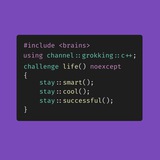
join
#опытным
Как прекрасно сделан в питоне метод join у строки. Чтобы соединить список строк разделителем нужно просто написать:
И как же сложно того же результата достичь в плюсах!
То делают через потоки:
то через std::accumulate:
Ну вы что! Стандартная строка же себе не может позволить иметь метод join, принимающий коллекцию строк и возвращающий объединенную строку с разделителями. Это же не универсально и никому не надо...
Но в С++23 наконец-то появилось хоть что-то похожее на адекватное решение. Используем std::views::join_with:
Можете обмазать все это шаблонами с головы до пят, чтобы получить универсальное решение, либо использовать этот код прям inplace, он и так довольно понятный.
И жизнь стала чуть-чуть счастливее...
Make thing simple. Stay cool.
#cpp23
#опытным
Как прекрасно сделан в питоне метод join у строки. Чтобы соединить список строк разделителем нужно просто написать:
my_list = ["John", "Peter", "Vicky"]
x = " ".join(my_list)
print(x)
# OUTPUT
# John Peter Vicky
И как же сложно того же результата достичь в плюсах!
То делают через потоки:
std::string join(const std::vector<std::string>& vec, const std::string& delimiter) {
if (vec.empty()) return "";
std::ostringstream oss;
oss << vec[0];
for (size_t i = 1; i < vec.size(); ++i) {
oss << delimiter << vec[i];
}
return oss.str();
}то через std::accumulate:
std::string join(const std::vector<std::string>& vec, const std::string& delimiter) {
if (vec.empty()) return "";
return std::accumulate(
std::next(vec.begin()), vec.end(),
vec[0],
[&delimiter](const std::string& a, const std::string& b) {
return a + delimiter + b;
}
);
}Ну вы что! Стандартная строка же себе не может позволить иметь метод join, принимающий коллекцию строк и возвращающий объединенную строку с разделителями. Это же не универсально и никому не надо...
Но в С++23 наконец-то появилось хоть что-то похожее на адекватное решение. Используем std::views::join_with:
std::string join(const std::vector<std::string> &vec,
const std::string &delimiter) {
return vec | std::views::join_with(delimiter) |
std::ranges::to<std::string>();
}
Можете обмазать все это шаблонами с головы до пят, чтобы получить универсальное решение, либо использовать этот код прям inplace, он и так довольно понятный.
И жизнь стала чуть-чуть счастливее...
Make thing simple. Stay cool.
#cpp23
{kind=link}
❤27👍11🔥9😁5
Как динамически выделить память на стеке?
#опытным
В книжке "Вредные советы для С++ программистов" от PVS-студии есть такой вредный совет: "массив на стеке - это лучшее решение"
Типа выделение памяти в куче - это зло. char c[256] хватит всем, а если не хватит, то потом поменяем на 512. В крайнем случае – на 1024.
Да, использование буферов, фиксированного размера действительно может привести в проблемам в коде. Запилили новую фичу, изменили размер данных, а забыли поменять размер массива. Пожалуйста, UB.
Но возникает вопрос: а как тогда можно динамически выделять память на стеке? Ведь стандартные C-style массивы работают только с известными в compile-time размерами.
Пара способов есть, но они с "нюансом":
1️⃣ Variable Length Array. Вы просто берете и создаете массив переменного размера:
Круто!
Да, но это не часть стандарта С++) Это фича языка С, доступная с С99. Однако GCC например поддерживает ее, как компиляторное расширение языка и вы сможете g++'ом сгенерировать код выше.
2️⃣ alloca. Функция, которая аллоцирует заданное количество байт на стеке:
Память, выделенная alloca автоматически освобождается при выходе из функции.
Эта также нестандартная функция, которая не является даже частью ANSI-C стандарта, но поддерживается многими компиляторами(в т.ч. является частью Linux API).
Ну и на этом все.
Стандартных решений нет. И на это есть причина. Дело в том, что такой код провоцирует возникновение в программах уязвимостей.
В стандарте MISRA C есть правило MISRA-C-18.8, указывающее не использовать VLA. Другие руководства, такие как SEI CERT C Coding Standard (ARR32-C) и Common Weakness Enumeration (CWE-129), не запрещают использовать эти массивы, но призывают проверять перед созданием их размер.
Не учли, что могут прийти неожиданные данные, выделили охренелион байт и получили переполнение стека. Это вариант DoS-атаки уровня приложения.
На счет alloca вообще есть интересные интересности. Представьте себе, что будет если компилятор попытается встроить код этой функции:
в вызывающий код:
Так как память, выделенная alloca освобождается только после завершения функции, а не выходе из скоупа, то получает взрыв размера стека.
И теперь представьте лицо программиста, который написал этот код с учетом вызова alloca именно во фрейме функции DoSomething.
Манипуляции со стеком - не очень безопасно, поэтому ничего такого и не вводят в плюсы.
Be safe. Stay cool.
#NONSTANDARD #goodoldc
#опытным
В книжке "Вредные советы для С++ программистов" от PVS-студии есть такой вредный совет: "массив на стеке - это лучшее решение"
Типа выделение памяти в куче - это зло. char c[256] хватит всем, а если не хватит, то потом поменяем на 512. В крайнем случае – на 1024.
Да, использование буферов, фиксированного размера действительно может привести в проблемам в коде. Запилили новую фичу, изменили размер данных, а забыли поменять размер массива. Пожалуйста, UB.
Но возникает вопрос: а как тогда можно динамически выделять память на стеке? Ведь стандартные C-style массивы работают только с известными в compile-time размерами.
Пара способов есть, но они с "нюансом":
1️⃣ Variable Length Array. Вы просто берете и создаете массив переменного размера:
void foo(size_t n) {
float array[n];
// ....
}Круто!
Да, но это не часть стандарта С++) Это фича языка С, доступная с С99. Однако GCC например поддерживает ее, как компиляторное расширение языка и вы сможете g++'ом сгенерировать код выше.
2️⃣ alloca. Функция, которая аллоцирует заданное количество байт на стеке:
void *alloca(size_t size);
void foo(size_t n) {
float array = (float)alloca(sizeof(float) * n);
}
Память, выделенная alloca автоматически освобождается при выходе из функции.
Эта также нестандартная функция, которая не является даже частью ANSI-C стандарта, но поддерживается многими компиляторами(в т.ч. является частью Linux API).
Ну и на этом все.
Стандартных решений нет. И на это есть причина. Дело в том, что такой код провоцирует возникновение в программах уязвимостей.
В стандарте MISRA C есть правило MISRA-C-18.8, указывающее не использовать VLA. Другие руководства, такие как SEI CERT C Coding Standard (ARR32-C) и Common Weakness Enumeration (CWE-129), не запрещают использовать эти массивы, но призывают проверять перед созданием их размер.
Не учли, что могут прийти неожиданные данные, выделили охренелион байт и получили переполнение стека. Это вариант DoS-атаки уровня приложения.
На счет alloca вообще есть интересные интересности. Представьте себе, что будет если компилятор попытается встроить код этой функции:
void DoSomething() {
char pStr = alloca(100);
//......
}в вызывающий код:
void Process() {
for (i = 0; i < 1000000; i++) {
DoSomething();
}
}Так как память, выделенная alloca освобождается только после завершения функции, а не выходе из скоупа, то получает взрыв размера стека.
И теперь представьте лицо программиста, который написал этот код с учетом вызова alloca именно во фрейме функции DoSomething.
Манипуляции со стеком - не очень безопасно, поэтому ничего такого и не вводят в плюсы.
Be safe. Stay cool.
#NONSTANDARD #goodoldc
{kind=link}
👍25❤14🔥8
Двойной unlock
#опытным
Если не пользоваться RAII, то можно наткнуться на массу проблем. Все знают про double free. Но менее известна проблема double unlock.
Все просто, вы используете ручной lock-unlock мьютекса и возможно попадаете в ситуацию двойного освобождения:
Практически всегда двойной unlock происходит из-за некорректного кода в той или иной степени. Забыть вызвать return кажется детской проблемой, но если вы например не написали тесты на эту ветку, то возможно вы наткнетесь на проблемы только в проде.
А проблемы могут быть примерно любыми. Потому что двойной unlock мьютекса - UB по стандарту. Соответственно, можете получить много непрятностей, от сегфолта до бесконечного ожидания.
Поэтому просто используйте RAII и спина болеть не будет:
Use safe technics. Stay cool.
#concurrency #cpp11
#опытным
Если не пользоваться RAII, то можно наткнуться на массу проблем. Все знают про double free. Но менее известна проблема double unlock.
Все просто, вы используете ручной lock-unlock мьютекса и возможно попадаете в ситуацию двойного освобождения:
void unsafe_function(int value) {
mtx.lock();
if (value < 0) {
std::cout << "Error: negative value\n";
mtx.unlock();
// forget to return!
}
shared_data = value;
std::cout << "Data has updated: " << shared_data << std::endl;
mtx.unlock(); // second unlock
}Практически всегда двойной unlock происходит из-за некорректного кода в той или иной степени. Забыть вызвать return кажется детской проблемой, но если вы например не написали тесты на эту ветку, то возможно вы наткнетесь на проблемы только в проде.
А проблемы могут быть примерно любыми. Потому что двойной unlock мьютекса - UB по стандарту. Соответственно, можете получить много непрятностей, от сегфолта до бесконечного ожидания.
Поэтому просто используйте RAII и спина болеть не будет:
void safe_function(int value) {
std::lock_guard lg{mtx};
if (value < 0) {
std::cout << "Error: negative value\n";
return;
}
shared_data = value;
std::cout << "Data has updated: " << shared_data << std::endl;
}Use safe technics. Stay cool.
#concurrency #cpp11
{kind=link}
👍23❤15🔥8😁3
enum class
#новичкам
Перечисления пришли в С++ еще из С и отлично живут. Однако плюсовикам не очень с ними комфортно работать с силу наследования слабой типизации и неявных преобразований enum'ов в числовые типы и в другие enum'ы
В С++11 появился новый тип перечислений - scoped enumerations. Или ограниченные областью видимости перечисления. Определяются они так:
Он решает две большие проблемы обычных перечислений:
👉🏿 Обычные перечисления неявно преобразуются в int и обратно, что вызывает ошибки, когда не предполагается использование перечисления в качестве целого числа.
Можно например попробовать получить следующее значение перечисления, просто прибавив единицу:
Что значит прибавить красному цвету единицу - решительно непонятно.
Неявные преобразования enum class'ов же запрещено:
Если вам сильно нужно преобразовать перечислитель к числу, то вы это должны сделать явно:
👉🏿 Обычные перечисления экспортируют свои перечислители в окружающую область видимости, вызывая конфликты имён с другими сущностями в этой окружающей области:
У scoped enum'ов такой проблемы нет. Имена перечислителей находятся в скоупе своего перечисления:
И все прекрасно компилируется.
С учетом неймспейсов и любви к явным кастам в коммьюнити, в С++ лучше использовать enum class'ы вместо обычных перечислений.
Protect your scope. Stay cool.
#cppcore #cpp11
#новичкам
Перечисления пришли в С++ еще из С и отлично живут. Однако плюсовикам не очень с ними комфортно работать с силу наследования слабой типизации и неявных преобразований enum'ов в числовые типы и в другие enum'ы
В С++11 появился новый тип перечислений - scoped enumerations. Или ограниченные областью видимости перечисления. Определяются они так:
enum class Enumeration {CATEGORY1, CATEGORY2, CATEGORY3};Он решает две большие проблемы обычных перечислений:
👉🏿 Обычные перечисления неявно преобразуются в int и обратно, что вызывает ошибки, когда не предполагается использование перечисления в качестве целого числа.
Можно например попробовать получить следующее значение перечисления, просто прибавив единицу:
cpp
enum Color { RED, GREEN, BLUE };
Color c = RED;
Color next = c + 1; // Implicit conversion to int and visa versa!
Что значит прибавить красному цвету единицу - решительно непонятно.
Неявные преобразования enum class'ов же запрещено:
enum class Color { RED, GREEN, BLUE };
Color c = Color::RED;
Color next = c + 1; // ERROR!Если вам сильно нужно преобразовать перечислитель к числу, то вы это должны сделать явно:
Color c = Color::RED;
Color next = static_cast<Color>(static_cast<int>(c) + 1);
👉🏿 Обычные перечисления экспортируют свои перечислители в окружающую область видимости, вызывая конфликты имён с другими сущностями в этой окружающей области:
enum Color { RED, GREEN, BLUE };
enum TrafficLight { RED, YELLOW, GREEN }; // ERROR!
void graphics_library() {
Color c = RED;
}У scoped enum'ов такой проблемы нет. Имена перечислителей находятся в скоупе своего перечисления:
enum class Color1 { RED, GREEN, BLUE };
enum class Color2 { RED, GREEN, BLUE };
void graphics_library() {
Color1 c1 = Color1::RED;
Color2 c2 = Color2::RED;
}И все прекрасно компилируется.
С учетом неймспейсов и любви к явным кастам в коммьюнити, в С++ лучше использовать enum class'ы вместо обычных перечислений.
Protect your scope. Stay cool.
#cppcore #cpp11
{kind=link}
👍42❤16🔥16
enum struct
#опытным
В прошлом посте мы рассказали про enum class. И в 99.999% случаев эту сущность будут писать в коде именно, как enum class.
Но можно написать enum struct и это тоже будет работать!
Немного кто знает вообще о существовании такой конструкции. Свойства enum struct абсолютно аналогичны enum class и структуры перечислений были введены просто для консистентности и поддержания паритета в возможности использования двух ключевых слов.
Вот такой короткий и бесполезный факт из мира плюсов)
Be useful. Stay cool.
#fun #cpp11
#опытным
В прошлом посте мы рассказали про enum class. И в 99.999% случаев эту сущность будут писать в коде именно, как enum class.
Но можно написать enum struct и это тоже будет работать!
enum class FileMode { Read, Write, Append };
enum struct LogLevel { Debug, Info, Warning, Error };
int main() {
FileMode mode = FileMode::Read;
LogLevel level = LogLevel::Info;
std::cout << (mode == FileMode::Read) << std::endl;
std::cout << (level == LogLevel::Info) << std::endl;
}Немного кто знает вообще о существовании такой конструкции. Свойства enum struct абсолютно аналогичны enum class и структуры перечислений были введены просто для консистентности и поддержания паритета в возможности использования двух ключевых слов.
Вот такой короткий и бесполезный факт из мира плюсов)
Be useful. Stay cool.
#fun #cpp11
{kind=link}
2👍37😁24❤9🔥7🤣5
Размер enum'а
#опытным
Перечисления - это по факту именованные числа. Каждому перечислителю ставится в соответствие число, к которому перечислитель может приводиться. Оно либо указывается явно, либо проставляется компилятором.
Но тогда встает вопрос: а сколько весит enum? Мы же про эффективность и хотим, чтобы данные занимали минимально возможное пространство.
Мы можем явно написать:
Мы как бы явно говорим, что ограничиваем размер enum'а 8-ью битами. Но будет ли его размер реально 8 бит?
Не факт. Компилятор может выбрать любой подходящий по размеру тип, главное, чтобы он мог вместить все элементы перечисления. Это может быть char, short или int. И все это разного размера.
Неприятно, что на это нельзя было влиять.
Но прочь неприятности, потому что в С++11, помимо enum class появилась возможность указания размера scoped и unscoped enum'ов:
И теперь вы может контролировать и сами задавать размер перечисления.
Control your size. Stay cool.
#cpp11
#опытным
Перечисления - это по факту именованные числа. Каждому перечислителю ставится в соответствие число, к которому перечислитель может приводиться. Оно либо указывается явно, либо проставляется компилятором.
Но тогда встает вопрос: а сколько весит enum? Мы же про эффективность и хотим, чтобы данные занимали минимально возможное пространство.
Мы можем явно написать:
enum MY_FAVOURITE_FRUITS
{
E_APPLE = 0x01,
E_WATERMELON = 0x02,
E_COCONUT = 0x04,
E_STRAWBERRY = 0x08,
E_CHERRY = 0x10,
E_PINEAPPLE = 0x20,
E_BANANA = 0x40,
E_MANGO = 0x80,
E_MY_FAVOURITE_FRUITS_FORCE8 = 0xFF // 'Force' 8bits, how can you tell?
};
Мы как бы явно говорим, что ограничиваем размер enum'а 8-ью битами. Но будет ли его размер реально 8 бит?
Не факт. Компилятор может выбрать любой подходящий по размеру тип, главное, чтобы он мог вместить все элементы перечисления. Это может быть char, short или int. И все это разного размера.
Неприятно, что на это нельзя было влиять.
Но прочь неприятности, потому что в С++11, помимо enum class появилась возможность указания размера scoped и unscoped enum'ов:
enum class E_MY_FAVOURITE_FRUITS : unsigned char
{
E_APPLE = 0x01,
E_WATERMELON = 0x02,
E_COCONUT = 0x04,
E_STRAWBERRY = 0x08,
E_CHERRY = 0x10,
E_PINEAPPLE = 0x20,
E_BANANA = 0x40,
E_MANGO = 0x80,
E_DEVIL_FRUIT = 0xFF
};
И теперь вы может контролировать и сами задавать размер перечисления.
Control your size. Stay cool.
#cpp11
{kind=link}
❤25👍14🔥4😁4
Удобно превращаем enum в число
#опытным
В прошлом посте мы выяснили, что с С++11 можно самостоятельно указывать нижележащий тип, который и хранит все элементы enum'а.
Но вот представьте себе, что вам где-то нужно получить числовое представление одного из перечислителя. К какому типу кастовать?
Это важно, потому что scoped enum неявно не приводится к числам. Нам нужно явно указывать тип:
Если вам просто нужно вывести число в поток, то кастуйте к инту, ничего страшного не будет. Однако математические операции над полученным числом могут доставить неприятности, если тип будет не тот и будут использоваться сужающие-расширяющие преобразования.
Современные IDE-шки возможно будут вам показывать нужный тип, а возможно и нет. Если тип enum'а явно указан, то можно взять его. Но если нет, то гадать не хочется. Хочется стандартного решения.
С++11 также вводит тип шаблонный тип std::underlying_type, который предоставляет зависимый тип type, содержащий подкапотный тип enum'a:
Соответственно, для каста нужно сделать такую штуку:
Плохо, что это очень громоздкая конструкция, где к тому же типы повторяются. Поэтому в С++23 ввели хэлпер-сахарок std::to_underlying, который за нас все это делает:
Красота!
Know your type. Stay cool.
#cpp11 #cpp23
#опытным
В прошлом посте мы выяснили, что с С++11 можно самостоятельно указывать нижележащий тип, который и хранит все элементы enum'а.
Но вот представьте себе, что вам где-то нужно получить числовое представление одного из перечислителя. К какому типу кастовать?
Это важно, потому что scoped enum неявно не приводится к числам. Нам нужно явно указывать тип:
enum class ColorMask : std::uint32_t
{
red = 0xFF,
green = (red << 8),
blue = (green << 8),
alpha = (blue << 8)
};
// std::cout << ColorMask::red << std::endl; // ERROR
std::cout << static_cast<int>(ColorMask::red) << std::endl;
Если вам просто нужно вывести число в поток, то кастуйте к инту, ничего страшного не будет. Однако математические операции над полученным числом могут доставить неприятности, если тип будет не тот и будут использоваться сужающие-расширяющие преобразования.
Современные IDE-шки возможно будут вам показывать нужный тип, а возможно и нет. Если тип enum'а явно указан, то можно взять его. Но если нет, то гадать не хочется. Хочется стандартного решения.
С++11 также вводит тип шаблонный тип std::underlying_type, который предоставляет зависимый тип type, содержащий подкапотный тип enum'a:
enum e1 {};
enum class e2 {};
enum class e3 : unsigned {};
enum class e4 : int {};
constexpr bool e1_t = std::is_same_v<std::underlying_type_t<e1>, int>;
constexpr bool e2_t = std::is_same_v<std::underlying_type_t<e2>, int>;
constexpr bool e3_t = std::is_same_v<std::underlying_type_t<e3>, int>;
constexpr bool e4_t = std::is_same_v<std::underlying_type_t<e4>, int>;
std::cout
<< "underlying type for 'e1' is " << (e1_t ? "int" : "non-int") << '\n'
<< "underlying type for 'e2' is " << (e2_t ? "int" : "non-int") << '\n'
<< "underlying type for 'e3' is " << (e3_t ? "int" : "non-int") << '\n'
<< "underlying type for 'e4' is " << (e4_t ? "int" : "non-int") << '\n';
// OUTPUT
// underlying type for 'e1' is non-int
// underlying type for 'e2' is int
// underlying type for 'e3' is non-int
// underlying type for 'e4' is intСоответственно, для каста нужно сделать такую штуку:
auto num = static_cast<std::underlying_type_t<ColorMask>>(ColorMask::red);
Плохо, что это очень громоздкая конструкция, где к тому же типы повторяются. Поэтому в С++23 ввели хэлпер-сахарок std::to_underlying, который за нас все это делает:
auto num = std::to_underlying(ColorMask::red);
Красота!
Know your type. Stay cool.
#cpp11 #cpp23
{kind=link}
👍21🔥14❤9🥱1
magic_enum
#опытным
Много раз уже упоминали эту библиотечку в комментах, пора удостоить ее отдельного поста.
В чем проблема: хочется enum сериализовывать/десериализовывать в строку и из строки. То есть значение перечислителя заменить его строковым представлением в коде.
Такая задача требует рефлексии, которая в С++ только в 26 стандарте появится. Рефлексия - способность программы знать о том, как она написана на языке программирования. В скомпилированной программе перечислитель это всего лишь число, а чтобы получить имя, которое он имел в С++ коде, в программе должна эта информация где-то сохраниться.
Ну то есть, если у вас нет С++26, то нужно терпеть(но мы привыкли) и писать костыли. Что делается обычно:
Для больших перечислений опупеете писать эти мапы, плюс код в принципе засоряется ими.
Но на любую проблему стандартных плюсов найдется своя библиотека, которая ее решит. В этом случае пригодится magic_enum.
Это хэдэр-онли С++17 библиотечка, которая предоставляет статическую рефлексию для перечислений и работает без макросни в интерфейсе и без бойлерплейта.
Простой пример:
Как это работает?
magic_enum рассчитан на работу с небольшими enum'ами. По дефолту интервал underlying значений от -128 до 127.
Если сильно упрощенно, то magic_enum пытается инстанцировать специальную функцию для каждого значения из этого интервала. Так как шаблонный параметр будет NTTP, его значение будет вшито в саму сигнатуру функции. А ее можно получить с помощью __PRETTY_FUNCTION__ или __FUNCSIG__:
Только для реально существующих перечислителей __PRETTY_FUNCTION__ будет содержать корректное имя. Так и происходит маппинг значений перечислителей на их имена.
Вот примеры сигнатуры функции для существующего и несуществующего перечислителя:
Чтобы это все реализовать и вместе собрать нужно еще много шаблонной магии, но суть такова.
magic_enum еще много чего умеет:
👉🏿 Обратный маппинг имен на значения перечисления
👉🏿 Доступ к элементам перечисления по индексу
👉🏿 Можно получить количество элементов enum'а:
👉🏿 Свои перегруженные io операторы:
и много чего еще.
Обзор фукнциональности можно найти в репе на гитхабе. Обратите особое внимание на ограничения библиотеки.
Use magic. Stay cool.
#tools #template
#опытным
Много раз уже упоминали эту библиотечку в комментах, пора удостоить ее отдельного поста.
В чем проблема: хочется enum сериализовывать/десериализовывать в строку и из строки. То есть значение перечислителя заменить его строковым представлением в коде.
Такая задача требует рефлексии, которая в С++ только в 26 стандарте появится. Рефлексия - способность программы знать о том, как она написана на языке программирования. В скомпилированной программе перечислитель это всего лишь число, а чтобы получить имя, которое он имел в С++ коде, в программе должна эта информация где-то сохраниться.
Ну то есть, если у вас нет С++26, то нужно терпеть(но мы привыкли) и писать костыли. Что делается обычно:
enum class Color { RED, GREEN, BLUE };
std::unordered_map<Color, std::string> map = {{Color::RED, "RED"}, {Color::GREEN, "GREEN"}, {Color::BLUE, "BLUE"}};
std::cout << map[Color::RED] << std::endl;Для больших перечислений опупеете писать эти мапы, плюс код в принципе засоряется ими.
Но на любую проблему стандартных плюсов найдется своя библиотека, которая ее решит. В этом случае пригодится magic_enum.
Это хэдэр-онли С++17 библиотечка, которая предоставляет статическую рефлексию для перечислений и работает без макросни в интерфейсе и без бойлерплейта.
Простой пример:
Color color = Color::RED;
std::string color_name = magic_enum::enum_name(color);
assert(color_name == "RED);
Как это работает?
magic_enum рассчитан на работу с небольшими enum'ами. По дефолту интервал underlying значений от -128 до 127.
Если сильно упрощенно, то magic_enum пытается инстанцировать специальную функцию для каждого значения из этого интервала. Так как шаблонный параметр будет NTTP, его значение будет вшито в саму сигнатуру функции. А ее можно получить с помощью __PRETTY_FUNCTION__ или __FUNCSIG__:
template <auto V>
constexpr std::string_view get_enum_name() {
return extract_name(PRETTY_FUNCTION);
}
Только для реально существующих перечислителей __PRETTY_FUNCTION__ будет содержать корректное имя. Так и происходит маппинг значений перечислителей на их имена.
Вот примеры сигнатуры функции для существующего и несуществующего перечислителя:
enum class Color { RED, GREEN, BLUE };
constexpr Color c = static_cast<Color>(4);
get_enum_name<c>(); // constexpr void get_enum_name() [with auto V = (Color)4]
get_enum_name<Color::GREEN>(); // constexpr void get_enum_name() [with auto V = Color::GREEN]Чтобы это все реализовать и вместе собрать нужно еще много шаблонной магии, но суть такова.
magic_enum еще много чего умеет:
👉🏿 Обратный маппинг имен на значения перечисления
std::string color_name{"GREEN"};
auto color = magic_enum::enum_cast<Color>(color_name);
if (color.has_value()) {
// color.value() -> Color::GREEN
}👉🏿 Доступ к элементам перечисления по индексу
std::size_t i = 0;
Color color = magic_enum::enum_value<Color>(i);
👉🏿 Можно получить количество элементов enum'а:
constexpr std::size_t color_count = magic_enum::enum_count<Color>();
👉🏿 Свои перегруженные io операторы:
using magic_enum::iostream_operators::operator<<; // out-of-the-box ostream operators for enums.
Color color = Color::BLUE;
std::cout << color << std::endl; // "BLUE"
и много чего еще.
Обзор фукнциональности можно найти в репе на гитхабе. Обратите особое внимание на ограничения библиотеки.
Use magic. Stay cool.
#tools #template
{kind=link}
1🔥29👍12❤10😱2
Мувать не всегда дешево
#новичкам
С приходом мув семантики настали "прекрасные плюсы будущего". Нет никакого копирования, чудо-оптимизации бороздят просторы стека и кучи. Не жизнь, а сказка.
Но мир не такой уж солнечный и приветливый. Это очень опасное...
Если вы придерживаетесь RAII, пользуетесь контейнерами и умными указателями, то вы практически всегда пользуетесь правилом нуля и никогда не определяете самостоятельно специальные методы класса и, в частности, конструктор перемещения и оператор перемещающего присваивания. Компилятор сгенерирует их за вас, ленивых дядь.
Рано или поздно вы немного отрываетесь от "низов": вас уже не интересует КАК конкретно эти методы реализованы. Вы оперируете более высокоуровневыми сущностями и полагаетесь на компилятор.
И вот вы в ситуации, когда у вас есть данные, обернутые в класс, которые легально по контексту кода можно мувнуть или скопировать. Условно говоря, у вас есть функция Process, которая принимает данные по значению, чтобы поддержать оба варианта передачи: копирование и мув:
Что выбрать?
"Конечно мувнуть, это же не долгое копирование, выполнится быстро" - вот к таким не совсем корректным мыслям может привести "оторванность от низов".
Кажется, что у некоторых людей есть ощущение, что данные из одного объекта как-то перетекают в другой объект и это происходит очень быстро.
Но это не так! Перемещение - это поверхностное копирование.
Возьмем простой пример:
Что будет происходить при перемещении
Чуть сложнее:
Что будет при перемещении
Можно еще занулить конечно, но это редко происходит из соображений перфоманса.
Получается, что реально "переместить" вы можете только данные, выделенные на куче. И то они никуда не перемещаются. Вы просто копируете указатель из одного объекта в другой, при этом сами данные никак не затрагиваются.
Более того. Даже если вы используете std::string, то не всегда мув будет быстрее копирования! Thanks to SSO.
Получается, что никто никуда не течет. Все так же пресловуто копируется, кроме динамических данных под указателями.
Теперь снова актуализируем вопрос: мувать или копировать?
И ответ уже не плоскости оптимизации, а в плоскости логики кода. Перемещайте, когда вам в текущем скоупе объект больше не нужен и копируйте, если нужен. Тогда вы не пытаетесь оптимизировать код, а передаете владение объектом другому коду. Редко, когда вы на авито продаете вещи, чтобы заработать. Вы их продаете, чтобы от лишнего избавиться и дать их тем, кому они нужны, особой выгоды не ожидая. Вот здесь примерно это и должно происходить.
В реальности все немного сложнее и всегда будут исключения, но просто хочу обратить внимание, что мув семантика - это в первую очередь про передачу владения объектом и только потом уже оптимизация.
Think logically. Stay cool.
#cppcore #cpp11
#новичкам
С приходом мув семантики настали "прекрасные плюсы будущего". Нет никакого копирования, чудо-оптимизации бороздят просторы стека и кучи. Не жизнь, а сказка.
Но мир не такой уж солнечный и приветливый. Это очень опасное...
Если вы придерживаетесь RAII, пользуетесь контейнерами и умными указателями, то вы практически всегда пользуетесь правилом нуля и никогда не определяете самостоятельно специальные методы класса и, в частности, конструктор перемещения и оператор перемещающего присваивания. Компилятор сгенерирует их за вас, ленивых дядь.
Рано или поздно вы немного отрываетесь от "низов": вас уже не интересует КАК конкретно эти методы реализованы. Вы оперируете более высокоуровневыми сущностями и полагаетесь на компилятор.
И вот вы в ситуации, когда у вас есть данные, обернутые в класс, которые легально по контексту кода можно мувнуть или скопировать. Условно говоря, у вас есть функция Process, которая принимает данные по значению, чтобы поддержать оба варианта передачи: копирование и мув:
void Process(Data data);
Что выбрать?
"Конечно мувнуть, это же не долгое копирование, выполнится быстро" - вот к таким не совсем корректным мыслям может привести "оторванность от низов".
Кажется, что у некоторых людей есть ощущение, что данные из одного объекта как-то перетекают в другой объект и это происходит очень быстро.
Но это не так! Перемещение - это поверхностное копирование.
Возьмем простой пример:
struct Data {
int a;
double b;
};
Data obj1{3, 3.14};
Data obj2 = std::move(obj1);Что будет происходить при перемещении
obj1? Копирование a и b.Чуть сложнее:
struct Data {
std::array<int, 5> arr;
};
Data obj1{.arr = {1, 2, 3, 4, 5}};
Data obj2 = std::move(obj1);Что будет при перемещении
obj1, а значит и arr? Тоже копирование! std::array - это массив, фиксированного размера, расположенный на стеке. Как вы собираетесь его перемещать в другой объект? Под другой объект уже выделена своя память на стеке, вы не можете один кусок стека переместить в другой. Вы можете только скопировать значения.Можно еще занулить конечно, но это редко происходит из соображений перфоманса.
Получается, что реально "переместить" вы можете только данные, выделенные на куче. И то они никуда не перемещаются. Вы просто копируете указатель из одного объекта в другой, при этом сами данные никак не затрагиваются.
struct Data {
std::string * str;
// member functions for making it work properly
};
Data obj1{.str = new std::string("Hello, World!")};
Data obj2 = std::move(obj1);obj2 теперь имеет такое же значение указателя str, как и obj1, но сама строка оказалась нетронутой.Более того. Даже если вы используете std::string, то не всегда мув будет быстрее копирования! Thanks to SSO.
Получается, что никто никуда не течет. Все так же пресловуто копируется, кроме динамических данных под указателями.
Теперь снова актуализируем вопрос: мувать или копировать?
И ответ уже не плоскости оптимизации, а в плоскости логики кода. Перемещайте, когда вам в текущем скоупе объект больше не нужен и копируйте, если нужен. Тогда вы не пытаетесь оптимизировать код, а передаете владение объектом другому коду. Редко, когда вы на авито продаете вещи, чтобы заработать. Вы их продаете, чтобы от лишнего избавиться и дать их тем, кому они нужны, особой выгоды не ожидая. Вот здесь примерно это и должно происходить.
В реальности все немного сложнее и всегда будут исключения, но просто хочу обратить внимание, что мув семантика - это в первую очередь про передачу владения объектом и только потом уже оптимизация.
Think logically. Stay cool.
#cppcore #cpp11
{kind=link}
3👍38❤15🔥6😎5
Передача владения
#новичкам
Захотелось совсем немного развить тему предыдущего поста.
В целом, мув семантика она не столько про оптимизацию(для этого есть например rvo/nrvo), сколько про передачу владения объектами. И то, что std::move ничего не мувает(а пытается сделать каст к rvalue reference) хорошо укладывается в эту концепцию. Данные не перемещаются, но вы говорите, что передаете владение этими данными.
Здесь мы передаем владение вектором из foo в bar. Заметьте, что bar оперирует правой ссылкой, то есть никакие перемещающие конструкторы не вызывались. Но такая сигнатура говорит о главном: bar ожидает эксклюзивного права владения над этим вектором. Вы должны явно мувнуть объект, чтобы вызвать bar. И не важно, что он дальше bar с этим вектором делает. Может ничего не сделает, а может и использует как-то данные. Но так решил автор кода: вызов bar предполагает передачу ему владения вектором.
Другой пример:
Функция double_elements принимает вектор по значению и возвращает набор из удвоенных элементов.
Функция foo 2 раза вызывает удвоение значений элементов. По логике функции foo, ей еще нужен vec в целости и сохранности(нужно доложить в него элемент). Поэтому она и передает в первый раз vec в double_elements по значению. Но после второго вызова вектор ей больше не нужен. Поэтому можно передать владение им в double_elements: возможно он им распорядится лучше.
Еще одна вещь, которая подчеркивает передачу владения: moved-from объект практически никак в общем случае нельзя безопасно использовать, кроме как безопасно разрушить или переприсвоить(в комментах под прошлым постом более конкретно обсуждали этот момент). Даже если функция принимает rvalue reference, это не значит, что она не изменяет объект: возможно внутренние вызовы это делают.
Поэтому можно принять за правило, что, передав владение, вы больше физически не имеете права пользоваться объектом. Это как продав компанию, вы бы продолжили иметь то же влияние на нее. Нетушки. Либо крестик снимите, либо трусы наденьте. Либо передали владение и забыли, либо скопировали и дальше попользовались.
Give away what you don't need. Stay cool.
#cppcore #cpp11
#новичкам
Захотелось совсем немного развить тему предыдущего поста.
В целом, мув семантика она не столько про оптимизацию(для этого есть например rvo/nrvo), сколько про передачу владения объектами. И то, что std::move ничего не мувает(а пытается сделать каст к rvalue reference) хорошо укладывается в эту концепцию. Данные не перемещаются, но вы говорите, что передаете владение этими данными.
void bar(std::vector<int>&& vec) {
// do nothing
}
void foo() {
std::vector<int> vec = {1, 2, 3};
bar(std::move(vec));
}Здесь мы передаем владение вектором из foo в bar. Заметьте, что bar оперирует правой ссылкой, то есть никакие перемещающие конструкторы не вызывались. Но такая сигнатура говорит о главном: bar ожидает эксклюзивного права владения над этим вектором. Вы должны явно мувнуть объект, чтобы вызвать bar. И не важно, что он дальше bar с этим вектором делает. Может ничего не сделает, а может и использует как-то данные. Но так решил автор кода: вызов bar предполагает передачу ему владения вектором.
Другой пример:
std::vector<int> double_elements(std::vector<int> vec) {
for (auto& elem: vec) {
elem *= 2;
}
return vec;
}
void foo() {
std::vector<int> vec = {1, 2, 3};
{
auto doubled = double_elements(vec);
std::println("{}", doubled);
}
vec.push_back(4);
{
auto doubled = double_elements(std::move(vec));
std::println("{}", doubled);
}
}
Функция double_elements принимает вектор по значению и возвращает набор из удвоенных элементов.
Функция foo 2 раза вызывает удвоение значений элементов. По логике функции foo, ей еще нужен vec в целости и сохранности(нужно доложить в него элемент). Поэтому она и передает в первый раз vec в double_elements по значению. Но после второго вызова вектор ей больше не нужен. Поэтому можно передать владение им в double_elements: возможно он им распорядится лучше.
Еще одна вещь, которая подчеркивает передачу владения: moved-from объект практически никак в общем случае нельзя безопасно использовать, кроме как безопасно разрушить или переприсвоить(в комментах под прошлым постом более конкретно обсуждали этот момент). Даже если функция принимает rvalue reference, это не значит, что она не изменяет объект: возможно внутренние вызовы это делают.
Поэтому можно принять за правило, что, передав владение, вы больше физически не имеете права пользоваться объектом. Это как продав компанию, вы бы продолжили иметь то же влияние на нее. Нетушки. Либо крестик снимите, либо трусы наденьте. Либо передали владение и забыли, либо скопировали и дальше попользовались.
Give away what you don't need. Stay cool.
#cppcore #cpp11
{kind=link}
❤18👍12🔥6
Оборачиваем вспять байты
#новичкам
Когда мы низкоуровнево работаем с сетью, то надо понимать, что в данных, полученных по сети, нужно реверсировать порядок байтов, чтобы правильно интерпретировать значения. Также реверсировать порядок нужно при отправке данных по сети. Это происходит из-за того, что в стеке протоколов TCP/IP принят порядок Big-endian - старший байт хранится по младшему адресу. А на большинстве хостов(десктопов и серверов) - Little-endian: младший байт хранится по младшему адресу.
Соответственно нужны функции для реверсирования байтов. Обычно для этого используют либо компиляторные интринсики:
Либо системное апи:
Либо какое-нибудь библиотечное решение:
Но в С++23 появилась стандартная функция для разворачивания порядка байтов!
Работает она только для интегральных типов и вот ее возможная реализация:
Результат у нее собственно ровно тот, который и ожидается:
Как всегда стандарт запаздывает лет на 10-15-20, но хорошо, что все-таки завезли эту полезную функцию, которую можно кроссплатформенно использовать.
Use standard solutions. Stay cool.
#cpp23
#новичкам
Когда мы низкоуровнево работаем с сетью, то надо понимать, что в данных, полученных по сети, нужно реверсировать порядок байтов, чтобы правильно интерпретировать значения. Также реверсировать порядок нужно при отправке данных по сети. Это происходит из-за того, что в стеке протоколов TCP/IP принят порядок Big-endian - старший байт хранится по младшему адресу. А на большинстве хостов(десктопов и серверов) - Little-endian: младший байт хранится по младшему адресу.
Соответственно нужны функции для реверсирования байтов. Обычно для этого используют либо компиляторные интринсики:
### GCC/Clang
uint16_t swapped16 = __builtin_bswap16(value);
uint32_t swapped32 = __builtin_bswap32(value);
uint64_t swapped64 = __builtin_bswap64(value);
### MSVC:
uint16_t swapped16 = _byteswap_ushort(value);
uint32_t swapped32 = _byteswap_ulong(value);
uint64_t swapped64 = _byteswap_uint64(value);
Либо системное апи:
#include <arpa/inet.h> // Linux/macOS
// или
#include <winsock2.h> // Windows
uint16_t network_to_host16 = ntohs(value);
uint16_t host_to_network16 = htons(value);
uint32_t network_to_host32 = ntohl(value);
uint32_t host_to_network32 = htonl(value);
uint64_t network_to_host64 = ntohll(value);
uint64_t host_to_network64 = htonll(value);
Либо какое-нибудь библиотечное решение:
#include <boost/endian/conversion.hpp>
uint32_t value = 0x12345678;
uint32_t swapped = boost::endian::endian_reverse(value);
uint32_t to_big = boost::endian::native_to_big(value);
uint32_t to_little = boost::endian::native_to_little(value);
Но в С++23 появилась стандартная функция для разворачивания порядка байтов!
template< class T >
constexpr T byteswap( T n ) noexcept;
Работает она только для интегральных типов и вот ее возможная реализация:
template<std::integral T>
constexpr T byteswap(T value) noexcept
{
static_assert(std::has_unique_object_representations_v<T>,
"T may not have padding bits");
auto value_representation = std::bit_cast<std::array<std::byte, sizeof(T)>>(value);
std::ranges::reverse(value_representation);
return std::bit_cast<T>(value_representation);
}
Результат у нее собственно ровно тот, который и ожидается:
template<std::integral T>
void dump(T v, char term = '\n')
{
std::cout << std::hex << std::uppercase << std::setfill('0')
<< std::setw(sizeof(T) * 2) << v << " : ";
for (std::size_t i{}; i != sizeof(T); ++i, v >>= 8)
std::cout << std::setw(2) << static_cast<unsigned>(T(0xFF) & v) << ' ';
std::cout << std::dec << term;
}
int main()
{
static_assert(std::byteswap('a') == 'a');
std::cout << "byteswap for U16:\n";
constexpr auto x = std::uint16_t(0xCAFE);
dump(x);
dump(std::byteswap(x));
std::cout << "\nbyteswap for U32:\n";
constexpr auto y = std::uint32_t(0xDEADBEEFu);
dump(y);
dump(std::byteswap(y));
std::cout << "\nbyteswap for U64:\n";
constexpr auto z = std::uint64_t{0x0123456789ABCDEFull};
dump(z);
dump(std::byteswap(z));
}
// OUTPUT
// byteswap for U16:
// CAFE : FE CA
// FECA : CA FE
// byteswap for U32:
// DEADBEEF : EF BE AD DE
// EFBEADDE : DE AD BE EF
// byteswap for U64:
// 0123456789ABCDEF : EF CD AB 89 67 45 23 01
// EFCDAB8967452301 : 01 23 45 67 89 AB CD EF
Как всегда стандарт запаздывает лет на 10-15-20, но хорошо, что все-таки завезли эту полезную функцию, которую можно кроссплатформенно использовать.
Use standard solutions. Stay cool.
#cpp23
{kind=link}
❤28👍12😁8🔥5
Атрибуты лямбды
#опытным
В прошлом посте код с картинки реально компилируется и, если вы не поняли, что это за чертовщина, то следующие несколько постов будут для вас.
В С++11 у нас появилась возможность указывать атрибуты для функции. Например:
Вы можете, например, пометить возвращаемое значение функции, как то, которое нельзя игнорировать, и компилятор даст вам по сопатке, если вы его все же заигнорите.
Ну это функции. А как же лямбды? Хочется и для них указывать атрибуты.
И атрибуты для возвращаемого значения лямбды завезли в С++23. Выглядит это так:
После скобок для захвата вы указываете список атрибутов в квадратных скобках. Выглядит интересно. Не очень элегантно, но интересно.
Одни скажут: "усложнение синтаксиса!". Другие скажут, что давно пора лямбды подтягивать ко всем возможностям обычных функций.
Тут как бы все просто: не хотите - не используйте. У лямбды и так полно опциональных обвесок, одним больше, одним меньше. Можно определить шаблонную лямбду и обвесить ее всякими концептами с trailing return type. И это будет страшный зверь. Можно сделать отдельный пост, как может выглядеть ультимативная лямбда.
Ну а если вы хотите немного больше синтаксически говорить кодом, то теперь можете использовать атрибуты для лямбд.
Don't ignore. Stay cool.
#cpp23
#опытным
В прошлом посте код с картинки реально компилируется и, если вы не поняли, что это за чертовщина, то следующие несколько постов будут для вас.
В С++11 у нас появилась возможность указывать атрибуты для функции. Например:
[[nodiscard]] int ComplicatedCompute() {
return 2*2;
}
ComplicatedCompute();
// warning: ignoring return value of 'int ComplicatedCompute()',
// declared with attribute nodiscardВы можете, например, пометить возвращаемое значение функции, как то, которое нельзя игнорировать, и компилятор даст вам по сопатке, если вы его все же заигнорите.
Ну это функции. А как же лямбды? Хочется и для них указывать атрибуты.
И атрибуты для возвращаемого значения лямбды завезли в С++23. Выглядит это так:
auto complicated_compute = [] [[nodiscard]] () { return 2 * 2; };
complicated_compute();
// warning: ignoring return value of 'main()::<lambda()>',
// declared with attribute 'nodiscard'После скобок для захвата вы указываете список атрибутов в квадратных скобках. Выглядит интересно. Не очень элегантно, но интересно.
Одни скажут: "усложнение синтаксиса!". Другие скажут, что давно пора лямбды подтягивать ко всем возможностям обычных функций.
Тут как бы все просто: не хотите - не используйте. У лямбды и так полно опциональных обвесок, одним больше, одним меньше. Можно определить шаблонную лямбду и обвесить ее всякими концептами с trailing return type. И это будет страшный зверь. Можно сделать отдельный пост, как может выглядеть ультимативная лямбда.
Ну а если вы хотите немного больше синтаксически говорить кодом, то теперь можете использовать атрибуты для лямбд.
Don't ignore. Stay cool.
#cpp23
{kind=link}
❤21👍9🔥8😁3
Атрибуты везде
#опытным
Используют атрибуты функций не только лишь все, мало кто знает, куда их можно пихать.
Есть на самом деле 3 легальных места для навешивания атрибутов на функцию.
1️⃣ Перед типом возвращаемого значения:
Тогда он работает при непосредственном использовании функции.
2️⃣ После имени функции:
В таком виде атрибут тоже применяется к самой функции.
3️⃣ После параметров:
Тогда атрибут применяется к типу функции, а не к самой функции. Разница вот в чем:
Обычный вызов функции прекрасно компилируется. Но вот использование типа функции через decltype помечается как устаревшее.
Причем gcc и clang по-разному интерпретируют эту ситуацию. Clang говорит, что gnu::deprecated нельзя применять к типам и игнорирует атрибут. Вот ссылка на годболт для интересующихся.
Соответственно, в лямбде в тех же местах можно ставить атрибуты:
Признавайтесь, знали?)
Have your own opinion. Stay cool.
#cppcore
#опытным
Используют атрибуты функций не только лишь все, мало кто знает, куда их можно пихать.
Есть на самом деле 3 легальных места для навешивания атрибутов на функцию.
1️⃣ Перед типом возвращаемого значения:
[[deprecated]] int foo() { return 42; }Тогда он работает при непосредственном использовании функции.
foo();
// warning: 'int foo()' is deprecated
2️⃣ После имени функции:
int foo [[deprecated]] () { return 42; }В таком виде атрибут тоже применяется к самой функции.
3️⃣ После параметров:
int foo() [[gnu::deprecated]] { return 42; }Тогда атрибут применяется к типу функции, а не к самой функции. Разница вот в чем:
int foo() [[gnu::deprecated]] { return 42; }
int main() {
foo(); // no warnings
using FuncType = decltype(foo); // use of type is deprecated
}Обычный вызов функции прекрасно компилируется. Но вот использование типа функции через decltype помечается как устаревшее.
Причем gcc и clang по-разному интерпретируют эту ситуацию. Clang говорит, что gnu::deprecated нельзя применять к типам и игнорирует атрибут. Вот ссылка на годболт для интересующихся.
Соответственно, в лямбде в тех же местах можно ставить атрибуты:
auto complicated_compute = [] [[nodiscard]] () [[gnu::deprecated]] {
return 2 * 2;
};Признавайтесь, знали?)
Have your own opinion. Stay cool.
#cppcore
{kind=link}
👍23🤯19❤9🔥6
Атрибуты параметров функции
#новичкам
Атрибуты можно также применять к параметрам функции. Это помогает чуть полнее в коде функции аннотировать некоторые свойства параметров.
Вы определили какой-то интерфейс с методом, принимающим один параметр. И в какой-то момент появилась необходимость создать наследника, реализующего этот интерфейс, однако реализации не нужен параметр param. Возможно Implementation - это какой-то мок, у которого в принципе пустая реализация.
Если вы активно используете варнинги компилятора и прочие линтеры, при попытке собрать такой код вы скорее всего увидите предупреждение/ошибку компиляции. Чтобы стало все чётенько, стоит пометить
Однако из стандартных атрибутов по сути имеет смысл использовать только этот самый maybe_unused.
Но атрибуты - это не только средство общения с компилятором. Это еще и средство налаживания коммуникации между автором кода и его пользователями/читателями.
Например:
Вы поместили в хэдэр такое объявление, тем самым явно сказав пользователю и компилятору, что указатели не должны быть нулевыми. Если компилятор докажет в compile-time, что в функцию передали nullptr, то он выкинет предупреждение. Ну а пользователь четко по сигнатуре видит, что функция не ожидает нулевой указатель и как порядочный гражданин не будет его передавать.
Annotate your code. Stay cool.
#cppcore
#новичкам
Атрибуты можно также применять к параметрам функции. Это помогает чуть полнее в коде функции аннотировать некоторые свойства параметров.
class Interface {
public:
virtual void method(int param) = 0;
};
class Implementation : public Interface {
public:
void method(int param) override {
// this implementation doesn't use param so mark it
}
};Вы определили какой-то интерфейс с методом, принимающим один параметр. И в какой-то момент появилась необходимость создать наследника, реализующего этот интерфейс, однако реализации не нужен параметр param. Возможно Implementation - это какой-то мок, у которого в принципе пустая реализация.
Если вы активно используете варнинги компилятора и прочие линтеры, при попытке собрать такой код вы скорее всего увидите предупреждение/ошибку компиляции. Чтобы стало все чётенько, стоит пометить
param атрибутом maybe_unused, тем самым явно указав компилятору, что параметр не используется намеренно. И проблема исчезнет.Однако из стандартных атрибутов по сути имеет смысл использовать только этот самый maybe_unused.
Но атрибуты - это не только средство общения с компилятором. Это еще и средство налаживания коммуникации между автором кода и его пользователями/читателями.
Например:
size_t safe_strcpy(
[[gnu::nonnull]] char* dest,
[[gnu::nonnull]] const char* src,
size_t dest_size
);
Вы поместили в хэдэр такое объявление, тем самым явно сказав пользователю и компилятору, что указатели не должны быть нулевыми. Если компилятор докажет в compile-time, что в функцию передали nullptr, то он выкинет предупреждение. Ну а пользователь четко по сигнатуре видит, что функция не ожидает нулевой указатель и как порядочный гражданин не будет его передавать.
Annotate your code. Stay cool.
#cppcore
{kind=link}
❤21🔥14👍8🤯1
Множество атрибутов
#опытным
Если вы хотите указать несколько атрибутов для вашей функции, вы можете использовать следующий синтаксис:
1️⃣ Списочный. Внутри одних скобок перечисляете все атрибуты:
2️⃣ Многоскобочный. Для больших любителей распиленных квадратов. Очень больших:
Больше квадратных скобок!
Также если вы используете несколько атрибутов из какого-то одного неймспейса, то можете использовать директиву using:
Но тогда котлеты отдельно, мухи отдельно. Все атрибуты одного неймспейса нужно уносить в отдельные скобки. Это фича С++17.
Что интересно, вы можете написать полную чупуху:
И это скомпилируется! Стандарт поддерживает любые implementation-defined атрибуты. Причем неизвестные атрибуты просто игнорируются. Правда игнор спровождается варнингами, которые тем не менее можно скрыть опциями, подобным -Wno-attributes.
Таким образом, если ваш код компилируется под разные системы, то вы можете не стесняясь использовать дублирующие атрибуты, предоставляемые разными компиляторами. Так на любой платформе можно получить одинаковое поведение.
Love squares. Stay cool.
#cppcore #cpp17
#опытным
Если вы хотите указать несколько атрибутов для вашей функции, вы можете использовать следующий синтаксис:
1️⃣ Списочный. Внутри одних скобок перечисляете все атрибуты:
[[gnu::always_inline, gnu::const, gnu::hot, nodiscard]] int f();
2️⃣ Многоскобочный. Для больших любителей распиленных квадратов. Очень больших:
[[gnu::always_inline]] [[gnu::hot]] [[gnu::const]] [[nodiscard]] int f();
Больше квадратных скобок!
Также если вы используете несколько атрибутов из какого-то одного неймспейса, то можете использовать директиву using:
[[using gnu : always_inline, const, hot]] [[nodiscard]] int f();
Но тогда котлеты отдельно, мухи отдельно. Все атрибуты одного неймспейса нужно уносить в отдельные скобки. Это фича С++17.
Что интересно, вы можете написать полную чупуху:
[[rust, will, replace, cpp]] int f();
И это скомпилируется! Стандарт поддерживает любые implementation-defined атрибуты. Причем неизвестные атрибуты просто игнорируются. Правда игнор спровождается варнингами, которые тем не менее можно скрыть опциями, подобным -Wno-attributes.
Таким образом, если ваш код компилируется под разные системы, то вы можете не стесняясь использовать дублирующие атрибуты, предоставляемые разными компиляторами. Так на любой платформе можно получить одинаковое поведение.
Love squares. Stay cool.
#cppcore #cpp17
{kind=link}
🔥21❤12👍9👎1
Яндекс приглашает на встречу РГ21 С++ 15 декабря в Москве
Собираемся сообществом экспертов и энтузиастов С++, чтобы обсудить развитие стандарта, участие российских разработчиков в нем, а еще — внезапные новинки.
В центре встречи — выступление Антона Полухина, руководителя группы разработки общих компонентов в Яндексе. Он поделится новостями с последней встречи международного Комитета по стандартизации, расскажет о прогрессе в работе над С++26 и ответит на вопросы о том, как российским разработчикам участвовать в развитии стандарта языка.
Когда: 15 декабря, 18:30
Где: Москва, офлайн + онлайн-трансляция
Регистрация на встречу
Собираемся сообществом экспертов и энтузиастов С++, чтобы обсудить развитие стандарта, участие российских разработчиков в нем, а еще — внезапные новинки.
В центре встречи — выступление Антона Полухина, руководителя группы разработки общих компонентов в Яндексе. Он поделится новостями с последней встречи международного Комитета по стандартизации, расскажет о прогрессе в работе над С++26 и ответит на вопросы о том, как российским разработчикам участвовать в развитии стандарта языка.
Когда: 15 декабря, 18:30
Где: Москва, офлайн + онлайн-трансляция
Регистрация на встречу
🔥9❤3👍3
Парсим ужас
#новичкам
Вот мы и рассмотрели все необходимые компоненты, чтобы понять, что написано здесь:
Если включить clang-format, то код преобразится во что-то такое:
Давайте посмотрим, откуда так много скобок:
1️⃣ Перед типом возвращаемого значения main определены 2 пустые области для указания атрибутов функции main.
2️⃣ Перед телом функции main определена пустая область для атрибутов, применяемых к типу функции main.
3️⃣ После блока захвата лямбды определена пустая область для атрибутов, применяемых к самой лямбде.
4️⃣ Внутри списка параметров лямбды определена пустая область для атрибутов, применяемых к единственному параметру лямбды.
5️⃣ Сама лямбда является generic и принимает массив неизвестного типа.
6️⃣ Перед телом лямбды определены 2 пустые области для атрибутов, применяемых к типу лямбды.
7️⃣ Вызываем лямбду с помощью указателя на функцию main.
8️⃣ Ну и разбавили это дело несколькими лишними скоупами по пути.
Не так уж и сложно оказалось)
Так, новичковая часть закончилась.
#опытным
Интересно, что этот код компилируется на gcc, но не на clang.
cppinsights показывает, что лямбда раскрывается во что-то такое:
То есть по факту мы имеем шаблонный оператор с auto параметром.
Как интерпретировать эту штуку - дело нетривиальное и по ходу компиляторы это делают по-разному. Видимо gcc при попытке инстанцировать шаблон с параметром int() выводит auto как тот же самый тип функции int() и в итоге лямбда принимает указатель на функцию. А clang при попытке инстанцировать шаблон выводит тип параметра функции как массив функций int() и не может принять main в качестве такого параметра.
Пишите ваше мнение, кто прав, кто виноват)
Deal with horrible things step by step. Stay cool.
#cppcore #compiler
#новичкам
Вот мы и рассмотрели все необходимые компоненты, чтобы понять, что написано здесь:
[[]][[]]int main()[[]]{{[][][[]][[]]{{{}}}(main);}}Если включить clang-format, то код преобразится во что-то такое:
/*1*/[[]][[]] int main()/*2*/[[]] {
{
[]/*3*/[[]](/*4*/[[]] /*5*/auto [])/*6*/[[]][[]] {
{
{}
}
}/*7*/(main);
}
}Давайте посмотрим, откуда так много скобок:
1️⃣ Перед типом возвращаемого значения main определены 2 пустые области для указания атрибутов функции main.
2️⃣ Перед телом функции main определена пустая область для атрибутов, применяемых к типу функции main.
3️⃣ После блока захвата лямбды определена пустая область для атрибутов, применяемых к самой лямбде.
4️⃣ Внутри списка параметров лямбды определена пустая область для атрибутов, применяемых к единственному параметру лямбды.
5️⃣ Сама лямбда является generic и принимает массив неизвестного типа.
6️⃣ Перед телом лямбды определены 2 пустые области для атрибутов, применяемых к типу лямбды.
7️⃣ Вызываем лямбду с помощью указателя на функцию main.
8️⃣ Ну и разбавили это дело несколькими лишними скоупами по пути.
Не так уж и сложно оказалось)
Так, новичковая часть закончилась.
#опытным
Интересно, что этот код компилируется на gcc, но не на clang.
cppinsights показывает, что лямбда раскрывается во что-то такое:
class __lambda_5_17 {
public:
template <class type_parameter_0_0>
inline /*constexpr */ auto operator()(auto *) const {
{ {}; };
}
private:
template <class type_parameter_0_0>
static inline /*constexpr */ auto __invoke(auto *__param0) {
return __lambda_5_17{}.operator()<type_parameter_0_0>(__param0);
}
public:
// /*constexpr */ __lambda_5_17() = default;
};То есть по факту мы имеем шаблонный оператор с auto параметром.
Как интерпретировать эту штуку - дело нетривиальное и по ходу компиляторы это делают по-разному. Видимо gcc при попытке инстанцировать шаблон с параметром int() выводит auto как тот же самый тип функции int() и в итоге лямбда принимает указатель на функцию. А clang при попытке инстанцировать шаблон выводит тип параметра функции как массив функций int() и не может принять main в качестве такого параметра.
Пишите ваше мнение, кто прав, кто виноват)
Deal with horrible things step by step. Stay cool.
#cppcore #compiler
Telegram
Грокаем C++
И это все компилируется!
Сможете сказать, откуда каждая скобка взялась?)
Сможете сказать, откуда каждая скобка взялась?)
❤🔥21😁12❤7👍3🔥2
Мок собеседования
#новичкам #опытным
Представьте, что вы вкатун в АйТишку плюсовую. Прочитали несколько книжек, прошли кучу бесплатных курсов и дописали свой первыйвелосипед пет-проект.
Пора бы попробовать устроиться на работу. Но учеба и учебные проекты - это одно, а собеседования - это совсем другое. Надо знать, как их проходить, это отдельная наука.
Но как узнать, как проходить собесы, если никогда их не проходил?(оставим за скобками вопрос, как вообще добраться до собеса, это то еще шаманство)
Для этого существуют мок-собеседования. То есть дословно "имитация" собеседования.
В идеале его проводить с живым человеком, например вашим ментором или любым другим опытным чуваком, который изъявляет желание.
Но если вы стеснительный волк-одиночка, к тому же еще и бедный(за занятия с ментором нужно платить), то и для вас есть вариант.
В сети лежит куча готовых мок-собеседований по С++ на позиции разных уровней.
На самом деле видео мок-собесов - не бомже-вариант, а маст хэв для любого человека, неуверенного в своих скиллах прохождения собеседований. Весь из себя сеньор, выходивший на рынок 10 лет назад, тоже скорее всего для себя что-то подчерпнет.
Даже в русскоязычном пространстве можно найти много таких видосов. Основные мок-интервьюеры у нас это:
- Ambushed raccoon
- Владимир Балун
Ну а мы за вас собрали подборку всех(или почти всех) мок-собесов на русском языке по С++ и разбили их по уровням.
Junior:
- https://www.youtube.com/watch?v=_-EkLLZ5svk
- https://www.youtube.com/watch?v=H1mIHJxnm9E
- https://www.youtube.com/watch?v=PQ1C_0EAHFI
- https://www.youtube.com/watch?v=BCpHj698D8U
- https://youtu.be/7g8HufwNa0g?si=XVKRsuoHN20MJx3i
- https://youtu.be/a18qTcWn-II?si=OttfqKh0bHLjueOY
- https://www.youtube.com/live/rLOgkn6xVQA?si=lFqwGf_Wsr8IohHo
- https://youtu.be/VfoxaNLVtmQ?si=elt-OyZWB5tXp5hI
Middle:
- https://www.youtube.com/watch?v=nMdNehH8-Ss
- https://www.youtube.com/watch?v=Ed37R0FvkQ8
- https://www.youtube.com/watch?v=IDqMy4_xkb4
- https://www.youtube.com/watch?v=BOUEbS5L4-8
- https://www.youtube.com/watch?v=PwVMcxCBIkg
- https://www.youtube.com/watch?v=Np6UrKN6ZbA
- https://www.youtube.com/watch?v=1Ez3kbK_3bI
- https://www.youtube.com/watch?v=s6BXbEPaw5g
- https://www.youtube.com/watch?v=yfoFtu28n4o
- https://www.youtube.com/watch?v=cT3fonCyxJk
- https://www.youtube.com/watch?v=xwb2FAKxCUo
- https://www.youtube.com/watch?v=bOgz4K-ARzQ
- https://www.youtube.com/watch?v=wR4VRCp_BYo
- https://youtu.be/5enBKMwOST0?si=i-5mdyrxeeFiZKo1
Senior:
- https://www.youtube.com/watch?v=OwMEK_W8Ysw
- https://www.youtube.com/watch?v=dZpe58HKX-8
Просто вопросы и задачи с собесов:
- https://www.youtube.com/watch?v=boYk6gFg84E
- https://www.youtube.com/watch?v=ViHNB0_1j90
- https://www.youtube.com/watch?v=aYM7lksQ8yg
- https://www.youtube.com/watch?v=UdY_YMFx7SY
- https://www.youtube.com/watch?v=PStQ4jhhz08
- https://www.youtube.com/watch?v=wMYfg_iPqMQ
Просмотрев эти видосы(возможно по нескольку раз) и переписав ответы на все вопросы себе в тетрадочку или файлик, вы будете знать ответы на 95% устных вопросов, которые вам будут задавать в условной компании Х.
Возможно вы не все будете до конца понимать, но уж очень глупых ошибок точно не совершите.
Ну а для любителем native english есть канал Кодингового Иисуса. Он постоянно у себя на стримах спрашивает у людей за плюсы. В основном люди валятся на простых вопросах, но иногда попадаются качественные собеседники. По крайней мере практика языка вам будет точно обеспечена.
Еще раз. Смотреть эти видосы можно(и почти нужно) примерно всем, кто задумывается о смене работы. Кому-то вспомнить, кому-то заполнить пробелы, кому-то понять, что все совсем плохо и садиться учить базу. Каждый найдет себе занятие по душе.
Practice makes perfect. Stay cool.
#interview
#новичкам #опытным
Представьте, что вы вкатун в АйТишку плюсовую. Прочитали несколько книжек, прошли кучу бесплатных курсов и дописали свой первый
Пора бы попробовать устроиться на работу. Но учеба и учебные проекты - это одно, а собеседования - это совсем другое. Надо знать, как их проходить, это отдельная наука.
Но как узнать, как проходить собесы, если никогда их не проходил?(оставим за скобками вопрос, как вообще добраться до собеса, это то еще шаманство)
Для этого существуют мок-собеседования. То есть дословно "имитация" собеседования.
В идеале его проводить с живым человеком, например вашим ментором или любым другим опытным чуваком, который изъявляет желание.
Но если вы стеснительный волк-одиночка, к тому же еще и бедный(за занятия с ментором нужно платить), то и для вас есть вариант.
В сети лежит куча готовых мок-собеседований по С++ на позиции разных уровней.
На самом деле видео мок-собесов - не бомже-вариант, а маст хэв для любого человека, неуверенного в своих скиллах прохождения собеседований. Весь из себя сеньор, выходивший на рынок 10 лет назад, тоже скорее всего для себя что-то подчерпнет.
Даже в русскоязычном пространстве можно найти много таких видосов. Основные мок-интервьюеры у нас это:
- Ambushed raccoon
- Владимир Балун
Ну а мы за вас собрали подборку всех(или почти всех) мок-собесов на русском языке по С++ и разбили их по уровням.
Junior:
- https://www.youtube.com/watch?v=_-EkLLZ5svk
- https://www.youtube.com/watch?v=H1mIHJxnm9E
- https://www.youtube.com/watch?v=PQ1C_0EAHFI
- https://www.youtube.com/watch?v=BCpHj698D8U
- https://youtu.be/7g8HufwNa0g?si=XVKRsuoHN20MJx3i
- https://youtu.be/a18qTcWn-II?si=OttfqKh0bHLjueOY
- https://www.youtube.com/live/rLOgkn6xVQA?si=lFqwGf_Wsr8IohHo
- https://youtu.be/VfoxaNLVtmQ?si=elt-OyZWB5tXp5hI
Middle:
- https://www.youtube.com/watch?v=nMdNehH8-Ss
- https://www.youtube.com/watch?v=Ed37R0FvkQ8
- https://www.youtube.com/watch?v=IDqMy4_xkb4
- https://www.youtube.com/watch?v=BOUEbS5L4-8
- https://www.youtube.com/watch?v=PwVMcxCBIkg
- https://www.youtube.com/watch?v=Np6UrKN6ZbA
- https://www.youtube.com/watch?v=1Ez3kbK_3bI
- https://www.youtube.com/watch?v=s6BXbEPaw5g
- https://www.youtube.com/watch?v=yfoFtu28n4o
- https://www.youtube.com/watch?v=cT3fonCyxJk
- https://www.youtube.com/watch?v=xwb2FAKxCUo
- https://www.youtube.com/watch?v=bOgz4K-ARzQ
- https://www.youtube.com/watch?v=wR4VRCp_BYo
- https://youtu.be/5enBKMwOST0?si=i-5mdyrxeeFiZKo1
Senior:
- https://www.youtube.com/watch?v=OwMEK_W8Ysw
- https://www.youtube.com/watch?v=dZpe58HKX-8
Просто вопросы и задачи с собесов:
- https://www.youtube.com/watch?v=boYk6gFg84E
- https://www.youtube.com/watch?v=ViHNB0_1j90
- https://www.youtube.com/watch?v=aYM7lksQ8yg
- https://www.youtube.com/watch?v=UdY_YMFx7SY
- https://www.youtube.com/watch?v=PStQ4jhhz08
- https://www.youtube.com/watch?v=wMYfg_iPqMQ
Просмотрев эти видосы(возможно по нескольку раз) и переписав ответы на все вопросы себе в тетрадочку или файлик, вы будете знать ответы на 95% устных вопросов, которые вам будут задавать в условной компании Х.
Возможно вы не все будете до конца понимать, но уж очень глупых ошибок точно не совершите.
Ну а для любителем native english есть канал Кодингового Иисуса. Он постоянно у себя на стримах спрашивает у людей за плюсы. В основном люди валятся на простых вопросах, но иногда попадаются качественные собеседники. По крайней мере практика языка вам будет точно обеспечена.
Еще раз. Смотреть эти видосы можно(и почти нужно) примерно всем, кто задумывается о смене работы. Кому-то вспомнить, кому-то заполнить пробелы, кому-то понять, что все совсем плохо и садиться учить базу. Каждый найдет себе занятие по душе.
Practice makes perfect. Stay cool.
#interview
{kind=link}
❤49🔥17👍8❤🔥3🙏3