static_assert и if constexpr
Вернемся к прошлому примеру с функцией to\_str, но сделаем ее немножко безопасней.
Все просто. Функция std::to_string имеет перегрузки только для тривиальных арифметических типов, поэтому чтобы ее использовать и получить ошибку, нужно провести проверку на эту арифметичность. Если переданный в функцию to\_str тип не конструируется в строку или не является арифметическим типом, то не совсем понятно, как такой тип переводить в строку. Точнее так: в каждом конкретном случае мы можем сказать как, но общего поведения нет. Поэтому, чтобы детектировать такие нештатные ситуации, я поставлю ассерт времени компиляции.
И вроде всё хорошо, но да не всё...
Дело в том, что при попытке скомпилировать этот пример, процесс прервется на этом ассерте даже в том случае, когда мы попадем в первые две ветки.
Тут в чем прикол. Согласно стандарту, если хотя бы в одной из веток if constexpr не может быть сгенерировано ни одной валидной специализации, то программа - ill-formed и это ошибка. И вправду, false всегда будет false, как бы мы там не тужились родить что-то валидное.
Но даже сам cppreference предлагает нам способ обойти эту неприятную бяку. Мы можем подставить вместо false шаблонное constexpr типазависимое выражение, которое будет возвращать false. И тогда все магическим образом заработает.
Видимо из-за того, что шаблон можно вручную специализировать, то теоритически возможна специализация, которая будет возвращать true. И даже если она еще не инстанцирована, то возможность-то остается. Поэтому компилятор пропускает такую конструкцию.
Однако ситуация изменилась с приходом С++23, но об этом мы поговорим завтра.
Find loopholes in the system. Stay cool.
#cpp17 #template
Вернемся к прошлому примеру с функцией to\_str, но сделаем ее немножко безопасней.
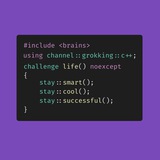
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_constructible_v<std::string, T>)
return t;
else if constexpr (std::is_arithmetic_v<T>)
return std::to_string(t);
else
static_assert(false, "cannot convert type to std::string");
}
Все просто. Функция std::to_string имеет перегрузки только для тривиальных арифметических типов, поэтому чтобы ее использовать и получить ошибку, нужно провести проверку на эту арифметичность. Если переданный в функцию to\_str тип не конструируется в строку или не является арифметическим типом, то не совсем понятно, как такой тип переводить в строку. Точнее так: в каждом конкретном случае мы можем сказать как, но общего поведения нет. Поэтому, чтобы детектировать такие нештатные ситуации, я поставлю ассерт времени компиляции.
И вроде всё хорошо, но да не всё...
Дело в том, что при попытке скомпилировать этот пример, процесс прервется на этом ассерте даже в том случае, когда мы попадем в первые две ветки.
Тут в чем прикол. Согласно стандарту, если хотя бы в одной из веток if constexpr не может быть сгенерировано ни одной валидной специализации, то программа - ill-formed и это ошибка. И вправду, false всегда будет false, как бы мы там не тужились родить что-то валидное.
Но даже сам cppreference предлагает нам способ обойти эту неприятную бяку. Мы можем подставить вместо false шаблонное constexpr типазависимое выражение, которое будет возвращать false. И тогда все магическим образом заработает.
template<typename>
inline constexpr bool dependent_false_v = false;
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_constructible_v<std::string, T>)
return t;
else if constexpr (std::is_arithmetic_v<T>)
return std::to_string(t);
else
static_assert(dependent_false_v<T>, "cannot convert type to std::string");
}
Видимо из-за того, что шаблон можно вручную специализировать, то теоритически возможна специализация, которая будет возвращать true. И даже если она еще не инстанцирована, то возможность-то остается. Поэтому компилятор пропускает такую конструкцию.
Однако ситуация изменилась с приходом С++23, но об этом мы поговорим завтра.
Find loopholes in the system. Stay cool.
#cpp17 #template
{kind=link}
🔥15👍8❤3😁1
Обновления в отношениях static_assert и if constexpr
Наш подписчик Вадим упомянул о важном изменении в отношениях static_assert и if constexpr. Эти изменения вступили в силу с приходом С++23 и говорят о том, что теперь программа не считается ill-formed, даже если static_assert фейлится для всех специализаций.
Посмотрим на уже заезженном примере:
Создали структуру пустышку и использовали функцию to_str по всем трем веткам условия. И если закомментировать последний вывод в консоль - все корректно компилируется и выполняется. Но как только мы инстанцируем специализацию с пессимистичной веткой условия, компиляция падает на ассерте.
Не у многих есть возможность попробовать 23-е плюсы на своих машинках, поэтому оставлю ссылку на годболт, чтобы вы могли поиграться с примером.
До прихода 23-х плюсов была очевидная проблема с этим static_assert'ом. Вроде бы это очень логично писать условия как в примере выше и ожидать, что это сработает. Да и наличие смешного донельзя воркэраунда с шаблонным типозависимым выражением, которое все равно возвращает false, как бы намекает, что что-то не так. Радостно видеть развитие языка и закрытие таких болючих пробелов.
Fix your flaws. Stay cool.
#cpp23 #template
Наш подписчик Вадим упомянул о важном изменении в отношениях static_assert и if constexpr. Эти изменения вступили в силу с приходом С++23 и говорят о том, что теперь программа не считается ill-formed, даже если static_assert фейлится для всех специализаций.
Посмотрим на уже заезженном примере:
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_constructible_v<std::string, T>)
return t;
else if constexpr (std::is_arithmetic_v<T>)
return std::to_string(t);
else
static_assert(false, "cannot convert type to std::string");
}
class A{};
int main()
{
std::cout << to_str("qwe") << std::endl; // OK
std::cout << to_str(5.0) << std::endl; // OK
std::cout << to_str(A{}) << std::endl; // static_assert failed
}
Создали структуру пустышку и использовали функцию to_str по всем трем веткам условия. И если закомментировать последний вывод в консоль - все корректно компилируется и выполняется. Но как только мы инстанцируем специализацию с пессимистичной веткой условия, компиляция падает на ассерте.
Не у многих есть возможность попробовать 23-е плюсы на своих машинках, поэтому оставлю ссылку на годболт, чтобы вы могли поиграться с примером.
До прихода 23-х плюсов была очевидная проблема с этим static_assert'ом. Вроде бы это очень логично писать условия как в примере выше и ожидать, что это сработает. Да и наличие смешного донельзя воркэраунда с шаблонным типозависимым выражением, которое все равно возвращает false, как бы намекает, что что-то не так. Радостно видеть развитие языка и закрытие таких болючих пробелов.
Fix your flaws. Stay cool.
#cpp23 #template
{kind=link}
👍11🔥6❤4👎1
static_assert
Раз уж так много его обсуждаем, почему бы не рассказать о том, что это вообще такое.
Это фича С++11, которая позволяет прерывать компиляцию программы, если определенное условие не выполнено. Естественно, условие должно быть bool-constexpr выражением, иначе ничего не выйдет. static_assert на то и static, потому что работает во время компиляции. Рантайм выражения в это время не могут быть вычислены.
На данный момент доступны 2 вида этого ассерта:
static_assert(bool-constexpr, unevaluated-string)
static_assert(bool-constexpr)
Первая версия доступна с 11-х плюсов, вторая с 17-х. Первая добавляет к сообщению об ошибке вашу кастомную, но захардкоженую, строку для более полного и понятного контекста. Вторая такого поведения не предполагает, но оно и не всегда нужно.
Ну собственно, примеры вы уже видели. Хотя тут стоит сказать пару ласковых.
Мне кажется, что не стоит ставить ассерты на определенный тип шаблонных параметров шаблонных сущностей. Как верно указал Михаил в [этом комментарии](https://t.iss.one/c/2009887601/2547), так будет сложно проверить на корректность перегрузку. Для такого рода ограничений лучше использовать концепты или sfinae. Единственное, что вы тогда потеряете вменяемое сообщение об ошибке и возможность его дополнить своим сообщением.
Статический ассерт может быть удобен для проверки размера структуры, которая взаимодействует с внешним миром. Например, низкоуровневый сетевой код может полагаться на один размер структуры, и какой-то нерадивый человек внес изменения в эту структуру и изменил ее размер без изменения всего связанного кода. Тогда возможны очень трудноотловимые ошибки. Этого можно избежать, поставив простой ассерт на размер этой структуры. И если размер вдруг изменится, то компиляция просто прервется. Тоже самое можно проводить и с размерами базовых типов. Правда тут возможно придется со всякими паддингами повозиться(эффективный рэндж беззнакового инта может быть [0, 65тыщ_что-то_там], а в памяти он будет занимать будет 4 байта).
Можно также проверять версию подключаемых библиотек, если они предоставляют свою версию в виде constexpr выражения, а не макроса(хотя это довольно редкое явление). Типа такого:
Ну и вообще, любые предположения о вашем коде, которые вы можете проверить в compile-time, стоит обернуть в эту конструкцию. Так вы убережете себя от долгих и бессмысленных сборок проектов, трудноотловимых багов и прочего. В общем, штука крутая.
Check your assumptions in advance. Stay cool.
#cpp11 #cpp17 #compiler
Раз уж так много его обсуждаем, почему бы не рассказать о том, что это вообще такое.
Это фича С++11, которая позволяет прерывать компиляцию программы, если определенное условие не выполнено. Естественно, условие должно быть bool-constexpr выражением, иначе ничего не выйдет. static_assert на то и static, потому что работает во время компиляции. Рантайм выражения в это время не могут быть вычислены.
На данный момент доступны 2 вида этого ассерта:
static_assert(bool-constexpr, unevaluated-string)
static_assert(bool-constexpr)
Первая версия доступна с 11-х плюсов, вторая с 17-х. Первая добавляет к сообщению об ошибке вашу кастомную, но захардкоженую, строку для более полного и понятного контекста. Вторая такого поведения не предполагает, но оно и не всегда нужно.
Ну собственно, примеры вы уже видели. Хотя тут стоит сказать пару ласковых.
Мне кажется, что не стоит ставить ассерты на определенный тип шаблонных параметров шаблонных сущностей. Как верно указал Михаил в [этом комментарии](https://t.iss.one/c/2009887601/2547), так будет сложно проверить на корректность перегрузку. Для такого рода ограничений лучше использовать концепты или sfinae. Единственное, что вы тогда потеряете вменяемое сообщение об ошибке и возможность его дополнить своим сообщением.
Статический ассерт может быть удобен для проверки размера структуры, которая взаимодействует с внешним миром. Например, низкоуровневый сетевой код может полагаться на один размер структуры, и какой-то нерадивый человек внес изменения в эту структуру и изменил ее размер без изменения всего связанного кода. Тогда возможны очень трудноотловимые ошибки. Этого можно избежать, поставив простой ассерт на размер этой структуры. И если размер вдруг изменится, то компиляция просто прервется. Тоже самое можно проводить и с размерами базовых типов. Правда тут возможно придется со всякими паддингами повозиться(эффективный рэндж беззнакового инта может быть [0, 65тыщ_что-то_там], а в памяти он будет занимать будет 4 байта).
Можно также проверять версию подключаемых библиотек, если они предоставляют свою версию в виде constexpr выражения, а не макроса(хотя это довольно редкое явление). Типа такого:
#include "SomeVeryC++ishLibrary.hpp"
static_assert(SomeVeryC++ishLibrary.::Version > 2,
"Old versions of SomeVeryC++ishLibrary. are missing functionality to destroy the world.
It is very desired functionality so cannot process!");
class DestroyTheWorld {
// BOOM!!
};
Ну и вообще, любые предположения о вашем коде, которые вы можете проверить в compile-time, стоит обернуть в эту конструкцию. Так вы убережете себя от долгих и бессмысленных сборок проектов, трудноотловимых багов и прочего. В общем, штука крутая.
Check your assumptions in advance. Stay cool.
#cpp11 #cpp17 #compiler
{kind=link}
👍13❤4🔥3😁1🙈1
Почему нельзя помещать определение шаблона в cpp файл
Что такое шаблон? Когда я был маленьким и тупеньким, мне объясняли концепцию объектов и классов вот так: класс - это чертеж корабля, а объект - построенный по этому чертежу конкретный корабль. Раньше мне критически не хватало такого объяснения, хотя сейчас это кажется интуитивно понятным. Суть в том, что класс - это не просто чертеж, а очень подробный чертеж со всеми мерками, подробными схемами работы всех отдельных частей, и схемами взаимодействия этих частей друг с другом. То есть какой-то сверхразум(компилятор) посмотрев на все это добро, может четко понять о будущем корабле буквально все и в соло построить его абсолютно рабочую версию, каждая деталь которого будет совпадать с планом.
Так вот шаблон класса - это похожий на класс чертеж, почти такой же подробный, только в этом чертеже практически нет описания каких-то отдельных частей. Только такие же подробные схемы взаимодействия этих отсутсвующих частей с другими частями корабля. Да, мы можем наложить какие-то ограничения на эти неизвестные части(sfinae, концепты), но подробного описания все равно не будет.
Так вот, чтобы получить этот полный подробный чертеж(класс), нужно добавить эти подробные схемы отдельных частей. То есть инстанцировать шаблон.
И пока этого не сделано, ни один сверхразум не сможет вам построить по неполной схеме готовый полноценный корабль.
И вот все сверхразумы мира договорились, что если они все равно не могут построить полноценный корабль, то даже если они получат чертеж, в котором будет описано все-превсе кроме одной детали, они даже не будут начинать строить этот корабль. А вдруг схему детали так и не завезут. Зачем стараться зря?
Вроде мы разобрались с аналогиями, перейдем в реальность.
Все рассуждения выше и ниже актуальны также и для других шаблонных сущностей. Это так, предвижу возможные вопросы.
Возьмем стандартную схему объявления шаблонного класса в хэдэре и ее реализацию в файле исходников.
Если бы это был обычный класс, тут бы все прокатило. Но здесь шаблон и это все меняет.
В чем прикол. В единице трансляции, соответствующей файлу ship.cpp, не будет сгенерировано никакого кода. Потому что в этой единице трансляции не предоставлено полной схемы типа T. И поэтому компилятор просто ничего не будет генерировать из этого шаблона.
А вы в main.cpp пытаетесь использовать уже сам объект. То есть полностью готовый корабль из полноценного чертежа. В файле main.cpp нет никакого чертежа. Ну хорошо, возможно там что-то в ship.hpp есть подобное. А там только объявление шаблона. Ну хорошо, компилятор на данном этапе может работать только с объявлением, как и с объявлениями обычных классов, ничего странного. Сейчас он поставит заглушки на моменты создания и использования объекта. Но он попытается на этапе линковки разрезолвить все символы. Но вот незадача - на этапе линковки компилятор не увидит сгенерированного кода специализации Ship<int>. Потому что в единице трансляции, соответствующей файлу ship.cpp, никакого полезного сгенерированного кода нет!
Решение тут простое - вынести определение шаблона в хэдэр и подключать его везде, чтобы компилятор уже на этапе компиляции видел это определение и смог сам инстанцировать подходящую специализацию.
Однако есть и другое решение!
Можно оставить определение в цппшнике, но нужно добавить немного магии. Знающих прошу не спойлерить в комментах, хочу оставить интригу до завтра)
Don't do extra work in vain. Stay cool.
#cppcore #template
Что такое шаблон? Когда я был маленьким и тупеньким, мне объясняли концепцию объектов и классов вот так: класс - это чертеж корабля, а объект - построенный по этому чертежу конкретный корабль. Раньше мне критически не хватало такого объяснения, хотя сейчас это кажется интуитивно понятным. Суть в том, что класс - это не просто чертеж, а очень подробный чертеж со всеми мерками, подробными схемами работы всех отдельных частей, и схемами взаимодействия этих частей друг с другом. То есть какой-то сверхразум(компилятор) посмотрев на все это добро, может четко понять о будущем корабле буквально все и в соло построить его абсолютно рабочую версию, каждая деталь которого будет совпадать с планом.
Так вот шаблон класса - это похожий на класс чертеж, почти такой же подробный, только в этом чертеже практически нет описания каких-то отдельных частей. Только такие же подробные схемы взаимодействия этих отсутсвующих частей с другими частями корабля. Да, мы можем наложить какие-то ограничения на эти неизвестные части(sfinae, концепты), но подробного описания все равно не будет.
Так вот, чтобы получить этот полный подробный чертеж(класс), нужно добавить эти подробные схемы отдельных частей. То есть инстанцировать шаблон.
И пока этого не сделано, ни один сверхразум не сможет вам построить по неполной схеме готовый полноценный корабль.
И вот все сверхразумы мира договорились, что если они все равно не могут построить полноценный корабль, то даже если они получат чертеж, в котором будет описано все-превсе кроме одной детали, они даже не будут начинать строить этот корабль. А вдруг схему детали так и не завезут. Зачем стараться зря?
Вроде мы разобрались с аналогиями, перейдем в реальность.
Все рассуждения выше и ниже актуальны также и для других шаблонных сущностей. Это так, предвижу возможные вопросы.
Возьмем стандартную схему объявления шаблонного класса в хэдэре и ее реализацию в файле исходников.
// ship.hpp
template<typename T>
struct Ship
{
// contain some fields
void TurnShip(T command);
};
// ship.cpp
#include "ship.hpp"
template <class T>
void Ship<T>::TurnShip(T command) {/* do stuff using command */}
// main.cpp
#include "ship.hpp"
int main() {
Ship<int> ship;
ship.TurnShip(5);
}
Если бы это был обычный класс, тут бы все прокатило. Но здесь шаблон и это все меняет.
В чем прикол. В единице трансляции, соответствующей файлу ship.cpp, не будет сгенерировано никакого кода. Потому что в этой единице трансляции не предоставлено полной схемы типа T. И поэтому компилятор просто ничего не будет генерировать из этого шаблона.
А вы в main.cpp пытаетесь использовать уже сам объект. То есть полностью готовый корабль из полноценного чертежа. В файле main.cpp нет никакого чертежа. Ну хорошо, возможно там что-то в ship.hpp есть подобное. А там только объявление шаблона. Ну хорошо, компилятор на данном этапе может работать только с объявлением, как и с объявлениями обычных классов, ничего странного. Сейчас он поставит заглушки на моменты создания и использования объекта. Но он попытается на этапе линковки разрезолвить все символы. Но вот незадача - на этапе линковки компилятор не увидит сгенерированного кода специализации Ship<int>. Потому что в единице трансляции, соответствующей файлу ship.cpp, никакого полезного сгенерированного кода нет!
Решение тут простое - вынести определение шаблона в хэдэр и подключать его везде, чтобы компилятор уже на этапе компиляции видел это определение и смог сам инстанцировать подходящую специализацию.
Однако есть и другое решение!
Можно оставить определение в цппшнике, но нужно добавить немного магии. Знающих прошу не спойлерить в комментах, хочу оставить интригу до завтра)
Don't do extra work in vain. Stay cool.
#cppcore #template
{kind=link}
👍29🔥10❤5😁5
Явная и неявная инстанциация шаблона
Как только компилятор видит полное определение шаблона, он может инстанцировать его с каким-то конкретным аргументом. И тут есть 2 варианта.
Вернемся к вчерашнему примеру с шаблоном корабля.
Согласно заветам предыдущего поста, мы перенесли все определение шаблона в хэдэр, подключили этот хэдэр в мэйн и использовали объект. И раз в мэйне мы используем объект, то в этом конкретном случае произошло неявное инстанцирование шаблона - компилятор все сделал за нас. Мы дали ему определение шаблона, укропу, кошачью жопу, ... и охапку дров, а он нам выдал плов. Точнее конкретный код, соответствующий конкретной специализации Ship<int>.
Но вы уже поняли, да? Раз есть неявное инстанцирование, то есть и явное! То есть, мы сами своими ручками-закарючками(осуждаю боди-шейминг, говорю про себя) можем сказать компилятору, что мы хотим, чтобы он инстанцировал нужную нам специализации и сгенерировал нам для нее код. И эта штука поможет нам решить проблему с определением шаблонов в цппшниках.
Представим себе, что наш корабль принимает команды только в текстовом виде. И на данный момент никаких других видов команд не предусмотрено. Тогда единственная планируемая специализация шаблона Ship будет со строками. В таком случае, мы можем заставить компилятор инстанцировать нужный нам шаблон в единице трансляции с его определением и тогда на этапе линковки компилятор сможет разрезолвить все символы и сгенерировать полноценный бинарник без ошибок. Для этого нужно добавить лишь одну строчку:
template class Ship<std::string> - яное инстанцирование шаблона. Синтаксис следующий:
template class-key template-name <argument-list>;
class-key - любое из struct/class/union, должно соответствовать оному в самом шаблоне.
Как видите, у этой прекрасной фичи есть ограничения. Если вы используете шаблон с большим количеством различных специализаций, то вам придется каждую из них указывать явно в ццпшнике с определением шаблона. Это немного уменьшает гибкость изменений.
А также никакой внешний код, который вы не можете трогать и представляете его как черный ящик, не сможет использовать ваш шаблон. Потому что вы не знаете, какие там специализации используются, а значит не сможете добавить его в цппшник с определением шаблона.
Но в целом, это хорошая практика. Поэтому используйте на здоровье.
Важно помнить, что явно инстанцировать шаблон можно всего раз во всей программе. Помните об этом, когда соберетесь поместить эту строчку в хэдэр.
Find a way out of your problems. Stay cool.
#cppcore #template
Как только компилятор видит полное определение шаблона, он может инстанцировать его с каким-то конкретным аргументом. И тут есть 2 варианта.
Вернемся к вчерашнему примеру с шаблоном корабля.
// ship.hpp
template<typename T>
struct Ship
{
// contain some fields
void TurnShip(T command) {// do some stuff}
};
// main.cpp
#include "ship.hpp"
int main() {
Ship<int> ship;
ship.TurnShip(5);
}
Согласно заветам предыдущего поста, мы перенесли все определение шаблона в хэдэр, подключили этот хэдэр в мэйн и использовали объект. И раз в мэйне мы используем объект, то в этом конкретном случае произошло неявное инстанцирование шаблона - компилятор все сделал за нас. Мы дали ему определение шаблона, укропу, кошачью жопу, ... и охапку дров, а он нам выдал плов. Точнее конкретный код, соответствующий конкретной специализации Ship<int>.
Но вы уже поняли, да? Раз есть неявное инстанцирование, то есть и явное! То есть, мы сами своими ручками-закарючками(осуждаю боди-шейминг, говорю про себя) можем сказать компилятору, что мы хотим, чтобы он инстанцировал нужную нам специализации и сгенерировал нам для нее код. И эта штука поможет нам решить проблему с определением шаблонов в цппшниках.
Представим себе, что наш корабль принимает команды только в текстовом виде. И на данный момент никаких других видов команд не предусмотрено. Тогда единственная планируемая специализация шаблона Ship будет со строками. В таком случае, мы можем заставить компилятор инстанцировать нужный нам шаблон в единице трансляции с его определением и тогда на этапе линковки компилятор сможет разрезолвить все символы и сгенерировать полноценный бинарник без ошибок. Для этого нужно добавить лишь одну строчку:
// ship.hpp
template<typename T>
struct Ship
{
// contain some fields
void TurnShip(T command);
};
// ship.cpp
#include "ship.hpp"
#include <string>
template <class T>
void Ship<T>::TurnShip(T command) {/* do stuff using command */}
template struct Ship<std::string>; // HERE IT IS!!
// main.cpp
#include "ship.hpp"
#include <string>
int main() {
Ship<std::string> ship;
ship.TurnShip(std::string{"Turn upside down"});
}
template class Ship<std::string> - яное инстанцирование шаблона. Синтаксис следующий:
template class-key template-name <argument-list>;
class-key - любое из struct/class/union, должно соответствовать оному в самом шаблоне.
Как видите, у этой прекрасной фичи есть ограничения. Если вы используете шаблон с большим количеством различных специализаций, то вам придется каждую из них указывать явно в ццпшнике с определением шаблона. Это немного уменьшает гибкость изменений.
А также никакой внешний код, который вы не можете трогать и представляете его как черный ящик, не сможет использовать ваш шаблон. Потому что вы не знаете, какие там специализации используются, а значит не сможете добавить его в цппшник с определением шаблона.
Но в целом, это хорошая практика. Поэтому используйте на здоровье.
Важно помнить, что явно инстанцировать шаблон можно всего раз во всей программе. Помните об этом, когда соберетесь поместить эту строчку в хэдэр.
Find a way out of your problems. Stay cool.
#cppcore #template
{kind=link}
🔥17👍13❤4
Внутрянка инстанциаций шаблонов
Хочу в этом небольшом посте в явном виде продемонстрировать вам, что значит определение шаблона и его явная/неявная инстанциация. Сразу говорю, что буду использовать gcc в качестве компилятора.
Возьмем тот же пример с кораблем и оставим от него только хэдэр и сорец:
Сейчас в единице трансляции, соответствующей ship.cpp, есть только объявление и определение шаблона, больше ничего. Это значит, что никакого кода для этого юнита генерироваться не будет.
Проверим это с помощью утилитки nm, которая показывает символы бинарника. Скомпилируем ship.cpp в объектный файл и посмотрим, какие там символы есть внутри:
Как говорят математики: ЧТД и точка!
Теперь проверим неявную инстанциацию. Добавим в ship.cpp функцию:
Посмотрим теперь на символы этого юнита. Помимо всего прочего побочного непотребства, получим следующее:
Теперь мы имеем скомпилированную функцию foo и метод TurnShip класса Ship параметризованного строкой.
Для явной инстанциации уберем из ship.cpp функцию foo и добавим строчку:
и посмотрим на символы:
Как и ожидалось в принципе.
Вот поэтому-то при использовании подхода разделения шаблона на объявление в хэдэре и определение в сорце без явной инстанциации будет ошибка линковки. В единице трансляции, соответствующей определению шаблона, не будет никакого кода. Единицы трансляции на этапе компиляции не обмениваются информацией, поэтому компилятор не сможет инстанцировать шаблон на этом этапе. А на этапе линковки уже поздно смотреть на определение шаблона, потому что его просто не будет. Текст уберется, а кода никакого сгенерировано не будет. Как-то так.
Я не просто так вам это все рассказываю. Это нужно для понимания дальнейших постов.
Don't rely on words, check them. Stay cool.
#cppcore #template #compiler
Хочу в этом небольшом посте в явном виде продемонстрировать вам, что значит определение шаблона и его явная/неявная инстанциация. Сразу говорю, что буду использовать gcc в качестве компилятора.
Возьмем тот же пример с кораблем и оставим от него только хэдэр и сорец:
// ship.hpp
template<typename T>
struct Ship
{
// contain some fields
void TurnShip(T command);
};
// ship.cpp
#include "ship.hpp"
#include <string>
template <class T>
void Ship<T>::TurnShip(T command) {/* do stuff using command */}
Сейчас в единице трансляции, соответствующей ship.cpp, есть только объявление и определение шаблона, больше ничего. Это значит, что никакого кода для этого юнита генерироваться не будет.
Проверим это с помощью утилитки nm, которая показывает символы бинарника. Скомпилируем ship.cpp в объектный файл и посмотрим, какие там символы есть внутри:
nm ship.o
//Output
ship.o: no symbols
Как говорят математики: ЧТД и точка!
Теперь проверим неявную инстанциацию. Добавим в ship.cpp функцию:
void foo() {
Ship<std::string> ship{};
ship.TurnShip(std::string{"Turn upside down"});
}
Посмотрим теперь на символы этого юнита. Помимо всего прочего побочного непотребства, получим следующее:
nm ship.o
//Output
0000000000000000 T __Z3foov
0000000000000060 T __ZN4ShipINSt3__112basic_stringIcNS0_11char_traitsIcEENS0_9allocatorIcEEEEE8TurnShipES6_
Теперь мы имеем скомпилированную функцию foo и метод TurnShip класса Ship параметризованного строкой.
Для явной инстанциации уберем из ship.cpp функцию foo и добавим строчку:
template struct Ship<std::string>;
и посмотрим на символы:
nm ship.o
//Output
0000000000000000 T __ZN4ShipINSt3__112basic_stringIcNS0_11char_traitsIcEENS0_9allocatorIcEEEEE8TurnShipES6_
Как и ожидалось в принципе.
Вот поэтому-то при использовании подхода разделения шаблона на объявление в хэдэре и определение в сорце без явной инстанциации будет ошибка линковки. В единице трансляции, соответствующей определению шаблона, не будет никакого кода. Единицы трансляции на этапе компиляции не обмениваются информацией, поэтому компилятор не сможет инстанцировать шаблон на этом этапе. А на этапе линковки уже поздно смотреть на определение шаблона, потому что его просто не будет. Текст уберется, а кода никакого сгенерировано не будет. Как-то так.
Я не просто так вам это все рассказываю. Это нужно для понимания дальнейших постов.
Don't rely on words, check them. Stay cool.
#cppcore #template #compiler
{kind=link}
🔥20👍8❤3
Extern template
Дисклеймер: здесь и далее в этой серии статей я буду называть "специализацией" шаблона его инстанциацию с конкретным шаблонным параметром.
Помните, как мы явно инстанцировали шаблон в файле реализации? Раз мы может сказать компилятору, чтобы он инстанцировал нужную специализацию в нужном нам файле, то очень удобно потом обращаться за кодом этой специализации конкретно в эту единицу трансляции. Потому что, как мы уже знаем, код одной и той же специализации может генерироваться во всех единицах трансляции, не вызывая при этом конфликтов и нарушения ODR(вектор интов инстанцируется много где, но никогда эти специализации не конфликтуют при линковке). Тут аналогия с inline сущностями.
В общем, хочется иметь один образцово-показательный код в одной TU и обращаться за нужными символами туда.
И такой инструмент есть!
Называется extern template declaration. Этот пост, а также несколько предыдущих и следующих, посвящается нашему олду @PyXiion и его просьбе разобрать этот вопрос.
Идея очень похожа на extern объявления других сущностей. С его помощью обеспечивается внешнее связывание и оно помогает компилятору понять, что такая сущность в программе есть, просто она описана в другой единице трансляции. Это значит, что на этапе линковки компилятор может посмотреть в эту самую другую TU и найти там все, что нужно для генерации полноценного кода.
Синтаксис следующий:
extern template class-key template-name <argument-list>;
Все то же самое, что и при явной инстанциации, только спереди добавляем extern. Фича из С++11 кстати и скорее всего средний разработчик даже не представляет о ее существовании.
Что происходит, когда мы добавляем эту строчку после определения шаблона? Неявная конкретизация этой специализации запрещается. То есть даже если компилятор видит полное определение шаблона и вы создаете объект конкретной специализации, то код для нее генерироваться не будет. Вместо этого компилятор будет ждать, что он найдет нужные символы и код для них в другой единице трансляции.
В основном, эта вещь решает проблему дублирования кода специализации во всех TU, где она используется. Очевидно, что если все TU будут обращаться к одной единственной за всем нужным, а не будут генерировать все сами, то будет всего один оригинал кода и соотвественно размер бинаря уменьшится. Как и время компиляции собственно.
Как это работает и какие еще проблемы решает эта фича, мы рассмотрим в следующих частях, все в один пост не влезет, много тонких моментов, требующих акцентов.
Learn new things. Stay cool.
#cppcore #cpp11 #template #compiler
Дисклеймер: здесь и далее в этой серии статей я буду называть "специализацией" шаблона его инстанциацию с конкретным шаблонным параметром.
Помните, как мы явно инстанцировали шаблон в файле реализации? Раз мы может сказать компилятору, чтобы он инстанцировал нужную специализацию в нужном нам файле, то очень удобно потом обращаться за кодом этой специализации конкретно в эту единицу трансляции. Потому что, как мы уже знаем, код одной и той же специализации может генерироваться во всех единицах трансляции, не вызывая при этом конфликтов и нарушения ODR(вектор интов инстанцируется много где, но никогда эти специализации не конфликтуют при линковке). Тут аналогия с inline сущностями.
В общем, хочется иметь один образцово-показательный код в одной TU и обращаться за нужными символами туда.
И такой инструмент есть!
Называется extern template declaration. Этот пост, а также несколько предыдущих и следующих, посвящается нашему олду @PyXiion и его просьбе разобрать этот вопрос.
Идея очень похожа на extern объявления других сущностей. С его помощью обеспечивается внешнее связывание и оно помогает компилятору понять, что такая сущность в программе есть, просто она описана в другой единице трансляции. Это значит, что на этапе линковки компилятор может посмотреть в эту самую другую TU и найти там все, что нужно для генерации полноценного кода.
Синтаксис следующий:
extern template class-key template-name <argument-list>;
Все то же самое, что и при явной инстанциации, только спереди добавляем extern. Фича из С++11 кстати и скорее всего средний разработчик даже не представляет о ее существовании.
Что происходит, когда мы добавляем эту строчку после определения шаблона? Неявная конкретизация этой специализации запрещается. То есть даже если компилятор видит полное определение шаблона и вы создаете объект конкретной специализации, то код для нее генерироваться не будет. Вместо этого компилятор будет ждать, что он найдет нужные символы и код для них в другой единице трансляции.
В основном, эта вещь решает проблему дублирования кода специализации во всех TU, где она используется. Очевидно, что если все TU будут обращаться к одной единственной за всем нужным, а не будут генерировать все сами, то будет всего один оригинал кода и соотвественно размер бинаря уменьшится. Как и время компиляции собственно.
Как это работает и какие еще проблемы решает эта фича, мы рассмотрим в следующих частях, все в один пост не влезет, много тонких моментов, требующих акцентов.
Learn new things. Stay cool.
#cppcore #cpp11 #template #compiler
{kind=link}
👍19❤5🔥5
Самая контринтуитивная задача
Давайте немного отвлечемся от шаблонной суеты интересной задачкой. Ее многие должны знать, она довольно известная, но менее интересной она от этого не становится. Особенно, учитывая, что ее объяснение быстро забывается и остается только сухой ответ в голове. Я сам и пара моих друзей такие, поэтому знаю, о чем говорю. Правда я немного изменю условие, чтобы некое разнообразие внести. Задачка совсем не программистская, но да и ладно, дадим немного вольности себе.
Представьте, что вы Бэтмен. Джокер похитил вашего младшего соратника Робина из бэтпещеры и держит его у себя в заложниках. В пещере он оставил свою фирменную визитку - карту Джокера с указанием локации, куда нужно прийти, чтобы спасти Робина.
И ничего не остается делать вам, кроме как идти спасать друга. Приходите по адресу и оказалось, что это завод Ace Chemicals, давший жизнь Джокеру. Входите внутрь и видите огромный чан с кислотой и три закрытые подвешанные к потолку клетки. Вы не видите, что в них находится. И тут появляется Джокер и говорит, что в одной из этих клеток находится Робин. Он точно знает, в какой конкретной клетке. И у него есть пульт, который открывает дно любой клетки.
Джокер больше всего на свете хочет играть с Бэтменом, поэтому предлагает вам игру. Вы должны выбрать одну из трех клеток. И если там будет Робин, то Джокер вернет вам товарища. Если нет, то он откроет дно клетки с Робином и он умрет в чане с кислотой. И без шуток тут! Если вы учудите что-нибудь, ваш друг помрет в ту же секунду. Так, что придется играть по его правилам.
И вот Бэтмен сделал свой выбор. Но Джокер - коварный враг. Он решает открыть другую клетку. И из нее ничего не вываливается. То есть Робин в одной и двух оставшихся клеток. И чтобы сделать Бэтмена еще неувереннее и попытаться обхитрить его, Джокер говорит, что он дает вам еще одну попытку выбрать нужную клетку.
Какой вы выбор сделаете: останетесь верны своему первому выбору или смените его?
В этот раз тред обсуждений будет только под этим постом, решение как всегда вечером. Прошу знающих людей не спойлерить и не писать решение задачи в комментах.
P.S. Немного душноты добавим, но это необходимо. Распределение Робина в клетках равновероятно, выбор Джокером свободной клетки равновероятен и при любом раскладе он предлагает второй раунд.
Раз, два, три, Джокера обхитри! То есть, погнали решать!
Trick your enemies. Stay cool.
#задачки
Давайте немного отвлечемся от шаблонной суеты интересной задачкой. Ее многие должны знать, она довольно известная, но менее интересной она от этого не становится. Особенно, учитывая, что ее объяснение быстро забывается и остается только сухой ответ в голове. Я сам и пара моих друзей такие, поэтому знаю, о чем говорю. Правда я немного изменю условие, чтобы некое разнообразие внести. Задачка совсем не программистская, но да и ладно, дадим немного вольности себе.
Представьте, что вы Бэтмен. Джокер похитил вашего младшего соратника Робина из бэтпещеры и держит его у себя в заложниках. В пещере он оставил свою фирменную визитку - карту Джокера с указанием локации, куда нужно прийти, чтобы спасти Робина.
И ничего не остается делать вам, кроме как идти спасать друга. Приходите по адресу и оказалось, что это завод Ace Chemicals, давший жизнь Джокеру. Входите внутрь и видите огромный чан с кислотой и три закрытые подвешанные к потолку клетки. Вы не видите, что в них находится. И тут появляется Джокер и говорит, что в одной из этих клеток находится Робин. Он точно знает, в какой конкретной клетке. И у него есть пульт, который открывает дно любой клетки.
Джокер больше всего на свете хочет играть с Бэтменом, поэтому предлагает вам игру. Вы должны выбрать одну из трех клеток. И если там будет Робин, то Джокер вернет вам товарища. Если нет, то он откроет дно клетки с Робином и он умрет в чане с кислотой. И без шуток тут! Если вы учудите что-нибудь, ваш друг помрет в ту же секунду. Так, что придется играть по его правилам.
И вот Бэтмен сделал свой выбор. Но Джокер - коварный враг. Он решает открыть другую клетку. И из нее ничего не вываливается. То есть Робин в одной и двух оставшихся клеток. И чтобы сделать Бэтмена еще неувереннее и попытаться обхитрить его, Джокер говорит, что он дает вам еще одну попытку выбрать нужную клетку.
Какой вы выбор сделаете: останетесь верны своему первому выбору или смените его?
В этот раз тред обсуждений будет только под этим постом, решение как всегда вечером. Прошу знающих людей не спойлерить и не писать решение задачи в комментах.
P.S. Немного душноты добавим, но это необходимо. Распределение Робина в клетках равновероятно, выбор Джокером свободной клетки равновероятен и при любом раскладе он предлагает второй раунд.
Раз, два, три, Джокера обхитри! То есть, погнали решать!
Trick your enemies. Stay cool.
#задачки
{kind=link}
❤7👍5🔥5🤡3
Когда НЕ стоит использовать extern template
Если вы будете гуглить инфу по этой теме, то непременно нарветесь на неправильное понимание принципов работы фичи. Стопроцентов вы наткнетесь на такое объяснение:
extern template в связке с явным инстанцированием шаблона помогает предотвратить дублирование кода в TU и уменьшить время компиляции. Выглядит это так:
Типа вот мы в ship.cpp добавили явную конкретизацию шаблона, а в мэйне объявили, что возьмем информацию о специализации в другом месте.
Но дело в том, что в этом случае extern template - лишний! В нем нет никакого смысла и вот почему.
Если мы уберем extern template из файла main, то ничего не изменится. Так как в этой единице трансляции и так никогда бы не была конкретизирована специализация Ship<int>. Потому что компилятору на момент компиляции файла main.cpp видно только объявление шаблона из файла ship.hpp и у него недостаточно информации для инстанцирования. И только при линковке линковщик найдет все символы в единице трансляции, соответствующей ship.cpp, и сгенерирует рабочую программу.
Так что запомните: если вы используете явную инстанциацию после определения шаблона в цппшнике и подключаете хэдэр с его объявлением, то вам НЕ НУЖНО использовать extern template.
Это кстати отличная защита от тех самых проблем при работе с шаблонами. Так что выносить определенения шаблонов в цппшники и делать в них явную инстанциацию - полезная вещь.
Также без подключения хэдэра эта вещь вообще не работает, в отличии например от глобальных переменных. Все-таки контекст extern здесь не совсем совпадает.
А вот когда это нужно использовать. Только тогда, когда у вас есть несколько единиц трансляции, где компилятор сам неявно может инстанцировать одинаковые специализации. Например, когда вы полностью определяете шаблон в хэдэре и везде его распространяете таким образом. Тогда получается, что без использования extern template в каждой из этих единиц трансляций, подключивших хэдэр с шаблоном и использующих одинаковую специализацию, эта специализация будет инстанцирована. Это значит, что код для нее будет присутствовать во всех объектниках. Это приводит к его дублированию и увеличению времени компиляции.
Теперь мы во всех TU, кроме одной, используем extern template и в этой оставшейся делаем явную специализацию. Получается, что для всех, кроме одной, TU компилятору будет запрещено самостоятельно инстанцировать эту специализацию. И все они будет обращаться в тот единственный объектник, в котором есть код для специализации. Именно за счет этого и не происходит раздувания итогового бинарника. Все просто полагаются на одну копию.
Rely on original information. Stay cool.
#cpp11 #cppcore #template #compiler
Если вы будете гуглить инфу по этой теме, то непременно нарветесь на неправильное понимание принципов работы фичи. Стопроцентов вы наткнетесь на такое объяснение:
extern template в связке с явным инстанцированием шаблона помогает предотвратить дублирование кода в TU и уменьшить время компиляции. Выглядит это так:
// ship.hpp
#pragma once
template<typename T>
struct Ship
{
void TurnShip(T command);
};
// ship.cpp
#include "ship.hpp"
template <class T>
void Ship<T>::TurnShip(T command) {}
template struct Ship<int>; // explicit instantiation definition
// main.cpp
#include "ship.hpp"
extern template struct Ship<int>; // explicit instantiation declaration
int main() {
Ship<int> ship;
ship.TurnShip(5);
}
Типа вот мы в ship.cpp добавили явную конкретизацию шаблона, а в мэйне объявили, что возьмем информацию о специализации в другом месте.
Но дело в том, что в этом случае extern template - лишний! В нем нет никакого смысла и вот почему.
Если мы уберем extern template из файла main, то ничего не изменится. Так как в этой единице трансляции и так никогда бы не была конкретизирована специализация Ship<int>. Потому что компилятору на момент компиляции файла main.cpp видно только объявление шаблона из файла ship.hpp и у него недостаточно информации для инстанцирования. И только при линковке линковщик найдет все символы в единице трансляции, соответствующей ship.cpp, и сгенерирует рабочую программу.
Так что запомните: если вы используете явную инстанциацию после определения шаблона в цппшнике и подключаете хэдэр с его объявлением, то вам НЕ НУЖНО использовать extern template.
Это кстати отличная защита от тех самых проблем при работе с шаблонами. Так что выносить определенения шаблонов в цппшники и делать в них явную инстанциацию - полезная вещь.
Также без подключения хэдэра эта вещь вообще не работает, в отличии например от глобальных переменных. Все-таки контекст extern здесь не совсем совпадает.
А вот когда это нужно использовать. Только тогда, когда у вас есть несколько единиц трансляции, где компилятор сам неявно может инстанцировать одинаковые специализации. Например, когда вы полностью определяете шаблон в хэдэре и везде его распространяете таким образом. Тогда получается, что без использования extern template в каждой из этих единиц трансляций, подключивших хэдэр с шаблоном и использующих одинаковую специализацию, эта специализация будет инстанцирована. Это значит, что код для нее будет присутствовать во всех объектниках. Это приводит к его дублированию и увеличению времени компиляции.
Теперь мы во всех TU, кроме одной, используем extern template и в этой оставшейся делаем явную специализацию. Получается, что для всех, кроме одной, TU компилятору будет запрещено самостоятельно инстанцировать эту специализацию. И все они будет обращаться в тот единственный объектник, в котором есть код для специализации. Именно за счет этого и не происходит раздувания итогового бинарника. Все просто полагаются на одну копию.
Rely on original information. Stay cool.
#cpp11 #cppcore #template #compiler
{kind=link}
👍18❤4🔥2👎1
Линковочная природа шаблонов
Когда мы говорим про шаблоны и их линковку, нам важно видеть все детали общей картины. Иначе полное понимание так и не придет. Поэтому сегодня немного больше приоткроем линковочные тайны темплейтов.
Думаю, что не будет грубым обобщением сказать, что каждый из нас пользовался шаблонным классом std::vector. И это хорошо, все имеют опыт с ним и всем будет проще понимать, о чем сейчас пойдет речь.
Представим, что мы разрабатываем какое-то приложение или отдельный сервис. Этот сервис состоит из отдельных кодовых модулей, которые отдельно компилируются и линкуются вместе для получения готового бинарника. Так вот очень легко допустить, что во многих модулях одного и того же сервиса используется вектор интов. std::vector<int>. Обычно мы просто инклюдим в эти модули хэдэр вектора и после используем его. Таким образом происходит неявная инстанциация. То есть компилятор на этапе компиляции модулей сам инстанциацирует интовую специализацию вектора в каждой единице трансляции и использует ее в коде текущего юнита.
Однако, погодите-ка. То есть у нас в нескольких единицах трансляции есть одна и та же скомпилированная сущность и при линковке это не вызывает никаких проблем. Как так?
Вот, что стандарт говорит по поводу этого:
Стандарт разрешает шаблонным сущностям иметь больше, чем одно определение на всю программу. И не более одного на каждую единицу трансляции.
И кстати, утверждение, что шаблоны неявно помечены inline - неверно. Но об этом позже.
За счет чего допускается возможность наличия нескольких определений сущности в программе? Если вы читали гайд по inline(можете найти в закрепе), то, наверняка, знаете ответ. За счет слабых символов.
Скомпилируем гццшкой самую простенькую функцию:
А утилитка nm покажет нам природу символов в бинаре. Там будет генерироваться оч много функций и символов связанных с вектором, поэтому разберем только один пример с конструктором, символ которого выглядит так:
0000000000000000 W std::vector<int, std::allocator<int> >::vector(unsigned long, std::allocator<int> const&)
Вот эта буковка W говорит, что этот символ - слабый. А слабые символы могут быть перезаписаны во время линковки. Линковщик просто сам выберет одно понравившееся ему определение из всех существующих в программе и перезапишет им остальные. Таким образом в программе останется всего одно определение шаблона и все будут ссылаться на него. Однако все равно до линковки во всех единицах трансляции будет своя копия интовой инстанциации шаблона.
Use your weaknesses to solve your problems. Stay cool.
#compiler #cppcore #template
Когда мы говорим про шаблоны и их линковку, нам важно видеть все детали общей картины. Иначе полное понимание так и не придет. Поэтому сегодня немного больше приоткроем линковочные тайны темплейтов.
Думаю, что не будет грубым обобщением сказать, что каждый из нас пользовался шаблонным классом std::vector. И это хорошо, все имеют опыт с ним и всем будет проще понимать, о чем сейчас пойдет речь.
Представим, что мы разрабатываем какое-то приложение или отдельный сервис. Этот сервис состоит из отдельных кодовых модулей, которые отдельно компилируются и линкуются вместе для получения готового бинарника. Так вот очень легко допустить, что во многих модулях одного и того же сервиса используется вектор интов. std::vector<int>. Обычно мы просто инклюдим в эти модули хэдэр вектора и после используем его. Таким образом происходит неявная инстанциация. То есть компилятор на этапе компиляции модулей сам инстанциацирует интовую специализацию вектора в каждой единице трансляции и использует ее в коде текущего юнита.
Однако, погодите-ка. То есть у нас в нескольких единицах трансляции есть одна и та же скомпилированная сущность и при линковке это не вызывает никаких проблем. Как так?
Вот, что стандарт говорит по поводу этого:
There can be more than one definition in a program of each of the following:
class type, enumeration type, inline function, inline variable(since C++17),
templated entity(template or member of template, but not full template specialization),
as long as all of the following is true[...]
Стандарт разрешает шаблонным сущностям иметь больше, чем одно определение на всю программу. И не более одного на каждую единицу трансляции.
И кстати, утверждение, что шаблоны неявно помечены inline - неверно. Но об этом позже.
За счет чего допускается возможность наличия нескольких определений сущности в программе? Если вы читали гайд по inline(можете найти в закрепе), то, наверняка, знаете ответ. За счет слабых символов.
Скомпилируем гццшкой самую простенькую функцию:
void foo() {
std::vector<int> vec(10);
vec[0] = 1;
}
А утилитка nm покажет нам природу символов в бинаре. Там будет генерироваться оч много функций и символов связанных с вектором, поэтому разберем только один пример с конструктором, символ которого выглядит так:
0000000000000000 W std::vector<int, std::allocator<int> >::vector(unsigned long, std::allocator<int> const&)
Вот эта буковка W говорит, что этот символ - слабый. А слабые символы могут быть перезаписаны во время линковки. Линковщик просто сам выберет одно понравившееся ему определение из всех существующих в программе и перезапишет им остальные. Таким образом в программе останется всего одно определение шаблона и все будут ссылаться на него. Однако все равно до линковки во всех единицах трансляции будет своя копия интовой инстанциации шаблона.
Use your weaknesses to solve your problems. Stay cool.
#compiler #cppcore #template
{kind=link}
🔥21👍11❤10
Шаблоны не подразумевают inline
Дисклеймер: в этом посте слово "специализация" будет значить конкретную программную сущность, объявленную через template<> с пустыми треугольными скобками, которая переопределяет поведения шаблона для конкретного типа.
В прошлом посте кратко коснулись этого. Сегодня разберемся в этом подробнее.
Мы уже знаем, что в программе может быть больше одного определения шаблона и это нормально. Ровно также может быть больше одного определения inline сущности. Так есть ли между этими утверждениями связь?
Очевидно, классы не могут быть inline. Разговор здесь пойдет только про inline функции и переменные(с С++14).
Во-первых, стандарт ничего не говорит по поводу того, что шаблоны по умолчанию inline. Хотя, например, для constexpr функций и статических полей класса это явно описано.
Во-вторых, в нем есть пара слов про явные специализации
Эта строчка говорит нам о том, что спецификаторы, которыми помечены явные специализации, могут не совпадать со спецификаторами самих шаблонов. Значит, что шаблоны имеет смысл помечать inline и мы даже может можем изменить это поведение в явной специализации. А значит, шаблоны не подразумевают inline. Их поведение только лишь схоже с inline сущностими в плане обхода ODR. Пример из стандарта:
Здесь нужно быть аккуратным, потому что на явные специализации распространяется ODR. Явные специализации - уже не шаблоны, поэтому, если вы хотите поместить их в хэдэр, то нужно помечать их inline, чтобы линковщик не ругался.
Если инлайн в нынешнее время в основном используется для обхода ODR, то есть ли смысл помечать шаблонные функции этим ключевым словом?
Особого смысла нет(помимо явных специализаций). Темплейты и так не подвержены ODR. А в остальном инлайн только лишь указывает компилятору, чтобы он сделал проверку на возможность inline expansion. Но он в принципе и так это делает для всех функций.
Differentiate things apart. Stay cool.
#template #cppcore #cpp14 #compiler
Дисклеймер: в этом посте слово "специализация" будет значить конкретную программную сущность, объявленную через template<> с пустыми треугольными скобками, которая переопределяет поведения шаблона для конкретного типа.
В прошлом посте кратко коснулись этого. Сегодня разберемся в этом подробнее.
Мы уже знаем, что в программе может быть больше одного определения шаблона и это нормально. Ровно также может быть больше одного определения inline сущности. Так есть ли между этими утверждениями связь?
Очевидно, классы не могут быть inline. Разговор здесь пойдет только про inline функции и переменные(с С++14).
Во-первых, стандарт ничего не говорит по поводу того, что шаблоны по умолчанию inline. Хотя, например, для constexpr функций и статических полей класса это явно описано.
Во-вторых, в нем есть пара слов про явные специализации
Whether an explicit specialization of a function or variable template is inline,
constexpr, constinit, or consteval is determined by the explicit specialization and
is independent of those properties of the template. Similarly, attributes appearing
in the declaration of a template have no effect on an explicit specialization of that
template...
Эта строчка говорит нам о том, что спецификаторы, которыми помечены явные специализации, могут не совпадать со спецификаторами самих шаблонов. Значит, что шаблоны имеет смысл помечать inline и мы даже может можем изменить это поведение в явной специализации. А значит, шаблоны не подразумевают inline. Их поведение только лишь схоже с inline сущностими в плане обхода ODR. Пример из стандарта:
template<class T> void f(T) { /* ... */ }
template<class T> inline T g(T) { /* ... */ }
template<> inline void f<>(int) { /* ... */ } // OK, inline
template<> int g<>(int) { /* ... */ } // OK, not inline
Здесь нужно быть аккуратным, потому что на явные специализации распространяется ODR. Явные специализации - уже не шаблоны, поэтому, если вы хотите поместить их в хэдэр, то нужно помечать их inline, чтобы линковщик не ругался.
Если инлайн в нынешнее время в основном используется для обхода ODR, то есть ли смысл помечать шаблонные функции этим ключевым словом?
Особого смысла нет(помимо явных специализаций). Темплейты и так не подвержены ODR. А в остальном инлайн только лишь указывает компилятору, чтобы он сделал проверку на возможность inline expansion. Но он в принципе и так это делает для всех функций.
Differentiate things apart. Stay cool.
#template #cppcore #cpp14 #compiler
{kind=link}
🔥17👍9❤2
Когда стоит использовать explicit template declaration
Мы поговорили о случае, в котором бесполезно использовать explicit template declaration. Теперь поговорим о наиболее уместном и логичном способе использования этой фичи.
Главная функция extern template - запретить компилятору неявную инстанциацию. Значит, для адекватного использования этой конструкции компилятору необходимо иметь возможность выполнить эту неявную инстанциацию. Единственным подходящим ситуации вариантом здесь будет нахождение полного определения шаблона в хэдэре, чтобы его могли видеть все заинтересованные лица(пофантизируйте в комментариях, как могло бы выглядеть лицо у единицы трансляции).
Дальше есть следующие 2 варианта - поместить все явные объявления инстанциации шаблона в этот же хэдэр и распихать по единицам трансляции. Как по мне, лучше иметь одну централизированную точку изменений, так как программисты - люди забывчивые и могут упустить момент добавления нового явного объявления и компилятор сам сделает неявную инстанциацию. Да и если помещать в разные места, то это приведет к дубликации кода. Поэтому оставляем extern template в хэдэре.
Ну и последний момент. Если есть явное объявление инстанциации, должно быть и ее явное определение. Причем это ВАЖНО. Нельзя при использовании extern template полагаться на неявную инстанциацию. В нашем случае это уже невозможно, потому что мы добавили в хэдэр с шаблоном запрет на неявную инстанциацию, но я все равно хочу на это обратить ваше внимание. Компилятор может ее оптимизировать, так что для нее больше не останется отдельно скомпилированной сущности и все вызовы просто встроятся. Тогда компановщик не сможет разрезолвить символы и будет undefined reference. Чуть позже расскажу об этом в отдельном посте.
Итак, explicit template instantiation. Мы помещаем явные определения всех нужных нам неявных специализаций в отдельный цппшник. И вот к коду в этой TU будет обращаться линкер, чтобы подставить адреса нужных вызовов. А в других TU не будет сгенерировано ничего связанного с шаблоном.
Продемонстрирую на примере:
Если мы отдельно скомпилируем main.cpp и посмотрим на символы объектника, то там будет только то, что связано с std::basic_string, но не с Ship. Как и было задумано.
Подводя итог: нам нужен хэдэр с полным определением шаблона и явными объявлениями extern template и сорец с явными определениями этих инстанциаций. Теперь мы можем везде тыкать наш хэдэр и ожидать уменьшения времени компиляции и меньшего размера объектников.
Choose the right way. Stay cool.
#template #compiler #cppcore
Мы поговорили о случае, в котором бесполезно использовать explicit template declaration. Теперь поговорим о наиболее уместном и логичном способе использования этой фичи.
Главная функция extern template - запретить компилятору неявную инстанциацию. Значит, для адекватного использования этой конструкции компилятору необходимо иметь возможность выполнить эту неявную инстанциацию. Единственным подходящим ситуации вариантом здесь будет нахождение полного определения шаблона в хэдэре, чтобы его могли видеть все заинтересованные лица(пофантизируйте в комментариях, как могло бы выглядеть лицо у единицы трансляции).
Дальше есть следующие 2 варианта - поместить все явные объявления инстанциации шаблона в этот же хэдэр и распихать по единицам трансляции. Как по мне, лучше иметь одну централизированную точку изменений, так как программисты - люди забывчивые и могут упустить момент добавления нового явного объявления и компилятор сам сделает неявную инстанциацию. Да и если помещать в разные места, то это приведет к дубликации кода. Поэтому оставляем extern template в хэдэре.
Ну и последний момент. Если есть явное объявление инстанциации, должно быть и ее явное определение. Причем это ВАЖНО. Нельзя при использовании extern template полагаться на неявную инстанциацию. В нашем случае это уже невозможно, потому что мы добавили в хэдэр с шаблоном запрет на неявную инстанциацию, но я все равно хочу на это обратить ваше внимание. Компилятор может ее оптимизировать, так что для нее больше не останется отдельно скомпилированной сущности и все вызовы просто встроятся. Тогда компановщик не сможет разрезолвить символы и будет undefined reference. Чуть позже расскажу об этом в отдельном посте.
Итак, explicit template instantiation. Мы помещаем явные определения всех нужных нам неявных специализаций в отдельный цппшник. И вот к коду в этой TU будет обращаться линкер, чтобы подставить адреса нужных вызовов. А в других TU не будет сгенерировано ничего связанного с шаблоном.
Продемонстрирую на примере:
// ship.hpp
#pragma once
#include <string>
template<typename T>
struct Ship
{
// contain some fields
void TurnShip(T command);
};
template <class T>
void Ship<T>::TurnShip(T command) {/* do stuff using command */}
extern template class Ship<std::string>; // text command
extern template class Ship<int>; // turn certain number of degrees clockwise
// ship.cpp
#include "ship.hpp"
template class Ship<std::string>;
template class Ship<int>;
// main.cpp
#include "ship.hpp"
#include <string>
int main() {
Ship<std::string> ship;
ship.TurnShip(std::string{"Turn upside down"});
Ship<int> ship1; // i know it's silly to instantiate 2 version of
// ship just to have a different style of turning,
// but stick to the goodold example
ship1.TurnShip(36'000); // just trying to make a giant whirlpool
}
Если мы отдельно скомпилируем main.cpp и посмотрим на символы объектника, то там будет только то, что связано с std::basic_string, но не с Ship. Как и было задумано.
Подводя итог: нам нужен хэдэр с полным определением шаблона и явными объявлениями extern template и сорец с явными определениями этих инстанциаций. Теперь мы можем везде тыкать наш хэдэр и ожидать уменьшения времени компиляции и меньшего размера объектников.
Choose the right way. Stay cool.
#template #compiler #cppcore
{kind=link}
👍21❤9🔥3
экспресс совет
Cнова ненадолго отвлечемся от шаблонов.
В моем программистком детстве меня всегда бесило, что когда мне нужно беззнаковое 32-битное число, мне приходилось писать это длинное unsigned. А если нужно большое беззнаковое - то вообще unsigned long long. Фу прям.
Да, size_t тоже представляет собой беззнаковое 64-битное число. Но я большой фанат семантики типов, а size_t обозначает размер чего-то. А не всегда числа представляют собой размер.
Но есть выход! Подключаете <cstdint> и кайфуете с человеческим представлением типов
std::int8_t
std::uint8_t
std::int16_t
std::uint16_t
std::int32_t
std::uint32_t
std::int64_t
std::uint64_t
и еще несколько менее важных(мб потом обсудим)
Насколько же они прекрасны! И короткие, и сразу понятно, какого размера переменная. И не надо голову морочить: а вот сколько там на этой железяке бит в инте?? В самом типе есть ответ.
Почти всегда пользуюсь этими обозначениями(пальцы так и наровят написать int вместо int32_t) и очень доволен процессом.
Особенно они незаменимы в каком-нибудь библиотечном коде с математическими функциями, когда много перегрузок под каждый тип.
Эти тайпдефы появились в стандарте с С++11. Раньше приходилось подключать сишный stdint.h. Этот хэдэр предоставляет те же алиасы с теми же свойствами, но без "std::". Это конечно не по-христианскиплюсовому, но для ленивых неяростных адептов с++ отлично подойдет.
И кстати, если реализация стандартной библиотеки предоставляет эти типы, то вы можете рассчитывать на то, что тип реально может хранить то число полезных битов, которое в нем указано. И без всяких паддингов. Это может быть важно в низкоуровневом программировании.
В общем, кто пользуется - меня поддержит, кто еще нет - берите на заметку.
Stay laconic. Stay cool.
#cppcore #cpp11
Cнова ненадолго отвлечемся от шаблонов.
В моем программистком детстве меня всегда бесило, что когда мне нужно беззнаковое 32-битное число, мне приходилось писать это длинное unsigned. А если нужно большое беззнаковое - то вообще unsigned long long. Фу прям.
Да, size_t тоже представляет собой беззнаковое 64-битное число. Но я большой фанат семантики типов, а size_t обозначает размер чего-то. А не всегда числа представляют собой размер.
Но есть выход! Подключаете <cstdint> и кайфуете с человеческим представлением типов
std::int8_t
std::uint8_t
std::int16_t
std::uint16_t
std::int32_t
std::uint32_t
std::int64_t
std::uint64_t
и еще несколько менее важных(мб потом обсудим)
Насколько же они прекрасны! И короткие, и сразу понятно, какого размера переменная. И не надо голову морочить: а вот сколько там на этой железяке бит в инте?? В самом типе есть ответ.
Почти всегда пользуюсь этими обозначениями(пальцы так и наровят написать int вместо int32_t) и очень доволен процессом.
Особенно они незаменимы в каком-нибудь библиотечном коде с математическими функциями, когда много перегрузок под каждый тип.
Эти тайпдефы появились в стандарте с С++11. Раньше приходилось подключать сишный stdint.h. Этот хэдэр предоставляет те же алиасы с теми же свойствами, но без "std::". Это конечно не по-
И кстати, если реализация стандартной библиотеки предоставляет эти типы, то вы можете рассчитывать на то, что тип реально может хранить то число полезных битов, которое в нем указано. И без всяких паддингов. Это может быть важно в низкоуровневом программировании.
В общем, кто пользуется - меня поддержит, кто еще нет - берите на заметку.
Stay laconic. Stay cool.
#cppcore #cpp11
{kind=link}
❤43👍20🔥5
std::for_each
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
for(auto & traitor: traitors) {
// exquisitely torture the traitor
}
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
struct SpaceHandler {
void operator()(std::string& str) {
auto new_end_it = std::remove_if(str.begin(), str.end(), [](const auto & ch){ return ch == ' ';});
space_count += str.size() - std::distance(str.begin(), new_end_it);
str.erase(new_end_it, str.end());
}
int space_count {0};
};
int main() {
std::vector<std::string> container = {"Ole-ole-ole ole", "C++ is great!",
"Just a random string just to make third elem"};
int i = std::for_each(container.begin(), container.end(), SpaceHandler()).space_count;
std::for_each(container.begin(), container.end(), [](const auto& str) { std::cout << str << std::endl;});
std::cout << "Average number of spaces is " << static_cast<double>(i) / container.size() << std::endl;
}
//Output
Ole-ole-oleole
C++isgreat!
Justarandomstringjusttomakethirdelem
Average number of spaces is 3.66667
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
{kind=link}
👍34🔥7❤3😁2💩2
Как узнать, что constexpr функция вычисляется в compile time
C constexpr функциями есть один прикол - они могут вычисляться и в рантайме, и компайлтайме. Но вот какой момент: мы же не зря пометили их constexpr. Нам важно, чтобы в тот момент, когда мы хотели разгрузить рантайм, он действительно разгружался. Не всегда просто бывает сходу понять, что все аргументы функции тоже являются вычислимыми во время компиляции. А это, собственно, одно из основных условий того, что и сама функция вычислится в это время.
Так вот интересно: а можно ли как-то убедиться в том, что выражение вычислено в compile-time?
На самом деле можно, для этого даже есть несколько вариантов. Не то, чтобы эти проверки нужны в продовом коде, но они могут быть полезны при отладке.
⚡️ Присвоить значение выражения constexpr переменной. Они могут инициализироваться только значениями, доступными на этапе компиляции, поэтому вам сразу же компилятор выдаст ошибку "constexpr variable must be initialized by a constant expression", если вы попытаетесь передать в функцию не constexpr значение.
Правда, здесь есть ограничение, что void выражения таким макаром не проверить.
⚡️ Поместить вызов функции в static_assert. Эта штука может проверять только вычислимые на этапе компиляции условия, поэтому компилятор опять же вам подскажет, облажались вы или нет.
Ограничение здесь даже еще жестче, чем в предыдущем пункте. Вы должны каким-то образом из возвращаемого значения функции получить булевое значение. Для тривиальных типов это довольно тривиальное преобразование, как бы тривиально это не звучало. Но для более сложных конструкций нужно будет чуть больше подумать.
⚡️ Использовать фичу С++20 - std::is_constant_evaluated(). Если коротко, то она позволяет внутри функции определить в каком контексте она вычисляется: constant evaluation context или runtime context. Здесь есть и практическая польза: в зависимости от контекста мы можем использовать constexpr-френдли операции(их набор довольно сильно ограничен и придется попотеть, чтобы что-то сложное реализовать) или обычные. Но для наших целей мы можем вот как использовать: мы можем заветвиться по контексту и вернуть из функции какое-то уникальное значение, которое соответствует только compile-time ветке. И уже по итоговому результату понять, когда произошли вычисления. А дальше уже набрасывать реальный код в ветки. Например:
Обратите внимание, что здесь используется обычный if, потому что в if constexpr is_constant_evaluated будет всегда возвращать true(в нем условие всегда в compile-time поверяется).
Наверняка, есть еще способы. Если знаете, напишите их в комментарии)
Check context of your life. Stay cool.
#cpp20 #cpp11 #compiler
C constexpr функциями есть один прикол - они могут вычисляться и в рантайме, и компайлтайме. Но вот какой момент: мы же не зря пометили их constexpr. Нам важно, чтобы в тот момент, когда мы хотели разгрузить рантайм, он действительно разгружался. Не всегда просто бывает сходу понять, что все аргументы функции тоже являются вычислимыми во время компиляции. А это, собственно, одно из основных условий того, что и сама функция вычислится в это время.
Так вот интересно: а можно ли как-то убедиться в том, что выражение вычислено в compile-time?
На самом деле можно, для этого даже есть несколько вариантов. Не то, чтобы эти проверки нужны в продовом коде, но они могут быть полезны при отладке.
⚡️ Присвоить значение выражения constexpr переменной. Они могут инициализироваться только значениями, доступными на этапе компиляции, поэтому вам сразу же компилятор выдаст ошибку "constexpr variable must be initialized by a constant expression", если вы попытаетесь передать в функцию не constexpr значение.
constexpr int JustRandomUselessFunction(int num) {
return num + 1;
}
int main() {
int usual_runtime_var = 0;
constexpr int error = JustRandomUselessFunction(usual_runtime_var);
//👆🏿Error: constexpr variable must be initialized by a constant expression
constexpr int constexpr_var = 5;
constexpr int ok = JustRandomUselessFunction(constexpr_var);
//👆🏿 OK since constexpr_var is constexpr
}
Правда, здесь есть ограничение, что void выражения таким макаром не проверить.
⚡️ Поместить вызов функции в static_assert. Эта штука может проверять только вычислимые на этапе компиляции условия, поэтому компилятор опять же вам подскажет, облажались вы или нет.
constexpr int JustRandomUselessFunction(int num) {
return num + 1;
}
int main() {
int usual_runtime_var = 0;
constexpr int constexpr_var = 5;
static_assert(JustRandomUselessFunction(usual_runtime_var));
//👆🏿 Error: static assertion expression is not an integral constant expression
static_assert(JustRandomUselessFunction(constexpr_var)); // OK
}
Ограничение здесь даже еще жестче, чем в предыдущем пункте. Вы должны каким-то образом из возвращаемого значения функции получить булевое значение. Для тривиальных типов это довольно тривиальное преобразование, как бы тривиально это не звучало. Но для более сложных конструкций нужно будет чуть больше подумать.
⚡️ Использовать фичу С++20 - std::is_constant_evaluated(). Если коротко, то она позволяет внутри функции определить в каком контексте она вычисляется: constant evaluation context или runtime context. Здесь есть и практическая польза: в зависимости от контекста мы можем использовать constexpr-френдли операции(их набор довольно сильно ограничен и придется попотеть, чтобы что-то сложное реализовать) или обычные. Но для наших целей мы можем вот как использовать: мы можем заветвиться по контексту и вернуть из функции какое-то уникальное значение, которое соответствует только compile-time ветке. И уже по итоговому результату понять, когда произошли вычисления. А дальше уже набрасывать реальный код в ветки. Например:
constexpr int CalculatePeaceNumber(double base)
{
if (std::is_constant_evaluated())
{
return 666; // That's how we can be sure about compile time evaluation
}
else
{
// some peaceful code
return 0; // true balance and peace
}
}
constexpr double pi = 3.14;
int main() {
const int result = CalculatePeaceNumber(pi);
std::cout << result << " " << CalculatePeaceNumber(pi) << std::endl;
}
//Output
666 0
Обратите внимание, что здесь используется обычный if, потому что в if constexpr is_constant_evaluated будет всегда возвращать true(в нем условие всегда в compile-time поверяется).
Наверняка, есть еще способы. Если знаете, напишите их в комментарии)
Check context of your life. Stay cool.
#cpp20 #cpp11 #compiler
{kind=link}
👍26❤3🔥2😁2
Квиз
Сегодня будет совсем простенький квиз, предвосхищающий раскрытие очень занудной, но важной темы. Ответ скину, по-классике, вечером.
Какой будет вывод у этого кода?
Сегодня будет совсем простенький квиз, предвосхищающий раскрытие очень занудной, но важной темы. Ответ скину, по-классике, вечером.
#include <iostream>
int main() {
int i = 10;
std::cout << (i & 1 == 0);
}
Какой будет вывод у этого кода?
🤔20👍6❤5🔥2❤🔥1🤡1
Нормальный человек подумает, что ответ на вопрос выше: 1. Но компьютер не человек, как и те, кто помнят наизусть приоритет операций😆. Эти машины ответят 0. Почему?
Потому что приоритет оператора сравнения больше приоритета битового И. Поэтому в начале сравнятся 1 и 0. Будет 0. А И с нулем будет всегда нуль. Ожидаемым результат будет, если расставить скобки:
Чтобы вас больше нельзя было перехитрить, приведу здесь приоритеты операций в С++.
1. Постфиксный инкремент/декремент:
2. Вызов функции:
3. Индексный доступ:
4. Доступ к члену:
5. Префиксный инкремент/декремент:
6. Операторы умножения:
7. Операторы сложения:
8. Побитовые сдвиги:
9. Операторы сравнения:
10. Операторы равенства:
11. Побитовое И:
12. Побитовое исключающее ИЛИ:
13. Побитовое ИЛИ:
14. Логическое И:
15. Логическое ИЛИ:
16. Тернарный оператор:
17. Операторы присваивания:
18. Оператор запятой:
Вообще, ставить скобки - самое универсальное правило, которое здесь можно придумать, чтобы не попадаться на такие приколы. Сильно не уверен, что стоит прям заучивать эти приоритеты. Скобки даже на уроках математики приучают ставить, поэтому это всем понятная нам концепция. А стихотворение забывается через 0.000234 секунды после прочтения (а иногда и во время). Выводы делайте сами.
Компилятор, кстати, может стать тут вашим помощником. Какие-то из них и без опций показывают ворнинг об опасности неожиданных результатов из-за порядка приоритета операций. Но чтобы было наверяка, просто добавьте опции компиляции -Wall -Wextra(ну или на крайняк -Wparentheses) и вам обязательно все покажут и расскажут,что вы за черт по жизни где вы могли бы облажаться.
Stay alert. Stay cool.
Потому что приоритет оператора сравнения больше приоритета битового И. Поэтому в начале сравнятся 1 и 0. Будет 0. А И с нулем будет всегда нуль. Ожидаемым результат будет, если расставить скобки:
#include <iostream>
int main() {
int i = 10;
std::cout << ((i & 1) == 0);
}
Чтобы вас больше нельзя было перехитрить, приведу здесь приоритеты операций в С++.
1. Постфиксный инкремент/декремент:
++, --2. Вызов функции:
()3. Индексный доступ:
[]4. Доступ к члену:
., ->5. Префиксный инкремент/декремент:
++, --, унарный плюс (+), унарный минус (-), логическое отрицание (!), побитовое дополнение (~), разыменование (*), взятие адреса (&), приведение типа (static_cast, dynamic_cast, reinterpret_cast, const_cast), sizeof6. Операторы умножения:
*, /, %7. Операторы сложения:
+, -8. Побитовые сдвиги:
<<, >>9. Операторы сравнения:
<, >, <=, >=10. Операторы равенства:
==, !=11. Побитовое И:
&12. Побитовое исключающее ИЛИ:
^13. Побитовое ИЛИ:
|14. Логическое И:
&&15. Логическое ИЛИ:
||16. Тернарный оператор:
? :17. Операторы присваивания:
=, +=, -=, *=, /=, %=, <<=, >>=, &=, ^=, |=18. Оператор запятой:
,Вообще, ставить скобки - самое универсальное правило, которое здесь можно придумать, чтобы не попадаться на такие приколы. Сильно не уверен, что стоит прям заучивать эти приоритеты. Скобки даже на уроках математики приучают ставить, поэтому это всем понятная нам концепция. А стихотворение забывается через 0.000234 секунды после прочтения (а иногда и во время). Выводы делайте сами.
Компилятор, кстати, может стать тут вашим помощником. Какие-то из них и без опций показывают ворнинг об опасности неожиданных результатов из-за порядка приоритета операций. Но чтобы было наверяка, просто добавьте опции компиляции -Wall -Wextra(ну или на крайняк -Wparentheses) и вам обязательно все покажут и расскажут,
Stay alert. Stay cool.
❤35🔥14👍11😁3
Мюсли подписчиков
Запускаем еще одну рубрику на канале: мюсли подписчиков. Здесь будут публиковаться их полнотекстовые статьи или небольшая превьюха к статье с ссылкой на оригинал.
Сегодняшним дебютантом будет наш добрый ленивец - @topin89.
Настройка окружения для запуска приложений - вещь далеко нетривиальная. Практически во всех проектах нужно от нескольких часов до нескольких дней, чтобы правильно проставить все нужные зависимости, установить все нужные приблуды и утилиты, чтобы только начать разрабатывать на новой машине. Это конечно никуда не годится. Вот можно было бы все настроить один раз и копипастить на все другие машинки все настройки сразу не тратить драгоценное время...
И такой способ есть! Называется контейнеризация. Обычно этот термин ассоциируется с каким-нибудь Docker'ом. Однако он не совсем подходит для создания окружения-как-ОС(рабочего окружения).
Автор статьи предлагает вам попробовать более подходящий инструмент для этого - systemd-nspawn. Хотя это даже не статья, а гайд по установке, настройке и минимальному запуску контейнеров с рабочим окружением. Причем такой гайд, что я прям охренел от степени проработки и подробности. Появился вопрос - далее по тексту определенно появится ответ. Все четко, структурировано и по делу. На все действия даны комментарии, так что вы точно будете знать, для чего предназначена та или иная строчка или команда.
В общем, крутой гайд от крутого специалиста и олда нашего канала. С вопросами по содержимому статьи можете приходить прямо к нему.
Ссылочка на статью вот. https://gist.github.com/topin89/f5078164e3dc53bd48838277baeb0d3b
Спасибо, Михаил, за то, что делитесь знаниями)
Share your knowledge. Stay cool.
#мюслиподписчиков
Запускаем еще одну рубрику на канале: мюсли подписчиков. Здесь будут публиковаться их полнотекстовые статьи или небольшая превьюха к статье с ссылкой на оригинал.
Сегодняшним дебютантом будет наш добрый ленивец - @topin89.
Настройка окружения для запуска приложений - вещь далеко нетривиальная. Практически во всех проектах нужно от нескольких часов до нескольких дней, чтобы правильно проставить все нужные зависимости, установить все нужные приблуды и утилиты, чтобы только начать разрабатывать на новой машине. Это конечно никуда не годится. Вот можно было бы все настроить один раз и копипастить на все другие машинки все настройки сразу не тратить драгоценное время...
И такой способ есть! Называется контейнеризация. Обычно этот термин ассоциируется с каким-нибудь Docker'ом. Однако он не совсем подходит для создания окружения-как-ОС(рабочего окружения).
Автор статьи предлагает вам попробовать более подходящий инструмент для этого - systemd-nspawn. Хотя это даже не статья, а гайд по установке, настройке и минимальному запуску контейнеров с рабочим окружением. Причем такой гайд, что я прям охренел от степени проработки и подробности. Появился вопрос - далее по тексту определенно появится ответ. Все четко, структурировано и по делу. На все действия даны комментарии, так что вы точно будете знать, для чего предназначена та или иная строчка или команда.
В общем, крутой гайд от крутого специалиста и олда нашего канала. С вопросами по содержимому статьи можете приходить прямо к нему.
Ссылочка на статью вот. https://gist.github.com/topin89/f5078164e3dc53bd48838277baeb0d3b
Спасибо, Михаил, за то, что делитесь знаниями)
Share your knowledge. Stay cool.
#мюслиподписчиков
Gist
systemd-nspawnd как рабочее место C++-программиста
systemd-nspawnd как рабочее место C++-программиста - systemd-nspawnd как рабочее место C++-программиста.md
👍23❤13🔥8😁1