
GraphML News (September 17th) - Chai-1, GenMS
🍓 This week offered a significant portion of strawberries that might result in major improvements in scientific applications. For now, let’s try to check what’s there beyond the berries.
🧬 Chai Discovery emerged from stealth and released Chai-1 - a reproduction of AlphaFold 3 with trained weights (thanks to a month on 128 A100 which saved you roughly $500k), a tech report, open inference server, and inference code (interestingly, no model code). Initial experiments report numbers close to AF 3. Chai is backed by OpenAI and many famous VCs, so it might appear as a new strong player in the industry, we’ll keep an eye.
🔮 Google DeepMind announced GenMS: Generative Hierarchical Materials Search by Sherry Yang, Simon Batzner, and the team that brought us UniMat last year. GenMS employs three components: (1) Gemini 1.5 to sample candidate formulae after a natural language query, eg, “give me the formula for a stable, chalcogenide with atom ratio 1:1:2 that's not in the ICSD database”. Samples are filtered through some rule-based heuristics and re-reranked by an LLM; (2) best candidates are sent to a diffusion model (non-equivariant, attention-based 3D Unet) to generate 3D structures; (3) the structures are scored by a pre-trained ML potential (NequIP) - if they are stable and exhibit target characteristics, we add them as a tree branch for the new iteration by LLMs. GenMS excels at perovskites, pyrochlore, and spinel crystals with structures confirmed by DFT formation energy calculations. Almost no geometric DL whatsoever 🙀
Weekend reading:
Recurrent Aggregators in Neural Algorithmic Reasoning by Kaijia Xu and Petar Veličković - the first model capable to solve quickselect from the CLRS benchmark happened to be a Triplet MPNN with a non permutation-invariant LSTM aggregator (GraphSAGE vibes). Back in January in our annual review post quickselect was the most unlikely candidate for traction, and looks like it is almost solved now!
On the design space between molecular mechanics and machine learning force fields by Yuanqing Wang and a huge collab of physicists and chemists led by NYU (feat. Kyunghyung Cho) - a nice intro to molecular mechanics, force fields, and potentials approachable by folks without a degree in physics. The survey includes a discussion on foundational ML potential models and “a nihilstic epilogue” worth checking out.
🍓 This week offered a significant portion of strawberries that might result in major improvements in scientific applications. For now, let’s try to check what’s there beyond the berries.
🧬 Chai Discovery emerged from stealth and released Chai-1 - a reproduction of AlphaFold 3 with trained weights (thanks to a month on 128 A100 which saved you roughly $500k), a tech report, open inference server, and inference code (interestingly, no model code). Initial experiments report numbers close to AF 3. Chai is backed by OpenAI and many famous VCs, so it might appear as a new strong player in the industry, we’ll keep an eye.
🔮 Google DeepMind announced GenMS: Generative Hierarchical Materials Search by Sherry Yang, Simon Batzner, and the team that brought us UniMat last year. GenMS employs three components: (1) Gemini 1.5 to sample candidate formulae after a natural language query, eg, “give me the formula for a stable, chalcogenide with atom ratio 1:1:2 that's not in the ICSD database”. Samples are filtered through some rule-based heuristics and re-reranked by an LLM; (2) best candidates are sent to a diffusion model (non-equivariant, attention-based 3D Unet) to generate 3D structures; (3) the structures are scored by a pre-trained ML potential (NequIP) - if they are stable and exhibit target characteristics, we add them as a tree branch for the new iteration by LLMs. GenMS excels at perovskites, pyrochlore, and spinel crystals with structures confirmed by DFT formation energy calculations. Almost no geometric DL whatsoever 🙀
Weekend reading:
Recurrent Aggregators in Neural Algorithmic Reasoning by Kaijia Xu and Petar Veličković - the first model capable to solve quickselect from the CLRS benchmark happened to be a Triplet MPNN with a non permutation-invariant LSTM aggregator (GraphSAGE vibes). Back in January in our annual review post quickselect was the most unlikely candidate for traction, and looks like it is almost solved now!
On the design space between molecular mechanics and machine learning force fields by Yuanqing Wang and a huge collab of physicists and chemists led by NYU (feat. Kyunghyung Cho) - a nice intro to molecular mechanics, force fields, and potentials approachable by folks without a degree in physics. The survey includes a discussion on foundational ML potential models and “a nihilstic epilogue” worth checking out.
GraphML News (September 21st) - AITHYRA, Fragrance 2o, LOG meetups
🧬 The Austrian Academy of Sciences together with Boehringer Ingelheim Foundation launched AITHYRA - the Institute for Biomedical AI - with a generous €150M funding over the next 12 years as a part of the Vienna BioCenter with Michael Bronstein as the first scientific director! AITHYRA plans to host 10-15 research groups supporting them with compute resources and robotic lab. Chances are AITHYRA might become the European version of the Institute for Protein Design (behold, David Baker) and the hub for Geometric Deep Learning research. Big win for Vienna 👏
👃 Osmo, a generative fragrance startup founded by ex-Google researchers who worked on the Principal Odor Map, uncovered a bit more details on the Fragrance 2o platform - essentially, this is a molecule search / generation for potential fragrance molecules with further conditional generation capabilities. It would certainly be exciting to discover a personalized scent like “of a sweaty researcher submitting an ICLR paper while camping in Yosemite forests”. We will keep you up to date whether GNNs conquer the perfume world and beauty industry and when Fragrantica starts to list LLM prompts as ingredients.
🍻 One of the unique ideas of the Learning on Graphs conference are local meetups about graph learning research. To date, seven meetups spanning October-December have been announced: Tel Aviv, New Jersey, Aachen, Amsterdam, Paris, Kunshan, and Siena - feel free to attend or organize one at your place!
Weekend reading:
Accelerating Training with Neuron Interaction and Nowcasting Networks by Boris Knyazev et al and collab between Samsung and Mila - pretty amazing work where every k-th optimization step model weights are predicted by a graph transformer conditioned on the neural net architecture (supports convnets, GPT2, BERT, Llama, and ViTs), brings up to 50% speed ups in optimization.
The Empirical Impact of Neural Parameter Symmetries, or Lack Thereof by Derek Lim, Moe Putterman feat. Haggai Maron - another interesting work on neural parameter symmetries. Turns out that fixing weights in MLPs via freezing or non-linearities breaks parameter symmetries and enables better model merging (you can interpolate between pre-trained models to get even better performance).
Can Graph Reordering Speed Up Graph Neural Network Training? An Experimental Study by Nikolai Merkel et al (VLDB 2025) - The answer is yes, avg speedup is 25%. The idea of partitioning the graph into several components to optimize memory reads is similar to the findings of Graph Segment Pre-training (by Google) and Sequential Aggregation and Rematerialization (Intel).
Deep learning-based predictions of gene perturbation effects do not yet outperform simple linear methods by Constantin Ahlmann-Eltze et al 🫳🎤
🧬 The Austrian Academy of Sciences together with Boehringer Ingelheim Foundation launched AITHYRA - the Institute for Biomedical AI - with a generous €150M funding over the next 12 years as a part of the Vienna BioCenter with Michael Bronstein as the first scientific director! AITHYRA plans to host 10-15 research groups supporting them with compute resources and robotic lab. Chances are AITHYRA might become the European version of the Institute for Protein Design (behold, David Baker) and the hub for Geometric Deep Learning research. Big win for Vienna 👏
👃 Osmo, a generative fragrance startup founded by ex-Google researchers who worked on the Principal Odor Map, uncovered a bit more details on the Fragrance 2o platform - essentially, this is a molecule search / generation for potential fragrance molecules with further conditional generation capabilities. It would certainly be exciting to discover a personalized scent like “of a sweaty researcher submitting an ICLR paper while camping in Yosemite forests”. We will keep you up to date whether GNNs conquer the perfume world and beauty industry and when Fragrantica starts to list LLM prompts as ingredients.
🍻 One of the unique ideas of the Learning on Graphs conference are local meetups about graph learning research. To date, seven meetups spanning October-December have been announced: Tel Aviv, New Jersey, Aachen, Amsterdam, Paris, Kunshan, and Siena - feel free to attend or organize one at your place!
Weekend reading:
Accelerating Training with Neuron Interaction and Nowcasting Networks by Boris Knyazev et al and collab between Samsung and Mila - pretty amazing work where every k-th optimization step model weights are predicted by a graph transformer conditioned on the neural net architecture (supports convnets, GPT2, BERT, Llama, and ViTs), brings up to 50% speed ups in optimization.
The Empirical Impact of Neural Parameter Symmetries, or Lack Thereof by Derek Lim, Moe Putterman feat. Haggai Maron - another interesting work on neural parameter symmetries. Turns out that fixing weights in MLPs via freezing or non-linearities breaks parameter symmetries and enables better model merging (you can interpolate between pre-trained models to get even better performance).
Can Graph Reordering Speed Up Graph Neural Network Training? An Experimental Study by Nikolai Merkel et al (VLDB 2025) - The answer is yes, avg speedup is 25%. The idea of partitioning the graph into several components to optimize memory reads is similar to the findings of Graph Segment Pre-training (by Google) and Sequential Aggregation and Rematerialization (Intel).
Deep learning-based predictions of gene perturbation effects do not yet outperform simple linear methods by Constantin Ahlmann-Eltze et al 🫳🎤
Discrete Neural Algorithmic Reasoning
Guest post by Gleb Rodionov
Paper: https://www.arxiv.org/abs/2402.11628
Blog: https://research.yandex.com/blog/discrete-neural-algorithmic-reasoning
Code: https://github.com/yandex-research/dnar
In this paper, we focus on generalizable and interpretable neural algorithmic reasoners. Starting with attention-based GNN, we inspect the reasons for generalization errors and propose several architectural modifications: feature discretization, hard attention and separating discrete and continuous data flows. All of these blocks are important for generalization:
⁃ State discretization prevents the model to use complex and redundant dependencies in the data;
⁃ Hard attention ensures that attention weights are not annealed for larger graphs. Also, hard attention limits the set of possible messages that each node can receive;
⁃ Separating discrete and continuous flows is needed to ensure that state discretization does not lose information about continuous data.
As a result, we achieve a model that provably imitates the execution of several algorithms for any test data when trained with hints. Practically, on SALSA-CLRS, trained on problem sizes of 16 nodes, the model demonstrates perfect graph- and node-level scores generalizing to problems of up to 1600 nodes.
For future work, it would be interesting to enhance the expressivity of the proposed model to a broader set of algorithms and investigate whether it is possible to train these models without hints.
Guest post by Gleb Rodionov
Paper: https://www.arxiv.org/abs/2402.11628
Blog: https://research.yandex.com/blog/discrete-neural-algorithmic-reasoning
Code: https://github.com/yandex-research/dnar
In this paper, we focus on generalizable and interpretable neural algorithmic reasoners. Starting with attention-based GNN, we inspect the reasons for generalization errors and propose several architectural modifications: feature discretization, hard attention and separating discrete and continuous data flows. All of these blocks are important for generalization:
⁃ State discretization prevents the model to use complex and redundant dependencies in the data;
⁃ Hard attention ensures that attention weights are not annealed for larger graphs. Also, hard attention limits the set of possible messages that each node can receive;
⁃ Separating discrete and continuous flows is needed to ensure that state discretization does not lose information about continuous data.
As a result, we achieve a model that provably imitates the execution of several algorithms for any test data when trained with hints. Practically, on SALSA-CLRS, trained on problem sizes of 16 nodes, the model demonstrates perfect graph- and node-level scores generalizing to problems of up to 1600 nodes.
For future work, it would be interesting to enhance the expressivity of the proposed model to a broader set of algorithms and investigate whether it is possible to train these models without hints.
GraphML News (September 28th) - AlphaChip, Generate + Novartis deal, MolPhenix
NeurIPS results for both tracks have arrived - congrats to those who made it, the datasets track this year was particularly egregious with hard score cutting below average 6.3. Good luck with the final ICLR push and see you in Vancouver!
💻 Google DeepMind presented AlphaChip - the improved version of the famous 2021 Nature paper that introduced the RL agent that uses edge-level GNNs for chip placement - that is, placing dozens of smaller blocks (often implementing certain logical function) on a canvas to optimize common design metrics like HPWL or PPA. The addendum highlights that pre-training with large compute is rather crucial and reports that AlphaChip has been successfully used for several generations of TPUs (25 RL-designed blocks in the latest TPU) as well as for external customers like MediaTek. The paper got some controversial reputation in the chip design community and some professors even argued for retracting the work from Nature for lack of clarity and reproducibility. Over time, however, it seems more like a skill issue of those who tried to replicate it - generally, the level of ML expertise in the chip design community is pretty low (some accepted papers at top venues like DAC are just 🫣) and most university teams are stuck somewhere between MLPs and convnets. Professors gonna hate, Google gonna continue making impactful real-world products, and we will have new pre-trained checkpoints of AlphaChip with some Colab tutorials 🍿.
💸 Generate:Biomedicines (the authors of Chroma, a generative model for protein design) announced collaboration with Novartis resulting in $65M upfront payments and $1B in biobucks (royalties and other performance-based milestones typically split across many years).
🐦 Valence Labs announced MolPhenix, a CLIP-like model to study phenomics (how cells respond to perturbations). Practically, it is trained on pairs of microscopy images and molecules using ViT as image encoder and MolGPS for molecules. Experiments report massive 10x improvements in Top-1% recall of active molecules over previous SOTA 👏.
Weekend reading:
TabGraphs: A Benchmark and Strong Baselines for Learning on Graphs with Tabular Node Features by Gleb Bazhenov et al - a fresh collection of new graph datasets where features are interpretable (numerical, categorical) - a stark contrast to boring text-attributed graphs or Planetoid datasets with bag-of-words as features.
Design of Ligand-Binding Proteins with Atomic Flow Matching by Junqi Liu et al feat. Jian Tang - generate a docked protein-ligand 3D structure conditioned just on 2D ligand graph and protein sequence with flow matching. Outperforms RFDiffusionAA on several metrics.
NeurIPS results for both tracks have arrived - congrats to those who made it, the datasets track this year was particularly egregious with hard score cutting below average 6.3. Good luck with the final ICLR push and see you in Vancouver!
💻 Google DeepMind presented AlphaChip - the improved version of the famous 2021 Nature paper that introduced the RL agent that uses edge-level GNNs for chip placement - that is, placing dozens of smaller blocks (often implementing certain logical function) on a canvas to optimize common design metrics like HPWL or PPA. The addendum highlights that pre-training with large compute is rather crucial and reports that AlphaChip has been successfully used for several generations of TPUs (25 RL-designed blocks in the latest TPU) as well as for external customers like MediaTek. The paper got some controversial reputation in the chip design community and some professors even argued for retracting the work from Nature for lack of clarity and reproducibility. Over time, however, it seems more like a skill issue of those who tried to replicate it - generally, the level of ML expertise in the chip design community is pretty low (some accepted papers at top venues like DAC are just 🫣) and most university teams are stuck somewhere between MLPs and convnets. Professors gonna hate, Google gonna continue making impactful real-world products, and we will have new pre-trained checkpoints of AlphaChip with some Colab tutorials 🍿.
💸 Generate:Biomedicines (the authors of Chroma, a generative model for protein design) announced collaboration with Novartis resulting in $65M upfront payments and $1B in biobucks (royalties and other performance-based milestones typically split across many years).
🐦 Valence Labs announced MolPhenix, a CLIP-like model to study phenomics (how cells respond to perturbations). Practically, it is trained on pairs of microscopy images and molecules using ViT as image encoder and MolGPS for molecules. Experiments report massive 10x improvements in Top-1% recall of active molecules over previous SOTA 👏.
Weekend reading:
TabGraphs: A Benchmark and Strong Baselines for Learning on Graphs with Tabular Node Features by Gleb Bazhenov et al - a fresh collection of new graph datasets where features are interpretable (numerical, categorical) - a stark contrast to boring text-attributed graphs or Planetoid datasets with bag-of-words as features.
Design of Ligand-Binding Proteins with Atomic Flow Matching by Junqi Liu et al feat. Jian Tang - generate a docked protein-ligand 3D structure conditioned just on 2D ligand graph and protein sequence with flow matching. Outperforms RFDiffusionAA on several metrics.
GraphML News (Oct 5th) - ICLR 2025 Graph and Geometric DL Submissions
📚 Brace yourselves, for your browser is about to endure 50+ new tabs. All accepted NeurIPS 2024 papers are now visible (titles and abstracts), and a new batch of goodies from ICLR’25 has just arrived. Tried to select the papers that haven't yet appeared during the ICML/NeurIPS cycles. PDFs will be available on the respective OpenReview pages shortly:
Towards Graph Foundation Models:
GraphProp: Training the Graph Foundation Models using Graph Properties
GFSE: A Foundational Model For Graph Structural Encoding
Towards Neural Scaling Laws for Foundation Models on Temporal Graphs
Graph Generative Models:
Quality Measures for Dynamic Graph Generative Models
Improving Graph Generation with Flow Matching and Optimal Transport
Equivariant Denoisers Cannot Copy Graphs: Align Your Graph Diffusion Models
Topology-aware Graph Diffusion Model with Persistent Homology
Hierarchical Equivariant Graph Generation
Smooth Probabilistic Interpolation Benefits Generative Modeling for Discrete Graphs
GNN Theory:
Towards a Complete Logical Framework for GNN Expressiveness
Rethinking the Expressiveness of GNNs: A Computational Model Perspective
Learning Efficient Positional Encodings with Graph Neural Networks
Equivariant GNNs:
Improving Equivariant Networks with Probabilistic Symmetry Breaking
Does equivariance matter at scale?
Beyond Canonicalization: How Tensorial Messages Improve Equivariant Message Passing
Spacetime E(n) Transformer: Equivariant Attention for Spatio-temporal Graphs
Rethinking Efficient 3D Equivariant Graph Neural Networks
Generative modeling with molecules (hundreds of them actually):
AssembleFlow: Rigid Flow Matching with Inertial Frames for Molecular Assembly
RoFt-Mol: Benchmarking Robust Fine-tuning with Molecular Graph Foundation Models
Multi-Modal Foundation Models Induce Interpretable Molecular Graph Languages
MolSpectra: Pre-training 3D Molecular Representation with Multi-modal Energy Spectra
Reaction Graph: Toward Modeling Chemical Reactions with 3D Molecular Structures
Accelerating 3D Molecule Generation via Jointly Geometric Optimal Transport
📚 Brace yourselves, for your browser is about to endure 50+ new tabs. All accepted NeurIPS 2024 papers are now visible (titles and abstracts), and a new batch of goodies from ICLR’25 has just arrived. Tried to select the papers that haven't yet appeared during the ICML/NeurIPS cycles. PDFs will be available on the respective OpenReview pages shortly:
Towards Graph Foundation Models:
GraphProp: Training the Graph Foundation Models using Graph Properties
GFSE: A Foundational Model For Graph Structural Encoding
Towards Neural Scaling Laws for Foundation Models on Temporal Graphs
Graph Generative Models:
Quality Measures for Dynamic Graph Generative Models
Improving Graph Generation with Flow Matching and Optimal Transport
Equivariant Denoisers Cannot Copy Graphs: Align Your Graph Diffusion Models
Topology-aware Graph Diffusion Model with Persistent Homology
Hierarchical Equivariant Graph Generation
Smooth Probabilistic Interpolation Benefits Generative Modeling for Discrete Graphs
GNN Theory:
Towards a Complete Logical Framework for GNN Expressiveness
Rethinking the Expressiveness of GNNs: A Computational Model Perspective
Learning Efficient Positional Encodings with Graph Neural Networks
Equivariant GNNs:
Improving Equivariant Networks with Probabilistic Symmetry Breaking
Does equivariance matter at scale?
Beyond Canonicalization: How Tensorial Messages Improve Equivariant Message Passing
Spacetime E(n) Transformer: Equivariant Attention for Spatio-temporal Graphs
Rethinking Efficient 3D Equivariant Graph Neural Networks
Generative modeling with molecules (hundreds of them actually):
AssembleFlow: Rigid Flow Matching with Inertial Frames for Molecular Assembly
RoFt-Mol: Benchmarking Robust Fine-tuning with Molecular Graph Foundation Models
Multi-Modal Foundation Models Induce Interpretable Molecular Graph Languages
MolSpectra: Pre-training 3D Molecular Representation with Multi-modal Energy Spectra
Reaction Graph: Toward Modeling Chemical Reactions with 3D Molecular Structures
Accelerating 3D Molecule Generation via Jointly Geometric Optimal Transport
Generative modeling with proteins (hundreds of them either):
EquiJump: Protein Dynamics Simulation via SO(3)-Equivariant Stochastic Interpolants
Design of Ligand-Binding Proteins with Atomic Flow Matching
RapidDock: Unlocking Proteome-scale Molecular Docking
Deep Learning for Protein-Ligand Docking: Are We There Yet?
ProteinBench: A Holistic Evaluation of Protein Foundation Models
Fast and Accurate Blind Flexible Docking
Solving Inverse Problems in Protein Space Using Diffusion-Based Priors
Crystals and Materials:
Flow Matching for Accelerated Simulation of Atomic Transport in Materials
MOFFlow: Flow Matching for Structure Prediction of Metal-Organic Frameworks
Learning the Hamiltonian of Disordered Materials with Equivariant Graph Networks
Designing Mechanical Meta-Materials by Learning Equivariant Flows
SymmCD: Symmetry-Preserving Crystal Generation with Diffusion Models
Rethinking the role of frames for SE(3)-invariant crystal structure modeling
A Periodic Bayesian Flow for Material Generation
ECD: A Machine Learning Benchmark for Predicting Enhanced-Precision Electronic Charge Density in Crystalline Inorganic Materials
Wyckoff Transformer: Generation of Symmetric Crystals
PDDFormer: Pairwise Distance Distribution Graph Transformer for Crystal Material Property Prediction
EquiJump: Protein Dynamics Simulation via SO(3)-Equivariant Stochastic Interpolants
Design of Ligand-Binding Proteins with Atomic Flow Matching
RapidDock: Unlocking Proteome-scale Molecular Docking
Deep Learning for Protein-Ligand Docking: Are We There Yet?
ProteinBench: A Holistic Evaluation of Protein Foundation Models
Fast and Accurate Blind Flexible Docking
Solving Inverse Problems in Protein Space Using Diffusion-Based Priors
Crystals and Materials:
Flow Matching for Accelerated Simulation of Atomic Transport in Materials
MOFFlow: Flow Matching for Structure Prediction of Metal-Organic Frameworks
Learning the Hamiltonian of Disordered Materials with Equivariant Graph Networks
Designing Mechanical Meta-Materials by Learning Equivariant Flows
SymmCD: Symmetry-Preserving Crystal Generation with Diffusion Models
Rethinking the role of frames for SE(3)-invariant crystal structure modeling
A Periodic Bayesian Flow for Material Generation
ECD: A Machine Learning Benchmark for Predicting Enhanced-Precision Electronic Charge Density in Crystalline Inorganic Materials
Wyckoff Transformer: Generation of Symmetric Crystals
PDDFormer: Pairwise Distance Distribution Graph Transformer for Crystal Material Property Prediction
GraphML News (Oct 12th) - Nobel Prizes, Mediterranean ML Summer School
🏅If you lived under the rock this week, Deep Learning got two Nobel Prizes this year: Geoff Hinton and John Hopfield got the physics prize (less expected), and David Baker, John Jumper, and Demis Hassabis got the chemistry prize (more than expected after AF 2 received almost all other scientific awards). The acknowledgement of deep learning advancements was not rushed as it might seem - it took already 10+ years since the ImageNet revolution and the entire new industry has grown on top of it. It roughly took the same time for CRISPR (another chemistry Nobel Prize in 2020) to get acknowledged. What does the prizes mean for the field and industry (other than DL researchers could claim to be a bit of physicists and chemists themselves)?
It is likely that AI 4 Science as a field in general would receive a significant attention with more researchers entering the area and more funding for commercializing some of the tech behind it. The potential of using DL methods in accelerating scientific discovery is still largely untapped (yes, Geometric DL did enable the recent successes in protein design and pharma but, for example, we can’t say that protein generative models truly learn underlying physics phenomena for now), so it is as exciting time as ever to start your research journey in this area. There is a plenty of space to do impactful research and we’ll probably see more labs and companies pivoting there. (Fun fact - brace yourselves as every 2nd talk at NeurIPS 2024 would probably start with the same Nobel Prize slides).
📺 The recordings of the Mediterranean ML Summer School are finally available! The school took place in September in Milan packing a week of talks on transformers, reasoning, diffusion models and flow matching, GNNs, RL, RLHF, optimization, and many more.
Weekend reading (while waiting for ICLR papers to go public) is featuring a fresh lineup of works by Google DeepMind on studying the guts of transformers:
softmax is not enough (for sharp out-of-distribution) by Petar Veličković et al arguing that softmax necessarily looses sharpness on longer OOD inputs
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning by Artur Back de Luca, George Giapitzakis, Shenghao Yang et al
Round and Round We Go! What makes Rotary Positional Encodings useful? by Federico Barbero et al
🏅If you lived under the rock this week, Deep Learning got two Nobel Prizes this year: Geoff Hinton and John Hopfield got the physics prize (less expected), and David Baker, John Jumper, and Demis Hassabis got the chemistry prize (more than expected after AF 2 received almost all other scientific awards). The acknowledgement of deep learning advancements was not rushed as it might seem - it took already 10+ years since the ImageNet revolution and the entire new industry has grown on top of it. It roughly took the same time for CRISPR (another chemistry Nobel Prize in 2020) to get acknowledged. What does the prizes mean for the field and industry (other than DL researchers could claim to be a bit of physicists and chemists themselves)?
It is likely that AI 4 Science as a field in general would receive a significant attention with more researchers entering the area and more funding for commercializing some of the tech behind it. The potential of using DL methods in accelerating scientific discovery is still largely untapped (yes, Geometric DL did enable the recent successes in protein design and pharma but, for example, we can’t say that protein generative models truly learn underlying physics phenomena for now), so it is as exciting time as ever to start your research journey in this area. There is a plenty of space to do impactful research and we’ll probably see more labs and companies pivoting there. (Fun fact - brace yourselves as every 2nd talk at NeurIPS 2024 would probably start with the same Nobel Prize slides).
📺 The recordings of the Mediterranean ML Summer School are finally available! The school took place in September in Milan packing a week of talks on transformers, reasoning, diffusion models and flow matching, GNNs, RL, RLHF, optimization, and many more.
Weekend reading (while waiting for ICLR papers to go public) is featuring a fresh lineup of works by Google DeepMind on studying the guts of transformers:
softmax is not enough (for sharp out-of-distribution) by Petar Veličković et al arguing that softmax necessarily looses sharpness on longer OOD inputs
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning by Artur Back de Luca, George Giapitzakis, Shenghao Yang et al
Round and Round We Go! What makes Rotary Positional Encodings useful? by Federico Barbero et al
GraphML News (Oct 19th) - Orb-v2, OMat24, Stanford Graph Learning Seminar, new PhD positions
🔥 The competition in materials science heats up: ML potentials (models that estimate the potential energy of an atomistic system and often predict energy, forces, and stresses) are one of the main drivers in the field as they can significantly speed up expensive molecular dynamics (MD) calculations. Matbench Discovery is one of the main benchmarks for ML potentials.
🔮 During the week, Orbital Materials released the code and weights of Orb-v2, the next version of the non-equivariant MPNN (Orbital folks explicitly bet against equivariant GNNs) that outperforms mighty MatterSim from MSR with just 25M parameters. Besides, Orb-v2 offers increased stability during MD calculations.
📈 A few days later, FAIR chemistry released OMat24, a new large dataset with 100M+ structures for training ML potentials (much larger than existing datasets) that required 400M+ core hours to complete DFT calculations for (preprint). Together with OMat24, FAIR released EquiformerV2, equivariant transformer, pre-trained on this dataset and fine-tuned on MatBench discovery (using just 64 A100s - 🌚 an entry-level 🌚 of compute those days) and claimed SOTA on Matbench Discovery. Interestingly, Equiformer got a significant performance boost when trained with the denoising objective - similar to what Orb models are trained on. It is likely that the benchmark will be fully saturated next year.
Meanwhile, Google DeepMind together with Japanese institutes released a paper on applying GNoME (the flagship tool for materials discovery introduced last year) to synthesizing cesium chlorides.
🎙️ The Stanford Graph Learning Workshop will take place on November 5th physically at Stanford with the online stream, expect some new announcements and releases!
🎓 Finally, the application season for PhD positions and internships is open: we’d highlight the call for fully-funded PhD positions from Viacheslav Borovitskiy at the University of Edinburgh on Geometric Learning and Uncertainty Quantification (Geometric Kernels is one of the most recent works). Application deadline: Dec 15th, start date: September 2025.
Let us know if your lab is hiring this season and we’ll compile a larger list of open geometric learning positions!
Weekend reading:
PDFs of ICLR 2025 submissions are now visible - you can open and read everything from the list we prepared a few weeks ago.
🔥 The competition in materials science heats up: ML potentials (models that estimate the potential energy of an atomistic system and often predict energy, forces, and stresses) are one of the main drivers in the field as they can significantly speed up expensive molecular dynamics (MD) calculations. Matbench Discovery is one of the main benchmarks for ML potentials.
🔮 During the week, Orbital Materials released the code and weights of Orb-v2, the next version of the non-equivariant MPNN (Orbital folks explicitly bet against equivariant GNNs) that outperforms mighty MatterSim from MSR with just 25M parameters. Besides, Orb-v2 offers increased stability during MD calculations.
📈 A few days later, FAIR chemistry released OMat24, a new large dataset with 100M+ structures for training ML potentials (much larger than existing datasets) that required 400M+ core hours to complete DFT calculations for (preprint). Together with OMat24, FAIR released EquiformerV2, equivariant transformer, pre-trained on this dataset and fine-tuned on MatBench discovery (using just 64 A100s - 🌚 an entry-level 🌚 of compute those days) and claimed SOTA on Matbench Discovery. Interestingly, Equiformer got a significant performance boost when trained with the denoising objective - similar to what Orb models are trained on. It is likely that the benchmark will be fully saturated next year.
Meanwhile, Google DeepMind together with Japanese institutes released a paper on applying GNoME (the flagship tool for materials discovery introduced last year) to synthesizing cesium chlorides.
🎙️ The Stanford Graph Learning Workshop will take place on November 5th physically at Stanford with the online stream, expect some new announcements and releases!
🎓 Finally, the application season for PhD positions and internships is open: we’d highlight the call for fully-funded PhD positions from Viacheslav Borovitskiy at the University of Edinburgh on Geometric Learning and Uncertainty Quantification (Geometric Kernels is one of the most recent works). Application deadline: Dec 15th, start date: September 2025.
Let us know if your lab is hiring this season and we’ll compile a larger list of open geometric learning positions!
Weekend reading:
PDFs of ICLR 2025 submissions are now visible - you can open and read everything from the list we prepared a few weeks ago.
GraphML News (Oct 26th) - LOG meetups, Orbital round, ESANN 2025
🍻 The Learning of Graphs conference continues to update the list of local meetups - the networks already includes 13 places from well-known graph learning places like Stanford, NYC, Paris, Oxford, Aachen, Amsterdam, Tel Aviv down to Tromsø, Uppsala, Siena, New Delhi, Suzhou, and Vancouver (Late November in Tromsø, talking graphs with a cup of glühwein and snow outside must be a quite a cozy venue). The call for meetups is still open!
On this note, the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2025) will host 3 special sessions on graph learning: Foundation and Generative Models for Graphs, Graph Generation for Life Sciences, and Network Science Meets AI. Submission deadline is November 20, 6 pages tops. Thanks to Manuel Dileo for the pointer! ESANN 2025 will take place on April 23-25 (2025) in Bruges (jokes about the movie and Tottenham are welcome).
💸 Orbital Materials secured a new funding round led by NVIDIA Ventures (financial details undisclosed) – timed nicely coinciding with the recent release of the ML potential GNN Orb-v2. A new unicorn from AI 4 Science is coming? 🤔
Weekend reading:
Learning Graph Quantized Tokenizers for Transformers by Limei Wang, Kaveh Hassani et al and Meta - an unorthodox approach for graph tokenization via vector quantization and codebook learning, conceptually similar to VQ-GNNs (NeurIPS 2021), strange to not see this older paper cited
Relaxed Equivariance via Multitask Learning by Ahmed Elhag et al feat Michael Bronstein - instead of baking equivariances right into models, let’s add it as a loss component and allow a model to learn and use as much equivariance as necessary, brings 10x inference speedups.
Homomorphism Counts as Structural Encodings for Graph Learning by Linus Bao, Emily Jin, et al - introduces motif structural encoding (MoSE) for graph transformers. Paired with GraphGPS, brings MAE on ZINC from 0.07 down to 0.062 and to 0.056 with GRIT.
🍻 The Learning of Graphs conference continues to update the list of local meetups - the networks already includes 13 places from well-known graph learning places like Stanford, NYC, Paris, Oxford, Aachen, Amsterdam, Tel Aviv down to Tromsø, Uppsala, Siena, New Delhi, Suzhou, and Vancouver (Late November in Tromsø, talking graphs with a cup of glühwein and snow outside must be a quite a cozy venue). The call for meetups is still open!
On this note, the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2025) will host 3 special sessions on graph learning: Foundation and Generative Models for Graphs, Graph Generation for Life Sciences, and Network Science Meets AI. Submission deadline is November 20, 6 pages tops. Thanks to Manuel Dileo for the pointer! ESANN 2025 will take place on April 23-25 (2025) in Bruges (jokes about the movie and Tottenham are welcome).
💸 Orbital Materials secured a new funding round led by NVIDIA Ventures (financial details undisclosed) – timed nicely coinciding with the recent release of the ML potential GNN Orb-v2. A new unicorn from AI 4 Science is coming? 🤔
Weekend reading:
Learning Graph Quantized Tokenizers for Transformers by Limei Wang, Kaveh Hassani et al and Meta - an unorthodox approach for graph tokenization via vector quantization and codebook learning, conceptually similar to VQ-GNNs (NeurIPS 2021), strange to not see this older paper cited
Relaxed Equivariance via Multitask Learning by Ahmed Elhag et al feat Michael Bronstein - instead of baking equivariances right into models, let’s add it as a loss component and allow a model to learn and use as much equivariance as necessary, brings 10x inference speedups.
Homomorphism Counts as Structural Encodings for Graph Learning by Linus Bao, Emily Jin, et al - introduces motif structural encoding (MoSE) for graph transformers. Paired with GraphGPS, brings MAE on ZINC from 0.07 down to 0.062 and to 0.056 with GRIT.
GraphML News (Nov 2nd) - The Debate on Equivariance, MoML and Stanford Graph workshop
🎃 Writing ICLR reviews and LOG rebuttals might have delivered you enough of the Halloween spirit with spooky papers and (semi)undead reviewers - it’s almost over though!
🥊 The debate on equivariance, namely, is it worth to bake symmetries right into the model or learn from data, remains to be a hot topic in the community with new evidence appearing every week supporting both sides. Is
In the blue corner, the work Does equivariance matter at scale? by Johann Brehmer et al compares a vanilla transformer with the E(3)-equivariant Geometric Algebra Transformer (GATr) on the rigid-body modelling task with a wide range of sizes to derive scaling laws (akin to Kaplan and Chinchilla laws) and finds that the equivariant transformer scales better overall.
In the red corner, we have The Importance of Being Scalable: Improving the Speed and Accuracy of Neural Network Interatomic Potentials Across Chemical Domains by Eric Qu et al who modify a vanilla transformer and outperform hefty Equiformer, GemNet, and MACE on ML potential benchmarks on molecules and crystals. Another wrestler in the red corner is the tech report on ORB v2 by Mark Neumann and Orbital Materials - ORB v2 is a vanilla MPNN potential trained with a denoising objective and delivers SOTA (or close to) performance while trained on only 8 A100s (compared to 64+ GPUs needed for Equiformer V2 but subject to different training datasets).
🏆 Overall, “no equivariance” wins this week 2-1 (2.5 - 1 if including a recent work on relaxed equivariance).
🎤 Next Tuesday, Nov 5th, is not just the election day in the US, but also the day of two graph learning events: MoML 2024 at MIT and the Graph Learning Workshop 2024 at Stanford. Programs of both events are now visible and there might be livestreams as well, keep an eye on the announcements.
Weekend reading:
Generator Matching: Generative modeling with arbitrary Markov processes by Peter Holderrieth feat. Ricky Chen and Yaron Lipman - a generalization of diffusion, flow matching (both continuous and discrete), and jump processes (outstanding paper award at ICLR’24). Expect a new generation of generative models for images / proteins / molecules / SBDD / RNAs / crystals to adopt this next year.
Long-context Protein Language Model by Yingheng Wang and (surprisingly) Amazon team - introduces a Mamba-based bidirectional protein LM that outperforms ESM-2 on a variety of tasks while being much smaller and faster.
Iambic announced NeuralPLexer 3 competitive with AlphaFold 3. While we are waiting for the tech report and more experiments, it seems that NP3 features Triton kernels for efficient triangular attention akin to FlashAttention but on triples of nodes.
🎃 Writing ICLR reviews and LOG rebuttals might have delivered you enough of the Halloween spirit with spooky papers and (semi)undead reviewers - it’s almost over though!
🥊 The debate on equivariance, namely, is it worth to bake symmetries right into the model or learn from data, remains to be a hot topic in the community with new evidence appearing every week supporting both sides. Is
torch.nn.TransformerEncoder all you need?In the blue corner, the work Does equivariance matter at scale? by Johann Brehmer et al compares a vanilla transformer with the E(3)-equivariant Geometric Algebra Transformer (GATr) on the rigid-body modelling task with a wide range of sizes to derive scaling laws (akin to Kaplan and Chinchilla laws) and finds that the equivariant transformer scales better overall.
In the red corner, we have The Importance of Being Scalable: Improving the Speed and Accuracy of Neural Network Interatomic Potentials Across Chemical Domains by Eric Qu et al who modify a vanilla transformer and outperform hefty Equiformer, GemNet, and MACE on ML potential benchmarks on molecules and crystals. Another wrestler in the red corner is the tech report on ORB v2 by Mark Neumann and Orbital Materials - ORB v2 is a vanilla MPNN potential trained with a denoising objective and delivers SOTA (or close to) performance while trained on only 8 A100s (compared to 64+ GPUs needed for Equiformer V2 but subject to different training datasets).
🏆 Overall, “no equivariance” wins this week 2-1 (2.5 - 1 if including a recent work on relaxed equivariance).
🎤 Next Tuesday, Nov 5th, is not just the election day in the US, but also the day of two graph learning events: MoML 2024 at MIT and the Graph Learning Workshop 2024 at Stanford. Programs of both events are now visible and there might be livestreams as well, keep an eye on the announcements.
Weekend reading:
Generator Matching: Generative modeling with arbitrary Markov processes by Peter Holderrieth feat. Ricky Chen and Yaron Lipman - a generalization of diffusion, flow matching (both continuous and discrete), and jump processes (outstanding paper award at ICLR’24). Expect a new generation of generative models for images / proteins / molecules / SBDD / RNAs / crystals to adopt this next year.
Long-context Protein Language Model by Yingheng Wang and (surprisingly) Amazon team - introduces a Mamba-based bidirectional protein LM that outperforms ESM-2 on a variety of tasks while being much smaller and faster.
Iambic announced NeuralPLexer 3 competitive with AlphaFold 3. While we are waiting for the tech report and more experiments, it seems that NP3 features Triton kernels for efficient triangular attention akin to FlashAttention but on triples of nodes.
arXiv.org
Does equivariance matter at scale?
Given large datasets and sufficient compute, is it beneficial to design neural architectures for the structure and symmetries of each problem? Or is it more efficient to learn them from data? We...
GraphML News (Nov 9th) - ELLIS PhD Applications, Protenix AF3, New papers
The next week is going to be busy with ICLR rebuttals, so we still have a bit of time to check the news and read new papers.
🎓 The call for PhD applications within ELLIS, the European network of ML and DL labs, is ending soon (November 15th) - this is a great opportunity to start (or continue) your academic journey in a top machine learning lab!
🧬 ByteDance released Protenix, a trainable PyTorch reproduction of AlphaFold 3, with model checkpoints (so you can run it locally) and with the inference server. The tech report is coming, would be interesting to compare with Chai-1 and other open source reproductions.
Weekend reading:
A Cosmic-Scale Benchmark for Symmetry-Preserving Data Processing by Julia Balla et al feat Tess Smidt - introduces cool new graph datasets - given a point cloud of 5000 galaxies, predict their cosmological properties on the graph level and node level (eg, galaxy velocity).
FlowLLM: Flow Matching for Material Generation with Large Language Models as Base Distributions by Anuroop Sriram and FAIR (NeurIPS 24): extension of FlowMM (ICML 2024), a flow matching model for crystal structure generation, but now instead of sampling from a Gaussian, the authors fine-tuned LLaMa 2 on the Materials Project to sample 10000 candidates (using just a small academic budget of 300 A100 gpus) - this prior yields 3x more stable structures.
Flow Matching for Accelerated Simulation of Atomic Transport in Materials by Juno Nam and MIT team feat. Rafael Gómez-Bombarelli - introduces LiFlow, a flow matching model for MD simulations of crystalline materials: where ab-initio methods would take 340 days to simulate 1 ns of a 200-atoms structure, LiFlow takes only 48 seconds 🏎️
The next week is going to be busy with ICLR rebuttals, so we still have a bit of time to check the news and read new papers.
🎓 The call for PhD applications within ELLIS, the European network of ML and DL labs, is ending soon (November 15th) - this is a great opportunity to start (or continue) your academic journey in a top machine learning lab!
🧬 ByteDance released Protenix, a trainable PyTorch reproduction of AlphaFold 3, with model checkpoints (so you can run it locally) and with the inference server. The tech report is coming, would be interesting to compare with Chai-1 and other open source reproductions.
Weekend reading:
A Cosmic-Scale Benchmark for Symmetry-Preserving Data Processing by Julia Balla et al feat Tess Smidt - introduces cool new graph datasets - given a point cloud of 5000 galaxies, predict their cosmological properties on the graph level and node level (eg, galaxy velocity).
FlowLLM: Flow Matching for Material Generation with Large Language Models as Base Distributions by Anuroop Sriram and FAIR (NeurIPS 24): extension of FlowMM (ICML 2024), a flow matching model for crystal structure generation, but now instead of sampling from a Gaussian, the authors fine-tuned LLaMa 2 on the Materials Project to sample 10000 candidates (using just a small academic budget of 300 A100 gpus) - this prior yields 3x more stable structures.
Flow Matching for Accelerated Simulation of Atomic Transport in Materials by Juno Nam and MIT team feat. Rafael Gómez-Bombarelli - introduces LiFlow, a flow matching model for MD simulations of crystalline materials: where ab-initio methods would take 340 days to simulate 1 ns of a 200-atoms structure, LiFlow takes only 48 seconds 🏎️
👍1
GraphML News (Nov 16th) - ICLR 2025 Stats, Official AlphaFold 3 and RFam, Faster MD
📊 PaperCopilot comprised the basic statistics of ICLR 2025 initial reviews and best scored papers - a few GNN papers are in top-100 and we’ll keep an eye on them! Meanwhile, Azmine Toushik Wasi compiled a list of accepted graph papers at NeurIPS 2024 grouped by categories - from GNN theory to generative models to transformers to OOD generalization and many more.
🧬 Google DeepMind finally released the official code for AlphaFold 3 featuring a monstrous 3k lines of code Structure class and some kernels implemented in Triton (supporting the fact that Triton is the future and you should implement your most expensive neural net ops as efficient kernelized ops). Somewhat orthogonally to AF3, the Baker Lab presented RFam, the improved version of RFdiffusion, in a paper about metallohydrolases. RFam now uses flow matching (welcome on board), allows for scaffolding arbitrary atom-level motifs and sequence-position-agnostic scaffolding. Waiting for the code soon!
🏎️ Microsoft Research announced AI2BMD - a freshly accepted to Nature method for accelerating ab-initio molecular dynamics of proteins with equivariant GNNs (based on VisNet, already in PyG) scaling it up to impressive 10k atoms in a structure (far beyond the capabilities of standard MD tools). Besides, the authors collected a new dataset of 20M DFT-computed snapshots which would be of great help to the MD community.
🌊 Continuing the simulation note, NXAI and JKU Linz presented NeuralDEM, a neural approach to replace Discrete Element Method (DEM) in complex physical simulations (like fluid dynamics) with transformers and neural operators. NeuralDEM is as accurate and stable as vanilla DEM while being much faster and allowing for longer sim times.
Weekend reading:
Generalization, Expressivity, and Universality of Graph Neural Networks on Attributed Graphs by Levi Rauchwerger, Stefanie Jegelka, and Ron Levie - it is known that the vanilla WL test assumes no node features. This is one of the first works to study GNN properties on featurized graphs.
GraphMETRO: Mitigating Complex Graph Distribution Shifts via Mixture of Aligned Experts by Shirley Wu et al feat. Bruno Ribeiro and Jure Leskovec
Scalable Message Passing Neural Networks: No Need for Attention in Large Graph Representation Learning by Haitz Borde et al feat. Michael Bronstein - a transformer-like block where multi-head attention is replaced with a GCN (keeping layer norms, residual stream and MLPs intact) is suprisingly competitive on very large graphs
📊 PaperCopilot comprised the basic statistics of ICLR 2025 initial reviews and best scored papers - a few GNN papers are in top-100 and we’ll keep an eye on them! Meanwhile, Azmine Toushik Wasi compiled a list of accepted graph papers at NeurIPS 2024 grouped by categories - from GNN theory to generative models to transformers to OOD generalization and many more.
🧬 Google DeepMind finally released the official code for AlphaFold 3 featuring a monstrous 3k lines of code Structure class and some kernels implemented in Triton (supporting the fact that Triton is the future and you should implement your most expensive neural net ops as efficient kernelized ops). Somewhat orthogonally to AF3, the Baker Lab presented RFam, the improved version of RFdiffusion, in a paper about metallohydrolases. RFam now uses flow matching (welcome on board), allows for scaffolding arbitrary atom-level motifs and sequence-position-agnostic scaffolding. Waiting for the code soon!
🏎️ Microsoft Research announced AI2BMD - a freshly accepted to Nature method for accelerating ab-initio molecular dynamics of proteins with equivariant GNNs (based on VisNet, already in PyG) scaling it up to impressive 10k atoms in a structure (far beyond the capabilities of standard MD tools). Besides, the authors collected a new dataset of 20M DFT-computed snapshots which would be of great help to the MD community.
🌊 Continuing the simulation note, NXAI and JKU Linz presented NeuralDEM, a neural approach to replace Discrete Element Method (DEM) in complex physical simulations (like fluid dynamics) with transformers and neural operators. NeuralDEM is as accurate and stable as vanilla DEM while being much faster and allowing for longer sim times.
Weekend reading:
Generalization, Expressivity, and Universality of Graph Neural Networks on Attributed Graphs by Levi Rauchwerger, Stefanie Jegelka, and Ron Levie - it is known that the vanilla WL test assumes no node features. This is one of the first works to study GNN properties on featurized graphs.
GraphMETRO: Mitigating Complex Graph Distribution Shifts via Mixture of Aligned Experts by Shirley Wu et al feat. Bruno Ribeiro and Jure Leskovec
Scalable Message Passing Neural Networks: No Need for Attention in Large Graph Representation Learning by Haitz Borde et al feat. Michael Bronstein - a transformer-like block where multi-head attention is replaced with a GCN (keeping layer norms, residual stream and MLPs intact) is suprisingly competitive on very large graphs
GLOW Reading Group on Nov 20th
🌟 Graph Learning on Wednesdays (GLOW) is a new reading group about foundations and latest developments in Graph Machine Learning - its inaugural meeting was held on Oct 9th, and the next one is happening on Wednesday, Nov 20th at 5pm CET (11am Eastern) featuring two papers presented by the first authors:
- On the Expressivity and Sample Complexity of Node-Individualized Graph Neural Networks by Paolo Pelizzoni
- Graph Neural Networks Use Graphs When They Shouldn’t by Maya Bechler-Speicher
The format of the RG is rather interactive: short presentations by the authors are followed by discussions and brainstorms, and sometimes expert panels study the paper together. Consider joining on Wednesday!
🌟 Graph Learning on Wednesdays (GLOW) is a new reading group about foundations and latest developments in Graph Machine Learning - its inaugural meeting was held on Oct 9th, and the next one is happening on Wednesday, Nov 20th at 5pm CET (11am Eastern) featuring two papers presented by the first authors:
- On the Expressivity and Sample Complexity of Node-Individualized Graph Neural Networks by Paolo Pelizzoni
- Graph Neural Networks Use Graphs When They Shouldn’t by Maya Bechler-Speicher
The format of the RG is rather interactive: short presentations by the authors are followed by discussions and brainstorms, and sometimes expert panels study the paper together. Consider joining on Wednesday!
GraphML News (Nov 23rd) - LOG 2024, Boltz-1 and Chai-1r, OCx24, cuEquivariance
🎙️ LOG 2024 starts next Tuesday! The schedule of orals and posters is already available, registration is free, we’ll be happy to see you there online or at one of many local meetups!
🧬 The “Stable Diffusion moment” in generative models for structural biology is spinning up: two models released during the past week starting with fully open-source Boltz-1 from MIT (tech report, code) that achieves AF3-like quality and outperforms a recent Chai-1 (open inference code). Meanwhile, Chai folks released Chai-1r that supports complexes with user-specified restraints - and already compared with Boltz-1. Open source and competition really drive the field forward 👏 The next step for AF3-like models seems to be integrating the recent GPU-enabled MSA tool MMSeqs2-GPU that might shave off another order of magnitude of inference time of protein structure prediction models.
🧊 FAIR Chemistry at Meta, University of Toronto, and VSParticle presented Open Catalyst experiments (OCx24) - a new dataset of 600 mixed metal catalysts synthesized and probed physically in the lab (a huge step beyond DFT-only simulations) along with analytical data for 19k catalyst materials with 685M relaxations. It’s already the 3rd huge dataset openly published by Meta in addition to OpenDAC and OMAT - Meta is a firm leader in this area of AI 4 Science. Fun fact: models from the Open Catalyst ecosystem are directly used in Meta’s products like recent Orion AR glasses.
🔱 Faster spherical harmonics and tensor products for geometric GNNs: following EquiTriton, an open-source collection of Triton kernels for fast and memory-efficient computation of spherical harmonics developed by Intel Labs (enabling harmonics of up to the 10th order), NVIDIA released cuEquivariance - CUDA kernels (closed-source kernels with public bindings for PyTorch, JAX, and numpy) for spherical harmonics and tensor products which speed up DiffDock, MACE and other models by 2-20x, this is especially useful in tasks where a model is called multiple times like a generative model or MD calculations. cuEquivariance is a part of the new BioNeMo suite for drug discovery.
Weekend reading:
📚 Check out accepted orals and posters of LOG 2024 on OpenReview
🎙️ LOG 2024 starts next Tuesday! The schedule of orals and posters is already available, registration is free, we’ll be happy to see you there online or at one of many local meetups!
🧬 The “Stable Diffusion moment” in generative models for structural biology is spinning up: two models released during the past week starting with fully open-source Boltz-1 from MIT (tech report, code) that achieves AF3-like quality and outperforms a recent Chai-1 (open inference code). Meanwhile, Chai folks released Chai-1r that supports complexes with user-specified restraints - and already compared with Boltz-1. Open source and competition really drive the field forward 👏 The next step for AF3-like models seems to be integrating the recent GPU-enabled MSA tool MMSeqs2-GPU that might shave off another order of magnitude of inference time of protein structure prediction models.
🧊 FAIR Chemistry at Meta, University of Toronto, and VSParticle presented Open Catalyst experiments (OCx24) - a new dataset of 600 mixed metal catalysts synthesized and probed physically in the lab (a huge step beyond DFT-only simulations) along with analytical data for 19k catalyst materials with 685M relaxations. It’s already the 3rd huge dataset openly published by Meta in addition to OpenDAC and OMAT - Meta is a firm leader in this area of AI 4 Science. Fun fact: models from the Open Catalyst ecosystem are directly used in Meta’s products like recent Orion AR glasses.
🔱 Faster spherical harmonics and tensor products for geometric GNNs: following EquiTriton, an open-source collection of Triton kernels for fast and memory-efficient computation of spherical harmonics developed by Intel Labs (enabling harmonics of up to the 10th order), NVIDIA released cuEquivariance - CUDA kernels (closed-source kernels with public bindings for PyTorch, JAX, and numpy) for spherical harmonics and tensor products which speed up DiffDock, MACE and other models by 2-20x, this is especially useful in tasks where a model is called multiple times like a generative model or MD calculations. cuEquivariance is a part of the new BioNeMo suite for drug discovery.
Weekend reading:
📚 Check out accepted orals and posters of LOG 2024 on OpenReview
👍2
GraphML News (Nov 30th) - LOG recordings, The Chip Has Sailed, Illustrated Flow Matching
📺 LOG 2024 has just wrapped up, and all recordings are now available on the official YouTube channel, featuring:
- Keynotes from Yusu Wang (UCSD), Zach Ulissi (Meta), Xavier Bresson (NUS), Alden Hung (Isomorphic Labs)
- Tutorials on geometric generative models, neural algorithmic reasoning, GNNs for time series, heterophilic graph learning, and KGs + LLMs
- All oral presentations
A lot of stuff to digest over the weekend if you missed it!
⛵️ The GNNs for chip design saga continues:
- the seminal 2021 Nature paper (now known as AlphaChip) spun off some controversy from the chip design community about reproducibility (however, other people say it’s rather a skill issue and the CD community just doesn’t have proper deep learning chops),
- several rounds of message exchange led to the official Addendum on the Nature paper clarifying the concerns and adding that pre-training is a must.
- In Oct 2024, Igor Markov (Synopsys) published an article at ACM Communications with a further criticism of the approach.
- Recently, in Nov 2024, the lead authors of AlphaChip (Anna Goldie, Azalia Mirhoseini, and Jeff Dean himself) recently put an arxiv paper The Chip Has Sailed with the full timeline and emphasizing that the approach is actually already working within Google and AlphaChip has been used in several generations of chips used in production.
Perhaps one of the most important messages from this paper is that while academics and industry debate whether the approach could work, it is actually already working. We’ll keep you posted!
🖌️ A Visual Dive into Conditional Flow Matching by Anne Gagneux, Ségolène Martin, Rémi Emonet, Quentin Bertrand, and Mathurin Massias to flow matching is what the Illustrated Transformer to transformers - a detailed visual guide on the inner workings of flow matching and math behind it, a highly recommended reading.
🪠 PLUMBER from Bioptic is the new protein-ligand benchmark of 1.8M data points based on PLINDER and enriched with more data from BindingDB, ChEMBL, and BioLip 2 to probe robustness of protein-ligand binding models in more diverse compositional generalization tests.
📺 LOG 2024 has just wrapped up, and all recordings are now available on the official YouTube channel, featuring:
- Keynotes from Yusu Wang (UCSD), Zach Ulissi (Meta), Xavier Bresson (NUS), Alden Hung (Isomorphic Labs)
- Tutorials on geometric generative models, neural algorithmic reasoning, GNNs for time series, heterophilic graph learning, and KGs + LLMs
- All oral presentations
A lot of stuff to digest over the weekend if you missed it!
⛵️ The GNNs for chip design saga continues:
- the seminal 2021 Nature paper (now known as AlphaChip) spun off some controversy from the chip design community about reproducibility (however, other people say it’s rather a skill issue and the CD community just doesn’t have proper deep learning chops),
- several rounds of message exchange led to the official Addendum on the Nature paper clarifying the concerns and adding that pre-training is a must.
- In Oct 2024, Igor Markov (Synopsys) published an article at ACM Communications with a further criticism of the approach.
- Recently, in Nov 2024, the lead authors of AlphaChip (Anna Goldie, Azalia Mirhoseini, and Jeff Dean himself) recently put an arxiv paper The Chip Has Sailed with the full timeline and emphasizing that the approach is actually already working within Google and AlphaChip has been used in several generations of chips used in production.
Perhaps one of the most important messages from this paper is that while academics and industry debate whether the approach could work, it is actually already working. We’ll keep you posted!
🖌️ A Visual Dive into Conditional Flow Matching by Anne Gagneux, Ségolène Martin, Rémi Emonet, Quentin Bertrand, and Mathurin Massias to flow matching is what the Illustrated Transformer to transformers - a detailed visual guide on the inner workings of flow matching and math behind it, a highly recommended reading.
🪠 PLUMBER from Bioptic is the new protein-ligand benchmark of 1.8M data points based on PLINDER and enriched with more data from BindingDB, ChEMBL, and BioLip 2 to probe robustness of protein-ligand binding models in more diverse compositional generalization tests.
GraphML News (Dec 8th) - NeurIPS’24, ESM Cambrian, Antiviral Competition, The Well
🍻 NeurIPS 2024 starts next week, the full schedule is available, the main conference is scheduled for Wed-Fri with two days of workshops (Sat-Sun) and unknown amount of private parties and gatherings throughout the week. See you in Vancouver!
🧬 EvolutionaryScale announced ESM Cambrian (ESM C), a new family of embedding models replacing ESM-2 with better performance across all sizes (300M, 600M, and 6B), dramatically smaller memory requirements and faster inference (think of Triton kernels here). ESM C was trained on UniRef, MGnify, and JGI data, smaller models are already available on GitHub, the 6B is available through the API service.
💊 Polaris Hub launches the Antiviral Competition together with ASAP discovery and OpenADMET. The competition includes three tracks:
- Predicting ligand poses of MERS-CoV based on SARS-CoV2 structures (metric: RMSD)
- Predicting ligand fluorescence potencies based on SARS and MERS data (metrics: MAE of pIC50 and ranking)
- Predicting ligands’ ADMET properties (MAE and ranking)
The competition starts on Jan 13th and ends on March 25th, prepare your big GNNs ⚔️
⚛️ After the announcement in May, MSR released the code and weights of MatterSim, a universal ML potential akin to MACE-MP-0 and Orb models. MatterSim is based on the M3GNet message passing GNN and is available in 1M and 5M params versions.
🪣 Polymathic AI, Flatiron Institute, and a collab of universities and national labs released The Well, a 15 TB dataset of physical simulations (think PDEs and Neural Operators) covering 16 different areas from fluid dynamics to supernova explosions. In the accompanying preprint, the authors compared several variants of Fourier Neural Operators (FNO) and U-Nets. A great resource for scientific and industrial applications where expensive simulations eat up a huge bulk of supercomputers time.
🍻 NeurIPS 2024 starts next week, the full schedule is available, the main conference is scheduled for Wed-Fri with two days of workshops (Sat-Sun) and unknown amount of private parties and gatherings throughout the week. See you in Vancouver!
🧬 EvolutionaryScale announced ESM Cambrian (ESM C), a new family of embedding models replacing ESM-2 with better performance across all sizes (300M, 600M, and 6B), dramatically smaller memory requirements and faster inference (think of Triton kernels here). ESM C was trained on UniRef, MGnify, and JGI data, smaller models are already available on GitHub, the 6B is available through the API service.
💊 Polaris Hub launches the Antiviral Competition together with ASAP discovery and OpenADMET. The competition includes three tracks:
- Predicting ligand poses of MERS-CoV based on SARS-CoV2 structures (metric: RMSD)
- Predicting ligand fluorescence potencies based on SARS and MERS data (metrics: MAE of pIC50 and ranking)
- Predicting ligands’ ADMET properties (MAE and ranking)
The competition starts on Jan 13th and ends on March 25th, prepare your big GNNs ⚔️
⚛️ After the announcement in May, MSR released the code and weights of MatterSim, a universal ML potential akin to MACE-MP-0 and Orb models. MatterSim is based on the M3GNet message passing GNN and is available in 1M and 5M params versions.
🪣 Polymathic AI, Flatiron Institute, and a collab of universities and national labs released The Well, a 15 TB dataset of physical simulations (think PDEs and Neural Operators) covering 16 different areas from fluid dynamics to supernova explosions. In the accompanying preprint, the authors compared several variants of Fourier Neural Operators (FNO) and U-Nets. A great resource for scientific and industrial applications where expensive simulations eat up a huge bulk of supercomputers time.
❤2👍1
GraphML News (Dec 20th) - Thoughts after NeurIPS, ICLR workshops, new blogposts
In the last op-ed of this year and returning back from NeurIPS, it’s about time to reflect on the state of graph learning research. Comments to this post should be open (hopefully?)
🤔 At the age when o3 solves some of incredibly hard FrontierMath problems, when NotebookLM allows to call into a podcast generated about a paper of your choice, and Veo2 generates 4K videos with increasingly correct physics, it is somewhat frustrating to see that the graph learning (meaning vanilla 2D graph learning here, because geometric DL is flourishing in the AI 4 Science areas) community is still obsessed with WL tests, node classification on OGB, and other toy tasks that increasingly lose relevance in the modern deep learning world. Is it the issue of too toyish benchmarks, the lack of cool applications, or something else? Is Graph ML to be confined in the recsys and retail predictions domain or it could get its own “RLHF revival moment”?
🏗️ ICLR 2025 started announcing the accepted workshops, you might find some of those interesting:
- Frontiers in Probabilistic Inference: Sampling Meets Learning
- Generative and Experimental Perspectives for Biomolecular Design
- Weight Space Learning
- Learning Meaningful Representations of Life
- AI for Accelerated Materials Design will be back, too
📝 New blogposts! Understanding Transformer reasoning capabilities via graph algorithms by Google Research elaborating on the NeurIPS 2024 paper on when and where transformers can outperform GNNs on graph tasks. A massive 3-part study of pooling in GNNs by Filippo Maria Bianchi (Arctic University of Norway) introduces the common pooling framework (select-reduce-connect), studies a variety of pooling methods and their evaluation protocols.
In the last op-ed of this year and returning back from NeurIPS, it’s about time to reflect on the state of graph learning research. Comments to this post should be open (hopefully?)
🤔 At the age when o3 solves some of incredibly hard FrontierMath problems, when NotebookLM allows to call into a podcast generated about a paper of your choice, and Veo2 generates 4K videos with increasingly correct physics, it is somewhat frustrating to see that the graph learning (meaning vanilla 2D graph learning here, because geometric DL is flourishing in the AI 4 Science areas) community is still obsessed with WL tests, node classification on OGB, and other toy tasks that increasingly lose relevance in the modern deep learning world. Is it the issue of too toyish benchmarks, the lack of cool applications, or something else? Is Graph ML to be confined in the recsys and retail predictions domain or it could get its own “RLHF revival moment”?
🏗️ ICLR 2025 started announcing the accepted workshops, you might find some of those interesting:
- Frontiers in Probabilistic Inference: Sampling Meets Learning
- Generative and Experimental Perspectives for Biomolecular Design
- Weight Space Learning
- Learning Meaningful Representations of Life
- AI for Accelerated Materials Design will be back, too
📝 New blogposts! Understanding Transformer reasoning capabilities via graph algorithms by Google Research elaborating on the NeurIPS 2024 paper on when and where transformers can outperform GNNs on graph tasks. A massive 3-part study of pooling in GNNs by Filippo Maria Bianchi (Arctic University of Norway) introduces the common pooling framework (select-reduce-connect), studies a variety of pooling methods and their evaluation protocols.
❤7🔥7🤔2👍1
GraphML News (Jan 18th) - MatterGen release, Aviary, Metagene-1
We are getting back to the regular schedule after the winter break!
⚛️ MSR AI 4 Science has finally released code and weights of MatterGen, the generative model for inorganic materials, together with its publication on Nature (free and no paywall). The final version includes new evaluation pipeline that accounts for compositional disorder (which unrealistically increases performance metrics of recent generative models) and experimental validation of the first generated material TaCr2O6. MatterSim, an ML potential model, was also used during the filtering stages along with standard DFT calculations. Great result for MSR, materials science community, and diffusion model experts who can apply a bag of tricks to a new domain 👏
📜 Together with MatterGen, MaSIF-neosurf from EPFL got published on Nature as well. MaSIF-neosurf is a geometric model for studying surfaces of protein-ligand complexes which was experimentally evaluated on binders agains three real-world protein complexes. To conclude the celebration of massive scientific publications, ESM 3 - the foundation model for proteins - got accepted at Science.
🕊️ FutureHouse released Aviary, the agentic framework for scientific tasks like molecular cloning, protein stability, and scientific QA. Aviary extends the framework of PaperQA (the best open source scientific RAG tool) with learnable RL environments and demonstrated that even small LLMs like LLaMa 3.1 7B excel at these tasks with enough inference compute. Get ready to hear about inference time scaling all over 2025 😉
✏️ The AI 4 Science consortium published a blog post AI 4 Science 2024 highlighting AF3 and its replications, the success of non-equivariant models, scientific foundation models, new progress in small molecules and quantum chemistry. A short but insightful read.
🪣 Metagene-1 (by USC and Prime Intellect) is a foundation model trained on metagenomic sequences (”human wastewater samples” we all know what it means 💩) that might help in pandemic monitoring and pathogen detection. It’s a standard LLaMa 2-7B architecture but, interestingly, outperforms some state space models like HyenaDNA on genome understanding.
Weekend reading:
GenMol: A Drug Discovery Generalist with Discrete Diffusion by Seul Lee, NVIDIA and KAIST - a generalist generative model for a suite of drug discovery tasks like de-novo generation, fragment-conditioned generation, and lead optimization.
The Jungle of Generative Drug Discovery: Traps, Treasures, and Ways Out by Riza Özçelik and Francesca Grisoni - on metrics and benchmarking for generative models for molecules.
Explaining k-Nearest Neighbors: Abductive and Counterfactual Explanations by Pablo Barceló and CENIA team from Chile - a theoretical work tackling classical (but still important) kNN classifiers and how their predictions can be explained. Experiments on MNIST and can run on a laptop
We are getting back to the regular schedule after the winter break!
⚛️ MSR AI 4 Science has finally released code and weights of MatterGen, the generative model for inorganic materials, together with its publication on Nature (free and no paywall). The final version includes new evaluation pipeline that accounts for compositional disorder (which unrealistically increases performance metrics of recent generative models) and experimental validation of the first generated material TaCr2O6. MatterSim, an ML potential model, was also used during the filtering stages along with standard DFT calculations. Great result for MSR, materials science community, and diffusion model experts who can apply a bag of tricks to a new domain 👏
📜 Together with MatterGen, MaSIF-neosurf from EPFL got published on Nature as well. MaSIF-neosurf is a geometric model for studying surfaces of protein-ligand complexes which was experimentally evaluated on binders agains three real-world protein complexes. To conclude the celebration of massive scientific publications, ESM 3 - the foundation model for proteins - got accepted at Science.
🕊️ FutureHouse released Aviary, the agentic framework for scientific tasks like molecular cloning, protein stability, and scientific QA. Aviary extends the framework of PaperQA (the best open source scientific RAG tool) with learnable RL environments and demonstrated that even small LLMs like LLaMa 3.1 7B excel at these tasks with enough inference compute. Get ready to hear about inference time scaling all over 2025 😉
✏️ The AI 4 Science consortium published a blog post AI 4 Science 2024 highlighting AF3 and its replications, the success of non-equivariant models, scientific foundation models, new progress in small molecules and quantum chemistry. A short but insightful read.
🪣 Metagene-1 (by USC and Prime Intellect) is a foundation model trained on metagenomic sequences (”human wastewater samples” we all know what it means 💩) that might help in pandemic monitoring and pathogen detection. It’s a standard LLaMa 2-7B architecture but, interestingly, outperforms some state space models like HyenaDNA on genome understanding.
Weekend reading:
GenMol: A Drug Discovery Generalist with Discrete Diffusion by Seul Lee, NVIDIA and KAIST - a generalist generative model for a suite of drug discovery tasks like de-novo generation, fragment-conditioned generation, and lead optimization.
The Jungle of Generative Drug Discovery: Traps, Treasures, and Ways Out by Riza Özçelik and Francesca Grisoni - on metrics and benchmarking for generative models for molecules.
Explaining k-Nearest Neighbors: Abductive and Counterfactual Explanations by Pablo Barceló and CENIA team from Chile - a theoretical work tackling classical (but still important) kNN classifiers and how their predictions can be explained. Experiments on MNIST and can run on a laptop
👍23❤5🔥3
GraphML News (Jan 26th) - Graph learning overtakes ⚽, GPT-4b
⚽ TacticAI, the system for analyzing football games using MPNNs and geometric learning developed by Google DeepMind for Liverpool FC (one of the coolest applications highlighted in the post about 2023 graph learning advancements), is making rounds in the UK sports industry: now Arsenal FC is looking for Research Engineers to work on “spatiotemporal transformer with built-in geometric equivariances”. This hints about the success of the original TacticAI (as well as about the small world of English Premier League), and makes us wonder:
- Would graph learning get a surprising vanity boost from a rather unexpected place? Transfers of best GraphML researchers from one club to another along with the head coach team, eg, Christopher Morris to Borussia Dortmund or Stephan Günnemann to Bayern Munich?
- Would 💰 from sheikhs and rich owners of football clubs investing into GPUs result in more expected scaling laws (instead of ridiculously inflated players’ contracts)?
- When will Mikel Arteta (head coach of Arsenal) tell English newspapers “Equivariance rules!” like Geoff Hinton?
We will keep you posted about those important matters. Meanwhile, post your fantasy teams of graph researchers and FCs in the comments.
🧬 OpenAI reportedly finished training of GPT-4b, the protein LLM, together with Retro Biosciences (where Sam Altman conveniently invested $180M) that focuses on longevity studies. GPT-4b aims at re-engineering a specific set of proteins, Yamanaka factors, that can turn human skin cells into young stem cells. We don’t know more details, the model is likely to stay closed - one could hypothesize it might look like the ESM family of protein models with the knowledge of protein function and trained on a massive dataset of proprietary data (the key to a successful biotech startup in 2025).
🎙️ The Graph Signal Processing Workshop 2025 will take place on May 14-16 at Mila in Montreal supported by Centre de recherches mathématiques (CRM) and Valence Labs. The workshop invites theoretical works in signal processing on graphs and will showcase examples of applications in gene expression patterns defined on top of gene networks, the spread of epidemics over a social network, the congestion level at the nodes of a telecommunication network, and patterns of brain activity defined on top of a brain network. Submission deadline is Feb 1st.
Weekend reading:
ICLR 2025 announced accepted papers but the full list is not yet available. Moreover, expect a flurry of the announcements next week after the ICML submission deadline.
⚽ TacticAI, the system for analyzing football games using MPNNs and geometric learning developed by Google DeepMind for Liverpool FC (one of the coolest applications highlighted in the post about 2023 graph learning advancements), is making rounds in the UK sports industry: now Arsenal FC is looking for Research Engineers to work on “spatiotemporal transformer with built-in geometric equivariances”. This hints about the success of the original TacticAI (as well as about the small world of English Premier League), and makes us wonder:
- Would graph learning get a surprising vanity boost from a rather unexpected place? Transfers of best GraphML researchers from one club to another along with the head coach team, eg, Christopher Morris to Borussia Dortmund or Stephan Günnemann to Bayern Munich?
- Would 💰 from sheikhs and rich owners of football clubs investing into GPUs result in more expected scaling laws (instead of ridiculously inflated players’ contracts)?
- When will Mikel Arteta (head coach of Arsenal) tell English newspapers “Equivariance rules!” like Geoff Hinton?
We will keep you posted about those important matters. Meanwhile, post your fantasy teams of graph researchers and FCs in the comments.
🧬 OpenAI reportedly finished training of GPT-4b, the protein LLM, together with Retro Biosciences (where Sam Altman conveniently invested $180M) that focuses on longevity studies. GPT-4b aims at re-engineering a specific set of proteins, Yamanaka factors, that can turn human skin cells into young stem cells. We don’t know more details, the model is likely to stay closed - one could hypothesize it might look like the ESM family of protein models with the knowledge of protein function and trained on a massive dataset of proprietary data (the key to a successful biotech startup in 2025).
🎙️ The Graph Signal Processing Workshop 2025 will take place on May 14-16 at Mila in Montreal supported by Centre de recherches mathématiques (CRM) and Valence Labs. The workshop invites theoretical works in signal processing on graphs and will showcase examples of applications in gene expression patterns defined on top of gene networks, the spread of epidemics over a social network, the congestion level at the nodes of a telecommunication network, and patterns of brain activity defined on top of a brain network. Submission deadline is Feb 1st.
Weekend reading:
ICLR 2025 announced accepted papers but the full list is not yet available. Moreover, expect a flurry of the announcements next week after the ICML submission deadline.
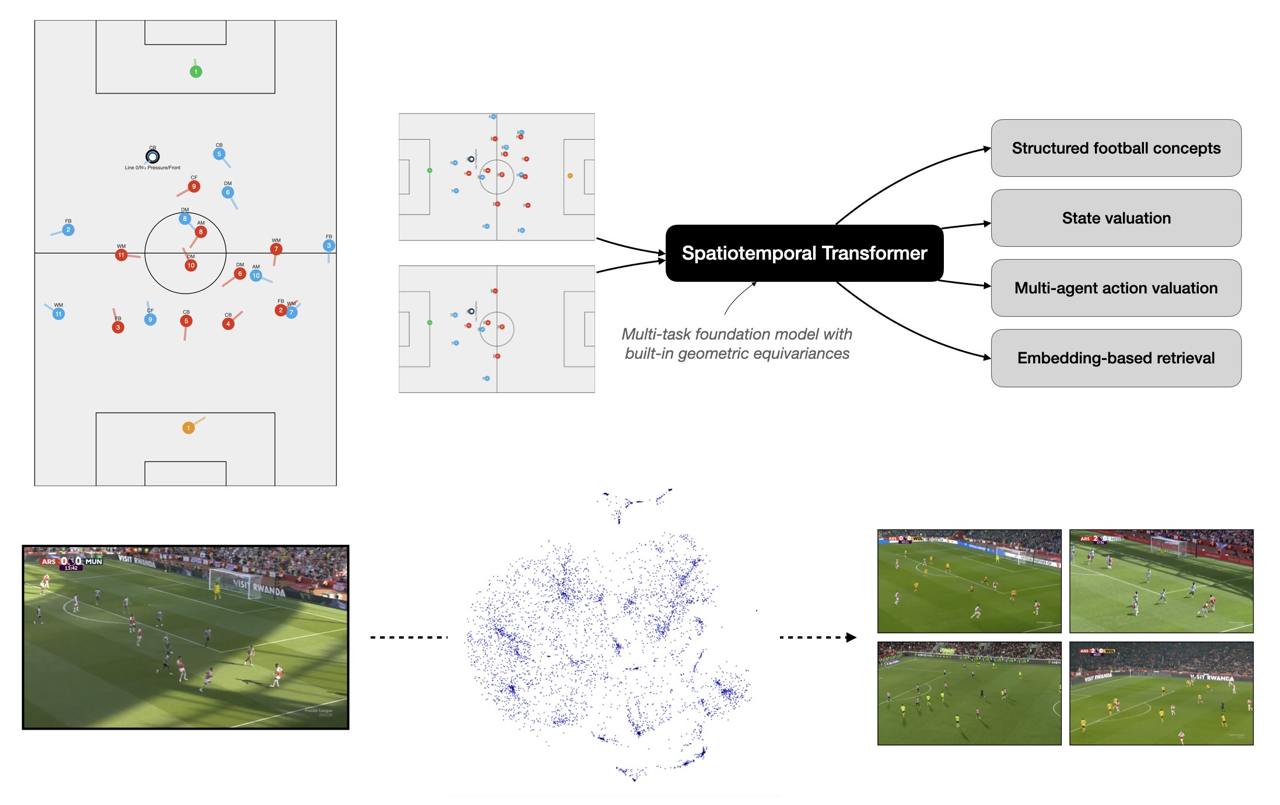{kind=link}
👍28🔥8❤4
GraphML News (Feb 8th) - EEML 2025, Weather models, Science agents
Yaay, we got a handful of news this week worth writing about.
🇧🇦 The Eastern European Summer School (EEML) 2025 is coming to Sarajevo July 21-26 (right after ICML) and features a stellar group of speakers, tutorial heads, and organizers. Invited talks include Aaron Courville (Mila, UdeM), Aldan Hung (Isomorphic Labs), Diana Borsa (Google DeepMind), Samy Bengio (Apple) with tutorials led by the Oxford and DeepMind crew - which indicates the presence of graph and geometric learning will be quite strong 📈 There is a plenty of time to apply: the deadline is March 31st, it’s worth attending if you have an opportunity.
🌍 ML-based weather prediction models permeate more into everyday use: first, a few weeks ago Silurian released the Earth API to their Generative Forecasting Transformer (1.5B params) capable of short- and long-range predictions. And DeepMind released the WeatherNext bundle of GraphCast and GenCast (featured many times in media) on Google Cloud. Competition drives the progress (looking at you, DeepSeek-R1, hehe), and weather prediction models are gaining the momentum.
🤖 Andrew White (FutureHouse) published an interesting piece AI for science with reasoning models discussing how frontier models with reasoning and agentic capabilities improve scientific workflows (spoiler: by a good margin). Fast-forward to February 2025, and all major LLM providers offer their Deep Research agents who automatically digest enormous amounts of internet to create reports about your problem: Google offered Gemini Deep Research already in Dec 2024 (powered by Gemini 2.0 Flash Thinking model), OpenAI added Deep Research this week (powered by o3), and HuggingFace is building an open source version of that. One more moat is gone which could be both sad for agentic startups and happy for users who can enjoy the ecosystem they prefer.
Weekend reading:
On the Emergence of Position Bias in Transformers by Xinyi Wu et al. feat Stefanie Jegelka - a graph-based approach to analyzing positional encodings in Transformers, well in line with Round and Round we Go and other recent works on Transformer PEs
Do Graph Diffusion Models Accurately Capture and Generate Substructure Distributions? by Xiyuan Wang et al. feat Muhan Zhang - the answer is no, but if you use more expressive GNNs, then maybe. A similar finding is in HOG-Diff: Higher-Order Guided Diffusion for Graph Generation by Yiming Huang and Tolga Birdal.
GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation by Linhan Luo et al - an approach based on our ULTRA can be very effective in RAG
Yaay, we got a handful of news this week worth writing about.
🇧🇦 The Eastern European Summer School (EEML) 2025 is coming to Sarajevo July 21-26 (right after ICML) and features a stellar group of speakers, tutorial heads, and organizers. Invited talks include Aaron Courville (Mila, UdeM), Aldan Hung (Isomorphic Labs), Diana Borsa (Google DeepMind), Samy Bengio (Apple) with tutorials led by the Oxford and DeepMind crew - which indicates the presence of graph and geometric learning will be quite strong 📈 There is a plenty of time to apply: the deadline is March 31st, it’s worth attending if you have an opportunity.
🌍 ML-based weather prediction models permeate more into everyday use: first, a few weeks ago Silurian released the Earth API to their Generative Forecasting Transformer (1.5B params) capable of short- and long-range predictions. And DeepMind released the WeatherNext bundle of GraphCast and GenCast (featured many times in media) on Google Cloud. Competition drives the progress (looking at you, DeepSeek-R1, hehe), and weather prediction models are gaining the momentum.
🤖 Andrew White (FutureHouse) published an interesting piece AI for science with reasoning models discussing how frontier models with reasoning and agentic capabilities improve scientific workflows (spoiler: by a good margin). Fast-forward to February 2025, and all major LLM providers offer their Deep Research agents who automatically digest enormous amounts of internet to create reports about your problem: Google offered Gemini Deep Research already in Dec 2024 (powered by Gemini 2.0 Flash Thinking model), OpenAI added Deep Research this week (powered by o3), and HuggingFace is building an open source version of that. One more moat is gone which could be both sad for agentic startups and happy for users who can enjoy the ecosystem they prefer.
Weekend reading:
On the Emergence of Position Bias in Transformers by Xinyi Wu et al. feat Stefanie Jegelka - a graph-based approach to analyzing positional encodings in Transformers, well in line with Round and Round we Go and other recent works on Transformer PEs
Do Graph Diffusion Models Accurately Capture and Generate Substructure Distributions? by Xiyuan Wang et al. feat Muhan Zhang - the answer is no, but if you use more expressive GNNs, then maybe. A similar finding is in HOG-Diff: Higher-Order Guided Diffusion for Graph Generation by Yiming Huang and Tolga Birdal.
GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation by Linhan Luo et al - an approach based on our ULTRA can be very effective in RAG
👍29❤2