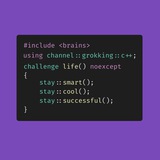
Получаем адрес перегрузки
#новичкам
Представьте, что у вас есть функция, которая вызывает любой коллбэк:
И есть другая функция, которую вы вызываете через call_callback.
Все работает прекрасно. Но теперь мы добавляем перегрузку func и пытаемся их вызвать через call_callback.
Получаем ошибку
Компилятор не может понять, какую конкретно перегрузку вы имели ввиду.
Дело в том, что имя функции неявно приводится к указателю на эту функцию. Тип указателя на функцию зависит от ее сигнатуры. И просто по имени невозможно понять, с какой сигнатурой функцию мы имеем ввиду.
Что же делать?
Дать компилятору подсказку и использовать static_cast.
Теперь все работает, как надо.
Give useful hints. Stay cool.
#cppcore
#новичкам
Представьте, что у вас есть функция, которая вызывает любой коллбэк:
template<class T, class... Args>
void call_callback(T callback, Args... args) {
callback(args...);
}
И есть другая функция, которую вы вызываете через call_callback.
int func() {
return 42;
}
call_callback(func);Все работает прекрасно. Но теперь мы добавляем перегрузку func и пытаемся их вызвать через call_callback.
int func() {
return 42;
}
int func(int num) {
return num;
}
call_callback(func);
call_callback(func, 42);Получаем ошибку
error: no matching function for call to
‘call_callback(<unresolved overloaded function type>)
Компилятор не может понять, какую конкретно перегрузку вы имели ввиду.
Дело в том, что имя функции неявно приводится к указателю на эту функцию. Тип указателя на функцию зависит от ее сигнатуры. И просто по имени невозможно понять, с какой сигнатурой функцию мы имеем ввиду.
Что же делать?
Дать компилятору подсказку и использовать static_cast.
call_callback(static_cast<int(*)()>(func));
call_callback(static_cast<int(*)(int)>(func), 42);
Теперь все работает, как надо.
Give useful hints. Stay cool.
#cppcore
{kind=link}
21👍29❤11🔥9😁2
std::visit
#опытным
Не так уж и просто работать с вариантными типами. Надо точно знать, какого типа объект находится внутри. Если не угадали - получили исключение. Ну или тестить объект на содержание в нем конкретного типа с помощью лапши из if-else.
Так вот чтобы голова не болела при работе с std::variant надо 2 раза в день после еды принимать std::visit.
Эта функция позволяет применять функтор к одному или нескольким объектам std::variant. И самое главное, что вам не нужно беспокоиться по поводу того, какой именно объект находится за личиной варианта. Компилятор все сам сделает.
Так выглядят ее сигнатуры. Первым параметром передаем функтор, дальше идут варианты.
Попробуем использовать эту функцию:
Главное, чтобы функтор умел обрабатывать любую комбинацию типов, которую вы можете передать в него. Обратите внимание, что мы используем здесь generic лямбду, которая может принимать один аргумент любого типа.
Если вы хотите передать в std::visit несколько объектов, то функтор должен принимать ровно такое же количество аргументов и уметь обрабатывать любую комбинацию типов, которая может содержаться в вариантах.
Используем здесь дженерик вариадик лямбду, чтобы она могла принимать столько аргументов, сколько нам нужно. И эта конструкция работает для любого количества переданных объектов std::variant;
Так что std::variant и std::visit - закадычные друзья и им друг без друга грустно! Не заставляйте их грустить.
Have a trustworthy helper. Stay cool.
#template #cpp17
#опытным
Не так уж и просто работать с вариантными типами. Надо точно знать, какого типа объект находится внутри. Если не угадали - получили исключение. Ну или тестить объект на содержание в нем конкретного типа с помощью лапши из if-else.
Так вот чтобы голова не болела при работе с std::variant надо 2 раза в день после еды принимать std::visit.
Эта функция позволяет применять функтор к одному или нескольким объектам std::variant. И самое главное, что вам не нужно беспокоиться по поводу того, какой именно объект находится за личиной варианта. Компилятор все сам сделает.
template< class Visitor, class... Variants >
constexpr visit( Visitor&& vis, Variants&&... vars );
template< class R, class Visitor, class... Variants >
constexpr R visit( Visitor&& vis, Variants&&... vars );
Так выглядят ее сигнатуры. Первым параметром передаем функтор, дальше идут варианты.
Попробуем использовать эту функцию:
using var_t = std::variant<int, long, double, std::string>;
std::vector<var_t> vec = {10, 15l, 1.5, "hello"};
for (auto& v: vec)
{
var_t w = std::visit([](auto&& arg) -> var_t { return arg + arg; }, v);
std::visit([](auto&& arg){ std::cout << arg; }, w);
}
//OUTPUT:
// 20 30 3 hellohello
Главное, чтобы функтор умел обрабатывать любую комбинацию типов, которую вы можете передать в него. Обратите внимание, что мы используем здесь generic лямбду, которая может принимать один аргумент любого типа.
Если вы хотите передать в std::visit несколько объектов, то функтор должен принимать ровно такое же количество аргументов и уметь обрабатывать любую комбинацию типов, которая может содержаться в вариантах.
std::visit([](auto&&... arg){ ((std::cout << arg << " "),
...,
(std::cout << std::endl)); }, vec[0], vec[1]);
std::visit([](auto&&... arg){ ((std::cout << arg << " "),
...,
(std::cout << std::endl)); }, vec[0], vec[1], vec[2]);
// OUTPUT
// 10 15
// 10 15 1.5Используем здесь дженерик вариадик лямбду, чтобы она могла принимать столько аргументов, сколько нам нужно. И эта конструкция работает для любого количества переданных объектов std::variant;
Так что std::variant и std::visit - закадычные друзья и им друг без друга грустно! Не заставляйте их грустить.
Have a trustworthy helper. Stay cool.
#template #cpp17
3👍27❤6🔥6❤🔥3⚡2🤔2
Почему перегрузки не могут иметь разные возвращаемые значения
#новичкам
Обычно люди просто принимают на веру факт, что перегрузки различаются только набором аргументов. Впрочем, как и все, что вливается в голову в начале обучения.
Но никогда не поздно задуматься над смыслом. А почему мы не можем перегружать функции по возвращаемому значению?
Может вот так абстрактно рассуждая, и не сразу придет ответ. Но на самом деле все просто, если посмотреть на конкретный пример. Давайте представим, что никаких запретов нет. Теперь перегрузки могут различаться только возвращаемым значением. И у нас есть 2 функции, почти одинаковые , но имеют разные возвращаемые значения.
Пускай мы хотим генерировать и целые числа, и дробные числа. И то, и то число, общее название оправдано.
Теперь попробуем вызвать первую версию.
А вы уверены, что мы сейчас вызвали именно первую версию? Флоат спокойно кастуется к инту. Ничего не мешает компилятору выбрать вторую версию для этого вызова.
Ситуация становится комичной, если использовать auto:
Тут как бы вообще нет ни намека на то, какую версию вызывать. Компилятор не умеет читать ваши мысли и намерения. Он не знает, какую версию вы хотели вызвать. Просто рандомно он выбрать не может. Появляется парадокс и вселенная схлопывается.
Вот и получили противоречие.
Компилятор просто не может отличить вызовы таких функций. Поэтому это и запрещено.
Don't be confusing. Stay cool.
#cppcore
#новичкам
Обычно люди просто принимают на веру факт, что перегрузки различаются только набором аргументов. Впрочем, как и все, что вливается в голову в начале обучения.
Но никогда не поздно задуматься над смыслом. А почему мы не можем перегружать функции по возвращаемому значению?
Может вот так абстрактно рассуждая, и не сразу придет ответ. Но на самом деле все просто, если посмотреть на конкретный пример. Давайте представим, что никаких запретов нет. Теперь перегрузки могут различаться только возвращаемым значением. И у нас есть 2 функции, почти одинаковые , но имеют разные возвращаемые значения.
int GetRandomNumber();
float GetRandomNumber();
Пускай мы хотим генерировать и целые числа, и дробные числа. И то, и то число, общее название оправдано.
Теперь попробуем вызвать первую версию.
int number = GetRandomNumber();
А вы уверены, что мы сейчас вызвали именно первую версию? Флоат спокойно кастуется к инту. Ничего не мешает компилятору выбрать вторую версию для этого вызова.
Ситуация становится комичной, если использовать auto:
auto number = GetRandomNumber();
Тут как бы вообще нет ни намека на то, какую версию вызывать. Компилятор не умеет читать ваши мысли и намерения. Он не знает, какую версию вы хотели вызвать. Просто рандомно он выбрать не может. Появляется парадокс и вселенная схлопывается.
Вот и получили противоречие.
Компилятор просто не может отличить вызовы таких функций. Поэтому это и запрещено.
Don't be confusing. Stay cool.
#cppcore
{kind=link}
❤21🔥13👍7😁4❤🔥1
Баг универсальной инициализации
В С++11 нам завезли прекрасную фичу - автоматический вывод типов с помощью ключевого слова auto. Теперь мы можем не беспокоится по поводу выяснения типа итераторов для какой-нибудь мапы от мапы о вектора и написания этого типа. Вместо этого можно просто сделать вот так:
И тогда же ввели еще одну замечательную фичу - braced initialization. Она предотвращает парсинг вашей инициализации, как объявления функции, и убирает эффекты неявного приведения типов. Например, при компиляции такого кода
компилятор выдаст что-то такое: warning: empty parentheses interpreted as a function declaration.
Ну вот захотел я вызвать дефолтный конструктор явно. А мое определение трактуют как объявление функции(most vexing parse). Если круглые скобки заменить на фигурные, то все будет пучком.
Однако эта универсальная инициализация, как ее называет Майерс, принесла с собой и несколько багов. Один из них мы уже обсуждали в этом посте. Но сегодня посмотрим еще на один.
Вот хотим мы объявить целочисленную переменную и вдруг забыли как пишется int. Да, здесь мы сильно натягваем даже не сову, а прям воробья на глобус.
А что, имеем право. auto ведь из инициализатора выводит тип, да?. Передали в качестве инициализатора целочисленный литерал.
Какой тип будет у i?
i будет иметь тип std::initializer_list<int>. Снова проблема именно в синтаксисе определения std::initializer_list и фигурными скобками.
Такое поведение совсем контринтуитивное. Считается, что фигурноскобочная инициализация - более предпочитаемый паттерн для использования, но такие приколюхи сильно снижают универсальность этого паттерна.
Да, в будущих стандартах эту "особенность" убрали, но не все могут пользоваться самими современными стандартами. Но хорошие новости, что, скорее всего, на современных версиях компиляторов при -std=c++11 вы не получите этого бага. Этот момент я объясню в следующем посте.
Don't be confusing. Stay cool.
#cpp11 #cppcore
В С++11 нам завезли прекрасную фичу - автоматический вывод типов с помощью ключевого слова auto. Теперь мы можем не беспокоится по поводу выяснения типа итераторов для какой-нибудь мапы от мапы о вектора и написания этого типа. Вместо этого можно просто сделать вот так:
const auto it = map_of_map_of_vectors_by_string_key.find(value);
И тогда же ввели еще одну замечательную фичу - braced initialization. Она предотвращает парсинг вашей инициализации, как объявления функции, и убирает эффекты неявного приведения типов. Например, при компиляции такого кода
struct MyClass {
int a = 0;
};
int main() {
MyClass x();
std::cout << x.a << std::endl;
}компилятор выдаст что-то такое: warning: empty parentheses interpreted as a function declaration.
Ну вот захотел я вызвать дефолтный конструктор явно. А мое определение трактуют как объявление функции(most vexing parse). Если круглые скобки заменить на фигурные, то все будет пучком.
Однако эта универсальная инициализация, как ее называет Майерс, принесла с собой и несколько багов. Один из них мы уже обсуждали в этом посте. Но сегодня посмотрим еще на один.
Вот хотим мы объявить целочисленную переменную и вдруг забыли как пишется int. Да, здесь мы сильно натягваем даже не сову, а прям воробья на глобус.
auto i{0};А что, имеем право. auto ведь из инициализатора выводит тип, да?. Передали в качестве инициализатора целочисленный литерал.
Какой тип будет у i?
i будет иметь тип std::initializer_list<int>. Снова проблема именно в синтаксисе определения std::initializer_list и фигурными скобками.
Такое поведение совсем контринтуитивное. Считается, что фигурноскобочная инициализация - более предпочитаемый паттерн для использования, но такие приколюхи сильно снижают универсальность этого паттерна.
Да, в будущих стандартах эту "особенность" убрали, но не все могут пользоваться самими современными стандартами. Но хорошие новости, что, скорее всего, на современных версиях компиляторов при -std=c++11 вы не получите этого бага. Этот момент я объясню в следующем посте.
Don't be confusing. Stay cool.
#cpp11 #cppcore
{kind=link}
👍30🔥11❤🔥4❤1🎄1
Фикс баги с инициализацией инта
В прошлом посте говорили об одной неприятности при использовании универсальной инициализации интов. При таком написании:
auto i = {0};
i будет иметь тип std::initializer_list<int>.
С++17 исправил такое поведение. Но для полного понимания мы должны определить два способа инициализации: копирующая и прямая. Приведу примеры
Для прямой инициализации вводятся следующие правила:
• Если внутри скобок 1 элемент, то тип инициализируемого объекта - тип объекта в скобках.
• Если внутри скобок больше одного элемента, то тип инициализируемого объекта просто не может быть выведен.
Примеры:
Этот фикс компиляторы реализовали задолго до того, как стандарт с++17 был окончательно утвержден. Поэтому даже с флагом -std=c++11 вы можете не увидеть некорректное поведение. Оно воспроизводится только на древних версиях. Можете убедиться тут.
Fix your flaws. Stay cool.
#cpp11 #cpp17 #compiler
В прошлом посте говорили об одной неприятности при использовании универсальной инициализации интов. При таком написании:
auto i = {0};
i будет иметь тип std::initializer_list<int>.
С++17 исправил такое поведение. Но для полного понимания мы должны определить два способа инициализации: копирующая и прямая. Приведу примеры
auto x = foo(); // копирующая инициализация
auto x{foo()}; // прямая инициализация,
// проинициализирует initializer_list (до C++17)
int x = foo(); // копирующая инициализация
int x{foo()}; // прямая инициализация
Для прямой инициализации вводятся следующие правила:
• Если внутри скобок 1 элемент, то тип инициализируемого объекта - тип объекта в скобках.
• Если внутри скобок больше одного элемента, то тип инициализируемого объекта просто не может быть выведен.
Примеры:
auto x1 = { 1, 2 }; // decltype(x1) - std::initializer_list<int>
auto x2 = { 1, 2.0 }; // ошибка: тип не может быть выведен,
// потому что внутри скобок объекты разных типов
auto x3{ 1, 2 }; // ошибка: не один элемент в скобках
auto x4 = { 3 }; // decltype(x4) - std::initializer_list<int>
auto x5{ 3 }; // decltype(x5) - intЭтот фикс компиляторы реализовали задолго до того, как стандарт с++17 был окончательно утвержден. Поэтому даже с флагом -std=c++11 вы можете не увидеть некорректное поведение. Оно воспроизводится только на древних версиях. Можете убедиться тут.
Fix your flaws. Stay cool.
#cpp11 #cpp17 #compiler
{kind=link}
❤19👍11🔥4❤🔥1👎1
Доступ к элементам многомерных структур
#опытным
Если вы спросите разработчиков C++ о том, как они получают доступ к элементам многомерных массивов, скорее всего, вы получите несколько различных ответов в зависимости от их опыта.
Если вы спросите кого-то, кто не очень опытен или работает в нематематической области, есть большая вероятность, что ответ будет таким, что вы должны использовать несколько операторов[] подряд: myMatrix[x][y].
Есть несколько проблем с таким подходом:
⛔️ Это не очень удобно чисто внешне. Все номальные люди используют синтаксис [x, y].
⛔️ Это работает "из коробки" на реально многомерных структурах, типа вложенных массивов(типа вектора векторов). Чтобы поддержать даже такой синтаксис для кастомных классов, придется несколько приседать.
⛔️ Поэтому многие находят лазейки, чтобы делать что-то похожее на [x, y], этих лазеек много, нет какого-то стандарта.
⛔️ Стандарт использует operator[] с одним аргументом для получения доступа к элементам массивов.
⛔️ Лазейки неконсистентны с одноразмерными массивами в плане получения доступа к элементам.
⛔️ Некоторые из них преполагают спорную семантику, а некоторые делают практически нечитаемыми сообщения об ошибках компиляции.
⛔️ Возможные проблемы с инлайнингом.
Рассмотрим лазейки в будущем, а сейчас сфокусируемся на решении проблемы.
В С++23 наконец завезли многоаргументный operator[]. Теперь при проектировании своей матрицы или даже тензора перегружать оператор[] для 1, 2, 3 и более входных аргументов. Так для матрицы можно возвращать элемент, если мы передали 2 размерности, или возвращать всю строку, если мы передали только одну размерность.
Здесь мы создали матрицу 4х3, заполнили ее буквами алфавита и вывели на экран каждый элемент через matrix[x, y]. А также дальше получили целую строку матрицы через matrix[x] и вывели ее содержимое на экран:
В качестве обертки для строки используем std::span из С++20.
Очень красиво и удобно. Разработчикам математических библиотек сделали большой подарок.
Be consistent. Stay cool.
#cpp23 #cpp20
#опытным
Если вы спросите разработчиков C++ о том, как они получают доступ к элементам многомерных массивов, скорее всего, вы получите несколько различных ответов в зависимости от их опыта.
Если вы спросите кого-то, кто не очень опытен или работает в нематематической области, есть большая вероятность, что ответ будет таким, что вы должны использовать несколько операторов[] подряд: myMatrix[x][y].
Есть несколько проблем с таким подходом:
⛔️ Это не очень удобно чисто внешне. Все номальные люди используют синтаксис [x, y].
⛔️ Это работает "из коробки" на реально многомерных структурах, типа вложенных массивов(типа вектора векторов). Чтобы поддержать даже такой синтаксис для кастомных классов, придется несколько приседать.
⛔️ Поэтому многие находят лазейки, чтобы делать что-то похожее на [x, y], этих лазеек много, нет какого-то стандарта.
⛔️ Стандарт использует operator[] с одним аргументом для получения доступа к элементам массивов.
⛔️ Лазейки неконсистентны с одноразмерными массивами в плане получения доступа к элементам.
⛔️ Некоторые из них преполагают спорную семантику, а некоторые делают практически нечитаемыми сообщения об ошибках компиляции.
⛔️ Возможные проблемы с инлайнингом.
Рассмотрим лазейки в будущем, а сейчас сфокусируемся на решении проблемы.
В С++23 наконец завезли многоаргументный operator[]. Теперь при проектировании своей матрицы или даже тензора перегружать оператор[] для 1, 2, 3 и более входных аргументов. Так для матрицы можно возвращать элемент, если мы передали 2 размерности, или возвращать всю строку, если мы передали только одну размерность.
template <typename T, std::size_t ROWS, std::size_t COLS>
class Martrix {
std::array<T, ROWS * COLS> a;
public:
Martrix() = default;
Martrix(Martrix const&) = default;
constexpr T& operator[](std::size_t row, std::size_t col) { // C++23 required
assert(row < ROWS and col < COLS);
return a[COLS * row + col];
}
constexpr std::span<T> operator[](std::size_t row) {
assert(row < ROWS);
return std::span{a.data() + row * COLS, COLS};
}
constexpr auto& underlying_array() { return a; }
};
int main() {
constexpr size_t ROWS = 4;
constexpr size_t COLS = 3;
Martrix<char, ROWS, COLS> matrix;
// fill in the underlying 1D array
auto& arr = matrix.underlying_array();
std::iota(arr.begin(), arr.end(), 'A');
for (auto row {0U}; row < ROWS; ++row) {
std::cout << "│ ";
for (auto col {0U}; col < COLS; ++col) {
std::cout << matrix[row, col] << " │ ";
}
std::cout << "\n";
}
std::cout << "\n";
auto row = matrix[1];
for (auto col {0U}; col < COLS; ++col) {
std::cout << row[col] << ' ';
}
}
Здесь мы создали матрицу 4х3, заполнили ее буквами алфавита и вывели на экран каждый элемент через matrix[x, y]. А также дальше получили целую строку матрицы через matrix[x] и вывели ее содержимое на экран:
│ A │ B │ C │
│ D │ E │ F │
│ G │ H │ I │
│ J │ K │ L │
D E F
В качестве обертки для строки используем std::span из С++20.
Очень красиво и удобно. Разработчикам математических библиотек сделали большой подарок.
Be consistent. Stay cool.
#cpp23 #cpp20
{kind=link}
🔥39👍17❤7👎5🤯2❤🔥1
std::mdspan
#опытным
"Я понял, что можно перегружать оператор[] для разного числа аргументов. Но это только для моих классов. А что делать со стандартными контейнерами типа std::vector? Могу я как-то на нем использовать многоаргументный оператор, если по факту я храню в нем матрицу?"
И нет, и да.
Интерфейс семантически одномерного контейнера никто менять не будет.
Однако вместе с С++23 появился еще один полезный класс std::mdspan. Это фактически тот же std::span, то есть это view над одномерной последовательностью элементов, только он интерпретирует ее, как многомерный массив.
То есть вы теперь буквально можете интерпретировать свой std::array или std::vector, как многомерный массив.
И! У std::mdspan переопределен оператор[], который может принимать несколько измеренений и выдает ссылку на соответствующий элемент.
Вывод:
В этом примере мы интерпретируем один и тот же массив, как матрицу и как такую кубическую структуру. Ну и играемся с выводом, чтобы продемонстировать, что мы реально можем манипулировать многомерной структурой, как хотим. В начале заполняем массив, как матрицу с двумя строчками(значения в строчках отличаются на 1000). Дальше читаем массив, как 3-хмерную структуру 2х3х2. Разрезаем ее на 2 части и получаются две матрицы 3х2, которые и выводим на экран.
Для создания mdspan нужно передать в конструктор начальный итератор и последовательные размерности. Их может быть сколько угодно. Число элементов или последний элемент последовательности не нужны, так как набор размерностей однозначно задает число элементов.
Метод extend возвращает размер вьюхи по заданному ранк индексу.
Так что скоро можно даже будет обойтись без сооружения своих оберток над стандартными контейнерами для получения доступа к многомерному оператору[]. И использовать стандартный инструмент std::mdspan.
Use standard things. Stay cool.
#cpp23 #STL
#опытным
"Я понял, что можно перегружать оператор[] для разного числа аргументов. Но это только для моих классов. А что делать со стандартными контейнерами типа std::vector? Могу я как-то на нем использовать многоаргументный оператор, если по факту я храню в нем матрицу?"
И нет, и да.
Интерфейс семантически одномерного контейнера никто менять не будет.
Однако вместе с С++23 появился еще один полезный класс std::mdspan. Это фактически тот же std::span, то есть это view над одномерной последовательностью элементов, только он интерпретирует ее, как многомерный массив.
То есть вы теперь буквально можете интерпретировать свой std::array или std::vector, как многомерный массив.
И! У std::mdspan переопределен оператор[], который может принимать несколько измеренений и выдает ссылку на соответствующий элемент.
std::vector v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
// View data as contiguous memory representing 2 rows of 6 ints each
auto ms2 = std::mdspan(v.data(), 2, 6);
// View the same data as a 3D array 2 x 3 x 2
auto ms3 = std::mdspan(v.data(), 2, 3, 2);
// Write data using 2D view
for (std::size_t i = 0; i != ms2.extent(0); i++)
for (std::size_t j = 0; j != ms2.extent(1); j++)
ms2[i, j] = i * 1000 + j;
// Read back using 3D view
for (std::size_t i = 0; i != ms3.extent(0); i++)
{
std::println("slice @ i = {}", i);
for (std::size_t j = 0; j != ms3.extent(1); j++)
{
for (std::size_t k = 0; k != ms3.extent(2); k++)
std::print("{} ", ms3[i, j, k]);
std::println("");
}
}Вывод:
slice @ i = 0
0 1
2 3
4 5
slice @ i = 1
1000 1001
1002 1003
1004 1005
В этом примере мы интерпретируем один и тот же массив, как матрицу и как такую кубическую структуру. Ну и играемся с выводом, чтобы продемонстировать, что мы реально можем манипулировать многомерной структурой, как хотим. В начале заполняем массив, как матрицу с двумя строчками(значения в строчках отличаются на 1000). Дальше читаем массив, как 3-хмерную структуру 2х3х2. Разрезаем ее на 2 части и получаются две матрицы 3х2, которые и выводим на экран.
Для создания mdspan нужно передать в конструктор начальный итератор и последовательные размерности. Их может быть сколько угодно. Число элементов или последний элемент последовательности не нужны, так как набор размерностей однозначно задает число элементов.
Метод extend возвращает размер вьюхи по заданному ранк индексу.
Так что скоро можно даже будет обойтись без сооружения своих оберток над стандартными контейнерами для получения доступа к многомерному оператору[]. И использовать стандартный инструмент std::mdspan.
Use standard things. Stay cool.
#cpp23 #STL
{kind=link}
👍19❤12🔥8😁2
Квиз
В тему индексирования многоразмерных массивов закину сегодня #quiz. Ничего супер запутанного, но от этого не менее интересно.
Вот мы в прошлых постах говорили, что начиная с С++23 мы можем определять оператор[], который принимает несколько аргументов.
А что будет, если мы просто возьмем и создадим многомерный массив, как нам бы это было удобно? И будет получать доступ к его элементам:
Видели когда-нибудь такое? Даже если нет, у меня к вам всего один вопрос.
Какой будет результат попытки компиляции и запуска этого кода ?
В тему индексирования многоразмерных массивов закину сегодня #quiz. Ничего супер запутанного, но от этого не менее интересно.
Вот мы в прошлых постах говорили, что начиная с С++23 мы можем определять оператор[], который принимает несколько аргументов.
А что будет, если мы просто возьмем и создадим многомерный массив, как нам бы это было удобно? И будет получать доступ к его элементам:
#include <iostream>
int main() {
auto array = new int[10, 20]{10};
std::cout << array[1, 0] << " " << array[11, 1] << std::endl;
}
Видели когда-нибудь такое? Даже если нет, у меня к вам всего один вопрос.
Какой будет результат попытки компиляции и запуска этого кода ?
❤7👍6❤🔥3🔥3☃1
Какой результат попытки компиляции и запуска кода?
Anonymous Poll
18%
Ошибка компиляции. Оператор же не может принять 2 аргумента, алё.
30%
Segmentation fault. Выходим за границы массива, так как пытаемся адресовать по несуществующей строке
24%
Какое-то незнакомое заклинание, ХЗ
19%
10 10
6%
0 0
16%
10 0
2%
0 10
🤔10🔥5😱3
Ответ
На самом деле в код выше я упустил оператор delete[], поэтому в нем есть утечка памяти. Этого я не учел, так как на другом концентировался.
Моя ошибка, но соль примера была в другом. Поэтому сейчас будем разбирать такой код:
Такой код соберется выведет на консоль "10 0" и успешно завершится.
Но то, что код успешно завершается не значит, что он понятен и работает, как мы ожидаем.
Основная загвоздка в том, что в С++ запятая - это не просто знак препинания. Это оператор! У него есть вполне четкое и прописанное поведение - он игнорирует результат любого выражения, кроме последнего.
То есть
Все выражения вычислятся, но результатом комбинированного выражения будет результат Expression3.
Поэтому когда мы пишем [i, j] до с++23, то это полностью эквивалентно [j]. Компилятор видит несколько параметров в [] и, так как сам оператор индексации не принимает несколько параметров, то выход только один - парсить через оператор запятая.
Получается, что с помощью
Ну и вообще, весь код полностью эквивалентен следующему:
На самом деле компилятор умеет выдавать предупреждения на использование оператора запятая. Поэтому использовании флагов компиляции -Werror -Wall, которые разрешают предупреждения и превращают их в ошибки компиляции, сборка упадет. Так что первый вариант ответа тоже был верным с какой-то стороны.
Теперь, почему
При аггрегированной инициализации мы можем в фигурных скобках указывать меньше элементов, чем может поместиться в массив или структуру. При этом остальные элементов будут инициализироваться так, как если бы они инициализировались от пустых скобок(аля array_elem = {};). Для интов это значит, что все элементы, кроме первого будут иметь нулевое значение.
То есть, никакого мусора. При использовании аггрегированной инициализации все поля будут иметь корректное и понятное значение.
Вот такая противная запятая.
Don't be confused. Stay cool.
#cpp23 #cppcore
На самом деле в код выше я упустил оператор delete[], поэтому в нем есть утечка памяти. Этого я не учел, так как на другом концентировался.
Моя ошибка, но соль примера была в другом. Поэтому сейчас будем разбирать такой код:
#include <iostream>
int main() {
auto array = new int[10, 20]{10};
std::cout << array[1, 0] << " " << array[11, 1] << std::endl;
delete[] array;
}
Такой код соберется выведет на консоль "10 0" и успешно завершится.
Но то, что код успешно завершается не значит, что он понятен и работает, как мы ожидаем.
Основная загвоздка в том, что в С++ запятая - это не просто знак препинания. Это оператор! У него есть вполне четкое и прописанное поведение - он игнорирует результат любого выражения, кроме последнего.
То есть
Expression1, Expression2, Expression3
Все выражения вычислятся, но результатом комбинированного выражения будет результат Expression3.
Поэтому когда мы пишем [i, j] до с++23, то это полностью эквивалентно [j]. Компилятор видит несколько параметров в [] и, так как сам оператор индексации не принимает несколько параметров, то выход только один - парсить через оператор запятая.
Получается, что с помощью
new int[10, 20] мы создали одномерный массив на 20 элементов.Ну и вообще, весь код полностью эквивалентен следующему:
#include <iostream>
int main() {
auto array = new int[20]{10};
std::cout << array[0] << " " << array[1] << std::endl;
delete[] array;
}
На самом деле компилятор умеет выдавать предупреждения на использование оператора запятая. Поэтому использовании флагов компиляции -Werror -Wall, которые разрешают предупреждения и превращают их в ошибки компиляции, сборка упадет. Так что первый вариант ответа тоже был верным с какой-то стороны.
Теперь, почему
10 0.При аггрегированной инициализации мы можем в фигурных скобках указывать меньше элементов, чем может поместиться в массив или структуру. При этом остальные элементов будут инициализироваться так, как если бы они инициализировались от пустых скобок(аля array_elem = {};). Для интов это значит, что все элементы, кроме первого будут иметь нулевое значение.
То есть, никакого мусора. При использовании аггрегированной инициализации все поля будут иметь корректное и понятное значение.
Вот такая противная запятая.
Don't be confused. Stay cool.
#cpp23 #cppcore
👍37🔥15❤9😱3🤣3
Оператор запятая внутри operator[]
Много народу попалось на ловушку запятой и выбрали неправильный ответ. Все потому что это поведение реально не интуитивное и реально легко ошибиться в семантике.
Именно поэтому начиная с С++20 использование оператора запятая внутри оператора квадратные скобки признано устаревшим(deprecated).
Это значит, что компиляторы будут обязаны выдавать предупреждение на такое использование, что делает детектирование опасной ситуации более простой задачей. Причем предупреждения появляются безо всяких флагов, наподобие Wall.
Итого:
Можно использовать оборачивание в круглые скобки и это будет валидным выражением с точки зрения стандарта. Но так намного проще будет опознать что-то неладное, чем без круглых скобок.
Кроме того, скорее всего уже были намеки, что в 23-х плюсах появится мультипараметрический интерфейс для operator[]. Поэтому стандарт заранее позаботился о том, чтобы был всего одна разрешенная семантика использования нескольких параметров в этом операторе.
Remove error-prone things. Stay cool.
#cpp20 #cpp23
Много народу попалось на ловушку запятой и выбрали неправильный ответ. Все потому что это поведение реально не интуитивное и реально легко ошибиться в семантике.
Именно поэтому начиная с С++20 использование оператора запятая внутри оператора квадратные скобки признано устаревшим(deprecated).
Это значит, что компиляторы будут обязаны выдавать предупреждение на такое использование, что делает детектирование опасной ситуации более простой задачей. Причем предупреждения появляются безо всяких флагов, наподобие Wall.
Итого:
void f(int *a, int b, int c)
{
a[b,c]; // deprecated
a[(b,c)]; // OK
}
Можно использовать оборачивание в круглые скобки и это будет валидным выражением с точки зрения стандарта. Но так намного проще будет опознать что-то неладное, чем без круглых скобок.
Кроме того, скорее всего уже были намеки, что в 23-х плюсах появится мультипараметрический интерфейс для operator[]. Поэтому стандарт заранее позаботился о том, чтобы был всего одна разрешенная семантика использования нескольких параметров в этом операторе.
Remove error-prone things. Stay cool.
#cpp20 #cpp23
{kind=link}
❤23👍18🔥7😁6🤯1
Новый год на пороге, а значит наступило время подводить итоги уходящего года! 🤩
Много всего произошло! Больше 7500 новых подписчиков и больше 300 авторских контентных постов было опубликовано. Очень круто, что у нас получилось постоянно вести этот проект, делиться с вами знаниями и самим учиться. Проект забирает много времени, не каждый готов вывести такую нагрузку.
Но то коммьюнити, которое мы здесь создаем, оно стоит каждого килоджоуля энергии, вложенной в канал. Столько крутых спецов, которые делятся своими знаниями и на постоянной основе обсуждают плюсы. Очень немногие ресурсы могут похвастаться этим.
Поэтому хочу выразить огромную благодарность вам всем.
С П А С И Б О !!! Вы драйверы этого канала и конечно же нашего развития. Почти каждый день выносить свои знания на суд огромной аудиторий потрясающих специалистов - конечно тут волей-неволей сильно прокачаешься во всех мелочах.
Круто, что канал выработал свой неповторимый стиль. Мы стараемся разбавлять нудятину о С++ всякими смешнявками и мемами. А также придумали несколько новых форматов. Мне лично очень зашел формат #ревью. Это очень крутой способ затронуть несколько сложных тем, проверить зоркость подписчиков, ну и просто потрындеть за плюсы. Вроде очевидная вещь, но я такого ни у кого не встречал.
Ну что это мы все о себе, да о себе...
Желаем вам в Новом году не останавливаться на достигнутом и мчаться вперед на всех парах! Ставьте перед собой цели и достигайте их. И главное - не давайте змею искусителю сбить вам с пути😉. Никаких питонов - только Плюсы, только хардкор!
Этим постом мы завершаем год и уходим на небольшой перерыв. Увидимся в следующем году! С праздником вас, дорогие положительные люди! 🥂🥳
Happy New Year! Stay cool.
Много всего произошло! Больше 7500 новых подписчиков и больше 300 авторских контентных постов было опубликовано. Очень круто, что у нас получилось постоянно вести этот проект, делиться с вами знаниями и самим учиться. Проект забирает много времени, не каждый готов вывести такую нагрузку.
Но то коммьюнити, которое мы здесь создаем, оно стоит каждого килоджоуля энергии, вложенной в канал. Столько крутых спецов, которые делятся своими знаниями и на постоянной основе обсуждают плюсы. Очень немногие ресурсы могут похвастаться этим.
Поэтому хочу выразить огромную благодарность вам всем.
С П А С И Б О !!! Вы драйверы этого канала и конечно же нашего развития. Почти каждый день выносить свои знания на суд огромной аудиторий потрясающих специалистов - конечно тут волей-неволей сильно прокачаешься во всех мелочах.
Круто, что канал выработал свой неповторимый стиль. Мы стараемся разбавлять нудятину о С++ всякими смешнявками и мемами. А также придумали несколько новых форматов. Мне лично очень зашел формат #ревью. Это очень крутой способ затронуть несколько сложных тем, проверить зоркость подписчиков, ну и просто потрындеть за плюсы. Вроде очевидная вещь, но я такого ни у кого не встречал.
Ну что это мы все о себе, да о себе...
Желаем вам в Новом году не останавливаться на достигнутом и мчаться вперед на всех парах! Ставьте перед собой цели и достигайте их. И главное - не давайте змею искусителю сбить вам с пути😉. Никаких питонов - только Плюсы, только хардкор!
Этим постом мы завершаем год и уходим на небольшой перерыв. Увидимся в следующем году! С праздником вас, дорогие положительные люди! 🥂🥳
Happy New Year! Stay cool.
{kind=link}
25🔥80🎄37👍17❤9☃6👎4
Допотопный доступ к многомерному массиву Ч1
#опытным
Начнем рассказ о том, как люди до С++23(то есть до сих пор) жили с оператором[], принимающим только один параметр.
И начнем мы с банальщины. Вот у нас есть класс матрицы. По всем канонам С++ мы должны получать доступ к ее элементам вот так matrix[i][j]. Этот формат сохраняет констистентность с доступом к элементам одномерных массивов.
Однако сразу натыкаемся на проблему. Класс один, а вызываем мы оператор два раза. Несостыковочка.
Ее решает паттерн прокси. Мы создаем прокси класс и возвращаем его объект из первого индекса. Дальше у этого прокси класса определяем оператор[] и на выходе получаем наш элемент.
Условно, из первого оператора возвращаем ссылку на строку матрицы, а из второго - уже сам элемент.
Выглядит это примерно так:
В примере мы 2 раза проходимся по матрице, чтобы продемонстрировать возможность индексации элементов через объект самой матрицы и объекта строки.
Можно было бы конечно не писать отдельно наш прокси тип ArraySpan, а использовать готовый std::span из С++20, но оставим так. Идея использовать такой легковесный объект понятна - нам не нужно лишнего оверхеда на копирование или создание сложного объекта, чтобы просто получить доступ к элементу матрицы.
Ну и здесь мы можем использовать прокси тип в качестве реальной строки матрицы, и не скрывать его в кишках класса. Так мы получаем доступ к большей вариативности в оперировании матрицами. Например, можно делать скалярное произведение строк и прочее.
В чем недостаток такого способа? Куча прокси классов, которые возможно и не нужны. Возможно, нам просто нужна двумерная структура, чтобы получать доступ к конкретным элементам. Использование карты для морского боя не предполагает использование отдельных строк или столбцов. Хотелось бы просто индексировать конкретные элементы. Но тем не менее мы вынуждены использовать прокси класс.
А если структура трухмерная? Уже 2 прокси нужно будет. Больше вложенность - больше классов-прослоек. Не очень удобно. Поэтому и придумали другие способы, о которых расскажу в следующих постах.
Find the way out. Stay cool.
#cppcore #cpp20 #cpp23
#опытным
Начнем рассказ о том, как люди до С++23(то есть до сих пор) жили с оператором[], принимающим только один параметр.
И начнем мы с банальщины. Вот у нас есть класс матрицы. По всем канонам С++ мы должны получать доступ к ее элементам вот так matrix[i][j]. Этот формат сохраняет констистентность с доступом к элементам одномерных массивов.
Однако сразу натыкаемся на проблему. Класс один, а вызываем мы оператор два раза. Несостыковочка.
Ее решает паттерн прокси. Мы создаем прокси класс и возвращаем его объект из первого индекса. Дальше у этого прокси класса определяем оператор[] и на выходе получаем наш элемент.
Условно, из первого оператора возвращаем ссылку на строку матрицы, а из второго - уже сам элемент.
Выглядит это примерно так:
template <typename T>
struct ArraySpan {
ArraySpan(T * arr, size_t arr_size) : data_{arr}, size_{arr_size} {}
ArraySpan(T * arr_begin, T * arr_end)
: data_{arr_begin}
, size_{std::distance(arr_begin, arr_end)} {}
T& operator[](std::size_t i) {
return *(data_ + i);
}
size_t size() const {return size_;}
T * data() {return data_;}
private:
T * data_;
size_t size_;
};
template <typename T>
struct Matrix {
Matrix() = default;
Matrix(size_t rows, size_t cols, T init) : ROWS{rows}, COLS{cols}, data(ROWS * COLS, init) {}
Matrix(Matrix const&) = default;
ArraySpan<T> operator[](std::size_t row) {
return ArraySpan{data.data() + row * COLS, COLS};
}
std::vector<T>& underlying_array() { return data; }
size_t row_count() const { return ROWS;}
size_t col_count() const { return COLS;}
private:
size_t ROWS;
size_t COLS;
std::vector<T> data;
};
int main() {
Matrix mtrx(4, 5, 0);
auto& interval_buffer = mtrx.underlying_array();
std::iota(interval_buffer.begin(), interval_buffer.end(), 0);
for (int i = 0; i < mtrx.row_count(); ++i) {
for (int j = 0; j < mtrx.col_count(); ++j) {
std::cout << std::setw(2) << mtrx[i][j] << " ";
}
std::cout << std::endl;
}
std::cout << std::endl;
for (int i = 0; i < mtrx.row_count(); ++i) {
auto row = mtrx[i];
for (int j = 0; j < row.size(); ++j) {
std::cout << std::setw(2) << row[j] << " ";
}
std::cout << std::endl;
}
}
В примере мы 2 раза проходимся по матрице, чтобы продемонстрировать возможность индексации элементов через объект самой матрицы и объекта строки.
Можно было бы конечно не писать отдельно наш прокси тип ArraySpan, а использовать готовый std::span из С++20, но оставим так. Идея использовать такой легковесный объект понятна - нам не нужно лишнего оверхеда на копирование или создание сложного объекта, чтобы просто получить доступ к элементу матрицы.
Ну и здесь мы можем использовать прокси тип в качестве реальной строки матрицы, и не скрывать его в кишках класса. Так мы получаем доступ к большей вариативности в оперировании матрицами. Например, можно делать скалярное произведение строк и прочее.
В чем недостаток такого способа? Куча прокси классов, которые возможно и не нужны. Возможно, нам просто нужна двумерная структура, чтобы получать доступ к конкретным элементам. Использование карты для морского боя не предполагает использование отдельных строк или столбцов. Хотелось бы просто индексировать конкретные элементы. Но тем не менее мы вынуждены использовать прокси класс.
А если структура трухмерная? Уже 2 прокси нужно будет. Больше вложенность - больше классов-прослоек. Не очень удобно. Поэтому и придумали другие способы, о которых расскажу в следующих постах.
Find the way out. Stay cool.
#cppcore #cpp20 #cpp23
{kind=link}
❤18👍12🔥7❤🔥2😁2
Допотопный доступ к многомерному массиву Ч2
Теперь пойдут способы доступов к элементам многомерных массивов не каноничным путем.
Самый простой из них - вместо оператора[], который может принимать только один параметр, использовать оператор(), который можно перегружать, как нашей душе угодно.
Он может принимать ничем не ограниченный набор параметров. И к тому же их несколько штук можно определить. Например, если передаем 1 аргумент, то возвращается ссылка на строку матрицы. А если 2 аргумента, то возвращаем ссылку на сам элемент.
Вот так это может выглядеть:
Идейно здесь все тоже самое, да и пример почти идентичный, только используем оператор() вместо квадратных скобок. Это нам позволило в одном классе определить, как мы хотим давать доступы по одному и двум индексам. Это также упростило компилятору задачу по инлайнингу доступа к элементу по двум индексам, так это один вызов функции.
Но у метода есть и недостатки. Самый очевидный - все привыкли использовать квадратные скобки для индексов, а теперь только для этих классов нужно использовать круглые. При чтении кода иногда сложно отличить одно от другого и будут ошибки. Конечно, в момент компиляции все встанет на свои места, но все равно неприятно. Но если вы не сами пишите все это добро, а используете какой-то мощный алгебраический фреймворк, типа Eigen, то вам нативные сущности могут вообще не понадобится. Фреймворк будет покрывать все потребности и код станет консистентным.
Из неочевидного: для типа строки тоже придется использовать круглые скобки, чтобы сохранить сходство обработки с матрицами(на примере во втором цикле для доступа к конкретному элементу прокси массива тоже используем ()). Ну или не придется, но тогда сходства работы не будет и возникнет еще сильнее путаница.
Ну и непонятно, мы вообще функцию вызываем или что??
Тем не менее, этот способ есть даже в FAQ на странице, посвященному стандарту C++. И он совместим с нотацией индексации в Фортране. Поэтому метод довольно распространенный.
Be consistent. Stay cool.
#cppcore
Теперь пойдут способы доступов к элементам многомерных массивов не каноничным путем.
Самый простой из них - вместо оператора[], который может принимать только один параметр, использовать оператор(), который можно перегружать, как нашей душе угодно.
Он может принимать ничем не ограниченный набор параметров. И к тому же их несколько штук можно определить. Например, если передаем 1 аргумент, то возвращается ссылка на строку матрицы. А если 2 аргумента, то возвращаем ссылку на сам элемент.
Вот так это может выглядеть:
template <typename T>
struct ArraySpan {
ArraySpan(T * arr, size_t arr_size) : data_{arr}, size_{arr_size} {}
ArraySpan(T * arr_begin, T * arr_end) : data_{arr_begin}, size_{std::distance(arr_begin, arr_end)} {}
T& operator()(std::size_t i) {
return *(data_ + i);
}
size_t size() const {return size_;}
T * data() {return data_;}
private:
T * data_;
size_t size_;
};
template <typename T>
struct Matrix {
Matrix() = default;
Matrix(size_t rows, size_t cols, T init) : ROWS{rows}, COLS{cols}, data(ROWS * COLS, init) {}
Matrix(Matrix const&) = default;
ArraySpan<T> operator()(std::size_t row) {
return ArraySpan{data.data() + row * COLS, COLS};
}
T& operator()(std::size_t row, std::size_t col) {
return data[row * COLS + col];
}
std::vector<T>& underlying_array() { return data; }
size_t row_count() const { return ROWS;}
size_t col_count() const { return COLS;}
private:
size_t ROWS;
size_t COLS;
std::vector<T> data;
};
int main() {
Matrix mtrx(4, 5, 0);
auto& interval_buffer = mtrx.underlying_array();
std::iota(interval_buffer.begin(), interval_buffer.end(), 0);
for (int i = 0; i < mtrx.row_count(); ++i) {
for (int j = 0; j < mtrx.col_count(); ++j) {
std::cout << std::setw(2) << mtrx(i, j) << " ";
}
std::cout << std::endl;
}
std::cout << std::endl;
for (int i = 0; i < mtrx.row_count(); ++i) {
auto row = mtrx(i);
for (int j = 0; j < row.size(); ++j) {
std::cout << std::setw(2) << row(j) << " ";
}
std::cout << std::endl;
}
}
Идейно здесь все тоже самое, да и пример почти идентичный, только используем оператор() вместо квадратных скобок. Это нам позволило в одном классе определить, как мы хотим давать доступы по одному и двум индексам. Это также упростило компилятору задачу по инлайнингу доступа к элементу по двум индексам, так это один вызов функции.
Но у метода есть и недостатки. Самый очевидный - все привыкли использовать квадратные скобки для индексов, а теперь только для этих классов нужно использовать круглые. При чтении кода иногда сложно отличить одно от другого и будут ошибки. Конечно, в момент компиляции все встанет на свои места, но все равно неприятно. Но если вы не сами пишите все это добро, а используете какой-то мощный алгебраический фреймворк, типа Eigen, то вам нативные сущности могут вообще не понадобится. Фреймворк будет покрывать все потребности и код станет консистентным.
Из неочевидного: для типа строки тоже придется использовать круглые скобки, чтобы сохранить сходство обработки с матрицами(на примере во втором цикле для доступа к конкретному элементу прокси массива тоже используем ()). Ну или не придется, но тогда сходства работы не будет и возникнет еще сильнее путаница.
Ну и непонятно, мы вообще функцию вызываем или что??
Тем не менее, этот способ есть даже в FAQ на странице, посвященному стандарту C++. И он совместим с нотацией индексации в Фортране. Поэтому метод довольно распространенный.
Be consistent. Stay cool.
#cppcore
{kind=link}
👍23🔥10❤🔥3⚡1😁1
Допотопный доступ к многомерному массиву Ч3
Последний пост из серии. Сегодня речь пойдет о не очень красивом, но довольно необычном способе многоаргументной индексации элементов в многомерных структурах.
Благодаря появившейся в С++11 аггрегированной инициализации, мы можем инициализировать структуры с помощью фигурных скобок:
Этим можно воспользоваться для индексирования многомерных массивов. Определяем оператор[], который принимает на вход структуру, а вызываем мы этот оператор с помощью списка инициализации, который превращается в структуру.
Получается, что мы индексируем элемент матрицы с помощью двух индексов в операторе квадратные скобки! Единственное, что надо добавлять еще и фигурные.
Не самый элегантный способ, но довольно просто реализуется.
У него есть недостаток, что нельзя переопределить опретора[] для другой структуры, которая может принимать другое число параметров.
Например, мы хотим по одному индексу получать всю строку сразу. Можно попробовать определить другую структуру с одним полем и также через {} инициализировать эту структуру в квадратных скобках.
Но такое не прокатит. Компилятор не сможет определить, какой конкретно оператор ему нужно вызвать.
Дело в том, что аггрегированно инициализировать типы можно и меньшим количеством аргументов. То есть с помощью {1} я могу создать и объект Index, и объект Indexes.
Поэтому способ довольно ограниченный.
Вообще, про эта небольшая серия была не про то, чтобы захейтить наследованный от С оператор[] с его одним аргументом. Я хотел показать интересные решения, до которых доходили люди в условиях ограничений стандарта. Возможно, в них было то, о чем вы никогда не думали. И это расширило ваш плюсовый кругозор.
Don't be limited. Stay cool.
#cppcore #cpp11
Последний пост из серии. Сегодня речь пойдет о не очень красивом, но довольно необычном способе многоаргументной индексации элементов в многомерных структурах.
Благодаря появившейся в С++11 аггрегированной инициализации, мы можем инициализировать структуры с помощью фигурных скобок:
struct Example {
int i, j;
};
Example test{1, 2};
std::cout << test.i << " " << test.j << std::endl;
// OUTPUT:
// 1 2Этим можно воспользоваться для индексирования многомерных массивов. Определяем оператор[], который принимает на вход структуру, а вызываем мы этот оператор с помощью списка инициализации, который превращается в структуру.
struct Indexes {
size_t row;
size_t col;
};
template <typename T>
struct Matrix {
Matrix() = default;
Matrix(size_t rows, size_t cols, T init)
: ROWS{rows}, COLS{cols}
, data(ROWS * COLS, init) {}
Matrix(Matrix const&) = default;
// MAGIC HERE
T& operator[](Indexes indexes) {
return data[indexes.row * COLS + indexes.col];
}
std::vector<T>& underlying_array() { return data; }
size_t row_count() const { return ROWS;}
size_t col_count() const { return COLS;}
private:
size_t ROWS;
size_t COLS;
std::vector<T> data;
};
int main() {
Matrix mtrx(4, 5, 0);
auto& interval_buffer = mtrx.underlying_array();
std::iota(interval_buffer.begin(), interval_buffer.end(), 0);
for (size_t i = 0; i < mtrx.row_count(); ++i) {
for (size_t j = 0; j < mtrx.col_count(); ++j) {
std::cout << std::setw(2) << mtrx[{i, j}] << " "; // MAGIC HERE
}
std::cout << std::endl;
}
}Получается, что мы индексируем элемент матрицы с помощью двух индексов в операторе квадратные скобки! Единственное, что надо добавлять еще и фигурные.
Не самый элегантный способ, но довольно просто реализуется.
У него есть недостаток, что нельзя переопределить опретора[] для другой структуры, которая может принимать другое число параметров.
Например, мы хотим по одному индексу получать всю строку сразу. Можно попробовать определить другую структуру с одним полем и также через {} инициализировать эту структуру в квадратных скобках.
struct Index {
size_t row;
};
template<typename T>
T& Matrix<T>::operator[](Index index) {
return ArraySpan{data.data() + index.row * COLS, COLS};
}
auto row = mtrx[{1}];Но такое не прокатит. Компилятор не сможет определить, какой конкретно оператор ему нужно вызвать.
Дело в том, что аггрегированно инициализировать типы можно и меньшим количеством аргументов. То есть с помощью {1} я могу создать и объект Index, и объект Indexes.
Поэтому способ довольно ограниченный.
Вообще, про эта небольшая серия была не про то, чтобы захейтить наследованный от С оператор[] с его одним аргументом. Я хотел показать интересные решения, до которых доходили люди в условиях ограничений стандарта. Возможно, в них было то, о чем вы никогда не думали. И это расширило ваш плюсовый кругозор.
Don't be limited. Stay cool.
#cppcore #cpp11
👍24🔥13❤4⚡1❤🔥1
Безымянный lock_guard
Бывает иногда, что при определение объекта забываешь что-то написать. Параметры конструктора, шаблонный параметр класса, точка с запятой - всякое бывает. Такое обычно спокойно детектируется на этапе компиляции и без проблем исправляется. Но вот есть одна "забывашка", которая может привести к действительно неприятным последствиям и не так просто детектируется.
Пишите вы такие критическую секцию. Например, просто хотите потокобезопасно обновить мапу. Как полагается в книжках, используете std::lock_guard, но забываете одну деталь.
Для С++17 вполне синтаксически верный код. И он будет запускаться. Но потокобезопасности не будет.
"Но как же! Я же использовал lock_guard!"
Да вот только этот lock_guard безымянный. То есть является временным объектом. Соответственно, его деструктор вызовется ровно до insert'а и мьютекс освободится. А значит ничего безопасного тут нет.
Мапа будет теперь постоянно в неконсистентном состоянии и удачи потом в поиске этого места, особенно с замыленным глазом.
Вроде банальная ошибка. На работе ее еще можно через ревью отловить. Но на пет-проектах или собесах даже опытные люди ее совершают. Так что будьте бдительны в следующий раз и будет вам многопоточное счастье!
Stay alerted. Stay cool.
#cppcore
Бывает иногда, что при определение объекта забываешь что-то написать. Параметры конструктора, шаблонный параметр класса, точка с запятой - всякое бывает. Такое обычно спокойно детектируется на этапе компиляции и без проблем исправляется. Но вот есть одна "забывашка", которая может привести к действительно неприятным последствиям и не так просто детектируется.
Пишите вы такие критическую секцию. Например, просто хотите потокобезопасно обновить мапу. Как полагается в книжках, используете std::lock_guard, но забываете одну деталь.
// std::map<std::string, std::string> SomeClass::map_;
// std::mutex SomeClass::mtx_;
bool SomeClass::UpdateMap(const std::string& key, const std::string& value) {
std::lock_guard{mtx_};
auto result = map_.insert({key, value});
return result.second;
}
Для С++17 вполне синтаксически верный код. И он будет запускаться. Но потокобезопасности не будет.
"Но как же! Я же использовал lock_guard!"
Да вот только этот lock_guard безымянный. То есть является временным объектом. Соответственно, его деструктор вызовется ровно до insert'а и мьютекс освободится. А значит ничего безопасного тут нет.
Мапа будет теперь постоянно в неконсистентном состоянии и удачи потом в поиске этого места, особенно с замыленным глазом.
Вроде банальная ошибка. На работе ее еще можно через ревью отловить. Но на пет-проектах или собесах даже опытные люди ее совершают. Так что будьте бдительны в следующий раз и будет вам многопоточное счастье!
Stay alerted. Stay cool.
#cppcore
{kind=link}
🔥40👍19😁9❤4
RAII обертки мьютекса
#новичкам
Иногда замечаю, что неопытные либо вообще не используют raii обертки над замками, либо используют их неправильно. Давайте сегодня разберемся с этим вопросом.
Для начала - для работы с мьютексами нужны обертки. Очень некрасиво в наше время использовать чистые вызовы lock и unlock. Это наплевательское отношение к современному и безопасному(посмеемся) С++.
Здесь прямая аналогия с выделением памяти. Для каждого new нужно вызывать соответствующий delete. Чтобы случайно не забыть этого сделать(а в большом объеме кода что-то забыть вообще не проблема), используют умные указатели. Это классы, используя концепцию Resource Acquisition Is Initialization, помогают нам автоматически освобождать ресурсы, когда они нам более не нужны.
Также для каждого lock нужно вызвать unlock. Так может по аналогии сделаем класс, который в конструкторе будет лочить мьютекс, а в деструкторе - разблокировать его?
Хорошая новость в том, что это уже сделали за нас. И таких классов даже несколько. Если не уходить в специфическую функциональность, то их всего 2. Это std::lock_guard и std::unique_lock.
lock_guard - базовая и самая простая обертка. В конструкторе лочим, в деструкторе разлачиваем. И все. Больше ничего мы с ним делать не можем. Мы можем только создать объект и удалить его. Даже получить доступ к самому мьютексу нельзя. Очень лаконичный и безопасный интерфейс. Но и юзкейсы его применения довольно ограничены. Нужна простая критическая секция. Обезопасил и идешь дальше.
unique_lock же больше походит на std::unique_ptr. Уже можно получить доступ в объекты, поменяться содержимым с другим объектом unique_lock, поменять нижележащий объект на другой. Ну и раз мы все равно даем возможность пользователю получить доступ к нижележащему объекту, то удобно вынести в публичный интерфейс unique_lock те же методы, которыми можно управлять самим мьютексом. То есть lock, unlock, try_lock и тд - это часть интерфейса std::unique_lock.
Уже понятно, что этот вид обертки нужно использовать в более сложных случаях, когда функциональности lock_guard не хватает.
А в основном не хватает возможности использовать методы lock и unlock. Например, при работе в кондварами std::unique_lock просто необходим. Читатель заходит в критическую секцию, локает замок и затем видит, что определенные условия еще не наступили. Допустим еще нет данных для чтения. В такой ситуации надо отпустить мьютекс и заснуть до лучших времен. А при пробуждении и наступлении подходящих условий, опять залочить замок и начать делать работу.
Кондвар в методе wait при ложном условии вызывает unlock у unique_lock. При пробуждении и правдивом условии вызывает lock и ждет освобождения мьютекса.
Юзкейсы можно обсуждать очень долго, но вывод один: всегда используйте обертки над мьютексами! Возможно, они спасут вашу жизнь.
А уж какую обертку использовать подскажет сама задача.
Stay safe. Stay cool.
#concurrency
#новичкам
Иногда замечаю, что неопытные либо вообще не используют raii обертки над замками, либо используют их неправильно. Давайте сегодня разберемся с этим вопросом.
Для начала - для работы с мьютексами нужны обертки. Очень некрасиво в наше время использовать чистые вызовы lock и unlock. Это наплевательское отношение к современному и безопасному(посмеемся) С++.
Здесь прямая аналогия с выделением памяти. Для каждого new нужно вызывать соответствующий delete. Чтобы случайно не забыть этого сделать(а в большом объеме кода что-то забыть вообще не проблема), используют умные указатели. Это классы, используя концепцию Resource Acquisition Is Initialization, помогают нам автоматически освобождать ресурсы, когда они нам более не нужны.
Также для каждого lock нужно вызвать unlock. Так может по аналогии сделаем класс, который в конструкторе будет лочить мьютекс, а в деструкторе - разблокировать его?
Хорошая новость в том, что это уже сделали за нас. И таких классов даже несколько. Если не уходить в специфическую функциональность, то их всего 2. Это std::lock_guard и std::unique_lock.
lock_guard - базовая и самая простая обертка. В конструкторе лочим, в деструкторе разлачиваем. И все. Больше ничего мы с ним делать не можем. Мы можем только создать объект и удалить его. Даже получить доступ к самому мьютексу нельзя. Очень лаконичный и безопасный интерфейс. Но и юзкейсы его применения довольно ограничены. Нужна простая критическая секция. Обезопасил и идешь дальше.
bool MapInsertSafe(std::unordered_map<Key, Value>& map, const Key& key, Value value) {
std::lock_guard lck(mtx);
if (auto it = map.find(key))
return false;
else {
it->second = std::move(value);
return true;
}
}
unique_lock же больше походит на std::unique_ptr. Уже можно получить доступ в объекты, поменяться содержимым с другим объектом unique_lock, поменять нижележащий объект на другой. Ну и раз мы все равно даем возможность пользователю получить доступ к нижележащему объекту, то удобно вынести в публичный интерфейс unique_lock те же методы, которыми можно управлять самим мьютексом. То есть lock, unlock, try_lock и тд - это часть интерфейса std::unique_lock.
Уже понятно, что этот вид обертки нужно использовать в более сложных случаях, когда функциональности lock_guard не хватает.
А в основном не хватает возможности использовать методы lock и unlock. Например, при работе в кондварами std::unique_lock просто необходим. Читатель заходит в критическую секцию, локает замок и затем видит, что определенные условия еще не наступили. Допустим еще нет данных для чтения. В такой ситуации надо отпустить мьютекс и заснуть до лучших времен. А при пробуждении и наступлении подходящих условий, опять залочить замок и начать делать работу.
void worker_thread()
{
std::unique_lock lk(m);
cv.wait(lk, []{ return ready; });
// process data
lk.unlock();
}
Кондвар в методе wait при ложном условии вызывает unlock у unique_lock. При пробуждении и правдивом условии вызывает lock и ждет освобождения мьютекса.
Юзкейсы можно обсуждать очень долго, но вывод один: всегда используйте обертки над мьютексами! Возможно, они спасут вашу жизнь.
А уж какую обертку использовать подскажет сама задача.
Stay safe. Stay cool.
#concurrency
{kind=link}
👍28🔥13❤6😁3
Еще один плюс RAII
#опытным
Основная мотивации использования raii - вам не нужно думать об освобождении ресурсов. Мол ручное управление ресурсами небезопасно, так как можно забыть освободить их и вообще не всегда понятно, когда это нужно делать.
Но не все всегда зависит от вашего понимания программы. Вы можете в правильных местах расставить все нужные освобождения, но код будет все равно небезопасен. В чем проблема? В исключениях.
Это такие противные малявки, которые прерывают нормальное выполнение программы в исключительных ситуациях. Так вот вы рассчитываете на "нормальное выполнение программы" и, исходя из этого, расставляете освобождения. А тут бац! И программа просто не доходит до нужной строчки.
Простой код запроса к базе с кэшом. Что будет в том случае, если метод Select бросит исключение? unlock никогда не вызовется и мьютекс коннектора к базе будет навсегда залочен! Это очень печально, потому что ни один поток больше не сможет получить доступ к критической секции. Даже может произойти deadlock текущего потока, если он еще раз попытается захватить этот мьютекс. А это очень вероятно, потому что на запросы к базе скорее всего есть ретраи.
Мы могли бы сделать обработку исключений и руками разлочить замок:
Однако самое обидное, что исключения, связанные с работой с базой, мы даже обработать не может внутри метода SelectWithCache. Это просто не его компетенция и код сверху некорректен с этой точки зрения.
А снаружи метода объекта мы уже не сможем разблокировать мьютекс при обработке исключения, потому что это приватное поле.
Выход один - использовать RAII.
При захвате исключения происходит раскрутка стека и вызов деструкторов локальных объектов. Это значит, что в любом случае вызовется деструктор lg и мьютекс освободится.
Спасибо Михаилу за идею)
Stay safe. Stay cool.
#cpp11 #concurrency #cppcore #goodpractice
#опытным
Основная мотивации использования raii - вам не нужно думать об освобождении ресурсов. Мол ручное управление ресурсами небезопасно, так как можно забыть освободить их и вообще не всегда понятно, когда это нужно делать.
Но не все всегда зависит от вашего понимания программы. Вы можете в правильных местах расставить все нужные освобождения, но код будет все равно небезопасен. В чем проблема? В исключениях.
Это такие противные малявки, которые прерывают нормальное выполнение программы в исключительных ситуациях. Так вот вы рассчитываете на "нормальное выполнение программы" и, исходя из этого, расставляете освобождения. А тут бац! И программа просто не доходит до нужной строчки.
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
mtx_.lock();
if (auto it = cache.find(key); it != cache_.end()) {
mtx_.unlock();
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
mtx_.unlock();
return result;
}
}Простой код запроса к базе с кэшом. Что будет в том случае, если метод Select бросит исключение? unlock никогда не вызовется и мьютекс коннектора к базе будет навсегда залочен! Это очень печально, потому что ни один поток больше не сможет получить доступ к критической секции. Даже может произойти deadlock текущего потока, если он еще раз попытается захватить этот мьютекс. А это очень вероятно, потому что на запросы к базе скорее всего есть ретраи.
Мы могли бы сделать обработку исключений и руками разлочить замок:
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
try {
mtx_.lock();
if (auto it = cache.find(key); it != cache_.end()) {
mtx_.unlock();
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
mtx_.unlock();
return result;
}
}
catch (...) {
Log("Caught an exception");
mtx_.unlock();
}
}Однако самое обидное, что исключения, связанные с работой с базой, мы даже обработать не может внутри метода SelectWithCache. Это просто не его компетенция и код сверху некорректен с этой точки зрения.
А снаружи метода объекта мы уже не сможем разблокировать мьютекс при обработке исключения, потому что это приватное поле.
Выход один - использовать RAII.
std::shared_ptr<Value> DB::SelectWithCache(const Key& key) {
std::lock_guard lg{mtx_};
if (auto it = cache.find(key); it != cache_.end()) {
return it->second;
} else {
std::shared_ptr<Value> result = Select(key);
cache.insert({key, result});
return result;
}
}При захвате исключения происходит раскрутка стека и вызов деструкторов локальных объектов. Это значит, что в любом случае вызовется деструктор lg и мьютекс освободится.
Спасибо Михаилу за идею)
Stay safe. Stay cool.
#cpp11 #concurrency #cppcore #goodpractice
{kind=link}
🔥33👍12❤6⚡2
Не вызывайте пользовательский код по локом
#опытным
Вы пишите свой потокобезопасный класс, вставляете свои любимые примитивы синхронизации, обмазываете это все подходящим интерфейсом. И тут вам понадобилось вызвать какой-то пользовательский код, какой-нибудь метод или функцию, которую вы сами не писали. И вы это вставляете под замок. Ошибка!
А вдруг эта функция очень долго выполняется? Какой-нибудь долгий запрос к базе. Тогда вы будете долго держать замок, что не очень хорошо. Другие потоки будут потенциально простаивать в ожидании вашего мьютекса. Это может сильно пессимизировать скорость обработки данных. Код под защитой должен быть максимально коротким.
А если функция сама использует блокировку? Локать несколько мьютексов подряд - плохая затея. Это повышает вероятность возникновения дедлока и придется заботиться о его предотвращении. Что довольно сложно сделать с кодом, который вы неполностью контролируете.
А если функция кинет исключение, а вы блокируете мьютекс без оберток(осуждаем)? Мьютекс не освободится. И при повторной его блокировке сразу получили UB. Это как раз пример из предыдущего поста.
То есть делайте все приготовления за пределами критической секции. Достаньте из базы нужные данные, решите большую систему уравнений, посчитайте факториал чего-нибудь на листочке, подумайте о великом, покурите(не пропаганда, администрация канала решительно осуждает никотин) и только потом локайте свою структуру данных, быстро поменяйте там что-нибудь и выходите. Вот примерно так оно должно быть.
GetDataWithCache - это метод интерфейсного класса IStorage и мы сделали приватный виртуальный метод GetData. За то, что делает GetData мы не отвечаем и там потенциально может быть много реализаций. При получении данных из файла там может быть еще один лок. А общение с базой может занять довольно много времени. Поэтому мы просто отпускаем замок перед вызовом этого метода и не паримся о последствиях.
Конечно, бывают всякие ситуации. Но, если у вас есть большая критическая секция, то это как минимум признак того, что неплохо бы посмотреть новым взглядом на это безобразие и, возможно, получится что-то улучшить.
Кстати, в этом примере есть одна не совсем очевидная проблема(помимо более очевидных хехе). Она не относится непосредственно к теме поста. Можете попробовать в комментах ее найти и предложить решение.
#goodpractice
#опытным
Вы пишите свой потокобезопасный класс, вставляете свои любимые примитивы синхронизации, обмазываете это все подходящим интерфейсом. И тут вам понадобилось вызвать какой-то пользовательский код, какой-нибудь метод или функцию, которую вы сами не писали. И вы это вставляете под замок. Ошибка!
А вдруг эта функция очень долго выполняется? Какой-нибудь долгий запрос к базе. Тогда вы будете долго держать замок, что не очень хорошо. Другие потоки будут потенциально простаивать в ожидании вашего мьютекса. Это может сильно пессимизировать скорость обработки данных. Код под защитой должен быть максимально коротким.
А если функция сама использует блокировку? Локать несколько мьютексов подряд - плохая затея. Это повышает вероятность возникновения дедлока и придется заботиться о его предотвращении. Что довольно сложно сделать с кодом, который вы неполностью контролируете.
А если функция кинет исключение, а вы блокируете мьютекс без оберток(осуждаем)? Мьютекс не освободится. И при повторной его блокировке сразу получили UB. Это как раз пример из предыдущего поста.
То есть делайте все приготовления за пределами критической секции. Достаньте из базы нужные данные, решите большую систему уравнений, посчитайте факториал чего-нибудь на листочке, подумайте о великом, покурите(не пропаганда, администрация канала решительно осуждает никотин) и только потом локайте свою структуру данных, быстро поменяйте там что-нибудь и выходите. Вот примерно так оно должно быть.
std::shared_ptr<Value> IStorage::GetDataWithCache(const Key& key) {
std::unique_lock ul{mtx_};
if (auto it = cache.find(key); it != cache.end()) {
return it->second;
} else {
ul.unlock(); // HERE
std::shared_ptr<Value> result = GetData(key);
ul.lock();
cache.insert({key, result});
return result;
}
}GetDataWithCache - это метод интерфейсного класса IStorage и мы сделали приватный виртуальный метод GetData. За то, что делает GetData мы не отвечаем и там потенциально может быть много реализаций. При получении данных из файла там может быть еще один лок. А общение с базой может занять довольно много времени. Поэтому мы просто отпускаем замок перед вызовом этого метода и не паримся о последствиях.
Конечно, бывают всякие ситуации. Но, если у вас есть большая критическая секция, то это как минимум признак того, что неплохо бы посмотреть новым взглядом на это безобразие и, возможно, получится что-то улучшить.
Кстати, в этом примере есть одна не совсем очевидная проблема(помимо более очевидных хехе). Она не относится непосредственно к теме поста. Можете попробовать в комментах ее найти и предложить решение.
#goodpractice
{kind=link}
🔥17👍9❤6❤🔥2