
Искренне радуюсь за людей, которые получает настоящее удовольствие от работы в коммерческой разработке.
Поначалу все круто и прикольно: технологии, фреймворки, языки программирования, подходы, практики... И все для того, чтобы перекладывать словари и списки из одного места в другое.
Иногда грустно от того, что все самое крутое с точки зрения технологий уже придумали.
Поначалу все круто и прикольно: технологии, фреймворки, языки программирования, подходы, практики... И все для того, чтобы перекладывать словари и списки из одного места в другое.
Иногда грустно от того, что все самое крутое с точки зрения технологий уже придумали.
Я прочитал слишком много псевдо-статей про псевдо-решения, утилизирующие слово "multi-cloud", и не могу больше молчать.
Толкать эту стратегию пытаются многие, как шарлатаны-консультанты и вендоры старой школы, так и обоснованно волнующиеся о продолжительности бизнеса управленцы. Спорить с последними излишне - никому не хочется становиться чьей-то коровой лишь только потому, что паровозик под названием Netflix смог построить бизнес невообразимых масштабов на небольшом никому неизвестном поставщике воздушных услуг.
Другое дело сам подход. Идея многооблачного развертывания в том, чтобы не зависеть от одного единственного поставщика. Раз стоит такое требование, то надо использовать открытые решения вкупе со своими разработками, а от провайдера брать только вычислительные мощности (например, виртуальные машины или планировщики задач). Ну и зачем тогда облачный провайдер, если можно закупиться дешевыми мощностями Servers.com, Hetzner, DO?
Есть еще имплементация, когда на конкретном провайдере разворачивается конкретное решение, потому что именно этот провайдер лучше решает задачу. Не секрет, что GCP быстрее и дешевле обрабатывает большие объемы данных, а значит логично запускать там BI системы, AWS предлагает широкий спектр узкоспециализированных услуг, а у Azure отличная интеграция с on-prem системами. Бизнес может раскидать свои продукты по трем провайдерам и даже сынтегрировать их друг с другом, только это не многооблачное решение, а просто распределенные по разным местам звенья одной цепи. Да и ваше предприятие зависит не от одного, а уже от трех поставщиков.
Каждый вендор или поставщик заинтересован в долгосрочных отношениях. Не лучше ли приложить усилия и ресурсы, чтобы эти отношения были полезными и продуктивными, нежели городить велосипед из костылей, получая и позор, и войну?
Толкать эту стратегию пытаются многие, как шарлатаны-консультанты и вендоры старой школы, так и обоснованно волнующиеся о продолжительности бизнеса управленцы. Спорить с последними излишне - никому не хочется становиться чьей-то коровой лишь только потому, что паровозик под названием Netflix смог построить бизнес невообразимых масштабов на небольшом никому неизвестном поставщике воздушных услуг.
Другое дело сам подход. Идея многооблачного развертывания в том, чтобы не зависеть от одного единственного поставщика. Раз стоит такое требование, то надо использовать открытые решения вкупе со своими разработками, а от провайдера брать только вычислительные мощности (например, виртуальные машины или планировщики задач). Ну и зачем тогда облачный провайдер, если можно закупиться дешевыми мощностями Servers.com, Hetzner, DO?
Есть еще имплементация, когда на конкретном провайдере разворачивается конкретное решение, потому что именно этот провайдер лучше решает задачу. Не секрет, что GCP быстрее и дешевле обрабатывает большие объемы данных, а значит логично запускать там BI системы, AWS предлагает широкий спектр узкоспециализированных услуг, а у Azure отличная интеграция с on-prem системами. Бизнес может раскидать свои продукты по трем провайдерам и даже сынтегрировать их друг с другом, только это не многооблачное решение, а просто распределенные по разным местам звенья одной цепи. Да и ваше предприятие зависит не от одного, а уже от трех поставщиков.
Каждый вендор или поставщик заинтересован в долгосрочных отношениях. Не лучше ли приложить усилия и ресурсы, чтобы эти отношения были полезными и продуктивными, нежели городить велосипед из костылей, получая и позор, и войну?
Servers.com
Dedicated Bare Metal Server Provider | servers.com
servers.com - The dedicated bare metal server provider you can rely on. Experience the highest performance, security & control with our bare metal servers.
Если на мульти-облачные решения еще можно закрыть глаза, то есть еще подвид решений и инструментов, с которым мириться совсем сложно.
Называются они cloud-agnostic. Про таких либо говорят, что они не привязаны к одному вендору, либо что они абсолютно универсальны и совместимы с любым провайдером.
Взять например тот же Terraform, который гордо нес звание cloud-agnostic инструмента для развертывания систем на любом провайдере. Много раз я слышал, что он позволяет не привязываться к одному провайдеру, а "просто развернуть инфраструктуру в другом облаке". Это, разумеется, не работает.
Многоплатформенность TF обеспечивается провайдерами, провайдеры - интерфейс-обвязка между декларативной инструкцией Terraform и API облачного поставщика. Действительно, вы можете сменить значение провайдера с одного на другое, но вдобавок придется переписать декларации всех ресурсов, поскольку атрибуты тоже отличаются.
Как результат, из cloud-agnostic у Terraform только его DSL.
По-настоящему cloud-agnostic решение будет автоматически определять, с каким облаком оно будет работать, и подключаться к нужным сервисам тоже само. AWS? DDB, Aurora и т.д. GCP? BigTable и Spanner и пр.
Ну и дальше по такой логике. Написать такое можно и круто, но остается тот же вопрос, что и в предыдущем посте.
Называются они cloud-agnostic. Про таких либо говорят, что они не привязаны к одному вендору, либо что они абсолютно универсальны и совместимы с любым провайдером.
Взять например тот же Terraform, который гордо нес звание cloud-agnostic инструмента для развертывания систем на любом провайдере. Много раз я слышал, что он позволяет не привязываться к одному провайдеру, а "просто развернуть инфраструктуру в другом облаке". Это, разумеется, не работает.
Многоплатформенность TF обеспечивается провайдерами, провайдеры - интерфейс-обвязка между декларативной инструкцией Terraform и API облачного поставщика. Действительно, вы можете сменить значение провайдера с одного на другое, но вдобавок придется переписать декларации всех ресурсов, поскольку атрибуты тоже отличаются.
Как результат, из cloud-agnostic у Terraform только его DSL.
По-настоящему cloud-agnostic решение будет автоматически определять, с каким облаком оно будет работать, и подключаться к нужным сервисам тоже само. AWS? DDB, Aurora и т.д. GCP? BigTable и Spanner и пр.
Ну и дальше по такой логике. Написать такое можно и круто, но остается тот же вопрос, что и в предыдущем посте.
Иногда бывает потребность делиться короткими мыслями и иметь обратную связь, в связи с чем вопрос: заводить вязаный твитер? И если заводить, будете его читать?
Anonymous Poll
25%
Да, буду.
75%
Нет, не буду.
30-ого числа у меня будет возможность послушать очень интересный доклад про AWS.
Рассказывать его будет инженер, проработавший на Проекте задолго до того, как до этого Проекта добрался я.
Страсть как хочется сравнить его историю с тем, что я увидел, когда заступил на новую должность.
Рассказывать его будет инженер, проработавший на Проекте задолго до того, как до этого Проекта добрался я.
Страсть как хочется сравнить его историю с тем, что я увидел, когда заступил на новую должность.
Когда вы работаете с большими нагрузками в AWS, возникает потребность иметь перед глазами простую визуализацию.
У AWS есть инструмент под названием CloudFormation Designer, который может генерировать шаблон из интерактивной карты и наоборот. Аналогичный функционал выкатил LucidChart, модифицировав его в поддержку сторонних провайдеров. Очень круто и удобно (если не считать того, что нужно какому-то левому приложению на левом сервере давать доступ к своему аккаунту). Все это имеет свои ограничения и не может покрыть всех требований.
И вот под фанфары сам вендор выкатывает новое прекрасное решение, разработанное в закромах AWSLabs. Бросая все, я бегу на сайт имплементации и вижу квинтессенцию шуток про запуск Wordpress на облаке Амазона.
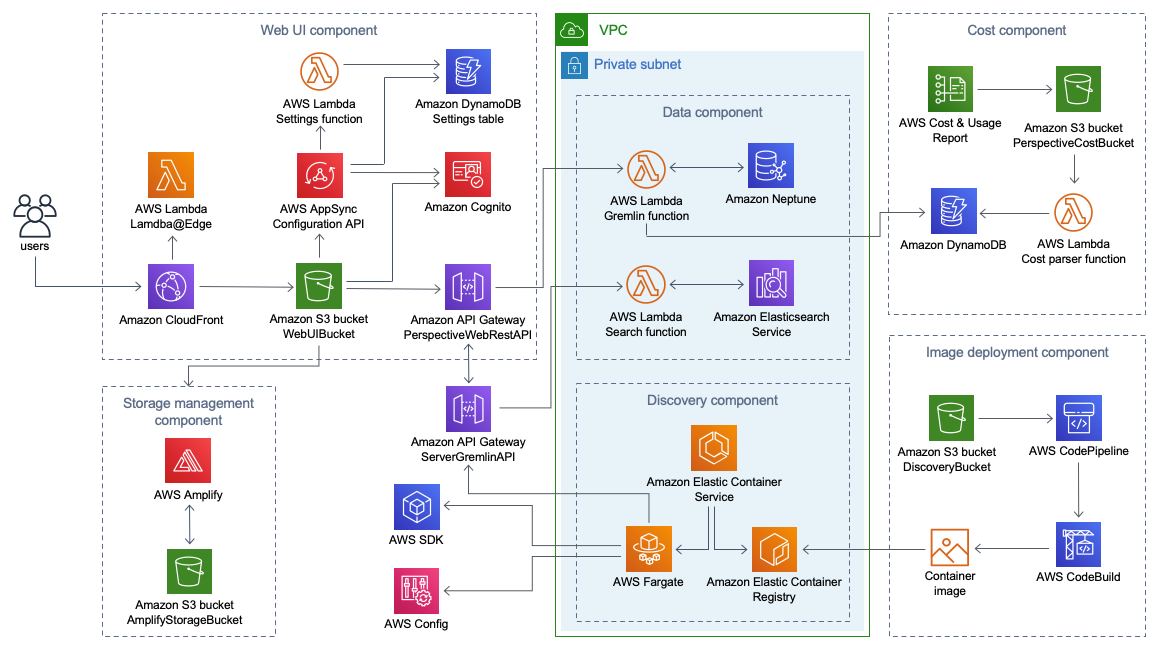
Итого, для того чтобы получить визуализацию моей нагрузки мне понадобятся: CDN (но... зачем?), GraphQL и RESTful API, IdP, пачка Lambda-функций, графовая база данных Neptune, контейнерная оркестрация с набором задач, build система (?!), AWS Config, DynamoDB и что еще я не разглядел на этой картинке.
Ну то есть, чтобы получить видимость большой инфраструктуры, мне нужна еще одна большая инфраструктура. 👍
У AWS есть инструмент под названием CloudFormation Designer, который может генерировать шаблон из интерактивной карты и наоборот. Аналогичный функционал выкатил LucidChart, модифицировав его в поддержку сторонних провайдеров. Очень круто и удобно (если не считать того, что нужно какому-то левому приложению на левом сервере давать доступ к своему аккаунту). Все это имеет свои ограничения и не может покрыть всех требований.
И вот под фанфары сам вендор выкатывает новое прекрасное решение, разработанное в закромах AWSLabs. Бросая все, я бегу на сайт имплементации и вижу квинтессенцию шуток про запуск Wordpress на облаке Амазона.
Итого, для того чтобы получить визуализацию моей нагрузки мне понадобятся: CDN (но... зачем?), GraphQL и RESTful API, IdP, пачка Lambda-функций, графовая база данных Neptune, контейнерная оркестрация с набором задач, build система (?!), AWS Config, DynamoDB и что еще я не разглядел на этой картинке.
Ну то есть, чтобы получить видимость большой инфраструктуры, мне нужна еще одна большая инфраструктура. 👍
{kind=link}
Собственно вот не так давно заведенный Твиттер. Туда я буду писать короткие и внезапные мысли (и не только рабочие), а также выкладывать ссылки на свои посты тут и на Медиум. Вестись он будет на английском, но русским брезговать не собираюсь. 🙂
Вдобавок, то чего не ждали ни вы, ни даже я - 5ая глава глубокого погружения в AWS IAM.
Как получить ключи доступа в AWS при наличии аккаунта в Google? Как использовать тэги для тонкой настройки доступа к ресурсам? Зачем версионировать политики? В этой главе я отвечаю на эти и другие вопросы.
Вдобавок, то чего не ждали ни вы, ни даже я - 5ая глава глубокого погружения в AWS IAM.
Как получить ключи доступа в AWS при наличии аккаунта в Google? Как использовать тэги для тонкой настройки доступа к ресурсам? Зачем версионировать политики? В этой главе я отвечаю на эти и другие вопросы.
Дорогие читатели, я рад сообщить, что мне официально был присужден статус APN Ambassador.
Что это означает? Из хорошего - будет много контента. Правда контент будет в большой степени про AWS. Из очень хорошего - мне выделили необходимых ресурсов, чтобы я мог экспериментировать!
Пишите мне в вязанный свитер, какие хитровыделанные вещи вы хотели попробовать сделать на AWS, но стесняетесь попасть на неприятно большой счет!
Самое хитрое, интересное и стремное (но про то, что можно и написать) будет мною изучено, развернуто и описано.
Со всеми регалиями тому безумцу, в чьей голове эта идея и родилась. 🙂
Что это означает? Из хорошего - будет много контента. Правда контент будет в большой степени про AWS. Из очень хорошего - мне выделили необходимых ресурсов, чтобы я мог экспериментировать!
Пишите мне в вязанный свитер, какие хитровыделанные вещи вы хотели попробовать сделать на AWS, но стесняетесь попасть на неприятно большой счет!
Самое хитрое, интересное и стремное (но про то, что можно и написать) будет мною изучено, развернуто и описано.
Со всеми регалиями тому безумцу, в чьей голове эта идея и родилась. 🙂
{kind=link}
Вчера на докладе прозвучал вопрос про ситуации с самобичеванием, мол я сегодня недостаточно хорошо работал, значит отдыхать тоже не буду.
В условиях пандемии это особенно проявляется с теми, кто работает из дома. Можно сказать, что это мутировавший рудимент Синдрома Самозванца с щепоткой Чувства Вины и нотками Прокрастинации.
Или обычный трудоголизм.
Я тогда предложил прочитать статью на Форбс, как раз посвященную трудоголизму у "детей 90-х".
Своим приятелям и друзьям, кто обращается ко мне с похожей жалобой, я делаю простое замечание: "Мертвецы и больные карьеру не строят."
По своему опыту - моя карьера пошла наверх ровно в тот момент, когда я наладил режим работы и отдыха.
В условиях пандемии это особенно проявляется с теми, кто работает из дома. Можно сказать, что это мутировавший рудимент Синдрома Самозванца с щепоткой Чувства Вины и нотками Прокрастинации.
Или обычный трудоголизм.
Я тогда предложил прочитать статью на Форбс, как раз посвященную трудоголизму у "детей 90-х".
Своим приятелям и друзьям, кто обращается ко мне с похожей жалобой, я делаю простое замечание: "Мертвецы и больные карьеру не строят."
По своему опыту - моя карьера пошла наверх ровно в тот момент, когда я наладил режим работы и отдыха.
Forbes.ru
Трудоголики, перфекционисты и невротики. Как менталитет 90-х повлиял на то, что мы все выгорели
Почему «дети 90-х» не умеют отдыхать, работают до нервных срывов и не могут справиться с болезненным перфекционизмом? А главное, при чем тут детские сериалы? Коуч трудоголиков Ольга Полищук рассказывает, почему это поколение успело выгореть уже к 30-
Вопрос амазонщикам: про что писать следующий Deep Dive?
Если хочется оба - можно оба, но первым в работу уйдет набравший больше всего голосов сервис.
Если хочется оба - можно оба, но первым в работу уйдет набравший больше всего голосов сервис.
Anonymous Poll
45%
Amazon Aurora
66%
Amazon DynamoDB
Сдал только что AWS Certified Database - Specialty.
Ожидание:
- Тонкая настройка Read Replicas
- Рассчитать консистентность Aurora Global Database в разных сценариях
- Всякий high load с моделированием данных
Реальность:
- Как подружить корпоративный AD с MS SQL Server
- Как затолкать Oracle в AWS
- RDS
- RDS
- DynamoDB
- DynamoDB
- DynamoDB
- DynamoDB
- Еще DynamoDB
Ну раз хотите динаму, будет вам динама!
Автор уходит на отдых и скоро вернется с первой главой Amazon DynamoDB Deep Dive.
Ожидание:
- Тонкая настройка Read Replicas
- Рассчитать консистентность Aurora Global Database в разных сценариях
- Всякий high load с моделированием данных
Реальность:
- Как подружить корпоративный AD с MS SQL Server
- Как затолкать Oracle в AWS
- RDS
- RDS
- DynamoDB
- DynamoDB
- DynamoDB
- DynamoDB
- Еще DynamoDB
Ну раз хотите динаму, будет вам динама!
Автор уходит на отдых и скоро вернется с первой главой Amazon DynamoDB Deep Dive.
Не поймите неправильно, я очень люблю Скрам как идею. Есть группа мульти-кросс-гиперфункциональных людей, которая за спринт заносят всякие ништячки заказчику.
Повторюсь, затея - космос. Есть только ряд недостатков: под заказную разработку либо неэффективно, либо избыточно; под инфраструктурные проекты не подходит, под большие организации тоже (можно тащить SAFe, но это очень дорого).
Да и мульти-кросс-гиперфункциональных людей (этакие Т-shape на стероидах) на рынке нет от слова совсем, надо перекупать у конкурентов. А наберете вы очень дорогих спецов, сверху еще потратив на их поиск и выкуп… Наверняка захотите на серьезный инфраструктурный внутряк или core business.
Что я понял из опыта - Скрам с его спринтами хорошо работает только для небольших проектов строго на микросервисах (где изменение завозится в течение пары недель), либо на молодых продуктах, судьба которых не определена. Инфраструктурщина и системная инженерия лучше работает по Канбану, причем по формуле “Это будет сделано, когда будет сделано.”
С адекватными и честными сроками, разумеется.
Повторюсь, затея - космос. Есть только ряд недостатков: под заказную разработку либо неэффективно, либо избыточно; под инфраструктурные проекты не подходит, под большие организации тоже (можно тащить SAFe, но это очень дорого).
Да и мульти-кросс-гиперфункциональных людей (этакие Т-shape на стероидах) на рынке нет от слова совсем, надо перекупать у конкурентов. А наберете вы очень дорогих спецов, сверху еще потратив на их поиск и выкуп… Наверняка захотите на серьезный инфраструктурный внутряк или core business.
Что я понял из опыта - Скрам с его спринтами хорошо работает только для небольших проектов строго на микросервисах (где изменение завозится в течение пары недель), либо на молодых продуктах, судьба которых не определена. Инфраструктурщина и системная инженерия лучше работает по Канбану, причем по формуле “Это будет сделано, когда будет сделано.”
С адекватными и честными сроками, разумеется.
Кого не пугает английский язык, приходите на AWS Community Day Amsterdam.
Я и остальные Летучие Голландцы будут там вещать.
Я и остальные Летучие Голландцы будут там вещать.
AWS Community Day NL 2025
Join us on September 24, 2025 for a full day conference in Kinepolis Jaarbeurs Utrecht with a variety of keynotes & breakout sessions for business & tech.
Ваше воскресное чтиво - первая ступень в нашем глубоком погружении в Amazon DynamoDB.
Что есть DynamoDB, в чем ее отличие от других NoSQL СУБД, как создать таблицу и что-то в нее записать - в этом обзорном материале.
Для смелых духом и опытных амазонщиков этот пост покажется излишне легким, но вам остается лишь чуть-чуть подождать.
Дальше будет гораздо сложнее и больше.
Что есть DynamoDB, в чем ее отличие от других NoSQL СУБД, как создать таблицу и что-то в нее записать - в этом обзорном материале.
Для смелых духом и опытных амазонщиков этот пост покажется излишне легким, но вам остается лишь чуть-чуть подождать.
Дальше будет гораздо сложнее и больше.
Medium
Amazon DynamoDB Deep Dive. Chapter 1: Essentials
The walkthrough of the one of the world’s fastest databases in a human-friendly format
Forwarded from anykeynotes
Я еще тут. И хочу поговорить с вами про аутсорсинг.
https://telegra.ph/Pro-greblyu-na-galerah-10-12
https://telegra.ph/Pro-greblyu-na-galerah-10-12
Telegraph
Про греблю на галерах
Галеры Что такое галера? Сленговое название аутсорсинга - галера. Работают на ней гребцы. Гребцы - потому что знаний не требуется, требуется много кода, плейбуков, чартов и так далее. Аутсорсинг - классическое определение Аутсо́рсинг — передача организацией…
Немного контекста: у меня с Мишей (@anykeynotes) был недавно разговор про работу в аутсорсе, который стал его постом выше. Продолжением беседы будет мой ему ответ.
Отвечать на весь пост смысла нет, буду выделять наиболее интересные для меня куски.
Говорить за всех аутсорсеров не берусь, использую только свои условия, информацию, которой владею, и говорю только о своем работодателе. Вместо слова “галера” я буду применять “консалтинг”, коим EPAM de facto и является.
Мнение, разумеется, только мое, и говорю я только от своего имени.
“Весь бизнес компании строится на том, что клиенту вас как сотрудника продают с наценкой, …”
Не совсем. У консалтинга есть определенное портфолио проектов с экспертизой в разных областях бизнеса. Заказчик приходит с запросом “Хочу Х”. Консалтинг “отгрузит” необходимое количество рук и мозгов, которое может реализовать желаемое в определенные сроки. Поскольку требования могут на ходу меняться (мы живем в реальном мире), то договор заключают как раз по месячной работе кадров разных профилей и специализаций. Отсюда и наваждение, что консалтинг это body shop.
“Клиент не оплатил вовремя, клиент долго стартует проект, у клиента кончились деньги и объем проекта уменьшился, у клиента резко сдвинулись сроки в меньшую сторону - всё это риски, которые несёт компания.”
1. Эти риски оговариваются в контракте. 2. Эти же риски могут присутствовать в любом внутреннем проекте большой компании с бюрократией, бюджетами и прочими прелестями enterprise-сектора. Смотрим “кладбище Google”.
“Единственная возможность хэджировать риски - набрать проектов больше. Пока заканчиваем один, стартуем другой.”
Не класть все яйца в одну корзину вполне логично, но ни один менеджер не станет назначать 100% billable сотрудника на несколько проектов. В теории, я могу договориться о работе на нескольких проектах одновременно (двух или трех), что приведет к тому… что я не буду работать ни на одном. Это не принесет пользы ни мне, ни работодателю, ни заказчику.
Для того, чтобы иметь возможность быстро подхватить проект, у консалтинга есть определенный пул незанятых людей.
“Единственный риск, который компания не может хэджировать - сроки сдачи проекта. Овертаймы в аутсорсинге будут всегда.”
Вздор. Срок контракта != Срок сдачи проекта. Если в проекте меняются или появляются новые требования, сроки сдачи всегда пересматриваются, и нормальный заказчик на это идет.
Другое дело, когда требования не изменились, а срок сдачи нарушается из-за архитектурных, управленческих или прочих ошибок. В таком случае переработки возможны, они всегда оплачиваются либо отгулом, либо деньгами, либо консалтинг закидывает дополнительных людей (заказчик за них не платит).
“Приёмосдаточные испытания лишь фикция, решения о принятии в эксплуатацию принимается где-то наверху и в этот момент должна работать лишь красивая дашборда, что там за ней никого не волнует.”
Действительно, решение о выходе в промышленную эксплуатацию принимает program/project board (ну а кто же еще). Это решение принимается на основе десятков ПМИ - performance test, dry-run и прочих, которые являются маркерами technical readiness.
Вдобавок есть еще operational readiness, при котором эксплуатация заказчика подписывается под тем, что готова обслуживать проект на первой и второй линии поддержи. Эксплуатация, к слову, хоть и не является членом program board и по сути обладает правом Вето.
—
Дальше идет то, что я просил Мишу раскрыть, а именно так называемое “галерное мышление”. Про это поговорим чуть позже.
Отвечать на весь пост смысла нет, буду выделять наиболее интересные для меня куски.
Говорить за всех аутсорсеров не берусь, использую только свои условия, информацию, которой владею, и говорю только о своем работодателе. Вместо слова “галера” я буду применять “консалтинг”, коим EPAM de facto и является.
Мнение, разумеется, только мое, и говорю я только от своего имени.
“Весь бизнес компании строится на том, что клиенту вас как сотрудника продают с наценкой, …”
Не совсем. У консалтинга есть определенное портфолио проектов с экспертизой в разных областях бизнеса. Заказчик приходит с запросом “Хочу Х”. Консалтинг “отгрузит” необходимое количество рук и мозгов, которое может реализовать желаемое в определенные сроки. Поскольку требования могут на ходу меняться (мы живем в реальном мире), то договор заключают как раз по месячной работе кадров разных профилей и специализаций. Отсюда и наваждение, что консалтинг это body shop.
“Клиент не оплатил вовремя, клиент долго стартует проект, у клиента кончились деньги и объем проекта уменьшился, у клиента резко сдвинулись сроки в меньшую сторону - всё это риски, которые несёт компания.”
1. Эти риски оговариваются в контракте. 2. Эти же риски могут присутствовать в любом внутреннем проекте большой компании с бюрократией, бюджетами и прочими прелестями enterprise-сектора. Смотрим “кладбище Google”.
“Единственная возможность хэджировать риски - набрать проектов больше. Пока заканчиваем один, стартуем другой.”
Не класть все яйца в одну корзину вполне логично, но ни один менеджер не станет назначать 100% billable сотрудника на несколько проектов. В теории, я могу договориться о работе на нескольких проектах одновременно (двух или трех), что приведет к тому… что я не буду работать ни на одном. Это не принесет пользы ни мне, ни работодателю, ни заказчику.
Для того, чтобы иметь возможность быстро подхватить проект, у консалтинга есть определенный пул незанятых людей.
“Единственный риск, который компания не может хэджировать - сроки сдачи проекта. Овертаймы в аутсорсинге будут всегда.”
Вздор. Срок контракта != Срок сдачи проекта. Если в проекте меняются или появляются новые требования, сроки сдачи всегда пересматриваются, и нормальный заказчик на это идет.
Другое дело, когда требования не изменились, а срок сдачи нарушается из-за архитектурных, управленческих или прочих ошибок. В таком случае переработки возможны, они всегда оплачиваются либо отгулом, либо деньгами, либо консалтинг закидывает дополнительных людей (заказчик за них не платит).
“Приёмосдаточные испытания лишь фикция, решения о принятии в эксплуатацию принимается где-то наверху и в этот момент должна работать лишь красивая дашборда, что там за ней никого не волнует.”
Действительно, решение о выходе в промышленную эксплуатацию принимает program/project board (ну а кто же еще). Это решение принимается на основе десятков ПМИ - performance test, dry-run и прочих, которые являются маркерами technical readiness.
Вдобавок есть еще operational readiness, при котором эксплуатация заказчика подписывается под тем, что готова обслуживать проект на первой и второй линии поддержи. Эксплуатация, к слову, хоть и не является членом program board и по сути обладает правом Вето.
—
Дальше идет то, что я просил Мишу раскрыть, а именно так называемое “галерное мышление”. Про это поговорим чуть позже.
Продолжим. Автор сделал два важных тезиса:
- Инженер неизбежно деградирует и отказывается улучшать решение.
- Архитектор/Менеджер неизбежно деградирует и теряет мягкие скиллы
Тут надо учитывать важный момент, а именно: никто не предлагает делать свою работу плохо. А если человек осознанно делает свою работу плохо, то в консалтинге к нему применяются те же методы стимуляции, что и в других компаниях.
Второе, на что стоит обращать внимание, это почему решение неэффективное. Со стороны удобно бросаться замечаниями о плохой/кривой/немасштабируемой/и т.д. архитектуре/инфраструктуре (чем ваш покорный очень любит заниматься), но стоит начать копаться в истории, так сразу всплывают всевозможные trade off’ы и ограничения, которых избежать не удалось.
Третье - завышенное ЧСВ и эго не имеет никакого отношения к сфере, в которой работает человек, и более того - подход “я - начальник, ты - дурак” присутствовал и до сих присутствует во всевозможного вида конторах. Честности ради, у себя на проекте я его не наблюдаю, но зовите меня выжившим с ошибками.
У консалтинга по факту есть два минуса. Очень серьезных минуса, о которых мало кто знает.
Во-первых, невсегда идет правильная работа с заказчиком. Используется подход “любой каприз за ваши деньги”, хотя по-хорошему заказчику нужно коммуницировать все риски и последствия тех или иных решений - с цифрами и альтернативным решением. Впрочем, сговорчивые и либерально настроенные заказчики попадаются гораздо чаще упертых и принципиальных.
Во-вторых, при проектной работе часто присутствует жесткий стек технологий, который в консалтинге знает многие (чтобы ускорить onboarding новых людей на проект). Это ограничивает творческую свободу инженеров, которые хотят изучать и применять ту или иную хайповую технологию, но вынуждены ковыряться в legacy.
Хотя legacy и в продукте хватает.
- Инженер неизбежно деградирует и отказывается улучшать решение.
- Архитектор/Менеджер неизбежно деградирует и теряет мягкие скиллы
Тут надо учитывать важный момент, а именно: никто не предлагает делать свою работу плохо. А если человек осознанно делает свою работу плохо, то в консалтинге к нему применяются те же методы стимуляции, что и в других компаниях.
Второе, на что стоит обращать внимание, это почему решение неэффективное. Со стороны удобно бросаться замечаниями о плохой/кривой/немасштабируемой/и т.д. архитектуре/инфраструктуре (чем ваш покорный очень любит заниматься), но стоит начать копаться в истории, так сразу всплывают всевозможные trade off’ы и ограничения, которых избежать не удалось.
Третье - завышенное ЧСВ и эго не имеет никакого отношения к сфере, в которой работает человек, и более того - подход “я - начальник, ты - дурак” присутствовал и до сих присутствует во всевозможного вида конторах. Честности ради, у себя на проекте я его не наблюдаю, но зовите меня выжившим с ошибками.
У консалтинга по факту есть два минуса. Очень серьезных минуса, о которых мало кто знает.
Во-первых, невсегда идет правильная работа с заказчиком. Используется подход “любой каприз за ваши деньги”, хотя по-хорошему заказчику нужно коммуницировать все риски и последствия тех или иных решений - с цифрами и альтернативным решением. Впрочем, сговорчивые и либерально настроенные заказчики попадаются гораздо чаще упертых и принципиальных.
Во-вторых, при проектной работе часто присутствует жесткий стек технологий, который в консалтинге знает многие (чтобы ускорить onboarding новых людей на проект). Это ограничивает творческую свободу инженеров, которые хотят изучать и применять ту или иную хайповую технологию, но вынуждены ковыряться в legacy.
Хотя legacy и в продукте хватает.
Я тут только прочитал блог на тему WET - антонима DRY, который означает Write Everything Twice.
Совпадение или нет, но он написан фронтендером.
Совпадение или нет, но он написан фронтендером.
Вчера AWS выпустил Origin Shield для CloudFront - своей услуги CDN. Из названия мне показалось, что речь про некий экран, который позволит пользователю получать контент только от узлов CDN, блокируя трафик до origin, но на деле нововведение оказалось гораздо полезнее.
Origin Shield имплементирует дополнительный уровень кеширования, который позволит Edge локациям (географически распределенные точки присутствия CloudFront) обновлять свой локальный кеш не из origin, а непосредственно из этого слоя.
Иными словами, если вы расположились в eu-west-1 и настроили CloudFront на раздачу по всему миру, то все Edge локации будут запрашивать контент у ваших серверов в eu-west-1, тем самым создавая серьезную нагрузку на ваш origin. В случае с Origin Shield обновление кеша будет запрашиваться непосредственно с узлов CloudFront в eu-west-1, и только локальный CloudFront будет “мучать” ваш origin.
Такое решение лучше всего подходит для динамического контента, такого как видеостриминг. Имплементация единого слоя кеширования позволит уменьшить затраты на вычислительные мощности origin’ов или перенаправив их в другое русло, хоть на то же транскодирование видеоконтента.
Важно! Имейте в виде, что Origin Shield имеет добавочную стоимость, так что прежде чем радостно ставить галочку в консоли CloudFront сравните расходы на трафик с Origin Shield с трафиком и ценой на compute origin’а.
А то будете потом писать мне, что клавды клятые вас грабят.
Origin Shield имплементирует дополнительный уровень кеширования, который позволит Edge локациям (географически распределенные точки присутствия CloudFront) обновлять свой локальный кеш не из origin, а непосредственно из этого слоя.
Иными словами, если вы расположились в eu-west-1 и настроили CloudFront на раздачу по всему миру, то все Edge локации будут запрашивать контент у ваших серверов в eu-west-1, тем самым создавая серьезную нагрузку на ваш origin. В случае с Origin Shield обновление кеша будет запрашиваться непосредственно с узлов CloudFront в eu-west-1, и только локальный CloudFront будет “мучать” ваш origin.
Такое решение лучше всего подходит для динамического контента, такого как видеостриминг. Имплементация единого слоя кеширования позволит уменьшить затраты на вычислительные мощности origin’ов или перенаправив их в другое русло, хоть на то же транскодирование видеоконтента.
Важно! Имейте в виде, что Origin Shield имеет добавочную стоимость, так что прежде чем радостно ставить галочку в консоли CloudFront сравните расходы на трафик с Origin Shield с трафиком и ценой на compute origin’а.
А то будете потом писать мне, что клавды клятые вас грабят.
Amazon
Announcing Amazon CloudFront Origin Shield - AWS
Discover more about what's new at AWS with Announcing Amazon CloudFront Origin Shield
#машины_разное
Как немногие из вас знают, я большой поклонник баз данных. А с недавних пор еще и поклонник того, что творится в их внутренностях.
Внутри СУБД реализован компонент под названием page cache (он же buffer pool, он же buffer cache - в разных СУБД и в разные времена оно называется по-разному, но суть та же). В это быстрое (потому что в памяти) и временное хранилище попадает транзакция, прежде чем закрепиться в бинарном логе, а затем уже и в файле данных на диске.
Page Cache во многих СУБД имплементирует ту самую комбинацию кеширований Lazy Loading и Write-Through. Свежий INSERT/UPDATE считается оттуда - Write-Through. SELECT, пришедший из диска, ляжет в него - Lazy Loading.
Однако читатели, сведущие во внутренностях *nix-подобных заметят - page cache присутствует не только в СУБД, он есть еще и в ОС! И будут совершенно правы. Linux kernel тоже кеширует page из диска в свободную оперативную память, чтобы эффективнее выполнять операции ввода/вывода (IO).
СУБД общается с хранилищем через Storage Engine, тот обращается к диску через VFS. Получается, что запрос от клиента идет по следующей цепочке: RDBMS Page Cache → OS Page Cache → Disk.
Совсем неэффективно, плюс дупликация информации, если один и тот же page хранится в кешах и СУБД, и ОС. Как же быть?
Вот здесь получился конфликт. Разработчики СУБД решили, что кеширование ОС им не нужно, и делают запросы в диск с использованием флага
Как немногие из вас знают, я большой поклонник баз данных. А с недавних пор еще и поклонник того, что творится в их внутренностях.
Внутри СУБД реализован компонент под названием page cache (он же buffer pool, он же buffer cache - в разных СУБД и в разные времена оно называется по-разному, но суть та же). В это быстрое (потому что в памяти) и временное хранилище попадает транзакция, прежде чем закрепиться в бинарном логе, а затем уже и в файле данных на диске.
Page Cache во многих СУБД имплементирует ту самую комбинацию кеширований Lazy Loading и Write-Through. Свежий INSERT/UPDATE считается оттуда - Write-Through. SELECT, пришедший из диска, ляжет в него - Lazy Loading.
Однако читатели, сведущие во внутренностях *nix-подобных заметят - page cache присутствует не только в СУБД, он есть еще и в ОС! И будут совершенно правы. Linux kernel тоже кеширует page из диска в свободную оперативную память, чтобы эффективнее выполнять операции ввода/вывода (IO).
СУБД общается с хранилищем через Storage Engine, тот обращается к диску через VFS. Получается, что запрос от клиента идет по следующей цепочке: RDBMS Page Cache → OS Page Cache → Disk.
Совсем неэффективно, плюс дупликация информации, если один и тот же page хранится в кешах и СУБД, и ОС. Как же быть?
Вот здесь получился конфликт. Разработчики СУБД решили, что кеширование ОС им не нужно, и делают запросы в диск с использованием флага
O_DIRECT, который говорит ядру: "Не смотри в своем кеше, отправь меня сразу в диск." Разумеется, одному финну это не понравилось, но консенсус не найден и вряд ли будет.