии? Редакция «Системного Блока» провела исследование, проследив динамику упоминаний женщин-режиссеров в статьях популярных киножурналов.
Мы оттолкнулись от предположения, что активная деятельность феминистского сообщества и внимание общественности к проблеме гендерного неравенства должны были изменить ситуацию в киноиндустрии в части дискриминации женщин. Наша гипотеза состояла в том, что количество упоминаний женщин-режиссеров в СМИ должно было значительно возрасти в последние несколько лет.
Оказывается, интерес к запросу в google по словосочетанию female director вырос вдвое за последние десять лет, но фактически — женщины-режиссеры по прежнему остаются незаметными.
https://sysblok.ru/research/nevidimye-kinozvezdy/
В 2010 году «Оскар» за лучшую режиссуру впервые получила женщина — Кэтрин Бигелоу с фильмом «Повелитель бури». Стали ли после этого режиссеры женского пола более заметными фигурами в киноиндустрии? Редакция «Системного Блока» провела исследование, проследив динамику упоминаний женщин-режиссеров в статьях популярных киножурналов.
Мы оттолкнулись от предположения, что активная деятельность феминистского сообщества и внимание общественности к проблеме гендерного неравенства должны были изменить ситуацию в киноиндустрии в части дискриминации женщин. Наша гипотеза состояла в том, что количество упоминаний женщин-режиссеров в СМИ должно было значительно возрасти в последние несколько лет.
Оказывается, интерес к запросу в google по словосочетанию female director вырос вдвое за последние десять лет, но фактически — женщины-режиссеры по прежнему остаются незаметными.
https://sysblok.ru/research/nevidimye-kinozvezdy/
{kind=link}
Обзор курсов по математике для Data Science
Всякое знакомство с машинным обучением неизбежно приводит к «линейной регрессии» и «градиентному спуску», «дифференцируемым функциям» и «экстремумам» – понятиям, которые вызывают священный трепет у изучавших высшую математику в вузе и страх у тех, кто с ними не знаком. В этой подборке мы собрали курсы по математике, которые позволят заполнить пробелы или освежить в памяти ключевые математические аспекты.
1. Курс «Essential Math for Machine Learning: Python Edition» от Microsoft
Входные требования: базовые знания математики, опыт программирования (предпочтительно на языке Python)
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
2. Курсы Khan Academy: «Linear Algebra», «Probability & Statistics», «Multivariable Calculus» и «Optimization»
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, математическая статистика и теория вероятностей, математический анализ, методы оптимизации
Подробнее:
Linear Algebra, Probability & Statistics, Multivariable Calculus, Optimization
3. Специализация «Mathematics for Machine Learning Specialization» от Imperial College London
Входные требования: базовые знания математики на школьном уровне
Доступность: платно, 3 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: линейная алгебра, математический анализ, PCA
Подробнее
4. Специализация «Mathematics for Data Science» от ВШЭ
Входные требования: базовые знания математики, основы программирования на языке Python
Доступность: платно, 2,5 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: дискретная математика, математический анализ, линейная алгебра, теория вероятностей
Подробнее
5. Курс «Математика и Python для анализа данных» от МФТИ и Яндекс
Входные требования: опыт программирования
Доступность: платно, 5 т.р./месяц. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid.
Язык: русский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
6. Курс «Математика для Data Science» от преподавателя ВШЭ Петра Лукьянченко и наших партнеров OTUS
Входные требования: достаточно знать математику на школьном уровне
Доступность: курс платный, доступен бесплатный вебинар, на котором можно узнать подробности про задачи курса
Язык: русский
О преподавателе: Петр Лукьянченко уже 10 лет преподает высшую математику в ВШЭ и имеет богатый опыт работы в Data Science.
Темы: математический анализ, линейная алгебра, теория вероятности и статистика
Подробнее
Бесплатный вебинар 27 января: регистрация.
Всякое знакомство с машинным обучением неизбежно приводит к «линейной регрессии» и «градиентному спуску», «дифференцируемым функциям» и «экстремумам» – понятиям, которые вызывают священный трепет у изучавших высшую математику в вузе и страх у тех, кто с ними не знаком. В этой подборке мы собрали курсы по математике, которые позволят заполнить пробелы или освежить в памяти ключевые математические аспекты.
1. Курс «Essential Math for Machine Learning: Python Edition» от Microsoft
Входные требования: базовые знания математики, опыт программирования (предпочтительно на языке Python)
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
2. Курсы Khan Academy: «Linear Algebra», «Probability & Statistics», «Multivariable Calculus» и «Optimization»
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, математическая статистика и теория вероятностей, математический анализ, методы оптимизации
Подробнее:
Linear Algebra, Probability & Statistics, Multivariable Calculus, Optimization
3. Специализация «Mathematics for Machine Learning Specialization» от Imperial College London
Входные требования: базовые знания математики на школьном уровне
Доступность: платно, 3 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: линейная алгебра, математический анализ, PCA
Подробнее
4. Специализация «Mathematics for Data Science» от ВШЭ
Входные требования: базовые знания математики, основы программирования на языке Python
Доступность: платно, 2,5 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: дискретная математика, математический анализ, линейная алгебра, теория вероятностей
Подробнее
5. Курс «Математика и Python для анализа данных» от МФТИ и Яндекс
Входные требования: опыт программирования
Доступность: платно, 5 т.р./месяц. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid.
Язык: русский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
6. Курс «Математика для Data Science» от преподавателя ВШЭ Петра Лукьянченко и наших партнеров OTUS
Входные требования: достаточно знать математику на школьном уровне
Доступность: курс платный, доступен бесплатный вебинар, на котором можно узнать подробности про задачи курса
Язык: русский
О преподавателе: Петр Лукьянченко уже 10 лет преподает высшую математику в ВШЭ и имеет богатый опыт работы в Data Science.
Темы: математический анализ, линейная алгебра, теория вероятности и статистика
Подробнее
Бесплатный вебинар 27 января: регистрация.