
БЛОКНОТ ФИЛОСОФА
Спасибо колегам за запись! Пока ссылка на драйв; чуть позже перезалью в VK. #выступления
❤2❤🔥1
Forwarded from Antibarbari HSE (Olga Alieva)
В этот цифровой понедельник публикуем последнее видео из модуля 5 курса “R для антиковедов”. Это модуль весь был посвящен письмам Цицерона Аттику. Мы научились анализировать эмоциональную тональность, лемматизировать греческий и латинский тексты и делать интерактивные карты.
Осталась самая малость — опубликовать нашу карту на сайте https://antibarbari.ru/. Показываю самую что ни на есть изнанку этого модного ресурса для бескомпромиссных интеллектуалов.
А заодно ловите ссылочки на интересные датасеты, на которых можно потренироваться делать свои карты:
1) Ancient Greek and Roman Sites in Turkey
2) An Urban Geography of the Roman World
3) An R package that collects data for the ancient world including territorial extents from the Ancient World Mapping Centre, routes and places from Orbis, roads and shipwrecks from the Digital Atlas of Roman and Medieval Civilizations, and mints from Nomisma.
4) Римские рудники, кораблекрушения, винные прессы и еще всякая всячина от The OXREP Databases.
Высший пилотаж: почти 6 млн римских монет на карте: https://chre.ashmus.ox.ac.uk/
Мы будем рады видеть, что у вас получается, здесь и на канале RAntiquity. Если что, для публикации карты не обязателен сайт 😉
Осталась самая малость — опубликовать нашу карту на сайте https://antibarbari.ru/. Показываю самую что ни на есть изнанку этого модного ресурса для бескомпромиссных интеллектуалов.
А заодно ловите ссылочки на интересные датасеты, на которых можно потренироваться делать свои карты:
1) Ancient Greek and Roman Sites in Turkey
2) An Urban Geography of the Roman World
3) An R package that collects data for the ancient world including territorial extents from the Ancient World Mapping Centre, routes and places from Orbis, roads and shipwrecks from the Digital Atlas of Roman and Medieval Civilizations, and mints from Nomisma.
4) Римские рудники, кораблекрушения, винные прессы и еще всякая всячина от The OXREP Databases.
Высший пилотаж: почти 6 млн римских монет на карте: https://chre.ashmus.ox.ac.uk/
Мы будем рады видеть, что у вас получается, здесь и на канале RAntiquity. Если что, для публикации карты не обязателен сайт 😉
VK Видео
R: Модуль 5 Урок 10. Публикация интерактивной карты на сайте с CMS Wordpress
Видео подготовлено по результатам проекта «Цифровая античность» при поддержке фонда «Гуманитарные исследования» ФГН НИУ «Высшая школа экономики» в 2023 году.
🔥2
Это я так учу, что математическое ожидание суммы случайных величин можно представить как сумму их математических ожиданий. https://youtu.be/uhsnlwRASYo
YouTube
Вафли.avi
Из к\ф "Пять вечеров"
👍1😁1
В компьютерных методах обработки текста есть такое понятие, как “мешок слов”. Это когда (никогда не начинайте определение с “это когда”!) мы рассматриваем текст как набор слов, не учитывая их порядок и взаимные связи. Сегодня неожиданно встретила это выражение у Платона. Сократ говорит Феодору: “Экий же ты любитель потолковать, если и меня по доброте своей почитаешь каким-то мешком (με οἴει λόγων τινὰ εἶναι θύλακον), из которого я без труда могу извлечь любое рассуждение и заявить, что все это не так”.
Так что вот вам “мешок слов” (или аргументов в данном случае): θύλακος λόγων / ὀνομάτων. Правильно же говорят, что в Древней Греции все есть.
Так что вот вам “мешок слов” (или аргументов в данном случае): θύλακος λόγων / ὀνομάτων. Правильно же говорят, что в Древней Греции все есть.
Системный Блокъ
Что такое мешок слов и автоматическая обработка текста?
Рассказываем, что такое мешок слов и как он может помочь в задачах автоматической обработки текста
👍6❤3😁1😱1
Forwarded from Antibarbari HSE (Olga Alieva)
📆 17 мая в 18:10 (мск) в Греко-латинском клубе Antibarbari состоится встреча со Светланой Яцык, к.и.н., научным сотрудником Лаборатории медиевистических исследований НИУ «ВШЭ», участницей проекта Distinguo.
Тема встречи: Распознавание рукописного текста (HTR): история, перспективы, текущие проекты
За последние несколько лет развитие технологий распознавания рукописного текста (HTR) сделало автоматизированную транскрипцию древних документов доступной для широкого круга ученых. Существующее программное обеспечение позволяет безболезненно развертывать конвейеры HTR, а данные для обучения моделей (ground truth) становятся все более доступными, что дает ученым возможность быстро получать транскрипции в объемах, которые ранее потребовали бы годы интенсивной работы.
На этом заседании клуба мы обсудим существующие методы автоматической транскрипции, познакомимся с готовыми инструментами (Tesseract, Transkribus, kraken / eScriptorium) и проектами, которые их применяют.
В частности, на примере платформы eScriptorium мы разберем, как
- готовить данные для тренировки;
- обучать модели и делать их тонкую настройку (fine-tuning);
- оценивать качество транскрипции;
- использовать «грязную» неотредактированную транскрипцию для решения дальнейших исследовательских задач. #antibarbari_colloquia
Встреча пройдет на платформе Zoom. Ссылка для подключения.
Тема встречи: Распознавание рукописного текста (HTR): история, перспективы, текущие проекты
За последние несколько лет развитие технологий распознавания рукописного текста (HTR) сделало автоматизированную транскрипцию древних документов доступной для широкого круга ученых. Существующее программное обеспечение позволяет безболезненно развертывать конвейеры HTR, а данные для обучения моделей (ground truth) становятся все более доступными, что дает ученым возможность быстро получать транскрипции в объемах, которые ранее потребовали бы годы интенсивной работы.
На этом заседании клуба мы обсудим существующие методы автоматической транскрипции, познакомимся с готовыми инструментами (Tesseract, Transkribus, kraken / eScriptorium) и проектами, которые их применяют.
В частности, на примере платформы eScriptorium мы разберем, как
- готовить данные для тренировки;
- обучать модели и делать их тонкую настройку (fine-tuning);
- оценивать качество транскрипции;
- использовать «грязную» неотредактированную транскрипцию для решения дальнейших исследовательских задач. #antibarbari_colloquia
Встреча пройдет на платформе Zoom. Ссылка для подключения.
❤1
Forwarded from Vox mediaevistae
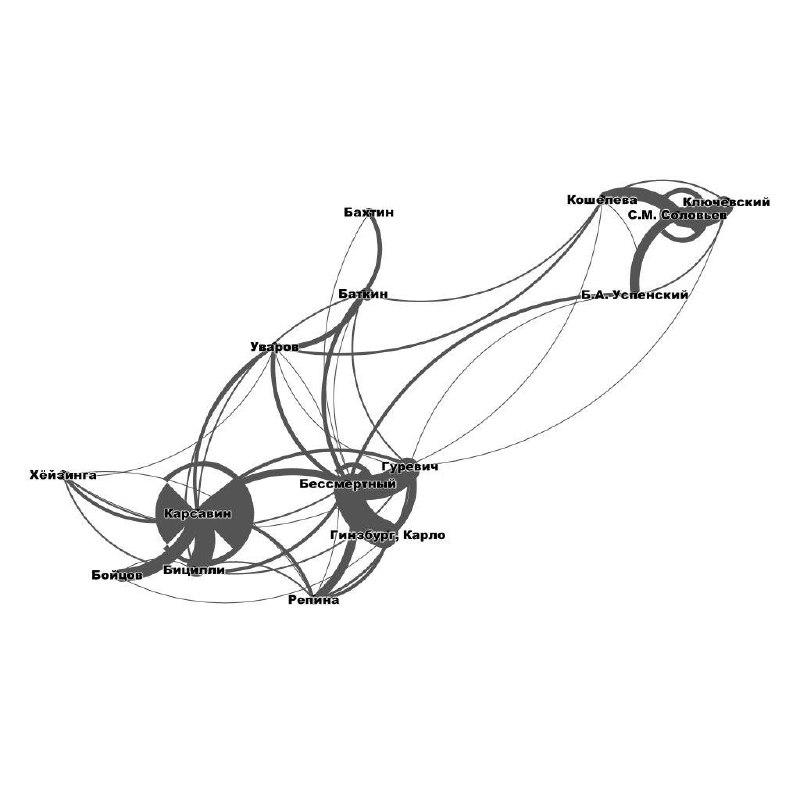
В рамках моего увлечения анализом сетей и постсоветской медиевистикой возникла идея посмотреть на то, на какие группы распадаются отечественные исследователи, отталкиваясь не от того, кто кого цитирует, а от того, кого особенно часто можно встретить в сносках в рамках одной статьи.
У Артема Клюева нашелся студент, который согласился подготовить данные. Мы решили начать с «Казуса» (руководствуясь его меньшим в сравнении со «Средними веками» объемом и гипотезой о большей гомогенности его авторов). Пока что удалось обсчитать первые 4 выпуска, и уже выходит любопытно: на картинке — авторы, которые в этих четырех номерах цитировались вместе от 25 до 75 раз.
У Артема Клюева нашелся студент, который согласился подготовить данные. Мы решили начать с «Казуса» (руководствуясь его меньшим в сравнении со «Средними веками» объемом и гипотезой о большей гомогенности его авторов). Пока что удалось обсчитать первые 4 выпуска, и уже выходит любопытно: на картинке — авторы, которые в этих четырех номерах цитировались вместе от 25 до 75 раз.
🔥2
Forwarded from Antibarbari HSE (Olga Alieva)
👾 В этот цифровой понедельник мы начинаем новый модуль курса “R для антиковедов.” Модуль будет посвящен методу латентно-семантического анализа. Этот метод основан на векторном представлении слов и документов.
В англоязычной литературе такие представления называют эмбеддингами. По-английски embedding означает «вложение». Представляя объект в виде вектора, мы как бы «вкладываем» его в векторное пространство, что позволяет найти «ближайших» к нему соседей.
LSA лежит в основе многих рекомендательных механизмов. Почему бы не сделать такую же штуку, но не для товаров или фильмов, а, скажем, для древних текстов? Прочитали «Категории» Аристотеля? Вам может понравиться «Исагога» Порфирия! Рекомендуем также заглянуть в Боэция.
Кодировать начнем на следующей неделе, а пока публикую вводное видео и рекомендую прочитать статью “Как понять, о чем текст, не читая его”, на портале “Системный блок”.
В англоязычной литературе такие представления называют эмбеддингами. По-английски embedding означает «вложение». Представляя объект в виде вектора, мы как бы «вкладываем» его в векторное пространство, что позволяет найти «ближайших» к нему соседей.
LSA лежит в основе многих рекомендательных механизмов. Почему бы не сделать такую же штуку, но не для товаров или фильмов, а, скажем, для древних текстов? Прочитали «Категории» Аристотеля? Вам может понравиться «Исагога» Порфирия! Рекомендуем также заглянуть в Боэция.
Кодировать начнем на следующей неделе, а пока публикую вводное видео и рекомендую прочитать статью “Как понять, о чем текст, не читая его”, на портале “Системный блок”.
VK Видео
R: Модуль 6. Латентно-семантический анализ: введение
О шестом модуле курса R для гуманитариев
👍5
Forwarded from Vox mediaevistae
Через два с половиной часа начинаем занятие, посвященное HTR. Уже можно посмотреть презентацию; в ней много ссылок на уже завершенные и полным ходом идущие проекты, на репозитории и сервисы (например, Calfa vision бесплатно предлагает студентам и докторантам распознать до 50 страниц текстов со сложной версткой и на экзотических языках).
Еще там есть список литературы для введения в тему и сокровища моей дизайнерской мысли.
Еще там есть список литературы для введения в тему и сокровища моей дизайнерской мысли.
🔥4
16-17 мая на базе УГИ УрФУ прошел научный семинар, посвященный проблемам и возможностям применения нейросетей в гуманитарных исследованиях. В качестве приглашенного спикера выступил Борис Валерьевич Орехов, кандидат филологических наук, доцент гуманитарного факультета НИУ ВШЭ, руководитель образовательной программы «Цифровые методы в гуманитарных науках».
Тема доклада: "Текст и знание в гуманитарных науках в эпоху больших языковых моделей". С любезного разрешения организаторов семинара и докладчика публикуем запись.
Отчуждаемо ли знание от текста? Можно ли считать, что критика “составителей речей” у Платона распространяется на ChatGPT? Где проще имитировать знание -- в гуманитарных науках или в естественных? Как выдает себя машина при написании курсовой по истории?
Об этом и многом другом доклад Б.В. Орехова.
Тема доклада: "Текст и знание в гуманитарных науках в эпоху больших языковых моделей". С любезного разрешения организаторов семинара и докладчика публикуем запись.
Отчуждаемо ли знание от текста? Можно ли считать, что критика “составителей речей” у Платона распространяется на ChatGPT? Где проще имитировать знание -- в гуманитарных науках или в естественных? Как выдает себя машина при написании курсовой по истории?
Об этом и многом другом доклад Б.В. Орехова.
Vk
Текст и знание в гуманитарных науках в эпоху больших языковых моделей
16-17 мая на базе УГИ УрФУ прошел научный семинар, посвященный проблемам и возможностям применения нейросетей в гуманитарных исследованиях. В качестве приглашенного спикера выступил Орехов Борис Валерьевич, кандидат филологических наук, доцент гуманитарного…
🔥5
Пока не успеваю делать что-то сверх цифровых понедельников (пора курсовых). Но они выходят исправно.
Telegram
Antibarbari HSE
👾 В первом видео 6-го модуля, посвященного LSA, мы подготовим для анализа данные:
1️⃣ скачаем (отсюда) описания для 250 самых популярных фильмов Кинопоиска (на русском),
2️⃣ лемматизируем,
3️⃣ удалим знаки препинания и стоп-слова,
4️⃣ посчитаем частотность…
1️⃣ скачаем (отсюда) описания для 250 самых популярных фильмов Кинопоиска (на русском),
2️⃣ лемматизируем,
3️⃣ удалим знаки препинания и стоп-слова,
4️⃣ посчитаем частотность…

{kind=link}
Forwarded from Antibarbari HSE (Olga Alieva)
👾 В этот #цифровой_понедельник представляем вашему вниманию короткометражный фильм “Кое-что о матрицах”. Совсем без них нельзя, так что разбираемся. В планах еще составить задачки к этому уроку, но это все позже.
Маленькое уточнение: на доске я записала транспонированную B так, как это делается в R; обычно, впрочем, пишут букву t как степень: B^t.
Маленькое уточнение: на доске я записала транспонированную B так, как это делается в R; обычно, впрочем, пишут букву t как степень: B^t.
VK Видео
R: Модуль 6 Урок 2. Операции с матрицами: сложение и умножение, транспонирование. Диагональная матрица
Видео подготовлено по результатам проекта «Цифровая античность» при поддержке фонда «Гуманитарные исследования» ФГН НИУ «Высшая школа экономики» в 2023 году.
👍1
Может ли так сложиться, что меня читает математик? Наверняка есть простое и элегантное решение, которое вернет мне покой и сон.
https://math.stackexchange.com/questions/4712648/r-from-word-embeddings-to-doc-embeddings-making-sense-of-the-lsa-formulas
https://math.stackexchange.com/questions/4712648/r-from-word-embeddings-to-doc-embeddings-making-sense-of-the-lsa-formulas
Mathematics Stack Exchange
R: From Word Embeddings to Doc Embeddings: Making Sense of the LSA Formulas
My question is more of a theoretical kind, and concerns the way of getting document embeddings using pre-trained word embeddings and LSA algorithm. A solution was offered here and it implies that a...
Forwarded from Antibarbari HSE (Olga Alieva)
👾 #цифровой_понедельник постепенно превращается в алгебраический: сегодня разбираемся, что такое определитель матрицы. Определитель матрицы нужен для понимания собственных векторов. Собственные векторы нужны для понимания сингулярных векторов. Сингулярные векторы нужны для понимания латентно-семантического анализа. Все пригодится, даже если сейчас неочевидно, как.
VK Видео
R: Модуль 6 Урок 3. Линейные преобразования. Определитель матрицы. Вырожденная матрица.
Видео подготовлено по результатам проекта «Цифровая античность» при поддержке фонда «Гуманитарные исследования» ФГН НИУ «Высшая школа экономики» в 2023 году.
Между тем, только что соорудила первый свой поисковик на основе LSA. Ранжирует диалоги платоновского корпуса по запросу (запрос пока — любое количество слов/лемм на древнегреческом). Смотрю на этот результат и думаю, что все так! Сама бы так рекомендовала. Ай, красота. Осталось понять, как это применимо в народном хозяйстве. #lsa
👍8
Кстати, здорово помог разобраться вот этот tutorial, поэтому сохраню ссылочку. Полностью воспроизвела в R, на выходе получила такую же картинку. Собственно, тут хорошо видно две особенности LSA: (1) запрос “кинжал, смерть” не содержит слов “ромео” и “джульета”, но документ d1 оказывается ближе к запросу, чем d5;
(2) d1 ближе (более релевантный), чем d2, хотя d2 содержит одно слово из запроса. #lsa
Документы:
d1 : Romeo and Juliet.
d2 : Juliet: O happy dagger!
d3 : Romeo died by dagger.
d4 : “Live free or die”, that’s the New-Hampshire’s motto.
d5 : Did you know, New-Hampshire is in New-England
(2) d1 ближе (более релевантный), чем d2, хотя d2 содержит одно слово из запроса. #lsa
Документы:
d1 : Romeo and Juliet.
d2 : Juliet: O happy dagger!
d3 : Romeo died by dagger.
d4 : “Live free or die”, that’s the New-Hampshire’s motto.
d5 : Did you know, New-Hampshire is in New-England
❤5
Ну и сразу подборка публикаций по теме #lsa , чтоб не потерять.
1) Latent Semantic Analysis (LSA) based ap-
proach to the Authorship Identification task (тыц)
2) Латентный семантический анализ и понимание текста (тыц)
3) A comparison of latent semantic analysis and
correspondence analysis of document-term matrices (тыц)
4) Annual review of information science and technology. Vol. 38, 2004 с хорошей обзорной статьей об LSA от создателей метода (тыц)
5) Indexing by LSA основа основ 1990 (тыц)
6) Еще одна основа основ 1988 (тыц) и еще одна 1991 (тыц)
1) Latent Semantic Analysis (LSA) based ap-
proach to the Authorship Identification task (тыц)
2) Латентный семантический анализ и понимание текста (тыц)
3) A comparison of latent semantic analysis and
correspondence analysis of document-term matrices (тыц)
4) Annual review of information science and technology. Vol. 38, 2004 с хорошей обзорной статьей об LSA от создателей метода (тыц)
5) Indexing by LSA основа основ 1990 (тыц)
6) Еще одна основа основ 1988 (тыц) и еще одна 1991 (тыц)
❤7