Какой результат попытки компиляции и запуска кода?
Anonymous Poll
25%
Ошибка компиляции
31%
copy ctor
14%
move ctor
9%
move ctor move ctor
11%
copy ctor move ctor
3%
move ctor copy ctor
7%
copy ctor copy ctor
👍12❤8🔥4👎1
Ответ
#новичкам
Многие из вас подумали, что будет ошибка компиляции. В целом, логичная цепочка мыслей: ну как же можно мувнуть данные из константной ссылки? Она же неизменяема.
Но она все же неверная. Правильный ответ: на консоль выведется "copy ctor".
Копия? Мы же муваем!
Сейчас разберемся. Но для начало вспомним сам пример:
На самом деле проблема в нейминге. Все вопросы к комитету. Это они имена всему плюсовому раздают.
std::move ничего не мувает. Она делает всего лишь static_cast. Но не просто каст к правой ссылке, это не совсем корректно. Посмотрим на реализацию std::move:
Обратите внимание, что от типа отрезается любая ссылочность и только затем добавляется правоссылочность. Но константность-то никуда не уходит. По сути результирующий тип выражения std::move({константная левая ссылка}) это константная правая ссылка.
Чтобы это проверить, перейдем на cppinsights:
Так как мы просто кастуем к валидному типу, мув успешно отрабатывает, но строчка
Теперь про копирование. Вспомним правила приведения типов. const T&& может приводится только к const T&. То есть единственный конструктор, который может вызваться - это копирующий конструктор.
Интересная ситуация, конечно, что "перемещение" может приводить к копированию в плюсах. Но имеем, что имеем. Терпим и продолжаем грызть гранит С++.
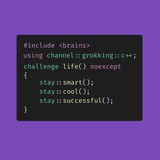
Give a proper name. Stay cool.
#cppcore #template
#новичкам
Многие из вас подумали, что будет ошибка компиляции. В целом, логичная цепочка мыслей: ну как же можно мувнуть данные из константной ссылки? Она же неизменяема.
Но она все же неверная. Правильный ответ: на консоль выведется "copy ctor".
Копия? Мы же муваем!
Сейчас разберемся. Но для начало вспомним сам пример:
#include <iostream>
struct Test {
Test() = default;
Test(const Test &other) {
std::cout << "copy ctor" << std::endl;
}
Test(Test &&other) {
std::cout << "move ctor" << std::endl;
}
Test &operator=(const Test &other) = default;
Test &operator=(Test &&other) = default;
~Test() = default;
};
int main() {
Test test;
const Test &ref = test;
(void)std::move(ref);
auto emigma = std::move(ref);
}
На самом деле проблема в нейминге. Все вопросы к комитету. Это они имена всему плюсовому раздают.
std::move ничего не мувает. Она делает всего лишь static_cast. Но не просто каст к правой ссылке, это не совсем корректно. Посмотрим на реализацию std::move:
template <class T>
constexpr typename std::remove_reference<T>::type&& move(T&& t) noexcept {
return static_cast<typename std::remove_reference<T>::type&&>(t);
}
Обратите внимание, что от типа отрезается любая ссылочность и только затем добавляется правоссылочность. Но константность-то никуда не уходит. По сути результирующий тип выражения std::move({константная левая ссылка}) это константная правая ссылка.
Чтобы это проверить, перейдем на cppinsights:
Test test;
const Test &ref = test;
using ExprType = decltype(std::move(ref));
// под капотом ExprType вот чему равен
using ExprType = const Test &&;
Так как мы просто кастуем к валидному типу, мув успешно отрабатывает, но строчка
(void)std::move(ref); не дает в консоли никакого вывода, потому что никаких новых объектов мы не создаем.Теперь про копирование. Вспомним правила приведения типов. const T&& может приводится только к const T&. То есть единственный конструктор, который может вызваться - это копирующий конструктор.
Интересная ситуация, конечно, что "перемещение" может приводить к копированию в плюсах. Но имеем, что имеем. Терпим и продолжаем грызть гранит С++.
Give a proper name. Stay cool.
#cppcore #template
{kind=link}
❤34👍14🔥7😁4🥱2💯1
Гарантии безопасности исключений
#новичкам
Программа на С++ - очень интересное явление. Вроде мощный, подкаченный, умный и скоростной парень. Но вот проблема. Ходить не умеет нормально. То в ноги себе стреляет, то падает периодически. В общем, беда у него с ходьбой. У этого могут быть разные причины. Все из них даже трудно в голове удержать. Но сегодня обсудим, какие есть гипсы, лангеты и костыли, которые помогут этому парню нормально ходить при работе с исключениями.
Даже не зная, что вы работаете с исключениями - вы уже работаете с ними. Даже обычный, казалось бы, безобидный new может кинуть std::bad_alloc. И это core языка. Стандартная библиотека пронизана исключениями.
Обрабатывать исключения можно по-разному и это будет давать разные результаты. От того, как обрабатываются исключения в модуле, зависит, какие гарантии он может дать в случае возникновения исключительной ситуации.
А это очень важная штука, потому что взаимодействующий с модулем код полагается на его адекватное поведение, которое с легкостью может быть нарушено, если нет гарантий безопасности.
Итак, существует 3 гарантии безопасности исключений:
Базовая гарантия. Формулировка разнится, но более общая звучит так: "после возникновения исключения и его обработки программа должна остаться в согласованном состоянии". Теперь на рабоче-крестьянском: не должно быть утечек ресурсов и должны сохраняться все инварианты классов. С утечками, думаю, все понятно. Инвариант - некое логически согласованное состояние системы. Если класс владеет массивом и содержит поле для его размера, то инвариантом этого класса будет совпадение реального размера массива со значением поля-размера. Для класса "легковая машина" инвариантом будет количество колес - 4. Обычная машина без одного или нескольких колес просто не едет. И для того, чтобы машина корректно работала, количество колес должно быть одинаково - 4. Или например, нельзя, чтобы дата создания чего-то была больше текущего дня, ну никак. Вот такие штуки должны сохраняться.
Строгая гарантия. Если при выполнении операции возникает исключение, операция не должна оказать на систему никакого влияния. То есть пан или пропал. Либо вся операция выполняется успешно и ее результат применяется, либо система откатывается в состояние до выполнения операции. Это свойство программы называется транзакционностью.
Гарантия отсутствия исключений. Ни при каких обстоятельствах не будет брошено исключение. Легко сказать, но тяжело сделать. С++ и его стандартная библиотека разрабатывались с учетом использования исключений. И это накладывает свои ограничения на отсутствие исключений. Мы все-таки не на Go пишем.
Ну и есть еще одна гарантия - отсутствие каких-либо гарантий. Мама - анархия, во всей красе.
Тема важная, будем потихоньку ее разбирать с примерами по каждой гарантии.
Be a guarantor. Stay cool.
#cppcore
#новичкам
Программа на С++ - очень интересное явление. Вроде мощный, подкаченный, умный и скоростной парень. Но вот проблема. Ходить не умеет нормально. То в ноги себе стреляет, то падает периодически. В общем, беда у него с ходьбой. У этого могут быть разные причины. Все из них даже трудно в голове удержать. Но сегодня обсудим, какие есть гипсы, лангеты и костыли, которые помогут этому парню нормально ходить при работе с исключениями.
Даже не зная, что вы работаете с исключениями - вы уже работаете с ними. Даже обычный, казалось бы, безобидный new может кинуть std::bad_alloc. И это core языка. Стандартная библиотека пронизана исключениями.
Обрабатывать исключения можно по-разному и это будет давать разные результаты. От того, как обрабатываются исключения в модуле, зависит, какие гарантии он может дать в случае возникновения исключительной ситуации.
А это очень важная штука, потому что взаимодействующий с модулем код полагается на его адекватное поведение, которое с легкостью может быть нарушено, если нет гарантий безопасности.
Итак, существует 3 гарантии безопасности исключений:
Базовая гарантия. Формулировка разнится, но более общая звучит так: "после возникновения исключения и его обработки программа должна остаться в согласованном состоянии". Теперь на рабоче-крестьянском: не должно быть утечек ресурсов и должны сохраняться все инварианты классов. С утечками, думаю, все понятно. Инвариант - некое логически согласованное состояние системы. Если класс владеет массивом и содержит поле для его размера, то инвариантом этого класса будет совпадение реального размера массива со значением поля-размера. Для класса "легковая машина" инвариантом будет количество колес - 4. Обычная машина без одного или нескольких колес просто не едет. И для того, чтобы машина корректно работала, количество колес должно быть одинаково - 4. Или например, нельзя, чтобы дата создания чего-то была больше текущего дня, ну никак. Вот такие штуки должны сохраняться.
Строгая гарантия. Если при выполнении операции возникает исключение, операция не должна оказать на систему никакого влияния. То есть пан или пропал. Либо вся операция выполняется успешно и ее результат применяется, либо система откатывается в состояние до выполнения операции. Это свойство программы называется транзакционностью.
Гарантия отсутствия исключений. Ни при каких обстоятельствах не будет брошено исключение. Легко сказать, но тяжело сделать. С++ и его стандартная библиотека разрабатывались с учетом использования исключений. И это накладывает свои ограничения на отсутствие исключений. Мы все-таки не на Go пишем.
Ну и есть еще одна гарантия - отсутствие каких-либо гарантий. Мама - анархия, во всей красе.
Тема важная, будем потихоньку ее разбирать с примерами по каждой гарантии.
Be a guarantor. Stay cool.
#cppcore
{kind=link}
❤23👍14🔥7👎2
Базовая гарантия исключений
#новичкам
Вспомним свойства базовой гарантии: после возникновения исключения в программе не должно быть утечек ресурсов и должны сохраняться все инварианты классов.
И не всегда базовой гарантии легко удовлетворить. Поскольку исключения добавляют в программу дополнительные пути выполнения кода, крайне важно учитывать последствия работы кода по таким путям и избегать любых нежелательных эффектов, которые в противном случае могут возникнуть. Давайте посмотрим на примере:
Внутренний инвариант класса IntArray - член
Код, который избегает подобных нежелательных эффектов, называется exception safe. То есть предоставление базовой гарантии уже говорит о том, что ваш код "exception safe".
Допустим, что ваш класс предоставляет базовую гарантию исключений. Какие выводы мы можем из этого сделать? Ну сохранены инварианты, а значения-то какие будут у полей?
В том-то и дело, что конкретные значения неизвестны. И это сильно ограничивает практическое использование таких объектов. По сути единственное, что с ним можно гарантировано безопасно сделать - это разрушить.
И это главное. Вся магия с раскруткой стека и вызовом деструктором локальных объектов работает только если деструкторы вызываются безопасно. А для этого объект должен быть в валидном, но необязательно определенном, состоянии. То есть вы в принципе не можете восстановить работоспособность приложения, если ваши инструменты не предоставляют хотя бы базовую гарантию.
Здесь кстати можно провести параллель с мувнутыми объектами: ими тоже особо не попользуешься и по хорошему их надо просто удалить.
Примером предоставления только базовой гарантии может быть использование какой-нибудь базы данных. Если при выполнении запроса фреймворк выкинул исключение, например потому что соединение отвалилось, то объект для работы с базой остался в валидном состоянии, но нет никакой информации о том, выполнился запрос или нет:
Поэтому мы должны иметь ввиду это неопределенное состояние коннекшена и базы при выполнении ретраев.
Provide guarantees. Stay cool.
#cppcore
#новичкам
Вспомним свойства базовой гарантии: после возникновения исключения в программе не должно быть утечек ресурсов и должны сохраняться все инварианты классов.
И не всегда базовой гарантии легко удовлетворить. Поскольку исключения добавляют в программу дополнительные пути выполнения кода, крайне важно учитывать последствия работы кода по таким путям и избегать любых нежелательных эффектов, которые в противном случае могут возникнуть. Давайте посмотрим на примере:
class IntArray {
int *array;
std::size_t nElems;
public:
// ...
~IntArray() { delete[] array; }
IntArray(const IntArray &that); // nontrivial copy constructor
IntArray &operator=(const IntArray &rhs) {
if (this != &rhs) {
delete[] array;
array = nullptr;
nElems = rhs.nElems;
if (nElems) {
array = new int[nElems];
std::memcpy(array, rhs.array, nElems * sizeof(*array));
}
}
return *this;
}
// ...
};Внутренний инвариант класса IntArray - член
array является валидным (возможно, нулевым) указателем, а член nElems хранит количество элементов в массиве. В операторе присваивания освобождается память текущего array'я и присваивается значение счётчику элементов nElems до выделения нового блока памяти для копии. В результате, если из new вылетит исключение, то array будет нулевым, а размер массива нет. Это нарушение инварианта и таким объектом просто небезопасно пользоваться. Метод size потенциально вернет ненулевой размер, а закономерное использование следом оператора[] приведет к неопределенному поведению.Код, который избегает подобных нежелательных эффектов, называется exception safe. То есть предоставление базовой гарантии уже говорит о том, что ваш код "exception safe".
Допустим, что ваш класс предоставляет базовую гарантию исключений. Какие выводы мы можем из этого сделать? Ну сохранены инварианты, а значения-то какие будут у полей?
В том-то и дело, что конкретные значения неизвестны. И это сильно ограничивает практическое использование таких объектов. По сути единственное, что с ним можно гарантировано безопасно сделать - это разрушить.
И это главное. Вся магия с раскруткой стека и вызовом деструктором локальных объектов работает только если деструкторы вызываются безопасно. А для этого объект должен быть в валидном, но необязательно определенном, состоянии. То есть вы в принципе не можете восстановить работоспособность приложения, если ваши инструменты не предоставляют хотя бы базовую гарантию.
Здесь кстати можно провести параллель с мувнутыми объектами: ими тоже особо не попользуешься и по хорошему их надо просто удалить.
Примером предоставления только базовой гарантии может быть использование какой-нибудь базы данных. Если при выполнении запроса фреймворк выкинул исключение, например потому что соединение отвалилось, то объект для работы с базой остался в валидном состоянии, но нет никакой информации о том, выполнился запрос или нет:
auto db = std::make_shared<DBConnection>(credentials);
try {
auto result = db->Execute("UPDATE ...");
process(result);
} catch (std::exception& ex) {
std::cout << "We can cannot rely on table state and must retry with that in mind" << std::endl;
// retry
}
Поэтому мы должны иметь ввиду это неопределенное состояние коннекшена и базы при выполнении ретраев.
Provide guarantees. Stay cool.
#cppcore
{kind=link}
👍11❤9🔥3😁3👎2
Строгая гарантия исключений
#новичкам
Базовая гарантия - это конечно хорошо, наше приложение будет корректно работать, даже если что-то пойдет не так. Но иногда этого недостаточно. Иногда нам нужно, чтобы ошибка операции вообще никак не повлияла на текущее состояние системы. Либо операция выполнилась и все хорошо, либо она бросила исключение, но после его отлова система находится в том же состоянии, что и до выполнения операции.
Такое свойство операций называется транзакционность. Транзакция может либо выполниться полностью, либо все результаты промежуточных операций в ней откатываются до состояния до начала исполнения транзакции.
Это важно, когда ваша операция требует выполнения нескольких промежуточных операций, постепенно меняющих систему. Если остановиться посередине, то уже невозможно или очень сложно будет восстановить консистентность данных.
Давайте перепишем оператор присваивания класс IntArray из предыдущего поста так, чтобы он предоставлял строгую гарантию:
В этот раз мы ничего не изменяем в самом объекте до тех пор, пока не выделим новый буфер и не скопируем туда элементы
Хрестоматийный пример из стандартной библиотеки - вектор с его методом push_back. Если у типа есть небросающий перемещающий конструктор, то метод предоставляет строгую гарантию. Вот примерно как это работает:
в хэлпере reallocate используется std::move_if_noexcept, который условно кастит в rvalue ссылке, если мув конструктор noexcept. И только в этом случае можно предоставить строгую гарантию: если вы уже повредили один из исходных объектов, его уже никак не восстановить. А безопасное перемещение элементов гарантирует готовый к использованию новый расширенный буфер.
Be strong. Stay cool.
#cppcore
#новичкам
Базовая гарантия - это конечно хорошо, наше приложение будет корректно работать, даже если что-то пойдет не так. Но иногда этого недостаточно. Иногда нам нужно, чтобы ошибка операции вообще никак не повлияла на текущее состояние системы. Либо операция выполнилась и все хорошо, либо она бросила исключение, но после его отлова система находится в том же состоянии, что и до выполнения операции.
Такое свойство операций называется транзакционность. Транзакция может либо выполниться полностью, либо все результаты промежуточных операций в ней откатываются до состояния до начала исполнения транзакции.
Это важно, когда ваша операция требует выполнения нескольких промежуточных операций, постепенно меняющих систему. Если остановиться посередине, то уже невозможно или очень сложно будет восстановить консистентность данных.
Давайте перепишем оператор присваивания класс IntArray из предыдущего поста так, чтобы он предоставлял строгую гарантию:
class IntArray {
int *array;
std::size_t nElems;
public:
// ...
~IntArray() { delete[] array; }
IntArray(const IntArray &that); // nontrivial copy constructor
IntArray &operator=(const IntArray &rhs) {
int *tmp = nullptr;
if (rhs.nElems) {
tmp = new int[rhs.nElems];
std::memcpy(tmp, rhs.array, rhs.nElems * sizeof(*array));
}
delete[] array;
array = tmp;
nElems = rhs.nElems;
return *this;
}
// ...
};В этот раз мы ничего не изменяем в самом объекте до тех пор, пока не выделим новый буфер и не скопируем туда элементы
rhs. И только после этого выполняем обновление самого объекта с помощью небросающих инструкций.Хрестоматийный пример из стандартной библиотеки - вектор с его методом push_back. Если у типа есть небросающий перемещающий конструктор, то метод предоставляет строгую гарантию. Вот примерно как это работает:
template <typename T>
class vector {
private:
T *data = nullptr;
size_t size = 0;
size_t capacity = 0;
void reallocate(size_t new_capacity) {
// allocate memory
T *new_data =
static_cast<T *>(::operator new(new_capacity * sizeof(T)));
size_t new_size = 0;
try {
// Move or copy elements
for (size_t i = 0; i < size; ++i) {
new (new_data + new_size) T(std::move_if_noexcept(data[i]));
++new_size;
}
} catch (...) {
// Rollback in case of exception
for (size_t i = 0; i < new_size; ++i) {
new_data[i].~T();
}
::operator delete(new_data);
throw;
}
// cleanup
// ...
}
public:
void push_back(const T &value) {
if (size >= capacity) {
size_t new_capacity = capacity == 0 ? 1 : capacity * 2;
// save for rollback
T *old_data = data;
size_t old_size = size;
size_t old_capacity = capacity;
try {
reallocate(new_capacity);
} catch (...) {
// restore
data = old_data;
size = old_size;
capacity = old_capacity;
throw;
}
}
// actually insert element
// ...
}
};
в хэлпере reallocate используется std::move_if_noexcept, который условно кастит в rvalue ссылке, если мув конструктор noexcept. И только в этом случае можно предоставить строгую гарантию: если вы уже повредили один из исходных объектов, его уже никак не восстановить. А безопасное перемещение элементов гарантирует готовый к использованию новый расширенный буфер.
Be strong. Stay cool.
#cppcore
{kind=link}
1❤14🔥8👍7👎3
Гарантия отсутствия исключений
#новичкам
Переходим к самой сильной гарантии - отсутствие исключений.
В сам язык С++(new, dynamic_cast), и в его стандартную библиотеку в базе встроены исключения. Поэтому писать код без исключений в использованием стандартных инструментов практически невозможно. Вы конечно можете использовать nothrow new и написать свой вариант стандартной библиотеки и других сторонних решений. И кто-то наверняка так делал. Но в этом случае разработка как минимум затянется, а как максимум вы бросите это гиблое дело.
Поэтому повсеместно предоставлять nothow гарантии с использованием стандартных инструментов не всегда реалистично.
Но если такой термин есть, значит такие гарантии можно предоставлять для отдельных сущностей. Давайте как раз об этих сущностях и поговорим.
Но для начала проясним термины.
Под гарантией отсутствия исключений подразумевается обычно 2 понятия: nothrow и nofail.
nothrow подразумевает отсутствие исключений, но не отсутствие ошибок. Говорится, что ошибки репортятся другими средствами(в основном через глобальное состояние, потому что деструктор ничего не возвращает) или полностью скрываются и игнорируются.
Примером сущностей с nothrow гарантией является деструкторы. С С++11 они по-умолчанию помечены noexcept. В основном это сделано для того, чтобы при раскрутке стека не получить double exception.
Но деструкторы могу фейлиться. Просто никаких средств, кроме глобальных переменных для репорта ошибок невозможно использовать. Они ведь ничего не возвращают, а исполняются скрытно от нас(если вы используете RAII конечно).
nofail же подразумевает полное отсутствие ошибок. nofail гарантия ожидается от std::swap, мув-конструкторов классов и других функций с помощью которых достигается строгая гарантия исключений.
Например в swap-идиоме std::swap и мув-конструкторы используются для определения небросающего оператора присваивания.
nofail гарантиями также должны обладать функторы-коллбэки модифицирующих алгоритмов. std::sort не предоставляет никаких гарантий на состояние системы, если компаратор бросит эксепшн.
В языке в целом эти гарантии обеспечиваются ключевым словом noexcept. При появлении этой нотации компилятор понимает, что для этой функций не нужно генерировать дополнительный код, необходимый для обработки исключений. Но у этого есть своя цена: если из noexcept функции вылетит исключение, то сразу же без разговоров вызовется std::terminate.
Provide guarantees. Stay cool.
#cppcore #cpp11
#новичкам
Переходим к самой сильной гарантии - отсутствие исключений.
В сам язык С++(new, dynamic_cast), и в его стандартную библиотеку в базе встроены исключения. Поэтому писать код без исключений в использованием стандартных инструментов практически невозможно. Вы конечно можете использовать nothrow new и написать свой вариант стандартной библиотеки и других сторонних решений. И кто-то наверняка так делал. Но в этом случае разработка как минимум затянется, а как максимум вы бросите это гиблое дело.
Поэтому повсеместно предоставлять nothow гарантии с использованием стандартных инструментов не всегда реалистично.
Но если такой термин есть, значит такие гарантии можно предоставлять для отдельных сущностей. Давайте как раз об этих сущностях и поговорим.
Но для начала проясним термины.
Под гарантией отсутствия исключений подразумевается обычно 2 понятия: nothrow и nofail.
nothrow подразумевает отсутствие исключений, но не отсутствие ошибок. Говорится, что ошибки репортятся другими средствами(в основном через глобальное состояние, потому что деструктор ничего не возвращает) или полностью скрываются и игнорируются.
Примером сущностей с nothrow гарантией является деструкторы. С С++11 они по-умолчанию помечены noexcept. В основном это сделано для того, чтобы при раскрутке стека не получить double exception.
Но деструкторы могу фейлиться. Просто никаких средств, кроме глобальных переменных для репорта ошибок невозможно использовать. Они ведь ничего не возвращают, а исполняются скрытно от нас(если вы используете RAII конечно).
nofail же подразумевает полное отсутствие ошибок. nofail гарантия ожидается от std::swap, мув-конструкторов классов и других функций с помощью которых достигается строгая гарантия исключений.
Например в swap-идиоме std::swap и мув-конструкторы используются для определения небросающего оператора присваивания.
nofail гарантиями также должны обладать функторы-коллбэки модифицирующих алгоритмов. std::sort не предоставляет никаких гарантий на состояние системы, если компаратор бросит эксепшн.
В языке в целом эти гарантии обеспечиваются ключевым словом noexcept. При появлении этой нотации компилятор понимает, что для этой функций не нужно генерировать дополнительный код, необходимый для обработки исключений. Но у этого есть своя цена: если из noexcept функции вылетит исключение, то сразу же без разговоров вызовется std::terminate.
Provide guarantees. Stay cool.
#cppcore #cpp11
{kind=link}
❤15👍8🔥5❤🔥3😁3👎1
WAT
#опытным
Спасибо, @Ivaneo, за любезно предоставленный примерчик в рамках рубрики #ЧЗХ.
"Век живи - век учись" - сказал Луций Сенека.
"Век живи - век учи С++" - реалии нашей жизни.
Просто посмотрите на следующий код:
И он компилируется.
WAT?
Это называется injected class name. Имя класса доступно из скоупа этого же класса. Так сделано для того, чтобы поиск имени
Такое поведение может быть полезно в таком сценарии:
injected class name гарантирует, что из метода
Это также полезно внутри шаблонов классов, где имя класса можно использовать без списка аргументов шаблона, например, используя просто Foo вместо полного идентификатора шаблона Foo<blah, blah, blah>.
Ну и побочным эффектом такого поведения является возможность написания длиннющей цепочки из имен класса.
Так что это не у вас в глазах двоится, это плюсы такие шебутные)
Find yourself within. Stay cool.
#cppcore
#опытным
Спасибо, @Ivaneo, за любезно предоставленный примерчик в рамках рубрики #ЧЗХ.
"Век живи - век учись" - сказал Луций Сенека.
"Век живи - век учи С++" - реалии нашей жизни.
Просто посмотрите на следующий код:
struct Foo
{
void Bar();
};
void Foo::Foo::Foo::Foo::Foo::Foo::Foo::Foo::Foo::Foo::Foo::Foo::Bar()
{
printf("Foofoo!");
}
int main()
{
Foo f;
f.Bar();
return 0;
}
И он компилируется.
WAT?
Это называется injected class name. Имя класса доступно из скоупа этого же класса. Так сделано для того, чтобы поиск имени
X внутри класса X всегда разрешался именно в этот класс.Такое поведение может быть полезно в таком сценарии:
void X() { }
class X {
public:
static X Сreate() { return X(); }
};injected class name гарантирует, что из метода
Сreate будет возвращен именно инстанс класса Х, а не результат вызова функции Х.Это также полезно внутри шаблонов классов, где имя класса можно использовать без списка аргументов шаблона, например, используя просто Foo вместо полного идентификатора шаблона Foo<blah, blah, blah>.
Ну и побочным эффектом такого поведения является возможность написания длиннющей цепочки из имен класса.
Так что это не у вас в глазах двоится, это плюсы такие шебутные)
Find yourself within. Stay cool.
#cppcore
{kind=link}
10🔥36🤯11❤9😁6⚡4👍4
data race
#новичкам
Конкретных проблем, которые можно допустить в многопоточной среде, существует оооочень много. Но все они делятся на несколько больших категорий. В этом и следующих постах мы на примерах разберем основные виды.
Начнем с data race. Это по сути единственная категория, которая четко определена в стандарте С++.
Скажем, что два обращения к памяти конфликтуют, если:
- они обращаются к одной и той же ячейке памяти.
- по крайней мере одно из обращений - запись.
Так вот гонкой данных называется 2 конфликтующих обращения к неатомарной переменной, между которыми не возникло отношение порядка "Произошло-Раньше".
Если не вдаваться в семантику отношений порядков, то отсутствие синхронизации с помощью примитивов(мьютексов и атомиков) при доступе к неатомикам карается гонкой данных и неопределененным поведением.
Простой пример:
В двух потоках пытаемся инкрементировать
Гонку данных относительно несложно определить по коду, просто следую стандарту, да и тред-санитайзеры, пользуясь определением гонки, могут ее детектировать. Поэтому как будто бы эта не самая основная проблема в многопоточке. Существуют другие, более сложные в детектировании и воспроизведении.
Have an order. Stay cool.
#cppcore #concurrency
#новичкам
Конкретных проблем, которые можно допустить в многопоточной среде, существует оооочень много. Но все они делятся на несколько больших категорий. В этом и следующих постах мы на примерах разберем основные виды.
Начнем с data race. Это по сути единственная категория, которая четко определена в стандарте С++.
Скажем, что два обращения к памяти конфликтуют, если:
- они обращаются к одной и той же ячейке памяти.
- по крайней мере одно из обращений - запись.
Так вот гонкой данных называется 2 конфликтующих обращения к неатомарной переменной, между которыми не возникло отношение порядка "Произошло-Раньше".
Если не вдаваться в семантику отношений порядков, то отсутствие синхронизации с помощью примитивов(мьютексов и атомиков) при доступе к неатомикам карается гонкой данных и неопределененным поведением.
Простой пример:
int a = 0;
void thread_1() {
for (int i = 0; i < 10000; ++i) {
++a;
}
}
void thread_2() {
for (int i = 0; i < 10000; ++i) {
++a;
}
}
std::jthread thr1{thread_1};
std::jthread thr1{thread_2};
std::cout << a << std::endl;
В двух потоках пытаемся инкрементировать
a. Проблема в том, что при выводе на консоль a не будет равна 20000, а скорее всего чуть меньшему числу. Инкремент инта - это неатомарная операция над неатомиком, поэтому 2 потока за счет отсутствия синхронизации кэшей будут читать и записывать неактуальные данные.Гонку данных относительно несложно определить по коду, просто следую стандарту, да и тред-санитайзеры, пользуясь определением гонки, могут ее детектировать. Поэтому как будто бы эта не самая основная проблема в многопоточке. Существуют другие, более сложные в детектировании и воспроизведении.
Have an order. Stay cool.
#cppcore #concurrency
{kind=link}
❤32😁15👍10🔥3👎1
race condition
#новичкам
Теперь состояние гонки. Это более общее понятие, чем гонка данных. Это ситуация в программе, когда поведение системы зависит от относительного порядка выполнения операций в потоках.
Внимание: состояние гонки есть даже в правильно синхронизированных программах. В однопоточной программе можно четко предсказать порядок обработки элементов. А вот если много потоков будут разгребать одну кучу задач - вы не сможете сказать заранее, какой выхлоп в следующий раз произведет конкретный поток. Потому что это зависит от шедулинга потоков.
Но нам и не важно это предсказание, потому что имеет значение поведение всей программы целиком.
Проблемы возникают, когда такие спорадические эффекты приводят к некорректным результатам. И именно эти ситуации обычно называют состоянием гонки. Мне кажется важным проговорить, что потоки всегда в состоянии гонки за чем-то и в этом отражение недетерминированности многопоточной среды. Но далее буду употреблять "состояние гонки" в негативном контексте.
Проблемы из-за состояния гонки могут происходить даже в программах без гонки данных.
Например:
Может так произойти, что поток 1 выполнится в промежутке между условием и выводом
Состояние гонки - это в основном ошибка проектирования в условиях многопоточности. Знаменитая проблема наличия метода size() у многопоточной очереди - состояние гонки:
Если между успешной и потокобезопасной проверкой, что очередь непустая, придет другой поток и заберет последний элемент из очереди, вы получите ub в попытке увидеть фронтальный элемент.
Основные черты состояния гонки:
🙈 Наличие логической ошибки при проектировании системы
🙈 Зависимость от планирования потоков
🙈 Зависимость от времени выполнения операции. Вчера в чате скинули мем, иллюстрирующий эту зависимость.
Многие путают или не понимают разницы между race condition и data race. Это даже частый вопрос на собеседованиях, на который 50% кандидатов отвечают что-то вообще невнятное. Но теперь вы подготовлены и вооружены правильным словарным аппаратом.
Be independent of other's schedule. Stay cool.
#design #concurrency #interview
#новичкам
Теперь состояние гонки. Это более общее понятие, чем гонка данных. Это ситуация в программе, когда поведение системы зависит от относительного порядка выполнения операций в потоках.
Внимание: состояние гонки есть даже в правильно синхронизированных программах. В однопоточной программе можно четко предсказать порядок обработки элементов. А вот если много потоков будут разгребать одну кучу задач - вы не сможете сказать заранее, какой выхлоп в следующий раз произведет конкретный поток. Потому что это зависит от шедулинга потоков.
Но нам и не важно это предсказание, потому что имеет значение поведение всей программы целиком.
Проблемы возникают, когда такие спорадические эффекты приводят к некорректным результатам. И именно эти ситуации обычно называют состоянием гонки. Мне кажется важным проговорить, что потоки всегда в состоянии гонки за чем-то и в этом отражение недетерминированности многопоточной среды. Но далее буду употреблять "состояние гонки" в негативном контексте.
Проблемы из-за состояния гонки могут происходить даже в программах без гонки данных.
Например:
std::atomic<int> x = 2;
void thread_1() {
x = 3;
}
void thread_2() {
if (x % 2 == 0) {
std::cout << x << std::endl;
}
}
Может так произойти, что поток 1 выполнится в промежутке между условием и выводом
x на консоль. Это очень маловероятная ситуация, однако на консоль может вывестись нечетное число 3 с учетом того, что перед выводом мы проверили на четность. Как минимум удивительный результат, хотя с программе нет гонки данных.Состояние гонки - это в основном ошибка проектирования в условиях многопоточности. Знаменитая проблема наличия метода size() у многопоточной очереди - состояние гонки:
template <typename T>
class ThreadSafeQueue {
...
size_t size() {
std::lock_guard lg{mtx_};
return queue_.size();
}
private:
std::deque<T> queue_;
...
};
ThreadSafeQueue<int> queue;
...
if (queue.size() > 0) {
auto item = std::move(queue.front());
queue.pop();
// process item
}
Если между успешной и потокобезопасной проверкой, что очередь непустая, придет другой поток и заберет последний элемент из очереди, вы получите ub в попытке увидеть фронтальный элемент.
Основные черты состояния гонки:
🙈 Наличие логической ошибки при проектировании системы
🙈 Зависимость от планирования потоков
🙈 Зависимость от времени выполнения операции. Вчера в чате скинули мем, иллюстрирующий эту зависимость.
Многие путают или не понимают разницы между race condition и data race. Это даже частый вопрос на собеседованиях, на который 50% кандидатов отвечают что-то вообще невнятное. Но теперь вы подготовлены и вооружены правильным словарным аппаратом.
Be independent of other's schedule. Stay cool.
#design #concurrency #interview
{kind=link}
1❤21👍11🔥6👎2😁2🤔1
Deadlock
#новичкам
Еще одна частая проблема из мира многопоточки. На канале уже много материалов про нее есть:
Определение и демонстрация
Начало серии статей про блокировку нескольких мьютексов, что часто приводит к дедлоку
Сколько нужно мьютексов, чтобы задедлокать 2 потока?
Что будет, если 2 раза подряд залочить мьютекс?
Но это все для чуть более опытных ребят. Что если вы совсем не понимаете эти потоки и мьютексы на практике, но очень хотите понять, что такое дедлок?
Есть знаменитая проблема обедающих философов. Формулируется она так:
В рамках этой проблемы можно продемонстрировать много проблем многопоточки, но сегодня о deadlock.
Представьте 5 философов по кругу. И у них стратегия - брать всегда первой левую вилку, а затем правую.
Что получится, если все философы одновременно возьмут левую вилку?
Никто из них никогда не поест. Для еды нужны обе вилки, а у всех по одной, все ждут освобождения правой вилки и никто никому не будет уступать. В конце концов они все дружно и помрут.
Это классический deadlock и наглядная его демонстрация. Вот так просто.
Но это данная конкретная стратегия приводит к дедлоку, есть и более оптимальные, обсуждение которых за рамками поста.
Как будто бы про дедлоки больше и не о чем писать. Если хотите разобрать какой-то их аспект - черканите в комментах.
Be unblockable. Stay cool.
#concurrency
#новичкам
Еще одна частая проблема из мира многопоточки. На канале уже много материалов про нее есть:
Определение и демонстрация
Начало серии статей про блокировку нескольких мьютексов, что часто приводит к дедлоку
Сколько нужно мьютексов, чтобы задедлокать 2 потока?
Что будет, если 2 раза подряд залочить мьютекс?
Но это все для чуть более опытных ребят. Что если вы совсем не понимаете эти потоки и мьютексы на практике, но очень хотите понять, что такое дедлок?
Есть знаменитая проблема обедающих философов. Формулируется она так:
Пять безмолвных философов сидят вокруг круглого стола, перед каждым философом стоит тарелка спагетти. На столе между каждой парой ближайших философов лежит по одной вилке.
Каждый философ может либо есть, либо размышлять. Приём пищи не ограничен количеством оставшихся спагетти — подразумевается бесконечный запас. Тем не менее, философ может есть только тогда, когда держит две вилки — взятую справа и слева.
Каждый философ может взять ближайшую вилку (если она доступна) или положить — если он уже держит её. Взятие каждой вилки и возвращение её на стол являются раздельными действиями, которые должны выполняться одно за другим.
Вопрос задачи заключается в том, чтобы разработать модель поведения, при которой ни один из философов не будет голодать, то есть будет вечно чередовать приём пищи и размышления.
В рамках этой проблемы можно продемонстрировать много проблем многопоточки, но сегодня о deadlock.
Представьте 5 философов по кругу. И у них стратегия - брать всегда первой левую вилку, а затем правую.
Что получится, если все философы одновременно возьмут левую вилку?
Никто из них никогда не поест. Для еды нужны обе вилки, а у всех по одной, все ждут освобождения правой вилки и никто никому не будет уступать. В конце концов они все дружно и помрут.
Это классический deadlock и наглядная его демонстрация. Вот так просто.
Но это данная конкретная стратегия приводит к дедлоку, есть и более оптимальные, обсуждение которых за рамками поста.
Как будто бы про дедлоки больше и не о чем писать. Если хотите разобрать какой-то их аспект - черканите в комментах.
Be unblockable. Stay cool.
#concurrency
{kind=link}
❤16❤🔥5😁3👍2🔥1
Лайвлок
#новичкам
Лайвлок(livelock) — это ситуация в многопоточном программировании, когда потоки не блокируются полностью, как при дедлоке, а продолжают выполняться, но не могут продвинуться в решении задачи из-за постоянной реакции на действия друг друга.
Потоки находятся в состоянии "живой блокировки" — они активны, cpu жжется, но их работа не приводит ни к какому прогрессу.
Лайвлоки не всегда приводят к вечной блокировке потоков. Просто в какие-то рандомные моменты времени условный rps может неконтролируемо вырасти в разы, а то и на порядки.
И так как ситуация сильно зависит от планирования потоков, то воспроизвести ее будет сложно.
Однако у этой проблемы есть характерные черты, облегчающие ее поиск:
🔍 Активное ожидание — потоки постоянно проверяют какие-то условия и крутятся в циклах.
🔍 Взаимозависимость — действия одного потока влияют на условия выполнения другого.
🔍 Неблокирующие алгоритмы - активное ожидание обычно идет за ручку с lockfree алгоритмами.
🔍 Поддавки - при потенциальном конфликте интересов стороны предпочитают уступать.
Аналогия из реальной жизни: вы идете по узкому тротуару и вам навстречу идет человек. Вы хотите разминуться, но отшагиваете вместе в одну и ту же сторону. И вы, как крабики, ходите вместе из стороны в сторону. Рано или поздно вы разойдетесь, но заранее нельзя сказать когда.
К лайвлоку может привести и использование стандартных инструментов. Например, std::scoped_lock, который предназначен для безопасной блокировки нескольких мьютексов. Стандарт требует, чтобы его реализация не приводила к дедлоку. Они используют неопределенную последовательность вызовов методов lock(), try_lock() и unlock(), которая гарантирует отсутствие дедлока. Но не гарантирует отсутствия лайвлока. Алгоритм там примерно такой: попробуй заблокировать столько мьютексов, сколько можешь, а если не получилось, то освободи их и попробуй сначала. Тут есть и циклы, и активное ожидание, и взаимозависимость, и поддавки.
Но компиляторы понимают эту проблему и современные реализации используют разные приемы, типа экспоненциального backoff'а, чтобы все-таки рано или поздно дать шанс одному из потоков полностью захватить все ресурсы.
Вот более "надежный" пример:
По сути это костыльная и наивная демонстрация принципа работы std::lock с помощью атомарных замков. Каждый поток пытается в своем порядке захватить замки и отпускает захваченный, если не получилось, и идет на следующую попытку. Можете позапускать этот код у себя и посмотреть, как много попыток захвата потоки будут делать от запуска к запуску.
Unlock your life. Stay cool.
#concurrency
#новичкам
Лайвлок(livelock) — это ситуация в многопоточном программировании, когда потоки не блокируются полностью, как при дедлоке, а продолжают выполняться, но не могут продвинуться в решении задачи из-за постоянной реакции на действия друг друга.
Потоки находятся в состоянии "живой блокировки" — они активны, cpu жжется, но их работа не приводит ни к какому прогрессу.
Лайвлоки не всегда приводят к вечной блокировке потоков. Просто в какие-то рандомные моменты времени условный rps может неконтролируемо вырасти в разы, а то и на порядки.
И так как ситуация сильно зависит от планирования потоков, то воспроизвести ее будет сложно.
Однако у этой проблемы есть характерные черты, облегчающие ее поиск:
🔍 Активное ожидание — потоки постоянно проверяют какие-то условия и крутятся в циклах.
🔍 Взаимозависимость — действия одного потока влияют на условия выполнения другого.
🔍 Неблокирующие алгоритмы - активное ожидание обычно идет за ручку с lockfree алгоритмами.
🔍 Поддавки - при потенциальном конфликте интересов стороны предпочитают уступать.
Аналогия из реальной жизни: вы идете по узкому тротуару и вам навстречу идет человек. Вы хотите разминуться, но отшагиваете вместе в одну и ту же сторону. И вы, как крабики, ходите вместе из стороны в сторону. Рано или поздно вы разойдетесь, но заранее нельзя сказать когда.
К лайвлоку может привести и использование стандартных инструментов. Например, std::scoped_lock, который предназначен для безопасной блокировки нескольких мьютексов. Стандарт требует, чтобы его реализация не приводила к дедлоку. Они используют неопределенную последовательность вызовов методов lock(), try_lock() и unlock(), которая гарантирует отсутствие дедлока. Но не гарантирует отсутствия лайвлока. Алгоритм там примерно такой: попробуй заблокировать столько мьютексов, сколько можешь, а если не получилось, то освободи их и попробуй сначала. Тут есть и циклы, и активное ожидание, и взаимозависимость, и поддавки.
Но компиляторы понимают эту проблему и современные реализации используют разные приемы, типа экспоненциального backoff'а, чтобы все-таки рано или поздно дать шанс одному из потоков полностью захватить все ресурсы.
Вот более "надежный" пример:
std::atomic<bool> lock1 = false;
std::atomic<bool> lock2 = false;
void thread1_work() {
while (true) {
// lock lock1
while (lock1.exchange(true))
;
std::cout << "Thread 1 has acquired lock1, try to acquire lock2..."
<< std::endl;
// try to lock lock2
if (!lock2.exchange(true)) {
std::cout << "Thread 1 has acquired both locks!" << std::endl;
lock2 = false;
lock1 = false;
break;
} else {
// Failed, release lock1 and try again
std::cout << "Thread 1 failed to acquire lock2, release lock1..."
<< std::endl;
lock1 = false;
}
}
}
void thread2_work() {
while (true) {
// lock lock2
while (lock2.exchange(true))
;
std::cout << "Thread 2 has acquired lock2, try to acquire lock1..."
<< std::endl;
// try to lock lock1
if (!lock1.exchange(true)) {
std::cout << "Thread 2 has acquired both locks!" << std::endl;
lock1 = false;
lock2 = false;
break;
} else {
// Failed, release lock2 and try again
std::cout << "Thread 2 failed to acquire lock1, release lock2..."
<< std::endl;
lock2 = false;
}
}
}
int main() {
std::jthread t1(thread1_work);
std::jthread t2(thread2_work);
}
По сути это костыльная и наивная демонстрация принципа работы std::lock с помощью атомарных замков. Каждый поток пытается в своем порядке захватить замки и отпускает захваченный, если не получилось, и идет на следующую попытку. Можете позапускать этот код у себя и посмотреть, как много попыток захвата потоки будут делать от запуска к запуску.
Unlock your life. Stay cool.
#concurrency
👍13🔥8❤6😱2
Contention
#опытным
Thread Contention (соревнование потоков) — это ситуация в многопоточном программировании, когда несколько потоков одновременно пытаются получить доступ к одному и тому же разделяемому ресурсу, но только один поток может использовать его в данный момент времени.
Это нормальная ситуация, на любом мьютексе потоки соревнуются. Но иногда это выходит за грани нормальности.
Многопоточное программирование же у нас должно повышать эффективность вычислений за счет разделения потоков обработки данных на независимые части и помещать их на свои потоки исполнения. Однако рано или поздно наступает приход в точку синхронизации: потоки конкурируют между собой за доступ к разделяемым данным.
И вот тут может появиться проблема. Один ресурс, а желающих завладеть им слишком много. Только один в итоге овладевает, а все остальные отправляются спать. И это конечно приводит к простою потоков и замедление общего прогресса.
Если к такой мапе одновременно будет получать доступ куча потоков, то все кроме одного будут простаивать. А если таких потоков 10 или 20? Неприятненько.
Как можно снизить Contention?
👉🏿 Read-Write Lock. Если у вас много читателе и мало писателей, то можно разрешить нескольким читателям одновременно получать доступ к данным с помощью std::shared_mutex:
👉🏿 Thread-Local Storage. Потоки пишут данные в свои локальные буферы, которые централизованно синхронизируют данные друг с другом, чтобы как можно меньше блокировать потоки.
👉🏿 Можно организовать свою структуру данных так, чтобы у нее была ячеистая структура и к каждой ячейке был отдельный замок. Теперь потребители данных распределятся по разным ячейкам и не будут толкаться.
👉🏿 Используйте lock-free структуры данных. Ну как бы тут логично: нет мьютексов, нет и сontention. Не в каждой задаче это реально применить, но иногда все же можно.
Compete and win. Stay cool.
#concurrency
#опытным
Thread Contention (соревнование потоков) — это ситуация в многопоточном программировании, когда несколько потоков одновременно пытаются получить доступ к одному и тому же разделяемому ресурсу, но только один поток может использовать его в данный момент времени.
Это нормальная ситуация, на любом мьютексе потоки соревнуются. Но иногда это выходит за грани нормальности.
Многопоточное программирование же у нас должно повышать эффективность вычислений за счет разделения потоков обработки данных на независимые части и помещать их на свои потоки исполнения. Однако рано или поздно наступает приход в точку синхронизации: потоки конкурируют между собой за доступ к разделяемым данным.
И вот тут может появиться проблема. Один ресурс, а желающих завладеть им слишком много. Только один в итоге овладевает, а все остальные отправляются спать. И это конечно приводит к простою потоков и замедление общего прогресса.
template <Key, Value>
class ThreadSafeMap {
mutable std::mutex mtx;
std::map<Key, Value> map;
public:
void Insert(const Key &key, const Value &value) {
std::lock_guard lg{mtx};
map.insert(key, value);
}
Value &Get(const Key &key) const {
std::lock_guard lg{mtx};
return map.at(key);
}
};
Если к такой мапе одновременно будет получать доступ куча потоков, то все кроме одного будут простаивать. А если таких потоков 10 или 20? Неприятненько.
Как можно снизить Contention?
👉🏿 Read-Write Lock. Если у вас много читателе и мало писателей, то можно разрешить нескольким читателям одновременно получать доступ к данным с помощью std::shared_mutex:
template <Key, Value>
class ThreadSafeMap {
mutable std::shared_mutex mtx;
std::map<Key, Value> map;
public:
void Insert(const Key &key, const Value &value) {
std::unique_lock ul{mtx};
map.insert(key, value);
}
Value &Get(const Key &key) const {
std::shared_lock sl{mtx};
return map.at(key);
}
};
👉🏿 Thread-Local Storage. Потоки пишут данные в свои локальные буферы, которые централизованно синхронизируют данные друг с другом, чтобы как можно меньше блокировать потоки.
👉🏿 Можно организовать свою структуру данных так, чтобы у нее была ячеистая структура и к каждой ячейке был отдельный замок. Теперь потребители данных распределятся по разным ячейкам и не будут толкаться.
template <Key, Value>
class FineGrainedMap {
struct Node {
std::mutex mtx;
std::map<Key, Value> data;
};
std::vector<Node> buckets{16}; // Много мелких блокировок
public:
Value& Get(const Key& key) const {
auto& bucket = buckets[std::hash<Key>{}(key) % buckets.size()];
std::lock_guard lock(bucket.mtx);
return bucket.data.at(key);
}
};
👉🏿 Используйте lock-free структуры данных. Ну как бы тут логично: нет мьютексов, нет и сontention. Не в каждой задаче это реально применить, но иногда все же можно.
Compete and win. Stay cool.
#concurrency
👍21❤11🔥6⚡2
Гайзенбаг
#новичкам
Человечеству свойственно все категоризировать и обзывать особенными именами. И конкретные виды багов не исключение.
Интересно, что многие из этих названий не соответствуют реальному явлению. Например, закон Стиглера, который не был открыт Стиглером и тд.
И Гайзенбаг примерно из той же серии.
Создатель впервые употребил этот термин в значении «ты смотришь на него — и он исчезает». Видимо он находил параллели с принципом неопределенности Гейзенберга, который говорит о том, что мы не можем одинаково хорошо измерить две любые характеристики частицы(например скорость и положение). Простыми словами: «чем более пристально вы глядите на один предмет, тем меньше внимания вы уделяете чему-то ещё».
Корректность параллелей вызывает большие сомнения.
Но это все лирика.
Что такой гейзенбаг?
На проде или в CI обнаружили багу. А она, собака, исчезает, как только мы пытаемся ее задетектировать, чтобы исправить.
Гайзенбаги возникают потому, что обычные попытки отладки программы, такие как добавление операторов вывода или запуск под отладчиком, обычно имеют побочный эффект — они изменяют поведение программы незаметными способами.
Например.
Один из распространенных примеров гейзенбага — ошибка, которая проявляется при компиляции программы с оптимизацией, но не проявляется при компиляции той же программы без оптимизации (что часто делается для исследования под отладчиком). При отладке значения, которые оптимизированная программа обычно хранит в регистрах, часто выталкиваются в основную память, что может изменить поведение программы. Да и даже просто компилятор может выкинуть кусок кода под оптимизациями, а под дебажной сборкой - оставить его.
Последнее может произойти не только с дебажной сборкой. Например, бесконечный цикл без сайдэффектов - это UB в С++, поэтому компилятор может его выкинуть. А если вы туда вставите принт, то сайдэффект появится и код попадет в бинарь.
Попытка отследить состояние программы может повлиять на тайминги исполнения, что может привести к видимому сокрытию состояния гонки и соответственно пропаже баги. И конкурентный код часто просто пронизан такими багами. В более привычном словаре их называют плавающими ошибками или спорадиками. В общем случае, это результат race condition, а конкретную причину можно находить долго и больно.
Люди часто винят в появление Гейзенбагов фазы Луны и космические лучи. Это конечно шутки, но подобное нельзя исключать.
Все же лучше качественно тестировать свое ПО, тогда тараканов в коде станет намного меньше.
Don't disappear. Stay cool
#fun
#новичкам
Человечеству свойственно все категоризировать и обзывать особенными именами. И конкретные виды багов не исключение.
Интересно, что многие из этих названий не соответствуют реальному явлению. Например, закон Стиглера, который не был открыт Стиглером и тд.
И Гайзенбаг примерно из той же серии.
Создатель впервые употребил этот термин в значении «ты смотришь на него — и он исчезает». Видимо он находил параллели с принципом неопределенности Гейзенберга, который говорит о том, что мы не можем одинаково хорошо измерить две любые характеристики частицы(например скорость и положение). Простыми словами: «чем более пристально вы глядите на один предмет, тем меньше внимания вы уделяете чему-то ещё».
Корректность параллелей вызывает большие сомнения.
Но это все лирика.
Что такой гейзенбаг?
На проде или в CI обнаружили багу. А она, собака, исчезает, как только мы пытаемся ее задетектировать, чтобы исправить.
Гайзенбаги возникают потому, что обычные попытки отладки программы, такие как добавление операторов вывода или запуск под отладчиком, обычно имеют побочный эффект — они изменяют поведение программы незаметными способами.
Например.
Один из распространенных примеров гейзенбага — ошибка, которая проявляется при компиляции программы с оптимизацией, но не проявляется при компиляции той же программы без оптимизации (что часто делается для исследования под отладчиком). При отладке значения, которые оптимизированная программа обычно хранит в регистрах, часто выталкиваются в основную память, что может изменить поведение программы. Да и даже просто компилятор может выкинуть кусок кода под оптимизациями, а под дебажной сборкой - оставить его.
Последнее может произойти не только с дебажной сборкой. Например, бесконечный цикл без сайдэффектов - это UB в С++, поэтому компилятор может его выкинуть. А если вы туда вставите принт, то сайдэффект появится и код попадет в бинарь.
Попытка отследить состояние программы может повлиять на тайминги исполнения, что может привести к видимому сокрытию состояния гонки и соответственно пропаже баги. И конкурентный код часто просто пронизан такими багами. В более привычном словаре их называют плавающими ошибками или спорадиками. В общем случае, это результат race condition, а конкретную причину можно находить долго и больно.
Люди часто винят в появление Гейзенбагов фазы Луны и космические лучи. Это конечно шутки, но подобное нельзя исключать.
Все же лучше качественно тестировать свое ПО, тогда тараканов в коде станет намного меньше.
Don't disappear. Stay cool
#fun
{kind=link}
❤17👍10🔥5😁5
Еще несколько именных багов
Мистер Хайзенберг не единственный, кто удостоялся чести дать свое имя багу. Сегодня расслабимся и покекаем, как нёрды ошибки называли.
🤓Борбаг(Bohrbug) — ошибка, которая, в противоположность гейзенбагу, не исчезает и не меняет своих свойств при попытке её обнаружения, аналогично стабильности модели электронных орбиталей Нильса Бора. Всегда воспроизводится при определенных условиях. Образцово-показательный баг. Не требует сил на воспроизведение.
🫠Мандельбаг(Mandelbug) — баг, названный в честь "отца" фрактальной математики Мендельброта. Типа эти баги очень сложные, непредсказуемые, вызваны нюансами взамодействия множества компонент программ и часто зависят от начальных условий. И этими характеристиками они похожи на фракталы. Есть конечно вопросики к неймингу, ну да ладно.
Такие баги имеют интересное свойство: их можно копать очень долго и в какой-то момент понимаешь, что проще переписать всю систему.
🤡Шрединбаг(Schrödinbug) — баг, существующий в суперпозиции. Код стабильно работает ровно до момента, когда вы читаете его и понимаете, что он не должен работать. После этого код начинает падать именно в этом месте. Сам факт осознания убивает функциональность. Наблюдатель заставляет волновую функцию коллапсировать в баг.
🤯Гинденбаг (Hindenbug) — катастрофический отказ. Не просто ломает функциональность, а делает это с огнем и спецэффектами. Назван в честь печально известного дирижабля "Гиндербург".
В современном мире докеров и кубернетисов Гинденбаги практически невозможны, потому что все приложения изолированы от исполняющей машины.
🧐Багсон Хиггса(Higgs-bugson) — теоретически предсказанный баг. Его существование доказано логами и пользовательскими reports, но воспроизвести в контролируемых условиях невозможно. Все знают, что он есть, но никто его не видел.
К этим багам можно отнести например UB, которое только в теории UB, а в реальности на конкретной архитектуре все нормально работает.
Give a proper name. Stay cool.
#fun
Мистер Хайзенберг не единственный, кто удостоялся чести дать свое имя багу. Сегодня расслабимся и покекаем, как нёрды ошибки называли.
🤓Борбаг(Bohrbug) — ошибка, которая, в противоположность гейзенбагу, не исчезает и не меняет своих свойств при попытке её обнаружения, аналогично стабильности модели электронных орбиталей Нильса Бора. Всегда воспроизводится при определенных условиях. Образцово-показательный баг. Не требует сил на воспроизведение.
🫠Мандельбаг(Mandelbug) — баг, названный в честь "отца" фрактальной математики Мендельброта. Типа эти баги очень сложные, непредсказуемые, вызваны нюансами взамодействия множества компонент программ и часто зависят от начальных условий. И этими характеристиками они похожи на фракталы. Есть конечно вопросики к неймингу, ну да ладно.
Такие баги имеют интересное свойство: их можно копать очень долго и в какой-то момент понимаешь, что проще переписать всю систему.
🤡Шрединбаг(Schrödinbug) — баг, существующий в суперпозиции. Код стабильно работает ровно до момента, когда вы читаете его и понимаете, что он не должен работать. После этого код начинает падать именно в этом месте. Сам факт осознания убивает функциональность. Наблюдатель заставляет волновую функцию коллапсировать в баг.
🤯Гинденбаг (Hindenbug) — катастрофический отказ. Не просто ломает функциональность, а делает это с огнем и спецэффектами. Назван в честь печально известного дирижабля "Гиндербург".
В современном мире докеров и кубернетисов Гинденбаги практически невозможны, потому что все приложения изолированы от исполняющей машины.
🧐Багсон Хиггса(Higgs-bugson) — теоретически предсказанный баг. Его существование доказано логами и пользовательскими reports, но воспроизвести в контролируемых условиях невозможно. Все знают, что он есть, но никто его не видел.
К этим багам можно отнести например UB, которое только в теории UB, а в реальности на конкретной архитектуре все нормально работает.
Give a proper name. Stay cool.
#fun
{kind=link}
❤21👍10😁9🔥8
Starvation
#опытным
Представьте, вы стоите в очереди в поликлинике. Казалось бы вы вот-вот должны зайти в кабинет, но тут перед вами влезают "мне только спросить". После - опять ваша очередь, но приходит следующий абонент с фразой "мне только больничный лист подписать". Вы уже выходите из себя, готовитесь идти напролом в кабинет, но вас прерывает зав отделением, у которого "очень важное дело". Думаю, что жиза для многих.
Итого, вы ждете своей очереди, но всегда появляется кто-то важнее вас, который влезает перед вами. А вы продолжаете ждать. Потенциально до окончания приема и полного обугливания жопы.
Эта сцена наглядно демонстрирует еще одну проблему многопоточного мира - starvation или голодание.
Голодовка в многопоточной передаче происходит, когда один или несколько потоков постоянно блокируются при доступе к ресурсам, в результате чего у них редко бывает возможность выполниться(потенциально никогда). В то время как дедлок замораживает все вовлеченные треды, голодание затрагивает только те невезучие потоки, которые остаются «ожидать в очереди», в то время как другие занимают все ресурсы.
Какие предпосылки появления голодания?
👉🏿 Приоритеты потоков. Хоть в стандарте С++ нельзя выставить приоритет потоков, это можно сделать, например, в pthreads. Потоки с большим приоритетом могут забирать всю работу у низкоприоритетных.
👉🏿 Короткий доступ к мьютексу. Есть два вида замков: справедливые и несправедливые. Поток, только что освободивший unfair мьютекс, имеет преимущество по его захвату, потому что мьютекс все еще может быть в кэше этого потока и у него еще не закончилось время на работу. И это может приводить к простую других потоков. Справедливая реализация учитывает порядок запроса блокировки мьютекса, например с помощью очереди.
👉🏿 Все хотят доступ к одному ресурсу. Когда много потоков пытаются получить доступ к ресурсу, охраняемому всего одним мьютексом, то полезную работу делает только один из них, а все остальные ждут.
👉🏿 Длинные задачи под мьютексом. В дополнение к предыдущему пункту. Мало того, что потоки просто долго ждут очереди, чтобы занять замок, так еще и каждый из них вечность делает свою задачу.
Простой пример:
Здесь на первый взгляд все четко, всего два конкурентных потока пытаются залезть в критическую секцию. Вот только незадача: тут конкурентности почти нет. Я конечно не могу говорить за все реализации, но мой личный опыт и годболт подсказывают мне, что практически в каждом прогоне в начале полностью выполнится первый поток, а потом полностью второй.
Но! Если вы добавите слип после релиза мьютекса, то картина становится более справедливой.
Как избавиться от голодания?
✅ Справедливый шедулинг и замки. В стандартных плюсах на это мы не можем повлиять, но в системном апи или самописных реализациях можем.
✅ Минимальный размер критической секции. Она должна менеждить хранение задачи, но не быть ответственной за выполненеие задачи. Это позволит ограничивать простой других потоков.
✅ Грамотно проектируйте разделяемые данные. Если у вас 100 потоков пинают одну несчастную потокобезопасную мапу, то есть высока вероятность пересмотреть архитектуру и межпоточное взаимодействие.
✅ Давайте возможность другим войти в критическую секцию. Учитывая второй пункт, поток, который постоянно стучится в критическую секцию, скорее всего выполняет в ней лишний код. Разгрузите секцию, займите поток чем-нибудь в перерывах между критическими секциями и будет вам счастье.
Remember that you have the highest priority. Stay cool.
#concurrency
#опытным
Представьте, вы стоите в очереди в поликлинике. Казалось бы вы вот-вот должны зайти в кабинет, но тут перед вами влезают "мне только спросить". После - опять ваша очередь, но приходит следующий абонент с фразой "мне только больничный лист подписать". Вы уже выходите из себя, готовитесь идти напролом в кабинет, но вас прерывает зав отделением, у которого "очень важное дело". Думаю, что жиза для многих.
Итого, вы ждете своей очереди, но всегда появляется кто-то важнее вас, который влезает перед вами. А вы продолжаете ждать. Потенциально до окончания приема и полного обугливания жопы.
Эта сцена наглядно демонстрирует еще одну проблему многопоточного мира - starvation или голодание.
Голодовка в многопоточной передаче происходит, когда один или несколько потоков постоянно блокируются при доступе к ресурсам, в результате чего у них редко бывает возможность выполниться(потенциально никогда). В то время как дедлок замораживает все вовлеченные треды, голодание затрагивает только те невезучие потоки, которые остаются «ожидать в очереди», в то время как другие занимают все ресурсы.
Какие предпосылки появления голодания?
👉🏿 Приоритеты потоков. Хоть в стандарте С++ нельзя выставить приоритет потоков, это можно сделать, например, в pthreads. Потоки с большим приоритетом могут забирать всю работу у низкоприоритетных.
👉🏿 Короткий доступ к мьютексу. Есть два вида замков: справедливые и несправедливые. Поток, только что освободивший unfair мьютекс, имеет преимущество по его захвату, потому что мьютекс все еще может быть в кэше этого потока и у него еще не закончилось время на работу. И это может приводить к простую других потоков. Справедливая реализация учитывает порядок запроса блокировки мьютекса, например с помощью очереди.
👉🏿 Все хотят доступ к одному ресурсу. Когда много потоков пытаются получить доступ к ресурсу, охраняемому всего одним мьютексом, то полезную работу делает только один из них, а все остальные ждут.
👉🏿 Длинные задачи под мьютексом. В дополнение к предыдущему пункту. Мало того, что потоки просто долго ждут очереди, чтобы занять замок, так еще и каждый из них вечность делает свою задачу.
Простой пример:
std::mutex mtx;
int counter = 0;
void worker(int id) {
for (int i = 0; i < 100; ++i) {
std::lock_guard lg{mtx};
++counter;
std::cout << "Thread " << id
<< " entered critical section, counter = " << counter
<< std::endl;
// do work
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main() {
std::jthread t1(worker, 1);
std::jthread t2(worker, 2);
}
Здесь на первый взгляд все четко, всего два конкурентных потока пытаются залезть в критическую секцию. Вот только незадача: тут конкурентности почти нет. Я конечно не могу говорить за все реализации, но мой личный опыт и годболт подсказывают мне, что практически в каждом прогоне в начале полностью выполнится первый поток, а потом полностью второй.
Но! Если вы добавите слип после релиза мьютекса, то картина становится более справедливой.
Как избавиться от голодания?
✅ Справедливый шедулинг и замки. В стандартных плюсах на это мы не можем повлиять, но в системном апи или самописных реализациях можем.
✅ Минимальный размер критической секции. Она должна менеждить хранение задачи, но не быть ответственной за выполненеие задачи. Это позволит ограничивать простой других потоков.
✅ Грамотно проектируйте разделяемые данные. Если у вас 100 потоков пинают одну несчастную потокобезопасную мапу, то есть высока вероятность пересмотреть архитектуру и межпоточное взаимодействие.
✅ Давайте возможность другим войти в критическую секцию. Учитывая второй пункт, поток, который постоянно стучится в критическую секцию, скорее всего выполняет в ней лишний код. Разгрузите секцию, займите поток чем-нибудь в перерывах между критическими секциями и будет вам счастье.
Remember that you have the highest priority. Stay cool.
#concurrency
{kind=link}
❤13🔥9👍7😁1😱1
Голодание. Приоритетные очереди
#опытным
Голодание бывает не только у потоков, но и у других сущностей с приоритетами.
Допустим у вас есть система задач с 3-мя приоритетами: High, Medium, Low. Продюсеры кладут каждую задачу в очередь, соответствующую ее приоритету. А консюмеры всегда должны потреблять задачи с самым высоким возможным приоритетом.
То есть, пока High очередь не опустеет, никто не будет брать Middle задачи. И никто не возьмет в обработку Low задачи, пока High и Middle очереди не пусты.
Может возникнуть такая ситуация, при которой задачи High будут постоянно приходить так, что обработчики редко будут брать задачи Middle и никогда не дойдут до Low очереди. Таким образом, эти очереди будут голодать от недостатка обработки.
Допустим, что эта проблема возникает не всегда, а только периодически. Если она постоянная, то проблема здесь в количестве обработчиков и/или их вычислительной мощности, либо вообще ваши задачи нужно обрабатывать как-то по-другому.
Кстати сам алгоритм называется Fixed-priority pre-emptive scheduling. В каждый момент времени выполняется задача с самым высоким приоритетом.
Решение проблемы - сменить алгоритм взятия задач из очередей.
Например, можно установить правило, что вы обрабатываете не более f(priority) элементов в любой данной очереди, прежде чем рассматривать элементы из очереди с более низким приоритетом.
Функция f может быть:
👉🏿 Линейной: f(p) = p. Обрабатывается не более 4 элементов с приоритетом 4 (высший), затем не более 3 с приоритетом 3,..., 1 с приоритетом 1.
👉🏿 Экспоненциальной: f(p) = 2^(p-1). Обрабатывается не более 8 элементов с приоритетом 4 (высший), затем не более 4 с приоритетом 3, затем не более 2 с приоритетом 2,..., 1 с приоритетом 1.
Конкретная функция выбирается из ожидаемой частоты появления задач
Возьмем экспоненциальный случай и предположим, что в каждой очереди много ожидающих задач. Мы планируем: 8 высших, 4 высоких, 2 средних, 1 низкий, 8 высших и т.д... Каждый цикл содержит 8 + 4 + 2 + 1 = 15 задач, поэтому задачи высшего приоритета занимают 8/15 времени потребителя, следующие — 4/15, следующие — 2/15, следующие — 1/15.
Сравниваем эти частоты с ожидаемыми и корректируем коэффициенты или используем другую функцию.
You are the highest priority. Stay cool.
#concurrency
#опытным
Голодание бывает не только у потоков, но и у других сущностей с приоритетами.
Допустим у вас есть система задач с 3-мя приоритетами: High, Medium, Low. Продюсеры кладут каждую задачу в очередь, соответствующую ее приоритету. А консюмеры всегда должны потреблять задачи с самым высоким возможным приоритетом.
То есть, пока High очередь не опустеет, никто не будет брать Middle задачи. И никто не возьмет в обработку Low задачи, пока High и Middle очереди не пусты.
Может возникнуть такая ситуация, при которой задачи High будут постоянно приходить так, что обработчики редко будут брать задачи Middle и никогда не дойдут до Low очереди. Таким образом, эти очереди будут голодать от недостатка обработки.
class Scheduler {
private:
std::vector<ThreadSafeQueue<std::string>> queues;
std::vector<std::string> priority_names;
public:
Scheduler() : queues(3), priority_names{"HIGH", "MEDIUM", "LOW"} {}
std::string Get() {
while(true) {
for(int i = 0; i < queues.size(); ++i) {
auto task = queues[i].take();
if (!task)
continue;
std::cout << "Get task " << priority_names[i] << ": " << task << std::endl;
return task;
}
// some kind of waiting mechanism in case of every queue is full
}
}
void AddTask(int priority, const std::string& task) {
queues[priority].push(task);
std::cout << "Add task " << priority_names[priority] << ": " << task << std::endl;
}
};Допустим, что эта проблема возникает не всегда, а только периодически. Если она постоянная, то проблема здесь в количестве обработчиков и/или их вычислительной мощности, либо вообще ваши задачи нужно обрабатывать как-то по-другому.
Кстати сам алгоритм называется Fixed-priority pre-emptive scheduling. В каждый момент времени выполняется задача с самым высоким приоритетом.
Решение проблемы - сменить алгоритм взятия задач из очередей.
Например, можно установить правило, что вы обрабатываете не более f(priority) элементов в любой данной очереди, прежде чем рассматривать элементы из очереди с более низким приоритетом.
Функция f может быть:
👉🏿 Линейной: f(p) = p. Обрабатывается не более 4 элементов с приоритетом 4 (высший), затем не более 3 с приоритетом 3,..., 1 с приоритетом 1.
👉🏿 Экспоненциальной: f(p) = 2^(p-1). Обрабатывается не более 8 элементов с приоритетом 4 (высший), затем не более 4 с приоритетом 3, затем не более 2 с приоритетом 2,..., 1 с приоритетом 1.
Конкретная функция выбирается из ожидаемой частоты появления задач
Возьмем экспоненциальный случай и предположим, что в каждой очереди много ожидающих задач. Мы планируем: 8 высших, 4 высоких, 2 средних, 1 низкий, 8 высших и т.д... Каждый цикл содержит 8 + 4 + 2 + 1 = 15 задач, поэтому задачи высшего приоритета занимают 8/15 времени потребителя, следующие — 4/15, следующие — 2/15, следующие — 1/15.
Сравниваем эти частоты с ожидаемыми и корректируем коэффициенты или используем другую функцию.
You are the highest priority. Stay cool.
#concurrency
❤18👍12🔥8
Тулзы для поиска проблем многопоточности
#опытным
Мы уже с вами убедились, что в мире многопоточности куча проблем. И шанс на них наткнуться, мягко говоря, немаленький. А на самом деле почти любой мало-мальски полезный конкурентный код, написаный с нуля, будет содержать как минимум одну такую проблему.
А уж если она есть, то просто так вы от нее не отвяжитесь. Это же многопоточность, тут нет места детерминизму. На одной машине все работает, а на другой - зависает. Поэтому очень важно применять полный спектр инструментов для валидации многопоточного кода, как нам и говорят кор гайдлайны. Перечислим некоторые известные инструменты, которые могут помочь.
✅ Юнит тесты. Код без тестов - деньги на ветер. Это я перефразировал известную поговорку, но она и в данном контексте хорошо отражает суть. Если вы не тестируете код, то проблема может проявиться в самый неподходящий момент и это может стоить вам кучу зеленых фантиков.
Даже в рамках отсутствия детерминизма можно написать хорошие тесты. Используйте слипы, а лучше фьючи-промисы для того, чтобы притормозить или остановить одни потоки и зафиксировать стейт, чтобы изолированно проверять работу отдельных потоков. Придумывайте разные сценарии поведения программы и тестируйте их. Обратите особое внимание на граничные случаи - например остановку работы системы.
✅ Cppcheck. Пользуйтесь инструментами статического анализа, например Cppcheck. Определять проблемы синхронизации по коду программы - занятие конечно увлекательное и вряд ли вы много багов так найдете, но собственно почему бы и нет.
Надо лишь установить сам cppcheck, а запускается он просто:
✅ Thread San. Без динамического анализа в многопоточке никуда. ThreadSanitizer - это детектор гонок данных для C/C++. Санитайзер определяет гонку ровно как в стандарте: если у вас много потоков получают доступ к ячейке памяти и хотя бы один из них - несинхронизированная запись. И это же и является принципом детектирования гонок.
Работает на GCC и Clang. Достаточно лишь при сборке указать нужные флаги и ждать прилета сообщений о багах:
✅ Helgrind. Это одна из тулзов Valgrind'а, работающая конкретно с багами многопоточности. Достаточно при запуске валгринда указать
Helgrind детектирует такие проблемы, как:
- разблокировка невалидного мьютекса
- разблокировка не заблокированного мьютекса
- разблокировка мьютекса, удерживаемого другим потоком
- уничтожение невалидного или заблокированного мьютекса
- рекурсивная блокировка нерекурсивного мьютекса
- освобождение памяти, содержащей заблокированный мьютекс
и еще кучу всего.
✅ Vtune. Не все проблемы конкурентности связаны с некорректным использованием инструментов. С точки зрения стандартов, программа может корректно работать, но в ней будут лайв локи или голодовки. Тогда нужен хороший профилировщик, способный отследить, например, влияние lock contention на общую производительность, неэффективную синхронизацию или неравномерную нагрузку между потоками.
VTune в принципе очень мощный профилировщик даже не касательно многопоточности. Если есть возможность заморочится с ним, то это стоит сделать.
Test your system. Stay cool.
#concurrency #tools
#опытным
Мы уже с вами убедились, что в мире многопоточности куча проблем. И шанс на них наткнуться, мягко говоря, немаленький. А на самом деле почти любой мало-мальски полезный конкурентный код, написаный с нуля, будет содержать как минимум одну такую проблему.
А уж если она есть, то просто так вы от нее не отвяжитесь. Это же многопоточность, тут нет места детерминизму. На одной машине все работает, а на другой - зависает. Поэтому очень важно применять полный спектр инструментов для валидации многопоточного кода, как нам и говорят кор гайдлайны. Перечислим некоторые известные инструменты, которые могут помочь.
✅ Юнит тесты. Код без тестов - деньги на ветер. Это я перефразировал известную поговорку, но она и в данном контексте хорошо отражает суть. Если вы не тестируете код, то проблема может проявиться в самый неподходящий момент и это может стоить вам кучу зеленых фантиков.
Даже в рамках отсутствия детерминизма можно написать хорошие тесты. Используйте слипы, а лучше фьючи-промисы для того, чтобы притормозить или остановить одни потоки и зафиксировать стейт, чтобы изолированно проверять работу отдельных потоков. Придумывайте разные сценарии поведения программы и тестируйте их. Обратите особое внимание на граничные случаи - например остановку работы системы.
✅ Cppcheck. Пользуйтесь инструментами статического анализа, например Cppcheck. Определять проблемы синхронизации по коду программы - занятие конечно увлекательное и вряд ли вы много багов так найдете, но собственно почему бы и нет.
Надо лишь установить сам cppcheck, а запускается он просто:
cppcheck --enable=all --inconclusive thread_app.cpp
✅ Thread San. Без динамического анализа в многопоточке никуда. ThreadSanitizer - это детектор гонок данных для C/C++. Санитайзер определяет гонку ровно как в стандарте: если у вас много потоков получают доступ к ячейке памяти и хотя бы один из них - несинхронизированная запись. И это же и является принципом детектирования гонок.
Работает на GCC и Clang. Достаточно лишь при сборке указать нужные флаги и ждать прилета сообщений о багах:
clang++ -fsanitize=thread -g -O2 -o my_app main.cpp
g++ -fsanitize=thread -g -O2 -o my_app main.cpp
✅ Helgrind. Это одна из тулзов Valgrind'а, работающая конкретно с багами многопоточности. Достаточно при запуске валгринда указать
--tool=helgrind и ждите писем счастья. Главное, чтобы ваши примитивы синхронизации использовали под капотом pthread. Helgrind детектирует такие проблемы, как:
- разблокировка невалидного мьютекса
- разблокировка не заблокированного мьютекса
- разблокировка мьютекса, удерживаемого другим потоком
- уничтожение невалидного или заблокированного мьютекса
- рекурсивная блокировка нерекурсивного мьютекса
- освобождение памяти, содержащей заблокированный мьютекс
и еще кучу всего.
✅ Vtune. Не все проблемы конкурентности связаны с некорректным использованием инструментов. С точки зрения стандартов, программа может корректно работать, но в ней будут лайв локи или голодовки. Тогда нужен хороший профилировщик, способный отследить, например, влияние lock contention на общую производительность, неэффективную синхронизацию или неравномерную нагрузку между потоками.
vtune -collect threading -result-dir my_analysis ./my_application
VTune в принципе очень мощный профилировщик даже не касательно многопоточности. Если есть возможность заморочится с ним, то это стоит сделать.
Test your system. Stay cool.
#concurrency #tools
{kind=link}
1❤21👍11🔥5😁1
Читаем мысли
Задача любого большого продукта — завлечь пользователя к себе, удержать полезными фичами и побольше на нем заработать. И вот последние 2 пункта можно интересно раскачать с помощью бэкенда.
Если замечали, то ютуб при первом открытии довольно быстро отдает первую страницу ленты видосов. А ручные обновления ленты работают ощутимо дольше. «Пользователи хотят зайти на ютуб и сразу начать смотреть!» — подумали исследователи пользовательского опыта и дали задачу программистам заранее подзагружать в кэш ленту. А из кэша данные достаются намного быстрее, чем прогон полного пайплайна формирования обновлений ленты.
Или на вб, пока юзер изучает какой-то товар, коварные капиталисты уже сформировали список рекомендованных товаров, которые попадут точно ему в сердечко, и он заплатит за них много деняк💰. А когда пользователь пролистал описание, ему уже показываются готовые карточки.
Общий подход такой — предугадываем поведение пользователя и что-то предвычисляем заранее на основе этой гипотезы.
Идея этого поста родилась из текста Вани Ходора, бэкенд-разработчика Лавки. В своем посте он подробно объяснил паттерн speculative execution, привел кучу примеров, а также рассказал о рисках, сопряженных с его обузингом.
Предлагаю порефлексировать в комментах, где эта тонкая грань между тем, чтобы не дать пользователю на секунду заскучать, и нагрузки на систему от кучи предвычислений.
Задача любого большого продукта — завлечь пользователя к себе, удержать полезными фичами и побольше на нем заработать. И вот последние 2 пункта можно интересно раскачать с помощью бэкенда.
Если замечали, то ютуб при первом открытии довольно быстро отдает первую страницу ленты видосов. А ручные обновления ленты работают ощутимо дольше. «Пользователи хотят зайти на ютуб и сразу начать смотреть!» — подумали исследователи пользовательского опыта и дали задачу программистам заранее подзагружать в кэш ленту. А из кэша данные достаются намного быстрее, чем прогон полного пайплайна формирования обновлений ленты.
Или на вб, пока юзер изучает какой-то товар, коварные капиталисты уже сформировали список рекомендованных товаров, которые попадут точно ему в сердечко, и он заплатит за них много деняк💰. А когда пользователь пролистал описание, ему уже показываются готовые карточки.
Общий подход такой — предугадываем поведение пользователя и что-то предвычисляем заранее на основе этой гипотезы.
Идея этого поста родилась из текста Вани Ходора, бэкенд-разработчика Лавки. В своем посте он подробно объяснил паттерн speculative execution, привел кучу примеров, а также рассказал о рисках, сопряженных с его обузингом.
Предлагаю порефлексировать в комментах, где эта тонкая грань между тем, чтобы не дать пользователю на секунду заскучать, и нагрузки на систему от кучи предвычислений.
Telegram
this->notes.
#highload
Есть такой паттерн speculative execution (⢄⠣⠌ ⠅⡠⢆⠒⢔⢄⢢⣀⠍ ⢃⠎⠚⡐⢰⡰⡰⡢⠲ ⢌⠥⠜⢅⠊⠃⡌⢈⡂⠰⡃ ⠡⡢ ⡅⠍ ⣄⡔⡘⡠⠉⠃⡆⢂⠓⠪⠩⢐⡠ ⡢⠩⢆⠱⠚⡡⢈⠦⡢⠕). Паттерн заключается в том, чтобы делать префетч данных ещё до того, как пользователь захочет что-то увидеть, чтобы в момент, когда он…
Есть такой паттерн speculative execution (⢄⠣⠌ ⠅⡠⢆⠒⢔⢄⢢⣀⠍ ⢃⠎⠚⡐⢰⡰⡰⡢⠲ ⢌⠥⠜⢅⠊⠃⡌⢈⡂⠰⡃ ⠡⡢ ⡅⠍ ⣄⡔⡘⡠⠉⠃⡆⢂⠓⠪⠩⢐⡠ ⡢⠩⢆⠱⠚⡡⢈⠦⡢⠕). Паттерн заключается в том, чтобы делать префетч данных ещё до того, как пользователь захочет что-то увидеть, чтобы в момент, когда он…
❤10👍4🔥4
Увидел тут в одной запрещенной сети такой пост с картинкой выше:
Кажется, что людям свойственно обсуждать давно решенные проблемы😅
Причем подобные вопросы(форматирование) можно вообще обсуждать сколько угодно и по каждому отдельно взятому кусочку кода. Программисты любят холивары, для некоторых день без холивара был прожит зря.
Я конечно не эксперт, но кажется, что любые вопросы по форматированию решаются настройкой clang-format. Надо его просто установить, поставить нужные правила(вот здесь можете один раз похоливарить всей командой, но один раз!) и радоваться жизни. Для vscode можно поставить расширение и настроить его, чтобы форматирование применялось на каждое сохранение файла. Ну или используйте любой другой линтер на ваш вкус.
С этого вообще должен начинаться каждый новый проект и без линтера любой старый проект превращается во франкенштейна, в котором разные части написаны в разных стилях.
А вы как считаете: разница очевидна и она не в пользу оригинального?😆
Don't reinvent the wheel. Stay cool.
#tools #goodpractice
Пожалуй, брошу еще один камень в огород любителей длинных строк в коде.
На скриншоте первый фрагмент -- это оригинальный код, а второй -- это как бы я его записал. ИМХО, разница очевидна и она не в пользу оригинального 😎
Если же попытаться говорить объективно, то с кодом должно быть комфортно работать в любых условиях. Хоть на 13.3" ноутбуке, хоть на 34" 5K дисплее. А длинные строки этому физически препятствуют.
...
Кажется, что людям свойственно обсуждать давно решенные проблемы😅
Причем подобные вопросы(форматирование) можно вообще обсуждать сколько угодно и по каждому отдельно взятому кусочку кода. Программисты любят холивары, для некоторых день без холивара был прожит зря.
Я конечно не эксперт, но кажется, что любые вопросы по форматированию решаются настройкой clang-format. Надо его просто установить, поставить нужные правила(вот здесь можете один раз похоливарить всей командой, но один раз!) и радоваться жизни. Для vscode можно поставить расширение и настроить его, чтобы форматирование применялось на каждое сохранение файла. Ну или используйте любой другой линтер на ваш вкус.
С этого вообще должен начинаться каждый новый проект и без линтера любой старый проект превращается во франкенштейна, в котором разные части написаны в разных стилях.
А вы как считаете: разница очевидна и она не в пользу оригинального?😆
Don't reinvent the wheel. Stay cool.
#tools #goodpractice
🔥17👍12❤10😁2🤔2
Недостатки std::make_shared. Деаллокация
#новичкам
Представляете, забыл выложить один важный пост из серии про недостатки std::make_shared. Затерялся он в пучине заметок. Исправляюсь.
В предыдущих сериях:
Кастомный new и delete
Непубличные конструкторы
Кастомные делитеры
А теперь поговорим про деаллокацию.
В этом посте мы рассказали о том, что std::make_shared выделяет один блок памяти под объект и контрольный блок. 1 аллокация вместо 2-х = большая производительность. Однако у монеты всегда две стороны.
Что происходит с объектом и памятью при работе с shared_ptr напрямую через конструктор?
Отдельно выделяется память и конструируется разделяемый объект с помощью явного вызова new, отдельно выделяется память и конструируется контрольный блок.
Деструктор разделяемого объекта и освобождение памяти для него происходит ровно в тот момент, когда счетчик сильных ссылок становится нулем. При этом контрольный блок остается живым до момента уничтожения последнего std::weak_ptr:
Мы переопределили глобальный delete, чтобы увидеть момент освобождения памяти на разных этапах.
Деструктор и delete для разделяемого объекта вызываются ровно в момент выхода объекта
Что же происходит при использовании std::make_shared? В какой момент освобождается вся выделенная память?
Только когда оба счетчика сильных и слабых ссылок будут равны нулю. То есть не осталось ни одного объекта std::shared_ptr и std::weak_ptr, которые указывают на объект. Тем не менее семантически разделяемый объект уничтожается при разрушении последней сильной ссылки:
Отметьте вызов деструктора после выхода из скоупа, но при этом память еще не освобождается. Она делает это только после reset и уничтожении последней слабой ссылки.
Учитывайте эти особенности, когда используете weak_ptr(например в кэше или списках слушателей).
Consider both sides of the coin. Stay cool.
#cpp11 #memory
#новичкам
Представляете, забыл выложить один важный пост из серии про недостатки std::make_shared. Затерялся он в пучине заметок. Исправляюсь.
В предыдущих сериях:
Кастомный new и delete
Непубличные конструкторы
Кастомные делитеры
А теперь поговорим про деаллокацию.
В этом посте мы рассказали о том, что std::make_shared выделяет один блок памяти под объект и контрольный блок. 1 аллокация вместо 2-х = большая производительность. Однако у монеты всегда две стороны.
Что происходит с объектом и памятью при работе с shared_ptr напрямую через конструктор?
Отдельно выделяется память и конструируется разделяемый объект с помощью явного вызова new, отдельно выделяется память и конструируется контрольный блок.
Деструктор разделяемого объекта и освобождение памяти для него происходит ровно в тот момент, когда счетчик сильных ссылок становится нулем. При этом контрольный блок остается живым до момента уничтожения последнего std::weak_ptr:
void operator delete(void *ptr) noexcept {
std::cout << "Global delete " << std::endl;
std::free(ptr);
}
class MyClass {
public:
~MyClass() {
std::cout << "Деструктор MyClass вызван.\n";
}
};
int main() {
std::weak_ptr<MyClass> weak;
{
std::shared_ptr<MyClass> shared(new MyClass());
weak = shared;
std::cout
<< "shared_ptr goes out of scope...\n";
} // Here shared is deleting
std::cout << "weak.expired(): " << weak.expired()
<< '\n';
weak.reset();
std::cout << "All memory has been freed!\n";
}
// OUTPUT:
// shared_ptr goes out of scope...
// Dtor MyClass called.
// Global delete
// weak.expired(): 1
// Global delete
// All memory has been freed!Мы переопределили глобальный delete, чтобы увидеть момент освобождения памяти на разных этапах.
Деструктор и delete для разделяемого объекта вызываются ровно в момент выхода объекта
shared из своего скоупа. Тем не менее weak_ptr жив, он знает, что объекта уже нет, но своим наличием продлевает время жизни контрольного блока. После ресета weak ожидаемо происходит деаллокация блока.Что же происходит при использовании std::make_shared? В какой момент освобождается вся выделенная память?
Только когда оба счетчика сильных и слабых ссылок будут равны нулю. То есть не осталось ни одного объекта std::shared_ptr и std::weak_ptr, которые указывают на объект. Тем не менее семантически разделяемый объект уничтожается при разрушении последней сильной ссылки:
void operator delete(void *ptr) noexcept {
std::cout << "Global delete " << std::endl;
std::free(ptr);
}
class MyClass {
public:
~MyClass() {
std::cout << "Деструктор MyClass вызван.\n";
}
};
int main() {
std::weak_ptr<MyClass> weak;
{
auto shared = std::make_shared<MyClass>();
weak = shared;
std::cout << "shared_ptr goes out of scope...\n";
} // shared уничтожается здесь
std::cout << "weak.expired(): " << weak.expired()
<< '\n'; // true
weak.reset();
std::cout << "All memory has been freed!\n";
}
// shared_ptr goes out of scope...
// Dtor MyClass called.
// weak.expired(): 1
// Global delete
// All memory has been freed!Отметьте вызов деструктора после выхода из скоупа, но при этом память еще не освобождается. Она делает это только после reset и уничтожении последней слабой ссылки.
Учитывайте эти особенности, когда используете weak_ptr(например в кэше или списках слушателей).
Consider both sides of the coin. Stay cool.
#cpp11 #memory
{kind=link}
1🔥16👍10❤7❤🔥3😁1