
Пока у меня остался свежий стенд с ELK Stack, решил попробовать софт для разбора NetFlow потоков в Elasticsearch - Elastiflow. Идея там такая. Ставите куда угодно коллектор, который собирает NetFlow и принимаете трафик. А этот коллектор передаёт всю информацию в Elasticsearch. В комплекте с Elastiflow идёт все необходимое для визуализации данных - шаблоны, дашборды для Kibana.
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
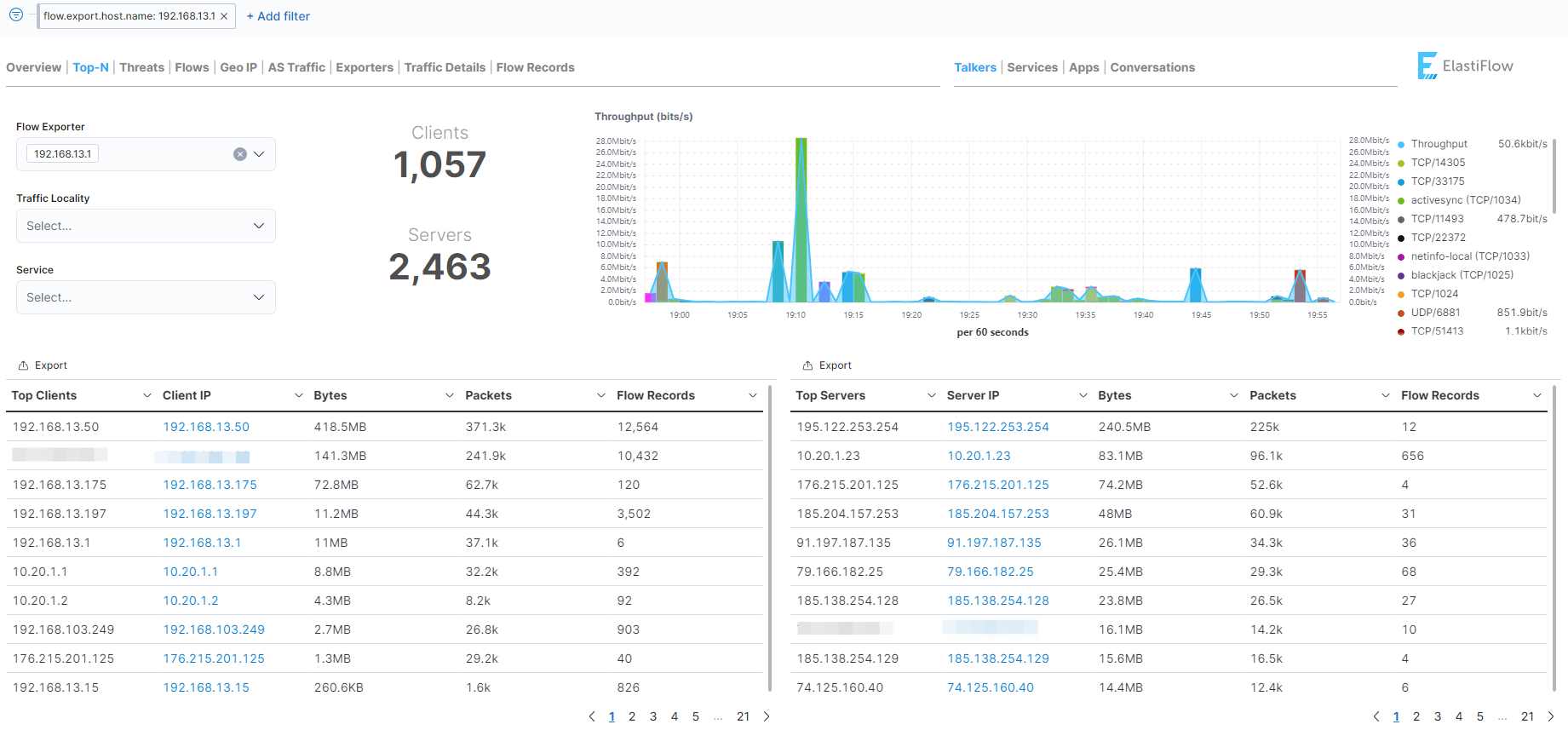
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
{kind=link}
Я уже неоднократно писал, что в качестве сервера для совместного редактирования документов обычно использую Onlyoffice, если получается вписаться в его бесплатные лимиты. Написал несколько статей по этой теме.
Вчера была рассылка, в которой упоминалось про обновление Android приложения для работы с документами. Я решил попробовать. Раньше даже не пытался это сделать. Установил приложение, подключился к своему порталу. Работает все очень неплохо. Понятно, что со смартфона редактировать документы и тем более таблицы не очень удобно просто в силу маленького размера экрана. Но если надо что-то поправить и посмотреть, то никаких проблем.
Так что имейте ввиду, если кому-то нужен подобный функционал. Onlyoffice хороший self-hosted продукт для использования приватного сервера документов. Не без проблем и глюков, но лучше все равно ничего нет.
#onlyoffice
Вчера была рассылка, в которой упоминалось про обновление Android приложения для работы с документами. Я решил попробовать. Раньше даже не пытался это сделать. Установил приложение, подключился к своему порталу. Работает все очень неплохо. Понятно, что со смартфона редактировать документы и тем более таблицы не очень удобно просто в силу маленького размера экрана. Но если надо что-то поправить и посмотреть, то никаких проблем.
Так что имейте ввиду, если кому-то нужен подобный функционал. Onlyoffice хороший self-hosted продукт для использования приватного сервера документов. Не без проблем и глюков, но лучше все равно ничего нет.
#onlyoffice
{kind=link}
Продолжаю обзор бесплатных self-hosted решений для командной работы с паролями. Сегодня речь пойдёт о psono. Я много раз слышал его упоминание в комментариях к предыдущим статьям этой серии, так что решил посмотреть на него.
Это полностью open source проект. Доступны исходники мобильных и обычных клиентов, а также сервера. Есть 2 редакции: Community Edition (CE) и Enterprise Edition (EE). Первая без ограничений, но функционал беден. Нет ни интеграции ldap, ни логов аудита. Редакция EE все это имеет, но бесплатна только для 10-ти пользователей. Дальше уже нужно лицензии на каждого пользователя приобретать.
Из особенностей psono я заметил возможность встроенной интеграции с файловым хранилищем на базе различных технологий (s3, ftp, sftp и т.д.) для хранения зашифрованных файлов. Причём можно не только подключать что-то стороннее, но и поднимать свой psonofileserver с функционалом HA и Failover. Было удивительно всё это видеть в данном продукте. Если кто-то все это настраивал и использовал, то скажите, что это за решение. В чём его смысл и стоит ли пользоваться. Я не стал тратить время на его настройку и проверку.
Второй полезной особенностью является встроенная интеграция с сервисом haveibeenpwned.com, который позволяет автоматически проверять ваши пароли на нахождение в публичных базах.
Сам psono достаточно просто поднимается в Docker. Но перед этим ему нужна будет база данных Postgres. Я сначала начал всё это настраивать у себя, но когда поднял сервер, понял, что он выполняет роль только бэкенда. Далее нужно ставить отдельно клиент для администрирования (веб панель) и для пользователей (веб панель или приложение). Понял, что муторно всё это делать, и пошел регистрироваться в Demo. Там и посмотрел, как всё выглядит на практике.
Сначала прохладно отнёсся к psono, но потом, когда вник в его структуру и особенности, он мне показался весьма интересным. Распределённая структура приложения будет скорее плюсом, чем минусом, особенно для больших распределённых команд. Удобнее настроить и ограничить доступ. Да и в целом разделение бэкенда и фронта для подобного продукта выглядит разумным подходом.
Сайт - https://psono.com/
Документация - https://doc.psono.com/
DockerHub - https://hub.docker.com/r/psono/psono-server/
Исходники - https://gitlab.com/psono
Demo - https://www.psono.pw/
#password #selfhosted
Это полностью open source проект. Доступны исходники мобильных и обычных клиентов, а также сервера. Есть 2 редакции: Community Edition (CE) и Enterprise Edition (EE). Первая без ограничений, но функционал беден. Нет ни интеграции ldap, ни логов аудита. Редакция EE все это имеет, но бесплатна только для 10-ти пользователей. Дальше уже нужно лицензии на каждого пользователя приобретать.
Из особенностей psono я заметил возможность встроенной интеграции с файловым хранилищем на базе различных технологий (s3, ftp, sftp и т.д.) для хранения зашифрованных файлов. Причём можно не только подключать что-то стороннее, но и поднимать свой psonofileserver с функционалом HA и Failover. Было удивительно всё это видеть в данном продукте. Если кто-то все это настраивал и использовал, то скажите, что это за решение. В чём его смысл и стоит ли пользоваться. Я не стал тратить время на его настройку и проверку.
Второй полезной особенностью является встроенная интеграция с сервисом haveibeenpwned.com, который позволяет автоматически проверять ваши пароли на нахождение в публичных базах.
Сам psono достаточно просто поднимается в Docker. Но перед этим ему нужна будет база данных Postgres. Я сначала начал всё это настраивать у себя, но когда поднял сервер, понял, что он выполняет роль только бэкенда. Далее нужно ставить отдельно клиент для администрирования (веб панель) и для пользователей (веб панель или приложение). Понял, что муторно всё это делать, и пошел регистрироваться в Demo. Там и посмотрел, как всё выглядит на практике.
Сначала прохладно отнёсся к psono, но потом, когда вник в его структуру и особенности, он мне показался весьма интересным. Распределённая структура приложения будет скорее плюсом, чем минусом, особенно для больших распределённых команд. Удобнее настроить и ограничить доступ. Да и в целом разделение бэкенда и фронта для подобного продукта выглядит разумным подходом.
Сайт - https://psono.com/
Документация - https://doc.psono.com/
DockerHub - https://hub.docker.com/r/psono/psono-server/
Исходники - https://gitlab.com/psono
Demo - https://www.psono.pw/
#password #selfhosted
{kind=link}
В мире Unix и Linux существует полезная утилита at, о которой многие даже не слышали. Я редко где-то вижу, чтобы её использовали. Сам я с ней знаком еще со времён Freebsd. Это планировщик наподобие cron, используется только для разовых задач.
Например, с помощью at можно запланировать откат правил фаервола через 5 минут, если что-то пошло не так. Именно для этой задачи я с at и познакомился, пока не узнал, что в Freebsd есть встроенный скрипт change_rules.sh для безопасной настройки правил ipfw.
Для того, чтобы планировщик at работал, должен быть запущен демон atd. Проверить можно через systemd:
Создание задания на выполнение в 20:07:
Дальше откроется простая оболочка, где можно ввести текст. Напишите команду, которую хотите выполнить:
Затем нажмите ctrl+shift+d для сохранения задания. Получите об этом информацию:
Можно автоматом создать эту же задачу одной командой через pipe:
Посмотреть очередь задач можно так:
Подробности задачи:
Удалить задачу:
Когда будете писать команды, используйте полные пути к бинарникам, чтобы не было проблем с несуществующим path. Лог выполненных команд можно посмотреть там же, куда стекаются логи cron. По крайней мере в Centos.
Утилиту at любят использовать всякие зловреды, чтобы маскировать свою деятельность. Про cron все знают и помнят, поэтому сразу туда идут проверять подозрительную активность. А вместо этого вирус может насоздавать кучу задач at, которые не сразу догадаются посмотреть.
Я, когда подключаюсь к незнакомым серверам, чаще всего сразу проверяю очередь заданий atq. Мало ли, какие там сюрпризы могут быть.
С помощью файлов /etc/at.allow и /etc/at.deny можно ограничивать список пользователей, которым разрешено использовать at.
#terminal
Например, с помощью at можно запланировать откат правил фаервола через 5 минут, если что-то пошло не так. Именно для этой задачи я с at и познакомился, пока не узнал, что в Freebsd есть встроенный скрипт change_rules.sh для безопасной настройки правил ipfw.
Для того, чтобы планировщик at работал, должен быть запущен демон atd. Проверить можно через systemd:
# systemctl status atdСоздание задания на выполнение в 20:07:
# at 20:07Дальше откроется простая оболочка, где можно ввести текст. Напишите команду, которую хотите выполнить:
at> /usr/bin/echo "Hello" > /tmp/hello.txtЗатем нажмите ctrl+shift+d для сохранения задания. Получите об этом информацию:
at> <EOT>job 6 at Wed Oct 20 20:07:00 2021Можно автоматом создать эту же задачу одной командой через pipe:
echo '/usr/bin/echo "Hello" > /tmp/hello.txt' | at 20:55Посмотреть очередь задач можно так:
# atqПодробности задачи:
# at -c 7Удалить задачу:
# atrm 7Когда будете писать команды, используйте полные пути к бинарникам, чтобы не было проблем с несуществующим path. Лог выполненных команд можно посмотреть там же, куда стекаются логи cron. По крайней мере в Centos.
Утилиту at любят использовать всякие зловреды, чтобы маскировать свою деятельность. Про cron все знают и помнят, поэтому сразу туда идут проверять подозрительную активность. А вместо этого вирус может насоздавать кучу задач at, которые не сразу догадаются посмотреть.
Я, когда подключаюсь к незнакомым серверам, чаще всего сразу проверяю очередь заданий atq. Мало ли, какие там сюрпризы могут быть.
С помощью файлов /etc/at.allow и /etc/at.deny можно ограничивать список пользователей, которым разрешено использовать at.
#terminal
{kind=link}
👍5
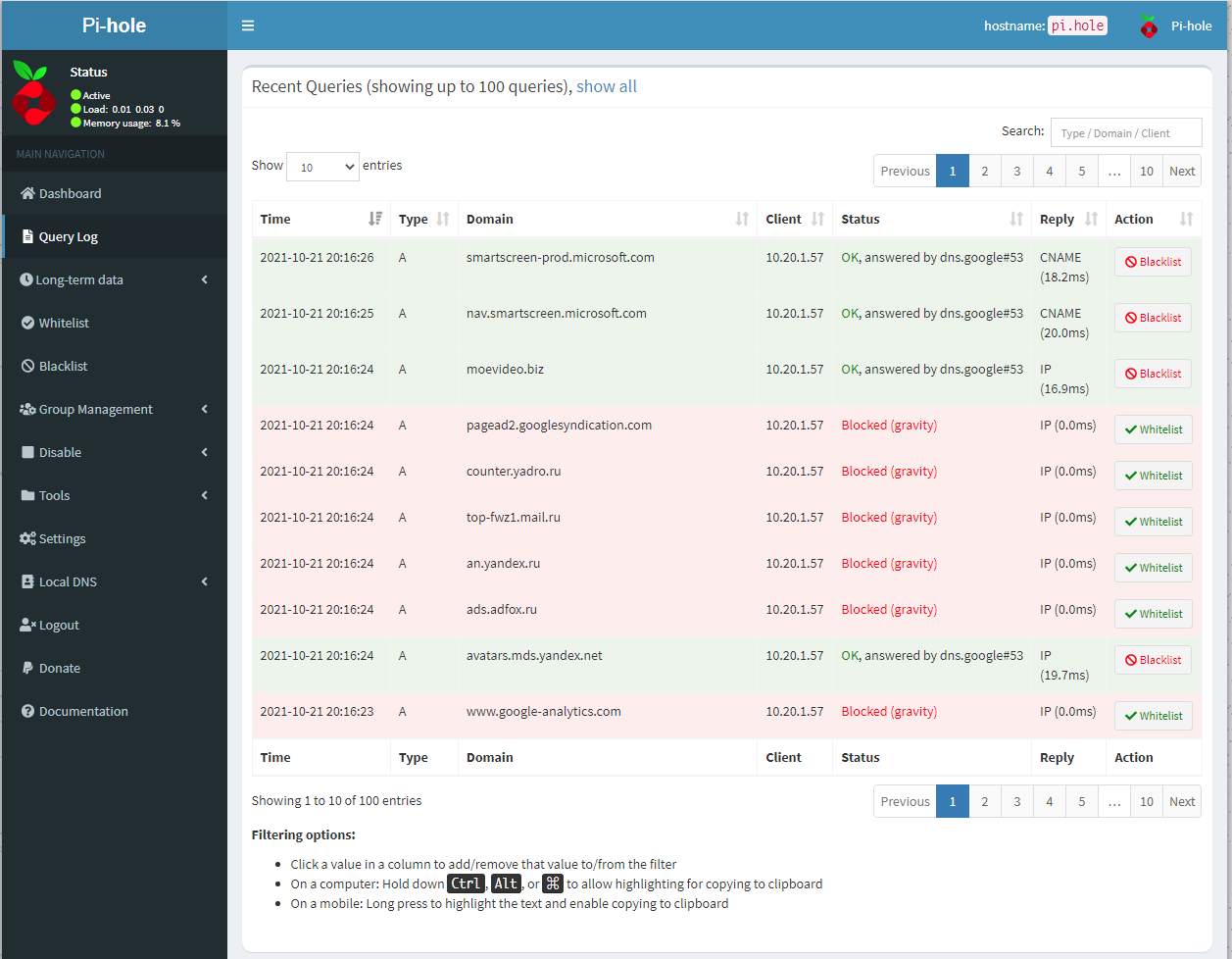
Есть простой и эффективный фильтрующий DNS сервер Pi-hole. Построен на базе известного dnsmasq. Pi-hole вполне можно использовать для реализации функций dns и dhcp сервера с удобным веб интерфейсом.
Основная задумка Pi-hole - фильтрация dns запросов для блокировки рекламы. Я прохладно отношусь к подобным решениям на базе DNS. Если что-то будет глючить на сайте из-за блокировки, нельзя быстро настроить исключение. Надо либо dns сервер менять, либо идти в настройки сервера и разбираться, что именно приводит к проблемам.
Pi-hole имеет очень удобный веб интерфейс. Его даже без блокировки рекламы имеет смысл использовать, если нужен функционал dns сервера с удобным управлением. Запускать проще всего в Docker. Буквально за одну команду всё стартует и начинает работать. Есть готовый скрипт для этого.
Подобные решения удобно использовать, чтобы быстро понять, куда в сеть обращается программа или устройство. Запускаете контейнер с Pi-hole, назначаете его в качестве dns на целевой машине. Потом в веб интерфейсе проверяете все dns запросы.
Такой же функционал есть у adguard. Тестировал его. Запускается тоже очень быстро и просто в контейнере. Лично мне веб интерфейс Pi-hole понравился больше.
Сайт - https://pi-hole.net/
Исходники - https://github.com/pi-hole/pi-hole
Основная задумка Pi-hole - фильтрация dns запросов для блокировки рекламы. Я прохладно отношусь к подобным решениям на базе DNS. Если что-то будет глючить на сайте из-за блокировки, нельзя быстро настроить исключение. Надо либо dns сервер менять, либо идти в настройки сервера и разбираться, что именно приводит к проблемам.
Pi-hole имеет очень удобный веб интерфейс. Его даже без блокировки рекламы имеет смысл использовать, если нужен функционал dns сервера с удобным управлением. Запускать проще всего в Docker. Буквально за одну команду всё стартует и начинает работать. Есть готовый скрипт для этого.
Подобные решения удобно использовать, чтобы быстро понять, куда в сеть обращается программа или устройство. Запускаете контейнер с Pi-hole, назначаете его в качестве dns на целевой машине. Потом в веб интерфейсе проверяете все dns запросы.
Такой же функционал есть у adguard. Тестировал его. Запускается тоже очень быстро и просто в контейнере. Лично мне веб интерфейс Pi-hole понравился больше.
Сайт - https://pi-hole.net/
Исходники - https://github.com/pi-hole/pi-hole
{kind=link}
👍4
Как на самом деле пишется и проверяется код в больших технологичных компаниях? Ответ в видео.
https://www.youtube.com/watch?v=rR4n-0KYeKQ
Для тех, кто не понял, поясню. Чувак (junior) что-то накодил, но его код не проходил один тест. Он просто удалил этот тест, а тот, кто должен был проверять его работу (senior), не обратил внимание, что тестов стало на один меньше.
Нет теста, нет ошибки, нет проблемы.
LGTM = Looks good to me.
#юмор
https://www.youtube.com/watch?v=rR4n-0KYeKQ
Для тех, кто не понял, поясню. Чувак (junior) что-то накодил, но его код не проходил один тест. Он просто удалил этот тест, а тот, кто должен был проверять его работу (senior), не обратил внимание, что тестов стало на один меньше.
Нет теста, нет ошибки, нет проблемы.
LGTM = Looks good to me.
#юмор
YouTube
how we write/review code in big tech companies
📱 SOCIAL MEDIA
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
https://www.instagram.com/jomakaze/
https://twitter.com/jomakaze
https://www.facebook.com/jomakaze
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
https://www.instagram.com/jomakaze/
https://twitter.com/jomakaze
https://www.facebook.com/jomakaze
👍2
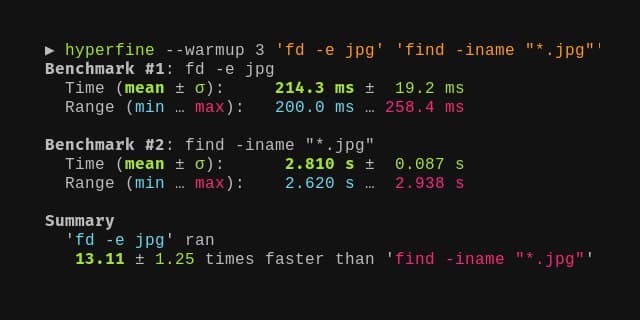
Иногда бывает нужно замерить время выполнения какой-то команды. Есть специальная утилита, в которой это сделать очень удобно - Hyperfine. Это более продвинутый аналог time. Если запустить её без дополнительных параметров, то по умолчанию она не менее 10 раз выполнит заданную команду и выведет среднее время выполнения.
Проще всего проверить работу программы на команде sleep:
Где это может пригодиться кому-то из вас, не знаю. Первое, что приходит на ум, в мониторинге. Например, я иногда делаю item в Zabbix для мониторинга за локальным nginx следующего типа. Через curl дергал https://localhost/nginx-status и замерял время отклика. Ставил триггер на отклонение от среднего значения.
Для этих целей удобно использовать hyperfine, так как он умеет экспортировать результат в json. В том же Zabbix можно сразу же распарсить его в постобработке через jsonpath и записать результат. Если по нескольку раз дергать какой-то url и замерять через hyperfine, то точность мониторинга будет выше, чем есть в стандартном функционале.
На выходе получите сразу же min, max, медианное время выполнения запроса. Если любопытно, можете просто сравнить отклик сайта по http и https.
В общем, утилита интересная, может пригодиться в хозяйстве. Есть deb пакет, всё остальное из репозитория можно взять. Это просто бинарник.
# wget https://github.com/sharkdp/hyperfine/releases/download/v1.12.0/hyperfine_1.12.0_amd64.deb
# dpkg -i hyperfine_1.12.0_amd64.deb
Исходники - https://github.com/sharkdp/hyperfine
#terminal #утилита
Проще всего проверить работу программы на команде sleep:
# hyperfine 'sleep 0.5'Benchmark 1: sleep 0.5 Time (mean ± σ): 501.3 ms ± 0.2 ms [User: 1.2 ms, System: 0.1 ms] Range (min … max): 501.0 ms … 501.8 ms 10 runsГде это может пригодиться кому-то из вас, не знаю. Первое, что приходит на ум, в мониторинге. Например, я иногда делаю item в Zabbix для мониторинга за локальным nginx следующего типа. Через curl дергал https://localhost/nginx-status и замерял время отклика. Ставил триггер на отклонение от среднего значения.
Для этих целей удобно использовать hyperfine, так как он умеет экспортировать результат в json. В том же Zabbix можно сразу же распарсить его в постобработке через jsonpath и записать результат. Если по нескольку раз дергать какой-то url и замерять через hyperfine, то точность мониторинга будет выше, чем есть в стандартном функционале.
# hyperfine 'curl https://127.0.0.1:80' --export-json ~/curl.jsonНа выходе получите сразу же min, max, медианное время выполнения запроса. Если любопытно, можете просто сравнить отклик сайта по http и https.
# hyperfine 'curl https://127.0.0.1' 'curl https://127.0.0.1'В общем, утилита интересная, может пригодиться в хозяйстве. Есть deb пакет, всё остальное из репозитория можно взять. Это просто бинарник.
# wget https://github.com/sharkdp/hyperfine/releases/download/v1.12.0/hyperfine_1.12.0_amd64.deb
# dpkg -i hyperfine_1.12.0_amd64.deb
Исходники - https://github.com/sharkdp/hyperfine
#terminal #утилита
{kind=link}
У меня есть статья про работу с Google API на примере сбора данных оттуда в Zabbix. Она разбита на 2 части. В первой я разбираю, как в целом работать с Google API на основе его токенов. Там очень мутная тема и разобраться с ней не очень просто. Токены временные, их надо постоянно обновлять, чтобы всё автоматизировать.
Во второй части я показываю, как в Zabbix забирать данные из Adsense API. Так как у меня есть доход с баннеров на сайте, я собираю статистику по ним в Zabbix. Делюсь там скриптами и готовым шаблоном с несколькими метриками по доходу и балансу. По аналогии не трудно сделать всё остальное, что вам может понадобиться.
Недавно Google сменил API с версии 1.4 на 2.0. Поменялось там почти всё, так что пришлось и скрипты, и шаблоны переделывать. Обновил статью. Информация там хоть и не сильно востребованная, так как тема специфичная, но уникальная. Нигде никакой информации по теме вообще не нашёл, так что во всём разбирался сам.
https://serveradmin.ru/dostup-k-google-api-adsense-cherez-zabbix/
Во второй части я показываю, как в Zabbix забирать данные из Adsense API. Так как у меня есть доход с баннеров на сайте, я собираю статистику по ним в Zabbix. Делюсь там скриптами и готовым шаблоном с несколькими метриками по доходу и балансу. По аналогии не трудно сделать всё остальное, что вам может понадобиться.
Недавно Google сменил API с версии 1.4 на 2.0. Поменялось там почти всё, так что пришлось и скрипты, и шаблоны переделывать. Обновил статью. Информация там хоть и не сильно востребованная, так как тема специфичная, но уникальная. Нигде никакой информации по теме вообще не нашёл, так что во всём разбирался сам.
https://serveradmin.ru/dostup-k-google-api-adsense-cherez-zabbix/
Server Admin
Доступ к Google API AdSense через Zabbix | serveradmin.ru
https://accounts.google.com/o/oauth2/auth?client_id=[client_id]&redirect_uri=urn:ietf:wg:oauth:2.0:oob&scope=[scope]&response_type=code. В моем случае ссылка получается такая:...
Если вы еще не поняли, что JavaScript захватывает мир (привет фреймворкам на его основе и тормозным приложениям), у вас есть шанс запрыгнуть в уходящий поезд. Предлагаю вашему вниманию игру Screeps: World.
В этой игре вам придётся программировать искусственный интеллект юнитов на JavaScript. Игра идёт в реальном времени, это многопользовательская стратегия. Так что чем лучше закодите поведение своих болванчиков, тем больше они сделают без вашего участия.
Немного отзывов:
Рекомендую!
- Баги? Твой код - твои баги
- Геймплей? Твой код - твой геймплей
- Оптимизация? Твой код - твоя оптимизация
- Обновы? Твой код - твои обновы
- Игра? Твой код - твоя игра
Самое топовое ММО из всех что я видел!
Тебе не нравится тупой ии в новой ртс?Тебе понравился колобот но хочется больше ХАРДКОРА?А может быть ты соскучился по томагочи?Или ищешь игру которая похожа на работу?Дружище! ты пришел по адресу.
Отличная игра.
Никак руки не доходили до JS. Работаю со стеками, где нет JS (в 2017 без JS, серьезно?).
А теперь вместо того, чтобы работать - пишу скриптики моим ботам на JS.
Вместо того, чтобы проводить время с семьей и друзьями - пишу скриптики моим ботам.
Вместо того, чтобы спать - пишу скриптики моим ботам.
Разработчики игры, кстати, русскоязычные.
Steam - https://store.steampowered.com/app/464350/Screeps_World/
Torrent 😱 - https://byrut.org/11635-screeps.html
Трейлер - https://www.youtube.com/watch?v=ZboTgOajnGg
#игра
В этой игре вам придётся программировать искусственный интеллект юнитов на JavaScript. Игра идёт в реальном времени, это многопользовательская стратегия. Так что чем лучше закодите поведение своих болванчиков, тем больше они сделают без вашего участия.
Немного отзывов:
Рекомендую!
- Баги? Твой код - твои баги
- Геймплей? Твой код - твой геймплей
- Оптимизация? Твой код - твоя оптимизация
- Обновы? Твой код - твои обновы
- Игра? Твой код - твоя игра
Самое топовое ММО из всех что я видел!
Тебе не нравится тупой ии в новой ртс?Тебе понравился колобот но хочется больше ХАРДКОРА?А может быть ты соскучился по томагочи?Или ищешь игру которая похожа на работу?Дружище! ты пришел по адресу.
Отличная игра.
Никак руки не доходили до JS. Работаю со стеками, где нет JS (в 2017 без JS, серьезно?).
А теперь вместо того, чтобы работать - пишу скриптики моим ботам на JS.
Вместо того, чтобы проводить время с семьей и друзьями - пишу скриптики моим ботам.
Вместо того, чтобы спать - пишу скриптики моим ботам.
Разработчики игры, кстати, русскоязычные.
Steam - https://store.steampowered.com/app/464350/Screeps_World/
Torrent 😱 - https://byrut.org/11635-screeps.html
Трейлер - https://www.youtube.com/watch?v=ZboTgOajnGg
#игра
{kind=link}
👍3
Мне для автоматизации с помощью bash скриптов понадобилось получить информацию о прошлом месяце, а именно:
◽ год
◽ номер месяца
◽ первый и последний день
Набросал быстро скрипт, которым делюсь с вами. Оптимальный способ не искал, остановился, как только максимально быстро получил желаемый результат.
Тестировать можно с помощью faketime:
Рекомендую забрать в закладки. Если пишите на bash, рано или поздно пригодится.
#bash #script
◽ год
◽ номер месяца
◽ первый и последний день
Набросал быстро скрипт, которым делюсь с вами. Оптимальный способ не искал, остановился, как только максимально быстро получил желаемый результат.
#!/bin/bashLAST_MONTH=$(date "+%F" -d "$(date +'%Y-%m-01') -1 month")YEAR=$(date "+%Y" -d "$(date +'%Y-%m-01') -1 month")MONTH=$(date "+%m" -d "$(date +'%Y-%m-01') -1 month")DAY_START=$(date "+%d" -d "$(date +'%Y-%m-01') -1 month")DAY_END=$(date "+%d" -d "$LAST_MONTH +1 month -1 day")echo "Полная дата: $LAST_MONTH"echo "Год прошлого месяца: $YEAR"echo "Номер прошлого месяца: $MONTH"echo "Первый день прошлого месяца: $DAY_START"echo "Последний день прошлого месяца: $DAY_END"Тестировать можно с помощью faketime:
# faketime '2021-12-24 08:15:42' last-month.shРекомендую забрать в закладки. Если пишите на bash, рано или поздно пригодится.
#bash #script
{kind=link}
👍2
После подключения к Linux серверу, на нём останутся следы вашей активности. Вопрос очистки истории команд терминала я уже касался в прошлой заметке. Сейчас рассмотрю, какая еще информация остаётся о вас в самой системе.
Команда last покажет последних подключившихся пользователей, а также события reboot или shutdown.
Информацию команда берёт из бинарного файла /var/log/wtmp, которую туда пишет программа login.
Команда lastlog покажет историю подключений каждого пользователя системы. Причем в том же порядке, как они записаны в файле /etc/passwd.
Информацию команда берёт из бинарного файла /var/log/lastlog.
Если вы использовали неверные учётные данные при подключении, то информацию об этом можно посмотреть командой lastb.
Информацию команда берёт из бинарного файла /var/log/btmp.
Также информация о ваших подключениях будет в логе сервиса sshd. В rpm дистрибутивах это обычно /var/log/secure, в deb - /var/log/auth.log. Это текстовые файлы, можно посмотреть любым редактором.
Если хотите почистить за собой следы, то эти файлы можно просто обнулить:
Если же следите за безопасностью, то обязательно организуйте удаленную передачу информации из этих файлов куда-то во вне. Поможет расследовать инциденты.
#terminal #security
Команда last покажет последних подключившихся пользователей, а также события reboot или shutdown.
# lastroot pts/0 192.168.13.197 Sun Oct 23 22:45 still logged inИнформацию команда берёт из бинарного файла /var/log/wtmp, которую туда пишет программа login.
Команда lastlog покажет историю подключений каждого пользователя системы. Причем в том же порядке, как они записаны в файле /etc/passwd.
# lastlogUsername Port From Latestroot pts/0 192.168.13.197 Sun Oct 23 22:45:11 +0300 2021Информацию команда берёт из бинарного файла /var/log/lastlog.
Если вы использовали неверные учётные данные при подключении, то информацию об этом можно посмотреть командой lastb.
# lastbuser1 ssh:notty 192.168.13.197 Sun Oct 23 23:04 - 23:04 (00:00)Информацию команда берёт из бинарного файла /var/log/btmp.
Также информация о ваших подключениях будет в логе сервиса sshd. В rpm дистрибутивах это обычно /var/log/secure, в deb - /var/log/auth.log. Это текстовые файлы, можно посмотреть любым редактором.
Если хотите почистить за собой следы, то эти файлы можно просто обнулить:
# echo > /var/log/wtmp# echo > /var/log/btmp# echo > /var/log/lastlog# echo > /var/log/secureЕсли же следите за безопасностью, то обязательно организуйте удаленную передачу информации из этих файлов куда-то во вне. Поможет расследовать инциденты.
#terminal #security
{kind=link}
Хорошее наглядное видео от Zabbix на маленькую узкую тему. В видео за 2 минуты показано, как настроить анализ логов веб сервера apache и отправлять уведомления при появлении там ошибки, то есть слова error.
В записи нет никакого упрощения. Всё реально делается очень быстро и просто. Будет актуально для любых текстовых логов. Я часто пользуюсь такой возможностью. Нужно только понимать, что этот метод не подходит для очень больших логов, а также для их исторического хранения и анализа. Классическая sql база плохо подходит для хранения объемных логов. Для этого надо использовать специализированные решения.
В описываемом примере лог хранится только сутки, так что его размер не очень критичен. Функционал используется конкретно для оповещения о проблеме.
https://www.youtube.com/watch?v=rrgz9unRtSk
#zabbix #видео
В записи нет никакого упрощения. Всё реально делается очень быстро и просто. Будет актуально для любых текстовых логов. Я часто пользуюсь такой возможностью. Нужно только понимать, что этот метод не подходит для очень больших логов, а также для их исторического хранения и анализа. Классическая sql база плохо подходит для хранения объемных логов. Для этого надо использовать специализированные решения.
В описываемом примере лог хранится только сутки, так что его размер не очень критичен. Функционал используется конкретно для оповещения о проблеме.
https://www.youtube.com/watch?v=rrgz9unRtSk
#zabbix #видео
YouTube
Zabbix Handy Tips: ''Find" history function
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In Zabbix 5.4 release, we have introduced a new trigger expression syntax and added over 60 new trigger functions. One of them is the new history function “find” and…
Pspy - интересный и полезный инструмент командной строки, предназначенный для наблюдения за процессами без прав root. С его помощью можно видеть команды, выполняемые другими пользователями, в том числе системными. Программа наглядно демонстрирует, почему не стоит светить паролями, постоянными токенами и т.д. в виде аргументов к командам.
Работает она очень просто. Идём в репозиторий и скачиваем исполняемый файл под обычным пользователем.
# wget https://github.com/DominicBreuker/pspy/releases/download/v1.2.0/pspy64
# chmod +x pspy64
# ./pspy64
А теперь подключаемся второй вкладкой и запускаем dump базы mysql от рута с передачей пароля через консоль. Результат увидите в прилагаемом скриншоте.
Я совсем недавно узнал про эту утилиту. Раньше не предполагал, что так просто можно утянуть процессы root непривилегированным пользователем. А дело вон как обстоит.
#terminal #security
Работает она очень просто. Идём в репозиторий и скачиваем исполняемый файл под обычным пользователем.
# wget https://github.com/DominicBreuker/pspy/releases/download/v1.2.0/pspy64
# chmod +x pspy64
# ./pspy64
А теперь подключаемся второй вкладкой и запускаем dump базы mysql от рута с передачей пароля через консоль. Результат увидите в прилагаемом скриншоте.
Я совсем недавно узнал про эту утилиту. Раньше не предполагал, что так просто можно утянуть процессы root непривилегированным пользователем. А дело вон как обстоит.
#terminal #security
{kind=link}
👍3
Забавно видеть прокачанный мониторинг от Beeline на базе Zabbix с кучей активных дефолтных триггеров, которые в первую очередь стоит либо откалибровать, либо отключить. Ну кому сейчас нужен триггер на swap (less then 20% free 🙀), когда его чаще всего вообще нет?
По памяти и заполненности диска тоже активны дефолтные триггеры, которые чаще всего не годятся в исходном виде с %, так как памяти может быть 16 Гб, а может 512 Гб. Видно, что никто особо с мониторингом и не заморачивался. Взяли дефолтный Zabbix, дефолтный плагин для Grafana и связали их.
В статье всё это преподносится как замена решениям за $500 000 и $1 000 000. Zabbix может заменить все эти решения, но шаблоны придётся всё же свои написать полностью, а не взять готовые с метриками и триггерами для условно дефолтной инфраструктуры. Когда я делаю кастомизированный мониторинг по ТЗ, шаблоны собираю с нуля, убирая всё лишнее и меняя дефолты под текущие условия.
https://habr.com/ru/company/beeline/blog/585536/
#zabbix
По памяти и заполненности диска тоже активны дефолтные триггеры, которые чаще всего не годятся в исходном виде с %, так как памяти может быть 16 Гб, а может 512 Гб. Видно, что никто особо с мониторингом и не заморачивался. Взяли дефолтный Zabbix, дефолтный плагин для Grafana и связали их.
В статье всё это преподносится как замена решениям за $500 000 и $1 000 000. Zabbix может заменить все эти решения, но шаблоны придётся всё же свои написать полностью, а не взять готовые с метриками и триггерами для условно дефолтной инфраструктуры. Когда я делаю кастомизированный мониторинг по ТЗ, шаблоны собираю с нуля, убирая всё лишнее и меняя дефолты под текущие условия.
https://habr.com/ru/company/beeline/blog/585536/
#zabbix
👍3
Решил сделать напоминание о приятной халяве от Oracle, про которую писал уже, но достаточно давно. Думаю, многие заметку не видели или не помнят. Кратко скажу, что вы можете получить бесплатно 2 полноценные виртуальные машины с внешними ip у них в облаке навечно бесплатно. Читайте в прошлой заметке, как именно это сделать.
Поднимаю эту тему, чтобы актуализировать информацию. Скажите, кто после прошлого моего сообщения смог там зарегистрироваться и получить виртуалки? Я лично ими до сих пор пользуюсь. Работают нормально. Использую их для тестов и под vpn. Очень доволен. Судя по описанию программы, условия остались те же и обе виртуалки обещают.
Попробуйте, может вам повезет зарегистрироваться и получить их. После моей прошлой заметки у кого-то получилось, а кого-то динамить начали с подтверждением учетной записи и платёжной карты. Её нужно будет добавить и подтвердить. Я использовал пластиковую от яндекс.денег (теперь yoomoney) и потом заблочил у неё онлайн платежи, так как пользуюсь только в офлайне ей.
#бесплатно
Поднимаю эту тему, чтобы актуализировать информацию. Скажите, кто после прошлого моего сообщения смог там зарегистрироваться и получить виртуалки? Я лично ими до сих пор пользуюсь. Работают нормально. Использую их для тестов и под vpn. Очень доволен. Судя по описанию программы, условия остались те же и обе виртуалки обещают.
Попробуйте, может вам повезет зарегистрироваться и получить их. После моей прошлой заметки у кого-то получилось, а кого-то динамить начали с подтверждением учетной записи и платёжной карты. Её нужно будет добавить и подтвердить. Я использовал пластиковую от яндекс.денег (теперь yoomoney) и потом заблочил у неё онлайн платежи, так как пользуюсь только в офлайне ей.
#бесплатно
{kind=link}
Не совсем по теме канала информация, но тем не менее, мне кажется, она многим будет полезна. Речь пойдёт про расширение для браузера OneTab. С недавних пор мой основной браузер - Microsoft Edge. Причём вообще без плагинов. Я давно уже обхожусь возможностями чистого браузера. Для работы мне не нужны никакие расширения. Все плагины собраны в Firefox, который я иногда запускаю.
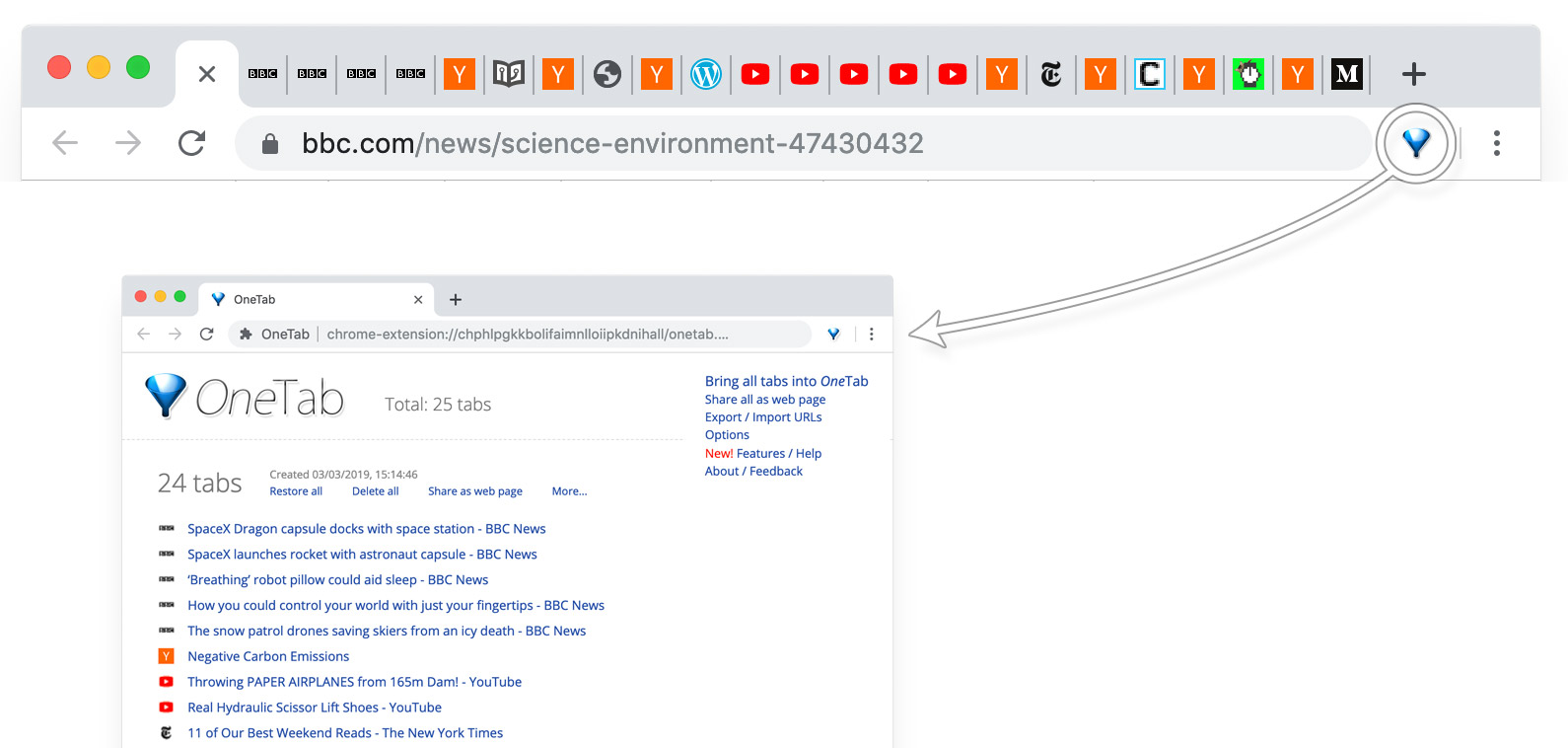
Недавно сделал исключение для указанного дополнения OneTab. Он обладает очень простым функционалом - создаёт html страницу и помещает на неё все открытые вкладки в виде ссылок, а сами вкладки закрывает. Я знаю, что многие пользователи любят открывать десятки, а некоторые и сотни вкладок. Мне лично это мешает. Когда вкладок больше 20, снижается продуктивность. В этот момент я обычно запускаю вторую копию браузера и работаю в ней. А кучу вкладок оставляю в отдельном окне, если они еще нужны.
Onetab позволяет избавиться от практики нескольких копий браузера. Когда вкладки начинают мешать, я их просто выгружаю в html страницу. Там они формируются в простом и наглядном списке, куда влезают полные имена заголовков. Очень удобно ориентироваться в ссылках.
В общем, советую попробовать. Мне очень зашел инструмент. Теперь редко когда бывает открыто более 10-ти вкладок. Обычно 5-7. У некоторых вижу браузеры с десятками открытых вкладок, на которых кроме иконок ничего не видно. По ним даже мышкой трудно попасть. Ума не приложу, зачем держать такое количество вкладок. В них же неудобно разбираться.
Chrome web store
#разное
Недавно сделал исключение для указанного дополнения OneTab. Он обладает очень простым функционалом - создаёт html страницу и помещает на неё все открытые вкладки в виде ссылок, а сами вкладки закрывает. Я знаю, что многие пользователи любят открывать десятки, а некоторые и сотни вкладок. Мне лично это мешает. Когда вкладок больше 20, снижается продуктивность. В этот момент я обычно запускаю вторую копию браузера и работаю в ней. А кучу вкладок оставляю в отдельном окне, если они еще нужны.
Onetab позволяет избавиться от практики нескольких копий браузера. Когда вкладки начинают мешать, я их просто выгружаю в html страницу. Там они формируются в простом и наглядном списке, куда влезают полные имена заголовков. Очень удобно ориентироваться в ссылках.
В общем, советую попробовать. Мне очень зашел инструмент. Теперь редко когда бывает открыто более 10-ти вкладок. Обычно 5-7. У некоторых вижу браузеры с десятками открытых вкладок, на которых кроме иконок ничего не видно. По ним даже мышкой трудно попасть. Ума не приложу, зачем держать такое количество вкладок. В них же неудобно разбираться.
Chrome web store
#разное
{kind=link}
👍3
Мои изменения стандартного шаблона для Windows в Zabbix
Если взять стандартный шаблон и применить его к виндовым хостам, получится так себе решение. Вас завалит практически бесполезными триггерами, плюс будет собираться куча ненужной информации. Ниже то, что я делаю практически всегда.
1️⃣ Отключаю правило автообнаружения служб Windows. Вообще не вижу смысла мониторить их все. Zabbix будет слать уведомления каждый раз, когда будет остановлена служба с параметром автозапуска. Вас завалит этими уведомлениями. Если нужен мониторинг какой-то службы, то настраиваю это отдельно.
2️⃣ Запускаю вручную автообнаружение сетевых интерфейсов на хосте и отключаю все те, что не нужны. А это большая часть. Наряду с физическим интерфейсом, там будет огромный список встроенных виртуальных. Все они попадут в мониторинг. Зачем это сделано по дефолту, я не понимаю. Мало того, что это бесполезная информация, так она еще и нехило забивает базу, а сбор нагружает сервер. Если у вас много Windows машин, в обязательном порядке отключить или изменить автообнаружение сетевых интерфейсов в исходном шаблоне. Это значительно снизит нагрузку на мониторинг.
3️⃣ Редактирую триггеры на занятое место на дисках. Здесь нет универсального совета, так как зависит от ваших условий. Обычно отключаю триггер на 80% и добавляю еще один критический на 95%.
4️⃣ Отключаю триггеры на время отклика диска. Эти значения сильно зависят от производительности дисков и по умолчанию толку от них нет. Если вам нужны эти уведомления, то триггеры надо калибровать в зависимости от средних значений конкретно ваших дисков.
5️⃣ Редактирую триггеры на использование оперативной памяти в зависимости от конкретных условий. Есть хосты, которые всегда работают с полной загрузкой памяти, буквально до 95-98%. Сразу отключаю триггер на использование swap.
Из основного всё, что вспомнил по ходу дела. А вообще, я стараюсь больше фокусироваться на мониторинге конечных приложений, а не системных метриках. Если приложение нормально работает, какая нам разница, что там какие-то всплески по CPU и отклику диска. Сейчас они есть, через пол часа их нет, а приложение работает нормально. Важны исторические данные для расследования, это да. А здесь и сейчас нужно реагировать на действительно важные события.
#zabbix
Если взять стандартный шаблон и применить его к виндовым хостам, получится так себе решение. Вас завалит практически бесполезными триггерами, плюс будет собираться куча ненужной информации. Ниже то, что я делаю практически всегда.
1️⃣ Отключаю правило автообнаружения служб Windows. Вообще не вижу смысла мониторить их все. Zabbix будет слать уведомления каждый раз, когда будет остановлена служба с параметром автозапуска. Вас завалит этими уведомлениями. Если нужен мониторинг какой-то службы, то настраиваю это отдельно.
2️⃣ Запускаю вручную автообнаружение сетевых интерфейсов на хосте и отключаю все те, что не нужны. А это большая часть. Наряду с физическим интерфейсом, там будет огромный список встроенных виртуальных. Все они попадут в мониторинг. Зачем это сделано по дефолту, я не понимаю. Мало того, что это бесполезная информация, так она еще и нехило забивает базу, а сбор нагружает сервер. Если у вас много Windows машин, в обязательном порядке отключить или изменить автообнаружение сетевых интерфейсов в исходном шаблоне. Это значительно снизит нагрузку на мониторинг.
3️⃣ Редактирую триггеры на занятое место на дисках. Здесь нет универсального совета, так как зависит от ваших условий. Обычно отключаю триггер на 80% и добавляю еще один критический на 95%.
4️⃣ Отключаю триггеры на время отклика диска. Эти значения сильно зависят от производительности дисков и по умолчанию толку от них нет. Если вам нужны эти уведомления, то триггеры надо калибровать в зависимости от средних значений конкретно ваших дисков.
5️⃣ Редактирую триггеры на использование оперативной памяти в зависимости от конкретных условий. Есть хосты, которые всегда работают с полной загрузкой памяти, буквально до 95-98%. Сразу отключаю триггер на использование swap.
Из основного всё, что вспомнил по ходу дела. А вообще, я стараюсь больше фокусироваться на мониторинге конечных приложений, а не системных метриках. Если приложение нормально работает, какая нам разница, что там какие-то всплески по CPU и отклику диска. Сейчас они есть, через пол часа их нет, а приложение работает нормально. Важны исторические данные для расследования, это да. А здесь и сейчас нужно реагировать на действительно важные события.
#zabbix
👍4
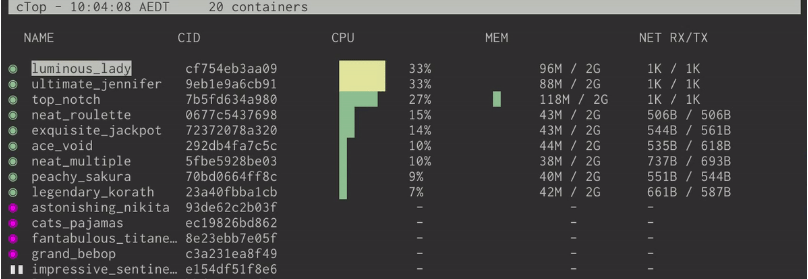
Очень удобная программа для просмотра используемых ресурсов контейнерами - Сtop. Это прям то, что мне очень не хватало при работе с контейнерами. Я за ними всегда через htop смотрел и другие инструменты общего назначение. А в ctop все метрики собраны в одно место для каждого контейнера. Очень удобно.
Docker обычно запускаю на Ubuntu, для неё есть репа:
После этого запускаете ctop и наслаждаетесь красотой. Можно вообще ничего не устанавливать локально, а запустить ctop в docker, пробросив ему docker.sock.
Помимо непосредственно отображения используемых ресурсов, можно выбрать контейнер и быстро посмотреть его логи, остановить/перезапустить или провалиться внутрь через exec shell. Если постоянно работаете с контейнерами, то программа must have, особенно для разработчиков, которые постоянно эти контейнеры гоняют. Посоветуйте им, спасибо скажут.
Репозиторий - https://github.com/bcicen/ctop
#docker
Docker обычно запускаю на Ubuntu, для неё есть репа:
# echo "deb https://packages.azlux.fr/debian/ buster main" \| tee /etc/apt/sources.list.d/azlux.list# wget -qO - https://azlux.fr/repo.gpg.key | apt-key add -# apt update# apt install docker-ctopПосле этого запускаете ctop и наслаждаетесь красотой. Можно вообще ничего не устанавливать локально, а запустить ctop в docker, пробросив ему docker.sock.
# docker run --rm -ti \ --name=ctop \ --volume /var/run/docker.sock:/var/run/docker.sock:ro \ quay.io/vektorlab/ctop:latestПомимо непосредственно отображения используемых ресурсов, можно выбрать контейнер и быстро посмотреть его логи, остановить/перезапустить или провалиться внутрь через exec shell. Если постоянно работаете с контейнерами, то программа must have, особенно для разработчиков, которые постоянно эти контейнеры гоняют. Посоветуйте им, спасибо скажут.
Репозиторий - https://github.com/bcicen/ctop
#docker
{kind=link}
Рассказываю про еще один инструмент для совместного хранения и использования паролей - KeePassXC. Это бесплатный мультиплатформенный форк известного KeePass, который я использую для своих паролей. Но при этом в KeePassXC есть уникальный функционал под названием KeeShare.
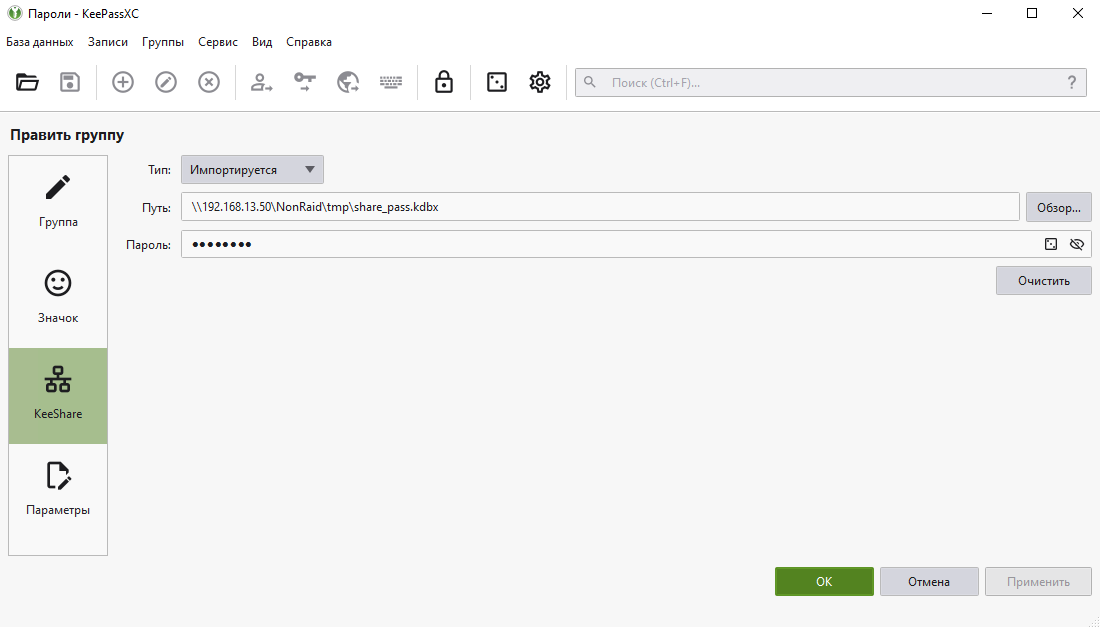
С помощью KeeShare вы можете один и тот же файл с паролями, к которому есть общий доступ, открыть в разных клиентах KeePassXC. При этом есть возможность ограничивать доступ, настраивать параметры синхронизации этого файла. Он может быть доступен для остальных в режиме только чтения или обоюдной синхронизации.
Я попробовал этот функционал. Настраивается просто. Положил файл с паролями на сетевой диск, подключил его к разным клиентам как отдельную папку в существующем локальном хранилище. Одному в режиме записи, второму - чтения.
Внешний вид KeePassXC лично мне не понравился по сравнению с классическим KeePass. Но тут уж выбирать не приходится. Подобных возможностей лично я ни в одной другой программе (не сервисе) для хранения паролей не видел. Приходилось просто на общий диск класть файл и кричать на весь кабинет, чтобы отпустили файл, когда в него что-то записать нужно было.
Сайт - https://keepassxc.org/
Исходники - https://github.com/keepassxreboot/keepassxc
#password
С помощью KeeShare вы можете один и тот же файл с паролями, к которому есть общий доступ, открыть в разных клиентах KeePassXC. При этом есть возможность ограничивать доступ, настраивать параметры синхронизации этого файла. Он может быть доступен для остальных в режиме только чтения или обоюдной синхронизации.
Я попробовал этот функционал. Настраивается просто. Положил файл с паролями на сетевой диск, подключил его к разным клиентам как отдельную папку в существующем локальном хранилище. Одному в режиме записи, второму - чтения.
Внешний вид KeePassXC лично мне не понравился по сравнению с классическим KeePass. Но тут уж выбирать не приходится. Подобных возможностей лично я ни в одной другой программе (не сервисе) для хранения паролей не видел. Приходилось просто на общий диск класть файл и кричать на весь кабинет, чтобы отпустили файл, когда в него что-то записать нужно было.
Сайт - https://keepassxc.org/
Исходники - https://github.com/keepassxreboot/keepassxc
#password
{kind=link}
👍2
Я уже постил видео с этого канала, но как-то не проникся сразу самим каналом, бегло почитав заголовки роликов. А потом решил посмотреть и очень зашло. Отличная игра актёров и перевод. Посмотрел почти все видео про VLDL Bored. Не могу сказать, что там есть что-то прям супер интересное. Они все плюс-минус одинаково забавные. Это скетчи из компьютерного магазина.
Пример с интригой - Плоский кликер:
https://www.youtube.com/watch?v=GgOk_pE5MGg
Я не догадался по ходу дела о чём шла речь. Не буду рассказывать, на что подумал при просмотре. Попробуйте сами догадаться, что хочет покупатель.
#юмор
Пример с интригой - Плоский кликер:
https://www.youtube.com/watch?v=GgOk_pE5MGg
Я не догадался по ходу дела о чём шла речь. Не буду рассказывать, на что подумал при просмотре. Попробуйте сами догадаться, что хочет покупатель.
#юмор