
На этой неделе я опубликовал перевод отчета Gartner за 2018 год. И специально для тех, кто подозрительно относится к разным отчётам, аналитики Gartner в конце сделали приписочку:
Очень правильно сказано. Наилучший подход когда вас не устраивает текущее решение по мониторингу — составить список функциональных требований и обратиться с ним к внешним организациям или консультантам.
В любой системе мониторинга есть ограничения, о которых вы не узнаете на странице Features или в разделах с описанием. Некоторые производители, например, заявляют о поддержке мониторинга микросервисной архитектуры. На деле это оказывается обычной установкой агента внутри контейнера. При использовании Kubernetes или Mesos (а сегодня наличие контейнеризации практически однозначно говорит и о наличии оркестратора для этого хозяйства), вам будут недоступны обзор взаимосвязей контейнеров и параметры их производительности. Если вам предлагают провести пилот, обязательно уточняйте методику мониторинга, просите показать визуализацию и желательно на живой системе. А иначе впустую потратите время.
ИТ-организациям не следует использовать квадрант лидеров как чёткий список поставщиков на выбор, вместо этого нужно составить список критериев, описывающих текущие и будущие потребности, а затем выбрать производителей, которые наилучшим образом отвечают этим требованиям.Очень правильно сказано. Наилучший подход когда вас не устраивает текущее решение по мониторингу — составить список функциональных требований и обратиться с ним к внешним организациям или консультантам.
В любой системе мониторинга есть ограничения, о которых вы не узнаете на странице Features или в разделах с описанием. Некоторые производители, например, заявляют о поддержке мониторинга микросервисной архитектуры. На деле это оказывается обычной установкой агента внутри контейнера. При использовании Kubernetes или Mesos (а сегодня наличие контейнеризации практически однозначно говорит и о наличии оркестратора для этого хозяйства), вам будут недоступны обзор взаимосвязей контейнеров и параметры их производительности. Если вам предлагают провести пилот, обязательно уточняйте методику мониторинга, просите показать визуализацию и желательно на живой системе. А иначе впустую потратите время.
Как сделать ИТ прозрачным для бизнеса (спойлер: настроить тру бизнес-мониторинг)
Чтобы разобраться в этом вопросе, предлагаю ввести два понятия: бизнес-процесс и бизнес-система. Как подсказывает капитан очевидность, доступность бизнес-процесса говорит о работе бизнеса, а бизнес-системы об ИТ. В реальной жизни эти две сущности связаны по рукам, ногам и головам. Если загибается система, то загибается и сам процесс, который она поддерживала. Об этом отправляются уведомления, лампочки на условной Grafana краснеют и какой-нибудь верхнеуровневый чувак видит, что остановился условный бизнес-процесс продажи товаров через интернет-магазин. Дядя вице-президент по продажам берет трубку, звонит и велит готовить бизнес-гель…
Но теперь представим, что система не загнулась, а на некоем сервере неожиданно до 99,5% подскочила утилизация CPU. Настроенные связи, конечно, сразу же передали влияние дальше по цепочке и вот уже руководство в своем кабинете видит, что процесс приобрел недобрый красный оттенок. Дядя вице-президент по продажам берет трубку, звонит и велит готовить бизнес-гель… А зря. Продажи-то идут. Ему объясняют, что ничего, мол, страшного, айфоны мы как продавали так и продаём, просто одному и сервачков фермы плохо. Ложечки нашлись, но осадочек остался. Очевидно, что подобные вещи не должны быть видны руководству и решаться внутри ИТ.
Так как же не пропустить мелкие проблемы (которые могут превратиться в крупные) и не отвлекать бизнес по пустякам?
На доступность процесса должны влиять только напрямую связанные с этим показатели: количество проданного товара, выручка, новые регистрации клиентов, успешные оплаты заказов и другие. Для систем должно быть отдельное представление с возможностью просмотра связанных процессов. Таким образом владелец системы сможет спокойно решать сугубо ИТшные вопросы без лишних нервяков для бизнеса. Коммерческие системы с таким функционалом мне не встречались, но реализовать этот подход самостоятельно не составит особого труда.
Чтобы разобраться в этом вопросе, предлагаю ввести два понятия: бизнес-процесс и бизнес-система. Как подсказывает капитан очевидность, доступность бизнес-процесса говорит о работе бизнеса, а бизнес-системы об ИТ. В реальной жизни эти две сущности связаны по рукам, ногам и головам. Если загибается система, то загибается и сам процесс, который она поддерживала. Об этом отправляются уведомления, лампочки на условной Grafana краснеют и какой-нибудь верхнеуровневый чувак видит, что остановился условный бизнес-процесс продажи товаров через интернет-магазин. Дядя вице-президент по продажам берет трубку, звонит и велит готовить бизнес-гель…
Но теперь представим, что система не загнулась, а на некоем сервере неожиданно до 99,5% подскочила утилизация CPU. Настроенные связи, конечно, сразу же передали влияние дальше по цепочке и вот уже руководство в своем кабинете видит, что процесс приобрел недобрый красный оттенок. Дядя вице-президент по продажам берет трубку, звонит и велит готовить бизнес-гель… А зря. Продажи-то идут. Ему объясняют, что ничего, мол, страшного, айфоны мы как продавали так и продаём, просто одному и сервачков фермы плохо. Ложечки нашлись, но осадочек остался. Очевидно, что подобные вещи не должны быть видны руководству и решаться внутри ИТ.
Так как же не пропустить мелкие проблемы (которые могут превратиться в крупные) и не отвлекать бизнес по пустякам?
Нужно отключить зависимость визуализации бизнес-процессов от доступности бизнес-систем.
На доступность процесса должны влиять только напрямую связанные с этим показатели: количество проданного товара, выручка, новые регистрации клиентов, успешные оплаты заказов и другие. Для систем должно быть отдельное представление с возможностью просмотра связанных процессов. Таким образом владелец системы сможет спокойно решать сугубо ИТшные вопросы без лишних нервяков для бизнеса. Коммерческие системы с таким функционалом мне не встречались, но реализовать этот подход самостоятельно не составит особого труда.
Создавайте два несвязанных контура мониторинга: бизнес-процессов и бизнес-систем. У ответственных за бизнес-процесс лиц должна быть возможность взглянуть на связанные с процессом системы.
Аномалии != Алерты
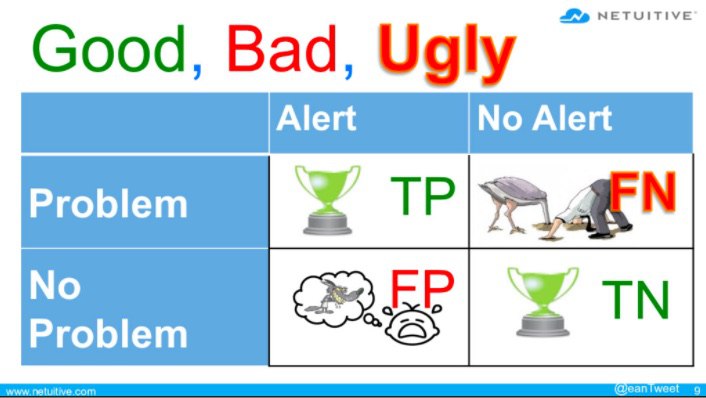
Есть такое понятие Alert Fatigue, буквально означает «усталость от оповещений». Такое бывает когда BDSM — основной стиль работы ИТ в компании. Некоторые готовы обрабатывать тысячи событий в минуту и даже считают, что кому-то кроме них это нужно. ОК, если это летящий Syslog, который просто анализируется и не ОК, если это добро прилетает в консоль событий. Действия системы алертинга (буду так его называть, но на самом деле это система оповещений о событиях) можно разделить на 4 категории:
TP — True Positive. С показателем всё ок и оповещения нет
TN — True Negative. С показателем всё хреново и система об этом уведомляет
FP — False Positive. С показателем всё ок и прилетает оповещение, то бишь это ложное срабатывание
FN — False Negative. С показателем всё хреново и оповещения нет.
Первые два хорошо, вторые два не очень (а последний вообще ужасный). Посмотрите видео выступления Бетси Николс на конференции «Мониторама», которая интересно рассказывает о научном подходе к снижению шума и показывает непонятные математические формулы. Она главный научный сотрудник Netuitive Inc., где отвечает за технологии компании в области науки, аналитики, моделирования и алгоритмов. Бетси применяла математику для создания игр, оптимизации полетов космических кораблей, управления производственными процессами, оптимизации цепочки поставок, моделей безопасности ИТ и управления рисками.
Видео
Слайды презентации
Есть такое понятие Alert Fatigue, буквально означает «усталость от оповещений». Такое бывает когда BDSM — основной стиль работы ИТ в компании. Некоторые готовы обрабатывать тысячи событий в минуту и даже считают, что кому-то кроме них это нужно. ОК, если это летящий Syslog, который просто анализируется и не ОК, если это добро прилетает в консоль событий. Действия системы алертинга (буду так его называть, но на самом деле это система оповещений о событиях) можно разделить на 4 категории:
TP — True Positive. С показателем всё ок и оповещения нет
TN — True Negative. С показателем всё хреново и система об этом уведомляет
FP — False Positive. С показателем всё ок и прилетает оповещение, то бишь это ложное срабатывание
FN — False Negative. С показателем всё хреново и оповещения нет.
Первые два хорошо, вторые два не очень (а последний вообще ужасный). Посмотрите видео выступления Бетси Николс на конференции «Мониторама», которая интересно рассказывает о научном подходе к снижению шума и показывает непонятные математические формулы. Она главный научный сотрудник Netuitive Inc., где отвечает за технологии компании в области науки, аналитики, моделирования и алгоритмов. Бетси применяла математику для создания игр, оптимизации полетов космических кораблей, управления производственными процессами, оптимизации цепочки поставок, моделей безопасности ИТ и управления рисками.
Видео
Слайды презентации
{kind=link}
Многим Zendesk известен как инструмент автоматизации Service Desk. В квадрант Gartner этот вендор не входит просто потому что умеет автоматизировать только несколько процессов. Поделюсь с вами любопытной статистикой, которую Zendesk публикует по результатам биг-дата-машин-лёрнинг аналитики своих клиентов. В агрегированном виде это выглядит так:
📌94% пользователей удовлетворены результатом обращения в службу поддержки
📌8 ответов от службы поддержки потребовалось для закрытия обращения
📌20 часов заняло время закрытия обращения
📌4 часа прошло до первого ответа от службы поддержки
📌259 запросов в месяц получает служба поддержки
📌39% запросов решается после одного ответа от службы поддержки
У Zendesk ещё много других интересных исследований на основе данных своей клиентской базы. Например, они говорят, что процент удовлетворенности обратившихся через чат пользователей самый большой и составляет 92%. Не обессудьте, но просмотр полных версий отчётов потребует от вас адреса электронной почты.
📌94% пользователей удовлетворены результатом обращения в службу поддержки
📌8 ответов от службы поддержки потребовалось для закрытия обращения
📌20 часов заняло время закрытия обращения
📌4 часа прошло до первого ответа от службы поддержки
📌259 запросов в месяц получает служба поддержки
📌39% запросов решается после одного ответа от службы поддержки
У Zendesk ещё много других интересных исследований на основе данных своей клиентской базы. Например, они говорят, что процент удовлетворенности обратившихся через чат пользователей самый большой и составляет 92%. Не обессудьте, но просмотр полных версий отчётов потребует от вас адреса электронной почты.
{kind=link}
Вчерашняя статья на Хабре о безопасности системы мониторинга Zabbix. Рассказывают как можно перехватить zbx_sessionid, получить доступ к Zabbix и выполнить произвольный скрипт на удалённом мониторящемся сервере. Все описанные проблемы решаются двумя простыми шагами: настройкой HTTPS и шифрованием данных между агентом/сервером/прокси. Не забывайте включать шифрование везде где только можно, особенно при использовании SaaS.
Хабр
Система мониторинга как точка проникновения на компьютеры предприятия
Это продолжение памятки про систему мониторинга Zabbix, опубликованной недавно в нашем блоге. Выражаем огромную благодарность пользователю Shodin, который внес з...
Небольшой обзор статьи на Хабре о подходе к снижению количества ложных срабатываний и своевременном оповещении.
Telegraph
И снова о снижении ложных срабатываний
Несколькими постами выше я уже писал про борьбу Бетси Николс с ложными срабатываниями. Вчера на Хабрахабре появилась интересная статья по связанной тематике — снижению количества ложных срабатываний. Автор предлагает делить обработку событий в системе мониторинга…
А если лень делать свой машин лернинг, ребята из anomaly.io уже сделали такую тулзу. Но просят за неё денег. Если у вас все остальные части системы мониторинга бесплатные, то $1440 в месяц вообще же не деньги, правда?
Anomaly
Anomaly Detection and Monitoring Service
Anomaly detection in real time by predicting future problems. Detect unusual patterns and monitor any time series metrics using math and advanced analytics.
{kind=link}
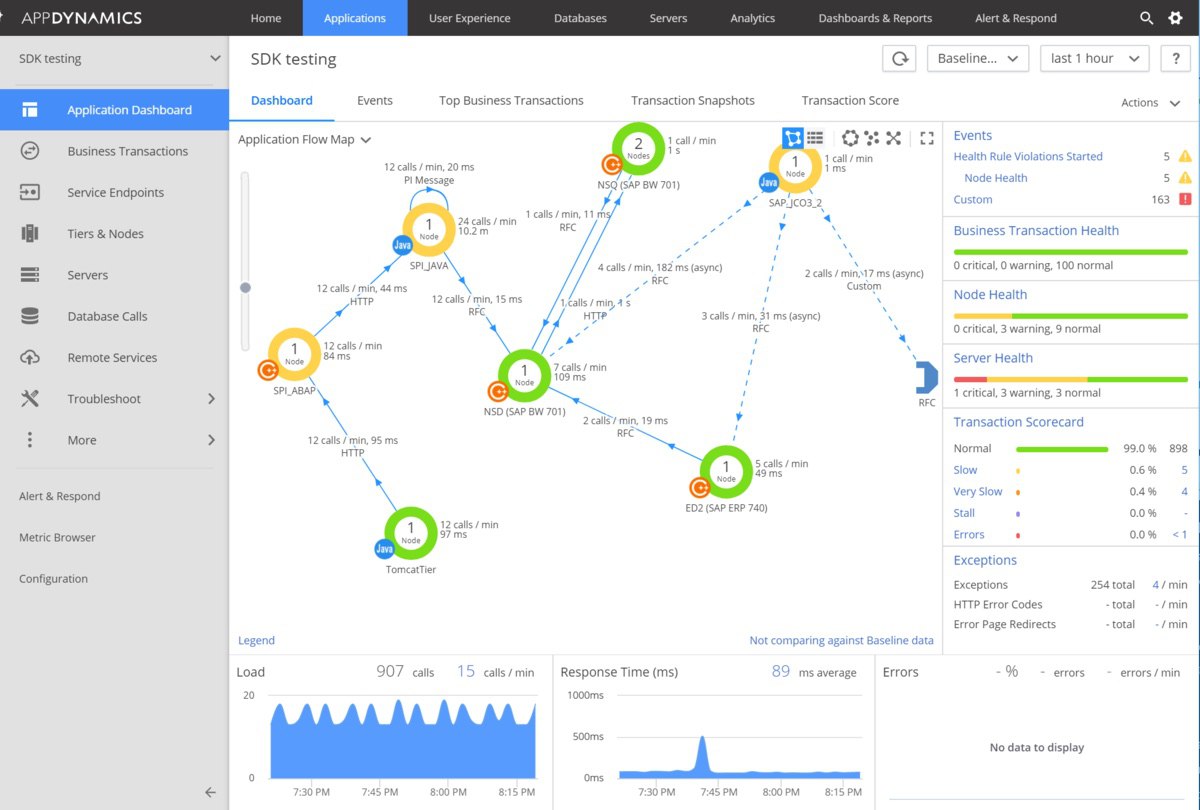
Вау! 2 дня назад Appdynamics объявил о поддержке мониторинга SAP . Теперь умеет инструментировать ABAP и код в БД.
{kind=link}
На днях при разговоре с заказчиком мне сказали: "к нам приходил Oracle и не смог ничего предложить для мониторинга наших микросервисов. Неужели у вас есть что-то для нашего ненаглядного Kubernetes?" Я ответил: "да полно разных инструментов!" Некоторые думают, что микросервисы это далекий космос, который недостижим для именитых вендоров решений для мониторинга. Ну для некоторых именитых недостижим, но есть же и другие инструменты, которые пока не доросли до попадания в квадрант APM Gartner (а может им это даже и не нужно). О таких инструментах я готовлю статью на Хабре, а пока вот тоже не менее интересно пишут о Kubernetes.
{kind=link}
Сегодня три интересных статьи-сравнения из блога Overops (мониторинг кода с коллстэками, строчками кода и переменными на вход во время аварии). Статьи прошлых лет, но подход, который используют вендоры, остался без существенных изменений. Интересно проследить историю приобретений и как это отразилось на дальнейшей стратегии компаний. Статьи на английском.
1. ELK vs. Splunk
2. Appdynamics vs. NewRelic
3. Appdynamics vs. Dynatrace
Приятного чтения!
1. ELK vs. Splunk
2. Appdynamics vs. NewRelic
3. Appdynamics vs. Dynatrace
Приятного чтения!
OverOps
The fastest way to why: Instantly identify critical issues and fix them quickly.
OverOps issue root cause analysis at runtime instantly pinpoints why a critical issue broke your complex backend Java or .Net application in pre-prod and production. Eliminate the detective work of searching logs for the cause. Resolve issues in minutes.
В 2017 году Google выпустил книгу Site Reliability Engineering, где описываются вопросы поддержания работоспособоности веб-приложений как это видит для себя интернет-гигант. Я готовлю перевод одной из глав о мониторинге и скоро его здесь опубликую, а пока предлагаю вашему вниманию ссылку на книгу для ознакомления. В онлайне можно читать абсолютно бесплатно. После прочтения будете лихо готовить концепции по мониторингу и говорить, что Google использует точно такой же подход 🙂
{kind=link}
Кстати, вчера началась ежегодная конференция Monitorama, посвященная мониторингу, DevOps и близким к этому штукам. Есть стрим на их сайте с записями предыдущих дней. А если захочется посмотреть прошлогодние видосы (не в виде стрима, а отдельных выступлений) — приходите к ним на канал в Vimeo. Из прошлогодних выступлений больше мне всего запомнилось о сравнении типов событий от систем мониторинга.
Vimeo
Monitorama
Monitorama is a member of Vimeo, the home for high quality videos and the people who love them.
Если увлекаетесь контейнерами, кубернейтсом и сопутствующими штуками, посмотрите 20 докер-экспертов и 15 кубернейтс-экспертов в блоге New Relic. В статьях приведены ссылки на соцсети, блоги и сайты этих людей, в которых можно следить за последними новостями и узнавать некоторые полезные для работы вещи.
{kind=link}