
//АйТи интерн pinned «IT - наш потерянный табель о рангах. Не люблю канал "Русские норм", но иногда там достойные гости. Их новый выпуск про IT - https://www.youtube.com/watch?v=qlZmGV4QMhs Такое количество героев и их конкурентоспособность доказывает, что наши способности в…»
Что я хотел бы знать об IT в 20 лет. Максим Дорофеев.
Этот доклад был сделан им более 8 лет назад, но он до сих пор актуален для начинающих программистов.
https://www.youtube.com/watch?v=fY8hhOv7lmE
Максим Дорофеев проработал более 15 лет в различных IT компаниях до того как начать писать книги про продуктивность.
Этот доклад был сделан им более 8 лет назад, но он до сих пор актуален для начинающих программистов.
https://www.youtube.com/watch?v=fY8hhOv7lmE
Максим Дорофеев проработал более 15 лет в различных IT компаниях до того как начать писать книги про продуктивность.
YouTube
Что я хотел бы знать об IT в 20 лет. Максим Дорофеев
Enjoy the videos and music you love, upload original content, and share it all with friends, family, and the world on YouTube.
👍7
Игра в найм.
Недавно перечитал пост про субъективность собеседования - https://t.iss.one/it_intern/57
Понял, что этот тезис не потеряет своей актуальности еще очень долго. У меня появилась новая история, которая это подтверждает. Собеседования - это субъективный процесс, результаты которого могут отличаться от компании к компании.
Год назад я решил менять работу. Я не готовился и был очень уверен в себе. После первого собеседования моя корона слетела. Да, вопросы были странные и очень теоретические, но это моя вина, что к тому я был не готов. В другие компании я проходил собеседования лучше и получил 6 офферов (не считая внутренних офферов на удержание).
Мы можем сделать мысленный эксперимент (но все же поняли, что это реальная история, да?). Давайте представим, что интервьюер с моего первого собеседования проходит собеседование в компанию, в которую я прошел с прекрасными результатами. Он может пройти его хуже, а может и завалить. Но может пройти так же хорошо, как бы он прошел свое собеседник в свою компанию.
Это и есть та самая субъективность процесса найма и вероятность попасть или не попасть в вопросы. Есть два способа снизить субъективность.
Первый - иметь очень большой, глубокий и разнообразный опыт, который позволит отвечать на все вопросы. Для этого нужно время. Это лучший способ быть готовым почти ко всему.
Второй - играть по правилам собеседований. Это игра, в которую играют обе стороны. Для игры по этим правилам нужно актуализировать свои знания, подготовиться к ответам на типичные вопросы и понять принципы решения задач.
Я не могу однозначно сказать плох ли второй вариант для ищущих работу и нанимающих компаний. Все относительно. Есть плюсы и минусы для обеих сторон. Можно поразмышлять об этом в отдельном посте.
Для себя я выбираю второй способ с постоянным стремлением перейти к первому. Сейчас я где-то посередине.
Успехов!
#собеседования #поиск_работы
Недавно перечитал пост про субъективность собеседования - https://t.iss.one/it_intern/57
Понял, что этот тезис не потеряет своей актуальности еще очень долго. У меня появилась новая история, которая это подтверждает. Собеседования - это субъективный процесс, результаты которого могут отличаться от компании к компании.
Год назад я решил менять работу. Я не готовился и был очень уверен в себе. После первого собеседования моя корона слетела. Да, вопросы были странные и очень теоретические, но это моя вина, что к тому я был не готов. В другие компании я проходил собеседования лучше и получил 6 офферов (не считая внутренних офферов на удержание).
Мы можем сделать мысленный эксперимент (но все же поняли, что это реальная история, да?). Давайте представим, что интервьюер с моего первого собеседования проходит собеседование в компанию, в которую я прошел с прекрасными результатами. Он может пройти его хуже, а может и завалить. Но может пройти так же хорошо, как бы он прошел свое собеседник в свою компанию.
Это и есть та самая субъективность процесса найма и вероятность попасть или не попасть в вопросы. Есть два способа снизить субъективность.
Первый - иметь очень большой, глубокий и разнообразный опыт, который позволит отвечать на все вопросы. Для этого нужно время. Это лучший способ быть готовым почти ко всему.
Второй - играть по правилам собеседований. Это игра, в которую играют обе стороны. Для игры по этим правилам нужно актуализировать свои знания, подготовиться к ответам на типичные вопросы и понять принципы решения задач.
Я не могу однозначно сказать плох ли второй вариант для ищущих работу и нанимающих компаний. Все относительно. Есть плюсы и минусы для обеих сторон. Можно поразмышлять об этом в отдельном посте.
Для себя я выбираю второй способ с постоянным стремлением перейти к первому. Сейчас я где-то посередине.
Успехов!
#собеседования #поиск_работы
Telegram
//АйТи интерн
Собеседование без оффера.
Хорошо пройти собеседование и не получить оффер - нередкая ситуация в процессе поиска работы.
Найм нового сотрудника - субъективный процесс со всеми вытекающими. Вы можете пройти техническую часть Вашего интервью, но не исключено…
Хорошо пройти собеседование и не получить оффер - нередкая ситуация в процессе поиска работы.
Найм нового сотрудника - субъективный процесс со всеми вытекающими. Вы можете пройти техническую часть Вашего интервью, но не исключено…
🔥6👍2
Стажировки.
Весенний семестр - это лучшее время для старта своей карьеры в IT. Он маленький, а впереди лето, во время которого можно сфокусироваться на работе.
Сформировал для вас поисковый запрос для поиска стажировок на HH - https://spb.hh.ru/search/vacancy?area=2&area=1&area=2019&employment=probation&employment=full&search_field=name&search_field=company_name&search_field=description&industry=7&text=%D1%81%D1%82%D0%B0%D0%B6%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0
Есть очень интересные стажировки во многих областях - фронт, бек, ML, DevOps. Есть даже R&D позиции. Есть фулл-тайм и есть парт-тайм вакансии.
Если вы хотите опубликовать вашу вакансию, то пишете нам на @it_intern_creator
#вакансии
@it_intern
Весенний семестр - это лучшее время для старта своей карьеры в IT. Он маленький, а впереди лето, во время которого можно сфокусироваться на работе.
Сформировал для вас поисковый запрос для поиска стажировок на HH - https://spb.hh.ru/search/vacancy?area=2&area=1&area=2019&employment=probation&employment=full&search_field=name&search_field=company_name&search_field=description&industry=7&text=%D1%81%D1%82%D0%B0%D0%B6%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0
Есть очень интересные стажировки во многих областях - фронт, бек, ML, DevOps. Есть даже R&D позиции. Есть фулл-тайм и есть парт-тайм вакансии.
Если вы хотите опубликовать вашу вакансию, то пишете нам на @it_intern_creator
#вакансии
@it_intern
spb.hh.ru
Работа в Санкт-Петербурге, поиск персонала и публикация вакансий - spb.hh.ru
spb.hh.ru — сервис, который помогает найти работу и подобрать персонал в Санкт-Петербурге более 20 лет! Создавайте резюме и откликайтесь на вакансии. Набирайте сотрудников и публикуйте вакансии.
🔥7
Распределенный вперед.
Стажеру или джуну простят незнание архитектуры, но сеньору - никогда. Понимание принципов построения архитектуры поможет разобраться быстрее в проектах, над которыми вам предстоит работать. А понимание терминов поможет говорить с командой на одном языке и сэкономить кучу времени.
На третий месяц своей первой работы в крупной компании я дебажил одну сложную проблему развертки приложения. Я его не писал, но мне нужно было с ним работать. После его запуска происходила запись данных, но это всегда завершалось ошибкой.
Я потратил несколько дней на эту проблему, а потом подошел к своему тимлиду и он сказал: “так у тебя 2 мастера, это split brain, нет консенсуса, пофикси.” Понятнее тогда мне не стало, но я узнал о совершенно новом для себя пласте проблем после часа общения с гуглом.
Этот пласт - отказоустойчивые распределенные системы. Конечно, отказоустойчивость относится не только к распределенным системам, но я не мог ее не упомянуть. Во-первых, приложение методов и практик построения отказоустойчивых решений напрямую относятся к распределенным системам. А во-вторых, я про это писал диплом. Зря что ли?
Известный и признанный исследователь Мартин Клеппман определяет распределенную систему как систему, в которой множество узлов (компьютеры, телефоны, сервера, роботы, и т.д.) выполняют какую-то вычислительную задачу вместе, взаимодействуя друг с другом по коммуникационной сети.
Он также написал всемирно известную книгу “Designing Data-Intensive Applications” про создание больших, производительных и поддерживаемых систем. По-русски книжка называется “кабанчик”.
Распределенные системы сделали возможным создание надежных и производительных сервисов, обрабатывающих сотни тысяч запросов в секунду, работающих с петабайтами данных и конечно же радующих пользователей.
Этим постом мы открываем серию небольших заметок про распределенные системы и большую тематику постов про архитектуру в целом. В следующий раз мы расскажем про основные проблемы распределенных систем - Split-brain. И методы их решения - Quorum и Fencing.
@it_intern
#архитектура #распределенные_системы
Стажеру или джуну простят незнание архитектуры, но сеньору - никогда. Понимание принципов построения архитектуры поможет разобраться быстрее в проектах, над которыми вам предстоит работать. А понимание терминов поможет говорить с командой на одном языке и сэкономить кучу времени.
На третий месяц своей первой работы в крупной компании я дебажил одну сложную проблему развертки приложения. Я его не писал, но мне нужно было с ним работать. После его запуска происходила запись данных, но это всегда завершалось ошибкой.
Я потратил несколько дней на эту проблему, а потом подошел к своему тимлиду и он сказал: “так у тебя 2 мастера, это split brain, нет консенсуса, пофикси.” Понятнее тогда мне не стало, но я узнал о совершенно новом для себя пласте проблем после часа общения с гуглом.
Этот пласт - отказоустойчивые распределенные системы. Конечно, отказоустойчивость относится не только к распределенным системам, но я не мог ее не упомянуть. Во-первых, приложение методов и практик построения отказоустойчивых решений напрямую относятся к распределенным системам. А во-вторых, я про это писал диплом. Зря что ли?
Известный и признанный исследователь Мартин Клеппман определяет распределенную систему как систему, в которой множество узлов (компьютеры, телефоны, сервера, роботы, и т.д.) выполняют какую-то вычислительную задачу вместе, взаимодействуя друг с другом по коммуникационной сети.
Он также написал всемирно известную книгу “Designing Data-Intensive Applications” про создание больших, производительных и поддерживаемых систем. По-русски книжка называется “кабанчик”.
Распределенные системы сделали возможным создание надежных и производительных сервисов, обрабатывающих сотни тысяч запросов в секунду, работающих с петабайтами данных и конечно же радующих пользователей.
Этим постом мы открываем серию небольших заметок про распределенные системы и большую тематику постов про архитектуру в целом. В следующий раз мы расскажем про основные проблемы распределенных систем - Split-brain. И методы их решения - Quorum и Fencing.
@it_intern
#архитектура #распределенные_системы
O’Reilly Online Learning
Designing Data-Intensive Applications
Data is at the center of many challenges in system design today. Difficult issues need to be figured out, such as scalability, consistency, reliability, efficiency, and... - Selection from Designing Data-Intensive Applications [Book]
👍8❤5
Split-brain, Quorum и Fencing.
Говоря о распределенных системах многие по умолчанию подразумевают, что они должны быть высокодоступны (high availability - HA ) и по возможности еще и отказоустойчивы ( fault tolerance).
Упрощенно высокую доступность можно свести к автоматическому включению в работу запасного ресурса при остановке или проблемах основного. Что-то упало - мы запускаем его другую копию, которая уже должна быть готова к этому.
Допустим у нас есть 3 сервера “A”, “B”, “C” на которых запущены копии одного приложения. Они умеют общаться друг с другом по сети. У этих копий есть основной экземпляр (главноый, main, master) и есть запасные. Другими словами у нас есть кластер какого-то приложения.
Тут сразу же возникают вопросы: сколько копий (по-умному это называется “реплика”) нам нужно запускать, как отличить падение мастера от реплики? Например, у сервера “C” (картиночка ниже отдельным постом) пропал доступ к сети, и он не может коммуницировать с “А” и “B”. При этом запросы в систему приходят на “B” и на одинокий “C” (почему такое возможно обсудим позже).
Это и есть фундаментальная проблема распределенных систем - Split-brain.
Split-brain возникает при расщеплении распределенной системы на несколько частей, которые не могут взаимодействовать друг с другом. Эту проблему должен уметь решать любой софт, который пытается обеспечить HA. Основными методами решения этой проблемы - Quorum и Fencing. Многие инструменты, которые используют разработчики в своей работе, умеют с этим справляться из коробки, но если вы пишите свое кластерное решение, то вам придется это сделать самим.
Это, пожалуй, самая трудная проблема распределенных систем и обеспечения высокой доступности. На практике такая ситуация встречается нечасто, но чаще, чем хотелось бы и тогда когда ты не ждешь 🙂
@it_intern
#архитектура #распределенные_системы
Говоря о распределенных системах многие по умолчанию подразумевают, что они должны быть высокодоступны (high availability - HA ) и по возможности еще и отказоустойчивы ( fault tolerance).
Упрощенно высокую доступность можно свести к автоматическому включению в работу запасного ресурса при остановке или проблемах основного. Что-то упало - мы запускаем его другую копию, которая уже должна быть готова к этому.
Допустим у нас есть 3 сервера “A”, “B”, “C” на которых запущены копии одного приложения. Они умеют общаться друг с другом по сети. У этих копий есть основной экземпляр (главноый, main, master) и есть запасные. Другими словами у нас есть кластер какого-то приложения.
Тут сразу же возникают вопросы: сколько копий (по-умному это называется “реплика”) нам нужно запускать, как отличить падение мастера от реплики? Например, у сервера “C” (картиночка ниже отдельным постом) пропал доступ к сети, и он не может коммуницировать с “А” и “B”. При этом запросы в систему приходят на “B” и на одинокий “C” (почему такое возможно обсудим позже).
Это и есть фундаментальная проблема распределенных систем - Split-brain.
Split-brain возникает при расщеплении распределенной системы на несколько частей, которые не могут взаимодействовать друг с другом. Эту проблему должен уметь решать любой софт, который пытается обеспечить HA. Основными методами решения этой проблемы - Quorum и Fencing. Многие инструменты, которые используют разработчики в своей работе, умеют с этим справляться из коробки, но если вы пишите свое кластерное решение, то вам придется это сделать самим.
Это, пожалуй, самая трудная проблема распределенных систем и обеспечения высокой доступности. На практике такая ситуация встречается нечасто, но чаще, чем хотелось бы и тогда когда ты не ждешь 🙂
@it_intern
#архитектура #распределенные_системы
❤6👍2🔥2
Кабанчик.
Меня спросили про "кабанчика". Кабанчик - это на программистком сленге название книги “Designing Data-Intensive Applications” от Мартина Клеппмана.
Она действительно стала легендарной. Я думаю, что она качественно улучшила и систематизировала знания об архитектуре современных разработчиков. Компании рекомендуют эту книгу для подготовки к архитектурным секциям или указывают ее в обратной связи после собесов.
Ее автор - Мартин Клеппман, ученый-информатик. Работает и читает лекции в Кембриджском университете, исследует распределенные системы. Также он у него есть аккаунт на Патреоне с большим количеством спонсоров. Что очень необычно для такого человека, но это вселяет веру в человечество.
Несколько лет назад я мог посетить конференцию с его участием и лично. У меня был доступ к спикерской зоне, но я поленился ехать, а потом началась корона ;(
Не упускайте возможности!
@it_intern
#архитектура #распределенные_системы #книги
Меня спросили про "кабанчика". Кабанчик - это на программистком сленге название книги “Designing Data-Intensive Applications” от Мартина Клеппмана.
Она действительно стала легендарной. Я думаю, что она качественно улучшила и систематизировала знания об архитектуре современных разработчиков. Компании рекомендуют эту книгу для подготовки к архитектурным секциям или указывают ее в обратной связи после собесов.
Ее автор - Мартин Клеппман, ученый-информатик. Работает и читает лекции в Кембриджском университете, исследует распределенные системы. Также он у него есть аккаунт на Патреоне с большим количеством спонсоров. Что очень необычно для такого человека, но это вселяет веру в человечество.
Несколько лет назад я мог посетить конференцию с его участием и лично. У меня был доступ к спикерской зоне, но я поленился ехать, а потом началась корона ;(
Не упускайте возможности!
@it_intern
#архитектура #распределенные_системы #книги
👍15
Quorum.
В прошлый раз мы говорили о проблеме Split-brain’а. Она происходит, когда распределенная система разделяется на несколько частей. Ее можно решить с помощью Quorum и Fencing.
”Quorum praesentia sufficit - установленное законом, уставом организации или регламентом число участников собрания (заседания), достаточное для признания данного собрания правомочным принимать решения по вопросам его повестки дня.”
Это определение не из информатики, но верно передающее суть происходящего в распределенных системах (удивительно!). Кворум - это минимальное количество голосов от узлов системы для фиксации выполнения какого-нибудь действия в распределенной системе, требующего согласования. Обычно это запись данных внутрь системы или обновление состояние самой системы.
Кворумы - это часть более глобальной проблемы, решение которой обеспечивает согласованность данных в распределенных системах. Эта проблема - консенсуса.
Алгоритм консенсуса — это процесс, используемый для достижения согласия по одному значению данных, предложенное одним из узлов распределенной системы. Например, пользователь записал данные в систему, а узлы системы должны прийти к консенсусу и записать это значение. Проблема при выполнении этого в распределенной системе заключается в том, что сообщения могут быть потеряны или узлы могут выйти из строя.
Узлы не придут к консенсусу, если отказов узлов в системе больше половины. Это число связано с кворумами, т.к. почти любой шаг алгоритмов консенсуса считается завершенным, только когда есть кворум. Если отказов узлов больше половины, то кворум не соберется, и система скорее всего не будет отвечать клиенту. Но этот момент зависит от алгоритмов консенсуса, от выбранных моделей консистентности данных, ну и конечно от бизнес требований.
Если есть кворум, т.е. большинство голосов, то распределенная система может сохранять новые входящие данные даже при разделении ее на части. Поэтому в распределенных системах делают нечетное количество узлов (3, 5, 7), чтобы избежать разделение кластера на несколько частей с одинаковым числом узлов.
Но и это может не гарантировать наличие кворума и консенсуса 🙂 Вот такие они распределенные системы.
Успехов!
@it_intern
#архитектура #распределенные_системы
В прошлый раз мы говорили о проблеме Split-brain’а. Она происходит, когда распределенная система разделяется на несколько частей. Ее можно решить с помощью Quorum и Fencing.
”Quorum praesentia sufficit - установленное законом, уставом организации или регламентом число участников собрания (заседания), достаточное для признания данного собрания правомочным принимать решения по вопросам его повестки дня.”
Это определение не из информатики, но верно передающее суть происходящего в распределенных системах (удивительно!). Кворум - это минимальное количество голосов от узлов системы для фиксации выполнения какого-нибудь действия в распределенной системе, требующего согласования. Обычно это запись данных внутрь системы или обновление состояние самой системы.
Кворумы - это часть более глобальной проблемы, решение которой обеспечивает согласованность данных в распределенных системах. Эта проблема - консенсуса.
Алгоритм консенсуса — это процесс, используемый для достижения согласия по одному значению данных, предложенное одним из узлов распределенной системы. Например, пользователь записал данные в систему, а узлы системы должны прийти к консенсусу и записать это значение. Проблема при выполнении этого в распределенной системе заключается в том, что сообщения могут быть потеряны или узлы могут выйти из строя.
Узлы не придут к консенсусу, если отказов узлов в системе больше половины. Это число связано с кворумами, т.к. почти любой шаг алгоритмов консенсуса считается завершенным, только когда есть кворум. Если отказов узлов больше половины, то кворум не соберется, и система скорее всего не будет отвечать клиенту. Но этот момент зависит от алгоритмов консенсуса, от выбранных моделей консистентности данных, ну и конечно от бизнес требований.
Если есть кворум, т.е. большинство голосов, то распределенная система может сохранять новые входящие данные даже при разделении ее на части. Поэтому в распределенных системах делают нечетное количество узлов (3, 5, 7), чтобы избежать разделение кластера на несколько частей с одинаковым числом узлов.
Но и это может не гарантировать наличие кворума и консенсуса 🙂 Вот такие они распределенные системы.
Успехов!
@it_intern
#архитектура #распределенные_системы
{kind=link}
❤5🔥4
Fencing (не Fendi).
Fencing — один из способов решения проблемы Split Brain’а и обеспечения High Availability в распределенных системах. В прошлый раз мы рассматривали кворумы и проблему консенсуса (к ней еще вернемся).
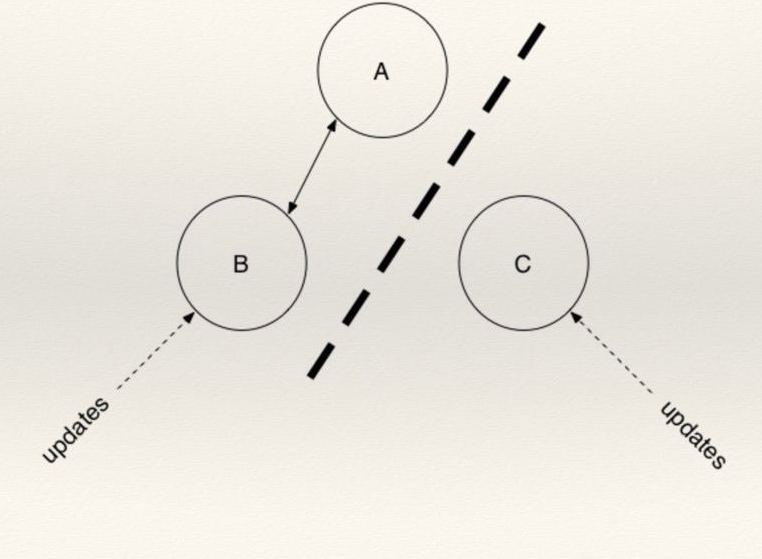
Во время эксплуатации распределенной системы возникает ситуация, когда один из узлов системы начинает вести себя “странно” - не отвечать на запросы, рассылать неверную информацию, передавать состояние, которое не может быть у этого узла, и т.д.
Для избежания дальнейших проблем с общими ресурсами кластера, система изолирует этот узел, делая для него fence (русск. заграждающая метка).
То есть когда мы делаем fencing (пунктир на картинке) для узла “C”, то на вопрос: “будет ли узел “C” отвечать за ресурс X или на вопрос Y?”, - мы всегда будем получать ответ: “НЕТ!”. Таким образом нам не нужно беспокоиться о том в каком состоянии узел “А”.
Для выполнения fencing существуют 2 основных техники:
- fencing ресурсов - изоляция ресурса, который использует или владеет неработающий корректно узел. Например, отзыв доступа к сетевому хранилищу данных с этого узла.
- node fencing - изоляция всего узла от всех ресурсов, не разбирая какие ресурсы, он в действительности использует. Грубо и жестко. Это также называют “STONITH” - Shoot The Other Node In The Head.
С помощью fencing мы можем изолировать проблемные узлы кластера, не мешая основной работе системы. Fencing считается хорошей техникой для организации безопасного и предсказуемого доступа к общим ресурсам и предотвращения ошибок в данных.
Во взрослом мире промышленного программирования fencing недостаточен для эксплуатации распределенных систем. Есть сценарии и ошибки, когда разработчикам приходится использовать другие техники или их комбинации. Часть из них мы рассмотрели, а другая часть требует детального погружения в распределенные системы.
Дальше поговорим про алгоритмы консенсуса. Их могут спросить на собесах, да и полезно их знать.
Успехов!
@it_intern
#архитектура #распределенные_системы
Fencing — один из способов решения проблемы Split Brain’а и обеспечения High Availability в распределенных системах. В прошлый раз мы рассматривали кворумы и проблему консенсуса (к ней еще вернемся).
Во время эксплуатации распределенной системы возникает ситуация, когда один из узлов системы начинает вести себя “странно” - не отвечать на запросы, рассылать неверную информацию, передавать состояние, которое не может быть у этого узла, и т.д.
Для избежания дальнейших проблем с общими ресурсами кластера, система изолирует этот узел, делая для него fence (русск. заграждающая метка).
То есть когда мы делаем fencing (пунктир на картинке) для узла “C”, то на вопрос: “будет ли узел “C” отвечать за ресурс X или на вопрос Y?”, - мы всегда будем получать ответ: “НЕТ!”. Таким образом нам не нужно беспокоиться о том в каком состоянии узел “А”.
Для выполнения fencing существуют 2 основных техники:
- fencing ресурсов - изоляция ресурса, который использует или владеет неработающий корректно узел. Например, отзыв доступа к сетевому хранилищу данных с этого узла.
- node fencing - изоляция всего узла от всех ресурсов, не разбирая какие ресурсы, он в действительности использует. Грубо и жестко. Это также называют “STONITH” - Shoot The Other Node In The Head.
С помощью fencing мы можем изолировать проблемные узлы кластера, не мешая основной работе системы. Fencing считается хорошей техникой для организации безопасного и предсказуемого доступа к общим ресурсам и предотвращения ошибок в данных.
Во взрослом мире промышленного программирования fencing недостаточен для эксплуатации распределенных систем. Есть сценарии и ошибки, когда разработчикам приходится использовать другие техники или их комбинации. Часть из них мы рассмотрели, а другая часть требует детального погружения в распределенные системы.
Дальше поговорим про алгоритмы консенсуса. Их могут спросить на собесах, да и полезно их знать.
Успехов!
@it_intern
#архитектура #распределенные_системы
{kind=link}
👍4🔥4❤1
Raft.
Мы говорили про проблему консенсуса и кворума. Для решения задач консенсуса существует несколько алгоритмов и подходов. Наверное, самый используемый алгоритм сейчас - это Raft.
Raft решает задачу консенсуса в распределенных системах в ненадежных коммуникационных сетях. Он разрабатывался на основе опыта более старого алгоритма Paxos (также его называют семейством протоколов). Raft получился более простым теоретически и в реализации. Существует множество реализаций Raft с открытым исходным кодом на разных языках программирования.
Paxos действительно сложный алгоритм. Признаюсь, что я не до конца его понимаю. Наверное, потому что я с ним не работал в проде. Сейчас я искал хорошую и простую визуализацию этого алгоритма и не нашел ее. Есть только заумные и сложные научные статьи. Поэтому я не очень хотел писать про этот алгоритм, но это нужно для понимания откуда произошел Raft. Если вы хотите разобраться с Paxos, то вот неплохие статьи - раз и два.
А вот про Raft хороших статей много и есть даже прекрасный эксплейнер. На этом ресурсе еще раз рассказывают про проблему распределенного консенсуса и кворума, про типы узлов кластера в терминах Raft, процесс выбора лидера (leader election), и самое важное про то как действует алгоритм при проблемах с сетями.
Понимание Raft дает человеку основное представление о проблемах, возникающих в распределенных системах и о том, как их можно решить. Про Raft меня спрашивали несколько раз на собеседованиях на уровень Senior, но узнать про него раньше точно никому не помешает 😉
Успехов!
@it_intern
#архитектура #распределенные_системы
Мы говорили про проблему консенсуса и кворума. Для решения задач консенсуса существует несколько алгоритмов и подходов. Наверное, самый используемый алгоритм сейчас - это Raft.
Raft решает задачу консенсуса в распределенных системах в ненадежных коммуникационных сетях. Он разрабатывался на основе опыта более старого алгоритма Paxos (также его называют семейством протоколов). Raft получился более простым теоретически и в реализации. Существует множество реализаций Raft с открытым исходным кодом на разных языках программирования.
Paxos действительно сложный алгоритм. Признаюсь, что я не до конца его понимаю. Наверное, потому что я с ним не работал в проде. Сейчас я искал хорошую и простую визуализацию этого алгоритма и не нашел ее. Есть только заумные и сложные научные статьи. Поэтому я не очень хотел писать про этот алгоритм, но это нужно для понимания откуда произошел Raft. Если вы хотите разобраться с Paxos, то вот неплохие статьи - раз и два.
А вот про Raft хороших статей много и есть даже прекрасный эксплейнер. На этом ресурсе еще раз рассказывают про проблему распределенного консенсуса и кворума, про типы узлов кластера в терминах Raft, процесс выбора лидера (leader election), и самое важное про то как действует алгоритм при проблемах с сетями.
Понимание Raft дает человеку основное представление о проблемах, возникающих в распределенных системах и о том, как их можно решить. Про Raft меня спрашивали несколько раз на собеседованиях на уровень Senior, но узнать про него раньше точно никому не помешает 😉
Успехов!
@it_intern
#архитектура #распределенные_системы
Telegram
//АйТи интерн
Quorum.
В прошлый раз мы говорили о проблеме Split-brain’а. Она происходит, когда распределенная система разделяется на несколько частей. Ее можно решить с помощью Quorum и Fencing.
”Quorum praesentia sufficit - установленное законом, уставом организации…
В прошлый раз мы говорили о проблеме Split-brain’а. Она происходит, когда распределенная система разделяется на несколько частей. Ее можно решить с помощью Quorum и Fencing.
”Quorum praesentia sufficit - установленное законом, уставом организации…
❤4🔥3👍2
Алгосы нужны?
Когда-то давно в одном из каналов прочитал о книжке Джона Бентли “Programming Pearls”. Недавно добрался до нее, вычитал одну любопытную историю, ставящую под сомнения некоторые “договоренности” в IT.
Физик Андрей Аппеля симулировал движение 10 000 планет. По его подсчетам работа "брутфорсного" алгоритма заняла бы несколько лет. Поэтому ученому пришлось углубиться в тюнинг производительности программы.
Ему удалось переписать выполнение 1 шага алгоритма с
Вишенкой стало переписывание на ассемблер одной функции, время выполнение которой занимало 98% от времени работы программы, а также покупка более производительного оборудования и изменение разрядности чисел с 64 бит на 32 бита.
В книжке эти данные собрали в таблицу, из которой станет понятно, что правильный алгоритм и подходящая структура данных дали бОльшую часть выигрыша производительности. Но ему пришлось делать свою модель менее точной, но зато работающей не года, а всего лишь 1 день.
Это еще один урок, и он не только про алгоритмы и структуры данных, но и про то, что разработка программного обеспечения это всегда компромиссы ("trade-off", его чаще используют в сленге) и программные системы - это не сферический конь в вакууме, а что-то работающее в реальном мире.
Получается, что алгоритмы все же нужны?
@it_intern
#алгоритмы #книги
Когда-то давно в одном из каналов прочитал о книжке Джона Бентли “Programming Pearls”. Недавно добрался до нее, вычитал одну любопытную историю, ставящую под сомнения некоторые “договоренности” в IT.
Физик Андрей Аппеля симулировал движение 10 000 планет. По его подсчетам работа "брутфорсного" алгоритма заняла бы несколько лет. Поэтому ученому пришлось углубиться в тюнинг производительности программы.
Ему удалось переписать выполнение 1 шага алгоритма с
O(N^2) на O(N*logN), что дало ускорение в 12 раз. Как это удалось сделать? Пришлось сделать модель менее точной за счет добавления предположений и упрощения исходной задачи, чтобы использовать дерево поиска. Еще он оптимизировал сам алгоритм, обрабатывая некоторые краевые случаи отдельно.Вишенкой стало переписывание на ассемблер одной функции, время выполнение которой занимало 98% от времени работы программы, а также покупка более производительного оборудования и изменение разрядности чисел с 64 бит на 32 бита.
В книжке эти данные собрали в таблицу, из которой станет понятно, что правильный алгоритм и подходящая структура данных дали бОльшую часть выигрыша производительности. Но ему пришлось делать свою модель менее точной, но зато работающей не года, а всего лишь 1 день.
Это еще один урок, и он не только про алгоритмы и структуры данных, но и про то, что разработка программного обеспечения это всегда компромиссы ("trade-off", его чаще используют в сленге) и программные системы - это не сферический конь в вакууме, а что-то работающее в реальном мире.
Получается, что алгоритмы все же нужны?
@it_intern
#алгоритмы #книги
{kind=link}
👍9❤3🔥2
Возвращаемся в эфир...
Что могу сказать? Могу только поставить реакцию "взрыв башки".
Мир теперь постоянно пересобирается и реконфигурируется по несколько раз в месяц. И как модно говорить нужно быть "гибким", а не прогибаться, подстраивать обстоятельства под себя, а не под них (Стэтхэм вошел в канал).
Я верю, что имея хорошее образование и навыки можно найти свое место в мире по все его стороны.
Я долго думал чем я могу помочь здесь обычным людям. И я нашел ответы. Про них скоро узнаете.
А я пока готовлюсь к выходу в новое место работы и запуска пары новых проектов в том числе и образовательных.
Успехов!
@it_intern
Что могу сказать? Могу только поставить реакцию "взрыв башки".
Мир теперь постоянно пересобирается и реконфигурируется по несколько раз в месяц. И как модно говорить нужно быть "гибким", а не прогибаться, подстраивать обстоятельства под себя, а не под них (Стэтхэм вошел в канал).
Я верю, что имея хорошее образование и навыки можно найти свое место в мире по все его стороны.
Я долго думал чем я могу помочь здесь обычным людям. И я нашел ответы. Про них скоро узнаете.
А я пока готовлюсь к выходу в новое место работы и запуска пары новых проектов в том числе и образовательных.
Успехов!
@it_intern
❤12👍1🔥1
Что у нас на приборах?
Thoughtworks - компания по разработке софта почти с 30 летней истории. Ее сотрудниками являются довольно известные личности (например, Мартин Фаулер). Компания оказала большое влияние на развитие нашей индустрии, делая вклад в open-source, развитие Agile практик и своими исследованиями и обзорами на технологии. В общем, крутые ребята с большим вкладом в нашу индустрию.
Примером этого является - TechRadar. По словам Thoughtworks TechRadar - это "путеводитель по передовым технологиям". Техлиды Thoughtworks регулярно встречаются и отслеживают тренды в IT, а потом выпускают TechRadar.
Я слежу за его каждым выпуском для того, чтобы понимать тенденции и узнавать про новые технологии, которые начнут восстание машин. Его полезном читать всем - от джуна до СТО.
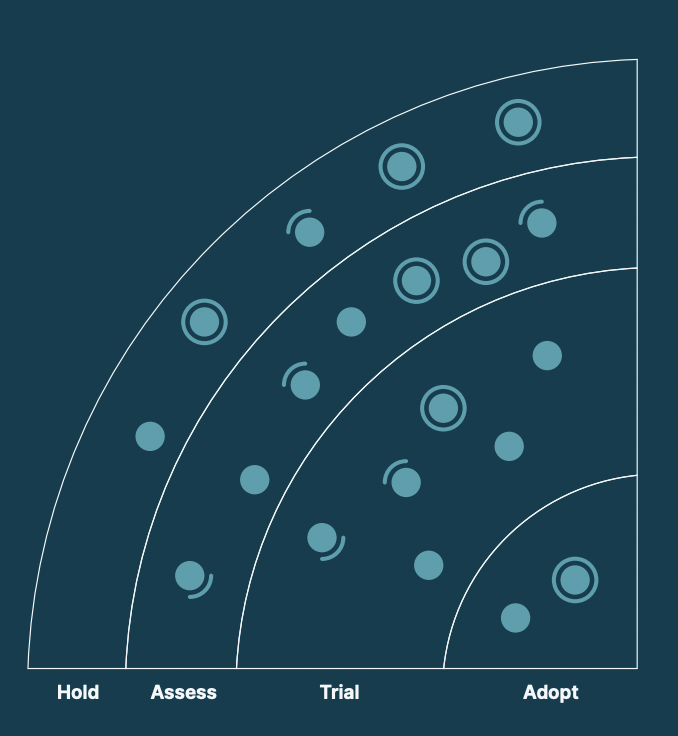
В TechRadar графически сгруппированы:
- Techniques: техники (подходы), которые могут использоваться при разработке.
- Tools: инструменты для разработки и разработчиков.
- Platforms: инфраструктурные штуки.
- Languages & Frameworks: языки программирования и все что к ним относится.
Каждая группа разделена на 4 раздела:
- Adopt: однозначно можно применять в проектах.
- Trial: можно начинать интегрировать в проекты, но с определенной долей риска.
- Assess: стоит изучить технологию, провести R&D и понять как эта технология может повлиять на вас, так сказать "пощупать руками".
- Hold: нужно подождать с использованием или может быть совсем отказаться от технологии.
Также есть инструмент для создания своего TechRadar. Очень круто, если нанимающая компания имеет своей радар и показывает кандидатам. Таких компаний пока у нас мало, но их количество растет.
Подписаться и быть всегда в тренде, чтобы решать свои задачи эффективно, можно тут - https://www.thoughtworks.com/radar
Успехов!
@it_intern
Thoughtworks - компания по разработке софта почти с 30 летней истории. Ее сотрудниками являются довольно известные личности (например, Мартин Фаулер). Компания оказала большое влияние на развитие нашей индустрии, делая вклад в open-source, развитие Agile практик и своими исследованиями и обзорами на технологии. В общем, крутые ребята с большим вкладом в нашу индустрию.
Примером этого является - TechRadar. По словам Thoughtworks TechRadar - это "путеводитель по передовым технологиям". Техлиды Thoughtworks регулярно встречаются и отслеживают тренды в IT, а потом выпускают TechRadar.
Я слежу за его каждым выпуском для того, чтобы понимать тенденции и узнавать про новые технологии, которые начнут восстание машин. Его полезном читать всем - от джуна до СТО.
В TechRadar графически сгруппированы:
- Techniques: техники (подходы), которые могут использоваться при разработке.
- Tools: инструменты для разработки и разработчиков.
- Platforms: инфраструктурные штуки.
- Languages & Frameworks: языки программирования и все что к ним относится.
Каждая группа разделена на 4 раздела:
- Adopt: однозначно можно применять в проектах.
- Trial: можно начинать интегрировать в проекты, но с определенной долей риска.
- Assess: стоит изучить технологию, провести R&D и понять как эта технология может повлиять на вас, так сказать "пощупать руками".
- Hold: нужно подождать с использованием или может быть совсем отказаться от технологии.
Также есть инструмент для создания своего TechRadar. Очень круто, если нанимающая компания имеет своей радар и показывает кандидатам. Таких компаний пока у нас мало, но их количество растет.
Подписаться и быть всегда в тренде, чтобы решать свои задачи эффективно, можно тут - https://www.thoughtworks.com/radar
Успехов!
@it_intern
{kind=link}
🔥7👍2❤1