👁Open3D - computer vision библиотека с интерфейсами на Python и C++ и реализованными алгоритмами фотограмметрии.
https://github.com/intel-isl/Open3D
#photogrammetry
https://github.com/intel-isl/Open3D
#photogrammetry
GitHub
GitHub - isl-org/Open3D: Open3D: A Modern Library for 3D Data Processing
Open3D: A Modern Library for 3D Data Processing. Contribute to isl-org/Open3D development by creating an account on GitHub.
Слайды о том как работает человеческое зрение:
https://courses.cs.washington.edu/courses/cse455/09wi/Lects/lect8.pdf
https://courses.cs.washington.edu/courses/cse455/09wi/Lects/lect8.pdf
🌖 Еще про distortion
Часто встречаются distortion 3х видов
⁃ Barrel
⁃ Picushion
⁃ Mustache
Они возникают при использовании разных видов линз и разных комбинаций линз.
👽 Интересно, что помимо убирания distortion как чего-то плохого, иногда нам наоборот нужно его эмулировать.
Например в VR, для того чтобы когда изображение было “пропущено” через линзы оно выглядело адекватно для человека.
У Google Cardboard существует специальное приложение которое подбирает barrel искажение конкретно для вашего дисплея и кардборда.
Выглядит это вот так:
Часто встречаются distortion 3х видов
⁃ Barrel
⁃ Picushion
⁃ Mustache
Они возникают при использовании разных видов линз и разных комбинаций линз.
👽 Интересно, что помимо убирания distortion как чего-то плохого, иногда нам наоборот нужно его эмулировать.
Например в VR, для того чтобы когда изображение было “пропущено” через линзы оно выглядело адекватно для человека.
У Google Cardboard существует специальное приложение которое подбирает barrel искажение конкретно для вашего дисплея и кардборда.
Выглядит это вот так:
🤖 Можно самим написать такое преобразование, для этого для каждого пикселя выходной картинки мы применяем уравнения, где k1, k2, k3 выставляем сами в зависимости от того чего хотим добиться.
Советую поэкспериментировать с этими коэффициентами, можно например итеративно менять их и отображать в динамике:
https://gist.github.com/PavelKatunin/836e3937ada68cca722f58240e94fe81
Код написан для наглядности для CPU, просто перебираются пиксели, написать шейдер по этому примеру тоже просто.
Заметим, что это не аффинное преобразование, так как параллельность прямых не сохраняется
Получается вот такая картинка:
Советую поэкспериментировать с этими коэффициентами, можно например итеративно менять их и отображать в динамике:
https://gist.github.com/PavelKatunin/836e3937ada68cca722f58240e94fe81
Код написан для наглядности для CPU, просто перебираются пиксели, написать шейдер по этому примеру тоже просто.
Заметим, что это не аффинное преобразование, так как параллельность прямых не сохраняется
Получается вот такая картинка:
Gist
simple example of distortion on CPU
simple example of distortion on CPU. GitHub Gist: instantly share code, notes, and snippets.
🧩 Говорят, что научили робота собирать незнакомые вещи с успехом в 86% случаев. Для обучения придумали остроумную вещь: сначала заставили робота разбирать вещи, что довольно просто реализовать (детали просто кладутся в случайные места), а потом обучали на прокурученных назад записях.
https://www.youtube.com/watch?v=O8l4Kn-j-5M
https://www.youtube.com/watch?v=O8l4Kn-j-5M
YouTube
This Robot Arm Learned To Assemble Objects It Hasn’t Seen Before
❤️ Check out Lambda here and sign up for their GPU Cloud: https://lambdalabs.com/papers
📝 The paper "Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly" is available here:
https://form2fit.github.io/
❤️ Watch these videos in early…
📝 The paper "Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly" is available here:
https://form2fit.github.io/
❤️ Watch these videos in early…
Тут подогнали новый state of the art алгоритм сегментации объектов на изображении:
https://arxiv.org/pdf/2001.00309.pdf
https://arxiv.org/pdf/2001.00309.pdf
🏛 Как же детектировали объекты на изображениях древние? (70е - 80е)
🏢 Шаблоном по скользящему окну.
1. Выделяем границы, например, детектором Canny. (Композиция гауссовой свертки и дифференцирования + пороговая функция + некоторый способ сохранения связности линий)
2. Берем наш шаблон в виде какого-то контура и начинаем идти по изображению скользящим окном.
3. Используем Distance Transform, чтобы ускорить следующую операцию.
4. Используем одну из метрик: Chamfer Distance, Hausdorff Distance. (Суммируем или вычисляем максимум расстояния от нашего шаблона до выделенных краев на изображении)
Вообще про древних - это конечно была шутка, часто и сейчас можно пользоваться алгоритмами без машинного обучения.
Обычно их используют когда у вас не очень изменчивая среда и сам объект, где не очень необходимо выделять какую-то
семантику.
⚙️ Например, вам нужно определять правильной ли формы у вас детали на конвейере в какой-то момент.
Конечно, у себя на заводе вы часто можете фиксировать освещение, фон, да и правильные детали всегда одной формы.
✈️ 🛰 🗺 Или например их можно использовать для более интересных, военных целей.
Представьте себе снимок со спутника, нормаль поверхности практически всегда смотрит в камеру, количество разновидностей,
например, самолетов не такое уж и большое. Размер одинаковых объектов не меняется из-за одинаковой высоты.
🏢 Шаблоном по скользящему окну.
1. Выделяем границы, например, детектором Canny. (Композиция гауссовой свертки и дифференцирования + пороговая функция + некоторый способ сохранения связности линий)
2. Берем наш шаблон в виде какого-то контура и начинаем идти по изображению скользящим окном.
3. Используем Distance Transform, чтобы ускорить следующую операцию.
4. Используем одну из метрик: Chamfer Distance, Hausdorff Distance. (Суммируем или вычисляем максимум расстояния от нашего шаблона до выделенных краев на изображении)
Вообще про древних - это конечно была шутка, часто и сейчас можно пользоваться алгоритмами без машинного обучения.
Обычно их используют когда у вас не очень изменчивая среда и сам объект, где не очень необходимо выделять какую-то
семантику.
⚙️ Например, вам нужно определять правильной ли формы у вас детали на конвейере в какой-то момент.
Конечно, у себя на заводе вы часто можете фиксировать освещение, фон, да и правильные детали всегда одной формы.
✈️ 🛰 🗺 Или например их можно использовать для более интересных, военных целей.
Представьте себе снимок со спутника, нормаль поверхности практически всегда смотрит в камеру, количество разновидностей,
например, самолетов не такое уж и большое. Размер одинаковых объектов не меняется из-за одинаковой высоты.
🤖 Kornia и tensorflow.image - альтернативы для OpenCV с фокусом на работе с GPU
Kornia под собой использует PyTorch, а tensorflow.image соответственно tensorflow.
В них реализованы основные классические методы обработки изображений и еще их удобно встраивать в пайплайны ML.
https://kornia.github.io/
https://www.tensorflow.org/api_docs/python/tf/image
Kornia под собой использует PyTorch, а tensorflow.image соответственно tensorflow.
В них реализованы основные классические методы обработки изображений и еще их удобно встраивать в пайплайны ML.
https://kornia.github.io/
https://www.tensorflow.org/api_docs/python/tf/image
This media is not supported in your browser
VIEW IN TELEGRAM
Обзор алгоритмов градиентного спуска https://ruder.io/optimizing-gradient-descent/
◀️ ⏺ ☁︎ От уголков, кружков и пятен к AR
👁Как работают алгоритмы фотограмметрии и позиционирования камеры в AR?
Для того, чтобы, вычленить какое-то трехмерное представление из серии двухмерных картинок,
нам нужно понять, как изменилось положение камеры (например сотового телефона) при переходе от одной картинки к другой.
Именно по этому все AR приложения обычно просят немного поводить камерой туда сюда для определения своего положения.
Чтобы понять, как изменился угол обзора, нам нужно найти точки, соответствующие одной и той же точке в пространстве на двух изображениях. Найти самые характерные точки, желательно чтобы они были инвариантны к масштабу, освещению и тд.
Если мы найдем много таких точек, то мы сможем компенсировать то, что некоторые из них потеряются или перестанут быть инвариантаными.
👁Как работают алгоритмы фотограмметрии и позиционирования камеры в AR?
Для того, чтобы, вычленить какое-то трехмерное представление из серии двухмерных картинок,
нам нужно понять, как изменилось положение камеры (например сотового телефона) при переходе от одной картинки к другой.
Именно по этому все AR приложения обычно просят немного поводить камерой туда сюда для определения своего положения.
Чтобы понять, как изменился угол обзора, нам нужно найти точки, соответствующие одной и той же точке в пространстве на двух изображениях. Найти самые характерные точки, желательно чтобы они были инвариантны к масштабу, освещению и тд.
Если мы найдем много таких точек, то мы сможем компенсировать то, что некоторые из них потеряются или перестанут быть инвариантаными.
После сопоставления этих характерных точек, можно попробовать понять, какое геометрическое преобразование привело к такому изменению расположения характерных точек, и даже понять какую трехмерную форму имеют объекты. + конечно же нам может помочь акселерометр.
🧠 Что мы можем считать характерными точками?
Вот здесь нам и помогут алгоритмы распознавания некоторых особенностей в изображении.
⁃ Первое, что мы можем рассмотреть - это углы на изображении. Еще бы хорошо нам уметь определять, что эти углы примерно равны, и примерно равны в масштабе.
⁃ Вторыми характерными признаками могут оказаться круги разного размера!
⁃ И наконец иногда могут помочь характерные пятна.
Алгоритмы для определения углов:
⁃ Harris (Frostner)
⁃ Harris-Laplace
Круги:
⁃ LoG
⁃ DoG
Пятна:
⁃ IBR
⁃ MSER
Не стоит забывать, что это все необходимо делать в реальном времени, что конечно усложняет нам задачу.
Чуть позже мы разберём эти алгоритмы подробнее.
🧠 Что мы можем считать характерными точками?
Вот здесь нам и помогут алгоритмы распознавания некоторых особенностей в изображении.
⁃ Первое, что мы можем рассмотреть - это углы на изображении. Еще бы хорошо нам уметь определять, что эти углы примерно равны, и примерно равны в масштабе.
⁃ Вторыми характерными признаками могут оказаться круги разного размера!
⁃ И наконец иногда могут помочь характерные пятна.
Алгоритмы для определения углов:
⁃ Harris (Frostner)
⁃ Harris-Laplace
Круги:
⁃ LoG
⁃ DoG
Пятна:
⁃ IBR
⁃ MSER
Не стоит забывать, что это все необходимо делать в реальном времени, что конечно усложняет нам задачу.
Чуть позже мы разберём эти алгоритмы подробнее.
Google добавил фич в свой поисковик датасетов
https://blog.google/products/search/discovering-millions-datasets-web/
https://blog.google/products/search/discovering-millions-datasets-web/
Google
Discovering millions of datasets on the web
Dataset Search launches publicly with an index of 25 million datasets, helping scientists, journalists, students, data geeks to find data.
Полиция Лондона объявила о том, что они начали внедрять распозначание лиц в реальном времени. Как заявляется, для обнаружения местоположения конкретных людей попавших в розыск.
https://news.met.police.uk/news/met-begins-operational-use-of-live-facial-recognition-lfr-technology-392451
https://news.met.police.uk/news/met-begins-operational-use-of-live-facial-recognition-lfr-technology-392451
Boston Dynamics опубликовала свою SDK для управления роботом Spot. Там можно получать карты глубин со стереокамер на роботе, данные о поверхности и тд.
Надеюсь рост популярности этого робота даст нам ещё очень много датасетов с использованием их сенсоров. Ведь они могут снимать и сохранять данные практически постоянно.
https://nplus1.ru/news/2020/01/24/spot-sdk
Надеюсь рост популярности этого робота даст нам ещё очень много датасетов с использованием их сенсоров. Ведь они могут снимать и сохранять данные практически постоянно.
https://nplus1.ru/news/2020/01/24/spot-sdk
nplus1.ru
Boston Dynamics открыла четвероногого робота Spot для сторонних разработчиков
Компания Boston Dynamics опубликовала на GitHub набор средств разработки (SDK), позволяющий любому разработчику создавать приложения для четвероногого робота Spot или адаптировать для него дополнительное оборудование. Кроме того, она объявила, что в мае проведет…
Задача:
На видео появляются подобные артефакты, см. изображение. Внутри красных окружностей.
Можете ли вы объяснить природу их появления?
#задача
На видео появляются подобные артефакты, см. изображение. Внутри красных окружностей.
Можете ли вы объяснить природу их появления?
#задача
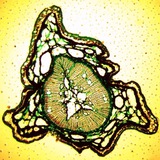
Участвую в биологическо / computer vision / робото проекте в University of Sheffield.
Вот видео системы автоматической фокусировки микроскопа.
https://twitter.com/CalcNeuro/status/1222118221614059520
Подписывайтесь на твиттер, будем постить всякое интересное:
https://twitter.com/CalcNeuro
Блог проекта:
https://neurocalc.blog/
Вот видео системы автоматической фокусировки микроскопа.
https://twitter.com/CalcNeuro/status/1222118221614059520
Подписывайтесь на твиттер, будем постить всякое интересное:
https://twitter.com/CalcNeuro
Блог проекта:
https://neurocalc.blog/
Twitter
NeuroCalc
Our version of motorised Z-stage with (future) perfect focusing system. In collaboration with @KatuninP https://t.co/aqamjUlhJv