
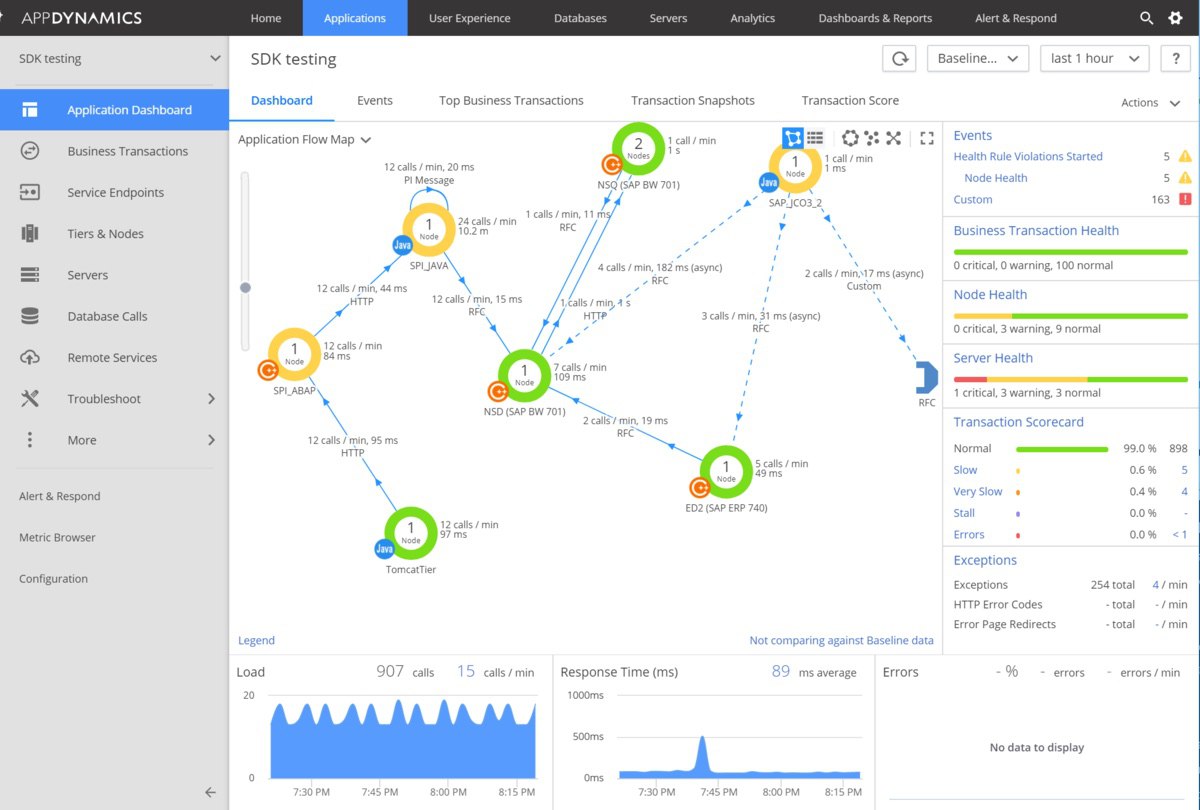
Вау! 2 дня назад Appdynamics объявил о поддержке мониторинга SAP . Теперь умеет инструментировать ABAP и код в БД.
На днях при разговоре с заказчиком мне сказали: "к нам приходил Oracle и не смог ничего предложить для мониторинга наших микросервисов. Неужели у вас есть что-то для нашего ненаглядного Kubernetes?" Я ответил: "да полно разных инструментов!" Некоторые думают, что микросервисы это далекий космос, который недостижим для именитых вендоров решений для мониторинга. Ну для некоторых именитых недостижим, но есть же и другие инструменты, которые пока не доросли до попадания в квадрант APM Gartner (а может им это даже и не нужно). О таких инструментах я готовлю статью на Хабре, а пока вот тоже не менее интересно пишут о Kubernetes.
Сегодня три интересных статьи-сравнения из блога Overops (мониторинг кода с коллстэками, строчками кода и переменными на вход во время аварии). Статьи прошлых лет, но подход, который используют вендоры, остался без существенных изменений. Интересно проследить историю приобретений и как это отразилось на дальнейшей стратегии компаний. Статьи на английском.
1. ELK vs. Splunk
2. Appdynamics vs. NewRelic
3. Appdynamics vs. Dynatrace
Приятного чтения!
1. ELK vs. Splunk
2. Appdynamics vs. NewRelic
3. Appdynamics vs. Dynatrace
Приятного чтения!
OverOps
The fastest way to why: Instantly identify critical issues and fix them quickly.
OverOps issue root cause analysis at runtime instantly pinpoints why a critical issue broke your complex backend Java or .Net application in pre-prod and production. Eliminate the detective work of searching logs for the cause. Resolve issues in minutes.
В 2017 году Google выпустил книгу Site Reliability Engineering, где описываются вопросы поддержания работоспособоности веб-приложений как это видит для себя интернет-гигант. Я готовлю перевод одной из глав о мониторинге и скоро его здесь опубликую, а пока предлагаю вашему вниманию ссылку на книгу для ознакомления. В онлайне можно читать абсолютно бесплатно. После прочтения будете лихо готовить концепции по мониторингу и говорить, что Google использует точно такой же подход 🙂
Кстати, вчера началась ежегодная конференция Monitorama, посвященная мониторингу, DevOps и близким к этому штукам. Есть стрим на их сайте с записями предыдущих дней. А если захочется посмотреть прошлогодние видосы (не в виде стрима, а отдельных выступлений) — приходите к ним на канал в Vimeo. Из прошлогодних выступлений больше мне всего запомнилось о сравнении типов событий от систем мониторинга.
Vimeo
Monitorama
Monitorama is a member of Vimeo, the home for high quality videos and the people who love them.
Если увлекаетесь контейнерами, кубернейтсом и сопутствующими штуками, посмотрите 20 докер-экспертов и 15 кубернейтс-экспертов в блоге New Relic. В статьях приведены ссылки на соцсети, блоги и сайты этих людей, в которых можно следить за последними новостями и узнавать некоторые полезные для работы вещи.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Есть такой ивент консолидатор (или, по-нашему, зонтичная система мониторинга) BigPanda. Когда смотришь на эту картинку, понимание величины рынка мониторинга приходит само собой. Разумеется, это только малая часть этих систем. И обратите внимание на классификацию: Enterprise Suits, APM, Log Management и т.д. Актуальную версию можно посмотреть на странице bigpanda.io/resource-library/monitoringscape. На этой странице у каждой системы указано в каком формате она работает: SaaS или on-prem.
{kind=link}
В начале июня писал о конференции Monitorama, посвящённую DevOps, но по большей части мониторингу. На их канале на Vimeo появились записи выступлений. Кстати, теперь они проводят такую же конференцию и в Европе в Амстердаме. Поэтому если у вас есть два свободных дня в начале сентября и €700 — почему бы вам не зарегистрироваться?
{kind=link}
Серфинг в сети натолкнул меня на одно интересное решение и идею написания этой статьи. Для Хабра она не очень катит, а вот для личного блога самое оно
Medium
Трейсинг информационных потоков распределённого приложения и другие подходы к мониторингу
Специально для телеграм-канала Мониторим ИТ.
Есть такой зверь Customer Impact Assessment (CIA), на русский переводится как оценка влияния на пользователя. Думаю, вам уже понятно, что контексте предоставления ИТ-сервиса этот процесс может оказаться очень полезен. Это ретроспектива (обычно недельная) всех зафиксированных событий/инцидентов. Если вы сейчас скажете:"да хрена лысого я смогу все свои события за неделю просмотреть, мне на это жизни не хватит", значит что-то с вашим мониторингом не то. И это дополнительный повод проводить такую оценку, потому что так вы добьётесь снижения количества ложных/шумовых событий, выявите пару-тройку причинно-следственных связей возникших инцидентов и со спокойной душой передадите это разработчикам. После нескольких таких итераций нагрузка на колл-центр/техподдержку снизится сама собой.
{kind=link}
В книге Site Reliability Engeneering Google рассказывает о 4 золотых сигналах (или метриках), на которые они рекомендуют ориентироваться в мониторинге приложений. Инженеры Google считают фундаментальными метрики: время задержки (latency), трафик (traffic), количество ошибок (errors) и насыщенность (saturation). Ниже расскажу подробнее.
1. Время задержки (latency). Время, затрачиваемое на обработку запроса, с уделением особого внимания различию между задержкой выполнения успешных запросов и задержкой выполнения неудачных запросов.
2. Трафик (traffic) Метрика уровня спроса на услугу — количества запросов к сервису. Например, количество HTTP-запросов в секунду в случае мониторинга HTTP REST API.
3. Количество ошибок (errors) Количество неудачных запросов. Ошибки могут быть явными (например, ошибки HTTP 500) или неявными (например, HTTP 200 OK с телом ответа, имеющим слишком мало элементов).
4. Насыщенность (saturation) Метрика уровня нагруженности сервиса. Показатель использования системы с упором на ресурсы, которые наиболее ограничены (например, утилизация памяти, диска или процессора). По мере приближения к высокой нагрузке качество сервиса ухудшается.
Будьте как Google — контролируйте эти метрики!
1. Время задержки (latency). Время, затрачиваемое на обработку запроса, с уделением особого внимания различию между задержкой выполнения успешных запросов и задержкой выполнения неудачных запросов.
2. Трафик (traffic) Метрика уровня спроса на услугу — количества запросов к сервису. Например, количество HTTP-запросов в секунду в случае мониторинга HTTP REST API.
3. Количество ошибок (errors) Количество неудачных запросов. Ошибки могут быть явными (например, ошибки HTTP 500) или неявными (например, HTTP 200 OK с телом ответа, имеющим слишком мало элементов).
4. Насыщенность (saturation) Метрика уровня нагруженности сервиса. Показатель использования системы с упором на ресурсы, которые наиболее ограничены (например, утилизация памяти, диска или процессора). По мере приближения к высокой нагрузке качество сервиса ухудшается.
Будьте как Google — контролируйте эти метрики!
Ниже мой небольшой инсайт. Может быть вам полезен, если занимаетесь пресейлами и/или продажами ИТ-продуктов. Поставьте, лайк, если материал был полезен.
Интервью — обязательная часть пресейловых активностей по продвижению решений мониторинга. (конечно, не только мониторинга, но мы тут только об этом). Как ещё узнаешь о болях клиента? Если вы интегратор (или вендор) — ваша задача решить проблему клиента, если клиент — задача опять-таки решить проблему. Получается, задачи обоих сторон идентичны. Customer Development — методика эффективного интервью для выявления реальных потребностей клиента. Если правильно её применять, можно заметно повысить КПД интервью для обоих сторон: продающая сторона будет решать реальную проблему, а покупающая лучше разберётся в своих задачах. Как следствие: не нужно встречаться повторно, созваниваться и вести дополнительную переписку для уточнения деталей. Как видите, сплошной win-win. И ничего сложного. Что нужно же делать? А вот что.
1. Гипотеза
Перед встречей сформулируйте несколько гипотез, которые позволят выявить проблемы клиента, о которых он мог и не догадываться. Перечень гипотез подскажет только прошлый опыт. Например:
- у вас дофига событий, вам они не досаждают?
- у вас дофига консолей мониторинга, ваша дежурная смена ещё не обзавелась фасеточным зрением как мухи?
- насколько быстро удаётся решать проблемы при наличии текущих систем мониторинга?
- и так далее.
Все свои гипотезы нужно оставить на время, когда клиент уже расскажет о своих проблемах, чтобы не сбивать его с мысли.
2. Процедура интервью
Во время интервью (и это показывает опыт) важно:
- не продавать
- задавать открытые вопросы
- искать причину мотивации собеседника
- спрашивать про прошлое и настоящее
- просить привести примеры конкретных ситуаций
- занимать нейтральную позицию, не учить жизни
2. Подготовленный гайд
Сделанная заранее домашка (вопросы) поможет узнать всё что хотелось и ни о чём не забыть. В гайд входят также и гипотезы. А вопросы могут быть такими:
- как сейчас вырешаете задачу мониторинга? — вопрос про реальный опыт.
- почему вас беспокоит текущий подход к мониторингу? — открытый вопрос, вопрос про реальные мотивы приглашения вас как экспертов
- каковы последствия этой ситуации? — поможет оценить важность проблемы для клиента.
- расскажите подробнее, что произошло в последний раз? — выявит подробности о ситуации и причинах появления проблемы.
- что ещё пытались сделать? — поможет понять серьезность немерений клиента при решении проблемы.
- как решаете проблему сейчас? — открытый вопрос для выявления текущих альтернативы для сравнения вашего предложения с потенциальными конкурентами
- с кем ещё стоит поговорить об этом? — поможет приобрести новый контакт. Если вас порекомендовали, значит вы попали в целевую аудиторию и верно нащупали боли.
2. Правильные люди
У интервьюируемого должно быть правильное представление о текущей ситуации. Желательно, чтобы на встрече были не только люди из ИТ, но и присутствовал бизнес, чтобы вы могли услышать две точки зрения (бывает очень полезно). В общем, главное найти людей, у которых есть полное представление о ситуации.
Кроме всего сказанного, разумеется нужно: иметь позитивный настрой, быть доброжелательным и улыбаться 🙂
Интервью — обязательная часть пресейловых активностей по продвижению решений мониторинга. (конечно, не только мониторинга, но мы тут только об этом). Как ещё узнаешь о болях клиента? Если вы интегратор (или вендор) — ваша задача решить проблему клиента, если клиент — задача опять-таки решить проблему. Получается, задачи обоих сторон идентичны. Customer Development — методика эффективного интервью для выявления реальных потребностей клиента. Если правильно её применять, можно заметно повысить КПД интервью для обоих сторон: продающая сторона будет решать реальную проблему, а покупающая лучше разберётся в своих задачах. Как следствие: не нужно встречаться повторно, созваниваться и вести дополнительную переписку для уточнения деталей. Как видите, сплошной win-win. И ничего сложного. Что нужно же делать? А вот что.
1. Гипотеза
Перед встречей сформулируйте несколько гипотез, которые позволят выявить проблемы клиента, о которых он мог и не догадываться. Перечень гипотез подскажет только прошлый опыт. Например:
- у вас дофига событий, вам они не досаждают?
- у вас дофига консолей мониторинга, ваша дежурная смена ещё не обзавелась фасеточным зрением как мухи?
- насколько быстро удаётся решать проблемы при наличии текущих систем мониторинга?
- и так далее.
Все свои гипотезы нужно оставить на время, когда клиент уже расскажет о своих проблемах, чтобы не сбивать его с мысли.
2. Процедура интервью
Во время интервью (и это показывает опыт) важно:
- не продавать
- задавать открытые вопросы
- искать причину мотивации собеседника
- спрашивать про прошлое и настоящее
- просить привести примеры конкретных ситуаций
- занимать нейтральную позицию, не учить жизни
2. Подготовленный гайд
Сделанная заранее домашка (вопросы) поможет узнать всё что хотелось и ни о чём не забыть. В гайд входят также и гипотезы. А вопросы могут быть такими:
- как сейчас вырешаете задачу мониторинга? — вопрос про реальный опыт.
- почему вас беспокоит текущий подход к мониторингу? — открытый вопрос, вопрос про реальные мотивы приглашения вас как экспертов
- каковы последствия этой ситуации? — поможет оценить важность проблемы для клиента.
- расскажите подробнее, что произошло в последний раз? — выявит подробности о ситуации и причинах появления проблемы.
- что ещё пытались сделать? — поможет понять серьезность немерений клиента при решении проблемы.
- как решаете проблему сейчас? — открытый вопрос для выявления текущих альтернативы для сравнения вашего предложения с потенциальными конкурентами
- с кем ещё стоит поговорить об этом? — поможет приобрести новый контакт. Если вас порекомендовали, значит вы попали в целевую аудиторию и верно нащупали боли.
2. Правильные люди
У интервьюируемого должно быть правильное представление о текущей ситуации. Желательно, чтобы на встрече были не только люди из ИТ, но и присутствовал бизнес, чтобы вы могли услышать две точки зрения (бывает очень полезно). В общем, главное найти людей, у которых есть полное представление о ситуации.
Кроме всего сказанного, разумеется нужно: иметь позитивный настрой, быть доброжелательным и улыбаться 🙂
Я тут задумался: а почему Kubernetes иногда ещё называют K8s? Вы не поверите! Цифра 8 означает всего лишь количество букв между k и s. Век живи — век гугли. 👍 — если знали, 👎 — если не знали, 👀 — если не знали что такое Kubernetes.
Если вы долго хотели, но никак не могли начать чтение Site Reliability Engineering (SRE) от Google, то вот сейчас неплохой момент начать знакомство. По ссылке перевод 6 главы о мониторинге распределённых систем. В статье есть ссылка на полную электронную версию книги в оригинале. Кто не знает, в этой книге Google описывает свои подходы к обеспечению доступности веб-сервисов.
Medium
Мониторинг распределённых систем — опыт Google
Это перевод Главы 6 Monitoring Distributed Systems книги Site Reliability Engineering от Google. Специально для телеграм-канала…
Написал на Хабр пост про 9 инструментов для трекинга кода приложений. Комментарии можно оставить там.
{kind=link}
А не пора ли выкатить перевод новой главы из книги Site Reliability Engineering (SRE) от Google? Наверное, пора! В этот раз драматическая история о правильном выборе SLO, SLA, SLI и рассказ об их отличиях. По ссылке Глава 4 Service Level Objectives (SLO) или Цели Уровня Обслуживания с точки зрения Google.
Medium
Цели уровня обслуживания — опыт Google
Перевод Главы 4 Service Level Objectives книги Site Reliability Engineering от Google. Специально для телеграм-канала @monitorim_it.
Я уже как-то писал в канале об интересных лекция с конференции Мониторама, где только и говорят, что про DevOps. Понятно, что одной Мониторамой сыт не будешь и в процессе поиска полезных выступлений с разных выступлений, я собрал шорт-лист из 16 DevOps конференций, о которых написал на Хабре. Ссылки на записи там прилагаются.
{kind=link}
О проблемах, которые нужно учитывать при миграции монолита на распределённую систему от консультанта по ИТ Джефа Ходжеса. Статья была написана 5 лет назад, но не потеряет актуальности до тех пор, пока в мире останется хотя бы одна монолитная система. Статья на английском, если что. https://bit.ly/2MctGep
А вот издательство Питер выкатило перевод книги Site Reliability Engineering. По ссылке статья на Хабре о книге и промо-код на бумажное издание.
Habr
Книга «Site Reliability Engineering. Надежность и безотказность как в Google»
Вот уже почти 20 лет компания Google обеспечивает работу невообразимо сложных и масштабных систем, которые чутко реагируют на запросы пользователей. Поисковик Google находит ответ на любые вопросы за...
Мониторинг Kubernetes в Prometheus. Как устроен Kubernetes (оркестратор для контейнеров), как с ним работает Prometheus (система мониторинга), как это всё отображается в Grafana (система визуализации метрик) рассказыват на RootConf Дмитрий Столяров CTO компании Флант. Много полезной информации для понимания принципов микросервисной архитектуры. https://youtu.be/zj6SlzzBRaA
YouTube
Мониторинг и Kubernetes (Дмитрий Столяров, Флант, RootConf 2018)
Доклад Дмитрия Столярова, технического директора компании «Флант» (https://flant.ru/), на конференции RootConf 2018 в рамках фестиваля РИТ++ (28 мая 2018). Рассказывается об опыте настройки мониторинга с Prometheus, который был получен в результате эксплуатации…