
Forwarded from Книжный клад | IT
Иан_Милл,_Эйдан_Хобсон_Сейерс_Docker_на_практике_2020,_ДМК_Пресс.pdf
8.8 MB
Книга "Docker на практике"
Forwarded from Deleted Account
рекомендую ресурс: https://github.com/chekh/awesome-mlops
GitHub
GitHub - chekh/awesome-mlops: :sunglasses: A curated list of awesome MLOps tools
:sunglasses: A curated list of awesome MLOps tools - GitHub - chekh/awesome-mlops: :sunglasses: A curated list of awesome MLOps tools
🔥2
Forwarded from Physics.Math.Code
📕 Kubernetes в действии [2019] Лукша
💾 Скачать книгу
Kubernetes по-гречески означает “рулевой”. Это ваш проводник по неизведанным водам. Система контейнерной оркестровки Kubernetes безопасно управляет структурой распределенного приложения и последовательностью его выполнения, с максимальной эффективностью организуя контейнеры и службы. Kubernetes служит в качестве операционной системы для ваших кластеров, устраняя необходимость учитывать лежащую в основе сетевую и серверную инфраструктуру в ваших проектах.
💾 Скачать книгу
Kubernetes по-гречески означает “рулевой”. Это ваш проводник по неизведанным водам. Система контейнерной оркестровки Kubernetes безопасно управляет структурой распределенного приложения и последовательностью его выполнения, с максимальной эффективностью организуя контейнеры и службы. Kubernetes служит в качестве операционной системы для ваших кластеров, устраняя необходимость учитывать лежащую в основе сетевую и серверную инфраструктуру в ваших проектах.
Forwarded from Physics.Math.Code
Kubernetes в действии [2019] Лукша.pdf
10.8 MB
📕 Kubernetes в действии [2019] Лукша
Эта книга учит использовать Kubernetes для развертывания распределенных контейнеризированных приложений. Перед тем, как собрать свой первый кластер Kubernetes, вы начнете с обзора систем Docker и Kubernetes. Вы будете постепенно расширять свое начальное приложение, добавляя новые функциональные возможности и углубляя свои знания архитектуры и принципа работы Kubernetes. Также вы изучите такие важные темы, такие как мониторинг, настройка и масштабирование.
#linux #Docker #Kubernetes #web #программирование
Эта книга учит использовать Kubernetes для развертывания распределенных контейнеризированных приложений. Перед тем, как собрать свой первый кластер Kubernetes, вы начнете с обзора систем Docker и Kubernetes. Вы будете постепенно расширять свое начальное приложение, добавляя новые функциональные возможности и углубляя свои знания архитектуры и принципа работы Kubernetes. Также вы изучите такие важные темы, такие как мониторинг, настройка и масштабирование.
#linux #Docker #Kubernetes #web #программирование
Forwarded from hahacker_news
Bootstrapping_Microservices_with_Docker,_Kubernetes,_and_Terraform.pdf
13.7 MB
Bootstrapping Microservices with Docker, Kubernetes, and Terraform: A project-based guide (2021)
Автор: Ashley Davis
Автор: Ashley Davis
❤3
Если честно мой пост о том как прокачать свои пет проекты зашёл слишком далеко и я буквально от ML ушёл в fullstack. Я постараюсь минимизировать инфу...
И если заметить то книги по docker -> K8s -> bootstrapping microservices не просто так тут!)
Проблема в том, что инфы много, время мало, желания что то делать ещё меньше, но я надеюсь получиться более менее структурировать инфу, по крайней мере я помогу сделать roadmap и оценить сложность от времени, которое вы готовы на это потратить. Как дай человеку рыбу и он будет сыт один день, а дай ему удочку и он будет сыт всегда. Вот и я вам дам roadmap, а вы от него сможете как то отталкиваться и основные понятия что зачем нужно делать и какие инструменты вам нужны. (но чем глубжн это качается backend/devops, тем хуже могут быть мои советы 🙈, так что доверяйте, но проверяйте)
Upd постараюсь к концу следующей недели сделать, но не обещаю
И если заметить то книги по docker -> K8s -> bootstrapping microservices не просто так тут!)
Проблема в том, что инфы много, время мало, желания что то делать ещё меньше, но я надеюсь получиться более менее структурировать инфу, по крайней мере я помогу сделать roadmap и оценить сложность от времени, которое вы готовы на это потратить. Как дай человеку рыбу и он будет сыт один день, а дай ему удочку и он будет сыт всегда. Вот и я вам дам roadmap, а вы от него сможете как то отталкиваться и основные понятия что зачем нужно делать и какие инструменты вам нужны. (но чем глубжн это качается backend/devops, тем хуже могут быть мои советы 🙈, так что доверяйте, но проверяйте)
Upd постараюсь к концу следующей недели сделать, но не обещаю
❤14
Первая пошла
У нас тут кластерный анализ на кегле подъехал. Ухххх, держите меня, щас я эти кернели штопать буду...
Но пока сыровато, что за ночь успел. Сегодня сяду отредачу ещё кернел по млопс, надо его допилить.
Сделать про прокачку пет-проектов постик, это верно.
В планах ещё кернел
* про временные ряды
* хочу минигайд про RF сделать если получиться, не обещаю.
* хочу много маленьких гайдов про млопс инструменты типо wb и тд
* хочу про модели ещё сделать много маленьких кернелов. (в основном нелинейные)
* начать про сеточки что то делать? 🤔
Че думаете такой объем реально вообще сделать?) я, конечно, не Википедия, но очень круто если вы допустим идёте на собес, взяли мои кернелы посмотрели и вспомнили че там к чему)
https://www.kaggle.com/code/kartushovdanil/tps-jul-22-transformations
У нас тут кластерный анализ на кегле подъехал. Ухххх, держите меня, щас я эти кернели штопать буду...
Но пока сыровато, что за ночь успел. Сегодня сяду отредачу ещё кернел по млопс, надо его допилить.
Сделать про прокачку пет-проектов постик, это верно.
В планах ещё кернел
* про временные ряды
* хочу минигайд про RF сделать если получиться, не обещаю.
* хочу много маленьких гайдов про млопс инструменты типо wb и тд
* хочу про модели ещё сделать много маленьких кернелов. (в основном нелинейные)
* начать про сеточки что то делать? 🤔
Че думаете такой объем реально вообще сделать?) я, конечно, не Википедия, но очень круто если вы допустим идёте на собес, взяли мои кернелы посмотрели и вспомнили че там к чему)
https://www.kaggle.com/code/kartushovdanil/tps-jul-22-transformations
Kaggle
🔥TPS Jul 22 🔥 ADVANCED + 2% SOL
Explore and run machine learning code with Kaggle Notebooks | Using data from Tabular Playground Series - Jul 2022
❤6🔥3
image_2022-07-05_23-31-18.png
9.1 KB
То самое чувство, когда ты смотришь смотришь код грандамстеров, а там твой линк...
❤8🔥6
Привет мои дорогие, многие ждали, да я и сам ждал и вот он долгожданный пост о том как прокачать свои пет-проекты.
Сегодня мы немного отойдем от идеи машинного обучения и посмотрим на все это дело с точки зрения рекрутмента или ревьюера.
Я предлагаю вам представить себя в роли тим-лида, который нанимает в свою команду интерна, джуна, мидла. И про это можно почитать вот в этом канале https://t.iss.one/start_ds, автором которого является @RAVasiliev
Конечно, мы не можем сделать идеальные пет проекты для каждого тех-лида, но можем набрать условный минимум, которым сможем как то апеллировать в будущем. Если интересно, можем пообщаться на эту тему в комментариях, я могу скинуть пару подкастов, которые помогут повысить ваши шансы уже на самом собесе (На мой взгляд).
И так, мы тех-лид IT или МЛ отдела, нам нужны джун/мидл разработчики. Представим что в нашем выдуманном мире остались 3 вакансии, которые мы готовы рассмотреть Вася, Петя и Федя.
У каждого из кандидата одинаковый опыт, хорошо составленные резюме. То-есть мы изолируем все факторы кроме пет-проектов, ведь речь идет о них. Тим лид заходит на гит каждого и смотрит.
Допустим наша компания - Яндекс Лавка/Еда. Следовательно нас будут интересовать рекомендательные системы, матчинг, отток клиентов и анализ данных и тп.
И так первый гит первого кандидата - три репозитория, без описания и лишь файлики Jupyter Notebook. Ну нам не сложно, откроем их в google colab. Смотрим, и понимаем, что Вася что-то делал, но проверить мы это не можем, потому что библиотеки устарели, а код его не работает на новых версиях и вообще работает он долго.
Да, такой кандидат совсем ничего не сказал о себе, мы его даже оценить никак не можем.
Ну тогда давайте посмотрим Петю, может у него что-то получше. Открываем гит, а там и описание уже есть, и активность коммитов есть. Есть какие то результаты репозиториев и даже ноутбук в гите отрендерили. Да, тут уже получше. Открываем первый проект, допустим Титаник и там даже прописаны версии и скачиваение зависимости. Вот это уже что-то. Такого кандидата можно и взять, но давайте посмотрим другие репозитории. Смотрим второй, третий репозиторий, а там вообще ничего про ритейл и то что хоть как то может быть для нас полезно.
Эх хороший кандидат был, а проекты совсем не релевантные, но на джуна можно взять, может переучиться. Но сначала следующий кондидат.
И так открываем мы репозиторий Феди и видим красивую картину. И описание в гите есть и резюме приложил, а активность ну каждый день что-то делает.
Смотрим на репозитории, а там так вообще сказка, там не только jupyternotebook, а целые проекты с бекендом в скриптах. И указано как все скачать и запустить, и результаты указаны.
А проекты то какие, релевантные, а самое главное бизнес ценность в описание написана.
Сегодня мы немного отойдем от идеи машинного обучения и посмотрим на все это дело с точки зрения рекрутмента или ревьюера.
Я предлагаю вам представить себя в роли тим-лида, который нанимает в свою команду интерна, джуна, мидла. И про это можно почитать вот в этом канале https://t.iss.one/start_ds, автором которого является @RAVasiliev
Конечно, мы не можем сделать идеальные пет проекты для каждого тех-лида, но можем набрать условный минимум, которым сможем как то апеллировать в будущем. Если интересно, можем пообщаться на эту тему в комментариях, я могу скинуть пару подкастов, которые помогут повысить ваши шансы уже на самом собесе (На мой взгляд).
И так, мы тех-лид IT или МЛ отдела, нам нужны джун/мидл разработчики. Представим что в нашем выдуманном мире остались 3 вакансии, которые мы готовы рассмотреть Вася, Петя и Федя.
У каждого из кандидата одинаковый опыт, хорошо составленные резюме. То-есть мы изолируем все факторы кроме пет-проектов, ведь речь идет о них. Тим лид заходит на гит каждого и смотрит.
Допустим наша компания - Яндекс Лавка/Еда. Следовательно нас будут интересовать рекомендательные системы, матчинг, отток клиентов и анализ данных и тп.
И так первый гит первого кандидата - три репозитория, без описания и лишь файлики Jupyter Notebook. Ну нам не сложно, откроем их в google colab. Смотрим, и понимаем, что Вася что-то делал, но проверить мы это не можем, потому что библиотеки устарели, а код его не работает на новых версиях и вообще работает он долго.
Да, такой кандидат совсем ничего не сказал о себе, мы его даже оценить никак не можем.
Ну тогда давайте посмотрим Петю, может у него что-то получше. Открываем гит, а там и описание уже есть, и активность коммитов есть. Есть какие то результаты репозиториев и даже ноутбук в гите отрендерили. Да, тут уже получше. Открываем первый проект, допустим Титаник и там даже прописаны версии и скачиваение зависимости. Вот это уже что-то. Такого кандидата можно и взять, но давайте посмотрим другие репозитории. Смотрим второй, третий репозиторий, а там вообще ничего про ритейл и то что хоть как то может быть для нас полезно.
Эх хороший кандидат был, а проекты совсем не релевантные, но на джуна можно взять, может переучиться. Но сначала следующий кондидат.
И так открываем мы репозиторий Феди и видим красивую картину. И описание в гите есть и резюме приложил, а активность ну каждый день что-то делает.
Смотрим на репозитории, а там так вообще сказка, там не только jupyternotebook, а целые проекты с бекендом в скриптах. И указано как все скачать и запустить, и результаты указаны.
А проекты то какие, релевантные, а самое главное бизнес ценность в описание написана.
🔥12
Вот и небольшая притча о том как делать пет проекты. А сейчас я бы хотел рассказать, что вообще стоит исследовать и с чего начинать.
Безусловно первое что мы делаем - ищем проблему которую нужно решить, почему проблему? Потому что спрос рождает предложение, а предложение не рождает спрос. Если вы сделаете что-то полезное, то можно будет даже продать это или сделать свой маленький стартап и вообще последующее развитие всегда лучше прокрастинации.
Допустим проблему мы определили - нам нужно собрать или взять данные, я вам рекомендую делать непрерывные парсинг данный, это будет несколько сложнее, придется заморочиться с системой мониторинга, но это круче чем ничего не делать и CI/CD опять же подключить можно. Второй вариант это просто скачать откуда то, тоже можно, почему нет, а можно скачать откуда то, а еще и парсить.
Наш следующий шаг правильно создать окружение тут нужны следующие инструменты на мой взгял: docker, git, github/gitlab, poetry + pyenv. И прописать установку окружения и в нем уже создавать свои контейнеры, которые можно запускать. Тот же парсер.
Теперь - рисерч. Допустим мы быстренько написали парсер уже у нас достаточные данные. Нам нужно почистить данные, проверсти тесты и убедиться что мы можем что-то прогназироватью. Сделайте презентацию какую то или дашборд по данным, что бы потом внедрить в мониторинг систему, я думаю это круто и в дальнейшем вам будет что показать.
И так после ричерча мы поняли, что данные очень волатильны и вообще непонятно что происходит с дисперсией, мы хотим использовать деревья для этого они нам дают прекрасный результат, они непараметрические и шумов у нас не так много в данных. Теперь мы будем строить пайплайн.
Что для этого нужно, помимо либ, которые вы используете в обучение: Соотвественно все перевести в скрипты, где каждый файл отдельный миниалгоритм pytest, pydantic для верификации данных и скриптов. Хотим мониторить обучение моделей и данных - WandB. Хотим что бы после изменения данных, пайплайн сам запускался - DVC.
Отлично, давайте посмотрим, что у нас есть:
docker и gitlab проект, так же у нас парсер, который сейчас все сохраняет в csv, какой то скрипт, который создает датасет. У нас есть скрипт по созданию дополнительных данных и чистке. У нас есть скрипт по обучению модели. Получение различных метрик и репортов. И какой то аля сохранение дашбордов в png.
Это, конечно, замечательно. Но как то хочется что бы оно само работало, да и вообще мы устали все вручную запускать через main.py так еще и забываем иногда парсер запускать.
Для этого нам нужно изучить CI/CD, GitLab CI, CLI и разобраться как пользоваться серверами. Допустим на Yandex Cloud.
Тут уже многое зависит от вас, как вы хотите все это сделать. Но что я могу посоветовать: MLOps у ODS и курс Yandex Practicum по Облокам
И так у в итоге кое как получилось создать сервер, теперь у нас парсинг запускается каждые 2 часа, после этого обучаются модели и мы получаем какие то output по метрикам и какие то png дашборды. Как то неправильно, мы хотим что бы вообще все работало автономно.
Теперь начинается наверное самое сложное - backend/ frontend.
И так во первых - нужно создать отдельно папку frontend/backend/database все они будут запускать 3 различных контейнера (в идеале):
Нам нужно знать REST API, gunicorn - что бы связать фронт и бек. А еще как то обращаться к БД. Я бы использовал FastApi для backend и react для фронта.
Теперь у нас есть фронтенд, который должен отсылать запрос к бекенду, бекенд отсылал бы ответ и реакт бы рендерил то что хочет пользователь, например наши дашборды. Они уже не PNG, а какая то динамично изменяющаяся картиночка.
А самое главное, даже если у нас ляжет сервер, так как мы использовали gitlab ci и gitops, мы сможем развернуть наш сервер без проблем на другом.
Возможно я упустил какие то точности и не претендую на лучшего эксперта фронтенда и бекенда, devops, но это то, что я изучал последние несколько недель, пришлось посмотреть достаточно много видос, особенно про gitops. Это не панацея, но на мой взгляд, так и нужно реализовывать проекты.
Еще советую linear.app!
Безусловно первое что мы делаем - ищем проблему которую нужно решить, почему проблему? Потому что спрос рождает предложение, а предложение не рождает спрос. Если вы сделаете что-то полезное, то можно будет даже продать это или сделать свой маленький стартап и вообще последующее развитие всегда лучше прокрастинации.
Допустим проблему мы определили - нам нужно собрать или взять данные, я вам рекомендую делать непрерывные парсинг данный, это будет несколько сложнее, придется заморочиться с системой мониторинга, но это круче чем ничего не делать и CI/CD опять же подключить можно. Второй вариант это просто скачать откуда то, тоже можно, почему нет, а можно скачать откуда то, а еще и парсить.
Наш следующий шаг правильно создать окружение тут нужны следующие инструменты на мой взгял: docker, git, github/gitlab, poetry + pyenv. И прописать установку окружения и в нем уже создавать свои контейнеры, которые можно запускать. Тот же парсер.
Теперь - рисерч. Допустим мы быстренько написали парсер уже у нас достаточные данные. Нам нужно почистить данные, проверсти тесты и убедиться что мы можем что-то прогназироватью. Сделайте презентацию какую то или дашборд по данным, что бы потом внедрить в мониторинг систему, я думаю это круто и в дальнейшем вам будет что показать.
И так после ричерча мы поняли, что данные очень волатильны и вообще непонятно что происходит с дисперсией, мы хотим использовать деревья для этого они нам дают прекрасный результат, они непараметрические и шумов у нас не так много в данных. Теперь мы будем строить пайплайн.
Что для этого нужно, помимо либ, которые вы используете в обучение: Соотвественно все перевести в скрипты, где каждый файл отдельный миниалгоритм pytest, pydantic для верификации данных и скриптов. Хотим мониторить обучение моделей и данных - WandB. Хотим что бы после изменения данных, пайплайн сам запускался - DVC.
Отлично, давайте посмотрим, что у нас есть:
docker и gitlab проект, так же у нас парсер, который сейчас все сохраняет в csv, какой то скрипт, который создает датасет. У нас есть скрипт по созданию дополнительных данных и чистке. У нас есть скрипт по обучению модели. Получение различных метрик и репортов. И какой то аля сохранение дашбордов в png.
Это, конечно, замечательно. Но как то хочется что бы оно само работало, да и вообще мы устали все вручную запускать через main.py так еще и забываем иногда парсер запускать.
Для этого нам нужно изучить CI/CD, GitLab CI, CLI и разобраться как пользоваться серверами. Допустим на Yandex Cloud.
Тут уже многое зависит от вас, как вы хотите все это сделать. Но что я могу посоветовать: MLOps у ODS и курс Yandex Practicum по Облокам
И так у в итоге кое как получилось создать сервер, теперь у нас парсинг запускается каждые 2 часа, после этого обучаются модели и мы получаем какие то output по метрикам и какие то png дашборды. Как то неправильно, мы хотим что бы вообще все работало автономно.
Теперь начинается наверное самое сложное - backend/ frontend.
И так во первых - нужно создать отдельно папку frontend/backend/database все они будут запускать 3 различных контейнера (в идеале):
Нам нужно знать REST API, gunicorn - что бы связать фронт и бек. А еще как то обращаться к БД. Я бы использовал FastApi для backend и react для фронта.
Теперь у нас есть фронтенд, который должен отсылать запрос к бекенду, бекенд отсылал бы ответ и реакт бы рендерил то что хочет пользователь, например наши дашборды. Они уже не PNG, а какая то динамично изменяющаяся картиночка.
А самое главное, даже если у нас ляжет сервер, так как мы использовали gitlab ci и gitops, мы сможем развернуть наш сервер без проблем на другом.
Возможно я упустил какие то точности и не претендую на лучшего эксперта фронтенда и бекенда, devops, но это то, что я изучал последние несколько недель, пришлось посмотреть достаточно много видос, особенно про gitops. Это не панацея, но на мой взгляд, так и нужно реализовывать проекты.
Еще советую linear.app!
🔥12
Пост настолько большой получился, что телега разделила на два сообщения D:
Надеюсь после моего поста you lead the way to your best pet projects
Надеюсь после моего поста you lead the way to your best pet projects
❤12
Forwarded from Машинное обучение RU
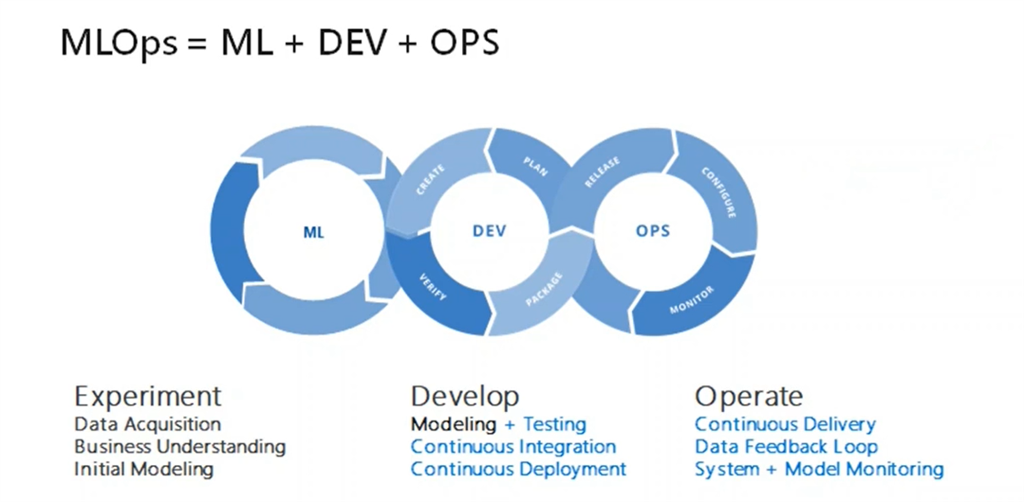
MLOps: как внедрить систему рекомендаций товаров
Одна из самых распространенных задач электронной коммерции — создание хорошо работающей модели рекомендаций и категоризации товаров. Рекомендательная система товаров используется для предоставления пользователям аналогичных предложений. Она позволяет увеличить общее время пребывания на платформе и сумму, потраченную в расчете на одного пользователя.
Кроме того, на платформах электронной коммерции, особенно тех, где большая часть контента создается пользователями (например, на сайтах объявлений), необходима модель категоризации продуктов. Она используется для “отлова” неправильно категорированных продуктов и размещения их по соответствующим категориям. Это способствует улучшению общего пользовательского опыта на платформе.
Данная статья состоит из двух основных частей. В первой поговорим о том, как построить систему рекомендаций товаров для электронной коммерции и провести категоризацию товаров (примеры кода помогут продемонстрировать эти процессы). Во второй обсудим, как реализовать этот проект в несколько шагов с помощью MLOps-платформы под названием Layer.
Читать дальше
@machinelearning_ru
Одна из самых распространенных задач электронной коммерции — создание хорошо работающей модели рекомендаций и категоризации товаров. Рекомендательная система товаров используется для предоставления пользователям аналогичных предложений. Она позволяет увеличить общее время пребывания на платформе и сумму, потраченную в расчете на одного пользователя.
Кроме того, на платформах электронной коммерции, особенно тех, где большая часть контента создается пользователями (например, на сайтах объявлений), необходима модель категоризации продуктов. Она используется для “отлова” неправильно категорированных продуктов и размещения их по соответствующим категориям. Это способствует улучшению общего пользовательского опыта на платформе.
Данная статья состоит из двух основных частей. В первой поговорим о том, как построить систему рекомендаций товаров для электронной коммерции и провести категоризацию товаров (примеры кода помогут продемонстрировать эти процессы). Во второй обсудим, как реализовать этот проект в несколько шагов с помощью MLOps-платформы под названием Layer.
Читать дальше
@machinelearning_ru
{kind=link}
❤3
Forwarded from Start Career in DS
Подборка ресурсов по математике для Data Science:
Уровни:
⭐️ - закончил универ сто лет назад, ничего не помню
⭐️⭐️ - знаю и помню базу (матан, линал, тервер, матстат)
⭐️⭐️⭐️ - хорошо разбираюсь в высшей математике, хочу поднатаскать специфические для DS темы
⭐️Наглядный разбор теории в серии «X для чайников»: что такое вектор, как считать производную, матричные уравнения и т.д.
⭐️Материалы с лекций и семинаров ВМК МГУ от «Ёжика в матане»: VK, YouTube. Тут можете спокойно начинать с лекций и семинаров Никитина по математическому анализу, их читают в самом начале
⭐️⭐️ Хорошие задачки с подробным разбором решений на Матбюро: линейная алгебра, теория вероятностей, математическая статистика.
⭐️⭐️Курс Райгородского «Основы теории вероятностей». Тут наглядно и на пальцах объясняются базовые аспекты
⭐️⭐️ [Eng] Курс «Matrix Methods in Data Analysis, Signal Processing, and Machine Learning», в нём есть вся ключевая математика для DS
⭐️⭐️⭐️[Eng] Сборник задач и теории по базовой математике (линейная алгебра, оптимизация, графы) и машинному обучению:
Pen and Paper Exercises in Machine Learning
⭐️⭐️⭐️[Eng] Книга «Математика для Data Science»: https://mml-book.github.io/
Уровни:
⭐️ - закончил универ сто лет назад, ничего не помню
⭐️⭐️ - знаю и помню базу (матан, линал, тервер, матстат)
⭐️⭐️⭐️ - хорошо разбираюсь в высшей математике, хочу поднатаскать специфические для DS темы
⭐️Наглядный разбор теории в серии «X для чайников»: что такое вектор, как считать производную, матричные уравнения и т.д.
⭐️Материалы с лекций и семинаров ВМК МГУ от «Ёжика в матане»: VK, YouTube. Тут можете спокойно начинать с лекций и семинаров Никитина по математическому анализу, их читают в самом начале
⭐️⭐️ Хорошие задачки с подробным разбором решений на Матбюро: линейная алгебра, теория вероятностей, математическая статистика.
⭐️⭐️Курс Райгородского «Основы теории вероятностей». Тут наглядно и на пальцах объясняются базовые аспекты
⭐️⭐️ [Eng] Курс «Matrix Methods in Data Analysis, Signal Processing, and Machine Learning», в нём есть вся ключевая математика для DS
⭐️⭐️⭐️[Eng] Сборник задач и теории по базовой математике (линейная алгебра, оптимизация, графы) и машинному обучению:
Pen and Paper Exercises in Machine Learning
⭐️⭐️⭐️[Eng] Книга «Математика для Data Science»: https://mml-book.github.io/
{kind=link}
Хотите про временные узнать?
Линейные Нелинейные Нейросети Постараюсь сделать с кодом!)
Линейные Нелинейные Нейросети Постараюсь сделать с кодом!)
Final Results
90%
Yes 👍
10%
No 😢
А как насчет различных методов оптимизации для подбора гиперпараметров?
( я не про grid search и optuna, что-то более оригинальное)
( я не про grid search и optuna, что-то более оригинальное)
Final Results
96%
Just do it and take my money👍🏻
4%
it sucks👎🏻
Краткие план по этим двум постам
Временные ряды
1. Про временные ряды в целом и общие понятия, которые будем рассматривать.
2. Линейные модели ARIMA (autoTS)
3. Нелинейные модели CatBoost
4. PyCaret
5. Prophet
6. Трансфорсеры в TSS
Оптимизации подбора гиперпараметров
1. Свой собственный гридсерч, но умнее (based on Ambrosm)
2. Генетический алгоритм
3. Эволюционный алгоритм
4. Многорукие бандиты
5. Reinforcement learning ( если получиться )
Если есть идея, что добавить, пишите посмотрю ваши варианты
Кстати говоря все эти алгоритмы оптимизации лучше подходят для пайплайнов чем тот же гридсерч и оптуна (на мой взгляд), которые запускаются одноразово и по сути вам достаточно внести еще один параметр состояния и с его изменением будет запускать оптимизация и будет бесконечный цикл ее оптимизации)
Но они более трудоемкие
Временные ряды
1. Про временные ряды в целом и общие понятия, которые будем рассматривать.
2. Линейные модели ARIMA (autoTS)
3. Нелинейные модели CatBoost
4. PyCaret
5. Prophet
6. Трансфорсеры в TSS
Оптимизации подбора гиперпараметров
1. Свой собственный гридсерч, но умнее (based on Ambrosm)
2. Генетический алгоритм
3. Эволюционный алгоритм
4. Многорукие бандиты
5. Reinforcement learning ( если получиться )
Если есть идея, что добавить, пишите посмотрю ваши варианты
Кстати говоря все эти алгоритмы оптимизации лучше подходят для пайплайнов чем тот же гридсерч и оптуна (на мой взгляд), которые запускаются одноразово и по сути вам достаточно внести еще один параметр состояния и с его изменением будет запускать оптимизация и будет бесконечный цикл ее оптимизации)
Но они более трудоемкие
🔥10