
Я не так давно делал заметку про исчерпание свободного места на PBS (Proxmox Backup Server). Напомню, что если у вас закончилось свободное место, то нет штатной возможности освободить его здесь и сейчас, кроме как удалить весь Datastore полностью. Если вы просто удалите ненужные бэкапы, то придётся ждать сутки, когда они реально освободят занимаемое место.
В комментариях предложили способ, который обходит это ограничение. Я им уже активно пользуюсь, очень удобно. Комментарии читают не все, поэтому решил вынести в отдельную публикацию.
Итак, чтобы моментально освободить место, занимаемое ненужными бэкапами, сделайте следующее:
1️⃣ Удалите лишние бэкапы в разделе Datastore ⇨ Content
2️⃣ Перейдите в консоль PBS и выполните там команду:
3️⃣ Идём опять в веб интерфейс, выбираем наш Datastore и запускаем Garbage Collect.
Все удалённые бэкапы удалятся окончательно, освободив свободное место.
Поясню, что мы тут сделали. Я уже когда-то описывал возможности утилиты
После работы
Если я всё правильно понимаю, то штатный процесс Garbage Collect удаляет все помеченные на удаление блоки со временем последнего изменения больше суток назад. Соответственно, меняя дату блоков на 2 суток назад, мы гарантированно провоцируем их удаление. Не совсем понимаю, почему нельзя было сделать отдельным пунктом GC удаление помеченных на удаление блоков здесь и сейчас, но как есть, так есть.
❗️Используйте это на свой страх и риск, когда отступать уже некуда. Я не знаю точно, к каким последствиям это может привести, но у меня сработало несколько раз ожидаемо. Я специально проверял по результатам работы GC. Если удалить некоторые бэкапы и сдвинуть дату всех блоков на 2 дня назад, то очередная работа GC удаляет только помеченные на удаление бэкапы. Верификация оставшихся бэкапов проходит нормально.
#proxmox
В комментариях предложили способ, который обходит это ограничение. Я им уже активно пользуюсь, очень удобно. Комментарии читают не все, поэтому решил вынести в отдельную публикацию.
Итак, чтобы моментально освободить место, занимаемое ненужными бэкапами, сделайте следующее:
1️⃣ Удалите лишние бэкапы в разделе Datastore ⇨ Content
2️⃣ Перейдите в консоль PBS и выполните там команду:
find /path2pbs-datastore/.chunks -type f -print0 | xargs -0 touch -d "-2 days"3️⃣ Идём опять в веб интерфейс, выбираем наш Datastore и запускаем Garbage Collect.
Все удалённые бэкапы удалятся окончательно, освободив свободное место.
Поясню, что мы тут сделали. Я уже когда-то описывал возможности утилиты
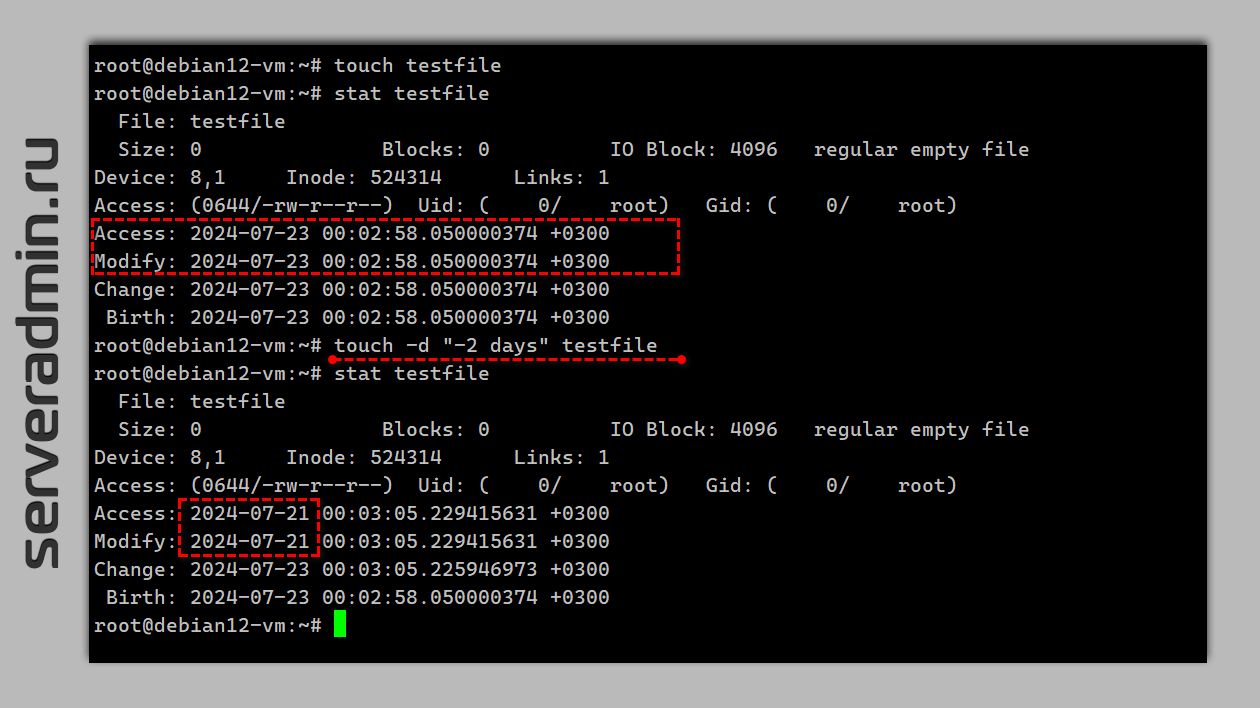
touch. С её помощью можно изменять параметры файла, меняя временные метки. Об этом рассказано тут и тут. Покажу на примере. Создадим файл и изменим дату его изменения на 2 дня назад:# touch testfile# stat testfile# touch -d "-2 days" testfile# stat testfileПосле работы
touch с ключом -d метка Modify уехала на 2 дня назад.Если я всё правильно понимаю, то штатный процесс Garbage Collect удаляет все помеченные на удаление блоки со временем последнего изменения больше суток назад. Соответственно, меняя дату блоков на 2 суток назад, мы гарантированно провоцируем их удаление. Не совсем понимаю, почему нельзя было сделать отдельным пунктом GC удаление помеченных на удаление блоков здесь и сейчас, но как есть, так есть.
❗️Используйте это на свой страх и риск, когда отступать уже некуда. Я не знаю точно, к каким последствиям это может привести, но у меня сработало несколько раз ожидаемо. Я специально проверял по результатам работы GC. Если удалить некоторые бэкапы и сдвинуть дату всех блоков на 2 дня назад, то очередная работа GC удаляет только помеченные на удаление бэкапы. Верификация оставшихся бэкапов проходит нормально.
#proxmox
{kind=link}
👍110👎4
Ещё один пример расскажу про неочевидное использование Zabbix. Люблю эту систему мониторинга больше всех остальных именно за то, что это с одной стороны целостная система, а с другой - конструктор, из которого можно слепить всё, что угодно. Безграничный простор для построения велосипедов и костылей.
У Zabbix есть тип элемента данных - SSH Агент. Он может ходить по SSH на хосты с аутентификацией по паролю или ключу, выполнять какие-то действия и сохранять вывод. С помощью этого можно, к примеру, сохранять бэкапы Микротиков. Причём встроенные возможности Zabbix позволят без каких-то дополнительных телодвижений отбрасывать неизменившиеся настройки, чтобы не хранить одну и ту же информацию много раз. А также можно оповещать об изменениях в конфигурациях, если сохранённая ранее отличается от полученной в новой проверке.
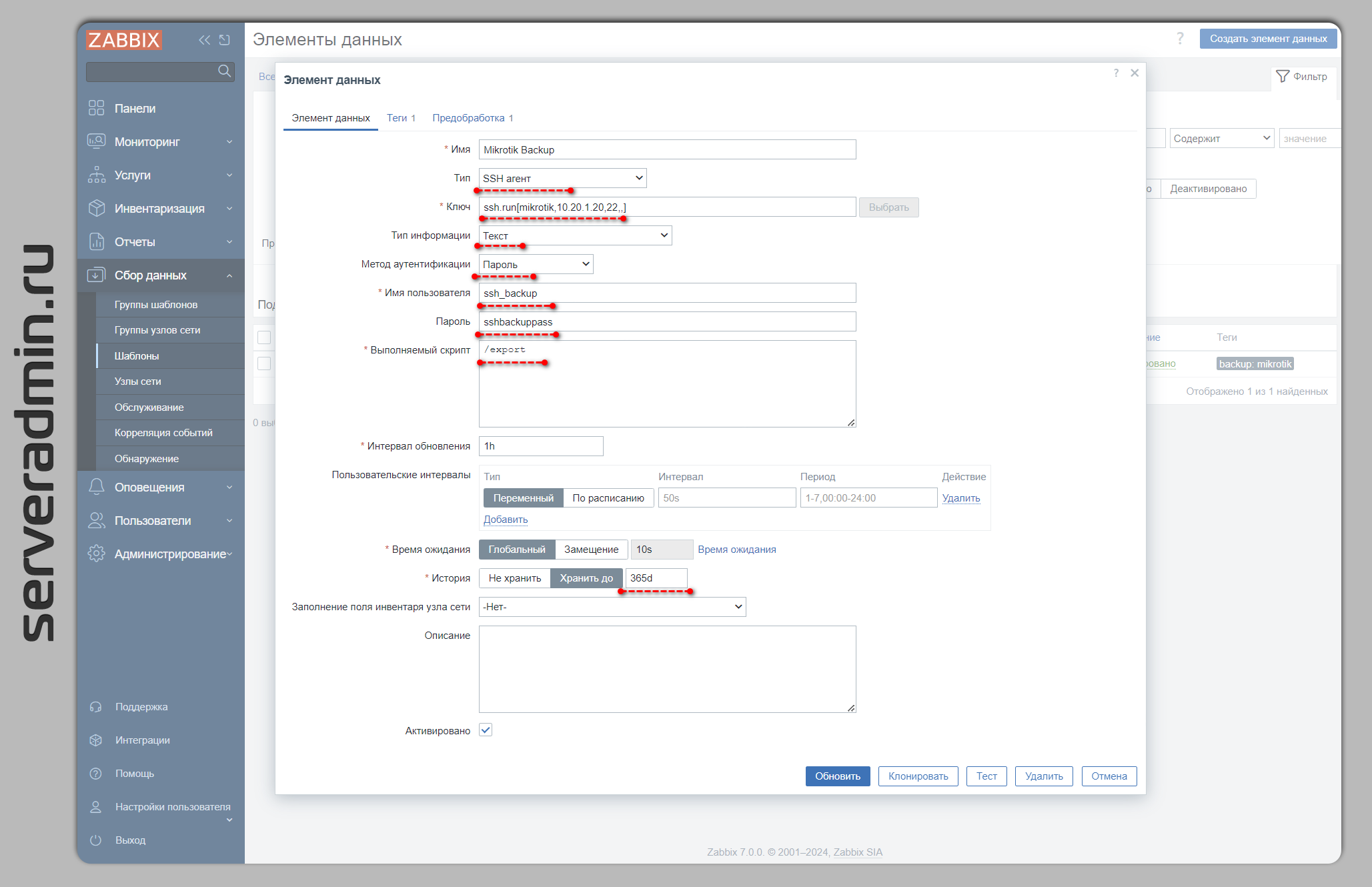
Рассказываю, как это настроить. Создаём новый шаблон. Я всегда рекомендую использовать сразу шаблоны, не создавать айтемы и триггеры на хостах. Это неудобно и труднопереносимо. Лучше сразу делать в шаблоне. Добавляем новый айтем:
◽Тип: SSH агент
◽Ключ: ssh.run[mikrotik,10.20.1.20,22,,]
Формат этого ключа: ssh.run[description,<ip>,<port>,<encoding>,<ssh options>]
◽Тип информации: Текст
◽Метод аутентификации: Пароль (можете выбрать ключ)
◽Выполняемый скрипт:
Остальные параметры ставите по желанию. Логин и пароль лучше вынести в макросы шаблона и скрыть их, так будет удобнее и безопаснее. Я указал явно для наглядности. Переходим в этом же айтеме на вкладку Предобработка и добавляем один шаг:
◽Отбрасывать не изменившееся
Тэги добавьте по желанию. Сохраняем. Сразу добавим триггер, который сработает, если конфигурация изменилась. Параметры там выставляйте по желанию. Выражение можно сделать такое:
Сработает, если текст последней проверки будет отличаться от предыдущей.
Теперь можно прикрепить этот шаблон к хосту, который будет делать подключения и проверить. Я обычно на Zabbix Server подобную функциональность вешаю. Но это зависит от вашей конфигурации сети. Сервер должен мочь заходить по SSH на указанный в айтеме адрес.
В разделе Мониторинг -> Последние данные увидите выгрузку конфигурации своего Микротика. Единственный момент, который не понравился - добавляются лишние пустые строки. Не знаю, с чем это связано. Всё остальное проверил, конфиг нормальный. Символы не теряются. На вид рабочий.
Не знаю, насколько актуально делать бэкапы таким способом. В принципе, почему бы и нет. Тут сразу и бэкап, и мониторинг изменений в одном лице. Сам так не делал никогда. Написал эту заметку, чтобы просто продемонстрировать возможность. Вдохновился вот этой статьёй в блоге Zabbix, где они скрестили мониторинг с Oxidized:
⇨ https://blog.zabbix.com/monitoring-configuration-backups-with-zabbix-and-oxidized/28260/
Неплохой материал. Там берут json со статусами бэкапов из Oxidized и с помощью lld и jsonpath парсят его на статусы отдельных устройств.
Возвращаясь к бэкапу Микротиков. Если таки надумаете его делать, то в случае больших выгрузок увеличьте таймауты на сервере. И следите за размером бэкапов. У Zabbix вроде есть ограничение на размер текстовой записи айтема в 64KB. Если у вас конфиг будет больше, то он обрежется без каких-либо уведомлений. Ну а в общем случае всё заработает, и сбор, и триггер. Я лично проверил на своём стенде во время написания заметки.
А вообще интересна тема разных проверок с помощью Zabbix? Я могу много всяких примеров привести ещё. Что-то я уже писал раньше, что-то нет. С Zabbix постоянно работаю.
#zabbix #mikrotik
У Zabbix есть тип элемента данных - SSH Агент. Он может ходить по SSH на хосты с аутентификацией по паролю или ключу, выполнять какие-то действия и сохранять вывод. С помощью этого можно, к примеру, сохранять бэкапы Микротиков. Причём встроенные возможности Zabbix позволят без каких-то дополнительных телодвижений отбрасывать неизменившиеся настройки, чтобы не хранить одну и ту же информацию много раз. А также можно оповещать об изменениях в конфигурациях, если сохранённая ранее отличается от полученной в новой проверке.
Рассказываю, как это настроить. Создаём новый шаблон. Я всегда рекомендую использовать сразу шаблоны, не создавать айтемы и триггеры на хостах. Это неудобно и труднопереносимо. Лучше сразу делать в шаблоне. Добавляем новый айтем:
◽Тип: SSH агент
◽Ключ: ssh.run[mikrotik,10.20.1.20,22,,]
Формат этого ключа: ssh.run[description,<ip>,<port>,<encoding>,<ssh options>]
◽Тип информации: Текст
◽Метод аутентификации: Пароль (можете выбрать ключ)
◽Выполняемый скрипт:
/exportОстальные параметры ставите по желанию. Логин и пароль лучше вынести в макросы шаблона и скрыть их, так будет удобнее и безопаснее. Я указал явно для наглядности. Переходим в этом же айтеме на вкладку Предобработка и добавляем один шаг:
◽Отбрасывать не изменившееся
Тэги добавьте по желанию. Сохраняем. Сразу добавим триггер, который сработает, если конфигурация изменилась. Параметры там выставляйте по желанию. Выражение можно сделать такое:
last(/SSH Get/ssh.run[mikrotik,10.20.1.20,22,,],#1)<>last(/SSH Get/ssh.run[mikrotik,10.20.1.20,22,,],#2)Сработает, если текст последней проверки будет отличаться от предыдущей.
Теперь можно прикрепить этот шаблон к хосту, который будет делать подключения и проверить. Я обычно на Zabbix Server подобную функциональность вешаю. Но это зависит от вашей конфигурации сети. Сервер должен мочь заходить по SSH на указанный в айтеме адрес.
В разделе Мониторинг -> Последние данные увидите выгрузку конфигурации своего Микротика. Единственный момент, который не понравился - добавляются лишние пустые строки. Не знаю, с чем это связано. Всё остальное проверил, конфиг нормальный. Символы не теряются. На вид рабочий.
Не знаю, насколько актуально делать бэкапы таким способом. В принципе, почему бы и нет. Тут сразу и бэкап, и мониторинг изменений в одном лице. Сам так не делал никогда. Написал эту заметку, чтобы просто продемонстрировать возможность. Вдохновился вот этой статьёй в блоге Zabbix, где они скрестили мониторинг с Oxidized:
⇨ https://blog.zabbix.com/monitoring-configuration-backups-with-zabbix-and-oxidized/28260/
Неплохой материал. Там берут json со статусами бэкапов из Oxidized и с помощью lld и jsonpath парсят его на статусы отдельных устройств.
Возвращаясь к бэкапу Микротиков. Если таки надумаете его делать, то в случае больших выгрузок увеличьте таймауты на сервере. И следите за размером бэкапов. У Zabbix вроде есть ограничение на размер текстовой записи айтема в 64KB. Если у вас конфиг будет больше, то он обрежется без каких-либо уведомлений. Ну а в общем случае всё заработает, и сбор, и триггер. Я лично проверил на своём стенде во время написания заметки.
А вообще интересна тема разных проверок с помощью Zabbix? Я могу много всяких примеров привести ещё. Что-то я уже писал раньше, что-то нет. С Zabbix постоянно работаю.
#zabbix #mikrotik
{kind=link}
👍176👎4
Как можно закрыть веб интерфейс Proxmox от посторонних глаз? Если, к примеру, вы арендуете одиночный сервер и он смотрит напрямую в интернет. Как вы понимаете, способов тут может быть очень много. Расскажу про самые простые, быстрые в настройке и эффективные. Они все будут проще, чем настроить VPN и организовать доступ через него.
1️⃣ Самый простой способ - настроить ограничение по IP с помощью настроек pveproxy. Я об этом подробно рассказывал в отдельной заметке. Достаточно создать файл
И после этого перезапустить службу:
2️⃣ С помощью iptables. Если заранее не настроили iptables, то на работающем сервере лучше не пробовать настраивать, если у вас нет прямого доступа к консоли. Если файрвол вообще не настраивали, то в общем случае понадобятся два правила:
Первое разрешает подключения из подсети 192.168.13.0/24 и ip адреса 1.1.1.1. Второе правило запрещает все остальные подключения к веб интерфейсу. Правила эти можно сохранить в файл и подгружать во время загрузки сервера или явно прописать в
Если уже есть другие правила, то их надо увязывать вместе в зависимости от ситуации. Тут нет универсальной подсказки, как поступить. Если не разбираетесь в iptables, не трогайте его. Используйте другие методы.
Я сам всегда использую iptables. Настраиваю его по умолчанию на всех гипервизорах. Примерный набор правил показывал в заметке.
3️⃣ Вы можете установить Nginx прямо на хост с Proxmox, так как по своей сути это почти обычный Debian. У Nginx есть свои способы ограничения доступа по ip через allow/deny в конфигурации, либо по пользователю/паролю через basic auth. Бонусом сюда же идёт настройка TLS сертификатов от Let's Encrypt и доступ по 443 порту, а не стандартному 8006.
Ставим Nginx:
Настраиваем базовый конфиг /
Разрешили подключаться только с указанных адресов. Это пример с использованием стандартных сертификатов. Для Let's Encrypt нужна отдельная настройка, которая выходит за рамки этой заметки. Для того, чтобы закрыть доступ паролем, а не списком IP адресов, необходимо настроить auth_basic. Настройка легко гуглится по ключевым словам nginx auth_basic, не буду об этом рассказывать, так как не умещается в заметку. Там всё просто.
Этот же Nginx сервер можно использовать для проксирования запросов внутрь виртуалок. Удобный и универсальный способ, если вы не используете отдельную виртуалку для управления доступом к внутренним ресурсам.
После настройки Nginx, доступ к веб интерфейсу по порту 8006 можно закрыть либо через pveproxy, либо через iptables.
#proxmox
1️⃣ Самый простой способ - настроить ограничение по IP с помощью настроек pveproxy. Я об этом подробно рассказывал в отдельной заметке. Достаточно создать файл
/etc/default/pveproxy примерно такого содержимого:ALLOW_FROM="192.168.13.0/24,1.1.1.1"DENY_FROM="all"POLICY="allow"И после этого перезапустить службу:
# systemctl restart pveproxy.service2️⃣ С помощью iptables. Если заранее не настроили iptables, то на работающем сервере лучше не пробовать настраивать, если у вас нет прямого доступа к консоли. Если файрвол вообще не настраивали, то в общем случае понадобятся два правила:
/usr/sbin/iptables -A INPUT -i enp5s0 -s 192.168.13.0/24,1.1.1.1 -p tcp --dport 8006 -j ACCEPT/usr/sbin/iptables -A INPUT -i enp5s0 -p tcp --dport 8006 -j DROPПервое разрешает подключения из подсети 192.168.13.0/24 и ip адреса 1.1.1.1. Второе правило запрещает все остальные подключения к веб интерфейсу. Правила эти можно сохранить в файл и подгружать во время загрузки сервера или явно прописать в
/etc/network/interfaces примерно так:auto enp5s0iface enp5s0 inet static address 5.6.7.8/24 dns-nameservers 188.93.17.19 188.93.16.19 gateway 5.6.7.1 post-up /usr/sbin/iptables -A INPUT -i enp5s0 -s 192.168.13.0/24,1.1.1.1 -p tcp --dport 8006 -j ACCEPT post-up /usr/sbin/iptables -A INPUT -i enp5s0 -p tcp --dport 8006 -j DROPЕсли уже есть другие правила, то их надо увязывать вместе в зависимости от ситуации. Тут нет универсальной подсказки, как поступить. Если не разбираетесь в iptables, не трогайте его. Используйте другие методы.
Я сам всегда использую iptables. Настраиваю его по умолчанию на всех гипервизорах. Примерный набор правил показывал в заметке.
3️⃣ Вы можете установить Nginx прямо на хост с Proxmox, так как по своей сути это почти обычный Debian. У Nginx есть свои способы ограничения доступа по ip через allow/deny в конфигурации, либо по пользователю/паролю через basic auth. Бонусом сюда же идёт настройка TLS сертификатов от Let's Encrypt и доступ по 443 порту, а не стандартному 8006.
Ставим Nginx:
# apt install nginxНастраиваем базовый конфиг /
etc/nginx/sites-available/default:server { listen 80 default_server; server_name _; allow 192.168.13.0/24; allow 1.1.1.1/32; deny all; return 301 https://5.6.7.8;}server { listen 443 ssl; server_name _; ssl_certificate /etc/pve/local/pve-ssl.pem; ssl_certificate_key /etc/pve/local/pve-ssl.key; proxy_redirect off; allow 192.168.13.0/24; allow 1.1.1.1/32; deny all; location / { proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_pass https://localhost:8006; proxy_buffering off; client_max_body_size 0; }}Разрешили подключаться только с указанных адресов. Это пример с использованием стандартных сертификатов. Для Let's Encrypt нужна отдельная настройка, которая выходит за рамки этой заметки. Для того, чтобы закрыть доступ паролем, а не списком IP адресов, необходимо настроить auth_basic. Настройка легко гуглится по ключевым словам nginx auth_basic, не буду об этом рассказывать, так как не умещается в заметку. Там всё просто.
Этот же Nginx сервер можно использовать для проксирования запросов внутрь виртуалок. Удобный и универсальный способ, если вы не используете отдельную виртуалку для управления доступом к внутренним ресурсам.
После настройки Nginx, доступ к веб интерфейсу по порту 8006 можно закрыть либо через pveproxy, либо через iptables.
#proxmox
👍106👎3
Я смотрю, заметки с Zabbix бодро заходят, а если ещё Mikrotik или Proxmox добавить, то вообще отлично. Сегодня опять Микротики будут. Типовая задача по настройке переключения канала с основного на резервный и обратно. Плюс, там ещё поднимается VPN канал. Хочется мониторить и переключение каналов, то есть получать уведомления, если канал переключился, и состояние VPN соединения, и состояние каналов, чтобы не получилось так, что резерв уже давно не работает, а мы не знаем об этом. Плюс, если точка висит на резервном канале, то это подсвечивается триггером в дашборде Zabbix.
Я делал это на базе скриптов Mikrotik. Как это может выглядеть, отражено в моей статье про переключение провайдеров. Это один из примеров. Я эти скрипты много раз менял, дорабатывал под конкретные условия. Там может быть много нюансов. Да, переключение провайдеров можно сделать проще через динамическую маршрутизацию, но это только часть задачи. Скрипт решает не только переключение, но и логирование, плюс выполнение некоторых других задач - сброс сетевых соединений, выключение и включение VPN соединения, чтобы оно сразу переподключилось через нового провайдера и т.д.
В итоге, я через скрипты настраивал переключение канала и проверку доступности каналов. Примерно так может выглядеть проверка работы канала:
Результат работы скриптов выводился в стандартный лог Микротика. Дальше этот лог может уезжать куда-то на хранение и анализ. Например, в ELK или Rsyslog. Если мы настраиваем мониторинг через Zabbix, то выбираем rsyslog.
Zabbix Server забирает к себе все логи через стандартный айтем с типом данных лог и анализирует. Потом создаётся триггер с примерно таким выражением, если брать приведённый выше скрипт Микротика:
и восстановление:
В таком подходе есть одно неудобство. Все триггеры будут привязаны к Zabbix Server, а имя устройства видно только в описании триггера. Если вам это не подходит, придётся использовать что-то другое.
Я придумывал другую схему, чтобы триггеры о состоянии каналов были привязаны к самим устройствам, чтобы на географической карте были видны хосты с проблемами. Уже точно не помню реализацию, но вроде порты куда-то внутрь пробрасывал через разные каналы. И делал стандартные TCP проверки этих портов через Zabbix сервер. Если какой-то порт не отвечает, то канал, через который он работает, считается неработающим.
И ещё один вариант мониторинга каналов. Через каждого провайдера поднимаем разное VPN соединение и мониторим его любым способом. Можно простыми пингами, если Zabbix сервер или его прокси заведён в эти VPN сети, можно по SNMP.
Мне лично больше всего нравятся варианты с логами. Я люблю всё собирать и хранить. Логи удобно анализировать, всегда на месте исторические данные по событиям. Другое дело, что Zabbix не любит большие логи и нагружать его ими не стоит. Он всё хранит в SQL базе, а она для логов плохо подходит. Какие-то простые вещи, типа вывод работы скриптов без проблем можно заводить, а вот полноценный сбор масштабных логов с их анализом устраивать не надо.
Через анализ логов удобно слать уведомления о каких-то событиях в системных логах. Например, информировать об аутентификации в системе через анализ лог файла
#mikrotik #zabbix
Я делал это на базе скриптов Mikrotik. Как это может выглядеть, отражено в моей статье про переключение провайдеров. Это один из примеров. Я эти скрипты много раз менял, дорабатывал под конкретные условия. Там может быть много нюансов. Да, переключение провайдеров можно сделать проще через динамическую маршрутизацию, но это только часть задачи. Скрипт решает не только переключение, но и логирование, плюс выполнение некоторых других задач - сброс сетевых соединений, выключение и включение VPN соединения, чтобы оно сразу переподключилось через нового провайдера и т.д.
В итоге, я через скрипты настраивал переключение канала и проверку доступности каналов. Примерно так может выглядеть проверка работы канала:
:local PingCount 3;:local CheckIp1 77.88.8.1;:local CheckIp8 77.88.8.8;:local isp1 [/ping $CheckIp1 count=$PingCount interface="ether1"];:local isp2 [/ping $CheckIp8 count=$PingCount interface="lte1"];:if ($isp1=0) do={:log warning "MAIN Internet NOT work";} else={:log warning "MAIN Internet WORK";}:if ($isp2=0) do={:log warning "RESERV Internet NOT work";} else={:log warning "RESERV Internet WORK";}Результат работы скриптов выводился в стандартный лог Микротика. Дальше этот лог может уезжать куда-то на хранение и анализ. Например, в ELK или Rsyslog. Если мы настраиваем мониторинг через Zabbix, то выбираем rsyslog.
Zabbix Server забирает к себе все логи через стандартный айтем с типом данных лог и анализирует. Потом создаётся триггер с примерно таким выражением, если брать приведённый выше скрипт Микротика:
find(/Mikrotik logs/log[/var/log/mikrotik/mikrotik.log],#1,"like","Router-01: MAIN Internet NOT work")=1'и восстановление:
find(/Mikrotik logs/log[/var/log/mikrotik/mikrotik.log],#1,"like","Router-01: MAIN Internet WORK")=1В таком подходе есть одно неудобство. Все триггеры будут привязаны к Zabbix Server, а имя устройства видно только в описании триггера. Если вам это не подходит, придётся использовать что-то другое.
Я придумывал другую схему, чтобы триггеры о состоянии каналов были привязаны к самим устройствам, чтобы на географической карте были видны хосты с проблемами. Уже точно не помню реализацию, но вроде порты куда-то внутрь пробрасывал через разные каналы. И делал стандартные TCP проверки этих портов через Zabbix сервер. Если какой-то порт не отвечает, то канал, через который он работает, считается неработающим.
И ещё один вариант мониторинга каналов. Через каждого провайдера поднимаем разное VPN соединение и мониторим его любым способом. Можно простыми пингами, если Zabbix сервер или его прокси заведён в эти VPN сети, можно по SNMP.
Мне лично больше всего нравятся варианты с логами. Я люблю всё собирать и хранить. Логи удобно анализировать, всегда на месте исторические данные по событиям. Другое дело, что Zabbix не любит большие логи и нагружать его ими не стоит. Он всё хранит в SQL базе, а она для логов плохо подходит. Какие-то простые вещи, типа вывод работы скриптов без проблем можно заводить, а вот полноценный сбор масштабных логов с их анализом устраивать не надо.
Через анализ логов удобно слать уведомления о каких-то событиях в системных логах. Например, информировать об аутентификации в системе через анализ лог файла
/var/log/auth.log. Можно о slow логах mysql или php-fpm сообщать. Это актуально, если у вас нет другой, полноценной системы для хранения и анализа логов. #mikrotik #zabbix
👍127👎7
Если вам нужно ограничить процессу потребление памяти, то с systemd это сделать очень просто. Причём там есть гибкие варианты настройки. Вообще, все варианты ограничения ресурсов с помощью systemd описаны в документации. Там внушительный список. Покажу на примере памяти, какие настройки за что отвечают.
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
Потестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
Команда будет висеть без ошибок, по По
Теперь зажимаем её:
Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
Вообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
◽MemoryAccounting=1
Включение подсчёта памяти (Turn on process and kernel memory accounting for this unit)
◽MemoryHigh=16G
Это основной механизм ограничения потребления памяти (This is the main mechanism to control memory usage of a unit). Указанный лимит может быть превышен, если это необходимо, но процесс при этом будет замедляться, а память у него активно забираться назад.
◽MemoryMax=20G
Жёсткий лимит по потреблению памяти. Если процесс до него дойдет, то он будет завершён OOM Killer. В общем случае этот лимит лучше не использовать, только в крайних случаях, чтобы сохранить работоспособность системы.
◽MemorySwapMax=3G
Ограничение по использованию swap.
◽Restart=on-abnormal
Параметр не имеет отношения к потреблению памяти, но добавил сюда для справки. Если хотите, чтобы процесс перезапускался автоматически после того, как его прибьют по превышению MemoryMax, то используйте этот параметр.
◽OOMPolicy=stop
Тоже косвенный параметр, который устанавливает то, как OOM Killer будет останавливать процесс. Либо это будет попытка корректно остановить процесс через stop, либо он его просто прибьёт через kill. Выбирайте в зависимости от того, что ограничиваете. Если у процесса жор памяти означает, что он завис и его надо прибить, то ставьте kill. А если он ещё живой и может быть остановлен, тогда stop.
Параметры эти описываются в секции юнита [Service] примерно так:
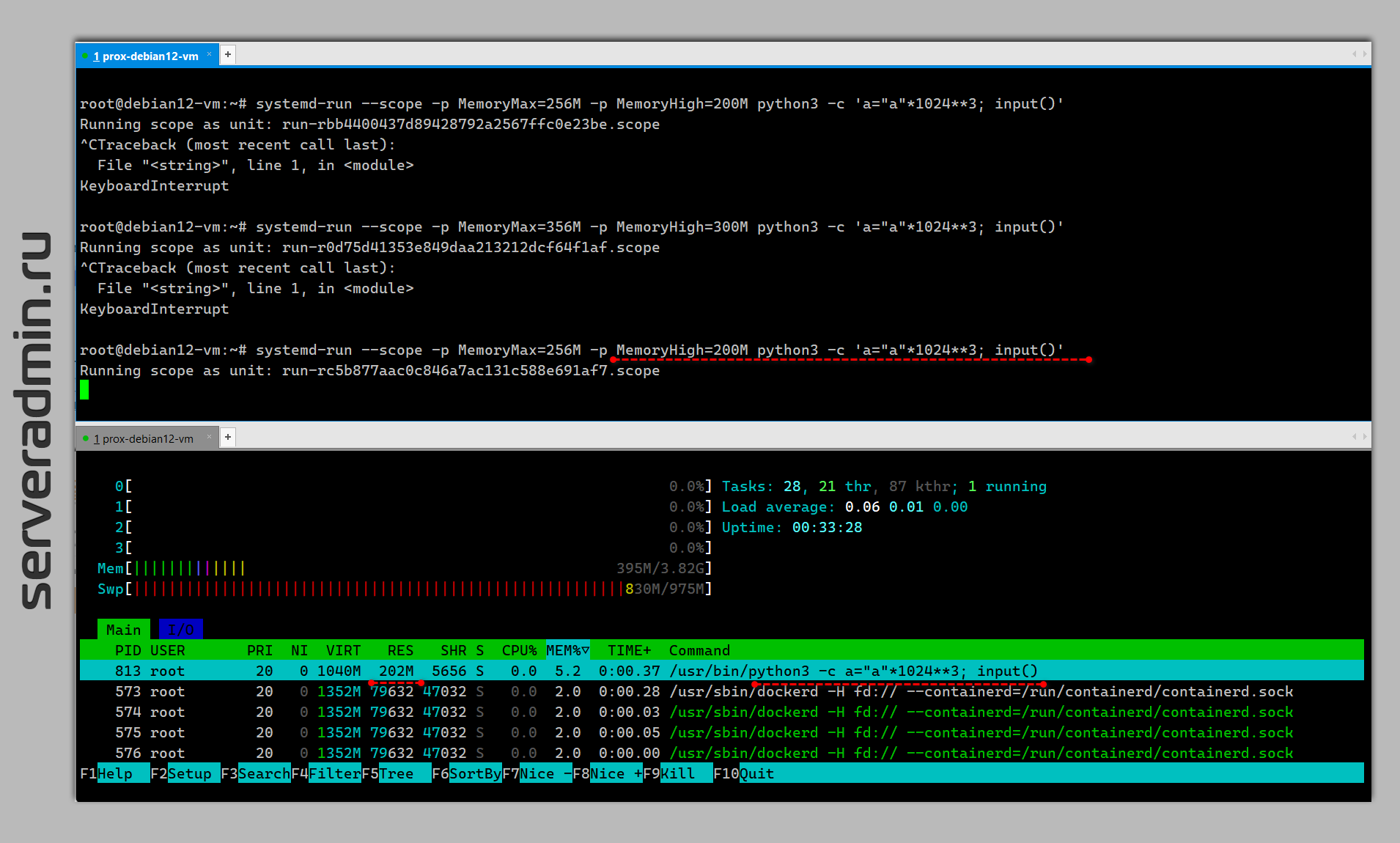
[Unit]Description=Python ScriptAfter=network.target[Service]WorkingDirectory=/opt/runExecStart=/opt/run/scrape.pyRestart=on-abnormalMemoryAccounting=1MemoryHigh=16GMemoryMax=20GMemorySwapMax=3GOOMPolicy=stop[Install]WantedBy=multi-user.targetПотестировать лимиты можно в консоли. Для примера возьмём python и съедим гигабайт памяти:
# python3 -c 'a="a"*1024**3; input()'Команда будет висеть без ошибок, по По
ps или free -m будет видно, что скушала 1G оперативы. Теперь зажимаем её:
# systemd-run --scope -p MemoryMax=256M -p MemoryHigh=200M python3 -c 'a="a"*1024**3; input()'Процесс работает, но потребляет разрешённые ему 200M. На практике чуть меньше. Смотрим через pmap:
# ps ax | grep python 767 pts/0 S+ 0:00 /usr/bin/python3 -c a="a"*1024**3; input()# pmap 767 -x | grep totaltotal kB 1065048 173992 168284Значения в килобайтах. Первое - виртуальная память (VSZ), сколько процесс запросил, столько получил. Занял весь гигабайт. Второе значение - RSS, что условно соответствует реальному потреблению физической памяти, и тут уже работает лимит. Реальной памяти процесс потребляет не больше лимита.
RSS можно ещё вот так быстро глянуть:
# ps -e -o rss,args --sort -rssВообще, с памятью у Linux всё непросто. Кому интересно, я как-то пытался в этом разобраться и рассказать простым языком.
Systemd удобный инструмент в плане управления лимитами процессов. Легко настраивать и управлять.
Считаю, что эта заметка достойна того, чтобы быть сохранённой в избранном.
#systemd
{kind=link}
👍143👎3
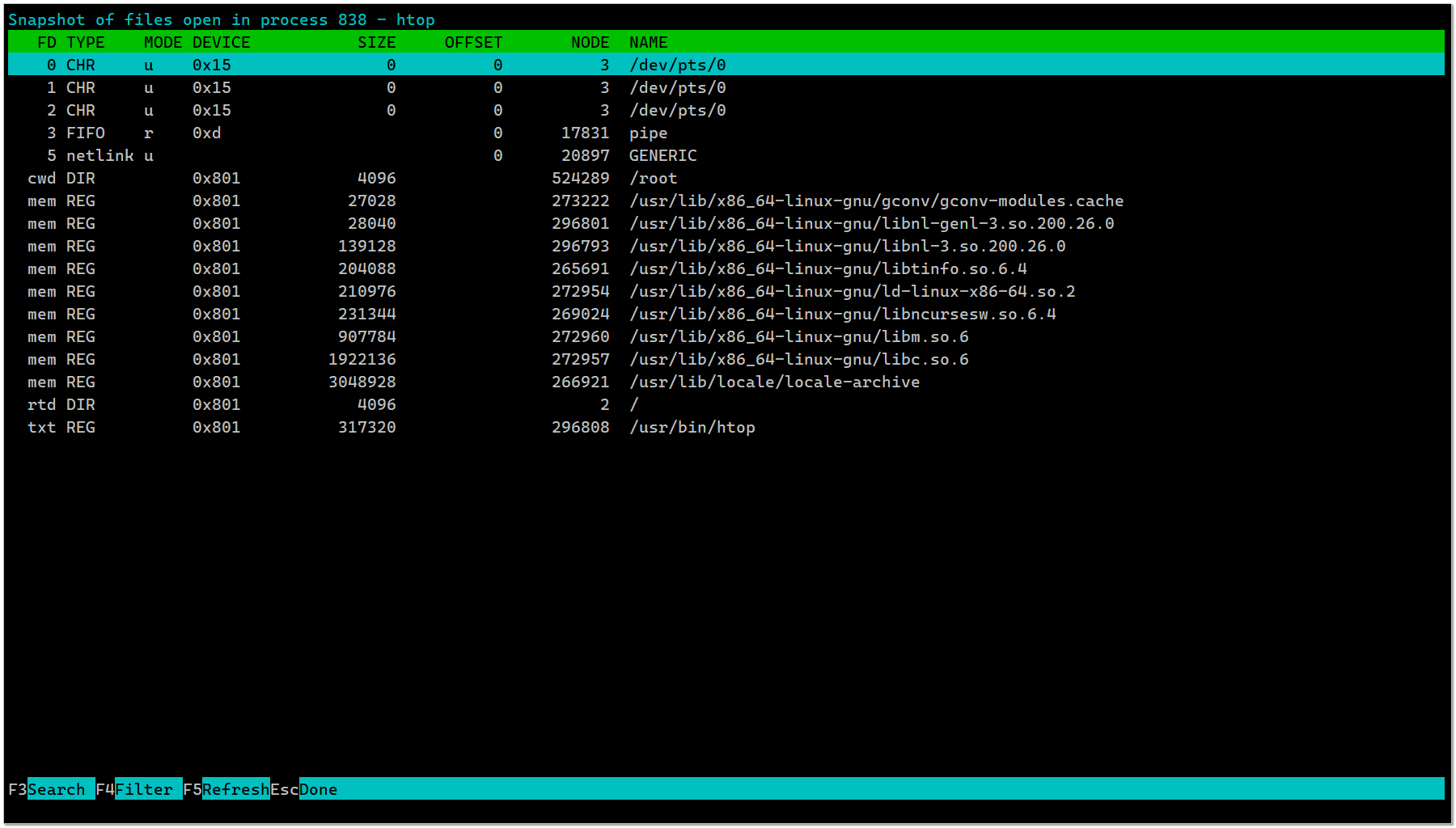
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}
👍147👎3
Media is too big
VIEW IN TELEGRAM
Один из самых прикольных моментов сериала Кремниевая Долина (Silicon Valley).
Вы создали форк бомбу и закрыли мне доступ в мою же систему.
Сервак не реагирует на клавиши. Не могу даже SIGKILL послать.
На экране в консоли видно, как удаляются .mov файлы из точки монтирования
#юмор
Вы создали форк бомбу и закрыли мне доступ в мою же систему.
Сервак не реагирует на клавиши. Не могу даже SIGKILL послать.
На экране в консоли видно, как удаляются .mov файлы из точки монтирования
/mount/gluster/originals/ от glusterfs. Редкое явление, когда в фильмах пытаются хоть что-то правдоподобное говорить и показывать по IT тематике. Обычно там какая-то бессмысленная бутафория. А тут постарались.#юмор
👍184👎4
Всем привет и хороших выходных, точнее, выходного, если кто ещё или уже не в отпуске. У меня начинается отпуск, так что канал на 3 недели прекращает свою деятельность. Вернусь с новыми публикациями 19-го августа. Чат закрою от новых комментариев, чтобы за спамерами не следить.
Уйду на некоторое время в символический поход, но почти без связи и точно без электричества. Немного переживаю. Мысли проскакивают, нафиг я вообще в это ввязался. Не помню, когда последний раз оказывался в такой ситуации. Хоть и не припоминаю, чтобы хоть раз в отпуске приходилось прямо таки решать какие-то серьёзные проблемы, но на связи обычно всегда был и по мелочи мог что-то посмотреть, сказать, сделать.
У вас как проходят отпуска? На связи остаётесь? Приходится рабочими вопросами заниматься? Ритм современной жизни такой, что часто людям приходится это делать и не только в нашей профессии. Особенно если ты руководитель.
Сегодня вечером будет реклама мероприятия Яндекса. Они прям в последний момент успели, когда я уже подготовил последнюю публикацию и заявки не принимал. По самому мероприятию ничего не скажу, смотрите сами, кому это подходит, но рекомендую посмотреть видео, которое будет в этом сообщении. Мне оно понравилось, так что решил его опубликовать. Очень, такое, проникновенно-ностальгическое.
Уйду на некоторое время в символический поход, но почти без связи и точно без электричества. Немного переживаю. Мысли проскакивают, нафиг я вообще в это ввязался. Не помню, когда последний раз оказывался в такой ситуации. Хоть и не припоминаю, чтобы хоть раз в отпуске приходилось прямо таки решать какие-то серьёзные проблемы, но на связи обычно всегда был и по мелочи мог что-то посмотреть, сказать, сделать.
У вас как проходят отпуска? На связи остаётесь? Приходится рабочими вопросами заниматься? Ритм современной жизни такой, что часто людям приходится это делать и не только в нашей профессии. Особенно если ты руководитель.
Сегодня вечером будет реклама мероприятия Яндекса. Они прям в последний момент успели, когда я уже подготовил последнюю публикацию и заявки не принимал. По самому мероприятию ничего не скажу, смотрите сами, кому это подходит, но рекомендую посмотреть видео, которое будет в этом сообщении. Мне оно понравилось, так что решил его опубликовать. Очень, такое, проникновенно-ностальгическое.
👍196👎9
Всем привет. Закончился продолжительный отпуск в 3 недели. Никогда такого не было. С самого начала моей трудовой деятельности везде отпуска были по 2 недели 2 раза в год. В этот раз получилось организовать 3 полных недели. Вообще выпал из рабочих будней. В походе замёрз ночью пипец (+8-9 несколько ночей было, спал в куртке, штанах, шапке). Убедился, что походы и жизнь в палатке это не моё. Больше не пойду. Сын тоже не проникся, хотя мы всего неделю в палатках прожили. Ещё неделю на даче родителей с семьёй прожил, и неделю у себя на даче поработал.
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
{kind=link}
👍280👎8
🔝 Пока был в отпуске, закончился месяц. Но ТОП постов не хочу пропускать, поэтому подготовил его. Мне самому нравится такой формат. Иногда просматриваю, плюс, любопытно ещё раз посмотреть на самые удачные публикации.
Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год.
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.iss.one/boost/srv_admin.
📌 Больше всего пересылок:
◽️Сборка Windows 11 Enterprise G (612)
◽️Настройка NFS сервера (482)
◽️RDP Defender для защиты RDP подключений (409)
◽️Утилита ss вместо netstat (387)
◽️Ограничение потребления памяти с помощью systemd (364)
📌 Больше всего комментариев:
◽️Массовый BSOD на Windows (362)
◽️Настройка NFS сервера (223)
◽️Гипервизор для одной виртуальной машины (207)
📌 Больше всего реакций:
◽️Гипервизор для одной виртуальной машины (233)
◽️Сборка Windows 11 Enterprise G (200)
◽️Утилита ss вместо netstat (181)
📌 Больше всего просмотров:
◽️Массовый BSOD на Windows (9855)
◽️Бесплатные курсы от Selectel (9854)
◽️Дистрибутивы Linux в браузере (9635)
#топ
Все самые популярные публикации по месяцам можно почитать со соответствующему хэштэгу #топ. Отдельно можно посмотреть ТОП за прошлый год.
Пользуясь случаем, хочу попросить проголосовать за мой канал, так как это открывает некоторые дополнительные возможности по настройке: https://t.iss.one/boost/srv_admin.
📌 Больше всего пересылок:
◽️Сборка Windows 11 Enterprise G (612)
◽️Настройка NFS сервера (482)
◽️RDP Defender для защиты RDP подключений (409)
◽️Утилита ss вместо netstat (387)
◽️Ограничение потребления памяти с помощью systemd (364)
📌 Больше всего комментариев:
◽️Массовый BSOD на Windows (362)
◽️Настройка NFS сервера (223)
◽️Гипервизор для одной виртуальной машины (207)
📌 Больше всего реакций:
◽️Гипервизор для одной виртуальной машины (233)
◽️Сборка Windows 11 Enterprise G (200)
◽️Утилита ss вместо netstat (181)
📌 Больше всего просмотров:
◽️Массовый BSOD на Windows (9855)
◽️Бесплатные курсы от Selectel (9854)
◽️Дистрибутивы Linux в браузере (9635)
#топ
👍52👎1
Настраивал скрипт бэкапа с автоматическим удалением старых копий. Во время отладки и бэкапы, и сам скрипт лежали в одной директории. Напутал с условием удаления и случайно был удалён сам скрипт после выполнения. Так как ещё не успел его никуда сохранить, это была единственная копия.
Не сказать, что там была какая-то особенная информация, но откровенно не хотелось всё переписывать с нуля. Не знаю, как вы, а меня полностью деморализует ситуация, когда надо повторить ту же задачу, которую ты только что решал. Так что решил попытаться восстановить то, что только что удалил. На практике это сделать не так трудно, а шанс восстановление небольшого файла велик, если сделать это сразу же.
Сразу вспомнил про программу scalpel, о которой уже когда-то давно писал. Но там был пример синтетический, хотя он и сработал. А тут будет самый что ни на есть реальный. Ставим программу:
Далее нам нужно указать сигнатуры восстанавливаемых файлов. Часть сигнатур есть в самом файле конфигураций -
В данном случае
zabbix-vg-root - корневой и единственный lvm раздел этого сервера. Если у вас не используется lvm, то это будет что-то вроде /dev/sda2 и т.д.
Программа минуты за 3-4 просканировала раздел на 50G и вывела результаты в указанную директорию. Там было около сотни различных текстовых скриптов, а нужный мне был где-то в самом начале списка, так что мне даже по содержимому искать не пришлось. Сразу нашёл при беглом осмотре. Всё содержимое файла сохранилось.
Так что сохраняйте заметку и берите на вооружение. Кто знает, когда пригодится. Мне спустя более двух лет в итоге понадобилась информация, о которой писал ранее.
#restore #linux
Не сказать, что там была какая-то особенная информация, но откровенно не хотелось всё переписывать с нуля. Не знаю, как вы, а меня полностью деморализует ситуация, когда надо повторить ту же задачу, которую ты только что решал. Так что решил попытаться восстановить то, что только что удалил. На практике это сделать не так трудно, а шанс восстановление небольшого файла велик, если сделать это сразу же.
Сразу вспомнил про программу scalpel, о которой уже когда-то давно писал. Но там был пример синтетический, хотя он и сработал. А тут будет самый что ни на есть реальный. Ставим программу:
# apt install scalpelДалее нам нужно указать сигнатуры восстанавливаемых файлов. Часть сигнатур есть в самом файле конфигураций -
/etc/scalpel/scalpel.conf. Ещё более подробный список можно посмотреть тут в репозитории. Я не совсем понял, какие заголовки должный быть у обычного текстового файла, коим являлся мой скрипт. По идее там особых заголовков и нет, а искать можно по содержимому. Так что я добавил в scalpel.conf следующее: NONE y 1000 #!/bin/bashВ данном случае
#!/bin/bash это начало моего скрипта. Я их все так начинаю. Запускаем сканирование с выводом результатов в /tmp/restored:# mkdir /tmp/restored# scalpel /dev/mapper/zabbix-vg-root -o /tmp/restoredzabbix-vg-root - корневой и единственный lvm раздел этого сервера. Если у вас не используется lvm, то это будет что-то вроде /dev/sda2 и т.д.
Программа минуты за 3-4 просканировала раздел на 50G и вывела результаты в указанную директорию. Там было около сотни различных текстовых скриптов, а нужный мне был где-то в самом начале списка, так что мне даже по содержимому искать не пришлось. Сразу нашёл при беглом осмотре. Всё содержимое файла сохранилось.
Так что сохраняйте заметку и берите на вооружение. Кто знает, когда пригодится. Мне спустя более двух лет в итоге понадобилась информация, о которой писал ранее.
#restore #linux
{kind=link}
👍219👎4
Подготовил небольшой список действий на основе своего опыта и знаний, которые имеет смысл выполнить, если у вас есть подозрения на то, что ваш сервер был взломан тем или иным способом. То есть на нём исполняется вредоносный код. Чаще всего это нужно не для восстановления работоспособности, а для расследования, чтобы понять, что конкретно случилось. Если сервер был скомпрометирован, лучше его полностью переустановить, перенеся полезную нагрузку.
1️⃣ Если это веб сервер, то имеет смысл начать с анализа его лог файлов. Если знаете, что у вас была какая-то незакрытая уязвимость в коде, то искать следует её эксплуатацию, либо запуск веб-шеллов.
Обычно уязвимость находят в каком-то конкретном файле, так что смотрим обращения к нему. Если по описанию уязвимости вы видите, что зловред создаёт или загружает новый файл и потом к нему обращается, то ищите эти обращения.
2️⃣ Можно посмотреть список изменённых файлов за последнее время. Не факт, что поможет, так как изменить дату модификации файла не сложно, но тем не менее, это может помочь:
Тут мы выводим все изменённые файлы за последние 30 дней, кроме сегодняшнего и сортируем их по дате изменения от более свежей к старой. Если список большой, лучше сразу его в файл отправить и анализировать там. Это, кстати, полезная команда именно в таком виде и выводе. Рекомендую сохранить.
3️⃣ Смотрим журналы операционной системы, в том числе аутентификации по SSH. На них хорошо бы ставить мониторинг и отправлять эту информацию на сторонний лог сервер. Смотрим задачи cron, at и systemd timers. Куда конкретно смотреть, писал в отдельной заметке по запланированным задачам.
4️⃣ Не часто, но иногда можно что-то увидеть в истории shell команд или истории команд клиентов СУБД:
◽
◽
◽
◽
5️⃣ Имеет смысл проверить целостность исполняемых файлов согласно эталонным хеш-значениям из DEB и RPM пакетов.
6️⃣ Проверяем системных пользователей, прописанные для них шеллы, прописанные ключи для SSH соединений. Проверяем домашние директории пользователей, от которых работает веб сервер и другие запущенные службы, на предмет подозрительных скриптов. То же самое делаем во временных директориях.
7️⃣ Проверяем прослушиваемые приложениями порты и исходящие подключения:
8️⃣ На всякий случай можно посмотреть и список процессов. Иногда там и вручную глаз за что-то зацепится. Майнеров сразу будет видно.
Больше ничего в голову не приходит. Если знаете, чем ещё можно дополнить этот список, делитесь информацией. Специально его составил, чтобы в нужный момент не думать о том, куда и что смотреть, а просто пройтись по списку. Не скажу, что мне часто приходится сталкиваться с подобными проверками, но тем не мнее, делал это не раз и не два. Когда-то даже статьи об этом писал, но сейчас уже нет времени на них. Примеры статей:
⇨ Взлом сервера centos через уязвимость Bash Shellshock
⇨ Взлом сервера через уязвимость на сайте
⇨ Заражение web сервера вирусом криптомайнером
⇨ Как взламывают веб сервера
#security
1️⃣ Если это веб сервер, то имеет смысл начать с анализа его лог файлов. Если знаете, что у вас была какая-то незакрытая уязвимость в коде, то искать следует её эксплуатацию, либо запуск веб-шеллов.
Обычно уязвимость находят в каком-то конкретном файле, так что смотрим обращения к нему. Если по описанию уязвимости вы видите, что зловред создаёт или загружает новый файл и потом к нему обращается, то ищите эти обращения.
2️⃣ Можно посмотреть список изменённых файлов за последнее время. Не факт, что поможет, так как изменить дату модификации файла не сложно, но тем не менее, это может помочь:
# find /var/www/site -type f -mtime -30 ! -mtime -1 -printf '%TY-%Tm-%Td %TT %p\n' | sort -rТут мы выводим все изменённые файлы за последние 30 дней, кроме сегодняшнего и сортируем их по дате изменения от более свежей к старой. Если список большой, лучше сразу его в файл отправить и анализировать там. Это, кстати, полезная команда именно в таком виде и выводе. Рекомендую сохранить.
3️⃣ Смотрим журналы операционной системы, в том числе аутентификации по SSH. На них хорошо бы ставить мониторинг и отправлять эту информацию на сторонний лог сервер. Смотрим задачи cron, at и systemd timers. Куда конкретно смотреть, писал в отдельной заметке по запланированным задачам.
4️⃣ Не часто, но иногда можно что-то увидеть в истории shell команд или истории команд клиентов СУБД:
◽
# cat ~/.bash_history◽
# cat ~/.mysql_history◽
# sudo -u postgres psql◽
# \s5️⃣ Имеет смысл проверить целостность исполняемых файлов согласно эталонным хеш-значениям из DEB и RPM пакетов.
# dpkg --verify# rpm -Va6️⃣ Проверяем системных пользователей, прописанные для них шеллы, прописанные ключи для SSH соединений. Проверяем домашние директории пользователей, от которых работает веб сервер и другие запущенные службы, на предмет подозрительных скриптов. То же самое делаем во временных директориях.
7️⃣ Проверяем прослушиваемые приложениями порты и исходящие подключения:
# ss -tulnp | column -t# ss -ntu8️⃣ На всякий случай можно посмотреть и список процессов. Иногда там и вручную глаз за что-то зацепится. Майнеров сразу будет видно.
# ps axfБольше ничего в голову не приходит. Если знаете, чем ещё можно дополнить этот список, делитесь информацией. Специально его составил, чтобы в нужный момент не думать о том, куда и что смотреть, а просто пройтись по списку. Не скажу, что мне часто приходится сталкиваться с подобными проверками, но тем не мнее, делал это не раз и не два. Когда-то даже статьи об этом писал, но сейчас уже нет времени на них. Примеры статей:
⇨ Взлом сервера centos через уязвимость Bash Shellshock
⇨ Взлом сервера через уязвимость на сайте
⇨ Заражение web сервера вирусом криптомайнером
⇨ Как взламывают веб сервера
#security
{kind=link}
👍134
В продуктах Proxmox не так давно появилась возможность использовать сторонние SMTP сервера для отправки уведомлений. Точнее, стало возможно через веб интерфейс настроить аутентификацию на внешнем сервере. В PVE вроде бы с 8-го релиза появилась эта настройка, в PBS не помню точно.
В разделе меню Notification обоих продуктов появился новый тип уведомлений SMTP, где можно указать привычные параметры внешних почтовых серверов. Тем не менее, если для отправки используется бесплатный почтовый сервис типа Yandex, Mail или Gmail, я предпочитаю настраивать по старинке через локальный Postfix, который так же использует внешний SMTP сервер с аутентификацией.
Причина этого в том, что через Postfix отправляются и другие системные сообщение, плюс есть нормальное логирование, где можно сразу понять, если по какой-то причине письма не будут отправляться. У Postfix очень информативный лог. Его и мониторить удобно, и решать возникающие проблемы.
Настройка Postfix простая. Не помню, устанавливается ли он в свежих версиях PVE и PBS по умолчанию, но если нет, то надо поставить:
И затем добавить в конфиг
Если эти же параметры где-то выше уже объявлены, то закомментируйте их там. Создаём файл
Эти данные нужны для аутентификации. Убедитесь, что у файла права 600, чтобы никто, кроме рута, не смог его прочитать.
Создайте файл
Здесь мы настраиваем, чтобы все письма от локального пользователя root сервера с именем pve отправлялись с заменой адреса отправителя на [email protected]. Иначе Яндекс не примет письмо к отправке. У других почтовых сервисов может не быть таких ограничений и этот шаг можно будет пропустить.
Формируем на основе текстовых файлов локальные базы данных, с которыми будет работать postfix, и перезапускаем его:
Можно проверять отправку. Проще всего это сделать в веб интерфейсе PVE. Для этого идём в раздел Datacenter ⇨ Notification. Там по умолчанию уже есть способ отправки типа sendmail с указанным Target mail-to-root. Это как раз отправка почты с помощью Postfix на ящик системного пользователя root@pam. Ящик для него можно указать в настройках пользователя: Datacenter ⇨ Permissions ⇨ Users ⇨ root ⇨ E-Mail.
Выбираем способ отправки sendmail и жмём Test. Можно сходить в консоль сервера и проверить лог отправки. Если всё прошло успешно, то в
Сервер успешно использовал relay=smtp.yandex.ru и отправил с его помощью письмо [email protected], получив status=sent. Письмо ушло адресату, отправляющий сервер принял его в обработку.
Подобная настройка будет актуальна для любого сервера с Linux, так что можете сохранить на память готовую инструкцию.
#proxmox
В разделе меню Notification обоих продуктов появился новый тип уведомлений SMTP, где можно указать привычные параметры внешних почтовых серверов. Тем не менее, если для отправки используется бесплатный почтовый сервис типа Yandex, Mail или Gmail, я предпочитаю настраивать по старинке через локальный Postfix, который так же использует внешний SMTP сервер с аутентификацией.
Причина этого в том, что через Postfix отправляются и другие системные сообщение, плюс есть нормальное логирование, где можно сразу понять, если по какой-то причине письма не будут отправляться. У Postfix очень информативный лог. Его и мониторить удобно, и решать возникающие проблемы.
Настройка Postfix простая. Не помню, устанавливается ли он в свежих версиях PVE и PBS по умолчанию, но если нет, то надо поставить:
# apt install postfixИ затем добавить в конфиг
/etc/postfix/main.cf, например, для Яндекса:relayhost = smtp.yandex.ru:465
smtp_use_tls = yes
smtp_sasl_auth_enable = yes
smtp_sasl_security_options =
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
smtp_tls_CAfile = /etc/ssl/certs/Entrust_Root_Certification_Authority.pem
smtp_tls_session_cache_database = btree:/var/lib/postfix/smtp_tls_session_cache
smtp_tls_session_cache_timeout = 3600s
smtp_tls_wrappermode = yes
smtp_tls_security_level = encrypt
smtp_generic_maps = hash:/etc/postfix/generic
Если эти же параметры где-то выше уже объявлены, то закомментируйте их там. Создаём файл
/etc/postfix/sasl_passwd такого содержания:smtp.yandex.ru [email protected]:userpass123Эти данные нужны для аутентификации. Убедитесь, что у файла права 600, чтобы никто, кроме рута, не смог его прочитать.
Создайте файл
/etc/postfix/generic:root@pve [email protected]Здесь мы настраиваем, чтобы все письма от локального пользователя root сервера с именем pve отправлялись с заменой адреса отправителя на [email protected]. Иначе Яндекс не примет письмо к отправке. У других почтовых сервисов может не быть таких ограничений и этот шаг можно будет пропустить.
Формируем на основе текстовых файлов локальные базы данных, с которыми будет работать postfix, и перезапускаем его:
# postmap /etc/postfix/generic /etc/postfix/sasl_passwd# systemctl restart postfixМожно проверять отправку. Проще всего это сделать в веб интерфейсе PVE. Для этого идём в раздел Datacenter ⇨ Notification. Там по умолчанию уже есть способ отправки типа sendmail с указанным Target mail-to-root. Это как раз отправка почты с помощью Postfix на ящик системного пользователя root@pam. Ящик для него можно указать в настройках пользователя: Datacenter ⇨ Permissions ⇨ Users ⇨ root ⇨ E-Mail.
Выбираем способ отправки sendmail и жмём Test. Можно сходить в консоль сервера и проверить лог отправки. Если всё прошло успешно, то в
/var/log/mail.log будет примерно следующее:pve postfix/pickup[941603]: 4C81718E07A1: uid=0 from=<[email protected]>
pve postfix/cleanup[941760]: 4C81718E07A1: message-id=<20240820202545.4C81718E07A1@pve>
pve postfix/qmgr[941604]: 4C81718E07A1: from=<[email protected]>, size=894, nrcpt=1 (queue active)
pve postfix/smtp[941762]: 4C81718E07A1: to=<[email protected]>, relay=smtp.yandex.ru[77.88.21.158]:465, delay=0.48, delays=0.03/0.02/0.17/0.26, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued on mail-nwsmtp-smtp-production-main-17.iva.yp-c.yandex.net 1724185545-jPUEPlgXtGk0-KOiggjh6)
pve postfix/qmgr[941604]: 4C81718E07A1: removed
Сервер успешно использовал relay=smtp.yandex.ru и отправил с его помощью письмо [email protected], получив status=sent. Письмо ушло адресату, отправляющий сервер принял его в обработку.
Подобная настройка будет актуальна для любого сервера с Linux, так что можете сохранить на память готовую инструкцию.
#proxmox
👍129👎2
Вчера в комментариях к заметке со скриптом речь зашла про шебанг (shebang). Слово какое-то непонятное. Я первые года и Unix админил, и скрипты писал, и слова такого не знал, пока случайно не услышал.
Шебанг - это то, с чего начинается практически любой скрипт:
или так
Интуитивно и так было понятно, для чего это. Конструкцию с
Хотя указывать его можно не только так. Но абсолютно во всех дистрибутивах, с которыми я работал, по
Тем не менее, шебанг можно указать и более точно без привязки к конкретному пути в файловой системе:
Расположение bash будет взято из окружения, в котором будет запускаться скрипт. Так писать дольше, поэтому я такую конструкцию не использую.
Вообще, шебанг просто помогает понять, в какой оболочке запускать скрипт. Если его не писать, то эту оболочку придётся явно указывать при запуске скрипта:
А если не указать явно, то будет использована оболочка по умолчанию. Большая часть скриптов, с которыми я работаю, успешно отработает и в sh, и в bash. Именно эти оболочки наиболее распространены, остальное экзотика для серверов. Есть ещё dash, но, насколько я помню, она полностью совместима с sh.
В шебанге можно указать какие-то нюансы интерпретатора. В основном это актуально для python. Он как минимум может быть разных версий на одной и той же системе. Особенно это было актуально во времена перехода с python2 на python3. Когда был только python2 в шебангах могли указать python и скрипт выполнялся 2-й версией, так как именно она была в системе по умолчанию. Когда в системах стала появляться 3-я версия, для старых скриптов надо было отдельно ставить 2-ю и явно её указывать, либо редактируя шебанги в скриптах, либо запуская нужную версию явно:
Из экзотического применения шебангов можно привести примеры с awk или ansible:
И awk, и ansible-playbook являются интерпретаторами кода, так что для простого и быстрого запуска скриптов, написанных для них, можно использовать соответствующие шебанги, чтобы сразу запускать скрипт по аналогии с башем:
На практике я такое применение ни разу не встречал, хотя почему бы и нет. Но лично я всегда всё, что не bash, явно указываю в консоли. Это актуально и для php, код которого не так уж и редко приходится исполнять в консоли сервера.
Строки с шебангом могут содержать дополнительные аргументы, которые передаются интерпретатору (см. пример для awk -f выше). Однако, обработка аргументов может различаться, для переносимости лучше использовать только один аргумент без пробелов внутри. Теоретически это можно обойти в env, но на практике я не проверял. Увидел сам вчера в комментариях:
#bash
Шебанг - это то, с чего начинается практически любой скрипт:
#!/bin/bashили так
#!/bin/shИнтуитивно и так было понятно, для чего это. Конструкцию с
sh я использовал, когда работал с FreeBSD. Перейдя на Linux, стал использовать bash. Причём именно в таком виде:#!/bin/bashХотя указывать его можно не только так. Но абсолютно во всех дистрибутивах, с которыми я работал, по
/bin/bash был именно bash либо в явном виде, либо символьной ссылкой на него. Так что если не хотите лишний раз забивать себе голову новой информацией, то пишите так же. Вероятность, что что-то пойдёт не так, очень мала. У меня ни разу за всю мою карьеру с таким шебангом проблем на Linux с bash скриптами не было. Исключение - контейнеры. Там отсутствие bash - обычное дело. Но там тогда и скрипты не будут нужны.Тем не менее, шебанг можно указать и более точно без привязки к конкретному пути в файловой системе:
#!/usr/bin/env bashРасположение bash будет взято из окружения, в котором будет запускаться скрипт. Так писать дольше, поэтому я такую конструкцию не использую.
Вообще, шебанг просто помогает понять, в какой оболочке запускать скрипт. Если его не писать, то эту оболочку придётся явно указывать при запуске скрипта:
# bash script.shА если не указать явно, то будет использована оболочка по умолчанию. Большая часть скриптов, с которыми я работаю, успешно отработает и в sh, и в bash. Именно эти оболочки наиболее распространены, остальное экзотика для серверов. Есть ещё dash, но, насколько я помню, она полностью совместима с sh.
В шебанге можно указать какие-то нюансы интерпретатора. В основном это актуально для python. Он как минимум может быть разных версий на одной и той же системе. Особенно это было актуально во времена перехода с python2 на python3. Когда был только python2 в шебангах могли указать python и скрипт выполнялся 2-й версией, так как именно она была в системе по умолчанию. Когда в системах стала появляться 3-я версия, для старых скриптов надо было отдельно ставить 2-ю и явно её указывать, либо редактируя шебанги в скриптах, либо запуская нужную версию явно:
# python2 script.pyИз экзотического применения шебангов можно привести примеры с awk или ansible:
#!/usr/bin/awk -f#!/usr/bin/env ansible-playbookИ awk, и ansible-playbook являются интерпретаторами кода, так что для простого и быстрого запуска скриптов, написанных для них, можно использовать соответствующие шебанги, чтобы сразу запускать скрипт по аналогии с башем:
# ./my-playbook.yamlНа практике я такое применение ни разу не встречал, хотя почему бы и нет. Но лично я всегда всё, что не bash, явно указываю в консоли. Это актуально и для php, код которого не так уж и редко приходится исполнять в консоли сервера.
Строки с шебангом могут содержать дополнительные аргументы, которые передаются интерпретатору (см. пример для awk -f выше). Однако, обработка аргументов может различаться, для переносимости лучше использовать только один аргумент без пробелов внутри. Теоретически это можно обойти в env, но на практике я не проверял. Увидел сам вчера в комментариях:
#!/usr/bin/env -S python3 -B -E -s#bash
👍100👎4
Приезжал на днях в квартиру, где совершенно не работает Youtube. Всё лето живу на даче с мобильным интернетом. С замедлением ютуба не сталкивался. На мобильном он работает нормально. А в квартире мобильная связь не очень, пользоваться некомфортно, поэтому всё на проводном интернете. Без ютуба совсем грустно. В качестве роутера работает Mikrotik.
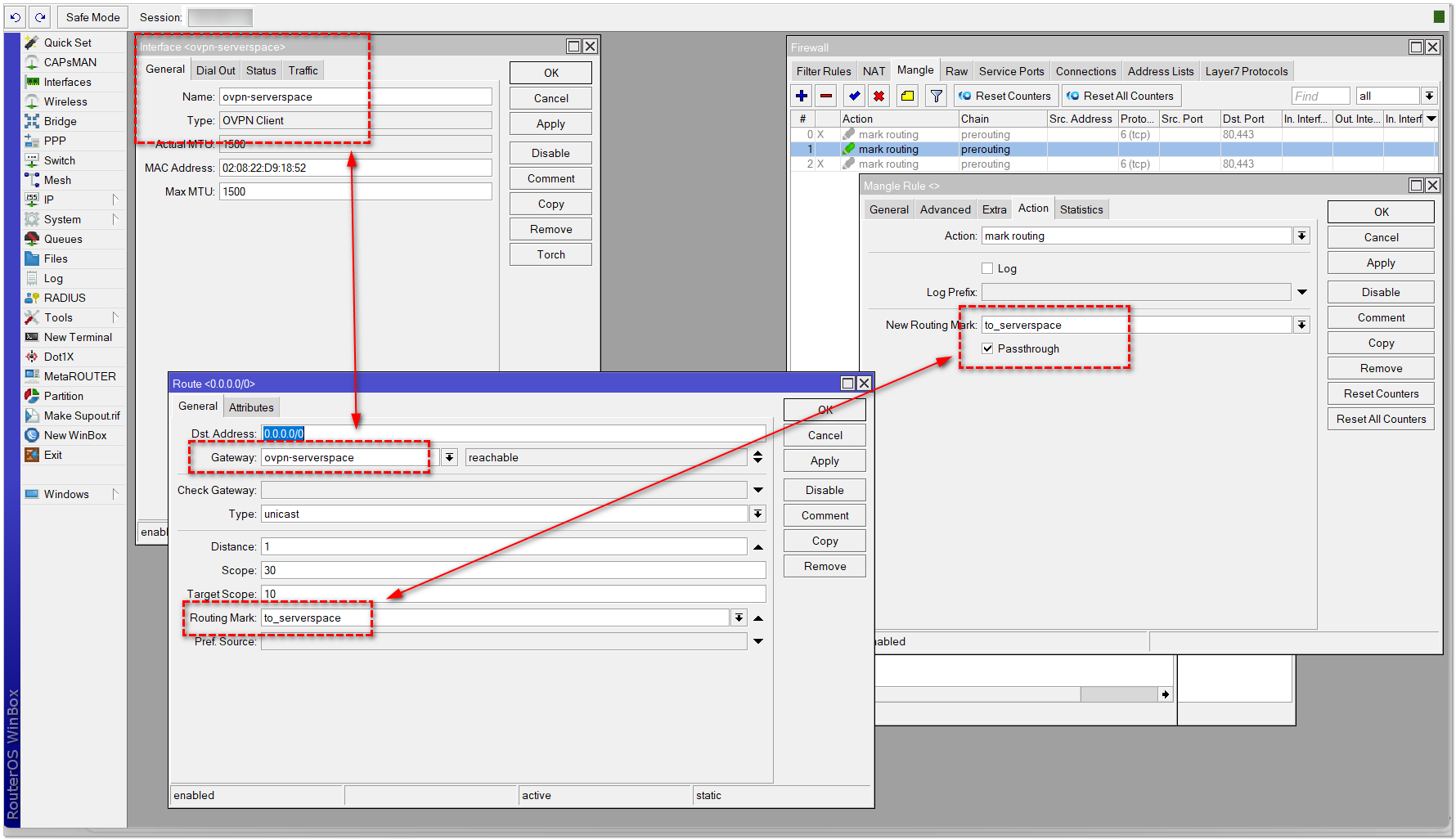
У меня уже давно есть несколько VPS заграницей. К сожалению, теперь законом запрещено делиться информацией по обходу блокировок, поэтому я не смогу вам подробно рассказать, как у меня всё устроено. Могу только дать несколько подсказок. Мне понадобился список IP адресов ютуба. Нашёл в интернете вот такой. Привожу сразу экспорт из Mikrotik, чтобы вы могли быстро его к себе добавить, если у вас устройство этого вендора:
⇨ https://disk.yandex.ru/d/RAbdhp0lAFBfOw
Я промаркировал этот список через mangle и сделал отдельный маршрут для этого маркированного списка через зарубежный VPS, к которому подключаюсь по OpenVPN. Теперь Youtube работает нормально сразу для всех домашних. Простое и удобное решение без лишних заморочек. Несмотря на то, что многие говорят, что openvpn и wireguard блокируют, у меня они пока работают нормально. Провайдер - Ростелеком.
#mikrotik
У меня уже давно есть несколько VPS заграницей. К сожалению, теперь законом запрещено делиться информацией по обходу блокировок, поэтому я не смогу вам подробно рассказать, как у меня всё устроено. Могу только дать несколько подсказок. Мне понадобился список IP адресов ютуба. Нашёл в интернете вот такой. Привожу сразу экспорт из Mikrotik, чтобы вы могли быстро его к себе добавить, если у вас устройство этого вендора:
⇨ https://disk.yandex.ru/d/RAbdhp0lAFBfOw
Я промаркировал этот список через mangle и сделал отдельный маршрут для этого маркированного списка через зарубежный VPS, к которому подключаюсь по OpenVPN. Теперь Youtube работает нормально сразу для всех домашних. Простое и удобное решение без лишних заморочек. Несмотря на то, что многие говорят, что openvpn и wireguard блокируют, у меня они пока работают нормально. Провайдер - Ростелеком.
#mikrotik
{kind=link}
👍215👎9
Для редактирования и совместной работы с документами через браузер есть два наиболее популярных движка с открытым исходным кодом:
▪️ OnlyOffice
▪️ Collabora Online
Про #OnlyOffice я регулярно пишу, можно посмотреть материалы под соответствующим тэгом. Там же есть инструкции по быстрому запуску продукта. Решил то же самое подготовить по Collabora Online, чтобы можно было быстро их сравнить и выбрать то, что больше понравится.
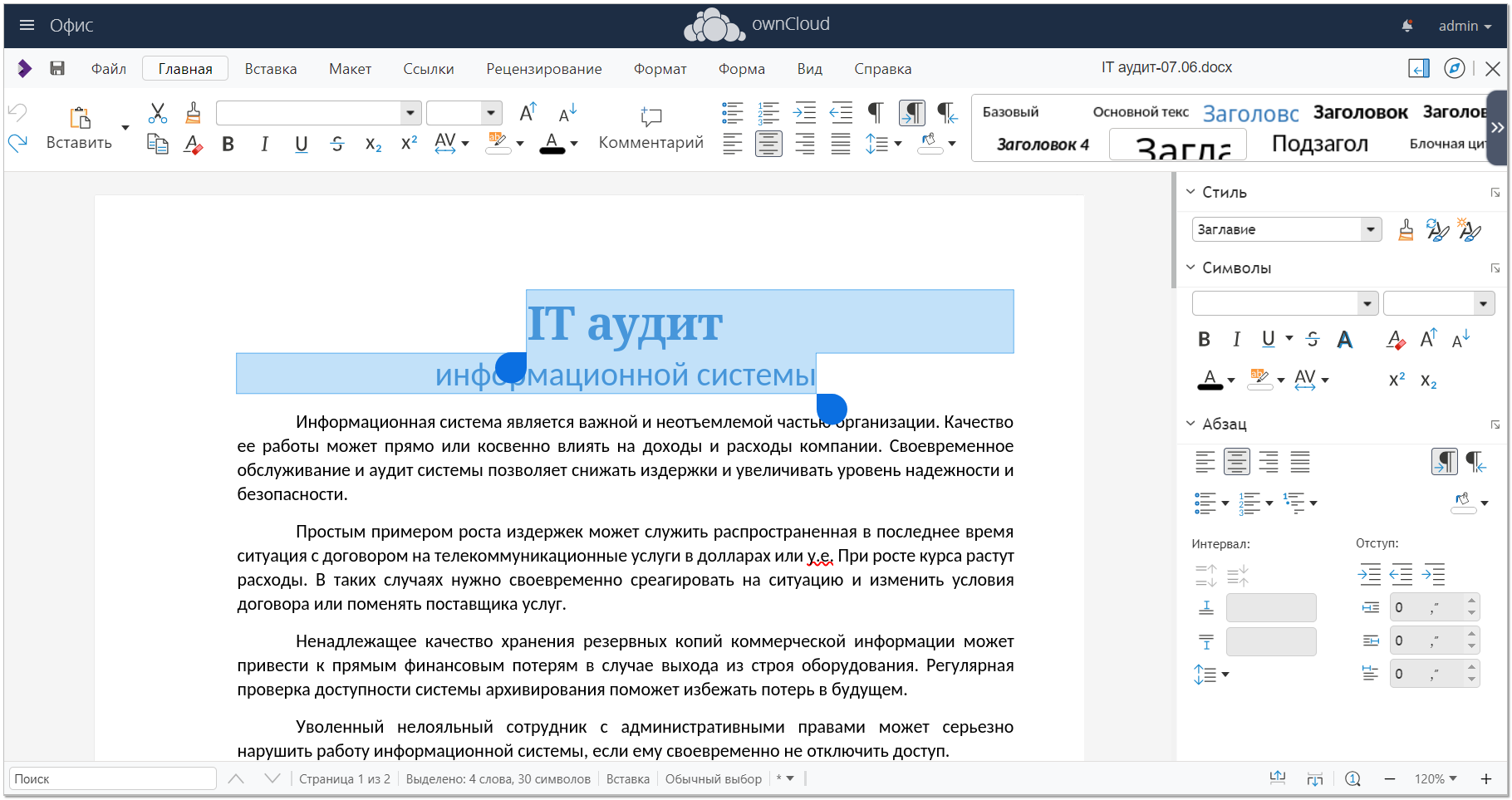
Движок для редактирования документов работает в связке с каким-то другим продуктом по управлению файлами. Проще всего потестировать его в связке с ownCloud. Запускаем его:
Идём по IP адресу сервера https://10.20.1.36, создаём учётку админа и логинимся. В левом верхнем углу нажимаем на 3 полоски, раскрывая меню и переходим в раздел Market. Ставим приложение Collabora Online.
Переходим опять в консоль сервера и запускаем сервер collabora:
Возвращаемся в веб интерфейс owncloud, переходим в Настройки ⇨ Администрирование ⇨ Дополнительно. В качестве адреса сервера Collabora Online указываем https://10.20.1.36:9980. На этом всё. Можно загружать документы и открывать их с помощью Collabora Online. У меня без каких-либо проблем сразу всё заработало по этой инструкции. Работает, кстати, эта связка довольно шустро. Мне понравилось. Погонял там с десяток своих документов и таблиц.
Редактор Collabora Online сильно отличается от Onlyoffice как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняется на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice. Но при таком подходе надёжнее работает совместное редактирование, так как реально оно происходит на сервере, а клиентам передаётся только картинка.
Интерфейс Onlyoffice больше похож на Excel, интуитивно с ним проще работать. Основные форматы - .docx, .xlsx, .pptx. Соответственно и совместимость с ними лучше. Collabora построена на базе LibreOffice, а он заметно отличается от Excel, так что переход будет более болезненный. Основные форматы - .odt, .ods, .odp. Майкрософтовские документы открывает хуже.
Какой из этих продуктов лучше и предпочтительнее в использовании, сказать трудно. Надо тестировать самому на своём наборе документов. В целом, оба продукта уже давно на рынке, каких-то критических проблем с ними нет, люди работают. Но, разумеется, есть свои нюансы, проблемы и особенности.
#docs #fileserver
▪️ OnlyOffice
▪️ Collabora Online
Про #OnlyOffice я регулярно пишу, можно посмотреть материалы под соответствующим тэгом. Там же есть инструкции по быстрому запуску продукта. Решил то же самое подготовить по Collabora Online, чтобы можно было быстро их сравнить и выбрать то, что больше понравится.
Движок для редактирования документов работает в связке с каким-то другим продуктом по управлению файлами. Проще всего потестировать его в связке с ownCloud. Запускаем его:
# docker run -d -p 80:80 owncloudИдём по IP адресу сервера https://10.20.1.36, создаём учётку админа и логинимся. В левом верхнем углу нажимаем на 3 полоски, раскрывая меню и переходим в раздел Market. Ставим приложение Collabora Online.
Переходим опять в консоль сервера и запускаем сервер collabora:
# docker run -t -d -p 9980:9980 -e "extra_params=--o:ssl.enable=false" collabora/codeВозвращаемся в веб интерфейс owncloud, переходим в Настройки ⇨ Администрирование ⇨ Дополнительно. В качестве адреса сервера Collabora Online указываем https://10.20.1.36:9980. На этом всё. Можно загружать документы и открывать их с помощью Collabora Online. У меня без каких-либо проблем сразу всё заработало по этой инструкции. Работает, кстати, эта связка довольно шустро. Мне понравилось. Погонял там с десяток своих документов и таблиц.
Редактор Collabora Online сильно отличается от Onlyoffice как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняется на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice. Но при таком подходе надёжнее работает совместное редактирование, так как реально оно происходит на сервере, а клиентам передаётся только картинка.
Интерфейс Onlyoffice больше похож на Excel, интуитивно с ним проще работать. Основные форматы - .docx, .xlsx, .pptx. Соответственно и совместимость с ними лучше. Collabora построена на базе LibreOffice, а он заметно отличается от Excel, так что переход будет более болезненный. Основные форматы - .odt, .ods, .odp. Майкрософтовские документы открывает хуже.
Какой из этих продуктов лучше и предпочтительнее в использовании, сказать трудно. Надо тестировать самому на своём наборе документов. В целом, оба продукта уже давно на рынке, каких-то критических проблем с ними нет, люди работают. Но, разумеется, есть свои нюансы, проблемы и особенности.
#docs #fileserver
{kind=link}
2👍66👎3
▶️ Сегодня у нас пятница, и это будет день видео. Вечером будет подборка роликов, а сейчас я хочу рассказать про одно конкретное выступление, потому что оно мне понравилось, как по тематике, так и по изложению:
⇨ Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Выступление двухгодичной давности, но я его посмотрел только на днях. У крупной компании возникла потребность в большом файловом хранилище (100 TБ данных и 100 ТБ трафика в месяц). Готовые решения отбросили из-за дороговизны. Решили строить своё на базе известного сервера MinIO.
📌 Причины, почему выбрали MinIO:
◽Open Source
◽Производительный
◽Распределённая архитектура
◽Легко масштабируется и разворачивается
◽Сжатие файлов на лету
◽Общая популярность проекта
📌 Проблемы, с которыми столкнулись при внедрении и эксплуатации:
▪️ Не очень информативная документация
▪️ По умолчанию модель отказоустойчивости такова, что при неудачном стечении обстоятельств выход из строя буквально нескольких дисков на одном сервере может привести к потере информации, хотя на первый взгляд кажется, что чуть ли не потеря половины кластера не приведёт к этому
▪️ Нельзя расширить существующий кластер. Можно только создать новый и присоединить его к текущему.
▪️ При обновлении нельзя перезапускать ноды по очереди. Рестартить надо разом весь кластер, так что без простоя сервиса не обойтись.
▪️ Вылезла куча критических багов, когда пропадали все пользователи и политики, бились сжатые файлы, неверно работало кэширование и т.д.
▪️ Реальный срок восстановления после замены диска непрогнозируемый. Нагрузка при этом на диски сопоставима с эксплуатацией RAID5.
▪️ Нет мониторинга производительности дисков. Если один диск жёстко тормозит, тормозит весь кластер. Эту проблему ты должен решать самостоятельно.
Для полноценного теста отказоустойчивого распределённого хранилища достаточно следующего железа. 3 одинаковые ноды:
- 8 CPU
- 16G RAM
- SSD NVME для горячих данных
- HDD для холодных
MinIO поверх ZFS работает значительно лучше, чем на обычной файловой системе, хотя разработчики это не рекомендуют. При расширении ZFS пулов, MinIO адекватно это переваривает и расширяется сам. Это позволяет решать вопрос с расширением кластера налету. Для дополнительной отказоустойчивости и возможности обновления без даунтайма автор к каждой ноде MinIO поставил кэш на базе Nginx. Пока сервер перезапускается, кэши отдают горячие данные.
В итоге автор делает следующий вывод. Minio неплохое локальное решение в рамках одной стойки или дата центра, но для большого распределённого кластера он плохо подходит из-за архитектуры и багов.
Отдельно было интересно узнать мнение автора о Ceph. Они от него отказались из-за сложности в обслуживании. MinIO настроили один раз и он работает практически без присмотра. Ceph требует постоянного наблюдения силами специально обученных людей.
#S3
⇨ Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Выступление двухгодичной давности, но я его посмотрел только на днях. У крупной компании возникла потребность в большом файловом хранилище (100 TБ данных и 100 ТБ трафика в месяц). Готовые решения отбросили из-за дороговизны. Решили строить своё на базе известного сервера MinIO.
📌 Причины, почему выбрали MinIO:
◽Open Source
◽Производительный
◽Распределённая архитектура
◽Легко масштабируется и разворачивается
◽Сжатие файлов на лету
◽Общая популярность проекта
📌 Проблемы, с которыми столкнулись при внедрении и эксплуатации:
▪️ Не очень информативная документация
▪️ По умолчанию модель отказоустойчивости такова, что при неудачном стечении обстоятельств выход из строя буквально нескольких дисков на одном сервере может привести к потере информации, хотя на первый взгляд кажется, что чуть ли не потеря половины кластера не приведёт к этому
▪️ Нельзя расширить существующий кластер. Можно только создать новый и присоединить его к текущему.
▪️ При обновлении нельзя перезапускать ноды по очереди. Рестартить надо разом весь кластер, так что без простоя сервиса не обойтись.
▪️ Вылезла куча критических багов, когда пропадали все пользователи и политики, бились сжатые файлы, неверно работало кэширование и т.д.
▪️ Реальный срок восстановления после замены диска непрогнозируемый. Нагрузка при этом на диски сопоставима с эксплуатацией RAID5.
▪️ Нет мониторинга производительности дисков. Если один диск жёстко тормозит, тормозит весь кластер. Эту проблему ты должен решать самостоятельно.
Для полноценного теста отказоустойчивого распределённого хранилища достаточно следующего железа. 3 одинаковые ноды:
- 8 CPU
- 16G RAM
- SSD NVME для горячих данных
- HDD для холодных
MinIO поверх ZFS работает значительно лучше, чем на обычной файловой системе, хотя разработчики это не рекомендуют. При расширении ZFS пулов, MinIO адекватно это переваривает и расширяется сам. Это позволяет решать вопрос с расширением кластера налету. Для дополнительной отказоустойчивости и возможности обновления без даунтайма автор к каждой ноде MinIO поставил кэш на базе Nginx. Пока сервер перезапускается, кэши отдают горячие данные.
В итоге автор делает следующий вывод. Minio неплохое локальное решение в рамках одной стойки или дата центра, но для большого распределённого кластера он плохо подходит из-за архитектуры и багов.
Отдельно было интересно узнать мнение автора о Ceph. Они от него отказались из-за сложности в обслуживании. MinIO настроили один раз и он работает практически без присмотра. Ceph требует постоянного наблюдения силами специально обученных людей.
#S3
YouTube
Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Приглашаем на конференцию Saint HighLoad++ 2025, которая пройдет 23 и 24 июня в Санкт-Петербурге!
Программа, подробности и билеты по ссылке: https://highload.ru/spb/2025
________
Saint HighLoad++ 2022
Презентация и тезисы:
https://highload.ru/spb/20…
Программа, подробности и билеты по ссылке: https://highload.ru/spb/2025
________
Saint HighLoad++ 2022
Презентация и тезисы:
https://highload.ru/spb/20…
1👍91👎2
▶️ Пока ещё Youtube худо-бедно работает, продолжаем впитывать информацию. Тормозить стал уже и на мобильном интернете. Вчера явно заметил разницу. Пришлось пустить траф на ноуте через внешнюю прокси, чтобы нормально смотреть видео.
Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными и полезными.
⇨ Настройка роутера MikroTik с BGP для просмотра видео дома
Автор рассказал, как решить вопрос со скоростью ютуб с помощью динамической маршрутизации на роутерах Mikrotik.
⇨ Proxmox CLUSTER. Что это и зачем? Создание кластера из 3 узлов (nodes)
Описание работы кластера Proxmox и пример настройки кластера из трёх нод. Автор настраивает сеть, объединяет узлы в кластер, показывает на практике, как работает миграция виртуальных машин между узлами кластера, настраивает HA.
⇨ RocketChat - Powerful, Chat and Communications platform. Rivals Slack, Teams, and more!
Обзор бесплатного self-hosted чат-сервера. У меня было много заметок по нему на канале, можно найти через поиск. Я сам постоянно обслуживаю и немного использую Rocket.Chat. Знаю его неплохо. Не могу сказать, что он мне нравится, но из бесплатного ничего лучше не знаю. В целом, работает нормально. Если у кого-то есть по нему вопросы, можно задавать.
⇨ Подробное описание начальной настройки OPNsense с нуля
Огромное (1,5 часа) видео по настройке программного шлюза OPNsense. Автор разобрал настройки файрвола, vlan, управляемого свитча.
⇨ Установка Next Generation FireWall Zenarmor в OPNsense
Установка и настройка бесплатного NGFW (Next Generation Firewall) Zenarmor в софтовый файрвол OPNsense. Интересное решение, раньше не слышал о нём.
⇨ Proxmox: LXC контейнер показывает ерунду по CPU
Небольшой баг с LXC контейнерами в Proxmox, когда они показывают нагрузку не за себя, а по всему хосту. Я с этим, кстати, тоже сталкивался, но думал, что так и надо. Просто забивал. Решение очень простое, в видео приведено.
⇨ Synology BACKUP! Active Backup for Business. Обзор функий, настройка. Windows и Linux backup. VM
Встроенная в Synology система бэкапа для компьютеров и серверов под управлением Windows и Linux, а так же сетевых дисков и некоторых систем виртуализации. Автор на конкретных примерах показал, как это работает. Весьма функциональная, удобная и простая в настройке штука.
⇨ Поднимаем Кафку, не опуская рук. Отказоустойчивый кластер на вашем ПК
Кафка - популярный инструмент на сегодняшний день. Много где используется. В этой свежей записи трансляции есть как теория по продукту, так и непосредственно практика по установке. Можно очень быстро въехать в тему, добавить её в резюме и попросить повышение к зарплате.
#видео
Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными и полезными.
⇨ Настройка роутера MikroTik с BGP для просмотра видео дома
Автор рассказал, как решить вопрос со скоростью ютуб с помощью динамической маршрутизации на роутерах Mikrotik.
⇨ Proxmox CLUSTER. Что это и зачем? Создание кластера из 3 узлов (nodes)
Описание работы кластера Proxmox и пример настройки кластера из трёх нод. Автор настраивает сеть, объединяет узлы в кластер, показывает на практике, как работает миграция виртуальных машин между узлами кластера, настраивает HA.
⇨ RocketChat - Powerful, Chat and Communications platform. Rivals Slack, Teams, and more!
Обзор бесплатного self-hosted чат-сервера. У меня было много заметок по нему на канале, можно найти через поиск. Я сам постоянно обслуживаю и немного использую Rocket.Chat. Знаю его неплохо. Не могу сказать, что он мне нравится, но из бесплатного ничего лучше не знаю. В целом, работает нормально. Если у кого-то есть по нему вопросы, можно задавать.
⇨ Подробное описание начальной настройки OPNsense с нуля
Огромное (1,5 часа) видео по настройке программного шлюза OPNsense. Автор разобрал настройки файрвола, vlan, управляемого свитча.
⇨ Установка Next Generation FireWall Zenarmor в OPNsense
Установка и настройка бесплатного NGFW (Next Generation Firewall) Zenarmor в софтовый файрвол OPNsense. Интересное решение, раньше не слышал о нём.
⇨ Proxmox: LXC контейнер показывает ерунду по CPU
Небольшой баг с LXC контейнерами в Proxmox, когда они показывают нагрузку не за себя, а по всему хосту. Я с этим, кстати, тоже сталкивался, но думал, что так и надо. Просто забивал. Решение очень простое, в видео приведено.
⇨ Synology BACKUP! Active Backup for Business. Обзор функий, настройка. Windows и Linux backup. VM
Встроенная в Synology система бэкапа для компьютеров и серверов под управлением Windows и Linux, а так же сетевых дисков и некоторых систем виртуализации. Автор на конкретных примерах показал, как это работает. Весьма функциональная, удобная и простая в настройке штука.
⇨ Поднимаем Кафку, не опуская рук. Отказоустойчивый кластер на вашем ПК
Кафка - популярный инструмент на сегодняшний день. Много где используется. В этой свежей записи трансляции есть как теория по продукту, так и непосредственно практика по установке. Можно очень быстро въехать в тему, добавить её в резюме и попросить повышение к зарплате.
#видео
YouTube
Настройка роутера MikroTik с BGP для просмотра потокового видео дома
В этом руководстве я покажу, как настроить роутер MikroTik с использованием протокола BGP для просмотра YouTube и других ресурсов на любых устройствах вашей домашней сети.
Статья: https://bafista.ru/nastroim-mikrotik-s-bgp/
Забросить донат https://yoomo…
Статья: https://bafista.ru/nastroim-mikrotik-s-bgp/
Забросить донат https://yoomo…
👍100👎6
Для быстрого доступа к СУБД Mysql очень удобно использовать небольшой скрипт Adminer, который представляет из себя ровно один php файл и запускается на любом хостинге. Я бы не писал о нём в очередной раз, если бы не столкнулся на днях с некоторыми нюансами при его использовании, так что решил оформить в заметку, чтобы самому потом не забыть.
С помощью Adminer можно создать пользователя и базу данных, назначить или изменить права, посмотреть содержимое таблиц, выгрузить или загрузить дамп. Лично мне для административных целей больше ничего и не надо. Разработчики, работая над сайтом, обычно просят phpmyadmin. Я не очень его люблю, потому что он монструозный, для него надо ставить дополнительные расширения php, поддерживать это дело.
Если я пользуюсь сам, то обычно просто закидываю adminer на сайт, делаю, что мне надо и потом сразу удаляю. В этот раз решил оставить на некоторое время и закрыть через basic_auth в Nginx (на самом деле в Angie). Вроде бы нет ничего проще:
Закрываем паролем. Создаём файл с учёткой:
Добавляем в Nginx:
Перезапускаю Nginx, проверяю. Пароль не спрашивает, доступ прямой. Всё внимательно проверяю, ошибок нет. Я 100 раз это проделывал. Тут нет никаких нюансов. Но не работает.
Быстро догадался, в чём тут дело. В Nginx есть определённые правила обработки locations. Я с этой темой когда-то разбирался подробно и кое-что в памяти осело. Ниже для php файлов уже есть location:
Он с регулярным выражением, поэтому обрабатывается раньше и при первом же совпадении поиск прекращается. Так что до моего location с паролем очередь просто не доходит. Сделать надо так:
Тут надо указать все те же настройки, что у вас стоят для всех остальных php файлов в
Затем nginx проверяет location’ы, заданные регулярными выражениями, в порядке их следования в конфигурационном файле. При первом же совпадении поиск прекращается и nginx использует совпавший location.
Вообще, это очень важная тема, так как сильно влияет на безопасность и многие другие вещи. Есть проект сложный с множеством locations, надо очень аккуратно их описывать и располагать в конфигурационном файле.
#webserver #nginx #mysql
С помощью Adminer можно создать пользователя и базу данных, назначить или изменить права, посмотреть содержимое таблиц, выгрузить или загрузить дамп. Лично мне для административных целей больше ничего и не надо. Разработчики, работая над сайтом, обычно просят phpmyadmin. Я не очень его люблю, потому что он монструозный, для него надо ставить дополнительные расширения php, поддерживать это дело.
Если я пользуюсь сам, то обычно просто закидываю adminer на сайт, делаю, что мне надо и потом сразу удаляю. В этот раз решил оставить на некоторое время и закрыть через basic_auth в Nginx (на самом деле в Angie). Вроде бы нет ничего проще:
# wget https://github.com/vrana/adminer/releases/download/v4.8.1/adminer-4.8.1-mysql-en.php# mv adminer-4.8.1-mysql-en.php /var/www/html/adminer.phpЗакрываем паролем. Создаём файл с учёткой:
# htpasswd -c /etc/nginx/.htpasswd admineruser21Добавляем в Nginx:
location /adminer.php { auth_basic "Administrator’s Area"; auth_basic_user_file /etc/nginx/.htpasswd; }Перезапускаю Nginx, проверяю. Пароль не спрашивает, доступ прямой. Всё внимательно проверяю, ошибок нет. Я 100 раз это проделывал. Тут нет никаких нюансов. Но не работает.
Быстро догадался, в чём тут дело. В Nginx есть определённые правила обработки locations. Я с этой темой когда-то разбирался подробно и кое-что в памяти осело. Ниже для php файлов уже есть location:
location ~ \.php$ { .... }Он с регулярным выражением, поэтому обрабатывается раньше и при первом же совпадении поиск прекращается. Так что до моего location с паролем очередь просто не доходит. Сделать надо так:
location ~ adminer.php { auth_basic "Administrator’s Area"; auth_basic_user_file /etc/nginx/.htpasswd; ....................... }Тут надо указать все те же настройки, что у вас стоят для всех остальных php файлов в
location ~ \.php$. И расположить location с adminer выше location для остальных php файлов. Это важно, так как судя по документации:Затем nginx проверяет location’ы, заданные регулярными выражениями, в порядке их следования в конфигурационном файле. При первом же совпадении поиск прекращается и nginx использует совпавший location.
Вообще, это очень важная тема, так как сильно влияет на безопасность и многие другие вещи. Есть проект сложный с множеством locations, надо очень аккуратно их описывать и располагать в конфигурационном файле.
#webserver #nginx #mysql
{kind=link}
👍92👎5