
Забавно в книге SRE Workbook ссылаются на фразу Льва Толстого из Анны Карениной:
All happy families are alike; each unhappy family is unhappy in its own way.
Все счастливые семьи счастливы одинаково, каждая несчастливая несчастна по-своему.
В контексте SRE они переиначили это как:
Effective operations approaches are all alike, whereas broken approaches are all broken in their own way.
Эффективные подходы к эксплуатации одинаковы, неэффективные подходы все разные.
Можно с таким согласиться? Я больше склоняюсь к согласиться при условии, что эффективные подходы — это те, про которые пишут книгах, содержащих слова DevOps, SRE или Agile, а неэффективные — это результат подходов к работе внутри организации, которые появились без оглядки на опыт других (типа разработки собственного велосипеда без педалей).
Обращаю внимание, что под каждым постом есть кнопка для комментариев.
👍 — согласен.
👎 — не согласен.
👀 — а что такое SRE?
All happy families are alike; each unhappy family is unhappy in its own way.
Все счастливые семьи счастливы одинаково, каждая несчастливая несчастна по-своему.
В контексте SRE они переиначили это как:
Effective operations approaches are all alike, whereas broken approaches are all broken in their own way.
Эффективные подходы к эксплуатации одинаковы, неэффективные подходы все разные.
Можно с таким согласиться? Я больше склоняюсь к согласиться при условии, что эффективные подходы — это те, про которые пишут книгах, содержащих слова DevOps, SRE или Agile, а неэффективные — это результат подходов к работе внутри организации, которые появились без оглядки на опыт других (типа разработки собственного велосипеда без педалей).
Обращаю внимание, что под каждым постом есть кнопка для комментариев.
👍 — согласен.
👎 — не согласен.
👀 — а что такое SRE?
Goodreads
A quote from Anna Karenina
All happy families are alike; each unhappy family is unhappy in its own way.
В эту пятницу на Хабре вышла статья в блоге Фланта, в которой они пишут как проходили свой путь работы с событиями. Это расшифровка выступления Дмитрия Столярова с прошлогодней конференции DevOops.
Давайте я тут приведу свои комментарии к мыслям из этой статьи, которые мне особенно понравились.
1️⃣ Центральное хранилище. Нельзя слать алерты разными путями — все они должны приходить в одно место.
Речь о единой точке сбора событий из разных систем. Из этой точки события уже должны уходить в виде оповещений в Service Desk, Slack или куда вы там ещё их отправляете. В традиционных категориях это можно назвать зонтичной системой мониторинга. У такого подхода невероятное количество плюсов: защита от дупликации событий, возможность навернуть логику на события из разных систем, обогащать события данными из CMDB, базы знаний и т.д. и т.п.
2️⃣ Транспорт. <…>Мы решили, что существующие способы транспорта для алертов не подходят и сделали свою систему. В ней ответственный сотрудник вынужден для каждого алерта нажимать на кнопку «я увидел(а)»: если этого не происходит, к нему приходят запросы по другим каналам.
Общий телеграм-канал или канал в Slack, конечно, нужны только как вспомогательный инструмент. Основной — это прямое уведомление дежурного. В Флант решили сразу не беспокоить дежурных, а вываливать им уведомление в интерфейсе. Может и были какие-то на это причины, но для экономии времени лучше б сразу уведомить дежурного.
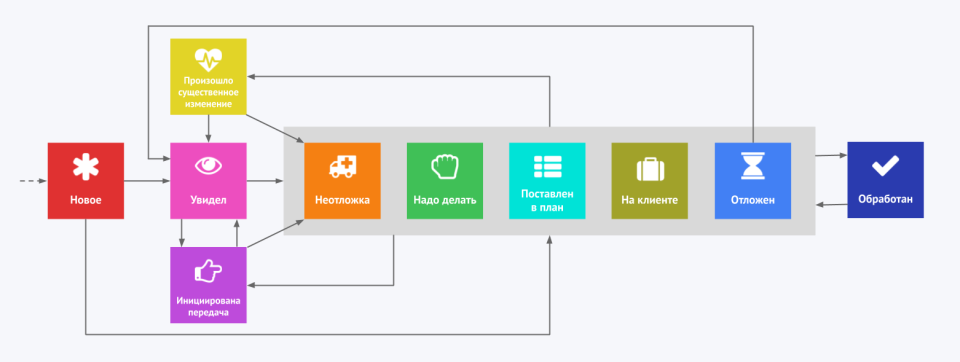
3️⃣ Инцидент не равен алерту. Чтобы это окончательно осознать, у нас ушло несколько лет. Алерт — это сообщение о проблеме, а инцидент — это сама проблема. Инцидент может содержать много сообщений о проблеме с разных сторон, и мы стали их объединять.
Я бы написал так: инцидент != событию != алерту. Инцидент — сущность системы тикетов (Service Desk — хороший пример этого семейства), событие — системы мониторинга, а алерт это да, сообщение о проблеме.
4️⃣ Лейблы. Всю идентификацию алертов надо строить на лейблах (key=value) — это стало особенно актуальным с приходом Kubernetes. Если алерт с физического сервера — в лейбле указано название этого сервера, а если с DaemonSet'а — там его название и пространство имён.
Лейблы нужны. Например, в Zabbix можно навесить тэги на хосты или триггеры. В Prometheus, соответственно, лейблы, которые навешиваются на временные ряды при экспозиции.
5️⃣ Чтобы избавиться от подобного психологического эффекта, «полупотушенные» инциденты надо попросту убрать, но сделать это правильно. Я называю это умный игнор, а его идея сводится к операции «отложить инцидент».
Тут речь идёт о событиях типа отказал диск, заказали новый. Т.е. о тех, по которым ожидается какой-то результат, не зависящий от эксплуатации. События при таком умном игноре должны висеть в открытых (т.к. в консоли обычно выполняется сортировка по времени, они будут в хвосте ленты) и на еженедельных ревью по мониторингу (если они у вас, конечно, есть) по всем таким должны быть проведены апдейты.
6️⃣ В компаниях, где часто что-то меняется, весьма актуальна ещё одна проблема: документация.
Документацию еще можно назвать контекстом. По каждому событию в системе мониторинга должен быть доступен контекст. Это может быть страница на вики, история возникновения аналогичных событий и т.д. Дежурному должна быть доступна эта информация по ссылке из события.
В один пост всё не влезло, поэтому п.7 будет идти следом.
Давайте я тут приведу свои комментарии к мыслям из этой статьи, которые мне особенно понравились.
1️⃣ Центральное хранилище. Нельзя слать алерты разными путями — все они должны приходить в одно место.
Речь о единой точке сбора событий из разных систем. Из этой точки события уже должны уходить в виде оповещений в Service Desk, Slack или куда вы там ещё их отправляете. В традиционных категориях это можно назвать зонтичной системой мониторинга. У такого подхода невероятное количество плюсов: защита от дупликации событий, возможность навернуть логику на события из разных систем, обогащать события данными из CMDB, базы знаний и т.д. и т.п.
2️⃣ Транспорт. <…>Мы решили, что существующие способы транспорта для алертов не подходят и сделали свою систему. В ней ответственный сотрудник вынужден для каждого алерта нажимать на кнопку «я увидел(а)»: если этого не происходит, к нему приходят запросы по другим каналам.
Общий телеграм-канал или канал в Slack, конечно, нужны только как вспомогательный инструмент. Основной — это прямое уведомление дежурного. В Флант решили сразу не беспокоить дежурных, а вываливать им уведомление в интерфейсе. Может и были какие-то на это причины, но для экономии времени лучше б сразу уведомить дежурного.
3️⃣ Инцидент не равен алерту. Чтобы это окончательно осознать, у нас ушло несколько лет. Алерт — это сообщение о проблеме, а инцидент — это сама проблема. Инцидент может содержать много сообщений о проблеме с разных сторон, и мы стали их объединять.
Я бы написал так: инцидент != событию != алерту. Инцидент — сущность системы тикетов (Service Desk — хороший пример этого семейства), событие — системы мониторинга, а алерт это да, сообщение о проблеме.
4️⃣ Лейблы. Всю идентификацию алертов надо строить на лейблах (key=value) — это стало особенно актуальным с приходом Kubernetes. Если алерт с физического сервера — в лейбле указано название этого сервера, а если с DaemonSet'а — там его название и пространство имён.
Лейблы нужны. Например, в Zabbix можно навесить тэги на хосты или триггеры. В Prometheus, соответственно, лейблы, которые навешиваются на временные ряды при экспозиции.
5️⃣ Чтобы избавиться от подобного психологического эффекта, «полупотушенные» инциденты надо попросту убрать, но сделать это правильно. Я называю это умный игнор, а его идея сводится к операции «отложить инцидент».
Тут речь идёт о событиях типа отказал диск, заказали новый. Т.е. о тех, по которым ожидается какой-то результат, не зависящий от эксплуатации. События при таком умном игноре должны висеть в открытых (т.к. в консоли обычно выполняется сортировка по времени, они будут в хвосте ленты) и на еженедельных ревью по мониторингу (если они у вас, конечно, есть) по всем таким должны быть проведены апдейты.
6️⃣ В компаниях, где часто что-то меняется, весьма актуальна ещё одна проблема: документация.
Документацию еще можно назвать контекстом. По каждому событию в системе мониторинга должен быть доступен контекст. Это может быть страница на вики, история возникновения аналогичных событий и т.д. Дежурному должна быть доступна эта информация по ссылке из события.
В один пост всё не влезло, поэтому п.7 будет идти следом.
{kind=link}
Продолжение предыдущего поста.
7️⃣ Отправляя множество алертов, мы на них по сути вручную не реагируем — спасибо автоматизации разбора.
Где-то на десяток постов выше я писал про работу с событийной усталостью:
События должны быть только по тому, что требует вмешательства. Если можно автоматизировать реакцию на событие — это нужно сделать как можно скорее и никого об этом не оповещать.
Это один из важных моментов автоматизации. Второй момент касается событий, на которые всё-таки нужно реагировать. Важно попытаться собрать максимум диагностической информации до того, как дежурный приступит к работе над событием. Диагностикой могут являться хелс-чеки смежных сервисов, проверка доступности БД и аналогичные проверки связанных с проблемных сервисом вещей.
В комментариях к статье на Хабре я задал пару вопросов. Посмотрим ещё, что на них ответят. Могу позже сюда тоже их ответ запостить.
7️⃣ Отправляя множество алертов, мы на них по сути вручную не реагируем — спасибо автоматизации разбора.
Где-то на десяток постов выше я писал про работу с событийной усталостью:
События должны быть только по тому, что требует вмешательства. Если можно автоматизировать реакцию на событие — это нужно сделать как можно скорее и никого об этом не оповещать.
Это один из важных моментов автоматизации. Второй момент касается событий, на которые всё-таки нужно реагировать. Важно попытаться собрать максимум диагностической информации до того, как дежурный приступит к работе над событием. Диагностикой могут являться хелс-чеки смежных сервисов, проверка доступности БД и аналогичные проверки связанных с проблемных сервисом вещей.
В комментариях к статье на Хабре я задал пару вопросов. Посмотрим ещё, что на них ответят. Могу позже сюда тоже их ответ запостить.
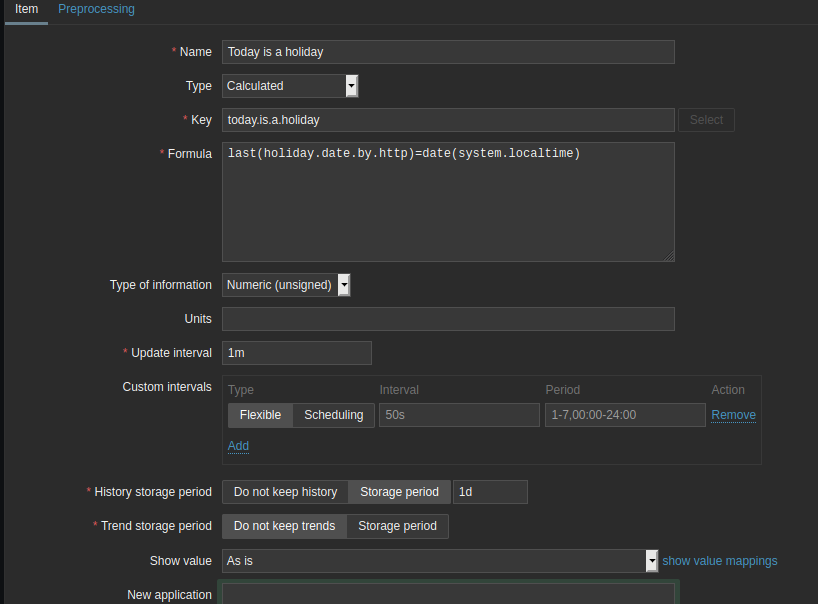
Подключение производственного календаря к системе мониторинга — ещё один шаг на пути к снижению количества шумовых событий. В этой статье рассказывают об интеграции Zabbix с производственным календарём и даже дают ссылку на репозиторий на Github.
Если у вас один только Zabbix, описанный подход выглядит логично. Когда систем мониторинга больше единицы, более правильным выглядит подход к обработке событий на уровне консолидатора событий. Тем более, так будет проще рассчитывать SLO для всех SLI, чтобы обеспечить SLA. 🙂
А ваш мониторинг меняет своё поведение в зависимости от выходных и праздничных дней?
👍 — да, есть интеграция с производственным календарём или аналогом.
👎 — нет, но стоит этим заняться.
👀 — поведение систем, которые стоят у меня на мониторинге не меняется в зависимости от выходных/праздничных дней.
.
Если у вас один только Zabbix, описанный подход выглядит логично. Когда систем мониторинга больше единицы, более правильным выглядит подход к обработке событий на уровне консолидатора событий. Тем более, так будет проще рассчитывать SLO для всех SLI, чтобы обеспечить SLA. 🙂
А ваш мониторинг меняет своё поведение в зависимости от выходных и праздничных дней?
👍 — да, есть интеграция с производственным календарём или аналогом.
👎 — нет, но стоит этим заняться.
👀 — поведение систем, которые стоят у меня на мониторинге не меняется в зависимости от выходных/праздничных дней.
.
{kind=link}
Если нужно быстро поставить на мониторинг Weblogic при помощи готового решения — на Хабре подсказывают решение. Речь про утилиту WLSDM. Там внутри есть дашборды и уже даже проставлены рекомендуемые пороги. Хоть сейчас выводи на телевизор.
В комментариях к статье пророчат набег адептов Prometheus, которые запинают автора из-за использования нишевого решения в мониторинге. Пока никто не пришёл и не набросил.
В комментариях к статье пророчат набег адептов Prometheus, которые запинают автора из-за использования нишевого решения в мониторинге. Пока никто не пришёл и не набросил.
Хабр
Как при помощи большого монитора и консольной утилиты WLSDM смотреть за Oracle WebLogic Server
На просторах утилит консольных расширений Oracle WebLogic Server встретилась одна очень полезная — WLSDM , как ее позиционируют сами авторы — утилита мониторинга WebLogic Server с большим набором...
Подробная статья о том, как работает Istio. Начиная с основ и к практическому применению. Если говорить по-простому, Istio — дополнительный уровень абстракции микросервисного приложения, при помощи которого можно собирать статистику по взаимодействию сервисов, настраивать дополнительную логику их взаимодействию (повторные передачи пакетов и т.д.), изменять потоки трафика (например, в случае канареечных релизов). Короче, полезная такая штука. И так доступно объясняется.
So, what is latency? Latency is how long it takes to do something. How long does it take to have a response back? How long does it take to process a message in a queue?
Итак, что же такое задержка? Задержка — это как много времени заняло выполнение чего-либо. Как долго возвращался ответ? Как долго обрабатывалось сообщение в очереди?
А ещё задержка — входит в четвёрку золотых сигналов, о которых Google рассказывал в своей книге SRE (Site Reliability Engineering).
В статье на Медиуме, инженер из Google Джаана Доган рассказывает почему критически важно измерять задержку по каждому запросу к системе.
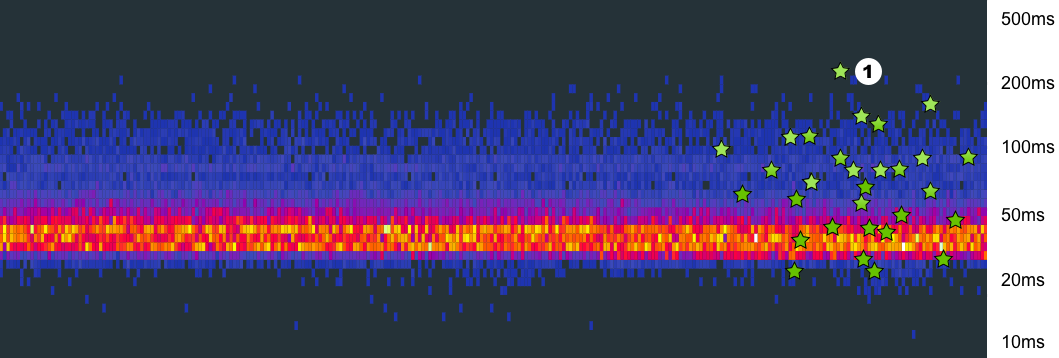
Посмотрите на звёздочки на приложенной картинке. Это тестовые запросы, которые пуляют намеренно, чтобы расставлять некие рэперные точки для будущего возможного дебага излишней задержки запросов. Подробнее о таких тестовых запросах в этом видео.
Итак, что же такое задержка? Задержка — это как много времени заняло выполнение чего-либо. Как долго возвращался ответ? Как долго обрабатывалось сообщение в очереди?
А ещё задержка — входит в четвёрку золотых сигналов, о которых Google рассказывал в своей книге SRE (Site Reliability Engineering).
В статье на Медиуме, инженер из Google Джаана Доган рассказывает почему критически важно измерять задержку по каждому запросу к системе.
Посмотрите на звёздочки на приложенной картинке. Это тестовые запросы, которые пуляют намеренно, чтобы расставлять некие рэперные точки для будущего возможного дебага излишней задержки запросов. Подробнее о таких тестовых запросах в этом видео.
{kind=link}
Как-то был я на митапе по Elastic Stack в Озоне. Ребята рассказывали как у них устроен поиск на сайте с использованием Elasticsearch. Особенно запомнились примеры плохих поисков. Например, при поисковом запросе «товары для взрослых», выводились товары для взрослых кошек, собак и других животных. Среди них, конечно, были реально товары для взрослых, но как-то немного. Митап был несколько месяцев назад, сразу после него я проверил этот поисковый запрос — всё было точно также как и на слайдах: много товаров для взрослых животных. Проверил этот запрос сегодня — вуаля, реально товары для взрослых. Чего там только нет🙂
В самом Elastic в последнее время озаботились развитием продукта, чтобы его было удобно использовать в качестве поискового движка и добавляют фишки вроде AppSearch. По этой ссылке вы найдёте небольшой DIY-гайд, где рассказано как быстро раскатать поиск на базе Elasticsearch. Может он пригодится, а может и нет, но хотя бы будете знать, что для поиска Elastic вполне себе можно использовать.
В самом Elastic в последнее время озаботились развитием продукта, чтобы его было удобно использовать в качестве поискового движка и добавляют фишки вроде AppSearch. По этой ссылке вы найдёте небольшой DIY-гайд, где рассказано как быстро раскатать поиск на базе Elasticsearch. Может он пригодится, а может и нет, но хотя бы будете знать, что для поиска Elastic вполне себе можно использовать.
Medium
Elasticsearch: Building the Search Workflow
A tutorial to build working search of SQL entities via Elasticsearch
❤1
Пост для тех, у кого Kubernetes. В этой статье Ким Вюсткамп (сертифицированный по k8s, кстати) рассказывает о подходах к мониторингу через Prometheus потребления памяти и CPU подами kubernetes.
{kind=link}
Менеджер по инфраструктуре Netflix рассказывает почему он решил попробовать поработать в дежурной смене и что из этого узнал.
{kind=link}
Ещё один способ мониторинга сети при помощи анализа netflow-трафика — утилита ntop. На этом видео с конференции Fosdem (она про открытые решения) рассказывают с какими проблемами столкнулись после разворачивани решения для мониторинга университетской сети в Мюнхене. Архитектура, которую они у себя навернули, на приложенном скриншоте.
{kind=link}
Сообщество Monhouse анонсировало календарь мероприятий по мониторингу на 2020 год (посмотрите весь календарь). Всего будет 7 митапов, 2 круглых стола и 1 конфа в два потока.
Сейчас они активно ищут спикеров на:
1) митапы по анонсированным темам (в приоритете митап по CI/CD процессам (19 марта)).
2) BMM 5 Conf (15 апреля).
Пишите @art_berd, если хотели бы выступить и рассказать о своём опыте в мониторинге и не только.
Сейчас они активно ищут спикеров на:
1) митапы по анонсированным темам (в приоритете митап по CI/CD процессам (19 марта)).
2) BMM 5 Conf (15 апреля).
Пишите @art_berd, если хотели бы выступить и рассказать о своём опыте в мониторинге и не только.
В этом видео (тоже с Fosdem 2020) «Distributed Tracing for beginners» показывают как работает трейсинг вызовов в распредлённом приложении. Этакий live-coding. В приложении добавляются специальные вызовы инструмента jaeger, который как раз отвечает за трейсинг вызовов. Смотреть на сам процесс (а не сухие слайды) очень увлекательно.
{kind=link}
Матвей Кукуй — CEO и сооснователь компании Amixr.IO рассказывает об опыте работы с событями мониторинга и алертингом. По ссылке расшифровка выступления и само видео.
В основном там про подходы работы с алертами из разных систем, их взаимная обработка и умное оповещение в Amixr. К сожалению, Amixr работает только с облачным Slack и (пока) не поддерживает более приземлённые вещи вроде Mattermost или Rocketchat.
В основном там про подходы работы с алертами из разных систем, их взаимная обработка и умное оповещение в Amixr. К сожалению, Amixr работает только с облачным Slack и (пока) не поддерживает более приземлённые вещи вроде Mattermost или Rocketchat.
{kind=link}
Мониторинг PostgreSQL нннада? Я сам в Postgre так глубоко не разбираюсь, но в этом переводе статьи полезные метрики производительности этой БД можно брать голыми руками.
Хабр
Простое обнаружение проблем производительности в PostgreSQL
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж мн...
В этой статье о подходе к древовидному именованию метрик для упрощения управления мониторингом. Понятное именование метрик — один из ингредиентов SRE.
{kind=link}
Grafana стремится стать как можно более универсальным инструментом для Observability. У них были метрики, логи и вот-вот должны появиться трейсы. В этом анонсе в блоге Grafana Lab они приводят демонстрацию нового плагина Jaeger.
Если кто не знал, у Grafana есть и платная версия Enterprise, доступная по подписке, которая, в частности, расширяет набор доступных плагинов (добавляются Splunk, NewRelic, Appdynamics, Oracle и т.д.). Но т.к. Jaeger сам по себе бесплатен, не думаю, что они включат его в платный пакет.
Интересно, кто-то из читателей использует платную версию?
👍 — да, у нас есть подписка Enterprise
👎 — хватает бесплатной версии
👀 — не использкю Grafana в своём стеке мониторинга
Если кто не знал, у Grafana есть и платная версия Enterprise, доступная по подписке, которая, в частности, расширяет набор доступных плагинов (добавляются Splunk, NewRelic, Appdynamics, Oracle и т.д.). Но т.к. Jaeger сам по себе бесплатен, не думаю, что они включат его в платный пакет.
Интересно, кто-то из читателей использует платную версию?
👍 — да, у нас есть подписка Enterprise
👎 — хватает бесплатной версии
👀 — не использкю Grafana в своём стеке мониторинга
Grafana Labs
KubeCon Demo: A Preview of Grafana & Jaeger | Grafana Labs
Here’s a preview of a future feature of Grafana: distributed tracing datasources.
Ребята из Monqlab, разрабатывающие платформу UX-мониторинга и инцидент-менеджмента MONQ, приглашают поучаствовать в опросе о потребительских предпочтениях в области мониторинга и автоматизации инцидент-менеджмента.
Прохождение опроса займет не более 15-20 минут, но за это они обещают интересный подарок.
Результаты опроса в обобщённом виде опубликую в канале.
Для перехода к опросу нажмите на кнопку в конце поста.
Прохождение опроса займет не более 15-20 минут, но за это они обещают интересный подарок.
Результаты опроса в обобщённом виде опубликую в канале.
Для перехода к опросу нажмите на кнопку в конце поста.
monq.ru
Monq – корпоративный ИТ-мониторинг нового поколения
Мониторинг инфраструктуры, приложений, пользовательских интерфейсов и зонтичный мониторинг – всё в одной платформе. Работает на low и no-code автоматизации.
Для линукс-админов. Петя Зайцев на конференции Fosdem 2020 рассказывает о важных аппаратных метриках производительности Linux, которые он настоятельно рекомендует собирать. Петя Зайцев — CEO в Percona.
{kind=link}
Сегодня в 11 часов МСК Quest и Мерлион проведут совместный вебинар по системе мониторинга Spotlight. Spotlight — легковесная система мониторинга БД SQL Server и Oracle вместе с метриками соответствующих операционных систем. Прямо в интерфейсе при наведении на проблемную метрику Spotlight выдаёт рекомендации как эту проблему пофиксить. У Spotlight есть облачная версия и мобильное приложение.
Рега по ссылке в конце поста.
Рега по ссылке в конце поста.
{kind=link}
Если всё думаете как подступиться к Elastic Stack, то вот неплохая вводная статья. Здесь в основном про использования его в качестве движка для поиска, но раскрывается много архитектурных деталей.
{kind=link}