
Всем хорошего отдыха. Заметка будет не по теме канала, но, мне кажется, много кому может быть полезной. Речь пойдёт про пережатие самописных видеороликов.
У меня очень много семейных видеороликов, записанных на смартфоны или фотоаппараты. Думаю, тема знакома, у кого много детей. Праздники, утренники, да и просто прогулки. Всё это копится и занимает огромное количество места. Я только докупаю место на яндекс диске и харды для домашних бэкапов. Решение вопроса постоянно откладывал, хотя знал, что надо что-то делать.
Последней каплей стал видеоролик с выпускного из садика дочки. Прислали файл на 14 ГБ. Понял, что хватит это терпеть. В теме я вообще не разбираюсь. Ни про кодеки, ни про битрейты, ни про выравнивание и прочее ничего не знаю. Если вы такой же как я, и хотите просто решить вопрос без погружения в тему, то берите мой совет.
Я скачал бесплатную программу HandBrake. Это open source. Запустил со стандартными настройками. Ничего особо не менял. Стоял стандартный пресет Fast 1080p30. На вкладке видео указал качество 27 и кодек H.264. Не стал выбирать H.265. Он вроде лучше жмёт, но пока не везде поддерживается. И начал прогонять все свои ролики через эти настройки. На выходе файлы в 5-7 раз меньше. На глаз разницы в картинке я вообще не вижу.
Может в этой теме есть какие-то нюансы или варианты быстрее, проще все сделать (хотя куда проще), но я поступил вот так. Если не хотите заморачиваться и на ровном месте в разы сократить размер видеоархива, то попробуйте. Кстати, раньше, чтобы по-быстрому сжать видео, я заливал его на ютуб и скачивал обратно 😎
Домашний комп теперь круглые сутки жмёт видео. HandBrake позволяет создать очередь. Пережатие видео очень ресурсозатратный процесс. Тут я впервые ощутил, что неплохо бы заиметь железо помощнее. Хотя задача разовая, можно обойтись и без него.
⇨ Сайт / Исходники
#разное
У меня очень много семейных видеороликов, записанных на смартфоны или фотоаппараты. Думаю, тема знакома, у кого много детей. Праздники, утренники, да и просто прогулки. Всё это копится и занимает огромное количество места. Я только докупаю место на яндекс диске и харды для домашних бэкапов. Решение вопроса постоянно откладывал, хотя знал, что надо что-то делать.
Последней каплей стал видеоролик с выпускного из садика дочки. Прислали файл на 14 ГБ. Понял, что хватит это терпеть. В теме я вообще не разбираюсь. Ни про кодеки, ни про битрейты, ни про выравнивание и прочее ничего не знаю. Если вы такой же как я, и хотите просто решить вопрос без погружения в тему, то берите мой совет.
Я скачал бесплатную программу HandBrake. Это open source. Запустил со стандартными настройками. Ничего особо не менял. Стоял стандартный пресет Fast 1080p30. На вкладке видео указал качество 27 и кодек H.264. Не стал выбирать H.265. Он вроде лучше жмёт, но пока не везде поддерживается. И начал прогонять все свои ролики через эти настройки. На выходе файлы в 5-7 раз меньше. На глаз разницы в картинке я вообще не вижу.
Может в этой теме есть какие-то нюансы или варианты быстрее, проще все сделать (хотя куда проще), но я поступил вот так. Если не хотите заморачиваться и на ровном месте в разы сократить размер видеоархива, то попробуйте. Кстати, раньше, чтобы по-быстрому сжать видео, я заливал его на ютуб и скачивал обратно 😎
Домашний комп теперь круглые сутки жмёт видео. HandBrake позволяет создать очередь. Пережатие видео очень ресурсозатратный процесс. Тут я впервые ощутил, что неплохо бы заиметь железо помощнее. Хотя задача разовая, можно обойтись и без него.
⇨ Сайт / Исходники
#разное
{kind=link}
👍131👎6
На прошлой неделе рассказал про сервер для групповой работы Onlyoffice Workspace. Подобного рода бесплатных продуктов не так много. Из тех, что я описывал ранее, где есть совместная работа с документами:
- Nextcloud
- Onlyoffice Workspace
- Univention Corporate Server (UCS)
Последний не совсем то же самое, что первые два, но в целом на его базе можно собрать сервер для групповой работы. Про те, что уже не поддерживаются и не обновляются, не пишу (Kopano). Отдельно отмечу продукты, про которые я не писал: Group office, Grommunio.
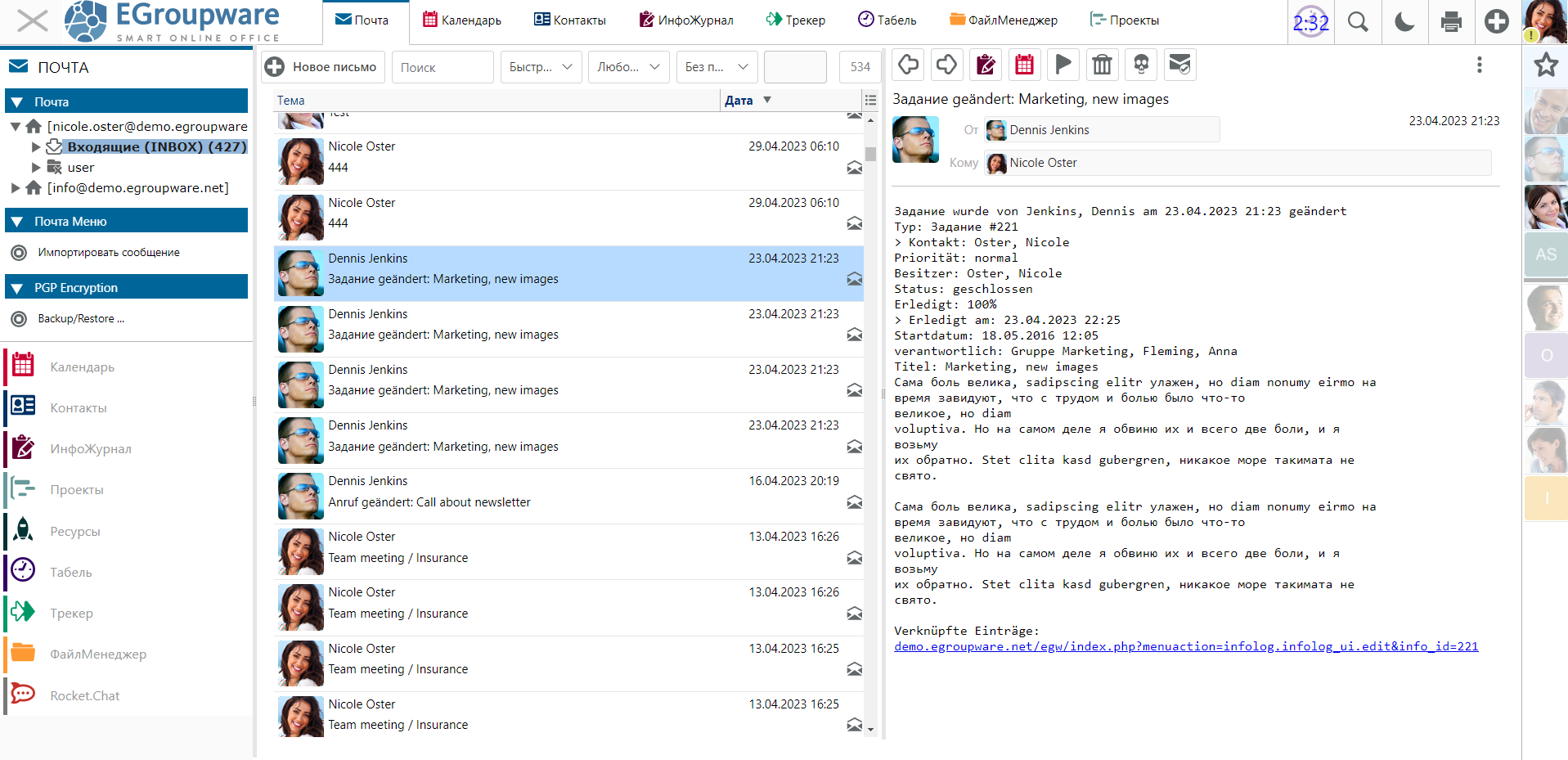
То есть в этой нише выбирать особо не из чего. Наиболее популярен сейчас, как мне кажется, Nextcloud. Он и Onlyoffice Workspace выглядят наиболее функционально и современно. Для полноты картины я решил рассмотреть ещё один open source проект, который активно развивается и поддерживается — EGroupware. Сразу скажу, что он мне не особо понравился. Но так как потратил время и получил информацию, поделюсь с вами.
Разворачивать у себя его не обязательно, так как есть Demo. Но я все равно развернул, чтобы посмотреть, как он устроен. Это сделать не трудно. Он хоть и работает на базе Docker, но при этом предоставляет свой репозиторий, где есть всё, что надо для установки. Сделано удобно. На Debian 11 поставил так:
Разворачивается Nginx в качестве прокси на самом хосте. А всё остальное живёт в Docker. Все данные вынесены в volumes для удобного бэкапа. Учётку для подключения смотреть в файле /var/lib/egroupware/egroupware-docker-install.log.
В целом, по возможностям, всё выглядит функционально и удобно. Плюс-минус как у всех - почтовый клиент, календарь, адресная книга, документы, проекты, интеграции и т.д. По умолчанию предлагает редактор документов Collabora Online в облачном сервисе, что стоит денег. Наверное можно как-то с бесплатной Collabora скрестить, но я не разбирался.
В публичной демке можно посмотреть, как Collabora Online работает, загрузить туда свои файлы. Кстати, хорошая возможность потестировать этот продукт. Он сильно отличается от Onlyoffice Docs как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняет на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice.
Мне не понравился внешний вид EGroupware. По нему сразу видно, что продукт из глубокого прошло (написан, кстати, на php). Интерфейс хоть и пытались освежить, но выглядит, как по мне, всё равно старовато. Ну не хочется им пользоваться. Хотя по настройкам и возможностям там всё очень хорошо. Добротный перевод на русский. Не возникло желания поскорее переключиться на английский язык. Более того, в настройках можно добавить свой перевод любой фразы и тут же применить изменения. Я попробовал, очень удобно. Перевёл один из пунктов меню по своему.
Из приятных особенностей EGroupware отмечу интеграцию с Rocket.Chat. По описанию все выглядит круто, но подозреваю, что будет куча нюансов. Надо будет ещё и Jitsi разворачивать, чтобы были видеозвонки. Я на практике знаю, что вся эта связка не так уж просто настраивается и обслуживается, особенно если работает за NAT и нужен доступ из интернета. Тем не менее, функционально всё это выглядит неплохо.
Если подыскиваете себе бесплатный groupware, то посмотрите EGroupware. Внешний вид — субъективный фактор. Возможно вам он будет некритичен.
⇨ Сайт / Исходники
#groupware #docs
- Nextcloud
- Onlyoffice Workspace
- Univention Corporate Server (UCS)
Последний не совсем то же самое, что первые два, но в целом на его базе можно собрать сервер для групповой работы. Про те, что уже не поддерживаются и не обновляются, не пишу (Kopano). Отдельно отмечу продукты, про которые я не писал: Group office, Grommunio.
То есть в этой нише выбирать особо не из чего. Наиболее популярен сейчас, как мне кажется, Nextcloud. Он и Onlyoffice Workspace выглядят наиболее функционально и современно. Для полноты картины я решил рассмотреть ещё один open source проект, который активно развивается и поддерживается — EGroupware. Сразу скажу, что он мне не особо понравился. Но так как потратил время и получил информацию, поделюсь с вами.
Разворачивать у себя его не обязательно, так как есть Demo. Но я все равно развернул, чтобы посмотреть, как он устроен. Это сделать не трудно. Он хоть и работает на базе Docker, но при этом предоставляет свой репозиторий, где есть всё, что надо для установки. Сделано удобно. На Debian 11 поставил так:
# echo 'deb https://download.opensuse.org/repositories/server:/eGroupWare/Debian_11/ /' \| tee /etc/apt/sources.list.d/server:eGroupWare.list# wget -nv https://download.opensuse.org/repositories/server:eGroupWare/Debian_11/Release.key -O - \| apt-key add - | tee /etc/apt/trusted.gpg.d/server:eGroupWare.asc# apt update && apt install egroupware-dockerРазворачивается Nginx в качестве прокси на самом хосте. А всё остальное живёт в Docker. Все данные вынесены в volumes для удобного бэкапа. Учётку для подключения смотреть в файле /var/lib/egroupware/egroupware-docker-install.log.
В целом, по возможностям, всё выглядит функционально и удобно. Плюс-минус как у всех - почтовый клиент, календарь, адресная книга, документы, проекты, интеграции и т.д. По умолчанию предлагает редактор документов Collabora Online в облачном сервисе, что стоит денег. Наверное можно как-то с бесплатной Collabora скрестить, но я не разбирался.
В публичной демке можно посмотреть, как Collabora Online работает, загрузить туда свои файлы. Кстати, хорошая возможность потестировать этот продукт. Он сильно отличается от Onlyoffice Docs как внешним видом, так и архитектурой. Если у Onlyoffice обработка выполняет на клиенте, что нагружает его, но снимает нагрузку с сервера, то Collabora Online всё обрабатывает на сервере. Мне кажется, это скорее плохо, чем хорошо. Ресурсов сервера потребляет в разы больше, чем Onlyoffice.
Мне не понравился внешний вид EGroupware. По нему сразу видно, что продукт из глубокого прошло (написан, кстати, на php). Интерфейс хоть и пытались освежить, но выглядит, как по мне, всё равно старовато. Ну не хочется им пользоваться. Хотя по настройкам и возможностям там всё очень хорошо. Добротный перевод на русский. Не возникло желания поскорее переключиться на английский язык. Более того, в настройках можно добавить свой перевод любой фразы и тут же применить изменения. Я попробовал, очень удобно. Перевёл один из пунктов меню по своему.
Из приятных особенностей EGroupware отмечу интеграцию с Rocket.Chat. По описанию все выглядит круто, но подозреваю, что будет куча нюансов. Надо будет ещё и Jitsi разворачивать, чтобы были видеозвонки. Я на практике знаю, что вся эта связка не так уж просто настраивается и обслуживается, особенно если работает за NAT и нужен доступ из интернета. Тем не менее, функционально всё это выглядит неплохо.
Если подыскиваете себе бесплатный groupware, то посмотрите EGroupware. Внешний вид — субъективный фактор. Возможно вам он будет некритичен.
⇨ Сайт / Исходники
#groupware #docs
{kind=link}
👍26👎1
Недавно планово обновлял один из серверов 1С в связке с PostgreSQL, работающий на Debian. Сервер настроен примерно так же, как описано в моей статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
А обновление делал по этой статье:
⇨ Обновление Сервера 1С под Linux
Статьи в целом актуальны. Обновление сделал сначала на тестовом сервере клоне. Обновил, проверил работу сервера, баз. Всё нормально. Потом перешёл к рабочему. Обновил штатно, но начались проблемы.
Выражалось это в том, что раза в 2-3 возросла нагрузка по CPU. В целом, всё работало, но очень медленно. Через панель администрирования было видно большое количество фоновых задач. При этом они не висели, но выполнялись явно медленно, поэтому их было в списке аномально много. Больше обычного в несколько раз.
Какое-то время разбирался в проблеме, пытаясь понять, с чем это связано. Полный дублёр этого сервера не имел таких проблем. В итоге заглянул в лог postgresql и заметил, что там куча сообщений об исчерпании лимита доступных подключений, хотя в обычное время их достаточно. Судя по всему по какой-то причине на боевом сервере зависли соединения.
Остановил сервер 1С, перезапустил postgresql и запустил заново 1С сервер. Работа нормализовалась. Контроль соединений к базе данных — один из ключевых параметров, которые надо мониторить. Здесь это не было сделано. Пришло время настроить.
На что ещё обратить внимание при обновлении:
1️⃣ Периодически установщик 1С ставит дополнительные пакеты. Например, в этот раз заметил, что он установил Apache. Мне он был не нужен, удалил.
2️⃣ Проверьте, что вы точно удалили из автозапуска службу со старой версией 1С. Я в одном месте ошибся и удалил неправильно. Там немного отличаются команды. Например, остановка сервиса выполняется командой:
А удаление из автозапуска:
Окончания в названиях службы разные. Я в одном месте ошибся и после перезагрузки получил две запущенные службы 1С сервера. Старая запустилась в качестве сервера, а новая версия валилась в ошибки постоянно. Самое удивительное, что заметили это только через 3 дня, так как платформа 1С у клиентов автоматически использовала старую версию и никто не обратил на это внимание.
#1С
⇨ Установка и настройка 1С на Debian с PostgreSQL
А обновление делал по этой статье:
⇨ Обновление Сервера 1С под Linux
Статьи в целом актуальны. Обновление сделал сначала на тестовом сервере клоне. Обновил, проверил работу сервера, баз. Всё нормально. Потом перешёл к рабочему. Обновил штатно, но начались проблемы.
Выражалось это в том, что раза в 2-3 возросла нагрузка по CPU. В целом, всё работало, но очень медленно. Через панель администрирования было видно большое количество фоновых задач. При этом они не висели, но выполнялись явно медленно, поэтому их было в списке аномально много. Больше обычного в несколько раз.
Какое-то время разбирался в проблеме, пытаясь понять, с чем это связано. Полный дублёр этого сервера не имел таких проблем. В итоге заглянул в лог postgresql и заметил, что там куча сообщений об исчерпании лимита доступных подключений, хотя в обычное время их достаточно. Судя по всему по какой-то причине на боевом сервере зависли соединения.
Остановил сервер 1С, перезапустил postgresql и запустил заново 1С сервер. Работа нормализовалась. Контроль соединений к базе данных — один из ключевых параметров, которые надо мониторить. Здесь это не было сделано. Пришло время настроить.
На что ещё обратить внимание при обновлении:
1️⃣ Периодически установщик 1С ставит дополнительные пакеты. Например, в этот раз заметил, что он установил Apache. Мне он был не нужен, удалил.
2️⃣ Проверьте, что вы точно удалили из автозапуска службу со старой версией 1С. Я в одном месте ошибся и удалил неправильно. Там немного отличаются команды. Например, остановка сервиса выполняется командой:
# systemctl stop [email protected]А удаление из автозапуска:
# systemctl disable [email protected]Окончания в названиях службы разные. Я в одном месте ошибся и после перезагрузки получил две запущенные службы 1С сервера. Старая запустилась в качестве сервера, а новая версия валилась в ошибки постоянно. Самое удивительное, что заметили это только через 3 дня, так как платформа 1С у клиентов автоматически использовала старую версию и никто не обратил на это внимание.
#1С
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
👍97👎2
Расскажу вам небольшую историю про расследование внезапной перезагрузки сервера, которая вывела меня на самого себя. Попутно я наполню статью командами, которые конкретно мне не помогли, но могут пригодиться в похожей ситуации, чтобы статья получилась полезной шпаргалкой.
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
Тут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
#linux #ошибка
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
# who -b system boot 2023-07-14 02:17# last -x | headroot pts/0 10.20.140.6 Mon Jul 17 11:24 still logged inrunlevel (to lvl 5) 5.15.39-3-pve Fri Jul 14 02:17 still runningreboot system boot 5.15.39-3-pve Fri Jul 14 02:17 still runningshutdown system down 5.15.39-3-pve Fri Jul 14 02:16 - 02:17 (00:00)root pts/0 10.20.140.6 Fri Jul 14 00:58 - down (01:17)Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
# history 380 apt update 381 apt upgrade 382 w 383 rebootТут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
# journalctl --list-boots# journalctl -b 0# last reboot#linux #ошибка
👍163👎2
Некоторое время назад я рассказывал про программу Vector, с помощью которой удобно управлять потоками данных. Сейчас покажу, как с её помощью отправить логи Nginx в сервис axiom.co, где бесплатно можно хранить и обрабатывать до 500 ГБ в месяц. Это отличная возможность быстро собрать дашборд для анализа логов веб сервера.
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
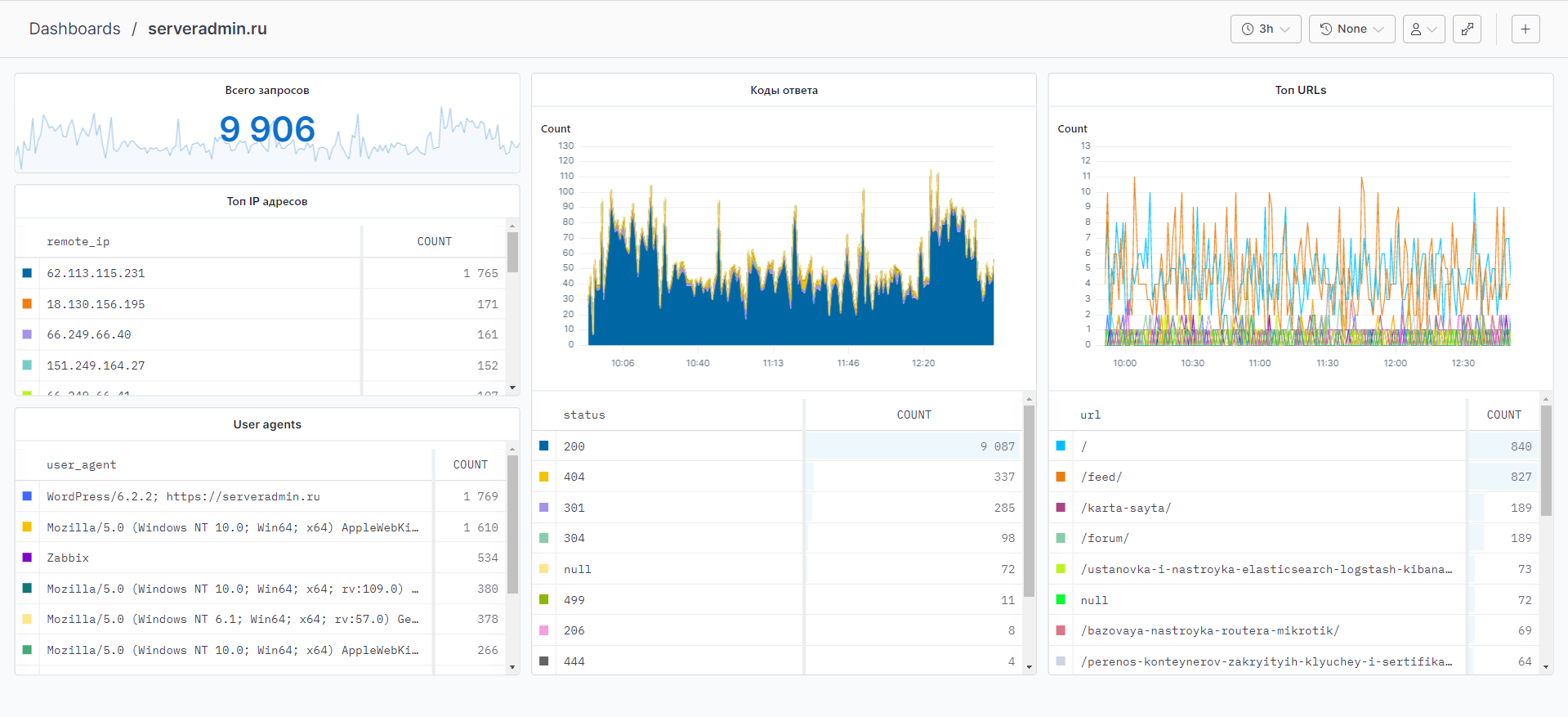
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
[sources.nginx_access_logs]type = "file"include = ["/var/log/nginx/access.log"][transforms.nginx_access_logs_parsed]type = "remap"inputs = ["nginx_access_logs"]source = '''. = parse_json!(.message)'''[sinks.axiom]inputs = ["nginx_access_logs_parsed"]type = "axiom"token = "xaat-36c1ff8f-447f-454e-99fd-abe804aeebf3"dataset = "webserver"У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
{kind=link}
👍63👎2
По мотивам вчерашней заметки по поводу того, как я перепутал и перезагрузил не тот сервер. В комментариях много разных советов дали. Приведу 3 из них, которые мне показались наиболее простыми и эффективными.
1️⃣ Установить пакет molly-guard.
Он делает очень простую вещь. При попытке через консоль перезагрузить или выключить сервер, требует в качестве подтверждения ввести имя сервера. Я впервые услышал про эту утилиту. Надо её добавить в список софта, обязательного для установки. На мой взгляд это самый простой и эффективный способ себя подстраховать.
2️⃣ Разукрасить консоль серверов. К примеру, в гипервизорах раскрасить приветствие консоли в красный цвет. Для этого добавьте в
Получите стандартный терминал, только имя пользователя и сервера в нём будут написаны красным цветом.
3️⃣ Настройте разные цвета вкладок у вашего SSH клиента. Мой, кстати, это поддерживает. Для некоторых серверов я использовал разные цвета, но мне быстро надоело их назначать. У меня много SSH соединений (больше сотни), так что постоянно заниматься раскраской лениво, хотя и стоит это делать. Это не сложнее, чем ставить molly-guard или раскрашивать терминал. По идее, это наиболее простой способ, который не требует выполнять дополнительные действия на самом сервере.
#linux
1️⃣ Установить пакет molly-guard.
# apt install molly-guardОн делает очень простую вещь. При попытке через консоль перезагрузить или выключить сервер, требует в качестве подтверждения ввести имя сервера. Я впервые услышал про эту утилиту. Надо её добавить в список софта, обязательного для установки. На мой взгляд это самый простой и эффективный способ себя подстраховать.
2️⃣ Разукрасить консоль серверов. К примеру, в гипервизорах раскрасить приветствие консоли в красный цвет. Для этого добавьте в
.bashrc:PS1='\e[31m\u@\h:\e[31m\W\e[0m\$ 'Получите стандартный терминал, только имя пользователя и сервера в нём будут написаны красным цветом.
3️⃣ Настройте разные цвета вкладок у вашего SSH клиента. Мой, кстати, это поддерживает. Для некоторых серверов я использовал разные цвета, но мне быстро надоело их назначать. У меня много SSH соединений (больше сотни), так что постоянно заниматься раскраской лениво, хотя и стоит это делать. Это не сложнее, чем ставить molly-guard или раскрашивать терминал. По идее, это наиболее простой способ, который не требует выполнять дополнительные действия на самом сервере.
#linux
{kind=link}
👍138👎2
И ещё одна заметка по мотивам прошлой, где я упоминал кодирование видео и программу HandBrake. Один человек, впечатлённый удобством HandBrake, создал веб интерфейс, очень похожий на интерфейс этой программы, только после выбора всех настроек, вы получаете консольную команду для ffmpeg. Что-то типа такого:
Ffmpeg очень мощная программа, которая умеет всё, что только может пожелать перекодировщик видео. Но разобраться в её ключах и настройках могут не только лишь все. Проект ffmpeg-commander помогает решить эту проблему.
Вы можете запустить его у себя, либо воспользоваться публичной веб версией:
⇨ https://alfg.dev/ffmpeg-commander
Это отличное решение для автоматизации процесса через скрипты. Удобно перекодировать видео и удалить исходник. Только надо каким-то образом проверить, что всё прошло успешно. А вот как это сделать автоматически, я не очень представляю. Стандартного выхода процесса кодирования без ошибки, мне кажется, в данном случае недостаточно для того, чтобы удалить исходник. Надо как-то подстраховаться.
Кстати, если воспользоваться другим проектом этого автора — ffmpegd, можно через веб интерфейс ffmpeg-commander выполнять непосредственно кодирование.
⇨ Сайт / Исходники
#разное
# ffmpeg -i movie.mp4 -c:v libx264 -b:v 3000 -c:a copy -pass 1 /dev/null \&& ffmpeg -i movie.mp4 -c:v libx264 -b:v 3000 -c:a copy -pass 2 output.mp4 Ffmpeg очень мощная программа, которая умеет всё, что только может пожелать перекодировщик видео. Но разобраться в её ключах и настройках могут не только лишь все. Проект ffmpeg-commander помогает решить эту проблему.
Вы можете запустить его у себя, либо воспользоваться публичной веб версией:
⇨ https://alfg.dev/ffmpeg-commander
Это отличное решение для автоматизации процесса через скрипты. Удобно перекодировать видео и удалить исходник. Только надо каким-то образом проверить, что всё прошло успешно. А вот как это сделать автоматически, я не очень представляю. Стандартного выхода процесса кодирования без ошибки, мне кажется, в данном случае недостаточно для того, чтобы удалить исходник. Надо как-то подстраховаться.
Кстати, если воспользоваться другим проектом этого автора — ffmpegd, можно через веб интерфейс ffmpeg-commander выполнять непосредственно кодирование.
⇨ Сайт / Исходники
#разное
{kind=link}
👍68👎2
Рассказываю про отличный сервис, который позволит выводить уведомления, к примеру, от системы мониторинга в пуши смартфона или приложение на десктопе. При этом всё бесплатно и можно поднять у себя.
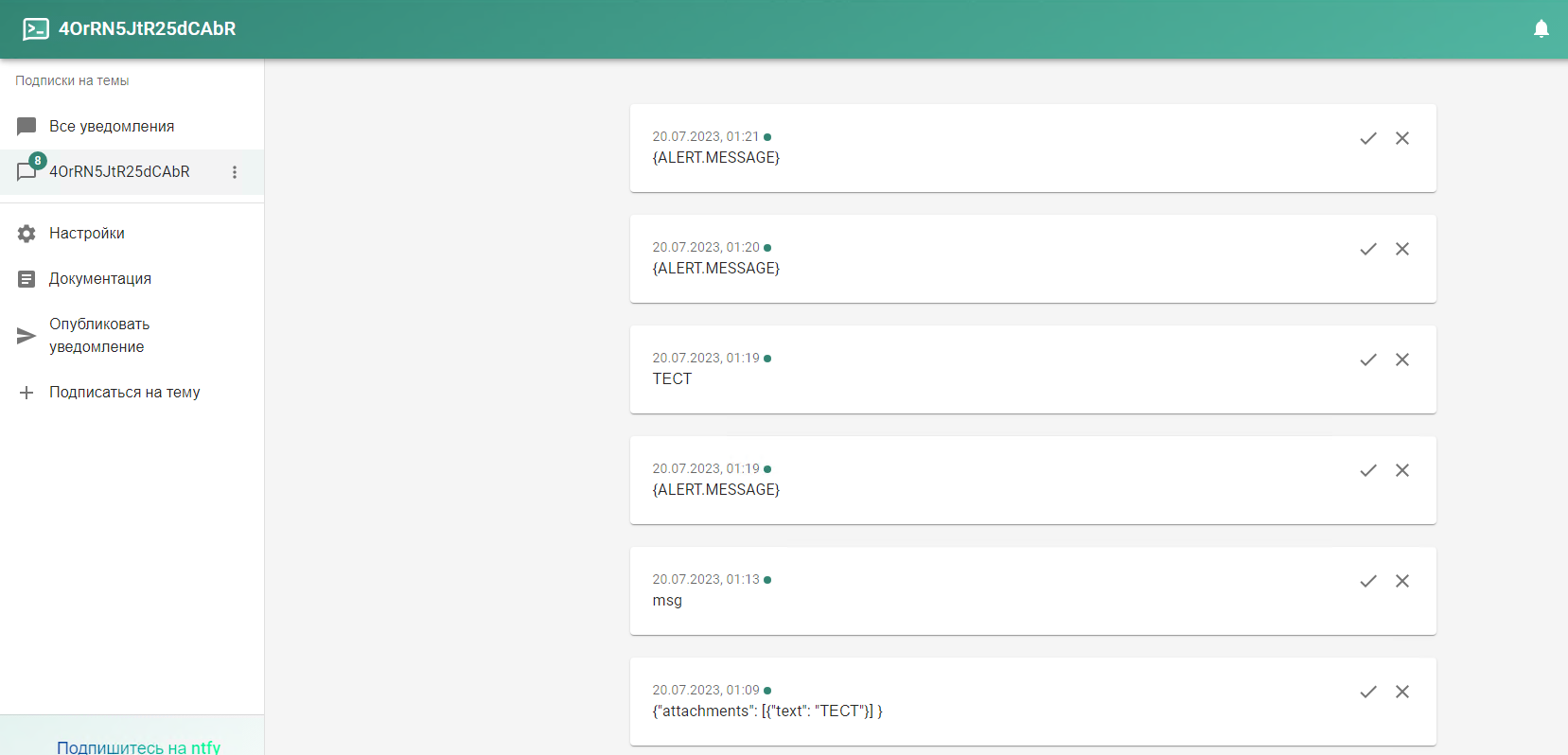
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
Получаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERt.iss.oneSSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
Если бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
# curl -d "Test Message" ntfy.sh/Stkclnoid6pLCpqUПолучаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
var response, payload, params = JSON.parse(value), wurl = params.URL, msg = params.Message, request = new CurlHttpRequest(); request.AddHeader('Content-Type: text/plain'); response = request.Post(wurl, msg);В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERt.iss.oneSSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
# rsync -a /mnt/data [email protected]:/backups/srv01 \ && curl -H prio:low -d "SRV01 backup succeeded" ntfy.sh/Stkclnoid \ || curl -H tags:warning -H prio:high -d "SRV01 backup failed" ntfy.sh/StkclnoidЕсли бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
{kind=link}
👍134👎5
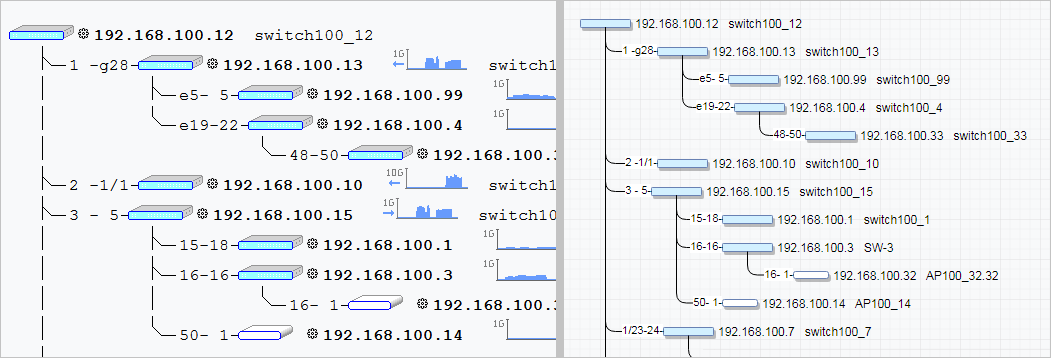
Маленькая простая программа для выполнения одной задачи - рисование топологии локальной сети, построенной на коммутаторах с включённой службой snmp - LanTopoLog. Я её знаю очень давно, ещё в бытность работы в техподдержке.
Программа не требует установки, но при желании может работать в качестве службы Windows. Работает, соответственно, только под Windows. По качеству работы эта программа одна из лучших именно для автоматического построения карты сети. Она использует snmp запросы к коммутаторам для получения и сопоставления информации. Так что для её корректной работы включение snmp обязательно на всех коммутаторах. С Микротиками, кстати, тоже нормально работает.
Программа условно-бесплатная. Без лицензии через некоторое время после запуска, отключается часть возможностей. Для разового просмотра схемы не критично. А если захотите пользоваться постоянно, то придётся купить лицензию. Благо она бессрочная, включает все последующие обновления и стоит 50$ для физиков или 9070₽ для юр. лиц.
📌 Помимо построения схемы, имеет другие возможности:
◽может публиковать схему на веб сервере;
◽следит за доступностью узлов и может уведомлять об этом в telegram или email;
◽отображает скорость портов коммутаторов, утилизацию канала;
◽умеет экспортировать схему в Draw.io;
🔥отслеживает все MAC адреса подключенных к коммутаторам устройств, осуществляет поиск по ним.
Описание можно послушать от админа, который реально пользуется этой программой на работе: https://www.youtube.com/watch?v=Js8N70nmYIg Смотрел раньше все видео с канала этого админа, но он что-то забросил его.
Программа, кстати, от нашего соотечественника. До сих пор поддерживается и обновляется, хотя ей уже 17 лет.
⇨ Сайт
#network #отечественное
Программа не требует установки, но при желании может работать в качестве службы Windows. Работает, соответственно, только под Windows. По качеству работы эта программа одна из лучших именно для автоматического построения карты сети. Она использует snmp запросы к коммутаторам для получения и сопоставления информации. Так что для её корректной работы включение snmp обязательно на всех коммутаторах. С Микротиками, кстати, тоже нормально работает.
Программа условно-бесплатная. Без лицензии через некоторое время после запуска, отключается часть возможностей. Для разового просмотра схемы не критично. А если захотите пользоваться постоянно, то придётся купить лицензию. Благо она бессрочная, включает все последующие обновления и стоит 50$ для физиков или 9070₽ для юр. лиц.
📌 Помимо построения схемы, имеет другие возможности:
◽может публиковать схему на веб сервере;
◽следит за доступностью узлов и может уведомлять об этом в telegram или email;
◽отображает скорость портов коммутаторов, утилизацию канала;
◽умеет экспортировать схему в Draw.io;
🔥отслеживает все MAC адреса подключенных к коммутаторам устройств, осуществляет поиск по ним.
Описание можно послушать от админа, который реально пользуется этой программой на работе: https://www.youtube.com/watch?v=Js8N70nmYIg Смотрел раньше все видео с канала этого админа, но он что-то забросил его.
Программа, кстати, от нашего соотечественника. До сих пор поддерживается и обновляется, хотя ей уже 17 лет.
⇨ Сайт
#network #отечественное
{kind=link}
👍76👎4
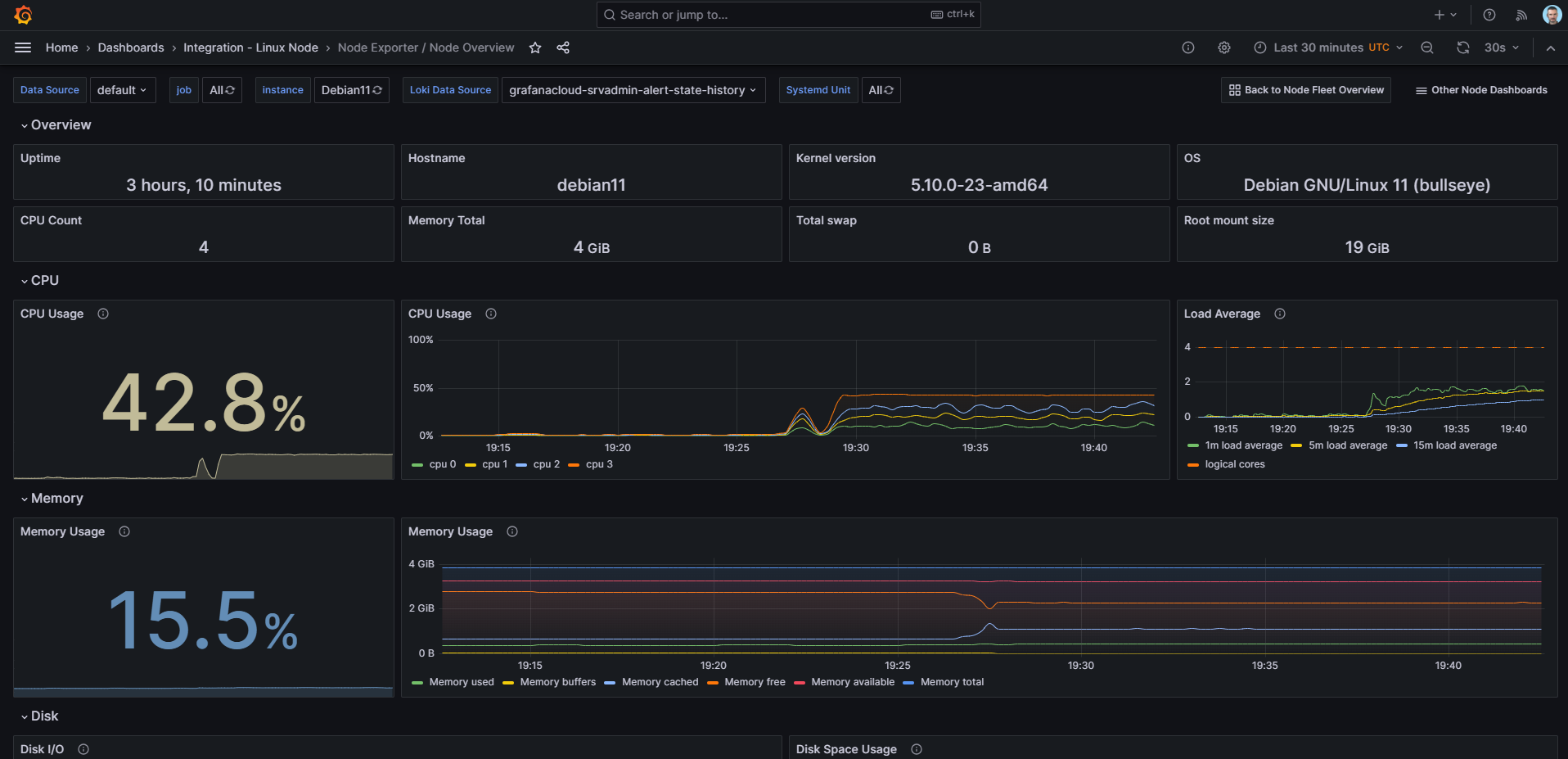
Напомню тем, кто не знает. У Grafana есть облачный сервис по мониторингу и сбору логов с бесплатным тарифным планом. Называется, как нетрудно догадаться - Grafana Cloud. Для регистрации не надо ничего, кроме адреса почты. Есть бесплатный тарифный план с комфортными ограничениями: 50 GB логов в месяц, 10k метрик.
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
{kind=link}
👍69👎3
На неделе попался забавный мем, который сохранил себе. Понимая, как работают некоторые информационные системы, приходится реально подстраховывать себя.
Например, я всегда храню у себя в бумажном виде всё лечение зубов, все снимки и манипуляции, что мне делали (к сожалению, обширная практика 😔). Хотя лечусь всегда в одной клинике, у которой база данных клиентов и там всё хранится. Но зная, как там это обслуживается, я понимаю, что в один прекрасный момент всё может пропасть.
Я храню все платёжки по ЖКХ, штрафам, оплатам за детей и т.д. Всё, что можно сохранить после оплаты в pdf, сохраняю и кладу в папочку. Уже не раз меня это выручало. И видел, как страдали другие в поисках своих платежей, кто не делает так же. Мне же достаточно был отправить pdf.
Билеты, купленные в онлайн, в обязательном порядке всегда печатаю. Ну и т.д. В общем, этот мем мне очень близок и понятен. Хотя допускаю, что кому-то это может показаться духотой или паранойей. Но мне так комфортнее.
#мем
Например, я всегда храню у себя в бумажном виде всё лечение зубов, все снимки и манипуляции, что мне делали (к сожалению, обширная практика 😔). Хотя лечусь всегда в одной клинике, у которой база данных клиентов и там всё хранится. Но зная, как там это обслуживается, я понимаю, что в один прекрасный момент всё может пропасть.
Я храню все платёжки по ЖКХ, штрафам, оплатам за детей и т.д. Всё, что можно сохранить после оплаты в pdf, сохраняю и кладу в папочку. Уже не раз меня это выручало. И видел, как страдали другие в поисках своих платежей, кто не делает так же. Мне же достаточно был отправить pdf.
Билеты, купленные в онлайн, в обязательном порядке всегда печатаю. Ну и т.д. В общем, этот мем мне очень близок и понятен. Хотя допускаю, что кому-то это может показаться духотой или паранойей. Но мне так комфортнее.
#мем
👍190👎8
Недавно в новостях проскочила информация о сервисе windowsupdaterestored.com. Группа энтузиастов задалась целью восстановить работу системы обновления для Windows архивных моделей: 95, NT, 98, Millennium, 2000, XP, Server 2003, Vista. Сразу поясню, что это не новые обновления для старых систем. Это всё те же обновления, что выпускала Microsoft в прошлом, а сейчас просто закрыла сайты с обновлениями для этих систем.
Пока полная поддержка только до XP, то есть работают версии Windows Update v3.1 и v4. У меня есть виртуалка с Windosw XP. Решил попробовать на ней этот сервис. Для неё нужна версия Windows Update v5, поддержка которой ещё не полная. Нужно выполнить некоторые манипуляции на самой системе. Я немного повозился, почти всё получилось, служба заработала в итоге, но обновления так и не пошли. Надо подождать, когда доделают. Хотя на сайте есть ролик, где уже всё работает. Но у меня почему-то не получилось.
Зачем всё это нужно сейчас, я не знаю. Чисто для развлечения. Новых обновлений всё равно нет. Можно найти где-нибудь образы со всеми последними обновлениями и использовать их для установки, если уж понадобится система.
А так сайт прикольный. Прям старина. Мне нравится иногда загрузить старую систему и там потыкать. XP на современном железе в виртуалке просто летает. Так непривычно нажать на ярлык Internet Explorer, и он загружается мгновенно. Быстрее, чем современный браузер на современном компьютере. Хотя я помню, как IE раньше тормозил при первом запуске и меня это жутко раздражало.
Прям даже как-то обидно за прогресс. Параметры железа растут, а отклик приложений падает. Понятно, что возможности софта тоже заметно выросли. Но хотелось бы всё равно увидеть что-то быстрое, пусть и совсем простое, без наворотов. Какой-нибудь браузер на быстром движке, чтобы просто отображать страницы, без дополнительных сервисов, интеграций, виджетов, плагинов и т.д.
#windows
Пока полная поддержка только до XP, то есть работают версии Windows Update v3.1 и v4. У меня есть виртуалка с Windosw XP. Решил попробовать на ней этот сервис. Для неё нужна версия Windows Update v5, поддержка которой ещё не полная. Нужно выполнить некоторые манипуляции на самой системе. Я немного повозился, почти всё получилось, служба заработала в итоге, но обновления так и не пошли. Надо подождать, когда доделают. Хотя на сайте есть ролик, где уже всё работает. Но у меня почему-то не получилось.
Зачем всё это нужно сейчас, я не знаю. Чисто для развлечения. Новых обновлений всё равно нет. Можно найти где-нибудь образы со всеми последними обновлениями и использовать их для установки, если уж понадобится система.
А так сайт прикольный. Прям старина. Мне нравится иногда загрузить старую систему и там потыкать. XP на современном железе в виртуалке просто летает. Так непривычно нажать на ярлык Internet Explorer, и он загружается мгновенно. Быстрее, чем современный браузер на современном компьютере. Хотя я помню, как IE раньше тормозил при первом запуске и меня это жутко раздражало.
Прям даже как-то обидно за прогресс. Параметры железа растут, а отклик приложений падает. Понятно, что возможности софта тоже заметно выросли. Но хотелось бы всё равно увидеть что-то быстрое, пусть и совсем простое, без наворотов. Какой-нибудь браузер на быстром движке, чтобы просто отображать страницы, без дополнительных сервисов, интеграций, виджетов, плагинов и т.д.
#windows
{kind=link}
👍88👎15
Когда настраиваешь мониторинг на ненагруженных машинах, хочется дать какую-то среднюю нагрузку, чтобы посмотреть, как выглядят получившиеся графики и дашборды. Для стресс тестов есть специальные утилиты, типа stress. Но чаще всего не хочется что-то устанавливать для этого.
Для этих целей в Linux часто используют псевдоустройства
Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
Увеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
Она загрузит только одно ядро. Для двух можно запустить их в паре:
Процессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
Это так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
Причём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
Если убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
Съели 1G памяти.
#bash #linux #terminal
Для этих целей в Linux часто используют псевдоустройства
/dev/urandom или /dev/zero, направляя куда-нибудь их вывод. Вот простой пример:# while true; do dd if=/dev/urandom count=30M bs=1 \| bzip2 -9 > /tmp/tempfile ; rm -f /tmp/tempfile ; done Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
# sync; dd if=/dev/zero of=/tmp/tempfile bs=1M count=1024; syncУвеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
# dd if=/dev/zero of=/dev/nullОна загрузит только одно ядро. Для двух можно запустить их в паре:
# cpuload() { dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null & }; \cpuload; read; pkill ddПроцессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
# sha1sum /dev/zeroЭто так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
# seq 4 | xargs -P0 -n1 timeout 10 yes > /dev/nullПричём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
# seq 2 | xargs -P0 -n1 timeout 10 sha1sum /dev/zeroЕсли убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
# python3 -c 'a="a"*1024**3; input()'Съели 1G памяти.
#bash #linux #terminal
👍117👎3
Могу посоветовать необычную связку для доступа извне к внутренним ресурсам без необходимости настройки VPN или программных клиентов. Всё будет работать через браузер. Подход нестандартный, но вполне рабочий. Я реализовывал лично на одиночном сервере для безопасного и простого доступа к виртуалкам.
Задача стояла настроить на Proxmox несколько виртуальных машин: Windows Server для работы с 1С, Debian для PostgreSQL + 1С сервер, Debian для локальных изолированных бэкапов. Плюс я добавил сюда одну служебную виртуалку для шлюза с iptables. Задача была максимально упростить доступ клиентов к 1С без дополнительных настроек, но при этом обезопасить его.
В итоге что я сделал. На служебной виртуалке, которая являлась шлюзом в интернет для остальных виртуальных машин, настроил связку:
1️⃣ Labean — простой сервис, который при обнаружении открытия определённого url на установленном рядом веб сервере, добавляет временное или постоянное правило в iptables. Для настройки надо уметь работать с iptables.
2️⃣ Apache Guacamole — шлюз удалённых подключений, через который с помощью браузера можно по RDP или SSH попасть на сервер.
Работает всё это очень просто. Пользователю отправляются две ссылки. При переходе по первой ссылке labean создаёт правило в iptables для ip адреса клиента, разрешающее ему подключиться к Apache Guacamole. А вторая ссылка ведёт к веб интерфейсу Apache Guacamole, куда пользователю открылся доступ. В Apache Guacamole настраивается учётка для каждого пользователя, где добавлены сервера, к которым ему можно подключаться.
Ссылки для labean настраиваются вручную с не словарными путями, которые невозможно подобрать. Нужно точно знать URL. В данном случае Apache Guacamole выступает для удобства подключения пользователей. Если они готовы настраивать себе клиенты RDP, то можно в labean настраивать сразу проброс по RDP. А можно и то и другое. И каждый сам решает, как он хочется зайти: через RDP клиент или через браузер. Работа в браузере накладывает свои ограничения и не всем подходит.
Вместо labean можно использовать port knocking или настроить HTTP доступ через nginx proxy, закрыв его basic auth. Лично мне реализация через url для labean кажется наиболее простой и удобной для конечного пользователя.
Разумеется, помимо labean, должен быть ещё какой-то путь попасть на эти сервера для управления. Белые списки IP или тот же VPN. Администратору, думаю, будет не трудно настроить себе VPN. Я, кстати, на данном сервере в том числе настроил и OpenVPN для тех, кто готов им пользоваться в обход описанной выше схемы.
#security #gateway #network
Задача стояла настроить на Proxmox несколько виртуальных машин: Windows Server для работы с 1С, Debian для PostgreSQL + 1С сервер, Debian для локальных изолированных бэкапов. Плюс я добавил сюда одну служебную виртуалку для шлюза с iptables. Задача была максимально упростить доступ клиентов к 1С без дополнительных настроек, но при этом обезопасить его.
В итоге что я сделал. На служебной виртуалке, которая являлась шлюзом в интернет для остальных виртуальных машин, настроил связку:
1️⃣ Labean — простой сервис, который при обнаружении открытия определённого url на установленном рядом веб сервере, добавляет временное или постоянное правило в iptables. Для настройки надо уметь работать с iptables.
2️⃣ Apache Guacamole — шлюз удалённых подключений, через который с помощью браузера можно по RDP или SSH попасть на сервер.
Работает всё это очень просто. Пользователю отправляются две ссылки. При переходе по первой ссылке labean создаёт правило в iptables для ip адреса клиента, разрешающее ему подключиться к Apache Guacamole. А вторая ссылка ведёт к веб интерфейсу Apache Guacamole, куда пользователю открылся доступ. В Apache Guacamole настраивается учётка для каждого пользователя, где добавлены сервера, к которым ему можно подключаться.
Ссылки для labean настраиваются вручную с не словарными путями, которые невозможно подобрать. Нужно точно знать URL. В данном случае Apache Guacamole выступает для удобства подключения пользователей. Если они готовы настраивать себе клиенты RDP, то можно в labean настраивать сразу проброс по RDP. А можно и то и другое. И каждый сам решает, как он хочется зайти: через RDP клиент или через браузер. Работа в браузере накладывает свои ограничения и не всем подходит.
Вместо labean можно использовать port knocking или настроить HTTP доступ через nginx proxy, закрыв его basic auth. Лично мне реализация через url для labean кажется наиболее простой и удобной для конечного пользователя.
Разумеется, помимо labean, должен быть ещё какой-то путь попасть на эти сервера для управления. Белые списки IP или тот же VPN. Администратору, думаю, будет не трудно настроить себе VPN. Я, кстати, на данном сервере в том числе настроил и OpenVPN для тех, кто готов им пользоваться в обход описанной выше схемы.
#security #gateway #network
{kind=link}
👍84👎7
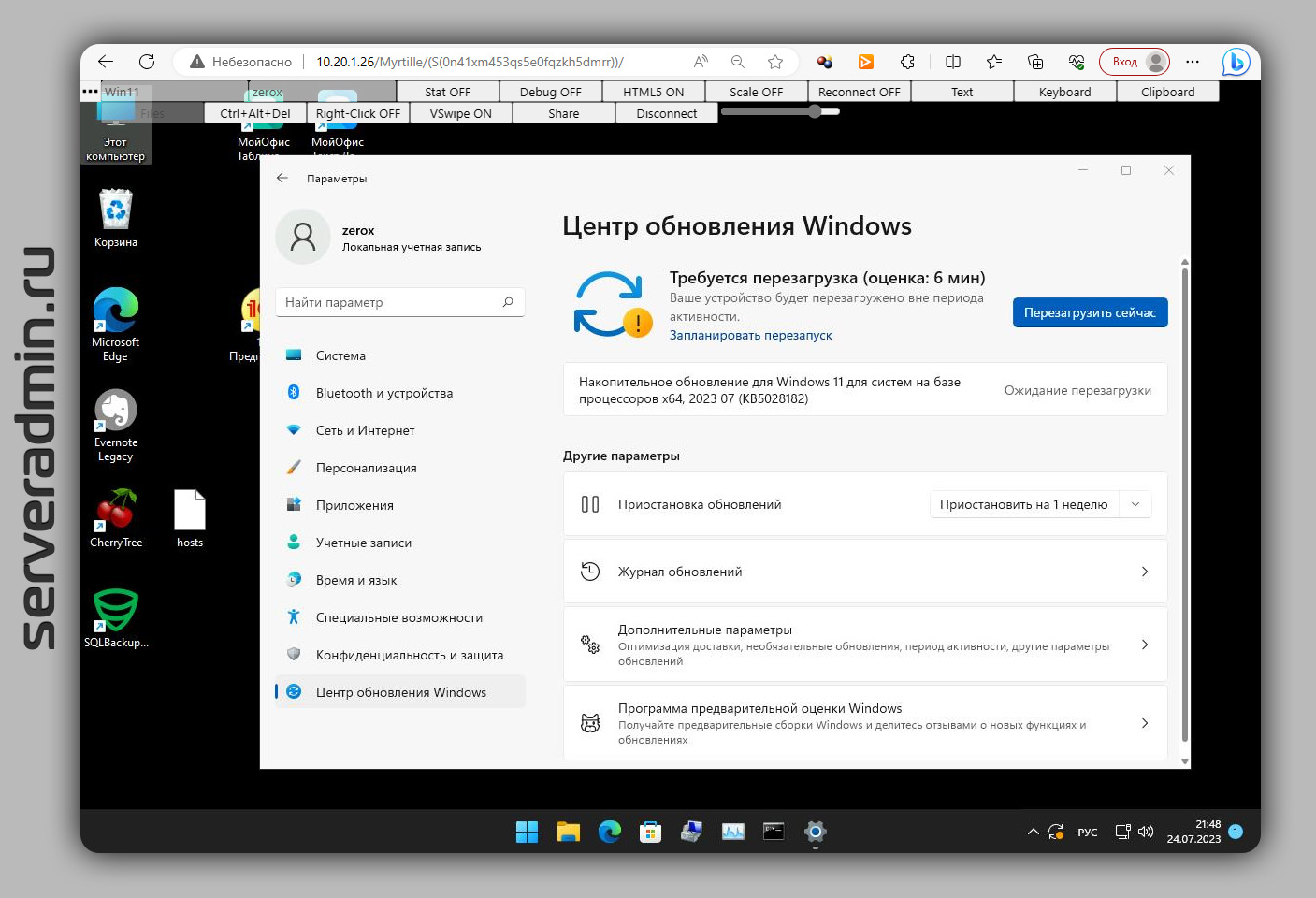
Продолжаю тему RDP и SSH клиентов в браузере. Представляю вам аналог Apache Guacamole, только под Windows — Myrtille. Я давно про неё слышал, ещё когда делал первую заметку про Guacamole, но руки дошли попробовать только сейчас.
Я установил и настроил Myrtille у себя на Windows Server 2019. Достаточно скачать и установить небольшой (46 Мб) msi пакет. Он всё сделал сам. В процессе установки вам предложат указать сервер API и ещё какие-то параметры. Я ничего не указывал. Просто оставил эти поля пустыми. Использовал все параметры по умолчанию.
Потом перезагрузил сервер и зашёл в браузере на страницу
⇨ https://10.20.1.26/Myrtille/
Myrtille выпускает самоподписанный сертификат. Работает программа на базе IIS.
Вас встречает RDP клиент на базе технологии HTML4 или HTML5. Достаточно ввести IP адрес машины, логин, пароль. И вы подключитесь по RDP. Принцип работы такой же, как у Apache Guacamole. В целом, мне понравился этот продукт. Прежде всего простотой настройки. Guacamole пока настроишь, пуд соли съешь: куча пакетов, конфигов, параметров. А тут мышкой клац-клац и всё работает.
У Myrtille куча возможностей. Отмечу некоторые из них:
◽Есть возможность подготовить URL, в котором будут зашиты параметры подключения (сервер, логин, пароль и т.д.). Переходите по ссылке и сразу попадаете на нужную машину. Есть возможность сделать её одноразовой. Подключиться можно будет только один раз.
◽Во время вашей активной сессии можно подготовить ссылку и отправить её другому человеку, чтобы он подключился в ваш сеанс с полными правами, или только для просмотра. Ссылка также будет одноразовой.
◽Если установить Myrtille на гипервизор Hyper-V, есть возможность напрямую подключаться к консоли виртуальных машин.
◽В URL можно зашить программу, которая автоматом запустится после подключения пользователя.
◽Есть REST API, интеграция с Active Directory, Multi-factor аутентификация.
Сразу дам несколько подсказок тем, кто будет тестировать. Учётка по умолчанию: admin / admin. Попасть в интерфейс управления можно либо сразу по ссылке https://10.20.1.26/Myrtille/?mode=admin, либо из основного интерфейса клиента, нажав на ссылку Hosts management. Я не сразу это заметил, поэтому провозился какое-то время, пока нашёл. Параметры подключений в файле C:\Program Files (x86)\Myrtille\js\config.js. Описание параметров в документации.
По умолчанию запускается версия без возможности создания пользователей и групп, чтобы назначать им преднастроенные соединения. То есть либо они ручками подключаются, используют HTTP клиент и заполняя все параметры подключения, либо используют подготовленные заранее ссылки. По умолчанию будет доступен только один пользователь admin, которому можно добавить настроенные соединения. Чтобы это изменить, надо запустить программу в режиме Enterprise Mode. Как это сделать, описано в документации. Я так понял, что для этого нужен AD.
В целом, полезная программа. Если использовать её для себя в административных целях, то вообще никакой настройки не надо. Достаточно веб интерфейс скрыть от посторонних глаз каким-либо способом.
Полезные ссылки, некоторые тоже пришлось поискать:
⇨ Сайт / Исходники / Загрузка / Документация
#remote #windows
Я установил и настроил Myrtille у себя на Windows Server 2019. Достаточно скачать и установить небольшой (46 Мб) msi пакет. Он всё сделал сам. В процессе установки вам предложат указать сервер API и ещё какие-то параметры. Я ничего не указывал. Просто оставил эти поля пустыми. Использовал все параметры по умолчанию.
Потом перезагрузил сервер и зашёл в браузере на страницу
⇨ https://10.20.1.26/Myrtille/
Myrtille выпускает самоподписанный сертификат. Работает программа на базе IIS.
Вас встречает RDP клиент на базе технологии HTML4 или HTML5. Достаточно ввести IP адрес машины, логин, пароль. И вы подключитесь по RDP. Принцип работы такой же, как у Apache Guacamole. В целом, мне понравился этот продукт. Прежде всего простотой настройки. Guacamole пока настроишь, пуд соли съешь: куча пакетов, конфигов, параметров. А тут мышкой клац-клац и всё работает.
У Myrtille куча возможностей. Отмечу некоторые из них:
◽Есть возможность подготовить URL, в котором будут зашиты параметры подключения (сервер, логин, пароль и т.д.). Переходите по ссылке и сразу попадаете на нужную машину. Есть возможность сделать её одноразовой. Подключиться можно будет только один раз.
◽Во время вашей активной сессии можно подготовить ссылку и отправить её другому человеку, чтобы он подключился в ваш сеанс с полными правами, или только для просмотра. Ссылка также будет одноразовой.
◽Если установить Myrtille на гипервизор Hyper-V, есть возможность напрямую подключаться к консоли виртуальных машин.
◽В URL можно зашить программу, которая автоматом запустится после подключения пользователя.
◽Есть REST API, интеграция с Active Directory, Multi-factor аутентификация.
Сразу дам несколько подсказок тем, кто будет тестировать. Учётка по умолчанию: admin / admin. Попасть в интерфейс управления можно либо сразу по ссылке https://10.20.1.26/Myrtille/?mode=admin, либо из основного интерфейса клиента, нажав на ссылку Hosts management. Я не сразу это заметил, поэтому провозился какое-то время, пока нашёл. Параметры подключений в файле C:\Program Files (x86)\Myrtille\js\config.js. Описание параметров в документации.
По умолчанию запускается версия без возможности создания пользователей и групп, чтобы назначать им преднастроенные соединения. То есть либо они ручками подключаются, используют HTTP клиент и заполняя все параметры подключения, либо используют подготовленные заранее ссылки. По умолчанию будет доступен только один пользователь admin, которому можно добавить настроенные соединения. Чтобы это изменить, надо запустить программу в режиме Enterprise Mode. Как это сделать, описано в документации. Я так понял, что для этого нужен AD.
В целом, полезная программа. Если использовать её для себя в административных целях, то вообще никакой настройки не надо. Достаточно веб интерфейс скрыть от посторонних глаз каким-либо способом.
Полезные ссылки, некоторые тоже пришлось поискать:
⇨ Сайт / Исходники / Загрузка / Документация
#remote #windows
{kind=link}
👍87👎3
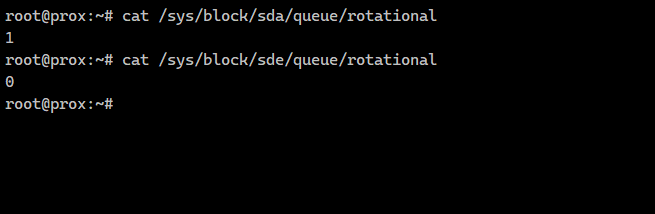
Очень простой и быстрый способ в Linux узнать, какой тип диска у вас в системе, HDD или SSD:
Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
# cat /sys/block/sda/queue/rotational1# cat /sys/block/sde/queue/rotational0Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
{kind=link}
👍86👎1
Вчера слушал вебинар Rebrain по поводу бэкапов MySQL. Мне казалось, что я в целом всё знаю по этой теме. Это так и оказалось, кроме одного маленького момента. Существует более продвинутый аналог mysqldump для создания логических бэкапов — mydumper. Решил сразу сделать про него заметку, чтобы не забыть и самому запомнить инструмент.
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
{kind=link}
👍120👎1
Просматривал список необычных утилит Linux, и зацепился взгляд за броское название — fakeroot. Сразу стало интересно, что это за фейковый рут. Впервые услышал это название. Причём утилита старая, есть в базовых репах. Немного почитал про неё, но не сразу въехал, что это в итоге такое и зачем надо.
Покажу сразу на примере. После установки:
Можно запустить:
И вы как будто сделали sudo su. Появилось приветствие в консоли root:
Создаём новый файл и проверяем его права:
Как будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
Fakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
Покажу сразу на примере. После установки:
# apt install fakerootМожно запустить:
# fakerootИ вы как будто сделали sudo su. Появилось приветствие в консоли root:
root@T480:~#Создаём новый файл и проверяем его права:
# touch file.txt# ls -la file.txt-rw-r--r-- 1 root root 0 Jul 26 00:55 file.txtКак будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
# exit# ls -la file.txt-rw-r--r-- 1 zerox zerox 0 Jul 26 00:55 file.txtFakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
👍89👎3
Необычный бесплатный сервис для обеспечения дополнительной безопасности какого-то периметра — canarytokens.org. С его помощью можно создавать "ловушки", которые сработают, когда кто-то выполнит то или иное действие. Покажу сразу на самом наглядном примере.
Вы можете с помощью сервиса создать документ Word или Exсel, указав свой email адрес. Сервис сгенерирует вам документ, открыв который пользователь увидит пустой лист. При этом о факте открытия вам придёт уведомление на почту с IP адресом того человека, который открыл этот файл.
Конкретно эта проверка с файлом Word работает следующим образом. Документ подписывается сертификатом. Он проверяется при открытии. В сертификате указан список отозванных сертификатов (CRL) на внешнем урле. Офис идёт туда за списком и это обращение отслеживается. Вам тут же приходит уведомление на почту с информацией о том, кто обращался к урлу с CRL списком из вашего документа.
И таких проверок у этого сервиса много. Например, можете сгенерировать URL и получать уведомления, когда кто-то по нему пройдёт. А можете отслеживать даже не переходы, а DNS резолвы поддомена этого урла. Вы увидите информацию о конечном DNS сервере, который обратился за резолвом этого домена. Я проверил эту тему, реально работает проверка с DNS. Можете делать ловушки для подключений Wireguard, для выполнения SQL запросов на MSSQL сервере, для сканирования QR кода и т.д.
Для чего всё это нужно? А тут уже каждый сам может придумать, где и как ему пользоваться. Можете куда-то в свои важные документы положить word файл с именем passwords.docx и следить за ним. Если кто-то откроет этот файл, значит у вас проблемы с безопасностью ваших файлов.
Можете в почту зашить url к какой-нибудь картинке и отследить, когда кто-то откроет это письмо. Или в виндовый файл desktop.ini, в котором хранятся настройки каталога, можно зашить путь к адресу иконки где-то на внешнем сервере. Когда кто-то будет проводником открывать вашу директорию, будете получать уведомления.
В общем, вариантов использования этого сервиса очень много. Посмотрите сами его возможности. Можно использовать как готовый сервис по указанному в начале публикации адресу, так и поднять его у себя. Он open source.
⇨ Сайт / Исходники
#security #сервис
Вы можете с помощью сервиса создать документ Word или Exсel, указав свой email адрес. Сервис сгенерирует вам документ, открыв который пользователь увидит пустой лист. При этом о факте открытия вам придёт уведомление на почту с IP адресом того человека, который открыл этот файл.
Конкретно эта проверка с файлом Word работает следующим образом. Документ подписывается сертификатом. Он проверяется при открытии. В сертификате указан список отозванных сертификатов (CRL) на внешнем урле. Офис идёт туда за списком и это обращение отслеживается. Вам тут же приходит уведомление на почту с информацией о том, кто обращался к урлу с CRL списком из вашего документа.
И таких проверок у этого сервиса много. Например, можете сгенерировать URL и получать уведомления, когда кто-то по нему пройдёт. А можете отслеживать даже не переходы, а DNS резолвы поддомена этого урла. Вы увидите информацию о конечном DNS сервере, который обратился за резолвом этого домена. Я проверил эту тему, реально работает проверка с DNS. Можете делать ловушки для подключений Wireguard, для выполнения SQL запросов на MSSQL сервере, для сканирования QR кода и т.д.
Для чего всё это нужно? А тут уже каждый сам может придумать, где и как ему пользоваться. Можете куда-то в свои важные документы положить word файл с именем passwords.docx и следить за ним. Если кто-то откроет этот файл, значит у вас проблемы с безопасностью ваших файлов.
Можете в почту зашить url к какой-нибудь картинке и отследить, когда кто-то откроет это письмо. Или в виндовый файл desktop.ini, в котором хранятся настройки каталога, можно зашить путь к адресу иконки где-то на внешнем сервере. Когда кто-то будет проводником открывать вашу директорию, будете получать уведомления.
В общем, вариантов использования этого сервиса очень много. Посмотрите сами его возможности. Можно использовать как готовый сервис по указанному в начале публикации адресу, так и поднять его у себя. Он open source.
⇨ Сайт / Исходники
#security #сервис
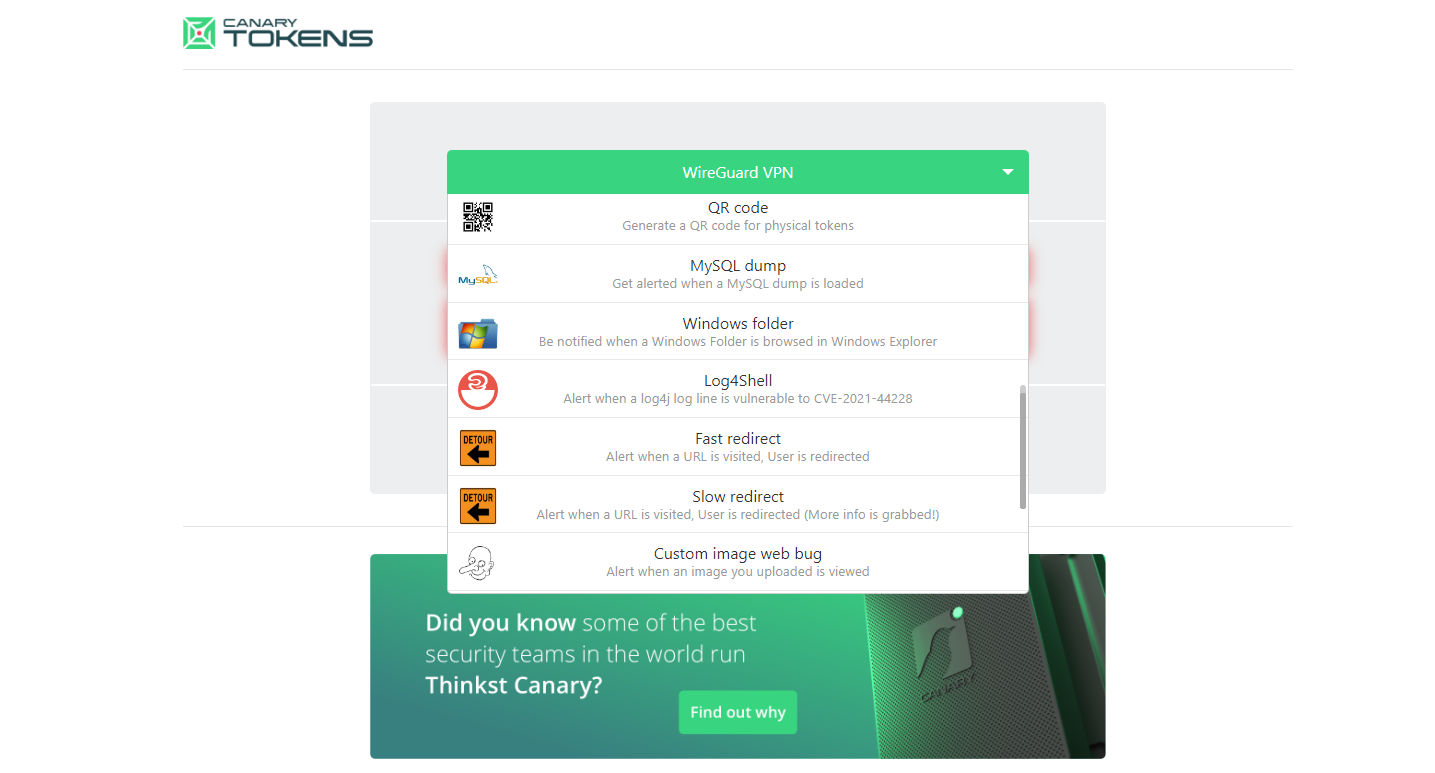{kind=link}
👍119👎2
Если вам нужно заблокировать какую-то страну, чтобы ограничить доступ к вашим сервисам, например, с помощью iptables или nginx, потребуется список IP адресов по странам.
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
Тут я создаю список IP адресов для ipset, а потом использую его в iptables:
Если в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
#!/bin/bash# Удаляем список, если он уже естьipset -X whitelist# Создаем новый списокipset -N whitelist nethash# Скачиваем файлы тех стран, что нас интересуют и сразу объединяем в единый списокwget -O netwhite https://www.ipdeny.com/ipblocks/data/countries/{ru,ua,kz,by,uz,md,kg,de,am,az,ge,ee,tj,lv}.zoneecho -n "Загружаем белый список в IPSET..."# Читаем список сетей и построчно добавляем в ipsetlist=$(cat netwhite)for ipnet in $list do ipset -A whitelist $ipnet doneecho "Завершено"# Выгружаем созданный список в файл для проверки составаipset -L whitelist > w-exportТут я создаю список IP адресов для ipset, а потом использую его в iptables:
iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 80 -j ACCEPTЕсли в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
{kind=link}
👍141👎5