
Дополнение к вчерашней заметке про бэкапы. На днях отключил синхронизацию локальных бэкапов с удаленным хранилищем, пока настройки некоторые делал. И, как водится, забыл включить обратно. Если бы не было мониторинга, заметил скорее всего где-то через неделю-две, когда глазами просматривал бэкапы (делаю это регулярно).
А так пришло письмо. Сразу понял, в чем дело, пошел и включил снова синхронизацию. Как реализовать мониторинг бэкапов - отдельный вопрос. Он сильно зависит от конкретной ситуации. Как это иногда делаю я, показываю в статье - https://serveradmin.ru/monitoring-bekapov-s-pomoshhyu-zabbix/
Нужно понимать, что это частный случай и показан просто пример. Готовые системы мониторинга чаще всего этот функционал имеют по умолчанию. Если есть возможность использовать их - используйте.
❗️ Главное, о чем хотел сказать - мониторьте все подряд. Спать будете спокойнее (на ночь мобилу выключаем 😁)
#backup #zabbix
А так пришло письмо. Сразу понял, в чем дело, пошел и включил снова синхронизацию. Как реализовать мониторинг бэкапов - отдельный вопрос. Он сильно зависит от конкретной ситуации. Как это иногда делаю я, показываю в статье - https://serveradmin.ru/monitoring-bekapov-s-pomoshhyu-zabbix/
Нужно понимать, что это частный случай и показан просто пример. Готовые системы мониторинга чаще всего этот функционал имеют по умолчанию. Если есть возможность использовать их - используйте.
❗️ Главное, о чем хотел сказать - мониторьте все подряд. Спать будете спокойнее (на ночь мобилу выключаем 😁)
#backup #zabbix
{kind=link}
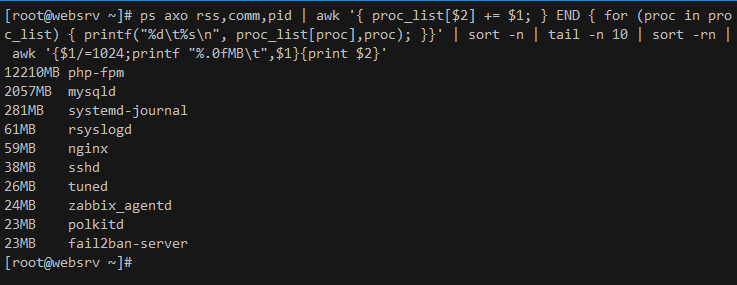
Решил поделиться с вами, а заодно и разобрать работу одной консольной команды в linux, которая позволяет быстро посмотреть, кто занимает оперативную память на сервере. Сразу предупреждаю, что тема с памятью в linux очень замороченная. Ее нельзя просто взять, посмотреть и все понять :)
Если захотите разобраться в этом вопросе, то гуглите "linux memory rss virt" и читайте, разбирайтесь, проверяйте. Я буду подсчитывать использование rss памяти. Для этого предлагаю следующий скрипт, который можно запустить в bash консоли:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Разбираем, что он делает:
1️⃣ ps axo rss,comm,pid - выводит список всех процессов, указывая pid, само название процесса и потребление памяти rss. Если у вас работает, к примеру, php-fpm, то у него может быть сотни процессов, так что сама по себе эта команда малоинформативна, так как генерирует огромный список. Начинаем его обрабатывать.
2️⃣ awk '{ proc_list[$2] += $1; } END - в данном случае $2 это второй столбец (название процесса) списка, полученного из первой команды, $1 (rss) - первый. Таким образом мы создаем словарь из названий процессов и в этом словаре сразу же суммируем rss всех процессов с одним и тем же именем. То есть записываем примерно следующее:
proc_list = ( [php-fpm]=51224, [mysql]=31441 ) и т.д.
3️⃣ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' - заключительная часть обработки в awk, которая в цикле перебирает все названия процессов в словаре и выводит их по одному в каждой строке. В данном случае proc_list[proc] будет выводить rss процесса, proc - его название, конструкция "%d\t%s\n" определяет формат вывода: %d - десятичное число, \t - табуляция, %s - строка, \n - переход на новую строку.
4️⃣ | sort -n | tail -n 10 | sort -rn - это самая простая часть. Тут мы сначала сортируем предыдущий список по первому столбцу (rss) от меньшего к большему, потом оставляем только 10 последних значений (можете изменить, если вам надо больше), и делаем обратную сортировку, от большего к меньшему.
5️⃣ | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' - здесь мы просто причесываем вывод, деля rss на 1024, чтобы перевести в мегабайты и их же дописываем в конце. %.0f - округление до целого, \t - добавляет табуляцию. Можете это убрать, если вам не нужно.
Надеюсь после этого разбора магия bash вам покажется чуть более понятной. Такие однострочные конструкции трудно сходу воспринять и понять, если нет нормального опыта программирования на bash.
Я не сказать, что хорошо на нем программирую. Более того, даже этот скрипт я придумал не сам. Увидел когда-то и сохранил. Он достаточно известный и хорошо гуглится. Но вот разбора с описанием не найти. Восполняю пробел.
Сохрани на память. Частенько бывает нужен, если работаешь в консоли.
Если захотите разобраться в этом вопросе, то гуглите "linux memory rss virt" и читайте, разбирайтесь, проверяйте. Я буду подсчитывать использование rss памяти. Для этого предлагаю следующий скрипт, который можно запустить в bash консоли:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Разбираем, что он делает:
1️⃣ ps axo rss,comm,pid - выводит список всех процессов, указывая pid, само название процесса и потребление памяти rss. Если у вас работает, к примеру, php-fpm, то у него может быть сотни процессов, так что сама по себе эта команда малоинформативна, так как генерирует огромный список. Начинаем его обрабатывать.
2️⃣ awk '{ proc_list[$2] += $1; } END - в данном случае $2 это второй столбец (название процесса) списка, полученного из первой команды, $1 (rss) - первый. Таким образом мы создаем словарь из названий процессов и в этом словаре сразу же суммируем rss всех процессов с одним и тем же именем. То есть записываем примерно следующее:
proc_list = ( [php-fpm]=51224, [mysql]=31441 ) и т.д.
3️⃣ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' - заключительная часть обработки в awk, которая в цикле перебирает все названия процессов в словаре и выводит их по одному в каждой строке. В данном случае proc_list[proc] будет выводить rss процесса, proc - его название, конструкция "%d\t%s\n" определяет формат вывода: %d - десятичное число, \t - табуляция, %s - строка, \n - переход на новую строку.
4️⃣ | sort -n | tail -n 10 | sort -rn - это самая простая часть. Тут мы сначала сортируем предыдущий список по первому столбцу (rss) от меньшего к большему, потом оставляем только 10 последних значений (можете изменить, если вам надо больше), и делаем обратную сортировку, от большего к меньшему.
5️⃣ | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' - здесь мы просто причесываем вывод, деля rss на 1024, чтобы перевести в мегабайты и их же дописываем в конце. %.0f - округление до целого, \t - добавляет табуляцию. Можете это убрать, если вам не нужно.
Надеюсь после этого разбора магия bash вам покажется чуть более понятной. Такие однострочные конструкции трудно сходу воспринять и понять, если нет нормального опыта программирования на bash.
Я не сказать, что хорошо на нем программирую. Более того, даже этот скрипт я придумал не сам. Увидел когда-то и сохранил. Он достаточно известный и хорошо гуглится. Но вот разбора с описанием не найти. Восполняю пробел.
Сохрани на память. Частенько бывает нужен, если работаешь в консоли.
{kind=link}
👍2
Я тут забавную серию роликов нашел на тему айтишного юмора. Не сказать, что сильно понравилось, но тем не менее, нормально сделано. Если бы еще матерились поменьше.
Серия про майнинг больше всего понравилась - https://youtu.be/O91Xv6TJg0I
Только между нами, майнил кто-нибудь на работе? Я лично ни разу не пробовал. Один раз настраивал мониторинг транспортабельного миницода. Было очень неудобно, что его оставляли включенным только с 9 до 18.
Только через некоторое время понял, зачем его обесточивали, когда все уходили из офиса. Подозреваю, боялись, что кто-то из тех, кто удаленно с ним работал, начнет майнить на нем. Это была тестовая установка.
#юмор #псевдопятница
Серия про майнинг больше всего понравилась - https://youtu.be/O91Xv6TJg0I
Только между нами, майнил кто-нибудь на работе? Я лично ни разу не пробовал. Один раз настраивал мониторинг транспортабельного миницода. Было очень неудобно, что его оставляли включенным только с 9 до 18.
Только через некоторое время понял, зачем его обесточивали, когда все уходили из офиса. Подозреваю, боялись, что кто-то из тех, кто удаленно с ним работал, начнет майнить на нем. Это была тестовая установка.
#юмор #псевдопятница
YouTube
ITить-КОЛОТИТЬ 5 серия 1 сезон
Пятая серия ситкома про борьбу админа, ИТ-руководителя, генерального директора на полях сражений с мировыми катаклизмами, проверяющими органами, раздолбайством и собственным самолюбием.
Подпишись на канал и будь первым, кто увидит следующую серию.
=====…
Подпишись на канал и будь первым, кто увидит следующую серию.
=====…
👍2
Подытожил свой небольшой опыт работы с файловыми базами 1С. Тема весьма популярная для малого бизнеса. Да что там говорить, я сам свою бухгалтерию веду в файловой базе 1С и считаю это удобным продуктом. Пробовал другие, но в итоге остановился на 1С.
В статье рассказываю, как можно относительно простыми и дешевыми способами существенно повысить производительность файловых баз и отложить тот момент, когда придется выложить круглую сумму на переход к клиент - серверной схеме работы с базами 1С.
Как обычно, делюсь своим личным опытом работы с описываемым продуктом.
https://serveradmin.ru/fajlovaya-baza-1s-tormozit/
#1с #статья
В статье рассказываю, как можно относительно простыми и дешевыми способами существенно повысить производительность файловых баз и отложить тот момент, когда придется выложить круглую сумму на переход к клиент - серверной схеме работы с базами 1С.
Как обычно, делюсь своим личным опытом работы с описываемым продуктом.
https://serveradmin.ru/fajlovaya-baza-1s-tormozit/
#1с #статья
Server Admin
Файловая база 1С тормозит. Как ускорить?
Последнее время пришлось немного поработать с 1С и решить несколько проблем. Все они были связаны с медленной работой файловых баз 1С. Поделюсь своими советами на тему того, как их немного...
Хочу прокомментировать любопытную статью, которую недавно прочитал в корпоративном блоге компании Флант - https://habr.com/ru/company/flant/blog/542540/
Она немного выбивается из общего тренда статей крупных аутсорсеров, которые преимущественно работают с облачными сервисами, исповедуют подход infrastructure as code, используют кубернетис и т.д.
В данном случае они увидели, что на трафик с AWS уходит $2000 в месяц и подумали, как можно сократить эти расходы. Нашелся какой-то здравомыслящий человек, который предложил немыслимое - настроить кэш статики на одиночном сервере за $60 в месяц с бесплатным трафиком.
Они это сделали и все получилось. На ровном месте минус $1940 расходов без потери отказоустойчивости, так как AWS остался в резерве на случай аварии этого сервера. Просто там теперь нет трафика.
Что хотел сказать? Я часто вижу комментарии, что надо выползать из дремучей древности, переходить в облака, кластеры, осваивать новое и вот это вот все. Я согласен, что надо развиваться и изучать новое. Но новое должно быть оправдано в каждом конкретном случае. Если одиночный сервер за 60 баксов решает поставленную задачу, зачем эту нагрузку тащить в облако?
#мысли
Она немного выбивается из общего тренда статей крупных аутсорсеров, которые преимущественно работают с облачными сервисами, исповедуют подход infrastructure as code, используют кубернетис и т.д.
В данном случае они увидели, что на трафик с AWS уходит $2000 в месяц и подумали, как можно сократить эти расходы. Нашелся какой-то здравомыслящий человек, который предложил немыслимое - настроить кэш статики на одиночном сервере за $60 в месяц с бесплатным трафиком.
Они это сделали и все получилось. На ровном месте минус $1940 расходов без потери отказоустойчивости, так как AWS остался в резерве на случай аварии этого сервера. Просто там теперь нет трафика.
Что хотел сказать? Я часто вижу комментарии, что надо выползать из дремучей древности, переходить в облака, кластеры, осваивать новое и вот это вот все. Я согласен, что надо развиваться и изучать новое. Но новое должно быть оправдано в каждом конкретном случае. Если одиночный сервер за 60 баксов решает поставленную задачу, зачем эту нагрузку тащить в облако?
#мысли
Хабр
Как мы сэкономили 2000 USD на трафике из Amazon S3 с помощью nginx-кэша
Эта небольшая история — живое свидетельство того, как самые простые решения (иногда) могут оказаться очень эффективными. В одном из проектов руководство взяло курс на оптимизацию бюджета на...
Небольшая статья на тему конвертации Centos 8 в Centos Stream - https://serveradmin.ru/centos-8-to-centos-stream/. Судя по всему, Centos все же останется популярной системой, несмотря на то, что ее перевели на rolling release. Есть, к примеру, такая новость - https://servernews.ru/1029891
Разработчики из Facebook и Twitter планируют создать новую группу, которая займётся развёртыванием CentOS Stream в крупномасштабной инфраструктуре. Разработчики отмечают три основных направления, на которых они хотели бы сосредоточить внимание группы. Первым и основным является сверхбыстрое развёртывание определённых пакетов. Они будут доступны через собственные репозитории, а не через общие для CentOS Stream.
Поживем увидим, пока рано делать выводы, что из этого получится. Предупреждаю на всякий случай, что на Stream переехать просто, а вот обратно либо очень сложно, либо невозможно. Со временем разница между этими дистрибутивами будет увеличиваться. Так что это путь в один конец.
#статья
Разработчики из Facebook и Twitter планируют создать новую группу, которая займётся развёртыванием CentOS Stream в крупномасштабной инфраструктуре. Разработчики отмечают три основных направления, на которых они хотели бы сосредоточить внимание группы. Первым и основным является сверхбыстрое развёртывание определённых пакетов. Они будут доступны через собственные репозитории, а не через общие для CentOS Stream.
Поживем увидим, пока рано делать выводы, что из этого получится. Предупреждаю на всякий случай, что на Stream переехать просто, а вот обратно либо очень сложно, либо невозможно. Со временем разница между этими дистрибутивами будет увеличиваться. Так что это путь в один конец.
#статья
Server Admin
Конвертация Centos 8 в Centos Stream | serveradmin.ru
# dnf install centos-release-stream Указываем новый репозиторий дефолтным: # dnf swap centos-{linux,stream}-repos Синхронизируем установленные пакеты в соответствии с новым репозиторием. # dnf...
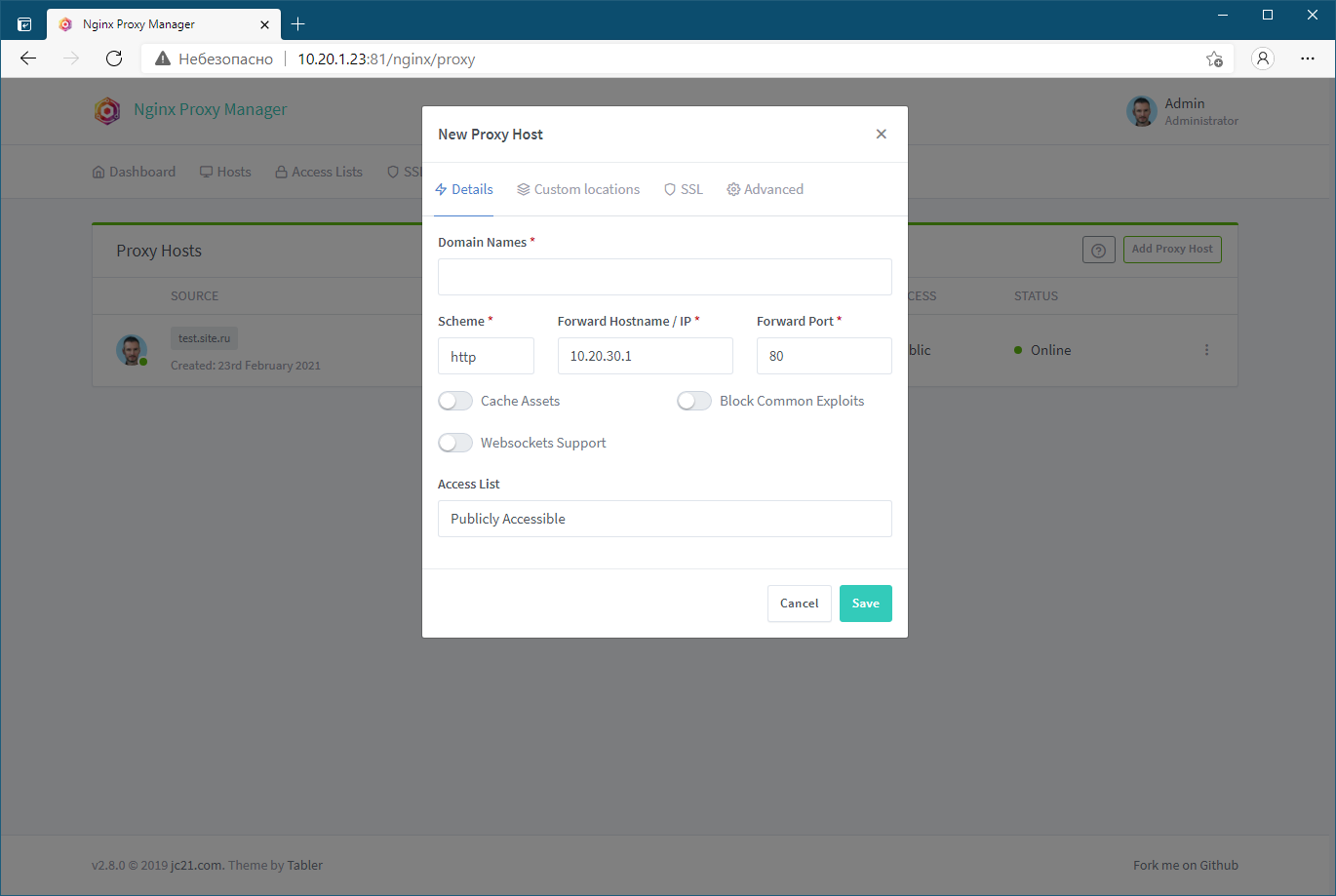
Некоторое время назад я рассказывал о режиме работы nginx - proxy_pass. Мне посоветовали в комментариях любопытную надстройку над проксирующим nginx под названием Nginx Proxy Manager - https://nginxproxymanager.com
Это панель управления nginx в режиме прокси с помощью веб интерфейса. Разворачивается через docker-compose, так что никаких заморочек с установкой нет. Запускается в одну команду. Там всего два контейнера. Один непосредственно с nginx и веб интерфейсом, второй с базой данных, где хранится вся информация панели.
Я запустил и попробовал. Выглядит интересно и удобно. Я не знаю, насколько продукт подходит для прода, там надо разбираться. Но для тестовых систем очень удобно. Не надо тратить лишнее время на настройки. Через браузер можно настроить все, что нужно.
Основное из того, что он умеет:
1️⃣ Собственно, управлять конфигом nginx через web интерфейс.
2️⃣ Использование сертификатов, как своих, так и Let's Encrypt. При этом есть готовые интеграции со многими популярными dns хостингами для автоматического подтверждения доменов через dns.
3️⃣ Настройка доступа к сайтам на основе basic auth или списков доступа для allow и deny.
4️⃣ Доступ к панели на основе пользователей и прав для них, логирование действий пользователей.
Это opensource проект, репа на гитхабе - https://github.com/jc21/nginx-proxy-manager. Мне понравилась панель. Приятный и удобный интерфейс. Все, как сейчас модно - стильно, быстро, в докере :)
Ничего знать про nginx не надо, запустил и пошел настраивать. В целом, рекомендую попробовать, если есть потребность в подобном функционале. Я себе в закладки добавил.
#nginx #webserver
Это панель управления nginx в режиме прокси с помощью веб интерфейса. Разворачивается через docker-compose, так что никаких заморочек с установкой нет. Запускается в одну команду. Там всего два контейнера. Один непосредственно с nginx и веб интерфейсом, второй с базой данных, где хранится вся информация панели.
Я запустил и попробовал. Выглядит интересно и удобно. Я не знаю, насколько продукт подходит для прода, там надо разбираться. Но для тестовых систем очень удобно. Не надо тратить лишнее время на настройки. Через браузер можно настроить все, что нужно.
Основное из того, что он умеет:
1️⃣ Собственно, управлять конфигом nginx через web интерфейс.
2️⃣ Использование сертификатов, как своих, так и Let's Encrypt. При этом есть готовые интеграции со многими популярными dns хостингами для автоматического подтверждения доменов через dns.
3️⃣ Настройка доступа к сайтам на основе basic auth или списков доступа для allow и deny.
4️⃣ Доступ к панели на основе пользователей и прав для них, логирование действий пользователей.
Это opensource проект, репа на гитхабе - https://github.com/jc21/nginx-proxy-manager. Мне понравилась панель. Приятный и удобный интерфейс. Все, как сейчас модно - стильно, быстро, в докере :)
Ничего знать про nginx не надо, запустил и пошел настраивать. В целом, рекомендую попробовать, если есть потребность в подобном функционале. Я себе в закладки добавил.
#nginx #webserver
{kind=link}
▶️ Любопытное видео на тему построения HA-кластера Zabbix (High-Availability, кластер высокой доступности). На своем примере инженеры Megafon показали, как они построили кластер мониторинга Zabbix.
Выступление в первую очередь интересно тем, что такого материала в принципе не много. Всегда полезно посмотреть и послушать, как настроили другие. Особенно когда они придумали что-то уникальное, а не взяли готовый вариант.
Выступающий не только рассказывает о своей текущей реализации кластера, но кратко рассказывает, какие варианты балансировки они рассматривали и почему отказались. Среди них были Citrix Netscaler, HAProxy. В итоге балансировку они реализовали своими самописными инструментами с помощью Zabbix API.
В случае выхода из строя одной из проксей, хосты распределяются между остальными оставшимися прокси. Сам кластер мониторинга двунодовый, работает в режиме Primary / Standby. При выходе из строя основного сервера, запасной становится основным и наоборот. Ноды полностью идентичны.
https://www.youtube.com/watch?v=OH4CVR7URR8 (33 минуты)
#zabbix #видео
Выступление в первую очередь интересно тем, что такого материала в принципе не много. Всегда полезно посмотреть и послушать, как настроили другие. Особенно когда они придумали что-то уникальное, а не взяли готовый вариант.
Выступающий не только рассказывает о своей текущей реализации кластера, но кратко рассказывает, какие варианты балансировки они рассматривали и почему отказались. Среди них были Citrix Netscaler, HAProxy. В итоге балансировку они реализовали своими самописными инструментами с помощью Zabbix API.
В случае выхода из строя одной из проксей, хосты распределяются между остальными оставшимися прокси. Сам кластер мониторинга двунодовый, работает в режиме Primary / Standby. При выходе из строя основного сервера, запасной становится основным и наоборот. Ноды полностью идентичны.
https://www.youtube.com/watch?v=OH4CVR7URR8 (33 минуты)
#zabbix #видео
{kind=link}
Это будет пост с советами для настоящих админов. Какой сейчас админ без микротика? Одно название. Ниже список практических рекомендаций при работе с mikrotik.
1️⃣ Когда подключились к Микротику удаленно и включили режим Safe Mode не забудьте проверить, нет ли еще подключений через winbox. Если они будут, то Safе mode не сработает.
2️⃣ Так же при удаленном подключении, убедитесь, что нет запущенных сессий Winbox с Safe mode. Если кто-то подключился, что-то настроил в этом режиме и забыл отключиться, а вы его принудительно отрубите, все настройки откатите обратно.
3️⃣ Safe Mode хранит ограниченное количество изменений. Поэтому лучше всего в этом режиме действовать следующим образом. Включили режим, внесли важные настройки, убедились, что все в порядке, режим выключили. Не надо постоянно сидеть с включенным Safe Mode.
4️⃣ Если нужно рестартануть интерфейс, через который выполнено удаленное подключение, то просто сделать disable и обратно enable не получится. Вас отключит. Вместо этого достаточно нажать enable. Микротик в этом случае все равно выключает интерфейс и тут же включает обратно. Очевидно, что если с интерфейсом какие-то проблемы и он не поднимется, то все пропало :) Так что использовать на свой страх и риск.
5️⃣ Safe Mode не панацея, он может сглючить и не откатить настройки. Можно подстраховаться скриптом, который делает бэкап, спит какое-то время и загружает бэкап обратно. Логика такая. Запустили скрипт, он сделал бэкап. Дальше вы делаете какие-то настройки. Если вас не отключило, останавливаете скрипт. Если отключило, ждете, когда скрипт откатит конфиг. Примерный текст скрипта:
Если у вас есть еще какие-то советы или лайфхаки по микротикам из практики, делитесь. Этот пост - компиляция комментариев к постам на сайте и tg с vk. Сам я не очень суровый и с микротиками мало работаю. Но дома и на даче стоит, так что проф пригоден.
#mikrotik
1️⃣ Когда подключились к Микротику удаленно и включили режим Safe Mode не забудьте проверить, нет ли еще подключений через winbox. Если они будут, то Safе mode не сработает.
2️⃣ Так же при удаленном подключении, убедитесь, что нет запущенных сессий Winbox с Safe mode. Если кто-то подключился, что-то настроил в этом режиме и забыл отключиться, а вы его принудительно отрубите, все настройки откатите обратно.
3️⃣ Safe Mode хранит ограниченное количество изменений. Поэтому лучше всего в этом режиме действовать следующим образом. Включили режим, внесли важные настройки, убедились, что все в порядке, режим выключили. Не надо постоянно сидеть с включенным Safe Mode.
4️⃣ Если нужно рестартануть интерфейс, через который выполнено удаленное подключение, то просто сделать disable и обратно enable не получится. Вас отключит. Вместо этого достаточно нажать enable. Микротик в этом случае все равно выключает интерфейс и тут же включает обратно. Очевидно, что если с интерфейсом какие-то проблемы и он не поднимется, то все пропало :) Так что использовать на свой страх и риск.
5️⃣ Safe Mode не панацея, он может сглючить и не откатить настройки. Можно подстраховаться скриптом, который делает бэкап, спит какое-то время и загружает бэкап обратно. Логика такая. Запустили скрипт, он сделал бэкап. Дальше вы делаете какие-то настройки. Если вас не отключило, останавливаете скрипт. Если отключило, ждете, когда скрипт откатит конфиг. Примерный текст скрипта:
/system backup save password="secret" name=disconnectdelay 180/system backup load name=disconnect.backup password="secret"Если у вас есть еще какие-то советы или лайфхаки по микротикам из практики, делитесь. Этот пост - компиляция комментариев к постам на сайте и tg с vk. Сам я не очень суровый и с микротиками мало работаю. Но дома и на даче стоит, так что проф пригоден.
#mikrotik
{kind=link}
👍3
Недавно у меня было несколько заметок про 1С на канале. Хотел сразу прокомментировать некоторые вещи, но руки только сейчас дошли. В комментариях много обсуждали, какую конфигурацию для 1С можно использовать. По большому счету выбор есть из трех вариантов:
1️⃣ Файловая база. Тут все просто. Самый дешевый вариант.
2️⃣ Сервер 1С + база Posgresql на Linux. Более дорогой вариант, но к первому добавляется только лицензия на сам сервер 1С.
3️⃣ Сервер 1С + база MSSQL на Windows Server. Это самый дорогой вариант, так как тут нужно будет купить кучу лицензий: 1С сервер, Windows Server, MSSQL сервер и CALs к нему.
Если в лоб сравнить стоимость второго и третьего вариантов, то неподготовленному человеку станет не понятно, зачем платить столько денег за третий вариант, если есть второй, на котором тоже все будет работать. Особенно если нагрузки не очень большие.
Я администрировал все указанные варианты, причем достаточно плотно, так что могу их сравнить. При прочих равных, я бы рекомендовал вариант номер 3, несмотря на то, что он значительно дороже второго. Логика тут простая.
MSSQL сервер очень прост в обслуживании, несмотря на свой огромный функционал. То есть тут простота не обманчивая. Он очень функционален и быстр и при этом легко и просто настраивается в связке с 1С по многочисленным манулам в интернете. Его производительность будет предсказуема. Его легко бэкапить, обслуживать, восстанавливать. С этим справится любой эникей.
С Postgresql ситуация будет другая. Во-первых, нужен будет админ со знанием Linux как минимум, а по хорошему и с опытом postgresql. Этот специалист будет требовать зарплату раза в 2 выше, чем эникей, способный нормально управлять mssql. На длинном промежутке времени никакой экономии не получится, при условии, что у вас нет и не планируется в штат подобный сотрудник.
Во-вторых, хоть 1С вроде как и старается оптимизировать работу своих конфигураций под postgresql, а postgresql pro пытается делать сборки под 1С, но на деле, 1С под posgre работает медленнее, чем под mssql. А в каких-то нестандартных ситуациях катастрофически медленнее, чем в mssql. Я сталкивался с такими ситуациями. Расследовать и разбираться в этом не просто. Надо подключаться программистов 1С и смотреть, какие запросы работают медленно и в чем там проблемы. Все это денежные затраты, если у вас нет в штате подобных специалистов.
Так что при просчете расходов на тот или иной продукт обязательно нужно учитывать не только стоимость его покупки, но и расходы на всем сроке эксплуатации, в том числе и зарплату обслуживающего персонала. На длительном интервале они могут быть значительными. Больше чем стоимость самого программного продукта.
#1с
1️⃣ Файловая база. Тут все просто. Самый дешевый вариант.
2️⃣ Сервер 1С + база Posgresql на Linux. Более дорогой вариант, но к первому добавляется только лицензия на сам сервер 1С.
3️⃣ Сервер 1С + база MSSQL на Windows Server. Это самый дорогой вариант, так как тут нужно будет купить кучу лицензий: 1С сервер, Windows Server, MSSQL сервер и CALs к нему.
Если в лоб сравнить стоимость второго и третьего вариантов, то неподготовленному человеку станет не понятно, зачем платить столько денег за третий вариант, если есть второй, на котором тоже все будет работать. Особенно если нагрузки не очень большие.
Я администрировал все указанные варианты, причем достаточно плотно, так что могу их сравнить. При прочих равных, я бы рекомендовал вариант номер 3, несмотря на то, что он значительно дороже второго. Логика тут простая.
MSSQL сервер очень прост в обслуживании, несмотря на свой огромный функционал. То есть тут простота не обманчивая. Он очень функционален и быстр и при этом легко и просто настраивается в связке с 1С по многочисленным манулам в интернете. Его производительность будет предсказуема. Его легко бэкапить, обслуживать, восстанавливать. С этим справится любой эникей.
С Postgresql ситуация будет другая. Во-первых, нужен будет админ со знанием Linux как минимум, а по хорошему и с опытом postgresql. Этот специалист будет требовать зарплату раза в 2 выше, чем эникей, способный нормально управлять mssql. На длинном промежутке времени никакой экономии не получится, при условии, что у вас нет и не планируется в штат подобный сотрудник.
Во-вторых, хоть 1С вроде как и старается оптимизировать работу своих конфигураций под postgresql, а postgresql pro пытается делать сборки под 1С, но на деле, 1С под posgre работает медленнее, чем под mssql. А в каких-то нестандартных ситуациях катастрофически медленнее, чем в mssql. Я сталкивался с такими ситуациями. Расследовать и разбираться в этом не просто. Надо подключаться программистов 1С и смотреть, какие запросы работают медленно и в чем там проблемы. Все это денежные затраты, если у вас нет в штате подобных специалистов.
Так что при просчете расходов на тот или иной продукт обязательно нужно учитывать не только стоимость его покупки, но и расходы на всем сроке эксплуатации, в том числе и зарплату обслуживающего персонала. На длительном интервале они могут быть значительными. Больше чем стоимость самого программного продукта.
#1с
{kind=link}
👍2
❗️ А у вас есть Кубернетис?
Это видео так прекрасно, что его даже комментировать не хочется. Просто смотрите и думайте.
https://www.youtube.com/watch?v=LeVULLqWwcg
Это видео так прекрасно, что его даже комментировать не хочется. Просто смотрите и думайте.
https://www.youtube.com/watch?v=LeVULLqWwcg
YouTube
А у вас есть кубернетес?
👍3
Вчера сидел, в очередной раз просматривал вакансии. У меня привычка это делать регулярно, чего и вам советую. Не раз уже писал об этом.
Обратил внимание, что удаленных вакансий с каждым днем все больше и больше. И при этом работодатели не пытаются снизить зарплату, в надежде, что из регионов люди будут согласны работать за небольшие деньги.
Зарплаты на удалёнке сопоставимы с московскими локальными. И при этом компании реально готовы брать людей из других регионов, не требуя их переезда в Москву. Законодательную базу приняли для полностью удаленного оформления. Оно уже работает.
На ИТ специалистов просто бум сейчас. Жесткая нехватка кадров. Ребят, используйте свой шанс. Не тупите и не тратьте время на ерунду. Развивайтесь, учитесь, осваивайте новое и устраивайтесь на хорошие зарплаты. Сейчас это все реально, более чем когда-либо.
На картинках пример моей ленты рекомендаций вакансий. Я не стал разворачивать ее еще дальше, и так наскринил полно хороших предложений.
Обратил внимание, что удаленных вакансий с каждым днем все больше и больше. И при этом работодатели не пытаются снизить зарплату, в надежде, что из регионов люди будут согласны работать за небольшие деньги.
Зарплаты на удалёнке сопоставимы с московскими локальными. И при этом компании реально готовы брать людей из других регионов, не требуя их переезда в Москву. Законодательную базу приняли для полностью удаленного оформления. Оно уже работает.
На ИТ специалистов просто бум сейчас. Жесткая нехватка кадров. Ребят, используйте свой шанс. Не тупите и не тратьте время на ерунду. Развивайтесь, учитесь, осваивайте новое и устраивайтесь на хорошие зарплаты. Сейчас это все реально, более чем когда-либо.
На картинках пример моей ленты рекомендаций вакансий. Я не стал разворачивать ее еще дальше, и так наскринил полно хороших предложений.
👍2
Инвентаризация и мониторинг железа
В пятницу на одном из арендуемых серверов вышел из строя жесткий диск. Он просто пропал из системы. Проблем это не создало, так как настроен рейд массив.
Вам надо знать серийный номер, чтобы попросить техподдержку заменить диск. А диск не доступен. Что делать? Можно перечислить серийные номера рабочих дисков и попросить заменить тот, которого нет в списке. А если дисков 16 штук?
В тех. поддержку надо давать максимально простую и четкую информацию. Они не будут заморачиваться и внимательно сверяться по списку из 16 серийников. Так что подобные вопросы надо решать заранее.
Я просто зашел в мониторинг и посмотрел серийный номер выпавшего диска. Создал тикет на замену. Мониторинг настраиваю обычно вот так - https://serveradmin.ru/monitoring-smart-v-zabbix/ Это если речь идет о сервере без рейд контроллера. Если используется контроллер, то отталкиваемся от него, примерно так - https://serveradmin.ru/monitoring-intel-raid-s-pomoshhyu-raidcfg-i-zabbix/
Для всех популярных рейд контроллеров есть шаблоны для Zabbix. Для мегарейдов точно есть. Я статью не писал, но сам постоянно пользуюсь. Беру из гугла.
Я часто вижу, что подобными вещами не заморачиваются. Иногда забавно почитать переписку с тех поддержкой по замене диска, который неожиданно сломался пол года назад, но этого никто не заметил, потому что не было мониторинга. А потом сервер завис и из ребута не вышел. Читал такие истории у заказчиков в тикетах.
Так что хотя бы запишите в exel табличку или какую-нибудь wiki все основные параметры своего железа. В ктирических ситуациях это сильно поможет и упростит задачи по решению проблем.
#zabbix
В пятницу на одном из арендуемых серверов вышел из строя жесткий диск. Он просто пропал из системы. Проблем это не создало, так как настроен рейд массив.
Вам надо знать серийный номер, чтобы попросить техподдержку заменить диск. А диск не доступен. Что делать? Можно перечислить серийные номера рабочих дисков и попросить заменить тот, которого нет в списке. А если дисков 16 штук?
В тех. поддержку надо давать максимально простую и четкую информацию. Они не будут заморачиваться и внимательно сверяться по списку из 16 серийников. Так что подобные вопросы надо решать заранее.
Я просто зашел в мониторинг и посмотрел серийный номер выпавшего диска. Создал тикет на замену. Мониторинг настраиваю обычно вот так - https://serveradmin.ru/monitoring-smart-v-zabbix/ Это если речь идет о сервере без рейд контроллера. Если используется контроллер, то отталкиваемся от него, примерно так - https://serveradmin.ru/monitoring-intel-raid-s-pomoshhyu-raidcfg-i-zabbix/
Для всех популярных рейд контроллеров есть шаблоны для Zabbix. Для мегарейдов точно есть. Я статью не писал, но сам постоянно пользуюсь. Беру из гугла.
Я часто вижу, что подобными вещами не заморачиваются. Иногда забавно почитать переписку с тех поддержкой по замене диска, который неожиданно сломался пол года назад, но этого никто не заметил, потому что не было мониторинга. А потом сервер завис и из ребута не вышел. Читал такие истории у заказчиков в тикетах.
Так что хотя бы запишите в exel табличку или какую-нибудь wiki все основные параметры своего железа. В ктирических ситуациях это сильно поможет и упростит задачи по решению проблем.
#zabbix
Server Admin
Мониторинг SMART в Zabbix
Настройка мониторинга smart параметров жесткого диска с помощью сервера мониторинга zabbix. Оповещение о проблемах с диском.
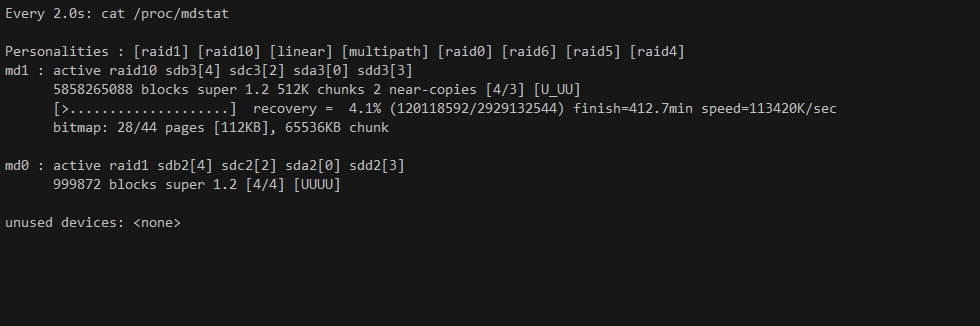
В продолжении темы выхода из строя диска, напишу себе и остальным на память последовательность действий при замене сбойного диска в массиве mdadm. Инструкция не уникальна, потому что на моей памяти синтаксис mdadm не менялся ни разу. Я как 10 лет назад менял так диски, продолжаю это делать и сейчас. Правда все реже и реже.
Проверяем, какой диск выпал из массива:
Сбойный диск будет помечен буквой F. Помечаем его сбойным и выводим из массива:
Меняем сбойный диск. После этого убеждаемся, что он появился в системе.
Там же смотрим на его разметку. Если новый диск, разметки не будет. Копируем на него разметку с любого диска массива:
Не перепутайте тут имена дисков и не затрите рабочий диск пустой разметкой нового. Тут мы разметку с sda скопировали на sdb.
Добавляем новый диск в массив.
Должны увидеть инфу:
Дальше наблюдаем за ребилдом в режиме реального времени:
В это время сервер лучше не нагружать и не перезагружать. У меня много раз было такое, что сервер перегружался в момент ребилда. К проблемам это не приводило, просто ребил начинался заново с самого начала.
Инструкция 100% рабочая и много раз проверенная, можно сохранить себе. Прониклись олдскулом? Это вам не девопс какой-нибудь, а настоящее железо :) Но кроме шуток, вот это обычный сервер с 4 дисками по 3Tb в raid10 под бэкапы. Стоит 5200 в месяц с i7 и 32gb оперативки на борту. Трафик безлимитный.
Используется под бэкапы, а так как память позволяет, иногда там тестовые виртуалки запускаются под разовые нужды.
Где еще за такие деньги получить столько места на персональном десятом рейде? Работает шустро, хороший проц, можно активно жать данные. При этом не просто хранилище, а полноценный сервер, который позволяет очень гибко настраивать бэкапы, их управление и т.д.
Он сам везде ходит по ssh и забирает все к себе. Это важно, так как условный зловред на целевом сервере не получит доступа к бэкапам. Можно подключить по nfs к какому-нибудь гипервизору и бэкапить туда виртуалки.
#backup
Проверяем, какой диск выпал из массива:
cat /proc/mdstatСбойный диск будет помечен буквой F. Помечаем его сбойным и выводим из массива:
mdadm /dev/md0 --fail /dev/sdb1mdadm /dev/md0 --remove /dev/sdb1Меняем сбойный диск. После этого убеждаемся, что он появился в системе.
fdisk -lТам же смотрим на его разметку. Если новый диск, разметки не будет. Копируем на него разметку с любого диска массива:
sfdisk -d /dev/sda | sfdisk /dev/sdbНе перепутайте тут имена дисков и не затрите рабочий диск пустой разметкой нового. Тут мы разметку с sda скопировали на sdb.
Добавляем новый диск в массив.
mdadm --add /dev/md0 /dev/sdb1Должны увидеть инфу:
mdadm: added /dev/sdb1Дальше наблюдаем за ребилдом в режиме реального времени:
watch cat /proc/mdstatВ это время сервер лучше не нагружать и не перезагружать. У меня много раз было такое, что сервер перегружался в момент ребилда. К проблемам это не приводило, просто ребил начинался заново с самого начала.
Инструкция 100% рабочая и много раз проверенная, можно сохранить себе. Прониклись олдскулом? Это вам не девопс какой-нибудь, а настоящее железо :) Но кроме шуток, вот это обычный сервер с 4 дисками по 3Tb в raid10 под бэкапы. Стоит 5200 в месяц с i7 и 32gb оперативки на борту. Трафик безлимитный.
Используется под бэкапы, а так как память позволяет, иногда там тестовые виртуалки запускаются под разовые нужды.
Где еще за такие деньги получить столько места на персональном десятом рейде? Работает шустро, хороший проц, можно активно жать данные. При этом не просто хранилище, а полноценный сервер, который позволяет очень гибко настраивать бэкапы, их управление и т.д.
Он сам везде ходит по ssh и забирает все к себе. Это важно, так как условный зловред на целевом сервере не получит доступа к бэкапам. Можно подключить по nfs к какому-нибудь гипервизору и бэкапить туда виртуалки.
#backup
{kind=link}
👍12