
Я время от времени настраиваю сервера 1С для небольших организаций на основе файловых баз с публикацией в веб. Получается удобное, безопасное и законченное решение, которое почти не требует обслуживания и участия со стороны IT специалиста. Расскажу, как это всё выглядит на практике.
Арендуется выделенный сервер в Selectel. Последний из заказанных серверов стоил 5200р. и имел конфигурацию i7, 64 гига оперативы и 2 SSD диска по 480Гб. На таком сервере файловая 1С работает очень шустро. Для двух-трех человек в базе нормальный вариант. Баз может быть много.
Далее на сервер ставится гипервизор Proxmox на софтовый RAID1 mdadm. На нём настраиваются 3 виртуальные машины:
1. Windows, где будет работать 1С.
2. Debian 11 для Nginx и Apache Guacamole.
3. Debian 11 для локальных бэкапов.
Первым делом настраивается сам гипервизор и фаервол на нём. Максимально закрывается доступ, настраиваются пробросы к виртуальным машинам. Весь доступ к инфраструктуре будет через Apache Guacamole, так что пробрасываем порты к нему и открываем 80 и 443 порты к виртуалке с Nginx. Всё остальное закрываем.
Следующим этапом настраивается Nginx, который будет проксировать запросы на 1С. Я закрываю туда доступ через Basic Auth. И тут же настраиваем Apache Guacamole для доступа к виртуальным машинам через браузер. Особенно это актуально для доступа к Windows машине, так как проброс RDP порта с полным доступом из интернета делать нельзя. Дополнительно при желании через Nginx можно закрыть паролем доступ к самому Guacamole и веб интерфейсу Proxmox. В данном случае Apache Guacamole заменяет нам VPN, обеспечивая дополнительную безопасность и возможность получить прямой доступ к серверам напрямую через интернет. Пользователям ничего у себя настраивать не надо.
На Windows сервере устанавливается как обычно платформа 1С и веб сервер Apache. Делается публикация баз. Тут никакой экзотики, всё стандартно.
На третьем сервере настраивается Samba, создаётся сетевой диск с доступом только на чтение. Этот диск подключается к Windows машине. В этот сетевой диск ежедневно делаются бэкапы файловых баз, старые удаляются. Работает скрипт на самом сервере с бэкапами. Монтирует папку с Windows сервера и забирает файлы к себе, а отдаёт их уже только в режиме чтения. Это сделано, чтобы был оперативный доступ к бэкапам с Windows машины, но при этом их нельзя было удалить с неё. С самого бэкап сервера базы копируются куда-то во вне в зависимости от имеющихся ресурсов для хранения. Это может быть и обычный Яндекс.Диск.
Схема получается гибкая. Вместо файловых баз можно настроить и клиент-серверную архитектуру на базе MSSQL или PostgreSQL. А сам внешний доступ будет такой же.
Если хотите настроить что-то подобное, можете заказать настройку у меня. Готовых инструкций с подобной настройкой в сети нет.
#1C
Арендуется выделенный сервер в Selectel. Последний из заказанных серверов стоил 5200р. и имел конфигурацию i7, 64 гига оперативы и 2 SSD диска по 480Гб. На таком сервере файловая 1С работает очень шустро. Для двух-трех человек в базе нормальный вариант. Баз может быть много.
Далее на сервер ставится гипервизор Proxmox на софтовый RAID1 mdadm. На нём настраиваются 3 виртуальные машины:
1. Windows, где будет работать 1С.
2. Debian 11 для Nginx и Apache Guacamole.
3. Debian 11 для локальных бэкапов.
Первым делом настраивается сам гипервизор и фаервол на нём. Максимально закрывается доступ, настраиваются пробросы к виртуальным машинам. Весь доступ к инфраструктуре будет через Apache Guacamole, так что пробрасываем порты к нему и открываем 80 и 443 порты к виртуалке с Nginx. Всё остальное закрываем.
Следующим этапом настраивается Nginx, который будет проксировать запросы на 1С. Я закрываю туда доступ через Basic Auth. И тут же настраиваем Apache Guacamole для доступа к виртуальным машинам через браузер. Особенно это актуально для доступа к Windows машине, так как проброс RDP порта с полным доступом из интернета делать нельзя. Дополнительно при желании через Nginx можно закрыть паролем доступ к самому Guacamole и веб интерфейсу Proxmox. В данном случае Apache Guacamole заменяет нам VPN, обеспечивая дополнительную безопасность и возможность получить прямой доступ к серверам напрямую через интернет. Пользователям ничего у себя настраивать не надо.
На Windows сервере устанавливается как обычно платформа 1С и веб сервер Apache. Делается публикация баз. Тут никакой экзотики, всё стандартно.
На третьем сервере настраивается Samba, создаётся сетевой диск с доступом только на чтение. Этот диск подключается к Windows машине. В этот сетевой диск ежедневно делаются бэкапы файловых баз, старые удаляются. Работает скрипт на самом сервере с бэкапами. Монтирует папку с Windows сервера и забирает файлы к себе, а отдаёт их уже только в режиме чтения. Это сделано, чтобы был оперативный доступ к бэкапам с Windows машины, но при этом их нельзя было удалить с неё. С самого бэкап сервера базы копируются куда-то во вне в зависимости от имеющихся ресурсов для хранения. Это может быть и обычный Яндекс.Диск.
Схема получается гибкая. Вместо файловых баз можно настроить и клиент-серверную архитектуру на базе MSSQL или PostgreSQL. А сам внешний доступ будет такой же.
Если хотите настроить что-то подобное, можете заказать настройку у меня. Готовых инструкций с подобной настройкой в сети нет.
#1C
👍87👎13
Расскажу про простую в использовании и полезную утилиту Linux, которая позволяет относительно быстро и просто восстановить удалённые файлы (иногда) или порушенную таблицу разделов (часто) - TestDisk. Меня лично она выручала не раз. Рассказывал про её использование в статье про Восстановление таблицы разделов в Linux.
TestDisk есть в базовых репах Debian и Ubuntu и обычно всегда присутствует во всяких Rescue Live CD. Она умеет следующее:
- исправлять таблицу разделов, восстанавливать удаленные разделы;
- восстанавливать загрузочные сектора;
- восстанавливать удалённые файлы;
Пользоваться утилитой достаточно просто, в сети много инструкций. Разделы я с её помощью восстанавливал. Файлы - нет. Иногда она видела удалённые файлы, но восстановить не получалось. Они все были нулевого размера. Так что на Linux я вообще не знаю и не использовал программы, которые реально могли бы восстановить удалённые файлы. Под виндой такие знаю и использовал, реально восстанавливал файлы. Если кто-то на практике восстанавливал что-то в Linux, поделитесь софтом.
Помимо восстановления разделов и файлов, Testdisk может сохранить образ раздела для передачи и дальнейшего исследования где-то в другом месте. Также она сама умеет работать с образами дисков.
Сайт с описанием и реальными примерами восстановления данных или разделов - https://www.cgsecurity.org/wiki/TestDisk_RU
Сохраните программу, когда-нибудь она может здорово выручить.
#restore #terminal
TestDisk есть в базовых репах Debian и Ubuntu и обычно всегда присутствует во всяких Rescue Live CD. Она умеет следующее:
- исправлять таблицу разделов, восстанавливать удаленные разделы;
- восстанавливать загрузочные сектора;
- восстанавливать удалённые файлы;
Пользоваться утилитой достаточно просто, в сети много инструкций. Разделы я с её помощью восстанавливал. Файлы - нет. Иногда она видела удалённые файлы, но восстановить не получалось. Они все были нулевого размера. Так что на Linux я вообще не знаю и не использовал программы, которые реально могли бы восстановить удалённые файлы. Под виндой такие знаю и использовал, реально восстанавливал файлы. Если кто-то на практике восстанавливал что-то в Linux, поделитесь софтом.
Помимо восстановления разделов и файлов, Testdisk может сохранить образ раздела для передачи и дальнейшего исследования где-то в другом месте. Также она сама умеет работать с образами дисков.
Сайт с описанием и реальными примерами восстановления данных или разделов - https://www.cgsecurity.org/wiki/TestDisk_RU
Сохраните программу, когда-нибудь она может здорово выручить.
#restore #terminal
{kind=link}
👍61👎4
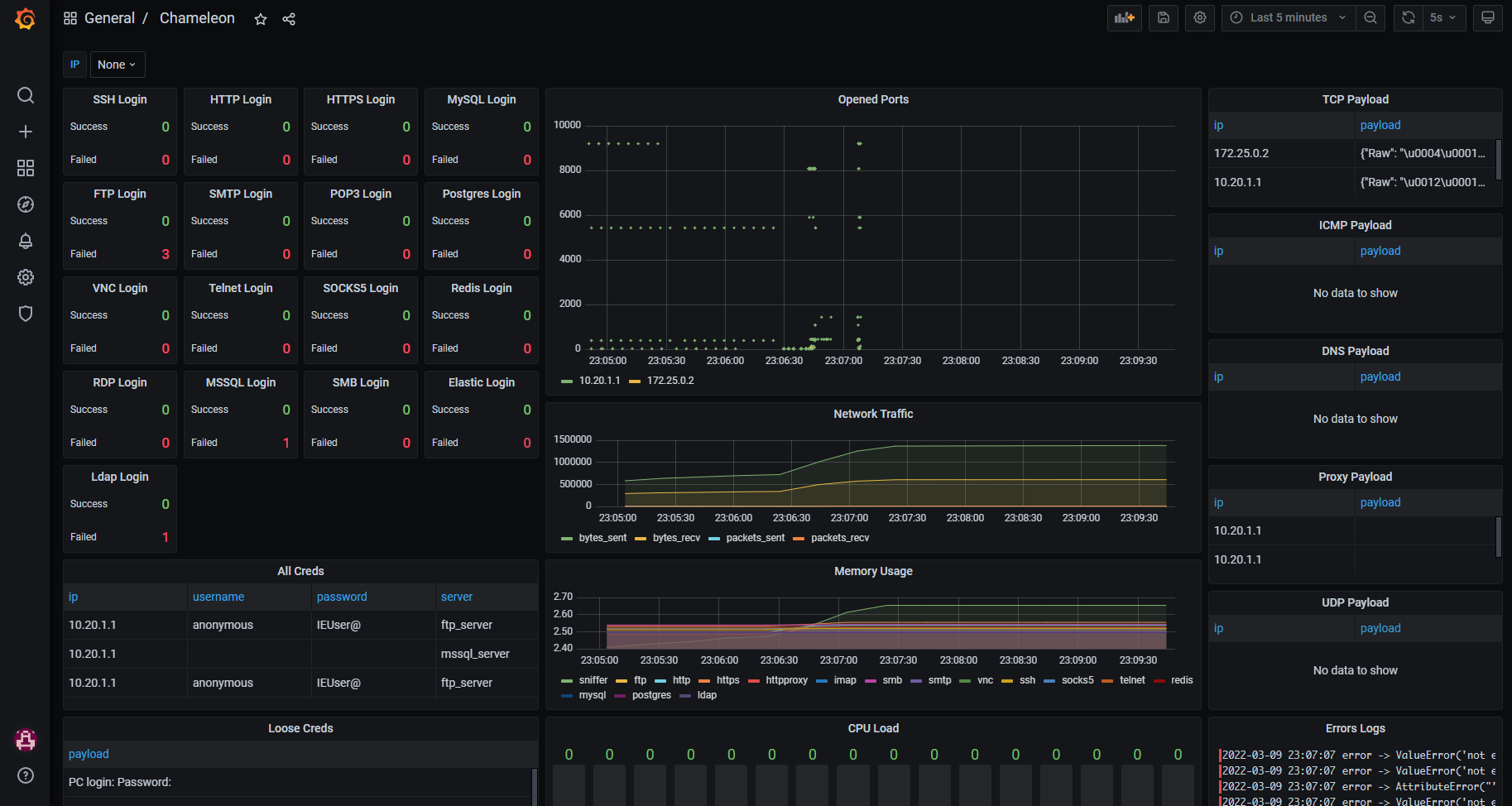
Ещё один готовый преднастроенный honeypot с простой установкой и интерфейсом на базе Grafana - Chameleon. В отличие от упомянутой ранее T-Pot это более легковесное решение, которое можно установить в том числе на Raspberry Pi.
У Chameleon в наборе все стандартные honeypots, такие как dns, ssh, imap, rdp, vnc и т.д. Данные хранит в PostgreSQL, веб интерфейс, как уже сказал, на базе Grafana. Установка максимально простая:
Будет установлена куча пакетов, собраны и запущены докер контейнеры. Используйте для теста отдельную виртуалку, так как система будет заполнена кучей дополнительных пакетов. И ещё важный момент. По умолчанию запускается в том числе honeypot для ssh на 22-м порту. Необходимо любо отключить sshd, либо перенести на другой порт. Я просто отключил и запустил установку с консоли сервера. Если этого не сделать, то установка будет завершаться ошибкой.
После завершения установки автоматически запустится веб интерфейс Grafana на порту 3000. Авторизация под учёткой changeme457f6460cb287 / changemed23b8cc6a20e0. Откройте дашборд Chameleon. Там будет вся информация по наблюдению.
Теперь для теста можно запустить nmap и посмотреть на результаты. С помощью Grafana Alerts можно настроить оповещения о подключениях к тем или иным портам. Все просто и быстро. Разобраться намного проще, чем в T-Pot, где под капотом ELK. Grafana более интуитивная и простая в освоении, чем Kibana.
Исходники - https://github.com/qeeqbox/chameleon
#security #honeypot
У Chameleon в наборе все стандартные honeypots, такие как dns, ssh, imap, rdp, vnc и т.д. Данные хранит в PostgreSQL, веб интерфейс, как уже сказал, на базе Grafana. Установка максимально простая:
# git clone https://github.com/qeeqbox/chameleon.git# cd chameleon# chmod +x ./run.sh# ./run.sh deployБудет установлена куча пакетов, собраны и запущены докер контейнеры. Используйте для теста отдельную виртуалку, так как система будет заполнена кучей дополнительных пакетов. И ещё важный момент. По умолчанию запускается в том числе honeypot для ssh на 22-м порту. Необходимо любо отключить sshd, либо перенести на другой порт. Я просто отключил и запустил установку с консоли сервера. Если этого не сделать, то установка будет завершаться ошибкой.
После завершения установки автоматически запустится веб интерфейс Grafana на порту 3000. Авторизация под учёткой changeme457f6460cb287 / changemed23b8cc6a20e0. Откройте дашборд Chameleon. Там будет вся информация по наблюдению.
Теперь для теста можно запустить nmap и посмотреть на результаты. С помощью Grafana Alerts можно настроить оповещения о подключениях к тем или иным портам. Все просто и быстро. Разобраться намного проще, чем в T-Pot, где под капотом ELK. Grafana более интуитивная и простая в освоении, чем Kibana.
Исходники - https://github.com/qeeqbox/chameleon
#security #honeypot
{kind=link}
👍51👎4
Расскажу вам про узкотематический инструмент, который пригодится не многим, но тому, кому актуально, может сильно упростить жизнь. Думаю, все знакомы с сервисом по рисованию всевозможных схем draw.io. Я уже неоднократно писал про него. Сам использую и считаю удобным, универсальным решением для рисования схем IT инфраструктуры.
Существует библиотека для Python N2G, с помощью которой можно автоматизировать рисование схем сетевых устройств, реализовав их создание в русле современного принципа infrastructure as a code. Если вы не умеет программировать на Python, может показаться, что это слишком сложно для вас. Но на самом деле ничего сложного нет. Я на пальцах покажу, как нарисовать в автоматическом режиме схему сети в draw.io с помощью библиотеки N2G.
Первым делом ставим на сервер Python и Pip. Установка будет зависеть от вашего дистрибутива. В общем случае это делается так:
Далее ставим необходимые библиотеки и модули.
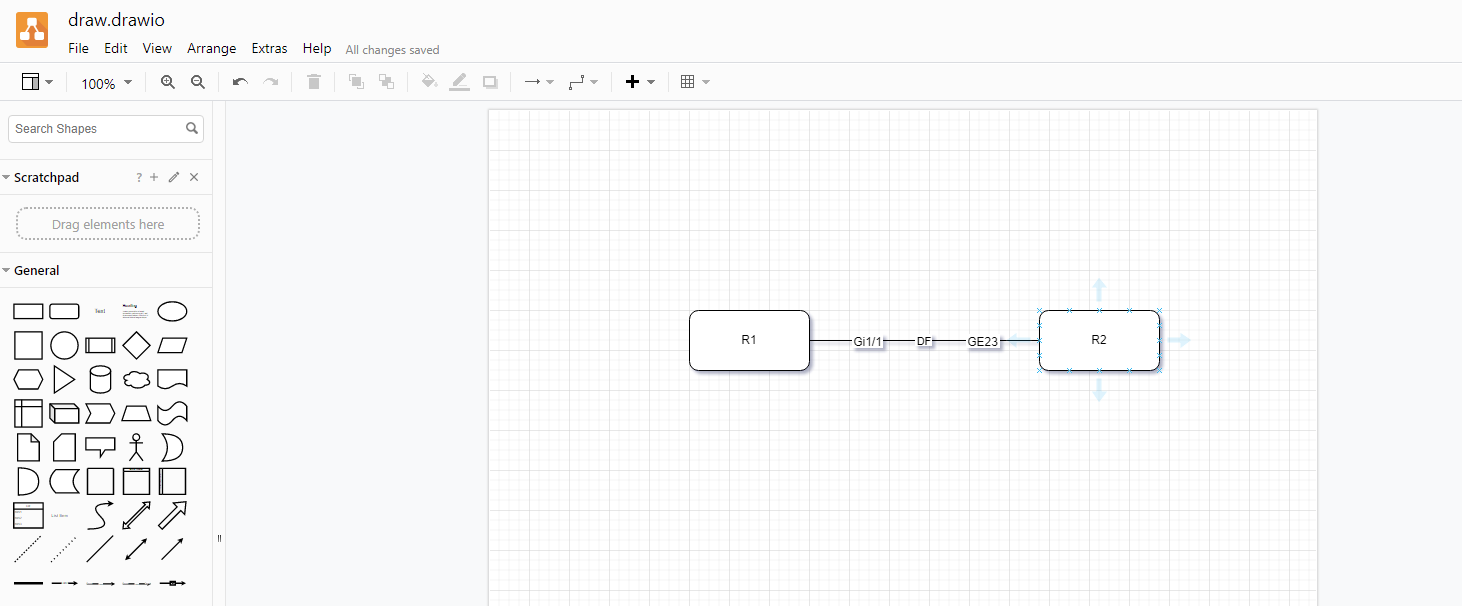
Вот и вся установка. Теперь создадим простейший код на python, который будет генерировать схему с соединением двух сетевых устройств.
Сохраняем файл и запускаем его с помощью python.
В директории со скриптом будет создана поддиректория Output, где будет лежать файл Sample_graph.drawio. Его можно загрузить в сервис draw.io и посмотреть схему. В данном примере мы создали одну страницу, в ней две ноды и показали связь между ними через определённые сетевые интерфейсы.
Синтаксис библиотеки нагляден и понятен. Знать Python не нужно, чтобы создавать схемы. У библиотеки есть хорошая документация с примерами. Там и про иконки рассказано, и как красоту навести, и всё остальное. С помощью этой библиотеки можно хранить схемы в git с контролем версий и изменений.
Я описал только часть функционала этой библиотеки, с которой разобрался сам и которая показалась полезной лично мне. А так она много чего ещё умеет делать. Все подробности в документации.
Исходники - https://github.com/dmulyalin/N2G
Документация - https://n2g.readthedocs.io/en/latest/diagram_plugins/DrawIo%20Module.html
#network
Существует библиотека для Python N2G, с помощью которой можно автоматизировать рисование схем сетевых устройств, реализовав их создание в русле современного принципа infrastructure as a code. Если вы не умеет программировать на Python, может показаться, что это слишком сложно для вас. Но на самом деле ничего сложного нет. Я на пальцах покажу, как нарисовать в автоматическом режиме схему сети в draw.io с помощью библиотеки N2G.
Первым делом ставим на сервер Python и Pip. Установка будет зависеть от вашего дистрибутива. В общем случае это делается так:
# apt install python3-pip# dnf install python3Далее ставим необходимые библиотеки и модули.
pip install N2G python-igraph openpyxlВот и вся установка. Теперь создадим простейший код на python, который будет генерировать схему с соединением двух сетевых устройств.
from N2G import drawio_diagramdiagram = drawio_diagram()diagram.add_diagram("Page-1")diagram.add_node(id="R1")diagram.add_node(id="R2")diagram.add_link("R1", "R2", label="DF", src_label="Gi1/1", trgt_label="GE23")diagram.layout(algo="kk")diagram.dump_file(filename="Sample_graph.drawio", folder="./Output/")Сохраняем файл и запускаем его с помощью python.
# python3 diagram.pyВ директории со скриптом будет создана поддиректория Output, где будет лежать файл Sample_graph.drawio. Его можно загрузить в сервис draw.io и посмотреть схему. В данном примере мы создали одну страницу, в ней две ноды и показали связь между ними через определённые сетевые интерфейсы.
Синтаксис библиотеки нагляден и понятен. Знать Python не нужно, чтобы создавать схемы. У библиотеки есть хорошая документация с примерами. Там и про иконки рассказано, и как красоту навести, и всё остальное. С помощью этой библиотеки можно хранить схемы в git с контролем версий и изменений.
Я описал только часть функционала этой библиотеки, с которой разобрался сам и которая показалась полезной лично мне. А так она много чего ещё умеет делать. Все подробности в документации.
Исходники - https://github.com/dmulyalin/N2G
Документация - https://n2g.readthedocs.io/en/latest/diagram_plugins/DrawIo%20Module.html
#network
{kind=link}
👍63👎2
🛡 Продолжаю тему безопасности. Существует класс продуктов для защиты веб приложений под названием Web Application Firewall. Они работают на прикладном уровне модели OSI, анализируют входящий и исходящий трафик приложения и принимают решение о предоставлении доступа или запрете.
Одним из таких продуктов является Nemesida WAF. Рассказать именно про неё я решил, потому что есть функциональная бесплатная версия, которой можно нормально пользоваться. Работает она примерно следующим образом. Можно либо зеркалить на неё весь трафик, делая только анализ и какие-то действия в будущем на основе анализа. А можно сразу принимать трафик на WAF и тут же отсекать неподходящий.
Функционал бесплатной версии:
- Выявление атак сигнатурным методом
- Автоматическая блокировка атакующего по IP-адресу
- Вывод информации об атаках, генерация отчетов и статистики работы
- Веб интерфейс для управления и просмотра отчётов
Установить Nemesida WAF просто, так как есть репозитории с пакетами под все популярные системы (Centos Stream, Debian, Ubuntu). Сам продукт состоит из следующих компонентов:
1. Динамический модуль для Nginx. Установка.
2. Nemesida WAF API. Этот компонент собирает информацию об атаках и уязвимостях. Установка.
3. Личный кабинет. Используется для визуализации и систематизации информации об атаках и выявленных уязвимостях. Установка.
Для тех, кто не хочет самостоятельно заниматься настройкой, есть готовый образ VM для запуска.
Посмотреть на панель управления Nemesida WAF можно на демо стенде:
https://demo.lk.nemesida-waf.com/
[email protected] / pentestit
#security #webserver #waf
Одним из таких продуктов является Nemesida WAF. Рассказать именно про неё я решил, потому что есть функциональная бесплатная версия, которой можно нормально пользоваться. Работает она примерно следующим образом. Можно либо зеркалить на неё весь трафик, делая только анализ и какие-то действия в будущем на основе анализа. А можно сразу принимать трафик на WAF и тут же отсекать неподходящий.
Функционал бесплатной версии:
- Выявление атак сигнатурным методом
- Автоматическая блокировка атакующего по IP-адресу
- Вывод информации об атаках, генерация отчетов и статистики работы
- Веб интерфейс для управления и просмотра отчётов
Установить Nemesida WAF просто, так как есть репозитории с пакетами под все популярные системы (Centos Stream, Debian, Ubuntu). Сам продукт состоит из следующих компонентов:
1. Динамический модуль для Nginx. Установка.
2. Nemesida WAF API. Этот компонент собирает информацию об атаках и уязвимостях. Установка.
3. Личный кабинет. Используется для визуализации и систематизации информации об атаках и выявленных уязвимостях. Установка.
Для тех, кто не хочет самостоятельно заниматься настройкой, есть готовый образ VM для запуска.
Посмотреть на панель управления Nemesida WAF можно на демо стенде:
https://demo.lk.nemesida-waf.com/
[email protected] / pentestit
#security #webserver #waf
{kind=link}
👍40👎3
Перенос инфраструктуры в Yandex.Cloud от Fevlake.
За последние 2 годы мы с командой инженеров перенесли более 20 инфраструктур в Yandex.Cloud (из AWS / Azure / GCP / Bare Metal)
Felake это:
⁃ Сервисный партнер Yandex.Cloud с 2019 года
⁃ Команда DevOps инженеров Middle и Senior уровня
⁃ Разработчик совместного с Яндекс Облаком практикума Kubernetes в Yandex.Cloud
Более 10 лет обслуживаем и проектируем IT инфраструктуры.
Оставляйте заявку на аудит.
#реклама
За последние 2 годы мы с командой инженеров перенесли более 20 инфраструктур в Yandex.Cloud (из AWS / Azure / GCP / Bare Metal)
Felake это:
⁃ Сервисный партнер Yandex.Cloud с 2019 года
⁃ Команда DevOps инженеров Middle и Senior уровня
⁃ Разработчик совместного с Яндекс Облаком практикума Kubernetes в Yandex.Cloud
Более 10 лет обслуживаем и проектируем IT инфраструктуры.
Оставляйте заявку на аудит.
#реклама
👎32👍16
▶️ У автора отличного канала realmanual по системному администрированию и Devops вышла серия подробных инструкций по настройке своего Gitlab сервера а так же интеграция его же с FreeIPA.
Ролики:
◽ Gitlab - валим на свой сервер ч1. Разбор, зачем нужен свой сервер Gitlab. Размещаем репозиторий.
◽ Gitlab - валим на свой сервер ч2.1. Работа с переменными, зачем нужны и как управлять.
◽ Gitlab - валим на свой сервер ч2.2. Запуск сборки и разбор сопутствующих проблем.
◽ Gitlab - валим на свой сервер ч3. Настройка бэкапов и интеграции с LDAP.
◽ Дружим Freeipa и Gitlab-CI. Как настроить связь между внешним приложением Gitlab-CI и каталогом FreeIPA.
Ранее я уже упоминал в заметках про данный канал. Кто ещё не подписан, подписывайтесь.
#видео #devops
Ролики:
◽ Gitlab - валим на свой сервер ч1. Разбор, зачем нужен свой сервер Gitlab. Размещаем репозиторий.
◽ Gitlab - валим на свой сервер ч2.1. Работа с переменными, зачем нужны и как управлять.
◽ Gitlab - валим на свой сервер ч2.2. Запуск сборки и разбор сопутствующих проблем.
◽ Gitlab - валим на свой сервер ч3. Настройка бэкапов и интеграции с LDAP.
◽ Дружим Freeipa и Gitlab-CI. Как настроить связь между внешним приложением Gitlab-CI и каталогом FreeIPA.
Ранее я уже упоминал в заметках про данный канал. Кто ещё не подписан, подписывайтесь.
#видео #devops
{kind=link}
👍68👎2
Во всех Linux и Unix дистрибутивах, с которыми мне приходилось работать, существовала маленькая утилита, которая вызывалась в командной строке всего одной буквой - w. У меня давняя привычка запускать её сразу после подключения по ssh. Просто проверить, нет ли кого-то ещё на сервере, посмотреть uptime, загрузку.
На днях знакомый попросил помочь ему на одном сервере. Я подключился и сразу же на автомате запустил w, проверил, кто тут ещё есть. Спросил его, он ли это подключен с определённого ip адреса. На что он удивился и не понял, как я так быстро увидел его ip адрес. Несмотря на то, что с линуксами он давно работает, про эту команду не знал.
С помощью w легко увидеть свой внешний ip адрес, или адрес из vpn туннеля, чтобы точно знать, как тебя видит сервер, чтобы настроить исключения для фаервола.
Подводя итог, w показывает:
- текущее время и uptime
- load average
- залогиненного пользователя, его терминал, время логина, ip адрес и что у него запущено в данный момент
W удобно использовать вместо who, так как писать меньше. Знали про эту утилиту?
#terminal
На днях знакомый попросил помочь ему на одном сервере. Я подключился и сразу же на автомате запустил w, проверил, кто тут ещё есть. Спросил его, он ли это подключен с определённого ip адреса. На что он удивился и не понял, как я так быстро увидел его ip адрес. Несмотря на то, что с линуксами он давно работает, про эту команду не знал.
С помощью w легко увидеть свой внешний ip адрес, или адрес из vpn туннеля, чтобы точно знать, как тебя видит сервер, чтобы настроить исключения для фаервола.
Подводя итог, w показывает:
- текущее время и uptime
- load average
- залогиненного пользователя, его терминал, время логина, ip адрес и что у него запущено в данный момент
W удобно использовать вместо who, так как писать меньше. Знали про эту утилиту?
#terminal
{kind=link}
👍322👎6
Пост не совсем по теме канала, но мне кажется в наше время всевозможных ограничений доступа к информации со всех сторон он будет актуален многим. Надумал сохранить себе с youtube некоторую информацию, которая не устаревает со временем. Я и раньше это делал, но в основном для документальных фильмов. Сейчас расширил список того, что надо сохранить.
В первую очередь на ум приходит известный проект youtube-dl, но качать через него сейчас практически невозможно, так как скорость стабильно держится в районе 70 кб/c. Погуглил немного, понял, что проблема не только у меня.
Работающей альтернативой служит yt-dlp (https://github.com/yt-dlp/yt-dlp). У него всё в порядке со скоростью загрузки. Я закинул бинарник в WLS под виндой и качаю оттуда. Вот прямая ссылка на загрузку последней версии:
https://github.com/yt-dlp/yt-dlp/releases/download/2022.03.08.1/yt-dlp
Использовать очень просто. Достаточно указать либо ссылку на видео, либо на плейлист. Он выкачает весь плейлист в порядке расположения в нём роликов:
# ./yt-dlp https://www.youtube.com/watch?v=wmdO58eZqCY
# ./yt-dlp https://www.youtube.com/playlist?list=PL5BwB5wUDXk2keesVmLDkLaP9m_2Fo9is
У меня всё качалось на максимальной скорости канала в интернет - 100 мегабит. Скачал всё, что надо было.
Возвращаются времена домашних NAS и торрентов. У меня такой стоит на базе старенького HP Microserver с шестью дисками.
#разное
В первую очередь на ум приходит известный проект youtube-dl, но качать через него сейчас практически невозможно, так как скорость стабильно держится в районе 70 кб/c. Погуглил немного, понял, что проблема не только у меня.
Работающей альтернативой служит yt-dlp (https://github.com/yt-dlp/yt-dlp). У него всё в порядке со скоростью загрузки. Я закинул бинарник в WLS под виндой и качаю оттуда. Вот прямая ссылка на загрузку последней версии:
https://github.com/yt-dlp/yt-dlp/releases/download/2022.03.08.1/yt-dlp
Использовать очень просто. Достаточно указать либо ссылку на видео, либо на плейлист. Он выкачает весь плейлист в порядке расположения в нём роликов:
# ./yt-dlp https://www.youtube.com/watch?v=wmdO58eZqCY
# ./yt-dlp https://www.youtube.com/playlist?list=PL5BwB5wUDXk2keesVmLDkLaP9m_2Fo9is
У меня всё качалось на максимальной скорости канала в интернет - 100 мегабит. Скачал всё, что надо было.
Возвращаются времена домашних NAS и торрентов. У меня такой стоит на базе старенького HP Microserver с шестью дисками.
#разное
{kind=link}
👍107👎9
На днях помогал навести порядок в серверной с одной единственной стойкой. Её нужно было пересобрать и уплотнить по серверам, чтобы всё необходимое влезло. Всё это на территории производства располагается и сделано было много лет назад как придётся.
В итоге сетевые кабели были в одном коробе с силовыми. Пока серверов было не много, проблем это не доставляло. После того, как увеличилась нагрузка, начались неведомые проблемы, которые не сразу распознали. Вся основная нагрузка была внутри самой стойки, так что наводки от кабелей особо не мешали и в мониторинге не отсвечивали.
А вот оконечные устройства пользователей начали глючить. DHCP не всегда выдавал настройки, SIP телефоны подвисали и т.д. Но в целом всё работало и особо никто не жаловался. Я понял, что что-то не то, когда линк от стойки до одного из свитчей стал падать с одного гигабита на 100 мегабит. При этом мониторинг нормально отрабатывал и жёстко связь не отваливалась. Я решил помониторить обычным icmp внутри локалки и тут стали видны проблемы - частые потери пакетов.
Так как я серверную видел и сам обратил внимание, что провода с силовыми в одном коробе идут, сразу подумал на наводки. Попросил кабель отдельно от стойки кинуть мимо силовых. Проблема сразу решилась. Если бы лично не побывал на месте, фиг знает, сколько бы времени ушло на решение проблемы. Очевидно, что замена патчкордов, сетевого оборудования тут бы не помогла.
Я знаю, что силовые с сетевыми часто в один короб кладут, особенно когда по офисам разводку рабочих мест делают. Там реально это не даёт никаких проблем, так как токи небольшие. А когда нагрузки растут, так делать уже нельзя.
#железо
В итоге сетевые кабели были в одном коробе с силовыми. Пока серверов было не много, проблем это не доставляло. После того, как увеличилась нагрузка, начались неведомые проблемы, которые не сразу распознали. Вся основная нагрузка была внутри самой стойки, так что наводки от кабелей особо не мешали и в мониторинге не отсвечивали.
А вот оконечные устройства пользователей начали глючить. DHCP не всегда выдавал настройки, SIP телефоны подвисали и т.д. Но в целом всё работало и особо никто не жаловался. Я понял, что что-то не то, когда линк от стойки до одного из свитчей стал падать с одного гигабита на 100 мегабит. При этом мониторинг нормально отрабатывал и жёстко связь не отваливалась. Я решил помониторить обычным icmp внутри локалки и тут стали видны проблемы - частые потери пакетов.
Так как я серверную видел и сам обратил внимание, что провода с силовыми в одном коробе идут, сразу подумал на наводки. Попросил кабель отдельно от стойки кинуть мимо силовых. Проблема сразу решилась. Если бы лично не побывал на месте, фиг знает, сколько бы времени ушло на решение проблемы. Очевидно, что замена патчкордов, сетевого оборудования тут бы не помогла.
Я знаю, что силовые с сетевыми часто в один короб кладут, особенно когда по офисам разводку рабочих мест делают. Там реально это не даёт никаких проблем, так как токи небольшие. А когда нагрузки растут, так делать уже нельзя.
#железо
👍149👎3
Я на днях затрагивал тему восстановления файлов на Linux с помощью testdisk. Решил немного изучить вопрос и попробовать что-то ещё. Выбор пал на программу scalpel, которая оказалась в стандартном репозитории Debian.
Поставил её так:
Scalpel использует базу данных заголовков и колонтитулов файлов. Так что для поиска нужно будет заполнить шаблоны этих файлов. Для наиболее популярных форматов в дефолтном конфиге уже есть эти шаблоны. Найти конфиг можно по адресу /etc/scalplel/scalpel.conf
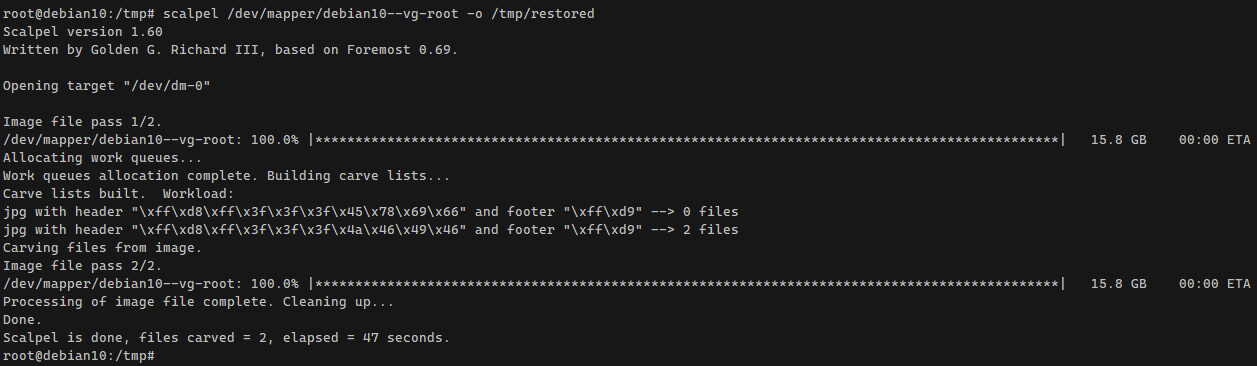
Я для теста раскомментировал в конфиге шаблоны для jpg файлов. Закинул на диск пару картинок и удалил их. Запустил scalpel для поиска:
В данном случае /dev/mapper/debian10--vg-root это корневой раздел системы на lvm томе. На удивление поиск прошёл довольно быстро. Искал по ssd диску примерно на максимальной для него скорости чтения в 400 мб/сек.
В итоге нашёл оба файла и положил их в указанную папку /tmp/restored. Там же был отчёт в audit.txt. Я скинул файлы на комп, проверил, всё в порядке. Это те же картинки. Scalpel может искать не только с диска, но и с образа. Так что если надо срочно что-то восстановить, можно тут же погасить машину, снять с неё образ диска и передать куда-то для восстановления данных.
Результат мне очень понравился. Понятно, что восстановление будет зависеть от множества параметров. Тут система была в простое. Я удалил файлы и почти сразу же стал их искать. Почти идеальные условия. Но тем не менее, без лишних заморочек я очень быстро восстановил удалённые файлы. Если случайно грохните какой-то файл по ошибке, можно быстро с помощью scalpel его восстановить. Так что сохраните заметку в закладки, может пригодиться.
Есть важный нюанс. Scalpel ищет по преднастроенной таблице шаблонов файлов. Вам нужно будет самим сделать такой шаблон, если придётся искать файлы, которых в дефолтном шаблоне нет. Для этого нужно будет взять образец файла, открыть его в hex редакторе и изучить его заголовки (signatures). Либо попробовать нагуглить их, что может оказаться значительно проще и быстрее. Под популярные форматы скорее всего найдёте сигнатуры.
#restore
Поставил её так:
# apt install scalpelScalpel использует базу данных заголовков и колонтитулов файлов. Так что для поиска нужно будет заполнить шаблоны этих файлов. Для наиболее популярных форматов в дефолтном конфиге уже есть эти шаблоны. Найти конфиг можно по адресу /etc/scalplel/scalpel.conf
Я для теста раскомментировал в конфиге шаблоны для jpg файлов. Закинул на диск пару картинок и удалил их. Запустил scalpel для поиска:
# scalpel /dev/mapper/debian10--vg-root -o /tmp/restoredВ данном случае /dev/mapper/debian10--vg-root это корневой раздел системы на lvm томе. На удивление поиск прошёл довольно быстро. Искал по ssd диску примерно на максимальной для него скорости чтения в 400 мб/сек.
В итоге нашёл оба файла и положил их в указанную папку /tmp/restored. Там же был отчёт в audit.txt. Я скинул файлы на комп, проверил, всё в порядке. Это те же картинки. Scalpel может искать не только с диска, но и с образа. Так что если надо срочно что-то восстановить, можно тут же погасить машину, снять с неё образ диска и передать куда-то для восстановления данных.
Результат мне очень понравился. Понятно, что восстановление будет зависеть от множества параметров. Тут система была в простое. Я удалил файлы и почти сразу же стал их искать. Почти идеальные условия. Но тем не менее, без лишних заморочек я очень быстро восстановил удалённые файлы. Если случайно грохните какой-то файл по ошибке, можно быстро с помощью scalpel его восстановить. Так что сохраните заметку в закладки, может пригодиться.
Есть важный нюанс. Scalpel ищет по преднастроенной таблице шаблонов файлов. Вам нужно будет самим сделать такой шаблон, если придётся искать файлы, которых в дефолтном шаблоне нет. Для этого нужно будет взять образец файла, открыть его в hex редакторе и изучить его заголовки (signatures). Либо попробовать нагуглить их, что может оказаться значительно проще и быстрее. Под популярные форматы скорее всего найдёте сигнатуры.
#restore
{kind=link}
👍56👎2
Летом рассказывал про сервис healthchecks.io, которым я в итоге сам стал пользоваться и пользуюсь до сих пор. Вчера оповещение прилетело, вспомнил про него и решил ещё раз упомянуть, потому что в той заметке я не знал и не рассказал о том, что это open source продукт и вы можете этот мониторинг развернуть у себя. Плюс, в тот момент я его сам впервые увидел, а сейчас уже попользовался.
Конкретно я его использую на одиночных хостах, для которых нет какого-то специального мониторинга. Я вешаю результат работы кронов по продлению сертификатов, созданию и проверки бэкапов на оповещения в этом сервисе. Если скрипт отрабатывает с ошибкой, мне приходит уведомление и я иду проверять. Всё просто, быстро, бесплатно. Не надо городить никакой мониторинг результатов работы.
Понятно, что всё это можно наколхозить своими скриптами и отправлять письма себе на почту прямо из скрипта или из крона. Но тут всё сделано аккуратно, удобно, централизованно, с отчётами и статистикой. В общем, мне нравится, сам пользуюсь. У себя не ставил, использую бесплатную облачную версию. Если установите у себя, то никаких ограничений не будет.
Исходники - https://github.com/healthchecks/healthchecks
#мониторинг
Конкретно я его использую на одиночных хостах, для которых нет какого-то специального мониторинга. Я вешаю результат работы кронов по продлению сертификатов, созданию и проверки бэкапов на оповещения в этом сервисе. Если скрипт отрабатывает с ошибкой, мне приходит уведомление и я иду проверять. Всё просто, быстро, бесплатно. Не надо городить никакой мониторинг результатов работы.
Понятно, что всё это можно наколхозить своими скриптами и отправлять письма себе на почту прямо из скрипта или из крона. Но тут всё сделано аккуратно, удобно, централизованно, с отчётами и статистикой. В общем, мне нравится, сам пользуюсь. У себя не ставил, использую бесплатную облачную версию. Если установите у себя, то никаких ограничений не будет.
Исходники - https://github.com/healthchecks/healthchecks
#мониторинг
{kind=link}
👍46👎2
Хочу поделиться показательной историей от одного читателя, который обратился ко мне с вопросом, который звучал вот так:
Добрый вечер!
Столкнулся с проблемой 100% заполнения корневого диска. Поиск через DF/DU ничего не дал. Совокупный размер всех папок показывает менее 4Гб.
Команды ниже, также не показали проблемы.
lsof | grep '(deleted)'
find /proc/*/fd -ls | grep '(deleted)'
Перезагрузка не помогает. Как узнать чем занято?
Перечисленные решения лично мне всегда помогали. Если место ушло и ты не знаешь куда, проверь удалённые файлы, которые какой-то сервис держит открытыми и пишет туда. Обычно это помогает.
Дополнительно я посоветовал проверить диск утилитой fsck. Проблема оказалась совсем не в той плоскости, где её искали. Была папка /mnt, которую плотно забили файлами так, что места на диске не осталось. А потом в эту директорию смонтировали внешнее хранилище. В итоге локальные файлы в папке /mnt стало не видно, но они остались на диске и добраться до них нельзя было, пока не отмонтировано внешнее хранилище.
Ровно по этой причине я никогда не кладу никакие файлы в директорию /mnt напрямую. И никогда не монтирую туда внешние ресурсы прямо в /mnt. Всегда создаю отдельную директорию и уже туда монтирую. Например, в /mnt/backup, /mnt/external и т.д. Это как раз для того делается, чтобы не было путаницы. Название директории /mnt как бы намекает на то, что это отличное место для подключения отдельных хранилищ и плохое место для хранения локальных файлов.
А вы туда кладёте файлы напрямую? Есть какие-то свои правила создания точек монтирования?
#linux
Добрый вечер!
Столкнулся с проблемой 100% заполнения корневого диска. Поиск через DF/DU ничего не дал. Совокупный размер всех папок показывает менее 4Гб.
Команды ниже, также не показали проблемы.
lsof | grep '(deleted)'
find /proc/*/fd -ls | grep '(deleted)'
Перезагрузка не помогает. Как узнать чем занято?
Перечисленные решения лично мне всегда помогали. Если место ушло и ты не знаешь куда, проверь удалённые файлы, которые какой-то сервис держит открытыми и пишет туда. Обычно это помогает.
Дополнительно я посоветовал проверить диск утилитой fsck. Проблема оказалась совсем не в той плоскости, где её искали. Была папка /mnt, которую плотно забили файлами так, что места на диске не осталось. А потом в эту директорию смонтировали внешнее хранилище. В итоге локальные файлы в папке /mnt стало не видно, но они остались на диске и добраться до них нельзя было, пока не отмонтировано внешнее хранилище.
Ровно по этой причине я никогда не кладу никакие файлы в директорию /mnt напрямую. И никогда не монтирую туда внешние ресурсы прямо в /mnt. Всегда создаю отдельную директорию и уже туда монтирую. Например, в /mnt/backup, /mnt/external и т.д. Это как раз для того делается, чтобы не было путаницы. Название директории /mnt как бы намекает на то, что это отличное место для подключения отдельных хранилищ и плохое место для хранения локальных файлов.
А вы туда кладёте файлы напрямую? Есть какие-то свои правила создания точек монтирования?
#linux
👍101👎6
На днях настраивал openvpn сервер по своей статье и решил поделиться информацией. Статья полностью актуальная, можно настраивать копипастом на любом клоне Centos. Помимо многих очевидных плюсов openvpn, о которых я так или иначе уже писал, хочу рассказать ещё об одном, за который люблю эту программу.
Openvpn без проблем запускает на одной и той же машине любое количество тоннелей с разными настройками. Просто кладёте рядом конфиг очередного сервера и запускаете через systemd новый экземпляр с этим конфигом.
У меня на одном сервере запросто живут следующие конфигурации openvpn:
▪ протокол udp с шифрованием для общих случаев, порт любой;
▪ протокол tcp для подключения микротиков, порт любой;
▪ протокол tcp и 443 порт для подключения из мест, где остальные порты закрыты.
и т.д.
Создаются одновременно любые конфигурации с разными протоколами, наличием или отсутствием сжатия, различными протоколами шифрования и т.д. SIP юзеров в один тоннель сажаем, админов в другой, обычных юзеров в третий, филиалы в четвёртый и т.д. У каждого тоннеля своя подсеть, под которую создаются правила firewall. Я стараюсь максимально сегментировать подключения. Так безопаснее и удобнее управлять.
Отмечу до кучи остальные особенности openvpn, за которые я её люблю:
◽ Простой и удобный механизм передачи маршрутов клиенту. Все настраивается и управляется централизованно с сервера. Считаю это основным преимуществом openvpn.
◽ Есть клиенты под все популярные платформы и системы. Конфигурация передается в одном файле.
◽ Популярный и проверенный временем продукт. Легко настраивается, легко решаются проблемы. Хорошее логирование на стороне клиента. Легко дебажить проблемы.
Для организации vpn всегда выберу openvpn, если он подходит под технические условия задачи. А вы на чём предпочитаете строить vpn сети?
#openvpn #vpn
Openvpn без проблем запускает на одной и той же машине любое количество тоннелей с разными настройками. Просто кладёте рядом конфиг очередного сервера и запускаете через systemd новый экземпляр с этим конфигом.
У меня на одном сервере запросто живут следующие конфигурации openvpn:
▪ протокол udp с шифрованием для общих случаев, порт любой;
▪ протокол tcp для подключения микротиков, порт любой;
▪ протокол tcp и 443 порт для подключения из мест, где остальные порты закрыты.
и т.д.
Создаются одновременно любые конфигурации с разными протоколами, наличием или отсутствием сжатия, различными протоколами шифрования и т.д. SIP юзеров в один тоннель сажаем, админов в другой, обычных юзеров в третий, филиалы в четвёртый и т.д. У каждого тоннеля своя подсеть, под которую создаются правила firewall. Я стараюсь максимально сегментировать подключения. Так безопаснее и удобнее управлять.
Отмечу до кучи остальные особенности openvpn, за которые я её люблю:
◽ Простой и удобный механизм передачи маршрутов клиенту. Все настраивается и управляется централизованно с сервера. Считаю это основным преимуществом openvpn.
◽ Есть клиенты под все популярные платформы и системы. Конфигурация передается в одном файле.
◽ Популярный и проверенный временем продукт. Легко настраивается, легко решаются проблемы. Хорошее логирование на стороне клиента. Легко дебажить проблемы.
Для организации vpn всегда выберу openvpn, если он подходит под технические условия задачи. А вы на чём предпочитаете строить vpn сети?
#openvpn #vpn
{kind=link}
👍85👎3
❓ Хотите научиться настраивать веб-сервера и разобраться, как работает SSL-сертификат?
Мы подготовили мини-практикум NGINX by REBRAIN.
NGINX — самый популярный веб-сервер в мире, используемый на абсолютном большинстве сайтов.
Для кого?
Системных инженеров, DevOps-инженеров, разработчиков и тестировщиков.
За 6 дней узнайте все об NGINX. Наша программа включает:
◽ 13 заданий
◽ 13 обзорных видео по задачам
◽ Best Practices
◽ Автопроверки + проверка инженерами
◽ Чат с авторами и кураторами
◽ Сертификат о прохождении программы
Программа охватывает все основные аспекты работы с NGINX.
Рейтинг программы 9/10 (по опросу пользователей REBRAIN)
*программу проходит более 600 человек
Научимся:
✔️ Настраивать веб-сервер
✔️ Получать SSL-сертификаты
✔️ Делать reverse proxy с балансировкой и мониторингом нод
Освоим:
Virtual Hosts, Locations, URL Rewrite, Letsencrypt, Basic Auth, TLS Auth, Modules (GeoIP), Reverse, Proxy, Upstream Check, If/map, CORS, Monitoring.
На этой неделе на программу действует скидка 30%
Приобрести можно за 4 990 р. (вместо 6 990 р.)
После прохождения вы получите сертификат об успешном прохождении программы NGINX by REBRAIN.
Когда можно начать?
Подключайтесь к онлайн-тренажеру NGINX.
Проходите в удобное для вас время. Материалы останутся с вами навсегда.
👉 Успевайте подключиться
#реклама
Мы подготовили мини-практикум NGINX by REBRAIN.
NGINX — самый популярный веб-сервер в мире, используемый на абсолютном большинстве сайтов.
Для кого?
Системных инженеров, DevOps-инженеров, разработчиков и тестировщиков.
За 6 дней узнайте все об NGINX. Наша программа включает:
◽ 13 заданий
◽ 13 обзорных видео по задачам
◽ Best Practices
◽ Автопроверки + проверка инженерами
◽ Чат с авторами и кураторами
◽ Сертификат о прохождении программы
Программа охватывает все основные аспекты работы с NGINX.
Рейтинг программы 9/10 (по опросу пользователей REBRAIN)
*программу проходит более 600 человек
Научимся:
✔️ Настраивать веб-сервер
✔️ Получать SSL-сертификаты
✔️ Делать reverse proxy с балансировкой и мониторингом нод
Освоим:
Virtual Hosts, Locations, URL Rewrite, Letsencrypt, Basic Auth, TLS Auth, Modules (GeoIP), Reverse, Proxy, Upstream Check, If/map, CORS, Monitoring.
На этой неделе на программу действует скидка 30%
Приобрести можно за 4 990 р. (вместо 6 990 р.)
После прохождения вы получите сертификат об успешном прохождении программы NGINX by REBRAIN.
Когда можно начать?
Подключайтесь к онлайн-тренажеру NGINX.
Проходите в удобное для вас время. Материалы останутся с вами навсегда.
👉 Успевайте подключиться
#реклама
{kind=link}
👎13👍12
Возникла на днях рутинная задача по очистке одного диска от старых файлов, так как заканчивалось место, а старые файлы уже не нужны. Но перед тем, как их удалить, захотел посмотреть, сколько я освобожу места, захватив тот или иной период времени. В итоге получилась вот такая конструкция:
find /mnt/zz_archive/upload -type f -size +30M -newermt '2018-01-01 00:01' ! -newermt '2018-06-30 23:59' -exec ls -lh '{}' \; | awk '{print $5}' | sed 's/.$//' | awk '{n += $1}; END{print n}'
Сначала использую стандартный синтаксис find: ищу файлы больше 30 мегабайт и в заданном интервале времени. Затем в консоль вывожу информацию с помощью ls о каждом файле, указав размер в мегабайтах (ключ -h). Далее печатаю только столбец с размером с помощью awk, в этом столбце в конце убираю последний символ, так как он содержит букву M (было 512М стало 512). Потом суммирую то, что осталось. То есть только столбец с размером в мегабайтах.
Решение ни на что не претендует. Просто сходу что пришло в голову, так и реализовал. Наверняка кто-то придумает другое решение, возможно значительно проще. Я обычно не заморачиваюсь на таких разовых задачах. Главное быстро решить вопрос и записать решение, чтобы потом заново его не изобретать.
#bash #terminal
find /mnt/zz_archive/upload -type f -size +30M -newermt '2018-01-01 00:01' ! -newermt '2018-06-30 23:59' -exec ls -lh '{}' \; | awk '{print $5}' | sed 's/.$//' | awk '{n += $1}; END{print n}'
Сначала использую стандартный синтаксис find: ищу файлы больше 30 мегабайт и в заданном интервале времени. Затем в консоль вывожу информацию с помощью ls о каждом файле, указав размер в мегабайтах (ключ -h). Далее печатаю только столбец с размером с помощью awk, в этом столбце в конце убираю последний символ, так как он содержит букву M (было 512М стало 512). Потом суммирую то, что осталось. То есть только столбец с размером в мегабайтах.
Решение ни на что не претендует. Просто сходу что пришло в голову, так и реализовал. Наверняка кто-то придумает другое решение, возможно значительно проще. Я обычно не заморачиваюсь на таких разовых задачах. Главное быстро решить вопрос и записать решение, чтобы потом заново его не изобретать.
#bash #terminal
👍74👎4
Ранее я уже рассказывал про отличный open source проект по управлению удалёнными компьютерами через браузер - MeshCentral. Это реально удобное и функциональное решение, о котором многие отзываются положительно.
Существует проект Tactical RMM для мониторинга и управления компьютерами на базе Windows. Особенность его в том, что он интегрируется с MeshCentral и использует его в своей инфраструктуре для подключения к компьютерам. Получается очень функциональная и удобная связка на основе только open source продуктов.
Tactical RMM по закрываемым задачам похож на такие продукты как Spiceworks, Snipe-IT и подобные программы. Сюда можно было бы добавить glpi и itop, но всё же это более навороченные и сложные продукты, в отличие от Tactical RMM. Но зато интеграция с MeshCentral делает его очень удобным в ежедневной рутине по поддержке пользователей.
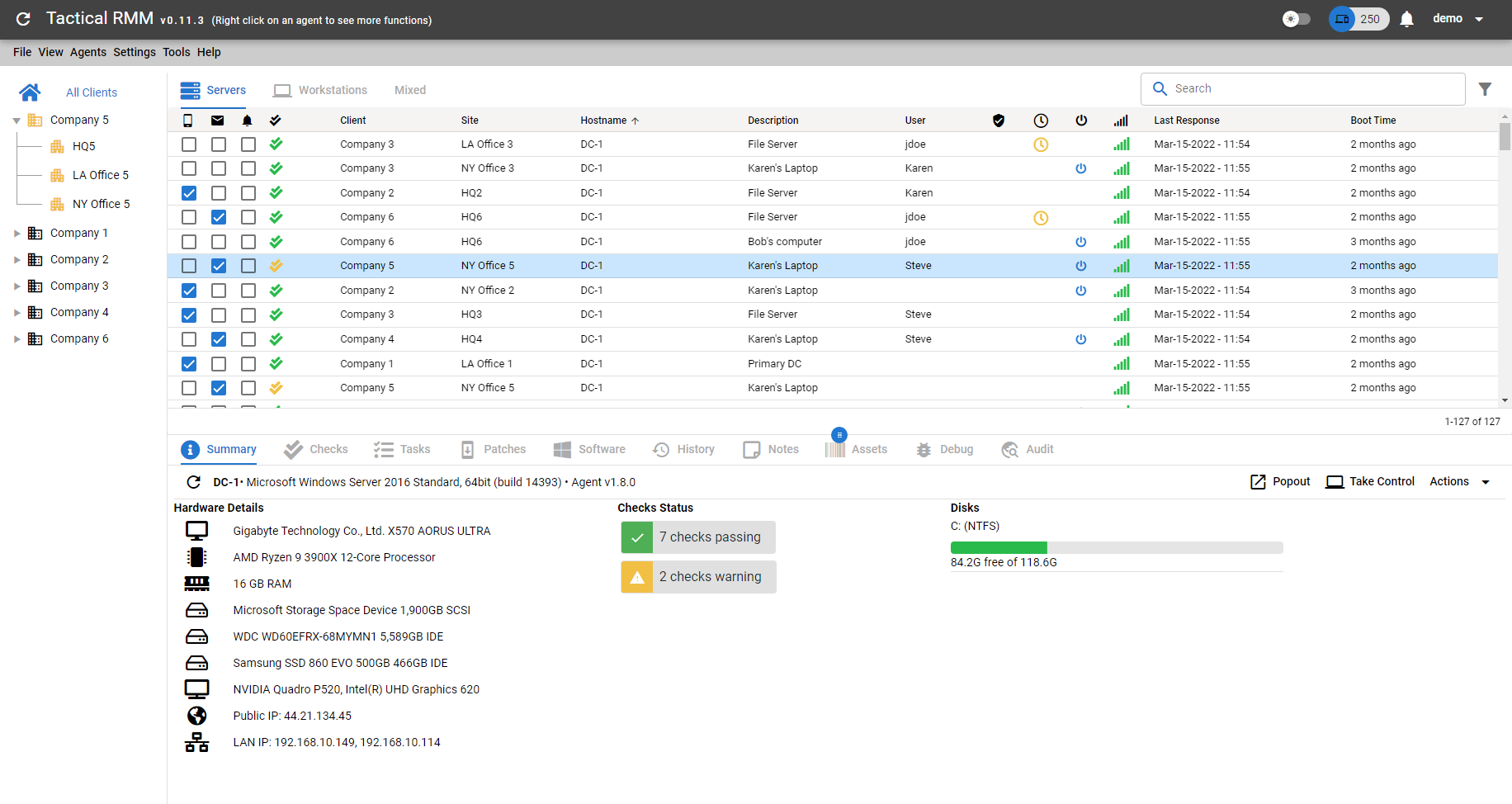
Есть публичная демка для обзора возможностей. Я как зашёл туда, сразу полюбил продукт. Интерфейс простой, удобный, современный, понятный. Всё, что нужно на виду. Умеет он следующее:
- подключаться к remote shell;
- выполнять удалённо скрипты;
- показывать логи машин;
- управлять службами, обновлениями;
- устанавливать софт через chocolatey;
- выполнять инвентаризацию железа и ПО;
- показывать основные метрики системы;
- выполнять проверки на тему работы какой-то службы, наличия свободного, места на дисках, загрузки CPU и RAM и т.д.;
- отправлять уведомления.
Установить Tactical RMM можно с помощью готового скрипта, который лежит в репозитории. Он всё поставит сам. В основе там Django, NodeJS, Postgresql, MongoDB. Скрипт всё это сам поставит и подготовит конфиги. Либо можно использовать готовый Docker контейнер. Всё это описано в документации.
В качестве агента на хостах используется агент от MeshCentral. После установки сервера можно сформировать установщик, который автоматически будет подключать агенты к серверу.
Продукт мне очень понравился. Я не знаю, как он в деле, но на вид выглядит круто и удобно. Поделитесь информацией, если его кто-то уже использовал.
Исходники - https://github.com/amidaware/tacticalrmm
Демо - https://demo.tacticalrmm.com/
Документация - https://docs.tacticalrmm.com/
#remote #управление #ITSM
Существует проект Tactical RMM для мониторинга и управления компьютерами на базе Windows. Особенность его в том, что он интегрируется с MeshCentral и использует его в своей инфраструктуре для подключения к компьютерам. Получается очень функциональная и удобная связка на основе только open source продуктов.
Tactical RMM по закрываемым задачам похож на такие продукты как Spiceworks, Snipe-IT и подобные программы. Сюда можно было бы добавить glpi и itop, но всё же это более навороченные и сложные продукты, в отличие от Tactical RMM. Но зато интеграция с MeshCentral делает его очень удобным в ежедневной рутине по поддержке пользователей.
Есть публичная демка для обзора возможностей. Я как зашёл туда, сразу полюбил продукт. Интерфейс простой, удобный, современный, понятный. Всё, что нужно на виду. Умеет он следующее:
- подключаться к remote shell;
- выполнять удалённо скрипты;
- показывать логи машин;
- управлять службами, обновлениями;
- устанавливать софт через chocolatey;
- выполнять инвентаризацию железа и ПО;
- показывать основные метрики системы;
- выполнять проверки на тему работы какой-то службы, наличия свободного, места на дисках, загрузки CPU и RAM и т.д.;
- отправлять уведомления.
Установить Tactical RMM можно с помощью готового скрипта, который лежит в репозитории. Он всё поставит сам. В основе там Django, NodeJS, Postgresql, MongoDB. Скрипт всё это сам поставит и подготовит конфиги. Либо можно использовать готовый Docker контейнер. Всё это описано в документации.
В качестве агента на хостах используется агент от MeshCentral. После установки сервера можно сформировать установщик, который автоматически будет подключать агенты к серверу.
Продукт мне очень понравился. Я не знаю, как он в деле, но на вид выглядит круто и удобно. Поделитесь информацией, если его кто-то уже использовал.
Исходники - https://github.com/amidaware/tacticalrmm
Демо - https://demo.tacticalrmm.com/
Документация - https://docs.tacticalrmm.com/
#remote #управление #ITSM
{kind=link}
👍68👎4
CDN с защитой от DDoS-атак с геораспределённой системой узлов от российского хостинг-провайдера DDoS-Guard.
Сегодня многие российские компании подвергаются массированным кибератакам и сталкиваются с замедлением работы сервисов.
Наше решение позволит снизить нагрузку на ваш веб-сервер, разгрузить канал, ускорить доставку контента и защитить ресурс от вредоносных атак независимо от их масштаба и длительности. Мы предлагаем:
• Ускорение загрузки страниц
• Защита на уровнях L3-L4 и L7
• Прозрачное ценообразование
• Высокий уровень производительности сети
• Точки присутствия по всему миру
• Продвинутая функциональность
• Подробная статистика
• Гибкая система лимитов для исходящего трафика
• Отсутствие ограничения для полосы
Узнать подробно о тарифах и подключить можно по ссылке: https://clck.ru/dZ9rk
#реклама
Сегодня многие российские компании подвергаются массированным кибератакам и сталкиваются с замедлением работы сервисов.
Наше решение позволит снизить нагрузку на ваш веб-сервер, разгрузить канал, ускорить доставку контента и защитить ресурс от вредоносных атак независимо от их масштаба и длительности. Мы предлагаем:
• Ускорение загрузки страниц
• Защита на уровнях L3-L4 и L7
• Прозрачное ценообразование
• Высокий уровень производительности сети
• Точки присутствия по всему миру
• Продвинутая функциональность
• Подробная статистика
• Гибкая система лимитов для исходящего трафика
• Отсутствие ограничения для полосы
Узнать подробно о тарифах и подключить можно по ссылке: https://clck.ru/dZ9rk
#реклама
👍13👎10
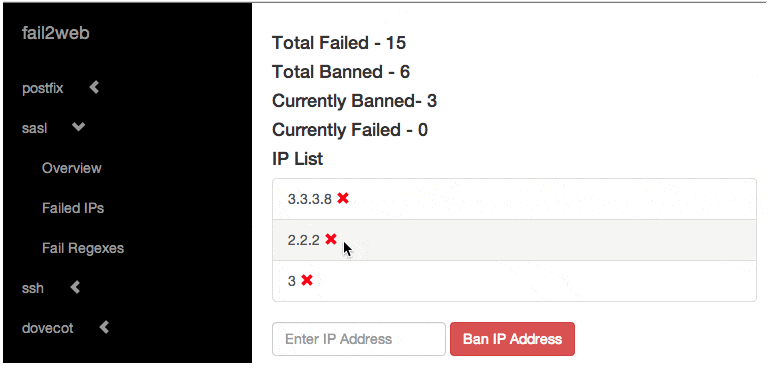
На одном из чужих серверов, на котором пришлось выполнять некоторые работы, заметил новый для себя инструмент fail2web. Заинтересовался и решил посмотреть, что это такое. Это оказался web интерфейс для управления fail2ban. Так как последний я постоянно использую, решил посмотреть, как всё это выглядит.
Программа очень старая (8 лет назад написана и не развивается) и инфы по ней почти нет, кроме непосредственно репозиториев. У меня получилось разобраться и запустить. В целом, там ничего сложного.
Сначала ставим fail2rest. Это служба, которая взаимодействует с fail2ban. Написана на GO.
В директории ~/go/bin будет бинарник fail2rest. Для его запуска нужно создать конфиг config.json с двумя параметрами:
После этого можно запустить fail2rest:
Проверить работу можно отправив запрос на указанный адрес и порт:
Можно настроить запуск через systemd (поменяйте пути на свои):
Теперь качаем веб интерфейс:
И настраиваем виртуальный хост apache или nginx. Я для простоты nginx взял:
Не забудьте создать файл /var/www/htpasswd и добавить туда юзера. Ну и конечно желательно на HTTPS перейти, если реально будете использовать.
На этом собственно всё, можно заходить на настроенный виртуальный хост и управлять fail2ban. Сделано простенько, но функционально. Если реально постоянно какая-то движуха идёт с fail2ban, может быть полезно. Я нашёл всё то же самое, только на Docker, но уже не стал проверять.
Сразу подскажу тем, кто будет реально разбираться. Если видите в веб интерфейсе ошибку:
Смотрите лог или настройки fail2ban. Например, если нет ни одного jail, будет эта ошибка. Если неправильно настроены action тоже будут ошибки. В общем, если есть какие-то проблемы с fail2ban, вы будете видеть ошибку соединения с fail2rest, что несколько сбивает с толку.
По сути эта заметка готовая инструкция. Других в интернете вообще нет, так что можно сохранить на память.
Исходники: https://github.com/Sean-Der/fail2rest
https://github.com/Sean-Der/fail2web
Обсуждение: https://www.reddit.com/r/linux/comments/294fn3/fail2web_a_fail2ban_web_gui/
#security #fail2ban
Программа очень старая (8 лет назад написана и не развивается) и инфы по ней почти нет, кроме непосредственно репозиториев. У меня получилось разобраться и запустить. В целом, там ничего сложного.
Сначала ставим fail2rest. Это служба, которая взаимодействует с fail2ban. Написана на GO.
# dnf install golang git gcc nginx# go get -v github.com/Sean-Der/fail2rest# go install -v github.com/Sean-Der/fail2restВ директории ~/go/bin будет бинарник fail2rest. Для его запуска нужно создать конфиг config.json с двумя параметрами:
{ "Addr": "127.0.0.1:5000", "Fail2banSocket": "/var/run/fail2ban/fail2ban.sock"}После этого можно запустить fail2rest:
# fail2rest --config=config.jsonПроверить работу можно отправив запрос на указанный адрес и порт:
# curl https://127.0.0.1:5000/global/ping"pong"Можно настроить запуск через systemd (поменяйте пути на свои):
[Unit]Description=fail2ban REST serverDocumentation=man:fail2rest(1)ConditionPathExists=/etc/fail2rest.jsonAfter=fail2ban.service[Service]ExecStart=/usr/bin/fail2rest -config=/etc/fail2rest.json[Install]WantedBy=multi-user.targetТеперь качаем веб интерфейс:
# git clone --depth=1 https://github.com/Sean-Der/fail2web.git /var/www/fail2web# rm -rf /var/www/fail2web/.gitИ настраиваем виртуальный хост apache или nginx. Я для простоты nginx взял:
server { listen 80; server_name YOUR_SERVER_NAME; auth_basic "Restricted"; auth_basic_user_file /var/www/htpasswd; location / { root /var/www/fail2web; } location /api/ { proxy_pass https://127.0.0.1:5000/; proxy_redirect off; }}Не забудьте создать файл /var/www/htpasswd и добавить туда юзера. Ну и конечно желательно на HTTPS перейти, если реально будете использовать.
На этом собственно всё, можно заходить на настроенный виртуальный хост и управлять fail2ban. Сделано простенько, но функционально. Если реально постоянно какая-то движуха идёт с fail2ban, может быть полезно. Я нашёл всё то же самое, только на Docker, но уже не стал проверять.
Сразу подскажу тем, кто будет реально разбираться. Если видите в веб интерфейсе ошибку:
502 Bad Gateway - Couldn't contact fail2restСмотрите лог или настройки fail2ban. Например, если нет ни одного jail, будет эта ошибка. Если неправильно настроены action тоже будут ошибки. В общем, если есть какие-то проблемы с fail2ban, вы будете видеть ошибку соединения с fail2rest, что несколько сбивает с толку.
По сути эта заметка готовая инструкция. Других в интернете вообще нет, так что можно сохранить на память.
Исходники: https://github.com/Sean-Der/fail2rest
https://github.com/Sean-Der/fail2web
Обсуждение: https://www.reddit.com/r/linux/comments/294fn3/fail2web_a_fail2ban_web_gui/
#security #fail2ban
{kind=link}
👍82👎1
Затрагивал уже ранее тему WAF (Web Application Firewall), решил её развить, так как актуальность подобных продуктов в последнее время выросла. Как мне кажется, наиболее известным представителем фаерволов веб приложений является Modsecurity.
Это open source продукт, который может работать с популярными веб серверами. Как минимум, я видел упоминания, что он умеет работать в связке с Nginx, Apache, IIS. Я обычно его видел в работе с Nginx. У него для этого есть отдельный модуль. В сети есть много инструкций на эту тему, так что непосредственно установка не представляет какой-то большой сложности, хотя и не сказать, что она простая. Нужно будет взять исходники Nginx, ModSecurity, Nginx Connector и всё это собрать вместе.
В комплекте с модулем есть готовые наборы правил, так что для включения базовой защиты не требуется сразу погружаться в их написание. Просто взять и написать какое-то правило самому будет не так просто. Там куча регекспов, а ещё и язык свой для этих правил. Хорошая новость в том, что в репозитории наборы правил уже разбиты на отдельные файлы, относящиеся к наиболее популярным движкам сайтов, например для wordpress или cpanel.
Вначале можно запустить только обнаружение атак без выполнения каких-то действий, а потом уже принимать решение и том, какие правила оставлять и как реагировать на срабатывание защиты. И ещё сразу предупрежу, что использование любых WAF сильно нагружает систему. Так что нужно подходить аккуратно к настройке и запуску подобных продуктов на реальных веб проектах.
Видео по сборке и настройке - https://www.youtube.com/watch?v=XzeO2EL4sLU
Инструкция от Nginx - https://www.nginx.com/blog/compiling-and-installing-modsecurity-for-open-source-nginx/
Исходники: https://github.com/SpiderLabs/ModSecurity
https://github.com/SpiderLabs/ModSecurity-nginx
#security #waf
Это open source продукт, который может работать с популярными веб серверами. Как минимум, я видел упоминания, что он умеет работать в связке с Nginx, Apache, IIS. Я обычно его видел в работе с Nginx. У него для этого есть отдельный модуль. В сети есть много инструкций на эту тему, так что непосредственно установка не представляет какой-то большой сложности, хотя и не сказать, что она простая. Нужно будет взять исходники Nginx, ModSecurity, Nginx Connector и всё это собрать вместе.
В комплекте с модулем есть готовые наборы правил, так что для включения базовой защиты не требуется сразу погружаться в их написание. Просто взять и написать какое-то правило самому будет не так просто. Там куча регекспов, а ещё и язык свой для этих правил. Хорошая новость в том, что в репозитории наборы правил уже разбиты на отдельные файлы, относящиеся к наиболее популярным движкам сайтов, например для wordpress или cpanel.
Вначале можно запустить только обнаружение атак без выполнения каких-то действий, а потом уже принимать решение и том, какие правила оставлять и как реагировать на срабатывание защиты. И ещё сразу предупрежу, что использование любых WAF сильно нагружает систему. Так что нужно подходить аккуратно к настройке и запуску подобных продуктов на реальных веб проектах.
Видео по сборке и настройке - https://www.youtube.com/watch?v=XzeO2EL4sLU
Инструкция от Nginx - https://www.nginx.com/blog/compiling-and-installing-modsecurity-for-open-source-nginx/
Исходники: https://github.com/SpiderLabs/ModSecurity
https://github.com/SpiderLabs/ModSecurity-nginx
#security #waf
{kind=link}
👍26👎2
Решал на днях задачу перенаправления запросов с одного домена на другой. В целом понятно, что это не сложно сделать с помощью nginx и его возможности proxy_pass. У меня есть подробная статья на эту тему. Но лично мне на практике никогда не приходилось именно с домена на домен перенаправления делать.
Простым и очевидным способом, описанным в статье, ничего не получилось. Перенаправленные ресурсы отдавали ошибку 404. Сходу не понял, почему так. Всё перепроверил - пути, права и т.д. Но ничего не помогло. Откуда, думаю, тут 404 берётся? Посидел, немного подумал и понял, в чём проблема.
После перенаправления запрос с первого домена уходит на второй с заголовками в запросе от первого домена. А второй про него ничего не знает, так как он настроен на другой домен. При переадресации запроса надо поменять в заголовке старый домен на новый. В итоге рабочий (упрощённый) вариант конфига получился такой:
То есть в директиве:
proxy_set_header Host server2.ru;
Ставим в заголовок второй домен server2.ru. В данном случае запросы уходят на другой сервер 10.20.50.3, который домен server1.ru вообще не знает.
#nginx
Простым и очевидным способом, описанным в статье, ничего не получилось. Перенаправленные ресурсы отдавали ошибку 404. Сходу не понял, почему так. Всё перепроверил - пути, права и т.д. Но ничего не помогло. Откуда, думаю, тут 404 берётся? Посидел, немного подумал и понял, в чём проблема.
После перенаправления запрос с первого домена уходит на второй с заголовками в запросе от первого домена. А второй про него ничего не знает, так как он настроен на другой домен. При переадресации запроса надо поменять в заголовке старый домен на новый. В итоге рабочий (упрощённый) вариант конфига получился такой:
server { listen 80; server_name server1.ru; access_log /var/log/nginx/server1.ru-access.log; error_log /var/log/nginx/server1.ru-error.log;location /dir_redir { proxy_pass https://10.20.50.3/dir_redir; proxy_set_header Host server2.ru; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; }То есть в директиве:
proxy_set_header Host server2.ru;
Ставим в заголовок второй домен server2.ru. В данном случае запросы уходят на другой сервер 10.20.50.3, который домен server1.ru вообще не знает.
#nginx
{kind=link}
👍68👎4