
GraphML News (Jan 13th) - New material discovered by geometric models, LOWE
What time could be better than the time in between ICLR announcements (Jan 15th) and the ICML deadline (Feb 1st) 🫠. As far as we know, the graph community is working on some huge blog posts - you can expect those coming in the next few days. The two big news from this week:
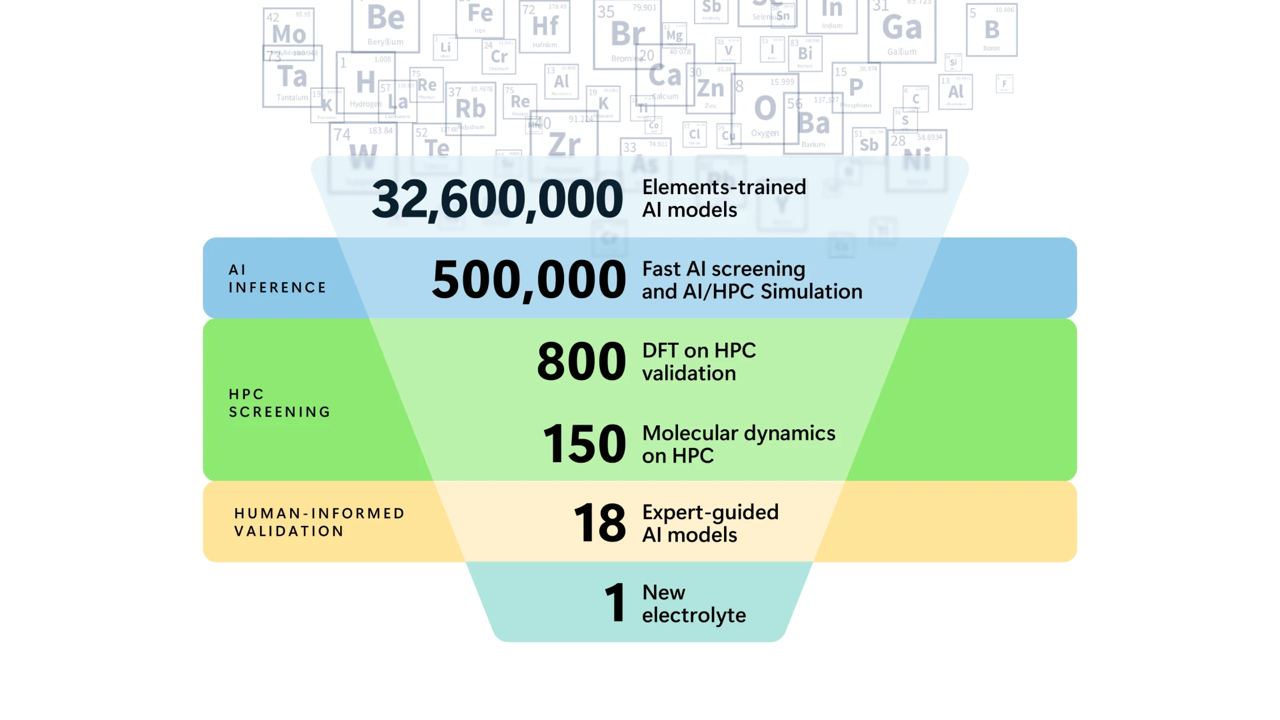
Microsoft Azure Quantum together with Pacific Northwest National Lab announced successful synthesis and validation of a potentially new electrolyte candidate suitable for solid-state batteries. The fresh accompanying paper describes the pipeline from generating 32M candidates and stepwise filtering of those down to 500K, 800, 18, and 1 final candidate. The main bulk of the job of filtering millions of candidates was done by the geometric ML potential model M3GNet (published in 2022 in Nature Computational Science) while later stages with a dozen candidates included HPC simulations of molecular dynamics. Geometric DL for materials discovery is rising! 🚀
Valence & Recursion announced LOWE (LLM-orchestrated Workflow Engine). LOWE is an LLM agent that strives to do all things around drug discovery - from screening and running geometric generative models to the procurement of materials. Was ChemCrow 🐦⬛ the inspiration for LOWE?
Weekend reading:
Accelerating computational materials discovery with artificial intelligence and cloud high-performance computing: from large-scale screening to experimental validation by Chen, Nguyen, et al - the paper behind the newly discovered material by Azure Quantum and PNNL.
MACE-OFF23: Transferable Machine Learning Force Fields for Organic Molecules by Kovács, Moore, et al - similarly to MACE-MP-0 from the last week, MACE-OFF23 is a transferable ML potential for organic molecules but smaller - Medium and Large models were trained on a single A100 for 10/14 days.
Improved motif-scaffolding with SE(3) flow matching by Yim et al - the improved version of FrameFlow (based on trendy flow matching), originally for protein backbone generation, to motif-scaffolding. On some benchmarks, new FrameFlow is on par or better than mighty RFDiffusion 💪
What time could be better than the time in between ICLR announcements (Jan 15th) and the ICML deadline (Feb 1st) 🫠. As far as we know, the graph community is working on some huge blog posts - you can expect those coming in the next few days. The two big news from this week:
Microsoft Azure Quantum together with Pacific Northwest National Lab announced successful synthesis and validation of a potentially new electrolyte candidate suitable for solid-state batteries. The fresh accompanying paper describes the pipeline from generating 32M candidates and stepwise filtering of those down to 500K, 800, 18, and 1 final candidate. The main bulk of the job of filtering millions of candidates was done by the geometric ML potential model M3GNet (published in 2022 in Nature Computational Science) while later stages with a dozen candidates included HPC simulations of molecular dynamics. Geometric DL for materials discovery is rising! 🚀
Valence & Recursion announced LOWE (LLM-orchestrated Workflow Engine). LOWE is an LLM agent that strives to do all things around drug discovery - from screening and running geometric generative models to the procurement of materials. Was ChemCrow 🐦⬛ the inspiration for LOWE?
Weekend reading:
Accelerating computational materials discovery with artificial intelligence and cloud high-performance computing: from large-scale screening to experimental validation by Chen, Nguyen, et al - the paper behind the newly discovered material by Azure Quantum and PNNL.
MACE-OFF23: Transferable Machine Learning Force Fields for Organic Molecules by Kovács, Moore, et al - similarly to MACE-MP-0 from the last week, MACE-OFF23 is a transferable ML potential for organic molecules but smaller - Medium and Large models were trained on a single A100 for 10/14 days.
Improved motif-scaffolding with SE(3) flow matching by Yim et al - the improved version of FrameFlow (based on trendy flow matching), originally for protein backbone generation, to motif-scaffolding. On some benchmarks, new FrameFlow is on par or better than mighty RFDiffusion 💪
{kind=link}
Graph & Geometric ML in 2024: Where We Are and What’s Next
📣 Two new blog posts - a comprehensive review of Graph and Geometric ML in 2023 with predictions for 2024. Together with Michael Bronstein, we asked 30 academic and industrial experts about the most important things happened in their areas and open challenges to be solved.
1️⃣ Part I: https://towardsdatascience.com/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-i-theory-architectures-3af5d38376e1
2️⃣ Part II: https://medium.com/towards-data-science/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-ii-applications-1ed786f7bf63
Part I covers: theory of GNNs, new and exotic message passing, going beyong graphs (with Topology, Geometric Algebras, and PDEs), robustness, graph transformers, new datasets, community events, and, of course, top memes of 2023 (that’s what you are here for, right).
Part II covers applications in structural biology, materials science, Molecular Dynamics and ML potentials, geometric generative models on manifolds, Very Large Graphs, algorithmic reasoning, knowledge graph reasoning, LLMs + Graphs, cool GNN applications, and The Geometric Wall Street Bulletin 💸
New things this year:
- the industrial perspective on important problems in structural biology that are often overlooked by researchers;
- The Geometric Wall Street Bulletin prepared with Nathan Benaich, the author of the State of AI report
It was a huge community effort and we are very grateful to all our experts for their availability around winter holidays. Here is the slide with all the contributors, the best “thank you” would be to follow all of them on Twitter!
📣 Two new blog posts - a comprehensive review of Graph and Geometric ML in 2023 with predictions for 2024. Together with Michael Bronstein, we asked 30 academic and industrial experts about the most important things happened in their areas and open challenges to be solved.
1️⃣ Part I: https://towardsdatascience.com/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-i-theory-architectures-3af5d38376e1
2️⃣ Part II: https://medium.com/towards-data-science/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-ii-applications-1ed786f7bf63
Part I covers: theory of GNNs, new and exotic message passing, going beyong graphs (with Topology, Geometric Algebras, and PDEs), robustness, graph transformers, new datasets, community events, and, of course, top memes of 2023 (that’s what you are here for, right).
Part II covers applications in structural biology, materials science, Molecular Dynamics and ML potentials, geometric generative models on manifolds, Very Large Graphs, algorithmic reasoning, knowledge graph reasoning, LLMs + Graphs, cool GNN applications, and The Geometric Wall Street Bulletin 💸
New things this year:
- the industrial perspective on important problems in structural biology that are often overlooked by researchers;
- The Geometric Wall Street Bulletin prepared with Nathan Benaich, the author of the State of AI report
It was a huge community effort and we are very grateful to all our experts for their availability around winter holidays. Here is the slide with all the contributors, the best “thank you” would be to follow all of them on Twitter!
{kind=link}
GraphML News (Jan 20th) - More Blogs, MACE pre-trained potentials, AlphaFold 🤝 Psychedelics
ICLR 2024 announced the accepted papers together with orals and spotlights — we’ll probably make a rundown on the coolest papers but meanwhile you can check one-line tl;dr’s by the famous Compressor by Vitaly Kurin. See you in Vienna in May!
📝 In addition to the megapost on the state of affairs in Graph & Geometric ML, the community delivered two more reviews:
- On Temporal Graph Learning by Shenyang Huang, Emanuele Rossi, Michael Galkin, Andrea Cini, Ingo Scholtes.
- On AI 4 Science by the organizers of the AI for Science workshops (that you see at all major ML venues) including Sherry Lixue Cheng, Yuanqi Du, Chenru Duan, Ada Fang, Tianfan Fu, Wenhao Gao, Kexin Huang, Ziming Liu, Di Luo, and Lijing Wang
⚛️ The MACE team released two foundational ML potential checkpoints: MP for inorganic crystals from the Materials Project and OFF for organic materials and molecular liquids. We covered those in the previous posts — now you can run some MD simulations with them on a laptop.
🍭 AlphaFold discovers potentially new psychedelic molecules (thousands of candidates!) - practically, those can be new antidepressants (would some researchers be willing to try some just for the sake of science and scientific method?)
Besides, the article mentions some works that apply AlphaFold to target G-protein-coupled receptors (GPCR). Apart from having its own Wiki page, GPCR was the main subject of the 2012 Nobel Prize in chemistry. The Nobel Prize for AlphaFold seems even closer?
Weekend reading:
You want to say you finished all those blogposts? 😉
ICLR 2024 announced the accepted papers together with orals and spotlights — we’ll probably make a rundown on the coolest papers but meanwhile you can check one-line tl;dr’s by the famous Compressor by Vitaly Kurin. See you in Vienna in May!
📝 In addition to the megapost on the state of affairs in Graph & Geometric ML, the community delivered two more reviews:
- On Temporal Graph Learning by Shenyang Huang, Emanuele Rossi, Michael Galkin, Andrea Cini, Ingo Scholtes.
- On AI 4 Science by the organizers of the AI for Science workshops (that you see at all major ML venues) including Sherry Lixue Cheng, Yuanqi Du, Chenru Duan, Ada Fang, Tianfan Fu, Wenhao Gao, Kexin Huang, Ziming Liu, Di Luo, and Lijing Wang
⚛️ The MACE team released two foundational ML potential checkpoints: MP for inorganic crystals from the Materials Project and OFF for organic materials and molecular liquids. We covered those in the previous posts — now you can run some MD simulations with them on a laptop.
🍭 AlphaFold discovers potentially new psychedelic molecules (thousands of candidates!) - practically, those can be new antidepressants (would some researchers be willing to try some just for the sake of science and scientific method?)
Besides, the article mentions some works that apply AlphaFold to target G-protein-coupled receptors (GPCR). Apart from having its own Wiki page, GPCR was the main subject of the 2012 Nobel Prize in chemistry. The Nobel Prize for AlphaFold seems even closer?
Weekend reading:
You want to say you finished all those blogposts? 😉
Exploring the Power of Graph Neural Networks in Solving Linear Optimization Problems
guest post by Chendi Qian, Didier Chételat, Christopher Morris
📜 Paper: arxiv (accepted to AISTATS 2024)
🛠️ Code: https://github.com/chendiqian/IPM_MPNN
Recent research shows growing interest in training message-passing graph neural networks (MPNNs) to mimic classical algorithms, particularly for solving linear optimization problems (LPs). For example, in integer linear optimization, state-of-the-art solvers rely on the branch-and-bound algorithm, in which one must repeatedly select variables, subdividing the search space. The best-known heuristic for variable selection is known as strong branching which entails solving LPs to score the variables. This heuristic is too computationally expensive to use in practice. However, in recent years, a collection of works, e.g., Gasse et al. (2019), have proposed using MPNNs to imitate strong branching with impressive success. However, it remained to be seen why such approaches work.
Hence, our paper explores the intriguing possibility of MPNNs approximating general LPs by interpreting various interior-point methods (IPMs) as MPNNs with specific architectures and parameters. We prove that standard MPNN steps can emulate a single iteration of the IPM algorithm on the LP’s tripartite graph representation. This theoretical insight suggests that MPNNs may succeed in LP solving by effectively imitating IPMs.
Despite our theoretical model, our empirical results indicate that MPNNs with fewer layers can approximate the output of practical IPMs for LP solving. Empirically, our approach reduces solving times compared to a state-of-the-art LP solver and other neural network-based methods. Our study enhances the theoretical understanding of data-driven optimization using MPNNs and highlights the potential of MPNNs as efficient proxies for solving LPs.
guest post by Chendi Qian, Didier Chételat, Christopher Morris
📜 Paper: arxiv (accepted to AISTATS 2024)
🛠️ Code: https://github.com/chendiqian/IPM_MPNN
Recent research shows growing interest in training message-passing graph neural networks (MPNNs) to mimic classical algorithms, particularly for solving linear optimization problems (LPs). For example, in integer linear optimization, state-of-the-art solvers rely on the branch-and-bound algorithm, in which one must repeatedly select variables, subdividing the search space. The best-known heuristic for variable selection is known as strong branching which entails solving LPs to score the variables. This heuristic is too computationally expensive to use in practice. However, in recent years, a collection of works, e.g., Gasse et al. (2019), have proposed using MPNNs to imitate strong branching with impressive success. However, it remained to be seen why such approaches work.
Hence, our paper explores the intriguing possibility of MPNNs approximating general LPs by interpreting various interior-point methods (IPMs) as MPNNs with specific architectures and parameters. We prove that standard MPNN steps can emulate a single iteration of the IPM algorithm on the LP’s tripartite graph representation. This theoretical insight suggests that MPNNs may succeed in LP solving by effectively imitating IPMs.
Despite our theoretical model, our empirical results indicate that MPNNs with fewer layers can approximate the output of practical IPMs for LP solving. Empirically, our approach reduces solving times compared to a state-of-the-art LP solver and other neural network-based methods. Our study enhances the theoretical understanding of data-driven optimization using MPNNs and highlights the potential of MPNNs as efficient proxies for solving LPs.
{kind=link}
GraphML News (Jan 27th) - New Blogs, LigandMPNN is available
Seems like everyone is grinding for the ICML’24 deadline next week so there isn’t much news those days. A few highlights:
Dimension Research published 2/3 parts of their ML x Bio review of NeurIPS’23: on Generative Protein Design, and on Generative Molecular Design, the last one is going to be about drug target interaction prediction.
The blog post on Exphormer by Ameya Velingker and Balaji Venkatachalam from Google Research on the neat ICML’23 sparse graph transformer architecture that scales to graphs much larger than molecules. Glad to see GraphGPS and Long Range Graph Benchmark mentioned a few times 🙂
LigandMPNN was released on GitHub this week after appearing as a module in several recent protein generation papers. LigandMPNN significantly improves over ProteinMPNN in modeling non-protein components like small molecules, metals, and nucleotides.
Weekend reading:
Equivariant Graph Neural Operator for Modeling 3D Dynamics by Minkai Xu, Jiaqi Han feat Jure Leskovec and Stefano Ermon: equivariant GNNs 🤝 neural operators, also provides a nice condensed intro to the topic
Towards Principled Graph Transformers by Luis Müller and Christopher Morris - study of the Edge Transformer with triangular attention applied to graph tasks. Edge Transformer has shown remarkable systematic generalization capabilities and it’s intriguing to see how it works on graphs (O(N^3) complexity for now though).
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility - turns out that papers shared on X / Twitter by AK and Aran Komatsuzaki have significantly more citations. Time to revive your old sci-Twitter account
Seems like everyone is grinding for the ICML’24 deadline next week so there isn’t much news those days. A few highlights:
Dimension Research published 2/3 parts of their ML x Bio review of NeurIPS’23: on Generative Protein Design, and on Generative Molecular Design, the last one is going to be about drug target interaction prediction.
The blog post on Exphormer by Ameya Velingker and Balaji Venkatachalam from Google Research on the neat ICML’23 sparse graph transformer architecture that scales to graphs much larger than molecules. Glad to see GraphGPS and Long Range Graph Benchmark mentioned a few times 🙂
LigandMPNN was released on GitHub this week after appearing as a module in several recent protein generation papers. LigandMPNN significantly improves over ProteinMPNN in modeling non-protein components like small molecules, metals, and nucleotides.
Weekend reading:
Equivariant Graph Neural Operator for Modeling 3D Dynamics by Minkai Xu, Jiaqi Han feat Jure Leskovec and Stefano Ermon: equivariant GNNs 🤝 neural operators, also provides a nice condensed intro to the topic
Towards Principled Graph Transformers by Luis Müller and Christopher Morris - study of the Edge Transformer with triangular attention applied to graph tasks. Edge Transformer has shown remarkable systematic generalization capabilities and it’s intriguing to see how it works on graphs (O(N^3) complexity for now though).
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility - turns out that papers shared on X / Twitter by AK and Aran Komatsuzaki have significantly more citations. Time to revive your old sci-Twitter account
GraphML News (Feb 3rd) - DGL 2.0 ⚡
All ICML deadlines have passed - congratulations to all who made it through the sleepless nights over the last week! We will start seeing some fresh submissions relatively soon on social media (among 10k submitted papers and ~220 position papers)
Meanwhile, DGL 2.0 was released featuring GraphBolt - a new tool for streaming data loading and sampling offering around 30% speedups in node classification and up to 400% in link prediction 🚀 Besides that, the new version includes utilities for building graph transformers and a handful of new datasets - LRGB and a recent suite of heterophilic datasets
The AppliedML Days @ EPFL will take place on March 25 and 26th - the call for the AI and Molecular world track is still open
Weekend reading:
Combinatorial prediction of therapeutic perturbations using causally-inspired neural networks by Guadalupe Gonzalez feat Michael Bronstein and Marinka Zitnik - introduces PDGrapher, a causally-inspired GNN model to predict therapeutically useful perturbagens
VC dimension of Graph Neural Networks with Pfaffian activation functions by D’Inverno et al - extension of the WL meets VC paper to new non-linearities like sigmoid and hyperbolic tangent
NetInfoF Framework: Measuring and Exploiting Network Usable Information (still anon by accepted to ICLR’24) - introduces the “network usable information” and a fingerpring-like approach to quantity the gains brought by a GNN model compared to a non-GNN baselne.
All ICML deadlines have passed - congratulations to all who made it through the sleepless nights over the last week! We will start seeing some fresh submissions relatively soon on social media (among 10k submitted papers and ~220 position papers)
Meanwhile, DGL 2.0 was released featuring GraphBolt - a new tool for streaming data loading and sampling offering around 30% speedups in node classification and up to 400% in link prediction 🚀 Besides that, the new version includes utilities for building graph transformers and a handful of new datasets - LRGB and a recent suite of heterophilic datasets
The AppliedML Days @ EPFL will take place on March 25 and 26th - the call for the AI and Molecular world track is still open
Weekend reading:
Combinatorial prediction of therapeutic perturbations using causally-inspired neural networks by Guadalupe Gonzalez feat Michael Bronstein and Marinka Zitnik - introduces PDGrapher, a causally-inspired GNN model to predict therapeutically useful perturbagens
VC dimension of Graph Neural Networks with Pfaffian activation functions by D’Inverno et al - extension of the WL meets VC paper to new non-linearities like sigmoid and hyperbolic tangent
NetInfoF Framework: Measuring and Exploiting Network Usable Information (still anon by accepted to ICLR’24) - introduces the “network usable information” and a fingerpring-like approach to quantity the gains brought by a GNN model compared to a non-GNN baselne.
GraphML News (Feb 10th) - TensorFlow GNN 1.0, New ICML submissions
🔧 The official release of TensforFlow-GNN 1.0 by Google (after several road show presentations from the team at ICML and NeurIPS) - production-level library for training GNNs on large graphs with the first-class citizen support for heterogeneous graphs. Check the blog post and github repo for more practical examples and documentation
⚛️ The Denoising force fields repository from Microsoft Research for diffusion models trained on coarse-grained protein dynamics data - you can use it for standard density modeling or extract force fields from coarse-grained structures to use in Langevin dynamics simulations. The repo contains several pre-trained models you can play around with.
The ICML deadline has passed and we saw a flurry of cool new preprints submitted to arxiv this week. Some notable mentions:
🐍 Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces by Chloe Wang et al: state space models like Mamba are all the rage those days in NLP and CV (although so far attention still rules), this is a nice adaptation of SSMs to graphs, tested on the LRGB!
🗣️ Let Your Graph Do the Talking: Encoding Structured Data for LLMs by Bryan Perozzi feat. Anton Tsitsulin present GraphToken (extension of Talk Like a Graph, ICLR 2024): using trainable set- or graph encoders to get soft prompt tokens improves the performance of frozen LLMs in answering natural language questions about basic graph properties. The last resort of hardcore graph mining teams jumps into LLMs 🗿
⏩ Link Prediction with Relational Hypergraphs by Xingyue Huang feat. Pablo Barcelo, Michael Bronstein, and Ismail Ceylan: extends conditional message passing models like NBFNet to relational hypergraphs (dubbed HC-MPNN) with nice theoretical guarantees and impressive inductive performance boosts.
📈 Neural Scaling Laws on Graphs by Jingzhe Liu feat. Neil Shah and Jilian Tang: one of the first systematic studies of scaling laws for graph models (GNNs and Graph Transformers) and data (mostly OGB datasets) where the number of edges is selected as the universal size metric. Basically, scaling does happen but with certain nuances as to model depth and architecture (transformers seem to scale more monotonically). The church of scaling laws opens its doors to the graph learning crowd ⛪
📚 On the Completeness of Invariant Geometric Deep Learning Models by Zian Li feat. Muhan Zhang: theoretical study of DimeNet, GemNet, and SphereNet with the proofs of their E(3)-completeness through the nested GNN extension (Nested GNNs from NeurIPS’21)
📚 On dimensionality of feature vectors in MPNNs by Cesar Bravo et al - turns out the WL-MPNN equivalence holds even for 1-dimensional node features when using non-polynomial activations like sigmoid.
Next time, we’ll look into some new position papers.
🔧 The official release of TensforFlow-GNN 1.0 by Google (after several road show presentations from the team at ICML and NeurIPS) - production-level library for training GNNs on large graphs with the first-class citizen support for heterogeneous graphs. Check the blog post and github repo for more practical examples and documentation
⚛️ The Denoising force fields repository from Microsoft Research for diffusion models trained on coarse-grained protein dynamics data - you can use it for standard density modeling or extract force fields from coarse-grained structures to use in Langevin dynamics simulations. The repo contains several pre-trained models you can play around with.
The ICML deadline has passed and we saw a flurry of cool new preprints submitted to arxiv this week. Some notable mentions:
🐍 Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces by Chloe Wang et al: state space models like Mamba are all the rage those days in NLP and CV (although so far attention still rules), this is a nice adaptation of SSMs to graphs, tested on the LRGB!
🗣️ Let Your Graph Do the Talking: Encoding Structured Data for LLMs by Bryan Perozzi feat. Anton Tsitsulin present GraphToken (extension of Talk Like a Graph, ICLR 2024): using trainable set- or graph encoders to get soft prompt tokens improves the performance of frozen LLMs in answering natural language questions about basic graph properties. The last resort of hardcore graph mining teams jumps into LLMs 🗿
⏩ Link Prediction with Relational Hypergraphs by Xingyue Huang feat. Pablo Barcelo, Michael Bronstein, and Ismail Ceylan: extends conditional message passing models like NBFNet to relational hypergraphs (dubbed HC-MPNN) with nice theoretical guarantees and impressive inductive performance boosts.
📈 Neural Scaling Laws on Graphs by Jingzhe Liu feat. Neil Shah and Jilian Tang: one of the first systematic studies of scaling laws for graph models (GNNs and Graph Transformers) and data (mostly OGB datasets) where the number of edges is selected as the universal size metric. Basically, scaling does happen but with certain nuances as to model depth and architecture (transformers seem to scale more monotonically). The church of scaling laws opens its doors to the graph learning crowd ⛪
📚 On the Completeness of Invariant Geometric Deep Learning Models by Zian Li feat. Muhan Zhang: theoretical study of DimeNet, GemNet, and SphereNet with the proofs of their E(3)-completeness through the nested GNN extension (Nested GNNs from NeurIPS’21)
📚 On dimensionality of feature vectors in MPNNs by Cesar Bravo et al - turns out the WL-MPNN equivalence holds even for 1-dimensional node features when using non-polynomial activations like sigmoid.
Next time, we’ll look into some new position papers.
The LoG meetup in New Jersey
The LoG meetup in the NYC area will happen on Feb 29th-March 1st at New Jersey Institute of Technology with invited speakers including Bryan Perozzi and Anton Tsitsulin (both Google Research), Ricky Chen (Meta AI), Jie Gao (Rutgers), and many others.
Come to NJIT@JerseyCity to learn from and connect with the local graph learning community!
Register here, check the Twitter announcement
The LoG meetup in the NYC area will happen on Feb 29th-March 1st at New Jersey Institute of Technology with invited speakers including Bryan Perozzi and Anton Tsitsulin (both Google Research), Ricky Chen (Meta AI), Jie Gao (Rutgers), and many others.
Come to NJIT@JerseyCity to learn from and connect with the local graph learning community!
Register here, check the Twitter announcement
{kind=link}
GraphML News (Feb 17th) - PyG 2.5, VantAI deal, Discrete Flow Matching, Position papers
Sora and Gemini 1.5 took all the ML news feeds this week - let’s check what is there in graph learning beyond the main wave of AI anxiety and stress for grad students.
🔥 A fresh release PyG 2.5 features a new distributed training framework (co-authored by Intel engineers), RecSys support with easy retrieval techniques like MIPS over node embeddings, new Edge Index representation instead of sparse tensors, and rewritten Message Passing class for torch.compile. Lots of new cool stuff!
📚 Xavier Bresson (NUS Singapore) started publishing the slides and notebooks of his most recent 22/23 GraphML course - highly recommended to check it out. Hopefully, this initiative would encourage folks running Graph & Geometric DL courses at Oxbrige to publish their lectures as well 😉
💸 The $674M (in biobucks) deal was announced between VantAI and Bristol Myers Squibb for developing molecular glues. Besides publishing on generative models, VantAI runs open seminars on GenAI for drug discovery (the most recent talk on FoldFlow is already on YouTube).
📐 Two papers from the MIT team of Regina Barzilay and Tommi Jaakkola introduce flow matching for discrete variables (like atom types or DNA base pairs):
Dirichlet Flow Matching with Applications to DNA Sequence Design by Hannes Stärk, Bowen Jing, feat. Gabriele Corso - by defining flows on a simplex where the prior is a uniform Dirichlet distribution. Also supports classifier-free guidance and Consistency models-like distillation to perform generation in one forward pass.
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design by Andrew Campbell, Jason Yim, et al - by using Continuous Time Markov Chains (CTMC) where the prior distribution is either a uniform or all-mask absorbed state (similar to discrete diffusion models). The resulting Multiflow model now has all necessary components of protein backbone generation implemented as flow matching (translation and rotation as continuous FM, and amino acids as discrete FM).
Position papers for the weekend reading:
Future Directions in Foundations of Graph Machine Learning by Chris Morris feat. Haggai Maron, Michael Bronstein, Stefanie Jegelka and others - on expressive power, generalization, and optimization of GNNs.
Position Paper: Challenges and Opportunities in Topological Deep Learning by Theodore Papamarkou feat. Bastian Rieck, Michael Schaub, Petar Veličković and a huge authors team - on theoretical and practical challenges of TDL.
Graph Foundation Models by Haitao Mao feat. Neil Shah, Michael Galkin, and Jilian Tang - finally, a non-LLM discussion on designing foundation models on graphs and for all kinds of graph tasks. The authors hypothesize what could be the transferable and invariant graph vocabulary given heterogeneity of graph structures and their features spaces, and how Graph FMs might benefit from scaling laws (namely, what should be scaled and where it doesn’t bring benefits)
Sora and Gemini 1.5 took all the ML news feeds this week - let’s check what is there in graph learning beyond the main wave of AI anxiety and stress for grad students.
🔥 A fresh release PyG 2.5 features a new distributed training framework (co-authored by Intel engineers), RecSys support with easy retrieval techniques like MIPS over node embeddings, new Edge Index representation instead of sparse tensors, and rewritten Message Passing class for torch.compile. Lots of new cool stuff!
📚 Xavier Bresson (NUS Singapore) started publishing the slides and notebooks of his most recent 22/23 GraphML course - highly recommended to check it out. Hopefully, this initiative would encourage folks running Graph & Geometric DL courses at Oxbrige to publish their lectures as well 😉
💸 The $674M (in biobucks) deal was announced between VantAI and Bristol Myers Squibb for developing molecular glues. Besides publishing on generative models, VantAI runs open seminars on GenAI for drug discovery (the most recent talk on FoldFlow is already on YouTube).
📐 Two papers from the MIT team of Regina Barzilay and Tommi Jaakkola introduce flow matching for discrete variables (like atom types or DNA base pairs):
Dirichlet Flow Matching with Applications to DNA Sequence Design by Hannes Stärk, Bowen Jing, feat. Gabriele Corso - by defining flows on a simplex where the prior is a uniform Dirichlet distribution. Also supports classifier-free guidance and Consistency models-like distillation to perform generation in one forward pass.
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design by Andrew Campbell, Jason Yim, et al - by using Continuous Time Markov Chains (CTMC) where the prior distribution is either a uniform or all-mask absorbed state (similar to discrete diffusion models). The resulting Multiflow model now has all necessary components of protein backbone generation implemented as flow matching (translation and rotation as continuous FM, and amino acids as discrete FM).
Position papers for the weekend reading:
Future Directions in Foundations of Graph Machine Learning by Chris Morris feat. Haggai Maron, Michael Bronstein, Stefanie Jegelka and others - on expressive power, generalization, and optimization of GNNs.
Position Paper: Challenges and Opportunities in Topological Deep Learning by Theodore Papamarkou feat. Bastian Rieck, Michael Schaub, Petar Veličković and a huge authors team - on theoretical and practical challenges of TDL.
Graph Foundation Models by Haitao Mao feat. Neil Shah, Michael Galkin, and Jilian Tang - finally, a non-LLM discussion on designing foundation models on graphs and for all kinds of graph tasks. The authors hypothesize what could be the transferable and invariant graph vocabulary given heterogeneity of graph structures and their features spaces, and how Graph FMs might benefit from scaling laws (namely, what should be scaled and where it doesn’t bring benefits)
GraphML News (Feb 24th) - Orbital Materials Round, GNNs at LinkedIn, MLX-graphs
⚛️ Orbital Materials (founded by ex-DeepMind researchers) raised $16M Series A led by Radical Ventures and Toyota Ventures. OM focuses on materials science and shed some light on LINUS - the in-house 3D foundation model for material design (apparently, an ML potential and a generative model) with the ambition to become the AlphaFold of materials science. GNNs = 💸
🏋️♀️ LinkedIn published some details of their GNN architecture and GNN-powered services in the KDD’24 paper LiGNN: Graph Neural Networks at LinkedIn. The main graph is heterogeneous, multi-relational, and contains about 100B nodes and few hundred billion edges (rather sparse). The core GNN model is GraphSAGE is trained on linked prediction with various tweaks like temporal neighborhood sampling (from latest to older), PPR-based node sampling, and node ID embeddings. A few engineering tricks like multi-processing shared memory and smart node grouping allowed to speed up training from 24h down to 3 hours. LiGNN boosts recommendations and ads CTR. The bottom line: GNNs = 💸
🍏 Apple presented MLX-graphs: the GNN library for the MLX framework specifically optimized for Apple Silicon. Since the CPU/GPU memory is shared on M1/M2/M3, you don’t have to worry about moving tensors around and at the same time you can enjoy massive GPU memory of latest M2/M3 chips (64 GB MBPs and MacMinis are still much cheaper than A100 80 GB). For starters, MLX-graphs includes GCN, GAT, GIN, GraphSAGE, and MPNN models and a few standard datasets.
🧬 The OpenFold consortium announced SoloSeq and OpenFold-Multimer, open source and open weights analogues of ESMFold and AlphaFold-Multimer, respectively. The OpenFold repo already showed some signs of new modules, and now there is a public release.
👨🏫 Steven L Brunton (U Washington) released a new lecture video series on Physics Informed ML covering AI 4 Science applications enabled by (mostly geometric) deep learning that respect physical symmetries and invariances of the modeled system. This includes, for example, modeling fluid dynamics, PDEs, turbulence, and optimal control. A nice entrypoint into scientific applications!
Weekend reading:
Proteus: pioneering protein structure generation for enhanced designability and efficiency by Chentong Wang feat. Longxing Cao from Westlake - finally, a new protein generation model that seems to beat RFDiffusion and Chroma!
Universal Physics Transformers by Benedikt Alkin feat Johannes Brandstetter
Pard: Permutation-Invariant Autoregressive Diffusion for Graph Generation by Lingxiao Zhao, Xueying Ding, and Leman Akoglu (all CMU)
⚛️ Orbital Materials (founded by ex-DeepMind researchers) raised $16M Series A led by Radical Ventures and Toyota Ventures. OM focuses on materials science and shed some light on LINUS - the in-house 3D foundation model for material design (apparently, an ML potential and a generative model) with the ambition to become the AlphaFold of materials science. GNNs = 💸
🏋️♀️ LinkedIn published some details of their GNN architecture and GNN-powered services in the KDD’24 paper LiGNN: Graph Neural Networks at LinkedIn. The main graph is heterogeneous, multi-relational, and contains about 100B nodes and few hundred billion edges (rather sparse). The core GNN model is GraphSAGE is trained on linked prediction with various tweaks like temporal neighborhood sampling (from latest to older), PPR-based node sampling, and node ID embeddings. A few engineering tricks like multi-processing shared memory and smart node grouping allowed to speed up training from 24h down to 3 hours. LiGNN boosts recommendations and ads CTR. The bottom line: GNNs = 💸
🍏 Apple presented MLX-graphs: the GNN library for the MLX framework specifically optimized for Apple Silicon. Since the CPU/GPU memory is shared on M1/M2/M3, you don’t have to worry about moving tensors around and at the same time you can enjoy massive GPU memory of latest M2/M3 chips (64 GB MBPs and MacMinis are still much cheaper than A100 80 GB). For starters, MLX-graphs includes GCN, GAT, GIN, GraphSAGE, and MPNN models and a few standard datasets.
🧬 The OpenFold consortium announced SoloSeq and OpenFold-Multimer, open source and open weights analogues of ESMFold and AlphaFold-Multimer, respectively. The OpenFold repo already showed some signs of new modules, and now there is a public release.
👨🏫 Steven L Brunton (U Washington) released a new lecture video series on Physics Informed ML covering AI 4 Science applications enabled by (mostly geometric) deep learning that respect physical symmetries and invariances of the modeled system. This includes, for example, modeling fluid dynamics, PDEs, turbulence, and optimal control. A nice entrypoint into scientific applications!
Weekend reading:
Proteus: pioneering protein structure generation for enhanced designability and efficiency by Chentong Wang feat. Longxing Cao from Westlake - finally, a new protein generation model that seems to beat RFDiffusion and Chroma!
Universal Physics Transformers by Benedikt Alkin feat Johannes Brandstetter
Pard: Permutation-Invariant Autoregressive Diffusion for Graph Generation by Lingxiao Zhao, Xueying Ding, and Leman Akoglu (all CMU)
Learning on Graphs @ NYC meetup (Feb 29th - March 1st) online streaming
The 2-day LoG meetup taking place in Jersey City will be streamed online openly for everyone! The talks include the Google Research team (who will for sure talk like a graph), Ricky Chen and Brandon Amos from Meta AI, biotech presence with Matthew McPartlon, Luca Naef from VantAI and Samuel Stanton from Genentech, and many more (see the schedule attached).
The 2-day LoG meetup taking place in Jersey City will be streamed online openly for everyone! The talks include the Google Research team (who will for sure talk like a graph), Ricky Chen and Brandon Amos from Meta AI, biotech presence with Matthew McPartlon, Luca Naef from VantAI and Samuel Stanton from Genentech, and many more (see the schedule attached).
{kind=link}
GraphML News (March 2nd) - Categorical Deep Learning, Evo, and NeuralPlexer 2
🔀 A fresh look on deep learning from the category theory perspective: Categorical Deep Learning: An Algebraic Theory of Architectures by Bruno Gavranović, Paul Lessard, Andrew Dudzik, featuing Petar Veličković. The position paper attempts to generalize Geometric Deep Learning even further - by the means of monad algebras that generalize invariance, equivariance, and symmetries (🍞 and 🧈 of GDL). The main part quickly ramps up to some advanced category theory concepts but the appendix covers the basics (still recommend Cats4AI as a pre-requisite though).
🧬 Evo - a foundation model by Arc Institute for RNA/DNA/protein sequences based on the StripedHyena architecture (state space models and convolutions) with the context length of 131K tokens. Some applications include zero-shot function prediction for ncRNA and regulatory DNA, CRISPR system generation, generating whole genome sequences, and many more. Adepts of the church of scaling laws might be interested in promising scaling capabilities of Evo that seems to outperform Transformers and recent Mamba
🪢 NeuralPlexer 2, a generative model for protein-ligand docking from Iambic, Caltech, and NVIDIA, challenges Alphafold-latest in several benchmarks: 75.4% RMSD <2Å on PoseBusters vs 73.6 of Alphafold-latest without site specification, and up to 93.8% with site specification, while being about 50x faster than AlphaFold. The race in comp bio intensifies, moats are challenged, and for us it means we’ll see more cool results - at the cost of more proprietary models and closed data though.
Weekend reading:
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning by Man Wu et al.
TorchMD-Net 2.0: Fast Neural Network Potentials for Molecular Simulations by Raul P. Pelaez, Guillem Simeon, et al - the next version of the popular ML potential package, now up to 10x faster thanks to torch compile! (from that perspective, a switch to JAX seems inevitable)
Weisfeiler-Leman at the margin: When more expressivity matters by Billy Franks, Chris Morris, Ameya Velingker, and Floris Geerts - a new study on expressivity and generalization of MPNNs that continues WL meet VC
🔀 A fresh look on deep learning from the category theory perspective: Categorical Deep Learning: An Algebraic Theory of Architectures by Bruno Gavranović, Paul Lessard, Andrew Dudzik, featuing Petar Veličković. The position paper attempts to generalize Geometric Deep Learning even further - by the means of monad algebras that generalize invariance, equivariance, and symmetries (🍞 and 🧈 of GDL). The main part quickly ramps up to some advanced category theory concepts but the appendix covers the basics (still recommend Cats4AI as a pre-requisite though).
🧬 Evo - a foundation model by Arc Institute for RNA/DNA/protein sequences based on the StripedHyena architecture (state space models and convolutions) with the context length of 131K tokens. Some applications include zero-shot function prediction for ncRNA and regulatory DNA, CRISPR system generation, generating whole genome sequences, and many more. Adepts of the church of scaling laws might be interested in promising scaling capabilities of Evo that seems to outperform Transformers and recent Mamba
🪢 NeuralPlexer 2, a generative model for protein-ligand docking from Iambic, Caltech, and NVIDIA, challenges Alphafold-latest in several benchmarks: 75.4% RMSD <2Å on PoseBusters vs 73.6 of Alphafold-latest without site specification, and up to 93.8% with site specification, while being about 50x faster than AlphaFold. The race in comp bio intensifies, moats are challenged, and for us it means we’ll see more cool results - at the cost of more proprietary models and closed data though.
Weekend reading:
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning by Man Wu et al.
TorchMD-Net 2.0: Fast Neural Network Potentials for Molecular Simulations by Raul P. Pelaez, Guillem Simeon, et al - the next version of the popular ML potential package, now up to 10x faster thanks to torch compile! (from that perspective, a switch to JAX seems inevitable)
Weisfeiler-Leman at the margin: When more expressivity matters by Billy Franks, Chris Morris, Ameya Velingker, and Floris Geerts - a new study on expressivity and generalization of MPNNs that continues WL meet VC
GraphML News (March 10th) - Protein Design Community Principles, RF All Atom weights, ICLR workshops
🤝 More than 100 prominent researchers in protein design, structural biology, and geometric deep learning committed to the principles of Responsible AI in Biodesign. Recognizing the increasing capabilities of deep learning models in designing functional biological molecules, the community came up with several core values and principles such as the benefit of society, safety and security, openness, equity, international collaboration, and responsibility. Particular commitments include more scrutiny towards hazardous biomolecules before their manufacturing, better evaluation and risk assessment of DL models. Good for the protein design community, let’s hope those would be practically implemented!
🧬 Committing to the newly introduced principles, Baker’s lab released RosettaFold All-Atom and RFDiffusion All-Atom together with their model weights and several inference examples. Folks on Twitter who interpret the principles as “closed-source AI taking over” are obviously wrong 😛
📚 ICLR 2024 workshops started posting accepted papers - so far we see the papers from AI 4 Differential Equations, Representational Alignment, and Time Series for Health. ICLR workshop papers are usually good proxies for ICML and NeurIPS submissions, so you might be interested to check those of your domain.
Weekend reading:
A Survey of Graph Neural Networks in Real world: Imbalance, Noise, Privacy and OOD Challenges by Wei Ju et al
Graph neural network outputs are almost surely asymptotically constant by Sam Adam-Day et al. feat. Ismail Ilkan Ceylan
Pairwise Alignment Improves Graph Domain Adaptation by Shikun Liu et al feat. Pan Li
Understanding Biology in the Age of Artificial Intelligence by Elsa Lawrence, Adham El-Shazly, Srijit Seal feat. our own Chaitanya K. Joshi
🤝 More than 100 prominent researchers in protein design, structural biology, and geometric deep learning committed to the principles of Responsible AI in Biodesign. Recognizing the increasing capabilities of deep learning models in designing functional biological molecules, the community came up with several core values and principles such as the benefit of society, safety and security, openness, equity, international collaboration, and responsibility. Particular commitments include more scrutiny towards hazardous biomolecules before their manufacturing, better evaluation and risk assessment of DL models. Good for the protein design community, let’s hope those would be practically implemented!
🧬 Committing to the newly introduced principles, Baker’s lab released RosettaFold All-Atom and RFDiffusion All-Atom together with their model weights and several inference examples. Folks on Twitter who interpret the principles as “closed-source AI taking over” are obviously wrong 😛
📚 ICLR 2024 workshops started posting accepted papers - so far we see the papers from AI 4 Differential Equations, Representational Alignment, and Time Series for Health. ICLR workshop papers are usually good proxies for ICML and NeurIPS submissions, so you might be interested to check those of your domain.
Weekend reading:
A Survey of Graph Neural Networks in Real world: Imbalance, Noise, Privacy and OOD Challenges by Wei Ju et al
Graph neural network outputs are almost surely asymptotically constant by Sam Adam-Day et al. feat. Ismail Ilkan Ceylan
Pairwise Alignment Improves Graph Domain Adaptation by Shikun Liu et al feat. Pan Li
Understanding Biology in the Age of Artificial Intelligence by Elsa Lawrence, Adham El-Shazly, Srijit Seal feat. our own Chaitanya K. Joshi
GraphML News (March 16th) - RelationRx round, Caduceus, Blogposts, WholeGraph
💸 Relation Therapeutics, the drug discovery company, raises $35M seed funding led by DCVC and NVentures (VC arm of NVIDIA) - making it $60M in total after factoring in the previous round in 2022. Relation is developing treatments for osteoporosis and other bone-related diseases.
⚕️The race between Mamba and Hyena-like architectures for long-context DNA modeling is heating up: Caduceus by Yair Schiff featuring Tri Dao and Albert Gu is the first bi-directional Mamba equivariant to the reverse complement (RC) symmetry of DNA. Similarly to the recent Evo, it supports sequence lengths up to 131k. In turn, a new blog post by Hazy Research on Evo hinted upon the new Mechanistic Architecture Design framework that employs synthetic probes to check long-range modeling capabilities.
💬 A new Medium blogpost by Xiaoxin He (NUS Singapore) on chatting with your graph - dedicated to the recent G-Retriever paper on graph-based RAG for question answering tasks. The post goes through the technical details (perhaps the most interesting part is prize-collecting Steiner Tree for subgraph retrieval) and positions the work in the flurry of recent Graph + LLM approaches including Talk Like a Graph (highlighted in the recent Google Research blogpost) and Let the Graph do the Talking. Fun fact: now we have 2 different datasets named GraphQA with completely different contents and tasks (one from G-Retriever, another one from the Google papers).
💽 The WholeGraph Storage by NVIDIA for PyG and DGL - a handy way for distributed setups to keep a single graph in the shared storage accessible by the workers. WholeGraph comes in three flavors: continuous, chunked, and distributed.
Weekend reading:
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks by Marco De Nadai, Francesco Fabbri, and the Spotify team - Heterogeneous GNNs + The Two (MLP) Towers for SOTA RecSys.
Universal Representation of Permutation-Invariant Functions on Vectors and Tensors by Puoya Tabaghi and Yusu Wang (UCSD) - when encoding sets of N elements of D-dimensional vectors, DeepSets require a latent dimension of N^D. This cool work reduces this bound to 2ND 👀.
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields by Yi-Lun Liao, Tess Smidt, Abhishek Das - the success of a Noisy Nodes-like auxiliary denoising objective is extended to non-equilibrium structures thanks to encoding forces of non-equilibrium structures. Yields SOTA on OpenCatalyst (if you have 16-128 V100’s though).
💸 Relation Therapeutics, the drug discovery company, raises $35M seed funding led by DCVC and NVentures (VC arm of NVIDIA) - making it $60M in total after factoring in the previous round in 2022. Relation is developing treatments for osteoporosis and other bone-related diseases.
⚕️The race between Mamba and Hyena-like architectures for long-context DNA modeling is heating up: Caduceus by Yair Schiff featuring Tri Dao and Albert Gu is the first bi-directional Mamba equivariant to the reverse complement (RC) symmetry of DNA. Similarly to the recent Evo, it supports sequence lengths up to 131k. In turn, a new blog post by Hazy Research on Evo hinted upon the new Mechanistic Architecture Design framework that employs synthetic probes to check long-range modeling capabilities.
💬 A new Medium blogpost by Xiaoxin He (NUS Singapore) on chatting with your graph - dedicated to the recent G-Retriever paper on graph-based RAG for question answering tasks. The post goes through the technical details (perhaps the most interesting part is prize-collecting Steiner Tree for subgraph retrieval) and positions the work in the flurry of recent Graph + LLM approaches including Talk Like a Graph (highlighted in the recent Google Research blogpost) and Let the Graph do the Talking. Fun fact: now we have 2 different datasets named GraphQA with completely different contents and tasks (one from G-Retriever, another one from the Google papers).
💽 The WholeGraph Storage by NVIDIA for PyG and DGL - a handy way for distributed setups to keep a single graph in the shared storage accessible by the workers. WholeGraph comes in three flavors: continuous, chunked, and distributed.
Weekend reading:
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks by Marco De Nadai, Francesco Fabbri, and the Spotify team - Heterogeneous GNNs + The Two (MLP) Towers for SOTA RecSys.
Universal Representation of Permutation-Invariant Functions on Vectors and Tensors by Puoya Tabaghi and Yusu Wang (UCSD) - when encoding sets of N elements of D-dimensional vectors, DeepSets require a latent dimension of N^D. This cool work reduces this bound to 2ND 👀.
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields by Yi-Lun Liao, Tess Smidt, Abhishek Das - the success of a Noisy Nodes-like auxiliary denoising objective is extended to non-equilibrium structures thanks to encoding forces of non-equilibrium structures. Yields SOTA on OpenCatalyst (if you have 16-128 V100’s though).
GraphML News (March 23rd) - Profluent round, Biology 2.0, TacticAI
💸 Profluent, a Berkley biotech startup founded in 2022, raises $35M (overall $44M so far). The company focuses on protein generation models in the context of CRISPR gene editing. VC funding in the biotech industry is on fire in 2024!
🧬 A huge blogpost The Road to Biology 2.0 Will Pass Through Black-Box Data by Michael Bronstein and Luca Naef offers a new perspective on the area of ML for biology and its common problem of lacking large amounts of labeled data. The idea is to leverage low-cost high-throughput data (eg, obtained from experimental facilities), coined as “black-box data”, that might not be directly understandable by humans (or experts) but can be used for training large-scale ML models even in the self-supervised regime. It is then hypothesized that the competitive edge would belong to the companies that manage to build such data pipelines and models. Time to convince old-school chemists about the benefits of black-box data.
⚽ Google DeepMind officially introduced TacticAI with the publication in Nature Communication (we wrote about it in the End-Of-The-Year post a few months ago at the preprint stage). TacticAI uses group-equivariant convnets and is designed for football games to give tactical insights for many practical cases such as corner kicks. Interestingly, experts prefer TacticAI outputs 90% of the time. Equivariance + ⚽ = 📈
Weekend reading:
Atomically accurate de novo design of single-domain antibodies from the Baker Lab - RFDiffusion for antibodies
Weisfeiler and Leman Go Loopy: A New Hierarchy for Graph Representational Learning by Raffaele Paolino, Sohir Maskey, Pascal Welke, and Gitta Kutyniok - WL visited one more location ✅
💸 Profluent, a Berkley biotech startup founded in 2022, raises $35M (overall $44M so far). The company focuses on protein generation models in the context of CRISPR gene editing. VC funding in the biotech industry is on fire in 2024!
🧬 A huge blogpost The Road to Biology 2.0 Will Pass Through Black-Box Data by Michael Bronstein and Luca Naef offers a new perspective on the area of ML for biology and its common problem of lacking large amounts of labeled data. The idea is to leverage low-cost high-throughput data (eg, obtained from experimental facilities), coined as “black-box data”, that might not be directly understandable by humans (or experts) but can be used for training large-scale ML models even in the self-supervised regime. It is then hypothesized that the competitive edge would belong to the companies that manage to build such data pipelines and models. Time to convince old-school chemists about the benefits of black-box data.
⚽ Google DeepMind officially introduced TacticAI with the publication in Nature Communication (we wrote about it in the End-Of-The-Year post a few months ago at the preprint stage). TacticAI uses group-equivariant convnets and is designed for football games to give tactical insights for many practical cases such as corner kicks. Interestingly, experts prefer TacticAI outputs 90% of the time. Equivariance + ⚽ = 📈
Weekend reading:
Atomically accurate de novo design of single-domain antibodies from the Baker Lab - RFDiffusion for antibodies
Weisfeiler and Leman Go Loopy: A New Hierarchy for Graph Representational Learning by Raffaele Paolino, Sohir Maskey, Pascal Welke, and Gitta Kutyniok - WL visited one more location ✅
GraphML News (March 30th) - AlphaFold course, Upcoming Summer Schools
The first week of ICML rebuttals has passed, one week to go - good luck everyone 💪
EMBL-EBI together with Google DeepMind released a free entry-level course about the basics of protein folding and using AlphaFold for structure prediction. The course helps to understand inputs and outputs of AlphaFold, how to interpret the metrics and predictions, and a bit of more advanced usage.
A handful of summer schools covering lots of Graph and Geometric DL were announced recently:
- Eastern European ML Summer School | 15-20 July 2024, Novi Sad, Serbia
- ELLIS Summer School on Machine Learning for Healthcare and Biology | 11-13 June 2024, Manchester, UK
- Generative Modeling Summer School | 24-28th June 2024, Eindhoven, Netherlands
- The workshop on mining and learning with graphs (MLG) will be co-located with ECML PKDD in Vilnius, Lithuania in September 2024 featuring keynotes by Yllka Velaj and Haggai Maron.
Weekend reading:
A new version of the Hitchhiker’s guide on Geometric GNNs featuring frame-based invariant GNNs and unconstrained GNNs (btw, the paper will be presented at the next LoGaG reading group on Monday, April 1st)
Space Group Informed Transformer for Crystalline Materials Generation - autoregressive, transformer-based crystal generation that takes into account space groups and Wyckoff positions (a competing diffusion model DiffCSP++ was accepted at ICLR’24)
Graphs Generalization under Distribution Shifts by Tian et al
Addressing heterophily in node classification with graph echo state networks by Alessio Micheli and Domenico Tortorella — applies a reservoir computing approach, that is, randomly initialize GNN weights to obtain a desired Lipschitz constant
The first week of ICML rebuttals has passed, one week to go - good luck everyone 💪
EMBL-EBI together with Google DeepMind released a free entry-level course about the basics of protein folding and using AlphaFold for structure prediction. The course helps to understand inputs and outputs of AlphaFold, how to interpret the metrics and predictions, and a bit of more advanced usage.
A handful of summer schools covering lots of Graph and Geometric DL were announced recently:
- Eastern European ML Summer School | 15-20 July 2024, Novi Sad, Serbia
- ELLIS Summer School on Machine Learning for Healthcare and Biology | 11-13 June 2024, Manchester, UK
- Generative Modeling Summer School | 24-28th June 2024, Eindhoven, Netherlands
- The workshop on mining and learning with graphs (MLG) will be co-located with ECML PKDD in Vilnius, Lithuania in September 2024 featuring keynotes by Yllka Velaj and Haggai Maron.
Weekend reading:
A new version of the Hitchhiker’s guide on Geometric GNNs featuring frame-based invariant GNNs and unconstrained GNNs (btw, the paper will be presented at the next LoGaG reading group on Monday, April 1st)
Space Group Informed Transformer for Crystalline Materials Generation - autoregressive, transformer-based crystal generation that takes into account space groups and Wyckoff positions (a competing diffusion model DiffCSP++ was accepted at ICLR’24)
Graphs Generalization under Distribution Shifts by Tian et al
Addressing heterophily in node classification with graph echo state networks by Alessio Micheli and Domenico Tortorella — applies a reservoir computing approach, that is, randomly initialize GNN weights to obtain a desired Lipschitz constant
GraphML News (April 6th) - Leash Bio Round, The BELKA Kaggle Competition, Sparse Ops speedups
💸 Leash Biosciences (founded by ex-Recursion folks) announced a $9.3M seed round led by Springtide Ventures. Leash focuses on building huge proprietary datasets for protein-molecule interactions.
🐿️ At the same time, Leash launched a new Kaggle competition on predicting the binding affinity of small molecules to proteins using the Big Encoded Library for Chemical Assessment (BELKA). The dataset contains about 133M small molecules vs 3 proteins (sEH, BRD4 and HSA). Protein-ligand binding diffusion models like DiffDock are allowed as well. Who will win: comp bio folks with domain expertise or Kaggle grandmasters with expertise on finding data leakages? 🤔 We’ll see in 3 months.
📈 Zhongming Yu and the team from UCSD, Stanford, and Intel released GeOT - a tensor centric library for GNNs via efficient segment reduction on GPU. The library ships efficient CUDA kernels for sparse operations like scatter summation and fused message-aggregation kernels. On average, GeOT brings 1.7-3.5x speedups over PyG sparse ops, and 2.3-3.6x over PyG dense ops. Looking forward seeing the kernels in major libraries and, hopefully, the Triton version.
🧜♂️ Recently, I played around quite a lot writing Triton kernels for fusing message and aggregation steps of several GNN architectures into one kernel call and can highly recommend trying to speed up your models with them. Triton kernels are written in Python (saving your feet from C++ code shootings), are compiled automatically into efficient code on several platforms (CUDA, ROCm, and even Intel GPUs), and are often faster than CUDA kernels.
Weekend reading (UC San Diego was on fire this week):
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
On the Theoretical Expressive Power and the Design Space of Higher-Order Graph Transformers by Cai Zhou, Rose Yu, Yusu Wang - the authors prove that k-order graph transformers are not more expressive than k-WL unless positional encodings are supplied. The results extend nicely our work Attending to Graph Transformers (recently accepted to TMLR)
DE-HNN: An effective neural model for Circuit Netlist representation by Zhishang Luo feat. Yusu Wang) - properly representing analog and digital circuits is a big pain in the chip design community. This work demonstrated the benefits of using directed hypergraphs for netlists and proposed a new big dataset for experiments.
💸 Leash Biosciences (founded by ex-Recursion folks) announced a $9.3M seed round led by Springtide Ventures. Leash focuses on building huge proprietary datasets for protein-molecule interactions.
🐿️ At the same time, Leash launched a new Kaggle competition on predicting the binding affinity of small molecules to proteins using the Big Encoded Library for Chemical Assessment (BELKA). The dataset contains about 133M small molecules vs 3 proteins (sEH, BRD4 and HSA). Protein-ligand binding diffusion models like DiffDock are allowed as well. Who will win: comp bio folks with domain expertise or Kaggle grandmasters with expertise on finding data leakages? 🤔 We’ll see in 3 months.
📈 Zhongming Yu and the team from UCSD, Stanford, and Intel released GeOT - a tensor centric library for GNNs via efficient segment reduction on GPU. The library ships efficient CUDA kernels for sparse operations like scatter summation and fused message-aggregation kernels. On average, GeOT brings 1.7-3.5x speedups over PyG sparse ops, and 2.3-3.6x over PyG dense ops. Looking forward seeing the kernels in major libraries and, hopefully, the Triton version.
🧜♂️ Recently, I played around quite a lot writing Triton kernels for fusing message and aggregation steps of several GNN architectures into one kernel call and can highly recommend trying to speed up your models with them. Triton kernels are written in Python (saving your feet from C++ code shootings), are compiled automatically into efficient code on several platforms (CUDA, ROCm, and even Intel GPUs), and are often faster than CUDA kernels.
Weekend reading (UC San Diego was on fire this week):
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
On the Theoretical Expressive Power and the Design Space of Higher-Order Graph Transformers by Cai Zhou, Rose Yu, Yusu Wang - the authors prove that k-order graph transformers are not more expressive than k-WL unless positional encodings are supplied. The results extend nicely our work Attending to Graph Transformers (recently accepted to TMLR)
DE-HNN: An effective neural model for Circuit Netlist representation by Zhishang Luo feat. Yusu Wang) - properly representing analog and digital circuits is a big pain in the chip design community. This work demonstrated the benefits of using directed hypergraphs for netlists and proposed a new big dataset for experiments.
🥰1
Deep learning for dynamic graphs: models and benchmarks
Guest post by Alessio Gravina
Published in IEEE Transactions on Neural Networks and Learning Systems
📜 arxiv preprint: link
🛠️ code: GitHub
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on real world systems of interconnected entities, which evolve over time.
In light of this, in this paper we proposed, at first, a survey that focuses on recent representation learning techniques for dynamic graphs under a uniform formalism consolidated from existing literature. Second, we provide the research community with a fair performance comparison among the most popular methods of the three families of dynamic graph problems, by leveraging a reproducible experimental environment.
We believe that this work will help fostering the research in the domain of dynamic graphs by providing a clear picture of the current development status and a good baseline to test new architectures and approaches.
Guest post by Alessio Gravina
Published in IEEE Transactions on Neural Networks and Learning Systems
📜 arxiv preprint: link
🛠️ code: GitHub
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on real world systems of interconnected entities, which evolve over time.
In light of this, in this paper we proposed, at first, a survey that focuses on recent representation learning techniques for dynamic graphs under a uniform formalism consolidated from existing literature. Second, we provide the research community with a fair performance comparison among the most popular methods of the three families of dynamic graph problems, by leveraging a reproducible experimental environment.
We believe that this work will help fostering the research in the domain of dynamic graphs by providing a clear picture of the current development status and a good baseline to test new architectures and approaches.
{kind=link}
GraphML News (April 13th) - MoML’24, ICML workshops, ICLR blogposts
🏆 Big news: Avi Wigderson received the Turing Award Prize 2024 for his contributions to randomness in computation along with other works in complexity theory, cryptography, and graph theory. Particularly in graph theory, Avi is well-known for studying expander graphs which recently became quite popular in Graph ML, eg, with Expander Graph Propagation and Exphormer as a sparse attention mechanism in graph transformers. Read more about Avi in this Quanta article.
🧬 Valence Labs and Mila announced the Molecular ML Conference 2024 (MoML) (June 19th) as the key part of the larger 2-week program on structural biology and geometric DL including the Drug Discovery Summer School (June 12-18) and Hackathon (June 20-21). All events will take place in Montreal (and June is the best time to be in Montreal). MoML will feature talks by Dominique Beaini (Valence), Jian Tang (Mila), Christine Allen (U of Toronto), and Max Jaderberg (Isomorphic Labs). The summer school will feature talks by Michael Bronstein, Mario Geiger, Yoshua Bengio, Connor Coley, Charlotte Bunne, and other prominent researchers. A perfect event for ML folks to learn bio, and for biologists to learn SOTA ML methods.
🎤 ICML’24 published a list of accepted workshops: you might be interested in:
- Geometry-grounded Representation Learning and Generative Modeling (GRaM)
- Structured Probabilistic Inference and Generative Modeling
- AI for Science: Scaling in AI for Scientific Discovery
- ML for Life and Material Science: From Theory to Industry Applications
Besides, ICLR published the blog posts accepted to the Blog Post track (a hidden treasure of ICLR) - check out the posts on deriving diffusion models, flow matching, equilibrium models for algorithmic reasoning, and even on computing Hessian-vector products.
📚 Weekend reading:
Simplicial Representation Learning with Neural k-Forms (ICLR 2024) by Kelly Maggs, Celia Hacker, Bastian Rieck - an alternative to message passing using neural k-forms and simplicial complexes
Benchmarking ChatGPT on Algorithmic Reasoning by Sean McLeish, Avi Schwarzschild, Tom Goldstein - turns out that ChatGPT with code interpreter can beat many GNNs on the CLRS benchmark when posing questions and data in natural language (who knew that quickselect, unsolvable by GNNs, could be almost perfectly solved by an LLM?). To be fair, the paper generated quite active discussions on Twitter as to the OOD generalization aspect of CLRS and the fact that LLMs saw all those algorithms many times during pre-training.
Empowering Biomedical Discovery with AI Agents by Shanghua Gao feat. Marinka Zitnik - a survey on advances of AI agents in biomedical discovery and open challenges
🏆 Big news: Avi Wigderson received the Turing Award Prize 2024 for his contributions to randomness in computation along with other works in complexity theory, cryptography, and graph theory. Particularly in graph theory, Avi is well-known for studying expander graphs which recently became quite popular in Graph ML, eg, with Expander Graph Propagation and Exphormer as a sparse attention mechanism in graph transformers. Read more about Avi in this Quanta article.
🧬 Valence Labs and Mila announced the Molecular ML Conference 2024 (MoML) (June 19th) as the key part of the larger 2-week program on structural biology and geometric DL including the Drug Discovery Summer School (June 12-18) and Hackathon (June 20-21). All events will take place in Montreal (and June is the best time to be in Montreal). MoML will feature talks by Dominique Beaini (Valence), Jian Tang (Mila), Christine Allen (U of Toronto), and Max Jaderberg (Isomorphic Labs). The summer school will feature talks by Michael Bronstein, Mario Geiger, Yoshua Bengio, Connor Coley, Charlotte Bunne, and other prominent researchers. A perfect event for ML folks to learn bio, and for biologists to learn SOTA ML methods.
🎤 ICML’24 published a list of accepted workshops: you might be interested in:
- Geometry-grounded Representation Learning and Generative Modeling (GRaM)
- Structured Probabilistic Inference and Generative Modeling
- AI for Science: Scaling in AI for Scientific Discovery
- ML for Life and Material Science: From Theory to Industry Applications
Besides, ICLR published the blog posts accepted to the Blog Post track (a hidden treasure of ICLR) - check out the posts on deriving diffusion models, flow matching, equilibrium models for algorithmic reasoning, and even on computing Hessian-vector products.
📚 Weekend reading:
Simplicial Representation Learning with Neural k-Forms (ICLR 2024) by Kelly Maggs, Celia Hacker, Bastian Rieck - an alternative to message passing using neural k-forms and simplicial complexes
Benchmarking ChatGPT on Algorithmic Reasoning by Sean McLeish, Avi Schwarzschild, Tom Goldstein - turns out that ChatGPT with code interpreter can beat many GNNs on the CLRS benchmark when posing questions and data in natural language (who knew that quickselect, unsolvable by GNNs, could be almost perfectly solved by an LLM?). To be fair, the paper generated quite active discussions on Twitter as to the OOD generalization aspect of CLRS and the fact that LLMs saw all those algorithms many times during pre-training.
Empowering Biomedical Discovery with AI Agents by Shanghua Gao feat. Marinka Zitnik - a survey on advances of AI agents in biomedical discovery and open challenges
GraphML News (April 20th) - Near-Linear Min Cut, New blog posts, scaling GNNs
LLaMa 3 dominated the ML media this week but let’s try to see through it to find some graph gems.
✂️ Google Research published a new blog post on the recently proposed near-linear min-cut algorithm for weighted graphs. Existing near-linear algorithms are either randomized or work on rather simple graphs. In contrast, the proposed algorithm is deterministic and supports weighted graphs. The key points of the devised approach:
(1) the observation that cuts likely won’t change if we sparsify the graph a bit;
(2) min-cuts must have low graph conductance), hence partitioning algorithms (producing well-connected clusters) might be approximately consistent with min-cuts;
(3) the theory is actually applicable to weighted graphs.
The work received the best paper at SODA’24 👏
🌊 Tor Fjelde, Emile Mathieu and Vincent Dutordoir released an insightful introduction to flow matching starting from the basics of conditional normalizing flows up to the most recent stochastic interpolants and mini-batch optimal transport coupling. We are a little late to the party (the post dates to January) but it’s never too late to catch up with generative modeling and flow matching.
On the Scalability of GNNs for Molecular Graphs by Maciej Sypetkowski, Frederik Wenkel, and Valence / Mila folks - one of the first in-depth studies of scaling GNNs and Transformers for molecular tasks. In particular, they trained modified versions of MPNN, GPS, and vanilla Transformer models (with structural encodings of course) varying the size from 1M to 1B parameters on the LargeMix dataset of 5M molecules. Scaling does improve pretraining and downstream performance of all models but there is a clear signal that pre-training dataset size is not enough - experiments on the UltraLarge dataset with 83M molecules are likely in the works.
Weekend reading:
HelixFold-Multimer: Elevating Protein Complex Structure Prediction to New Heights by Xiaomin Fang and Baidu - a contender to AlphaFold 2.3 showing strong results on antibody-antigen and nanobody-antigen docking.
Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective by Victor-Alexandru Darvariu and UCL
VN-EGNN: E(3)-Equivariant Graph Neural Networks with Virtual Nodes Enhance Protein Binding Site Identification by Florian Sestak and ELLIS Linz - virtual nodes encode representations of the whole binding site
LLaMa 3 dominated the ML media this week but let’s try to see through it to find some graph gems.
✂️ Google Research published a new blog post on the recently proposed near-linear min-cut algorithm for weighted graphs. Existing near-linear algorithms are either randomized or work on rather simple graphs. In contrast, the proposed algorithm is deterministic and supports weighted graphs. The key points of the devised approach:
(1) the observation that cuts likely won’t change if we sparsify the graph a bit;
(2) min-cuts must have low graph conductance), hence partitioning algorithms (producing well-connected clusters) might be approximately consistent with min-cuts;
(3) the theory is actually applicable to weighted graphs.
The work received the best paper at SODA’24 👏
🌊 Tor Fjelde, Emile Mathieu and Vincent Dutordoir released an insightful introduction to flow matching starting from the basics of conditional normalizing flows up to the most recent stochastic interpolants and mini-batch optimal transport coupling. We are a little late to the party (the post dates to January) but it’s never too late to catch up with generative modeling and flow matching.
On the Scalability of GNNs for Molecular Graphs by Maciej Sypetkowski, Frederik Wenkel, and Valence / Mila folks - one of the first in-depth studies of scaling GNNs and Transformers for molecular tasks. In particular, they trained modified versions of MPNN, GPS, and vanilla Transformer models (with structural encodings of course) varying the size from 1M to 1B parameters on the LargeMix dataset of 5M molecules. Scaling does improve pretraining and downstream performance of all models but there is a clear signal that pre-training dataset size is not enough - experiments on the UltraLarge dataset with 83M molecules are likely in the works.
Weekend reading:
HelixFold-Multimer: Elevating Protein Complex Structure Prediction to New Heights by Xiaomin Fang and Baidu - a contender to AlphaFold 2.3 showing strong results on antibody-antigen and nanobody-antigen docking.
Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective by Victor-Alexandru Darvariu and UCL
VN-EGNN: E(3)-Equivariant Graph Neural Networks with Virtual Nodes Enhance Protein Binding Site Identification by Florian Sestak and ELLIS Linz - virtual nodes encode representations of the whole binding site
GraphML News (April 27th) - 🧬 The Protein Edition: OpenCRISPR, Xaira, ScaleFold
✂️ 🧬 Profluent Bio announced OpenCRISPR - an initiative to share CRISPR-Cas like proteins generated by protein LMs (a-la ESM 2). Profluent managed to generate rather novel proteins hundreds of mutations away from the known ones, and those new work surprisingly well — check out the thread by Ali Madani and a fresh preprint for more details. CRISRP is a genome editing tool that was awarded with 2020 Nobel Prize in Chemistry and got recently approved by FDA as a therapy for sickle cell disease (and a huge potential in other areas as well). Jennifer Doudna, one of the OG authors, gave a keynote at ICML’23 and even attended graph learning and comp bio workshops!
💸 A new biotech startup Xaira Therapeutics was established with $1B+ funding with David Baker as a co-founder. Investors include ARCH, Sequoia, Two Sigma, and other prominent VC bros. Perhaps we could hypothesize that the scaled up technology stack behind RF Diffusion (both ML and lab) is going to play a key role in Xaira. In related news, Max Welling announced his departure from MSR and co-founding of a new startup on molecular and materials discovery together with Chad Edwards.
📈 ScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours - you only need 2080 H100’s to train AlphaFold in 7 hours (that’s roughly $130M given $500k price tag for a DGX with 8 H100 gpus). Gross extrapolation suggests that GPU-rich places like Meta could train a few AlphaFolds in less than an hour at the same time. Next milestone: train an AlphaFold-like model during a coffee break 👀.
📉 Artificial Intelligence Driving Materials Discovery? Perspective on the Article: Scaling Deep Learning for Materials Discovery - a critical look at the recently published GNoMe database of discovered crystalline structures. The two main points are (1) a lot of those structures contain radioactive elements making them impractical for real-world use; (2) a lot of those structures are isomorphic to well-known structures in crystallographic terms, eg, replacing one element with that of a similar group that induces pretty much the same crystal structure.
Weekend reading:
The GeometricKernels library by Viacheslav Borovitskiy et al that implements kernels for Riemannian manifolds, graphs, and meshes with TF, PT, and Jax bindings.
Learning with 3D rotations, a hitchhiker's guide to SO(3) by A. René Geist et al - a great introductory paper and resource for studying geometric rotations, a perfect companion to the Hitchhiker’s guide to Geometric GNNs
From Local to Global: A Graph RAG Approach to Query-Focused Summarization by Darren Edge and MSR - we mentioned GraphRAG a few times and here is the full preprint.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases by Shirley Wu, Shiyu Zhao et al feat. Jure Leskovec - a new benchmark for question answering on texts and structured sources
✂️ 🧬 Profluent Bio announced OpenCRISPR - an initiative to share CRISPR-Cas like proteins generated by protein LMs (a-la ESM 2). Profluent managed to generate rather novel proteins hundreds of mutations away from the known ones, and those new work surprisingly well — check out the thread by Ali Madani and a fresh preprint for more details. CRISRP is a genome editing tool that was awarded with 2020 Nobel Prize in Chemistry and got recently approved by FDA as a therapy for sickle cell disease (and a huge potential in other areas as well). Jennifer Doudna, one of the OG authors, gave a keynote at ICML’23 and even attended graph learning and comp bio workshops!
💸 A new biotech startup Xaira Therapeutics was established with $1B+ funding with David Baker as a co-founder. Investors include ARCH, Sequoia, Two Sigma, and other prominent VC bros. Perhaps we could hypothesize that the scaled up technology stack behind RF Diffusion (both ML and lab) is going to play a key role in Xaira. In related news, Max Welling announced his departure from MSR and co-founding of a new startup on molecular and materials discovery together with Chad Edwards.
📈 ScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours - you only need 2080 H100’s to train AlphaFold in 7 hours (that’s roughly $130M given $500k price tag for a DGX with 8 H100 gpus). Gross extrapolation suggests that GPU-rich places like Meta could train a few AlphaFolds in less than an hour at the same time. Next milestone: train an AlphaFold-like model during a coffee break 👀.
📉 Artificial Intelligence Driving Materials Discovery? Perspective on the Article: Scaling Deep Learning for Materials Discovery - a critical look at the recently published GNoMe database of discovered crystalline structures. The two main points are (1) a lot of those structures contain radioactive elements making them impractical for real-world use; (2) a lot of those structures are isomorphic to well-known structures in crystallographic terms, eg, replacing one element with that of a similar group that induces pretty much the same crystal structure.
Weekend reading:
The GeometricKernels library by Viacheslav Borovitskiy et al that implements kernels for Riemannian manifolds, graphs, and meshes with TF, PT, and Jax bindings.
Learning with 3D rotations, a hitchhiker's guide to SO(3) by A. René Geist et al - a great introductory paper and resource for studying geometric rotations, a perfect companion to the Hitchhiker’s guide to Geometric GNNs
From Local to Global: A Graph RAG Approach to Query-Focused Summarization by Darren Edge and MSR - we mentioned GraphRAG a few times and here is the full preprint.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases by Shirley Wu, Shiyu Zhao et al feat. Jure Leskovec - a new benchmark for question answering on texts and structured sources