
РЕД ОС 8 теперь и с KDE
РЕД ОС – третья по распространению ОС на рынке импортозамещения и единственная из серьезных игроков, кто предлагает RHEL-совместимую платформу.
Причем именно RHEL-совместимую, дистрибутив не является клоном ни RHEL, ни Centos/EL. Система использует собственные репозитории со своим набором пакетов.
В прошлых версиях в качестве графической оболочки использовалась исключительно Mate, хоть и сильно кастомизированная. Но Mate – это все-таки оболочка второго эшелона, да нетребовательная, но и выглядящая непритязательно. Словом – эконом класс.
Для рабочей офисной лошадки, в общем и целом, сойдет, но есть и более требовательные пользователи.
Поэтому прочно став на ноги и получив свою долю рынка в РЕД СОФТ задумались об этом и добавили в набор оболочек KDE и GNOME.
Вариант с KDE 5 получился симпатичным, по умолчанию темная тема, выдержанная в фирменных оттенках красного, но можно легко переключиться на светлую.
Теперь не стыдно и взыскательным пользователям товар лицом показать.
РЕД ОС – третья по распространению ОС на рынке импортозамещения и единственная из серьезных игроков, кто предлагает RHEL-совместимую платформу.
Причем именно RHEL-совместимую, дистрибутив не является клоном ни RHEL, ни Centos/EL. Система использует собственные репозитории со своим набором пакетов.
В прошлых версиях в качестве графической оболочки использовалась исключительно Mate, хоть и сильно кастомизированная. Но Mate – это все-таки оболочка второго эшелона, да нетребовательная, но и выглядящая непритязательно. Словом – эконом класс.
Для рабочей офисной лошадки, в общем и целом, сойдет, но есть и более требовательные пользователи.
Поэтому прочно став на ноги и получив свою долю рынка в РЕД СОФТ задумались об этом и добавили в набор оболочек KDE и GNOME.
Вариант с KDE 5 получился симпатичным, по умолчанию темная тема, выдержанная в фирменных оттенках красного, но можно легко переключиться на светлую.
Теперь не стыдно и взыскательным пользователям товар лицом показать.
👍27❤9👎4🤔3🤡3
Попробовать себя в новой IT-профессии? На раз-два!
Где «раз» – вы записываетесь на подготовительный курс по Python-разработке.
А «два» – завершаете его через две недели с сертификатом и собственным проектом на руках.
С нас:
– 72 урока прямо в браузере в онлайн-тренажере;
– 3 встречи с наставником в режиме реального времени;
– 1 встреча для лайвкодинг-сессии, где вы напишете свою первую программу.
И все это за 990 рублей!
⏰ Старт уже 2 июля!
Где «раз» – вы записываетесь на подготовительный курс по Python-разработке.
А «два» – завершаете его через две недели с сертификатом и собственным проектом на руках.
С нас:
– 72 урока прямо в браузере в онлайн-тренажере;
– 3 встречи с наставником в режиме реального времени;
– 1 встреча для лайвкодинг-сессии, где вы напишете свою первую программу.
И все это за 990 рублей!
⏰ Старт уже 2 июля!
Критическая уязвимость в VMWare vCenter
Очередная критическая уязвимость, точнее даже несколько в популярной коммерческой системе виртуализации.
Начнем с VMware vCenter Server multiple heap-overflow vulnerabilities (CVE-2024-37079, CVE-2024-37080), данной уязвимости сами разработчики присвоили уровень 9,8 по шкале CVSSv3, т.е. критический.
Она использует ошибки в реализации протокола DCERPC и позволяет злоумышленнику, сформировав специальный пакет, выполнить произвольный код на устройстве.
Обходных путей для купирования данной уязвимости нет, только установка обновлений. Без них система становится уязвима к удаленным атакам.
Вторая уязвимость VMware vCenter multiple local privilege escalation vulnerabilities (CVE-2024-37081) связана с некорректной реализацией механизма sudo, которая позволяет пользователю, не имеющему административных прав поднять их до уровня суперпользователя. Важность по шкале CVSSv3 – 7,8 (высокая).
Обе уязвимости сами по себе неприятные, но вместе создают просто убойный коктейль, позволяющий выполнить удаленную атаку на получение полных прав над системой.
А самым неприятным в данной ситуации является то, что закрываются уязвимости только обновлениями, которые требуют перехода на новую подписную модель лицензирования. Про любителей «лицензий с торрентов» мы вообще не говорим.
Причем это далеко не первый серьезный инцидент с VMWare, есть информация что недавняя атака на СДЭК, приведшая к полной остановке деятельности предприятия на несколько дней, также была осуществлена через уязвимости в данном продукте.
Ну а при невозможности своевременно установить обновления следует принять все меры по серьезному ограничению сетевого доступа к уязвимым системам.
Очередная критическая уязвимость, точнее даже несколько в популярной коммерческой системе виртуализации.
Начнем с VMware vCenter Server multiple heap-overflow vulnerabilities (CVE-2024-37079, CVE-2024-37080), данной уязвимости сами разработчики присвоили уровень 9,8 по шкале CVSSv3, т.е. критический.
Она использует ошибки в реализации протокола DCERPC и позволяет злоумышленнику, сформировав специальный пакет, выполнить произвольный код на устройстве.
Обходных путей для купирования данной уязвимости нет, только установка обновлений. Без них система становится уязвима к удаленным атакам.
Вторая уязвимость VMware vCenter multiple local privilege escalation vulnerabilities (CVE-2024-37081) связана с некорректной реализацией механизма sudo, которая позволяет пользователю, не имеющему административных прав поднять их до уровня суперпользователя. Важность по шкале CVSSv3 – 7,8 (высокая).
Обе уязвимости сами по себе неприятные, но вместе создают просто убойный коктейль, позволяющий выполнить удаленную атаку на получение полных прав над системой.
А самым неприятным в данной ситуации является то, что закрываются уязвимости только обновлениями, которые требуют перехода на новую подписную модель лицензирования. Про любителей «лицензий с торрентов» мы вообще не говорим.
Причем это далеко не первый серьезный инцидент с VMWare, есть информация что недавняя атака на СДЭК, приведшая к полной остановке деятельности предприятия на несколько дней, также была осуществлена через уязвимости в данном продукте.
Ну а при невозможности своевременно установить обновления следует принять все меры по серьезному ограничению сетевого доступа к уязвимым системам.
{kind=link}
🤣9👍6❤1👀1
Песенка про дятлов
В обсуждениях ни раз и ни два поднимается вопрос «ненадежности» современной техники с ностальгическими отсылками, что раньше было лучше и что старые добрые модели до сих пор работают.
В частности, это касается накопителей, так как они сейчас активно развиваются и как говорится, находятся на острие прогресса.
Основным типом современного накопителя является NVMe, т.е. диск работающий с использованием указанного протокола по шине PCIe, вне зависимости от форм-фактора и разъема.
Емкости таких дисков, как и скорости постоянно растут, при этом, естественно, появляются различные проблемы и сложности которых раньше не существовало и можно подумать, что вот раньше…
А раньше тоже все было далеко не гладко и безоблачно, а крупные проколы совершали даже лидеры рынка. Давайте вернемся в самое начало нулевых.
Именно в это время IBM выпустил новаторские модели жестких дисков Deskstar 75GXP и 40GV (DTLA) прозванных в народе «дятлами». Диски использовали стеклянные пластины с плотностью записи 20 Гбайт, скорость вращения 7200 оборотов/мин и интерфейс Ultra ATA/100.
IBM в те годы была одним из признанных лидеров рынка, а «дятлы» по совокупности характеристик были одними из лучших моделей дисков, равно как и самыми дорогими. Но ведь это топ от признанного лидера, это примерно, как сегодня SSD от Samsung.
В общем, продажи шли хорошо, но… Все чаще и чаще стали поступать сообщения об отказах DTLA. Диски могли начать издавать странные звуки, стучать головами или просто стремительно сыпаться.
Поначалу серьезного значения этому никто не придал, ну бракованная партия, бывает. Но отказов было все больше и больше и стало понятно, что это не просто производственный брак.
Но сама фирма IBM попыталась сделать хорошую мину при плохой игре и обвинила в этом «неправильную» работу чипсетов Intel 440BX, AMD 751 и VIA KT133A. И если последний действительно имел кое-какие проблемы при работе с накопителями, то вносить в список массовый и популярный 440BX явно было опрометчивым действием.
Тем более что проблемы возникали и с другими чипсетами, и с аппаратными RAID-контроллерами.
Вскоре был найден еще один «виноватый», им назначили ОС семейства Windows 9х/Me, они «слишком быстро» выключали жесткий диск, что он не успевал завершить отложенную запись, что могло привести к порче данных, а в некоторых случаях и самой пластины.
Microsoft в ответ выпустила специальные исправления, но уже практически всем становилось очевидно, что проблема в конструктивных ошибках заложенных на этапе разработки дисков.
Косвенно это подтверждалось и тем, что IBM по гарантии меняла «дятлов» не на новые диски такой же модели, а на винчестеры совсем другой серии 60GXP.
Попутно предлагались совсем беспомощные решения этой проблемы, например, понизить режим с Ultra ATA/100 на Ultra ATA/33, т.е. понизить производительность в три раза и это для топовой модели диска!
А позже стало известно о том, что в апреле 2001 IBM полностью прекратила производство серии DTLA.
Итоги этой истории оказались далеко не радостными. Компания серьезно подорвала свою репутацию и по большому счету так и не оправилась после провала. Вскоре подразделение по производству жестких дисков перешло к Hitachi, а сегодня им владеет Toshiba.
Пользователи не простили компании отказ сразу признать свою ошибку и постоянное вранье с поиском и назначением «виноватых» вместо того, чтобы принять меры к исправлению ситуации. Вот так вот в одночасье жесткие диски IBM из признанных топов превратились в жупел, от которого все шарахались достаточно долгое время.
В обсуждениях ни раз и ни два поднимается вопрос «ненадежности» современной техники с ностальгическими отсылками, что раньше было лучше и что старые добрые модели до сих пор работают.
В частности, это касается накопителей, так как они сейчас активно развиваются и как говорится, находятся на острие прогресса.
Основным типом современного накопителя является NVMe, т.е. диск работающий с использованием указанного протокола по шине PCIe, вне зависимости от форм-фактора и разъема.
Емкости таких дисков, как и скорости постоянно растут, при этом, естественно, появляются различные проблемы и сложности которых раньше не существовало и можно подумать, что вот раньше…
А раньше тоже все было далеко не гладко и безоблачно, а крупные проколы совершали даже лидеры рынка. Давайте вернемся в самое начало нулевых.
Именно в это время IBM выпустил новаторские модели жестких дисков Deskstar 75GXP и 40GV (DTLA) прозванных в народе «дятлами». Диски использовали стеклянные пластины с плотностью записи 20 Гбайт, скорость вращения 7200 оборотов/мин и интерфейс Ultra ATA/100.
IBM в те годы была одним из признанных лидеров рынка, а «дятлы» по совокупности характеристик были одними из лучших моделей дисков, равно как и самыми дорогими. Но ведь это топ от признанного лидера, это примерно, как сегодня SSD от Samsung.
В общем, продажи шли хорошо, но… Все чаще и чаще стали поступать сообщения об отказах DTLA. Диски могли начать издавать странные звуки, стучать головами или просто стремительно сыпаться.
Поначалу серьезного значения этому никто не придал, ну бракованная партия, бывает. Но отказов было все больше и больше и стало понятно, что это не просто производственный брак.
Но сама фирма IBM попыталась сделать хорошую мину при плохой игре и обвинила в этом «неправильную» работу чипсетов Intel 440BX, AMD 751 и VIA KT133A. И если последний действительно имел кое-какие проблемы при работе с накопителями, то вносить в список массовый и популярный 440BX явно было опрометчивым действием.
Тем более что проблемы возникали и с другими чипсетами, и с аппаратными RAID-контроллерами.
Вскоре был найден еще один «виноватый», им назначили ОС семейства Windows 9х/Me, они «слишком быстро» выключали жесткий диск, что он не успевал завершить отложенную запись, что могло привести к порче данных, а в некоторых случаях и самой пластины.
Microsoft в ответ выпустила специальные исправления, но уже практически всем становилось очевидно, что проблема в конструктивных ошибках заложенных на этапе разработки дисков.
Косвенно это подтверждалось и тем, что IBM по гарантии меняла «дятлов» не на новые диски такой же модели, а на винчестеры совсем другой серии 60GXP.
Попутно предлагались совсем беспомощные решения этой проблемы, например, понизить режим с Ultra ATA/100 на Ultra ATA/33, т.е. понизить производительность в три раза и это для топовой модели диска!
А позже стало известно о том, что в апреле 2001 IBM полностью прекратила производство серии DTLA.
Итоги этой истории оказались далеко не радостными. Компания серьезно подорвала свою репутацию и по большому счету так и не оправилась после провала. Вскоре подразделение по производству жестких дисков перешло к Hitachi, а сегодня им владеет Toshiba.
Пользователи не простили компании отказ сразу признать свою ошибку и постоянное вранье с поиском и назначением «виноватых» вместо того, чтобы принять меры к исправлению ситуации. Вот так вот в одночасье жесткие диски IBM из признанных топов превратились в жупел, от которого все шарахались достаточно долгое время.
{kind=link}
👍53
Освойте популярные подходы к мониторингу СУБД PostgreSQL в Zabbix!
✨ Приглашаем 27 июня в 20:00 мск на бесплатный вебинар «Мониторинг PostgreSQL в Zabbix»
Вебинар является частью полноценного онлайн-курса "Observability: мониторинг, логирование, трейсинг от Отус".
➡️ Записаться на вебинар: https://otus.pw/QGDu/?erid=LjN8KTDu8
На вебинаре мы разберем:
✅ основные метрики, за которыми нужно наблюдать;
✅ процессы, которые обеспечивают работоспособность кластера PostgreSQL;
✅ каким образом можно мониторить реплики и бэкапы данной СУБД;
✅ ответы на все возникающие вопросы.
🎙 Спикер Иван Федоров — опытный технический директор и капитан команды IBI Solutions.
Записывайтесь сейчас, а мы потом напомним. Участие бесплатно.
✨ Приглашаем 27 июня в 20:00 мск на бесплатный вебинар «Мониторинг PostgreSQL в Zabbix»
Вебинар является частью полноценного онлайн-курса "Observability: мониторинг, логирование, трейсинг от Отус".
➡️ Записаться на вебинар: https://otus.pw/QGDu/?erid=LjN8KTDu8
На вебинаре мы разберем:
✅ основные метрики, за которыми нужно наблюдать;
✅ процессы, которые обеспечивают работоспособность кластера PostgreSQL;
✅ каким образом можно мониторить реплики и бэкапы данной СУБД;
✅ ответы на все возникающие вопросы.
🎙 Спикер Иван Федоров — опытный технический директор и капитан команды IBI Solutions.
Записывайтесь сейчас, а мы потом напомним. Участие бесплатно.
👍1👎1
Обязательное подписывание SMB-пакетов в Windows 11
С выходом Windows 11 24H2 многие пользователи столкнулись с проблемами доступа к сетевым ресурсам при помощи SMB. Виной тому изменение политики подписывания SMB-пакетов, которая по умолчанию стала обязательной.
SMB Signing - это одно из средств безопасности средств протокола общего доступа к файлам SMB/CIFS. Когда оно включено, каждое SMB сообщение подписывается в заголовке цифровой подписью.
Такая подпись позволяет гарантировать, что содержимое сообщение не было изменено и проверить подлинность отправителя. Это позволяет предотвратить реализацию SMB атак типа man-in-the-middle и NTLM relay.
Ранее SMB подписывание требовалось только при доступе к сетевым папкам SYSVOL и NETLOGON на контроллерах домена AD.
В дальнейшем данную политику обещают распространить и на другие версии Windows.
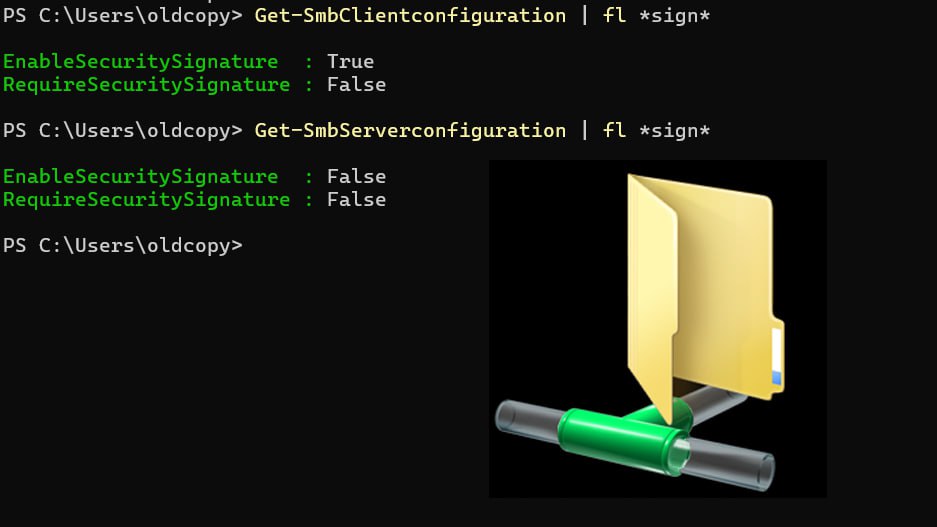
При обращении такого клиента к серверу не использующему подписывание пакетов будет появляться ошибка:
Поэтому самое время разобраться с действующими в системе политиками, для этого выполним в консоли PowerShell две команды, которые покажут настройки клиента и сервера SMB:
Например, в версии Windows 11 23H2 для клиента установлены следующие политики:
Политика EnableSecuritySignature для клиента и сервера SMB2+ игнорируется, а так как SMB1 везде по умолчанию отключен, то можем не обращать на нее внимание.
В современных системах для подписывания используется политика RequireSecuritySignature, которая определяет необходимость подписи по принципу логического ИЛИ. Т.е. если хоть одна сторона будет требовать подписывания (клиент или сервер) – пакет будет подписан.
Таким образом, чтобы отключит подписывание, мы должны отключить его и на клиенте, и на сервере.
Для этого можно использовать команды:
Если политику нужно включить, то замените $false на $true.
При этом не следует бежать и отключать требование подписи везде где только можно, потому что это довольно важное средство обеспечения безопасности, а только там, где использование подписи невозможно по техническим причинам.
Так если весь парк ПК состоит из современных систем, то имеет смысл отключать требование подписи только на клиенте, чтобы они могли работать с не умеющими подписывать пакеты серверами и оставлять ее включенной для серверов, что обеспечит использование подписи при наличии такой возможности.
С выходом Windows 11 24H2 многие пользователи столкнулись с проблемами доступа к сетевым ресурсам при помощи SMB. Виной тому изменение политики подписывания SMB-пакетов, которая по умолчанию стала обязательной.
SMB Signing - это одно из средств безопасности средств протокола общего доступа к файлам SMB/CIFS. Когда оно включено, каждое SMB сообщение подписывается в заголовке цифровой подписью.
Такая подпись позволяет гарантировать, что содержимое сообщение не было изменено и проверить подлинность отправителя. Это позволяет предотвратить реализацию SMB атак типа man-in-the-middle и NTLM relay.
Ранее SMB подписывание требовалось только при доступе к сетевым папкам SYSVOL и NETLOGON на контроллерах домена AD.
В дальнейшем данную политику обещают распространить и на другие версии Windows.
При обращении такого клиента к серверу не использующему подписывание пакетов будет появляться ошибка:
0xc000a000 The cryptographic signature is invalid
Поэтому самое время разобраться с действующими в системе политиками, для этого выполним в консоли PowerShell две команды, которые покажут настройки клиента и сервера SMB:
Get-SmbClientconfiguration | fl *sign*
Get-SmbServerconfiguration | fl *sign*
Например, в версии Windows 11 23H2 для клиента установлены следующие политики:
EnableSecuritySignature : True
RequireSecuritySignature : False
Политика EnableSecuritySignature для клиента и сервера SMB2+ игнорируется, а так как SMB1 везде по умолчанию отключен, то можем не обращать на нее внимание.
В современных системах для подписывания используется политика RequireSecuritySignature, которая определяет необходимость подписи по принципу логического ИЛИ. Т.е. если хоть одна сторона будет требовать подписывания (клиент или сервер) – пакет будет подписан.
Таким образом, чтобы отключит подписывание, мы должны отключить его и на клиенте, и на сервере.
Для этого можно использовать команды:
Set-SmbClientConfiguration -RequireSecuritySignature $false
Set-SmbServerConfiguration -RequireSecuritySignature $false
Если политику нужно включить, то замените $false на $true.
При этом не следует бежать и отключать требование подписи везде где только можно, потому что это довольно важное средство обеспечения безопасности, а только там, где использование подписи невозможно по техническим причинам.
Так если весь парк ПК состоит из современных систем, то имеет смысл отключать требование подписи только на клиенте, чтобы они могли работать с не умеющими подписывать пакеты серверами и оставлять ее включенной для серверов, что обеспечит использование подписи при наличии такой возможности.
{kind=link}
👍47👀2💯1
Подписывание SMB-пакетов в Samba
В нашей предыдущей заметке мы говорили о подписывании SMB пакетов в Windows.
SMB Signing это одно из средств безопасности средств протокола общего доступа к файлам SMB/CIFS. Когда оно включено, каждое SMB сообщение подписывается в заголовке цифровой подписью. Это позволяет предотвратить реализацию SMB атак типа MitM и NTLM relay.
Начиная с Windows 11 24H2 клиент будет требовать обязательного подписывания пакетов, в дальнейшем эту политику обещают распространить на все поддерживаемые ОС.
В Linux также не трудно настроить подписывание пакетов, для этого в секции
Для сервера это
▫️ auto - подписывание SMB предлагается
▫️ mandatory - подписывание SMB обязательно
▫️ disabled - подписывание SMB отключено
По умолчанию применяется значение disabled.
Для клиента используется опция
▫️ auto - подписывание SMB предлагается
▫️ mandatory - подписывание SMB обязательно
▫️ disabled - подписывание SMB отключено
Значение по умолчанию: auto.
В современных условиях оптимальными настройками будет изменение режима сервера также на auto:
Это позволит работать с современными клиентами, не снижая уровня защиты, но при этом сохраняя совместимость с клиентами не поддерживающими подписывание.
В этом плане Samba позволяет более гибко управлять настройками чем SMB в Windows, там сторона может либо требовать подписывание для всех, либо нет, режим согласования отсутствует.
В нашей предыдущей заметке мы говорили о подписывании SMB пакетов в Windows.
SMB Signing это одно из средств безопасности средств протокола общего доступа к файлам SMB/CIFS. Когда оно включено, каждое SMB сообщение подписывается в заголовке цифровой подписью. Это позволяет предотвратить реализацию SMB атак типа MitM и NTLM relay.
Начиная с Windows 11 24H2 клиент будет требовать обязательного подписывания пакетов, в дальнейшем эту политику обещают распространить на все поддерживаемые ОС.
В Linux также не трудно настроить подписывание пакетов, для этого в секции
[global] файла smb.conf потребуется указать две опции.Для сервера это
server signing, которая может принимать следующие значения:▫️ auto - подписывание SMB предлагается
▫️ mandatory - подписывание SMB обязательно
▫️ disabled - подписывание SMB отключено
По умолчанию применяется значение disabled.
Для клиента используется опция
client signing с доступными значениями:▫️ auto - подписывание SMB предлагается
▫️ mandatory - подписывание SMB обязательно
▫️ disabled - подписывание SMB отключено
Значение по умолчанию: auto.
В современных условиях оптимальными настройками будет изменение режима сервера также на auto:
[global]
server signing = auto
Это позволит работать с современными клиентами, не снижая уровня защиты, но при этом сохраняя совместимость с клиентами не поддерживающими подписывание.
В этом плане Samba позволяет более гибко управлять настройками чем SMB в Windows, там сторона может либо требовать подписывание для всех, либо нет, режим согласования отсутствует.
{kind=link}
👍46
Курс по нейросетям. Получите самые востребованные скиллы в 2024 году.
“Основы нейронных сетей: создание и настройка" от Академии Кодебай:
- разработка продвинутых архитектур нейронных сетей и их применение в Data Science
- решение типичных проблем при обучении сетей
Курс будет полезен, если вы:
- Аналитик данных и хотите освоить продвинутые инструменты, чтобы выйти на новый уровень
- Разработчик с опытом программирования и хотите применить свои знания в новой области
- Руководитель IT-проектов и хотите лидировать современные бизнес-процессы
Старт потока: 1 июля
Пишите нам @Codeby_Academy
Подробнее о курсе
“Основы нейронных сетей: создание и настройка" от Академии Кодебай:
- разработка продвинутых архитектур нейронных сетей и их применение в Data Science
- решение типичных проблем при обучении сетей
Курс будет полезен, если вы:
- Аналитик данных и хотите освоить продвинутые инструменты, чтобы выйти на новый уровень
- Разработчик с опытом программирования и хотите применить свои знания в новой области
- Руководитель IT-проектов и хотите лидировать современные бизнес-процессы
Старт потока: 1 июля
Пишите нам @Codeby_Academy
Подробнее о курсе
👍1
Деградация данных
Деградация данных (bitrot, битовое гниение) – это достаточно актуальный в настоящее время тип разрушения цифровых данных вследствие накопления некритичных ошибок на запоминающем устройстве.
К сожалению, многие коллеги путают деградацию с выходом из строя ячеек накопителя (бед-блоки) и не придают этому вопросу серьезного значения. А зря.
С бед-блоками достаточно эффективно позволяет справляться RAID, когда в случае ошибки чтения блок заменяется резервным, а его содержимое считывается с исправной копии. Да, возможен эффект появления скрытых бед-блоков, но он решается периодическом перечитыванием содержимого массива.
Проблема битового гниения лежит глубже и именно этот термин представляется нам наиболее удачным. Как и обычное гниение он медленно и незаметно повреждает данные до тех пор, пока разрушения не перейдут в критическую фазу.
Причинами битового гниения становятся ошибки в процессе записи, не связанные с повреждением непосредственно ячеек, они могут даже произойти в оперативной памяти и при отсутствии ECC ваши данные также могут быть незаметно повреждены.
Чаще всего деградация данных происходит при длительном хранении, вследствие деградации заряда ячейки или уровня намагниченности сектора. Ошибок чтения с накопителя это не вызывает, но приводит к нарушению целостности данных.
Как правило большинство современных форматов данных имеют избыточность и изменение одного бита может быть откорректировано встроенными средствами, но для этого эти данные нужно хотя бы открыть.
В противном случае подобные ошибки могут накапливаться и в определенный момент привести к невосстановимому повреждению данных. При этом процесс битового гниения не сопровождается ошибками чтения с накопителя и может происходить на полностью исправном диске.
А так как нет никаких ошибок, то и RAID вам ничем не поможет, особенно уровни без четности. Так, например, в случае зеркала у нас могут оказаться изменены биты в произвольных местах обоих копий. И чем больше по размеру файл и реже обращения к нему – тем вероятнее такое развитие событий.
Некоторую защиту могут предоставлять массивы с четностью (RAID 5 и 6), но здесь многое зависит от контроллера или программной реализации, главное у которых – уметь производить такую проверку в фоновом режиме.
В таком случае имея одну правильную копию и целые данные четности массив может проверить целостность данных и автоматически восстановить их.
Но оптимальным решением проблемы будет вынос таких проверок на уровень файловой системы, так как это позволяет действовать наиболее эффективно и с наименьшей нагрузкой на систему.
Современные системы с контролем целостности – это ZFS, btrfs и ReFS – и именно они рекомендуются для систем хранения больших объемов информации. Каждая из них умеет в фоновом режиме проверять целостность файлов и восстанавливать поврежденные фрагменты используя контрольные суммы (при наличии избыточности, разумеется).
И именно по этой причине тот же Proxmox категорически не рекомендует использование mdadm для хранилищ виртуальных машин в производственных средах.
Деградация данных (bitrot, битовое гниение) – это достаточно актуальный в настоящее время тип разрушения цифровых данных вследствие накопления некритичных ошибок на запоминающем устройстве.
К сожалению, многие коллеги путают деградацию с выходом из строя ячеек накопителя (бед-блоки) и не придают этому вопросу серьезного значения. А зря.
С бед-блоками достаточно эффективно позволяет справляться RAID, когда в случае ошибки чтения блок заменяется резервным, а его содержимое считывается с исправной копии. Да, возможен эффект появления скрытых бед-блоков, но он решается периодическом перечитыванием содержимого массива.
Проблема битового гниения лежит глубже и именно этот термин представляется нам наиболее удачным. Как и обычное гниение он медленно и незаметно повреждает данные до тех пор, пока разрушения не перейдут в критическую фазу.
Причинами битового гниения становятся ошибки в процессе записи, не связанные с повреждением непосредственно ячеек, они могут даже произойти в оперативной памяти и при отсутствии ECC ваши данные также могут быть незаметно повреждены.
Чаще всего деградация данных происходит при длительном хранении, вследствие деградации заряда ячейки или уровня намагниченности сектора. Ошибок чтения с накопителя это не вызывает, но приводит к нарушению целостности данных.
Как правило большинство современных форматов данных имеют избыточность и изменение одного бита может быть откорректировано встроенными средствами, но для этого эти данные нужно хотя бы открыть.
В противном случае подобные ошибки могут накапливаться и в определенный момент привести к невосстановимому повреждению данных. При этом процесс битового гниения не сопровождается ошибками чтения с накопителя и может происходить на полностью исправном диске.
А так как нет никаких ошибок, то и RAID вам ничем не поможет, особенно уровни без четности. Так, например, в случае зеркала у нас могут оказаться изменены биты в произвольных местах обоих копий. И чем больше по размеру файл и реже обращения к нему – тем вероятнее такое развитие событий.
Некоторую защиту могут предоставлять массивы с четностью (RAID 5 и 6), но здесь многое зависит от контроллера или программной реализации, главное у которых – уметь производить такую проверку в фоновом режиме.
В таком случае имея одну правильную копию и целые данные четности массив может проверить целостность данных и автоматически восстановить их.
Но оптимальным решением проблемы будет вынос таких проверок на уровень файловой системы, так как это позволяет действовать наиболее эффективно и с наименьшей нагрузкой на систему.
Современные системы с контролем целостности – это ZFS, btrfs и ReFS – и именно они рекомендуются для систем хранения больших объемов информации. Каждая из них умеет в фоновом режиме проверять целостность файлов и восстанавливать поврежденные фрагменты используя контрольные суммы (при наличии избыточности, разумеется).
И именно по этой причине тот же Proxmox категорически не рекомендует использование mdadm для хранилищ виртуальных машин в производственных средах.
{kind=link}
👍52
Доверять мало, надо еще и проверять, причем постоянно
Все мы используем различные проекты с открытым исходным кодом, которые, в теории, более безопасны чем закрытое ПО, но в любом случае наши отношения с авторами строятся на доверии.
Но доверие – вещь такая, что ее нужно постоянно контролировать, особенно в случае смены владельца. Так и произошло с библиотекой Polyfill, это открытая JavaScript-библиотека, предназначенная для обеспечения совместимости для старых версий браузеров.
Особенность данного скрипта, что он динамически генерируется на основании User Agent и генерирует функции с реализацией недостающих методов, свойств и API в зависимости от типа и версии браузера. Поэтому его невозможно было использовать в виде локальной версии и он всегда подгружался с официального CDN разработчика.
В феврале этого года проект Polyfill был продан китайской компании Funnull. Через несколько месяцев новый владелец решил альтернативно модернизировать проект и начал выполнять при помощи библиотеки автоматическое перенаправление пользователей на сомнительные сайты, такие как букмекерские конторы или казино.
При этом библиотека отслеживала куки и если обнаруживала сессию администратора сайта, то редирект не выполнялся, при обнаружении систем веб-аналитики переход задерживался, чтобы не попадать в статистику.
Таким образом реальный владелец сайта мог долгое время находиться в неведении, а пользователи могли подумать, что перенаправление инициативой именно владельца сайта.
Также новый владелец старательно удаляет из GitHub жалобы на подобное поведение, чтобы дольше создавать у пользователей видимость непричастности библиотеки к нежелательному поведению сайта.
По предварительным оценкам пострадало более 110 тыс. сайтов, но на самом деле их может быть значительно больше.
Как быть в такой ситуации? Никакого разумного выхода здесь нет, вы или доверяете владельцу проекта или не доверяете. Но вы никак не застрахованы от его деструктивных действий (либо его преемника).
Небольшую страховку дает использование открытых проектов через посредников, например, получать пакет не из репозитория разработчика, а из репозитория дистрибутива, желательно LTS. Что оставляет вас на более старых версиях, но в тоже время страхует от подобных угроз. Как пример – недавняя уязвимость в XZ Utils.
При использовании же динамически подключаемых библиотек вам только остается доверять разработчику и время от времени контролировать состояние дел проекта, по мере сил и возможностей.
Все мы используем различные проекты с открытым исходным кодом, которые, в теории, более безопасны чем закрытое ПО, но в любом случае наши отношения с авторами строятся на доверии.
Но доверие – вещь такая, что ее нужно постоянно контролировать, особенно в случае смены владельца. Так и произошло с библиотекой Polyfill, это открытая JavaScript-библиотека, предназначенная для обеспечения совместимости для старых версий браузеров.
Особенность данного скрипта, что он динамически генерируется на основании User Agent и генерирует функции с реализацией недостающих методов, свойств и API в зависимости от типа и версии браузера. Поэтому его невозможно было использовать в виде локальной версии и он всегда подгружался с официального CDN разработчика.
В феврале этого года проект Polyfill был продан китайской компании Funnull. Через несколько месяцев новый владелец решил альтернативно модернизировать проект и начал выполнять при помощи библиотеки автоматическое перенаправление пользователей на сомнительные сайты, такие как букмекерские конторы или казино.
При этом библиотека отслеживала куки и если обнаруживала сессию администратора сайта, то редирект не выполнялся, при обнаружении систем веб-аналитики переход задерживался, чтобы не попадать в статистику.
Таким образом реальный владелец сайта мог долгое время находиться в неведении, а пользователи могли подумать, что перенаправление инициативой именно владельца сайта.
Также новый владелец старательно удаляет из GitHub жалобы на подобное поведение, чтобы дольше создавать у пользователей видимость непричастности библиотеки к нежелательному поведению сайта.
По предварительным оценкам пострадало более 110 тыс. сайтов, но на самом деле их может быть значительно больше.
Как быть в такой ситуации? Никакого разумного выхода здесь нет, вы или доверяете владельцу проекта или не доверяете. Но вы никак не застрахованы от его деструктивных действий (либо его преемника).
Небольшую страховку дает использование открытых проектов через посредников, например, получать пакет не из репозитория разработчика, а из репозитория дистрибутива, желательно LTS. Что оставляет вас на более старых версиях, но в тоже время страхует от подобных угроз. Как пример – недавняя уязвимость в XZ Utils.
При использовании же динамически подключаемых библиотек вам только остается доверять разработчику и время от времени контролировать состояние дел проекта, по мере сил и возможностей.
{kind=link}
👍23🔥5🤯5
Хотите быстро улучшить свой английский? Актуальная лексика, понятные разборы грамматики, квизы и другие полезные материалы на канале «Гапонова и её английский»:
🔹Планы на выходные: подборка бесплатных материалов, чтобы заняться английским уже сейчас
🔹Что посмотреть и послушать на youtube
🔹Что делать, если застрял на среднем уровне и не видишь результатов?
Ещё больше английского для жизни и работы на канале Лены Гапоновой — преподавателя английского и автора курсов Gaponova School.
✅Подписывайтесь на @gaponova
erid: LjN8JyLdD
🔹Планы на выходные: подборка бесплатных материалов, чтобы заняться английским уже сейчас
🔹Что посмотреть и послушать на youtube
🔹Что делать, если застрял на среднем уровне и не видишь результатов?
Ещё больше английского для жизни и работы на канале Лены Гапоновой — преподавателя английского и автора курсов Gaponova School.
✅Подписывайтесь на @gaponova
erid: LjN8JyLdD
Можно ли восстановить данные с SSD
Несмотря на то, что твердотельные накопители давно используются в качестве основных среди пользователей и коллег до сих пор присутствуют неверные взгляды на возможность восстановления данных с таких дисков.
Поэтому предлагаем вам освежить знания на основе нашего практического материала, материал не новый, но свой актуальности он не потерял, так как заблуждений меньше не становится.
https://interface31.ru/tech_it/2022/05/mozhno-li-vosstanovit-dannye-s-tverdotel-nogo-nakopitelya-ssd.html
Несмотря на то, что твердотельные накопители давно используются в качестве основных среди пользователей и коллег до сих пор присутствуют неверные взгляды на возможность восстановления данных с таких дисков.
Поэтому предлагаем вам освежить знания на основе нашего практического материала, материал не новый, но свой актуальности он не потерял, так как заблуждений меньше не становится.
https://interface31.ru/tech_it/2022/05/mozhno-li-vosstanovit-dannye-s-tverdotel-nogo-nakopitelya-ssd.html
{kind=link}
👍30
Настраиваем динамическое обновление DNS-сервера BIND 9 при помощи Kea DHCP
По мере роста любой сети возникает необходимость перехода от обращения к узлам с IP адресов на FQDN, что позволяет полностью отвязаться от IP-адресации и использовать постоянные и удобные для запоминания доменные имена.
А задачу преобразования доменных имен в IP-адреса берет на себя DNS-сервер.
Но как быть с узлами, которые получают IP-адрес по DHCP?
Все просто - необходимо настроить динамическое обновление записей DNS-сервера и сегодня мы расскажем, как сделать это для DHCP-сервера Kea.
https://interface31.ru/tech_it/2024/06/nastraivaem-dinamicheskoe-obnovlenie-dns-servera-bind-9-pri-pomoshhi-kea-dhcp.html
По мере роста любой сети возникает необходимость перехода от обращения к узлам с IP адресов на FQDN, что позволяет полностью отвязаться от IP-адресации и использовать постоянные и удобные для запоминания доменные имена.
А задачу преобразования доменных имен в IP-адреса берет на себя DNS-сервер.
Но как быть с узлами, которые получают IP-адрес по DHCP?
Все просто - необходимо настроить динамическое обновление записей DNS-сервера и сегодня мы расскажем, как сделать это для DHCP-сервера Kea.
https://interface31.ru/tech_it/2024/06/nastraivaem-dinamicheskoe-obnovlenie-dns-servera-bind-9-pri-pomoshhi-kea-dhcp.html
{kind=link}
👍19🔥1
Непонятное поведение принтера по умолчанию в Windows 10 и 11
После очередных обновлений к нам стали поступать жалобы пользователей на непонятное поведение принтера по умолчанию в Windows 10 и 11. А именно принтер по умолчанию начал произвольно меняться.
Что вызывало массу неудобств и разных нехороших ситуаций, когда какой-нибудь второстепенный отчет на много листов уходил на дорогой цветной принтер или струйник с фотобумагой.
Выяснилось, что теперь в Windows возникла новая возможность, а именно автоматическое управление принтером, используемым по умолчанию.
Согласно этой политике, если она включена (а по умолчанию она включена) принтером по умолчанию становится тот принтер, на котором пользователь успешно печатал последний раз в текущем местоположении.
В целом идея здравая и удобна для мобильных пользователей, которые перемещаются между сетями, теперь дома система будет автоматически печатать на домашний принтер, а в офисе – на рабочий.
Но все меняется, если принтеров в текущем местоположении становится более одного. В этом случае такая функция вносит только хаос и запутывание, так как все время нужно проверять на какой ты принтер печатаешь.
К счастью, отключается эта функция достаточно просто, достаточно в приложении Параметры в разделе Принтеры и сканеры выключить параметр. Разрешить Windows управлять принтером, используемым по умолчанию.
Либо в разделе реестра:
Найти параметр LegacyDefaultPrinterMode и установить для него значение 1.
В любом случае основной претензией к Microsoft является то, что подобные функции включаются автоматически и без предупреждения. Это приводит к поведению отличному от ожидаемого с возможными неприятными последствиями, что закономерно вызывает у пользователей негатив и неприятие.
Хотя, сама новая функция в ряде сценариев будет полезной и удобной.
После очередных обновлений к нам стали поступать жалобы пользователей на непонятное поведение принтера по умолчанию в Windows 10 и 11. А именно принтер по умолчанию начал произвольно меняться.
Что вызывало массу неудобств и разных нехороших ситуаций, когда какой-нибудь второстепенный отчет на много листов уходил на дорогой цветной принтер или струйник с фотобумагой.
Выяснилось, что теперь в Windows возникла новая возможность, а именно автоматическое управление принтером, используемым по умолчанию.
Согласно этой политике, если она включена (а по умолчанию она включена) принтером по умолчанию становится тот принтер, на котором пользователь успешно печатал последний раз в текущем местоположении.
В целом идея здравая и удобна для мобильных пользователей, которые перемещаются между сетями, теперь дома система будет автоматически печатать на домашний принтер, а в офисе – на рабочий.
Но все меняется, если принтеров в текущем местоположении становится более одного. В этом случае такая функция вносит только хаос и запутывание, так как все время нужно проверять на какой ты принтер печатаешь.
К счастью, отключается эта функция достаточно просто, достаточно в приложении Параметры в разделе Принтеры и сканеры выключить параметр. Разрешить Windows управлять принтером, используемым по умолчанию.
Либо в разделе реестра:
HKEY_CURRENT_USER\Software\Microsoft\Windows NT\CurrentVersion\Windows
Найти параметр LegacyDefaultPrinterMode и установить для него значение 1.
В любом случае основной претензией к Microsoft является то, что подобные функции включаются автоматически и без предупреждения. Это приводит к поведению отличному от ожидаемого с возможными неприятными последствиями, что закономерно вызывает у пользователей негатив и неприятие.
Хотя, сама новая функция в ряде сценариев будет полезной и удобной.
{kind=link}
👍36🤣8👀3❤1🤬1
Из пункта A в пункт Б
Как показывает практика – маршрутизация всегда была непростым вопросом, особенно если речь идет о маршрутизации между сетями. И чаще всего бывает так – я все сделал по инструкции, но ничего не работает.
Как быть, что делать, куда бежать? А бежать никуда не надо, надо просто взять в руки два простых инструмента и заняться диагностикой. Эти инструменты всем известны: пинг и трассировка.
Но прежде посмотрим на схему внизу материала. Где:
🔹 A и F – конечные устройства в разных сетях
🔹 B и E – внутренние интерфейсы VPN-серверов (роутеры)
🔹 С и D – стороны туннеля
🔹 X и Y – внешние адреса серверов
Итак, наша задача попасть из пункта A в пункт F и для начала мы посмотрим, как должна выглядеть правильная трассировка. Нам должны ответить по очереди следующие узлы:
1️⃣ B
2️⃣ D
3️⃣ F
И никакие другие. Почему? Потому что пакет по дороге совершает три прыжка: от компьютера-источника A на VPN-сервер B, с него на противоположный конец туннеля – D и оттуда в пункт назначения F, интерфейсы С и E в передаче пакета не участвуют (точнее используются только как интерфейсы выхода).
Если у вас в трассировке появились другие узлы – следовательно вы неправильно настроили маршрутизацию.
Теперь начнем диагностику. Если наша трассировка не доходит даже до первого промежуточного узла B, то берем ping и проверяем его доступность. Если он недоступен – то тут все понятно.
Но может ли быть так, что узел B пингуется, а трассировка не проходит? Может, в том случае, если VPN-сервер не является основным шлюзом сети и это означает что у вас не работает локальная маршрутизация.
В этом случае следует прописать маршрут к удаленной сети через узел B либо непосредственно на узле А, либо на основном шлюзе сети.
Здесь разобрались, идем дальше. Если у нас недоступен следующий узел трассировки – D, то это означает что пакет не удалось отправить на другую сторону туннеля.
В этом случае проверяем доступность (пингом) узла C, что покажет нам поднят ли туннельный интерфейс и отвечает ли он на наши запросы.
Если интерфейс поднят, но не отвечает на пинг, то проверяем включена ли маршрутизация на VPN-сервере и не блокирует ли данные соединения брандмауэр.
Интерфейс поднят и отвечает. Отлично. Теперь самое время разобраться в типе нашего VPN-подключения. Соединения на основе PPP, OpenVPN или AnyConnect строятся по клиент-серверной схеме.
Если с вашей стороны клиент, то доступность туннельного интерфейса означает что туннель поднят и работает, за редкими исключениями. Например, в OpenVPN при неправильно выставленных настройках сжатия туннель поднимается, но не работает.
Поэтом пробуем пропинговать точку D непосредственно с сервера. Если пинг проходит, то смотрим маршруты непосредственно на VPN-сервере (на самом деле клиенте) или проверяем брандмауэр на другой стороне.
Если мы сами сервер – то в первую очередь проверяем подключен ли к нам клиент со стороны D, далее точно также – маршруты и брандмауэр.
Другое дело stateless туннели, это GRE, IP-IP и WireGuard. Они ничего не знают о состоянии другой стороны и всегда подняты. В этом случае проверяем доступность узла противоположной стороны – Y, проверяем параметры туннеля с обоих сторон, правильность настроек.
Потому что в случае неправильных настроек туннельные интерфейсы с обоих сторон все равно будут подняты, также они будут подняты даже если узлы X и Y будут недоступны.
Если же трассировка прерывается на последнем этапе, то переходим к этапу 1, только с другой стороны. Мало доставить пакет от узла A к узлу F, надо еще чтобы узел F сумел доставить нам ответ.
В этом случае проверяем, включена ли маршрутизация на VPN-сервере с другой стороны, смотрим, не блокирует ли нас брандмауэр, а после этого смотрим, умеет ли узел F отправлять пакеты в сеть узла A. Для этого лучше всего выполнить встречную трассировку.
Ну и конечно же убедитесь, что все конечные и промежуточные узлы могут отвечать на пинг, например, Windows с настройками брандмауэра по умолчанию этого не делает.
Как показывает практика – маршрутизация всегда была непростым вопросом, особенно если речь идет о маршрутизации между сетями. И чаще всего бывает так – я все сделал по инструкции, но ничего не работает.
Как быть, что делать, куда бежать? А бежать никуда не надо, надо просто взять в руки два простых инструмента и заняться диагностикой. Эти инструменты всем известны: пинг и трассировка.
Но прежде посмотрим на схему внизу материала. Где:
🔹 A и F – конечные устройства в разных сетях
🔹 B и E – внутренние интерфейсы VPN-серверов (роутеры)
🔹 С и D – стороны туннеля
🔹 X и Y – внешние адреса серверов
Итак, наша задача попасть из пункта A в пункт F и для начала мы посмотрим, как должна выглядеть правильная трассировка. Нам должны ответить по очереди следующие узлы:
1️⃣ B
2️⃣ D
3️⃣ F
И никакие другие. Почему? Потому что пакет по дороге совершает три прыжка: от компьютера-источника A на VPN-сервер B, с него на противоположный конец туннеля – D и оттуда в пункт назначения F, интерфейсы С и E в передаче пакета не участвуют (точнее используются только как интерфейсы выхода).
Если у вас в трассировке появились другие узлы – следовательно вы неправильно настроили маршрутизацию.
Теперь начнем диагностику. Если наша трассировка не доходит даже до первого промежуточного узла B, то берем ping и проверяем его доступность. Если он недоступен – то тут все понятно.
Но может ли быть так, что узел B пингуется, а трассировка не проходит? Может, в том случае, если VPN-сервер не является основным шлюзом сети и это означает что у вас не работает локальная маршрутизация.
В этом случае следует прописать маршрут к удаленной сети через узел B либо непосредственно на узле А, либо на основном шлюзе сети.
Здесь разобрались, идем дальше. Если у нас недоступен следующий узел трассировки – D, то это означает что пакет не удалось отправить на другую сторону туннеля.
В этом случае проверяем доступность (пингом) узла C, что покажет нам поднят ли туннельный интерфейс и отвечает ли он на наши запросы.
Если интерфейс поднят, но не отвечает на пинг, то проверяем включена ли маршрутизация на VPN-сервере и не блокирует ли данные соединения брандмауэр.
Интерфейс поднят и отвечает. Отлично. Теперь самое время разобраться в типе нашего VPN-подключения. Соединения на основе PPP, OpenVPN или AnyConnect строятся по клиент-серверной схеме.
Если с вашей стороны клиент, то доступность туннельного интерфейса означает что туннель поднят и работает, за редкими исключениями. Например, в OpenVPN при неправильно выставленных настройках сжатия туннель поднимается, но не работает.
Поэтом пробуем пропинговать точку D непосредственно с сервера. Если пинг проходит, то смотрим маршруты непосредственно на VPN-сервере (на самом деле клиенте) или проверяем брандмауэр на другой стороне.
Если мы сами сервер – то в первую очередь проверяем подключен ли к нам клиент со стороны D, далее точно также – маршруты и брандмауэр.
Другое дело stateless туннели, это GRE, IP-IP и WireGuard. Они ничего не знают о состоянии другой стороны и всегда подняты. В этом случае проверяем доступность узла противоположной стороны – Y, проверяем параметры туннеля с обоих сторон, правильность настроек.
Потому что в случае неправильных настроек туннельные интерфейсы с обоих сторон все равно будут подняты, также они будут подняты даже если узлы X и Y будут недоступны.
Если же трассировка прерывается на последнем этапе, то переходим к этапу 1, только с другой стороны. Мало доставить пакет от узла A к узлу F, надо еще чтобы узел F сумел доставить нам ответ.
В этом случае проверяем, включена ли маршрутизация на VPN-сервере с другой стороны, смотрим, не блокирует ли нас брандмауэр, а после этого смотрим, умеет ли узел F отправлять пакеты в сеть узла A. Для этого лучше всего выполнить встречную трассировку.
Ну и конечно же убедитесь, что все конечные и промежуточные узлы могут отвечать на пинг, например, Windows с настройками брандмауэра по умолчанию этого не делает.
{kind=link}
👍38🔥6
А зачем нам DNS если у нас нет домена?
Довольно часто встречаемся с этим вопросом, особенно когда поднимаем службу DNS в сравнительно небольших сетях. Почему-то у многих коллег DNS прочно ассоциируется с Active Directory. Может быть что и там, и там домен?
Но тем не менее DNS-это одна из важнейших сетевых служб, даже для небольших сетей и хороший задел на будущее.
Но начнем мы немного издалека. Еще в начале нулевых, когда сети стали не роскошью, а средством взаимодействия компьютеров пришло понимание, что бегать и прописывать статику по узлам сети контрпродуктивно и самое широкое внедрение нашли службы DHCP.
Сегодня представить сеть без нее невозможно. Статика осталась только на серверах, да и то не на всех, а только на ключевых, где без нее никуда. А для клиентских узлов DHCP стало нормой жизни. Все привыкли, что достаточно подключить ПК к сети, а там он как-то сам справится.
А дальше? А дальше коллеги пытаются жить среди плоских имен и IP-адресов, но ни то, ни другое не доставляет хорошего настроения.
Плоские имена, это имена, не являющиеся полностью определенным доменным именем (FQDN), например, PC-02. Разрешение данных имен осуществляется через широковещательные протоколы и действует только внутри широковещательного домена (сегмента сети).
Если у вас появляются филиалы, соединенные с основной сетью через VPN, то обращаться к удаленным компьютерам по именам вы не сможете. Плюс широковещание также не всегда хорошо работает и в пределах одного сегмента, например, на конечном узле может быть выключено сетевое обнаружение.
Поэтому многие не заморачиваются и используют IP- адреса, чем закладывают себе мину замедленного действия. Пока сеть небольшая и администратор держит в голове всю адресацию, то такая идея может даже показаться неплохой.
Но IP-адреса тяжело использовать пользователям, особенно если приходится диктовать их по телефону. Поди объясни, где там точки, где еще чего.
Но это все ерунда, по сравнению с тем, когда IP-адреса используются в настройках программ и сервисов, ярлыках пользователей и т.д. и т.п.
Почему? Потому что сеть имеет свойство расти и наступает момент, когда возникает потребность навести порядок в адресации или вынести узлы в отдельные сегменты сети.
И вот тут возникает занимательный квест: найди все места, где были забиты IP-адреса и поменяй их. Как показывает опыт – с первого раза его еще никто не проходил.
Отдельная песня – мобильные пользователи, мы ни раз и ни два видели наборы ярлыков «Общая папка офис», «Общая папка из дома» и т.д. и т.п. Связанные с тем, что в разных расположениях один и тот же сервис имел разную IP-адресацию.
Какой выход напрашивается из всего этого? Не использовать IP-адреса для обращения к узлам сети, они для этого не предназначены, для обращения к узлам следует использовать имена.
А поможет нам с этим служба DNS. Для того, чтобы узел понимал к какому домену он относится достаточно распространить через DHCP доменный суффикс, а разрешением имен займется локальная служба DNS.
Теперь вам не нужно вспоминать какой адрес имеет тот или иной узел, достаточно знать его имя, плоское. Система сама дополнит его до FQDN при помощи доменного суффикса и разрешит имя в адрес при помощи DNS-сервера.
Но это потребует определенного порядка и системы в наименовании узлов, потому как если компьютеры у вас называются как-то вроде DESKTOP-7GRSBHN, то толку от перехода на обращение по именам будет немного.
Если же сделать все по уму, то вам больше не придется каждый раз лазить в записи, чтобы посмотреть какой адрес у принтера на втором этаже в отделе кадров в 214 кабинете, вы всегда знаете, что это PRINTER-214.
После чего у вас полностью развязываются руки в плане IP-адресации, вы можете наводить в ней порядок, менять, переносить узлы из сегмента в сегмент – главное, чтобы это все отражалось на DNS-сервере.
Также это поможет и для удаленных пользователей, достаточно организовать двойной горизонт DNS, когда в офисе и за его пределами для одного и того же ресурса DNS-сервера будут выдавать различные IP-адреса.
Довольно часто встречаемся с этим вопросом, особенно когда поднимаем службу DNS в сравнительно небольших сетях. Почему-то у многих коллег DNS прочно ассоциируется с Active Directory. Может быть что и там, и там домен?
Но тем не менее DNS-это одна из важнейших сетевых служб, даже для небольших сетей и хороший задел на будущее.
Но начнем мы немного издалека. Еще в начале нулевых, когда сети стали не роскошью, а средством взаимодействия компьютеров пришло понимание, что бегать и прописывать статику по узлам сети контрпродуктивно и самое широкое внедрение нашли службы DHCP.
Сегодня представить сеть без нее невозможно. Статика осталась только на серверах, да и то не на всех, а только на ключевых, где без нее никуда. А для клиентских узлов DHCP стало нормой жизни. Все привыкли, что достаточно подключить ПК к сети, а там он как-то сам справится.
А дальше? А дальше коллеги пытаются жить среди плоских имен и IP-адресов, но ни то, ни другое не доставляет хорошего настроения.
Плоские имена, это имена, не являющиеся полностью определенным доменным именем (FQDN), например, PC-02. Разрешение данных имен осуществляется через широковещательные протоколы и действует только внутри широковещательного домена (сегмента сети).
Если у вас появляются филиалы, соединенные с основной сетью через VPN, то обращаться к удаленным компьютерам по именам вы не сможете. Плюс широковещание также не всегда хорошо работает и в пределах одного сегмента, например, на конечном узле может быть выключено сетевое обнаружение.
Поэтому многие не заморачиваются и используют IP- адреса, чем закладывают себе мину замедленного действия. Пока сеть небольшая и администратор держит в голове всю адресацию, то такая идея может даже показаться неплохой.
Но IP-адреса тяжело использовать пользователям, особенно если приходится диктовать их по телефону. Поди объясни, где там точки, где еще чего.
Но это все ерунда, по сравнению с тем, когда IP-адреса используются в настройках программ и сервисов, ярлыках пользователей и т.д. и т.п.
Почему? Потому что сеть имеет свойство расти и наступает момент, когда возникает потребность навести порядок в адресации или вынести узлы в отдельные сегменты сети.
И вот тут возникает занимательный квест: найди все места, где были забиты IP-адреса и поменяй их. Как показывает опыт – с первого раза его еще никто не проходил.
Отдельная песня – мобильные пользователи, мы ни раз и ни два видели наборы ярлыков «Общая папка офис», «Общая папка из дома» и т.д. и т.п. Связанные с тем, что в разных расположениях один и тот же сервис имел разную IP-адресацию.
Какой выход напрашивается из всего этого? Не использовать IP-адреса для обращения к узлам сети, они для этого не предназначены, для обращения к узлам следует использовать имена.
А поможет нам с этим служба DNS. Для того, чтобы узел понимал к какому домену он относится достаточно распространить через DHCP доменный суффикс, а разрешением имен займется локальная служба DNS.
Теперь вам не нужно вспоминать какой адрес имеет тот или иной узел, достаточно знать его имя, плоское. Система сама дополнит его до FQDN при помощи доменного суффикса и разрешит имя в адрес при помощи DNS-сервера.
Но это потребует определенного порядка и системы в наименовании узлов, потому как если компьютеры у вас называются как-то вроде DESKTOP-7GRSBHN, то толку от перехода на обращение по именам будет немного.
Если же сделать все по уму, то вам больше не придется каждый раз лазить в записи, чтобы посмотреть какой адрес у принтера на втором этаже в отделе кадров в 214 кабинете, вы всегда знаете, что это PRINTER-214.
После чего у вас полностью развязываются руки в плане IP-адресации, вы можете наводить в ней порядок, менять, переносить узлы из сегмента в сегмент – главное, чтобы это все отражалось на DNS-сервере.
Также это поможет и для удаленных пользователей, достаточно организовать двойной горизонт DNS, когда в офисе и за его пределами для одного и того же ресурса DNS-сервера будут выдавать различные IP-адреса.
{kind=link}
👍53❤1🤔1
Используете ли вы DNS в небольших сетях?
Anonymous Poll
47%
Да, обязательно
9%
Да, если сеть крупная
11%
Иногда использую
1%
Использовал, теперь нет, лишняя нагрузка
7%
Не использовал, но собираюсь
7%
Нет, не задумывался
6%
Нет, не вижу смысла
6%
Какие еще DNS? Тут если роутер дороже 1000 рублей купили - и то хорошо.
2%
Что делай, что не делай, все равно будут ходить по IP
4%
Ничего не понятно, но очень интересно
🧠 Тайны пользователей — открытый вебинар для тех, кто только начал свой путь в изучении Linux
👉 Ждём вас на открытом практическом уроке от OTUS, где мы:
- поговорим о типах пользователей;
- узнаем, где хранится информация о локальных пользователях;
- выясним, для чего нужны sudo и su.
🏆 Спикер Андрей Буранов — системный администратор в VK, входит в топ-3 лучших преподавателей образовательных порталов.
⏰ Встречаемся 11 июля в 20:00 мск в преддверии старта курса «Administrator Linux.Basic». Все участники вебинара получат специальную цену на обучение!
Регистрируйтесь для участия: https://otus.pw/3oGr/?erid=LjN8JyK2X
👉 Ждём вас на открытом практическом уроке от OTUS, где мы:
- поговорим о типах пользователей;
- узнаем, где хранится информация о локальных пользователях;
- выясним, для чего нужны sudo и su.
🏆 Спикер Андрей Буранов — системный администратор в VK, входит в топ-3 лучших преподавателей образовательных порталов.
⏰ Встречаемся 11 июля в 20:00 мск в преддверии старта курса «Administrator Linux.Basic». Все участники вебинара получат специальную цену на обучение!
Регистрируйтесь для участия: https://otus.pw/3oGr/?erid=LjN8JyK2X
👍1
Сертификаты плотно вошли в нашу жизнь и сегодня трудно представить себе рабочую систему, использующую незащищенные коммуникации.
Но несмотря на это тема использования сертификатов все еще вызывает затруднения у многих коллег, особенно когда они сталкиваются с тем, что разные системы и приложения могут требовать различных форматов сертификата.
Поэтому снова возвращаемся к напечатанному и советуем освежить свои знания при помощи нашей статьи
Форматы сертификатов X.509 (SSL) и преобразования между ними
Но несмотря на это тема использования сертификатов все еще вызывает затруднения у многих коллег, особенно когда они сталкиваются с тем, что разные системы и приложения могут требовать различных форматов сертификата.
Поэтому снова возвращаемся к напечатанному и советуем освежить свои знания при помощи нашей статьи
Форматы сертификатов X.509 (SSL) и преобразования между ними
{kind=link}
🔥23👍6