
Раньше машинные переводчики работали по правилам, которые писали лингвисты. Лингвистов нужно было много, правила писались долго, а перевод все равно получался далеким от идеала. Но потом на помощь человеку пришла статистика, и появился он — рецепт хорошего перевода:
1) Загрузить в компьютер много текстов с готовыми переводами.
2) Указать какие предложения на разных языках соответствуют друг другу.
3) Научить компьютер находить соответствия между конкретными фразами, даже если они разной длины в разных языках.
4) Готово! Теперь компьютер, пользуясь своей коллекцией текстов, научился переводить.
Разобраться подробнее, с примерами и понятными картинками, можно тут:
https://sysblok.ru/knowhow/kak-rabotaet-statisticheskij-perevod-po-frazam/
1) Загрузить в компьютер много текстов с готовыми переводами.
2) Указать какие предложения на разных языках соответствуют друг другу.
3) Научить компьютер находить соответствия между конкретными фразами, даже если они разной длины в разных языках.
4) Готово! Теперь компьютер, пользуясь своей коллекцией текстов, научился переводить.
Разобраться подробнее, с примерами и понятными картинками, можно тут:
https://sysblok.ru/knowhow/kak-rabotaet-statisticheskij-perevod-po-frazam/
Системный Блокъ
Как работает статистический перевод по фразам? - Системный Блокъ
Разбираемся, как научиться переводить, не зная ни одного языка
Почему на Невском есть модная кофейня, а на моей улице нет?
Рассказываем, почему мы редко гуляем по спальным районам, часто ездим в центр, стоим в пробках, и при чем тут космический синтаксис.
https://sysblok.ru/urban/i-na-tvoej-vysoko-integrirovannoj-ulice-budet-prazdnik/
Рассказываем, почему мы редко гуляем по спальным районам, часто ездим в центр, стоим в пробках, и при чем тут космический синтаксис.
https://sysblok.ru/urban/i-na-tvoej-vysoko-integrirovannoj-ulice-budet-prazdnik/
Системный Блокъ
И на твоей (высоко интегрированной) улице будет праздник - Системный Блокъ
В каждом городе есть улицы, где людей больше, и улицы, где людей меньше. Потому ли, что на центральной улице много магазинов, ресторанов и кофеен? А может, потому что на тихой улице спального района нечем заняться, кроме как на лавочке сидеть? А причём тут…
“стоят перед ним три собаки: собака с глазами, как чайные чашки, собака с глазами, как мельничные колеса, и собака с глазами, как круглая башня...”
С чем писатели чаще всего сравнивают размеры предметов?
https://sysblok.ru/nlp/fasolina-ili-jajco-s-chem-sravnivajut-razmery-veshhej/
С чем писатели чаще всего сравнивают размеры предметов?
https://sysblok.ru/nlp/fasolina-ili-jajco-s-chem-sravnivajut-razmery-veshhej/
Системный Блокъ
Фасолина или яйцо? С чем сравнивают размеры вещей - Системный Блокъ
Какие метафоры популярны при описании габаритов предмета, как они изменялись со временем и почему из сравнений исчезли голубиные яйца
Диалоги в голливудских фильмах: герои против героинь
В последнее время Голливуд борется с неравенством на экране. Но белые мужчины все равно получают больше экранного времени. Насколько больше?
Исследователи из проекта The Pudding рассмотрели гендер в кино со всех сторон и посчитали реплики персонажей мужского и женского пола в 8000 сценариев, которые потом превратились в 2000 фильмов. Теперь мы знаем, что даже в мультике про Мулан женщины произносят только четверть всех слов — что уж говорить про Стар Трек (9%) или боевики.
А еще женщины с возрастом получают все меньше и меньше ролей. У мужчин такие проблемы начинаются после 60 — до этого режиссеры с удовольствием их снимают.
https://sysblok.ru/society/dialogi-v-gollivudskih-filmah-geroi-protiv-geroin/
В последнее время Голливуд борется с неравенством на экране. Но белые мужчины все равно получают больше экранного времени. Насколько больше?
Исследователи из проекта The Pudding рассмотрели гендер в кино со всех сторон и посчитали реплики персонажей мужского и женского пола в 8000 сценариев, которые потом превратились в 2000 фильмов. Теперь мы знаем, что даже в мультике про Мулан женщины произносят только четверть всех слов — что уж говорить про Стар Трек (9%) или боевики.
А еще женщины с возрастом получают все меньше и меньше ролей. У мужчин такие проблемы начинаются после 60 — до этого режиссеры с удовольствием их снимают.
https://sysblok.ru/society/dialogi-v-gollivudskih-filmah-geroi-protiv-geroin/
Системный Блокъ
Диалоги в голливудских фильмах: герои против героинь - Системный Блокъ
8000 сценариев. 2000 фильмов. 2 гендера
Сверточные нейросети – как это работает?
С технологиями компьютерного зрения мы встречаемся каждый день, но часто не замечаем этого. Мы привыкли, что в ВК, Фейсбуке или Инстаграме можно за пару секунд наложить фильтр: размыть картинку, подправить цвет, яркость и контрастность. Если разобраться, окажется, что в своей основе фильтр размытия в Инстаграме и сверточная нейросеть работают одинаково:
Сначала алгоритм выделяет на картинке очень конкретные и низкоуровневые признаки - группы пикселей, оказавшихся рядом с каким-нибудь цветовым пятном. Эти признаки усложняются, а исходное изображение превращается в бесконечные комбинации, где активированы те или иные пиксели. Так изображение медленно сжимается, доходя в размерах до единственной точки - сигнала, передаваемого нейроном. Такой сигнал комбинируется с другими сигналами и активирует нейронную цепочку в полносвязной сети, на конце которой один-единственный нейрон, сложив достаточное количество «очков» от других нейронов, заявляет: «Я вижу на картинке лицо!»
Подробнее рассказываем в наших материалах по этой теме:
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
С технологиями компьютерного зрения мы встречаемся каждый день, но часто не замечаем этого. Мы привыкли, что в ВК, Фейсбуке или Инстаграме можно за пару секунд наложить фильтр: размыть картинку, подправить цвет, яркость и контрастность. Если разобраться, окажется, что в своей основе фильтр размытия в Инстаграме и сверточная нейросеть работают одинаково:
Сначала алгоритм выделяет на картинке очень конкретные и низкоуровневые признаки - группы пикселей, оказавшихся рядом с каким-нибудь цветовым пятном. Эти признаки усложняются, а исходное изображение превращается в бесконечные комбинации, где активированы те или иные пиксели. Так изображение медленно сжимается, доходя в размерах до единственной точки - сигнала, передаваемого нейроном. Такой сигнал комбинируется с другими сигналами и активирует нейронную цепочку в полносвязной сети, на конце которой один-единственный нейрон, сложив достаточное количество «очков» от других нейронов, заявляет: «Я вижу на картинке лицо!»
Подробнее рассказываем в наших материалах по этой теме:
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
Системный Блокъ
Как работают фильтры в Инстаграме: устройство свёрточных нейросетей - Системный Блокъ
Разбираемся в том, как устроено компьютерное зрение, что такое ядро свертки — и при чем тут фильтры в Инстаграме
6 июня центре Москвы был задержан спецкор «Медузы» Иван Голунов — один из лучших журналистов-расследователей в России. Голунова обвиняют в распространении наркотиков, которые у него якобы нашли полицейские. Сам журналист говорит, что наркотики грубо подбросили — его рюкзак после задержания был у сотрудников МВД. Сверток лежал поверх вещей Голунова — то есть его могли подложить в любой момент. Далее полиция заявила, что наркотики найдены у Голунова дома, но фотографии «нарколаборатории» оказались не из его квартиры. Сейчас Голунов помещен под домашний арест.
В защиту журналиста выступили Юрий Дудь, Оксимирон, Борис Гребенщиков, Юрий Шевчук, Владимир Познер, а также тысячи людей, вышедших на пикеты по всей России. Все они уверены, что арест Голунова — месть за расследования, в которых журналист вскрывал коррупционные схемы московских властей и властных группировок в других регионах, провокации ФСБ и Роснефти, сомнительную деятельность ГРУ, махинации депутатов Госдумы. Путаница и подлоги в заявлениях МВД о наркотиках подтверждают эту версию.
Всего Иван Голунов написал для «Медузы» свыше сотни текстов. Так как не у всех есть время читать длинные расследования, мы собрали статистику и сделали инфографику по текстам Голунова. По инфографике можно понять, какие темы освещал Иван Голунов — и какие «болевые точки» коррумпированной власти он задевал.
Из списка наиболее частотных слов (за вычетом служебных слов и глаголов вроде «говорить») видно, что Голунов занимался экономическими расследованиями — и в основном в Москве. Топ-5 слов во всем массиве его текстов на Медузе — компания, рубль, Москва, Россия, миллион. Очень часто упоминаются мэрия, центр, деньги, миллиард. Голунов и правда много писал о том, как Москва тратит огромные деньги на сомнительные закупки — то бордюров, то плитки, то туалетов, то новогодних украшений. А миллиарды за это получали люди, давно и тесно связанные с городскими или федеральными властями.
Самые интересные расследования Ивана Голунова о Москве:
— Откуда берется гранитная плитка на московских улицах и почему она со временем ржавеет
— Кто будет вывозить мусор из Москвы и как они связаны с московской мэрией
— Кто заработал на новогоднем оформлении Москвы — и при чем тут братья Ротенберги
— Как чиновники, силовики и бандиты делят похоронный рынок — и при чем тут Максим Тесак
Еще заметнее городская тематика, если взять только 2019 год. Здесь мэрия входит в топ 10 самых частых слов, округ — в топ-5, Москва на 3 месте по частоте упоминания, а слово квартира — на втором (первая по-прежнему компания).
В 2019 Голунов написал о
— Ограждениях для сугробов, на которых заработали приближенные префекта ЦАО
— Конфликте вокруг Дома звукозаписи на Малой Никитской. Там находится уникальная звукозаписывающая студия размером с концертный зал, изолированная от внешних шумов по принципу «комната в комнате». Здание передали под офисы издательству «Известия», которым руководит дочь фигуранта расследования «Он вам не Димон», посвященного Дмитрию Медведеву.
— Очередном масштабном «перекопе» Москвы летом 2019 года
Настойчивый интерес Голунова к действиям московских городских властей виден и на графиках упоминания мэрии за три года. Кстати, лично мэра Москвы Сергея Собянина Голунов тоже упоминает в своих расследованиях регулярно. Сочетание «мэр Москвы Сергей Собянин» — одна из самых частотных 4-грамм (сочетаний из 4 слов) в текстах Голунова.
В защиту журналиста выступили Юрий Дудь, Оксимирон, Борис Гребенщиков, Юрий Шевчук, Владимир Познер, а также тысячи людей, вышедших на пикеты по всей России. Все они уверены, что арест Голунова — месть за расследования, в которых журналист вскрывал коррупционные схемы московских властей и властных группировок в других регионах, провокации ФСБ и Роснефти, сомнительную деятельность ГРУ, махинации депутатов Госдумы. Путаница и подлоги в заявлениях МВД о наркотиках подтверждают эту версию.
Всего Иван Голунов написал для «Медузы» свыше сотни текстов. Так как не у всех есть время читать длинные расследования, мы собрали статистику и сделали инфографику по текстам Голунова. По инфографике можно понять, какие темы освещал Иван Голунов — и какие «болевые точки» коррумпированной власти он задевал.
Из списка наиболее частотных слов (за вычетом служебных слов и глаголов вроде «говорить») видно, что Голунов занимался экономическими расследованиями — и в основном в Москве. Топ-5 слов во всем массиве его текстов на Медузе — компания, рубль, Москва, Россия, миллион. Очень часто упоминаются мэрия, центр, деньги, миллиард. Голунов и правда много писал о том, как Москва тратит огромные деньги на сомнительные закупки — то бордюров, то плитки, то туалетов, то новогодних украшений. А миллиарды за это получали люди, давно и тесно связанные с городскими или федеральными властями.
Самые интересные расследования Ивана Голунова о Москве:
— Откуда берется гранитная плитка на московских улицах и почему она со временем ржавеет
— Кто будет вывозить мусор из Москвы и как они связаны с московской мэрией
— Кто заработал на новогоднем оформлении Москвы — и при чем тут братья Ротенберги
— Как чиновники, силовики и бандиты делят похоронный рынок — и при чем тут Максим Тесак
Еще заметнее городская тематика, если взять только 2019 год. Здесь мэрия входит в топ 10 самых частых слов, округ — в топ-5, Москва на 3 месте по частоте упоминания, а слово квартира — на втором (первая по-прежнему компания).
В 2019 Голунов написал о
— Ограждениях для сугробов, на которых заработали приближенные префекта ЦАО
— Конфликте вокруг Дома звукозаписи на Малой Никитской. Там находится уникальная звукозаписывающая студия размером с концертный зал, изолированная от внешних шумов по принципу «комната в комнате». Здание передали под офисы издательству «Известия», которым руководит дочь фигуранта расследования «Он вам не Димон», посвященного Дмитрию Медведеву.
— Очередном масштабном «перекопе» Москвы летом 2019 года
Настойчивый интерес Голунова к действиям московских городских властей виден и на графиках упоминания мэрии за три года. Кстати, лично мэра Москвы Сергея Собянина Голунов тоже упоминает в своих расследованиях регулярно. Сочетание «мэр Москвы Сергей Собянин» — одна из самых частотных 4-грамм (сочетаний из 4 слов) в текстах Голунова.
{kind=link}
Корпус статей Ивана Голунова и скрипт для его получения выложен в нашем репозитории на github'e. Скрипт для скачивания корпуса написан на Python и использует фреймворк Scrapy. Теперь все желающие могут сами поэкспериментировать с визуализацией и аналитикой по расследованиям.
Мы использовали сервис WordClouds для построения облаков слов и сервис Voyant-Tools для отрисовки графика.
Вы можете попробовать сделать что-то более сложное — например, извлечь персон-фигурантов расследований и названия компаний, построить сеть связей между ними... Напишите нам, если готовы поучаствовать.
Мы использовали сервис WordClouds для построения облаков слов и сервис Voyant-Tools для отрисовки графика.
Вы можете попробовать сделать что-то более сложное — например, извлечь персон-фигурантов расследований и названия компаний, построить сеть связей между ними... Напишите нам, если готовы поучаствовать.
GitHub
GitHub - sysblok/corpus_golunov_articles: Свободу Ивану Голунову! https://gg.gg/golunov-petition
Свободу Ивану Голунову! https://gg.gg/golunov-petition - sysblok/corpus_golunov_articles
Если вам срочно понадобилось написать роман, скорее всего, вы начнете придумывать сюжет.
Но есть ли какие-то правила, по которым надо его строить?
Чтобы понять, как формируется «традиционный» английский сюжет, исследователи из Cтэнфордской литературной лаборатории составили корпус из ~50 тысяч английских романов и посчитали, как 50 самых употребимых английских слов распределяются внутри повествования.
Каждый текст корпуса делится на N одинаковых по размеру фрагментов. Дальше мы можем подсчитать, сколько раз нужное нам слово повторяется в каждом из них во всех романах сразу. Например слово любовь встречается 9418 раз в первой части повествования и 25 132 раз в последней.
Это очень простой способ оценить семантическую нагрузку каждого слова, и определить имеет ли наша любовь (или смерть) тенденцию группироваться в какой-то части текста.
Начало романов чаще всего заполнено описаниями людей, мест и вещей, рождения, детства, образования, перечислениями семейных отношений. Оружие, смерть и война достигают пика употребления в кульминационных моментах. В середине романа у героя зачастую случается внутренний кризис и переоценка ценностей, а в финалах выбор невелик, там царят брак и смерть.
Некоторые слова демонстрируют и менее очевидные закономерности. Например все, что связанно с едой, разговорами и женскими персонажами, группируется в первых 10-20% повествования. Обед или званый ужин — очень удобный способ «познакомить» и «представить» читателю действующих лиц (Вспомните ту же Войну и Мир или Лунный Камень).
Но есть ли какие-то правила, по которым надо его строить?
Чтобы понять, как формируется «традиционный» английский сюжет, исследователи из Cтэнфордской литературной лаборатории составили корпус из ~50 тысяч английских романов и посчитали, как 50 самых употребимых английских слов распределяются внутри повествования.
Каждый текст корпуса делится на N одинаковых по размеру фрагментов. Дальше мы можем подсчитать, сколько раз нужное нам слово повторяется в каждом из них во всех романах сразу. Например слово любовь встречается 9418 раз в первой части повествования и 25 132 раз в последней.
Это очень простой способ оценить семантическую нагрузку каждого слова, и определить имеет ли наша любовь (или смерть) тенденцию группироваться в какой-то части текста.
Начало романов чаще всего заполнено описаниями людей, мест и вещей, рождения, детства, образования, перечислениями семейных отношений. Оружие, смерть и война достигают пика употребления в кульминационных моментах. В середине романа у героя зачастую случается внутренний кризис и переоценка ценностей, а в финалах выбор невелик, там царят брак и смерть.
Некоторые слова демонстрируют и менее очевидные закономерности. Например все, что связанно с едой, разговорами и женскими персонажами, группируется в первых 10-20% повествования. Обед или званый ужин — очень удобный способ «познакомить» и «представить» читателю действующих лиц (Вспомните ту же Войну и Мир или Лунный Камень).
{kind=link}
«Системный Блокъ» поговорил с Александрой Элбакян — создателем проекта Sci-Hub.
Исследователи по всему миру ежедневно используют его в научной работе — а власти и издательства пытаются заблокировать доступ к сайту, не признающему копирайт. Александра рассказала как возник и работает Sci-Hub, а еще о том, почему открытый доступ к научной информации это важно.
«Я ожидала, что Sci-Hub будет кейсом, который доказывает, что авторское право, которое препятствует распространению науки, должно быть отменено».
«Без закрытого доступа организовать процесс рецензирования возможно. Это не какая-то фантазия — это то, что уже работает».
https://sysblok.ru/interviews/hochu-sdelat-sci-hub-legalnoj-platformoj/
Исследователи по всему миру ежедневно используют его в научной работе — а власти и издательства пытаются заблокировать доступ к сайту, не признающему копирайт. Александра рассказала как возник и работает Sci-Hub, а еще о том, почему открытый доступ к научной информации это важно.
«Я ожидала, что Sci-Hub будет кейсом, который доказывает, что авторское право, которое препятствует распространению науки, должно быть отменено».
«Без закрытого доступа организовать процесс рецензирования возможно. Это не какая-то фантазия — это то, что уже работает».
https://sysblok.ru/interviews/hochu-sdelat-sci-hub-legalnoj-platformoj/
Системный Блокъ
«Хочу сделать Sci-Hub легальной платформой» - Системный Блокъ
Создатель Sci-Hub Александра Элбакян — о том, как работает Sci-Hub, что нужно, чтобы этот ресурс стал легальным, и чем грозит изоляция Рунета.
Розовые слоны и красные деревья: цвета в языке и в реальной жизни
Системный блок писал про дистрибутивную семантику и раньше, а в этой статье речь будет идти о том, как с помощью нее можно сравнивать цвета в языке и в реальном мире.
Интерес к связи между языком и восприятием возник ещё в 1950-е годы, когда была сформулирована гипотеза Сепира-Уорфа: человеческое восприятие формируется под воздействием семантических и грамматических категорий языка. Цветовое поле предоставляет материал, который удобен для подтверждения или опровержения этой гипотезы. Чтобы выяснить, в каком отношении находятся цветовые характеристики и категории восприятия в языке и в реальном мире, было проведено несколько экспериментов.
В первом эксперименте сравниваются цветовые обозначения для понятий из разных категорий: животные, растения, одежда. Нас интересует, для каких категорий будет характерно большее цветовое разнообразие, а какие описываются меньшим количеством цветов.
Для описания животных или цветочных растений люди используют десятки оттенков, но обычно один из цветов доминирует. Розы скорее будут красными, васильки голубыми, львы жёлтыми. А для описания предметов одежды, тоже очень разных по цветовой гамме, доминантного цвета обычно нет.
Чтобы выяснить, для каких категорий характерно разнообразие, мы извлекаем вектора совместной встречаемости слов с цветовыми понятиями, а затем для каждого слова вычисляем дисперсию значений. Слова с высокой дисперсией (то есть большим разнообразием) относятся к категориям «животные» и «растения», как мы и предполагали. Слова с низкой дисперсией включают в себя черты внешности и абстрактные понятия.
Во втором эксперименте мы подсчитываем совместную встречаемость слова с цветами (сколько раз слово «слон» встречалось со словом «красный», «синий», «фиолетовый» и т.д.) и опускаем все остальные слова. Для 500 слов с наибольшей вариативностью цветов и 500 слов с наименьшей вариативностью (слова взяты из первого эксперимента) мы извлекаем ближайших семантических соседей в обоих дистрибутивных пространствах.
Если соседи-слова в полном пространстве и во втором «цветовом» дистрибутивном пространстве совпадут, то это означает, что для данного конкретного слова цвет действительно очень важен.
Елизавета Кузьменко
https://sysblok.ru/nlp/rozovye-slony-i-krasnye-derevja-cveta-v-jazyke-i-v-realnoj-zhizni/
Системный блок писал про дистрибутивную семантику и раньше, а в этой статье речь будет идти о том, как с помощью нее можно сравнивать цвета в языке и в реальном мире.
Интерес к связи между языком и восприятием возник ещё в 1950-е годы, когда была сформулирована гипотеза Сепира-Уорфа: человеческое восприятие формируется под воздействием семантических и грамматических категорий языка. Цветовое поле предоставляет материал, который удобен для подтверждения или опровержения этой гипотезы. Чтобы выяснить, в каком отношении находятся цветовые характеристики и категории восприятия в языке и в реальном мире, было проведено несколько экспериментов.
В первом эксперименте сравниваются цветовые обозначения для понятий из разных категорий: животные, растения, одежда. Нас интересует, для каких категорий будет характерно большее цветовое разнообразие, а какие описываются меньшим количеством цветов.
Для описания животных или цветочных растений люди используют десятки оттенков, но обычно один из цветов доминирует. Розы скорее будут красными, васильки голубыми, львы жёлтыми. А для описания предметов одежды, тоже очень разных по цветовой гамме, доминантного цвета обычно нет.
Чтобы выяснить, для каких категорий характерно разнообразие, мы извлекаем вектора совместной встречаемости слов с цветовыми понятиями, а затем для каждого слова вычисляем дисперсию значений. Слова с высокой дисперсией (то есть большим разнообразием) относятся к категориям «животные» и «растения», как мы и предполагали. Слова с низкой дисперсией включают в себя черты внешности и абстрактные понятия.
Во втором эксперименте мы подсчитываем совместную встречаемость слова с цветами (сколько раз слово «слон» встречалось со словом «красный», «синий», «фиолетовый» и т.д.) и опускаем все остальные слова. Для 500 слов с наибольшей вариативностью цветов и 500 слов с наименьшей вариативностью (слова взяты из первого эксперимента) мы извлекаем ближайших семантических соседей в обоих дистрибутивных пространствах.
Если соседи-слова в полном пространстве и во втором «цветовом» дистрибутивном пространстве совпадут, то это означает, что для данного конкретного слова цвет действительно очень важен.
Елизавета Кузьменко
https://sysblok.ru/nlp/rozovye-slony-i-krasnye-derevja-cveta-v-jazyke-i-v-realnoj-zhizni/
{kind=link}
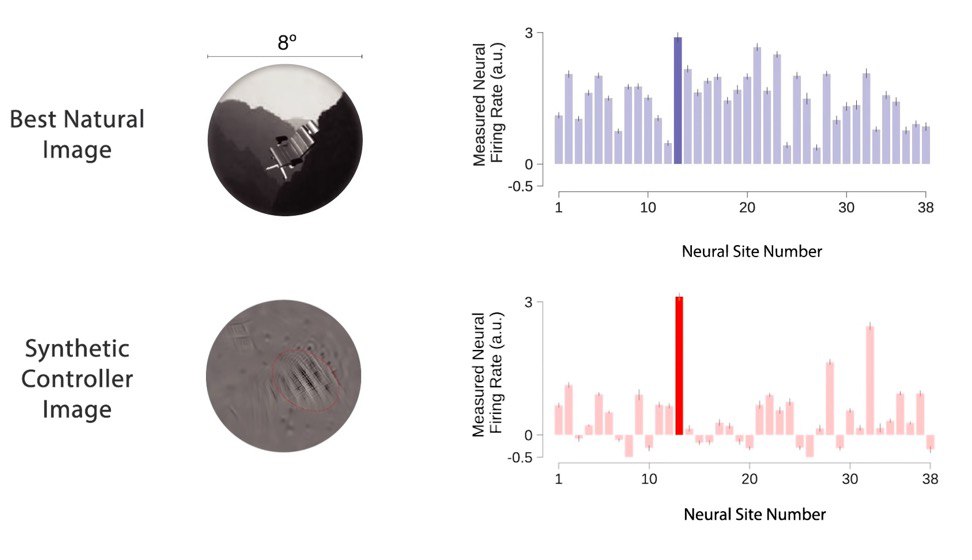
Как искусственные нейроны помогают управлять живыми
Специалисты по нейросетям из Массачусетского технологического института создали и протестировали на животных компьютерные модели, имитирующие работу зрительной коры мозга.
Модели обучались на более чем 1 миллионе изображений: на вход подавалось размеченная картинка с указанием самого важного объекта на ней, а модель по разметке училась распознавать, что на изображении - стул или самолет. Так ученые определили, что в ответ на одно и то же изображение искусственные нейроны генерируют сигналы, схожие с сигналами нейронов зрительной коры.
А можно ли с помощью этих моделей контролировать нейронную активность коры головного мозга? Для ответа на этот вопрос ученые сопоставили активность нейронов модели и нейронов животных в ответ на изображения и составили карту поля V4 зрительной коры, которое отвечает за восприятие цветов. Каждому нейрону соответствовал узел компьютерной модели. Но поскольку в зоне V4 миллионы нейронов, карты были составлены для групп из 5-40 нейронов.
Затем ученые попытались использовать предсказания полученной модели, чтобы управлять активностью нейронов зрительной коры мозга. Первой целью было создать изображение, на которое нейрон отреагировал бы сильнее, чем на обычную картинку. Эти искусственные картинки были созданы моделями и не были похожи ни на какие реальные объекты.
В результате, на эти изображения нейроны отреагировали в среднем на 40% активнее. Это первый случай подобного управления активностью нейронов. Кроме того, ученым удалось создать изображение, которое повысило активность целевого нейрона, снизив при этом реакцию соседних.
Модели также использовали, чтобы предсказать реакцию нейронов мозга на искусственные изображения. Точность предсказаний составила около 54%. Сейчас ученые стремятся приблизить этот показатель к точности предсказаний моделей на реальных изображениях, которая доходит до 90%.
В будущем управление нейронами мозга может помочь в лечении расстройств настроения, например депрессии. Сейчас ученые расширяют свою модель до височной доли, в которой есть миндалина, участвующая в эмоциональных реакциях.
Ксения Михайлова
Специалисты по нейросетям из Массачусетского технологического института создали и протестировали на животных компьютерные модели, имитирующие работу зрительной коры мозга.
Модели обучались на более чем 1 миллионе изображений: на вход подавалось размеченная картинка с указанием самого важного объекта на ней, а модель по разметке училась распознавать, что на изображении - стул или самолет. Так ученые определили, что в ответ на одно и то же изображение искусственные нейроны генерируют сигналы, схожие с сигналами нейронов зрительной коры.
А можно ли с помощью этих моделей контролировать нейронную активность коры головного мозга? Для ответа на этот вопрос ученые сопоставили активность нейронов модели и нейронов животных в ответ на изображения и составили карту поля V4 зрительной коры, которое отвечает за восприятие цветов. Каждому нейрону соответствовал узел компьютерной модели. Но поскольку в зоне V4 миллионы нейронов, карты были составлены для групп из 5-40 нейронов.
Затем ученые попытались использовать предсказания полученной модели, чтобы управлять активностью нейронов зрительной коры мозга. Первой целью было создать изображение, на которое нейрон отреагировал бы сильнее, чем на обычную картинку. Эти искусственные картинки были созданы моделями и не были похожи ни на какие реальные объекты.
В результате, на эти изображения нейроны отреагировали в среднем на 40% активнее. Это первый случай подобного управления активностью нейронов. Кроме того, ученым удалось создать изображение, которое повысило активность целевого нейрона, снизив при этом реакцию соседних.
Модели также использовали, чтобы предсказать реакцию нейронов мозга на искусственные изображения. Точность предсказаний составила около 54%. Сейчас ученые стремятся приблизить этот показатель к точности предсказаний моделей на реальных изображениях, которая доходит до 90%.
В будущем управление нейронами мозга может помочь в лечении расстройств настроения, например депрессии. Сейчас ученые расширяют свою модель до височной доли, в которой есть миндалина, участвующая в эмоциональных реакциях.
Ксения Михайлова
{kind=link}
Может ли машина видеть так же, как человек?
Для компьютера найти и описать движение объекта на видео — значит многократно найти этот объект на отдельных неподвижных кадрах. Но чтобы не рассматривать огромное полотно пикселей каждого изображения, нужно как-то сократить количество данных, на которые обращает внимание наша машина. Человечество придумало для этого несколько интересных уловок:
Можно представить человеческое лицо как созвездие, и за счет этого отлеживать движение лицевых точек.
Можно опознавать лица при помощи регрессии — вручную отмечая лицевые точки на каждой фотографии и определяя выражение лица.
Можно при помощи локального бинарного шаблона закодировать более темные и более яркие пиксели, чтобы определять лицо через их изменение.
А можно вообще использовать алгоритм Виолы-Джонса, преобразуя изображения в интегральный формат и определяя в какой части изображения лица точно нет.
https://sysblok.ru/knowhow/mozhet-li-mashina-videt-tak-zhe-kak-chelovek/
Для компьютера найти и описать движение объекта на видео — значит многократно найти этот объект на отдельных неподвижных кадрах. Но чтобы не рассматривать огромное полотно пикселей каждого изображения, нужно как-то сократить количество данных, на которые обращает внимание наша машина. Человечество придумало для этого несколько интересных уловок:
Можно представить человеческое лицо как созвездие, и за счет этого отлеживать движение лицевых точек.
Можно опознавать лица при помощи регрессии — вручную отмечая лицевые точки на каждой фотографии и определяя выражение лица.
Можно при помощи локального бинарного шаблона закодировать более темные и более яркие пиксели, чтобы определять лицо через их изменение.
А можно вообще использовать алгоритм Виолы-Джонса, преобразуя изображения в интегральный формат и определяя в какой части изображения лица точно нет.
https://sysblok.ru/knowhow/mozhet-li-mashina-videt-tak-zhe-kak-chelovek/
{kind=link}
Если у вас мурашки от музыки — у вас необычный мозг
Некоторые люди описывают удовольствие от прослушивания музыки как сложное взаимодействие психологических и физиологических состояний: взволнованность, легкое покалывание на коже головы и шеи, мурашки. Но подобные ощущения от музыки испытывают не все, а у феномена есть биологическое обоснование.
Связь между сенсорными ощущениями и эстетическим удовольствием до конца не изучена, однако известно, что подобные состояния проявляются в нейрональной активности зон обработки эмоций и вознаграждения (прилежащее ядро, передняя островковая доля, медиальная префронтальная кора) и изменениях в ритме сердцебиения, электрической активности кожи.
Чтобы понять, что именно позволяет получать широкий спектр психологических и физиологических ощущений от прослушивания музыки, Matthew Sachs провел исследование, в котором с помощью опросника Aesthetic Experience Scale in Music (AES-M) выделил две группы людей: с сильными и слабыми эмоциональными реакциями на музыку. В ходе эксперимента обе группы прослушивали несколько любимых музыкальных произведений, а исследователи записывали их физиологические показатели: кожно-гальваническую реакцию и ритм сердцебиения.
Для того чтобы выявить структурные различия в головном мозге двух групп, исследователи исользовали диффузионно-тензорную МРТ — методику, измеряющую диффузию молекул воды в биологических тканях. Диффузионно-тензорная МРТ позволяет получить информацию о строении и расположении пучков нервных волокон и о соединениях между различными зонами головного мозга.
Результаты исследования показали, что люди, которые испытывают сильное эмоциональное возбуждение при прослушивании любимой музыки, имеют иную структуру головного мозга. В их мозге больше тканей, которые соединяют слуховую кору с зонами обработки эмоций. Это означает, что данные зоны — верхняя височная извилина и передняя островковая доля вместе с медиальной префронтальной корой — сообщаются между собой лучше. Объем белого вещества коррелирует со склонностью людей испытывать сильные психологические и физиологические реакции в ответ на музыку: чем больше соединений между перечисленными зонами, тем чаще у человека возникают мурашки при прослушивании любимой музыки.
Карина Акопян
Некоторые люди описывают удовольствие от прослушивания музыки как сложное взаимодействие психологических и физиологических состояний: взволнованность, легкое покалывание на коже головы и шеи, мурашки. Но подобные ощущения от музыки испытывают не все, а у феномена есть биологическое обоснование.
Связь между сенсорными ощущениями и эстетическим удовольствием до конца не изучена, однако известно, что подобные состояния проявляются в нейрональной активности зон обработки эмоций и вознаграждения (прилежащее ядро, передняя островковая доля, медиальная префронтальная кора) и изменениях в ритме сердцебиения, электрической активности кожи.
Чтобы понять, что именно позволяет получать широкий спектр психологических и физиологических ощущений от прослушивания музыки, Matthew Sachs провел исследование, в котором с помощью опросника Aesthetic Experience Scale in Music (AES-M) выделил две группы людей: с сильными и слабыми эмоциональными реакциями на музыку. В ходе эксперимента обе группы прослушивали несколько любимых музыкальных произведений, а исследователи записывали их физиологические показатели: кожно-гальваническую реакцию и ритм сердцебиения.
Для того чтобы выявить структурные различия в головном мозге двух групп, исследователи исользовали диффузионно-тензорную МРТ — методику, измеряющую диффузию молекул воды в биологических тканях. Диффузионно-тензорная МРТ позволяет получить информацию о строении и расположении пучков нервных волокон и о соединениях между различными зонами головного мозга.
Результаты исследования показали, что люди, которые испытывают сильное эмоциональное возбуждение при прослушивании любимой музыки, имеют иную структуру головного мозга. В их мозге больше тканей, которые соединяют слуховую кору с зонами обработки эмоций. Это означает, что данные зоны — верхняя височная извилина и передняя островковая доля вместе с медиальной префронтальной корой — сообщаются между собой лучше. Объем белого вещества коррелирует со склонностью людей испытывать сильные психологические и физиологические реакции в ответ на музыку: чем больше соединений между перечисленными зонами, тем чаще у человека возникают мурашки при прослушивании любимой музыки.
Карина Акопян
{kind=link}
Нейронные сети в машинном переводе: статус-кво
За последние 30 лет системы машинного перевода прошли несколько этапов развития. До начала 90-х годов прошлого века почти все системы опирались на определенные наборы правил, которые, конечно, не могли полностью исключать неточности и ошибки.
Когда ученые из компании IBM предложили статистический метод, опирающийся на примеры уже переведенных людьми предложений, многие увидели в этом подходе будущее. А в начале двухтысячных системы машинного перевода были кардинально улучшены за счет перевода отдельных фраз.
Наконец, в 2014–2016 годах в машинном переводе произошла, можно сказать, революция. Системы, основанные на нейросетях, очень быстро захватили не только умы ученых, но и стали применяться в коммерческих приложениях.
Что сейчас происходит в нейронном машинном переводе и каково состояние дел в отрасли?
Публикуем рассказ ведущего разработчика систем машинного обучения
https://sysblok.ru/nlp/nejronnye-seti-v-mashinnom-perevode-status-kvo/
За последние 30 лет системы машинного перевода прошли несколько этапов развития. До начала 90-х годов прошлого века почти все системы опирались на определенные наборы правил, которые, конечно, не могли полностью исключать неточности и ошибки.
Когда ученые из компании IBM предложили статистический метод, опирающийся на примеры уже переведенных людьми предложений, многие увидели в этом подходе будущее. А в начале двухтысячных системы машинного перевода были кардинально улучшены за счет перевода отдельных фраз.
Наконец, в 2014–2016 годах в машинном переводе произошла, можно сказать, революция. Системы, основанные на нейросетях, очень быстро захватили не только умы ученых, но и стали применяться в коммерческих приложениях.
Что сейчас происходит в нейронном машинном переводе и каково состояние дел в отрасли?
Публикуем рассказ ведущего разработчика систем машинного обучения
https://sysblok.ru/nlp/nejronnye-seti-v-mashinnom-perevode-status-kvo/
Системный Блокъ
Нейронные сети в машинном переводе: статус-кво - Системный Блокъ
Что сейчас происходит в нейронном машинном переводе и каково состояние дел в отрасли? Публикуем рассказ ведущего разработчика систем машинного обучения
Дружелюбные города
Какие места располагают к связям с незнакомцами?
Сегодняшний мир — мир городов, и с каждым годом их роль в экономике, общественной жизни и культуре только возрастает. Одна из главных черт, присущих городской жизни − высокая плотность, в том числе социальных связей и взаимодействия: здесь происходят судьбоносные встречи, завязываются дружеские и деловые отношения.
Новые технологии обработки данных позволили исследователям из Senseable Сity Lab Массачусетского университета изучить пространственные закономерности, характеризующие взаимодействие и общение людей в Сингапуре. Как люди проводят рабочее и свободное время? Как в разное время суток используется городское пространство? Это ключевые вопросы не только для науки, но и для многих практик городского планирования.
В исследовании использовалась база данных крупнейшего мобильного оператора Сингапура, собранная в течение 50 дней в 2011 году. С помощью изучения «пространственного следа» 2,1 млн пользователей мобильных телефонов, была рассчитана вероятность нахождения каждого человека в определенном районе города в разное время.
Для проведения исследования были введены два показателя:
1. Bonding capability — рассчитывается как средняя вероятность того, что два друга будут находиться в одном месте в определенное время. Чем выше индекс, тем большей способностью «свести вместе» друзей обладает место в городе.
2. Bridging capability — средняя вероятность того, что в данном месте встретятся два незнакомца. Чем выше индекс, тем больше потенциал места для образования так называемых «слабых» связей: доказано, что именно из таких связей чаще всего рождаются деловые отношения.
В дневное время рабочие дни места с высокой bridging capability были в основном сконцентрированы в даунтауне Сингапура, где находится большинство госорганизаций и бизнескорпораций. Высокую bonding capability показали крупнейшие университеты города — Национальный университет Сингапура или Технологический университет.
В выходные различия сглаживаются — обе метрики распределены похоже. Большинство мест с высокой способностью «объединять» как друзей, так и «незнакомцев», были привязаны к торговым центрам и моллам.
Источник: Friendly Cities (здесь можно подробнее прочитать о методике сбора и обработки информации в этом исследовании)
Ирина Зябрева
Какие места располагают к связям с незнакомцами?
Сегодняшний мир — мир городов, и с каждым годом их роль в экономике, общественной жизни и культуре только возрастает. Одна из главных черт, присущих городской жизни − высокая плотность, в том числе социальных связей и взаимодействия: здесь происходят судьбоносные встречи, завязываются дружеские и деловые отношения.
Новые технологии обработки данных позволили исследователям из Senseable Сity Lab Массачусетского университета изучить пространственные закономерности, характеризующие взаимодействие и общение людей в Сингапуре. Как люди проводят рабочее и свободное время? Как в разное время суток используется городское пространство? Это ключевые вопросы не только для науки, но и для многих практик городского планирования.
В исследовании использовалась база данных крупнейшего мобильного оператора Сингапура, собранная в течение 50 дней в 2011 году. С помощью изучения «пространственного следа» 2,1 млн пользователей мобильных телефонов, была рассчитана вероятность нахождения каждого человека в определенном районе города в разное время.
Для проведения исследования были введены два показателя:
1. Bonding capability — рассчитывается как средняя вероятность того, что два друга будут находиться в одном месте в определенное время. Чем выше индекс, тем большей способностью «свести вместе» друзей обладает место в городе.
2. Bridging capability — средняя вероятность того, что в данном месте встретятся два незнакомца. Чем выше индекс, тем больше потенциал места для образования так называемых «слабых» связей: доказано, что именно из таких связей чаще всего рождаются деловые отношения.
В дневное время рабочие дни места с высокой bridging capability были в основном сконцентрированы в даунтауне Сингапура, где находится большинство госорганизаций и бизнескорпораций. Высокую bonding capability показали крупнейшие университеты города — Национальный университет Сингапура или Технологический университет.
В выходные различия сглаживаются — обе метрики распределены похоже. Большинство мест с высокой способностью «объединять» как друзей, так и «незнакомцев», были привязаны к торговым центрам и моллам.
Источник: Friendly Cities (здесь можно подробнее прочитать о методике сбора и обработки информации в этом исследовании)
Ирина Зябрева
{kind=link}
Филолог-тютчевед, писатель Роман Лейбов рассказал Системному Блоку о прошлом рунета, будущем digital humanities и о том, почему ЖЖ - жив.
«Не всякому филологу нужны точные методы: литературной историей и критикой спокойно можно заниматься без этого <…> но я бы предпочел, чтобы точные методы были — хотя бы потому, что математика очень хорошо дисциплинирует»
https://sysblok.ru/interviews/pod-zontikom-dh/
«Не всякому филологу нужны точные методы: литературной историей и критикой спокойно можно заниматься без этого <…> но я бы предпочел, чтобы точные методы были — хотя бы потому, что математика очень хорошо дисциплинирует»
https://sysblok.ru/interviews/pod-zontikom-dh/
Системный Блокъ
Под зонтиком Digital Humanities - Системный Блокъ
Ученый и писатель Роман Лейбов о том, что делать с корпусом, учить ли гуманитарию математику и чем заниматься в Рунете, если ты его пионер
О чем говорят крысы?
Крысы — весьма болтливые социальные животные, но грызуны отчасти общаются в ультразвуке, недоступном нашему слуху. Молодые ученые школы медицины Вашингтонского университета разработали специальное программное обеспечение под названием «DeepSqueak», которое помогает понять, что же говорят крысы.
Как это работает?
DeepSqueak — это сверточные нейронные сети архитектуры Faster R-CNN и интерфейс, понятный даже пользователю, не разбирающемуся в анализе ультразвуковой речи. Сначала программа преобразовывает оригинал записи ультразвуковых писков в привычном формате аудиофайлов, в спектрограммы. На вход нейронной сети подается датасет из спектрограмм.
В первую очередь происходит детекция для отделения шумов от ультразвуков. Затем последние кластеризуются для отслеживания, сравнения и анализа паттернов писков. С помощью интерфейса можно задать пользовательские настройки для кластеризации спектрограмм ультразвуков.
В итоге мы получаем инструмент, который позволяет понять, о чем говорят крысы, и описать их эмоциональное и физическое состояние в ходе экспериментов.
DeepSqueak позволяет не только измерить сердцебиение или уровень кортизола в крови крысы, но и узнать, как она себя чувствует. Таким образом мы получаем более полную картину взаимоотношений в стае, влияния лекарств и наркотиков на организм. И, конечно, чувствуем себя немного Золушкой, разговаривающей с маленькими зверюшками.
Источники:
‘Deep Squeak’ Helps Researchers Decode Rodent Chatter
Deep Learning for Rat Squeaks, Machine Learning for Intent Signals
Ксения Михайлова
Крысы — весьма болтливые социальные животные, но грызуны отчасти общаются в ультразвуке, недоступном нашему слуху. Молодые ученые школы медицины Вашингтонского университета разработали специальное программное обеспечение под названием «DeepSqueak», которое помогает понять, что же говорят крысы.
Как это работает?
DeepSqueak — это сверточные нейронные сети архитектуры Faster R-CNN и интерфейс, понятный даже пользователю, не разбирающемуся в анализе ультразвуковой речи. Сначала программа преобразовывает оригинал записи ультразвуковых писков в привычном формате аудиофайлов, в спектрограммы. На вход нейронной сети подается датасет из спектрограмм.
В первую очередь происходит детекция для отделения шумов от ультразвуков. Затем последние кластеризуются для отслеживания, сравнения и анализа паттернов писков. С помощью интерфейса можно задать пользовательские настройки для кластеризации спектрограмм ультразвуков.
В итоге мы получаем инструмент, который позволяет понять, о чем говорят крысы, и описать их эмоциональное и физическое состояние в ходе экспериментов.
DeepSqueak позволяет не только измерить сердцебиение или уровень кортизола в крови крысы, но и узнать, как она себя чувствует. Таким образом мы получаем более полную картину взаимоотношений в стае, влияния лекарств и наркотиков на организм. И, конечно, чувствуем себя немного Золушкой, разговаривающей с маленькими зверюшками.
Источники:
‘Deep Squeak’ Helps Researchers Decode Rodent Chatter
Deep Learning for Rat Squeaks, Machine Learning for Intent Signals
Ксения Михайлова
{kind=link}
Что такое кросс-языковая морфология и зачем она нужна?
Основная идея кросс-языковой морфологии в том, что если языки — родственные (из одной семьи), то их структурные сходства прослеживаются на разных уровнях. Лингвистам, и особенно компьютерным, это свойство межъязыковой схожести очень интересно: оно позволяет моделировать и переносить процессы одного языка на другой.
Естественные человеческие языки различаются степенью изученности и доступным объемом данных. Например, английский и турецкий хорошо описаны и изучены. А вот каталанский, фарерский или крымскотатарский уступают им в ресурсах. Такие языки называются малоресурсными (МРЯ, low-resourced, under-resourced) и с ними сложнее работать: например, мы не можем построить хорошую векторную модель для работы с семантикой слов — она требует наличия большого корпуса текстов. Еще сложнее будет с машинным переводом, ведь там нужен уже двуязычный параллельный корпус. Что же делать, когда данных для классических алгоритмов и методов типа «обучить на корпусе Х » недостаточно?
Одним из решений является перенос на малоресурсный язык статистических моделей, построенных на данных большого родственного языка. Например, чтобы создать морфологический анализатор (инструмент, представляющий начальную форму или парадигму изменения слова) для крымскотатарского, можно создать модель и обучить ее на данных для турецкого, казахского и др. Такие методы применяются как при создании морфоанализатора как конечного продукта, так и на подготовительных этапах, в любом NLP-инструменте.
Мы с моими коллегами из НИУ ВШЭ Владиславом Михайловым, Олегом Сериковым и Лоренцо Този использовали свойства кросс-языковой морфологии при создании универсального морфоанализатора для малоресурсных языков, где написание классического анализатора под каждый язык не представляется возможным из-за малого количества данных. И даже написали статью о результатах.
На данный момент алгоритм умеет лемматизировать (приводить начальную форму слова) и проводить морфологический анализ для слов малоресурсных языков. Пока он работает на языках агглютинатинативного типа (как турецкий и крымскотатарский) и романского (как испанский и сардинский), в дальнейшем можно будет добавить славянские языки!
Таким образом, кросс-языковая морфология позволяет решать многие прикладные задачи компьютерной лингвистики для языков, на которых нет большого объема данных для машинного обучения. Эта возможность сильно облегчает жизнь исследователям, ведь теперь у них есть инструменты автоматического анализа не только для крупных языков, но и для их младших братьев.
Анастасия Хорошева
Основная идея кросс-языковой морфологии в том, что если языки — родственные (из одной семьи), то их структурные сходства прослеживаются на разных уровнях. Лингвистам, и особенно компьютерным, это свойство межъязыковой схожести очень интересно: оно позволяет моделировать и переносить процессы одного языка на другой.
Естественные человеческие языки различаются степенью изученности и доступным объемом данных. Например, английский и турецкий хорошо описаны и изучены. А вот каталанский, фарерский или крымскотатарский уступают им в ресурсах. Такие языки называются малоресурсными (МРЯ, low-resourced, under-resourced) и с ними сложнее работать: например, мы не можем построить хорошую векторную модель для работы с семантикой слов — она требует наличия большого корпуса текстов. Еще сложнее будет с машинным переводом, ведь там нужен уже двуязычный параллельный корпус. Что же делать, когда данных для классических алгоритмов и методов типа «обучить на корпусе Х » недостаточно?
Одним из решений является перенос на малоресурсный язык статистических моделей, построенных на данных большого родственного языка. Например, чтобы создать морфологический анализатор (инструмент, представляющий начальную форму или парадигму изменения слова) для крымскотатарского, можно создать модель и обучить ее на данных для турецкого, казахского и др. Такие методы применяются как при создании морфоанализатора как конечного продукта, так и на подготовительных этапах, в любом NLP-инструменте.
Мы с моими коллегами из НИУ ВШЭ Владиславом Михайловым, Олегом Сериковым и Лоренцо Този использовали свойства кросс-языковой морфологии при создании универсального морфоанализатора для малоресурсных языков, где написание классического анализатора под каждый язык не представляется возможным из-за малого количества данных. И даже написали статью о результатах.
На данный момент алгоритм умеет лемматизировать (приводить начальную форму слова) и проводить морфологический анализ для слов малоресурсных языков. Пока он работает на языках агглютинатинативного типа (как турецкий и крымскотатарский) и романского (как испанский и сардинский), в дальнейшем можно будет добавить славянские языки!
Таким образом, кросс-языковая морфология позволяет решать многие прикладные задачи компьютерной лингвистики для языков, на которых нет большого объема данных для машинного обучения. Эта возможность сильно облегчает жизнь исследователям, ведь теперь у них есть инструменты автоматического анализа не только для крупных языков, но и для их младших братьев.
Анастасия Хорошева
Где в России учат на цифрового гуманитария?
Куда можно зайти с дипломом филолога (историка, культуролога, мемолога...) — и выйти с навыками программирования, анализа и визуализации данных, веб-разработки, с опытом работы в междисциплинарной исследовательской команде? «Системный Блокъ» рассказывает про российские магистерские программы в области Digital Humanities. Приемная кампания в самом разгаре!
1. «Цифровые методы в гуманитарных науках», НИУ ВШЭ, Москва.
Программа от DH-центра Вышки. Здесь учат программировать, анализировать и визуализировать данные, применять методы из компьютерной лингвистики/NLP к сложным гуманитарным объектам. Студенты осваивают популярные в современных Digital Humanities подходы вроде сетевого анализа, GIS-ов или стилометрии.
У магистратуры есть лингво-филологический уклон, но не жесткий — историки и культурологи себя тоже найдут. Не потеряются и программисты: Вышка хорошо умеет объединять гуманитариев и технарей в совместные команды. Проектная работа в режиме научных стартапов — одна из «фишек» магистратуры в Вышке.
Группа в Vk
2. Анализ культурных данных и визуализация/ Data, Culture and Visualization, ИТМО, Санкт-Петербург.
Англоязычная программа от лаборатории DH Lab в ИТМО. Здесь тоже есть и программирование, и анализ данных, и сети с GIS-ами, и, конечно, визуализация. Внутри магистратуры три трека на выбор:
— трек для гуманитариев — с введением в работу с данными и практикой постановки задач IT-специалистам
— трек для аналитиков культуры (в нём поровну гуманитарных и технических навыков)
— трек по машинному обучению — для технарей, желающих применить себя в гуманитарных областях и прикоснуться к прекрасному.
У команды, которая делает эту магистратуру, есть крутой проект по созданию цифровой культурной карты Санкт-Петербурга — там можно будет узнать, куда ходил обедать Чайковский и где гулял Пушкин. Еще один плюс программы — компьютерные спецы из ИТМО под боком.
3. «Гуманитарная информатика» и «Цифровые технологии в социогуманитарных практиках», ТГУ, Томск.
Две «сестринские» программы от Лаборатории гуманитарных проблем информатики ТГУ. «Гуманитарная информатика» —более гуманитарно-философская, здесь есть курсы по философии искусственного интеллекта, цифровой культуре и т.п. Прикладные навыки тоже дают — учат разработке пользовательских интерфейсов, анализу данных, азам 3D-графики. Вторая программа, «Цифровые технологии в социогуманитарных практиках», рассчитана на технарей. В учебном плане много технических дисциплин: программирования, баз данных, и компьютерной графики, основной фокус — разработка и дизайн интерфейсов.
Группа в Vk
4. Прикладная информатика в области искусств и гуманитарных наук, СФУ, Красноярск.
Программу делает Кафедра информационных технологий в креативных и культурных индустриях СФУ — известные специалисты по музейной оцифровке и сохранению культурного наследия в электронной форме. Здесь учат техникам оцифровки и визуализации музейных экспонатов (например, могут научить 3D-моделированию) и прочему digital preservation. Есть курсы по математическому моделированию и проектированию информационных систем.
5. Историческая информатика, МГУ им. Ломоносова, Москва
В отличие от Digital History, историческая информатика не считает себя частью Digital Humanities и не стремится к междисциплинарности. Вот и в этой магистратуре от Кафедры исторической информатики МГУ занимаются серьезной академической наукой, не выходя за рамки истории. Если вам интересно математическое моделирование исторических процессов или, к примеру, применение статистических методов в экономической истории — вам сюда. Не-историков берут, мы знаем успешные примеры.
Куда можно зайти с дипломом филолога (историка, культуролога, мемолога...) — и выйти с навыками программирования, анализа и визуализации данных, веб-разработки, с опытом работы в междисциплинарной исследовательской команде? «Системный Блокъ» рассказывает про российские магистерские программы в области Digital Humanities. Приемная кампания в самом разгаре!
1. «Цифровые методы в гуманитарных науках», НИУ ВШЭ, Москва.
Программа от DH-центра Вышки. Здесь учат программировать, анализировать и визуализировать данные, применять методы из компьютерной лингвистики/NLP к сложным гуманитарным объектам. Студенты осваивают популярные в современных Digital Humanities подходы вроде сетевого анализа, GIS-ов или стилометрии.
У магистратуры есть лингво-филологический уклон, но не жесткий — историки и культурологи себя тоже найдут. Не потеряются и программисты: Вышка хорошо умеет объединять гуманитариев и технарей в совместные команды. Проектная работа в режиме научных стартапов — одна из «фишек» магистратуры в Вышке.
Группа в Vk
2. Анализ культурных данных и визуализация/ Data, Culture and Visualization, ИТМО, Санкт-Петербург.
Англоязычная программа от лаборатории DH Lab в ИТМО. Здесь тоже есть и программирование, и анализ данных, и сети с GIS-ами, и, конечно, визуализация. Внутри магистратуры три трека на выбор:
— трек для гуманитариев — с введением в работу с данными и практикой постановки задач IT-специалистам
— трек для аналитиков культуры (в нём поровну гуманитарных и технических навыков)
— трек по машинному обучению — для технарей, желающих применить себя в гуманитарных областях и прикоснуться к прекрасному.
У команды, которая делает эту магистратуру, есть крутой проект по созданию цифровой культурной карты Санкт-Петербурга — там можно будет узнать, куда ходил обедать Чайковский и где гулял Пушкин. Еще один плюс программы — компьютерные спецы из ИТМО под боком.
3. «Гуманитарная информатика» и «Цифровые технологии в социогуманитарных практиках», ТГУ, Томск.
Две «сестринские» программы от Лаборатории гуманитарных проблем информатики ТГУ. «Гуманитарная информатика» —более гуманитарно-философская, здесь есть курсы по философии искусственного интеллекта, цифровой культуре и т.п. Прикладные навыки тоже дают — учат разработке пользовательских интерфейсов, анализу данных, азам 3D-графики. Вторая программа, «Цифровые технологии в социогуманитарных практиках», рассчитана на технарей. В учебном плане много технических дисциплин: программирования, баз данных, и компьютерной графики, основной фокус — разработка и дизайн интерфейсов.
Группа в Vk
4. Прикладная информатика в области искусств и гуманитарных наук, СФУ, Красноярск.
Программу делает Кафедра информационных технологий в креативных и культурных индустриях СФУ — известные специалисты по музейной оцифровке и сохранению культурного наследия в электронной форме. Здесь учат техникам оцифровки и визуализации музейных экспонатов (например, могут научить 3D-моделированию) и прочему digital preservation. Есть курсы по математическому моделированию и проектированию информационных систем.
5. Историческая информатика, МГУ им. Ломоносова, Москва
В отличие от Digital History, историческая информатика не считает себя частью Digital Humanities и не стремится к междисциплинарности. Вот и в этой магистратуре от Кафедры исторической информатики МГУ занимаются серьезной академической наукой, не выходя за рамки истории. Если вам интересно математическое моделирование исторических процессов или, к примеру, применение статистических методов в экономической истории — вам сюда. Не-историков берут, мы знаем успешные примеры.
www.hse.ru
Магистерская программа «Цифровые методы в гуманитарных науках»
8 главных прорывов в нейросетевом NLP
Как компьютерная лингвистика подсела на нейронные сети и диплернинг, какие подходы сегодня в тренде и почему они так хороши? 8 важнейших достижений, около 15 лет плодотворной работы ученых:
2001 — Нейронные языковые модели
Тренировочная площадка для применения RNN. Многие недавние достижения в области обработки естественного языка сводятся к одному из видов языкового моделирования.
2008 — Многозадачное обучение
Совместное использование одних и тех же векторных представлений слов позволяет моделям взаимодействовать и обмениваться некоторыми «базовыми» представлениями об элементах текстов.
2013 — Word embeddings (векторное представление слов)
Word2vec модели позволяют провести массовое обучение векторных представлений слов и определить отношения и смыслы, стоящие за этими словами. (и даже за пределами уровня слова)
2013 — Нейронные сети для обработки естественного языка
Рекуррентные, сверточные и рекурсивные нейронные сети как три разных продуктивных способа работы с текстом.
2014 — Модели sequence-to-sequence (seq2seq)
Преобразование одной последовательности в другую с использованием нейронной сети. Благодаря своей гибкости, в настоящее время эта структура является ключевой для решения задач генерации естественного языка.
2015 — Внимание
Внимание позволило моделям нейронного машинного перевода превзойти классические системы перевода, основанные на переводе фраз.
2015 — Нейронные сети с ассоциативной памятью
Модели с ассоциативной памятью применяются в решении задач, для которых полезно хранить информацию в течение длительного времени, например, в языковом моделировании или чтении с пониманием прочитанного.
2018 — Предварительно обученные языковые модели
Предварительно обученные языковые модели доказали возможность обучения на очень ограниченном количестве данных. Они особенно полезны при работе с малоресурсными языками.
https://sysblok.ru/nlp/8-glavnyh-proryvov-v-nejrosetevom-nlp/
Как компьютерная лингвистика подсела на нейронные сети и диплернинг, какие подходы сегодня в тренде и почему они так хороши? 8 важнейших достижений, около 15 лет плодотворной работы ученых:
2001 — Нейронные языковые модели
Тренировочная площадка для применения RNN. Многие недавние достижения в области обработки естественного языка сводятся к одному из видов языкового моделирования.
2008 — Многозадачное обучение
Совместное использование одних и тех же векторных представлений слов позволяет моделям взаимодействовать и обмениваться некоторыми «базовыми» представлениями об элементах текстов.
2013 — Word embeddings (векторное представление слов)
Word2vec модели позволяют провести массовое обучение векторных представлений слов и определить отношения и смыслы, стоящие за этими словами. (и даже за пределами уровня слова)
2013 — Нейронные сети для обработки естественного языка
Рекуррентные, сверточные и рекурсивные нейронные сети как три разных продуктивных способа работы с текстом.
2014 — Модели sequence-to-sequence (seq2seq)
Преобразование одной последовательности в другую с использованием нейронной сети. Благодаря своей гибкости, в настоящее время эта структура является ключевой для решения задач генерации естественного языка.
2015 — Внимание
Внимание позволило моделям нейронного машинного перевода превзойти классические системы перевода, основанные на переводе фраз.
2015 — Нейронные сети с ассоциативной памятью
Модели с ассоциативной памятью применяются в решении задач, для которых полезно хранить информацию в течение длительного времени, например, в языковом моделировании или чтении с пониманием прочитанного.
2018 — Предварительно обученные языковые модели
Предварительно обученные языковые модели доказали возможность обучения на очень ограниченном количестве данных. Они особенно полезны при работе с малоресурсными языками.
https://sysblok.ru/nlp/8-glavnyh-proryvov-v-nejrosetevom-nlp/
{kind=link}
Translate-баттл: могут ли онлайн-переводчики передавать стиль текста?
Когда мы получаем онлайн-перевод нужного нам текста, то сразу можем сказать, хороший он или плохой. Но экспертам и разработчикам онлайн-сервисов машинного перевода нужны более четкие критерии оценки, так они смогут увидеть, в каких аспектах тот или иной сервис «слабоват» и что можно сделать, чтобы его улучшить.
В современном переводоведении машинный перевод можно оценить ручным и автоматическим способами. Ручная шкала оценивания содержит от пяти до одного баллов:
1 балл - если грамматика и стиль предложения не требуют постредактирования.
5 баллов - если в тексте большое количество грамматических, лексических и стилистических ошибок, а смысл предложения с трудом понимается даже после внимательного изучения.
Метрики автоматической оценки сейчас тоже достаточно популярны, однако их существенный недостаток заключается в том, что при такой оценке не ставится задача понимания семантики и стилистики текста, а это может привести к весьма неточному конечному результату.
О результатах сравнительного анализа переводов Яндекс Переводчика, Google Translate и других онлайн-сервисов в нашей полной статье:
https://sysblok.ru/nlp/translate-battl-mogut-li-onlajn-perevodchiki-peredavat-stil-teksta/
Когда мы получаем онлайн-перевод нужного нам текста, то сразу можем сказать, хороший он или плохой. Но экспертам и разработчикам онлайн-сервисов машинного перевода нужны более четкие критерии оценки, так они смогут увидеть, в каких аспектах тот или иной сервис «слабоват» и что можно сделать, чтобы его улучшить.
В современном переводоведении машинный перевод можно оценить ручным и автоматическим способами. Ручная шкала оценивания содержит от пяти до одного баллов:
1 балл - если грамматика и стиль предложения не требуют постредактирования.
5 баллов - если в тексте большое количество грамматических, лексических и стилистических ошибок, а смысл предложения с трудом понимается даже после внимательного изучения.
Метрики автоматической оценки сейчас тоже достаточно популярны, однако их существенный недостаток заключается в том, что при такой оценке не ставится задача понимания семантики и стилистики текста, а это может привести к весьма неточному конечному результату.
О результатах сравнительного анализа переводов Яндекс Переводчика, Google Translate и других онлайн-сервисов в нашей полной статье:
https://sysblok.ru/nlp/translate-battl-mogut-li-onlajn-perevodchiki-peredavat-stil-teksta/
Системный Блокъ
Translate-баттл: могут ли онлайн-переводчики передавать стиль текста? - Системный Блокъ
«Мой мозг застрял в черепе», «He was introduced to the wells», «филиал исследований» и другие приключения онлайн-перевода