
Forwarded from AWS Notes
🔐 Взлом RSA 2048 с помощью квантовых компьютеров ⁉️
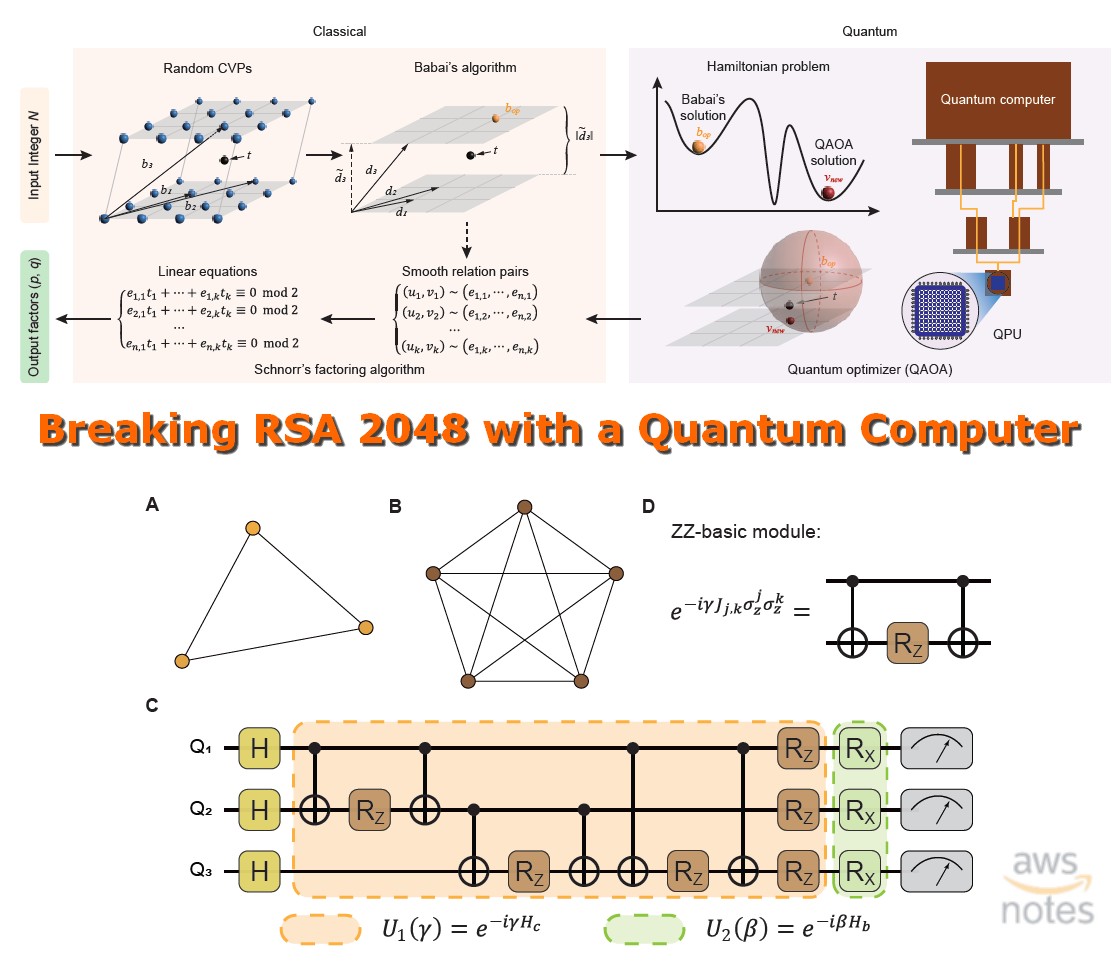
🇨🇳 22 декабря 2022-го года было опубликовано исследование китайских учёных, где говорится о возможности взлома RSA 2048 с применением квантовых компьютеров, доступных уже сейчас, а не лет через 10, как до этого предполагалось.
🔑 С помощью предложенного алгоритма удалось вычислить 2048-битный ключ на компьютере с 372 кубитами, в то время, как ранее для такого предполагалось, что потребуется 4000-8000+ кубитов, из чего и делалось предположение NIST, что такая технологическая возможность будет достигнута лишь к тридцатым годам.
📌 Известный гуру по безопасности Bruce Schneier
написал в своём блоге, что к этому нужно относиться очень серьёзно:
https://www.schneier.com/blog/archives/2023/01/breaking-rsa-with-a-quantum-computer.html
📚 Roger Grimes, автор книги Cryptography Apocalypse: Preparing for the Day When Quantum Computing Breaks Today's Crypto, нагнетает ещё больше в своей заметке «Has the Quantum Break Just Happened?»:
https://community.spiceworks.com/topic/2472644-has-the-quantum-break-just-happened
💻 Где говорится, что 432 кубита ломают RSA 2048, в то время как IBM уже в этом году грозится выпустить 1000-кубитный компьютер. В частности про этот прогноз было на слайдах re:Invent 2020 — Building post-quantum cryptography for the cloud.
⚠ Он также отмечает, что данное исследование делает уязвимым все Lattice-based алгоритмы, которые были совсем недавно приняты NIST в качестве защиты для Post Quantum эпохи шифрования.
🔒 Со своей стороны отмечу, что уже доступный в AWS KMS алгоритм BIKE, который попал в NIST PQC Round 4, принадлежит к Code-based типу алгоритмов и потому не попадает под этот вектор атаки. Если, конечно, всё это подтвердится (исследование будет доказано). 😀
🔺Но даже если и не подтвердится, то, всё равно — тема обеспечения безопасности во "внезапно" наступившей эпохе квантовых компьютеров — резко возрастёт, когда все осознают, что чуть меньше, чем всё, базирующееся на привычном ассиметричном шифровании (HTTPS, WiFi, Auth etc), может быть взломано.
🎄 С новым квантовым годом! 😁
#security #KMS
🇨🇳 22 декабря 2022-го года было опубликовано исследование китайских учёных, где говорится о возможности взлома RSA 2048 с применением квантовых компьютеров, доступных уже сейчас, а не лет через 10, как до этого предполагалось.
🔑 С помощью предложенного алгоритма удалось вычислить 2048-битный ключ на компьютере с 372 кубитами, в то время, как ранее для такого предполагалось, что потребуется 4000-8000+ кубитов, из чего и делалось предположение NIST, что такая технологическая возможность будет достигнута лишь к тридцатым годам.
📌 Известный гуру по безопасности Bruce Schneier
написал в своём блоге, что к этому нужно относиться очень серьёзно:
https://www.schneier.com/blog/archives/2023/01/breaking-rsa-with-a-quantum-computer.html
📚 Roger Grimes, автор книги Cryptography Apocalypse: Preparing for the Day When Quantum Computing Breaks Today's Crypto, нагнетает ещё больше в своей заметке «Has the Quantum Break Just Happened?»:
https://community.spiceworks.com/topic/2472644-has-the-quantum-break-just-happened
💻 Где говорится, что 432 кубита ломают RSA 2048, в то время как IBM уже в этом году грозится выпустить 1000-кубитный компьютер. В частности про этот прогноз было на слайдах re:Invent 2020 — Building post-quantum cryptography for the cloud.
⚠ Он также отмечает, что данное исследование делает уязвимым все Lattice-based алгоритмы, которые были совсем недавно приняты NIST в качестве защиты для Post Quantum эпохи шифрования.
🔒 Со своей стороны отмечу, что уже доступный в AWS KMS алгоритм BIKE, который попал в NIST PQC Round 4, принадлежит к Code-based типу алгоритмов и потому не попадает под этот вектор атаки. Если, конечно, всё это подтвердится (исследование будет доказано). 😀
🔺Но даже если и не подтвердится, то, всё равно — тема обеспечения безопасности во "внезапно" наступившей эпохе квантовых компьютеров — резко возрастёт, когда все осознают, что чуть меньше, чем всё, базирующееся на привычном ассиметричном шифровании (HTTPS, WiFi, Auth etc), может быть взломано.
🎄 С новым квантовым годом! 😁
#security #KMS
{kind=link}
Forwarded from Блог*
#prog #performancetrap #video
"Performance Matters" by Emery Berger
Фактически презентация двух инструментов для анализа производительности.
Первый — Stabilizer. Производительность программ в немалой степени зависит от того, как данные располагаются в памяти, и от окружения, в котором программы запускаются. Автор видео ссылается на статью, которая показывает, что эффект этих переменных может быть весьма значителен и перекрывать даже разницу между оптимизированным и неоптимизированным кодом. Stabilizer в рантайме каждые пол-секунды меняет раскладку кода и данных в куче, что позволяет снимать профиль производительности с учётом всех возможных влияний раскладки кода. Из-за применимости в данном случае центральной предельной теоремы общее влияние раскладки описывается (для достаточно большого количества исследованных данных) нормальным распределением, что позволяет задействовать статистические методы для того, чтобы замерить, насколько вклад в изменение производительности обусловлен изменениями в коде. К сожалению, этот инструмент более активно не развивается.
Второй инструмент (более живой) — это coz, causal profiler. Этот профайлер позволяет ценой небольших аннотаций исходного кода оценить, насколько сильно изменение производительности одного компонента сказывается на производительности системы в целом. Так как просто взять и ускорить код невозможно, coz достигает требуемых эффектов за счёт замедления всех остальных компонентов. В видео рассказывается о том, как coz помог в реальных случаях, на какие неожиданные узкие места указывал и о том, насколько хорошо замеренные прибавки в производительности согласовывались с предсказаниями инструмента.
Забавно, что это видео я уже смотрел, Даня упоминал coz у себя на канале, но только сейчас наткнулся на него снова и выложил у себя.
"Performance Matters" by Emery Berger
Фактически презентация двух инструментов для анализа производительности.
Первый — Stabilizer. Производительность программ в немалой степени зависит от того, как данные располагаются в памяти, и от окружения, в котором программы запускаются. Автор видео ссылается на статью, которая показывает, что эффект этих переменных может быть весьма значителен и перекрывать даже разницу между оптимизированным и неоптимизированным кодом. Stabilizer в рантайме каждые пол-секунды меняет раскладку кода и данных в куче, что позволяет снимать профиль производительности с учётом всех возможных влияний раскладки кода. Из-за применимости в данном случае центральной предельной теоремы общее влияние раскладки описывается (для достаточно большого количества исследованных данных) нормальным распределением, что позволяет задействовать статистические методы для того, чтобы замерить, насколько вклад в изменение производительности обусловлен изменениями в коде. К сожалению, этот инструмент более активно не развивается.
Второй инструмент (более живой) — это coz, causal profiler. Этот профайлер позволяет ценой небольших аннотаций исходного кода оценить, насколько сильно изменение производительности одного компонента сказывается на производительности системы в целом. Так как просто взять и ускорить код невозможно, coz достигает требуемых эффектов за счёт замедления всех остальных компонентов. В видео рассказывается о том, как coz помог в реальных случаях, на какие неожиданные узкие места указывал и о том, насколько хорошо замеренные прибавки в производительности согласовывались с предсказаниями инструмента.
Забавно, что это видео я уже смотрел, Даня упоминал coz у себя на канале, но только сейчас наткнулся на него снова и выложил у себя.
YouTube
"Performance Matters" by Emery Berger
Performance clearly matters to users. For example, the most common software update on the AppStore is "Bug fixes and performance enhancements." Now that Moore's Law has ended, programmers have to work hard to get high performance for their applications. But…
Forwarded from ITGram
Raft: Understandable Distributed Consensus is amazingly clear, beautiful, and interactive visualization of how Raft algorithm works. Raft is the algorithm for picking a leader node and synchronizing changes across multiple nodes in a distributed system. This is the magic behind the replication of RabbitMQ, Nats, Etcd, CockroachDB, and many others.
Forwarded from Блог*
#prog #rust #article
The registers of Rust
Лодочник рассматривает существующие эффекты в Rust (асинхронность, итерирование, ошибочность) с точки зрения регистров (не процессорных, а в том смысле, в котором это слово используется в социолингвистике) и довольно аргументированно доказывает, что усилия по развитию асинхронности в Rust идут в не совсем нужном направлении. Даже если вы с ним не согласны, предложенный им способ рассмотрения фич языка программирования довольно полезен.
И продолжения:
Patterns & Abstractions
Const as an auto trait
The registers of Rust
Лодочник рассматривает существующие эффекты в Rust (асинхронность, итерирование, ошибочность) с точки зрения регистров (не процессорных, а в том смысле, в котором это слово используется в социолингвистике) и довольно аргументированно доказывает, что усилия по развитию асинхронности в Rust идут в не совсем нужном направлении. Даже если вы с ним не согласны, предложенный им способ рассмотрения фич языка программирования довольно полезен.
И продолжения:
Patterns & Abstractions
Const as an auto trait
Forwarded from Experimental chill
Paxos, Raft и тд
Моё отношение к консенсусным протоколам менялось. В универе я их понял на уровне, что консенсусы возможны, потом на практике я видел как баги в Paxos/Raft есть и будут всегда, но последние 1-2 года багов стало как-то сильно меньше, и привыкнув к алгоритмам, потихоньку приходит осознание в их детальных различиях, в том числе полученные горьким опытом.
Мне захотелось ещё раз прочитать разницу между Paxos и Raft и как они живут вместе с FLP теоремой.
Последняя гласит, что детерминированный консенсус невозможен в полностью асинхронной сети, когда сообщения могут не доставляться или доставляться с задержкой. Выбор лидера в Raft может никогда не завершиться, на практике борются с этим с помощью случайных таймаутов. У Paxos два proposer могут никогда не договориться о решении, что тоже на практике лечат случайными таймаутами. Это отличный вопрос на собеседовании, чтобы отсечь тех, кто видит в Raft ответы на все вопросы, о негативных результатах надо тоже знать.
По моему мнению на практике самая большая разница в том, что при потере лидера Paxos может медленнее восстанавливаться:
1. Paxos выбирает лидера исходя из id узла, и если он отстает на немного от закоммиченных значений, то ему надо их применить, поэтому если сервер с большим id выигрывает, бывают проблемы и спайки в ожидании запросов. Случайный id не всегда хорошо коррелирует с живностью. На практике в больших системах много работы надо доделать, например, всякие обновления метаданных, и это начинает быть заметно.
2. В Raft узлы с бОльшим количеством закоммиченных чаще выигрывают, но зато у Raft больше шансов получить ситуацию, когда много проголосовали за 2 кандидата и надо переизбрать ещё раз. Вторая ситуация происходит реже, поэтому Raft более практичен.
Другое отличие, что так как алгоритмы достаточно сложные для программиста и хотелось бы едва понять любую из статей, происходит следующее
1. Raft и Paxos имплементируются по статьям.
2. В Raft есть проблемы с network partitioning, если узлы видят разные подмножества, может быть бабах (Cloudflare). Подробный разбор и как сконфигурировать etcd и всё сломать можно прочитать в статье.
Дальше происходит, что написание нового кода приводит к багам, которые чинятся годами. Тем не менее, ситуация намного улучшилась, в etcd 3.4 добавили Raft Prevotes, чтобы избежать проблем с сетью. Но потом чинить баги всё равно пришлось. Вещи становятся лучше со временем в таких примитивах, это не может не радовать.
Самое удивительное в этой индустрии, насколько она наполнена людьми, которые, мол, думают, что поняли консенсус. Из-за того, что консенсусы нетривиальны, редки, я вижу много от людей в виде: "выучи TLA+", "напиши автоматическое доказательство", "а ты слышал про EPaxos, он лучше, чем Paxos". Ребят, мне бы понять первую статью. И не врать себе, что задача просто сложная.
Я очевидно во всем не разобрался, но спустя годы оно стало лучше. Поэтому если вам кажется, что вы не можете это понять, дайте себе время. За несколько месяцев и лет, из-за важности свойств, сложность осядет, и вы поймете, что к чему. Читайте потихоньку, пытайтесь понять примитивы, читайте имплементации (хороших много на github), не бойтесь спрашивать.
[1] Различия Paxos и Raft
[2] Вообще читайте всё, что написано от Heidi Howard, она топ эксперт в мире по консенсусным протоколам
[3] etcd network partitioning failure, инцидент от Cloudflare
[4] Имплементации Raft
[5] Ещё более простое объяснение Raft с иммутабельными цепочками. Чем больше иммутабельности, тем легче нам понимаются перезаписи и тд
Моё отношение к консенсусным протоколам менялось. В универе я их понял на уровне, что консенсусы возможны, потом на практике я видел как баги в Paxos/Raft есть и будут всегда, но последние 1-2 года багов стало как-то сильно меньше, и привыкнув к алгоритмам, потихоньку приходит осознание в их детальных различиях, в том числе полученные горьким опытом.
Мне захотелось ещё раз прочитать разницу между Paxos и Raft и как они живут вместе с FLP теоремой.
Последняя гласит, что детерминированный консенсус невозможен в полностью асинхронной сети, когда сообщения могут не доставляться или доставляться с задержкой. Выбор лидера в Raft может никогда не завершиться, на практике борются с этим с помощью случайных таймаутов. У Paxos два proposer могут никогда не договориться о решении, что тоже на практике лечат случайными таймаутами. Это отличный вопрос на собеседовании, чтобы отсечь тех, кто видит в Raft ответы на все вопросы, о негативных результатах надо тоже знать.
По моему мнению на практике самая большая разница в том, что при потере лидера Paxos может медленнее восстанавливаться:
1. Paxos выбирает лидера исходя из id узла, и если он отстает на немного от закоммиченных значений, то ему надо их применить, поэтому если сервер с большим id выигрывает, бывают проблемы и спайки в ожидании запросов. Случайный id не всегда хорошо коррелирует с живностью. На практике в больших системах много работы надо доделать, например, всякие обновления метаданных, и это начинает быть заметно.
2. В Raft узлы с бОльшим количеством закоммиченных чаще выигрывают, но зато у Raft больше шансов получить ситуацию, когда много проголосовали за 2 кандидата и надо переизбрать ещё раз. Вторая ситуация происходит реже, поэтому Raft более практичен.
Другое отличие, что так как алгоритмы достаточно сложные для программиста и хотелось бы едва понять любую из статей, происходит следующее
1. Raft и Paxos имплементируются по статьям.
2. В Raft есть проблемы с network partitioning, если узлы видят разные подмножества, может быть бабах (Cloudflare). Подробный разбор и как сконфигурировать etcd и всё сломать можно прочитать в статье.
Дальше происходит, что написание нового кода приводит к багам, которые чинятся годами. Тем не менее, ситуация намного улучшилась, в etcd 3.4 добавили Raft Prevotes, чтобы избежать проблем с сетью. Но потом чинить баги всё равно пришлось. Вещи становятся лучше со временем в таких примитивах, это не может не радовать.
Самое удивительное в этой индустрии, насколько она наполнена людьми, которые, мол, думают, что поняли консенсус. Из-за того, что консенсусы нетривиальны, редки, я вижу много от людей в виде: "выучи TLA+", "напиши автоматическое доказательство", "а ты слышал про EPaxos, он лучше, чем Paxos". Ребят, мне бы понять первую статью. И не врать себе, что задача просто сложная.
Я очевидно во всем не разобрался, но спустя годы оно стало лучше. Поэтому если вам кажется, что вы не можете это понять, дайте себе время. За несколько месяцев и лет, из-за важности свойств, сложность осядет, и вы поймете, что к чему. Читайте потихоньку, пытайтесь понять примитивы, читайте имплементации (хороших много на github), не бойтесь спрашивать.
[1] Различия Paxos и Raft
[2] Вообще читайте всё, что написано от Heidi Howard, она топ эксперт в мире по консенсусным протоколам
[3] etcd network partitioning failure, инцидент от Cloudflare
[4] Имплементации Raft
[5] Ещё более простое объяснение Raft с иммутабельными цепочками. Чем больше иммутабельности, тем легче нам понимаются перезаписи и тд
The Cloudflare Blog
A Byzantine failure in the real world
When we review design documents at Cloudflare, we are always on the lookout for Single Points of Failure (SPOFs). But is redundancy enough? In this post we present a timeline of a real world incident, and how an interesting failure mode known as a Byzantine…
Forwarded from Блог*
#prog #rust #rustasync #article
Efficient indexing with Quickwit Rust actor framework
Или немного о том, почему разработчики Quickwit решили реализовать свой акторный фреймворк. Также в тексте есть ссылка на статью Actors with Tokio, которая описывает, как создавать свои акторы, имея асинхронный рантайм, и показывает некоторые частые ошибки при подобном наивном подходе.
Efficient indexing with Quickwit Rust actor framework
Или немного о том, почему разработчики Quickwit решили реализовать свой акторный фреймворк. Также в тексте есть ссылка на статью Actors with Tokio, которая описывает, как создавать свои акторы, имея асинхронный рантайм, и показывает некоторые частые ошибки при подобном наивном подходе.
quickwit.io
Efficient indexing with Quickwit Rust actor framework
At Quickwit, we are building the most cost-efficient search engine for logs and traces. Such an engine typically ingests massive amounts of data while serving a comparatively low number of search queries. Under this workload, most of your CPU is spent on…