
Древнегреческий философ Платон оставил не меньше загадок для филологов, чем Уильям Шекспир. До нас дошло немало диалогов под его именем, но какие были действительно написаны им, а какие более поздний подлог? Кроме того, Платон был умелым стилистом: он хорошо писал в разных жанрах и отлично имитировал речи и тексты других людей, включая женщин того времени. Все это создаёт проблемы в хронологической периодизации его сочинений. С учётом влияния, которое платонизм оказал на всю европейскую философию, культуру и религию, установление подлинного авторства ряда диалогов представляет важную проблему.
Как в этом могут помочь статистические методы, такие как стилометрия, рассказывает в своей авторской колонке на IQ.HSE доцент факультета гуманитарных наук НИУ ВШЭ, основательница телеграм-канала о древних языках, античной культуре и философии Antibarbari HSE, Ольга Алиева @rantiquity.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤10❤🔥3🔥3👏1
В лекциях и статьях по векторной семантике часто упоминается, что за всей этой историей со смыслом, производным от контекста, есть что-то от “речевых игр” Витгенштейна. Но обычно ссылки следуют на Харриса и Ферса, и не очень ясно, какими путями в компьютерную лингвистику проник Витгенштейн (понятно, что после войны он был везде, но хотелось бы поконкретнее).
Сегодня нашла одну интересную ниточку. Маргарет Мастерман, в 1933-1934 была одной из студентов Витгенштейна, чьи заметки легли в основу “Голубой книги”. В 1955 г. основала лабораторию Cambridge Language Research Unit, которая занималась исследованиями в области компьютерной семантики и автоматического перевода. Среди прочего, Мастерман разработала алгоритмы, которые позволяли переводить с английского налатынь (куда же еще?). Об этом здесь.
А я вспомнила про другую Маргарет, Гамильтон, которая тоже не только умела кодить, но и знала древние языки.
Сегодня нашла одну интересную ниточку. Маргарет Мастерман, в 1933-1934 была одной из студентов Витгенштейна, чьи заметки легли в основу “Голубой книги”. В 1955 г. основала лабораторию Cambridge Language Research Unit, которая занималась исследованиями в области компьютерной семантики и автоматического перевода. Среди прочего, Мастерман разработала алгоритмы, которые позволяли переводить с английского на
А я вспомнила про другую Маргарет, Гамильтон, которая тоже не только умела кодить, но и знала древние языки.
❤10❤🔥1
Forwarded from Гуманитарии в цифре
«В компьютерных играх иногда так бывает, что есть у персонажа линейки разных качеств: мораль, сила, магия, выносливость. По сравнению, например, с руководством лаборатории внутри университета, когда ты становишься ректором, такие качества нужно всерьёз прокачать?»
Узнаем, послушав новый выпуск «Лиги Айвы»: в подкасте Бориса Орехова («об университете как о республике ученых») вышла беседа с ректором СФУ Максимом Румянцевым.
🌐 YouTube
🫥 Mave
🎵 Яндекс.Музыка
🌐 VK Видео
🍏 Apple podcasts
#людиdh
Узнаем, послушав новый выпуск «Лиги Айвы»: в подкасте Бориса Орехова («об университете как о республике ученых») вышла беседа с ректором СФУ Максимом Румянцевым.
#людиdh
Please open Telegram to view this post
VIEW IN TELEGRAM
❤6⚡2🔥2
Новость дня: лофи-герл теперь на средневековой волне. Вам, цифровые медиевисты, музыка для кодинга.
YouTube
medieval lofi radio 🏰 - beats to scribe manuscripts to
💿 | 7 days left to pre-order the limited edition vinyl!
→ https://vinyl.lofirecords.com/products/journey-trough-time-various-artists
🎼 | Listen on Spotify, Apple music and more
→ https://fanlink.tv/Medieval-Lofi
🌎 | Lofi Girl on all social media
→ h…
→ https://vinyl.lofirecords.com/products/journey-trough-time-various-artists
🎼 | Listen on Spotify, Apple music and more
→ https://fanlink.tv/Medieval-Lofi
🌎 | Lofi Girl on all social media
→ h…
❤11😁4😍4🔥1
🐍 Друзья, посоветуйте, пожалуйста, онлайн-интерпретатор питона, бесплатный, для групповой работы, с хорошей синхронизацией. Collab не сразу отражает изменения, а мне надо, чтобы как на Miro/Figma, было видно, кто что делает. Вообще бывает такое?
Уже сейчас.
Telegram
Гуманитарии в цифре
А вот и подробная программа дистанционной летней школы молодых ученых: здесь можно присмотреться к перечню лекций и мастер-классов по актуальным проблемам исторической информатики (тут и 3D-моделирование, и ресурсы для создания ГИС, язык R, статистические…
❤6
RAntiquity
Мне уже приходилось рассказывать о том, что количественные исследования в платоноведении начались во второй половине 19 в., когда никаких компьютеров не было даже в планах, но вот чего вы скорее всего не знали — несколько таких работ написаны на латыни. Такова…
Продолжаю пополнять латинский словарь цифрового гуманиста.
🌺 lingua programmandi язык программирования
🪄 programmator / -trix программист
🌺 Salve, munde! Hello, world
🪄 Interrete Интернет
🌺 situs interretialis сайт
🪄 intellegentia artificialis искуственный интеллект
🌺 machina autodidacta / machina autodocens машинное обучение (как область знания -- ars machinae autodidactae / autodocentis)
Последнее подслушала в латинской речи одного гарвардского выпускника, который написал нейросетку для классификации текстов Платона. Прекрасная диссертация, прекрасная латынь (и греческий, само собой).
Последнее подслушала в латинской речи одного гарвардского выпускника, который написал нейросетку для классификации текстов Платона. Прекрасная диссертация, прекрасная латынь (и греческий, само собой).
Please open Telegram to view this post
VIEW IN TELEGRAM
YouTube
Undergraduate Latin Address by Jordan Bliss Perry | Honoring the Harvard Class of 2021
Senior Latin speaker Jordan Bliss Perry A.B. '21 addresses fellow students in the Class of 2021 virtual celebration ceremony on May 27, 2021.
🔥15😍7👍3
RAntiquity
Сегодня полезная штуковина для тех, кто занимается сравнением переводов, версий документа и т.п. Выравниватель на основе алгоритма Смита — Ватермана. library(text.alignment) a <- "Gallia est omnis divisa in pates tres." b <- "Gallia omnis divisa in partes…
Есть у меня замысел сравнить один оригинальный перевод Платона с версией, решительно исправленной редактором. Желательно не вручную. Вспомнила про старый пост о выравнивателе. Как бы от этого перейти к html?
Пока придумала задействовать регулярные выражения, чтобы расставить html-теги:
Это вернет табличку как на картинке. От которой несложно перейти к html как на картинке. Чувствую, что будут еще подвохи на этом пути, но хочется пробовать. Может быть надо идти через ecomparatio, но почему-то этот путь кажется мне проще.
Пока придумала задействовать регулярные выражения, чтобы расставить html-теги:
library(text.alignment)
a <- "Gallia est omnis divisa partes tres."
b <- "Gallia omnis divisa in partes tres"
res <- smith_waterman(a, b, type = "words")
library(stringr)
library(tidyverse)
tbl <- tibble(a = res$a$alignment$tokens, b = res$b$alignment$tokens)
tbl_new <- tbl |> mutate(a_new = case_when(str_detect(a, "#+") ~ paste0("<mark>", b, "</mark>"), .default = a)) |> mutate(b_new = case_when(str_detect(b, "#+") ~ paste0("<mark>", a, "</mark>"), .default = b))
Это вернет табличку как на картинке. От которой несложно перейти к html как на картинке. Чувствую, что будут еще подвохи на этом пути, но хочется пробовать. Может быть надо идти через ecomparatio, но почему-то этот путь кажется мне проще.
❤1
RAntiquity
Уже сейчас.
Невероятно приятно и почетно получить такое письмо от одной из старейших профессиональных ассоциаций в области цифровых гуманитарных наук в России. Большое спасибо, коллеги, я очень тронута 💚
Please open Telegram to view this post
VIEW IN TELEGRAM
❤27🎉12😍5👍1
Forwarded from Antibarbari HSE (Olga Alieva)
colo «возделывать». Гораздо менее известно, что свое сельскохозяйственное значение существительное сохраняло почти до середины XIX в. Please open Telegram to view this post
VIEW IN TELEGRAM
❤5🔥4
Forwarded from ФГН НИУ ВШЭ
На программе преподают доценты ФГН Ольга Алиева, Анастасия Бонч-Осмоловская, Борис Орехов, которые давно занимаются разработками в этой области.
Список покрывает практически все аспекты цифровых методов, востребованных гуманитариями, и включает около 120 пунктов. В него вошли научные статьи, популярные публикации, видео лекций и докладов. Список будет пополняться по мере появления новых статей и выступлений, и доступен по ссылке
«Вряд ли где-то еще в России или даже в мире вы увидите такую широту и разнообразие компетенций, освоенных цифровыми гуманитариями Вышки», — сказал академический руководитель магистратуры доцент ФГН Борис Орехов.
В этом году магистратуре «Цифровые методы в гуманитарных науках» исполняется пять лет.
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥11❤3👍2🍓1
Forwarded from Vox mediaevistae
Только что закончилась последняя сессия IMC в Лидсе. На этот слот пришлась и наша с @verbaliquida секция. Я сделала доклад дистанционно, потому что мой паспорт все еще в заложниках в британском визовом центре. Это ужасно обидно: и денег жаль, и всех невстреченных. В этом году в IMC очно участвовало четыре члена редколлегии Вокса, невиданное дело.
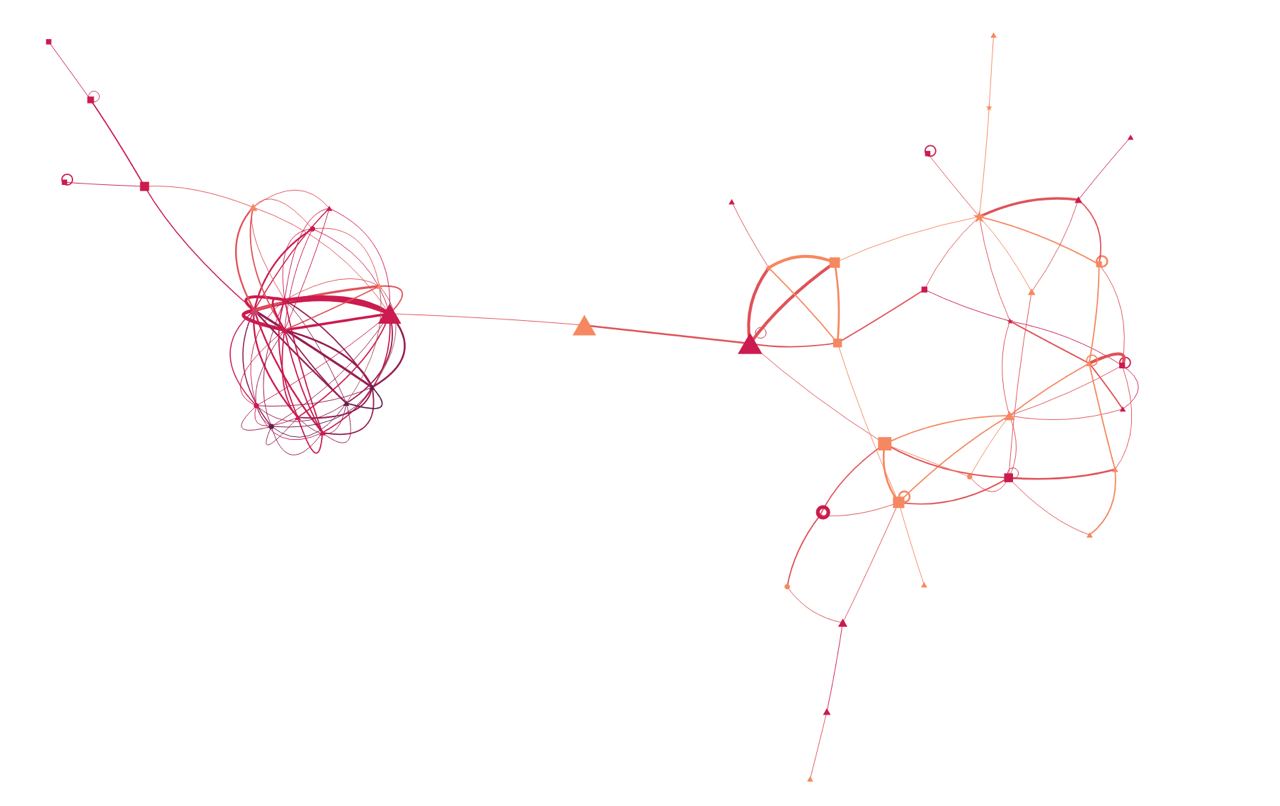
Я рассказала про эксперименты с построением сетей рукописей, в которых циркулировал Breviloquium. Вот визуализация, которой горжусь: на ней узлы — это рукописи, которые, помимо Breviloquium’а, делят с соседями еще хотя бы два других текста. Размер узла пропорционален его степени посредничества, а его форма указывает на размер сборника (в точках меньше 5 тектов, в треугольниках — от 5 до 10, в квадратах — от 15 до 25, и так далее, по мере нарастания углов у фигур). Цвет указывает на век создания рукописи (фиолетовые — XIII век, желтые — XVI).
На этом графе видно, что есть два плотных кластера, один относится к XIII-XIV вв., эти рукописи происходят из Франции и северной Италии, в них содержатся преимущественно сочинения Иоанна Уэльского, видимо, они связаны с францисканскими интеллектуальными центрами. Второй кластер происходит из Богемии и Германии, в этих рукописях можно найти младшую редакцию Breviloquium’а, контаминированную трактатом Якопо да Чессоле об игре в шахматы. А объединяет их рукопись из Кортоны, в которой, среди прочего, содержится единственное дошедшее до наших дней житие Иоанна. О житие я в докладе сказать не успела, но деталь эта трогательная, по-моему.
Код посмотреть и порассматривать сетки можно тут.
Я рассказала про эксперименты с построением сетей рукописей, в которых циркулировал Breviloquium. Вот визуализация, которой горжусь: на ней узлы — это рукописи, которые, помимо Breviloquium’а, делят с соседями еще хотя бы два других текста. Размер узла пропорционален его степени посредничества, а его форма указывает на размер сборника (в точках меньше 5 тектов, в треугольниках — от 5 до 10, в квадратах — от 15 до 25, и так далее, по мере нарастания углов у фигур). Цвет указывает на век создания рукописи (фиолетовые — XIII век, желтые — XVI).
На этом графе видно, что есть два плотных кластера, один относится к XIII-XIV вв., эти рукописи происходят из Франции и северной Италии, в них содержатся преимущественно сочинения Иоанна Уэльского, видимо, они связаны с францисканскими интеллектуальными центрами. Второй кластер происходит из Богемии и Германии, в этих рукописях можно найти младшую редакцию Breviloquium’а, контаминированную трактатом Якопо да Чессоле об игре в шахматы. А объединяет их рукопись из Кортоны, в которой, среди прочего, содержится единственное дошедшее до наших дней житие Иоанна. О житие я в докладе сказать не успела, но деталь эта трогательная, по-моему.
Код посмотреть и порассматривать сетки можно тут.
{kind=link}
👍7❤3👏3
Forwarded from Vox mediaevistae
manuscripts_network_strong_edges.html
722.9 KB
А вот файл, который можно позумить и потрогать.
Нужно знать, что Акакий Акакиевич изъяснялся большею частью предлогами, наречиями и, наконец, такими частицами, которые решительно не имеют никакого значения.
“Дельта Берроуза”, — догадался Штирлиц.
😁20🤣9❤3
RAntiquity
Photo
История получила продолжение; за усовершенствованный токенайзер спасибо agricolamz.
Telegram
Antibarbari HSE
Несколько лет назад антиварвары читали платоновского «Филеба» (плейлист), и все это время пользовались русским переводом Н.В. Самсонова, вошедшим в четырехтомник под редакцией А.Ф. Лосева. Сравнительно недавно, однако, нам удалось узнать кое-что новое и о…
🔥5🥰4❤2
Дорогие друзья, ушла в отпуск; ближе к сентябрю канал снова оживет! Пока набираюсь сил и идей для новых проектов.
👍27❤🔥10🐳4☃1
Forwarded from Boris Orekhov
Демонтаж красноречия
Разминулись
Был такой важный человек для современной науки о компьютерной атрибуции, Винценты Лютославский. Это он, по всей видимости, придумал слово «стилометрия». Учился одновременно на химика и философа, и вообще был мыслителем нетривиальным. В связи с платоновским…
👍3❤1🔥1
Boris Orekhov
https://schonenrede.hypotheses.org/305
Началось все с того, что Лютославский, оказывается был учеником Тейхмюллера, учился у него в Дерпте (Тарту), тогда это была территория Российской империи. У Тейхмюллера была большая семья, 9 детей, в Базеле ему было тяжело их обеспечивать, а в Дерпте ему предложили хорошие условия.
В моем сознании Тейхмюллер как исследователь Платона и Аристотеля и Лютославский как “стилометрист” до сих пор существовали отдельно. Но все намного сложнее: как выясняется, их объединяют в Юрьевскую школу неолейбницианства, которая оказала влияние, например, на Лосского.
(Простите, я и правда в отпуске, но такой интересный сюжет).
В моем сознании Тейхмюллер как исследователь Платона и Аристотеля и Лютославский как “стилометрист” до сих пор существовали отдельно. Но все намного сложнее: как выясняется, их объединяют в Юрьевскую школу неолейбницианства, которая оказала влияние, например, на Лосского.
(Простите, я и правда в отпуске, но такой интересный сюжет).
🔥9⚡1❤🔥1
Свежий обзор новейших МО-штуковин для древних языков: https://direct.mit.edu/coli/article/49/3/703/116160/Machine-Learning-for-Ancient-Languages-A-Survey
вникать буду позже, пока чтобы не потерять
вникать буду позже, пока чтобы не потерять
👀10👍4
Forwarded from aGricolaMZ
Дорогие все, вышел мой онлайн курс "Введение в анализ данных на R для гуманитарных и социальных наук" (https://openedu.ru/course/hse/IDAR/). Основная его концепция: только
- возможные продолжения дразнилки "Жадина-говядина" из исследования N+1
- роман Ф. М. Достоевского “Бесы”
- эпистолярные романы
- данные кладов Римских монет (https://chre.ashmus.ox.ac.uk/)
- время работы библиотек России
- высота и ширина утерянных или похищенных картин из музеев России
- многоязычие в Дагестане
- количество человек с злокачественными новообразованиями
- описания и рецепты из онлайн-магазина китайского чая
- и другие
Все формулировки заданий и код с решениями у меня в quarto занимают 20 тысяч строк.
Из смешного: одна из идей про датасет библиотек России так и не вылилась в задание на курсе, но вылилась в мою первую data-driven задачку.
Структуру курса я уже поменять не смогу, но если вы найдете опечатки или стилистические огрехи на сайте курса — пишите, я буду очень рад.
tidyverse и ноль программирования: я ставил себе цель, чтобы слушатели после окончания курса, получив данные, могли их обозреть и получить какие-то первые инсайты. Статистики в курсе всего одна неделя из девяти. К сожалению, я узнал, что Вышка дает посмотреть только две недели бесплатно, а потом просит денег (я даже увижу какую-то долю этих денег, если продолжу работать в Вышке). Но я не унываю, потому что в целом смотреть на видео как я блею на самом деле не очень интересно. Ведь я почти доделал онлайн ноутбук (https://agricolamz.github.io/daR4hs/) с комментариями и всем кодом, и он полностью открыт. Cейчас не хватает только последнего раздела про quarto. Для онлайн курса я подготовил достаточно большой пул заданий. Большинство заданий предполагает анализ какого-то датасета (и я потратил много времени, чтобы их собрать и сделать удобными ля заданий), поэтому я предлагаю оценить разброс:- возможные продолжения дразнилки "Жадина-говядина" из исследования N+1
- роман Ф. М. Достоевского “Бесы”
- эпистолярные романы
- данные кладов Римских монет (https://chre.ashmus.ox.ac.uk/)
- время работы библиотек России
- высота и ширина утерянных или похищенных картин из музеев России
- многоязычие в Дагестане
- количество человек с злокачественными новообразованиями
- описания и рецепты из онлайн-магазина китайского чая
- и другие
Все формулировки заданий и код с решениями у меня в quarto занимают 20 тысяч строк.
Из смешного: одна из идей про датасет библиотек России так и не вылилась в задание на курсе, но вылилась в мою первую data-driven задачку.
Структуру курса я уже поменять не смогу, но если вы найдете опечатки или стилистические огрехи на сайте курса — пишите, я буду очень рад.
agricolamz.github.io
Введение в анализ данных на R для гуманитарных и социальных наук
🔥19❤6👍2