
29 августа Gartner выпустил новый квадрант по ITSM системам. В лидерах BMC и ServiceNow. Читайте свежий отчёт, а ещё вы можете сравнить с таким же за 2017 год и попробовать найти 10 отличий.
{kind=link}
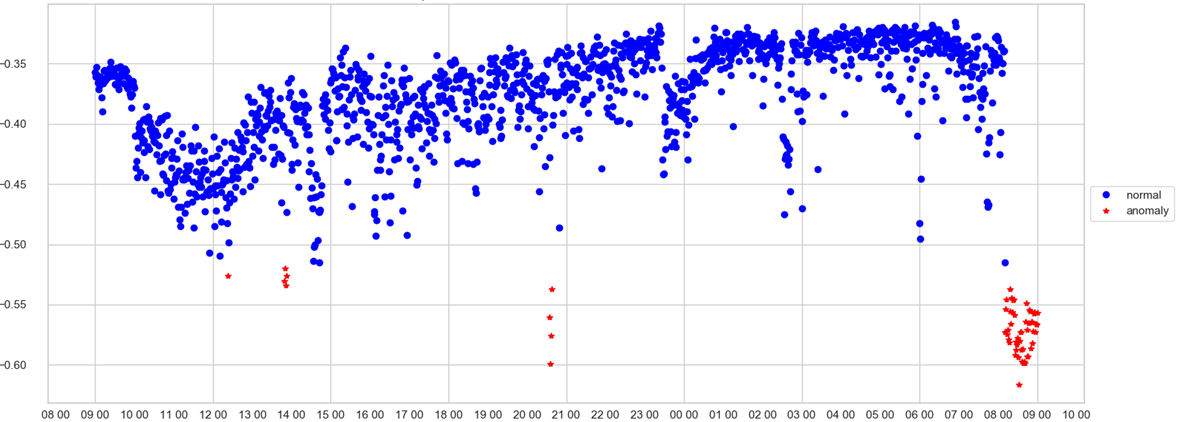
Кстати, с версии 4.2 Zabbix из коробки начал поддерживать TimescaleDB — расширение PostgreSQL. Почитайте описание работы на Хабре, но перед миграцией учитывайте грабли, на которые наступили коллеги. На картинке показана разница производительности TSDB и PG. Обратите внимание, что когда таблица истории незаполнена, скорость записи в TSDB сравнима со скоростью записи в PG, но, когда количество записей увеличивается, TSDB начинает вырываться в лидеры.
Используете TSDB в своём Zabbix? 👍 — да, 👎— нет, 👀 — не пользуюсь Zabbix.
Используете TSDB в своём Zabbix? 👍 — да, 👎— нет, 👀 — не пользуюсь Zabbix.
{kind=link}
В продолжение прошлой темы с TimescaleDB в Zabbix. Выступление инженера Zabbix SIA Андрея Гущина на Highload Conf. На Хабре вышла статья с текстовым описанием выступления.
👍 — обязательно посмотрю, 👎 — мне неинтересно, 👀 — уже видел.
👍 — обязательно посмотрю, 👎 — мне неинтересно, 👀 — уже видел.
YouTube
Высокая производительность и нативное партиционирование / Андрей Гущин (Zabbix)
Приглашаем на конференцию Saint HighLoad++ 2024, которая пройдет 24 и 25 июня в Санкт-Петербурге!
Программа, подробности и билеты по ссылке: https://vk.cc/cuyIqx
--------
--------
HighLoad++ Siberia 2019
Тезисы и презентация:
https://www.highload.ru/…
Программа, подробности и билеты по ссылке: https://vk.cc/cuyIqx
--------
--------
HighLoad++ Siberia 2019
Тезисы и презентация:
https://www.highload.ru/…
Одна большая разница: доступность бизнес-сервиса в 99,9% в год это 525,6 минут, а в неделю — 10,08 минут. При заключении SLA, лучше учесть этот момент. Или не учесть, если в соглашении не указан период этой доступности и вам его потом же и соблюдать.
👍 — полезно
👎 — так себе совет
👀 — от меня до SLA как до Марса
👍 — полезно
👎 — так себе совет
👀 — от меня до SLA как до Марса
Только что в личку уважаемый подписчик прислал полезный ресурс на тему доступности. Вводите туда уровень доступности и он автоматически показывает это в часах, минутах и секундах в день, неделю, месяц и год.
👍 — удобно, чо
👎 — я и сам могу посчитать
👀 — где я, а где доступность?
👍 — удобно, чо
👎 — я и сам могу посчитать
👀 — где я, а где доступность?
В Grafana 6.4 добавилась новая возможность — отображение логов. Об этом сообщается в блоге Grafana.
👍 — вот теперь заживём!
👎 — логи меня не интересуют, люблю смотреть на метрики
👀 — я смотрю логи в других местах
👍 — вот теперь заживём!
👎 — логи меня не интересуют, люблю смотреть на метрики
👀 — я смотрю логи в других местах
{kind=link}
Обнаружил интересную систему мониторинга ServicePilot. Французская. Признаться, из Франции до этого момента ничего не встречалось. Пишут, что умеют в фулстэк мониторинг. Может договорюсь с ними на вебинар, потом расскажу что да как.
👍 — расскажи потом. Интересно узнать что за система такая
👎 — не интересно
👀 — от меня до мониторинга несколько миллионов световых лет
👍 — расскажи потом. Интересно узнать что за система такая
👎 — не интересно
👀 — от меня до мониторинга несколько миллионов световых лет
{kind=link}
Компания Zabbix через свой блог на Хабре намекает, что зарелизила версию 4.4.
Что нового?
⚡️ Zabbix-агент теперь переписан на Go
⚡️ Официальная поддержка TimescaleDB
⚡️ Появилаьсь база знаний по элементам данных и триггерам
⚡️ Добавились новые возможности визуализации (ещё не Grafana, но приближаются)
⚡️ и много чего ещё (это ссылка на release notes))
👍 Zabbix — это стильно, модно, молодёжно
👎 Я свою коммерческую ласточку (платную систему мониторинга) ни на какой opensource не променяю
Что нового?
⚡️ Zabbix-агент теперь переписан на Go
⚡️ Официальная поддержка TimescaleDB
⚡️ Появилаьсь база знаний по элементам данных и триггерам
⚡️ Добавились новые возможности визуализации (ещё не Grafana, но приближаются)
⚡️ и много чего ещё (это ссылка на release notes))
👍 Zabbix — это стильно, модно, молодёжно
👎 Я свою коммерческую ласточку (платную систему мониторинга) ни на какой opensource не променяю
{kind=link}
Эту ссылку мне прислал Medium среди еженедельной подборки постов, которые могли бы мне понравится. Здесь рассказывают про подход к мониторингу ключевых метрик nginx при помощи Nginx_vts_exporter, Prometheus и Grafana. Энджой.
👍 — Полезно
👎 — Так себе
👀 — Не нужно мне nginx мониторить
👍 — Полезно
👎 — Так себе
👀 — Не нужно мне nginx мониторить
{kind=link}
В ноябре Gartner выпустил новый отчёт AIOps-решений на 2019-2020 годы. Там появились новые вендоры, остались некоторые старые и написано про общие тренды. Я прочитал отчёт и выделил основные моменты. По ссылке статья на Медиуме. Вэлкам.
AIOps — это подход к мониторингу с использованием алгоритмов искусственного интеллекта.
👍 — AIOps — это стильно, модно, молодёжно. Когда-нибудь он у меня тоже будет.
👎 — мне бы пинговалки нормально настроить, какой там AIOps?
👀 — машин лёрнинг и артифишиал интеллидженс для меня пшик.
AIOps — это подход к мониторингу с использованием алгоритмов искусственного интеллекта.
👍 — AIOps — это стильно, модно, молодёжно. Когда-нибудь он у меня тоже будет.
👎 — мне бы пинговалки нормально настроить, какой там AIOps?
👀 — машин лёрнинг и артифишиал интеллидженс для меня пшик.
{kind=link}
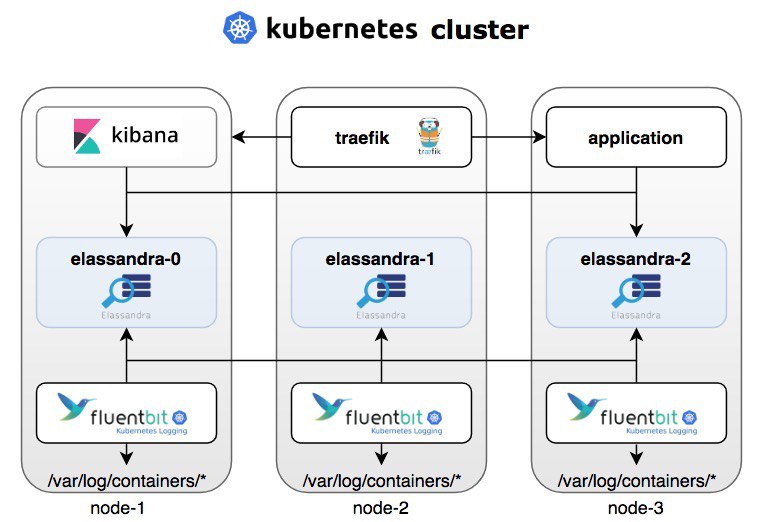
Из серии «Мичурину и не снилось». Оказывается учёным удалось скрестить Elasticsearch и Cassandra и получилось как думаете что? Elassandra.
{kind=link}
Исторически большая часть систем мониторинга вырастает вокруг какой-то информационной системы или стека систем. Это процесс, который очень сложно отследить, но который в итоге приводит к существованию нескольких (хорошо, если не нескольких десятков) систем мониторинга в одной организации.
В определённый момент времени ИТ-руководство видит, что при комплексной проблеме в приложении или инфре, трудно определить источник проблемы из-за разрозненности систем мониторинга. Нет, каждая решает конкретно поставленную задачу по мониторингу конкретной информационной системы, но в отрыве от остальных не даёт полной картины. И это серьёзная проблема.
Взять и перенести весь мониторинг в какую-то одну систему ещё одна большая проблема. Политическое решение принять можно, но заставить пользоваться новым продуктов администраторов, которые уже вложили душу во все собираемые метрики в своём микрозаббиксе задача не одного дня.
Чтобы не разрушать эффективно работающие и толково настроенные мониторинги есть выход — зонтичная система.
Но сбор событий в одном месте когда-нибудь приведёт к тому, что событий станет слишком много и дежурные на них не будут обращать должного внимания. Ручные выборки критичных и не очень событий может превратиться в непрерывный процесс. Но почему бы не поручить эту работу, которая будет сама выбирать критичные и не очень события? Да ещё и говорить, что вот это событие в будущем приведёт вот к этим двум и так далее.
Это была небольшая вводная про необходимость заиметь в хозяйстве одну из AIOps систем, которые постепенно захватывают мир. Я посмотрел вебинар и вкратце поделюсь впечатлениями. В целом, всё выглядит позитивно.
В определённый момент времени ИТ-руководство видит, что при комплексной проблеме в приложении или инфре, трудно определить источник проблемы из-за разрозненности систем мониторинга. Нет, каждая решает конкретно поставленную задачу по мониторингу конкретной информационной системы, но в отрыве от остальных не даёт полной картины. И это серьёзная проблема.
Взять и перенести весь мониторинг в какую-то одну систему ещё одна большая проблема. Политическое решение принять можно, но заставить пользоваться новым продуктов администраторов, которые уже вложили душу во все собираемые метрики в своём микрозаббиксе задача не одного дня.
Чтобы не разрушать эффективно работающие и толково настроенные мониторинги есть выход — зонтичная система.
Но сбор событий в одном месте когда-нибудь приведёт к тому, что событий станет слишком много и дежурные на них не будут обращать должного внимания. Ручные выборки критичных и не очень событий может превратиться в непрерывный процесс. Но почему бы не поручить эту работу, которая будет сама выбирать критичные и не очень события? Да ещё и говорить, что вот это событие в будущем приведёт вот к этим двум и так далее.
Это была небольшая вводная про необходимость заиметь в хозяйстве одну из AIOps систем, которые постепенно захватывают мир. Я посмотрел вебинар и вкратце поделюсь впечатлениями. В целом, всё выглядит позитивно.
{kind=link}
Посмотрите как можно контролировать инфраструктуру kubernetes с точки зрения сетевого взаимодействия при помощи анализа flow-трафика. Растислав (да, именно через «а») говорит, что дропы пакетов между подами, бутылочные горлышки, распределение трафика в кластере и подозрительную активность по-другому выявить не получится.
Flow-трафик извлекается при помощи CNI-плагина Contiv-VPP.
В качестве дополнительного инструмента диагностики — почему бы и нет?
Flow-трафик извлекается при помощи CNI-плагина Contiv-VPP.
В качестве дополнительного инструмента диагностики — почему бы и нет?
{kind=link}
Статья от начала декабря на Хабре о том, как ИТ-Град создавал объединенную систему мониторинга как услугу для облачных сервисов МТС, собственного IaaS и инфраструктуры 1cloud. Это типа всё объединилось.
Пишут:
В результате трансформации основными требованиями стали:
- система мониторинга должна работать не только на ИТ-ГРАД, но и стать внутренним сервисом для «Объединенного облачного провайдера» и услугой для заказчиков.
- требовалось решение, которое будет собирать статистику со всей IT-инфраструктуры.
- так как систем много, все события мониторинга должны сходиться в едином агрегаторе данных, где события и триггеры сверяются с единой CMDB и при необходимости происходит автоматическое оповещение пользователей.
В цитате выше смотреть нужно на 3 пункт. CMDB — полезная штука для сервисных провайдеров (и всех остальных). События/инциденты обогащаются данными оттуда и сразу видно какой заказчик, где оборудование, когда инсталлировано и т.д. Но в статье нет ничего про связи между КЕ (конфигурационными единицами). А наличие связей — очень большое преимущество. Если они есть, в инциденте можно сразу же показать соседние устройства.
Если к системе мониторинга прикрутить автоматизацию, то, до генерации события/инцидента эти соседние устройства можно пропинговать (или собрать любую другую статистику) и приложить к инциденту/событию. Получится некая первичная диагностика. Конечно, можно прикрутить и какие-то другие проверки. Вы удивитесь насколько быстрее будут решаться инциденты. Надеюсь, те ребята уже идут по этому пути.
Следующий момент. Обратите внимание на прилепленную к этому посту схему. Данные мониторинга собираются 4 различными системами — это 4 источника событий. В статье не сказано как в такой ситуации ведётся работа с шумовыми событиями. Но эту работу вести надо, иначе заказчики через некоторое время перестанут доверять такой системе мониторинга.
А теперь гипотетическая часть. Как там на самом деле я не знаю, но потеоретизирую. SCOM здесь, скорее всего, используется для серверов на Windows, а Zabbix для Unix. vCenter это, возможно, на самом деле система мониторинга vRealize. СХД может быть какими-то вендорскими схдешными решениями мониторинга. Очевидно, что часть Unix и Windows машин виртуализировано, следовательно, события по серверам приходят сразу из трёх систем мониторинга: SCOM, Zabbix, vRealize (vCenter). По СХД события приходят их двух источников: СХД и vRealize (vCenter). Вывод: шумовые события есть, их не может не быть.
Снижение количества шумовых событий отдельная и трудоёмкая задача. Здесь многое зависит от используемого стека систем мониторинга и сервис-деска. Можно почитать об этом коротку статью на Медиуме. Думаю, с этим тоже ведётся определённая работа.
Пишут:
В результате трансформации основными требованиями стали:
- система мониторинга должна работать не только на ИТ-ГРАД, но и стать внутренним сервисом для «Объединенного облачного провайдера» и услугой для заказчиков.
- требовалось решение, которое будет собирать статистику со всей IT-инфраструктуры.
- так как систем много, все события мониторинга должны сходиться в едином агрегаторе данных, где события и триггеры сверяются с единой CMDB и при необходимости происходит автоматическое оповещение пользователей.
В цитате выше смотреть нужно на 3 пункт. CMDB — полезная штука для сервисных провайдеров (и всех остальных). События/инциденты обогащаются данными оттуда и сразу видно какой заказчик, где оборудование, когда инсталлировано и т.д. Но в статье нет ничего про связи между КЕ (конфигурационными единицами). А наличие связей — очень большое преимущество. Если они есть, в инциденте можно сразу же показать соседние устройства.
Если к системе мониторинга прикрутить автоматизацию, то, до генерации события/инцидента эти соседние устройства можно пропинговать (или собрать любую другую статистику) и приложить к инциденту/событию. Получится некая первичная диагностика. Конечно, можно прикрутить и какие-то другие проверки. Вы удивитесь насколько быстрее будут решаться инциденты. Надеюсь, те ребята уже идут по этому пути.
Следующий момент. Обратите внимание на прилепленную к этому посту схему. Данные мониторинга собираются 4 различными системами — это 4 источника событий. В статье не сказано как в такой ситуации ведётся работа с шумовыми событиями. Но эту работу вести надо, иначе заказчики через некоторое время перестанут доверять такой системе мониторинга.
А теперь гипотетическая часть. Как там на самом деле я не знаю, но потеоретизирую. SCOM здесь, скорее всего, используется для серверов на Windows, а Zabbix для Unix. vCenter это, возможно, на самом деле система мониторинга vRealize. СХД может быть какими-то вендорскими схдешными решениями мониторинга. Очевидно, что часть Unix и Windows машин виртуализировано, следовательно, события по серверам приходят сразу из трёх систем мониторинга: SCOM, Zabbix, vRealize (vCenter). По СХД события приходят их двух источников: СХД и vRealize (vCenter). Вывод: шумовые события есть, их не может не быть.
Снижение количества шумовых событий отдельная и трудоёмкая задача. Здесь многое зависит от используемого стека систем мониторинга и сервис-деска. Можно почитать об этом коротку статью на Медиуме. Думаю, с этим тоже ведётся определённая работа.
{kind=link}
Дмитрий Комаров из Яндекс-денег рассказывает как они у себя делали MaaC — мониторинг как код. К приложению в виде зависимости добавляется дополнительный артефакт, который генерит новые дашборды в Grafana и порождает соответствующий сбор метрик через StatsD и Heka. Говорит, что Heka это хорошо из-за бестродействия в силу приёма метрик от приложений по протоколу UDP.
Ещё одна важная часть его выступления — это алертинг. Алертинг в Grafana оказался недостаточно гибким и они использовали Moira, которая позволила гибко создавать триггеры и использует собственное хранилище на базе Redis.
Ниже ссылки на соответствующие репозитории на Github:
→ moira-trigger-plugin
→ moira-kotlin-dsl
→ grafana-dashboard-dsl
→ moira-kotlin-client
→ grafana-dashboard-plugin
Ещё одна важная часть его выступления — это алертинг. Алертинг в Grafana оказался недостаточно гибким и они использовали Moira, которая позволила гибко создавать триггеры и использует собственное хранилище на базе Redis.
Ниже ссылки на соответствующие репозитории на Github:
→ moira-trigger-plugin
→ moira-kotlin-dsl
→ grafana-dashboard-dsl
→ moira-kotlin-client
→ grafana-dashboard-plugin
YouTube
Java Jam 2019 || Monitoring strikes back (Дмитрий Комаров)
Яндекс.Деньги провели традиционную встречу специалистов по Java. В программе доклады от бэкенд-команд Денег и спикера из Hazelcast.
Дмитрий Комаров, Java-программист (Яндекс.Деньги)
«Monitoring strikes back»
В докладе я представлю нашу инфраструктуру доставки…
Дмитрий Комаров, Java-программист (Яндекс.Деньги)
«Monitoring strikes back»
В докладе я представлю нашу инфраструктуру доставки…
👍1
Статья на Хабре про партиционирование MySQL под нужды Zabbix. Проблема партиционирования, конечно, решается использованием TimescaleDB, но, если по каким-то причинам её использование невозможно, статья будет полезна.
Хабр
Использование партиционирования в MySQL для Zabbix с большим количеством объектов мониторинга
Для мониторинга серверов и служб у нас давно, и все еще успешно, используется комбинированное решение на базе Nagios и Munin. Однако эта связка имеет ряд недоста...
{kind=link}
Если не знаешь о чём написать — напиши как настроить Заббикс. Х5 пишет как они сделали мониторинг складских помещений. Интересно почитать, если вы видите Заббикс в первый раз. Ну хотя бы узнали как выглядит их склад.
В бытность работы в Евросети я как-то подрабатывал под новый год на складе компании, когда там проводилась инветаризация и требовались люди. Самый кайф — это разогнаться как следует на рохле и прокатиться между стеллажами. Электрическую технику работники склада пришлым не доверяли. А зря! Так веселья было бы ещё больше.
В бытность работы в Евросети я как-то подрабатывал под новый год на складе компании, когда там проводилась инветаризация и требовались люди. Самый кайф — это разогнаться как следует на рохле и прокатиться между стеллажами. Электрическую технику работники склада пришлым не доверяли. А зря! Так веселья было бы ещё больше.
{kind=link}
Если используете для мониторинга TICK, то вот полезные хинты для обработки метрик в Kapacitor.
Хабр
Трюки для обработки метрик в Kapacitor
Скорее всего, сегодня уже ни у кого не возникает вопрос, зачем нужно собирать метрики сервисов. Следующий логичный шаг – настроить алертинг на собираемые метрики...
Популярная, говорят, штука этот service mesh. В комментариях к статье резонно подмечают:
Единственный плюс который я вижу — если в компании действительно есть микросервисы на разных языках программирования. Если всё пишется на одном — лучше общую либу.
Резонно, чо уж там.
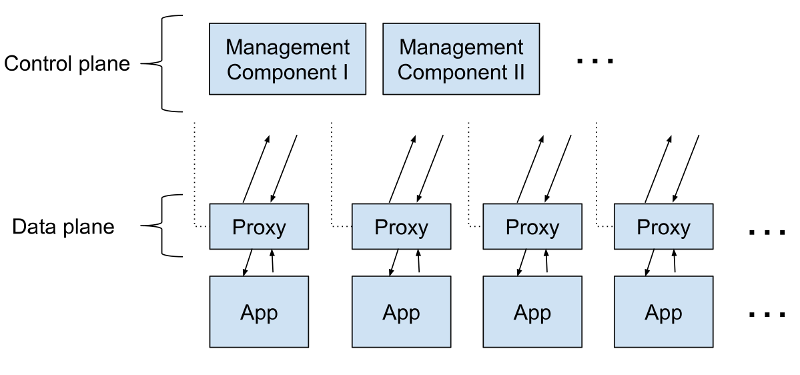
Что такое service mesh?
Несмотря на весь хайп, структурно service mesh устроена довольно просто. Это всего лишь куча userspace-прокси, расположенных «рядом» с сервисами (потом мы немного поговорим о том, что такое «рядом»), плюс набор управляющих процессов. Прокси в совокупности получили название data plane, а управляющие процессы именуются control plane. Data plane перехватывает вызовы между сервисами и делает с ними «всякое-разное»; control plane, соответственно, координирует поведение прокси и обеспечивает доступ для вас, т.е. оператора, к API, позволяя манипулировать сетью и измерять её как единое целое.
Единственный плюс который я вижу — если в компании действительно есть микросервисы на разных языках программирования. Если всё пишется на одном — лучше общую либу.
Резонно, чо уж там.
Что такое service mesh?
Несмотря на весь хайп, структурно service mesh устроена довольно просто. Это всего лишь куча userspace-прокси, расположенных «рядом» с сервисами (потом мы немного поговорим о том, что такое «рядом»), плюс набор управляющих процессов. Прокси в совокупности получили название data plane, а управляющие процессы именуются control plane. Data plane перехватывает вызовы между сервисами и делает с ними «всякое-разное»; control plane, соответственно, координирует поведение прокси и обеспечивает доступ для вас, т.е. оператора, к API, позволяя манипулировать сетью и измерять её как единое целое.
{kind=link}
{kind=link}