Можно ли явно вызывать деструктор объекта?
Вопрос скорее из категории "А что если?" и скорее всего большинство разработчиков не столкнуться с надобностью это делать. Однако менее интересным этот вопрос не становится, если немного глубже копнуть. А копаться в плюсах всегда интересно)
В целом, любой публичный метод может быть вызван снаружи. Поэтому ответ на вопрос - да, можно. Но вот какие у этого будут последствия?
Возьмем простую структурку
struct SomeDefaultDestructedType
{
SomeDefaultDestructedType(int b): a{b} {}
~SomeDefaultDestructedType() = default;
int getNumber() {return a;}
int a;
};
Как видим, у нее дефолтовый деструктор, то есть отдает генерацию кода для него в руки компилятора. А компилятор в этих вопросах тупой и прямолинейный. Для нетривиальных полей он вызывает деструкторы, а для тривиальных типов - ничего не делает. И все. Поэтому для нашего класса вызывали мы деструктор для объекта, не вызывали, значения не имеет. Даже можно вызвать метод getNumber после явного вызова деструктора и он вернет валидное значение. Семантически объект уничтожен, а на самом деле живее всех живых. Память для него на стеке есть, данные в этой области лежат, поэтому мы и можем оперировать им как полноценным объектом. И хорошо, если у класса все его поля будут рекурсивно default deconstructed, тогда мы ничего не сломает. Проблемы начинаются, когда класс имеет нетривиальный деструктор. Посмотрим на следующую структурку:
struct SomeNonTrivialDestructedType
{
SomeNonTrivialDestructedType(int b): a{new int(b)} {}
~SomeNonTrivialDestructedType() { delete a;}
int getNumber() {return *a;}
int * a;
};
Простенькое выделение и освобождение памяти в куче. Что будет сейчас при явном вызове деструктора? Ресурс освободится, а объект останется лежать на стеке. А что происходит с объектами, которые выделяются в автоматической области, при выходе из области их создания? У них вызывается деструктор. Поэтому будет двойное освобождение памяти. А если этот объект еще использовать как-то, например вызвать у него метод getNumber, это еще и неопределенное поведение, так как обращаемся к освобожденной памяти.
Для объектов, созданных в куче через new, проблема остается такой же. Потому что хорошей практикой разработки является вызывать delete на каждый выделенный с помощью new объект. А delete вызывает деструктор.
Да и вообще для любого класса с нетривиальным деструктором, явный вызов этого самого деструктора будет сопровождаться приведением объекта в неконсистентное состояние, когда объект семантически мертв, а на деле им можно еще пользоваться и его придется умертвить еще раз(самостоятельно через delete или автоматически при выходе из скоупа). Это может приводить к ошибкам самого широкого спектра, в зависимости от логики работы объекта.
Есть случаи, когда явный вызов деструктора оправдан, но это всегда связано с работой с памятью на низком уровне. Об этом поговорим как-нибудь в другой раз. А пока, если вам всерьез не приходила в голову мысль явно вызывать деструктор - и не нужно этого делать)
Stay safe. Stay cool.
#cppcore #fun #memory
Вопрос скорее из категории "А что если?" и скорее всего большинство разработчиков не столкнуться с надобностью это делать. Однако менее интересным этот вопрос не становится, если немного глубже копнуть. А копаться в плюсах всегда интересно)
В целом, любой публичный метод может быть вызван снаружи. Поэтому ответ на вопрос - да, можно. Но вот какие у этого будут последствия?
Возьмем простую структурку
struct SomeDefaultDestructedType
{
SomeDefaultDestructedType(int b): a{b} {}
~SomeDefaultDestructedType() = default;
int getNumber() {return a;}
int a;
};
Как видим, у нее дефолтовый деструктор, то есть отдает генерацию кода для него в руки компилятора. А компилятор в этих вопросах тупой и прямолинейный. Для нетривиальных полей он вызывает деструкторы, а для тривиальных типов - ничего не делает. И все. Поэтому для нашего класса вызывали мы деструктор для объекта, не вызывали, значения не имеет. Даже можно вызвать метод getNumber после явного вызова деструктора и он вернет валидное значение. Семантически объект уничтожен, а на самом деле живее всех живых. Память для него на стеке есть, данные в этой области лежат, поэтому мы и можем оперировать им как полноценным объектом. И хорошо, если у класса все его поля будут рекурсивно default deconstructed, тогда мы ничего не сломает. Проблемы начинаются, когда класс имеет нетривиальный деструктор. Посмотрим на следующую структурку:
struct SomeNonTrivialDestructedType
{
SomeNonTrivialDestructedType(int b): a{new int(b)} {}
~SomeNonTrivialDestructedType() { delete a;}
int getNumber() {return *a;}
int * a;
};
Простенькое выделение и освобождение памяти в куче. Что будет сейчас при явном вызове деструктора? Ресурс освободится, а объект останется лежать на стеке. А что происходит с объектами, которые выделяются в автоматической области, при выходе из области их создания? У них вызывается деструктор. Поэтому будет двойное освобождение памяти. А если этот объект еще использовать как-то, например вызвать у него метод getNumber, это еще и неопределенное поведение, так как обращаемся к освобожденной памяти.
Для объектов, созданных в куче через new, проблема остается такой же. Потому что хорошей практикой разработки является вызывать delete на каждый выделенный с помощью new объект. А delete вызывает деструктор.
Да и вообще для любого класса с нетривиальным деструктором, явный вызов этого самого деструктора будет сопровождаться приведением объекта в неконсистентное состояние, когда объект семантически мертв, а на деле им можно еще пользоваться и его придется умертвить еще раз(самостоятельно через delete или автоматически при выходе из скоупа). Это может приводить к ошибкам самого широкого спектра, в зависимости от логики работы объекта.
Есть случаи, когда явный вызов деструктора оправдан, но это всегда связано с работой с памятью на низком уровне. Об этом поговорим как-нибудь в другой раз. А пока, если вам всерьез не приходила в голову мысль явно вызывать деструктор - и не нужно этого делать)
Stay safe. Stay cool.
#cppcore #fun #memory
{kind=link}
🔥5❤4❤🔥2
Всем привет!
Мы проставили хэштеги на каждый пост
А также на канале появился закрепленный пост, где собраны все эти хэштеги
Поэтому теперь вы можете:
1️⃣ В один клик перейти в самое начало канала и читать подряд все посты, не тратя время на прокручивание ленты
2️⃣ Быстро искать посты по интересующим тематикам, просто жмакнув на нужный хэштег
Давно эта штука напрашивалась и вот она появилась!
Уверен, что ваш юзер экспириенс качественно улучшится с этим нововведением)
Всем замечательного дня!
Stay cool.
Мы проставили хэштеги на каждый пост
А также на канале появился закрепленный пост, где собраны все эти хэштеги
Поэтому теперь вы можете:
1️⃣ В один клик перейти в самое начало канала и читать подряд все посты, не тратя время на прокручивание ленты
2️⃣ Быстро искать посты по интересующим тематикам, просто жмакнув на нужный хэштег
Давно эта штука напрашивалась и вот она появилась!
Уверен, что ваш юзер экспириенс качественно улучшится с этим нововведением)
Всем замечательного дня!
Stay cool.
👍14❤4🔥3
Порядок вычислений в С++
Рассмотрим простой вызов функции:
foo(std::unique_ptr{new A}, std::unique_ptr{new B});
Что может пойти здесь не так?
Есть 2 противоположных ответа на этот вопрос, но выбор каждого из них определяется версией плюсов.
Что было до С++17?
Был бардак, одним словом. Нормальный человек подумает, что в начале вычисляем new A, потом конструктор unique_ptr, потом new B и второй конструктор. Но это же С++. Компилятор на самом деле мог сгенерировать код, который вычисляет это выражение в любом рандомном порядке. Именно поэтому существует эта известная проблема, что компилятор так переупорядочит вызовы, что первым будет вызов new A, а вторым будет вызов new B и дальше конструкторы. Прикол в том, что если new B бросит std::bad_alloc, то мы получим утечку памяти. Успешно отработавший new выдаст указатель на память, которая никогда не будет возвращена обратно системе. Это мог бы сделать unique_ptr, но его конструктор так и не был вызван.
Да и вообще там много приколов неприятных было. Самые знаменитые примеры:
i = i++ + i++;
std::string s = "but I have heard it works even if you don't believe in it";
s.replace(0, 4, "").replace(s.find("even"), 4, "only").replace(s.find(" don't"), 6, "");
В обоих примерах компилятор мог так переставить операции, что в первом случае i будет равно нулю, а во втором случае будет совсем каша.
Порядок вычислений неспецифицирован. Конечно, там много правил под капотом и все-таки какие-то гарантии там есть, но объяснение их всех явно влезет в этот пост.
Именно поэтому std::make_unique и std::make_shared были незаменимы до 17-х плюсов. Потому что содержали внутри себя аллокацию памяти и давали базовую гарантию безопасности исключений.
Что стало после С++17?
Порядок вычислений стал более понятен. Там ввели кучу ужесточающих правил, не буду их всех приводить, потому что они скучные и скорее всего вы с ними не пересечетесь в своей работе. Главное, что в самом первом примере с функций foo и умными указателями теперь не сможет случиться утечка памяти. Новый закон таков, что не указано, в каком порядке должны быть вычислены аргументы функций, но каждый из них должен быть полностью вычислен до того, как начнет вычисляться следующий. Если второй new бросит bad_alloc, то первый указатель уже будет обернут в unique_ptr и при разворачивании стека будет вызван его деструктор и память освободится.
Тема на самом деле не простая. Если кто хочет поподробнее ее разобрать, то можете почитать тут и тут.
Stay safe. Stay cool.
#cpp17 #memory
Рассмотрим простой вызов функции:
foo(std::unique_ptr{new A}, std::unique_ptr{new B});
Что может пойти здесь не так?
Есть 2 противоположных ответа на этот вопрос, но выбор каждого из них определяется версией плюсов.
Что было до С++17?
Был бардак, одним словом. Нормальный человек подумает, что в начале вычисляем new A, потом конструктор unique_ptr, потом new B и второй конструктор. Но это же С++. Компилятор на самом деле мог сгенерировать код, который вычисляет это выражение в любом рандомном порядке. Именно поэтому существует эта известная проблема, что компилятор так переупорядочит вызовы, что первым будет вызов new A, а вторым будет вызов new B и дальше конструкторы. Прикол в том, что если new B бросит std::bad_alloc, то мы получим утечку памяти. Успешно отработавший new выдаст указатель на память, которая никогда не будет возвращена обратно системе. Это мог бы сделать unique_ptr, но его конструктор так и не был вызван.
Да и вообще там много приколов неприятных было. Самые знаменитые примеры:
i = i++ + i++;
std::string s = "but I have heard it works even if you don't believe in it";
s.replace(0, 4, "").replace(s.find("even"), 4, "only").replace(s.find(" don't"), 6, "");
В обоих примерах компилятор мог так переставить операции, что в первом случае i будет равно нулю, а во втором случае будет совсем каша.
Порядок вычислений неспецифицирован. Конечно, там много правил под капотом и все-таки какие-то гарантии там есть, но объяснение их всех явно влезет в этот пост.
Именно поэтому std::make_unique и std::make_shared были незаменимы до 17-х плюсов. Потому что содержали внутри себя аллокацию памяти и давали базовую гарантию безопасности исключений.
Что стало после С++17?
Порядок вычислений стал более понятен. Там ввели кучу ужесточающих правил, не буду их всех приводить, потому что они скучные и скорее всего вы с ними не пересечетесь в своей работе. Главное, что в самом первом примере с функций foo и умными указателями теперь не сможет случиться утечка памяти. Новый закон таков, что не указано, в каком порядке должны быть вычислены аргументы функций, но каждый из них должен быть полностью вычислен до того, как начнет вычисляться следующий. Если второй new бросит bad_alloc, то первый указатель уже будет обернут в unique_ptr и при разворачивании стека будет вызван его деструктор и память освободится.
Тема на самом деле не простая. Если кто хочет поподробнее ее разобрать, то можете почитать тут и тут.
Stay safe. Stay cool.
#cpp17 #memory
{kind=link}
👍9❤4🔥2⚡1
Remove-erase идиома
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
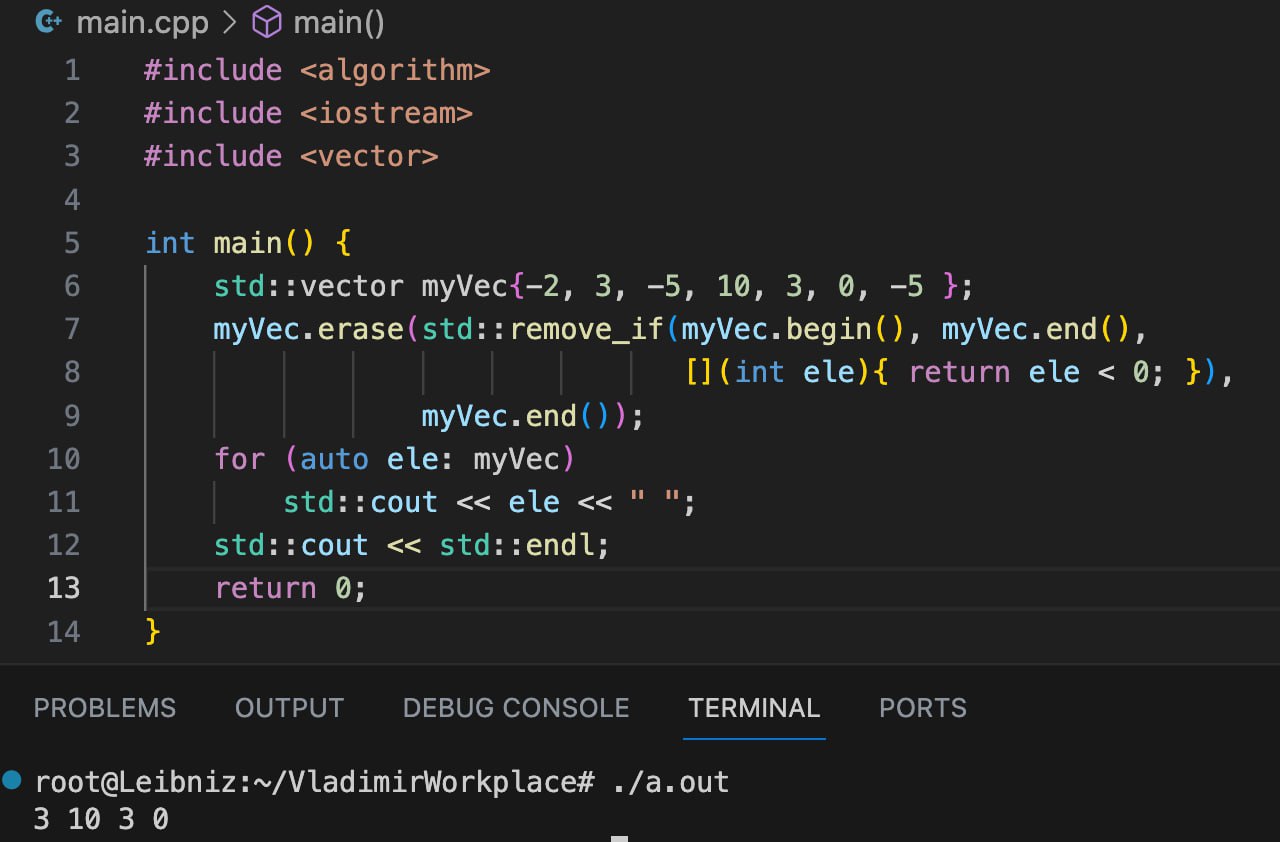
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
{kind=link}
👍9🔥6❤4
Квантовая суперпозиция bool переменных
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
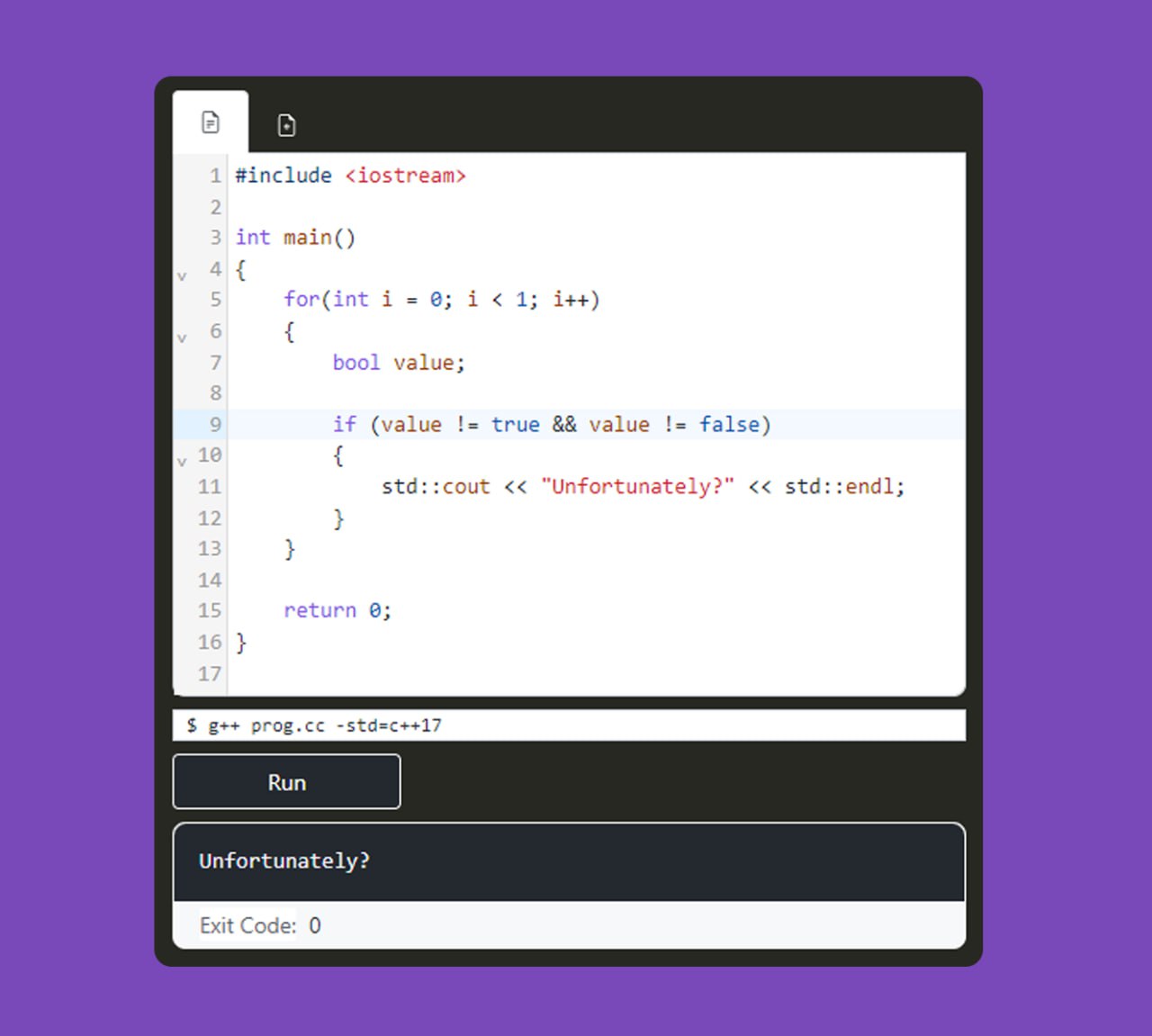
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
А-ля, если логическая переменная
Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
bool condition;
if (condition != true && condition != false)
{
// Недостижимый код?
}
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
0 -> false, иначе true. Приведу пример:if ( 0) // false
if ( 1) // true
if ( 2) // true
if (-1) // true
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
int condition; // Неинициализированное значение
if (condition != 1 && condition != 0)
{
// Вполне себе достимый код
}
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
10 != 1 - и никакой магии. Но увидеть это порой столь же неожиданно.У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
bool condition = ???;
int position = index + static_cast<int>(condition);
А-ля, если логическая переменная
condition == true (типа оно равно 1), значит index + 1, иначе index + 0. Так вот на самом деле нельзя с уверенностью сказать, какое целочисленное значение лежит под булем.Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
{kind=link}
👍11🔥5❤3
Всем привет!
Сегодня знаменательный день для нас всех(ну для админов точно) - мы достигли первой сотни подписчиков!
Один из методов продвижения, что мы используем - комментинг на других каналах. И после того, как я вчера в ночи оставил коммент на одном из каналов по плюсам, мне приснилось, что число подписчиков на этом канале стало 107. Проснувшись, я подумал, что слишком влажно мечтаю и что не нужно рассчитывать на такие цифры. Но удивлению не было предела, когда я увидел число 105. Это практически 20 живых людей за день, которым понравился контент и они решили подписаться, чтобы узнавать что-то новое и быть частью крутого сообщества. Жалко, что я так и не увидел круглую цифру, но это не так важно.
Спасибо всем-всем подписчикам за доверие!
То, что мы пока маленькие - ничего не значит. Это все временно. А статистика по охватам говорит, что вам реально нравится и вы вовлечены в то, что мы публикуем. Это самая главная метрика. Подписчикам должно быть интересно читать канал. И мы будем и дальше работать над этим.
Но и вы тоже можете сделать канал ещё более живым и интересным. Пишите комментарии. Любые, по сабжу и не по нему, «глупые» и «умные» вопросы, идеи для постов и тд. Комментариями вы можете помочь подснежникам втянуться в эту самую айтишечку, прояснить для себя вопрос, который долго мучал, потешить своё эго, что по вашему запросу написали пост, или ткнуть носом админа в его ошибку. Это будет полезно всему сообществу.
В любом случае, дальше - больше.
Всё, не буду отвлекать вас от важных государственных предновогодних дел.
Всем прекрасных выходных!!
Stay cool.
Сегодня знаменательный день для нас всех(ну для админов точно) - мы достигли первой сотни подписчиков!
Один из методов продвижения, что мы используем - комментинг на других каналах. И после того, как я вчера в ночи оставил коммент на одном из каналов по плюсам, мне приснилось, что число подписчиков на этом канале стало 107. Проснувшись, я подумал, что слишком влажно мечтаю и что не нужно рассчитывать на такие цифры. Но удивлению не было предела, когда я увидел число 105. Это практически 20 живых людей за день, которым понравился контент и они решили подписаться, чтобы узнавать что-то новое и быть частью крутого сообщества. Жалко, что я так и не увидел круглую цифру, но это не так важно.
Спасибо всем-всем подписчикам за доверие!
То, что мы пока маленькие - ничего не значит. Это все временно. А статистика по охватам говорит, что вам реально нравится и вы вовлечены в то, что мы публикуем. Это самая главная метрика. Подписчикам должно быть интересно читать канал. И мы будем и дальше работать над этим.
Но и вы тоже можете сделать канал ещё более живым и интересным. Пишите комментарии. Любые, по сабжу и не по нему, «глупые» и «умные» вопросы, идеи для постов и тд. Комментариями вы можете помочь подснежникам втянуться в эту самую айтишечку, прояснить для себя вопрос, который долго мучал, потешить своё эго, что по вашему запросу написали пост, или ткнуть носом админа в его ошибку. Это будет полезно всему сообществу.
В любом случае, дальше - больше.
Всё, не буду отвлекать вас от важных государственных предновогодних дел.
Всем прекрасных выходных!!
Stay cool.
❤11🎉4👍2😎2🔥1
std::span
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
{kind=link}
🔥12👍7❤2
std::make_unique
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
🔥10👍9❤3
std::make_unique. Part 2
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
👍13🔥4❤3
Идиома NVI
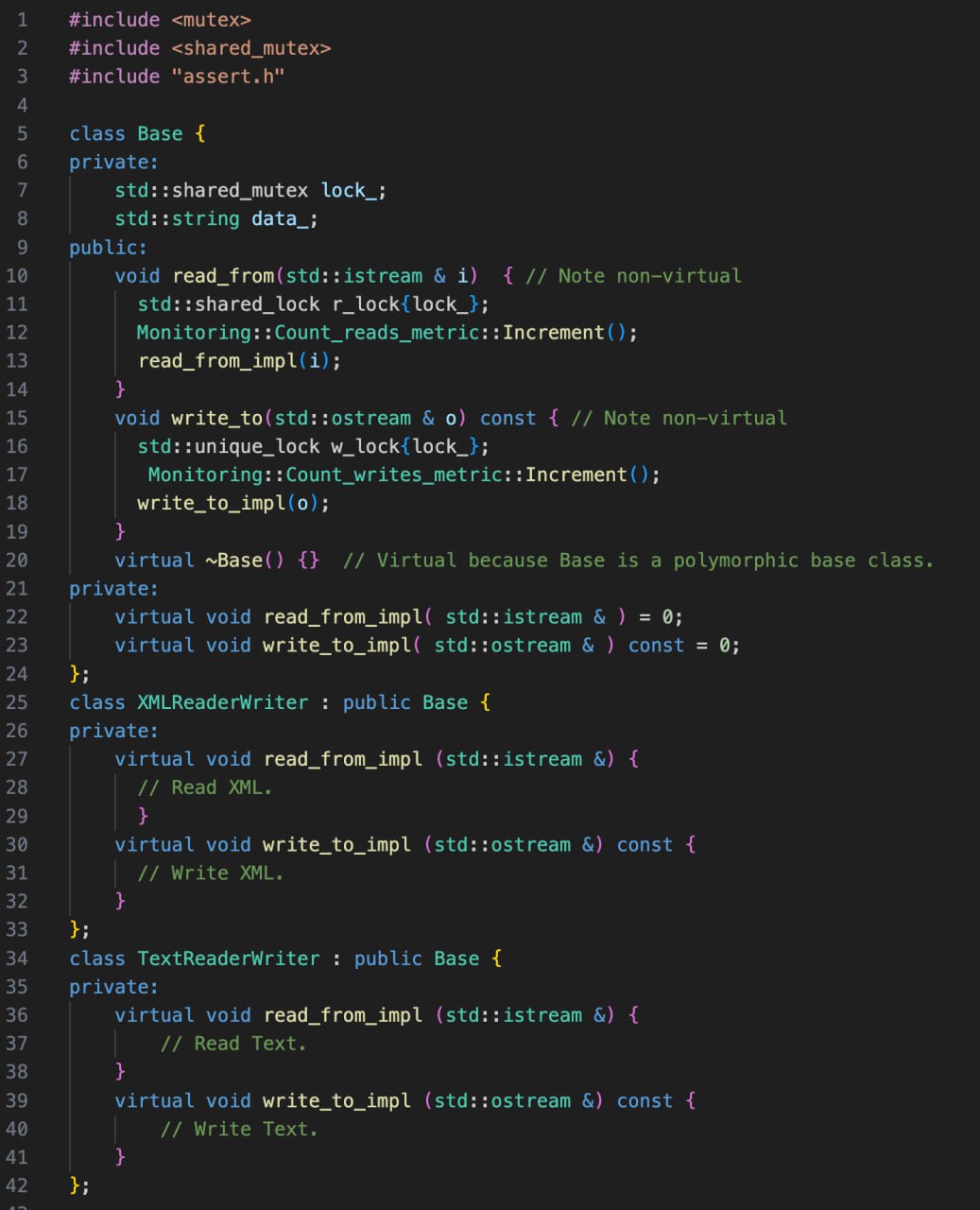
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:курица или яйцоидиома или эта цитата). Называется она non-virtual interface idiom. Говорящее название)
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
{kind=link}
🔥11👍10❤9
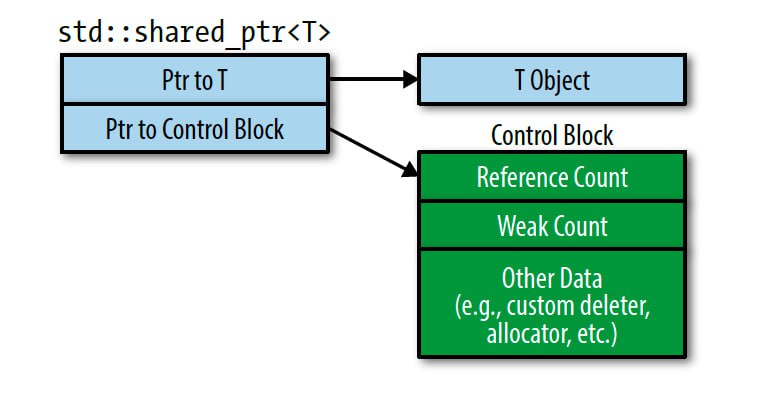
std::make_shared
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
{kind=link}
🔥9❤7👍4
Еще одна сотня - achieved!
Всем большое спасибо за доверие к нам!
Не думал, что это число покорится нам так быстро. Получился неожиданный такой подарок на Новый Год)
Очень показательно, что большая часть аудитории подписана на канал со включенными уведомлениями. Сравнивая с другими каналами - небо и земля. Это говорит о большой лояльности аудитории и о качестве контента в ваших глазах.
Будем и дальше развивать наше уютное коммьюнити.
А вам всем - замечательного дня и продуктивных приготовлений к праздникам!
Stay cool.
Всем большое спасибо за доверие к нам!
Не думал, что это число покорится нам так быстро. Получился неожиданный такой подарок на Новый Год)
Очень показательно, что большая часть аудитории подписана на канал со включенными уведомлениями. Сравнивая с другими каналами - небо и земля. Это говорит о большой лояльности аудитории и о качестве контента в ваших глазах.
Будем и дальше развивать наше уютное коммьюнити.
А вам всем - замечательного дня и продуктивных приготовлений к праздникам!
Stay cool.
🔥16👍5🎉4❤1💘1
Удаленные функции
Упоминали об этом вскользь, но, думаю, что стоит подсветить эту тему отдельно.
Все мы знаем, что, если нам нужно запретить объекту копироваться, то нужно пометить его копирующий конструктор и копирующий оператор присваивания как =delete;
Но помечать удаленной можно вообще любую функцию!
Этой частью функциональности вы будете пользоваться намного реже, но не стоит ее игнорировать. Это может значительно повысить безопасность ваших приложений или сократить возможность неожиданного поведения.
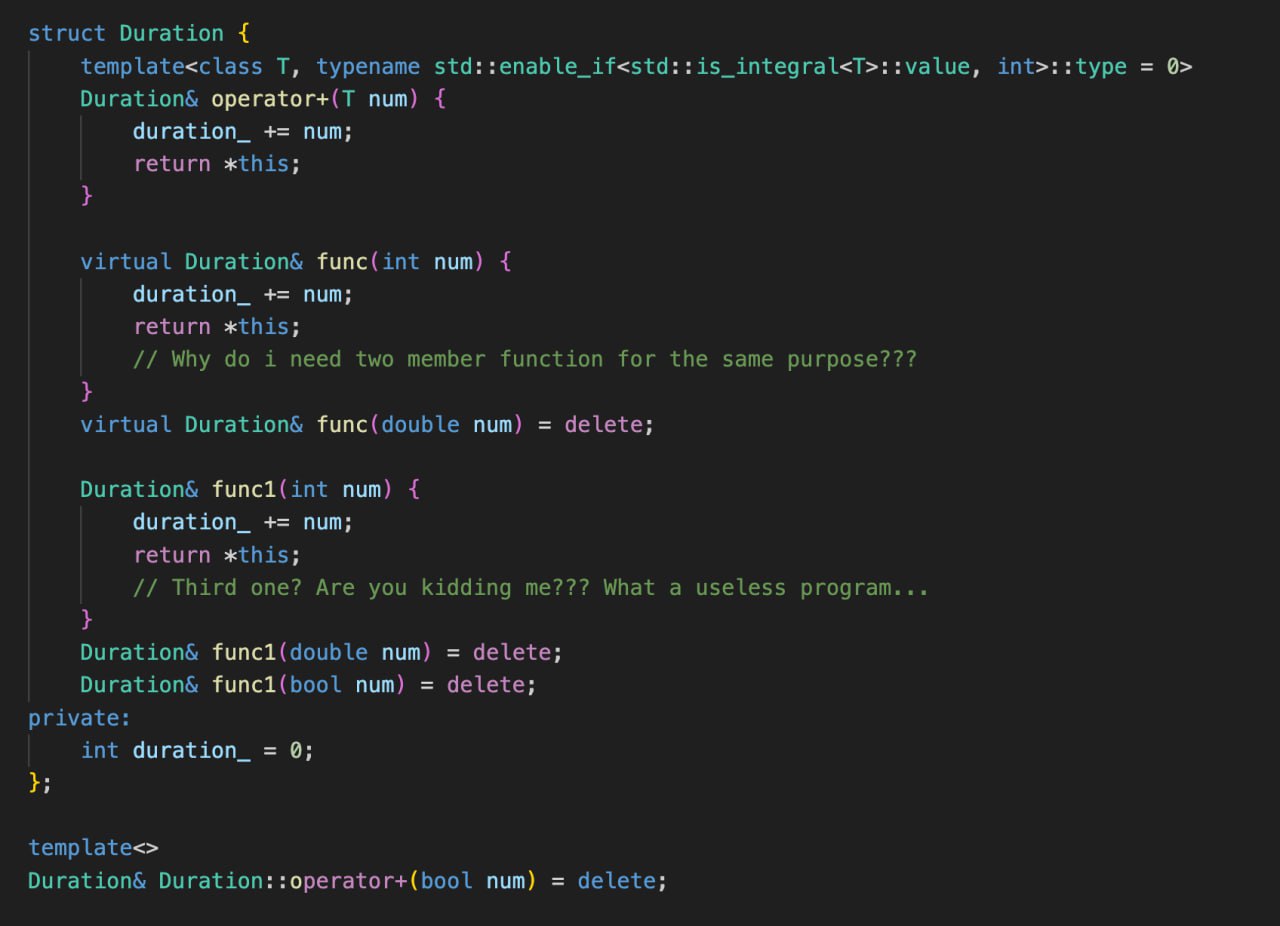
Допустим, у вас есть класс Duration(зачем он вам нужен это большой вопрос, но для примера покатит). Он отвечает за репрезентацию разницы в датах в миллисекундах. Легко можно представить необходимость переопределить оператор + для этого класса, чтобы эту длительность увеличивать за счет обычного числа. Итак пишем:
Duration& Duration::operator+(int num) {
duration_ += num;
return *this;
}
Все хорошо. А если мы туда передадим 5.5? Дробное число неявно преобразуется к инту и мы получим не совсем тот ответ, который могли бы ожидать. И единственный способ запретить такое поведение - объявить нежелательные перегрузки, как =delete.
Duration& Duration::operator+(double num) = delete;
Duration& Duration::operator+(bool num) = delete;
Удаление первой перегрузки также отбросит и float варинт, так как компилятор предпочтет преобразовать float к double, а не к int.
Какая-то выдуманная проблема, скажите вы, и решить ее можно через sfinae. Просто через шаблон запретить подстановки ненужных типов. Благо с 17-х плюсов пользоваться шаблонами стало попроще с помощью CTAD и не надо никакие шаблонные аргументы указывать. Давайте посмотрим, как это выглядит:
template<class T, typename std::enable_if<std::is_integral<T>::value, int>::type = 0>
Duration& Duration::operator+(T num) {
duration_ += num;
return *this;
}
Здесь проверяется, что тип должен быть числом, и только тогда метод сможет инстанцироваться. В чем проблема? Проблема в том, что bool - тоже целочисленный тип. Как же быть? Ровно так же:
template<>
Duration& Duration::operator+(bool num) = delete;
Решение через шаблоны рабочее, но не всегда его возможно применить. Например, вы не можете иметь шаблонный виртуальный метод. Поэтому можно пользоваться только удалением ненужных перегрузок.
Какова мораль. Используйте удаленные функции, когда это необходимо. И шаблонную, и обычную, и виртуальную функцию можно удалить. Это очень гибкий инструмент, предотвращающий неправильное использование вашего класса.
Stay safe. Stay cool
#cpp11 #cpp17 #goodpractice
Упоминали об этом вскользь, но, думаю, что стоит подсветить эту тему отдельно.
Все мы знаем, что, если нам нужно запретить объекту копироваться, то нужно пометить его копирующий конструктор и копирующий оператор присваивания как =delete;
Но помечать удаленной можно вообще любую функцию!
Этой частью функциональности вы будете пользоваться намного реже, но не стоит ее игнорировать. Это может значительно повысить безопасность ваших приложений или сократить возможность неожиданного поведения.
Допустим, у вас есть класс Duration(зачем он вам нужен это большой вопрос, но для примера покатит). Он отвечает за репрезентацию разницы в датах в миллисекундах. Легко можно представить необходимость переопределить оператор + для этого класса, чтобы эту длительность увеличивать за счет обычного числа. Итак пишем:
Duration& Duration::operator+(int num) {
duration_ += num;
return *this;
}
Все хорошо. А если мы туда передадим 5.5? Дробное число неявно преобразуется к инту и мы получим не совсем тот ответ, который могли бы ожидать. И единственный способ запретить такое поведение - объявить нежелательные перегрузки, как =delete.
Duration& Duration::operator+(double num) = delete;
Duration& Duration::operator+(bool num) = delete;
Удаление первой перегрузки также отбросит и float варинт, так как компилятор предпочтет преобразовать float к double, а не к int.
Какая-то выдуманная проблема, скажите вы, и решить ее можно через sfinae. Просто через шаблон запретить подстановки ненужных типов. Благо с 17-х плюсов пользоваться шаблонами стало попроще с помощью CTAD и не надо никакие шаблонные аргументы указывать. Давайте посмотрим, как это выглядит:
template<class T, typename std::enable_if<std::is_integral<T>::value, int>::type = 0>
Duration& Duration::operator+(T num) {
duration_ += num;
return *this;
}
Здесь проверяется, что тип должен быть числом, и только тогда метод сможет инстанцироваться. В чем проблема? Проблема в том, что bool - тоже целочисленный тип. Как же быть? Ровно так же:
template<>
Duration& Duration::operator+(bool num) = delete;
Решение через шаблоны рабочее, но не всегда его возможно применить. Например, вы не можете иметь шаблонный виртуальный метод. Поэтому можно пользоваться только удалением ненужных перегрузок.
Какова мораль. Используйте удаленные функции, когда это необходимо. И шаблонную, и обычную, и виртуальную функцию можно удалить. Это очень гибкий инструмент, предотвращающий неправильное использование вашего класса.
Stay safe. Stay cool
#cpp11 #cpp17 #goodpractice
{kind=link}
❤8👍5🔥5
Когда нужно явно вызывать деструктор?
В прошлом мы поговорили о том, можно ли явно вызывать деструкторы у объектов и какие последствия это за собой несет. Обещал рассказать, когда это делать разумно, собственно выполняю обещание.
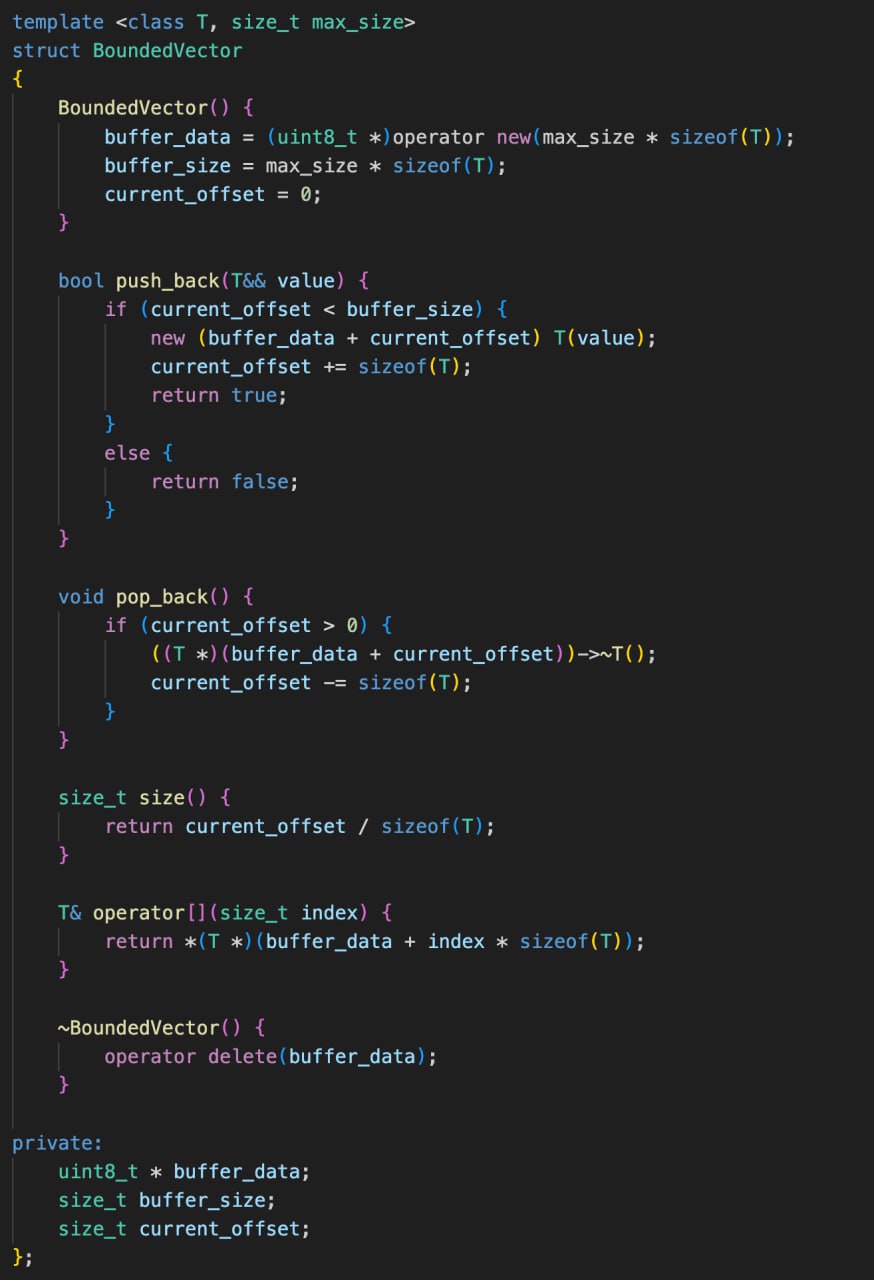
Проблема в том, что при выходе из скоупа автоматически вызывается деструктор для локальных объектов, а при выделении объектов на куче мы обязаны вручную это делать через delete, в том числе и чтобы освободить память. Прежде чем говорить о каких-то реальных приложениях, нам нужно найти способ, при котором аллокация памяти и создание/удаление объекта полностью и раздельно управляется программистом. И такой способ есть.
Мы знает, как выделить и удалить просто сырой кусок памяти. Статический массив чаров, комбинация malloc+free, и комбинация operator new + operator delete помогут это сделать. Последние операторы имеют ту же семантику, что и malloc+free.
Теперь нужен механизм, позволяющий конструировать объект на уже заранее известной области памяти. Этот механизм называется placement new. Тут п****ц какой-то с названиями на русском языке, на английском new expression - это то, что наиболее часто используют для аллокации+конструирования, operator new - функция, которая выполняет только аллокацию памяти, а placement new - конструирует объект на заданной памяти. И, наконец, явный вызов деструктора позволяет освободить ресурсы из объекта.
Применяя эти связки, мы добиваемся полного контроля над всеми этапами создания и удаления объекта. И в этом случае, проблем с double free или повторном освобождении ресурса происходить не будет. Но это все равно на какое-то время порождает зомби-объекты, для которых есть имя и мы знаем как к ним обратиться, но по факту они уже удалены.
Для чего нужно идти на риск неправильно использовать объекты ради возможности самостоятельно вызывать декструкторы? High risk - high reward. Смысл в оптимизации работы с памятью. Выделение объектов в куче - дело дорогостоящее в плане производительности и использования дополнительных ячеек памяти. Если мы очень сильно ограничены в ресурсах железки, то приходится идти на риск, чтобы добиться желаемого. Обычно выделяется какой-то чанк памяти и на этом чанке создаются и, что самое главное, пересоздаются объекты, потенциально разных типов. Это сильно сокращает используемое пространство памяти, уменьшает ее фрагментацию и снижает издержки на выделение новых ячеек. Сейчас сложно представить себе, что есть такие жесткие рамки, при которых нужно максимумально ужиматься в использовании ресурсов. Однако в прошлом, когда у компьютеров было несколько сот килобайт оперативы, ужимались все и во всем. Даже при работе со стеком нужно было использовать такие ухищрения.
Еще один пример использования явного деструктора - стандартный класс std::vector. Тут на самом деле ситуация очень похожая. У вектора есть некий внутренний буфер, который всегда выделяется с некоторым запасом, чтобы не аллоцировать память на каждое добавление элемента. Поэтому при этом самом добавлении элемента происходит конструирование объекта на нужном блоке памяти. И у вектора есть метод erase, который удаляет элемент из контейнера. Хотя удаляет - слишком общий термин. Он его уничтожает. При этом память, занимаемая этим объектом не освобождается. Поэтому в этом случае просто необходимо использовать явный вызов деструктора.
В принципе, в любом случае, когда необходимо раздельно аллоцировать память и конструировать объекты, будет использоваться явный вызов деструктора. Вряд ли обычные бэкэнд девелоперы когда-нибудь с этим столкнуться. Но знать, что такое есть, надо.
Расскажите о своих кейсах, когда вы знаете, что нужно использовать явный вызов деструктора. Будет интересно почитать другие варианты)
Stay optimized. Stay cool.
#cppcore #optimization #memory
В прошлом мы поговорили о том, можно ли явно вызывать деструкторы у объектов и какие последствия это за собой несет. Обещал рассказать, когда это делать разумно, собственно выполняю обещание.
Проблема в том, что при выходе из скоупа автоматически вызывается деструктор для локальных объектов, а при выделении объектов на куче мы обязаны вручную это делать через delete, в том числе и чтобы освободить память. Прежде чем говорить о каких-то реальных приложениях, нам нужно найти способ, при котором аллокация памяти и создание/удаление объекта полностью и раздельно управляется программистом. И такой способ есть.
Мы знает, как выделить и удалить просто сырой кусок памяти. Статический массив чаров, комбинация malloc+free, и комбинация operator new + operator delete помогут это сделать. Последние операторы имеют ту же семантику, что и malloc+free.
Теперь нужен механизм, позволяющий конструировать объект на уже заранее известной области памяти. Этот механизм называется placement new. Тут п****ц какой-то с названиями на русском языке, на английском new expression - это то, что наиболее часто используют для аллокации+конструирования, operator new - функция, которая выполняет только аллокацию памяти, а placement new - конструирует объект на заданной памяти. И, наконец, явный вызов деструктора позволяет освободить ресурсы из объекта.
Применяя эти связки, мы добиваемся полного контроля над всеми этапами создания и удаления объекта. И в этом случае, проблем с double free или повторном освобождении ресурса происходить не будет. Но это все равно на какое-то время порождает зомби-объекты, для которых есть имя и мы знаем как к ним обратиться, но по факту они уже удалены.
Для чего нужно идти на риск неправильно использовать объекты ради возможности самостоятельно вызывать декструкторы? High risk - high reward. Смысл в оптимизации работы с памятью. Выделение объектов в куче - дело дорогостоящее в плане производительности и использования дополнительных ячеек памяти. Если мы очень сильно ограничены в ресурсах железки, то приходится идти на риск, чтобы добиться желаемого. Обычно выделяется какой-то чанк памяти и на этом чанке создаются и, что самое главное, пересоздаются объекты, потенциально разных типов. Это сильно сокращает используемое пространство памяти, уменьшает ее фрагментацию и снижает издержки на выделение новых ячеек. Сейчас сложно представить себе, что есть такие жесткие рамки, при которых нужно максимумально ужиматься в использовании ресурсов. Однако в прошлом, когда у компьютеров было несколько сот килобайт оперативы, ужимались все и во всем. Даже при работе со стеком нужно было использовать такие ухищрения.
Еще один пример использования явного деструктора - стандартный класс std::vector. Тут на самом деле ситуация очень похожая. У вектора есть некий внутренний буфер, который всегда выделяется с некоторым запасом, чтобы не аллоцировать память на каждое добавление элемента. Поэтому при этом самом добавлении элемента происходит конструирование объекта на нужном блоке памяти. И у вектора есть метод erase, который удаляет элемент из контейнера. Хотя удаляет - слишком общий термин. Он его уничтожает. При этом память, занимаемая этим объектом не освобождается. Поэтому в этом случае просто необходимо использовать явный вызов деструктора.
В принципе, в любом случае, когда необходимо раздельно аллоцировать память и конструировать объекты, будет использоваться явный вызов деструктора. Вряд ли обычные бэкэнд девелоперы когда-нибудь с этим столкнуться. Но знать, что такое есть, надо.
Расскажите о своих кейсах, когда вы знаете, что нужно использовать явный вызов деструктора. Будет интересно почитать другие варианты)
Stay optimized. Stay cool.
#cppcore #optimization #memory
{kind=link}
❤8👍5🔥4😁1😢1
Сколько памяти вы можете аллоцировать?
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
{kind=link}
🤯12👍9😁6
Новый год на пороге, а значит наступило время подводить итоги уходящего года! 🤩
Днём рождения этого канала стоит считать вечер 26 сентября 2023 года, а местом -- Steak Me Truck, г. Нижний Новгород. С того момента прошло чуть более трех месяцев, было написано 94 поста, а к нам в канал присоединились более 230 участников!
Я и Владимир очень рады этому! Это наш первый канал, поэтому для нас это однозначный успех! ☺️ Наш опыт и представления о его судьбе основаны только на том, что мы раньше наблюдали со стороны и том, что мы бы хотели читать сами и чего нам не хватало во время своего обучения :)
Безусловно мы хотели взять всё самое лучшее, что мы повстречали и добавить своё видение, как это можно улучшить. Сделать наиболее качественный, но в то же время не душный контент (но без этого плюсы не живут, я их вообще крестами называю...)
Спасибо за ваше внимание, лайкосики и репосты, комментарии/замечания/критику -- мы все вместе становимся лучше! Думаю, для вас это интересно влиять на развитие нашего комьюнити. Помните, вы в числе первых!)
Желаем вам в Новом году не останавливаться на достигнутом и мчаться вперед на всех парах! Ставьте перед собой цели и достигайте их, а мы будем рядом со своими экспериментами, советами, и просто тем, что мы посчитали полезным для вас 😉
Этим постом мы завершаем этот год и уходим на небольшой перерыв. Увидимся в следующем году! С праздником вас, дорогие положительные люди! 🥂🥳
Днём рождения этого канала стоит считать вечер 26 сентября 2023 года, а местом -- Steak Me Truck, г. Нижний Новгород. С того момента прошло чуть более трех месяцев, было написано 94 поста, а к нам в канал присоединились более 230 участников!
Я и Владимир очень рады этому! Это наш первый канал, поэтому для нас это однозначный успех! ☺️ Наш опыт и представления о его судьбе основаны только на том, что мы раньше наблюдали со стороны и том, что мы бы хотели читать сами и чего нам не хватало во время своего обучения :)
Безусловно мы хотели взять всё самое лучшее, что мы повстречали и добавить своё видение, как это можно улучшить. Сделать наиболее качественный, но в то же время не душный контент (но без этого плюсы не живут, я их вообще крестами называю...)
Спасибо за ваше внимание, лайкосики и репосты, комментарии/замечания/критику -- мы все вместе становимся лучше! Думаю, для вас это интересно влиять на развитие нашего комьюнити. Помните, вы в числе первых!)
Желаем вам в Новом году не останавливаться на достигнутом и мчаться вперед на всех парах! Ставьте перед собой цели и достигайте их, а мы будем рядом со своими экспериментами, советами, и просто тем, что мы посчитали полезным для вас 😉
Этим постом мы завершаем этот год и уходим на небольшой перерыв. Увидимся в следующем году! С праздником вас, дорогие положительные люди! 🥂🥳
{kind=link}
🎄28❤8🔥5👍3🏆2🐳1😎1
Как система может выделить 131 Терабайт оперативы?
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
{kind=link}
❤13👍12🔥10
STL vs stdlib
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
{kind=link}
👍13❤4🔥4🎄4
Как создать поток с помощью метода?
Пост коротенький, но возможно вы не знали о такой фишке.
Если вдруг так случилось, что вам нужно запустить поток не с помощью свободной функции, а с помощью нестатического метода класса, то возникает вопрос. Метод ведь может быть вызван только из существующего объекта и не очевидно, как это можно сделать с вот таким набором конструкторов для класса потока:
thread() noexcept;
thread( thread&& other ) noexcept;
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
Поэтому рассказываю. Нужно первым аргументом передать в конструктор указатель на метод и вторым аргументом - сам объект. Тогда компилятор все поймёт и сгенерирует такой код, чтобы поток начал выполняться с методом класса. Прикрепил пример кода, как это выглядит.
Если метод принимает несколько аргументов, все они должны идти после указателя на объект третьим, четвёртым и тд аргументом.
Пост бы написан давно и в спешке. Теперь понимаю, что здесь можно несколько подробностей еще осветить, поэтому ждите продолжения)
Stay versatile. Stay cool.
#concurrency #cppcore
Пост коротенький, но возможно вы не знали о такой фишке.
Если вдруг так случилось, что вам нужно запустить поток не с помощью свободной функции, а с помощью нестатического метода класса, то возникает вопрос. Метод ведь может быть вызван только из существующего объекта и не очевидно, как это можно сделать с вот таким набором конструкторов для класса потока:
thread() noexcept;
thread( thread&& other ) noexcept;
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
Поэтому рассказываю. Нужно первым аргументом передать в конструктор указатель на метод и вторым аргументом - сам объект. Тогда компилятор все поймёт и сгенерирует такой код, чтобы поток начал выполняться с методом класса. Прикрепил пример кода, как это выглядит.
Если метод принимает несколько аргументов, все они должны идти после указателя на объект третьим, четвёртым и тд аргументом.
Пост бы написан давно и в спешке. Теперь понимаю, что здесь можно несколько подробностей еще осветить, поэтому ждите продолжения)
Stay versatile. Stay cool.
#concurrency #cppcore
{kind=link}
👍17🔥10❤6
std::byte
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
{kind=link}
👍11❤7🔥4