✒️ Собеседование Middle Python Engineer
00:00 - Опыт Разработки
06:08 - План Интервью
07:00 - _slots__
07:41 - match/case
08:24 - _call__
08:55 - Конструктор класса
10:10 - hash/hash table
11:12 - Доступ к элементам словаря
11:56 - Генераторы и итераторы
13:57 - Контекстные менеджеры
16:05 - Инкапсуляция
20:00 - Django vs DRF
22:07 - SerializerMethodField
22:40 - to_internal_value/to_representation
25:05 - Какой способ построения api с помощью DRF более удобный
25:57 - Миксины
27:34 - Django ORM
30:26 - @sync_to_async/@async_to_sync
31:23 - n+1
32:25 - django-debug-toolbar
33:27 - Когда prefetch_related увеличивает количество запросов
35:40 - Когда queryset делает запрос
38:01 - Онлайн кодинг
53:40 - БД
01:02:40 - Асинхронность, многопоточность, многопроцессорность
01:07:26 - Фидбек
https://www.youtube.com/watch?v=nbSbjbAwg9M
@python_job_interview
00:00 - Опыт Разработки
06:08 - План Интервью
07:00 - _slots__
07:41 - match/case
08:24 - _call__
08:55 - Конструктор класса
10:10 - hash/hash table
11:12 - Доступ к элементам словаря
11:56 - Генераторы и итераторы
13:57 - Контекстные менеджеры
16:05 - Инкапсуляция
20:00 - Django vs DRF
22:07 - SerializerMethodField
22:40 - to_internal_value/to_representation
25:05 - Какой способ построения api с помощью DRF более удобный
25:57 - Миксины
27:34 - Django ORM
30:26 - @sync_to_async/@async_to_sync
31:23 - n+1
32:25 - django-debug-toolbar
33:27 - Когда prefetch_related увеличивает количество запросов
35:40 - Когда queryset делает запрос
38:01 - Онлайн кодинг
53:40 - БД
01:02:40 - Асинхронность, многопоточность, многопроцессорность
01:07:26 - Фидбек
https://www.youtube.com/watch?v=nbSbjbAwg9M
@python_job_interview
👍28👏3❤2🔥1😢1
Расскажите о ПО позволяющее создавать виртуальное окружение в Python.
Ответ
Программное обеспечение, которое позволяет создавать виртуальные окружения в Python можно разделить на те, что входят в стандартную библиотеку Python и не входят в нее. Сделаем краткий обзор доступных инструментов (хороший пост на эту тем есть на stackoverflow).
Начнем с инструментов, которые входят в PyPI. Если кто не знает PyPI – это Python Package Index (PyPI) – репозиторий пакетов Python, доступный для любого разработчика и пользователя Python ().
virtualenv
Это, наверное, одни из самых популярных инструментов, позволяющих создавать виртуальные окружения. Он прост в установке и использовании. В сети довольно много руководств по virtualenv, самые интересные, на наш взгляд, будут собраны в конце урока в разделе “Полезные ссылки”. В общем, этот инструмент нужно обязательно освоить, как минимум, потому что описание развертывания и использования многих систем, созданных с использованием Python, включает в себя процесс создания виртуального окружения с помощью virtualenv.
pyenv
Инструмент для изоляции версий Python. Чаще всего применяется, когда на одной машине вам нужно иметь несколько версий интерпретатора для тестирования на них разрабатываемого вами ПО.
virtualenvwrapper
Virtualenvwrapper – это обертка для virtualenv позволяющая хранить все изолированные окружения в одном месте, создавать их, копировать и удалять. Предоставляет удобный способ переключения между окружениями и возможность расширять функционал за счет plug-in’ов.
Существуют ещё инструменты и plug-in’ы, выполняющие работу по изоляции частей системы Python, но мы их не будем рассматривать.
Инструменты, входящие в стандартную библиотеку Python.
venv
Этот модуль появился в Python3 и не может быть использован для решения задачи изоляции в Python2. По своему функционалу очень похож на virtualenv. Если вы работаете с третьим Python, то можете смело использовать данный инструмент.
➡️ Подробнее
@python_job_interview
Ответ
Программное обеспечение, которое позволяет создавать виртуальные окружения в Python можно разделить на те, что входят в стандартную библиотеку Python и не входят в нее. Сделаем краткий обзор доступных инструментов (хороший пост на эту тем есть на stackoverflow).
Начнем с инструментов, которые входят в PyPI. Если кто не знает PyPI – это Python Package Index (PyPI) – репозиторий пакетов Python, доступный для любого разработчика и пользователя Python ().
virtualenv
Это, наверное, одни из самых популярных инструментов, позволяющих создавать виртуальные окружения. Он прост в установке и использовании. В сети довольно много руководств по virtualenv, самые интересные, на наш взгляд, будут собраны в конце урока в разделе “Полезные ссылки”. В общем, этот инструмент нужно обязательно освоить, как минимум, потому что описание развертывания и использования многих систем, созданных с использованием Python, включает в себя процесс создания виртуального окружения с помощью virtualenv.
pyenv
Инструмент для изоляции версий Python. Чаще всего применяется, когда на одной машине вам нужно иметь несколько версий интерпретатора для тестирования на них разрабатываемого вами ПО.
virtualenvwrapper
Virtualenvwrapper – это обертка для virtualenv позволяющая хранить все изолированные окружения в одном месте, создавать их, копировать и удалять. Предоставляет удобный способ переключения между окружениями и возможность расширять функционал за счет plug-in’ов.
Существуют ещё инструменты и plug-in’ы, выполняющие работу по изоляции частей системы Python, но мы их не будем рассматривать.
Инструменты, входящие в стандартную библиотеку Python.
venv
Этот модуль появился в Python3 и не может быть использован для решения задачи изоляции в Python2. По своему функционалу очень похож на virtualenv. Если вы работаете с третьим Python, то можете смело использовать данный инструмент.
➡️ Подробнее
@python_job_interview
👍17❤3🔥3
Интервью Junior Python разработчик. Лайф кодинг
https://www.youtube.com/watch?v=c4nysYAufF0
@python_job_interview
https://www.youtube.com/watch?v=c4nysYAufF0
@python_job_interview
👍20😢1
С помощью чего можно получить логический xor двух переменных в Python?
Ответ
В Пайтоне есть оператор побитового XOR, который также отлично работает с логическими значениями, но его поведение легко повторить.
Исключающее "или" ведёт себя как обычное "или" за одним исключением — два True на входе даёт результат False.
Можно так и поступить — возвращать False в этом особом случае, во всех остальных использовать or.
Однако, если мы внимательно посмотрим на результаты, то окажется, что нам нужно True если значения не равны. Поэтому реализацию XOR можно записать проще (картинка 2).
@python_job_interview
Ответ
В Пайтоне есть оператор побитового XOR, который также отлично работает с логическими значениями, но его поведение легко повторить.
Исключающее "или" ведёт себя как обычное "или" за одним исключением — два True на входе даёт результат False.
Можно так и поступить — возвращать False в этом особом случае, во всех остальных использовать or.
Однако, если мы внимательно посмотрим на результаты, то окажется, что нам нужно True если значения не равны. Поэтому реализацию XOR можно записать проще (картинка 2).
@python_job_interview
👍11🔥3
🔥 Полезнейшая Подборка каналов
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
👍12🔥3😁1
В чем разница между func и func()?
Ответ
Вопрос должен проверить ваше понимание, что все функции в Python также являются объектами (см Картинку)
func — это представляющий функцию объект, который можно назначить переменной или передать другой функции. Функция func() с круглыми скобками вызывает функцию и возвращает результат.
@python_job_interview
Ответ
Вопрос должен проверить ваше понимание, что все функции в Python также являются объектами (см Картинку)
func — это представляющий функцию объект, который можно назначить переменной или передать другой функции. Функция func() с круглыми скобками вызывает функцию и возвращает результат.
@python_job_interview
👍18🔥2
Объясните, как работает функция map
Ответ
Она возвращает объект (итератор), который перебирает значения, применяя функцию к каждому элементу. В случае необходимости объект можно преобразовать в список. В примере на картинке к каждому элементу в списке мы добавляем число 3.
@python_job_interview
Ответ
Она возвращает объект (итератор), который перебирает значения, применяя функцию к каждому элементу. В случае необходимости объект можно преобразовать в список. В примере на картинке к каждому элементу в списке мы добавляем число 3.
@python_job_interview
👍36😁1
Расскажите про асинхронные web-фреймворки на Python.
Асинхронность уже не является просто модным словечком в сообществе Python. После выпуска библиотеки asyncio в версии 3.5, разработчики Python признали влияние Node.js в сфере веб-разработки и ввели в язык два новых ключевых слова – async и await. Это был крайне важный момент, потому что разработчики максимально осторожно относятся к расширению основного синтаксиса, если только нет острой необходимости, что только указывает на то, насколько принципиально необходимыми считались асинхронные возможности.
Перечислим некоторые из лучших асинхронных фреймворков:
- Tornado
- Sanic
- Vibora
- Quart
- FastApi
➡️ Читать дальше
@python_job_interview
Асинхронность уже не является просто модным словечком в сообществе Python. После выпуска библиотеки asyncio в версии 3.5, разработчики Python признали влияние Node.js в сфере веб-разработки и ввели в язык два новых ключевых слова – async и await. Это был крайне важный момент, потому что разработчики максимально осторожно относятся к расширению основного синтаксиса, если только нет острой необходимости, что только указывает на то, насколько принципиально необходимыми считались асинхронные возможности.
Перечислим некоторые из лучших асинхронных фреймворков:
- Tornado
- Sanic
- Vibora
- Quart
- FastApi
➡️ Читать дальше
@python_job_interview
👍15👎1
Объясните, как работает функция filter
Функция делает буквально то, о чем говорит ее название: она фильтрует элементы в последовательности.
Каждый элемент передается функции, которая включает его в последовательность, если по условию получает True, и отбрасывает в случае False.
Обратите внимание, как удалены все элементы, которые не делятся на 2.
@python_job_interview
Функция делает буквально то, о чем говорит ее название: она фильтрует элементы в последовательности.
Каждый элемент передается функции, которая включает его в последовательность, если по условию получает True, и отбрасывает в случае False.
Обратите внимание, как удалены все элементы, которые не делятся на 2.
@python_job_interview
👍26👎5🤨1
В чем разница между глубокой и мелкой копиями?
Обсудим это в контексте изменяемого объекта — списка. Для неизменяемых объектов глубокое и мелкое (поверхностное) копирование обычно не отличаются.
Рассмотрим три сценария.
I) Поставьте ссылку на исходный объект. Она отсылает новое имя li2 к тому же месту в памяти, на которое указывает li1. Поэтому любое изменение в li1 также происходит с li2:
II) Создайте мелкую копию оригинала. Ее можно создать с помощью конструктора list() или mylist.copy().
Мелкая копия создает новый объект, но заполняет его ссылками на оригинал. Таким образом, добавление нового объекта в исходный список li3 не отразится в li4, а вот изменение объектов в li3 — отразится:
III) Создайте глубокую копию. Это делается с помощью copy.deepcopy(). Оригинал и копия полностью независимы, а изменения в одном не оказывают никакого влияния на другой:
@python_job_interview
Обсудим это в контексте изменяемого объекта — списка. Для неизменяемых объектов глубокое и мелкое (поверхностное) копирование обычно не отличаются.
Рассмотрим три сценария.
I) Поставьте ссылку на исходный объект. Она отсылает новое имя li2 к тому же месту в памяти, на которое указывает li1. Поэтому любое изменение в li1 также происходит с li2:
li1 = [['a'],['b'],['c']]
li2 = li1
li1.append(['d'])
print(li2)
#=> [['a'], ['b'], ['c'], ['d']]II) Создайте мелкую копию оригинала. Ее можно создать с помощью конструктора list() или mylist.copy().
Мелкая копия создает новый объект, но заполняет его ссылками на оригинал. Таким образом, добавление нового объекта в исходный список li3 не отразится в li4, а вот изменение объектов в li3 — отразится:
li3 = [['a'],['b'],['c']]
li4 = list(li3)
li3.append([4])
print(li4)
#=> [['a'], ['b'], ['c']]
li3[0][0] = ['X']
print(li4)
#=> [[['X']], ['b'], ['c']]III) Создайте глубокую копию. Это делается с помощью copy.deepcopy(). Оригинал и копия полностью независимы, а изменения в одном не оказывают никакого влияния на другой:
import copy
li5 = [['a'],['b'],['c']]
li6 = copy.deepcopy(li5)
li5.append([4])
li5[0][0] = ['X']
print(li6)
#=> [['a'], ['b'], ['c']]@python_job_interview
👍28🔥3
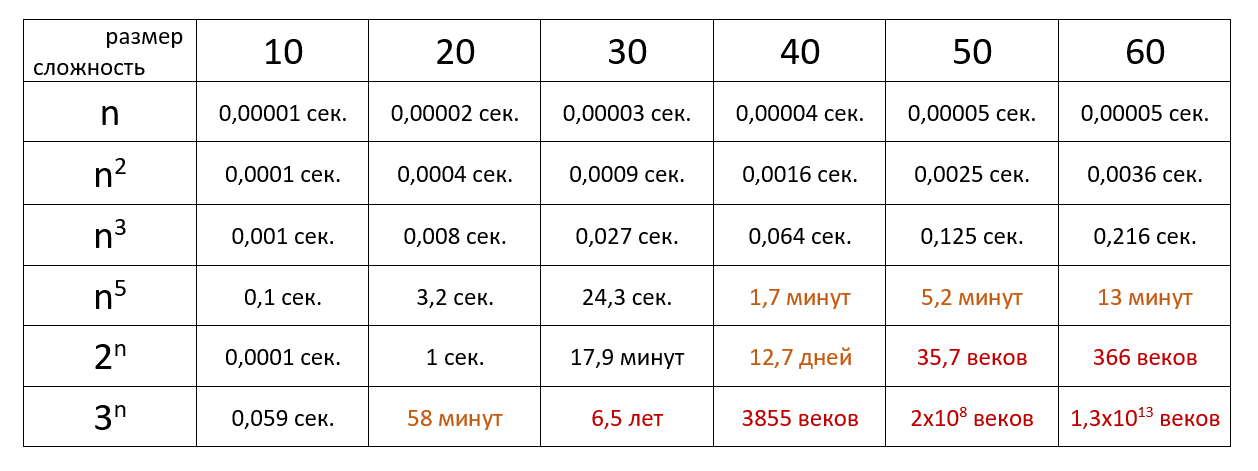
Что такое временная сложность алгоритма (time complexity)
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@python_job_interview
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@python_job_interview
{kind=link}
👍22🐳5❤🔥2
🐍 Собеседование Python. Разбор вопросов
00:00 Agenda
00:41 Как справиться со стрессом
04:00 Начало собеседования
13:37 Типы данных в Python
22:46 Lambda-функции
24:40 Тернарный оператор
26:50 Глубокая и поверхностная копия
28:40 Виртуальные окружения
33:45 Big O Notation
41:48 Классы
48:35 Декораторы
56:53 Абстрактные классы
59:57 Метаклассы
1:02:52 ООП
1:10:24 MRO
1:13:00 Итератор
1:14:24 Генератор
1:17:00 ОФФТОП
1:31:07 Конкурентность, асинхронность
1:36:20 Тестирование кода
1:43:32 ORM
1:46:34 Best practices
1:55:35 Базы данных
2:04:48 Git
2:07:28 Docker
2:12:37 Web
2:19:24 Linux
2:23:10 ОФФТОП
➡️ Смотреть
@python_job_interview
00:00 Agenda
00:41 Как справиться со стрессом
04:00 Начало собеседования
13:37 Типы данных в Python
22:46 Lambda-функции
24:40 Тернарный оператор
26:50 Глубокая и поверхностная копия
28:40 Виртуальные окружения
33:45 Big O Notation
41:48 Классы
48:35 Декораторы
56:53 Абстрактные классы
59:57 Метаклассы
1:02:52 ООП
1:10:24 MRO
1:13:00 Итератор
1:14:24 Генератор
1:17:00 ОФФТОП
1:31:07 Конкурентность, асинхронность
1:36:20 Тестирование кода
1:43:32 ORM
1:46:34 Best practices
1:55:35 Базы данных
2:04:48 Git
2:07:28 Docker
2:12:37 Web
2:19:24 Linux
2:23:10 ОФФТОП
➡️ Смотреть
@python_job_interview
👍29💩3
Объясните, как работает функция reduce
Ответ
Это может быть сложновато сразу понять, пока вы не используете ее несколько раз.
reduce принимает функцию и последовательность — и проходит по этой последовательности. На каждой итерации в функцию передаются как текущий элемент, так и выходные данные предыдущего элемента. В конце концов, возвращается одно значение .
Возвращается 11, что является суммой 1+2+3+5.
@python_job_interview
Ответ
Это может быть сложновато сразу понять, пока вы не используете ее несколько раз.
reduce принимает функцию и последовательность — и проходит по этой последовательности. На каждой итерации в функцию передаются как текущий элемент, так и выходные данные предыдущего элемента. В конце концов, возвращается одно значение .
from functools import reduce
def add_three(x,y):
return x + y
li = [1,2,3,5]
reduce(add_three, li)
#=> 11Возвращается 11, что является суммой 1+2+3+5.
@python_job_interview
👍21🤔3
Что такое _slots_ в Python ?
По умолчанию классы используют словарь для хранения атрибутов — это позволяет модифицировать набор атрибутов объекта прямо в ходе исполнения программы. Однако такой подход оказывается затратным для объектов, набор атрибутов которых невелик и/или ограничен. Это становится особенно заметно, когда создаётся большое количество экземпляров.
Поведение по умолчанию можно изменить, задав slots при определении класса. В slots могут быть перечислены атрибуты для значений которых требуется зарезервировать место (с точки зрения CPython в объекте класса резервируется место для массива указателей на Python-объекты). При этом ни dict, ни weakref для экземпляров автоматически созданы не будут (даже если в качестве значения строки указать пустую строку).
В качестве значения slots может быть указана строка, объект поддерживающий итерирование, или последовательность строк с именами атрибутов, использующихся экземплярами.
Слоты реализуются при помощи создания дескриптора для каждого из перечисленных атрибутов.
Попытки присвоить экземпляру атрибут, который не был перечислен в slots будет поднято исключение AttributeError.
2.3 Если требуется динамическое назначение атрибутов, следует указать в перечислении слотов '__dict__'.
Не имея атрибута weakref, экземпляры классов со slots не поддерживают слабые ссылки на себя.
2.3 Если требуется поддержка слабых ссылок, следует указать в перечислении слотов '__weakref__'.
Область действия слотов ограничено классом, в котором они определены, поэтому наследники (если конечно они не определили собственные слоты) будут иметь dict.
Если наследники тоже определяют слоты, то в перечислении должны содержаться лишь дополнительные. В последующих версиях возможно будет реализована проверка на совпадение имён.
Непустой slots не может быть использован для классов, наследующихся от встроенных типов переменной длины, например long, str и кортеж. При попытке сделать это будет поднято исключение TypeError.
Слот может принимать перечисления с «нестроками». Например, могут использоваться отображения, однако в будущих версиях значения по ключам могут быть наделены неким определённым смыслом.
2.6 Если назначается class, следует проследить, что для обоих классов определены одинаковые слоты.
@python_job_interview
По умолчанию классы используют словарь для хранения атрибутов — это позволяет модифицировать набор атрибутов объекта прямо в ходе исполнения программы. Однако такой подход оказывается затратным для объектов, набор атрибутов которых невелик и/или ограничен. Это становится особенно заметно, когда создаётся большое количество экземпляров.
Поведение по умолчанию можно изменить, задав slots при определении класса. В slots могут быть перечислены атрибуты для значений которых требуется зарезервировать место (с точки зрения CPython в объекте класса резервируется место для массива указателей на Python-объекты). При этом ни dict, ни weakref для экземпляров автоматически созданы не будут (даже если в качестве значения строки указать пустую строку).
В качестве значения slots может быть указана строка, объект поддерживающий итерирование, или последовательность строк с именами атрибутов, использующихся экземплярами.
Слоты реализуются при помощи создания дескриптора для каждого из перечисленных атрибутов.
class Ordinary(object):
"""Экземпляры этого класса могут дополняться атрибутами
во время исполнения.
"""
class WithSlots(object):
__slots__ = 'static_attr'
a = Ordinary()
b = WithSlots()
a.__dict__ # {}
b.__dict__ # AttributeError
a.__weakref__ # None
b.__weakref__ # AttributeError
a.static_attr = 1
b.static_attr = 1
a.dynamic_attr = 2
b.dynamic_attr = 2 # AttributeErrorПопытки присвоить экземпляру атрибут, который не был перечислен в slots будет поднято исключение AttributeError.
2.3 Если требуется динамическое назначение атрибутов, следует указать в перечислении слотов '__dict__'.
Не имея атрибута weakref, экземпляры классов со slots не поддерживают слабые ссылки на себя.
2.3 Если требуется поддержка слабых ссылок, следует указать в перечислении слотов '__weakref__'.
Область действия слотов ограничено классом, в котором они определены, поэтому наследники (если конечно они не определили собственные слоты) будут иметь dict.
Если наследники тоже определяют слоты, то в перечислении должны содержаться лишь дополнительные. В последующих версиях возможно будет реализована проверка на совпадение имён.
Непустой slots не может быть использован для классов, наследующихся от встроенных типов переменной длины, например long, str и кортеж. При попытке сделать это будет поднято исключение TypeError.
Слот может принимать перечисления с «нестроками». Например, могут использоваться отображения, однако в будущих версиях значения по ключам могут быть наделены неким определённым смыслом.
2.6 Если назначается class, следует проследить, что для обоих классов определены одинаковые слоты.
@python_job_interview
👍17🤔1
Расскажите о концепции распределенной архитектуры
Ответ
В больших системах, которые обрабатывают миллионы событий в день, некоторые вещи просто по определению обязаны пойти не по плану. Вот почему прежде, чем погружаться в планирование системы, нужно сделать самый важный шаг — принять решение о том, что для нас означает «здоровая» система. Степень «здоровья» должна быть чем-то таким, что на самом деле можно измерить. Общепринятым способом измерения «здоровья» системы являются SLA (service level agreements). Вот некоторые из самых распространённых видов SLA:
Доступность (Availability): процент времени, который сервис является работоспособным. Пусть существует искушение достичь 100% доступности, достижение этого результата может оказаться по-настоящему сложным занятием, да ещё вдобавок и весьма дорогостоящим. Даже крупные и критичные системы вроде сети карт VISA, Gmail или интернет-провайдеров не имеют 100% доступности — за годы они накопят секунды, минуты или часы, проведённые в даунтайме. Для многих систем, доступность в четыре девятки (99.99%, или примерно 50 минут даунтайма в год) считается высокой доступностью. Для того, чтобы добраться до этого уровня, придётся изрядно попотеть.
Точность (Accuracy): является ли допустимой потеря данных или их неточность? Если да, то какой процент является приемлимым? Для системы платежей, над которой я работал, этот показатель должен был составлять 100%, поскольку данные терять было нельзя.
Пропускная способность/мощность (Capacity): какую нагрузку должна выдерживать система? Этот показатель обычно выражается в запросах в секунду.
Задержка (Latency): за какое время система должна отвечать? За какое время должны быть обслужены 95% и 99% запросов? В подобных системах обычно многие из запросов являются «шумом», поэтому задержки p95 и p99 находят более практическое применение в реальном мире.
Горизонтальное и вертикальное масштабирование
По мере роста бизнеса, который использует нашу свежесозданную систему, нагрузка на неё будет лишь увеличиваться. В определенный момент, существующая установка будет неспособна выдержать дальнейшее увеличение нагрузки, и нам потребуется увеличить допустимую нагрузку. Две общепринятые стратегии масштабирования — это вертикальное или горизонтальное масштабирование.
Горизонтальное масштабирование заключается в добавлении большего количества машин (или узлов) в систему для увеличения пропускной способности (capacity). Горизонтальное масштабирование — это самый популярный способ масштабирования распределённых систем.
Вертикальное масштабирование — это по сути «купить машину побольше/посильнее» — (виртуальная) машина с большим числом ядер, лучшей вычислительной мощностью и большей памятью. В случае с рапределёнными системами, вертикальное масштабирование обычно менее популярно, поскольку оно может быть более дорогостоящим, чем масштабирование горизонтальное. Однако, некоторые известные большие сайты, вроде Stack Overflow, успешно масштабировались вертикально для соответствия нагрузке.
@python_job_interview
Ответ
В больших системах, которые обрабатывают миллионы событий в день, некоторые вещи просто по определению обязаны пойти не по плану. Вот почему прежде, чем погружаться в планирование системы, нужно сделать самый важный шаг — принять решение о том, что для нас означает «здоровая» система. Степень «здоровья» должна быть чем-то таким, что на самом деле можно измерить. Общепринятым способом измерения «здоровья» системы являются SLA (service level agreements). Вот некоторые из самых распространённых видов SLA:
Доступность (Availability): процент времени, который сервис является работоспособным. Пусть существует искушение достичь 100% доступности, достижение этого результата может оказаться по-настоящему сложным занятием, да ещё вдобавок и весьма дорогостоящим. Даже крупные и критичные системы вроде сети карт VISA, Gmail или интернет-провайдеров не имеют 100% доступности — за годы они накопят секунды, минуты или часы, проведённые в даунтайме. Для многих систем, доступность в четыре девятки (99.99%, или примерно 50 минут даунтайма в год) считается высокой доступностью. Для того, чтобы добраться до этого уровня, придётся изрядно попотеть.
Точность (Accuracy): является ли допустимой потеря данных или их неточность? Если да, то какой процент является приемлимым? Для системы платежей, над которой я работал, этот показатель должен был составлять 100%, поскольку данные терять было нельзя.
Пропускная способность/мощность (Capacity): какую нагрузку должна выдерживать система? Этот показатель обычно выражается в запросах в секунду.
Задержка (Latency): за какое время система должна отвечать? За какое время должны быть обслужены 95% и 99% запросов? В подобных системах обычно многие из запросов являются «шумом», поэтому задержки p95 и p99 находят более практическое применение в реальном мире.
Горизонтальное и вертикальное масштабирование
По мере роста бизнеса, который использует нашу свежесозданную систему, нагрузка на неё будет лишь увеличиваться. В определенный момент, существующая установка будет неспособна выдержать дальнейшее увеличение нагрузки, и нам потребуется увеличить допустимую нагрузку. Две общепринятые стратегии масштабирования — это вертикальное или горизонтальное масштабирование.
Горизонтальное масштабирование заключается в добавлении большего количества машин (или узлов) в систему для увеличения пропускной способности (capacity). Горизонтальное масштабирование — это самый популярный способ масштабирования распределённых систем.
Вертикальное масштабирование — это по сути «купить машину побольше/посильнее» — (виртуальная) машина с большим числом ядер, лучшей вычислительной мощностью и большей памятью. В случае с рапределёнными системами, вертикальное масштабирование обычно менее популярно, поскольку оно может быть более дорогостоящим, чем масштабирование горизонтальное. Однако, некоторые известные большие сайты, вроде Stack Overflow, успешно масштабировались вертикально для соответствия нагрузке.
@python_job_interview
👍16🔥2❤1
Задача. Есть три функции, в которых выполняются базовые операции (сортировка, фильтрация, возведение массива в квадрат). Нужно упорядочить эти три функции в порядке возрастания времени, идущего на их выполнение.
То есть на входе все функции имеют одинаковые данные, на выходе выдают одинаковый результат. Но из-за того, что внутри операции выполняются в разном порядке, время выполнения будет отличаться. Здесь нужно ориентироваться в алгоритмах и понимать, что происходит с твоими данными в процессе. Эту задачу может решить Junior, а может не решить и Middle. Казалось бы, такая мелочь, но когда мы работаем с большим количеством данных, важно, чтобы код был оптимизирован и программа выполнялась максимально быстро.
@python_job_interview
def f1(lIn):
l1 = sorted(lIn)
l2 = [i for i in l1 if i<0.5]
return [i*i for i in l2]
def f2(lIn):
l1 = [i for i in lIn if i<0.5]
l2 = sorted(l1)
return [i*i for i in l2]
def f3(lIn):
l1 = [i*i for i in lIn]
l2 = sorted(l1)
return [i for i in l1 if i<(0.5*0.5)]То есть на входе все функции имеют одинаковые данные, на выходе выдают одинаковый результат. Но из-за того, что внутри операции выполняются в разном порядке, время выполнения будет отличаться. Здесь нужно ориентироваться в алгоритмах и понимать, что происходит с твоими данными в процессе. Эту задачу может решить Junior, а может не решить и Middle. Казалось бы, такая мелочь, но когда мы работаем с большим количеством данных, важно, чтобы код был оптимизирован и программа выполнялась максимально быстро.
@python_job_interview
👍11❤1🔥1
#Вопросы_с_собеседования
❓Напишите программу, которая возвращает количество гласных букв в строке
Наша программа при помощи регулярного выражения, вычисляет количество гласных (A, E, I, O, U, Y) в строке.
@python_job_interview
❓Напишите программу, которая возвращает количество гласных букв в строке
Наша программа при помощи регулярного выражения, вычисляет количество гласных (A, E, I, O, U, Y) в строке.
@python_job_interview
👍12🔥2🤔2❤1