
#api
Нашел шикарное(хоть и древнее) эссе про дизайн Rest api от чувака который работал над Red Hat Enterprise Virtualization API. Очень рекомендую, узнал много интересного!
Например, вы знали, что если вам нужно уметь работать с версиями ресурсов, то в Rest'е есть нативный механизм для этого под названием variants?
Или про Link headers, позволяющие получить все ссылки из ответа на запрос без парсинга самого ответа?
Нашел шикарное(хоть и древнее) эссе про дизайн Rest api от чувака который работал над Red Hat Enterprise Virtualization API. Очень рекомендую, узнал много интересного!
Например, вы знали, что если вам нужно уметь работать с версиями ресурсов, то в Rest'е есть нативный механизм для этого под названием variants?
Или про Link headers, позволяющие получить все ссылки из ответа на запрос без парсинга самого ответа?
Forwarded from Админим с Буквой (bykva)
А еще я каким-то образом вдруг сделал вклад в опенсорс и написал (ну не только я, а еще с помощью моих коллег из ситимобил) ansible роли для разворачивания victoriametrics.
https://github.com/VictoriaMetrics/ansible-playbooks
https://github.com/VictoriaMetrics/ansible-playbooks
GitHub
GitHub - VictoriaMetrics/ansible-playbooks: Ansible Playbooks for Victoria Metrics monorepo
Ansible Playbooks for Victoria Metrics monorepo. Contribute to VictoriaMetrics/ansible-playbooks development by creating an account on GitHub.
#management
Наконец-то посмотрел доклад моего хорошего друга Коли Архипова с прошедшего РИТа. Если интересуетесь темой проверки продуктовых гипотез(да и если не интересуетесь😉), то крайне рекомендую к просмотру!
Наконец-то посмотрел доклад моего хорошего друга Коли Архипова с прошедшего РИТа. Если интересуетесь темой проверки продуктовых гипотез(да и если не интересуетесь😉), то крайне рекомендую к просмотру!
YouTube
Как мы побеждаем неопределенность в Delivery Club / Николай Архипов (Delivery Club)
Профессиональный онлайн-фестиваль для тех, кто делает Интернет РИТ++ 2020
Тезисы и презентация:
https://ritfest.ru/2020/abstracts/6836
Вы, конечно, слышали, что есть R&D. Но чем конкретно они занимаются? Алгоритмы, данные, математика, аналитика или разработка?…
Тезисы и презентация:
https://ritfest.ru/2020/abstracts/6836
Вы, конечно, слышали, что есть R&D. Но чем конкретно они занимаются? Алгоритмы, данные, математика, аналитика или разработка?…
Forwarded from oleg_log (Oleg Kovalov)
По поводу последнего (S02E15) выпуска @generictalks
Дебаг кубов. Я не знаю, что может быть лучше этого. Удивите и скиньте, если есть.
Правда вещь отличная, ты просто идешь по стрелочками и понимаешь, что не так. Обрадую, скорее всего вы получите ответ.
https://learnk8s.io/troubleshooting-deployments
Дебаг кубов. Я не знаю, что может быть лучше этого. Удивите и скиньте, если есть.
Правда вещь отличная, ты просто идешь по стрелочками и понимаешь, что не так. Обрадую, скорее всего вы получите ответ.
https://learnk8s.io/troubleshooting-deployments
LearnKube
A visual guide on troubleshooting Kubernetes deployments
Troubleshooting in Kubernetes can be a daunting task. In this article you will learn how to diagnose issues in Pods, Services and Ingress.
Forwarded from Kaznacheev Feed
#книги
Microservices Patterns - Chris Richardson
Наконец-то дочитал эту книгу, потребовалось всего лишь полгода.
Интересная книжка, которая покрывает достаточно широкий спектр проблем, связанных с разделением системы на микросервисы, а также их возможные решения.
🤔Кому интересно: разработчикам и архитекторам, занимающимся построением микросервисных систем.
👍Что понравилось: книга довольно подробно и постепенно рассказывает о переходе серверного приложения от монолитной к распределенной архитектуре, о том, с какими сложностями это связано, и как их решать. Помимо этого, каждый паттерн сопровождается описанием плюсов и минусов его применения, которым отводится достаточное место.
Особенно понравилась глава 2, где подробно рассматриваются принципы декомпозиции логики приложения на микросервисы, а также этапы разбиения с уровня высоких абстракций до конкретных реализаций.
Помимо этого, очень порадовали последние главы, описывающие тестирование, приемы трейсинга и мониторинга и описание service mesh и как его применять. Узнал много полезного, что буду применять в работе.
👎Как гласит название - это книга с примерами на Java. И это как раз та книга, где от их изобилия становится неприятно. Кроме того, автор постоянно рекламирует фреймворк, который разработан его собственным стартапом. В этом, в принципе, ничего плохого нет, но половина из примеров на Java являются примерами по решению задач с использованием этого фреймворка. С какого-то момента я просто начал проматывать листинги, так как толку от них для меня никакого.
Кроме того, что свойственно Java разработке, автор во многих местах начинает очень сильно переусложнять. Главы 4, 5, 6 прямо-таки отличный пример того, почему не стоит применять микросервисную архитектуру - в них показано, как простейшие для монолита вещи можно настолько усложнить, что разгребать придется введением дополнительных паттернов, которые, в свою очередь, придется разгребать еще несколько глав. При этом я так и не увидел, чтобы проблемы тех же распределенных транзакций были решены. Автор оперирует оркестрируемыми сагами так, как будто это простейший в реализации паттерн, учитывая предлагаемые над ним надстройки для приближенного выполнения ACID требований.
На деле это в какой-то момент превращается в абсурд и фарс, поверх которого ровным слоем намазана реклама разработанного автором фреймворка. Неподготовленный читатель может купиться на элегантность, с которой автор описывает эти решения, но на деле это сложнейшие в поддержке архитектурные элементы, которые изобилуют ограничениями и краевыми условиями.
👷♂️В книге уделяется много внимания объяснению паттернов и дается много примеров их реализации (хоть и на Java). В целом много информации, покрывающей полный цикл разработки микросервисных приложений, начиная от архитектуры и декомпозиции, заканчивая тестированием, развертыванием, мониторингом и запуском в облачных средах. Хорошее пособие для разработчиков микросенвисов, а также неплохая матчасть по этой теме, здорово упорядочивающаяся знания.
В целом книга интересная и довольно хорошая в плане пользы для читателя. Даже несмотря на огромное количество Java листингов, рекламы и явного переусложнения некоторых решений, материал все еще очень полезен для людей, испытывающих проблемы в поддержании и реализации микросервисных систем. Читать однозначно стоит, более того, книга построена таким образом, что к ней можно возвращаться за какими-то уточнениями по реализации паттернов, в конце по ним есть удобный указатель.
Microservices Patterns - Chris Richardson
Наконец-то дочитал эту книгу, потребовалось всего лишь полгода.
Интересная книжка, которая покрывает достаточно широкий спектр проблем, связанных с разделением системы на микросервисы, а также их возможные решения.
🤔Кому интересно: разработчикам и архитекторам, занимающимся построением микросервисных систем.
👍Что понравилось: книга довольно подробно и постепенно рассказывает о переходе серверного приложения от монолитной к распределенной архитектуре, о том, с какими сложностями это связано, и как их решать. Помимо этого, каждый паттерн сопровождается описанием плюсов и минусов его применения, которым отводится достаточное место.
Особенно понравилась глава 2, где подробно рассматриваются принципы декомпозиции логики приложения на микросервисы, а также этапы разбиения с уровня высоких абстракций до конкретных реализаций.
Помимо этого, очень порадовали последние главы, описывающие тестирование, приемы трейсинга и мониторинга и описание service mesh и как его применять. Узнал много полезного, что буду применять в работе.
👎Как гласит название - это книга с примерами на Java. И это как раз та книга, где от их изобилия становится неприятно. Кроме того, автор постоянно рекламирует фреймворк, который разработан его собственным стартапом. В этом, в принципе, ничего плохого нет, но половина из примеров на Java являются примерами по решению задач с использованием этого фреймворка. С какого-то момента я просто начал проматывать листинги, так как толку от них для меня никакого.
Кроме того, что свойственно Java разработке, автор во многих местах начинает очень сильно переусложнять. Главы 4, 5, 6 прямо-таки отличный пример того, почему не стоит применять микросервисную архитектуру - в них показано, как простейшие для монолита вещи можно настолько усложнить, что разгребать придется введением дополнительных паттернов, которые, в свою очередь, придется разгребать еще несколько глав. При этом я так и не увидел, чтобы проблемы тех же распределенных транзакций были решены. Автор оперирует оркестрируемыми сагами так, как будто это простейший в реализации паттерн, учитывая предлагаемые над ним надстройки для приближенного выполнения ACID требований.
На деле это в какой-то момент превращается в абсурд и фарс, поверх которого ровным слоем намазана реклама разработанного автором фреймворка. Неподготовленный читатель может купиться на элегантность, с которой автор описывает эти решения, но на деле это сложнейшие в поддержке архитектурные элементы, которые изобилуют ограничениями и краевыми условиями.
👷♂️В книге уделяется много внимания объяснению паттернов и дается много примеров их реализации (хоть и на Java). В целом много информации, покрывающей полный цикл разработки микросервисных приложений, начиная от архитектуры и декомпозиции, заканчивая тестированием, развертыванием, мониторингом и запуском в облачных средах. Хорошее пособие для разработчиков микросенвисов, а также неплохая матчасть по этой теме, здорово упорядочивающаяся знания.
В целом книга интересная и довольно хорошая в плане пользы для читателя. Даже несмотря на огромное количество Java листингов, рекламы и явного переусложнения некоторых решений, материал все еще очень полезен для людей, испытывающих проблемы в поддержании и реализации микросервисных систем. Читать однозначно стоит, более того, книга построена таким образом, что к ней можно возвращаться за какими-то уточнениями по реализации паттернов, в конце по ним есть удобный указатель.
Manning Publications
Microservices Patterns - Chris Richardson
This clearly-written practical guide offers experience-driven advice to help you design, implement, test, and deploy your microservices-based application.
#management
Пришлось мне тут на днях не очень технически подкованному коллеге объяснять как устроен наш релизный цикл. Для восприятия, конечно же лучше подходит формат картинки, но, как оказалось, нарисовать релизный цикл так, что бы это не превратилось в суп из стрелочек, квадратиков и т.д. довольно сложно.
Перепробовав несколько разных вариантов, нашел вот это. Имхо, если у Вас нет такой картинки, то надо срочно нарисовать, потому что, во-первых, это просто красиво! Для сравнения, аналогичная по смыслу sequence диаграмма выглядит как помесь ежа с ужом(длинная и со стрелками во все стороны). Рисуется все это великолепие за пол часа в draw.io
Пришлось мне тут на днях не очень технически подкованному коллеге объяснять как устроен наш релизный цикл. Для восприятия, конечно же лучше подходит формат картинки, но, как оказалось, нарисовать релизный цикл так, что бы это не превратилось в суп из стрелочек, квадратиков и т.д. довольно сложно.
Перепробовав несколько разных вариантов, нашел вот это. Имхо, если у Вас нет такой картинки, то надо срочно нарисовать, потому что, во-первых, это просто красиво! Для сравнения, аналогичная по смыслу sequence диаграмма выглядит как помесь ежа с ужом(длинная и со стрелками во все стороны). Рисуется все это великолепие за пол часа в draw.io
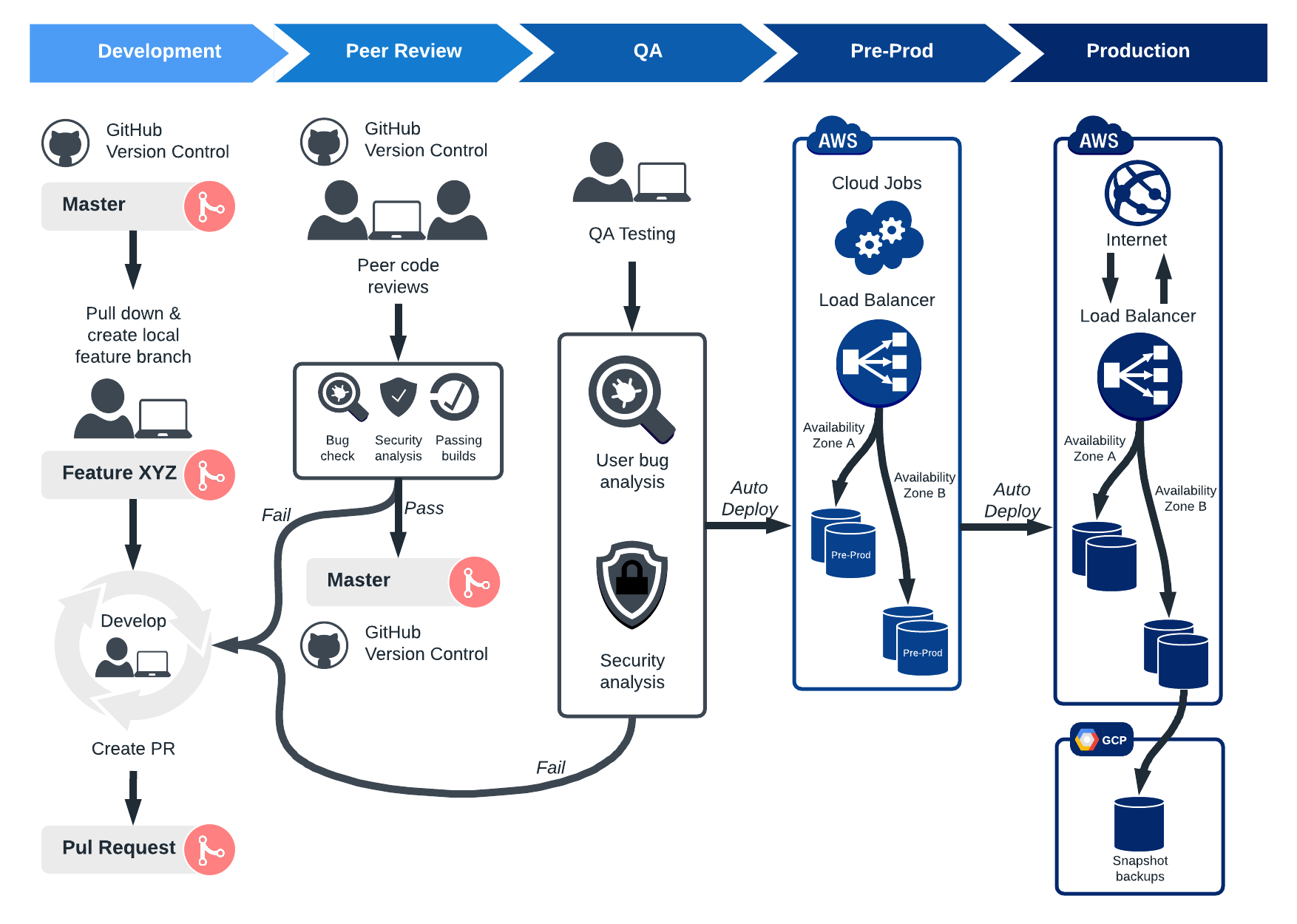{kind=link}
#api
Тут пришлось посмотреть несколько открытых API стандартов(Cisco, Microsoft, Atlassian, Heroku, Google и др). У всех у них много общего, но есть и интересные особенности. Дальше озвучу несколько инсайтов:
1. Все, за редким исключением юзают ETag'и для кеширования. ETag — отличный инструмент, который, впрочем, всегда казался мне немного маргинальным. Однако же, оказывается, это не так и все его активно используют
2. У Adidas отличное API. Не, серьезно, почитайте! Тут вам и HATEOAS и HAL и еще куча всего полезного
3. Почти у всех есть поддержка long-running operations, а вот batching многие обходят стороной. Мне это кажется странным, т.к. поддержка батчевых операций всегда казалась мне признаком зрелого API
4. У всех, конечно же, присутствует базовая гигиена а-ля стандартные форматы ошибок, пейджинг, фильтрация и т.д. Кто-то придумывает свои велосипеды типа Facebook projections, кто-то даже пытается это стандартизировать(привет OData). А что если я скажу, что есть RFC на API-ошибки и на кросс-ресурсные ссылки? Лично для меня это стало большим открытием
5. Мне очень понравилась идея использования content negotiation для версионирования API. Идея простая: клиент передает версию апи в заголовке Content-Type (например
6. Если для Вас отключение устаревшего API является большой проблемой, то замечательный Sunset Header может немного подсластить пилюлю
7. Если у вас часто тянут толстые ресурсы, то советую подсмотреть концепцию Delta queries. Это позволит ценой небольшого оверхеда отдавать только ту часть информации, которая изменилась с последнего запроса
8. Ну и закончу, пожалуй, мегахоливарным твитом Филдинга про версионирование. Похоже батя REST'а категорически против версий в url, что не мешает подавляющему большинству API версионироваться именно через url
Если Вы знаете\хотите поделиться своим крутым стандартом API(не важно REST\SOAP\(g)RPC\else) кидайте в комменты, Родина вас не забудет)
Тут пришлось посмотреть несколько открытых API стандартов(Cisco, Microsoft, Atlassian, Heroku, Google и др). У всех у них много общего, но есть и интересные особенности. Дальше озвучу несколько инсайтов:
1. Все, за редким исключением юзают ETag'и для кеширования. ETag — отличный инструмент, который, впрочем, всегда казался мне немного маргинальным. Однако же, оказывается, это не так и все его активно используют
2. У Adidas отличное API. Не, серьезно, почитайте! Тут вам и HATEOAS и HAL и еще куча всего полезного
3. Почти у всех есть поддержка long-running operations, а вот batching многие обходят стороной. Мне это кажется странным, т.к. поддержка батчевых операций всегда казалась мне признаком зрелого API
4. У всех, конечно же, присутствует базовая гигиена а-ля стандартные форматы ошибок, пейджинг, фильтрация и т.д. Кто-то придумывает свои велосипеды типа Facebook projections, кто-то даже пытается это стандартизировать(привет OData). А что если я скажу, что есть RFC на API-ошибки и на кросс-ресурсные ссылки? Лично для меня это стало большим открытием
5. Мне очень понравилась идея использования content negotiation для версионирования API. Идея простая: клиент передает версию апи в заголовке Content-Type (например
Content-Type: application/vnd.example.resource+json; version=2.1.3) и API обязано отдать ответ версии не ниже указанной или 4066. Если для Вас отключение устаревшего API является большой проблемой, то замечательный Sunset Header может немного подсластить пилюлю
7. Если у вас часто тянут толстые ресурсы, то советую подсмотреть концепцию Delta queries. Это позволит ценой небольшого оверхеда отдавать только ту часть информации, которая изменилась с последнего запроса
8. Ну и закончу, пожалуй, мегахоливарным твитом Филдинга про версионирование. Похоже батя REST'а категорически против версий в url, что не мешает подавляющему большинству API версионироваться именно через url
Если Вы знаете\хотите поделиться своим крутым стандартом API(не важно REST\SOAP\(g)RPC\else) кидайте в комменты, Родина вас не забудет)
GitHub
GitHub - CiscoDevNet/api-design-guide: Guidelines for designing REST APIs at Cisco
Guidelines for designing REST APIs at Cisco. Contribute to CiscoDevNet/api-design-guide development by creating an account on GitHub.
#arch #scheduling
Что-то за последнее время вышло достаточно много статей про task scheduler'ы. Решил подсобрать такое в одном посте потому что во-первых такие решения, это просто красиво, а во-вторых может поможет кому-то выбрать подходящее себе.
Сразу скажу, что это парад велосипедов от различных именитых(и не очень) компаний. Mesos и аналогов тут не будет, т.к. они достойны отдельных постов, а многие из них имеют даже свои пейперы. Ну погнали:
1. Открывает наш парад Яндекс со своим YT. На самом деле это целая экосистема очень похожая на экосистему Hadoop. Лично мне смысл ее создания не очень понятен(т.к., собственно, хадуп уже изобретен), да и MapReduce парадигма уже давно морально устарела, но выглядит все равно достаточно интересно. Буду благодарен, если Яндексоиды в коментах расскажут в чем был цимес ее создания
UPD. @sharpler в комментах классно рассказал про YT, за что большое спасибо!
2. Продолжим интересным решением от Drobox под названием ATF. Проект интересен тем, что он очень близок к serverless теме
3. Дальше у нас Facebook и Twine. На самом деле Twine это не просто шедулер, а настоящий оркестратор а-ля k8s. К сожалению, коллеги его незаопенсорсили, так что инфы про него не очень много. А жаль
4. Дальше у нас Netflix аж с 2мя поделками. Во-первых, это Fenzo, который дружит mesos с aws и, в частности, с автоскелером. Во-вторых, это Genie, который хоть сам ничего и не шедулит, но представляет удобную абстракцию над другими ресурсными менеджерами
Как всегда очень жду еще прикольных ссылок по теме от подписчиков в комментах!
Что-то за последнее время вышло достаточно много статей про task scheduler'ы. Решил подсобрать такое в одном посте потому что во-первых такие решения, это просто красиво, а во-вторых может поможет кому-то выбрать подходящее себе.
Сразу скажу, что это парад велосипедов от различных именитых(и не очень) компаний. Mesos и аналогов тут не будет, т.к. они достойны отдельных постов, а многие из них имеют даже свои пейперы. Ну погнали:
1. Открывает наш парад Яндекс со своим YT. На самом деле это целая экосистема очень похожая на экосистему Hadoop. Лично мне смысл ее создания не очень понятен(т.к., собственно, хадуп уже изобретен), да и MapReduce парадигма уже давно морально устарела, но выглядит все равно достаточно интересно. Буду благодарен, если Яндексоиды в коментах расскажут в чем был цимес ее создания
UPD. @sharpler в комментах классно рассказал про YT, за что большое спасибо!
2. Продолжим интересным решением от Drobox под названием ATF. Проект интересен тем, что он очень близок к serverless теме
3. Дальше у нас Facebook и Twine. На самом деле Twine это не просто шедулер, а настоящий оркестратор а-ля k8s. К сожалению, коллеги его незаопенсорсили, так что инфы про него не очень много. А жаль
4. Дальше у нас Netflix аж с 2мя поделками. Во-первых, это Fenzo, который дружит mesos с aws и, в частности, с автоскелером. Во-вторых, это Genie, который хоть сам ничего и не шедулит, но представляет удобную абстракцию над другими ресурсными менеджерами
Как всегда очень жду еще прикольных ссылок по теме от подписчиков в комментах!
Хабр
Архитектура отказоустойчивого планировщика задач. Доклад Яндекса
В Яндексе десятки тысяч машин, которые постоянно нагружены под завязку разными вычислительными задачами. Бо́льшая часть этих вычислений относится к так называемо...
#perf #scala
После нескольких лет боли и мучений с JMeter открыл для себя Gatling и огромным удовольствием нырнул в мир типобезопасных удобных DSL для нагрузочного тестирования.
Гатлинг замечателен всем, но вот с документацией есть некоторые проблемы, из-за чего кривая входа может быть достаточно крутой(особенно для не-скаланов). И вот тут я нашел совершенно замечательную статейку про циклы, control-flow statements и паузы с отличными примерами, блекджеком и герцогинями
После нескольких лет боли и мучений с JMeter открыл для себя Gatling и огромным удовольствием нырнул в мир типобезопасных удобных DSL для нагрузочного тестирования.
Гатлинг замечателен всем, но вот с документацией есть некоторые проблемы, из-за чего кривая входа может быть достаточно крутой(особенно для не-скаланов). И вот тут я нашел совершенно замечательную статейку про циклы, control-flow statements и паузы с отличными примерами, блекджеком и герцогинями
gatling.io
Gatling: Discover the most powerful load testing platform
The global standard for load testing. Uncover issues faster, integrate with your CI/CD, and scale anywhere. Trusted by 300,000+ organizations and millions of users.
#arch
Котаны, привет! Давно ничего не писал, опять затянули работа, семья и весеннее обострение отвращения к этому вашему АйТи
Благо нашел несколько заметок про системную архитектуру, которой, видимо, суждено увидеть в ближайшем будущем свет в виде серии постов. Пока планирую чиркануть про наиболее важные и (надеюсь)наименее обсуждаемые аспекты:
1. про измеримость
2. арх. надзор
3. проектирование "на берегу"
А пока я привожу это все в порядок, очень рекомендую шикарную статью и пост про нее от Юры Богомолова про личный бренд, выгорание и вот это все
Котаны, привет! Давно ничего не писал, опять затянули работа, семья и весеннее обострение отвращения к этому вашему АйТи
Благо нашел несколько заметок про системную архитектуру, которой, видимо, суждено увидеть в ближайшем будущем свет в виде серии постов. Пока планирую чиркануть про наиболее важные и (надеюсь)наименее обсуждаемые аспекты:
1. про измеримость
2. арх. надзор
3. проектирование "на берегу"
А пока я привожу это все в порядок, очень рекомендую шикарную статью и пост про нее от Юры Богомолова про личный бренд, выгорание и вот это все
I hate overtime
#arch Котаны, привет! Давно ничего не писал, опять затянули работа, семья и весеннее обострение отвращения к этому вашему АйТи Благо нашел несколько заметок про системную архитектуру, которой, видимо, суждено увидеть в ближайшем будущем свет в виде серии постов.…
Про измеримость
Вот за что не люблю современное IT, так это за то, что из инженерии оно плавно скатывается в карго-культ. Стоит только Фаулеру или компании Нетфликс опубликовать пост с обзором очередных микросервисов или дельта-лейка и каждое ООО "Рога и Копыта Inc" уже рвануло это внедрять.
В дискуссии с CV-driven карго-культистами бывает не просто: в попытках занести bleeding edge технологию или архитектурный стиль они обязательно будут аппелировать к своему личному опыту и/или публичной экспертизе IT-гигантов и рассказывать как наши корабли будут бороздить просторы бесконечной масштабируемости, отказоустойчивости и других НФТ. Проблема в том, что с одной стороны любое решение имеет свои границы применимости, которые, конечно же, почему-то опускаются, а с другой стороны размахивать руками и тратить рабочее время на митингах можно бесплатно и безнаказано. За косяк в архитектурных решениях отвечать придется еще ой как не скоро, а то и вообще не нам. Померять эту волшебную скалабилити нельзя... или можно?
Давайте представим себе, что мы написали некий простенький тест, который запускает нашу приложеньку в x и в 2х инстансов с измерением максимально-выдерживаемого количества транзакций на обоих инсталяциях. Кажется сложновато, но в наш век IaC и контейнеризации более чем реально и вот уже наша скалабилити стала вполне себе измеримой. Цимес тут в том, что даже самый простенький тест подсвечивает кучу проблем. Например, что масштабируемость далеко не всегда линейная, под приложеньками есть базы, о чем почему-то часто забывают. Кстати, поздравляю, мы только что вместе с вами изобрели простенькую fitness-функцию! Этот термин в свое время придумал Нил Форд и описал в своей замечательной книжке, где он демонстрирует всю мощь этого инструмента.
Фитнес-функции не обязательно должны быть настолько высокоуровневыми, на самом деле, они даже не обязательно должны быть автоматизированны. Главное тут то, что теперь вы можете измерять любые аспекты вашей системы, что отлично демонстрируется ката.
Основная идея очень проста: нужно определить какие-то минимальные пороговые значения характеристик системы, при которых она является "приемлемой" после чего придумать пачку таких фитнес-функций, успешное прохождение которых и будет являться гарантией того, что ваша система готова выйти в свет
Напоследок скажу, что после появления в вашей жизни этого замечательного инструмента, по-другому работать будет сложно. Без фитнесс-функций любое решение будет казаться неполным и создавать впечатление хождения в потемках. Наверняка для стартапа-однодневки или интернет-магазина на заказ тащить фитнес-функции не стоит, но для систем, действительно сложных и важных для бизнеса, они незаменимы. Кстати, фитнес-функции вошли в инструментарий Agile Architecture Framework от Open Group, т.е. скоро (надеюсь) станут стандартом и их перестанут незаслуженно обходить стороной
Вот за что не люблю современное IT, так это за то, что из инженерии оно плавно скатывается в карго-культ. Стоит только Фаулеру или компании Нетфликс опубликовать пост с обзором очередных микросервисов или дельта-лейка и каждое ООО "Рога и Копыта Inc" уже рвануло это внедрять.
В дискуссии с CV-driven карго-культистами бывает не просто: в попытках занести bleeding edge технологию или архитектурный стиль они обязательно будут аппелировать к своему личному опыту и/или публичной экспертизе IT-гигантов и рассказывать как наши корабли будут бороздить просторы бесконечной масштабируемости, отказоустойчивости и других НФТ. Проблема в том, что с одной стороны любое решение имеет свои границы применимости, которые, конечно же, почему-то опускаются, а с другой стороны размахивать руками и тратить рабочее время на митингах можно бесплатно и безнаказано. За косяк в архитектурных решениях отвечать придется еще ой как не скоро, а то и вообще не нам. Померять эту волшебную скалабилити нельзя... или можно?
Давайте представим себе, что мы написали некий простенький тест, который запускает нашу приложеньку в x и в 2х инстансов с измерением максимально-выдерживаемого количества транзакций на обоих инсталяциях. Кажется сложновато, но в наш век IaC и контейнеризации более чем реально и вот уже наша скалабилити стала вполне себе измеримой. Цимес тут в том, что даже самый простенький тест подсвечивает кучу проблем. Например, что масштабируемость далеко не всегда линейная, под приложеньками есть базы, о чем почему-то часто забывают. Кстати, поздравляю, мы только что вместе с вами изобрели простенькую fitness-функцию! Этот термин в свое время придумал Нил Форд и описал в своей замечательной книжке, где он демонстрирует всю мощь этого инструмента.
Фитнес-функции не обязательно должны быть настолько высокоуровневыми, на самом деле, они даже не обязательно должны быть автоматизированны. Главное тут то, что теперь вы можете измерять любые аспекты вашей системы, что отлично демонстрируется ката.
Основная идея очень проста: нужно определить какие-то минимальные пороговые значения характеристик системы, при которых она является "приемлемой" после чего придумать пачку таких фитнес-функций, успешное прохождение которых и будет являться гарантией того, что ваша система готова выйти в свет
Напоследок скажу, что после появления в вашей жизни этого замечательного инструмента, по-другому работать будет сложно. Без фитнесс-функций любое решение будет казаться неполным и создавать впечатление хождения в потемках. Наверняка для стартапа-однодневки или интернет-магазина на заказ тащить фитнес-функции не стоит, но для систем, действительно сложных и важных для бизнеса, они незаменимы. Кстати, фитнес-функции вошли в инструментарий Agile Architecture Framework от Open Group, т.е. скоро (надеюсь) станут стандартом и их перестанут незаслуженно обходить стороной
Forwarded from Грефневая Кафка (pro.kafka)
🔥 Ну что, лед тронулся ™?
Вышел релиз Apache Kafka® 2.8, в котором уже можно пощупать KIP-500 в действии.
НО НЕ НАДО ПОКА ВЫПИЛИВАТЬ ЗУКИПЕР ИЗ ПРОДА! ЭТО ТОЛЬКО НА ПОИГРАТЬСЯ!
Но и про новые фичи посмотрите видос https://youtu.be/vp-hV_li_bk
Вышел релиз Apache Kafka® 2.8, в котором уже можно пощупать KIP-500 в действии.
НО НЕ НАДО ПОКА ВЫПИЛИВАТЬ ЗУКИПЕР ИЗ ПРОДА! ЭТО ТОЛЬКО НА ПОИГРАТЬСЯ!
Но и про новые фичи посмотрите видос https://youtu.be/vp-hV_li_bk
{kind=link}
I hate overtime
#arch Котаны, привет! Давно ничего не писал, опять затянули работа, семья и весеннее обострение отвращения к этому вашему АйТи Благо нашел несколько заметок про системную архитектуру, которой, видимо, суждено увидеть в ближайшем будущем свет в виде серии постов.…
#arch
Про арх. надзор
Одной из основных моих обязанностей в бытность сис. архом было осуществление арх. надзора. Это означает то, что помимо проработки решения и реализации PoC надо было еще и, каким-то образом, гарантировать, что реализация концептуально не отличается от задумки.
Проблема в том, что "вас много а я одна". Читать внимательно весь код времени нет, свои задачи ждать не будут, да и глаз со временем замыливается, а джуны тем временем не дремлют и в результате все эти ваши воздушные замки на бумажке начинают очень слабо походить на то, что попадает на продуктив.
Серебряной пули тут, к большому сожалению, нет. Но есть несколько способов все-таки снизить вероятность деградации наших любимых НФТ из-за шаловливых ручек.
Первый из них это уже упомянутые фитнесс функции. В результате достаточно плотного покрытия ими, можно получить достаточно неплохую "приемку". К сожалению, не все НФТ можно дешево "зафитить"(как насчет расширяемости и maintainability, например). Тут в дело врываются гексагональная(ну или чистая) архитектура и DDD. При правильной мотивации и сноровке эти 2 инструмента дадут не только достаточно аккуратный код, но и даже уменьшат time to market. Но тут на первый план выходит вопрос мотивации. DDD и clean architecture очень хрупкие и сильно подвержены закону разбитых окон, поэтому вся тима без исключения должна быть единодушна в их использовании. Ведь стоит кому-то одному по незнанию или из-за давящих сроков "наговнякать" и скоро все ваши усилия и человекочасы потраченные на ивент сторминги и проработку модели пойдут прахом. На C# и Go мне удавалось более-менее успешно бороться с этим используя линтеры и статический анализ, но, тем не менее, ревью по прежнему жрало конскую долю моего рабочего времени.
Если вам повезло и у вас есть сильная система типов и HKT(и, конечно же, команда готова к такому повороту событий), то можно попробовать еще сильнее закрутить гайки и зафорсить архитектурный стиль через интерпритаторы. Тут мне, к сожалению, ничего не понятно, но очень интересно, так что сильно рекомендую послушать замечательный выпуск scalalaz'а про TF и джун-пруф девелопмент. Там гуру классно рассказывают, что это и как с этим жить.
В заключение скажу, что как не крути, но код читать придется. Причем много. И, скорее всего, плохого. И свои тикета из-за этого закрывать по ночам тоже придется(в лес не убегут, да). Но в результате, когда общий уровень команды поднимется, процессы устаканятся, вы незаметно перестанете просыпаться от pagerDuty по ночам. А это, как не крути, приятно)))
Про арх. надзор
Одной из основных моих обязанностей в бытность сис. архом было осуществление арх. надзора. Это означает то, что помимо проработки решения и реализации PoC надо было еще и, каким-то образом, гарантировать, что реализация концептуально не отличается от задумки.
Проблема в том, что "вас много а я одна". Читать внимательно весь код времени нет, свои задачи ждать не будут, да и глаз со временем замыливается, а джуны тем временем не дремлют и в результате все эти ваши воздушные замки на бумажке начинают очень слабо походить на то, что попадает на продуктив.
Серебряной пули тут, к большому сожалению, нет. Но есть несколько способов все-таки снизить вероятность деградации наших любимых НФТ из-за шаловливых ручек.
Первый из них это уже упомянутые фитнесс функции. В результате достаточно плотного покрытия ими, можно получить достаточно неплохую "приемку". К сожалению, не все НФТ можно дешево "зафитить"(как насчет расширяемости и maintainability, например). Тут в дело врываются гексагональная(ну или чистая) архитектура и DDD. При правильной мотивации и сноровке эти 2 инструмента дадут не только достаточно аккуратный код, но и даже уменьшат time to market. Но тут на первый план выходит вопрос мотивации. DDD и clean architecture очень хрупкие и сильно подвержены закону разбитых окон, поэтому вся тима без исключения должна быть единодушна в их использовании. Ведь стоит кому-то одному по незнанию или из-за давящих сроков "наговнякать" и скоро все ваши усилия и человекочасы потраченные на ивент сторминги и проработку модели пойдут прахом. На C# и Go мне удавалось более-менее успешно бороться с этим используя линтеры и статический анализ, но, тем не менее, ревью по прежнему жрало конскую долю моего рабочего времени.
Если вам повезло и у вас есть сильная система типов и HKT(и, конечно же, команда готова к такому повороту событий), то можно попробовать еще сильнее закрутить гайки и зафорсить архитектурный стиль через интерпритаторы. Тут мне, к сожалению, ничего не понятно, но очень интересно, так что сильно рекомендую послушать замечательный выпуск scalalaz'а про TF и джун-пруф девелопмент. Там гуру классно рассказывают, что это и как с этим жить.
В заключение скажу, что как не крути, но код читать придется. Причем много. И, скорее всего, плохого. И свои тикета из-за этого закрывать по ночам тоже придется(в лес не убегут, да). Но в результате, когда общий уровень команды поднимется, процессы устаканятся, вы незаметно перестанете просыпаться от pagerDuty по ночам. А это, как не крути, приятно)))
I hate overtime
#arch Котаны, привет! Давно ничего не писал, опять затянули работа, семья и весеннее обострение отвращения к этому вашему АйТи Благо нашел несколько заметок про системную архитектуру, которой, видимо, суждено увидеть в ближайшем будущем свет в виде серии постов.…
#arch
Про проектирование "на берегу"
Как-то я уже писал пост про эмержентную архитектуру. Это такая штука, которая позволяет вашей системе легко адаптироваться к новым требованиям(привет аджайл), но при этом не скатываться в большой комок известной субстанции. Так вот, не смотря на все модные аджайлы и лин-стартапы фаза проектирования никуда не девается. Просто она становится более верхнеуровневой и концептуальной.
Расскажу байку: в бытность моей гребли на галере у нас был очень крупный заказчик, которому мы делали и внедряли хранилище данных. Досталось мне это поделие уже на изрядной степени готовности и ребята там решили для витрины заиспользовать одну известную отечественную колоночную СУБД. Все бы хорошо, но вот только в документации к этой СУБД было черным по белому написано, что деньги в нее класть не стоит, т.к. при определенных положениях лун юпитера возможны частичные потери данных. Угадайте что лежало в хранилище? Проблема обострялась тем, что сайзинг уже был рассчитан и тачки закуплены, а значит признание и устранение этой ошибки нам влетало в штрафы примерно равные бюджетам проекта.
История кончилась хорошо, проблему вовремя эскалировали и все решилось без особых денежных и репутационных потерь, но с тех пор я и сам стараюсь и всех призываю первым делом понимать что является реально "архитектурными" решениями. Под архитектурными я понимаю то, что потом будет очень сложно или даже невозможно(как в истории выше) поменять. Такие вещи надо обсуждать на берегу, аккуратно принимать решение и не менее аккуратно документировать вместе с контекстом, альтернативами и участвовашими в принятии решения стейкхолдерами. Я пользуюсь замечательным шаблоном от Майка Нейгарда, но вот тут кажется уже собрали пару-тройку неплохих альтернатив.
Смысл в том, что ваши потомки, а может даже и вы сами через какое-то время точно забудете нюансы под давлением которых было принято решение, а тут получается нужно только смахнуть пыль с пары десятков(у меня пара десятков скапливается за несколько лет) вики-статей и вуаля, вы снова полностью в контексте и нет желания орать на весь опенспейс "ну и какого оно вот ТАК!"
Про проектирование "на берегу"
Как-то я уже писал пост про эмержентную архитектуру. Это такая штука, которая позволяет вашей системе легко адаптироваться к новым требованиям(привет аджайл), но при этом не скатываться в большой комок известной субстанции. Так вот, не смотря на все модные аджайлы и лин-стартапы фаза проектирования никуда не девается. Просто она становится более верхнеуровневой и концептуальной.
Расскажу байку: в бытность моей гребли на галере у нас был очень крупный заказчик, которому мы делали и внедряли хранилище данных. Досталось мне это поделие уже на изрядной степени готовности и ребята там решили для витрины заиспользовать одну известную отечественную колоночную СУБД. Все бы хорошо, но вот только в документации к этой СУБД было черным по белому написано, что деньги в нее класть не стоит, т.к. при определенных положениях лун юпитера возможны частичные потери данных. Угадайте что лежало в хранилище? Проблема обострялась тем, что сайзинг уже был рассчитан и тачки закуплены, а значит признание и устранение этой ошибки нам влетало в штрафы примерно равные бюджетам проекта.
История кончилась хорошо, проблему вовремя эскалировали и все решилось без особых денежных и репутационных потерь, но с тех пор я и сам стараюсь и всех призываю первым делом понимать что является реально "архитектурными" решениями. Под архитектурными я понимаю то, что потом будет очень сложно или даже невозможно(как в истории выше) поменять. Такие вещи надо обсуждать на берегу, аккуратно принимать решение и не менее аккуратно документировать вместе с контекстом, альтернативами и участвовашими в принятии решения стейкхолдерами. Я пользуюсь замечательным шаблоном от Майка Нейгарда, но вот тут кажется уже собрали пару-тройку неплохих альтернатив.
Смысл в том, что ваши потомки, а может даже и вы сами через какое-то время точно забудете нюансы под давлением которых было принято решение, а тут получается нужно только смахнуть пыль с пары десятков(у меня пара десятков скапливается за несколько лет) вики-статей и вуаля, вы снова полностью в контексте и нет желания орать на весь опенспейс "ну и какого оно вот ТАК!"
Cognitect.com
Documenting Architecture Decisions
Context
#concurrency
Очень хорошая статья из серии "да кто такие эти ваши фиберы/ко(го)рутины ...". В частности объясняют какую проблему они решают и почему так не получится сделать на обычных ОС тредах. Рекомендую!
З.Ы. не смотря на то, что блог java'овый про java в статье только пара упоминаний proj loom
Очень хорошая статья из серии "да кто такие эти ваши фиберы/ко(го)рутины ...". В частности объясняют какую проблему они решают и почему так не получится сделать на обычных ОС тредах. Рекомендую!
З.Ы. не смотря на то, что блог java'овый про java в статье только пара упоминаний proj loom
inside.java
On the Performance of User-Mode Threads and Coroutines
Discussions of coroutines and user-mode threads — like Project Loom's virtual threads or Go's goroutines — frequently turn to the subject of performance. The question I'll try answering here is, how do user-mode threads offer better application perf…
Forwarded from Грефневая Кафка (pro.kafka)
Кафка для детей от автора Mastering Kafka Streams and ksqlDB https://www.gentlydownthe.stream/
{kind=link}