
GraphML News (Nov 4th) - AlphaFold 2.3 for docking, OpenDAC, KwikBucks
🧬 Google DeepMind and Isomorphic Labs announced AlphaFold 2.3 (with a funny PDF name like Jupyter notebooks) - the newest iteration is crushing the baselines in 3 tasks: docking benchmarks (almost 2x better than DiffDock on PoseBusters), protein-nucleic acid interactions, and antibody-antigen prediction. Most of the paper’s content is devoted to experimental results and some examples. Following the trend of big AI labs, the document is authored by “teams” and has no details on the model architecture — from those 3 paragraphs in the model section, an educated guess might be an equivariant Transformer architecture. I would also add proper citations to the ML docking baselines, eg, DiffDock and TankBind, they deserved it 🙂
💎 Prepare your GemNets and EquiFormers: Open Direct Air Capture (OpenDAC) is a collab between Meta AI and Georgia Tech on discovering new sorbents for capturing CO2 from the air. OpenDAC is a massive dataset that includes 40M DFT calculations from 170K relaxations and will be a part of the OpenCatalyst (OCP) project. OCP delivers a lot of cool stuff this year - apart from OpenDAC they released AdsorbML for the NeurIPS’23 challenge.
💸 Google Research published a blog post on KwikBucks (the person who came up with the name deserves a peer bonus), a clustering method based on the graph representation. Mainly designed for text clustering and document retrieval, the algorithm also works on standard graphs like Cora and Amazon Photos. In case graphs have no features, the authors run Deep Graph Infomax (DGI) to get unsupervised features.
A few shorter updates:
The Workshop on AI-driven discovery for physics and astrophysics (AI4Phys) organized by Center for Data-Driven Discovery and Simons Foundations will take place on January 22-26th at the University of Tokyo. Meanwhile, the proceedings of the NeurIPS AI4Mat Workshop (AI for Accelerated Materials Design) are now available.
LoG is approaching and so are the local meetups! The LoG Meetup at EPFL in Lausanne will be held on Nov 22nd and the meetup at TUM in Munich will be held on Nov30th-Dec 1st.
Weekend reading:
Scaling Riemannian Diffusion Models by Aaron Lou, Minkai Xu, and Stefano Ermon (Stanford)
Equivariant Matrix Function Neural Networks by Ilyes Batatia feat. Gábor Csányi (Cambridge)
A Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning by Samuel E. Otto feat. Steven L. Brunton (UW) - a massive work on symmetries and equivariances in neural nets highlighting the effectiveness of Lie derivatives
Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks by Erfan Loghmani and MohammadAmin Fazli (Sharif) - on the losses for temporal graph learning, also introduces the Myket dataset already integrated into PyG
🧬 Google DeepMind and Isomorphic Labs announced AlphaFold 2.3 (with a funny PDF name like Jupyter notebooks) - the newest iteration is crushing the baselines in 3 tasks: docking benchmarks (almost 2x better than DiffDock on PoseBusters), protein-nucleic acid interactions, and antibody-antigen prediction. Most of the paper’s content is devoted to experimental results and some examples. Following the trend of big AI labs, the document is authored by “teams” and has no details on the model architecture — from those 3 paragraphs in the model section, an educated guess might be an equivariant Transformer architecture. I would also add proper citations to the ML docking baselines, eg, DiffDock and TankBind, they deserved it 🙂
💎 Prepare your GemNets and EquiFormers: Open Direct Air Capture (OpenDAC) is a collab between Meta AI and Georgia Tech on discovering new sorbents for capturing CO2 from the air. OpenDAC is a massive dataset that includes 40M DFT calculations from 170K relaxations and will be a part of the OpenCatalyst (OCP) project. OCP delivers a lot of cool stuff this year - apart from OpenDAC they released AdsorbML for the NeurIPS’23 challenge.
💸 Google Research published a blog post on KwikBucks (the person who came up with the name deserves a peer bonus), a clustering method based on the graph representation. Mainly designed for text clustering and document retrieval, the algorithm also works on standard graphs like Cora and Amazon Photos. In case graphs have no features, the authors run Deep Graph Infomax (DGI) to get unsupervised features.
A few shorter updates:
The Workshop on AI-driven discovery for physics and astrophysics (AI4Phys) organized by Center for Data-Driven Discovery and Simons Foundations will take place on January 22-26th at the University of Tokyo. Meanwhile, the proceedings of the NeurIPS AI4Mat Workshop (AI for Accelerated Materials Design) are now available.
LoG is approaching and so are the local meetups! The LoG Meetup at EPFL in Lausanne will be held on Nov 22nd and the meetup at TUM in Munich will be held on Nov30th-Dec 1st.
Weekend reading:
Scaling Riemannian Diffusion Models by Aaron Lou, Minkai Xu, and Stefano Ermon (Stanford)
Equivariant Matrix Function Neural Networks by Ilyes Batatia feat. Gábor Csányi (Cambridge)
A Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning by Samuel E. Otto feat. Steven L. Brunton (UW) - a massive work on symmetries and equivariances in neural nets highlighting the effectiveness of Lie derivatives
Effect of Choosing Loss Function when Using T-batching for Representation Learning on Dynamic Networks by Erfan Loghmani and MohammadAmin Fazli (Sharif) - on the losses for temporal graph learning, also introduces the Myket dataset already integrated into PyG
{kind=link}
GraphML News (Nov 11th) - MoML, GFlowNets workshop, NeurIPS workshops and blogs
👺 Brace yourselves, ICLR reviews are out and Reviewer 2 is most dangerous in those wildest conditions.
🧬 The Molecular ML conference at MIT happened a few days ago and brought together folks from geometric DL, computational biology, drug discovery, protein learning, and materials science. We won’t have the recordings, but the list of accepted posters is published and you can find many of them on arxiv already.
🌊 A handful of the MoML posters featured Generative Flow Networks (GFlowNets), and its authors at Mila organized a whole 3-day workshop on the basics of generative modeling and foundations of GFlowNets with many practical examples - all 24 hours of streams are available on YouTube now.
More NeurIPS workshops opened the lists of accepted papers: AI for Accelerated Materials Design, Temporal Graph Learning, Mathematical Reasoning and AI
✍️ And several new blogposts have arrived:
- Equivariant neural networks – *what*, *why* and *how* ? by Maurice Weiler - Part 1 out of the planned five chapters explaining the main ideas in the recent book on Equivariant and Coordinate Independent CNNs.
- ULTRA: Foundation Models for Knowledge Graph Reasoning by our small team featuring the invited guest Bruno Ribeiro (Purdue) where we give more visual explanation on the motivation and mechanisms behind our recent paper on KG reasoning.
Weekend reading:
From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction by Nima Shoghi feat. Larry Zitnick (Meta AI and CMU) - pretty much a foundation model for many molecular and materials science tasks - a pre-trained 230M params GemNet-OC, lots of engineering insights on training such complex models on diverse and imbalanced datasets
Examining graph neural networks for crystal structures: Limitations and opportunities for capturing periodicity by Sheng Gong feat. Tian Xie, Rafael Gomez-Bombarelli, Shuiwang Ji - on the eternal quest of designing abstractions for periodic structures where GNNs can still fail
Efficient Subgraph GNNs by Learning Effective Selection Policies by Beatrice Bevilacqua feat. Bruno Ribeiro, Haggai Maron - on improving notoriously hungry subgraph GNNs with Gumbel-Softmax and Straight-through estimation tricks
Locality-Aware Graph-Rewiring in GNNs (NeurIPS’23) by Federico Barbero feat Michael Bronstein and Francesco Di Giovanni - introduces the LASER graph rewiring method that produces a sequence of rewired graph snapshots with new edges selected based on the connectivity and locality constraints. Fast and effective!
👺 Brace yourselves, ICLR reviews are out and Reviewer 2 is most dangerous in those wildest conditions.
🧬 The Molecular ML conference at MIT happened a few days ago and brought together folks from geometric DL, computational biology, drug discovery, protein learning, and materials science. We won’t have the recordings, but the list of accepted posters is published and you can find many of them on arxiv already.
🌊 A handful of the MoML posters featured Generative Flow Networks (GFlowNets), and its authors at Mila organized a whole 3-day workshop on the basics of generative modeling and foundations of GFlowNets with many practical examples - all 24 hours of streams are available on YouTube now.
More NeurIPS workshops opened the lists of accepted papers: AI for Accelerated Materials Design, Temporal Graph Learning, Mathematical Reasoning and AI
✍️ And several new blogposts have arrived:
- Equivariant neural networks – *what*, *why* and *how* ? by Maurice Weiler - Part 1 out of the planned five chapters explaining the main ideas in the recent book on Equivariant and Coordinate Independent CNNs.
- ULTRA: Foundation Models for Knowledge Graph Reasoning by our small team featuring the invited guest Bruno Ribeiro (Purdue) where we give more visual explanation on the motivation and mechanisms behind our recent paper on KG reasoning.
Weekend reading:
From Molecules to Materials: Pre-training Large Generalizable Models for Atomic Property Prediction by Nima Shoghi feat. Larry Zitnick (Meta AI and CMU) - pretty much a foundation model for many molecular and materials science tasks - a pre-trained 230M params GemNet-OC, lots of engineering insights on training such complex models on diverse and imbalanced datasets
Examining graph neural networks for crystal structures: Limitations and opportunities for capturing periodicity by Sheng Gong feat. Tian Xie, Rafael Gomez-Bombarelli, Shuiwang Ji - on the eternal quest of designing abstractions for periodic structures where GNNs can still fail
Efficient Subgraph GNNs by Learning Effective Selection Policies by Beatrice Bevilacqua feat. Bruno Ribeiro, Haggai Maron - on improving notoriously hungry subgraph GNNs with Gumbel-Softmax and Straight-through estimation tricks
Locality-Aware Graph-Rewiring in GNNs (NeurIPS’23) by Federico Barbero feat Michael Bronstein and Francesco Di Giovanni - introduces the LASER graph rewiring method that produces a sequence of rewired graph snapshots with new edges selected based on the connectivity and locality constraints. Fast and effective!
GraphML News (Nov 18th) - GraphCast and Chroma release, Neural Circulation Models
While one half of the world digests the drama around OpenAI and comes up with conspiracy theories and another half is working on ICLR rebuttals and CVPR deadlines, let’s look at the GraphML news!
☔ Two models we first spotted and mentioned in 2023 The State of Affairs post were officially released as Science and Nature publications: GraphCast from Google DeepMind for weather prediction and Chroma for protein design from Generate Biomedicines. Both GraphCast and Chroma are open-sourced on Github (GraphCast repo, Chroma repo), huge kudos for the authors for doing that 👏
🏟️ Both Chroma and RFDiffusion will be the keynotes at the MLSB workshop at NeurIPS, and Gabriele Corso already suggests to prepare some 🍿 to see the final showdown of the two heavy-weight generative champions (with EvoDiff in the interlude).
Google Research and DeepMind went an extra mile and uploaded a new paper on Neural General Circulation Models that already outperforms GraphCast on several tasks. The core component of NeuralGCM is a differentiable ODE solver, but otherwise it’s the encode-process-decode architecture with MLPs.
Xiaoxin He compiled a list of graph papers to be presented at NeurIPS’23 - a handy tool to get ready for the poster sessions!
Weekend reading:
A new age in protein design empowered by deep learning by Hamed Khakzad et al feat Michael Bronstein and Bruno Correia - a survey on (geometric) DL models for protein design including hot generative models.
Exposition on over-squashing problem on GNNs: Current Methods, Benchmarks and Challenges by Dai Shi et al - a comprehensive survey on oversquashing and how to deal with it
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search by Abbas Mehrabian, Ankit Anand, Hyunjik Kim, et al (feat Petar Veličković) - an excellent read on approaching one of the classical graph theory problems with RL
While one half of the world digests the drama around OpenAI and comes up with conspiracy theories and another half is working on ICLR rebuttals and CVPR deadlines, let’s look at the GraphML news!
☔ Two models we first spotted and mentioned in 2023 The State of Affairs post were officially released as Science and Nature publications: GraphCast from Google DeepMind for weather prediction and Chroma for protein design from Generate Biomedicines. Both GraphCast and Chroma are open-sourced on Github (GraphCast repo, Chroma repo), huge kudos for the authors for doing that 👏
🏟️ Both Chroma and RFDiffusion will be the keynotes at the MLSB workshop at NeurIPS, and Gabriele Corso already suggests to prepare some 🍿 to see the final showdown of the two heavy-weight generative champions (with EvoDiff in the interlude).
Google Research and DeepMind went an extra mile and uploaded a new paper on Neural General Circulation Models that already outperforms GraphCast on several tasks. The core component of NeuralGCM is a differentiable ODE solver, but otherwise it’s the encode-process-decode architecture with MLPs.
Xiaoxin He compiled a list of graph papers to be presented at NeurIPS’23 - a handy tool to get ready for the poster sessions!
Weekend reading:
A new age in protein design empowered by deep learning by Hamed Khakzad et al feat Michael Bronstein and Bruno Correia - a survey on (geometric) DL models for protein design including hot generative models.
Exposition on over-squashing problem on GNNs: Current Methods, Benchmarks and Challenges by Dai Shi et al - a comprehensive survey on oversquashing and how to deal with it
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search by Abbas Mehrabian, Ankit Anand, Hyunjik Kim, et al (feat Petar Veličković) - an excellent read on approaching one of the classical graph theory problems with RL
GraphML News (Nov 25th) - LOG’23 starts next week, EEML’24,
The OpenAI drama has been successfully resolved and now the ML world is wandering about Q* that (allegedly) showed some amazing improvements towards AGI. Henceforth, Q-learning and classic A* search algorithm are among the hottest trends this week 🤣 (where I could insert a shameless plug and point that audience to the neural A*Net paper we’ll be presenting at NeurIPS’23). Besides that:
LoG 2023, the graph’iest ML conference, starts next Monday, November 27th — registration is free and participation is fully-remote. It would have been nicer to have a list of accepted papers and tutorials a bit before the very starting day of the conference 🙂 (perhaps the organizers are also busy with ICLR rebuttals and NeurIPS workshops).
The Eastern European ML Summer School (EEML) has just announced its 2024 installment (15-20 July, Novi Sad, Serbia) featuring a stellar lineup of speakers and organizers including Kyunghyun Cho, Doina Precup, Michael Bronstein, Alfredo Canziani, Petar Veličković, and many more prominent researchers (especially from DeepMind). So we would expect quite a few lectures and tutorials on graph learning!
Weekend reading:
Generalized Biomolecular Modeling and Design with RoseTTAFold All-Atom from the Baker Lab - all-atom versions of RosettaFold (RFAA) for structure prediction and RFdiffusionAA for protein-ligand binding generative model.
Geometric Algebra Transformer (GATr 🐊) by Johann Brehmer feat. Taco Cohen. GATr = Clifford Algebras + Transformers, built-in E(3) equivariance. Some applications include n-body dynamics, wall-shear-stress estimation of human arteries, and robotic planning. The code was recently published as well.
A Survey of Graph Meets Large Language Model: Progress and Future Directions by Yuhan Li et al. The subfield exists for a few months but there is already a survey about it.
The OpenAI drama has been successfully resolved and now the ML world is wandering about Q* that (allegedly) showed some amazing improvements towards AGI. Henceforth, Q-learning and classic A* search algorithm are among the hottest trends this week 🤣 (where I could insert a shameless plug and point that audience to the neural A*Net paper we’ll be presenting at NeurIPS’23). Besides that:
LoG 2023, the graph’iest ML conference, starts next Monday, November 27th — registration is free and participation is fully-remote. It would have been nicer to have a list of accepted papers and tutorials a bit before the very starting day of the conference 🙂 (perhaps the organizers are also busy with ICLR rebuttals and NeurIPS workshops).
The Eastern European ML Summer School (EEML) has just announced its 2024 installment (15-20 July, Novi Sad, Serbia) featuring a stellar lineup of speakers and organizers including Kyunghyun Cho, Doina Precup, Michael Bronstein, Alfredo Canziani, Petar Veličković, and many more prominent researchers (especially from DeepMind). So we would expect quite a few lectures and tutorials on graph learning!
Weekend reading:
Generalized Biomolecular Modeling and Design with RoseTTAFold All-Atom from the Baker Lab - all-atom versions of RosettaFold (RFAA) for structure prediction and RFdiffusionAA for protein-ligand binding generative model.
Geometric Algebra Transformer (GATr 🐊) by Johann Brehmer feat. Taco Cohen. GATr = Clifford Algebras + Transformers, built-in E(3) equivariance. Some applications include n-body dynamics, wall-shear-stress estimation of human arteries, and robotic planning. The code was recently published as well.
A Survey of Graph Meets Large Language Model: Progress and Future Directions by Yuhan Li et al. The subfield exists for a few months but there is already a survey about it.
The Learning on Graphs Conference 2023 will be taking place virtually for free from 27th -- 30th November.
LoG is an annual research conference started to provide a dedicated venue for areas broadly related to machine learning on graphs and geometric data, with a special focus on review quality (top reviewers are given monetary awards).
Website: https://logconference.org/
Slack: https://join.slack.com/t/logconference/shared_invite/zt-27nv8ba1y-pXspnAzgLOMdDzfKgpOafg
This year's program has an excited lineup of keynote speakers, oral presentations, and tutorials, as well as poster sessions and social hours. All the details on how to attend are available on the LoG website.
Tune in to hear about the latest trends in Graph Neural Network theory, applications of Geometric Deep Learning, and more!
LoG is an annual research conference started to provide a dedicated venue for areas broadly related to machine learning on graphs and geometric data, with a special focus on review quality (top reviewers are given monetary awards).
Website: https://logconference.org/
Slack: https://join.slack.com/t/logconference/shared_invite/zt-27nv8ba1y-pXspnAzgLOMdDzfKgpOafg
This year's program has an excited lineup of keynote speakers, oral presentations, and tutorials, as well as poster sessions and social hours. All the details on how to attend are available on the LoG website.
Tune in to hear about the latest trends in Graph Neural Network theory, applications of Geometric Deep Learning, and more!
GraphML News (Dec 2nd) - RelBench, GNoME, and 3 roasts of the week
The LoG’23 conference took place this week (along with numerous local meetups!) and all the steam recordings are already available on the YouTube channel including tutorials and keynotes by Jure Leskovec, Andreas Loukas, Stefanie Jegelka, and Kyle Cranmer — check them out over the weekend!
➡️ One of the huge LoG announcements is RelBench — a new benchmark for Relational Deep Learning introduced by Jure Leskovec and the PyG / TorchFrame team behind it. RelBench poses temporal classification and regression tasks over large tables that can be represented as multi-partite graphs (each row from each table is a unique node). Jure also hinted that temporal hypergraphs can be even more efficient. The first 🔥 roast of the week 🔥 goes to Jure for noticing all those modern graph databases being orders of magnitude slower for such tasks. Time to sell GDBMS stocks? 📉
⚛️ The second big announcement is GNoME from Google DeepMind - a GNN-based system that discovered 2.2M new crystal structures including about 380k stable structures. GNoME traces were already there in the Materials Project database since spring, and now we see a full release upon the publication in Nature. Practically, GNoME consists of two GNNs - a simple MPNN as a composition model and NequIP as a structural model for interatomic potentials. GNoME demonstrates impressive scaling capabilities and features sophisticated pipelines involving DFT calculations and active learning loops. The code and data are published on GitHub and we can enjoy the JAX implementation of NequIP - time to jump on the tensor product train 🚂 if you haven’t yet.
The GNoMe project spawned another accepted Nature paper on the experimental side of creating those materials in the automated lab, and it spawned quite some active community discussion. The second 🔥 roast of the week 🔥 goes to Robert Palgrave from UCL for highlighting many issues of that paper that might have been swept under the rug and compromised the methodology.
Weekend reading:
Relational Deep Learning: Graph Representation Learning on Relational Databases by Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, and Kumo + Stanford team. The RelBench paper
Scaling deep learning for materials discovery by Amil Merchant, Simon Batzner, et al. The GNoME paper.
Generating Molecular Conformer Fields by Wang et al and Apple - turns out a simple diffusion model without fancy equivariances can beat GeoDiff and Torsional Diffusion in conformer generation. Definitely deserves the third 🔥 roast of the week 🔥
The LoG’23 conference took place this week (along with numerous local meetups!) and all the steam recordings are already available on the YouTube channel including tutorials and keynotes by Jure Leskovec, Andreas Loukas, Stefanie Jegelka, and Kyle Cranmer — check them out over the weekend!
➡️ One of the huge LoG announcements is RelBench — a new benchmark for Relational Deep Learning introduced by Jure Leskovec and the PyG / TorchFrame team behind it. RelBench poses temporal classification and regression tasks over large tables that can be represented as multi-partite graphs (each row from each table is a unique node). Jure also hinted that temporal hypergraphs can be even more efficient. The first 🔥 roast of the week 🔥 goes to Jure for noticing all those modern graph databases being orders of magnitude slower for such tasks. Time to sell GDBMS stocks? 📉
⚛️ The second big announcement is GNoME from Google DeepMind - a GNN-based system that discovered 2.2M new crystal structures including about 380k stable structures. GNoME traces were already there in the Materials Project database since spring, and now we see a full release upon the publication in Nature. Practically, GNoME consists of two GNNs - a simple MPNN as a composition model and NequIP as a structural model for interatomic potentials. GNoME demonstrates impressive scaling capabilities and features sophisticated pipelines involving DFT calculations and active learning loops. The code and data are published on GitHub and we can enjoy the JAX implementation of NequIP - time to jump on the tensor product train 🚂 if you haven’t yet.
The GNoMe project spawned another accepted Nature paper on the experimental side of creating those materials in the automated lab, and it spawned quite some active community discussion. The second 🔥 roast of the week 🔥 goes to Robert Palgrave from UCL for highlighting many issues of that paper that might have been swept under the rug and compromised the methodology.
Weekend reading:
Relational Deep Learning: Graph Representation Learning on Relational Databases by Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, and Kumo + Stanford team. The RelBench paper
Scaling deep learning for materials discovery by Amil Merchant, Simon Batzner, et al. The GNoME paper.
Generating Molecular Conformer Fields by Wang et al and Apple - turns out a simple diffusion model without fancy equivariances can beat GeoDiff and Torsional Diffusion in conformer generation. Definitely deserves the third 🔥 roast of the week 🔥
Guest post by Maryan Ramezani:
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization
By Maryam Ramezani, Aryan Ahadinia, Amirmohammad Ziaei Bideh, and Hamid R Rabiee.
Published in ACM Transactions on Knowledge Discovery from Data (TKDD).
📢 Thrilled to unveil our latest research on #SocialNetworks! My paper dives into the challenges of missing data in large-scale networks from a novel point of view: partial observation of both the temporal cascades and the underlying structure. Introducing 'DiffStru,' a probabilistic generative model, we jointly uncover hidden diffusion activities and network structures through coupled matrix factorization. Excitingly, our approach not only fills gaps in data but also aids in network classification problems by learning coupled representations of temporal cascades and users. 🚀 Tested on synthetic and real datasets, the results are promising – detecting hidden behaviors and predicting links by unveiling latent features. 📊🔍
Our method uses the following input.
☝️ A partial observations of the underlying network as a graph: Nodes are representing users and directed links are corresponding to the following relations between users. All nodes are present but some links are omitted.
✌️ A partial sequential observation of user participations in information diffusion process, namely cascades: Users participate in cascades, e.g. retweeting a topic, in a social media. Our observation is a set of cascades with users participated in some of them in a specified timestamp.
The output of our method is as follows.
1️⃣ Predictions of omitted links in the underlying network.
2️⃣ Predictions of users' participations in cascades, including their timestamps.
3️⃣ A coupled representation of users and cascades which can be used for further analysis, e.g. community detection.
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization
By Maryam Ramezani, Aryan Ahadinia, Amirmohammad Ziaei Bideh, and Hamid R Rabiee.
Published in ACM Transactions on Knowledge Discovery from Data (TKDD).
🌐 ACM Digital Library: https://dl.acm.org/doi/abs/10.1145/3599237🌐 GitHub: https://github.com/maryram/DiffStru📢 Thrilled to unveil our latest research on #SocialNetworks! My paper dives into the challenges of missing data in large-scale networks from a novel point of view: partial observation of both the temporal cascades and the underlying structure. Introducing 'DiffStru,' a probabilistic generative model, we jointly uncover hidden diffusion activities and network structures through coupled matrix factorization. Excitingly, our approach not only fills gaps in data but also aids in network classification problems by learning coupled representations of temporal cascades and users. 🚀 Tested on synthetic and real datasets, the results are promising – detecting hidden behaviors and predicting links by unveiling latent features. 📊🔍
Our method uses the following input.
☝️ A partial observations of the underlying network as a graph: Nodes are representing users and directed links are corresponding to the following relations between users. All nodes are present but some links are omitted.
✌️ A partial sequential observation of user participations in information diffusion process, namely cascades: Users participate in cascades, e.g. retweeting a topic, in a social media. Our observation is a set of cascades with users participated in some of them in a specified timestamp.
The output of our method is as follows.
1️⃣ Predictions of omitted links in the underlying network.
2️⃣ Predictions of users' participations in cascades, including their timestamps.
3️⃣ A coupled representation of users and cascades which can be used for further analysis, e.g. community detection.
ACM Transactions on Knowledge Discovery from Data
Joint Inference of Diffusion and Structure in Partially Observed Social Networks Using Coupled Matrix Factorization | ACM Transactions…
Access to complete data in large-scale networks is often infeasible. Therefore, the
problem of missing data is a crucial and unavoidable issue in the analysis and modeling
of real-world social networks. However, most of the research on different aspects
...
problem of missing data is a crucial and unavoidable issue in the analysis and modeling
of real-world social networks. However, most of the research on different aspects
...
👍1
GraphML News (Dec 9th) - NeurIPS’23, MatterGen, new blogs, PygHO
🎷 NeurIPS’23 starts on Sunday in jazzy New Orleans including tons of Graph ML papers and workshops that we covered in the previous articles (search by “NeurIPS workshop”). Find Michael (jetlagged from Dagstuhl) in the unique meme-designed t-shirt at two poster sessions (one, two) to chat about papers, graphs, or relay your POV on the diffusion vs flow matching feud of the year.
⚛️ Following the announcements of UniMat and GNoME from DeepMind, MSR AI 4 Science announced MatterGen, a new generative model for inorganic materials design. Practically, unconditional MatterGen is a diffusion model based on the GemNet backbone with both continuous and discrete diffusion components, ie, continuous diffusion is applied to lattice parameters and fractional coordinates, discrete diffusion (absorbing state with the MASK token) is applied to atom compositions. A pre-trained MatterGen can then be steered in many directions with classifier-free guidance, and the authors report conditioning on target chemistry, energy, magnetic properties, and on a practical use-case of designing magnets. Seems like big labs are picking up on materials science and it will be a key topic of generative models in 2024 along with molecules and proteins.
Meanwhile, a few new blog posts have arrived:
- Cooperative GNNs by Ben Finkelshtein, Ismail Ceylan, Xingyue Huang, and Michael Bronstein on the recently proposed GNN architecture;
- Equivariant CNNs and steerable kernels - part 3 of the series based off the monumental book Equivariant CNN by Maurice Weiler
Xiyuan Wang and Muhan Zhang published PyTorch Geometric Higher Order (PygHO), a library that implements a collection of primitives to create higher-order GNNs (like subgraph GNNs, PPGN, Nested GNNs) and data wrappers with proper graph transformations.
Weekend reading:
MatterGen: a generative model for inorganic materials design by Zeni et al. - the MatterGen paper
Expressive Sign Equivariant Networks for Spectral Geometric Learning (NeurIPS’23) by Derek Lim, Joshua Robinson, Stefanie Jegelka, and Haggai Maron - extension of invariant SignNet to sign equivariance
Recurrent Distance-Encoding Neural Networks for Graph Representation Learning by Yuhui Ding et al. - Linear Recurrent Units (LRUs) straight from NLP arrived to GNNs
Variational Annealing on Graphs for Combinatorial Optimization by Sebastian Sanokowski feat. Sepp Hochreiter
🎷 NeurIPS’23 starts on Sunday in jazzy New Orleans including tons of Graph ML papers and workshops that we covered in the previous articles (search by “NeurIPS workshop”). Find Michael (jetlagged from Dagstuhl) in the unique meme-designed t-shirt at two poster sessions (one, two) to chat about papers, graphs, or relay your POV on the diffusion vs flow matching feud of the year.
⚛️ Following the announcements of UniMat and GNoME from DeepMind, MSR AI 4 Science announced MatterGen, a new generative model for inorganic materials design. Practically, unconditional MatterGen is a diffusion model based on the GemNet backbone with both continuous and discrete diffusion components, ie, continuous diffusion is applied to lattice parameters and fractional coordinates, discrete diffusion (absorbing state with the MASK token) is applied to atom compositions. A pre-trained MatterGen can then be steered in many directions with classifier-free guidance, and the authors report conditioning on target chemistry, energy, magnetic properties, and on a practical use-case of designing magnets. Seems like big labs are picking up on materials science and it will be a key topic of generative models in 2024 along with molecules and proteins.
Meanwhile, a few new blog posts have arrived:
- Cooperative GNNs by Ben Finkelshtein, Ismail Ceylan, Xingyue Huang, and Michael Bronstein on the recently proposed GNN architecture;
- Equivariant CNNs and steerable kernels - part 3 of the series based off the monumental book Equivariant CNN by Maurice Weiler
Xiyuan Wang and Muhan Zhang published PyTorch Geometric Higher Order (PygHO), a library that implements a collection of primitives to create higher-order GNNs (like subgraph GNNs, PPGN, Nested GNNs) and data wrappers with proper graph transformations.
Weekend reading:
MatterGen: a generative model for inorganic materials design by Zeni et al. - the MatterGen paper
Expressive Sign Equivariant Networks for Spectral Geometric Learning (NeurIPS’23) by Derek Lim, Joshua Robinson, Stefanie Jegelka, and Haggai Maron - extension of invariant SignNet to sign equivariance
Recurrent Distance-Encoding Neural Networks for Graph Representation Learning by Yuhui Ding et al. - Linear Recurrent Units (LRUs) straight from NLP arrived to GNNs
Variational Annealing on Graphs for Combinatorial Optimization by Sebastian Sanokowski feat. Sepp Hochreiter
A team including folks from Mila and Cambridge just released a “Hitchhiker’s Guide” for getting started with GNNs for 3D structural biology & chemistry -- we think it will be useful for newcomers to start their learning journey on the core architectures powering recent breakthroughs of graph ML in protein design, material discovery, molecular simulations, and more!
A Hitchhiker’s Guide to Geometric GNNs for 3D Atomic Systems
👥 Alexandre Duval, Simon V. Mathis, Chaitanya K. Joshi, Victor Schmidt, Santiago Miret, Fragkiskos Malliaros, Taco Cohen, Pietro Liò, Yoshua Bengio, and Michael Bronstein
📝 PDF: https://arxiv.org/abs/2312.07511
A Hitchhiker’s Guide to Geometric GNNs for 3D Atomic Systems
👥 Alexandre Duval, Simon V. Mathis, Chaitanya K. Joshi, Victor Schmidt, Santiago Miret, Fragkiskos Malliaros, Taco Cohen, Pietro Liò, Yoshua Bengio, and Michael Bronstein
📝 PDF: https://arxiv.org/abs/2312.07511
❤1🔥1
GraphML News (Dec 17th) - The NeurIPS edition, TGB and TpuGraphs
NeurIPS’23 happened this week in New Orleans with 3000+ papers, 50+ workshops and competitions, and 16000+ registered participants. The most important part of such enormous events is networking, and, based on my impressions, the Graph ML community is thriving with so many new ideas and projects (especially after attending the workshops).
We will be reflecting on the hot trends, ideas that fell out of favor / are solved, and update the predictions in the annual 2023-2024 post which is already in the works (so stay tuned).
PS > All the flow matching t-shirts found their owners 😉
New blogposts:
- Temporal Graph Benchmark by Andy Huang and Emanuele Rossi - introduces TGB, its design principles and supported tasks
- Advancements in ML for ML by Google on the new TpuGraphs dataset, Graph Segment Training for large graphs, and the recently finished Kaggle competition on the TpuGraphs dataset (GraphSAGE is in the most of the top winning solutions)
Weekend reading:
A Hitchhiker’s Guide to Geometric GNNs for 3D Atomic Systems by Alexandre Duval, Simon V. Mathis, Chaitanya K. Joshi, Victor Schmidt, et al - a handbook on geometric GNNs, see our previous post for more details
Are Graph Neural Networks Optimal Approximation Algorithms? by Morris Yau feat. Stefanie Jegelka - introduces OptGNN that performs very competitively on a bunch of combinatorial optimization tasks
TorchCFM, the main library for conditional flow matching, released a bunch of new tutorials in Jupyter notebooks - winter holidays are a perfect time to learn more about flow matching and optimal transport
NeurIPS’23 happened this week in New Orleans with 3000+ papers, 50+ workshops and competitions, and 16000+ registered participants. The most important part of such enormous events is networking, and, based on my impressions, the Graph ML community is thriving with so many new ideas and projects (especially after attending the workshops).
We will be reflecting on the hot trends, ideas that fell out of favor / are solved, and update the predictions in the annual 2023-2024 post which is already in the works (so stay tuned).
PS > All the flow matching t-shirts found their owners 😉
New blogposts:
- Temporal Graph Benchmark by Andy Huang and Emanuele Rossi - introduces TGB, its design principles and supported tasks
- Advancements in ML for ML by Google on the new TpuGraphs dataset, Graph Segment Training for large graphs, and the recently finished Kaggle competition on the TpuGraphs dataset (GraphSAGE is in the most of the top winning solutions)
Weekend reading:
A Hitchhiker’s Guide to Geometric GNNs for 3D Atomic Systems by Alexandre Duval, Simon V. Mathis, Chaitanya K. Joshi, Victor Schmidt, et al - a handbook on geometric GNNs, see our previous post for more details
Are Graph Neural Networks Optimal Approximation Algorithms? by Morris Yau feat. Stefanie Jegelka - introduces OptGNN that performs very competitively on a bunch of combinatorial optimization tasks
TorchCFM, the main library for conditional flow matching, released a bunch of new tutorials in Jupyter notebooks - winter holidays are a perfect time to learn more about flow matching and optimal transport
GraphML News (Dec 23rd) - Antibiotics discovered with GNNs, OpenCatalyst 23, TF GNN
A group of MIT and Harvard researchers reported (in the recent Nature paper) the discovery of a new class of antibiotics. The screening process was supported by ChemProp, a suite of GNNs for molecular property prediction. The authors trained an ensemble of 10 models to filter down the initial space of 11M compounds to 1.5K compounds. Most of those models are 5-layer MPNNs with hidden size of 1600. Pre-trained checkpoints and notebooks are available in the GitHub repo of the project. Exciting times for the field (and many bio startups)! 👏
The Open Catalyst project announced the winners of the recent OCP 23 challenge (aka AdsorbML) - the top approaches build around Equiformer V2 with the best model reaching 46% success rate. It is likely that the numbers can be bumped even further by training on even larger OCP splits as demonstrated by eSCN Large and Equiformer V2 in the paper.
Google released TensorFlow GNN v1.0, the library you can run in production on GPUs and TPUs. Heterogeneous graphs are of particular focus - have a look at the example notebooks to learn more.
We’ll probably take a break with the news the next week to enjoy the holiday season and get back in January with the massive year-review post. 🥂
Weekend reading:
Perspectives on the State and Future of Deep Learning - 2023 - opinions of prominent ML researchers (incl. Max Welling, Kyunghyun Cho, Andrew Gordon Wilson, and ChatGPT, lolz) on the current problems and challenges. High-quality holiday reading 👌
Graph Transformers for Large Graphs by Vijay Prakash Dwivedi feat. Xavier Bresson, Neil Shah. Scaling GTs to graphs of 100M nodes.
Harmonics of Learning: Universal Fourier Features Emerge in Invariant Networks by Giovanni Luca Marchetti et al. Turns out Fourier features do emerge in neural networks and help to identify symmetries. The nature of the Fourier kernels looks quite similar to the steerable kernels for irreducible representations
A group of MIT and Harvard researchers reported (in the recent Nature paper) the discovery of a new class of antibiotics. The screening process was supported by ChemProp, a suite of GNNs for molecular property prediction. The authors trained an ensemble of 10 models to filter down the initial space of 11M compounds to 1.5K compounds. Most of those models are 5-layer MPNNs with hidden size of 1600. Pre-trained checkpoints and notebooks are available in the GitHub repo of the project. Exciting times for the field (and many bio startups)! 👏
The Open Catalyst project announced the winners of the recent OCP 23 challenge (aka AdsorbML) - the top approaches build around Equiformer V2 with the best model reaching 46% success rate. It is likely that the numbers can be bumped even further by training on even larger OCP splits as demonstrated by eSCN Large and Equiformer V2 in the paper.
Google released TensorFlow GNN v1.0, the library you can run in production on GPUs and TPUs. Heterogeneous graphs are of particular focus - have a look at the example notebooks to learn more.
We’ll probably take a break with the news the next week to enjoy the holiday season and get back in January with the massive year-review post. 🥂
Weekend reading:
Perspectives on the State and Future of Deep Learning - 2023 - opinions of prominent ML researchers (incl. Max Welling, Kyunghyun Cho, Andrew Gordon Wilson, and ChatGPT, lolz) on the current problems and challenges. High-quality holiday reading 👌
Graph Transformers for Large Graphs by Vijay Prakash Dwivedi feat. Xavier Bresson, Neil Shah. Scaling GTs to graphs of 100M nodes.
Harmonics of Learning: Universal Fourier Features Emerge in Invariant Networks by Giovanni Luca Marchetti et al. Turns out Fourier features do emerge in neural networks and help to identify symmetries. The nature of the Fourier kernels looks quite similar to the steerable kernels for irreducible representations
Neural Algorithmic Reasoning Without Intermediate Supervision
Guest post by Gleb Rodionov
📝 Paper: https://openreview.net/forum?id=vBwSACOB3x (NeurIPS 2023)
🛠️ Code: in the supplementary on OpenReview
Algorithmic reasoning aims to capture computations with neural networks, imitating the execution of classical algorithms. Typically, the generalization abilities of such models are improved through various forms of intermediate supervision, which demonstrate a particular execution trajectory (a sequence of intermediate steps, called hints) that the model needs to follow.
However, progress can also be made on the other side of the spectrum, where models are trained only with input-output pairs. Such models are not tied to any particular execution trajectory and are free to converge to the optimal execution flow for their own architecture. We demonstrate that models without hints can be competitive with hint-based models or even outperform them:
1️⃣ We propose several architectural modifications for models trained without intermediate supervision, that are aimed at making the comparison versus hint-based models clearer and fairer.
2️⃣ We build a self-supervised objective that can regularize intermediate computations of the model without access to the algorithm trajectory.
We hope our work will encourage further investigation of neural algorithmic reasoners without intermediate supervision. For more details, see the blog post.
Guest post by Gleb Rodionov
📝 Paper: https://openreview.net/forum?id=vBwSACOB3x (NeurIPS 2023)
🛠️ Code: in the supplementary on OpenReview
Algorithmic reasoning aims to capture computations with neural networks, imitating the execution of classical algorithms. Typically, the generalization abilities of such models are improved through various forms of intermediate supervision, which demonstrate a particular execution trajectory (a sequence of intermediate steps, called hints) that the model needs to follow.
However, progress can also be made on the other side of the spectrum, where models are trained only with input-output pairs. Such models are not tied to any particular execution trajectory and are free to converge to the optimal execution flow for their own architecture. We demonstrate that models without hints can be competitive with hint-based models or even outperform them:
1️⃣ We propose several architectural modifications for models trained without intermediate supervision, that are aimed at making the comparison versus hint-based models clearer and fairer.
2️⃣ We build a self-supervised objective that can regularize intermediate computations of the model without access to the algorithm trajectory.
We hope our work will encourage further investigation of neural algorithmic reasoners without intermediate supervision. For more details, see the blog post.
{kind=link}
Adaptive Message Passing: A General Framework to Mitigate Oversmoothing, Oversquashing, and Underreaching
Guest post by Federico Errica
📖 Blog post: link
⚗️ Paper: https://arxiv.org/abs/2312.16560
Long-range interactions are essential for the correct description of complex systems in many scientific fields. Recently, deep graph networks have been employed as efficient, data-driven surrogate models for predicting properties of complex systems represented as graphs. In practice, most deep graph networks cannot really model long-range dependencies due to the intrinsic limitations of (synchronous) message passing, namely oversmoothing, oversquashing, and underreaching.
Motivated by these observations, we propose Adaptive Message Passing (AMP) to let the DGN decide how many messages each node should send -up to infinity! - and when to send them. In other words:
1️⃣ We learn the depth of the network during training (addressing underreaching)
2️⃣ We apply a differentiable, soft filter on messages sent by nodes, which in principle can completely shut down the propagation of a message (addressing oversmoothing and oversquashing).
❗️ AMP can easily and automatically improve the performances of your favorite message passing architecture, e.g., GCN/GIN. ❗️
We believe AMP will foster exciting research opportunities in the graph machine learning field and find successful applications in the fields of physics, chemistry, and material sciences.
Guest post by Federico Errica
📖 Blog post: link
⚗️ Paper: https://arxiv.org/abs/2312.16560
Long-range interactions are essential for the correct description of complex systems in many scientific fields. Recently, deep graph networks have been employed as efficient, data-driven surrogate models for predicting properties of complex systems represented as graphs. In practice, most deep graph networks cannot really model long-range dependencies due to the intrinsic limitations of (synchronous) message passing, namely oversmoothing, oversquashing, and underreaching.
Motivated by these observations, we propose Adaptive Message Passing (AMP) to let the DGN decide how many messages each node should send -up to infinity! - and when to send them. In other words:
1️⃣ We learn the depth of the network during training (addressing underreaching)
2️⃣ We apply a differentiable, soft filter on messages sent by nodes, which in principle can completely shut down the propagation of a message (addressing oversmoothing and oversquashing).
❗️ AMP can easily and automatically improve the performances of your favorite message passing architecture, e.g., GCN/GIN. ❗️
We believe AMP will foster exciting research opportunities in the graph machine learning field and find successful applications in the fields of physics, chemistry, and material sciences.
Medium
Adaptive Message Passing: Learning to Mitigate Oversmoothing, Oversquashing, and Underreaching
This blog post summarizes the findings of our new contribution:
❤1
GraphML News (Jan 6th) - ICLR’24 workshops, new blog posts, MACE-MP-0 potential
We are getting back with the weekly news, hope you had a nice winter holiday!
🎤 ICLR’24 started announcing accepted workshops, the list is (so far) incomplete, but we might expect some graph and geometric learning here:
- AI for Differential Equations in Science
- Generative and Experimental Perspectives for Biomolecular Design
- Machine Learning for Genomics Explorations
📝 New blogposts!
▶️ Pat Walters started a massive series on AI in Drug Discovery in 2023: part 1 covers benchmarks, deep learning for docking, and AlphaFold for ligand discovery and design. Part 2 will focus on LLMs and generative models, Part 3 will be on review articles.
▶️ Zhaocheng Zhu, Michael Galkin, Abulhair Saparov, Shibo Hao, and Yihong Chen review the landscape of LLM reasoning approaches covering tool usage, retrieval, planning, and open reasoning problems. Lots of unsolved theoretical and practical problems to work on in 2024!
⚛️ Ilyes Batatia and a huge collab from Cambrige, Oxford, and EU universities announced MACE-MP-0: a foundational ML potentials model that can accurately approximate DFT calculations needed for molecular dynamics and atomistic simulations. The model is based on MACE (equivariant MPNN) and was trained on the Materials Project to predict forces, energy, and stress on 150k crystal structures for 200 epochs on 40-80 A100’s (definitely not a GPU-poor project, perhaps GPU-middle class). The authors ran about 30 experiments studying a single pre-trained model with different crystal structures and atomistic systems. The race for ML potentials has officially started 🏎️
Weekend reading:
Learning Scalable Structural Representations for Link Prediction with Bloom Signatures by Zhang et al. feat Pan Li - hashing-based link prediction now with Bloom filters
Scalable network reconstruction in subquadratic time by Tiago Peixoto (Mr. GraphTool) - present a O(N log^2 N) algorithm for network reconstruction
A foundation model for atomistic materials chemistry by Batatia et al - MACE-MP-0
We are getting back with the weekly news, hope you had a nice winter holiday!
🎤 ICLR’24 started announcing accepted workshops, the list is (so far) incomplete, but we might expect some graph and geometric learning here:
- AI for Differential Equations in Science
- Generative and Experimental Perspectives for Biomolecular Design
- Machine Learning for Genomics Explorations
📝 New blogposts!
▶️ Pat Walters started a massive series on AI in Drug Discovery in 2023: part 1 covers benchmarks, deep learning for docking, and AlphaFold for ligand discovery and design. Part 2 will focus on LLMs and generative models, Part 3 will be on review articles.
▶️ Zhaocheng Zhu, Michael Galkin, Abulhair Saparov, Shibo Hao, and Yihong Chen review the landscape of LLM reasoning approaches covering tool usage, retrieval, planning, and open reasoning problems. Lots of unsolved theoretical and practical problems to work on in 2024!
⚛️ Ilyes Batatia and a huge collab from Cambrige, Oxford, and EU universities announced MACE-MP-0: a foundational ML potentials model that can accurately approximate DFT calculations needed for molecular dynamics and atomistic simulations. The model is based on MACE (equivariant MPNN) and was trained on the Materials Project to predict forces, energy, and stress on 150k crystal structures for 200 epochs on 40-80 A100’s (definitely not a GPU-poor project, perhaps GPU-middle class). The authors ran about 30 experiments studying a single pre-trained model with different crystal structures and atomistic systems. The race for ML potentials has officially started 🏎️
Weekend reading:
Learning Scalable Structural Representations for Link Prediction with Bloom Signatures by Zhang et al. feat Pan Li - hashing-based link prediction now with Bloom filters
Scalable network reconstruction in subquadratic time by Tiago Peixoto (Mr. GraphTool) - present a O(N log^2 N) algorithm for network reconstruction
A foundation model for atomistic materials chemistry by Batatia et al - MACE-MP-0
GraphML News (Jan 13th) - New material discovered by geometric models, LOWE
What time could be better than the time in between ICLR announcements (Jan 15th) and the ICML deadline (Feb 1st) 🫠. As far as we know, the graph community is working on some huge blog posts - you can expect those coming in the next few days. The two big news from this week:
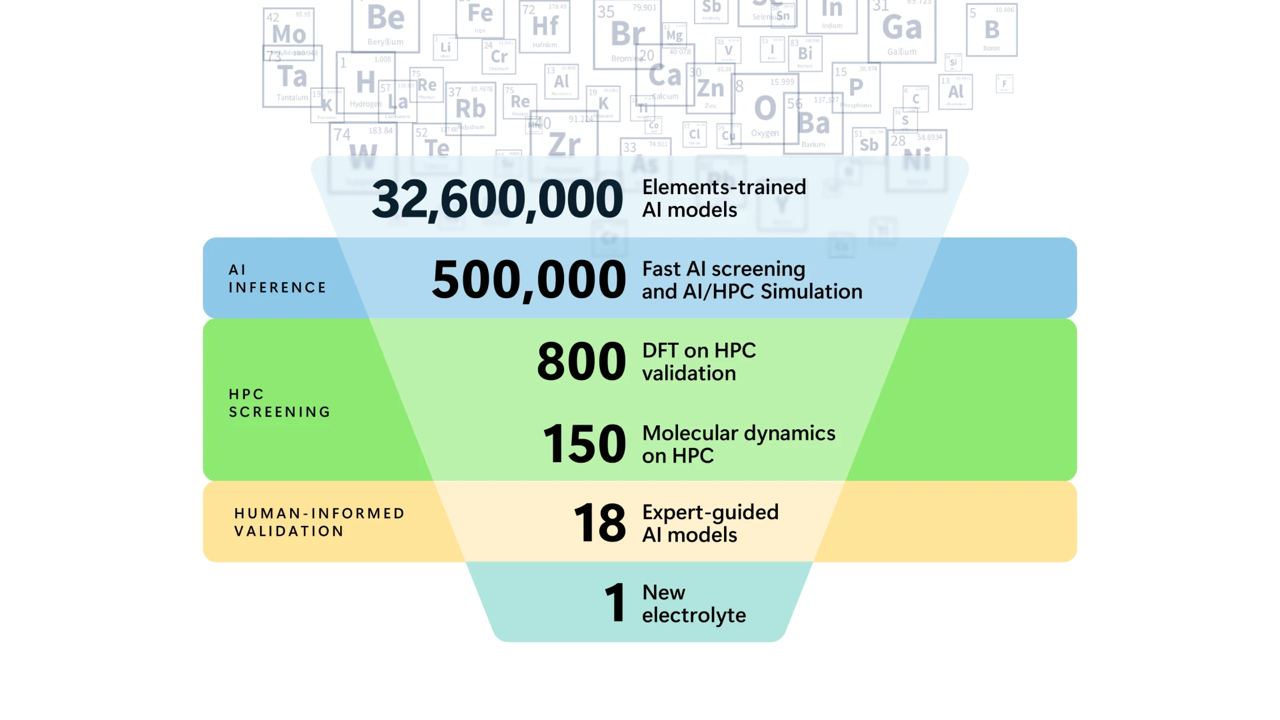
Microsoft Azure Quantum together with Pacific Northwest National Lab announced successful synthesis and validation of a potentially new electrolyte candidate suitable for solid-state batteries. The fresh accompanying paper describes the pipeline from generating 32M candidates and stepwise filtering of those down to 500K, 800, 18, and 1 final candidate. The main bulk of the job of filtering millions of candidates was done by the geometric ML potential model M3GNet (published in 2022 in Nature Computational Science) while later stages with a dozen candidates included HPC simulations of molecular dynamics. Geometric DL for materials discovery is rising! 🚀
Valence & Recursion announced LOWE (LLM-orchestrated Workflow Engine). LOWE is an LLM agent that strives to do all things around drug discovery - from screening and running geometric generative models to the procurement of materials. Was ChemCrow 🐦⬛ the inspiration for LOWE?
Weekend reading:
Accelerating computational materials discovery with artificial intelligence and cloud high-performance computing: from large-scale screening to experimental validation by Chen, Nguyen, et al - the paper behind the newly discovered material by Azure Quantum and PNNL.
MACE-OFF23: Transferable Machine Learning Force Fields for Organic Molecules by Kovács, Moore, et al - similarly to MACE-MP-0 from the last week, MACE-OFF23 is a transferable ML potential for organic molecules but smaller - Medium and Large models were trained on a single A100 for 10/14 days.
Improved motif-scaffolding with SE(3) flow matching by Yim et al - the improved version of FrameFlow (based on trendy flow matching), originally for protein backbone generation, to motif-scaffolding. On some benchmarks, new FrameFlow is on par or better than mighty RFDiffusion 💪
What time could be better than the time in between ICLR announcements (Jan 15th) and the ICML deadline (Feb 1st) 🫠. As far as we know, the graph community is working on some huge blog posts - you can expect those coming in the next few days. The two big news from this week:
Microsoft Azure Quantum together with Pacific Northwest National Lab announced successful synthesis and validation of a potentially new electrolyte candidate suitable for solid-state batteries. The fresh accompanying paper describes the pipeline from generating 32M candidates and stepwise filtering of those down to 500K, 800, 18, and 1 final candidate. The main bulk of the job of filtering millions of candidates was done by the geometric ML potential model M3GNet (published in 2022 in Nature Computational Science) while later stages with a dozen candidates included HPC simulations of molecular dynamics. Geometric DL for materials discovery is rising! 🚀
Valence & Recursion announced LOWE (LLM-orchestrated Workflow Engine). LOWE is an LLM agent that strives to do all things around drug discovery - from screening and running geometric generative models to the procurement of materials. Was ChemCrow 🐦⬛ the inspiration for LOWE?
Weekend reading:
Accelerating computational materials discovery with artificial intelligence and cloud high-performance computing: from large-scale screening to experimental validation by Chen, Nguyen, et al - the paper behind the newly discovered material by Azure Quantum and PNNL.
MACE-OFF23: Transferable Machine Learning Force Fields for Organic Molecules by Kovács, Moore, et al - similarly to MACE-MP-0 from the last week, MACE-OFF23 is a transferable ML potential for organic molecules but smaller - Medium and Large models were trained on a single A100 for 10/14 days.
Improved motif-scaffolding with SE(3) flow matching by Yim et al - the improved version of FrameFlow (based on trendy flow matching), originally for protein backbone generation, to motif-scaffolding. On some benchmarks, new FrameFlow is on par or better than mighty RFDiffusion 💪
{kind=link}
Graph & Geometric ML in 2024: Where We Are and What’s Next
📣 Two new blog posts - a comprehensive review of Graph and Geometric ML in 2023 with predictions for 2024. Together with Michael Bronstein, we asked 30 academic and industrial experts about the most important things happened in their areas and open challenges to be solved.
1️⃣ Part I: https://towardsdatascience.com/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-i-theory-architectures-3af5d38376e1
2️⃣ Part II: https://medium.com/towards-data-science/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-ii-applications-1ed786f7bf63
Part I covers: theory of GNNs, new and exotic message passing, going beyong graphs (with Topology, Geometric Algebras, and PDEs), robustness, graph transformers, new datasets, community events, and, of course, top memes of 2023 (that’s what you are here for, right).
Part II covers applications in structural biology, materials science, Molecular Dynamics and ML potentials, geometric generative models on manifolds, Very Large Graphs, algorithmic reasoning, knowledge graph reasoning, LLMs + Graphs, cool GNN applications, and The Geometric Wall Street Bulletin 💸
New things this year:
- the industrial perspective on important problems in structural biology that are often overlooked by researchers;
- The Geometric Wall Street Bulletin prepared with Nathan Benaich, the author of the State of AI report
It was a huge community effort and we are very grateful to all our experts for their availability around winter holidays. Here is the slide with all the contributors, the best “thank you” would be to follow all of them on Twitter!
📣 Two new blog posts - a comprehensive review of Graph and Geometric ML in 2023 with predictions for 2024. Together with Michael Bronstein, we asked 30 academic and industrial experts about the most important things happened in their areas and open challenges to be solved.
1️⃣ Part I: https://towardsdatascience.com/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-i-theory-architectures-3af5d38376e1
2️⃣ Part II: https://medium.com/towards-data-science/graph-geometric-ml-in-2024-where-we-are-and-whats-next-part-ii-applications-1ed786f7bf63
Part I covers: theory of GNNs, new and exotic message passing, going beyong graphs (with Topology, Geometric Algebras, and PDEs), robustness, graph transformers, new datasets, community events, and, of course, top memes of 2023 (that’s what you are here for, right).
Part II covers applications in structural biology, materials science, Molecular Dynamics and ML potentials, geometric generative models on manifolds, Very Large Graphs, algorithmic reasoning, knowledge graph reasoning, LLMs + Graphs, cool GNN applications, and The Geometric Wall Street Bulletin 💸
New things this year:
- the industrial perspective on important problems in structural biology that are often overlooked by researchers;
- The Geometric Wall Street Bulletin prepared with Nathan Benaich, the author of the State of AI report
It was a huge community effort and we are very grateful to all our experts for their availability around winter holidays. Here is the slide with all the contributors, the best “thank you” would be to follow all of them on Twitter!
{kind=link}
GraphML News (Jan 20th) - More Blogs, MACE pre-trained potentials, AlphaFold 🤝 Psychedelics
ICLR 2024 announced the accepted papers together with orals and spotlights — we’ll probably make a rundown on the coolest papers but meanwhile you can check one-line tl;dr’s by the famous Compressor by Vitaly Kurin. See you in Vienna in May!
📝 In addition to the megapost on the state of affairs in Graph & Geometric ML, the community delivered two more reviews:
- On Temporal Graph Learning by Shenyang Huang, Emanuele Rossi, Michael Galkin, Andrea Cini, Ingo Scholtes.
- On AI 4 Science by the organizers of the AI for Science workshops (that you see at all major ML venues) including Sherry Lixue Cheng, Yuanqi Du, Chenru Duan, Ada Fang, Tianfan Fu, Wenhao Gao, Kexin Huang, Ziming Liu, Di Luo, and Lijing Wang
⚛️ The MACE team released two foundational ML potential checkpoints: MP for inorganic crystals from the Materials Project and OFF for organic materials and molecular liquids. We covered those in the previous posts — now you can run some MD simulations with them on a laptop.
🍭 AlphaFold discovers potentially new psychedelic molecules (thousands of candidates!) - practically, those can be new antidepressants (would some researchers be willing to try some just for the sake of science and scientific method?)
Besides, the article mentions some works that apply AlphaFold to target G-protein-coupled receptors (GPCR). Apart from having its own Wiki page, GPCR was the main subject of the 2012 Nobel Prize in chemistry. The Nobel Prize for AlphaFold seems even closer?
Weekend reading:
You want to say you finished all those blogposts? 😉
ICLR 2024 announced the accepted papers together with orals and spotlights — we’ll probably make a rundown on the coolest papers but meanwhile you can check one-line tl;dr’s by the famous Compressor by Vitaly Kurin. See you in Vienna in May!
📝 In addition to the megapost on the state of affairs in Graph & Geometric ML, the community delivered two more reviews:
- On Temporal Graph Learning by Shenyang Huang, Emanuele Rossi, Michael Galkin, Andrea Cini, Ingo Scholtes.
- On AI 4 Science by the organizers of the AI for Science workshops (that you see at all major ML venues) including Sherry Lixue Cheng, Yuanqi Du, Chenru Duan, Ada Fang, Tianfan Fu, Wenhao Gao, Kexin Huang, Ziming Liu, Di Luo, and Lijing Wang
⚛️ The MACE team released two foundational ML potential checkpoints: MP for inorganic crystals from the Materials Project and OFF for organic materials and molecular liquids. We covered those in the previous posts — now you can run some MD simulations with them on a laptop.
🍭 AlphaFold discovers potentially new psychedelic molecules (thousands of candidates!) - practically, those can be new antidepressants (would some researchers be willing to try some just for the sake of science and scientific method?)
Besides, the article mentions some works that apply AlphaFold to target G-protein-coupled receptors (GPCR). Apart from having its own Wiki page, GPCR was the main subject of the 2012 Nobel Prize in chemistry. The Nobel Prize for AlphaFold seems even closer?
Weekend reading:
You want to say you finished all those blogposts? 😉
Exploring the Power of Graph Neural Networks in Solving Linear Optimization Problems
guest post by Chendi Qian, Didier Chételat, Christopher Morris
📜 Paper: arxiv (accepted to AISTATS 2024)
🛠️ Code: https://github.com/chendiqian/IPM_MPNN
Recent research shows growing interest in training message-passing graph neural networks (MPNNs) to mimic classical algorithms, particularly for solving linear optimization problems (LPs). For example, in integer linear optimization, state-of-the-art solvers rely on the branch-and-bound algorithm, in which one must repeatedly select variables, subdividing the search space. The best-known heuristic for variable selection is known as strong branching which entails solving LPs to score the variables. This heuristic is too computationally expensive to use in practice. However, in recent years, a collection of works, e.g., Gasse et al. (2019), have proposed using MPNNs to imitate strong branching with impressive success. However, it remained to be seen why such approaches work.
Hence, our paper explores the intriguing possibility of MPNNs approximating general LPs by interpreting various interior-point methods (IPMs) as MPNNs with specific architectures and parameters. We prove that standard MPNN steps can emulate a single iteration of the IPM algorithm on the LP’s tripartite graph representation. This theoretical insight suggests that MPNNs may succeed in LP solving by effectively imitating IPMs.
Despite our theoretical model, our empirical results indicate that MPNNs with fewer layers can approximate the output of practical IPMs for LP solving. Empirically, our approach reduces solving times compared to a state-of-the-art LP solver and other neural network-based methods. Our study enhances the theoretical understanding of data-driven optimization using MPNNs and highlights the potential of MPNNs as efficient proxies for solving LPs.
guest post by Chendi Qian, Didier Chételat, Christopher Morris
📜 Paper: arxiv (accepted to AISTATS 2024)
🛠️ Code: https://github.com/chendiqian/IPM_MPNN
Recent research shows growing interest in training message-passing graph neural networks (MPNNs) to mimic classical algorithms, particularly for solving linear optimization problems (LPs). For example, in integer linear optimization, state-of-the-art solvers rely on the branch-and-bound algorithm, in which one must repeatedly select variables, subdividing the search space. The best-known heuristic for variable selection is known as strong branching which entails solving LPs to score the variables. This heuristic is too computationally expensive to use in practice. However, in recent years, a collection of works, e.g., Gasse et al. (2019), have proposed using MPNNs to imitate strong branching with impressive success. However, it remained to be seen why such approaches work.
Hence, our paper explores the intriguing possibility of MPNNs approximating general LPs by interpreting various interior-point methods (IPMs) as MPNNs with specific architectures and parameters. We prove that standard MPNN steps can emulate a single iteration of the IPM algorithm on the LP’s tripartite graph representation. This theoretical insight suggests that MPNNs may succeed in LP solving by effectively imitating IPMs.
Despite our theoretical model, our empirical results indicate that MPNNs with fewer layers can approximate the output of practical IPMs for LP solving. Empirically, our approach reduces solving times compared to a state-of-the-art LP solver and other neural network-based methods. Our study enhances the theoretical understanding of data-driven optimization using MPNNs and highlights the potential of MPNNs as efficient proxies for solving LPs.
{kind=link}
GraphML News (Jan 27th) - New Blogs, LigandMPNN is available
Seems like everyone is grinding for the ICML’24 deadline next week so there isn’t much news those days. A few highlights:
Dimension Research published 2/3 parts of their ML x Bio review of NeurIPS’23: on Generative Protein Design, and on Generative Molecular Design, the last one is going to be about drug target interaction prediction.
The blog post on Exphormer by Ameya Velingker and Balaji Venkatachalam from Google Research on the neat ICML’23 sparse graph transformer architecture that scales to graphs much larger than molecules. Glad to see GraphGPS and Long Range Graph Benchmark mentioned a few times 🙂
LigandMPNN was released on GitHub this week after appearing as a module in several recent protein generation papers. LigandMPNN significantly improves over ProteinMPNN in modeling non-protein components like small molecules, metals, and nucleotides.
Weekend reading:
Equivariant Graph Neural Operator for Modeling 3D Dynamics by Minkai Xu, Jiaqi Han feat Jure Leskovec and Stefano Ermon: equivariant GNNs 🤝 neural operators, also provides a nice condensed intro to the topic
Towards Principled Graph Transformers by Luis Müller and Christopher Morris - study of the Edge Transformer with triangular attention applied to graph tasks. Edge Transformer has shown remarkable systematic generalization capabilities and it’s intriguing to see how it works on graphs (O(N^3) complexity for now though).
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility - turns out that papers shared on X / Twitter by AK and Aran Komatsuzaki have significantly more citations. Time to revive your old sci-Twitter account
Seems like everyone is grinding for the ICML’24 deadline next week so there isn’t much news those days. A few highlights:
Dimension Research published 2/3 parts of their ML x Bio review of NeurIPS’23: on Generative Protein Design, and on Generative Molecular Design, the last one is going to be about drug target interaction prediction.
The blog post on Exphormer by Ameya Velingker and Balaji Venkatachalam from Google Research on the neat ICML’23 sparse graph transformer architecture that scales to graphs much larger than molecules. Glad to see GraphGPS and Long Range Graph Benchmark mentioned a few times 🙂
LigandMPNN was released on GitHub this week after appearing as a module in several recent protein generation papers. LigandMPNN significantly improves over ProteinMPNN in modeling non-protein components like small molecules, metals, and nucleotides.
Weekend reading:
Equivariant Graph Neural Operator for Modeling 3D Dynamics by Minkai Xu, Jiaqi Han feat Jure Leskovec and Stefano Ermon: equivariant GNNs 🤝 neural operators, also provides a nice condensed intro to the topic
Towards Principled Graph Transformers by Luis Müller and Christopher Morris - study of the Edge Transformer with triangular attention applied to graph tasks. Edge Transformer has shown remarkable systematic generalization capabilities and it’s intriguing to see how it works on graphs (O(N^3) complexity for now though).
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility - turns out that papers shared on X / Twitter by AK and Aran Komatsuzaki have significantly more citations. Time to revive your old sci-Twitter account
GraphML News (Feb 3rd) - DGL 2.0 ⚡
All ICML deadlines have passed - congratulations to all who made it through the sleepless nights over the last week! We will start seeing some fresh submissions relatively soon on social media (among 10k submitted papers and ~220 position papers)
Meanwhile, DGL 2.0 was released featuring GraphBolt - a new tool for streaming data loading and sampling offering around 30% speedups in node classification and up to 400% in link prediction 🚀 Besides that, the new version includes utilities for building graph transformers and a handful of new datasets - LRGB and a recent suite of heterophilic datasets
The AppliedML Days @ EPFL will take place on March 25 and 26th - the call for the AI and Molecular world track is still open
Weekend reading:
Combinatorial prediction of therapeutic perturbations using causally-inspired neural networks by Guadalupe Gonzalez feat Michael Bronstein and Marinka Zitnik - introduces PDGrapher, a causally-inspired GNN model to predict therapeutically useful perturbagens
VC dimension of Graph Neural Networks with Pfaffian activation functions by D’Inverno et al - extension of the WL meets VC paper to new non-linearities like sigmoid and hyperbolic tangent
NetInfoF Framework: Measuring and Exploiting Network Usable Information (still anon by accepted to ICLR’24) - introduces the “network usable information” and a fingerpring-like approach to quantity the gains brought by a GNN model compared to a non-GNN baselne.
All ICML deadlines have passed - congratulations to all who made it through the sleepless nights over the last week! We will start seeing some fresh submissions relatively soon on social media (among 10k submitted papers and ~220 position papers)
Meanwhile, DGL 2.0 was released featuring GraphBolt - a new tool for streaming data loading and sampling offering around 30% speedups in node classification and up to 400% in link prediction 🚀 Besides that, the new version includes utilities for building graph transformers and a handful of new datasets - LRGB and a recent suite of heterophilic datasets
The AppliedML Days @ EPFL will take place on March 25 and 26th - the call for the AI and Molecular world track is still open
Weekend reading:
Combinatorial prediction of therapeutic perturbations using causally-inspired neural networks by Guadalupe Gonzalez feat Michael Bronstein and Marinka Zitnik - introduces PDGrapher, a causally-inspired GNN model to predict therapeutically useful perturbagens
VC dimension of Graph Neural Networks with Pfaffian activation functions by D’Inverno et al - extension of the WL meets VC paper to new non-linearities like sigmoid and hyperbolic tangent
NetInfoF Framework: Measuring and Exploiting Network Usable Information (still anon by accepted to ICLR’24) - introduces the “network usable information” and a fingerpring-like approach to quantity the gains brought by a GNN model compared to a non-GNN baselne.
GraphML News (Feb 10th) - TensorFlow GNN 1.0, New ICML submissions
🔧 The official release of TensforFlow-GNN 1.0 by Google (after several road show presentations from the team at ICML and NeurIPS) - production-level library for training GNNs on large graphs with the first-class citizen support for heterogeneous graphs. Check the blog post and github repo for more practical examples and documentation
⚛️ The Denoising force fields repository from Microsoft Research for diffusion models trained on coarse-grained protein dynamics data - you can use it for standard density modeling or extract force fields from coarse-grained structures to use in Langevin dynamics simulations. The repo contains several pre-trained models you can play around with.
The ICML deadline has passed and we saw a flurry of cool new preprints submitted to arxiv this week. Some notable mentions:
🐍 Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces by Chloe Wang et al: state space models like Mamba are all the rage those days in NLP and CV (although so far attention still rules), this is a nice adaptation of SSMs to graphs, tested on the LRGB!
🗣️ Let Your Graph Do the Talking: Encoding Structured Data for LLMs by Bryan Perozzi feat. Anton Tsitsulin present GraphToken (extension of Talk Like a Graph, ICLR 2024): using trainable set- or graph encoders to get soft prompt tokens improves the performance of frozen LLMs in answering natural language questions about basic graph properties. The last resort of hardcore graph mining teams jumps into LLMs 🗿
⏩ Link Prediction with Relational Hypergraphs by Xingyue Huang feat. Pablo Barcelo, Michael Bronstein, and Ismail Ceylan: extends conditional message passing models like NBFNet to relational hypergraphs (dubbed HC-MPNN) with nice theoretical guarantees and impressive inductive performance boosts.
📈 Neural Scaling Laws on Graphs by Jingzhe Liu feat. Neil Shah and Jilian Tang: one of the first systematic studies of scaling laws for graph models (GNNs and Graph Transformers) and data (mostly OGB datasets) where the number of edges is selected as the universal size metric. Basically, scaling does happen but with certain nuances as to model depth and architecture (transformers seem to scale more monotonically). The church of scaling laws opens its doors to the graph learning crowd ⛪
📚 On the Completeness of Invariant Geometric Deep Learning Models by Zian Li feat. Muhan Zhang: theoretical study of DimeNet, GemNet, and SphereNet with the proofs of their E(3)-completeness through the nested GNN extension (Nested GNNs from NeurIPS’21)
📚 On dimensionality of feature vectors in MPNNs by Cesar Bravo et al - turns out the WL-MPNN equivalence holds even for 1-dimensional node features when using non-polynomial activations like sigmoid.
Next time, we’ll look into some new position papers.
🔧 The official release of TensforFlow-GNN 1.0 by Google (after several road show presentations from the team at ICML and NeurIPS) - production-level library for training GNNs on large graphs with the first-class citizen support for heterogeneous graphs. Check the blog post and github repo for more practical examples and documentation
⚛️ The Denoising force fields repository from Microsoft Research for diffusion models trained on coarse-grained protein dynamics data - you can use it for standard density modeling or extract force fields from coarse-grained structures to use in Langevin dynamics simulations. The repo contains several pre-trained models you can play around with.
The ICML deadline has passed and we saw a flurry of cool new preprints submitted to arxiv this week. Some notable mentions:
🐍 Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces by Chloe Wang et al: state space models like Mamba are all the rage those days in NLP and CV (although so far attention still rules), this is a nice adaptation of SSMs to graphs, tested on the LRGB!
🗣️ Let Your Graph Do the Talking: Encoding Structured Data for LLMs by Bryan Perozzi feat. Anton Tsitsulin present GraphToken (extension of Talk Like a Graph, ICLR 2024): using trainable set- or graph encoders to get soft prompt tokens improves the performance of frozen LLMs in answering natural language questions about basic graph properties. The last resort of hardcore graph mining teams jumps into LLMs 🗿
⏩ Link Prediction with Relational Hypergraphs by Xingyue Huang feat. Pablo Barcelo, Michael Bronstein, and Ismail Ceylan: extends conditional message passing models like NBFNet to relational hypergraphs (dubbed HC-MPNN) with nice theoretical guarantees and impressive inductive performance boosts.
📈 Neural Scaling Laws on Graphs by Jingzhe Liu feat. Neil Shah and Jilian Tang: one of the first systematic studies of scaling laws for graph models (GNNs and Graph Transformers) and data (mostly OGB datasets) where the number of edges is selected as the universal size metric. Basically, scaling does happen but with certain nuances as to model depth and architecture (transformers seem to scale more monotonically). The church of scaling laws opens its doors to the graph learning crowd ⛪
📚 On the Completeness of Invariant Geometric Deep Learning Models by Zian Li feat. Muhan Zhang: theoretical study of DimeNet, GemNet, and SphereNet with the proofs of their E(3)-completeness through the nested GNN extension (Nested GNNs from NeurIPS’21)
📚 On dimensionality of feature vectors in MPNNs by Cesar Bravo et al - turns out the WL-MPNN equivalence holds even for 1-dimensional node features when using non-polynomial activations like sigmoid.
Next time, we’ll look into some new position papers.