
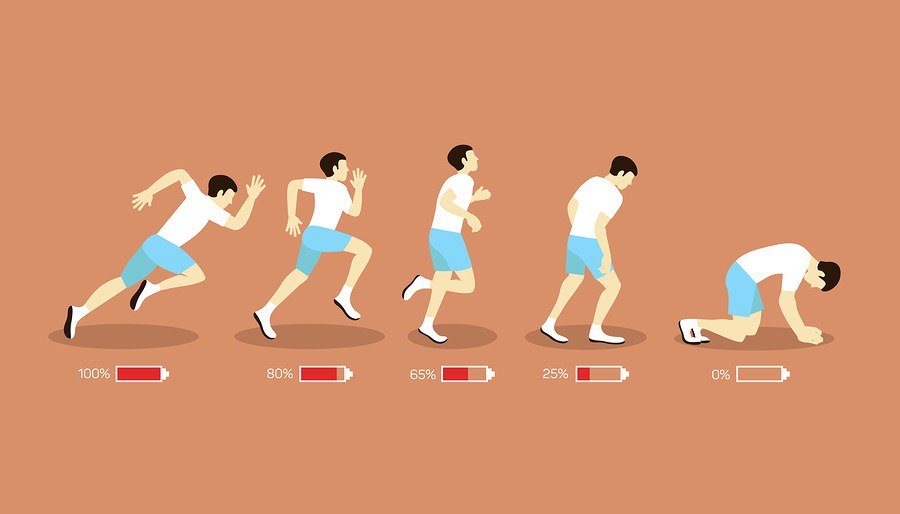
Есть такой зверь Customer Impact Assessment (CIA), на русский переводится как оценка влияния на пользователя. Думаю, вам уже понятно, что контексте предоставления ИТ-сервиса этот процесс может оказаться очень полезен. Это ретроспектива (обычно недельная) всех зафиксированных событий/инцидентов. Если вы сейчас скажете:"да хрена лысого я смогу все свои события за неделю просмотреть, мне на это жизни не хватит", значит что-то с вашим мониторингом не то. И это дополнительный повод проводить такую оценку, потому что так вы добьётесь снижения количества ложных/шумовых событий, выявите пару-тройку причинно-следственных связей возникших инцидентов и со спокойной душой передадите это разработчикам. После нескольких таких итераций нагрузка на колл-центр/техподдержку снизится сама собой.
{kind=link}
В книге Site Reliability Engeneering Google рассказывает о 4 золотых сигналах (или метриках), на которые они рекомендуют ориентироваться в мониторинге приложений. Инженеры Google считают фундаментальными метрики: время задержки (latency), трафик (traffic), количество ошибок (errors) и насыщенность (saturation). Ниже расскажу подробнее.
1. Время задержки (latency). Время, затрачиваемое на обработку запроса, с уделением особого внимания различию между задержкой выполнения успешных запросов и задержкой выполнения неудачных запросов.
2. Трафик (traffic) Метрика уровня спроса на услугу — количества запросов к сервису. Например, количество HTTP-запросов в секунду в случае мониторинга HTTP REST API.
3. Количество ошибок (errors) Количество неудачных запросов. Ошибки могут быть явными (например, ошибки HTTP 500) или неявными (например, HTTP 200 OK с телом ответа, имеющим слишком мало элементов).
4. Насыщенность (saturation) Метрика уровня нагруженности сервиса. Показатель использования системы с упором на ресурсы, которые наиболее ограничены (например, утилизация памяти, диска или процессора). По мере приближения к высокой нагрузке качество сервиса ухудшается.
Будьте как Google — контролируйте эти метрики!
1. Время задержки (latency). Время, затрачиваемое на обработку запроса, с уделением особого внимания различию между задержкой выполнения успешных запросов и задержкой выполнения неудачных запросов.
2. Трафик (traffic) Метрика уровня спроса на услугу — количества запросов к сервису. Например, количество HTTP-запросов в секунду в случае мониторинга HTTP REST API.
3. Количество ошибок (errors) Количество неудачных запросов. Ошибки могут быть явными (например, ошибки HTTP 500) или неявными (например, HTTP 200 OK с телом ответа, имеющим слишком мало элементов).
4. Насыщенность (saturation) Метрика уровня нагруженности сервиса. Показатель использования системы с упором на ресурсы, которые наиболее ограничены (например, утилизация памяти, диска или процессора). По мере приближения к высокой нагрузке качество сервиса ухудшается.
Будьте как Google — контролируйте эти метрики!
Ниже мой небольшой инсайт. Может быть вам полезен, если занимаетесь пресейлами и/или продажами ИТ-продуктов. Поставьте, лайк, если материал был полезен.
Интервью — обязательная часть пресейловых активностей по продвижению решений мониторинга. (конечно, не только мониторинга, но мы тут только об этом). Как ещё узнаешь о болях клиента? Если вы интегратор (или вендор) — ваша задача решить проблему клиента, если клиент — задача опять-таки решить проблему. Получается, задачи обоих сторон идентичны. Customer Development — методика эффективного интервью для выявления реальных потребностей клиента. Если правильно её применять, можно заметно повысить КПД интервью для обоих сторон: продающая сторона будет решать реальную проблему, а покупающая лучше разберётся в своих задачах. Как следствие: не нужно встречаться повторно, созваниваться и вести дополнительную переписку для уточнения деталей. Как видите, сплошной win-win. И ничего сложного. Что нужно же делать? А вот что.
1. Гипотеза
Перед встречей сформулируйте несколько гипотез, которые позволят выявить проблемы клиента, о которых он мог и не догадываться. Перечень гипотез подскажет только прошлый опыт. Например:
- у вас дофига событий, вам они не досаждают?
- у вас дофига консолей мониторинга, ваша дежурная смена ещё не обзавелась фасеточным зрением как мухи?
- насколько быстро удаётся решать проблемы при наличии текущих систем мониторинга?
- и так далее.
Все свои гипотезы нужно оставить на время, когда клиент уже расскажет о своих проблемах, чтобы не сбивать его с мысли.
2. Процедура интервью
Во время интервью (и это показывает опыт) важно:
- не продавать
- задавать открытые вопросы
- искать причину мотивации собеседника
- спрашивать про прошлое и настоящее
- просить привести примеры конкретных ситуаций
- занимать нейтральную позицию, не учить жизни
2. Подготовленный гайд
Сделанная заранее домашка (вопросы) поможет узнать всё что хотелось и ни о чём не забыть. В гайд входят также и гипотезы. А вопросы могут быть такими:
- как сейчас вырешаете задачу мониторинга? — вопрос про реальный опыт.
- почему вас беспокоит текущий подход к мониторингу? — открытый вопрос, вопрос про реальные мотивы приглашения вас как экспертов
- каковы последствия этой ситуации? — поможет оценить важность проблемы для клиента.
- расскажите подробнее, что произошло в последний раз? — выявит подробности о ситуации и причинах появления проблемы.
- что ещё пытались сделать? — поможет понять серьезность немерений клиента при решении проблемы.
- как решаете проблему сейчас? — открытый вопрос для выявления текущих альтернативы для сравнения вашего предложения с потенциальными конкурентами
- с кем ещё стоит поговорить об этом? — поможет приобрести новый контакт. Если вас порекомендовали, значит вы попали в целевую аудиторию и верно нащупали боли.
2. Правильные люди
У интервьюируемого должно быть правильное представление о текущей ситуации. Желательно, чтобы на встрече были не только люди из ИТ, но и присутствовал бизнес, чтобы вы могли услышать две точки зрения (бывает очень полезно). В общем, главное найти людей, у которых есть полное представление о ситуации.
Кроме всего сказанного, разумеется нужно: иметь позитивный настрой, быть доброжелательным и улыбаться 🙂
Интервью — обязательная часть пресейловых активностей по продвижению решений мониторинга. (конечно, не только мониторинга, но мы тут только об этом). Как ещё узнаешь о болях клиента? Если вы интегратор (или вендор) — ваша задача решить проблему клиента, если клиент — задача опять-таки решить проблему. Получается, задачи обоих сторон идентичны. Customer Development — методика эффективного интервью для выявления реальных потребностей клиента. Если правильно её применять, можно заметно повысить КПД интервью для обоих сторон: продающая сторона будет решать реальную проблему, а покупающая лучше разберётся в своих задачах. Как следствие: не нужно встречаться повторно, созваниваться и вести дополнительную переписку для уточнения деталей. Как видите, сплошной win-win. И ничего сложного. Что нужно же делать? А вот что.
1. Гипотеза
Перед встречей сформулируйте несколько гипотез, которые позволят выявить проблемы клиента, о которых он мог и не догадываться. Перечень гипотез подскажет только прошлый опыт. Например:
- у вас дофига событий, вам они не досаждают?
- у вас дофига консолей мониторинга, ваша дежурная смена ещё не обзавелась фасеточным зрением как мухи?
- насколько быстро удаётся решать проблемы при наличии текущих систем мониторинга?
- и так далее.
Все свои гипотезы нужно оставить на время, когда клиент уже расскажет о своих проблемах, чтобы не сбивать его с мысли.
2. Процедура интервью
Во время интервью (и это показывает опыт) важно:
- не продавать
- задавать открытые вопросы
- искать причину мотивации собеседника
- спрашивать про прошлое и настоящее
- просить привести примеры конкретных ситуаций
- занимать нейтральную позицию, не учить жизни
2. Подготовленный гайд
Сделанная заранее домашка (вопросы) поможет узнать всё что хотелось и ни о чём не забыть. В гайд входят также и гипотезы. А вопросы могут быть такими:
- как сейчас вырешаете задачу мониторинга? — вопрос про реальный опыт.
- почему вас беспокоит текущий подход к мониторингу? — открытый вопрос, вопрос про реальные мотивы приглашения вас как экспертов
- каковы последствия этой ситуации? — поможет оценить важность проблемы для клиента.
- расскажите подробнее, что произошло в последний раз? — выявит подробности о ситуации и причинах появления проблемы.
- что ещё пытались сделать? — поможет понять серьезность немерений клиента при решении проблемы.
- как решаете проблему сейчас? — открытый вопрос для выявления текущих альтернативы для сравнения вашего предложения с потенциальными конкурентами
- с кем ещё стоит поговорить об этом? — поможет приобрести новый контакт. Если вас порекомендовали, значит вы попали в целевую аудиторию и верно нащупали боли.
2. Правильные люди
У интервьюируемого должно быть правильное представление о текущей ситуации. Желательно, чтобы на встрече были не только люди из ИТ, но и присутствовал бизнес, чтобы вы могли услышать две точки зрения (бывает очень полезно). В общем, главное найти людей, у которых есть полное представление о ситуации.
Кроме всего сказанного, разумеется нужно: иметь позитивный настрой, быть доброжелательным и улыбаться 🙂
Я тут задумался: а почему Kubernetes иногда ещё называют K8s? Вы не поверите! Цифра 8 означает всего лишь количество букв между k и s. Век живи — век гугли. 👍 — если знали, 👎 — если не знали, 👀 — если не знали что такое Kubernetes.
Если вы долго хотели, но никак не могли начать чтение Site Reliability Engineering (SRE) от Google, то вот сейчас неплохой момент начать знакомство. По ссылке перевод 6 главы о мониторинге распределённых систем. В статье есть ссылка на полную электронную версию книги в оригинале. Кто не знает, в этой книге Google описывает свои подходы к обеспечению доступности веб-сервисов.
Medium
Мониторинг распределённых систем — опыт Google
Это перевод Главы 6 Monitoring Distributed Systems книги Site Reliability Engineering от Google. Специально для телеграм-канала…
Написал на Хабр пост про 9 инструментов для трекинга кода приложений. Комментарии можно оставить там.
{kind=link}
А не пора ли выкатить перевод новой главы из книги Site Reliability Engineering (SRE) от Google? Наверное, пора! В этот раз драматическая история о правильном выборе SLO, SLA, SLI и рассказ об их отличиях. По ссылке Глава 4 Service Level Objectives (SLO) или Цели Уровня Обслуживания с точки зрения Google.
Medium
Цели уровня обслуживания — опыт Google
Перевод Главы 4 Service Level Objectives книги Site Reliability Engineering от Google. Специально для телеграм-канала @monitorim_it.
Я уже как-то писал в канале об интересных лекция с конференции Мониторама, где только и говорят, что про DevOps. Понятно, что одной Мониторамой сыт не будешь и в процессе поиска полезных выступлений с разных выступлений, я собрал шорт-лист из 16 DevOps конференций, о которых написал на Хабре. Ссылки на записи там прилагаются.
{kind=link}
О проблемах, которые нужно учитывать при миграции монолита на распределённую систему от консультанта по ИТ Джефа Ходжеса. Статья была написана 5 лет назад, но не потеряет актуальности до тех пор, пока в мире останется хотя бы одна монолитная система. Статья на английском, если что. https://bit.ly/2MctGep
А вот издательство Питер выкатило перевод книги Site Reliability Engineering. По ссылке статья на Хабре о книге и промо-код на бумажное издание.
Habr
Книга «Site Reliability Engineering. Надежность и безотказность как в Google»
Вот уже почти 20 лет компания Google обеспечивает работу невообразимо сложных и масштабных систем, которые чутко реагируют на запросы пользователей. Поисковик Google находит ответ на любые вопросы за...
Мониторинг Kubernetes в Prometheus. Как устроен Kubernetes (оркестратор для контейнеров), как с ним работает Prometheus (система мониторинга), как это всё отображается в Grafana (система визуализации метрик) рассказыват на RootConf Дмитрий Столяров CTO компании Флант. Много полезной информации для понимания принципов микросервисной архитектуры. https://youtu.be/zj6SlzzBRaA
YouTube
Мониторинг и Kubernetes (Дмитрий Столяров, Флант, RootConf 2018)
Доклад Дмитрия Столярова, технического директора компании «Флант» (https://flant.ru/), на конференции RootConf 2018 в рамках фестиваля РИТ++ (28 мая 2018). Рассказывается об опыте настройки мониторинга с Prometheus, который был получен в результате эксплуатации…
Есть такое API для мониторинга — называется OpenTracing. Умеет профилировать вызовы между компонентами приложения. На основе этого API работают как бесплатные так и коммерческие инструменты для мониторинга распределённых приложений. Один из бесплатных инструментов, созданный в Uber, является Jaeger. Кто-то знает, а кто-то нет, но штука на самом деле мощная и её при желании можно интегрировать с инструментами визулизации. Почитайте интересную статью о том, как это работает.
Sematext
OpenTracing: Jaeger as Distributed Tracer - Sematext
Find out about Jaeger as distributed tracing system: another distributed tracing system that’s in process of massive adoption. Its architecture is built with scalability and parallelism in mind. The backend is implemented in Go language and it has support…
Прямо в точку (почти). Пост на Хабре от представителя Сбербанка (-теха). Его советы, конечно же, расширяются на любой проект по мониторингу (не только для инфраструктуры) и при некоторой модификации на проекты внедрения вообще любого софта.
📌1. НЕ внедряйте инструмент мониторинга
📌2. Интегратор НЕ сделает за вас всей работы
📌3. НЕ путайте мониторинг и администрирование ИТ-инфраструктуры
📌4. НЕ рассчитывайте, что ваши подчиненные будут использовать мониторинг, если вы сами этого не делаете
📌5. НЕ заставляйте сотрудников работать с системой мониторинга
📌6. НЕ концентрируйтесь на проверке функциональности системы мониторинга во время ее испытаний
📌7. Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
Особенно близким оказался для меня п.7. Очень часто, когда с начала и до конца проекта у заказчика нет понимания «а кто же будет пользоваться системой», проекты заканичваются внедрением системы, которой никто не будет пользоваться. А деньги потрачены. Лол.
📌1. НЕ внедряйте инструмент мониторинга
📌2. Интегратор НЕ сделает за вас всей работы
📌3. НЕ путайте мониторинг и администрирование ИТ-инфраструктуры
📌4. НЕ рассчитывайте, что ваши подчиненные будут использовать мониторинг, если вы сами этого не делаете
📌5. НЕ заставляйте сотрудников работать с системой мониторинга
📌6. НЕ концентрируйтесь на проверке функциональности системы мониторинга во время ее испытаний
📌7. Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
Особенно близким оказался для меня п.7. Очень часто, когда с начала и до конца проекта у заказчика нет понимания «а кто же будет пользоваться системой», проекты заканичваются внедрением системы, которой никто не будет пользоваться. А деньги потрачены. Лол.
Habr
Семь «НЕ» мониторинга ИТ-инфраструктуры
На протяжении своей работы я периодически наблюдал ситуации, когда внедрение мониторинга в компании не приносило ожидаемых результатов. Мониторинг работал плохо или не работал вообще. Анализируя такие...
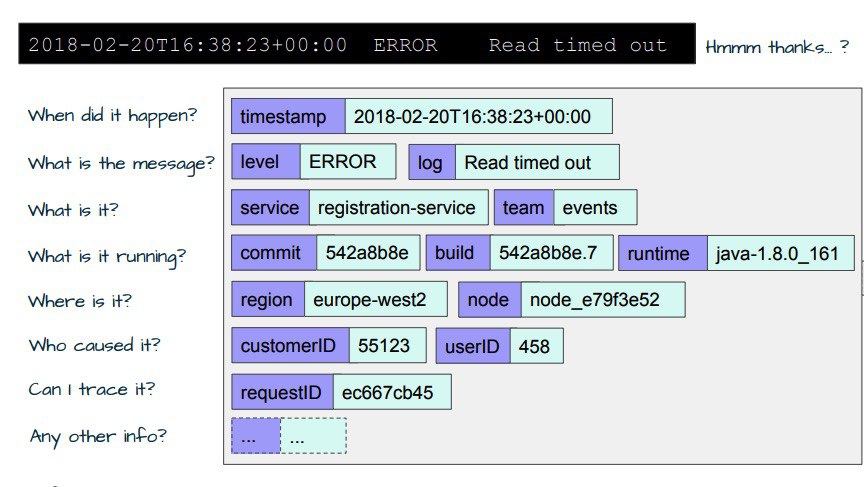
Опубликовал новую статью на Хабре. Теперь-то будет понятно куда смотреть
Хабр
Присматриваемся к инструментам для мониторинга распределенных приложений
Когда приложение было монолитным и вдруг, раз, стало распределённым, в формулу вычисления доступности добавляется ещё одна неизвестная — сетевая. Из-за проблем...
{kind=link}
«DevOps — это не просто автоматизация пайплайна по доставке софта, это доставка ценности конечному пользователю. Если ценность не доставлена, значит ваш DevOps 💩». Donovan Brown. Это одно из определений DevOps, но на самом деле никто не знает точного определения, даже те, кто пишет этот набор букв в своём резюме. Попробуйте-ка спросите у них.
По-моему картинка идеально подходит к неправильно настроенной системе мониторинга.
{kind=link}
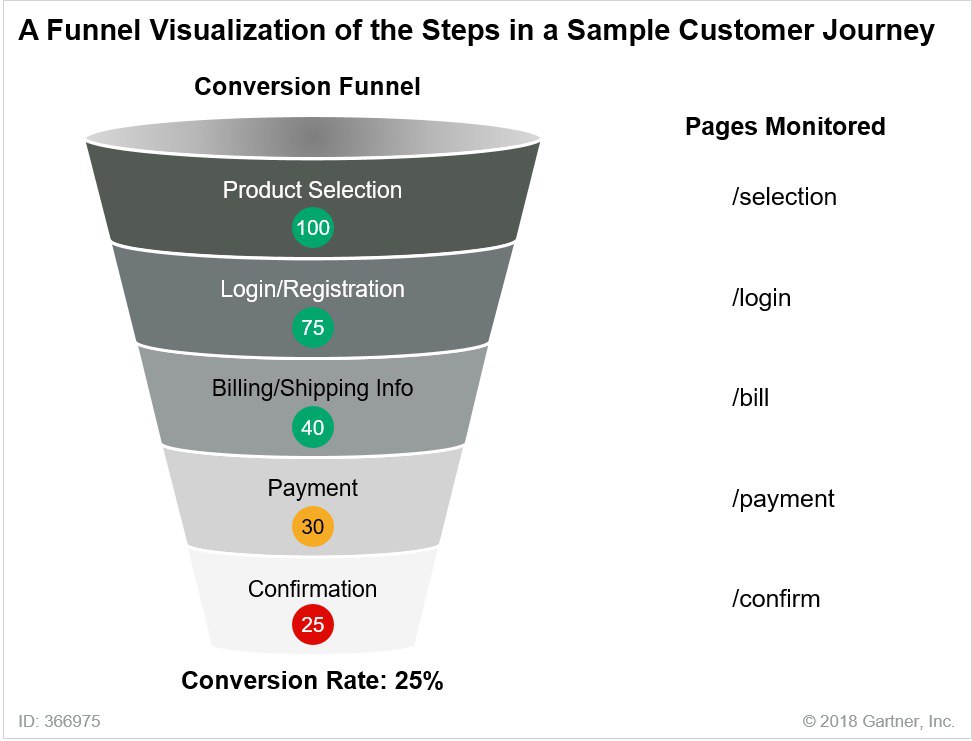
А вы знали, что есть целый класс софта для отрисовки customer journey? С аналитикой и прочими фичами. Данные из DEM-систем (DEM — Digital Experience Monitoring) могут стать основой для такой карты. Ну, конечно, наравне с данными из системы аналитики — Яндекс Метрики или Google Analytics. С DEM можно выявить влияние производительности кода на пользовательское поведение.
Подготовил несколько полезных ссылок по теме:
Статья на cossa.ru
Статья на vc.ru с реальными кейсами использования customer journey tool
20 приложений для создания customer journey map
👍знаю про customer journey tools, использую
👎знаю про customer journey tools, не использую
👀не знаю, не использую
Подготовил несколько полезных ссылок по теме:
Статья на cossa.ru
Статья на vc.ru с реальными кейсами использования customer journey tool
20 приложений для создания customer journey map
👍знаю про customer journey tools, использую
👎знаю про customer journey tools, не использую
👀не знаю, не использую
{kind=link}
По следам вчерашнего поста о Customer Journey. Как оказалось, ему даже обучают и даже в Москве. Если у кого-то есть желание изучить вопрос глубже — сходите на обучение. Это не реклама.
Как справедливо заметили некоторые читатели вчерашего поста, к сожалению, перечисленные в ссылках инструменты customer journey не позволяют на основе внешних данных строить карты в автоматическом режиме. Если вы вдруг знаете такие инструменты, напишите мне пжл в личку.
Как справедливо заметили некоторые читатели вчерашего поста, к сожалению, перечисленные в ссылках инструменты customer journey не позволяют на основе внешних данных строить карты в автоматическом режиме. Если вы вдруг знаете такие инструменты, напишите мне пжл в личку.
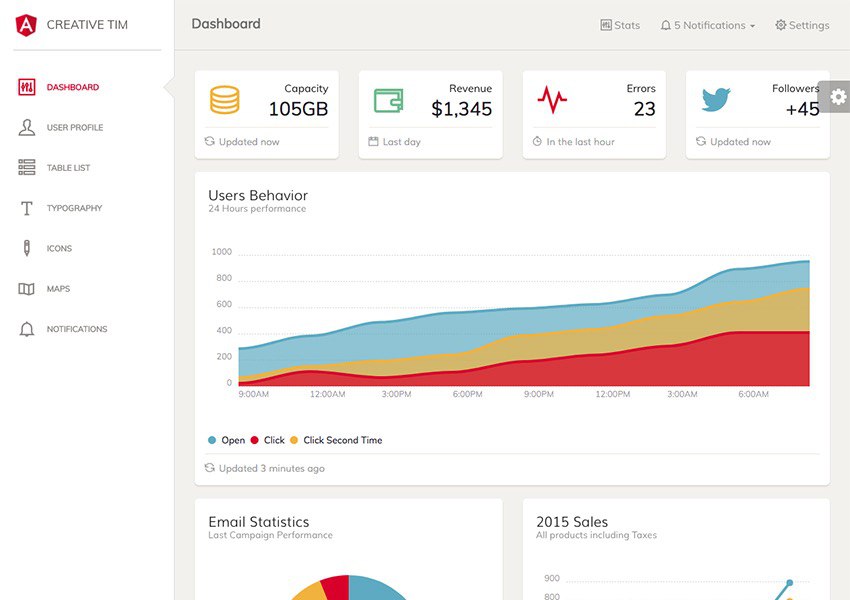
Написал колонку про идеальный дашборд. Перечислил 5 разных видов дашбордов, укажите сколько вы используете в своих системах мониторинга.
1️⃣,2️⃣,3️⃣,4️⃣ или все 5️⃣.
1️⃣,2️⃣,3️⃣,4️⃣ или все 5️⃣.
Medium
Можно ли сделать идеальный дашборд для мониторинга
Мне тут же вспомнилась статья в Тинькофф журнале «Как заработать на квартиру в пределах Мкада. Имея зарплату 100–200 тысяч рублей и не…
{kind=link}